YUDHA PERMADI. Kategorisasi Teks Menggunakan N-gram untuk Dokumen Berbahasa Indonesia. Dibimbing oleh JULIO ADISANTOSO dan FIRMAN ARDIANSYAH.
Luasnya sumber untuk mendapatkan suatu dokumen dengan topik atau tema tertentu dapat mengakibatkan banyaknya dokumen yang dicari memiliki topik yang sama walaupun dengan sudut pandang yang berbeda. Perbedaan sudut pandang ini kemudian dapat dikelompokkan berdasarkan pembahasan dari tiap sudut pandang. Namun jika dilihat dari akar permasalahan atau topik utamanya maka akan cukup sulit membedakan satu permasalahan dengan permasalahan lainnya.
Dalam bidang temu kembali informasi terdapat suatu model pengelompokan dokumen yang disebut kategorisasi teks. Model ini juga memiliki beberapa jenis metode pengelompokan dokumen yang salah satunya adalah metode N-gram. Metode N-gram merupakan suatu metode yang sering digunakan untuk mengenali kesalahan-kesalahan yang sering terjadi pada suatu dokumen. Menggunakan N-gram untuk proses kategorisasi teks, dokumen-dokumen dengan topik utama yang sama dapat dikelompokkan ke dalam beberapa kategori walaupun terdapat kesalahan tekstual.
Kinerja dari sistem ini dapat diketahui dengan membandingkan profil N-gram dari dokumen dengan kategori yang sudah ada. Dari proses perbandingan ini dapat ditentukan dan dikalkulasikan jarak antara dua profil tersebut, dan menentukan kategori mana yang memiliki jarak terkecil dengan dokumen tersebut. Dari penelitian ini didapatkan bahwa pemotongan Trigram memiliki persentase kebenaran kategorisasi terbesar yaitu 26,035%.
Oleh:
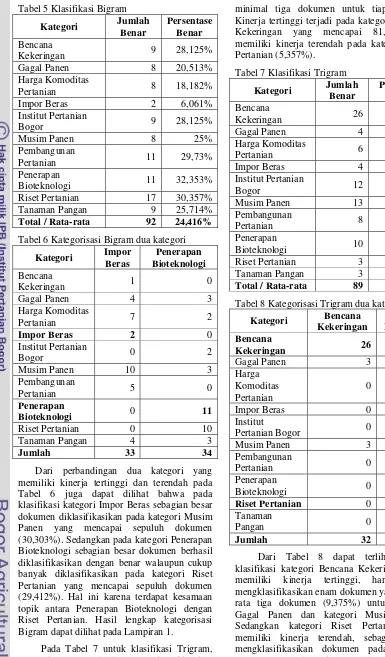
YUDHA PERMADI
G64102064
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Oleh:
YUDHA PERMADI
G64102064
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh:
YUDHA PERMADI
G64102064
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
YUDHA PERMADI. Kategorisasi Teks Menggunakan N-gram untuk Dokumen Berbahasa Indonesia. Dibimbing oleh JULIO ADISANTOSO dan FIRMAN ARDIANSYAH.
Luasnya sumber untuk mendapatkan suatu dokumen dengan topik atau tema tertentu dapat mengakibatkan banyaknya dokumen yang dicari memiliki topik yang sama walaupun dengan sudut pandang yang berbeda. Perbedaan sudut pandang ini kemudian dapat dikelompokkan berdasarkan pembahasan dari tiap sudut pandang. Namun jika dilihat dari akar permasalahan atau topik utamanya maka akan cukup sulit membedakan satu permasalahan dengan permasalahan lainnya.
Dalam bidang temu kembali informasi terdapat suatu model pengelompokan dokumen yang disebut kategorisasi teks. Model ini juga memiliki beberapa jenis metode pengelompokan dokumen yang salah satunya adalah metode N-gram. Metode N-gram merupakan suatu metode yang sering digunakan untuk mengenali kesalahan-kesalahan yang sering terjadi pada suatu dokumen. Menggunakan N-gram untuk proses kategorisasi teks, dokumen-dokumen dengan topik utama yang sama dapat dikelompokkan ke dalam beberapa kategori walaupun terdapat kesalahan tekstual.
Kinerja dari sistem ini dapat diketahui dengan membandingkan profil N-gram dari dokumen dengan kategori yang sudah ada. Dari proses perbandingan ini dapat ditentukan dan dikalkulasikan jarak antara dua profil tersebut, dan menentukan kategori mana yang memiliki jarak terkecil dengan dokumen tersebut. Dari penelitian ini didapatkan bahwa pemotongan Trigram memiliki persentase kebenaran kategorisasi terbesar yaitu 26,035%.
NRP :
G64102064
Menyetujui:
Pembimbing I,
Ir. Julio Adisantoso, M.Komp.
NIP 131578807
Pembimbing II,
Firman Ardiansyah, S.Kom, M.Si.
NIP 132311919
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. Drh. Hasim, DEA.
NIP 131578806
dari pasangan Agus Hendrayanto dan Sulastri. Penulis merupakan putra pertama dari dua bersaudara.
Pada tahun 2002 penulis lulus dari SMUN 3 Depok dan pada tahun yang sama lulus seleksi masuk IPB melalui jalur Seleksi Penerimaan Mahasiswa Baru. Penulis memilih Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT, karena atas rahmat dan hidayah-Nya penelitian ini dapat diselesaikan. Penelitian ini mengambil tema temu kembali informasi dengan judul Kategorisasi Teks Menggunakan N-gram untuk Dokumen Berbahasa Indonesia.
Dalam penyusunan tugas akhir ini, penulis memperoleh bimbingan dan bantuan dari berbagai pihak. Oleh karena itu, kata terima kasih sebesar-besarnya penulis ucapkan kepada Ayahanda dan Ibunda tercinta yang selalu mengalirkan do’a dan kasih sayangnya serta Adinda Imam Prayudhi yang selalu memberikan bantuan dan pengertiannya.
Bapak Ir. Julio Adisantoso, M.Komp. dan Bapak Firman Ardiansyah, S.Kom, M.Si. selaku pembimbing dan Bapak Sony Hartono Wijaya, S.Kom selaku penguji. Seluruh staf Departemen Ilmu Komputer.
Teman-teman lab TKI: Abdul Rahman, Nafi’ Ikhsani, Adam S. Akbar, M. Zaenal Arifin, dan Fridolin F. Paiki. Rekan-rekan ILKOMERZ 39 yang lain terutama Fajri Ma’rifatullah dan Sundoro A. Nugroho yang telah mendorong semangat penulis
Ummi Syarifah dan keluarga yang telah membantu cukup banyak dalam proses penelitian Akhir kata, penulis berharap agar hasil penelitian ini dapat bermanfaat bagi pembaca, terutama para pembaca yang berminat untuk melanjutkan dan menyempurnakan penelitian ini.
Depok, April 2008
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... vi
DAFTAR TABEL... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN... 1
Latar Belakang ... 1
Tujuan... 1
TINJAUAN PUSTAKA... 1
Temu Kembali Informasi... 1
Kategorisasi Teks ... 1
N-gram... 1
Kategorisasi Teks Menggunakan Frekuensi Statistik N-gram... 2
METODE PENELITIAN... 2
Penyusunan Frekuensi N-gram... 2
Perbandingan dan Perangkingan Frekuensi N-gram... 2
Pengujian Kategorisasi Teks pada Klasifikasi Tiap Kategori... 3
Koleksi Dokumen... 3
Lingkungan Pengembangan ... 3
HASIL DAN PEMBAHASAN ... 4
Koleksi Dokumen... 4
Kategori Dokumen ... 4
Pembuatan Profil ... 4
Hasil Perbandingan Jarak Profil ... 5
Evaluasi Klasifikasi Dokumen Berdasarkan Jenis N-gram ... 5
KESIMPULAN DAN SARAN ... 8
Kesimpulan... 8
Saran... 9
DAFTAR PUSTAKA ... 9
DAFTAR GAMBAR
Halaman
1 Distribusi Zipf dari frekuensi N-gram. ... 2
2 Ilustrasi pengukuran jarak. ... 3
3 Alur data kategorisasi teks... 3
4 Grafik jumlah N-gram dengan ukuran profil tiap kategori. ... 5
DAFTAR TABEL
Halaman 1 Profil kategori... 42 Kategori dokumen ... 4
3 Perbandingan jumlah dokumen ... 4
4 Jumlah N-gram tiap kategori ... 5
5 Klasifikasi Bigram... 6
6 Kategorisasi Bigram dua kategori ... 6
7 Klasifikasi Trigram... 6
8 Kategorisasi Trigram dua kategori ... 6
9 Klasifikasi Quadgram ... 7
10 Kategorisasi Quadgram dua kategori... 7
11 Kategorisasi Quadgram tanpa kategori Musim Panen... 7
12 Klasifikasi Ngram... 8
13 Klasifikasi Ngram dua kategori ... 8
14 Klasifikasi Ngram tanpa kategori Musim Panen ... 8
DAFTAR LAMPIRAN
Halaman 1 Kategorisasi teks menggunakan Bigram... 112 Kategorisasi teks menggunakan Trigram ... 12
3 Kategorisasi teks menggunakan Quadgram... 13
PENDAHULUAN
Latar Belakang
Dengan pesatnya perkembangan dan luasnya jangkauan Internet, maka banyak sekali sumber yang dapat digunakan untuk mendapatkan suatu dokumen. Bahkan untuk satu jenis pembahasan topik atau tema, banyak sekali dokumen-dokumen yang memiliki kesamaan walaupun pembahasan tema tiap-tiap dokumen dilihat dari beberapa sudut pandang. Contohnya untuk tema pertanian, dapat dibahas dalam beberapa sudut pandang, seperti pembangunan dalam bidang pertanian, penerapan metode tumpang sari, penelitian-penelitian bidang pertanian, dan lain-lain.
Beberapa perbedaan sudut pandang ini kemudian dapat digunakan untuk mengelompokkan dokumen-dokumen yang ada ke dalam beberapa pembahasan atau kelompok. Akan tetapi jika dilihat dari akar permasalahan atau tema utama dari dokumen-dokumen tersebut maka akan cukup sulit membedakan satu sudut pandang dengan sudut pandang yang lainnya. Akan lebih sulit juga apabila dokumen-dokumen yang akan dikelompokkan memiliki jumlah yang cukup banyak dan terus bertambah seiring waktu dan perkembangan jaman.
Oleh karena itu dibutuhkan suatu sistem yang dapat mengelompokkan dokumen-dokumen tersebut ke dalam beberapa kategori. Dalam bidang temu kembali informasi terdapat suatu model pengelompokan dokumen yang disebut kategorisasi teks. Dalam model ini terdapat berbagai jenis metode untuk mengelompokkan dokumen. Salah satu di antaranya adalah metode N-gram.
