PEMODELAN ATURAN DALAM MEMPREDIKSI PRESTASI
AKADEMIK MAHASISWA POLITEKNIK NEGERI MEDAN
DENGAN KERNEL K-MEANS CLUSTERING
TESIS
Oleh
HIKMAH ADWIN ADAM
097038004/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
M E D A N
PEMODELAN ATURAN DALAM MEMPREDIKSI PRESTASI
AKADEMIK MAHASISWA POLITEKNIK NEGERI MEDAN
DENGAN KERNEL K-MEANS CLUSTERING
TESIS
Oleh
HIKMAH ADWIN ADAM
097038004/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
M E D A N
PEMODELAN ATURAN DALAM MEMPREDIKSI PRESTASI
AKADEMIK MAHASISWA POLITEKNIK NEGERI MEDAN
DENGAN KERNEL K-MEANS CLUSTERING
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar Magister Komputer dalam Program Studi Magister
Teknik Informatika pada Program Pascasarjana Fakultas MIPA Universitas Sumatera Utara
Oleh
HIKMAH ADWIN ADAM
097038004/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
M E D A N
PENGESAHAN TESIS
Judul Tesis : PEMODELAN ATURAN DALAM
MEMPREDIKSI PRESTASI AKADEMIK MAHASISWA POLITEKNIK NEGERI MEDAN DENGAN KERNEL K-MEANS CLUSTERING Nama Mahasiswa : Hikmah Adwin Adam
Nomor Induk Mahasiswa : 097038004
Program studi : Teknik Informatika
Fakultas : Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara
Menyetujui Komisi Pembimbing
Ketua
Prof. Dr. Muhammad Zarlis
Ketua Program Studi, D e k a n,
Prof. Dr. Muhammad Zarlis Dr. Sutarman, M.Sc.
PERNYATAAN ORISINALITAS
PEMODELAN ATURAN DALAM MEMPREDIKSI PRESTASI
AKADEMIK MAHASISWA POLITEKNIK NEGERI MEDAN
DENGAN KERNEL K-MEANS CLUSTERING
TESIS
Dengan ini saya nyatakan bahwa saya mengakui semua karya tesis ini adalah hasil kerja saya sendiri kecuali kutipan dan ringkasan yang tiap bagiannya telah di jelaskan sumbernya dengan benar.
Medan, 27 Juli 2011
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini:
Nama : Hikmah Adwin Adam
NIM : 097038004
Program Studi : Magister (S2) Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty Free Right) atas Tesis saya yang berjudul:
PEMODELAN ATURAN DALAM MEMPREDIKSI PRESTASI AKADEMIK MAHASISWA POLITEKNIK NEGERI MEDAN
DENGAN KERNEL K-MEANS CLUSTERING
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk data-base, merawat dan mempublikasikan Tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 27 Juli 2011
Telah diuji pada Tanggal : 27 Juli 2011
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Herman Mawengkang Anggota : 1. Prof. Dr. Muhammad Zarlis
2. Amer Sharif, S.SI, M.Kom
RIWAYAT HIDUP
DATA PRIBADI
Nama Lengkap : Hikmah Adwin Adam, S.Kom Tempat dan Tanggal Lahir : Medan / 23 Maret 1970
Alamat Rumah : Jl. Amaliun Gg. Rajabatu 9/239 Medan - 20215 Telepon / HP : (061) 7364357 / 08196017879
e-mail : hikmah_adwin@yahoo.com Instansi : Politeknik Negeri Medan
Alamat Kantor : Jl. Almamater No. 1 Kampus USU Medan - 20155 Telepon / Faks : (061) 8213071, 8211235 / (061) 8215845
DATA PENDIDIKAN
SD : Kartini Medan Tamat : 1982
KATA PENGANTAR
Segala puji dan syukur bagi Allah SWT karena dengan rahmat dan karuniaNYA sehingga tesis ini dapat diselesaikan melalui bimbingan, arahan dan bantuan yang diberikan berbagai pihak khususnya pembimbing, pembanding, para dosen, teman-teman mahasiswa Program Studi Magister (S2) Teknik Informatika FMIPA Universitas Sumatera Utara.
Dengan selesainya tesis ini, perkenankanlah penulis mengucapkan banyak terima kasih kepada:
Direktur Politeknik Negeri Medan Ir. Zulkifli Lubis, M.I.Komp yang telah memberi izin, bantuan dan kesempatan kepada penulis untuk mengikuti pendidikan lanjutan pada Program Pascasarjana FMIPA USU.
Rektor Universitas Sumatera Utara, Prof. Dr. dr. Syahril Pasaribu, DTM&H, M.Sc (CTM), Sp. A(K) atas kesempatan yang diberikan kepada penulis untuk mengikuti dan menyelesaikan pendidikan Program Magister (S2).
Dekan Fakultas MIPA Universitas Sumatera Utara, Dr. Sutarman, MSc atas kesempatan yang diberikan kepada penulis untuk menjadi mahasiswa Program Magister (S2) pada Program Pascasarjana FMIPA Universitas Sumatera Utara.
Ketua Program Studi Magister (S2) Teknik Informatika, Prof. Dr. Muhammad Zarlis, Sekretaris Program Studi Magister (S2) Teknik Informatika, M. Andri Budiman, ST, M.Comp. Sc, M.EM beserta seluruh Staf Pengajar pada Program Studi Magister (S2) Teknik Informatika FMIPA Universitas Sumatera Utara.
dengan penuh perhatian telah memberikan dorongan, bimbingan, kritik dan saran sehingga penulis dapat menyelesaikan tesis ini.
Terimakasih yang tak terhingga penulis ucapkan kepada Sajadin Sembiring, S.Si, MSc.Comp yang dengan penuh perhatian telah memberikan dorongan, bimbingan, kritik dan saran serta memberikan bahan-bahan yang berkaitan dengan penyusunan tesis ini sehingga penulis dapat menyelesaikan tesis ini dengan baik.
Terima kasih yang tak terhingga penulis ucapkan kepada Prof. Dr. Herman Mawengkang, M. Andri Budiman, ST, M.Comp.Sc,MEM dan Amer Sharif, S. SI, M.Kom sebagai Pembanding yang telah memberikan saran, masukan dan arahan yang baik demi penyelesaian tesis ini.
Seluruh Staf Pengajar dan Administrasi Program Studi Magister (S2) Teknik Informatika FMIPA Universitas Sumatera Utara yang telah memberikan bantuan dan pelayanan yang baik kepada penulis selama mengikuti perkuliahan.
Orang tua tercinta Ayahanda (alm) H. Adwin Adam dan Ibunda Hj. Nurhayati, yang senantiasa memberikan curahan kasih sayang, dukungan, doa yang tiada henti kepada penulis, budi baik ini tidak dapat dibalas hanya diserahkan kepada Allah SWT.
Rekan mahasiswa Angkatan Pertama Program Studi Magister (S2) Teknik Informatika FMIPA Universitas Sumatera Utarayang telah banyak membantu penulis selama mengikuti perkuliahan.
Kepada semua pihak yang tidak dapat penulis sebutkan satu persatu, terima kasih atas segala bantuan dan dukungan yang diberikan. Sekecil apapun bantuan yang penulis terima turut menghantarkan penulis untuk menyelesaikan pendidikan yang ditempuh selama ini. Dengan segala kekurangan dan kerendahan hati, semoga kiranya Allah SWT membalas segala bantuan dan kebaikan yang telah diberikan. Amin.
Medan, Juli 2011
PEMODELAN ATURAN DALAM MEMPREDIKSI PRESTASI AKADEMIK MAHASISWA POLITEKNIK NEGERI MEDAN
DENGAN KERNEL K-MEANS CLUSTERING
ABSTRAK
Tesis ini mengusulkan sebuah model aturan dalam memprediksi prestasi akademik mahasiswa di Jurusan Teknik Elektro Politeknik Negeri Medan. Hingga saat ini memprediksi prestasi akademik mahasiswa masih menjadi perdebataan yang hangat di institusi-institusi pendidikan tinggi. Faktor-faktor yang berpengaruh secara dominan terhadap prestasi akademik mahasiswa masih belum dapat ditentukan secara pasti. Saat ini manajemen Politeknik Negeri Medan masih menggunakan cara manual dalam memprediksi prestasi akademik mahasiswa. Sehingga sangat mungkin terjadi kesalahan dalam memprediksi prestasi akademik. Hal ini akan berpengaruh terhadap hasil keputusan yang akan diambil oleh pihak manajemen Politeknik Negeri Medan. Untuk itu sangat penting dibuat sebuah model aturan untuk memprediksi prestasi akademik mahasiswa yang dapat digunakan pihak manajemen sebagai sistem pendukung dalam pengambilan keputusan. Data yang digunakan dalam penelitian ini berasal dari database akademik mahasiswa jurusan Teknik Elektro Politeknik Negeri Medan tahun ajaran 2008-2009. Dalam tesis ini algoritma Kernel K-Means Clustering telah digunakan untuk mendapatkan suatu model aturan prediksi prestasi akademik mahasiswa di jurusan Teknik Elektro Politeknik Negeri Medan. Model aturan yang diperoleh menunjukkan bahwa predikat dengan pujian dapat diperoleh jika nilai rata-rata teori, nilai rata-rata-rata-rata praktek dan kehadiran semakin tinggi.
