Data Pribadi
Nama : M Fikri Abror Siregar
Tempat/Tanggal Lahir : Pekanbaru, 30 Oktober 1993
Umur : 22 Tahun
Jenis Kelamin : Laki-laki
Alamat : Kubangsari VIII No.27 Kecamatan Coblong Kelurahan Sekeloa. Kode Pos 40134
No. Telepon : 083167530809
Riwayat Pendidikan
1999 – 2005 Lulus SDN 006 Pekanbaru 2005 – 2008 Lulus MTsN Andalan Pekanbaru 2008 – 2011 Lulus SMA Negeri 5 Pekanbaru
2011 – Sekarang Universitas Komputer Indonesia
Demikian riwayat hidup ini saya buat dengan sebenar - benarnya.
Bandung, 25 Agustus 2016 Penulis
IMPLEMENTASI FUZZY C-MEANS CLUSTERING
UNTUK PENGENALAN AKOR
SKRIPSI
Disusun untuk Menempuh Ujian Akhir Sarjana
M FIKRI ABROR SIREGAR
10111481
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iv
kesehatan, tenaga, waktu dan pikiran sehingga penulis dapat menyelesaikan skripsi yang berjudul “IMPLEMENTASI FUZZY C-MEANS CLUSTERING UNTUK PENGENALAN AKOR” untuk memenuhi salah satu syarat studi jenjang strata satu (S1) di Program Studi Teknik Informatika, Fakultas Teknik dan Ilmu Komputer, Universitas Komputer Indonesia.
Dikarenakan keterbatasan yang dimiliki penulis, penyusunan skripsi ini tidak akan terwujud tanpa adanya dukungan dari berbagai pihak. Untuk itu penulis melalui kata pengantar ini sangat menghargai dan berterima kasih yang sebesar-besarnya kepada:
1. Kedua orang tua yaitu Mastim Siregar dan Syarifah Nasution berserta kakak dan keluarga lainnya, Ivan Alvian, Isma Halida, Uli Syukriah, Ana Rozana, Rahmi Soraya dan Ibu Aisyah yang telah memberikan kasih sayang, doa dan dukungan baik moril maupun materi, sehingga Penulis dapat menyelesaikan skripsi ini.
2. Ibu Ednawati Rainarli, S.Si., M.Si., selaku dosen wali IF-11/2011 dan dosen pembimbing Penulis, yang telah memberikan bimbingan, masukan, saran dan nasehatnya selama penyusunan skripsi ini.
3. Ibu Ken Kinanti Purnamasi, S.Kom., M.T., selaku dosen reviewer yang telah memberikan bimbingan, masukan dan saran kepada Penulis.
4. Ibu Kania Evita Devi, S.Pd., M.Si., selaku dosen penguji yang memberikan saran kepada Penulis.
5. Bapak dan Ibu dosen serta seluruh staf pegawai Universitas Komputer Indonesia yang telah membantu Penulis selama proses perkuliahan.
v
8. Serta seluruh pihak yang tidak dapat Penulis sebutkan satu-persatu, terima kasih atas segala bentuk dukungan selama proses penyusunan skripsi ini.
Penulis menyadari bahwa penulisan skripsi ini masih jauh dari kata sempurna. Oleh karena itu, Penulis mengharapkan saran dan masukan yang bersifat membangun untuk perbaikan dan pengembangan skripsi ini selanjutnya. Akhir kata, semoga penulisan skripsi ini dapat bermanfaat bagi penulis khususnya dan bagi pembaca pada umumnya.
Bandung, Agustus 2016
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... xi
DAFTAR SIMBOL ... xv
DAFTAR LAMPIRAN ... xix
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Perumusan Masalah... 2
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah ... 3
1.5 Metodologi Penelitian ... 3
1.6 Sistematika Penulisan ... 6
BAB 2 TINJAUAN PUSTAKA ... 7
2.1 Teori Dasar Musik ... 7
2.1.1 Frekuensi dan Nada ... 7
2.1.2 Tangga Nada Kromatik ... 7
2.1.3 Tangga Nada Diatonis ... 8
2.1.4 Akor ... 9
2.1.4.1 Akor Mayor ... 9
2.1.4.2 Akor Minor ... 9
2.2 Format File Audio Wave ... 10
2.3 Preprocessing ... 10
vi
2.3.2 Normalisasi... 12
2.3.3 Frame Blocking ... 13
2.3.4 Windowing ... 14
2.3.5 Operasi Powering ... 15
2.3.6 Thresholding... 16
2.3.7 Fast Fourier Transform ... 16
2.4 Fuzzy c-means Clustering ... 18
2.5 Euclidean Distance ... 20
2.6 Pemrograman Berorientasi Objek ... 20
2.7 Python... 22
2.8 Unified Modelling Language (UML) ... 22
2.8.1 Use Case Diagram ... 23
2.8.2 Activity diagram ... 23
2.8.3 Class diagram ... 24
2.8.4 Sequence diagram ... 24
2.9 Pengujian ... 25
2.9.1 Pengujian Black Box ... 25
2.9.2 Confussion Matrix ... 26
2.9.3 Pengujian Validitas Fuzzy C-Means ... 26
2.9.3.1 Partition Coefficient Index (PCI) ... 27
2.9.3.2 Partition Entropy Index (PEI) ... 27
2.9.3.3 Modification Partition Coefficient Index (MPCI) ... 27
2.10 Tools Pembangunan Perangkat Lunak ... 28
2.10.1 Spyder ... 28
2.10.2 Qt Designer ... 28
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 29
3.1 Analisis Masalah ... 29
3.2 Analisis Proses ... 29
3.3 Analisis Data Masukan... 31
vii
3.4.1 Pre-processing ... 31
3.4.1.1 Konversi Analog Menjadi Digital (ADC) ... 31
3.4.1.2 Akuisisi Data ... 33
3.4.1.3 Normalisasi... 33
3.4.1.4 Frame Blocking ... 35
3.4.1.5 Windowing ... 37
3.4.1.6 Powering... 40
3.4.1.7 Thresholding... 43
3.4.1.8 Fast Fourier Transform... 45
3.4.2 Fuzzy c-means Clustering ... 50
3.4.3 Data Uji ... 59
3.4.4 Euclidean Distance ... 59
3.5 Analisis Kebutuhan Non Fungsional... 63
3.5.1 Analisis Kebutuhan Perangkat Keras ... 63
3.5.2 Analisis Kebutuhan Perangkat Lunak ... 63
3.5.3 Analisis Pengguna ... 63
3.6 Analisis Kebutuhan Fungsional ... 64
3.6.1 Use Case Diagram ... 64
3.6.2 Use case scenario ... 64
3.6.3 Activity diagram ... 67
3.6.4 Class diagram ... 70
3.6.5 Sequence diagram ... 70
3.7 Perancangan Sistem... 74
3.7.1 Perancangan Struktur Menu ... 74
3.7.2 Perancangan Antarmuka ... 74
3.7.3 Perancangan Pesan ... 77
3.7.4 Jaringan Semantik ... 77
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 79
4.1 Implementasi ... 79
viii
4.1.2 Implementasi Perangkat Lunak ... 79
4.1.3 Implementasi Class ... 80
4.1.4 Implementasi Antarmuka ... 80
4.2 Skenario Pengujian ... 80
4.2.1 Skenario Pengujian Black Box ... 81
4.2.2 Skenario Pengujian Parameter Fuzzy C-Means ... 81
4.2.3 Skenario Pengujian Validitas Fuzzy C-Means ... 82
4.2.3.1 Partititon Coeficient Index (PCI) ... 82
4.2.3.2 Partition Entropy Index (PEI) ... 83
4.2.3.3 Modification Partition Coefficient Index (MPCI) ... 83
4.3 Pengujian ... 83
4.3.1 Pengujian Black Box... 84
4.3.2 Pengujian Parameter Fuzzy c-means ... 86
4.3.3 Pengujian Validitas Fuzzy c-means ... 106
4.3.3.1 Partition Coefficient Index (PCI) ... 106
4.3.3.2 Partition Entropy Index (PEI) ... 107
4.3.3.3 Modification Partition Coefficient Index (MPCI) ... 108
4.4 Kesimpulan dan Hasil Pengujian ... 108
BAB 5 KESIMPULAN DAN SARAN... 109
5.1 Kesimpulan... 109
5.2 Saran ... 109
111
[1] Sudjana, Metoda Statistika, Bandung: Tarsito, 2002.
[2] Agusta, Yudi., “K-means-Penerapan, Permasalahan dan Metode Terkait”, Jurnal Sistem dan Informatika Vol 3: 47-60, 2007.
[3] Kusumadewi, Sri. Purnomo, Hari., Aplikasi Logika Fuzzy untuk Pendukung Keputusan., Graha Ilmu. Yogyakarta, 2004.
[4] Gaffar, Imam., “Aplikasi Pengkonversi Nada-Nada Instrumen Tunggal menjadi Chord Menggunakan Metode Pitch Class Profile”, PENELITIAN S-1 Teknik Elektro Universitas Diponegoro, 2012.