Metode N-gram sebenarnya merupakan suatu metode untuk mengenali kesalahan-kesalahan yang mungkin terjadi pada suatu dokumen. Kesalahan yang sering terjadi adalah kesalahan pengetikan dan kesalahan pengenalan suatu kata. Oleh karena itu, kategorisasi teks menggunakan N-gram akan memiliki beberapa karakteristik, antara lain:
• dapat berfungsi dengan baik walaupun terdapat kesalahan tekstual,
• dapat berjalan secara efisien, membutuhkan penyimpanan yang sederhana dan waktu proses yang cepat.
Tujuan
Penelitian ini bertujuan untuk mengimplementasikan dan menganalisis beberapa metode N-gram untuk kategorisasi
teks, serta mengetahui metode N-gram mana yang paling baik dalam proses kategorisasi teks. Penelitian ini dibatasi untuk dokumen-dokumen berbahasa Indonesia.
TINJAUAN PUSTAKA
Temu Kembali Informasi
Temu kembali informasi merupakan sebuah proses untuk membantu pengguna menemukan obyek informasi yang relevan dengan suatu tujuan atau masalah. Oleh karena itu, sebuah sistem temu kembali informasi memiliki sebuah tujuan untuk mengembalikan informasi yang relevan dan sesedikit mungkin (atau bahkan tidak) mengembalikan informasi yang tidak relevan terhadap yang diinginkan oleh pengguna (Baeza-Yates & Ribeiro-Neto 1999).
Untuk memenuhi tujuan dari sebuah sistem temu kembali informasi yang ideal, maka dikembangkan berbagai cara mengoptimalkan sistem temu kembali informasi. Beberapa cara untuk mengoptimalkan sebuah sistem temu kembali, adalah:
• mengembangkan pemrosesan dokumen, yaitu bagaimana dokumen direpresentasikan dalam sistem.
• mengembangkan ukuran kesamaan
(similarity measurement) antara dokumen
dengan kueri.
Kategorisasi Teks
Kategorisasi teks merupakan salah satu tahap pemrosesan dokumen pada temu kembali informasi, di mana dokumen-dokumen yang ada dikelompokkan atau diklasifikasikan ke dalam beberapa topik atau tema (Attardi 2004).
Pada kategorisasi teks, representasi suatu dokumen adalah kata, di mana tiap kata memiliki ciri khas yang berbeda. Oleh karena itu, pada sebagian besar proses kategorisasi teks, terdapat banyak ciri khas yang mungkin terjadi, baik ciri khas yang relevan dengan tema dokumen maupun yang tidak relevan dari proses kategorisasi. Adapun metode yang mengelompokkan semua ciri khas tersebut cenderung lebih baik daripada metode yang hanya mengelompokkan ciri khas yang relevan (Mooney 2001).
N-gram
pemotongan pada sebuah kata (Trenkle & Cavnar 1994). Khasnya adalah satu potongan kata menjadi seperangkat N-gram yang bertumpang tindih. Penambahan garis bawah
(blank) pada awal dan akhir kata digunakan
untuk membantu menentukan kondisi awal kata dan akhir kata. Maka pada kata ”TEKS” dapat dikomposisikan menjadi N-gram berikut:
Bi-gram: _T, TE, EK, KS, S_ Tri-gram: _TE, TEK, EKS, KS_, S_ _ Quad-gram: _TEK, TEKS, EKS_, KS_ _,
S_ _ _
Oleh karena itu, sebuah string dengan panjang k, ditambahkan dengan garis bawah, akan memiliki k+1 bigram, k+1 trigram, k+1 quadgram, dan seterusnya.
Pencocokan berdasarkan N-gram telah berhasil dalam menangani masukan yang tidak jernih seperti, dalam menafsirkan alamat pos, memulihkan teks, dan aplikasi pemrosesan bahasa alami. Kunci sukses pencocokan berdasarkan N-gram adalah karena tiap kata dikomposisikan menjadi bagian-bagian kecil, kesalahan yang muncul hanya mempengaruhi sejumlah kecil bagian tersebut, meninggalkan yang lain tetap utuh. Jika kita menghitung beberapa N-gram yang sama pada dua kata, kita akan mendapatkan ukuran kesamaan dua kata tersebut yang tidak terpengaruh oleh berbagai macam kesalahan tekstual.
Kategorisasi Teks Menggunakan Frekuensi Statistik N-gram
Bahasa manusia pada dasarnya memiliki beberapa kata yang lebih sering digunakan dari kata yang lainnya. Salah satu cara yang dapat digunakan untuk mengekspresikan ide ini adalah yang dikenal dengan Hukum Zipf yang berbunyi:
Kata ke-n yang paling umum pada teks bahasa manusia muncul dengan frekuensi yang berbanding terbalik pada n.
Implikasi dari hukum ini adalah bahwa selalu terdapat kata-kata yang paling mendominasi dari kata-kata lain dalam bahasa manusia pada frekuensi penggunaan tertentu. Implikasi ini cocok untuk kata-kata pada umumnya dan kata-kata yang spesifik pada subjek tertentu. Hukum Zipf mengimplikasikan bahwa mengklasifikasikan dokumen menggunakan frekuensi statistik N-gram tidak akan terlalu berpengaruh dalam pemotongan distribusi pada rank tertentu. Hal ini juga mengimplikasikan bahwa jika kita
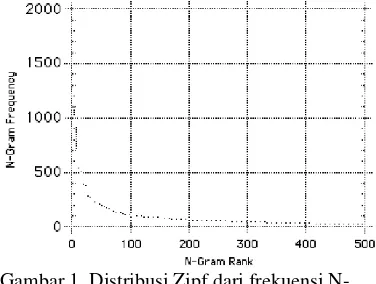
membandingkan dokumen dari kategori yang sama, maka dapat terlihat dokumen-dokumen tersebut memiliki distribusi frekuensi N-gram yang hampir sama (Trenkle & Cavnar 1994). Dari pernyataan tersebut dapat digambarkan implikasi Hukum Zipf seperti pada Gambar 1.
Gambar 1 Distribusi Zipf dari frekuensi N-gram.
METODE PENELITIAN
Penyusunan Frekuensi N-gram
Langkah ini dilakukan dengan membaca teks yang datang dan menghitung kemunculan dari ketiga N-gram. Adapun langkah-langkahnya adalah:
• Kata (token) diambil dari teks, dilakukan pembuangan stopword dan ditambahkan blank sebelum dan setelah token.
• N-gram dengan n = 2, 3, dan 4 dari token yang didapat kemudian disusun. Digunakan juga penambahan blank pada token.
• Dilakukan pemotongan untuk membentuk tabel untuk mendapatkan frekuensi untuk tiap N-gram. Tabel pemotongan diatur sedemikian rupa sehingga tiap N-gram memiliki frekuensi-nya masing-masing. • Setelah selesai, semua N-gram dan
frekuensi akhirnya serta jumlah N-gram tiap tabel ditampilkan.
• Akhirnya, frekuensi diurutkan berdasarkan banyaknya kemunculan, di mana yang digunakan hanya hasil pemotongan N-gram yang telah terurut dari banyaknya frekuensi.
Perbandingan dan Perangkingan Frekuensi N-gram
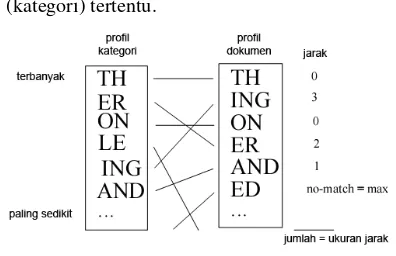
lainnya. Sehingga didapatkan ukuran jarak antara dokumen dan kumpulan dokumen (kategori) tertentu.
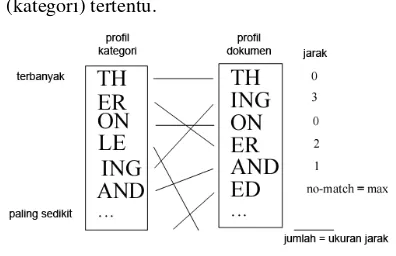
Gambar 2 Ilustrasi pengukuran jarak.
Seperti yang terlihat pada Gambar 2, pada profil dokumen dan profil kategori, N-gram ”TH” berada pada rank (baris) pertama, maka nilai jaraknya adalah 0. Jika N-gram ”ING” berada pada rank kedua pada profil dokumen dan pada rank kelima pada profil kategori, maka nilai jaraknya adalah 3. Apabila terdapat N-gram pada profil dokumen tapi tidak terdapat pada profil kategori, seperti N-gram ”ED”, maka nilai jaraknya adalah maksimum. Nilai maksimum yang dimaksud adalah jumlah N-gram dari profil kategori yang dibandingkan. Sedangkan ukuran jarak antara dokumen dengan kategori adalah jumlah dari nilai jarak dari tiap N-grampada profil dokumen.
Pengujian Kategorisasi Teks pada Klasifikasi Tiap Kategori
Pendekatan dalam kategorisasi teks dapat dilakukan dengan menggunakan frekuensi N-gram untuk mengukur kesamaan subjek (kategori) dari dokumen. Tentu saja pendekatannya berdasarkan dari isi dokumen yang mana menjadi daya tarik dari proses temu-kembali. Untuk menguji pendekatan ini, akan digunakan sistem klasifikasi untuk mengenali dokumen yang sesuai pada kategori yang akan digunakan. Seperti yang terlihat pada Gambar 3, prosedur untuk kategorisasi adalah sebagai berikut:
• Pengumpulan dokumen untuk tiap jenis sumber. Dokumen yang diambil adalah artikel surat kabar yang berkisar antara 686 bytes sampai 36 kilobytes.
• Penghitungan frekuensi N-gram pada tiap kategori (menyusun profil kategori). Frekuensi N-gram yang dimaksud adalah sama dengan frekuensi N-gram yang sebelumnya telah disebutkan.
• Penghitungan N-gram dari sebuah artikel dengan cara yang sama dengan
penghitungan frekuensi untuk tiap kategori (menyusun profil artikel / dokumen).
• Penghitungan keseluruhan ukuran jarak antara artikel dan kategori (mengukur jarak).
• Penentuan kumpulan dokumen terpilih dari sumber dokumen (memilih jarak terkecil).
Gambar 3 Alur data kategorisasi teks.
Koleksi Dokumen Pengujian
Untuk menguji sistem ini, digunakan koleksi dokumen (corpus) Adisantoso & Ridha (2004) yang berkaitan dengan masalah pertanian. Jumlah dokumen yang akan digunakan dalam penelitian ini sebanyak 1000 dokumen.