RULE MODELING IN PREDICTING ACADEMIC ACHIEVEMENT OF STUDENTS IN STATE POLYTECHNIC OF MEDAN WITH
KERNEL K-MEANS CLUSTERING
ABSTRACT
This thesis addresses a model of rule to predict students’ academic achievement in the Department of Electrical Engineering Polytechnic of Medan. Up till now predicting students' academic achievement is still a warm debate in institutions of higher education. Factors that affect predominantly on academic achievement of students still can not be determined exactly. Currently management of polytechnic of Medan is still using manual method in predicting students' academic achievement. So errors in predicting academic achievement are very probable. This will affect the result of decisions taken by the management of the Polytechnic of Medan. Because of this, it is very important to create a model to predict the academic achievement of students that can be used as a management support system in decision making. The data used in this study is based on a database of academic student majoring in Electrical Engineering Polytechnic Medan academic year 2008-2009. In this thesis algorithm Kernel K-Means Clustering has been used to obtain a prediction rule model of academic achievement of students in the Department of Electrical Engineering Polytechnic of Medan. Model rules obtained shows that the predicate with a compliment can be obtained if the average values of theory, practice and attendance are higher.
DAFTAR ISI
Halaman
KATA PENGANTAR i
ABSTRAK iii
ABSTRACT iv
DAFTAR ISI v
DAFTAR GAMBAR viii
DAFTAR TABEL ix
DAFTAR LAMPIRAN x
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 5
1.3 Batasan Masalah 5
1.4 Tujuan Penelitian 5
1.5 Manfaat Penelitian 6
BAB 2 TINJAUAN PUSTAKA 7
2.1 Pendahuluan 7
2.2 Data Mining : Knowledge Discovery Databases (KDD) 7
2.3 Tahapan Data Mining 9
2.4 Pengelompokan Data Mining 11
2.5 Algoritma Clustering (Clustering Algorithm) 13 2.5.1 Clustering Hirarkhi (Hierarchical Clustering) 16 2.5.2 Clustering Partisional (Partitional Clustering) 18
2.6 Analisis Cluster 20
2.7.2 Fungsi Kernel (Kernel Function) 22
2.7.3 Kernel Trick 24
2.7.4 Algoritma-algoritma Representatif 25
2.7.4.1 Pendahuluan 25
2.7.4.2 Algoritma K-Means Clustering (K-Means
Clustering Algorithm) 25 2.7.4.3 Kernel K-Means Clustering 27
2.8 Riset–riset Terkait 31
2.9 Persamaan dengan Riset-riset Lain 31 2.10 Perbedaan dengan Riset–riset Lain 32
2.11 Kontribusi Riset 32
BAB 3 METODOLOGI PENELITIAN 34
3.1 Pendahuluan 34
3.2 Lokasi dan Waktu Penelitian 34
3.3 Rancangan Penelitian 34
3.4 Pra Pemrosesan Data (Preprocessing Data) 35 3.5 Tools Analisis Rapidminer 5.1 38
3.6 Prosedur Penelitian 40
3.7 Diagram Aktivitas Penelitian 41
BAB 4 HASIL DAN PEMBAHASAN 42
4.1 Pendahuluan 42
4.2 Hasil Transformasi Data 42
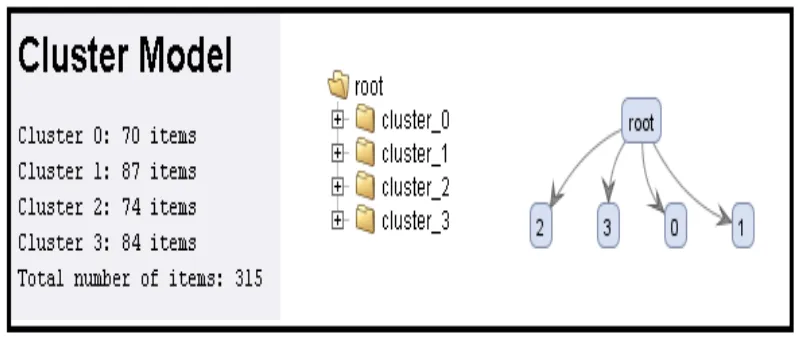
4.3 Cluster Model 43
4.4 Cluster Data Berdasarkan Predikat Prestasi Akademik 46
4.5 Analisis Cluster 47
4.5.1 Anggota Cluster (Cluster Membership) Berdasarkan
4.5.2 Interpretasi Cluster 49
BAB 5 KESIMPULAN DAN SARAN 51
5.1 Kesimpulan 51
5.2 Saran 51
DAFTAR PUSTAKA 53
DAFTAR GAMBAR Nomor
Gambar
J u d u l Halaman
2.1 Data Mining : Proses KDD 9
3.1 Tampilan RapidMiner 5.1 39
3.2 Prosedur Penelitian 40
3.3 Diagram Aktivitas Kerja Penelitian 41
4.1 Cluster Model 44
4.2 Tampilan Membership masing-masing Cluster 45 4.3 Distribusi data antara IPK dengan
DAFTAR TABEL Nomor
Tabel
J u d u l Halaman
3.1 Tampilan Data 35
3.2 Kategorisasi IPK 36
3.3 Kategorisasi Nilai Praktek dan Teori 36
3.4 Kategorisasi Prodi 36
3.5 Kategorisasi Agama 37
3.6 Kategorisasi Gender 37
3.7 Kategorisasi Kehadiran 37
3.8 Tampilan Kategorisasi Data 38
4.1 Hasil Transformasi Data 43
4.2 Tabel Cluster Model 45
4.3 Hasil Clustering dalam Data View 46 4.4 Jumlah Anggota Cluster terhadap Predikat 48
DAFTAR LAMPIRAN Nomor
Lampiran
J u d u l Halaman
Surat Pengumpulan Data Riset
A Data Numerik Lamp A – 1
B Data Kategorisasi Lamp B – 1
PEMODELAN ATURAN DALAM MEMPREDIKSI PRESTASI AKADEMIK MAHASISWA POLITEKNIK NEGERI MEDAN
DENGAN KERNEL K-MEANS CLUSTERING
ABSTRAK
Tesis ini mengusulkan sebuah model aturan dalam memprediksi prestasi akademik mahasiswa di Jurusan Teknik Elektro Politeknik Negeri Medan. Hingga saat ini memprediksi prestasi akademik mahasiswa masih menjadi perdebataan yang hangat di institusi-institusi pendidikan tinggi. Faktor-faktor yang berpengaruh secara dominan terhadap prestasi akademik mahasiswa masih belum dapat ditentukan secara pasti. Saat ini manajemen Politeknik Negeri Medan masih menggunakan cara manual dalam memprediksi prestasi akademik mahasiswa. Sehingga sangat mungkin terjadi kesalahan dalam memprediksi prestasi akademik. Hal ini akan berpengaruh terhadap hasil keputusan yang akan diambil oleh pihak manajemen Politeknik Negeri Medan. Untuk itu sangat penting dibuat sebuah model aturan untuk memprediksi prestasi akademik mahasiswa yang dapat digunakan pihak manajemen sebagai sistem pendukung dalam pengambilan keputusan. Data yang digunakan dalam penelitian ini berasal dari database akademik mahasiswa jurusan Teknik Elektro Politeknik Negeri Medan tahun ajaran 2008-2009. Dalam tesis ini algoritma Kernel K-Means Clustering telah digunakan untuk mendapatkan suatu model aturan prediksi prestasi akademik mahasiswa di jurusan Teknik Elektro Politeknik Negeri Medan. Model aturan yang diperoleh menunjukkan bahwa predikat dengan pujian dapat diperoleh jika nilai rata-rata teori, nilai rata-rata-rata-rata praktek dan kehadiran semakin tinggi.
RULE MODELING IN PREDICTING ACADEMIC ACHIEVEMENT OF STUDENTS IN STATE POLYTECHNIC OF MEDAN WITH
KERNEL K-MEANS CLUSTERING
ABSTRACT
This thesis addresses a model of rule to predict students’ academic achievement in the Department of Electrical Engineering Polytechnic of Medan. Up till now predicting students' academic achievement is still a warm debate in institutions of higher education. Factors that affect predominantly on academic achievement of students still can not be determined exactly. Currently management of polytechnic of Medan is still using manual method in predicting students' academic achievement. So errors in predicting academic achievement are very probable. This will affect the result of decisions taken by the management of the Polytechnic of Medan. Because of this, it is very important to create a model to predict the academic achievement of students that can be used as a management support system in decision making. The data used in this study is based on a database of academic student majoring in Electrical Engineering Polytechnic Medan academic year 2008-2009. In this thesis algorithm Kernel K-Means Clustering has been used to obtain a prediction rule model of academic achievement of students in the Department of Electrical Engineering Polytechnic of Medan. Model rules obtained shows that the predicate with a compliment can be obtained if the average values of theory, practice and attendance are higher.
