i
IDENTIFIKASI PROTEIN-PROTEIN SIGNIFIKAN YANG
BERASOSIASI DENGAN DIABETES MELLITUS (DM)
TIPE 2 MENGGUNAKAN ANALISIS TOPOLOGI
JEJARING PROTEIN PROTEIN INTERACTION
MUHAMMAD SYAFIUDDIN USMAN
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
iii
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa disertasi berjudul Identifikasi Protein-Protein Signifikan yang Berasosiasi dengan Diabetes Mellitus (DM) Tipe 2 Menggunakan Analisis Topologi Jejaring Protein-Protein Interaction adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Maret 2016
iv
RINGKASAN
M. SYAFIUDDIN USMAN. Identifikasi Protein-protein Signifikan yang Berasosiasi Dengan Diabetes Mellitus (DM) Tipe 2 Menggunakan Analisis Topologi Jejaring Protein-protein Interaction. Dibimbing oleh WISNU ANANTA KUSUMA dan FARIT MOCHAMAD EFENDI.
Identifikasi protein-protein signifikan yang berasosiasi dengan suatu penyakit merupakan proses awal yang dilakukan dalam penemuan obat baru menggunakan metode network pharmacology. Pendekatan yang digunakan dalam mengidentifikasi protein-protein signifikan tersebut adalah pendekatan komputasional. Pendekatan ini merupakan solusi dari dua kendala utama metode eksperimental yaitu waktu yang panjang dan biaya yang besar. Pendekatan ini mungkin dilakukan karena tersedianya data protein dan interaksi antar protein dalam jumlah yang banyak.
Proses identifikasi protein-protein signifikan yang berasosiasi dengan DM tipe 2 dimulai dengan mengumpulkan data kandidat protein-protein signifikan menggunakan basis data OMIM, selanjutnya kandidat protein-protein signifikan tersebut dijadikan sebagai data masukan pada basis data STRING untuk memperoleh data protein-protein interaction (PPI). Data PPI dikonstruksi menjadi jejaring PPI dan sebuah subnetwork dikonstruksi dari semua lintasan terpendek pasangan kandidat protein-protein signifikan yang memiliki total nilai degree terbesar dari seluruh node-nya yang ada pada jejaring PPI. Analisis topologi pada subnetwork dilakukan untuk memperoleh nilai Connectivity degree (k), betweenness centrality (BC) dan closeness centrality (CC). Ketiga nilai tersebut kemudian digunakan untuk menentukan protein-protein signifikan yang berasosiasi dengan DM tipe 2.
Pengujian terhadap konsistensi protein-protein signifikan dilakukan dengan mengkonstruksi jejaring penyangga dari protein-protein signifikan yang ada pada subnetwork. Akurasi jejaring penyangga dihitung terhadap tiap jejaring uji yang diciptakan dan dihitung nilai akurasi rata-ratanya. Nilai akurasi rata-rata inilah yang menunjukkan kekokohan jejaring penyangga atau konsistensi dari protein-protein signifikan yang ada pada jejaring penyangga.
Penelitian ini berhasil mengidentifikasi 21 protein signifikan yang berasosiasi dengan DM dengan menempatkan Insulin (INS) sebagai protein paling penting dan juga sebagai node pusat pada jejaring PPI. Terdapat 8 protein sebagai tetangga lagsung dari INS yaitu AKT1, TCF7L2, KCNJ11, PPARG, GCG, INSR, IAPP dan SOCS3. Hal yang menarik pada penelitian ini adalah dari 63 protein signifikan berasosiasi dengan DM yang diperoleh dari basis data OMIM, hanya 9 dari 21 protein yang berfungsi sebagai protein penting, 12 protein lainya merupakan protein yang diperoleh dari data PPI.
v
SUMMARY
M. SYAFIUDDIN USMAN. Identifications of Significant Proteins Associated with Diabetes Mellitus (DM) Type 2 Using Network Topology Analysis of Protein-Protein Interactions. Supervised by WISNU ANANTA KUSUMA and FARIT MOCHAMAD EFENDI.
The preliminary process in the discovery of new medicine using network pharmacology is identifications of significant proteins associated with a disease. In this research the computational approach was applied in order to identify significant proteins efficiently. It could be conducted because of the availability of proteins data and the interactions among then in large number.
Identification process of significant proteins associated with DM type 2 was started by collecting their data candidates using OMIM database. Next, the candidates were formed into input data on STRING database to obtain the protein-protein interaction (PPI). The PPI data were constructed into PPI network. A subnetwork was constructed from all candidates of the shortest paths of binary pairs from significant proteins which hadthe largest total of degree value of their node available in PPI network. The topology analysis on the subnetwork was conducted for obtaining the value of connectivity degree (k), betweenness centrality (BC) and closeness centrality (CC). Then, the three values were used to determine the significant proteins associated with DM type 2.
The tests against the consistency of significant proteins were conducted by constructing network buffer from significant proteins on the subnetwork. The accuracy of the network buffer was calculated against each network test created as well as their average accuracy. This average accuracy showed the solidity of network buffer or consistency of significant proteins available in the network buffer.
This research has successfully identified 21 significant proteins associated with DM by placing INS as the most significant protein as well as the central node in the PPI network. There are 8 proteins directly adjacent to INS: AKT1, TCF7L2, KCNJ11, PPARG, GCG, INSR, IAPP and SOCS3. The interesting finding in thise research was that from 63 significant proteins associated with DM, there were only 9 out of 21 proteins obtained from OMIM Database as important protein, and 12 other proteins were those which were obtained from PPI data.
vi
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
vii
IDENTIFIKASI PROTEIN-PROTEIN SIGNIFIKAN YANG
BERASOSIASI DENGAN DIABETES MELLITUS (DM)
TIPE 2 MENGGUNAKAN ANALISIS TOPOLOGI
JEJARING PROTEIN PROTEIN INTERACTION
MUHAMMAD SYAFIUDDIN USMAN
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Ilmu Komputer
pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
viii
ix
Judul Tesis : Identifikasi Protein-protein Signifikan Yang Berasosiasi Dengan Diabetes Mellitus (DM) Tipe 2 Menggunakan Analisis Topologi Jejaring Protein-Protein Interaction.
Nama : M. Syafiuddin Usman NIM : G651130481
Disetujui oleh
Komisi Pembimbing
Dr. Eng. Wisnu Ananta Kusuma, ST. MT Ketua
Dr. Farit Mochamad Afendi, M Si Anggota
Diketahui oleh
Ketua Program Studi Ilmu Komputer
Dr Ir. Sri Wahjuni, MT
Dekan Sekolah Pascasarjana
Dr. Ir. Dahrul Syah, M.Sc.Agr
x
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan September 2014 ini ialah Identifikasi Protein-protein Signifikan yang Berasosiasi Dengan Diabetes Mellitus (DM) Tipe 2 Menggunakan Analisis Topologi Jejaring Protein-protein Interaksi.
Terima kasih penulis ucapkan kepada Bapak Dr. Eng. Wisnu Ananta Kusuma, ST. MT. dan Bapak Dr. Farit Mochamad Afendi, MSi. selaku pembimbing, serta Bapak Rudi Heryanto, SSi. MSi. yang telah banyak memberi saran. Di samping itu, penghargaan yang besar penulis sampaikan kepada Bapak Dr. Ir. Agus Buono MSi. MKom. sebagai inspirator penulis dan seluruh dosen S2 yang telah berbagi ilmu kepada kami serta seluruh staff Departemen Ilmu Komputer IPB Dramaga yang telah memberikan pelayanan dan bantuan yang sangat berarti.