Lingkungan Pengembangan
Lingkungan pengembangan yang digunakan adalah sebagai berikut :
• Perangkat lunak: Windows XP Professional, Visual Basic .NET 2005, Microsoft Access 2003.
HASIL DAN PEMBAHASAN
Koleksi Dokumen
Koleksi dokumen yang digunakan pada penelitian ini berasal dari corpus Adisantoso & Ridha (2004). Jumlah dokumen pada koleksi ini adalah 1000 dokumen. Akan tetapi, koleksi yang terbagi dalam 30 kategori hanya 953 dokumen. Dalam penelitian ini, hanya digunakan 10 kategori yang memiliki jumlah dokumen terbanyak. Kemudian dari 10 kategori tersebut akan dibentuk profil kategori berdasarkan sebagian dari dokumen-dokumen dalam tiap kategori. Jumlah dari ukuran dokumen-dokumen yang akan digunakan sebagai profil kategori untuk tiap kategori dapat dilihat pada Tabel 1.
Tabel 1 Profil kategori
Kategori Ukuran
Profil (KB)
Bencana Kekeringan 40,9
Gagal Panen 61,3
Harga Komoditas Pertanian 140
Impor Beras 66,7
Institut Pertanian Bogor 58,8
Musim Panen 50,3
Pembangunan Pertanian 107 Penerapan Bioteknologi 72,9 Riset Pertanian 130 Tanaman Pangan 51,4
TOTAL 780
Kategori Dokumen
Penentuan kategori-kategori yang akan digunakan dalam penelitian adalah sepuluh kategori yang memiliki jumlah dokumen terbanyak pada koleksi dokumen. Dari tiap kategori yang telah ditentukan tersebut, dilakukan pembuatan profil untuk masing-masing kategori dan jenis-jenis kategori tersebut disimpan dalam tabel “Kategori”.
Jenis-jenis kategori dan jumlah dokumen perbandingan dalam penelitian ini dapat dilihat pada Tabel 2.
Pembuatan Profil
Proses pembuatan profil kategori dan profil dokumen pada dasarnya adalah sama, yaitu proses tokenizing, stopword, proses penambahan blank pada awal dan akhir tiap token, pemotongan N-gram untuk tiap nilai n, penyusunan ke dalam tabel-tabel tiap nilai n, dan pengurutan tabel-tabel tersebut berdasarkan jumlah tiap N-gramhasil pemotongan N-gram. Perbedaan proses pembuatan profil kategori dan
profil dokumen adalah pada banyaknya tabel yang dihasilkan.
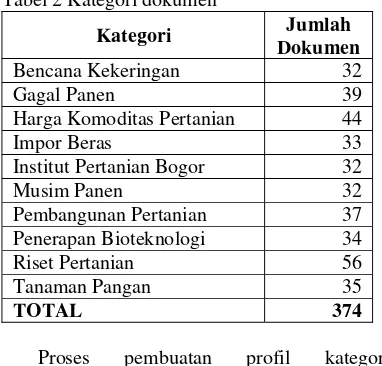
Tabel 2 Kategori dokumen
Kategori Jumlah
Dokumen
Bencana Kekeringan 32
Gagal Panen 39
Harga Komoditas Pertanian 44
Impor Beras 33
Institut Pertanian Bogor 32
Musim Panen 32
Pembangunan Pertanian 37 Penerapan Bioteknologi 34
Riset Pertanian 56
Tanaman Pangan 35
TOTAL 374
Proses pembuatan profil kategori menghasilkan empat tabel, yaitu tabel bigram (2gram), trigram (3gram), quadgram (4gram) dan Ngram (2gram, 3gram, 4gram). Sedangkan pada proses pembuatan profil dokumen hanya menghasilkan satu tabel, yaitu tabel dari jenis kategorisasi teks yang akan digunakan (2gram, 3gram, 4gram atau Ngram).
Tabel 3 Perbandingan jumlah dokumen
Kategori Jumlah
Profil
Jumlah Dokumen
%
Bencana
Kekeringan 7 39
17,949%
Gagal Panen 9 48 18,75%
Harga Komoditas Pertanian
11 55 20%
Impor Beras 8 41 19,512%
Institut Pertanian Bogor
8 40 20%
Musim Panen 8 40 20%
Pembangunan
Pertanian 9 46 19,565%
Penerapan
Bioteknologi 8 42 19,048%
Riset
Pertanian 13 69 18,841%
Tanaman
Pangan 8 43 18,605%
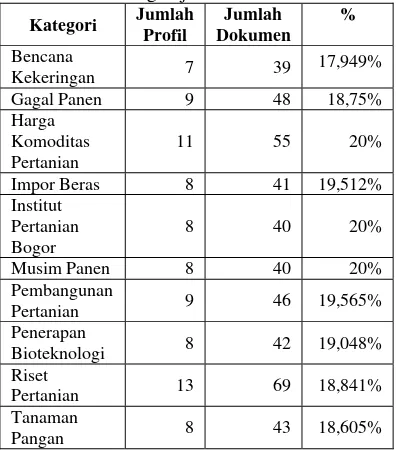
Pada Tabel 3 dapat dilihat bahwa jumlah dokumen yang akan digunakan dalam pembuatan profil tiap kategori adalah < 20% dari jumlah dokumen tiap kategori.
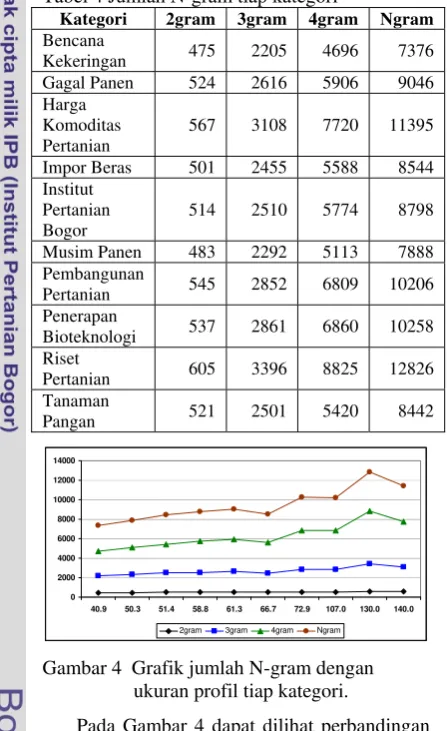
2000 – 4000 N-gram. Dan untuk Quadgram dan Ngram, jumlah N-gram mencapai lebih dari 4000 N-gram. Hal ini dapat disebabkan pada Bigram, tiap N-gram tidak memiliki pengertian yang jelas dalam pengelompokan N-gram. Pada Trigram, pengelompokan N-gram sudah memiliki pengertian jelas dalam tiap kelompok N-gram. Sedangkan pada Quadgram dan Ngram, tiap N-gram memiliki pengertian yang sangat jelas untuk dapat dikelompokkan seperti mengelompokkan kata dasar satu dengan yang lainnya atau kata dasar dengan imbuhannya. Tabel 4 Jumlah N-gram tiap kategori
Kategori 2gram 3gram 4gram Ngram
Bencana
Kekeringan 475 2205 4696 7376
Gagal Panen 524 2616 5906 9046
Harga Komoditas Pertanian
567 3108 7720 11395
Impor Beras 501 2455 5588 8544
Institut Pertanian Bogor
514 2510 5774 8798
Musim Panen 483 2292 5113 7888
Pembangunan
Pertanian 545 2852 6809 10206
Penerapan
Bioteknologi 537 2861 6860 10258
Riset
Pertanian 605 3396 8825 12826
Tanaman
Pangan 521 2501 5420 8442
0 2000 4000 6000 8000 10000 12000 14000
40.9 50.3 51.4 58.8 61.3 66.7 72.9 107.0 130.0 140.0
2gram 3gram 4gram Ngram
Gambar 4 Grafik jumlah N-gram dengan ukuran profil tiap kategori.
Pada Gambar 4 dapat dilihat perbandingan jumlah N-gram dengan ukuran profil tiap kategorinya, dapat diketahui bahwa semakin besar ukuran profil suatu kategori maka jumlah N-gram kategori tersebut juga cenderung semakin banyak. Meskipun hal ini juga sangat tergantung pada seberapa banyak kesalahan-kesalahan pada dokumen-dokumen yang digunakan untuk membuat profil kategori baik kesalahan pengetikan, pengejaan maupun kesalahan pengenalan suatu kata dalam dokumen. Semakin banyak kesalahan yang terjadi maka semakin banyak juga jumlah
N-gram yang dihasilkan pada proses pembuatan profil kategori.
Hasil Perbandingan Jarak Profil
Pengukuran jarak dalam proses kategorisasi teks adalah dengan menghitung perbedaan rank atau baris tabel tiap token antara profil dokumen dengan profil kategori. Hasil perbandingan ini kemudian dikalkulasikan untuk tiap kategori.
Proses perbandingan dilakukan berdasarkan banyaknya dokumen yang akan diklasifikasikan (374 dokumen). Tiap dokumen akan diklasifikasikan untuk tiap jenis N-gram (2gram, 3gram, 4gram dan Ngram).
Hal yang menarik dari hasil kalkulasi jarak tiap dokumen adalah semakin besar jumlah N-gram tiap profil dokumen maka akan semakin besar juga jarak antara dokumen tersebut dengan tiap kategori. Karena dengan semakin besar jumlah N-gram pada profil dokumen maka akan semakin bervariasi N-gram profil dokumen tersebut dan kondisi jarak maksimum akan semakin sering terjadi. Tetapi sebaliknya, semakin banyak jumlah N-gram pada profil suatu kategori maka akan semakin kecil jarak antara kategori tersebut dengan tiap dokumen. Hal ini disebabkan karena semakin banyak jumlah N-gram pada profil kategori maka kondisi jarak maksimum akan jarang terjadi.
Evaluasi Klasifikasi Dokumen Berdasarkan Jenis N-gram
Berdasarkan ukuran jarak yang telah didapatkan, kita dapat menentukan jarak suatu dokumen dengan tiap kategori. Dengan jarak tersebut kita dapat menentukan termasuk ke dalam kategori apa suatu dokumen dengan mencari nilai minimum jarak antara dokumen dan kategori tersebut.
Akan tetapi setiap jenis klasifikasi memiliki kinerja yang berbeda dan perlu dievaluasi. Hasil klasifikasi tiap jenis N-gram dapat dievaluasi sebagai berikut.