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Dengan kemajuan teknologi informasi sekarang ini, kebutuhan akan informasi yang akurat sangat dibutuhkan dalam kehidupan sehari-hari. Terkadang kebutuhan informasi yang tinggi tidak diimbangi dengan penyajian informasi yang memadai, sehingga sering kali informasi tersebut masih harus di gali ulang dari kumpulan data yang jumlahnya sangat besar. Kemajuan teknologi untuk mengumpulkan dan menyimpan berbagai jenis data jauh meninggalkan kemampuan untuk menganalisis, meringkas dan mengekstrak pengetahuan dari data. Metode tradisional untuk menganalisis data yang ada, tidak dapat menangani data dalam jumlah besar. Para pembuat keputusan berusaha untuk memanfaatkan kumpulan data yang sudah dimiliki untuk menggali informasi yang berguna dalam mengambil keputusan. Hal ini mendorong munculnya cabang ilmu baru untuk mengatasi masalah penggalian informasi yang penting dari kumpulan data, yang disebut dengan data mining.
Data mining sering juga disebut knowledge discovery in database (KDD), adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Santoso, 2007).
Teknik data mining secara garis besar dapat dibagi dalam dua kelompok yaitu verifikasi dan discovery. Metode verifikasi umumnya meliputi teknik-teknik statistik seperti goodness of fit, dan analisis variansi. Metode discovery lebih lanjut dapat dibagi atas model prediktif dan model deskriptif. Teknik prediktif melakukan prediksi terhadap data dengan menggunakan hasil-hasil yang telah diketahui dari data yang berbeda. Model ini dapat dibuat berdasarkan penggunaan data historis lain. Sementara itu, model deskriptif bertujuan mengidentifikasi pola-pola atau hubungan antar data dan memberikan cara untuk mengeksplorasi karakteristik data yang diselidiki (Dunhamm, 2003).
Perguruan tinggi saat ini dituntut untuk memiliki kemampuan bersaing dengan memanfaatkan semua sumber daya yang dimiliki. Selain sumber daya sarana, prasarana, dan manusia, sistem informasi adalah salah satu sumber daya yang dapat digunakan untuk meningkatkan kemampuan bersaing. Sistem informasi dapat digunakan untuk mendapatkan, mengolah dan menyebarkan informasi untuk menunjang kegiatan operasional sehari-hari sekaligus menunjang kegiatan pengambilan keputusan strategis.
Keberhasilan seorang mahasiswa dapat dilihat dari indeks prestasi yang dicapainya. Indeks prestasi merupakan penilaian keberhasilan belajar mahasiswa yang dinyatakan dengan nilai kredit rata-rata yang merupakan satuan nilai akhir yang menggambarkan mutu bahwa mahasiswa telah menyelesaikan seluruh mata kuliah pada satu semester.
Secara umum penilaian atas prestasi mahasiswa untuk suatu mata kuliah terdiri dari berbagai komponen yang meliputi beberapa atau semua komponen berikut: absen kehadiran, tugas mandiri, praktikum, kuis, Ujian Tengah Semester (UTS) dan Ujian Akhir Semester (UAS). Evaluasidan penilaianterhadap prestasi mahasiswa dilakukan dengan pemberian nilai oleh dosen pengajar kepada semua mahasiswa yang mengikuti mata kuliah yang diajarnya.
akademik mahasiswa bersangkutan sampai semester tersebut. IPK diperoleh dengan cara menjumlahkan seluruh nilai mutu semua mata kuliah yang telah diambil dan membaginya dengan total sks (satuan kredit semester). Oleh karena itu, IPK masih tetap merupakan faktor yang paling umum digunakan oleh perencana akademis untuk mengevaluasi perkembangan di lingkungan akademik (Sansgiry et al, 2006).
Banyak faktor yang menjadi penghalang bagi mahasiswa mencapai dan mempertahankan IPK tinggi yang mencerminkan usaha mereka secara keseluruhan selama masa kuliah di perguruan tinggi. Faktor tersebut dapat ditargetkan oleh pihak perguruan tinggi sebagai tindakan mengembangkan strategi untuk meningkatkan prestasi mahasiswa dan meningkatkan kinerja akademik dengan cara memantau perkembangan kinerja mereka. Oleh karena itu, evaluasi kinerja merupakan salah satu dasar untuk
Salah satu topik perdebatan di pendidikan tinggi adalah prediksi keberhasilan di perguruan tinggi. Tidak ada kepastian jika ada prediktor akademis yang akurat untuk menentukan apakah mahasiswa akan menjadi jenius, drop out, atau berprestasi rata-rata (Ryder, 1999). Tugas untuk mengembangkan prediktor efektif untuk keberhasilan akademis merupakan isu penting bagi para pendidik (Ryder, 1999).
memantau perkembangan prestasi akademik mahasiswa didalam perguruan tinggi (Oyelade, 2010).
Berdasarkan isu ini, pengelompokan mahasiswa kedalam kategori yang berbeda sesuai dengan prestasi mereka menjadi tugas yang rumit. Dengan pengelompokan mahasiswa secara tradisional berdasarkan nilai rata-rata mereka, maka sulit untuk memperoleh pandangan yang menyeluruh mengenai keadaan prestasi mahasiswa (Oyelade, 2010).
non-overlapping yang berbeda, meskipun dalam praktek pemisahan yang sempurna biasanya tidak bisa dicapai
Dalam Peraturan Akademik Politeknik Negeri Medan seorang mahasiswa dinyatakan lulus dengan ketentuan 2,00 ≤ IPK ≤ 2,75 dengan kriteria Memuaskan. Dengan mengetahui kategori karakteristik mahasiswa diharapkan para pengambil kebijakan dapat mendorong para mahasiswa untuk memperbaiki prestasi akademiknya sebelum masa studi berakhir.
(Oyelade, 2010).
Kemampuan untuk memprediksi prestasi akademik mahasiswa sangat penting dalam sistem lembaga pendidikan. Dalam penelitian ini, digunakan teknik data mining yaitu algoritma Kernel K-Means Clustering umtuk membuat model aturan dalam memprediksi prestasi akademik mahasiswa. Data yang digunakan dalam penelitian ini adalah data mahasiswa pada jurusan Teknik Elektro Politeknik Negeri Medan.
Algoritma K-Means mengklusterkan ukuran jarak Euclidean, di mana jarak dihitung adalah untuk mencari kuadrat dari jarak antara masing-masing nilai, menjumlahkan kuadrat dan menemukan akar kuadrat dari jumlah tersebut (Fahim, 2006).
Kernel K-Means adalah pengembangan dari algoritma K-Means yang menggunakan metode Kernel untuk memetakan data yang berdimensi tinggi pada space yang baru sehinga dapat dipisahkan secara linear. Hal ini dilakukan untuk meningkatkan akurasi hasil klaster. Didalam Kernel K-Means diharapkan data bisa dipisahkan dengan lebih baik karena data yang overlap atau data outlier bisa menjadi linier di ruang dimensi baru (Santosa, 2007).
Berdasarkan masalah diatas maka penelitian ini akan memaparkan algoritma Kernel K-Means Clustering untuk membuat model aturan dalam memprediksi prestasi akademik mahasiswa jurusan Teknik Elektro Politeknik Negeri Medan.
Dari uraian diatas maka p
1. Bagaimana menggunakan metode Kernel pada data akademik,
ermasalahan yang dicoba untuk diselesaikan dalam tesis ini secara detail adalah sebagai berikut :
2. Bagaimana menggunakan metode Kernel K-Means untuk membuat model aturan dalam memprediksi prestasi akademik mahasiswa sebelum masa studi berakhir.
1.3 Batasan Masalah
Untuk memfokuskan pada permasalahan diatas, maka permasalahan dalam penelitian ini dibatasi sebagai berikut :
1.
2.
Data diambil dari mahasiswa angkatan 2008-2009 pada jurusan Teknik Elektro di Politeknik Negeri Medan.
3.
Variabel yang digunakan dalam penelitian ini merupakan atribut data mahasiswa seperti nilai rata-rata teori, nilai rata-rata praktek, ipk, kehadiran dan data demografi seperti jenis kelamin, agama dan program studi.
Pengujian data menggunakan perangkat lunak RapidMiner 5.1.
1.4 Tujuan Penelitian
Tujuan yang ingin dicapai dari penelitian ini adalah :
1. Mengimplementasikan metode Kernel pada data yang bersumber dari perguruan tinggi.
1.5 Manfaat Penelitian
Adapun manfaat yang diharapkan dalam penelitian ini adalah :
1. Hasil penelitian ini dapat dijadikan sebagai model untuk memprediksi prestasi akademik mahasiswa di Politeknik Negeri Medan.
2. Penelitian ini dapat dijadikan masukan bagi pengambil keputusan di Politeknik Negeri Medan untuk meningkatkan prestasi akademik mahasiswa.