[5] A. S. Rosa dan M. Shalahuddin, Modul Pembelajaran Rekayasa Perangkat Lunak (Terstruktur dan Berorientasi Objek), Bandung: Modula, 2013. [6] R. S. Pressman, Rekayasa Perangkat Lunak, Yogyakarta: ANDI, 2012. [7] Prasetyo, Eko., “Data Mining Mengolah Data Menjadi Informasi
Menggunakan Matlab”, Yogyakarta: Andi, 2014.
[8] Yang, Y., Zheng, Ch., Lin, P., Fuzzy C- Means Clustering algorithm with a novel penalty term for image segmentation. Opto-Electronics Review, 13(4), 309-315, 2005.
[9] Budiarto, Arif ,”Penerapan LVQ Dengan Inisialisasi K-means Untuk Pengenalan Nada Gitar Dengan Ekstraksi Ciri MFCC”, Departemen Ilmu Komputer FMIPA Institut Pertanian Bogor. Bogor, 2014.
[10] Yuan, K., Wu L., Cheng,Q.S., Bao, S., Chen, C., Zhang, H.,: A novel Fuzzy c-means algorithm and its application, Int. J. Pattern Recognit. Artif. Intell , 2005.
[11] Raybaut, Pierre,. Spyder Documentation. available : https://pythonhosted.org/spyder/, 2009.
[12] Riverbank Computing Limited, Using Qt Designer. Available: http://pyqt.sourceforge.net/Docs/PyQt4/designer.html, 2015.
112
Lunak (Terstruktur dan Berorientasi Objek), Bandung: Modula, 2011. [15] H. Hamilton, “Confussion Matrix,” [Online]. Available: http://
www2.cs.uregina.ca/~dbd/cs831/notes/confusion_matrix/confusion_matri x.html. [Diakses 29 December 2015].
[16] Azzahra, Syahbani. Nabila. "Pembuatan Transkrip Akord Instrumen Tunggal Menggunakan Metode Enhanced Pitch Class Profile". Surabaya. [17] Putra, D., Resmawan, A., “Verifikasi Biometrika Suara Menggunakan
Metode MFCC Dan DTW” LONTAR KOMPUTER Vol 2 No.2: 10-15, 1 Juni 2011.
[18] Sumarno, Linggo., Pengenalan Nada Pianika Menggunakan Jendela Gaussian DCT dan Jarak Kosinus., Jurnal Penelitian vol 17, no 1, hal 8-15, 2013.
[19] Theoridis S. dan Koutroumbas k, pattern Recognition 4th edition, Burlington, Massachusetts, USA: Academic Press, 2009.
[20] Irsalina, Idni., Supriyati, Endang., Khotimah, Tutik., “Clustering Gender Berdasarkan Nilai Maksimum Minimum Amplitudo Suara Berbasis Fuzzy c-means(FCM)”, Program Studi Teknik Informatika, Universitas Muria
Kudus, GondangManis. 2014.
1
BAB 1
PENDAHULUAN
1.1 Latar Belakang Masalah
Manusia memiliki panca indra pendengaran yang selain untuk mendengar juga berguna untuk mengenali suara. Contohnya seseorang dapat mengenali pembicara melalui suara telepon karena seseorang tersebut pernah berkomunikasi sebelumnya. Begitu juga halnya akor pada alat musik. Bagi para pemula yang baru belajar alat musik, tentunya akan kesulitan mengenali akor. Salah satu metode yang dapat menanggulangi masalah tersebut adalah dengan cara komputerisasi [9].
Pengenalan akor atau chord recognition adalah bentuk transkripsi atau konversi dari suara, berupa file audio yang dideteksi menjadi akor, yang akan dapat dikelompokkan sesuai dengan karakteristik masing-masing. Fungsi untuk mengenali akor secara otomatis sangat penting dalam berbagai aplikasi musik, seperti sistem musik interaktif, aplikasi informasi musik berdasarkan konten atau pencarian sampel dan lagu tematik dalam basis data audio, serta aplikasi edukatif bagi para pemula yang ingin mempelajari akor [4].
Penelitian sebelumnya tentang pengenalan akor menggunakan ekstraksi ciri MFCC, inisialisasi k-means dan LVQ sebagai metode klasifikasi. Hasil penelitian terhadap klasifikasi akor dengan ekstraksi ciri MFCC memiliki akurasi maksimum yaitu 83,65% [9]. Penelitian tersebut menggunakan input file suara akor gitar yang direkam selama 3 detik. Suara yang direkam menggunakan input dua akor dalam satu file, sehingga tidak bisa digunakan untuk lebih dari dua akor dalam satu file.
frekuensi nada-nada yang nilainya sama tetapi dengan akor yang berbeda. Oleh karena itu k-means tidak sesuai untuk mengklasifikasikan data yang nilainya sama tetapi berbeda kluster. Atas dasar itu maka dibutuhkan metode pengalokasian data ke dalam masing-masing kluster, yang masing-masing data item diberikan nilai kemungkinan untuk bisa bergabung ke setiap kluster yang ada. Salah satu metode yang dapat mengklasifikasikan data dengan nilai yang sama dengan kluster yang berbeda yaitu dengan fuzzy c-means [2].
Logika fuzzy adalah suatu cara yang tepat untuk memetakan suatu ruang input kedalam suatu ruang output, yang mempunyai nilai kontinyu [3]. Pengenalan 3 akor secara berurutan atau lebih dalam satu file merupakan proses yang mempunyai nilai kontinyu. Oleh karena itu cara yang tepat untuk memetakan suatu ruang input kedalam suatu ruang output, yang mempunyai nilai kontinu adalah dengan cara fuzzy.
Metode fuzzy c-means mengalokasikan kembali data ke dalam masing-masing kluster dengan memanfaatkan teori fuzzy. Teori ini mengeneralisasikan metode pengalokasian yang bersifat tegas (hard) seperti yang digunakan pada metode k-means.
Berdasarkan penjabaran diatas maka dalam penelitian ini akan dilakukan implementsi fuzzy c-means clustering menentukan akor yang berurutan dari suatu
file.
1.2 Perumusan Masalah
Berdasarkan latar belakang yang telah dikemukakan maka rumusan masalah pada penelitian ini adalah penelitian sebelumnya yang hanya dapat mengenali 2 akor dalam satu file.
1.3 Maksud dan Tujuan
Adapun tujuan yang ingin dicapai dalam penelitian ini adalah menghasilkan suatu sistem yang dapat mengenali 3 akor atau lebih secara berurutan dalam satu
file.
1.4 Batasan Masalah
Adapun batasan masalah pada penulisan skripsi ini sebagai berikut: 1. File input berformat wave (*.wav)
2. Akor yang di uji adalah akor mayor dan minor 3. Akor berasal dari satu instrumen
4. Instrumen yang digunakan adalah keyboard 5. Akor berada pada oktav ke-5
6. File berisi akor yang berurutan 7. Tiap perpindahan akor ada jeda
8. Ekstraksi ciri menggunakan Fast Fourier Transform
1.5 Metodologi Penelitian
Studi
Gambar 1. 1 Metodologi Penelitian
Berikut penjelasan lengkap dari Gambar 1.1: 1. Studi Literatur
Merupakan teknik pengumpulan data dengan cara membaca dan mempelajari serta mengumpulkan literature. Sumber-sumber yang didapatkan berupa jurnal, buku, paper dan beberapa informasi uang relevan dengan penelitian.
2. Analisis dan Definisi Kebutuhan Meliputi : a. Analisis Masalah
b. Analisis Proses Pengenalan
Analisis proses menentukan akor terdiri dari 4 proses yaitu pengambilan data berupa audio wave (*.wav), ekstraksi ciri menggunakan, klasifikasi pola,menggunakan Jaringan Syaraf Tiruan Fuzzy c-means clustering, pengujian atau pencocokan kemudian hasil.
c. Kebutuhan Data
Kebutuhan data berupa audio yang telah direkam akor yang berurutan dalam suatu file.
d. Kebutuhan Non Fungsional
Kebutuhan non fungsional menjelaskan kebutuhan hardware, software dan
brainware dalam pembangunan aplikasi ini. e. Kebutuhan Fungsional
Kebutuhan fungsional dengan pendekatan berorientasi objek menggunakan pemodelan UML yang terdiri dari use case diagram, use case scenario, activity diagram, class diagram dan sequence diagram.
3. Perancangan Sistem
Perancangan sistem dilakukan untuk mengetahui rancangan dari basis data dan antarmuka dari pembangunan aplikasi ini.
4. Pemodelan dan Pembangunan Sistem
Pemodelan sistem disini merupakan model sistem proses pengenalan dari 4 proses tahap utama yang telah dilakukan analisis sebelumnya untuk menentukan akor, dan mengimplementasikannya ke dalam bahasa pemrograman dan memulai pembangunan aplikasi.
5. Analisis dan Evaluasi Hasil
1.6 Sistematika Penulisan
Sistematika penulisan penelitian ini disusun untuk memberikan gambaran umum mengenai penelitian yang dikerjakan. Sistematika penulisan penelitian sebagai berikut:
BAB 1 PENDAHULUAN
Bab ini berisi penjelasan mengenai latar belakang permasalahan, perumusan masalah, maksud dan tujuan, batasan masalah, metodologi penelitian, serta sistematika penulisan tentang implementasi Fuzzy c-means clustering untuk pengenalan akor.