Tabel 5 Klasifikasi Bigram
Kategori Jumlah
Benar
Persentase Benar
Bencana
Kekeringan 9 28,125%
Gagal Panen 8 20,513% Harga Komoditas
Pertanian 8 18,182%
Impor Beras 2 6,061% Institut Pertanian
Bogor 9 28,125%
Musim Panen 8 25%
Pembangunan
Pertanian 11 29,73%
Penerapan
Bioteknologi 11 32,353% Riset Pertanian 17 30,357% Tanaman Pangan 9 25,714%
Total / Rata-rata 92 24,416%
Tabel 6 Kategorisasi Bigram dua kategori
Kategori Impor
Beras
Penerapan Bioteknologi
Bencana
Kekeringan 1 0
Gagal Panen 4 3
Harga Komoditas
Pertanian 7 2
Impor Beras 2 0
Institut Pertanian
Bogor 0 2
Musim Panen 10 3
Pembangunan
Pertanian 5 0
Penerapan
Bioteknologi 0 11
Riset Pertanian 0 10
Tanaman Pangan 4 3
Jumlah 33 34
Dari perbandingan dua kategori yang memiliki kinerja tertinggi dan terendah pada Tabel 6 juga dapat dilihat bahwa pada klasifikasi kategori Impor Beras sebagian besar dokumen diklasifikasikan pada kategori Musim Panen yang mencapai sepuluh dokumen (30,303%). Sedangkan pada kategori Penerapan Bioteknologi sebagian besar dokumen berhasil diklasifikasikan dengan benar walaupun cukup banyak diklasifikasikan pada kategori Riset Pertanian yang mencapai sepuluh dokumen (29,412%). Hal ini karena terdapat kesamaan topik antara Penerapan Bioteknologi dengan Riset Pertanian. Hasil lengkap kategorisasi Bigram dapat dilihat pada Lampiran 1.
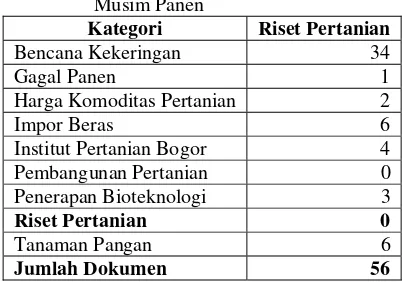
Pada Tabel 7 untuk klasifikasi Trigram, proses kategorisasi berhasil mengklasifikasikan
minimal tiga dokumen untuk tiap kategori. Kinerja tertinggi terjadi pada kategori Bencana Kekeringan yang mencapai 81,25% dan memiliki kinerja terendah pada kategori Riset Pertanian (5,357%).
Tabel 7 Klasifikasi Trigram
Kategori Jumlah
Benar
Persentase Benar
Bencana
Kekeringan 26 81,25%
Gagal Panen 4 10,256% Harga Komoditas
Pertanian 6 13,636%
Impor Beras 4 12,121% Institut Pertanian
Bogor 12 37,5%
Musim Panen 13 40,625% Pembangunan
Pertanian 8 21,622%
Penerapan
Bioteknologi 10 29,412%
Riset Pertanian 3 5,357% Tanaman Pangan 3 8,571%
Total / Rata-rata 89 26,035%
Tabel 8 Kategorisasi Trigram dua kategori
Kategori Bencana
Kekeringan
Riset Pertanian Bencana
Kekeringan 26 5
Gagal Panen 3 3
Harga Komoditas Pertanian
0 4
Impor Beras 0 5
Institut
Pertanian Bogor 0 6
Musim Panen 3 18
Pembangunan
Pertanian 0 0
Penerapan
Bioteknologi 0 10
Riset Pertanian 0 3
Tanaman
Pangan 0 2
Jumlah 32 56
(32,143%) dan kategori Penerapan Bioteknologi sebanyak sepuluh dokumen (17,857%). Hasil lengkap kategorisasi Trigram dapat dilihat pada Lampiran 2.
Tabel 9 Klasifikasi Quadgram
Kategori Jumlah
Benar
Persentase Benar
Bencana
Kekeringan 31 96,875%
Gagal Panen 1 2,564% Harga Komoditas
Pertanian 2 4,545%
Impor Beras 4 12,121% Institut Pertanian
Bogor 12 37,5%
Musim Panen 8 25%
Pembangunan
Pertanian 4 10,811%
Penerapan
Bioteknologi 2 5,882%
Riset Pertanian 0 0% Tanaman Pangan 4 11,429%
Total / Rata-rata 68 20,673%
Tabel 10 Kategorisasi Quadgram dua kategori
Kategori Bencana
Kekeringan
Riset Pertanian Bencana
Kekeringan 31 16
Gagal Panen 0 1
Harga Komoditas Pertanian
0 1
Impor Beras 0 4
Institut Pertanian Bogor
0 3
Musim Panen 1 28
Pembangunan
Pertanian 0 0
Penerapan
Bioteknologi 0 1
Riset
Pertanian 0 0
Tanaman
Pangan 0 2
Jumlah 32 56
Dengan melihat Tabel 9 dapat dikatakan bahwa pada klasifikasi Quadgram terdapat keanehan pada proses kategorisasi. Dapat terlihat pada kategori Bencana Kekeringan, proses kategorisasi berhasil mengklasifikasikan hampir semua dokumen dan memiliki kinerja tertinggi pada kategori ini yang mencapai 96,875%. Akan tetapi pada klasifikasi Quadgram, proses kategorisasi tidak
mengklasifikasikan satu dokumen pun dari 56 dokumen yang ada yang termasuk kategori Riset Pertanian.
Dengan melihat Tabel 10 dapat dikatakan bahwa kategori Bencana Kekeringan cukup mendominasi klasifikasi dokumen. Dengan mengklasifikasikan 31 dokumen benar dan hanya satu dokumen (3,125%) salah yang diklasifikasikan termasuk kategori Musim Panen. Sedangkan pada kategori Riset Pertanian, klasifikasi dokumen terkonsentrasi pada kategori Musim panen yang mencapai 28 dokumen atau 50% dari keseluruhan dokumen dan enam belas dokumen terklasifikasikan pada kategori Bencana Kekeringan tanpa ada satu dokumen pun yang termasuk klasifikasi kategori Riset Pertanian. Hasil lengkap kategorisasi Quadgram dapat dilihat pada Lampiran 3.
Dengan melihat pada Tabel 11 dapat dikatakan bahwa walaupun kategori Musim Panen dihilangkan dalam proses kategorisasi, klasifikasi Quadgram juga tidak berhasil mengklasifikasikan dokumen yang termasuk kategori Riset Pertanian dan lebih mengklasifikasikan sebagian besar dokumen pada kategori Bencana Kekeringan yang mencapai 34 dokumen (60,714%).
Tabel 11 Kategorisasi Quadgram tanpa kategori Musim Panen
Kategori Riset Pertanian
Bencana Kekeringan 34
Gagal Panen 1
Harga Komoditas Pertanian 2
Impor Beras 6
Institut Pertanian Bogor 4 Pembangunan Pertanian 0 Penerapan Bioteknologi 3
Riset Pertanian 0
Tanaman Pangan 6
Jumlah Dokumen 56
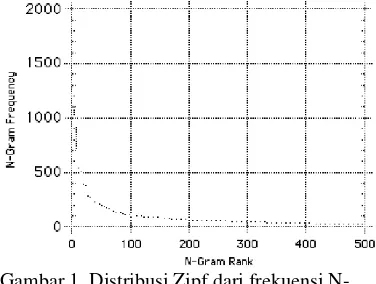
Pada klasifikasi Ngram memiliki beberapa kesamaan dengan klasifikasi Quadgram di mana pada klasifikasi kategori Bencana Kekeringan kinerja mencapai lebih dari 90%, yaitu 90,625% dan tidak mengklasifikasikan satu pun dokumen dari 56 dokumen kategori Riset Pertanian. Hasil lengkap dari klasifikasi Ngram dapat dilihat pada Tabel 12.
(3,125%) yang termasuk kategori Gagal Panen dan dua dokumen (6,25%) yang termasuk kategori Musim Panen. Sedangkan untuk kategori Riset Pertanian, proses kategorisasi mengklasifikasikan 27 dokumen (48,214%) yang termasuk kategori Musim Panen. Ini dapat terlihat pada Tabel 13. Hasil lengkap kategorisasi Ngram dapat dilihat pada Lampiran 4.
Tabel 12 Klasifikasi Ngram
Kategori Jumlah
Benar
Persentase Benar
Bencana
Kekeringan 29 90,625%
Gagal Panen 1 2,564% Harga Komoditas
Pertanian 4 9,091%
Impor Beras 6 18,182% Institut Pertanian
Bogor 17 53,125%
Musim Panen 9 28,125% Pembangunan
Pertanian 5 13,514%
Penerapan
Bioteknologi 7 20,588%
Riset Pertanian 0 0% Tanaman Pangan 3 8,571%
Total / Rata-rata 81 24,439%
Tabel 13 Klasifikasi Ngram dua kategori
Kategori Bencana
Kekeringan
Riset Pertanian Bencana
Kekeringan 29 9
Gagal Panen 1 1
Harga Komoditas Pertanian
0 2
Impor Beras 0 3
Institut
Pertanian Bogor 0 6
Musim Panen 2 27
Pembangunan
Pertanian 0 0
Penerapan
Bioteknologi 0 4
Riset Pertanian 0 0
Tanaman
Pangan 0 4
Jumlah 32 56
Hampir sama dengan hasil klasifikasi Quadgram, klasifikasi Ngram tanpa kategori Musim Panen juga tidak berhasil mengklasifikasikan dokumen untuk kategori Riset Pertanian. Akan tetapi pada klasifikasi Ngram, hasil klasifikasi dokumen
terdistribusikan hampir ke semua kategori dengan sebagian besar terklasifikasikan pada kategori Bencana Kekeringan sebanyak sembilan belas dokumen (33,929%) dan kategori Penerapan Bioteknologi sebanyak dua belas dokumen (21,429%). Hasil selengkapnya dapat dilihat pada Tabel 14.
Tabel 14 Klasifikasi Ngram tanpa kategori Musim Panen
Kategori Riset Pertanian
Bencana Kekeringan 19
Gagal Panen 2
Harga Komoditas Pertanian 3
Impor Beras 5
Institut Pertanian Bogor 8 Pembangunan Pertanian 1 Penerapan Bioteknologi 12
Riset Pertanian 0
Tanaman Pangan 6
Jumlah Dokumen 56
KESIMPULAN DAN SARAN
Kesimpulan
• Pada proses kategorisasi teks menggunakan N-gram, klasifikasi Trigram yang paling sesuai untuk dokumen-dokumen berbahasa Indonesia dengan persentase hasil 26,035%. • Klasifikasi Trigram juga cukup dapat
diandalkan untuk proses kategorisasi teks, karena semua kategori berhasil diklasifikasikan dengan benar dengan kinerja tertinggi 81,25% dan kinerja terendah 5,357%.