BAB 2
TINJAUAN PUSTAKA
2.1 Pendahuluan
Revolusi digital telah membuat manusia makin mudah untuk menangkap, memproses, menyimpan, mendistribusikan, dan mengirimkan informasi digital. Dengan kemajuan yang signifikan dalam komputasi dan teknologi yang terus berkembang, sejumlah besar karakteristik data yang beragam terus terkoleksi dan disimpan dalam database. volume data yang tersimpan berkembang sangat fenomenal. Penemuan pengetahuan dari volume data yang sangat besar merupakan sebuah tantangan
Ke
.
canggihan teknologi manajemen database dewasa ini memungkinkan untuk mengintegrasikan berbagai jenis data seperti video, gambar, teks, dan data numerik maupun non-numerik lainnya dalam database tunggal untuk memfasilitasi pengolahan multimedia. Akibatnya gabungan teknik statistik dan alat-alat manajemen data tradisional tidak lagi memadai untuk menganalisis koleksi data campuran ini. Teknik data mining merupakan solusi yang mungkin (Chakrabarti et al.2009).
2.2 Data Mining : Knowledge Discovery Databases (KDD)
dari data mining ini bisa dipakai untuk memperbaiki pengambilan keputusan di masa depan (Santoso, 2007). Data mining adalah kegiatan menemukan pola yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya. Data mining berkaitan dengan bidang ilmu-ilmu lain, seperti database system, data warehousing, statistik, machine learning, information retrieval, dan komputasi tingkat tinggi. Selain itu, data mining didukung oleh ilmu lain seperti neural network, pengenalan pola, spatial data analysis, image database, signal processing (Han, 2006). Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban, dkk. 2005).
Masalah-masalah yang sesuai untuk diselesaikan dengan teknik data mining dapat dicirikan dengan (Piatetsky & Shapiro, 2006) :
• Memerlukan keputusan yang bersifat knowlegde-based.
• Mempunyai lingkungan yang berubah.
• Metode yang ada sekarang bersifat sub-optimal.
• Tersedia data yang bisa diakses, cukup dan relevan.
• Memberikan keuntungan yang tinggi jika keputusan yang ambil tepat.
Data mining sering digunakan untuk membangun model prediksi/inferensi yang bertujuan untuk memprediksi tren masa depan atau perilaku berdasarkan analisis data terstruktur. Dalam konteks ini, prediksi adalah pembangunan dan penggunaan model untuk menilai kelas dari contoh tanpa label, atau untuk menilai jangkauan nilai atau contoh yang cenderung memiliki nilai atribut. Klasifikasi dan regresi adalah dua bagian utama dari masalah prediksi, dimana klasifikasi digunakan untuk memprediksi nilai diskrit atau nominal sedangkan regresi digunakan untuk memprediksi nilai terus-menerus atau nilai yang ditentukan (Larose, 2005).
2.3 Tahapan Data Mining
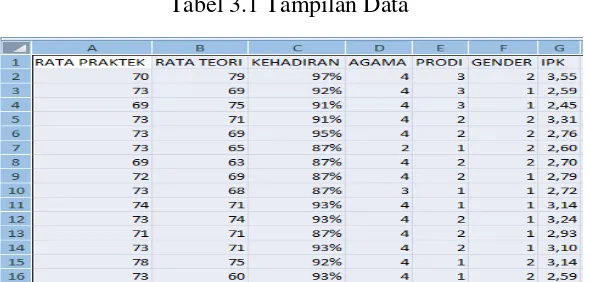
Data yang ada, tidak dapat langsung diolah dengan menggunakan sistem data mining. Data tersebut harus dipersiapkan terlebih dahulu agar hasil yang diperoleh dapat lebih maksimal, dan waktu komputasinya lebih minimal. Proses persiapan data ini sendiri dapat mencapai 60 % dari keseluruhan proses dalam data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut (Fayyad, 1996)
Gambar 2.1 Data Mining : Proses KDD Sumber : Fayyad 1996
Menurut Kusrini (Kusrini & Emha, 2009) proses KDD dapat diuraikan sebagai berikut :
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari database operasional.
• Pra-pemrosesan / Pembersihan (Pre-processing / Cleaning)
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
• Transformasi (Transformation)
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam database.
• Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data yang terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
• Interpretasi / Evaluasi (Interpretation / Evaluation)
2.4 Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Larose, 2005) :
1. Deskripsi (Description)
Terkadang penelitidan analis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menemukan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi (Estimation)
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik daripada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi (Prediction)
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa datang. Contoh prediksi dalam bisnis dan penelitian adalah :
• Prediksi harga beras dalam tiga bulan yang akan datang.
• Prediksi persentase kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan.
4. Klasifikasi (Classification)
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
Contoh lain klasifikasi dalam bisnis dan penelitian adalah :
• Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan.
• Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan suatu kredit yang baik atau buruk.
• Mendiagnosis penyakit seorang pasien untuk mendapatkan kategori penyakit apa.
5. Pengklusteran (Clustering)
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Cluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam cluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan record dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal.
Contoh pengklusteran dalam bisnis dan penelitian adalah :
• Melakukan pengklusteran terhadap ekspresi dari gen, untuk mendapatkan kemiripan perilaku dari gen dalam jumlah besar.
• Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk bagi perusahaan yang tidak memiliki dana pemasaran yang besar.
• Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilaku finansial dalam baik dan mencurigakan.
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja. Contoh asosiasi dalam bisnis dan penelitian adalah :
• Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli secara bersamaan.
• Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respons positif terhadap penawaran upgrade layanan yang diberikan.
2.5 Algoritma Clustering(Clustering Algorithm)
Clustering (pengelompokan data) mempertimbangkan sebuah pendekatan penting untuk mencari kesamaan dalam data dan menempatkan data yang sama ke dalam kelompok-kelompok. Clustering membagi kumpulan data ke dalam beberapa kelompok dimana kesamaan dalam sebuah kelompok adalah lebih besar daripada diantara kelompok-kelompok (Rui Xu & Donald 2009). Gagasan mengenai pengelompokan data, atau clustering, memiliki sifat yang sederhana dan dekat dengan cara berpikir manusia; kapanpun kepada kita dipresentasikan jumlah data yang besar, kita biasanya cenderung merangkumkan jumlah data yang besar ini ke dalam sejumlah kecil kelompok-kelompok atau kategori-kategori untuk memfasilitasi analisanya lebih lanjut. Selain dari itu, sebagian besar data yang dikumpulkan dalam banyak masalah terlihat memiliki beberapa sifat yang melekat yang mengalami pengelompokan-pengelompokan natural (Hammouda & Karray, 2003).
Algoritma-algoritma clustering digunakan secara ekstensif tidak hanya untuk mengorganisasikan dan mengkategorikan data, akan tetapi juga sangat bermanfaat untuk kompresi data dan konstruksi model. Melalui pencarian kesamaan dalam data, seseorang dapat merepresentasikan data yang sama dengan lebih sedikit simbol misalnya. Juga, jika kita dapat menemukan kelompok-kelompok data, kita dapat membangun sebuah model masalah berdasarkan pengelompokan-pengelompokan ini (Dubes & Jain, 1988).
Clustering menunjuk pada pengelompokan record, observasi-observasi, atau kasus-kasus ke dalam kelas-kelas objek yang sama. Cluster adalah sekumpulan record yang adalah sama dengan satu sama lain dan tidak sama dengan record dalam cluster lain. Clustering berbeda dari klasifikasi dimana tidak ada variabel target untuk clustering. Tugas clustering tidak mencoba untuk mengklasifikasikan, mengestimasi, atau memprediksi nilai variabel target (Larose, 2005). Bahkan, algoritma clustering berusaha mensegmentasikan seluruh kumpulan data ke dalam subkelompok-subkelompok atau cluster-cluster homogen secara relatif. Dimana kesamaan record dalam cluster dimaksimalkan dan kesamaan dengan record diluar cluster ini diminimalkan.
Clustering sering dilaksanakan sebagai langkah pendahuluan dalam proses pengumpulan data, dengan cluster-cluster yang dihasilkan digunakan sebagai input lebih lanjut ke dalam sebuah teknik yang berbeda, seperti neural network. Karena ukuran yang besar dari banyak database yang dipresentasikan saat ini, maka sering sangat membantu untuk menggunakan analisa clustering terlebih dahulu, untuk mengurangi ruang pencarian untuk algoritma-algoritma downstream. Aktivitas clustering pola khusus meliputi langkah-langkah berikut (Dubes & Jain, 1988) :
(I) Representasi pola (secara opsional termasuk ekstraksi dan/atau seleksi sifat)
(II) Definisi ukuran kedekatan pola yang tepat untuk domain data (III) Clustering pengelompokan
(V) Pengkajian output (jika dibutuhkan).