BAB 2 TINJAUAN PUSTAKA
Bab ini berisi berbagai konsep dan teori-teori para ahli yang berkaitan dengan topik penelitian pengenalan akor. Teori perancangan aplikasi yang akan dibangun menggunakan pemodelan UML seperti use case diagram, use case scenario, activity diagram, class diagram dan sequence diagram.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi tahapan untuk menganalisis masalah, proses, data yang digunakan, algoritma dari Fuzzy c-means clustering pada pengenalan akor dan perancangan perangkat lunak.
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi implementasi dan pengujian. Implementasi meliputi implementasi perangkat lunak, implementasi perangkat keras, implementasi basis data, implementasi class dan implementasi antarmuka. Pengujian pada bab ini berupa pengujian akurasi pengenalan akor untuk mengetahui seberapa besar akurasi uang diperoleh dari penerapan Fuzzy c-means clustering pada pengenalan akor. BAB 5 KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan dari semua hal yang di bahas pada bab sebelumnya, hasil seberapa besar akurasi dari penerapan Fuzzy c-means clustering
7
BAB 2
TINJAUAN PUSTAKA
2.1 Teori Dasar Musik
Dalam seni musik. Dikenal istilah tangga nada. Istilah tersebut berisikan kumpulan nada-nada yang harmonis. Nada-nada yang harmonis ini terjadi karena ada aturan dibalik itu semua. Dibawah ini akan dijelaskan mengenai frekuensi dan nada, tangga nada, diantaranya tangga nada kromatik dan tangga nada diatonik, serta akor [4].
2.1.1 Frekuensi dan Nada
Frekuensi merupakan komponen dasar pembentuk suara. Frekuensi adalah kecepatan perubahan amplitude terhadap waktu. Suara muncul karena adanya getaran pada udara. Jumlah getaran pembentuk suara dimuatakan dalam frekuensi atau jumlah getaran dalam satu satuan waktu. Frekuensi dinyatakan dalam satuan Hertz (Hz). Misalkan dalam suatu suara memiliki frekuensi sebesar 440 Hz, maka berarti dalam satu detik terjadi 440 buah getaran.
Setiap nada memiliki frekuensi masing-masing. Secara internasional, nada A4 (A pada oktaf ke-4) memiliki frekuensi 440 Hz. Dan untuk mengetahui berapa frekuensi nada-nada lainnya dapat menggunakan persamaan:
= ∗ (2.1)
fn adalah frekuensi nada dengan jarak-n yang dicarai, fo adalah frekuensi yang diketahui (A4= 440 Hz), an adalah / (symbol S menunjukkan perbedaan semi-tone antara fn dan fo) [4].
2.1.2 Tangga Nada Kromatik
nada selalu berulang untuk tiap oktaf yang ada, maka istilah tangga nada kromatik‟ sering dipakai untuk ke-12 nada dari tiap oktaf [4]. Tabel berikut ini menunjukkan frekuensi dari ke-12 nada antara nada A pada 440 Hz dan nada A satu oktaf di atasnya.
Tabel 2.1 Tangga Nada Kromatik Tangga Nada Kromatik
Oktaf ke-3 Frekuensi Oktaf ke-4 Frekuensi
A3 220,00 Hz A4 440,00 Hz
A♯3 233,08 Hz A♯4 466,16 Hz
B3 246,94 Hz B4 493,88 Hz
C3 261,63 Hz C4 523,25 Hz
C♯3 277,18 Hz C♯4 554,37 Hz
D3 293,66 Hz D4 587,33 Hz
D♯3 311,13 Hz D♯4 622,25 Hz
E3 329,63 Hz E4 659,26 Hz
F3 349,20 Hz F4 698,46 Hz
F♯3 369,99 Hz F♯4 739,98 Hz
G3 392,00 Hz G4 784,00 Hz
G♯3 415,30 Hz G♯4 830,60 Hz
Perbedaan antara dua buah pitch (nada) yang berdekatan disebut sebagai semiton. Meskipun ada 12 nada dalam 1 oktaf, tapi hanya 7 huruf pertama dari abjad yang dipakai untuk memberi nama pada nada, yaitu dari A sampai G. Kelima nada yang lain dalam tangga nada kromatik diberi nama dengan menempatkan tanda kres (♯) atau tanda mol (b) setelah notasi nada.
2.1.3 Tangga Nada Diatonis
Skala diatonik memiliki tujuh not yang berbeda dalam satu oktaf. Pada tangga nada diatonik di bagi dua yaitu [4]:
a. Mayor scales (Tangga nada Mayor)
Skala mayor merupakan tangga nada yang mempunyai jarak antar nada dengan rumus interfal 1-1-½-1-1-1-½
b. Minor scales (Tangga nada Minor)
dengan interfal 1-½-1-1-½-1-1 (untuk tangga nada minor alami /melodis menurun).
Tangga nada minor sendiri dapat dibagi menjadi tiga: 1. Tangga Nada Minor Alami (melodis menurun): Interval 1-½-1-1-1-1-½
2. Tangga Nada Minor Melodis (melodis menaik): Interval 1-½-1-1-½-1-1
3. Tangga Nada Minor Harmonis: Interval 1-½-1-1-½-1-½
2.1.4 Akor
Akor atau chord adalah gabungan beberapa nada dasar yang dibunyikan secara serempak ataupun terpisah sehingga menghasilkan suara harmonis. Umumnya antara akor dan kunci adalah hal yang sama bagi kebanyakan orang awam, namun secara istilah kedua hal ini berbeda. Akor dalam istilah musik merujuk pada tiga nada dasar atau lebih yang dibunyikan baik secara serempak maupun terpisah. Sementara kunci atau key dalam not balok diatandai dengan notasi kres (#) yang berarti nada dinaikkan setengah dari nada dari nada dasarnya dan mol (b) yang berarti nada diturunkan setengah nada dari nada dasarnya [4].
2.1.4.1 Akor Mayor
Akor mayor biasanya dituliskan hanya berupa huruf capital seperti C, D, E, F, G, A, B. Mencari chord mayor dapat dilakukan dengan menggunakan nada ke 1-3-5 dari tangga nada C mayor, Contoh: akor C = Nada C – E – G [4].
2.1.4.2 Akor Minor
dapat dengan mudah ditentukan yaitu dengan cara menurunkan nada yang ada ditengah sebanyak setengah interval. Contoh: Akor Cm = Nada C- D#/Eb – G [4].
2.2 Format File Audio Wave
WAV adalah format file audio standar Microsoft dan IBM untuk personal computer (PC), biasanya menggunakan pengkodean PCM (Pulse Code Modulation). WAV adalah data tidak terkompres sehingga seluruh sample audio disimpan semuanya di haridisk.
Secara umum data audio digital dari WAV memiliki karakteristik yang dapat dinyatakan dengan parameter-parameter berikut:
a. Laju sample (sampling rate) dalam sampel/detik, misalnya 22050 atau 44100 sampel/detik.
b. Jumlah bit tiap sample, misalnya 8 atau 16 bit.
c. Jumlah kanal (channel), yaitu 1 untuk mono dan 2 untuk stereo.
Biasanya laju sampel juga dinyatakan dengan satuan Hz atau kHz. Sebagai gambaran, data audio digital yang tersimpan dalam CD audio memiliki karakteristik laju sampel 44100 Hz, 16 bit persample, dan 2 kanal (stereo) yang berarti setiap satu detik suara tersusun dari 44100 sample, dan setiap sampel tersimpan dalam data sebesar 16-bit atau 2 byte. Laju sampel selalu dinyatakan untuk setiap satu kanal (channel). Jadi misalkan suatu data audio digital memiliki 2 kanal (channel) dengan laju sampel 8000 sampel/ detik, maka didalam setiap detiknya terdapat 16000 sampel [13].
2.3 Preprocessing
Preprocessing merupakan tahapan-tahapan yang dilakukan untuk mengkondisikan sinyal sebelum masuk kedalam tahap utama yaitu pengklasifikasian. Berikut adalah proses-prosesnya:
2.3.1 Konversi Analog Menjadi Digital
Signal – signal yang natural pada umumnya seperti signal suara merupakan
komputer, semua signal yang dapat diproses oleh komputer hanyalah signal discrete atau sering dikenal sebagai istilah digital signal. Agar signal natural dapat diproses oleh komputer, maka harus diubah terlebih dahulu dari data signal continue menjadi discrete. Hal itu dapat dilakukan melalui 3 proses, diantaranya sebagai berikut [17] :
1. Proses sampling adalah suatu proses untuk mengambil data signal continue
untuk setiap periode tertentu. Dalam melakukan proses sampling data, berlaku aturan Nyquist, yaitu bahwa frekuensi sampling (sampling rate) minimal harus 2 kali lebih tinggi dari frekuensi maksimum yang akan di sampling. Jika signal sampling kurang dari 2 kali frekuensi maksimum signal yang akan di sampling, maka akan timbul efek aliasing. Aliasing adalah suatu efek dimana signal yang dihasilkan memiliki frekuensi yang berbeda dengan signal aslinya.
2. Proses kuantisasi adalah proses untuk membulatkan nilai data ke dalam bilangan-bilangan tertentu yang telah ditentukan terlebih dahulu. Semakin banyak level yang dipakai maka semakin akurat pula data signal yang disimpan tetapi akan menghasilkan ukuran data besar dan proses yang lama.