• Klasifikasi Trigram dianggap paling sesuai untuk implementasi Kategorisasi Teks karena pada dokumen berbahasa Indonesia, Trigram dapat mengelompokkan kata-kata dalam bahasa Indonesia baik kata-kata dasar maupun kata-kata yang berimbuhan tanpa menggunakan proses stemming. • Kategorisasi teks menggunakan N-gram
terbukti cukup efektif dalam mengklasifikasikan dokumen karena metode ini menggunakan pendekatan “kategorisasi menggunakan contoh” dengan cara mengumpulkan dan menggunakan profil kategori dari dokumen yang sudah ada.
• Tingkat akurasi rata-rata semua jenis N-gram adalah 23,891%.
Saran
Terdapat beberapa hal yang dapat diperhatikan untuk penelitian-penelitian selanjutnya:
• dalam pembuatan profil kategori dapat menggunakan dokumen-dokumen yang lebih memperlihatkan perbedaan karakteristik untuk tiap kategori.
• dapat juga dikembangkan beberapa jenis N-gram lain untuk proses kategorisasi teks. • menggunakan beberapa macam metode
perhitungan jarak antara suatu dokumen dengan kategori yang ada.
• menggunakan metode yang berbeda dalam mempresentasikan profil suatu kategori.
DAFTAR PUSTAKA
Adisantoso J, Ridha A. 2004. Corpus Dokumen Teks Bahasa Indonesia untuk Pengujian Efektivitas Temu Kembali Informasi. Laporan Akhir Hibah Penelitian SP4. Bogor: Departemen Ilmu Komputer FMIPA IPB.
Attardi G. 2004. Text Categorization. Roma: Pisa University Pr.
Baeza-Yates R, Ribeiro-Neto B. 1999. Modern
Information Retrieval. England:
Addison-Wesley.
Mooney R. 2001. Intelligent Information Retrieval and Web Search. Austin: Texas University Pr.
Trenkle JM, Cavnar WB.1994. N-Gram-Based
Text Categorization. Di dalam: Lewis D,
editor. Proceedings of Third Annual Symposium on Document Analysis and
Information Retrieval; Las Vegas, 11-13
April 1994. Nevada: UNLV Publications/Reprographics. Hlm 161-175.
Zipf GK. 1949. Human Behavior and The Principle of Least Effort, An Introduction
To Human Ecology. England:
Lampiran 1 Kategorisasi teks menggunakan Bigram
Kategori Bencana Kekeringan
Gagal Panen
Harga Komoditas
Pertanian
Impor Beras
Institut Pertanian
Bogor
Musim Panen
Pembangunan Pertanian
Penerapan Bioteknologi
Riset Pertanian
Tanaman Pangan
Bencana Kekeringan 9 12 3 1 2 5 0 0 2 5
Gagal Panen 6 8 5 4 1 5 3 3 5 9
Harga Komoditas Pertanian 0 1 8 7 4 2 12 2 5 1
Impor Beras 1 0 1 2 1 1 2 0 1 1
Institut Pertanian Bogor 2 1 0 0 9 0 2 2 5 2
Musim Panen 2 5 12 10 5 8 0 3 2 0
Pembangunan Pertanian 1 0 5 5 2 1 11 0 3 2
Penerapan Bioteknologi 0 1 1 0 1 2 0 11 7 3
Riset Pertanian 1 0 4 0 5 1 1 10 17 3
Tanaman Pangan 10 11 5 4 2 7 6 3 9 9
Lampiran 2 Kategorisasi teks menggunakan Trigram
Kategori Bencana Kekeringan
Gagal Panen
Harga Komoditas
Pertanian
Impor Beras
Institut Pertanian
Bogor
Musim Panen
Pembangunan Pertanian
Penerapan Bioteknologi
Riset Pertanian
Tanaman Pangan
Bencana Kekeringan 26 30 4 1 4 11 4 0 5 13
Gagal Panen 3 4 1 2 0 2 1 4 3 0
Harga Komoditas Pertanian 0 0 6 6 0 2 8 1 4 0
Impor Beras 0 0 8 4 5 1 5 1 5 2
Institut Pertanian Bogor 0 1 1 0 12 0 3 1 6 1
Musim Panen 3 3 18 17 5 13 5 10 18 9
Pembangunan Pertanian 0 1 1 2 4 0 8 0 0 2
Penerapan Bioteknologi 0 0 2 0 1 2 0 10 10 5
Riset Pertanian 0 0 1 0 1 0 0 6 3 0
Tanaman Pangan 0 0 2 1 0 1 3 1 2 3
Lampiran 3 Kategorisasi teks menggunakan Quadgram
Kategori Bencana Kekeringan
Gagal Panen
Harga Komoditas
Pertanian
Impor Beras
Institut Pertanian
Bogor
Musim Panen
Pembangunan Pertanian
Penerapan Bioteknologi
Riset Pertanian
Tanaman Pangan
Bencana Kekeringan 31 34 8 7 14 20 10 5 16 20
Gagal Panen 0 1 1 0 0 0 1 3 1 0
Harga Komoditas Pertanian 0 0 2 1 0 0 3 0 1 0
Impor Beras 0 1 12 5 2 2 8 1 4 2
Institut Pertanian Bogor 0 1 1 1 12 0 2 0 3 0
Musim Panen 1 2 19 17 3 8 7 20 28 6
Pembangunan Pertanian 0 0 0 1 1 0 4 0 0 1
Penerapan Bioteknologi 0 0 0 0 0 1 0 2 1 2
Riset Pertanian 0 0 0 0 0 0 0 0 0 0
Tanaman Pangan 0 0 1 1 0 1 2 3 2 4
Lampiran 4 Kategorisasi teks menggunakan Ngram
Kategori Bencana Kekeringan
Gagal Panen
Harga Komoditas
Pertanian
Impor Beras
Institut Pertanian
Bogor
Musim Panen
Pembangunan Pertanian
Penerapan Bioteknologi
Riset Pertanian
Tanaman Pangan
Bencana Kekeringan 29 34 7 3 7 17 7 4 9 17
Gagal Panen 1 1 1 1 0 0 1 3 1 0
Harga Komoditas Pertanian 0 0 4 2 0 0 5 0 2 0
Impor Beras 0 1 10 6 3 3 10 1 3 2
Institut Pertanian Bogor 0 1 1 0 17 0 3 0 6 0
Musim Panen 2 2 19 18 3 9 2 16 27 8
Pembangunan Pertanian 0 0 0 3 2 0 5 0 0 2
Penerapan Bioteknologi 0 0 0 0 0 1 0 7 4 3
Riset Pertanian 0 0 0 0 0 0 0 1 0 0
Tanaman Pangan 0 0 2 0 0 2 4 2 4 3
PENDAHULUAN
Latar Belakang
Dengan pesatnya perkembangan dan luasnya jangkauan Internet, maka banyak sekali sumber yang dapat digunakan untuk mendapatkan suatu dokumen. Bahkan untuk satu jenis pembahasan topik atau tema, banyak sekali dokumen-dokumen yang memiliki kesamaan walaupun pembahasan tema tiap-tiap dokumen dilihat dari beberapa sudut pandang. Contohnya untuk tema pertanian, dapat dibahas dalam beberapa sudut pandang, seperti pembangunan dalam bidang pertanian, penerapan metode tumpang sari, penelitian-penelitian bidang pertanian, dan lain-lain.
Beberapa perbedaan sudut pandang ini kemudian dapat digunakan untuk mengelompokkan dokumen-dokumen yang ada ke dalam beberapa pembahasan atau kelompok. Akan tetapi jika dilihat dari akar permasalahan atau tema utama dari dokumen-dokumen tersebut maka akan cukup sulit membedakan satu sudut pandang dengan sudut pandang yang lainnya. Akan lebih sulit juga apabila dokumen-dokumen yang akan dikelompokkan memiliki jumlah yang cukup banyak dan terus bertambah seiring waktu dan perkembangan jaman.
Oleh karena itu dibutuhkan suatu sistem yang dapat mengelompokkan dokumen-dokumen tersebut ke dalam beberapa kategori. Dalam bidang temu kembali informasi terdapat suatu model pengelompokan dokumen yang disebut kategorisasi teks. Dalam model ini terdapat berbagai jenis metode untuk mengelompokkan dokumen. Salah satu di antaranya adalah metode N-gram.
Metode N-gram sebenarnya merupakan suatu metode untuk mengenali kesalahan-kesalahan yang mungkin terjadi pada suatu dokumen. Kesalahan yang sering terjadi adalah kesalahan pengetikan dan kesalahan pengenalan suatu kata. Oleh karena itu, kategorisasi teks menggunakan N-gram akan memiliki beberapa karakteristik, antara lain:
• dapat berfungsi dengan baik walaupun terdapat kesalahan tekstual,
• dapat berjalan secara efisien, membutuhkan penyimpanan yang sederhana dan waktu proses yang cepat.
Tujuan
Penelitian ini bertujuan untuk mengimplementasikan dan menganalisis beberapa metode N-gram untuk kategorisasi
teks, serta mengetahui metode N-gram mana yang paling baik dalam proses kategorisasi teks. Penelitian ini dibatasi untuk dokumen-dokumen berbahasa Indonesia.
TINJAUAN PUSTAKA
Temu Kembali Informasi
Temu kembali informasi merupakan sebuah proses untuk membantu pengguna menemukan obyek informasi yang relevan dengan suatu tujuan atau masalah. Oleh karena itu, sebuah sistem temu kembali informasi memiliki sebuah tujuan untuk mengembalikan informasi yang relevan dan sesedikit mungkin (atau bahkan tidak) mengembalikan informasi yang tidak relevan terhadap yang diinginkan oleh pengguna (Baeza-Yates & Ribeiro-Neto 1999).
Untuk memenuhi tujuan dari sebuah sistem temu kembali informasi yang ideal, maka dikembangkan berbagai cara mengoptimalkan sistem temu kembali informasi. Beberapa cara untuk mengoptimalkan sebuah sistem temu kembali, adalah:
• mengembangkan pemrosesan dokumen, yaitu bagaimana dokumen direpresentasikan dalam sistem.
• mengembangkan ukuran kesamaan
(similarity measurement) antara dokumen
dengan kueri.
Kategorisasi Teks
Kategorisasi teks merupakan salah satu tahap pemrosesan dokumen pada temu kembali informasi, di mana dokumen-dokumen yang ada dikelompokkan atau diklasifikasikan ke dalam beberapa topik atau tema (Attardi 2004).