Representasi pola merujuk pada jumlah kelas, jumlah pola-pola yang ada, dan jumlah, tipe dan skala fitur yang tersedia untuk algoritma clustering. Beberapa informasi ini dapat tidak bisa dikontrol oleh praktisioner. Seleksi sifat (fitur) adalah proses pengidentifikasian subset fitur original yang paling efektif untuk digunakan dalam clustering. Ekstraksi fitur adalah penggunaan satu atau lebih transformasi dari sifat-sifat input untuk menghasilkan sifat-sifat baru yang lebih baik.
Pertimbangkan dataset X yang terdiri dari point-point data (atau secara sinonim, objek-objek, hal-hal, kasus-kasus, pola, tuple, transaksi) xi = (xi1, …, xid) Є
A dalam ruang atribut A, dimana i = 1, N, dan setiap komponen adalah sebuah atribut A kategori numerik atau nominal. Sasaran akhir dari clustering adalah untuk menentukan point-point pada sebuah sistem terbatas dari subset k, cluster. Biasanya subset tidak berpotongan (asumsi ini terkadang dilanggar), dan kesatuan mereka sama dengan dataset penuh dengan pengecualian yang memungkinkan outlier. Ci
adalah sekelompok point data dalam dataset X, dimana X = Ci .. Ck .. Coutliers, Cj1 .. Cj2 = 0.
2.5.1 Clustering Hirarkhi (Hierarchical Clustering)
penghentian (seringkali, jumlah k yang diperlukan dari cluster) dicapai. Kelebihan cluster hirarkhi meliputi:
(I) Fleksibilitas yang tertanam mengenai level granularitas (II) Kemudahan menangani bentuk-bentuk kesamaan atau jarak (III) Pada akhirnya, daya pakai pada tipe-tipe atribut apapun.
Kelemahan dari clustering hirarkhi berhubungan dengan:
(I) ketidakjelasan kriteria terminasi
(II) Terhadap perbaikan hasil clustering, sebagian besar algoritma hirarkhi tidak mengunjungi kembali cluster-clusternya yang telah dikonstruksi.
Untuk clustering hirarkhi, menggbungkan atau memisahkan subset dari point-point dan bukan point-point individual, jarak antara point-point individu harus digeneralisasikan terhadap jarak antara subset.
Ukuran kedekatan yang diperoleh disebut metrik hubungan. Tipe metrik hubungan yang digunakan secara signifikan mempengaruhi algoritma hirarkhi, karena merefleksikan konsep tertentu dari kedekatan dan konektivitas. Metrik hubungan antar cluster utama (Murtagh 1985, Olson 1995) termasuk hubungan tunggal, hubungan rata-rata, dan hubungan sempurna. Semua metrik hubungan diatas dapat diperoleh sebagai jarak dari pembaharuan formula Lance-Williams (Lance & Williams, 1967).
D(Ci · · Cj , Ck = ɑ (i) d (Ci , Ck) + ɑ (k) d (Cj , Ck) + bd (Ci , Cj ) + c|d (Ci , Ck) – d(Cj , Cj
Dimana, a, b, c, adalah koefisien-koefisien yang sesuai dengan hubungan tertentu. Formula ini menyatakan sebuah metrik hubungan antara kesatuan dari dua cluster dan cluster ketiga dalam bentuk komponen-komponen yang mendasari.
) | (2.1)
Metrik-metrik hubungan berdasarkan jarak Euclidean untuk clustering hirarkhi dari data spatial secara natural mempengaruhi cluster-cluster dari bentuk-bentuk convex yang tepat. Sementara itu, scanning visual dari gambar-gambar spatial sering memperlihatkan cluster-cluster dengan tampilan curvy.
Dalam linguistik, pencarian informasi, dan taksonomi biner aplikasi clustering dokumen adalah sangat membantu. Metode-metode aljabar linear, yang didasarkan pada dekomposisi nilai singular (Singular Value Decomposition - SVD) digunakan untuk tujuan ini dalam filtering kolaboratif dan pencarian informasi (Berry & Browne, 1999). Aplikasi SVD terhadap clustering divisive hirarkhi dari kumpulan dokumen menghasilkan algoritma PDDP (Principal Direction Divisive Partitioning) (Boley, 1998). Algoritma ini membagi dua data dalam ruang Euclidean dengan sebuah hyperplane yang mengalir melalui centroid data secara ortogonal pada eigenvector dengan nilai singular yang besar. Pembagian cara k juga memungkinkan jika k nilai singular terbesar dipertimbangkan. Divisive hirarkhi yang membagi dua rata-rata k terbukti (Steinbach et al. 2000) dapat dipilih untuk clustering dokumen.
Algoritma clustering hirarkhi populer untuk data kategorikal COBWEB (Fisher, 1987) memiliki dua kualitas yang sangat penting. Pertama, menggunakan pembelajaran incremental. Daripada mengikuti pendekatan divisive atau agglomerative, secara dinamis membangun sebuah dendrogram melalui pengolahan satu point data pada suatu waktu. Kedua, COBWEB termasuk pada pembelajaran berdasarkan konseptual atau model. Ini berarti bahwa setiap cluster dianggap sebagai sebuah model yang dapat dijelaskan secara intrinsik, dan bukan sebagai sebuah kumpulan point yang ditentukan terhadapnya. Dendrogram COBWEB disebut pohon klasifikasi. Setiap node pohon C, sebuah cluster, berhubungan dengan probabilitas kondisional untuk pasangan-pasangan nilai-nilai atribut kategorikal, yakni :
2.5.2 Clustering Partisional (Partional Clustering)
Dengan mengetahui objek-objek database n, sebuah algoritma clustering partisional membentuk k bagian dari data, dimana setiap cluster mengoptimalkan kriteria clustering, seperti minimisasi jumlah jarak kuadrat dari rata-rata dalam setiap cluster.
Salah satu isu dengan algoritma-algoritma tersebut adalah kompleksitas tinggi, karena menyebutkan semua pengelompokan yang memungkinkan dan berusaha mencari optimum global. Bahkan untuk jumlah objek yang kecil, jumlah partisi adalah besar. Itulah sebabnya mengapa solusi-solusi umum dimulai dengan sebuah partisi awal, biasanya acak, dan berlanjut dengan penyempurnaannya.
Praktek yang lebih baik akan berupa pelaksanaan algoritma partisional untuk kumpulan point-point awal yang berbeda (yang dianggap sebagai representatif) dan meneliti apakah semua solusi menyebabkan partisi akhir yang sama atau tidak. Algoritma-algoritma clustering partisional berusaha memperbaiki secara lokal sebuah kriteria tertentu. Pertama, menghitung nilai-nilai kesamaan atau jarak, mengurutkan hasil, dan mengangkat nilai yang mengoptimalkan kriteria. Oleh karena itu, dapat dianggap sebagai algoritma seperti greedy.
Dalam pendekatan probabilistis, data dianggap sebuah sampel yang diambil secara independen dari sebuah model campuran dari beberapa distribusi probabilitas (McLachlan & Basford, 1988). Asumsi utama adalah point-point data dihasilkan melalui, pertama, pengambilan secara acak model j dengan probabilitas τj
L(X|C) = Π
, J = 1; k, dan, kedua, melalui pengambilan point x dari sebuah distribusi yang sesuai. Daerah sekitar rata-rata dari setiap distribusi (anggaplah unimodal) membentuk sebuah cluster natural. Kemungkinan menyeluruh dari data pelatihan adalah probabilitasnya untuk ditarik dari sebuah model campuran tertentu.
i =1:N j=1:k =�j Pr (Xi|Cj
Algoritma SNOB (Wallace & Dowe, 1994) menggunakan model campuran bersama dengan Minimum Message Length (MML) principal. Algoritma AUTOCLASS (Cheeseman & Stutz, 1996) menggunakan model campuran dan meliputi varietas distribusi yang luas, termasuk Bernoulli, Poisson, gaussian, dan distribusi-distribusi lognormal. Clustering probabilistis memiliki beberapa sifat penting:
) (2.3)
(I) Dapat memodifikasi untuk menangani record dari struktur kompleks.
(II) Dapat dihentikan dan dimulai kembali dengan batch data konsekutif, karena cluster-cluster memiliki representasi yang berbeda secara total dari kumpulan point-point.
(III) Pada tahap apapun dari proses iteratif, model campuran intermediate dapat digunakan untuk menentukan kasus-kasus (property on-line).
(IV) Menghasilkan sistem cluster yang dapat diinterpretasikan dengan mudah.
Large Applications berdasarkan Upon RANdomized Search) dalam konteks clustering dalam databasespatial.
2.6 Analisis Cluster
Analisis cluster adalah suatu analisis statistik yang bertujuan memisahkan obyek kedalam beberapa kelompok yang mempunyai sifat berbeda antar kelompok yang satu dengan yang lain. Dalam analisis ini tiap-tiap kelompok bersifat homogen antar anggota dalam kelompok atau variasi obyek dalam kelompok yang terbentuk sekecil mungkin (Prayudho, 2008)
Tujuan Analisis Cluster :
1. Untuk mengelompokkan objek-objek (individu-individu) menjadi kelompok-kelompok yang mempunyai sifat yang relatif sama (homogen).