3. Proses pengkodean adalah proses pemberian kode untuk tiap-tiap data signal
yang telah terkuantisasi berdasarkan level yang ditempati.
Gambar 2. 1 Proses Pembentukan Sinyal Digital
Pada Gambar 2.1 terjadi proses konversi sinyal analog menjadi sinyal digital, gambar sebelah kiri merupakan gambar sinyal asli yang masih berbentuk sinyal
proses konversi sinyal analog menjadi sinyal digital yang telah melalui proses sampling, kuantisasi dan pengkodean. Pada gambar sebelah kanan didapatkan data hasil dalam bentuk kode yaitu 100, 011, 001, 001, 010, 010, 010, 100, 101, 110, 100 dan 101.
2.3.2 Normalisasi
Normalisasi adalah proses dimana membuat penskalaan pada nilai amplitudo tiap data sinyal sesuai skala yang diinginkan. Proses ini dilakukan agar nilai amplitudo pada tiap data sinyal yang akan diolah bernilai sama. Besarnya nilai amplitudo sinyal suara manusia saat melakukan pengucapan selau berbeda-beda, sehingga penskalaan nilai amplitudo sinyal terhadap acuan skala yang diinginkan sangat diperlukan [18].
� = � ��� �
max � ��� � (2.3)
Keterangan:
� = hasil data sinyal normalisasi
� = amplitudo masukan
max � = amplitudo maksimal masukan (16000)
Gambar 2. 2 Contoh hasil proses normalisasi
2.3.3 Frame Blocking
Frame Blocking adalah proses dimana sinyal data masukan akan dibentuk dalm frame-frame. Dalam bentuk frame ini data akan lebih mudah untuk diketahui, sehinga tidak perlu memeriksa sinyal data scara keseluruhan secara langsung, Data dicek setiap frame sebesar nilai panjang frame yang telah ditentukan. Jika dalam pemeriksaan sinyal data melebihi maka akan mengalami overlap, dimana akan sinyal data yang berlebih tersebut akan dipotong sebesar nilai overlap [19].
Keterangan:
Frame1, frame2, frame3, frame4,frame5 adalah sinyal suara yang di frame blocking, dimana M panjang pipa frame dan N overlapping tiap frame-nya.
Jumlah frame = (( Total sinyal amplitudo/M)+N+1) (2.4)
Keterangan :
Jumlah frame = Total frame berdasarkan pembagian panjang frame dengan Overlapping
M = Panjang frame
N = Overlapping (M/2)
2.3.4 Windowing
Proses framing dapat menyebabkan terjadinya kebocoran spektral (spectral leakage) atau aliasing. Aliasing adalah signal baru dimana memiliki frekuensi yang berbeda dengan signal aslinya. Efek ini dapat terjadi karena rendahnya jumlah
sampling rate, ataupun karena proses frame blocking dimana menyebabkan signal
menjadi discontinue. Untuk mengurangi kemungkinan terjadinya kebocoran spektral, maka hasil dari proses framing harus melewati proses window [17].
Sebuah fungsi window yang baik harus menyempit pada bagian main lobe
dan melebar pada bagian side lobe-nya. Berikut ini adalah representasi dari fungsi
window terhadap signal suara yang diinputkan.
= (2.5) Keterangan :
n = 0,1,…,N-1
= nilai sampel signal hasil windowing
= nilai sampel dari frame signal ke i = fungsi window
Ada banyak fungsi window, namun yang paling sering digunakan dalam aplikasi speaker recognition adalah hamming window. Fungsi window ini menghasilkan sidelobe level yang tidak terlalu tinggi (kurang lebih -43 dB), selain itu noise yang dihasilkan pun tidak terlalu besar.
Fungsi Hammingwindow adalah sebagai berikut :
= . − . �− (2.6) Keterangan :
n = 0,1,...,M-1 M = panjang frame
2.3.5 Operasi Powering
Operasi powering dilakukan untuk menemukan peak dari tiap frame blocking. Pada proses ini sinyal input diproses dengan mengambil peak-peak
dominan. Sebelumnya, sinyal akan mengalami powering terlebih dahulu dengan melakukan pengkuadratan pada sinyal, dengan persamaan [16] :
� = ∑ |� |== (2.7) Keterangan :
P = power sinyal (dB) |Xi| = norm Frame ke-i (dB) N = Jumlah sampel per frame
i = sampel ke-i
yang ada. Jika nilai data mendekati nilai rata-rata, maka standar deviasinya lebih kecil (mendekati nol) dan sebaliknya. Ditunjukkan dengan persamaan [1].
= √ ∑ � − ∑ �
− (2.8)
Keterangan :
� = Frame ke-i n = jumlah frame
Sinyal dengan nilai power berada diatas standar deviasi, diambil sebagai awal dan akhir sinyal serta dianggap sebagai suatu suara.
2.3.6 Thresholding
Pada proses ini dilakukan pengambilan peak dominan dari sinyal dengan terlebih dahulu melakukan powering dan penentuan standar deviasi yang berguna sebagai pendeteksi awal dan akhir sinyal dalam frame. Setelah itu, sinyal dibagi menjadi frame-frame untuk mempermudah pemrosesan sinyal. Pengambilan sample setiap frame diambil dalam waktu milisecond (ms) [16].
2.3.7 Fast Fourier Transform
DFT (Discrete Fourier Transform) merupakan perluasan dari transformsi
fourier yang berlaku untuk signal-signal diskrit dengan panjang yang terhingga. Semua signal periodik terbentuk dari gabungan signal-signal sinusoidal yang menjadi satu yang dapat dirumuskan sebagai berikut.
[ ] = ∑ − [ ] − �� , ≤ ≤ −
= (2.7)
N = jumlah sampel yang akan diproses (N N)
[ ] = nilai sampel signal
= ∑ cos �
= − ∑ sin
�
= (2.8) Untuk menghitung hasil FFT digunakan rumus
| | = [ + � ] .9
Dengan persamaan 2.8 suatu signal suara dalam domain waktu dapat kita cari frekuensi pembentuknya. Hal inilah tujuan penggunaan analisa fourier pada data suara, yaitu untuk merubah data dari domain waktu menjadi data spektrum di domain frekuensi. Untuk pemrosesan signal suara, hal ini sangatlah menguntungkan karena data pada domain frekuensi dapat diproses dengan lebih mudah dibandingkan data pada domain waktu, karena pada domain frekuensi, keras lemahnya suara tidak seberapa berpengaruh [17].
Gambar 2. 4 Domain Waktu menjadi Domain Frekuensi
Pada Gambar 2.4 dapat dilihat bahwa gambar sebelah kiri menunjukan gambar domain waktu dan gambar sebelah kanan menunjukan gambar domain frekuensi.
2.4 Fuzzy c-means Clustering
Metode Fuzzy c-means pertama kali ditemukan oleh Jim Bezdek pada tahun 1981, meode Fuzzy C- Means merupakan salah satu teknik clustering yang mana keberadaan tiap titik data ditentukan oleh derajat keanggotaan (partisi). Teori Fuzzy keanggotaan sebuah data tidak deiberikan nilai secara tegas dengan nilai 1(menjadi anggota dan 0 (tidakmenjadi anggota), melainkan dengan nilai derjat keanggotaan yang jangkauan nilainya 0 sampai 1. Nilai keanggotaan suatu data dalam sebuah himpunan menjadi 0 sama sekali tidak menjadi anggota dan menjadi 1 jika menjadi anggota secara penuh dalam suatu himpunan. Umumnya nilai keanggotaannya antara 0 dan 1. Semakin tinggi nilai keanggotaannya maka semakin tinggi derajat keanggotaannya dan semakin kecil maka semakin rendah derajat keanggotaannya [8].
Konsep fuzzy c-means ini pertama kali adalah menentukan pusat cluster, yang menandai lokasi rata-rata tiap cluster. Kondisi awal pusat cluster ini belum akurat. Tiap-tiap titik data memiliki derajat keanggotaan untuk tiap-tiap cluster dengan cara memperbaiki pusat cluster dan derajat keanggotaan tiap-tiap titik data secara berulang, maka akan dapat dilihat bahwa pusat cluster akn bergerak menuju lokasi yang tepat. Perulangan ini didasarkan pada minimasi fungsi obyektif yang menggambarkan jarak dari titik data yang diberikan kepusat cluster yang erbobot oleh derajat keanggotaan titik data tersebut [7].
Algoritma Fuzzzy C-Means adalah sebagai berikut:
1. Penentuan pusat cluster yang menandai lokasi rata-rata untuk tiap cluster dengan kondisi awal tidak akurat.
2. Tiap data memiliki derajat keanggotaan untuk masing-masing cluster 3. Perulangan yang didasarkan pada minimasi fungsi obyektif, pusat cluster
dan nilai keanggotaan diperbaiki sehingga lokasi cluster bisa berada pada posisi yang benar.
Algoritma Fuzzy c-means didasarkan pada fungsi objektif yang diformulasikan dalam persaman sebagai berikut [10]
ukuran n x m(n= jumlah sampel data, m= atribut setiap data). Xij data sampel ke-i (i = 1,2,3,..,n), atribut ke-j (j = 1,2,3,..,m).