Pada kategorisasi teks, representasi suatu dokumen adalah kata, di mana tiap kata memiliki ciri khas yang berbeda. Oleh karena itu, pada sebagian besar proses kategorisasi teks, terdapat banyak ciri khas yang mungkin terjadi, baik ciri khas yang relevan dengan tema dokumen maupun yang tidak relevan dari proses kategorisasi. Adapun metode yang mengelompokkan semua ciri khas tersebut cenderung lebih baik daripada metode yang hanya mengelompokkan ciri khas yang relevan (Mooney 2001).
N-gram
PENDAHULUAN
Latar Belakang
Dengan pesatnya perkembangan dan luasnya jangkauan Internet, maka banyak sekali sumber yang dapat digunakan untuk mendapatkan suatu dokumen. Bahkan untuk satu jenis pembahasan topik atau tema, banyak sekali dokumen-dokumen yang memiliki kesamaan walaupun pembahasan tema tiap-tiap dokumen dilihat dari beberapa sudut pandang. Contohnya untuk tema pertanian, dapat dibahas dalam beberapa sudut pandang, seperti pembangunan dalam bidang pertanian, penerapan metode tumpang sari, penelitian-penelitian bidang pertanian, dan lain-lain.
Beberapa perbedaan sudut pandang ini kemudian dapat digunakan untuk mengelompokkan dokumen-dokumen yang ada ke dalam beberapa pembahasan atau kelompok. Akan tetapi jika dilihat dari akar permasalahan atau tema utama dari dokumen-dokumen tersebut maka akan cukup sulit membedakan satu sudut pandang dengan sudut pandang yang lainnya. Akan lebih sulit juga apabila dokumen-dokumen yang akan dikelompokkan memiliki jumlah yang cukup banyak dan terus bertambah seiring waktu dan perkembangan jaman.
Oleh karena itu dibutuhkan suatu sistem yang dapat mengelompokkan dokumen-dokumen tersebut ke dalam beberapa kategori. Dalam bidang temu kembali informasi terdapat suatu model pengelompokan dokumen yang disebut kategorisasi teks. Dalam model ini terdapat berbagai jenis metode untuk mengelompokkan dokumen. Salah satu di antaranya adalah metode N-gram.
Metode N-gram sebenarnya merupakan suatu metode untuk mengenali kesalahan-kesalahan yang mungkin terjadi pada suatu dokumen. Kesalahan yang sering terjadi adalah kesalahan pengetikan dan kesalahan pengenalan suatu kata. Oleh karena itu, kategorisasi teks menggunakan N-gram akan memiliki beberapa karakteristik, antara lain:
• dapat berfungsi dengan baik walaupun terdapat kesalahan tekstual,
• dapat berjalan secara efisien, membutuhkan penyimpanan yang sederhana dan waktu proses yang cepat.
Tujuan
Penelitian ini bertujuan untuk mengimplementasikan dan menganalisis beberapa metode N-gram untuk kategorisasi
teks, serta mengetahui metode N-gram mana yang paling baik dalam proses kategorisasi teks. Penelitian ini dibatasi untuk dokumen-dokumen berbahasa Indonesia.
TINJAUAN PUSTAKA
Temu Kembali Informasi
Temu kembali informasi merupakan sebuah proses untuk membantu pengguna menemukan obyek informasi yang relevan dengan suatu tujuan atau masalah. Oleh karena itu, sebuah sistem temu kembali informasi memiliki sebuah tujuan untuk mengembalikan informasi yang relevan dan sesedikit mungkin (atau bahkan tidak) mengembalikan informasi yang tidak relevan terhadap yang diinginkan oleh pengguna (Baeza-Yates & Ribeiro-Neto 1999).
Untuk memenuhi tujuan dari sebuah sistem temu kembali informasi yang ideal, maka dikembangkan berbagai cara mengoptimalkan sistem temu kembali informasi. Beberapa cara untuk mengoptimalkan sebuah sistem temu kembali, adalah:
• mengembangkan pemrosesan dokumen, yaitu bagaimana dokumen direpresentasikan dalam sistem.
• mengembangkan ukuran kesamaan
(similarity measurement) antara dokumen
dengan kueri.
Kategorisasi Teks
Kategorisasi teks merupakan salah satu tahap pemrosesan dokumen pada temu kembali informasi, di mana dokumen-dokumen yang ada dikelompokkan atau diklasifikasikan ke dalam beberapa topik atau tema (Attardi 2004).
Pada kategorisasi teks, representasi suatu dokumen adalah kata, di mana tiap kata memiliki ciri khas yang berbeda. Oleh karena itu, pada sebagian besar proses kategorisasi teks, terdapat banyak ciri khas yang mungkin terjadi, baik ciri khas yang relevan dengan tema dokumen maupun yang tidak relevan dari proses kategorisasi. Adapun metode yang mengelompokkan semua ciri khas tersebut cenderung lebih baik daripada metode yang hanya mengelompokkan ciri khas yang relevan (Mooney 2001).
N-gram
pemotongan pada sebuah kata (Trenkle & Cavnar 1994). Khasnya adalah satu potongan kata menjadi seperangkat N-gram yang bertumpang tindih. Penambahan garis bawah
(blank) pada awal dan akhir kata digunakan
untuk membantu menentukan kondisi awal kata dan akhir kata. Maka pada kata ”TEKS” dapat dikomposisikan menjadi N-gram berikut:
Bi-gram: _T, TE, EK, KS, S_ Tri-gram: _TE, TEK, EKS, KS_, S_ _ Quad-gram: _TEK, TEKS, EKS_, KS_ _,
S_ _ _
Oleh karena itu, sebuah string dengan panjang k, ditambahkan dengan garis bawah, akan memiliki k+1 bigram, k+1 trigram, k+1 quadgram, dan seterusnya.
Pencocokan berdasarkan N-gram telah berhasil dalam menangani masukan yang tidak jernih seperti, dalam menafsirkan alamat pos, memulihkan teks, dan aplikasi pemrosesan bahasa alami. Kunci sukses pencocokan berdasarkan N-gram adalah karena tiap kata dikomposisikan menjadi bagian-bagian kecil, kesalahan yang muncul hanya mempengaruhi sejumlah kecil bagian tersebut, meninggalkan yang lain tetap utuh. Jika kita menghitung beberapa N-gram yang sama pada dua kata, kita akan mendapatkan ukuran kesamaan dua kata tersebut yang tidak terpengaruh oleh berbagai macam kesalahan tekstual.
Kategorisasi Teks Menggunakan Frekuensi Statistik N-gram
Bahasa manusia pada dasarnya memiliki beberapa kata yang lebih sering digunakan dari kata yang lainnya. Salah satu cara yang dapat digunakan untuk mengekspresikan ide ini adalah yang dikenal dengan Hukum Zipf yang berbunyi:
Kata ke-n yang paling umum pada teks bahasa manusia muncul dengan frekuensi yang berbanding terbalik pada n.
Implikasi dari hukum ini adalah bahwa selalu terdapat kata-kata yang paling mendominasi dari kata-kata lain dalam bahasa manusia pada frekuensi penggunaan tertentu. Implikasi ini cocok untuk kata-kata pada umumnya dan kata-kata yang spesifik pada subjek tertentu. Hukum Zipf mengimplikasikan bahwa mengklasifikasikan dokumen menggunakan frekuensi statistik N-gram tidak akan terlalu berpengaruh dalam pemotongan distribusi pada rank tertentu. Hal ini juga mengimplikasikan bahwa jika kita
membandingkan dokumen dari kategori yang sama, maka dapat terlihat dokumen-dokumen tersebut memiliki distribusi frekuensi N-gram yang hampir sama (Trenkle & Cavnar 1994). Dari pernyataan tersebut dapat digambarkan implikasi Hukum Zipf seperti pada Gambar 1.
Gambar 1 Distribusi Zipf dari frekuensi N-gram.
METODE PENELITIAN
Penyusunan Frekuensi N-gram
Langkah ini dilakukan dengan membaca teks yang datang dan menghitung kemunculan dari ketiga N-gram. Adapun langkah-langkahnya adalah:
• Kata (token) diambil dari teks, dilakukan pembuangan stopword dan ditambahkan blank sebelum dan setelah token.
• N-gram dengan n = 2, 3, dan 4 dari token yang didapat kemudian disusun. Digunakan juga penambahan blank pada token.
• Dilakukan pemotongan untuk membentuk tabel untuk mendapatkan frekuensi untuk tiap N-gram. Tabel pemotongan diatur sedemikian rupa sehingga tiap N-gram memiliki frekuensi-nya masing-masing. • Setelah selesai, semua N-gram dan
frekuensi akhirnya serta jumlah N-gram tiap tabel ditampilkan.
• Akhirnya, frekuensi diurutkan berdasarkan banyaknya kemunculan, di mana yang digunakan hanya hasil pemotongan N-gram yang telah terurut dari banyaknya frekuensi.
Perbandingan dan Perangkingan Frekuensi N-gram
pemotongan pada sebuah kata (Trenkle & Cavnar 1994). Khasnya adalah satu potongan kata menjadi seperangkat N-gram yang bertumpang tindih. Penambahan garis bawah
(blank) pada awal dan akhir kata digunakan
untuk membantu menentukan kondisi awal kata dan akhir kata. Maka pada kata ”TEKS” dapat dikomposisikan menjadi N-gram berikut:
Bi-gram: _T, TE, EK, KS, S_ Tri-gram: _TE, TEK, EKS, KS_, S_ _ Quad-gram: _TEK, TEKS, EKS_, KS_ _,
S_ _ _
Oleh karena itu, sebuah string dengan panjang k, ditambahkan dengan garis bawah, akan memiliki k+1 bigram, k+1 trigram, k+1 quadgram, dan seterusnya.
Pencocokan berdasarkan N-gram telah berhasil dalam menangani masukan yang tidak jernih seperti, dalam menafsirkan alamat pos, memulihkan teks, dan aplikasi pemrosesan bahasa alami. Kunci sukses pencocokan berdasarkan N-gram adalah karena tiap kata dikomposisikan menjadi bagian-bagian kecil, kesalahan yang muncul hanya mempengaruhi sejumlah kecil bagian tersebut, meninggalkan yang lain tetap utuh. Jika kita menghitung beberapa N-gram yang sama pada dua kata, kita akan mendapatkan ukuran kesamaan dua kata tersebut yang tidak terpengaruh oleh berbagai macam kesalahan tekstual.
Kategorisasi Teks Menggunakan Frekuensi Statistik N-gram
Bahasa manusia pada dasarnya memiliki beberapa kata yang lebih sering digunakan dari kata yang lainnya. Salah satu cara yang dapat digunakan untuk mengekspresikan ide ini adalah yang dikenal dengan Hukum Zipf yang berbunyi:
Kata ke-n yang paling umum pada teks bahasa manusia muncul dengan frekuensi yang berbanding terbalik pada n.