Ungkapan terima kasih juga saya sampaikan kepada istriku Tita Rosita yang tidak pernah bosan memberi semangat dan dukungannya, serta kepada seluruh keluarga besar ilkom angkatan 15, atas segala doa dan perhatiannya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Maret 2016
xi
DAFTAR ISI
DAFTAR TABEL DAFTAR GAMBAR DAFTAR LAMPIRAN
1. PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
2. TINJAUAN PUSTAKA 3
Jejaring Protein-Protein Interaksi (PPI) dan Subnetwork dari Jejaring PPI 3
Analisis Topologi Jejaring 3
Algoritme All_Shortest_Paths 4
3. METODE PENELITIAN 5
Tahapan Penelitian 5
Pengumpulan Data 5
Konstruksi Jejaring Interaksi Antar Protein (PPI) 7 Konstruksi Subnetwork dari Semua Lintasan Terpendek Pasangan Biner Kandidat Protein-Protein Signifikan pada Jejaring PPI 8 Analisis Topologi Subnetwork dari Jejaring PPI 9 Menentukan Protein-protein Signifikan berdasarkan nilai BC dari
Subnetwork dan Konstruksi Jejaring Penyangga 10
Evaluasi Ketahanan Jejaring Penyangga 11
HASIL DAN PEMBAHASAN 13
Data Interaksi Antar Protein (PPI), Konstruksi Jejaring PPI dan Subnetwork dari Semua Lintasan Terpendek Interaksi Antar Kandidat Protein pada
Jejaring PPI 13
Mentukan Protein Kunci pada Subnetwork dari Jejaring PPI 17 Jejaring Penyangga dari Semua Protein BC Tinggi 20
Evaluasi Kekokohan Jejaring Penyangga 21
SIMPULAN DAN SARAN 23
Simpulan 23
Saran 23
DAFTAR PUSTAKA 24
LAMPIRAN 27
xii
DAFTAR TABEL
Kandidat protein-protein signifikan yang berasosiasi dengan DM tipe 2 13
Protein-protein dengan nilai BC tinggi pada subnetwork 18
Protein-protein dengan nilai degree besar pada subnetwork 18
Protein-protein dengan nilai BC tinggi dan degree besar 19
Protein-protein dengan nilai BC tinggi tanpa nilai degree besar 20
Protein-protein dengan nilai BC tinggi pada jejaring penyangga 20
Frekuensi kemunculan protein-protein dengan nilai BC tertinggi, nilai CC dan degree
terbesar pada 265 jejaring uji 22
DAFTAR GAMBAR
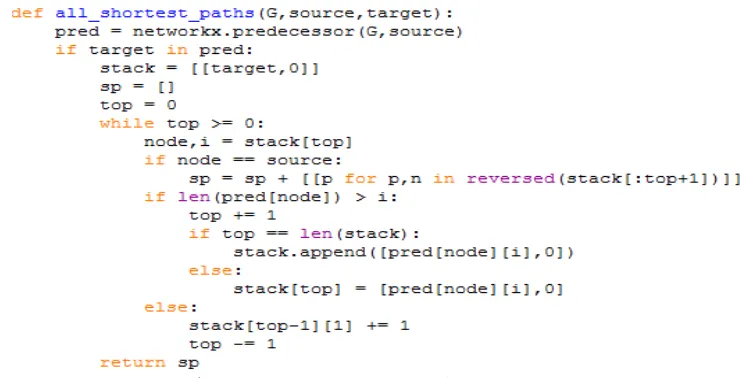
Source code dalam bahasa python untuk mencari semua lintasan terpendek 4
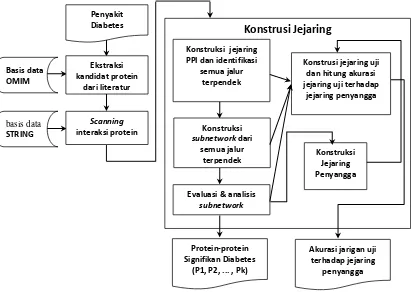
Skema tahapan penelitian identifikasi protein-protein signifikan 5
Tampilan depan dari basis data OMIM 6
Tampilan depan dari basis data STRING 6
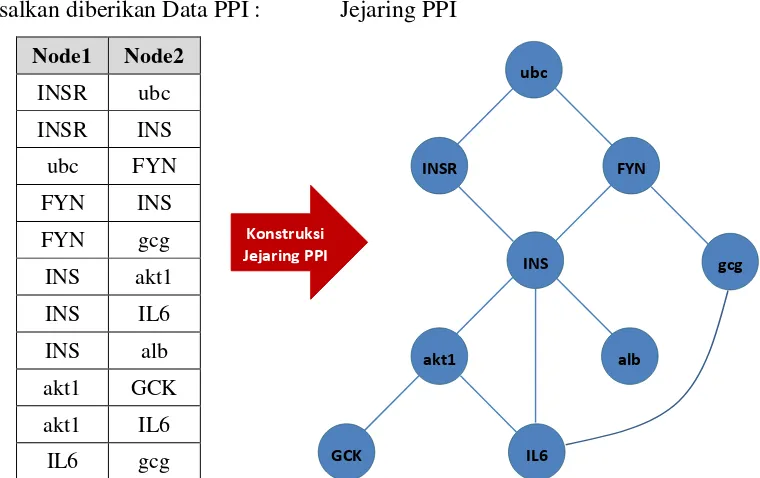
Ilustrasi konstruksi jejaring PPI 7
Konstruksi subnetwork dari semua lintasan terpendek pasangan kandiat protein-protein
signifikan 8
Ilustrasi menghitung nilai connectivity degree (k) 9
Ilustrasi menghitung nilai BC dari node INS 9
Ilustrasi menghitung nilai CC dari node INS 10
Daftar kandidat protein-protein signifikan 13
Data PPI dari HNF1A yang dikembalikan oleh basis data STRING 15
Jejaring PPI 16
Subnetwork dari semua lintasan terpendek pasangan kandidat protein signifikan 17
Jejaring penyangga dikonstruksi dari 21 protein BC tinggi 21
DAFTAR LAMPIRAN
Source code konstruksi jejaring PPI, subnetwork, analisis topologi dan
konstruksi jejaring penyangga 27
1
1. PENDAHULUAN
Latar Belakang
Keberadaan protein-protein signifikan dalam tubuh kita sangat diperlukan untuk pertumbuhan. Protein tersebut adalah media semua nutrisi yang dibutuhkan tubuh (Acencio ML, Lemke N. 2009). Namun, adanya infeksi kuman (Wolfe et al. 2007) atau pola hidup yang tidak sehat (Tuomilehto et al. 2001) dapat menimbulkan penyakit yang diakibatkan oleh gangguan fungsional dari protein-protein signifikan (Huang et al. 2011). Akibat paling buruk dari gangguan fungsional protein-protein signifikan ini adalah tidak berfungsinya organ-organ vital tertentu dalam tubuh (Escandon & Cipolla 2001). Salah satu penyakit yang diakibatkan oleh gangguan fungsional protein-protein signifikan adalah Diabetes mellitus (DM) tipe 2. Pada penyakit ini pankreas tidak dapat menghasilkan insulin dalam jumlah yang diperlukan tubuh atau bahkan sama sekali tidak dapat menghasilkan insulin (Colton & Avgoustiniatos 1991). Untuk mengembalikan fungsi protein-protein signifikan ke fungsi normalnya, perlu dilakukan terapi terhadap protein-protein tersebut dengan obat yang tepat (Huang et al. 2011).
Langkah awal dalam proses penemuan obat yang tepat untuk suatu penyakit adalah melakukan identifikasi protein-protein signifikan yang berasosiasi dengan penyakit tersebut (Li J et al. 2009). Penerapan metode eksperimental untuk mengidentifikasi protein-protein signifikan seperti knockouts gen tunggal (Giaever et al. 2002), interferensi RNA (Cullen et al. 2005) dan knockouts bersyarat (Roemer et al. 2003) dapat dilakukan. Akan terapi penerapan metode ini secara umum terkendala dengan biaya yang besar dan waktu yang panjang (Li Min et al. 2012).
Pendekatan komputasi untuk melakukan proses identifikasi protein-protein signifikan yang berasosiasi dengan sebuah penyakit diusulkan sebagai sebuah solusi terhadap kendala eksperimental. Salah satunya dengan mengkonstruksi dan menganalisis topologi jejaring protein-protein interaksi (PPI) (Li Min et al. 2012; Ran et al. 2013).
Ketersedian data interaksi antar protein dalam jumlah yang banyak dan kemajuan teknologi throughput tinggi telah menghasilkan peluang yang belum pernah terjadi sebelumnya untuk mendeteksi protein signifikan dari tingkat jejaring (Li Min et al. 2012). Platform komputasi yang mengintegrasikan jalur interaksi antar protein (Ran et al. 2013) dan perbedaan ekspresi genom menghasilkan jejaring interaksi antar obat-target yang komprehensif (Zhang et al. 2012). Selain itu analisis topologi jejaring ineraksi antar protein dapat digunakan untuk mengidentifikasi protein-protein signifikan suatu penyakit (Ran et al. 2013; Goni et al. 2008).
2
tersebut pada subnetwork. Pada penelitian ini analisis topologi jejaring dilakukan pada subnetwork bukan pada topologi jejaring PPI. Hal ini dilakukan dengan pertimbangan bahwa banyak node/protein pada jejaring PPI yang bukan kandidat protein/node signifikan yang tidak perlu di ikut sertakan dalam analisis topologi.
Perumusan Masalah
Bagaimana membangun jejaring protein-protein interaction (PPI) untuk selanjutnya melakukan analisis terhadap jejaring tersebut sehingga dapat ditentukan rangking protein-protein signifikan yang berasosiasi dengan DM tipe 2.
Tujuan Penelitian
Tujuan yang ingin dicapai pada penelitian ini adalah mengidentifikasi protein-protein signifikan yang berasosiasi dengan DM tipe 2 melalui pendekatan Network Pharmacology dengan mengkonstruksi jejaring PPI, kemudian melakukan analisis topologi terhadap jejaring PPI tersebut.
Manfaat Penelitian
Kontribusi penelitian ini adalah penemuan protein-protein signifikan yang berasosiasi dengan DM tipe 2 untuk digunakan dalam proses pengembangan dan penemuan obat diabetes baru menggunakan pendekatan network pharmacology.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah sebagai berikut :
1. Konstruksi dan analisis topologi jejaring PPI digunakan untuk mengidentifikasi protein-protein signifikan yang berasosiasi dengan DM tipe 2.
2. Hasil identifikasi penelitian ini merupakan usaha untuk memperkecil ruang pencarian protein protein signifikan yang berasosiasi dengan DM tipe 2 dari ribuan protein-protein yang ada.
3
2. TINJAUAN PUSTAKA
Jejaring Protein-Protein Interaksi (PPI) dan Subnetwork dari Jejaring PPI Protein-protein interaksi (PPI) adalah kontak fisik yang terbentuk antara dua protein yang telah dipelajari dari berbagai perspektif seperti biokimia, kimia kuantum, dinamika molekuler, transduksi sinyal dan gaya elektrostatik (Herce HD. 2013, Jones S and Thornton JM. 1996 dan Phizicky EM and Fieds S. 1995). Semua informasi interaksi biner antar protein yang diperoleh dari PPI dapat digunakan untuk mengkonstruksi sebuah model jejaring PPI (Raman K. 2010) sehingga dapat membantu untuk memahami bagaimana jejaring biologis beroperasi (Xia Y. et. al. 2004). Subnetwork merupakan jejaring interaksi antar protein dengan jumlah minimal node dari semua node (protein) yang ada pada jejaring PPI.