2. Tentukan julmlah cluster (c). Pangkat untuk matriks partisi (w), maksimum iterasi (MaxIter), error terkecil yang diharapkan, fungsi objektif awal (Po = 0), dan iterasi awal (t =1).
3. Bangkitkan bilangan random � , = , , . . , ; = , , … , sebagai elemen matriks partisi awal U
4. Hitung pusat cluster ke-k: , dengan k = 1,2,…,c, Dan j =1,2,..,m, menggunakan persamaan berikut:
= ∑= � �∗ �
∑ � �
= (2.10)
Keterangan:
= pusat cluster ke-k untuk atribut ke-j
� = derajat keanggotaan untuk data sampel ke-i pada cluster ke-k
= data ke-i, atribut ke-j
5. Hitung fungsi objektif pada iterasi ke-t menggunakan persaman berikut � = ∑ ∑� [∑= (� − ) ] �
=
= (2.11)
Keterangan:
= pusat cluster ke-k untuk atribut ke-j
= derajat keanggotaan untuk data sampel ke-i pada cluster ke-k
= data ke-i, atribut ke-j
� = fungsi objektif pada iterasi ke-T, data ke-i, dan kelas ke-k 6. Hitung perubahan matriks partisi menggunakan persamaan berikut:
� = [∑= � − ]�−
∑�= [∑= � − ]�−
(2.12)
Dengan I = 1,2,3,..,n, dan k = 1,2,..,c = pusat cluster ke-k untuk atribut ke-j
� = derajat keanggotaan untuk data sampel ke-i pada cluster ke-k
7. Cek kondisi berhenti:
Jika : (|Pt – Pt –I| < ξ) atau (t > MaxIter) maka akan berhenti, jika tidak :
T = t + I, ulangi langkah ke-4
2.5 Euclidean Distance
Euclidean distance adalah sebuah metode yang digunakan untuk mengukur jarak (distance). Euclidean distance sebenarnya merupakan generalisasi dari teorema phytagoras. Euclidean distance diformulasikan pada persamaan berikut:
, = √∑= − (2.10)
= jarak antara x dan y r = jumlah fitur dalam vektor
, = nilai fitur ke i dari x dan y
Jarak minimal yang mungkin antara dua vektor data adalah 0. Selain itu, jarak dari x ke y akan sama dengan y ke x, , = ,
2.6 Pemrograman Berorientasi Objek
Pemograman berorientasi objek adalah suatu strategi pembangunan perangkat lunak yang mengorganisasikan perangkat lunak sebagai kumpulan objek yang berisi data dan operasi yang diberlakukan terhadapnya. Menggunakan pendekatan berorientasi objek akan memandang sistem yang akan dikembangkan sebagai suatu kumpuln objek yang berkorespondensi dengan objek dunia nyata.
Dalam rekayasa perangkat lunak, konsep pendekatan berorientasi objek dapat diterapkan pada tahap analisis, perancangan, pemograman, dan pengujian perangkat lunak. Berikut adaah beberapa konsep dasar yang harus dipahami pemograman berorientasi objek [6] :
1. Kelas (Class)
kelakuan (operasi/metode), hubungan (relationship) dan arti. Suatu kelas dapat diturunkan dan kelas semula dapat diwariskan ke kelas yang baru.
2. Objek (Object)
Objek adalah abstraksi dan sesuatu yang mewakili dunia nyata seperti benda, manusia, satuan organisasi, tempat, kejadian, strutur, status, atau hal-hal lain yang bersifat abstrak. Objek merupakan suatu entitas yang mampu menyimpan informasi (status) dan mempunyai operasi (kelakuan) yang dapat diterapkan atau dapat berpengaruh pada status objeknya. Objek mempunyai siklus hidup yaitu diciptakan, dimanipulasi, dan dihancurkan.
3. Metode (Method)
Operasi atau metode pada sebuah kelas hampir sama dengan fungsi atau prosedur pada terstruktur. Sebuah kelas boleh memiliki lebih dari satu metode atau operasi. Metode atau operasi yang berfungsi untuk memanipulasi objek itu sendiri. 4. Atribut (Attribute)
Atribut dari sebuah kelas adalah variabel global yang dimiliki sebuah kelas. Atribut dapat berupa nilai atau elemen-elemen data yang dimiliki oleh objek 30 dalam kelas objek. Atribut secara individual oleh sebuah objek, misalnya berat, jenis, nama, dan sebagainya.
5. Abstraksi (Abstraction)
Prinsip untuk merepresentasikan dunia nyata yang kompleks menjadi satu bentuk model yang sederhana dengan mengabaikan aspek-aspek lain yang tidak sesuai dengan permasalahan.
6. Enkapulasi (Encapsulation)
Pembungkusan atribut data dan layanan (operasi-operasi) yang dipunyai objek untuk menyembunyikan implementasi dan objek sehingga objek lain tidak mengetahui cara kerja.
7. Pewarisan (Inheritance)
Mekanisme yang memungkinkan satu objek mewarisi sebagian atau seluruh definisi dan objek lain sebagai bagian dari dirinya.
Antarmuka atau interface sangat mirip dengan kelas, tetapi tanpa atribut kelas dan tanpa memiliki metode yang dideklarasikan. Antarmuka biasanya digunakan agar kelas lain tidak langsung mengakses ke suatu kelas.
9. Reusability
Pemanfaatan kembali objek yang sudah didefinisikan untuk suatu permasalahan pada permasalahan lainnya yang melibatkan objek tersebut.
10. Generalisasi dan Spesialisasi
Menunjukkan hubungan antara kelas dan objek yang umum dengan kelas dan objek yang khusus. Misalnya kelas yang lebih umum (generalisasi) adalah kendaraan darat dan kelas khususnya (spesialisasi) adalah mobil, motor, dan kereta. 11. Komunikasi antar objek
Komunikasi antar-objek dilakukan lewat pesan (message) yang dikirim dan satu objek ke objek lainnya.
12. Polimorfisme (Polymorphism)
Kemampuan suatu objek untuk digunakan dibanyak tujuan yang berbeda dengan nama yang sama sehingga menghemat baris program.
13. Package
Package adalah sebuah kontainer atau kemasan yang daoat digunakan untuk mengelompokkan kelas-kelas sehingga memungkinkan beberapa kelas yang bernama sama disimpan dalam package yang berbeda.
2.7 Python
2.8 Unified Modelling Language (UML)
UML singkatan dari Unifed Modeling Language yang berarti bahasa pemodelan standar. UML merupakan bahasa standar untuk merancang dan mendokumentasikan perangkat lunak dengan cara berorientasi objek. Ada beberapa diagram yang digunakan proses pembuatan perangkat lunak berorientasi objek diantaranya, use case diagram, activity diagram, class diagram dan sequence diagram [5].
2.8.1 Use Case Diagram
Use case diagram merupakan pemodelan untuk tingkah laku (behavior) pada sistem yang akan dibuat. Use case mendeskripsikan sebuah interaksi antara satu atau lebih aktor dengan sistem yang akan dibuat. Use case diagram digunakan untuk mengetahui fungsi apa saja yang terdapat pada sistem. Terdapat dua hal utama yang diperlukan dalam pembentukan suatu use case diagram yaitu aktor dan
use case.
1. Aktor merupakan orang, benda maupun sistem lain yang berinteraksi dengan sistem yang akan dibangun.
2. Use Case merupakan fungsionalitas atau layanan yang disediakan oleh sistem
sebagai unit-unit yang saling bertukar pesan antar unit atau actor [5].
2.8.2 Activity diagram
Activity diagram menggambarkan workflow (aliran kerja) atau aktivitas dari sebuah sistem, proses bisnis atau menu yang ada pada perangkat lunak. Setiap use case yang telah dibentuk digambarkan aktivitasnya dalam activity diagram, mulai dari peran aktor, peran sistem, dan decision. Activity diagram juga banyak digunakan untuk mendefinisikan hal-hal berikut [5]:
1. Rancangan proses bisnis dimana setiap urutan aktivitas yang digambarkan merupakan proses bisnis sistem.
3. Rancangan pengujian dimana setiap aktivitas dianggap memerlukan sebuah pengujian yang perlu didefinisikan kasus ujinya.
4. Rancangan menu yang ditampilkan pada perangkat lunak.
2.8.3 Class diagram
Class diagram menggambarkan interaksi dan relasi antar kelas yang ada di dalam suatu sistem. Kelas memiliki atribut dan metode. Atribut merupakan variabel-variabel yang dimiliki oleh suatu kelas. Metode adalah fungsi-fungsi yang dimiliki oleh suatu kelas. Atribut dan metode dapat memiliki salah satu sifat sebagai berikut [5]:
1. Private, tidak dapat dipanggil dari luar kelas yang bersangkutan.
2. Protected, hanya dapat dipanggil oleh kelas yang bersangkutan dan anak-anak yang mewarisinya.
3. Public, dapat dipanggil oleh siapa saja.
Class diagram menggambarkan relasi atau hubungan antar kelas dari sebuah sistem. Berikut ini beberapa gambaran relasi yang ada dalam class diagram: 1. Association
Hubungan antar class yang statis. Class yang mempunyai relasi asosiasi menggunakan class lain sebagai atribut pada dirinya.
2. Aggregation
Relasi yang membuat class yang saling terikat satu sama lain namun tidak terlalu berkegantungan.