Implikasi dari hukum ini adalah bahwa selalu terdapat kata-kata yang paling mendominasi dari kata-kata lain dalam bahasa manusia pada frekuensi penggunaan tertentu. Implikasi ini cocok untuk kata-kata pada umumnya dan kata-kata yang spesifik pada subjek tertentu. Hukum Zipf mengimplikasikan bahwa mengklasifikasikan dokumen menggunakan frekuensi statistik N-gram tidak akan terlalu berpengaruh dalam pemotongan distribusi pada rank tertentu. Hal ini juga mengimplikasikan bahwa jika kita
membandingkan dokumen dari kategori yang sama, maka dapat terlihat dokumen-dokumen tersebut memiliki distribusi frekuensi N-gram yang hampir sama (Trenkle & Cavnar 1994). Dari pernyataan tersebut dapat digambarkan implikasi Hukum Zipf seperti pada Gambar 1.
Gambar 1 Distribusi Zipf dari frekuensi N-gram.
METODE PENELITIAN
Penyusunan Frekuensi N-gram
Langkah ini dilakukan dengan membaca teks yang datang dan menghitung kemunculan dari ketiga N-gram. Adapun langkah-langkahnya adalah:
• Kata (token) diambil dari teks, dilakukan pembuangan stopword dan ditambahkan blank sebelum dan setelah token.
• N-gram dengan n = 2, 3, dan 4 dari token yang didapat kemudian disusun. Digunakan juga penambahan blank pada token.
• Dilakukan pemotongan untuk membentuk tabel untuk mendapatkan frekuensi untuk tiap N-gram. Tabel pemotongan diatur sedemikian rupa sehingga tiap N-gram memiliki frekuensi-nya masing-masing. • Setelah selesai, semua N-gram dan
frekuensi akhirnya serta jumlah N-gram tiap tabel ditampilkan.
• Akhirnya, frekuensi diurutkan berdasarkan banyaknya kemunculan, di mana yang digunakan hanya hasil pemotongan N-gram yang telah terurut dari banyaknya frekuensi.
Perbandingan dan Perangkingan Frekuensi N-gram
lainnya. Sehingga didapatkan ukuran jarak antara dokumen dan kumpulan dokumen (kategori) tertentu.
Gambar 2 Ilustrasi pengukuran jarak.
Seperti yang terlihat pada Gambar 2, pada profil dokumen dan profil kategori, N-gram ”TH” berada pada rank (baris) pertama, maka nilai jaraknya adalah 0. Jika N-gram ”ING” berada pada rank kedua pada profil dokumen dan pada rank kelima pada profil kategori, maka nilai jaraknya adalah 3. Apabila terdapat N-gram pada profil dokumen tapi tidak terdapat pada profil kategori, seperti N-gram ”ED”, maka nilai jaraknya adalah maksimum. Nilai maksimum yang dimaksud adalah jumlah N-gram dari profil kategori yang dibandingkan. Sedangkan ukuran jarak antara dokumen dengan kategori adalah jumlah dari nilai jarak dari tiap N-grampada profil dokumen.
Pengujian Kategorisasi Teks pada Klasifikasi Tiap Kategori
Pendekatan dalam kategorisasi teks dapat dilakukan dengan menggunakan frekuensi N-gram untuk mengukur kesamaan subjek (kategori) dari dokumen. Tentu saja pendekatannya berdasarkan dari isi dokumen yang mana menjadi daya tarik dari proses temu-kembali. Untuk menguji pendekatan ini, akan digunakan sistem klasifikasi untuk mengenali dokumen yang sesuai pada kategori yang akan digunakan. Seperti yang terlihat pada Gambar 3, prosedur untuk kategorisasi adalah sebagai berikut:
• Pengumpulan dokumen untuk tiap jenis sumber. Dokumen yang diambil adalah artikel surat kabar yang berkisar antara 686 bytes sampai 36 kilobytes.
• Penghitungan frekuensi N-gram pada tiap kategori (menyusun profil kategori). Frekuensi N-gram yang dimaksud adalah sama dengan frekuensi N-gram yang sebelumnya telah disebutkan.
• Penghitungan N-gram dari sebuah artikel dengan cara yang sama dengan
penghitungan frekuensi untuk tiap kategori (menyusun profil artikel / dokumen).
• Penghitungan keseluruhan ukuran jarak antara artikel dan kategori (mengukur jarak).
• Penentuan kumpulan dokumen terpilih dari sumber dokumen (memilih jarak terkecil).
Gambar 3 Alur data kategorisasi teks.
Koleksi Dokumen Pengujian
Untuk menguji sistem ini, digunakan koleksi dokumen (corpus) Adisantoso & Ridha (2004) yang berkaitan dengan masalah pertanian. Jumlah dokumen yang akan digunakan dalam penelitian ini sebanyak 1000 dokumen.
Lingkungan Pengembangan
Lingkungan pengembangan yang digunakan adalah sebagai berikut :
• Perangkat lunak: Windows XP Professional, Visual Basic .NET 2005, Microsoft Access 2003.
HASIL DAN PEMBAHASAN
Koleksi Dokumen
[image:30.595.315.506.120.303.2]Koleksi dokumen yang digunakan pada penelitian ini berasal dari corpus Adisantoso & Ridha (2004). Jumlah dokumen pada koleksi ini adalah 1000 dokumen. Akan tetapi, koleksi yang terbagi dalam 30 kategori hanya 953 dokumen. Dalam penelitian ini, hanya digunakan 10 kategori yang memiliki jumlah dokumen terbanyak. Kemudian dari 10 kategori tersebut akan dibentuk profil kategori berdasarkan sebagian dari dokumen-dokumen dalam tiap kategori. Jumlah dari ukuran dokumen-dokumen yang akan digunakan sebagai profil kategori untuk tiap kategori dapat dilihat pada Tabel 1.
Tabel 1 Profil kategori
Kategori Ukuran
Profil (KB)
Bencana Kekeringan 40,9
Gagal Panen 61,3
Harga Komoditas Pertanian 140
Impor Beras 66,7
Institut Pertanian Bogor 58,8
Musim Panen 50,3
Pembangunan Pertanian 107 Penerapan Bioteknologi 72,9 Riset Pertanian 130 Tanaman Pangan 51,4
TOTAL 780
Kategori Dokumen
Penentuan kategori-kategori yang akan digunakan dalam penelitian adalah sepuluh kategori yang memiliki jumlah dokumen terbanyak pada koleksi dokumen. Dari tiap kategori yang telah ditentukan tersebut, dilakukan pembuatan profil untuk masing-masing kategori dan jenis-jenis kategori tersebut disimpan dalam tabel “Kategori”.
Jenis-jenis kategori dan jumlah dokumen perbandingan dalam penelitian ini dapat dilihat pada Tabel 2.
Pembuatan Profil
Proses pembuatan profil kategori dan profil dokumen pada dasarnya adalah sama, yaitu proses tokenizing, stopword, proses penambahan blank pada awal dan akhir tiap token, pemotongan N-gram untuk tiap nilai n, penyusunan ke dalam tabel-tabel tiap nilai n, dan pengurutan tabel-tabel tersebut berdasarkan jumlah tiap N-gramhasil pemotongan N-gram. Perbedaan proses pembuatan profil kategori dan
[image:30.595.100.291.301.459.2]profil dokumen adalah pada banyaknya tabel yang dihasilkan.
Tabel 2 Kategori dokumen
Kategori Jumlah
Dokumen
Bencana Kekeringan 32
Gagal Panen 39
Harga Komoditas Pertanian 44
Impor Beras 33
Institut Pertanian Bogor 32
Musim Panen 32
Pembangunan Pertanian 37 Penerapan Bioteknologi 34
Riset Pertanian 56
Tanaman Pangan 35
TOTAL 374
[image:30.595.316.514.397.626.2]Proses pembuatan profil kategori menghasilkan empat tabel, yaitu tabel bigram (2gram), trigram (3gram), quadgram (4gram) dan Ngram (2gram, 3gram, 4gram). Sedangkan pada proses pembuatan profil dokumen hanya menghasilkan satu tabel, yaitu tabel dari jenis kategorisasi teks yang akan digunakan (2gram, 3gram, 4gram atau Ngram).
Tabel 3 Perbandingan jumlah dokumen
Kategori Jumlah
Profil
Jumlah Dokumen
%
Bencana
Kekeringan 7 39
17,949%
Gagal Panen 9 48 18,75%
Harga Komoditas Pertanian
11 55 20%
Impor Beras 8 41 19,512%
Institut Pertanian Bogor
8 40 20%
Musim Panen 8 40 20%
Pembangunan
Pertanian 9 46 19,565%
Penerapan
Bioteknologi 8 42 19,048%
Riset
Pertanian 13 69 18,841%
Tanaman
Pangan 8 43 18,605%
Pada Tabel 3 dapat dilihat bahwa jumlah dokumen yang akan digunakan dalam pembuatan profil tiap kategori adalah < 20% dari jumlah dokumen tiap kategori.
[image:30.595.316.514.401.626.2]2000 – 4000 N-gram. Dan untuk Quadgram dan Ngram, jumlah N-gram mencapai lebih dari 4000 N-gram. Hal ini dapat disebabkan pada Bigram, tiap N-gram tidak memiliki pengertian yang jelas dalam pengelompokan N-gram. Pada Trigram, pengelompokan N-gram sudah memiliki pengertian jelas dalam tiap kelompok N-gram. Sedangkan pada Quadgram dan Ngram, tiap N-gram memiliki pengertian yang sangat jelas untuk dapat dikelompokkan seperti mengelompokkan kata dasar satu dengan yang lainnya atau kata dasar dengan imbuhannya. Tabel 4 Jumlah N-gram tiap kategori
Kategori 2gram 3gram 4gram Ngram
Bencana
Kekeringan 475 2205 4696 7376
Gagal Panen 524 2616 5906 9046
Harga Komoditas Pertanian
567 3108 7720 11395
Impor Beras 501 2455 5588 8544
Institut Pertanian Bogor
514 2510 5774 8798
Musim Panen 483 2292 5113 7888
Pembangunan
Pertanian 545 2852 6809 10206
Penerapan
Bioteknologi 537 2861 6860 10258
Riset
Pertanian 605 3396 8825 12826
Tanaman
Pangan 521 2501 5420 8442
0 2000 4000 6000 8000 10000 12000 14000
40.9 50.3 51.4 58.8 61.3 66.7 72.9 107.0 130.0 140.0
[image:31.595.85.300.237.580.2]2gram 3gram 4gram Ngram
Gambar 4 Grafik jumlah N-gram dengan ukuran profil tiap kategori.