2. Untuk membedakan dengan jelas antara satu kelompok (cluster) dengan kelompok lainnya.
Adapun manfaat Analsis Cluster sebagai berikut:
1. Untuk menerapkan dasar-dasar pengelompokan dengan lebih konsisten.
2. Untuk mengembangkan suatu metode generalisasi secara induktif, yaitu pengambilan kesimpulan secara umum dengan berdasarkan fakta-fakta khusus. 3. Menemukan tipologi yang cocok dengan karakter obyek yang diteliti.
4. Mendiskripsikan sifat-sifat / karakteristik dari masing-masing kelompok.
Analisis cluster dilakukan dengan langkah-langkah berikut:
1. Merumuskan permasalahan.
5. Interpretasi dan profil dari cluster. 6. Menaksir reliabilitas dan validitas.
2.7 Metode Kernel (Kernel Methods) 2.7.1 Pendahuluan.
Machine learning untuk penelitian pengolah sinyal sangat dipengaruhi oleh metode yang populer kernel Mercer (Cristianini & Taylor, 2000). Point utama dalam metode kernel adalah apa yang disebut "kernel trick", yang memungkinkan penghitungan dalam beberapa inner product, kemungkinan dengan dimensi yang tidak terbatas, ruang fitur. Anggaplah xi dan xj adalah dua point data ruang input. Jika fungsi kernel k (.,.) memenuhi kondisi Mercer maka
k (x
:
i , xj) = {Φ(xi),Φ(xj)} (2.4)
Dimana (.,.) menunjukkan inner product, dan Φ (.) menunjukkan pemetaan non-linier dari ruang input ke ruang fitur kernel. Kernel trick memungkinkan pelaksanaan dari algoritma pembelajaran, yang dinyatakan dalam bentuk inner product ruang fitur kernel
Metode-metode Kernel .
adalah algoritma yang secara implisit melaksanakan, melalui penggantianinner product dengan Kernel Mercer yang tepat, sebuah pemetaan nonlinear dari data input ke ruang fitur berdimensi tinggi (Vapnik, 1995). Metode-metode kernel yang sangat disupervisi telah dikembangkan untuk menyelesaikan masalah-masalah klasifikasi dan regresi
K-means adalah algoritma unsupervised learning yang membagi kumpulan data ke dalam sejumlah cluster yang dipilih dibawah beberapa ukuran-ukuran optimisasi. Sebagai contoh, kita sering ingin meminimalkan jumlah kuadrat dari jarak Euclidean antara sampel dan centroid. Asumsi di belakang ukuran ini adalah keyakinan bahwa ruang data terdiri dari daerah elliptical yang terisolasi. Meskipun demikian, asumsi tersebut tidak selalu ada pada aplikasi spesifik. Untuk
menyelesaikan masalah ini, sebuah gagasan meneliti ukuran-ukuran lain, misalnya kesamaan kosinus yang digunakan dalam pencarian informasi. Gagasan lain adalah memetakan data pada ruang baru yang memenuhi persyaratan untuk ukuran optimisasi. Dalam hal ini, fungsi kernel merupakan pilihan yang baik.
2.7.2 Fungsi Kernel (Kernel Function)
Ada kalanya tidak cukup bagi machine learning untuk bekerja dalam ruang input karena asumsi di belakang mesin tidak menyesuaikan pola riil dari data. Sebagai contoh, SVM (support vector machine) dan Perceptron memerlukan data yang tidak dapat dipisahkan secara linear, sedangkan K-means dengan jarak Euclidean mengharapkan data terdistribusi ke dalam daerah elliptical. Ketika asumsi tersebut tidak digunakan, maka kita dapat menggunakan beberapa jenis transformasi pada data, dengan memetakan mereka pada ruang baru di mana machine learning dapat digunakan. Fungsi Kernel memberikan kepada kita sebuah alat untuk mendefinisikan transformasi.
Anggaplah kita diberikan sekumpulan sampel x1, x2, x3,…, xN, dimana xi ε RD, dan fungsi pemetaan Φ yang memetakan xi dari ruang input RD pada ruang baru
Q. Fungsi kernel didefinisikan sebagai dot product dalam ruang baru
H (x
Q:
i , xj) = Φ(xi) . Φ (xj
Sebuah fakta
) (2.5)
penting mengenai fungsi kernel adalah bahwa fungsi ini dibangun tanpa mengetahui bentuk konkrit dari Φ, yaitu, transformasi yang didefinisikan secara implisit. Tiga fungsi kernel yang secara umum tercantum di bawah ini
PolynomialH (x
Kelemahan utama dari fungsi Kernel meliputi, pertama, beberapa sifat dari ruang baru hilang, misalnya, dimensionalitas dan tingkatan nilainya, sehingga
2.7.3 Kernel Trick
Dot product sering dianggap sebagai ukuran kesamaan antara dua vektor input. Dot product Φ(xi) . Φ(xj) dapat dianggap sebagai ukuran kesamaan antara dua jarak xi
dan xj, dalam ruang
Kernel trick adalah suatu metode untuk menghitung kesamaan dalam ruang yang ditransformasikan dengan menggunakan kumpulan atribut orisinal. Pertimbangkan pemetaan fungsi Φ yang diberikan dalam persamaan (2.9).
yang ditransformasikan.
Analisa ini memperlihatkan bahwa dot product dalam ruang yang ditransformasikan dapat dinyatakan dalam bentuk fungsi kesamaan dalam ruang orisinal:
(2.10)
K( u , v ) = Φ(u) . Φ (v) = (u . v + 1 )2
Fungsi kesamaan, K, yang dihitung dalam ruang atribut orisinal, dikenal sebagai fungsi kernel. Kernel trick membantu mengatasi beberapa kecemasan tentang cara mengimplementasikan pada Support Vector Machine (SVM) nonlinear.
(2.11)
Pertama, kita tidak harus mengetahui bentuk yang tepat dari pemetaan fungsi
merupakan hasil dalam ruang orisinal, maka isu-isu yang berhubungan dengan masalah dimensi dapat dihindari.
2.7.4 Algoritma-algoritma Representatif 2.7.4.1 Pendahuluan
Sub Bab ini merupakan sebuah bagian metodologi dari penelitian ini. Dimulai dengan penjelasan-penjelasan menenai algoritma-algoritma representatif detail yang akan digunakan dalam penelitian ini. Diberikan sebuah kajian singkat mengenai konsep dasar dari algoritma K-Means clustering dan memperluas pada algoritma Kernel K-Means clustering.
2.7.4.2 Algoritma K-Means Clustering (K-Means Clustering Algorithm)
K-Means (MacQueen, 1967) adalah salah satu dari algoritma unsupervised learning yang paling sederhana untuk menyelesaikan masalah clustering yang telah dikenal. Prosedur ini mengikuti cara sederhana dan mudah untuk mengklasifikasikan kumpulan data tertentu melalui jumlah cluster tertentu (menganggap k cluster) yang telah ditetapkan sebelumnya.
dapat mengetahui bahwa centroid k mengubah lokasi mereka langkah demi langkah hingga tidak ada lagi perubahan yang dilakukan. Dengan kata lain, centroid tidak bergerak lagi. Akhirnya, algoritma ini membantu meminimalkan fungsi objektif, dalam hal ini sebuah fungsi kesalahan kuadrat.
Sekumpulan vektor n xj, j = 1, … n, akan dibagi ke dalam
kelompok-Kelompok-kelompok yang dibagi didefinisikan oleh matriks keanggotaan biner c x n, U, dimana elemen u
= ∑�,��∈��||��− ��||2 adalah fungsi biaya dalam kelompok i.
ij adalah 1 jika point data ke-j xj termasuk pada
kelompok i dan 0 atau sebaliknya. Begitu pusat cluster ci ditetapkan, peminimalan uij
1,�� ||�� − ��||2 ≤ |���− ���|2,������ℎ� ≠ � (2.13)
0,��ℎ������
untuk Persamaan (2.11) dapat diperoleh sebagai berikut:
Yang berarti bahwa xj termasuk pada kelompok i jika ci adalah pusat terdekat
diantara semua pusat. Sebaliknya, jika matriks keanggotaan ditetapkan, yakni jika uij ditetapkan, maka pusat optimal ci yang meminimalkan persamaan (2.12) adalah
��|���|∑��,��∈���Rk
rata-rata dari semua vektor dalam kelompok i :
(2.14)
Dimana| Gi |adalah ukuran dari Gi,
Algoritma dipresentasikan dengan kumpulan data x or|��| = ∑��=1�Rij
Algoritma 2.1
Langkah 1 Menginisialisasikan pusat cluster, ci
Ini biasanya dilakukan melalui pemilihan secara acak
point-point c diantara semua point-point-point-point data. , i=1,…,c.
Langkah 2 Menentukan matriks keanggotaan U melalui persamaan (2.11).
Langkah 3 Menghitung fungsi biaya menurut persamaan (2.10). Hentikan jika berada dibawah nilai toleransi tertentu atau
perbaikannya terhadap iterasi sebelumnya adalah dibawah
batas ambang tertentu.
Langkah 4 Perbaharui pusat-pusat cluster menurut persamaan (6.12). Lanjutkan ke langkah 2.
Walaupun dapat dibuktikan bahwa prosedur tersebut akan selalu berakhir, algoritma k-means tidak perlu mencari konfigurasi yang paling optimal, yang sesuai dengan minimum fungsi objektif global. Algoritma ini juga secara signifikan sensitif terhadap pusat-pusat cluster yang dipilih secara acak pada awalnya. Algoritma k-means dapat dijalankan beberapa kali untuk mengurangi efek ini.
2.7.4.3 Kernel K-Means Clustering
kernel trick, sedangkan dalam (Girolami, 2002) pemetaan data aktual diperkirakan melalui eigenvector dari apa yang disebut matriks kernel.
Secara eksperimental, penelitian-penelitian ini memperlihatkan bahwa keterbatasan k-means biasa telah teratasi, dan hasil yang baik dicapai juga untuk kumpulan-kumpulan data yang memiliki batasan-batasan cluster nonlinear. Motivasi untuk keinginan melaksanakan K-means dalam ruang fitur kernel dinyatakan secara longgar sebagai “masalah kemampuan memisahkan nonlinear yang dapat dielakkan oleh kelas melalui pemetaan data yang diamati pada ruang data berdimensi yang lebih tinggi dengan cara nonlinear sehingga setiap cluster untuk setiap kelas membentang ke dalam bentuk sederhana”. Meskipun demikian, tidak jelas bagaimana kernel K-means berhubungan dengan sebuah operasi pada kumpulan data ruang input. Juga tidak jelas cara menghubungkan lebar kernel dengan sifat-sifat kumpulan data input. Beberapa pemikiran yang disebutkan pada point-point ini telah dibuat dalam (Girolami, 2002; Cristianini & Taylor, 2000).
Biasanya perluasan dari k-means ke kernel k-means direalisasi melalui pernyataan jarak dalam bentuk fungsi kernel (Girolami, 2002; Muller et al 2003
Anggaplah kumpulan data memiliki N
). Meskipun demikian, implementasi tersebut mengalami masalah serius seperti biaya clustering tinggi karena kalkulasi yang berulang dari nilai-nilai kernel, atau memori yang tidak cukup untuk menyimpan matriks kernel, yang membuatnya tidak dapat sesuai untuk corpora yang besar.
sampel x1, x2,… xN. Algoritma K
-means bertujuan untuk membagi sampel N ke dalam cluster K, C1, C2, …, CK, dan
kemudian mengembalikan pusat dari setiap cluster, m1, m2, …., mK sebagai
Algoritma 2.2
Langkah 1 Pilih awal pusat K: m1, m2, …., m Langkah 2 Menentukan setiap sample x
K
i (1≤ i ≤ N ) pada pusat terdekat, yang membentuk cluster K. Yaitu, menghitung nilai fungsi
indikatorδ (xi, Ck), ( 1 ≤ k ≤ K ).
Langkah 4 Ulangi langkah 2 dan 3 hingga bertemu.
│= ∑� �
�=� (��,��)��
Langkah 5 Menghasilkan mk ( 1 ≤ k ≤ K )
Isu utama yang memperluas k-means tradisional ke kernel k-means adalah adalah penghitungan jarak dalam ruang baru. Anggaplah ui = Φ(xi) menunjukkan
adalah pusat cluster dalam ruang yang ditransformasikan dimana,
= H (xi , xi ) + f (xi , Ck) + g (Ck
Perbedaan utama antara kernel k-meansdengan versi tradisional k-meansada di langkah 5, dalam algoritma Kernel K-means. Karena cluster dalam ruang yang ditransformasikan tidak dapat dinyatakan secara eksplisit, maka harus memilih pseudo centre. Dengan menggunakan (2.15) pada tradisional k-means, diperoleh kernel berdasarkan algoritma K-Meanssebagai berikut
Algoritma 2.3
:
Langkah 1 Tentupkan�(�� , ��)(1≤ i ≤ N , 1 ≤ k ≤ K ) dengan nilai awal, yang membentuk cluster initial K C1, C2, … , C
Langkah 2 Untuk setiap cluster C
K.
k, hitunglah |Ck| dan g(Ck
Langkah 3 Untuk setiap sample latihan x
).
Langkah 4 Ulangi langkah 2 dan 3 hingga bertemu.
Langkah 5 Untuk setiap cluster Ck,, pilih sample yang terdekat dengan pusat sebagai representatif dari Ck., mk = Arg min D(Φ (xi),
zk). Xi, dimana δ(Xi, Ck ) = 1
Dalam Persamaan (2.5) faktor H (xi , xi ) ) diabaikan karena tidak
2.8 Riset-riset Terkait
Terdapat beberapa riset yang telah dilakukan oleh banyak peneliti berkaitan dengan prestasi akademik mahasiswa seperti yang akan dijelaskan dibawah ini :
Yu et al. (2010) dalam risetnya menjelaskan mengenai sebuah pendekatan data mining dapat diaplikasikan untuk meneliti faktor-faktor yang mempengaruhi tingkat daya ingat mahasiswa.
Oyelade et al. (2010) dalam risetnya mengimplementasikan algoritma k-means clustering dikombinasikan dengan deterministic model untuk menganalisa hasil prestasi mahasiswa pada perguruan tinggi swasta.
Paul Golding & Opal Donaldson dalam risetnya Predicting Academic Performance menguji hubungan prestasi akademik dengan prestasi matrikulasi di tahun pertama pada jurusan teknologi informasi. Yang mana prestasi pada tahun pertama memiliki hubungan yang signifikan dalam memprediksi prestasi mahasiswa.
2.9 Persamaan dengan Riset-riset lain
Kruck dan Lending (2003) dalam penelitiannya menjelaskan sebuah model untuk memprediksi kinerja akademis di tingkat perguruan tinggi dalam mata kuliah pengantar sistem informasi.
Ogor (2007) dalam penelitiannya menggunakan teknik data mining yang digunakan untuk membangun prototipe Penilaian Kinerja Monitoring System (PAMS) untuk mengevaluasi kinerja mahasiswa.
2.10 Perbedaan dengan Riset-riset lain
Dari beberapa riset yang dilakukan peneliti sebelumnya, terdapat beberapa titik perbedaan dengan riset yang akan dilakukan ini :
Analisa peningkatan indeks prestasi akademik dilakukan pada perguruan tinggi yang risetnya dilakukan di jurusan Elektro Politeknik Negeri Medan. Riset yang dilakukan penulis untuk membuat aturan atau rule berdasarkan rata-rata nilai teori, rata-rata nilai praktek dan kehadiran.
Pada penelitian ini hasil akhir yang diharapkan dengan analisa peningkatan indeks prestasi akademik berdasarkan rata-rata nilai teori, rata-rata nilai praktek dan kehadiran untuk mendapatkan predikat dengan pujian dan sangat memuaskan sehingga dapat dibuat sebelum masa studi berakhir.
2.11 Kontribusi Riset
Penelitian ini memberikan kontribusi pada pemahaman kita tentang hubungan rata-rata nilai teori, rata-rata nilai praktek dan kehadiran untuk meningkatkan proses belajar mengajar yang ditunjukkan dengan nilai IP semester berdasarkan predikat yang telah ditentukan oleh perguruan tinggi.
BAB 3
METODOLOGI PENELITIAN
3.1 Pendahuluan
Tujuan dari tesis ini adalah untuk membuat model aturan dalam memprediksi prestasi akademik mahasiswa menggunakan algoritma Kernel K-Means yang dapat digunakan sebagai alat bantu analitis oleh manajemen untuk membuat keputusan. Pada bagian ini kita mulai dengan menggambarkan kasus data mining pada sistem penilaian akademik di perguruan tinggi dan prosedur bagaimana mengumpulkan data yang digunakan pada penelitian ini.
3.2 Lokasi dan Waktu Penelitian
Penelitian dilakukan pada jurusan Teknik Elektro di Politeknik Negeri Medan, Jalan Almamater No. 1 Kampus USU Medan. Lamanya waktu yang dibutuhkan untuk menyelesaikan penelitian ini yaitu 3 bulan yang dimulai pada bulan April sampai bulan Juni 2011.
3.3 Rancangan Penelitian
Variabel yang dikumpulkan adalah ipk selama 4 semester, jenis kelamin mahasiswa, agama, program studi, nilai rata-rata teori, nilai rata-rata praktek dan absensi kehadiran. Data terdiri dari data demografi seperti jenis kelamin, agama, program studi dan variabel-variabel lain yang berkaitan dengan prestasi akademik mahasiswa.
Data yang diperoleh dalam bentuk xls dimodifikasi dan ditransformasi sehingga menjadi bentuk XML. Selanjutnya dilakukan pengujian terhadap data dengan menggunakan algoritma Kernel K-Means yang telah tersedia pada software open source RapidMiner. Dari pengujian diperoleh cluster dari data yang telah diuji selanjutnya dilakukan analisis cluster untuk menganalisis dan mendapatkan model aturan.