3. Composition
Relasi agregasi dengan mengikat satu sama lain dengan ikatan yang sangat kuat dan saling berkegantungan.
4. Dependency
Hubungan antar class dimana class yang memiliki relasi dependency
menggunakan class lain sebagai atribut pada method. 5. Realization
2.8.4 Sequence diagram
Sequence diagram menggambarkan kelakuan objek pada use case dengan mendeskripsikan waktu hidup objek dan message yang dikirimkan dan diterima antar objek. Oleh karena itu untuk menggambarkan sequence diagram maka harus diketahui objek-objek yang terlibat dalam sebuah use case beserta metode-metode yang dimiliki kelas yang diinstansiasi menjadi objek itu.
Banyaknya sequence diagram yang harus digambar adalah sebanyak pendefinisian use case yang memiliki proses sendiri atau yang penting semua use case yang telah didefinisikan interaksi jalannya pesan sudah dicakup pada sequence diagram sehingga semakin banyak use case yang didefinisikan maka sequence diagram yang harus dibuat juga semakin banyak. Penomoran pesan berdasarkan urutan iteraksi pesan. Penggambaran letak pesan harus berurutan, pesan yang lebih atas dari lainnya adalah pesan yang berjalan terlebih dahulu [5].
2.9 Pengujian
Pengujian yang dilakukan pada penelitian ini menggunakan pengujian
confussion matrix dan pengujian validitas fuzzy c-means sebagai berikut:
2.9.1 Pengujian Black Box
Pengujian Black Box berfokus kepada persyaratan fungsional perangkat lunak (software) yang dibuat. Black box Testing (pengujian kotak hitam) yaitu menguji perangkat lunak dari segi spesifikasi fungsional tanpa menguji desain dan kode program. Pengujian dimaksud untuk mengetahui apakah fungsi-fungsi, masukan, dan keluaran dari perangkat lunak sesuai dengan spesifikasi yang dibutuhkan [14].
Pengujian Black Box dilakukan dengan membuat kasus uji yang bersifat mencoba semua fungsi dengan memakai perangkat lunak apakah sesuai dengan spesifikasi yang dibutuhkan. Pengujian Black Box berusaha menemukan kesalahan dalam kategori sebagai berikut.
2. Kesalahan interface
3. Kesalahan dalam struktrur data atau akses database eksternal 4. Kesalahan kinerja
5. Inisialisasi dan kesalahan terminasi
2.9.2 Confussion Matrix
Untuk mengevaluasi performa dari hasil proses klasifiksi dapat ditampilkan pada confussion matrix. Confussion Matrix berisi tentang klasifikasi actual dan yang telah diprediksi yang dilakukan oleh sebuah system klasifikasi. Kinerja sebuah system klasifikasi umumnya dievaluasi dengan menggunakan data dalam matriks. Tabel 2.2 berikut menunjukan contoh confussion matrix untuk klasifikasi masalah biner dua kelas [15].
Tabel 2.2 Confussion Matrix
Predicted Class
Kelas = 1 Kelas = 0
Actual Class Kelas = 1 f11 f10
Kelas = 0 f01 f00
Berdasarkan isi confussion matrix, maka dapat diketahui jumlah data dari masing-masing kelas yang diprediksi secara benar yaitu (f11 + f00)dan data yang diklasifikasikan salah yaitu (f10 + f01). Untuk menghitung akurasi digunakan formula sebagai berikut :
� = � +� +� +�� +� (2.11)
2.9.3 Pengujian Validitas Fuzzy C-Means
Metode pengelompokkan yang menggunakan konsep konsep fuzzy
tersebut. Beberapa metode validitas fuzzy c-means yang digunakan adalah sebagai berikut.
2.9.3.1 Partition Coefficient Index (PCI)
Bezdek (1981) mengusulkan validitas dengan menghitung koefisien partisi atau partition coefficient (PC) sebagai evaluasi nilai keanggotaan data pada setiap cluster. Nilai PC Index (PCI) hanya mengevaluasi nilai keanggotaan, tanpa memandang nilai vektor (data) yang biasanya mengandung informasi geometrik (sebaran data). Nilainya dalam rentang [0,1], nilai yang semakin besar (mendekati 1 ) mempunyai arti bahwa kualitas cluster yang didapat semakin baik. Berikut formula untuk menghitung PC Index [7].
� � = (∑ = ∑�= ) (2.12) N adalah jumlah data dalam set data, K merupakan jumlah cluster, sedangkan menyatakan nilai keanggotaan data ke-i pada cluster ke-j.
2.9.3.2 Partition Entropy Index (PEI)
Bezdek (1974a,b) mengusulkan validitas dengan menghitung entropi partisi atau partition entropy (PE). Nilai PE Index (PEI) mengevaluasi keteracakan data dalam cluster. Nilainya dalam rentang [0,1], nilai yang semakin kecil (mendekati 0) mempunyai arti bahwa kualitas cluster didapat semakin baik. Berikut formula untuk menghitung PEI [7].
� � = − (∑ ∑�
=
= ) (2.13)
N adalah jumlah data dalam set data, K merupakan jumlah cluster, sedangkan menyatakan nilai keanggotaan data ke-i pada cluster ke-j.
2.9.3.3 Modification Partition Coefficient Index (MPCI)
Metode PCI dan PEI memiliki kecendrungan monotonik terhadap K. Modifikasi nilai PCI (MPCI) dilakukan oleh dave (1996) terhadap kecendrungan monotonik tersebut. Formula yang digunakan sebagai berikut.
Nilai MPCI yang didapat adalah 0 ≤ MPCI ≤ 1. Nilai MPCI ekuivalen dengan Non-Fuzzines Index (NFI).
2.10 Tools Pembangunan Perangkat Lunak
Adapun beberapa perangkat lunak pendukung dalam pembuatan aplikasi pengenalan akor ini diantaranya :
2.10.1 Spyder
Spyder adalah Scientific Python Developmen Environment yang merupakan salah satu IDE (Integrated Development Environment) dari Python. Spyder mempunyai ciri komputasi numerik yang didukung oleh IPython (enhanced interactive Python interpreter) dan pustaka popular pada python seperti NumPy (linear algebra), sciPy (Signal dan Image processing) atau matpLotLib (interactive 2D/3D plotting) [11].
2.10.2 Qt Designer
29
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
3.1 Analisis Masalah
Analisis masalah yang diangkat dalam penelitian ini adalah suatu gambaran masalah dalam menghasilkan sistem yang mampu menampilkan informasi akor dari input akor yang berurutan dalam suatu file. Sebelumnya telah dilakukan penelitian pengenalan akor yang melakukan pengenalan terhadap klasifikasi pengenalan akor dengan ekstraksi ciri MFCC dengan hasil percobaan menunjukkan akurasi maksimum yang diperoleh adalah 83,65% [9].
Sebagai klasifikator digunakan Fuzzy c-means clustering . Fuzzy c-means clustering melakukan pengelompokkan terhadap hasil dari feature extraction
menggunakan Fast Fourier Transform. Hasil dari pelatihan fuzzy c-means clustering akan disimpan sebagai model pattern pada database yang akan digunakan untuk proses pencocokan akor. Proses pencocokan akor dilakukan dengan pengukuran jarak terdekat menggunakan euclidean distance untuk mengetahui seberapa besar kemiripan akor data uji dengan model pattern.
Berdasarkan uraian diatas, pada penelitian ini akan diterapkan Fuzzy c-means clustering untuk mendeteksi akor yang berurutan dalam satu file.
3.2 Analisis Proses
Proses dari sistem pengenalan akor menggunakan metode Fuzzy c-means clustering adalah proses pengambilan atau penentuan file(file input), proses latih
(training mode) dan proses pengujian (testing mode).
File Input merupakan bagian yang bertugas menentukan file audio yang akan diekstraksi. Alat yang dibutuhkan dalam proses ini adalah file yang berformat (*.wav).
Testing Mode merupakan bagian yang bertugas mengenali akor. Pengenalan akor dilakukan dengan melakukan pencocokan data uji dengan data model pattern
pada database.
Proses pengenalan akor menggunakan Fuzzy c-means clustering dapat dilihat pada Gambar 3.1 Berikut:
Ambil Data
Gambar 3. 1 Alur Proses Pengenalan Akor
Gambar 3.1 merupakan alur proses pengenalan akor, berikut penjelasannya : 1. Pada file audio (.wav) Training mode akan dilakukan pre-processing.
Dalam preprocessing terdapat beberapat tahapan yaitu normalisasi, frame blocking, windowing, powering, thresholding, dan FFT. Kemudian data yang berupa frekuensi disimpan di database.
2. Keluaran fuzzy c- means berupa titik centroid yang kemudian dimasukkan ke
database
3. Pada file audio (.wav) data uji akan dilakukan pre-processing.
4. Keluaran Euclidean distance adalah jarak perbanding data latih dan data uji jarak terdekat akan diverifikasi sebagai akor yang di prediksi.
3.3 Analisis Data Masukan
Analisis data yaitu analisis data pada preprocessing untuk klasifikasi akor menggunakan fuzzy c-means . Pada proses preprocessing data masukan berbentuk berkas audio (*.wav). Data masukan berkas audio (*.wav) yang bersifat sinyal analog akan dikonversikan terlebih dahulu kedalam bentuk sinyal digital melalui proses konversi analog menjadi digital dan akuisisi data. Pada proses pencocokan akor yang digunakan merupakan data hasil fitur dari hasil akhir preprocessing yang berbentuk frekuensi.