Pada Gambar 4 dapat dilihat perbandingan jumlah N-gram dengan ukuran profil tiap kategorinya, dapat diketahui bahwa semakin besar ukuran profil suatu kategori maka jumlah N-gram kategori tersebut juga cenderung semakin banyak. Meskipun hal ini juga sangat tergantung pada seberapa banyak kesalahan-kesalahan pada dokumen-dokumen yang digunakan untuk membuat profil kategori baik kesalahan pengetikan, pengejaan maupun kesalahan pengenalan suatu kata dalam dokumen. Semakin banyak kesalahan yang terjadi maka semakin banyak juga jumlah
N-gram yang dihasilkan pada proses pembuatan profil kategori.
Hasil Perbandingan Jarak Profil
Pengukuran jarak dalam proses kategorisasi teks adalah dengan menghitung perbedaan rank atau baris tabel tiap token antara profil dokumen dengan profil kategori. Hasil perbandingan ini kemudian dikalkulasikan untuk tiap kategori.
Proses perbandingan dilakukan berdasarkan banyaknya dokumen yang akan diklasifikasikan (374 dokumen). Tiap dokumen akan diklasifikasikan untuk tiap jenis N-gram (2gram, 3gram, 4gram dan Ngram).
Hal yang menarik dari hasil kalkulasi jarak tiap dokumen adalah semakin besar jumlah N-gram tiap profil dokumen maka akan semakin besar juga jarak antara dokumen tersebut dengan tiap kategori. Karena dengan semakin besar jumlah N-gram pada profil dokumen maka akan semakin bervariasi N-gram profil dokumen tersebut dan kondisi jarak maksimum akan semakin sering terjadi. Tetapi sebaliknya, semakin banyak jumlah N-gram pada profil suatu kategori maka akan semakin kecil jarak antara kategori tersebut dengan tiap dokumen. Hal ini disebabkan karena semakin banyak jumlah N-gram pada profil kategori maka kondisi jarak maksimum akan jarang terjadi.
Evaluasi Klasifikasi Dokumen Berdasarkan Jenis N-gram
Berdasarkan ukuran jarak yang telah didapatkan, kita dapat menentukan jarak suatu dokumen dengan tiap kategori. Dengan jarak tersebut kita dapat menentukan termasuk ke dalam kategori apa suatu dokumen dengan mencari nilai minimum jarak antara dokumen dan kategori tersebut.
Akan tetapi setiap jenis klasifikasi memiliki kinerja yang berbeda dan perlu dievaluasi. Hasil klasifikasi tiap jenis N-gram dapat dievaluasi sebagai berikut.
Tabel 5 Klasifikasi Bigram
Kategori Jumlah
Benar
Persentase Benar
Bencana
Kekeringan 9 28,125%
Gagal Panen 8 20,513% Harga Komoditas
Pertanian 8 18,182%
Impor Beras 2 6,061% Institut Pertanian
Bogor 9 28,125%
Musim Panen 8 25%
Pembangunan
Pertanian 11 29,73%
Penerapan
Bioteknologi 11 32,353% Riset Pertanian 17 30,357% Tanaman Pangan 9 25,714%
Total / Rata-rata 92 24,416%
Tabel 6 Kategorisasi Bigram dua kategori
Kategori Impor
Beras
Penerapan Bioteknologi
Bencana
Kekeringan 1 0
Gagal Panen 4 3
Harga Komoditas
Pertanian 7 2
Impor Beras 2 0
Institut Pertanian
Bogor 0 2
Musim Panen 10 3
Pembangunan
Pertanian 5 0
Penerapan
Bioteknologi 0 11
Riset Pertanian 0 10
Tanaman Pangan 4 3
Jumlah 33 34
Dari perbandingan dua kategori yang memiliki kinerja tertinggi dan terendah pada Tabel 6 juga dapat dilihat bahwa pada klasifikasi kategori Impor Beras sebagian besar dokumen diklasifikasikan pada kategori Musim Panen yang mencapai sepuluh dokumen (30,303%). Sedangkan pada kategori Penerapan Bioteknologi sebagian besar dokumen berhasil diklasifikasikan dengan benar walaupun cukup banyak diklasifikasikan pada kategori Riset Pertanian yang mencapai sepuluh dokumen (29,412%). Hal ini karena terdapat kesamaan topik antara Penerapan Bioteknologi dengan Riset Pertanian. Hasil lengkap kategorisasi Bigram dapat dilihat pada Lampiran 1.
Pada Tabel 7 untuk klasifikasi Trigram, proses kategorisasi berhasil mengklasifikasikan
minimal tiga dokumen untuk tiap kategori. Kinerja tertinggi terjadi pada kategori Bencana Kekeringan yang mencapai 81,25% dan memiliki kinerja terendah pada kategori Riset Pertanian (5,357%).
Tabel 7 Klasifikasi Trigram
Kategori Jumlah
Benar
Persentase Benar
Bencana
Kekeringan 26 81,25%
Gagal Panen 4 10,256% Harga Komoditas
Pertanian 6 13,636%
Impor Beras 4 12,121% Institut Pertanian
Bogor 12 37,5%
Musim Panen 13 40,625% Pembangunan
Pertanian 8 21,622%
Penerapan
Bioteknologi 10 29,412%
Riset Pertanian 3 5,357% Tanaman Pangan 3 8,571%
Total / Rata-rata 89 26,035%
Tabel 8 Kategorisasi Trigram dua kategori
Kategori Bencana
Kekeringan
Riset Pertanian Bencana
Kekeringan 26 5
Gagal Panen 3 3
Harga Komoditas Pertanian
0 4
Impor Beras 0 5
Institut
Pertanian Bogor 0 6
Musim Panen 3 18
Pembangunan
Pertanian 0 0
Penerapan
Bioteknologi 0 10
Riset Pertanian 0 3
Tanaman
Pangan 0 2
Jumlah 32 56
(32,143%) dan kategori Penerapan Bioteknologi sebanyak sepuluh dokumen (17,857%). Hasil lengkap kategorisasi Trigram dapat dilihat pada Lampiran 2.
Tabel 9 Klasifikasi Quadgram
Kategori Jumlah
Benar
Persentase Benar
Bencana
Kekeringan 31 96,875%
Gagal Panen 1 2,564% Harga Komoditas
Pertanian 2 4,545%
Impor Beras 4 12,121% Institut Pertanian
Bogor 12 37,5%
Musim Panen 8 25%
Pembangunan
Pertanian 4 10,811%
Penerapan
Bioteknologi 2 5,882%
Riset Pertanian 0 0% Tanaman Pangan 4 11,429%
Total / Rata-rata 68 20,673%
Tabel 10 Kategorisasi Quadgram dua kategori
Kategori Bencana
Kekeringan
Riset Pertanian Bencana
Kekeringan 31 16
Gagal Panen 0 1
Harga Komoditas Pertanian
0 1
Impor Beras 0 4
Institut Pertanian Bogor
0 3
Musim Panen 1 28
Pembangunan
Pertanian 0 0
Penerapan
Bioteknologi 0 1
Riset
Pertanian 0 0
Tanaman
Pangan 0 2
Jumlah 32 56
Dengan melihat Tabel 9 dapat dikatakan bahwa pada klasifikasi Quadgram terdapat keanehan pada proses kategorisasi. Dapat terlihat pada kategori Bencana Kekeringan, proses kategorisasi berhasil mengklasifikasikan hampir semua dokumen dan memiliki kinerja tertinggi pada kategori ini yang mencapai 96,875%. Akan tetapi pada klasifikasi Quadgram, proses kategorisasi tidak
mengklasifikasikan satu dokumen pun dari 56 dokumen yang ada yang termasuk kategori Riset Pertanian.
Dengan melihat Tabel 10 dapat dikatakan bahwa kategori Bencana Kekeringan cukup mendominasi klasifikasi dokumen. Dengan mengklasifikasikan 31 dokumen benar dan hanya satu dokumen (3,125%) salah yang diklasifikasikan termasuk kategori Musim Panen. Sedangkan pada kategori Riset Pertanian, klasifikasi dokumen terkonsentrasi pada kategori Musim panen yang mencapai 28 dokumen atau 50% dari keseluruhan dokumen dan enam belas dokumen terklasifikasikan pada kategori Bencana Kekeringan tanpa ada satu dokumen pun yang termasuk klasifikasi kategori Riset Pertanian. Hasil lengkap kategorisasi Quadgram dapat dilihat pada Lampiran 3.
[image:33.595.309.510.440.581.2]Dengan melihat pada Tabel 11 dapat dikatakan bahwa walaupun kategori Musim Panen dihilangkan dalam proses kategorisasi, klasifikasi Quadgram juga tidak berhasil mengklasifikasikan dokumen yang termasuk kategori Riset Pertanian dan lebih mengklasifikasikan sebagian besar dokumen pada kategori Bencana Kekeringan yang mencapai 34 dokumen (60,714%).
Tabel 11 Kategorisasi Quadgram tanpa kategori Musim Panen
Kategori Riset Pertanian
Bencana Kekeringan 34
Gagal Panen 1
Harga Komoditas Pertanian 2
Impor Beras 6
Institut Pertanian Bogor 4 Pembangunan Pertanian 0 Penerapan Bioteknologi 3
Riset Pertanian 0
Tanaman Pangan 6
Jumlah Dokumen 56
Pada klasifikasi Ngram memiliki beberapa kesamaan dengan klasifikasi Quadgram di mana pada klasifikasi kategori Bencana Kekeringan kinerja mencapai lebih dari 90%, yaitu 90,625% dan tidak mengklasifikasikan satu pun dokumen dari 56 dokumen kategori Riset Pertanian. Hasil lengkap dari klasifikasi Ngram dapat dilihat pada Tabel 12.
(3,125%) yang termasuk kategori Gagal Panen dan dua dokumen (6,25%) yang termasuk kategori Musim Panen. Sedangkan untuk kategori Riset Pertanian, proses kategorisasi mengklasifikasikan 27 dokumen (48,214%) yang termasuk kategori Musim Panen. Ini dapat terlihat pada Tabel 13. Hasil lengkap kategorisasi Ngram dapat dilihat pada Lampiran 4.
Tabel 12 Klasifikasi Ngram
Kategori Jumlah
Benar
Persentase Benar
Bencana
Kekeringan 29 90,625%
Gagal Panen 1 2,564% Harga Komoditas
Pertanian 4 9,091%
Impor Beras 6 18,182% Institut Pertanian
Bogor 17 53,125%
Musim Panen 9 28,125% Pembangunan
Pertanian 5 13,514%
Penerapan
Bioteknologi 7 20,588%
Riset Pertanian 0 0% Tanaman Pangan 3 8,571%
Total / Rata-rata 81 24,439%
Tabel 13 Klasifikasi Ngram dua kategori
Kategori Bencana
Kekeringan
Ris