Analisis Topologi Jejaring
Connectivity degree (k), betweenness centrality (BC) dan closeness centrality (CC) adalah tiga parameter penting dalam teori graf yang dianalisis untuk mengidentifikasi protein-protein signifikan yang berasosiasi terhadap suatu penyakit (Hwang S. et. al. 2008) dalam sebuah jejaring PPI.
Degree (k) adalah karakteristik yang paling dasar dari sebuah node dalam jejaring didefinisikan sebagai jumlah interaksi satu protein dengan protein lain yang bertetanggaan langsung dengannya dalam jejaring. Dengan demikian semakin besar nilai degree sebuah node dalam jejaring maka node tersebut semakin banyak memiliki tetangga yang berinteraksi langsung dengannya dalam jejaring.
Betweenness centrality (BC) didefinisikan sebagai berapa kali sebuah node bertindak sebagai jembatan sepanjang lintasan terpendek antara dua node dalam jejaring dan dirumuskan sebagai berikut :
= ∑
≠�≠ ∈�� �� (1)di mana υ adalah node yang akan dihitung nilai BC-nya, s adalah source node, t adalah target node, σst(υ) adalah jumlah jalur terpendek dari s ke t yang melalui
node υ, dan σst adalah jumlah lintasan terpendek yang terbentuk dengan tidak
menjadikan node υ sebagai node source atau target. Nilai BC menunjukkan seberapa penting node tersebut dalam jejaring, sehingga semakin besar nilai BC sebuah node dalam jejaring maka semakin penting node tersebut dalam jejaring (Freeman LC. 1982) karena node tersebut semakin sering dijadikan “jembatan” sepanjang lintasan terpendek antara dua node.
4
mempertimbangkan semua jalur terpendek untuk setiap node dan dirumuskan sebagai berikut:
� =
∑ �−1� �,
∈�
(2)
di mana υ adalah node yang akan dihitung nilai CC-nya, t adalah target node, N adalah jumlah node, dG(υ,t) merupakan panjang lintasan terpendek antara dua
node υ dan t pada jejaring dan dG(υ, υ) = 0, dG(υ, t) = dG(t, υ) dalam undirected graph.
Algoritme All_Shortest_Paths
Merupakan algoritme pencarian semua jalur terpendek sepasang node (source - target) pada sebuah graph G. Algoritme ini merupakan salah satu algoritme yang terdapat dalam paket perangkat lunak berbahasa Python bernama NetworkX yang dirancang dan ditulis oleh Aric Hagberg, Dan Schult dan Pieter Swart 2002-2003 dan di publikasikan pertama kali pada bulan April 2005. Algoritme ini merupakan algoritme yang diadopsi dari algoritme brute force dengan kompleksitas waktu eksekusi untuk kasus terburuknya adalah O(n . n!). Algoritme ini memang tidak efisien akan tetapi algoritme ini sederhana, mudah diimplemantasikan dan merupakan algoritme yang kokoh (robust). Algoritme all_shortest_paths ini bekerja pada setiap siklus pemanggilanya sebagai berikut :
- Parameter masukan algoritme :
G - sebuah graph, Source (node) –node awal dan Target (node) –node akhir
- Menemukan semua node predecessor dari node source pada graph G
- Menelusuri lintasan terpendek dilakukan dimulai dari node target menuju node source berdasarkan data node predecessor yang telah ditemukan
- Tiap sebuah lintasan terpendek diperoleh, lintasan tersebut disimpan dalam sebuah list - Keluaran algoritme adalah sebuah list yang berisi semua lintasan terpendek dari
pasangan node source-target
Berikut source code dalam bahasa python algoritme all_shortest_paths diatas :
5
3. METODE PENELITIAN
Tahapan Penelitian
Penelitian ini terdiri atas tiga tahap utama yaitu praproses, proses identifikasi protein-protein signifikan dan pengujian jejaring penyangga. Aktifitas yang dilakukan pada praproses yaitu mengoleksi data kandidat protein-protein signifikan dengan menggunakan basis data OMIM dan data PPI dengan menggunakan basis data STRING. Pada proses identifikasi aktifitas yang dilakukan adalah mengkonstruksi jejaring protein-protein interaksi (jejaring PPI), menganalisis topologi jejaring PPI untuk memperoleh protein-protein signifikan yang kemudian dipergunaan untuk mengkonstruksi jejaring penyangga dan mengkonstruksi subnetwork dari jejaring PPI. Terakhir adalah mengkonstruksi jejaring uji untuk menguji kekokohan jejaring penyangga yang terbentuk. Tahapan penelitian ini digambarkan dalam bagan yang ditampilkan pada Gambar 2.
Pengumpulan Data
Data yang digunakan pada penelitian ini adalah (1) data kandidat protein-protein signifikan yang berasosiasi dengan DM yang diekstraksi dari basis data OMIM (Huang H et al. 2012). Basis data OMIM (http:// www.omim.org/) adalah
Konstrusi Jejaring
6
ensiklopedia gen-gen manusia dan penyakit genetik yang menghubungkan entry gen pada GenBank dan literatur ilmiah pada PubMed. Tipe query adalah “Gene
Map” dengan query key “diabetes mellitus” (Gambar 3).
Basis data OMIM mengambalikan sejumlah protein yang kemudian disebut kandidat protein signifikan yang berasosiasi dengan DM. Kandidat protein signifikan yang berasosiasi dengan DM merupakan sejumlah protein-protein yang diduga berkontribusi menyediakan nutrisi (Acencio ML, Lemke N. 2009) yang diperlukan untuk menghasilkan insulin dalam jumlah yang cukup bagi tubuh manusia. Kandidat protein-protein signifikan ini saling berinteraksi baik secara langsung maupun tidak langsung. (2) data protein-protein interaksi (PPI), data ini diperoleh dari basis data STRING (http://www.string-db.org/) dengan melibatkan 2,5 juta protein dari 630 organisme yang berbeda (Jensen et al. 2009).
HNF1A
Kandidat Protein Signifikan
Gambar 3. Tampilan depan dari basis data OMIM
7
Sebagai data masukan pada basis data STRING adalah semua Mouse Gene/protein yang berasosiasi dengan DM yang diperoleh dari basis data OMIM. Basis data STRING mengembalikan untuk tiap Mouse Gene/protein serangkaian data PPI. Dari data PPI yang diperoleh, selain kandidat protein-protein signifikan diperoleh pula protein-protein yang bukan kandidat protein signifikan yang menjadi perantara interaksi antar kandidat protein-protein signifikan.
Konstruksi Jejaring Interaksi Antar Protein (PPI)
Protein-protein interaksi (PPI) adalah kontak fisik yang terbentuk antara dua atau lebih protein yang telah dipelajari dari berbagai perspektif seperti biokimia, kimia kuantum, dinamika molekuler, transduksi sinyal dan gaya elektrostatik (Herce 2013; Jones & Thornton 1996; Phizicky & Fieds 1995). Data PPI tersebut kemudian dikonstruksi menjadi sebuah jejaring PPI. Topologi jejaring inilah yang selanjutnya dianalisis untuk mendapatkan protein-protein signifikan dan sekaligus dapat membantu memahami bagaimana jejaring biologis dari protein-protein tersebut beroperasi (Xia Y et al. 2004). Gambar 5 menunjukkan ilustrasi konstruksi jejaring PPI dari Data PPI yang dikembalikan oleh basis data SRTING.
Misalkan diberikan Data PPI : Jejaring PPI
Data PPI pada ilustrasi konstruksi Jejaring PPI diatas terdiri atas 5 protein sebagai kandidat protein-protein signifikan yang ditulis dengan huruf kapital (INSR, FYN, INS, IL6, GCK) dan 4 protein bukan kandidat protein-protein signifikan yang ditulis dengan huruf bukan kapital (ubc, gcg, alb, akt1).
Konstruksi
8
Konstruksi Subnetwork dari Semua Lintasan Terpendek Pasangan Biner
Kandidat Protein-Protein Signifikan pada Jejaring PPI
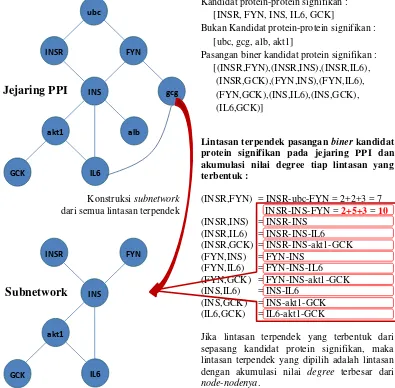
Subnetwork adalah jejaring interaksi antar protein dengan jumlah minimal node dari semua node (protein) pada jejaring PPI. Jejaring ini dikonstruksi untuk melihat konsistensi protein-protein jejaring penyangga yang diperoleh dari jejaring PPI. Node-node yang tidak dilalui lintasan terpendek pasangan biner interaksi antar kandidat protein-protein signifikan akan dihilangkan dari jejaring sehingga diperoleh jejaring yang hanya melibatkan node-node dengan nilai degree besar saja. Subnetwork dikonstruksi dari semua lintasan terpendek pasangan biner semua kandidat protein-protein signifikan yang dikumpulkan dari Jejaring PPI. Jejaring PPI dan subnetwork jejaring PPI dikonstruksi dengan bahasa pemrograman Python dan aplikasi Cytoscape (Shannon et al. 2003) untuk visualisasi jejaring. Ilustrasi konstruksi subnetwork dari jejaring PPI adalah sebagai berikut (Gambar 6) :
Lintasan terpendek pasangan biner kandidat protein signifikan pada jejaring PPI dan akumulasi nilai degree tiap lintasan yang terbentuk :
(INSR,FYN) = INSR-ubc-FYN = 2+2+3 = 7 INSR-INS-FYN = 2+5+3 = 10
(INSR,INS) = INSR-INS (INSR,IL6) = INSR-INS-IL6 (INSR,GCK) = INSR-INS-akt1-GCK (FYN,INS) = FYN-INS
Jika lintasan terpendek yang terbentuk dari sepasang kandidat protein signifikan, maka lintasan terpendek yang dipilih adalah lintasan dengan akumulasi nilai degree terbesar dari
node-nodenya.