3.4 Analisis Metode
Metode yang diterapkan pada pengenalan akor meliputi pre-processing dan
fuzzy c-means clustering. Pre-processing terdiri dari konversi Analog menjadi
Digital (ADC), akuisisi data, normalisasi, frame blocking, windowing, powering, thresholding, serta Fast fourier transform . Berikut analisis dari masing- masing metode yang digunakan:
3.4.1 Pre-processing
Sinyal suara yang kan diproses bersifat analog sehiingga jika akan dilakukan pengolahan secara digital, sinyal suara tersebut harus dikonversi menjadi sinyal digital, setelah menjadi sinyal digital yang berupa amplitudo maka proses dilanjutkan dengan pengolahan data sinyal dengan normalisasi, frame blocking,
windowing, powering, thresholding, Fast fourier transform serta peak detection
berikut penjelasan tiap prosesnya:
3.4.1.1 Konversi Analog Menjadi Digital (ADC)
sinyal digital, berupa urutan angka dengan tingkat presisi tertentu yang dinamakan
analog to digital conversion. Konsep kerja ADC terdiri dari tiga proses yaitu :
1. Sampling
Proses sampling adalah suatu proses untuk mengambil data signal continue
untuk setiap periode tertentu. Data berupa sinyal diambil dengan cara merekam keyboard yang terhubung dengan komputer, data akan disimpan menggunakan format berkas file audio wav. Frekuensi sampling yang digunakan pada proses perekaman adalah 44100Hz. Durasi perekaman dilakukan dengan waktu yang pendek yaitu 1 detik.
2. Kuantisasi
Proses kuantisasi adalah proses untuk membulatkan nilai data ke dalam bilangan-bilangan tertentu yang telah ditentukan terlebih dahulu. Proses ini melakukan pengkonversian nilai analog ke dalam suatu nilai diskrit. Selama proses kuantisasi, ADC menkonversi setiap nilai analog ke dalam bentuk diskrit.
3. Pengkodean
Proses pengkodean adalah proses pemberian kode untuk tiap-tiap data signal yang telah terkuantisasi berdasarkan level yang ditempati. Pada proses ini, tiap nilai diskrit yang telah didapat, direpresentasikan dengan angka binary n-bit. Cara konversinya adalah dengan membagi bilangan desimal dengan bilangan biner dengan memperhatikan hasil sisa pembagian.
3.4.1.2 Akuisisi Data
Data diperoleh dengan cara merekam suara akor dari keyboard yang terhubung dengan komputer. Data latih berjumlah 120 dengan 24 akor dan tiap-tiap akor direkam sebanyak 5 kali. Perekaman suara menggunakan frekuensi 44100 Hz dan menggunakan format berkas audio (.wav). Suara dengan format (.wav) ini bisa menggunakan 16 bits/sample dan 1 untuk channel mono.
Dalam analisis ini digunakan contoh durasi rekaman akor A mayor. Durasi suara dengan jangka waktu yang pendek akan lebih mudah untuk diambil perbedaan fiturnya. Nilai maksimal amplitudo adalah 16000 yang didapat dari hasil pembacaan file yang dan total sinyal amplitudo berjumlah 87000. Sebagai contoh diambil data masukan berupa 30 angka dari amplitudo seperti yang dapat dilihat pada tabel 3.1 berikut.
Tabel 3. 1 Data Masukan
No
Mulai Data masukan amplitudo, nilai maksimal amplitudo
Normalisasi = amplitudo/nilai maksimal amplitudo
Hasil normalisasi
Selesai
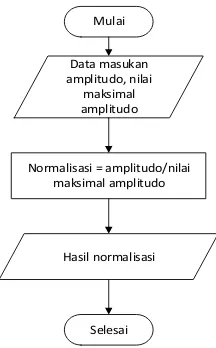
Gambar 3. 2 Flowchart Normalisasi
Hasil dari proses normalisasi ini dirancang agar batasan nilai puncak maksimum dari data akor tersebut diantara nilai 1 atau -1. Data masukan normalisasi berasal dari akuisisi data. Contoh proses normalisasi berikut ini menggunakan file A mayor yang menunjukan akor A. Amplitudo didapat dari hasil pembacaan file dan nilai maksimal didapat dari sinyal tertinggi. Persamaan pada normalisasi terdapat pada persamaan 2.3 sebagai berikut.
= � ��� �
max � ��� �
Keterangan :
= hasil data sinyal normalisasi = nilai data masukan (Amplitudo) �a� = nilai maksimal masukan (16000)
Pada amplitudo ke-0, maka :
= � ��� �
max � ��� � = = .
Tabel 3. 2 Data Masukan Normalisasi
Tabel 3. 3 Data Keluaran Normalisasi
No Normalisasi No Normalisasi No Normalisasi
Mulai
Nilai masukan total sinyal amplitudo, M (panjang frame),
dan N (Overlapping)
Jumlah frame = (total amplitdo/ M)+N+1
Data Jumlah frame
Selesai
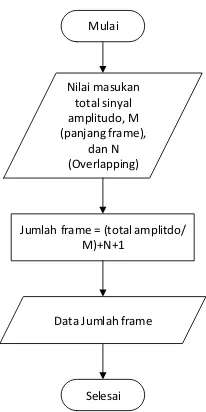
Gambar 3. 3 Flowchart Frame Blocking
Proses frame blocking dilakukan dengan cara memotong-motong sinyal dalam slot-slot waktu tertentu agar dapat dianggap invariant setiap potongan tersebut disebut frame. Total sinyal amplitudo didapat dari jumlah sinyal amplitudo pada pembacaan file. Nilai M didapat dari panjang frame 1 detik. Lebih jelas dapat dilihat pada gambar 3.4 berikut.
Gambar 3. 4 Frame Blocking
Persamaan untuk menghitung frame blocking dapat dilihat dalam persamaan 2.4 berikut.
Keterangan :
Jumlah frame = Total frame berdasarkan pembagian panjang frame dengan Overlapping
M = Panjang frame
N = Overlapping (M/2)
Total sinyal amplitudo dari pembacaan A.wav berjumlah 87000, untuk memproses sinyal dibutuhkan pemotongan-pemotongan sinyal dengan panjang satu
frame nya 1000 dan nilai overlapping 500. Ditetapkan :
M = 1000 N = 500
Hitung Jumlah Frame :
Ju�lah = Total si��al a�plitudo/M + N +
= 8 + + = 88
Jumlah frame adalah 588 frame dimana tiap frame memiliki 1000 nilai.
3.4.1.5 Windowing
Setelah melakukan proses frame blocking, proses selanjutnya adalah
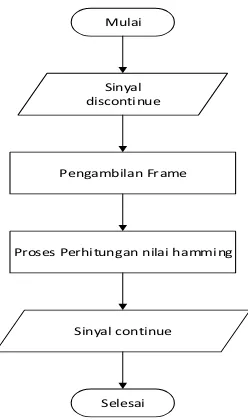
Mulai
Sinyal discontinue
Pengambilan Frame
Proses Perhitungan nilai hamming
Sinyal continue
Selesai
Gambar 3. 5 Flowchart Windowing
Fungsi pada proses windowing pada penelitian ini menggunakan Hamming Window persamaan 2.6 sebagai berikut:
= . − . � � − �
Keterangan :
n = 0,1,2,…,999
M (Panjang Frame) = 1000 = . − . � � −�
= , − , cos ( � , �− ) = , 8
Hitung dengan cara yang sama untuk n ke-1 hingga 999. Maka didapat hasil dari hamming window pada tabel 3.4 Berikut.
Tabel 3. 4 Window Hamming
No Window Hamming
0 0.08
1 0.080009098
2 0.080036392
No Window Hamming
4 0.080145564
5 0.080227437
6 0.080327497
7 0.080445741
8 0.080582163
9 0.080736759
10 0.080909522
…. …..
995 0.08014556
996 0.08008188
997 0.08003639
998 0.0800091
999 0. 08
Selanjutnya merepresentasikan fungsi window terhadap sinyal amplitudo yang telah di normalisasi yang terdapat pada tabel 3.3.
� = � . Keterangan :
n (data ke-) = 0,1,2,...,999 i (frame ke-) = 0,1,2,..,587
x(n) = nilai sampel sinyal hasil windowing � = nilai sampel dari frame signal ke i
= hasil window hamming
� = �
� = �
� = 0.001625 x 0.08 = 0.00013
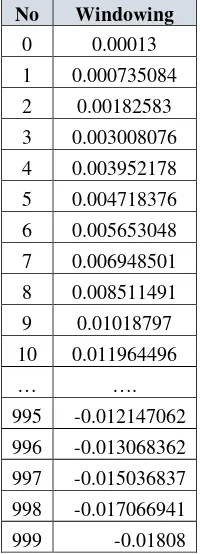
Tabel 3. 5 Data Windowing
No Windowing
0 0.00013
1 0.000735084
2 0.00182583
3 0.003008076 4 0.003952178
5 0.004718376 6 0.005653048 7 0.006948501 8 0.008511491
9 0.01018797
10 0.011964496
… ….