3.4 Pra Pemrosesan Data (Preprocessing Data)
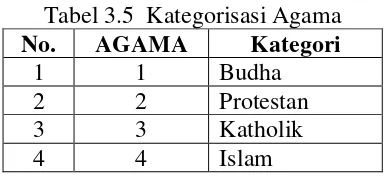
Untuk mendapatkan input yang baik dari teknik data mining, dilakukan preprocessing terhadap data yang akan digunakan. Preprocessing data merupakan tahap prapemrosesan. Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning (pembersihan) pada data yang menjadi fokus atau target KDD. Dalam kasus ini, data yang diambil sebanyak 315 mahasiswa tahun ajaran 2008-2009 dari jurusan Teknik Elektro Politeknik Negeri Medan. Atribut yang digunakan pada penelitian ini berupa IPK, PRAKTEK, TEORI, KEHADIRAN, AGAMA, PRODI dan GENDER.
Tabel 3.1 merupakan tampilan data yang diperoleh dari sistem file akademik jurusan Teknik Elektro Politeknik Negeri Medan tahun ajaran 2008-2009 yang terdiri dari rata-rata nilai teori, rata-rata nilai praktek, jenis kelamin, agama, absensi kehadiran, program studi dan IPK.
Selanjutnya dipilih field-field yang akan dikategorisasi. Field yang akan dikategorisasi adalah IPK. IPK dikategorisasi menjadi 4 kategori yaitu, Dengan Pujian, Sangat Memuaskan, Memuaskan dan Buruk sebagaimana terlihat pada tabel 3.2 berikut :
Berikutnya field yang akan dikategorisasi adalah PRAKTEK dan TEORI. Untuk field PRAKTEK dan TEORI dikategorisasi menjadi 3 kategori yaitu Tinggi, Sedang dan Rendah seperti pada tabel 3.3 berikut :
Tabel 3.3 Kategorisasi Nilai Praktek dan Teori No. PRAKTEK TEORI KATEGORI 1. Praktek < 58 Teori < 58 Rendah 2. 70 < Praktek < 58 70 < Teori < 58 Sedang 3. Praktek > 70 Teori > 70 Tinggi
Selanjutnya field yang akan dikategorisasi adalah PRODI. PRODI dikategorisasi menjadi 3 kategori yaitu Telkom, Elektronika dan Listrik seperti pada tabel 3.4 berikut :
Tabel 3.4 Kategorisasi Prodi No. PRODI Progstudi
1 1 Telkom
Selanjutnya field yang akan dikategorisasi adalah AGAMA. AGAMA dikategorisasi menjadi 4 kategori yaitu Islam, Protestan, Katolik dan Budha seperti pada tabel 3.5 berikut :
Tabel 3.5 Kategorisasi Agama No. AGAMA Kategori
1 1 Budha
2 2 Protestan 3 3 Katholik
4 4 Islam
Selanjutnya field yang akan dikategorisasi adalah GENDER. GENDER dikategorisasi menjadi 2 kategori yaitu Laki-laki dan Perempuan seperti pada tabel 3.6 berikut :
Tabel 3.6 Kategorisasi Gender No. GENDER Kategori
1 1 Laki-laki
2 2 Perempuan
Selanjutnya field yang akan dikategorisasi adalah KEHADIRAN. KEHADIRAN dikategorisasi menjadi 3 kategori yaitu Baik, Sedang dan Kurang seperti pada tabel 3.7 berikut :
Tabel 3.7 Kategorisasi Kehadiran No. KEHADIRAN Kategori
1 Kehadiran > 93% Baik 2 86% < Kehadiran < 93% Sedang 3 Kehadiran < 86% Kurang
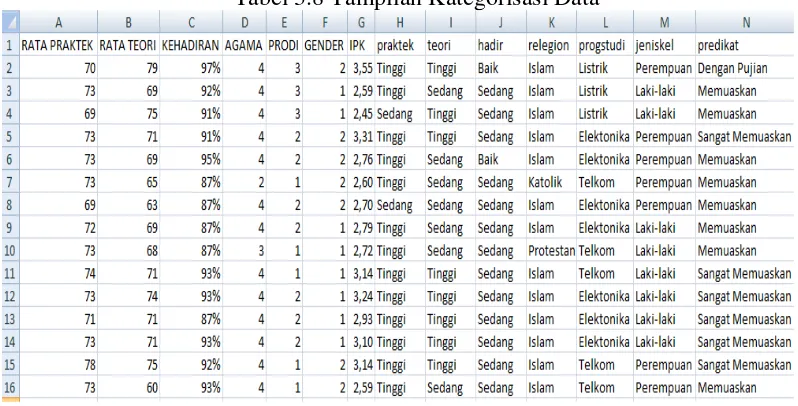
Tabel 3.8 Tampilan Kategorisasi Data
Hasil kategorisasi data akan digunakan untuk input data pada software open source RapidMiner. Setelah itu dilakukan transformasi data dari format xls menjadi XML sehingga dihasilkan data pengujian dalam format XML. Dilakukan pengujian terhadap data yang sudah dalam bentuk XML menggunakan algoritma Kernel K-Means. Dari pengujian diperoleh cluster dari data yang telah diuji selanjutnya dilakukan analisis cluster untuk menganalisis dan mendapatkan model aturan yang digambarkan dari hasil cluster.
3.5 Tools Analisis RapidMiner 5.1
Gambar 3.1 Tampilan RapidMiner
3.6 Prosedur Penelitian
Prosedur penelitian ini dilakukan seperti pada gambar 3.2 yaitu, data diperoleh dari database jurusan Teknik Elektro Politeknik Negeri Medan. Data akan mengalami modifikasi. Data dalam bentuk spreadsheet file excel 2003 (xls) sebagai masukan untuk software open source RapidMiner. RapidMiner melakukan transformasi dari data xls menjadi XML. Hasil pengolahan RapidMiner berupa cluster dari data yang akan dianalisis. Selanjutnya dilakukan analisis cluster untuk mendapatkan pengetahuan berupa model aturan.
Gambar 3.2 Prosedur Penelitian
Data Analisis
KNOWLEDGE Transformasi data xls
menjadi xml Pengumpulan data dari
database
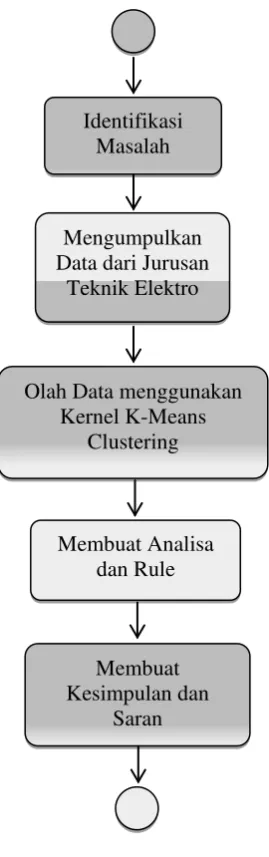
3.7 Diagram Aktivitas Penelitian
Berikut ini alur kerja yang akan dilakukan pada penelitian ini yang digambarkan dalam diagram aktivitas pada gambar 3.3 berikut :
Gambar 3.3 Diagram Aktivitas Kerja Penelitian
Membuat Analisa dan Rule Olah Data menggunakan
Kernel K-Means Clustering
Membuat Kesimpulan dan
Saran Identifikasi
Masalah
Mengumpulkan Data dari Jurusan
BAB 4
HASIL DAN PEMBAHASAN
4.1 Pendahuluan
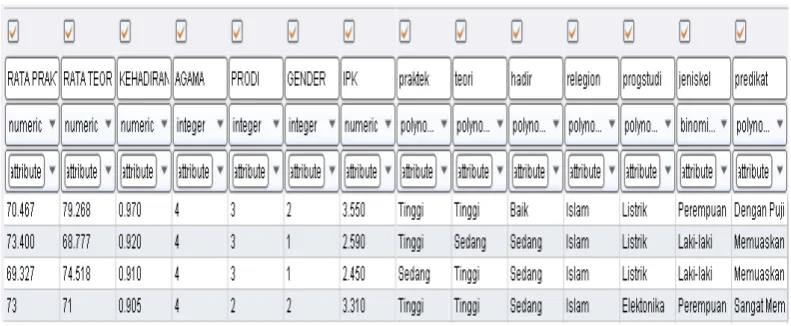
Bab ini menyajikan hasil yang diperoleh dari pengujian yang dilakukan terhadap data. Untuk memudahkan pemahaman maka dalam bab ini akan menguraikan hasil transformasi data dari format xls menjadi XML, cluster model hasil pengujian data, deskripsi data terhadap predikat prestasi, cluster membership dan analisis cluster untuk mendapat model aturan dalam memprediksi prestasi akademik mahasiswa di Politeknik Negeri Medan.
4.2 Hasil Transformasi Data