Kandidat protein-protein signifikan : [INSR, FYN, INS, IL6, GCK]
Bukan Kandidat protein-protein signifikan : [ubc, gcg, alb, akt1]
Pasangan biner kandidat protein signifikan : [(INSR,FYN),(INSR,INS),(INSR,IL6), (INSR,GCK),(FYN,INS),(FYN,IL6),
9
Analisis Topologi Subnetwork dari Jejaring PPI
Untuk menentukan protein-protein signifikan ada tiga parameter yang digunakan (Hwang S et al. 2008). Ketiga parameter tersebut adalah Connectivity degree (k), betweenness centrality (BC) dan closeness centrality (CC).
Connectivity degree (k) adalah nilai yang menunjukkan seberapa banyak sebuah node berinteraksi langsung dengan node lain dalam jejaring. Nilai ini akan digunakan untuk memilih satu lintasan terpendek dari beberapa lintasan terpendek yang mungkin terbentuk dari sepasang node dalam jejaring. Gambar 7 menunjukkan nilai connectivity degree (k) node-node dalam sebuah jejaring.
Node k
GCK 1
akt1 2
INS 3
INSR 1
IL6 1
Nilai BC akan menentukan seberapa penting node tersebut dibandingkan dengan node-node lain dalam jejaring, hal ini disebabkan karena seringnya sebuah node dilalui lintasan terpendek sepasang node lain dalam jejaring yang dirumuskan
� = ∑
≠�≠ ∈�� ��.
Berikut ilustrasi penghitungan nilai BC sebuah nodedalam jejaring sebagai berikut :
8a - σst (INS) = Jumlah lintasan terpendek yang melalui node INS = 5 8b - σst = Total lintasan terpendek yang terbentuk dengan tidak menjadikan node INS
sebagai node source atau target = 6 Jadi nilai BC dari node INS = 5/6 = 0.83333
Nilai k tiap node
pada Jejaring
1
2 3
4 5
1
2 3
4 5
6
a
b
Gambar 7. Nilai connectivity degree (k) tiap node dalam jejaring
10
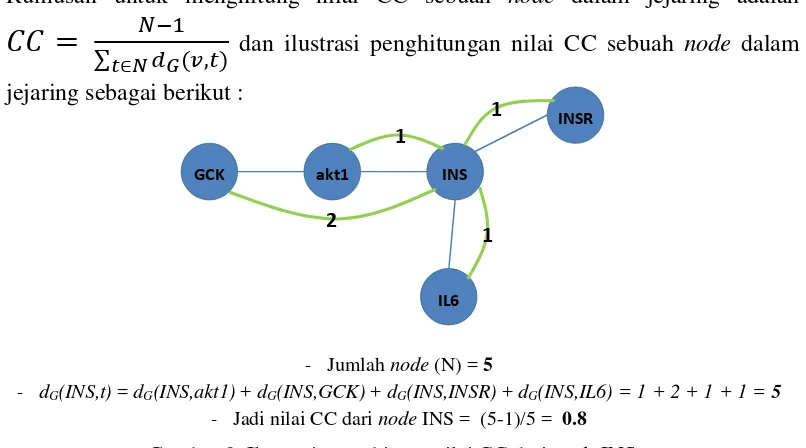
Nilai CC akan menentukan node yang menjadi pusat dari jejaring. Semakin besar nilai CC sebuah node maka semakin pusat node tersebut dalam jejaring. Rumusan untuk menghitung nilai CC sebuah node dalam jejaring adalah
=
∑ �−1� �,
∈� dan ilustrasi penghitungan nilai CC sebuah node dalam
jejaring sebagai berikut :
- Jumlah node (N) = 5
- dG(INS,t) = dG(INS,akt1) + dG(INS,GCK) + dG(INS,INSR) + dG(INS,IL6) = 1 + 2 + 1 + 1 = 5
- Jadi nilai CC dari node INS = (5-1)/5 = 0.8
Menentukan Protein-protein Signifikan berdasarkan nilai BC dari
Subnetwork dan Konstruksi Jejaring Penyangga
Subnetwork menggambarkan keterkaitan kandidat protein-protein signifikan yang lebih sederhana (Gambar 13). Protein-protein signifikan ditentukan dari protein yang banyak digunakan sebagai persimpangan atau protein-protein yang memiliki nilai BC tertinggi. Jumlah protein-protein dengan BC tinggi yang diambil sebagai protein-protein signifikan adalah 5% dari total node/protein pada jejaring (Goni et al. 2008; Kim et al. 2009). Semua protein-protein signifikan yang diperoleh digunakan untuk mengkonstruksi jejaring penyangga. Informasi protein-protein signifikan, protein-protein (node) pusat jejaring dan protein-protein-protein-protein yang bertetangga langsung dengan protein pusat diperoleh dari jejaring penyangga yang terbentuk. Protein pusat jejaring ditentukan dari protein (node) yang mempunyai nilai CC tertinggi dari subnetwork (Wasserman & Faust 1994).
Semua protein-protein signifikan yang telah ditentukan kemudian dikonstruksi menjadi jejaring penyangga. Jejaring ini menggambarkan keterkaitan antar protein signifikan dalam jejaring PPI baik secara langsung maupun tidak langsung. Karena jejaring ini terbentuk dari semua protein signifikan (memiliki nilai BC tinggi) dalam jejaring PPI di mana protein-protein tersebut menjadi jembatan sebagai besar lintasan terpendek tiap pasang protein-protein dalam jejaring, maka jejaring penyangga ini adalah jejaring utama (Ran J et al. 2013) pada jejaring PPI.
INSR
akt1 INS
IL6 GCK
1
1
1 2
11
Proses konstruksinya adalah (1) menelusuri semua lintasan terpendek antar protein-protein signifikan pada jejaring PPI, (2) semua lintasan terpendek yang ditemukan diubah menjadi data interaksi antar protein (PPI), (3) data interaksi antar protein ini digunakan untuk mengkonstruksi jejaring penyangga.
Evaluasi Ketahanan Jejaring Penyangga
Jejaring uji dikonstruksi untuk mengevaluasi ketahanan jejaring penyangga (konsistensi protein-protein yang menyusun jejaring penyangga) dengan tidak menjadikan beberapa kandidat protein-protein signifikan (yang dikembalikan oleh basis data OMIM) sebagai data input pada basis data STRING. Jumlah kandidat protein-protein signifikan yang tidak dijadikan sebagai data input pada basis data STRING adalah 10% (Ran et al. 2013) dari seluruh data kandidat protein-protein signifikan. Misalkan terdapat 72 kandidat protein-protein signifikan, maka jumlah kandidat protein-protein signifikan yang tidak dijadikan sebagai data input pada basis data STRING adalah 1 sampai 7 protein.
Jika 1 dari 72 kandidat protein-protein signifikan yang tidak dilibatkan sebagai data input pada basis data STRING yang dipilih secara bergantian, maka jumlah kombinasi kandidat protein-protein signifikan yang terbentuk adalah 72 kombinasi data input. Untuk 2 sampai 7 kandidat protein signifikan yang tidak dilibatkan sebagai data input, protein pusat (yang memiliki nilai CC terbesar) selalu termasuk protein yang idak dilibatkan sabagai data input pada basis data STRING. Hal ini dilakukan untuk menguji kekokohan protein pusat dalam jejaring. Dengan demikian jika ada 2 kandidat protein signifikan yang tidak dilibatkan sebagai data input, maka akan terbentuk 71 kombinasi data input. Adapun jika jumlah kandidat protein signifikan yang tidak dilibatkan sebagai data input adalah 3 sampai 7 protein, maka jumlah kombinasi kandidat protein signifikan sebagai data input adalah 30 kombinasi yang masing-masing dipilih secara acak (Ran et al. 2013). Sebagai ilustrasi jika ada 3 kandidat protein signifikan yang tidak dilibatkan sebagai data input pada basis data STRING, maka akan terbentuk 357.840 (72x71x70) kombinasi data input. Sehingga total jumlah kombinasi kandidat protein-protein signifikan sebagai data input pada basis data STRING adalah 293 (72 + 71 + (5 x 30)) kombinasi.
Langkah-langkah yang dilakukan dalam mengkonstruksi jejaring uji untuk tiap kombinasi kandidat protein-protein signifikan sebagai berikut :
a. Scanning data PPI pada basis data STRING untuk tiap kandidat protein signifikan yang ada pada data input.
b. Konstruksi jejaring PPI dari seluruh data PPI yang diperoleh.
12
d. Memilih node-node penting (protein-protein signifikan) dengan nilai BC tinggi sebanyak 5% dari semua node pada jejaring PPI.
e. Konstruksi jejaring uji dari semua node-node penting (protein-protein signifikan) yang terpilih.
f. Similaritas node-node (protein-protein) jejaring uji dihitung terhadap jejaring penyangga untuk mendapatkan nilai akurasi jejaring uji terhadap jejaring penyangga.
g. Mengakumulasi frekuensi node (protein) dengan nilai degree, BC dan CC terbesar untuk tiap jejaring uji yang terbentuk.
13
4. HASIL DAN PEMBAHASAN
Data Interaksi Antar Protein (PPI), Konstruksi Jejaring PPI dan Subnetwork
dari Semua Lintasan Terpendek Interaksi Antar Kandidat Protein pada Jejaring PPI
Basis data OMIM mengembalikan 83 kandidat protein-protein signifikan yang berasosiasi dengan DM tipe 2 (Tabel 1). Tiap data kandidat protein-protein signifikan yang diperoleh terdiri atas 10 item data (Gambar 10) yaitu Cytogenetic location, Genomic coordinates (GRCh37/From NCBI), Gene, Gene name, Gene MIM number, Comments, Phenotype, Phenotype MIM number, Pheno map key dan Mouse Gene (from MGI). Dari seluruh item data tersebut hanya item data
“Mouse Gene (from MGI)” yang akan digunakan sebagai data input pada basis data STRING untuk mendapakan data seed protein dalam bentuk protein-protein interaksi (PPI).
Gambar 10. Daftar protein-protein yang berasosiasi dengan DM yang dikembalikan oleh basis data OMIM
Tabel 1 menunjukkan daftar 83 kandidat protein-protein signifikan yang dikembalikan oleh basis data OMIM.
Tabel 1. Kandidat protein-protein signifikan yang berasosiasi dengan DM tipe 2
No Gene /
Protein Gene/Locus name
1 ABCC8 ATP-binding cassette, subfamily C, member 8 (sulfonylurea receptor) 2 ACE Angiotensin I converting enzyme (dipeptidyl carboxypeptidase-1)
3 AKT2 Murine thymoma viral (v-akt) homolog-2
4 AQP2 Aquaporin-2 (collecting duct)
5 AVP Arginine vasopressin (neurophysin II, antidiuretic hormone) 6 AVPR2 Arginine vasopressin receptor-2
7 BLK BLK nonreceptor tyrosine kinase
8 CAPN10 Calpain-10
9 CCR5 Chemokine (C-C) receptor 5
14
Tabel 1. Kandidat protein-protein signifikan yang berasosiasi dengan DM tipe 2
No Gene /
Protein Gene/Locus name
15 EPO Erythropoietin
16 FOXC2 Forkhead box C2
17 FOXP3 Forkhead box P3 (scurfin)
18 GCGR Glucagon receptor
19 GCK Glucokinase (hexokinase-4)
20 GLIS3 GLIS family zinc finger protein 3
21 GPD2 Glycerol-3-phosphate dehydrogenase 2 (mitochondrial)
22 HFE Hemochromatosis gene
23 HMGA1 High-mobility group AT-hook 1
24 HNF1A HNF1 homeobox B
25 HNF1B HNF1 homeobox B (transcription factor 2)
26 HNF4A Hepatocyte nuclear factor 4, alpha (transcription factor-14) 27 IAPP Islet amyloid polypeptide (diabetes-associated peptide; amylin) 28 IDDM1* Insulin-dependent diabetes mellitus-1
29 IDDM11* Insulin-dependent diabetes mellitus-11 30 IDDM13* Insulin-dependent diabetes mellitus-13 31 IDDM15* Insulin-dependent diabetes mellitus-15 32 IDDM17* Insulin-dependent diabetes mellitus-17 33 IDDM18* Insulin-dependent diabetes mellitus-18 34 IDDM19* Diabetes mellitus, insulin-dependent, 19 35 IDDM21* Diabetes mellitus, insulin-dependent, 21 36 IDDM23* Diabetes mellitus, insulin-dependent, 23 37 IDDM24* Diabetes mellitus, insulin-dependent, 24 38 IDDM3* Insulin-dependent diabetes mellitus-3 39 IDDM4* Insulin-dependent diabetes mellitus-4 40 IDDM6* Insulin-dependent diabetes mellitus-6 41 IDDM7* Insulin-dependent diabetes mellitus-7 42 IDDM8* Insulin-dependent diabetes mellitus-8
43 IDDMX* Diabetes mellitus, insulin-dependent, X-linked, susceptibility to 44 IER3IP1 Immediate-early response 3-interacting protein 1
45 IGF2BP2 Insulin-like growth factor 2 mRNA-binding protein 2 46 IL1RN Interleukin-1 receptor antagonist
47 IL2RA Interleukin-2 receptor
48 IL6 Interleukin-6 (interferon, beta-2)
49 INS Insulin
50 INSR Insulin receptor
51 IRS1 Insulin receptor substrate-1 52 IRS2 Insulin receptor substrate 2
53 ITPR3 Inositol 1,4,5-triphosphate receptor, type 3
54 KCNJ11 Potassium inwardly-rectifying channel, subfamily J, member 11 55 KLF11 Kruppel-like factor 11
56 LIPC Lipase, hepatic
57 MAPK8IP1 Mitogen-activated protein kinase 8-interacting protein 1 58 MTNR1B Melatonin receptor 1B
59 NEUROD1 Neurogenic differentiation 1
60 NIDDM2* Diabetes mellitus, noninsulin-dependent, 2 61 NIDDM3* Noninsulin-dependent diabetes mellitus 3 62 NIDDM4* Diabetes mellitus, noninsulin-dependent, 4 63 OAS1 2',5'-oligoadenylate synthetase-1
64 PAX4 Paired box homeotic gene-4
65 PBCA* Pancreatic beta cell, agenesis of
15
Tabel 1. Kandidat protein-protein signifikan yang berasosiasi dengan DM tipe 2
No Gene /
Protein Gene/Locus name
68 PON1 Paraoxonase-1
69 PPARG Peroxisome proliferator activated receptor, gamma 70 PTPN22 Protein tyrosine phosphatase, nonreceptor-type 22
71 RETN Resistin
72 RRAD Ras-related associated with diabetes
73 SLC2A2 Solute carrier family 2 (facilitated glucose transporter), member 2 74 SLC30A8 Solute carrier family 30 (zinc transporter), member 8
75 SOD2 Superoxide dismutase-2, mitochondrial 76 SPINK3 Serine protease inhibitor, Kazal type I 77 SUMO4 Small ubiquitin-like modifier 4 78 TBC1D4 TPC1 domain family, member 4 79 TCF7L2 Transcription factor 7-like 2
80 UCP3 Uncoupling protein-3
81 VEGFA Vascular endothelial growth factor
82 WFS1 Wolframin
83 ZFP57 Zinc finger protein 57, mouse, homolog of
* Protein-protein yang tidak memiliki data PPI pada basis data STRING
Selanjutnya 83 kandidat protein-protein signifikan tersebut digunakan sebagai data input pada basis data STRING dan hasilnya 63 kandidat protein signifikan memiliki 2053 data PPI dan 20 lainnya tidak memiliki data PPI. Karena terdapat 20 kandidat protein signifikan yang tidak memiliki data PPI, maka 20 protein tersebut tidak di ikut sertakan dalam konstruksi jaringan PPI. Dari seluruh data PPI yang diperoleh, terdapat 481 protein yang terlibat, 63 protein di antaranya adalah kandidat protein signifikan.
Gambar 11. Data PPI dari HNF1A yang dikembalikan oleh basis data STRING
16
(glycerol-3-phosphate dehydrogenase 2 (mitochondrial)) dan HFE (hemochromatosis gene). Karena kelima jejaring kecil yang tidak terhubung secara langsung ke jejaring besar, mereka mereka tidak diikut sertakan dalam proses analisis topologi jejaring PPI. Adapun komponen jejaring besar memiliki 426 node (58 node diantaranya adalah kandidat protein signifikan) dengan 1857 interaksi antara mereka. Untuk menggambarkan bagian-bagian dari protein tersebut pada jejaring, maka node protein dibedakan dengan warna dan hanya node kandidat protein signifikan saja yang diberi label (Gambar 12).
Jejaring besar yang tampak pada Gambar 12 merupakan jejaring dengan keterhubungan yang kompleks antar kandidat protein-protein signifikan dengan protein selain kandidat protein signifikan. Untuk itu dilakukan penyederhanaan jejaring dengan menkonstrusi subnetwork dari jejaring tersebut. Konstruksi subnetwork dimulai dengan menelusuri seluruh lintasan terpendek dari semua pasangan antar kandidat protein signifikan pada jejaring besar, kemudian memilih lintasan terpendek yang melalui node-node dengan nilai degree terbesar (Ran et al. 2013) untuk tiap pasang kandidat protein signifikan.
Pemilihan lintasan terpendek yang melalui node-node dengan nilai degree terbesar bertujuan untuk menghindari node palsu dari interaksi palsu (Lima-Mandez & Van Helden 2009). Dari hasil penelusuran terpilih 1596 lintasan terpendek dari 7169 lintasan terpendek yang terbentuk. 1596 lintasan terpendek
Gambar 12. Jejaring PPI. Jejaring ini tersusun atas 63 kandidat protein signifikan (node yang mempunyai nama) di mana 58 kandidat protein signifikan menyusun satu jejaring
besar dan 5 kandidat protein signifikan masing-masing membentuk satu jejaring kecil. Node yang berwarna hijau adalah kandidat protein signifikan, node yang berwarna biru adalah protein selain kandidat protein signifikan yang berada dalam jejaring besar dan node
17
yang terpilih kemudian diubah menjadi data interaksi antar protein dan selanjutnya subnetwork dikonstruksi dari semua data interaksi antar protein. Subnetwork yang terbentuk (Gambar 13) terdiri atas 91 node dengan 259 PPI. Node dengan nilai BC dan degree besar yang digambarkan dengan node berwarna biru berjumlah 16 protein, 5 protein (node berwarna hijau muda) dengan nilai BC besar saja, 29 protein (node berwarna orange) dengan nilai degree besar saja dan 57 selainya (node berukuran paling kecil).
Mentukan Protein Kunci pada Subnetwork dari Jejaring PPI
Nilai BC untuk setiap node pada jejaring digunakan sebagai dasar dalam menentukan node (protein) kunci pada jejaring. Node kunci yang kemudian disebut protein signifikan dipilih dari nilai BC tinggi dengan jumlah node yang ditetapkan 5% dari total node dalam jejaring PPI (Goni et al. 2008; Kim et al. 2009). Dari hasil analisis topologi pada subnetwork diperoleh 21 protein sebagai node dengan BC dan 9 protein di antaranya adalah kandidat protein signifikan (Tabel 2).
Semua protein dengan nilai BC tinggi pada Tabel 1 merupakan protein signifikan yang diduga mempunyai konstribusi dalam menyediakan nutrisi yang diperlukan untuk menghasikan insulin, terutama protein-protein yang berinteraksi langsung dengan insulin. Dari 21 protein tersebut berikutnya akan dikonstruksi jejaring penyangga (Ran J. et.al. 2013). Jejaring ini dikonstruksi untuk melihat
18
interaksi antar protein-protein signifikan dalam jejaring PPI baik secara lansung maupun tidak langsung.
Tabel 2. Protein-protein dengan nilai BC tinggi pada subnetwork
Simbol
Protein Nilai BC NilaiCC
Simbol kandidat protein, hanya 9 kandidat protein yang termasuk dari total 21 protein kunci dengan nilai BC tinggi dan 12 protein selebihnya merupakan seed protein yang diperoleh dari interaksi antar protein (PPI). Adapun protein dengan nilai degree besar diperoleh 29 protein dan 19 protein di antaranya adalah kandidat protein signifikan (Tabel 3).
Tabel 3. Protein-protein dengan nilai degree besar pada subnetwork
19
tertinggi. Oleh karena memiliki nilai BC tertinggi, INS merupakan node terpenting dari 21 protein kunci dengan nilai BC tinggi. Dari kedua tabel tersebut terlihat 16 protein sebagai node dengan BC tinggi dan degree besar (Tabel 4) dan 5 protein hanya dengan BC tinggi (Tabel 5). Untuk membedakan peran node-node pada tabel-tabel diatas, node-node tersebut digambarkan dengan warna dan ukuran yang berbeda (Gambar 13).
Tabel 4. Protein-protein dengan nilai BC tinggi dan degree besar Simbol
Protein Deskripsi
INS Insulin; Insulin decreases blood glucose concentration.
AKT1 v-Akt murine thymoma viral oncogene homolog 1; Regulate many processes including metabolism, proliferation, cell survival, growth and angiogenesis. UBC Ubiquitin C
TCF7L2 Transcription factor 7-like 2 (T-cell specific, HMG-box)
INSR Insulin receptor; Receptor tyrosine kinase which mediates the pleiotropic actions of insulin.
KCNJ11 Potassium inwardly-rectifying channel, subfamily J, member 11; This receptor is controlled by G proteins
GCG Glucagon; Glicentin may modulate gastric acid secretion and the gastro-pyloro-duodenal activity.
PPARG Peroxisome proliferator-activated receptor gamma
STAT3 Signal transducer and activator of transcription 3; Signal transducer and transcription activator that mediates cellular responses to interleukins, KITLG/SCF and other growth factors.
APOE Apolipoprotein E; Mediates the binding, internalization, and catabolism of lipoprotein particles.
FOXO1 Forkhead box O1; Transcription factor that is the main target of insulin signaling and regulates metabolic homeostasis in response to oxidative stress.
EP300 E1A binding protein p300; Functions as histone acetyltransferase and regulates transcription via chromatin remodeling.
WFS1 Wolfram syndrome 1 (wolframin); Participates in the regulation of cellular Ca(2+) homeostasis, at least partly, by modulating the filling state of the endoplasmic reticulum Ca(2+) store
MTNR1B Melatonin receptor 1B; High affinity receptor for melatonin. The activity of this receptor is mediated by pertussis toxin sensitive G proteins that inhibit adenylate cyclase activity.
SOCS3 Suppressor of cytokine signaling 3; SOCS3 is involved in negative regulation of cytokines that signal through the JAK/STAT pathway
20
Tabel 5. Protein-protein dengan nilai BC tinggi tanpa nilai degree besar Simbol
Protein Deskripsi
PTH Parathyroid hormone; PTH elevates calcium level by dissolving the salts in bone and preventing their renal excretion. Stimulates [1-14C]-2- deoxy-D-glucose (2DG) transport and glycogen synthesis in osteoblastic cells.
PRKACA Protein kinase, cAMP-dependent, catalytic, alpha; Regulates the abundance of compartmentalized pools of its regulatory subunits through phosphorylation of PJA2 which binds and ubiquitinates these subunits, leading to their subsequent proteolysis.
SOD3 Superoxide dismutase 3; Protect the extracellular space from toxic effect of reactive oxygen intermediates by converting superoxide radicals into hydrogen peroxide and oxygen
CTLA4 Cytotoxic T-lymphocyte-associated protein 4.
PPARA Peroxisome proliferator-activated receptor alpha; Ligand-activated transcription factor.
Jejaring Penyangga dari Semua Protein BC Tinggi
Jejaring penyangga dikonstruksi dari semua node BC tinggi hasil ekstraksi pada subnetwork. Nilai BC pada awalnya diperkenalkan untuk mengukur sentralitas node dalam jejaring. Node tersebut berfungsi sebagai pengontrol komunikasi antar node dalam jejaring. Jejaring penyangga dikonstruksi untuk mengetahui bagaimana interaksi semua node BC tinggi pada subnetwork. Hasil konstruksi jejaring penyangga ini diperoleh 21 node dengan 38 interaksi di antara mereka.
Pada jejaring ini, INS memiliki nilai BC tertinggi dan merupakan node yang berada pada pusat jejaring dengan nilai CC terbesar (Tabel 6). Adapun tetangga langsung INS ada 8 node protein yaitu AKT1, TCF7L2, KCNJ11, PPARG, GCG, INSR, IAPP dan SOCS3 (Gambar 14).
Tabel 6. Protein-protein dengan nilai BC tinggi pada jejaring penyangga
Simbol
Protein Nilai BC NilaiCC
Simbol
Protein Nilai BC Nilai CC INS 0,321111 0,625 PPARA 0,03114 0,408163 AKT1 0,24348 0,512821 WFS1 0,018567 0,444444 TCF7L2 0,200292 0,571429 APOE 0,016257 0,384615 KCNJ11 0,134211 0,5 FOXO1 0,009649 0,37037 UBC 0,109678 0,487805 STAT3 0,006579 0,350877 PPARG 0,095205 0,512821 PTH 0,004386 0,350877
GCG 0,077953 0,47619 CTLA4 0 0,344828
INSR 0,077544 0,5 MTNR1B 0 0,392157
IAPP 0,052632 0,434783 PRKACA 0 0,338983
SOCS3 0,051754 0,434783 SOD3 0 0,344828
21
Node INS merupakan node yang sangat terhubung pada jejaring karena INS memiliki nilai BC tertinggi dan nilai degree terbesar (Han et al. 2004) baik pada jejaring besar, subnetwork, maupun jejaring penyangga. Artinya node INS merupakan protein yang mengatur lalu lintas semua interaksi antar node dan mengikat node protein-protein lain yang berinteraksi langsung dengannya (Han et al. 2004).
Evaluasi Kekokohan Jejaring Penyangga
Dari tiga parameter (BC, C, Degree) evaluasi jejaring yang dihititung, diperoleh 4 protein dengan nilai BC tertinggi (INS, AKT1, TCF7L2, KCNJ11), 3 protein denga nilai CC terbesar (INS, TCF7L2, KCNJ11) dan 1 protein dengan nilai degree terbesar (INS) pada jejaring uji (Tabel 7). Berdasarkan data pengujian (tabel 7) INS menjadi pusat jejaring (CC terbesar) sebanyak 228 kali dari 265 pengujian, INS menjadi pengontrol lalu lintas seluruh interaksi antar protein (BC terbesar) sebanyak 208 kali dari 265 pengujian dan INS menjadi protein yang memiliki jumlah interaksi langsung terbanyak dengan protein lain dalam jejaring (degree terbesar) sebanyak 265 kali dari 265 pengujian.
Adapun nilai akurasi jejaring uji dengan jejaring penyangga cukup besar yaitu 0,84965204 (Tabel 7). Nilai akurasi di sini menunjukkan tingkat konsistensi kemunculan protein-protein signifikan terhadap n buah jejaring uji yang dibentuk.
Gambar 14. Jejaring penyangga dikonstruksi dari 21 protein BC tinggi yang diekstraksi dari subnetwork jejaring PPI, dan ukuran node merepresentasikan
22
Tabel 7. Frekuensi kemunculan protein-protein dengan nilai BC tertinggi, nilai CC dan degree terbesar pada 265 jejaring uji
Jumlah Protein yang Dihilangkan
Frekuensi Nilai BC, CC dan Degree Tertinggi / Terbesar pada Jejaring Tes Akurasi Jejaring Penyangga
Jumlah Jejaring
Uji
BC CC Degree
INS AKT1 TCF7L2 KCNJ11 INS TCF7L2 KCNJ11 INS
1 40 16 2 0 53 5 0 58 0,926929392 58
2 50 5 2 0 52 5 0 57 0,904761905 57
3 25 5 0 0 28 2 0 30 0,880952381 30
4 23 2 5 0 26 4 0 30 0,849206349 30
5 24 2 4 0 22 8 0 30 0,836507937 30
6 22 5 3 0 22 8 0 30 0,780952381 30
7 24 1 4 1 25 4 1 30 0,768253968 30
23
5. SIMPULAN DAN SARAN
Simpulan
Terdapat 21 protein signifikan yang berasosiasi dengan DM tipe 2, di mana INS merupakan protein terpenting dan 8 protein yang bertetanggaan langsung dengannya. Hasil penelitian ini juga ikut menguatkan penelitian-penelitian sebelumnya secara umum mengenai DM tipe 2, bahwa INS merupakan protein signifikan yang berperan utama dalam penyakit DM
Jejaring penyangga dikonstruksi untuk mengetahui interaksi antar protein-protein signifikan sehingga diperoleh gambaran protein-protein yang paling bertanggung jawab dalam mengatur lalu lintas interaksi antar protein dan sebagai pusat jejaring. Dari seluruh jejaring uji yang dikonstruksi, disimpulkan bahwa INS merupakan protein yang paling signifikan dibandingkan dengan 20 protein signifikan yang ada.
Saran
Hasil yang diperoleh pada penelitian ini belum menjelaskan patogenesis dari protein-protein signifikan tersebut dengan DM tipe 2. Oleh karena itu pada penelitian selanjutnya perlu dilakukan analisis terhapat ekspresi interaksi antar proteinnya. Selain itu, protein-protein signifikan yang diperoleh tetap harus dilakukan pengujian secara eksperimental pada laboratorium basah.
25
DAFTAR PUSTAKA
Acencio ML, Lemke N. 2009. Towards the prediction of essential genes by integration of network topology, cellular localization and biological process information. BMC Bioinforma, 10:290-307.
Colton CK and Avgoustiniatos ES. 2008. Bioengineering in Development of the Hybrid
Artificial Pancreas. J Biomech Eng 113(2), 152-170. Online. DOI:101115/1.2891229.
Cullen LM, Arndt GM. 2005. Genome-wide screening for gene function using RNAi in
mammalian cells. Immunol Cell Biol.83(3):217-223.
Escandon JC and Cipolla M. 2001. Diabetes and Endothelial Dysfunction: A Clinical
Perspective. Endocrine.22(1): 36–52. 0163-769X/01/$03.00/0.
Freeman LC. 1982. Centered graphs and the construction of ego networks. Math Social Sci 3: 291-304, 1982.
Giaever G, Chu AM, Ni L. 2002. Functional profiling of the Saccharomyces cerevisiae genome.
Nature. 418(6896):387-391.
Goni J, Esteban FJ, de Mendizábal NV, Sepulcre J, Ardanza-Trevijano S, Agirrezabal I, Villoslada P. 2008. A computational analysis of protein-protein interaction networks in
neurodegenerative diseases. BMC Systems Biology. 2:52.
Hamosh A, Scott AF, Amberger JS, Bocchini CA and McKusick VA. 2005. Online Mendelian Inheritance in Man (OMIM), a knowledgebase of human genes and genetic disorders.
Nucleic Acids Research. 33: D514–D517. Database issue. DOI:10.1093/nar/gki033.
Han JD, Bertin N, Hao T, Goldberg DS, Berriz GF, Zhang LV, Duduy D, Walhout AJ, Cusick ME, Roth FP, Vidal M. 2004. Evidence for dynamically organized modularity in the
yeast protein-protein interaction network. Nuture, 430:88-93.
Herce HD, Deng W, Helma J, Leonhardt H and Cardoso MC. 2013. Visualization and targeted disruption of protein interactions in living cells. Nature Communications. 4:2660. DOI:10.1038/ncomms3660.
Huang H, Wu X, Pandey R, Li J, Zhao G, Ibrahim S, Chen JY. 2012. C2Maps: a network pharmacology database with comprehensive disease-gene-drug connectivity
relationships. BMC Genomics. 13(Suppl 6):S17.
Hwang S, Son SW, Kim SC, Kim YJ, Jeong H, Lee D. 2008. A protein interaction network
associated with asthma. J Theor Biol. 252:722–731.
Jensen LJ, Kuhn M, Stark M, Chaffron S, Creevey C, Muller J, Doerks T, Julien P, Roth A,
Simonovic M, Bork P, von Mering C. 2009. STRING 8–a global view on proteins and
their functional interactions in 630 organisms. Nucleic Acids Res. 37:D412–D416.
Jones S and Thornton JM.1996. Principles of protein-protein interactions. Proc. Natl. Acad. Sci.
USA. 93: 13-20.
Kim KK, Kim HB. 2009. Protein interaction network related to Helicobacter pylori infection
response.World J Gastroenterol. 15:4518–4528.
Li J, Zhu X and Chen JY. 2009. Building Disease-Specific Drug-Protein Connectivity Maps
from Molecular Interaction Networks and PubMed Abstracts. PLoS Comput Biol 5(7):
e1000450. DOI:10.1371/journal.pcbi.1000450.
Lima-Mendez G, van Helden J. 2009. The powerful law of the power law and other myths in network biologi. Mol Biosyst.
Li Min, Zhang Hanhui, Wang Jian-xin, Pan Yi. 2012. A new essential protein discovery method
based on the integration of protein-protein interaction and gene expression data. BMC
Systems Biology. 6:15.
Phizicky EM and Fieds S. 1995. Protein-Protein Interactions: Methods for Detection and
26
Ran J, Li H, Fu J, Liu L, Xing Y, Li X, Shen H, Hen Y, Jiang X, Li Y and Huiwu. 2013. Construction and analysis of the protein-protein interaction network related to essential
hypertension. Ranet al. BMC Systems Biology. 7:32.
Roemer T, Jiang B, Davison J. 2003. Large-scale essential gene identification in Candida
albicans and applications to antifungal drug discovery. Mol Microbiol. 50:167-181.
Shannon P, Markiel A, Ozier O, Baliga NS, Wang JT, Ramage D, Amin N, Schwikowski B, and Ideker T. 2003. Cytoscape: A Software Environment for Integrated Models of
Biomolecular Interaction Networks. Cold Spring Harbor Laboratory Press. 13:2498–
2504.
Tuomilehto J, Lindstrom J, Eriksson JG, Valle TT, Hamaleinen H, Parikka PI, Kiukaanniemi SK, Laakso M, Louheranta A, Rastas M, Salminen V, and Uusitupa M. 2001. Prevention of type 2 diabetes mellitus by changes in lifestyle among subjects with impaired glucose
tolerance. N Engl J Med, 344:18.
Wasserman S and Faust K. 1994. Social Network Analysis. Cambridge University Press, Cambridge.
Wolfe ND, Dunavan CP and Diamond J. 2007. Origins of major human infectious diseases,
Nature. 447:279-283. DOI:10.1038/nature05775.
Xia Y, Yu H, Jansen R, Seringhaus M, Baxter S, Greenbaum D, Zhao H, Gerstein M. 2004.
Analyzing cellular biochemistry in terms of molecular networks. Ann Rev Biochem.
73:1051-1087.
Zhang A, Sun H, Yang B and Xijun Wang X. 2012. Predicting new molecular targets for rhein
27
LAMPIRAN
1. Lampiran source code konstruksi jejaring PPI, subnetwork, analisis
topologi dan konstruksi jejaring penyangga
import networkx as nx import xlwt as xl
'''
nama fungsi : gabung_2_fppi(ls_nm_file) 7an : menggabung dua file PPI
nama fungsi : fProt_to_lsProt(nm_fprot)
7an : memindahkan seed protein dari file --> list seed protein &
nama fungsi : lsProt_to_lsBProt(lsProt)
28
nama fungsi : fPPI_to_lsPPI(nm_fppi)
7an : memindahkan file interaksi biner protein yg diperoleh dari STRING.db atau HPRD --> list interaksi biner antar protein
input : nama file ppi
output : list PPI (lsPPI) : [('a','b'),('b','d'),...,('y','z')] peruntukan output : lsPPI : digunakan untuk membangun jejaring PPI '''
def fPPI_to_lsPPI(nm_fppi): f = open(nm_fppi) fileOk = True
listPPI = [] # list interaksi biner antar protein
bppi = f.readline() # membaca line pertama interaksi biner protein (ppi) dlm file not((p1,p2) in listPPI) and not((p2,p1) in listPPI) and p1!= '' and p2!='' :
listPPI = listPPI + [(p1,p2)] return listPPI
'''
nama fungsi : empty_graph()
7an : menciptakan sebuah graph G yang masih kosong input : ---
29
'''
def empty_graph(): return nx.Graph()
'''
nama fungsi : const_network(dtlsPPI)
7an : menciptakan graph G kemudian membangun network G PPI dari sebuah list PPI : [(p1,p7),(p3,p6),(p10,p22),...]
input : sebuah list PPI : dtlsPPI : [(p1,p7),(p3,p6),(p10,p22),...]
output : sebuah network graph PPI : G
peruntukan output : G PPI: untuk dilakukan analisis topologi '''
G.add_edges_from(lsPPI) return G
'''
nama fungsi : get_allshortespath(G, lsBProtAsal, tipe)
7an : mencari semua jalur terpendek dari pasangan biner protein untuk tiap pasangan biner protein asal
output : list shortest_path dari semua pasangan biner protein asal peruntukan output : untuk membangun subnetwork PPI dari network PPI '''
def get_allshortespath(G, lsBProtAsal, tipe, lspBC005): lsShortestPath = []
elif tipe == 2: # menemukan 1 jalur terpendek dengan metode dijkstar tiap pasang protein
31
#print('lsShortestPath:',lsShortestPath) return return lsPPI_Penyangga
'''
32
listPPI = []
for i in range(0,len(lsShortestPath)): path = lsShortestPath[i]
nama fungsi : lsProt_n_BC(tG)
7an : memdapatkan nilai BC dari semua node (protein) dalam graph tG
input : tG : graph subnetwork
output : list Protein dan nilai Betweenness_Centrality tiap Protein (listProt_nBC) dari graph tG
'''
def lsBCProt(tG): listProt_nBC = []
BCP = nx.betweenness_centrality(tG) ndProt = tG.nodes()
nama fungsi : lsProt_n_BC005(lsProt_nBC)
7an : memdapatkan semua protein dan nilai BC >= 5%
input : lsProt_nBC : list protein dan nilai BC-nya "listProt_nBC" output : list protein dan nilai BC >= 5% (listProt_nBC005)
'''
def lsProt005(lsProt, persen, jml, lsProtPPI): listProt005 = []
nama fungsi : lsProt_with_BC005(lsProt_nBC005)
7an : memdapatkan protein-protein dengan nilai BC >= 5%
for i in range(0,len(lsProt_nBC005)): prot = lsProt_nBC005[i][0]
listProt_wBC005 = listProt_wBC005 + [prot] return listProt_wBC005
'''
nama fungsi : CCProt(tG)
33
output : list Closeness_Centrality tiap Protein (listCCProt) dari graph tG
'''
def lsCCProt(tG): listCCProt = []
CCP = nx.closeness_centrality(tG) ndProt = tG.nodes()
nama fungsi : listDt_to_file(listDt, nmfile)
7an : memdapatkan nilai CC dari semua node (protein) input : tG : graph subnetwork
output : list Closeness_Centrality tiap Protein (listCCProt) dari graph tG
def listDt_to_fExcel(listDt, sheet, nm_file, tipe): wb = xl.Workbook()
34
ws.write(0,5,'NonKddPrt') KddProt = 0
ws.write(i+2,5,nonKddProt) wb.save(nm_file)
''' '''
def mix_BC_Degree(lsBC, lsDegree, lsgen, nm_file): wb = xl.Workbook()
ws1 = wb.add_sheet('BC_Degree') ws2 = wb.add_sheet('BC_NonDegree')
ws1.write(0,0,'BC Tinggi dan Degree Besar') ws1.write(1,0,'SN')
ws1.write(1,1,'SymbProt') ws1.write(1,2,'Func Desc')
ws2.write(0,0,'BC Tinggi tanpa Degree Besar') ws2.write(1,0,'SN')
35
folder = 'E:/Syaif/program/dtFromSTRING/fHasil Prog 1.2.0.2/55/' # list gen dan deskripsinya
lsgen_desk =
fgen_to_lsgen('E:/Syaif/program/dtFromSTRING/all_dtgen_deskripsi_A.txt') # list kandidat protein
lsKddProt = fProt_to_lsProt('E:/Syaif/program/dtFromSTRING/_dtgen1.txt') # list pasangan biner kandidat protein
lsBKddProt = lsProt_to_lsBProt(lsKddProt)
lsPPI =
fPPI_to_lsPPI('E:/Syaif/program/dtFromSTRING/_fppi_fromSTRING1.txt') G_PPI = const_network(lsPPI) # network PPI
NumOfNode_PPI = G_PPI.nodes()
36
# konstruksi subnetwork semua lintasan terpendek antar prot kandidat pada jejaring PPI
SP = get_allshortespath(G_PPI, lsBKddProt, 3, lsKddProt) lsAllShortestPath = SP[0] G_Subnet = const_network(lsPPI_dr_allSPath) # subnetwork PPI NumOfNode_Subnet = G_Subnet.nodes()
listDt_to_fExcel(lsPPI_dr_allSPath, '_fPPI_subnet', folder+'_PPI_subnet.xls',2) # save to excel
listDt_to_fExcel(NumOfNode_Subnet, '_NodeOf_GSubnet', folder+'_NodeOf_Subnet.xls',1) # save to excel
# mencari nilai CC dari semua node pada subnetwork
lsProt_nCC = sorted(lsCCProt(G_Subnet), key=lambda tup: tup[1], reverse=True)
listDt_to_fExcel(lsProt_nCC, '_Prot_nCC', folder+'_Prot_nCC.xls',2) # save to excel
# mencari node nilai BC tinggi pada subnetwork sebanyak 5% dr total node jejaring PPI
lsProt_nBC = sorted(lsBCProt(G_Subnet), key=lambda tup: tup[1], reverse=True)
listDt_to_fExcel(lsProt_nBC, '_Prot_nBC', folder+'_Prot_nBC.xls',2) # save to excel
lsProt_nBC005 = lsProt005(lsProt_nBC, 5, 0, NumOfNode_PPI) listDtBC_CC_to_fExcel(lsProt_nBC005, lsProt_nCC, lsKddProt, '_Prot_nBC005', folder+'_Prot_nBC005.xls',1) # save to excel lsProt_wBC005 = lsProt_with_BC005(lsProt_nBC005)
lsBProt_wBC005 = lsProt_to_lsBProt(lsProt_wBC005)
# mencari nilai degree dari semua node pada subnetwork lsDegree = G_Subnet.degree(weight='weight').items()
lsProt_nDegree = sorted(lsDegree, key=lambda tup: tup[1], reverse=True) listDt_to_fExcel(lsProt_nDegree, '_Prot_nDegree',
folder+'_Prot_nDegree.xls',2) # save to excel
lsProt_nDegree005 = lsProt005(lsProt_nDegree, 0, 29, NumOfNode_PPI) listDtBC_CC_to_fExcel(lsProt_nDegree005, lsProt_nCC, lsKddProt, '_Prot_nDegree005', folder+'_Prot_nDegree005.xls',2) # save to excel
# mix prot BC dan Degree
mix_BC_Degree(lsProt_nBC005, lsProt_nDegree005, lsgen_desk, folder+'_BC_n_Degree.xls')
# konstruksi jejaring penyangga dari semua node bc tinggi dari Subnetwork lsAllShortestPath_wBC005 = get_allshortespath(G_Subnet,lsBProt_wBC005, 3,
G_Penyangga = const_network(lsPPI_Penyangga) # jejaring penyanggah NumOfNode_Penyangga = G_Penyangga.nodes()
lsProt_nBC = sorted(lsBCProt(G_Penyangga), key=lambda tup: tup[1], reverse=True)
37
listDt_to_fExcel(lsProt_nBC, '_Prot_nBC',
folder+'_Prot_BC_Penyangga.xls',2) # save to excel listDt_to_fExcel(lsProt_nCC, '_Prot_nCC',
folder+'_Prot_CC_Penyangga.xls',2) # save to excel
listDt_to_fExcel(lsPPI_Penyangga, '_fPPI_penyangga', folder+'_PPI_penyangga.xls',2)# save to excel
listDt_to_fExcel(NumOfNode_Penyangga, '_NodeOf_GPenyangga', folder+'_NodeOf_GPenyangga.xls',1) # save to excel
lsDegree_Penyangga = G_Penyangga.degree(weight='weight').items() lsProt_nDegree_Penyangga = sorted(lsDegree_Penyangga, key=lambda tup: tup[1], reverse=True)
listDt_to_fExcel(lsProt_nDegree_Penyangga, '_Prot_nDegree_Penyangga', folder+'_Prot_nDegree_Penyangga.xls',2) # save to excel
Lampiran 2. Source code pengujian kekokohan jejaring penyangga
import networkx as nx
38 return(ls_allprot,ls_allppi)
def lsppi_from_prot_exist(lsallprot, lsallppi, lsprotexist): not((p2,p1) in lsppi_exist) and p1!= '' and p2!='' :
lsppi_exist = lsppi_exist + [tlsppi[j]] return(lsppi_exist)
39
40
CCP = nx.closeness_centrality(tG) ndProt = tG.nodes()
BCP = nx.betweenness_centrality(tG) ndProt = tG.nodes()
for i in range(0,len(lsProt_nBC005)): prot = lsProt_nBC005[i][0]
listProt_wBC005 = listProt_wBC005 + [prot] return listProt_wBC005
def lsProt005(lsProt, persen, lsProtPPI): not((p1,p2) in listPPI) and not((p2,p1) in listPPI) and p1!= '' and p2!='' :
listPPI = listPPI + [(p1,p2)] return listPPI
def uji(ls_kddprot,lsppi_exist,ls_BCpenyangga): # konstruksi jejaring PPI