995 -0.012147062
996 -0.013068362 997 -0.015036837 998 -0.017066941
999 -0.01808
Perhitungan yang sama dilakukan untuk frame ke-1 atau i ke-1 hingga frame ke-587 atau i ke-587.
3.4.1.6 Powering
Mulai Data Windowing
(Xn)
Sqr t (sum(Xn^2))
Data Power ing P[i]
Selesai
Gambar 3. 6 Flowchart Powering
Dari 0 sampai 587 frame yang didapat dari hasil windowing, tiap-tiap frame
yang mempunyai 1000 nilai akan dilakukan powering. Powering mempunyai persamaan 2.7 sebagai berikut.
� = ∑ == | | Keterangan :
P = power sinyal (dB) Xi = Frame ke-i (dB) i = 0,1,2,…,587 m = 0,1,2,…,999
Pada file A mayor, maka didapat nilai powering pada frame ke-0 yang mempunyai 1000 data sebagai berikut.
� = ∑ | |
=
=
= ∑ | | = .
=
=
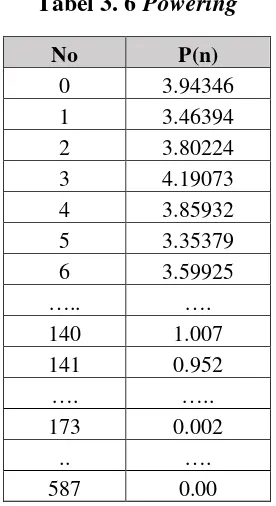
Tabel 3. 6 Powering
No P(n)
0 3.94346
1 3.46394
2 3.80224
3 4.19073
4 3.85932
5 3.35379
6 3.59925
….. ….
140 1.007
141 0.952
…. …..
173 0.002
.. ….
587 0.00
Agar lebih jelasnya dapat dilihat pada gambar 3.7 Berikut
Gambar 3. 7 Powering A mayor
Kemudian ditentukan nilai standar deviasi dari persamaan 2.8 berikut. � = √ ∑ � − ∑ �−
Keterangan :
� = Nilai Frame ke-i, n = jumlah frame
i = frame ke-0 hingga 587
Untuk menghindari bias maka nilai standar deviasi dibulatkan menjadi yaitu 1. Bias yang dimaksud adalah nilai dikategorikan sebagai noise karena berada pada nilai mendekati nol.
3.4.1.7 Thresholding
Setelah melakukan proses powering maka dilanjutkan dengan thresholding.
Thresholding dilakukan sebagai acuan untuk memisahkan voice. Thresholding
adalah membuat batas dan index masing-masing awal dan akhir yang didapat dari nilai hasil powering. Berikut flowchart dari thresholding.
Mulai
List Data Powering
Mencari nilai dari kiri
Selesai Melanjutkan pencarian nilai
P[i] > 1
Membuat tanda batas awal
ya
Tidak
Membuat tanda batas akhir
P[i] < 1
Mencocokan batas dengan index
Index awal dan akhir
ya
Standar deviasi yang adalah 1. Data hasil powering yang berada dibawah standar deviasi dianggap sebagai noise.
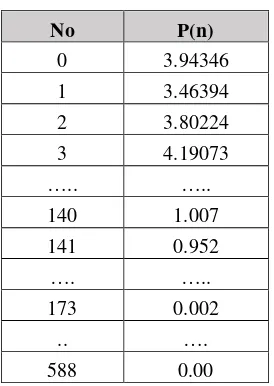
Tabel 3. 7 Hasil Powering
No P(n)
0 3.94346
1 3.46394
2 3.80224
3 4.19073
….. …..
140 1.007
141 0.952
…. …..
173 0.002
.. ….
588 0.00
Pada data tabel 3.7 data yang dibawah 1 berada pada frame ke-141 hingga 588, data tersebut dianggap noise. Berikut tabel 3.8 hasil thresholding.
Tabel 3. 8 Hasil Thresholding No P(n)
0 3.94346
1 3.46394
2 3.80224
3 4.19073
….. …..
140 1.007
Gambar 3. 8 Hasil Thresholding A mayor
Dari hasil pencarian data berdasarkan standar deviasi hasil powering dapat dilihat ada dua titik, pada posisi awal dan posisi akhir sinyal. Maka didapatkan data batas awal yang merupakan data ke-0 dan batas akhir yang merupakan data ke-140. Dari data tersebut kemudian dikembalikan ke bentuk index awal dan index akhir yang merupakan amplitudo dari hasil normalisasi. Berikut tabel batas dan index hasil thresholding.
Tabel 3. 9 Index dan Batas
Batas Awal Batas Akhir Index Awal Index Akhir
0 140 0 69860
3.4.1.8 Fast Fourier Transform
FFT merupakan salah satu metode untuk transformasi sinyal suara menjadi sinyal frekuensi. Artinya proses perekaman akor disimpan dalam bentuk digital
berupa gelombang spektrum suara berbasis frekuensi. Hasil dari proses fast fourier transform menghasilkan pendeteksian gelombang frekuensi domain dalam bentuk diskrit.
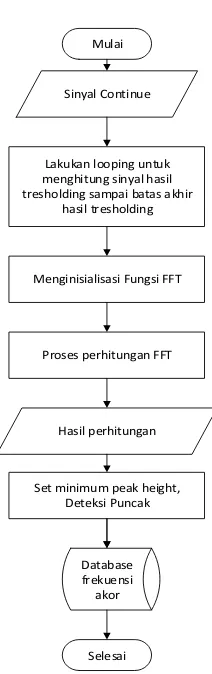
Mulai
Sinyal Continue
Menginisialisasi Fungsi FFT
Selesai Proses perhitungan FFT
Lakukan looping untuk menghitung sinyal hasil tresholding sampai batas akhir
hasil tresholding
Set minimum peak height, Deteksi Puncak Hasil perhitungan
Database frekuensi akor
Gambar 3. 9 Flowchart FFT
Setelah data Index awal dan index akhir diketahui maka selanjutnya dilakukan pengkonversian dari domain waktu ke domain frekuensi. Sampel yang akan di proses berjumlah 69860 – 1 = 69859 yang berasal dari thresholding. Contoh perhitungan FFT.
�[ ] = ∑�− [ ] − �� , ≤ ≤ −
= .
Keterangan :
N = jumlah sampel yang akan diproses (N N) S(n) = nilai sampel signal
= ∑ cos ��
= − ∑ si�
� � =
(3.6)
= [ . cos �∗ ∗ ] − �∗ ∗ +
⋯+[ . 88 cos �∗ ∗ ] − �∗ ∗ = 0.00008079
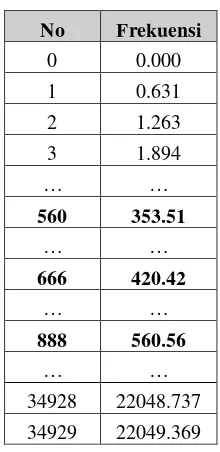
Hitung dengan cara yang sama untuk data yang lainnya. Namun hasil tersebut berasal dari dua sisi dikarenakan efek simetris FFT. Sehingga untuk menjadi satu frekuensi 69859/2 = 34929, maka akan didapatkan data sebagai berikut :
Tabel 3. 10 Fast Fourier Transform
No FFT
0 0.00008079
1 0.00008084
2 0.00008114
3 0.00008138
4 0.00008203
… …..
560 0.035673
… …
666 0.03210423
… …
888 0.03659571
. 34928 0.000000319
34929 0.000000230
Tabel 3. 11 Frekuensi FFT
No Frekuensi
0 0.000
1 0.631
2 1.263
3 1.894
… …
560 353.51
… …
666 420.42
… …
888 560.56
… …
34928 22048.737 34929 22049.369
Frekuensi puncak dari FFT akan menjadi ciri yang akan dimasukkan kedalam database. Sehingga file A mayor menghasilkan keluaran 3 data yaitu [ 353.51, 420.42, 560.56].
Gambar 3. 10 Frekuensi A mayor
Begitu juga dengan data selanjutnya. Tabel frekuensi akor dapat dilihat pada tabel 3.12 berikut.
Tabel 3. 12 Frekuensi Puncak Akor
Nama File Frekuensi Puncak Nama File Frekuensi Puncak
Nama File Frekuensi Puncak Nama File Frekuensi Puncak
3.4.2 Fuzzy c-means Clustering
Mulai
Tentukan : c = Jumlah cluster, w = Pangkat MaxIter = Maksimum iterasi, ξ = Error terkecil Po = Fungsi Objektif Awal, Iterasi awal = t
Selesai Inisialisasi awal Tentukan : n = jumlah sample data, m = atribut data
Matriks berukuran n x m Xij = data sample ke-i (i = 1,2, ,n) atribut ke-j (j=
Menghitung Pusat kluster ke- k: Vkj, dengan k = 1,2,..c; dan j = 1,2,..,m
Vkj = (Uik^w) . Xij/Uik^w
Menghitung Fungsi Objektif pada iterasi ke-t Pt = (Xij – Vkj)^2 . (Uik)^w)
Gambar 3. 11 Flowchart fuzzy c-means
Tahap-tahap yang dilakukan pada langkah ini dapat diuraikan detailnya sebagai berikut: