31
BAB III
ANALISIS DAN PERANCANGAN SISTEM
III.1 Analisis Sistem
Analisis sistem adalah penguraian dari suatu sistem informasi yang utuh kedalam bagian-bagian komponennya dengan maksud untuk mengidentifikasi dan mengevaluasi permasalahan, kesempatan, hambatan yang terjadi dan kebutuhan yang diharapkan sehingga dapat diusulkan perbaikan. Tahap analisis sistem merupakan tahapan yang sangat kritis dan penting, karena kesalahan di dalam tahap ini akan menyebabkan juga kesalahan di tahap selanjutnya. Tugas utama analisis sistem dalam tahap ini adalah menemukan kelemahan-kelemahan dari sistem yang berjalan sehingga dapat diusulkan perbaikannya. Dalam analisa sistem ini meliputi beberapa bagian, yaitu :
1. Analisis Masalah 2. Analisis Sumber Data 3. Analisis Preprocessing Data
4. Analisis Penerapan Metode Association Rule 5. Analisis Spesifikasi Kebutuhan Perangkat Lunak 6. Analisis Kebutuhan Non-Fungsional
7. Analisis Kebutuhan Fungsional
8. Spesifikasi Proses Kamus Data DFD
III.1.1 Analisis Masalah
Adapun analisis masalah di Kalvin Sock Production adalah sebagai berikut : a. Beragamnya jenis hasil kaos kaki yang diproduksi oleh Kalvin Socks Production membuat pihak bagian produksi sulit untuk menentukan jenis kaos kaki apa saja yang harus disediakan sebagai persediaan barang untuk dijual.
b. Penentuan jenis kaos kaki yang akan diproduksi berdasarkan history
Untuk mengurangi atau bahkan mengatasi permasalahan di atas, pihak terkait di perusahaan diharapkan dapat mengambil keputusan untuk menentukan jenis kaos kaki yang akan diproduksi. Agar dapat melaksanakan hal tersebut, perusahaan memerlukan informasi yang cukup untuk dapat dianalisis lebih lanjut. Informasi yang dihasilkan tentunya adalah hasil analisis dari pengolahan data penjualan di perusahaan tersebut. Data penjualan yang telah ada akan diolah atau dianalisis untuk megetahui pola pembelian pelanggan terhadap jenis kaos kaki tertentu, sehingga perusahaan dapat mengetahu jenis kaos kaki mana saja yang sering dibeli oleh pelanggannya. Hasil tersebut juga dapat dijadikan pertimbangan sebagai penentuan jenis kaos kaki apa saja yang harus diproduksi secara bersamaan untuk persediaan kaos kaki.
III.1.2 Analisis Sumber Data
III.1.2.1 Sumber data yang digunakan
Sumber data yang digunakan pada penelitian ini diambil dari :
III.1.3 Analisis Preprocessing Data
Adapun langkah-langkah preprocessing data dalam penelitian ini adalah sebagai berikut :
1. Pemilihan Atribut (atribut selection)
Berdasarkan informasi yang ingin didapat oleh pengguna mengenai jenis produk yang dibeli secara bersamaan, maka dalam tahap pemilihan atribut ini, atribut yang akan digunakan dari data hasil ekstraksi pada tabel D-1 dalam lampiran D adalah atribut NoNota dan kodeBarang. Atribut NoNota adalah ID dari transaksi dan atribut kodeBarang adalah kode dari jenis barang yang dibeli. Hasil pemilihan atribut pada tabel D-1 dapat dilihat pada tabel D-2 dalam lampiran A.
2. Pembersihan Data (data cleaning)
Pada tahap pembersihan data, hasil pemilihan atribut pada tabel D-2 akan dibersihkan dari data transaksi yang mengandung item tunggal. Data transaksi yang memiliki item tunggal ini tidak memiliki hubungan asosiasi dengan item lain yang sudah dibeli. Hasil pembersihan data dari tabel D-2 dapat dilihat pada tabel D-3 dalam lampiran D.
III.1.4 Analisis Penerapan Metode Association Rule
Penelitian ini bertujuan untuk menentukan jenis barang yang akan diproduksi menggunakan metode data mining associaation rule dengan cara menemukan aturan asosiatif atau pola kombinasi dari suatu item, sehingga dapat diketahui barang apa saja yang dibeli secara bersamaan.
Langkah-langkah proses pengerjaan algoritma apriori dalam penelitian ini adalah sebagai berikut :
1. Asumsi nilai minimum support yang akan digunakan sebesar 20% dari 17 sampel data transaksi yaitu 3,4 ≈ 4 . Data Frequent item dapat dilihat pada tabel D-4 dalam lampiran D.
2. Asumsi nilai minimum confidence yang akan digunakan sebesar 60% , nilai minimum confidence ini untuk menyakinkan kuatnya hubungan antara item
3. Dari data awal pada tabel D-4 dalam lampiran D dapat diketahui kandidat
itemset ke-1 (C1), jumlah transaksi dan nilai support yang dihitung dengan
persamaan II.1. Data tersebut dapat dilihat pada tabel D-5 dalam lampiran D. 4. Data yang nilai support-nya kurang dari nilai minimum support akan
dihilangkan. Data tersebut dapat dilihat pada tabel D-6 dalam lampiran D. 5. Setelah mendapatkan data yang nilai support-nya lebih dari sama dengan nilai
minimum support, untuk mendapatkan 2-itemset (C2) maka gabungkan hasil
dari L1 x L1. Maka hasilnya dapat dilihat pada tabel D-7 dalam lampiran D.
6. Data yang nilai support-nya kurang dari nilai minimum support akan dihilangkan. Data tersebut dapat dilihat pada tabel D-8 dalam lampiran D. 7. Setelah mendapatkan data yang nilai support-nya lebih dari sama dengan nilai
minimum support, untuk mendapatkan 3-itemset (C3) maka gabungkan hasil
dari L2 x L2. Itemset yang dapat digabungkan adalah itemset yang memiliki
kesamaan dalam k-1 item pertama. Maka hasilnya dapat dilihat pada tabel D-9 dalam lampiran D.
8. Data yang nilai support-nya kurang dari nilai minimum support akan dihilangkan. Data tersebut dapat dilihat pada tabel D-10 dalam lampiran D. 9. Dikarenakan data pada tabel D-10 dalam lampiran D kosong atau tidak
memiliki data yang memenuhi batas minimum support, maka proses untuk membentuk itemset selanjutnya terhenti.
10.Setelah itu, dari hasil itemset yang telah dihasilkan tersebut dibentuk aturan asosiasi yang memenuhi nilai support dan confidence yang telah ditentukan. Untuk menghitung nilai confidence dapat menggunakan persamaan II.4 dan hasilnya dapat dilihat pada tabel D-11 dalam lampiran D.
11.Adapun kesimpulan dari tabel D-11 dalam lampiran D adalah :
a.Jika pelanggan membeli ‘smp h kaoxin’ maka pelanggan juga membeli
‘smp p kaoxin’ dengan nilai support 23.52941 % dan nilai confidence 80 % .
b.Jika pelanggan membeli ‘smp h kaoxin’ maka pelanggan juga membeli
c.Jika pelanggan membeli ‘sma h kaoxin’ maka pelanggan juga membeli ‘sma p kaoxin’ dengan nilai support 29.41176 % dan nilai confidence 83,33333 % .
d.Jika pelanggan membeli ‘smp p kaoxin’ maka pelanggan juga membeli
III.2 Analisis Spesifikasi Kebutuhan Perangkat Lunak
Spesifikasi kebutuhan perangkat lunak adalah kebutuhan-kebutuhan apa saja yang diperlukan untuk membangun sebuah perangkat lunak berdasarkan kebutuhan pengguna. Ada dua bagian dalam spesifikasi kebutuhan perangkat lunak yaitu kebutuhan non-fungsional dan kebutuhan fungsional.
III.2.1 Analisis Kebutuhan Non-Fungsional
Analisis kebutuhan non fungsional dilakukan untuk mengetahui spesifikasi kebutuhan sistem. Spesifikasi kebutuhan melibatkan analisis perangkat keras (hardware), analisis perangkat lunak (software), dan analisis pengguna (user).
III.2.1.1 Analisis Kebutuhan Perangkat Keras
Perangkat keras pendukung dalam pembangunan perangkat lunak ini adalah sebagai berikut :
1. Analisis spesifikasi kebutuhan perangkat keras pada sistem yang sedang berjalan di Kalvin Socks Production adalah :
a. Processor : Intel Core Duo b.Harddisk : 250 GB
c. Memory : 2GB d.Monitor : 14” e. Keyboard : standard
f. Mouse : optical
2. Analisis spesifikasi minimum kebutuhan perangkat keras pada sistem yang akan dibangun membutuhkan :
a. Processor berkecepatan minimal 2Ghz b. Hardisk 1GB untuk penyimpanan data c. Memory 512 MB
d. Monitor e. Keyboard
3. Evaluasi kebutuhan perangkat keras
Dari data spesifikasi perangkat keras yang dimiliki oleh Kalvin Socks Production seperti diatas, perangkat keras yang telah dimiliki sudah cukup untuk dapat menjalankan aplikasi pengolahan data penjualan yang akan dibuat.
III.2.1.2 Analisis Kebutuhan Perangkat Lunak
kebutuhan perangkat lunak pendukung sangatlah penting bagi pembangunan perangkat lunak yang sedang dirancang. Perangkat lunak pendukung dalam pembangunan perangkat lunak ini adalah sebagai berikut :
1. Analisis kebutuhan perangkat lunak pada sistem yang sedang berjalan di Kalvin Socks Production adalah :
a. Sistem operasi Windows 7 b. Microsoft office
2. Analisis spesifikasi kebutuhan perangkat lunak untuk menjalankan sistem yang akan dibangun adalah :
a. Sistem Operasi Windows 7 b. XAMPP sebagai database server
c. Visualstudio 2010 d. SQLyog Enterprise
3. Evaluasi kebutuhan perangkat lunak
Berdasarkan analisis spesifikasi perangkat lunak yang ada di Kalvin Socks Production, spesifikasi perangkat lunak yang akan digunakan kurang memenuhi spesifikasi perangkat lunak yang dibutuhkan. Kekurangan tersebut dapat diatasi dengan meng-install XAMPP dan Visual Studio pada komputer yang digunakan.
III.2.1.3 Analisis User (Pengguna)
Tabel III. 1 Karakteristik Pengguna
Dengan kondisi yang terdapat diatas, dapat diambil kesimpulan bahwa aplikasi yang dibuat dapat dijalankan oleh staff di perusahaan tersebut. Pegawai Staff dalam hal ini adalah orang yang bekerja di bagian produksi yang akan menggunakan aplikasi yang dibangun.
III.2.1.4 Analisis Basis Data
Berikut adalah ERD dari perangkat lunak yang akan dibangun,
Detail_penjualan Hasil hasil_preprocessing
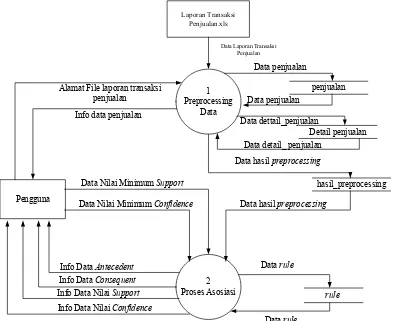
III.2.2 Analisis Kebutuhan Fungsional III.2.2.1 Diagram Konteks
Berikut adalah diagram konteks dari perangkat lunak yang akan dibangun.
PENGGUNA
Aplikasi Data Mining Association Rule Kalvin Socks Production Alamat file
Data nilai minimum support Data nilai minimum confidence
Info data Penjualan Info Data Frequent item
Info Data antecedent Info Data Consequent Info Data nilai minimum support Info Data nilai minimum confidence
Laporan Transaksi Penjualan.xls
Data Laporan Transaksi Penjualan
III.2.2.2 Data Flow Diagram
Data flow Diagram berfungsi untuk memudahkan pengguna yang kurang menguasai bidang komputer agar dapat mengerti perangkat lunak yang akan dijalankan. Berikut data flow diagram untuk perangkat lunak yang akan dibangun. III.2.2.2.1 DFD Level 1 Alamat File laporan transaksi
penjualan
penjualan Data penjualan
Data penjualan
Data Nilai Minimum Support
Data Nilai Minimum Confidence
rule
Info Data Nilai Support
Info Data Nilai Confidence
Detail penjualan Data dettail_penjualan
Data detail_ penjualan
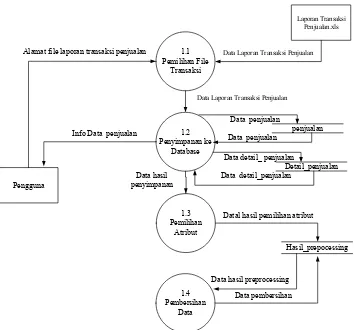
III.2.2.2.2 DFD Level 2 untuk Proses Preprocessing Data Alamat file laporan transaksi penjualan
Laporan Transaksi
Gambar III. 4 DFD level 2 untuk Proses Preprocessing Data
III.2.2.2.3 DFD Level 2 Untuk Proses Asosiasi
Pengguna
III.2.2.2.4 DFD Level 3 untuk proses Algoritma Apriori
Gambar III. 6 DFD level 3 untuk proses Algoritma Apriori
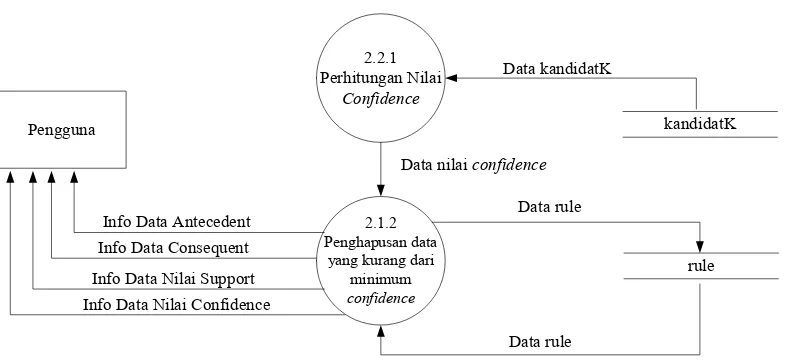
III.2.2.2.5 DFD Level 3 untuk Proses Pembentukan Aturan Asosiasi
Pengguna
III.2.2.3 Spesifikasi Proses
Untuk lebih menjelaskan tentang proses-proses yang ada dalam DFD maka dibuatlah spesifikasi proses. Tabel III.2 akan membahas tentang proses-proses yang ada dalam DFD dari perangkat lunak yang akan dibangun.
Tabel III. 2 Spesifikasi Proses
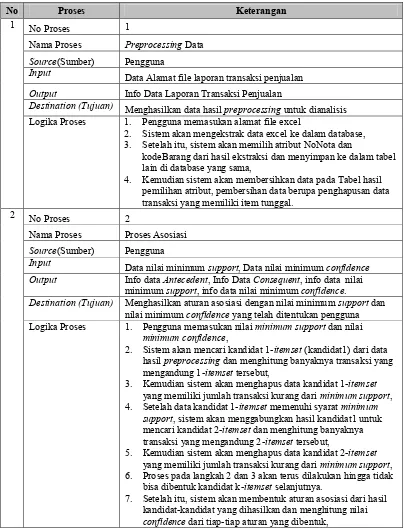
No Proses Keterangan
1 No Proses 1
Nama Proses Preprocessing Data
Source(Sumber) Pengguna
Input Data Alamat file laporan transaksi penjualan Output Info Data Laporan Transaksi Penjualan
Destination (Tujuan) Menghasilkan data hasil preprocessing untuk dianalisis
Logika Proses 1. Pengguna memasukan alamat file excel
2. Sistem akan mengekstrak data excel ke dalam database, 3. Setelah itu, sistem akan memilih atribut NoNota dan
kodeBarang dari hasil ekstraksi dan menyimpan ke dalam tabel lain di database yang sama,
4. Kemudian sistem akan membersihkan data pada Tabel hasil pemilihan atribut, pembersihan data berupa penghapusan data transaksi yang memiliki item tunggal.
2 No Proses 2
Nama Proses Proses Asosiasi
Source(Sumber) Pengguna
Input Data nilai minimum support, Data nilai minimum confidence Output Info data Antecedent, Info Data Consequent, info data nilai
minimum support, info data nilai minimum confidence.
Destination (Tujuan) Menghasilkan aturan asosiasi dengan nilai minimum support dan nilai minimum confidence yang telah ditentukan pengguna Logika Proses 1. Pengguna memasukan nilai minimum support dan nilai
minimum confidence,
2. Sistem akan mencari kandidat1-itemset (kandidat1) dari data hasil preprocessing dan menghitung banyaknya transaksi yang mengandung 1-itemset tersebut,
3. Kemudian sistem akan menghapus data kandidat 1-itemset
yang memiliki jumlah transaksi kurang dari minimum support, 4. Setelah data kandidat 1-itemset memenuhi syarat minimum
support, sistem akan menggabungkan hasil kandidat1 untuk mencari kandidat 2-itemset dan menghitung banyaknya transaksi yang mengandung 2-itemset tersebut,
5. Kemudian sistem akan menghapus data kandidat 2-itemset
yang memiliki jumlah transaksi kurang dari minimum support, 6. Proses pada langkah 2 dan 3 akan terus dilakukan hingga tidak
bisa dibentuk kandidat k-itemset selanjutnya.
7. Setelah itu, sistem akan membentuk aturan asosiasi dari hasil kandidat-kandidat yang dihasilkan dan menghitung nilai
8. Kemudian sistem akan melakukan penghapusan pada data aturan asosiasi yang tidak memenuhi nilai minimum confidence,
9. Setelah data aturan asosiasi memenuhi aturan minimum confidence, maka sistem akan menghasilkan data aturan asosiasi yang memenuhi nilai minimum support dan nilai
minimum confidence.
3 No Proses 1.1
Nama Proses Pemilihan File Transaksi
Source(sumber) Pengguna
Input Alamat File laporan transaksi penjualan, data laporan transaksi penjualan.
Output Memilih file laporan transaksi penjualan.xls yang akan disimpan ke dalam database.
Destination(Tujuan) Memilih file laporan transaksi penjualan untuk proses
preprocessing data
Logika Proses 1. Sistem akan menampilkan form untuk menyimpan data transaksi penjualan dalam bentuk file excel ke dalam database. 2. Pengguna mengklik tombol ‘Pilih File’untuk memilih file
laporan transaksi penjualan.xls
3. Sistem akan menampilkan tampilan explorer untuk mencari data laporan transaksi penjualan.xls yang akan disimpan. 4. Setelah file data laporan transaksi penjualan dipilih, maka
sistem akan menampilkan alamat file tersebut dalam isian teks alamat file.
4 No Proses 1.2
Nama Proses Penyimpanan ke database
Source(sumber) Data laporan transaksi penjualan
Input Data laporan transaksi penjualan
Output Menampilkan data laporan transaksi penjualan yang telah disimpan ke dalam database.
Destination(Tujuan) Menyimpan data laporan transaksi penjualan ke dalam database. Logika Proses 1. Setelah file data laporan transaksi penjualan dipilih, maka
sistem akan menampilkan alamat file tersebut dalam isian teks alamat file.
2. Pengguna mengklik ‘Simpan’ untuk menyimpan data laporan transaksi penjualan ke dalam database dan menampilkan data laporan transaksi penjualan yang telah tersimpan di dalam database.
3. Jika isian alamat file masih kosong, maka akan menampilkan pesan kesalahan.
5 No Proses 1.3
Nama Proses Pemilihan Atribut
Source(sumber) Data penjualan
Input Data transaksi penjualan hasil penyimpanan ke dalam database Output Data hasil pemilihan atribut
Logika Proses 1. Sistem men-scan data penjualan yang telah disimpan ke dalam database,
2. Sistem memilih atribut mana saja yang akan digunakan dalam proses data mining, atribut yang dipilih adalah NoNota dan kodeBarang
3. Hasil pemilihan atribut disimpan ke dalam tabel baru dalam database.
6 No Proses 1.4
Nama Proses Pembersihan Data
Source(sumber) Data hasil pemilihan atribut
Input Data hasil pemilihan atribut
Output Info data hasil pembersihan
Destination(Tujuan) Membersihkan data hasil pemilihan atribut yang memiliki transaksi dengan item tunggal.
Logika Proses 1. Sistem memilih data hasil pemilihan atribut yang telah disimpan dalam database.
2. Jika data hasil pemilihan atribut memiliki data transaksi yang memiliki item tunggal atau hanya memiliki satu jenis barang maka record tersebut akan dihapus .
3. Jika tidak memiliki data transaksi yang memiliki item tunggal maka data hasil pemilihan atribut sudah bersih dan dapat digunakan untuk proses data mining
7 No Proses 2.1
Nama Proses Algoritma Apriori
Source(Sumber) Pengguna
Input Data nilai minimumsupport, data nilai minimumconfidence Output Menghasilkan data kandidat k-itemset yang frequent dan memenuhi
nilai minimumsupport.
Destination (Tujuan) Menghasilkan data kandidat k-itemset yang frequent
Logika Proses 1. Sistem akan menampilkan form untuk proses asosiasi 2. Pengguna memasukan nilai minimum support dan nilai
minimum confidence dan mengklik tombol ‘Proses’
3. Jika nilai minimum support dan nilai minimum confidence
kososng, maka sistem akan menampilkan pesan kesalahan. 4. Sistem akan mencari kandidat1-itemset (kandidat1) dari data
hasil preprocessing dan menghitung banyaknya transaksi yang mengandung 1-itemset tersebut,
5. Kemudian sistem akan menghapus data kandidat 1-itemset
yang memiliki jumlah transaksi kurang dari minimum support, 6. Setelah data kandidat 1-itemset memenuhi syarat minimum
support, sistem akan menggabungkan hasil kandidat1 untuk mencari kandidat 2-itemset dan menghitung banyaknya transaksi yang mengandung 2-itemset tersebut
7. Kemudian sistem akan menghapus data kandidat 2-itemset
yang memiliki jumlah transaksi kurang dari minimum support
8. Proses pada langkah 6 dan 7 akan terus dilakukan hingga tidak bisa dibentuk kandidat k-itemset selanjutnya.
8 No Proses 2.2
III.2.2.4 Kamus Data DFD
Kamus data berfungsi untuk menjelaskan semua data yang digunakan di dalam sistem. Berikut adalah kamus data untuk perangkat lunak yang akan akan dibangun :
Tabel III. 3 Kamus Data DFD
Nama Laporan Transaksi penjualan
Deskripsi File excel Data laporan transaksi penjualan
Struktur Data Tanggal,NoNota,kodeBarang,namaBarang,jumlah
Deskripsi Berisi data penjualan dari laporan transaksi penjualan
Struktur Data Tanggal,NoNota
Tanggal yyyy-mm-dd
NoNota {0-9}
Nama Detail_penjualan
Deskripsi Berisi detail data penjualan
Struktur Data Id_detailTransaksi,NoNota,kodeBarang,namaBarang
id_detailTransaksi {0-9}
NoNota {0-9}
kodeBarang {A-Z|a-z|0-9}
NamaBarang {A-Z|a-z}
Nama hasil_Preprocessing
Deskripsi Berisi data hasil preprocessing dari data penjualan berupa no
nota dan kode barang
Struktur Data NoNota, kodeBarang
NoNota {0-9}
kodeBarang {A-Z|a-z|0-9}
Nama Rule
Deskripsi Berisi data akhir dari hasil proses data mining association
rule
Struktur Data No,Antecedent,Consequent,support,confidence
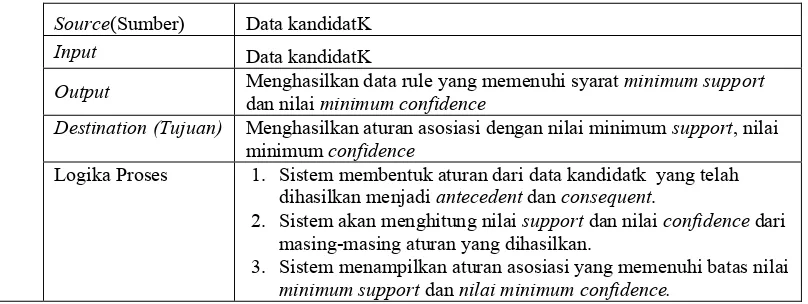
Source(Sumber) Data kandidatK
Input Data kandidatK
Output Menghasilkan data rule yang memenuhi syarat minimum support
dan nilai minimum confidence
Destination (Tujuan) Menghasilkan aturan asosiasi dengan nilai minimum support, nilai minimum confidence
Logika Proses 1. Sistem membentuk aturan dari data kandidatk yang telah dihasilkan menjadi antecedent dan consequent.
2. Sistem akan menghitung nilai support dan nilai confidence dari masing-masing aturan yang dihasilkan.
3. Sistem menampilkan aturan asosiasi yang memenuhi batas nilai
No_rule {0-9}
Antecedent {A-Z|a-z|0-9}
Consequent {A-Z|a-z|0-9}
support {0-9}
confidence {0-9}
Nama kandidatK
Deskripsi Data kandidat k-itemset
Struktur Data Item1,itemK,jml
Item1 {A-Z|a-z|0-9}
itemK {A-Z|a-z|0-9}
Jml {0-9}
Nama Alamat file laporan transaksi penjualan
Deskripsi Alamat file excel laporan transaksi penjualan
Struktur Data -
Nama Nilai Minimum Support
Deskripsi Jumlah minimum transaksi yang diinginkan pengguna
Struktur Data -
Nama Nilai Minimum confidence
Deskripsi Presentase nilai kepastian kuatnya hubungan antar-item
dalam aturan asosiasi yang diinginkan pengguna
III.2.2.5 Skema Relasi
Skema relasi dari aplikasi data mining yang akan dibangun dapat dilihat pada gambar dibawah ini,
rule
Gambar III. 8 Skema Relasi III.2.2.6 Struktur Tabel
Berikut adalah tabel-tabel yang terdapat dalam basis data yang digunakan dalam perangkat lunak yang akan dibangun :
Tabel III. 4 Struktur Tabel Penjualan
Nama Tabel : Penjualan
Nama Field Type Kunci Keterangan
tanggal date Not Null
NoNota Int(8) Primary Key Not Null
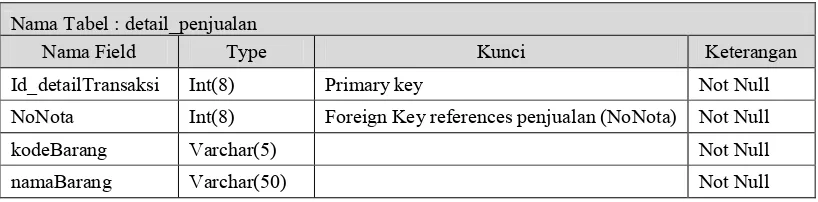
Tabel III. 5 struktur tabel detail penjualan
Nama Tabel : detail_penjualan
Nama Field Type Kunci Keterangan
Id_detailTransaksi Int(8) Primary key Not Null
NoNota Int(8) Foreign Key references penjualan (NoNota) Not Null
kodeBarang Varchar(5) Not Null
Tabel III. 6 struktur tabel hasil_preprocessing
Nama Tabel : hasil_preprocessing
Nama Field Type Kunci Keterangan
No Int(8) Primary Key (auto increment) Not Null
NoNota Int(8) Foreign Key references penjualan
(NoNota) Not Null
Tabel III. 7 struktur tabel kandidatK
Nama Tabel : kandidatK
Nama Field Type Kunci Keterangan
Item1 Varchar(5) Not Null
Itemk Varchar(5) Not Null
Jml Int(8) Not Null
Tabel III. 8 struktur tabel rule
Nama Tabel : Rule
Nama Field Type Kunci Keterangan
No_rule Int(8) Primary Key (auto increment) Not Null
No Int(8) Foreign Key references
hasil_preprocessing(No) Not Null
antecedent Varchar(50) Not Null
consequent Varchar(50) Not Null
Support Float Not Null
III.3 Perancangan Arsitekur
Perancangan arsitektur merupakan perancangan yang dbuat sebelum perangkat lunak dibangun. Perancangan Arsitektur ini terdiri dari perancangan struktur menu, perancangan antar muka, dan jaringan semantik.
III.3.1 Perancangan Struktur Menu
Dalam perancangan sebuah perangkat lunak dibutuhkan struktur menu yang berisikan menu dan submenu yang berfungsi untuk memudahkan user dalam menggunakan perangkat lunak tersebut. Berikut ini digambarkan mengenai struktur menu dalam aplikasi ini :
APLIKASI DATA MINING ASSOCIATION RULE KALVIN SOCKS PRODUCTION
Preprocessing Data Proses Asosiasi
III.3.2 Perancangan Antarmuka
Perancangan tampilan perangkat lunak bertujuan untuk memberikan gambaran-gambaran tenatang perangkat lunak yang akan dibangun, sehingga akan mempermudah dalam mengimplementasikan perangkat lunak. berikut merupakan perancangan antarmuka dari perangkat lunak yang akan dibangun :
III.3.2.1 Perancangan Tampilan Program
Perancangan tampilan program dari aplikasi data mining association rule yang akan dibangun adalah sebagai berikut :
a. Tampilan Halaman Utama
Ukuran, font, Background dan warna disesuaikan
· Klik ‘Preprocessing Data’ untuk menuju
T02
· Klik ‘Proses asosiasi’ ’
untuk menuju T03
APLIKASI DATA MINING ASSOCIATION RULE KALVIN SOCK PRODUCTION
T01 - X
Preprocessing Data Proses Asosiasi
Logo
b. Tampilan Preprocessing Data
Ukuran, font, Background dan warna disesuaikan
· Klik ‘Pilih File’ untuk
memilih file excel yang akan digunakan · klik ‘Simpan’ untuk
untuk menampilkan P01 danmenyimpan data file excel ke dalam database · Jika button simpan
diklik dan data alamat file masih kosong maka akan muncul P02
· Jika penyimpanan berhasil akan muncul P03
· Jika penyimpanan tidak berhasil muncul
Gambar III. 11 Tampilan Preprocesing Data(T02) c. Tampilan Proses Asosiasi
Ukuran, font, Background dan warna disesuaikan
· Isi textBox 1 dengan · Jika terjadi kesalahan
inputan data maka akan muncul pesan P05,P06,P07,P08
T03 - X
Total Transaksi Minimum Confidence textBox 2 Analisis
Tabel hasil pembentukan aturan asosiasi Minimum Support textBox 1
Preprocessing Data Proses Asosiasi
Tabel detail hasil pembentukan aturan asosiasi
III.3.2.2 Perancangan Tampilan Pesan
Berikut ini adalah perancangan pesan dari aplikasi yang akan dibangun.
Pilih File Terlebih dahulu !
OK
P01 X
Simpan Data Ke Database ?
No
P02 X
Yes
Data Berhasil Disimpan
OK
P03 X
Terjadi Kesalahan, Ulangi Pemilihan File
OK
P04 X
Nilai Minimum Support Tidak Boleh kosong !
OK
P05 X
Isi Nilai Minimum Support Antara 1-100
OK
P06 X
Nilai Minimum Confidence Tidak Boleh kosong !
OK
P07 X
Isi Nilai Minimum Confidence Antara 1-100
OK
P08 X
III.3.2.3 Jaringan Semantik
Berikut ini adalah jaringan sematik dari perangkat lunak yang akan dibuat untuk menunjukan keterhubungan antar objek perancangan.
T01
T02
T03 P01,P02,P03,P04
P05,P06,P07,P08
9
BAB II
TINJAUAN PUSTAKA
II.1 Tentang Kalvin Socks Production
Kalvin socks production merupakan perusahaan perorangan yamg bergerak dibidang produksi kaos kaki dan pemasaran dengan menggunakan sistem jaringan pemasaran yang menempatkan 14 agen pemasaran di beberapa lokasi pemasaran dengan tujuan untuk memasok pasar-pasar tradisional yang ada di Indonesia.
Pada awalnya H. Sutarna sebagai pemilik perusahaan, membangun usaha ini sekitar tahun 1987 dengan bermodalkan semangat dan jiwa usaha yang tinggi untuk meningkatkan taraf hidup dan kesejahteraan keluarga, ketika itu H. Sutarna masih bekerja sebagai karyawan di salah satu perusahaan textile yang ada di Bandung selatan, seiring dengan meningkatnya kebutuhan hidup dan tuntutan hidup yang semakin banyak, maka H. Sutarna berusaha merintis usaha dengan cara berdagang dari pasar ke pasar di waktu liburnya sebagai karyawan, dan setelah H. Sutarna merasa matang dalam berdagang dan mengetahui akan permintaan kaos kaki saat itu, maka H. Sutarna memutuskan memproduksi kaos kaki dengan menggunakan modal awal senilai Rp 1.250.000,00 dari uang pesangon dan 3 unit mesin kaos kaki manual ( mesin tangan).
Selain untuk meningkatkan taraf hidup keluarga, usaha ini dibangun juga atas dasar peduli pada keluarga, kerabat, dan lingkungan sekitar. Dengan menciptakan lapangan pekerjaan bagi mereka dan membantu program pemerintah dalam mengurangi tingkat pengangguran, mudah-mudahan usaha ini mendatangkan kebaikan dan memberikan nilai positif bagi kami semua.
Nama Perusahaan : KALVIN
Lokasi : Kp. Kebon Kalapa Rt04/Rw03 No. 39 Ds.Batukarut kec. Arjasari Kab. Bandung
Pemilik Perusahaan : H. Sutarna
II.1.1 Struktur organisasi perusahaan
Struktur organisasi perusahaan adalah gambar bagan yang menjelaskan posisi dan hierarki struktur kerja pegawai di dalam perusahaan. Struktur organisasi perusahaan dari Kalvin Sock Production dapat dilihat pada Gambar II.1.
Montir Teknisi Karyawan Harian Karyawan Borongan Karyawan Harian
Ka. Bagian Mesin Ka. Bagian Produksi
Hendra Ka. Bagian Gudang
Pengelola Yeni Meilawati, S.E
Pemimpin H. Sutarna
Gambar II. 1 Struktur Organisasi Kalvin Socks Production
Uraian tugas dan wewenang masing-masing bagian pada struktur organisasi Kalvin Socks Production adalah sebagai berikut :
1. Pengelola :
Mengawasi kegiatan produksi, penjualan, keuangan, pembelian, administrasi dan kegiatan lain dalam rangka pencapaian tujuan perusahaan 2. Kepala Bagian Mesin
Mengawasi Seluruh kegiatan produksi yang berhubungan dengan mesin atau alat produksi lainnya.
3. Kepala Bagian Produksi
Megawasi kegiatan produksi dari awal bahan mentah hingga akhir proses menjadi barang siap jual.
4. Kepala Bagian Gudang
II.2 Landasan Teori
Landasan teori yang berkaitan dengan materi atau teori yang digunakan sebagai acuan dalam melakukan penelitian. Landasan teori yang diuraikan merupakan hasil dari literatur dan buku-buku.
II.2.1 Pengertian data mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database[1].
Menurut Pramudiono, “Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang
selama ini tidak diketahui secara manual.”
Menurut Larose, “Data mining merupakan bidang dari beberapa bidang keilmuan yang menyatukan teknik dari pembelajaran mesin, pengenalan pola, statistik, database, dan visualisasi untuk penanganan permasalahan pengambilan informasi dari databaseyang besar.”
Menurut larose kemajuan luar biasa yang terus berlanjut dalam bidang
data mining didorong oleh beberapa faktor, antara lain : 1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses ke dalam database yang andal.
3. Adanya peningkatan akses data melalui navigasi web dan intranet.
4. Tekanan kompetensi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi.
5. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan.
Dari definisi-definisi yang telah disampaikan, hal penting yang terkait dengan data mining adalah :
3. Tujuan data mining adalah mendapatkan hubungan atau pola yang mungkin memberikan indikasi yang bermanfaat.
Adapun masalah-masalah yang sesuai untuk diselesaikan dengan teknik data mining bila dicirikan dengan[2]:
1. Memerlukan keputusan yang bersifat knowledge-based. 2. Mempunyai lingkungan yang berubah.
3. Metode yang ada sekarang bersifat sub-optimal. 4. Tersedia data yang bisa diakses, cukup dan relevan.
5. Memberikan keuntungan yang tinggi jika keputusan yang diambil tepat.
II.2.2 Tahapan data mining
Istilah data mining dan knowledge discovery in database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut[1]:
1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-Processing/cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses
dalam data digunakan dalam proses data mining. Proses ini dilakukan agar data yang akan digunakan sesuai dengan kebutuhan. Adapun langkah-langkah
preprocessing adalah sebagai berikut : a. Pemilihan Atribut (atribut selection)
Pemilihan atribut adalah proses pemilihan mana saja atribut data yang akan digunakan sehingga data tersebut dapat kita olah sesuai dengan kebutuhan proses data mining.
b. Pembersihan data (data cleaning)
Proses menghilangkan noise dan menghilangkan data yang tidak relevan
disebut pembersihan data.
3. Transformation
Coding adalah proses pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining adalah mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/evaluation
II.2.3 Arsitektur data mining
Umumnya sistem data mining terdiri dari komponen-komponen berikut: a. Database, data warehouse, atau media penyimpanan informasi
Media dalam hal ini bisa jadi berupa database, data warehouse, spreadsheets, atau jenis-jenis penampung informasi lainnya. Data cleaning dan data intregration
dapat dilakukan pada data-data tersebut. b. Database atau data warehouseserver
Database atau data warehouse server bertanggung jawab untuk menyediakan data yang relevan berdasarkan permintaan dari user pengguna data mining.
c. Basis Pengetahuan (knowledge base)
Merupakan basis pengetahuan yang digunakan sebagai panduan dalam pencarian pola.
d. Data mining engine
Yaitu bagian dari software yang menjalankan program berdasarkan algoritma yang ada.
e. Pattern evaluation module
Yaitu bagian dari software yang berfungsi untuk menemukan pattern atau pola-pola yang terdapat di dalam database yang diolah sehingga nantinya proses
data mining dapat menemukan knowledge yang sesuai.
f. Graphical user interface
Bagian ini merupakan sarana antara user dan sistem data mining untuk berkomunikasi, dimana user dapat berinteraksi dengan sistem melalui data mining query, untuk menyediakan informasi yang dapat membantu dalam pencarian
knowledge. Lebih jauh lagi, bagian ini mengijinkan user untuk melakukan
II.2.4 Asosiasi (Association)
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisi keranjang belanja. Aturan yang menyatakan asosiasi antara beberapa atribut sering disebut
affinity analiysis atau market basket analysis. Analisis asosiasi atau Association rule mining adalah teknik data mining untuk menemukan aturan asosiatif antara suatu kombinasi item.
Penting tidaknya suatu aturan asosiatif dapat diketahui dengan dua parameter, yaitu support dan confidence. Support (nilai penunjang) adalah presentase kombinasi item tersebut dalam database, sedangkan confidence (nilai kepastian) adalah kuatnya hubungan antar-item dalam aturan asosiasi.
Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan asosiasi yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence(minimum confidence).
Metodologi dasar analisis asosiasi terbagi menjadi dua tahap[1] : 1. Analisis pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai
support dalam database. Nilai support sebuah item diperoleh dengan rumus berikut.
….. Persamaan (II.1)
Sementara itu, nilai support dari 2 item diperoleh dari rumus berikut.
….. Persamaan (II.2)
2. Pembentukan Aturan Asosiasi
Setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan asosiasi yang cukup kuat tingkat ketergantungan antar item dalam antecedent (pendahulu) dan consequent (pengikut) serta memenuhi syarat minimum untuk confidence
dengan menghitung confidence aturan Asosiatif .
Misalkan D adalah himpunan transaksi, dimana setiap transaksi T dalam D merepresentasikan himpunan item yang berada dalam I. I adalah himpunan item
yang dijual. Misalkan kita memilih himpunan item A dan himpunan item lain B, kemudian aturan asosiasi akan berbentuk:
Dimana antecedent A dan consequent B merupakan subset dari I, dan A dan B merupakan mutually exclusive dimana aturan :
Tidak berarti
Sebuah itemset adalah himpunan item-item yang ada dalam I, dan k-itemset adalah
itemset yang berisi k item. Frekuensi itemset merupakan itemset yang memiliki
frekuensi kemunculan lebih dari nilai minimum yang telah ditentukan (ɸ). Misalkan ɸ = 2, maka semua itemset yang frekuensi kemunculannya lebih dari atau sama dengan 2 kali disebut frequent. Himpunan dari frequent k-itemset
dilambangkan dengan Fk.
Nilai confidence dari aturan diperoleh dari rumus berikut.
…..Persamaan(II.4)
II.2.4.1 Langkah-Langkah Proses Aturan Asosiasi
Proses aturan asosiasi terdiri dari beberapa tahap sebagai berikut[4] :
nilai supportnya tersebut dibandingkan dengan minimum support yang telah ditentukan, jika nilainya lebih besar atau sama dengan minimum support
maka itemset tersebut dalam largeitemset.
2. Itemset yang tidak termasuk dalam large itemset tidak diikutkan dalam itersi selanjutnya(di prune).
3. Pada iterasi kedua sistem akan menggunakan hasil large itemset pada iterasi pertama(L1) untuk membentuk kandidat itemset kedua(L2). Pada itersi
selanjutnya akan menggunakan hasil large itemset pada iterasi sebelumnya(Lk-1) untuk membentuk kandidat itemset berikut(LK). Sistem
akan menggabungkan(join) (Lk-1) dengan (Lk-1) untuk mendapatkan (Lk),
seperti pada iterasi sebelumnya sistem akan menghapus(prune) kombinasi
itemset yang tidak termasuk dalam large itemset.
4. Setelah dilakukan operasi join, maka pasangan itemset baru hasil proses join
tersebut dihitung supportnya.
5. Proses pembentuk kandidat yang terdiri dari proses join dan prune akan terus dilakukan hingga himpunan kandidat itemsetnya null, atau sudah tidak ada lagi kandidat yang akan dibentuk.
6. Setekah itu, dari hasil frequent itemset tersebut dibentuk association rule
yang memenuhi nilai support dan confidence yang telah ditentukan.
7. Pada pembentukan association rule, nilai yang sama dianggap sebagai satu nilai.
8. Association rule yang berbentuk harus memenuhi nilai minimum yang telah ditentukan.
9. Untuk setiap large itemset L, kita cari himpunan bagian L yang tidak kosong. Untuk setiap himpunan bagian tersebut, dihasilkan rule dengan bentuk aB(L-a)
jika supportnya (L) dan supportnya (a) lebih besar dari minimum support.
II.2.5 Algoritma Apriori
dasar dari algoritma ini ialah dimulai dengan mengembangkan frequent item set
dengan menggunakan satu item dan secara rekrusif mengembangkan frequent item set dengan dua item, tiga item dan seterusnyaa hingga frequent item set dengan semua ukuran. Untuk mengembangkan frequent item set dengan satu item
relatif mudah dilakukan dengan menghitung untuk setiap item, berapa banyak transakasi yang mengandung item tersebut. Jumlah transaksi yang didapat adalah support untuk set satu item tersebut. Selanjutnya kita bisa menghilangkan set satu
item yang nilai supportnya dibawah batas tertentu yang kita tetapkan untuk mendapatkan daftar frequent set dengan satu item.
Untuk mengembangkan frequent set dengan dua item, kita bisa menggunakan frequent set satu item. Alasannya adalah bila set satu item tidak melebihi support minimum, maka sembarang ukuran item set yang lebih besar tidak akan melebihi support minimum tersebut. Secara umum, mengembangkan
set dengan Fk – item menggunakan frequent set dengan k-1 item yang
dikembangkan dalam langkah sebelumnya. Setiap langkah memerlukan sekali pemeriksaan ke seluruh isi database, karena itu algoritma apriori sangat cepat bahkan untuk database dengan item-item unik dalam jumlah besar.
Langkah-langkah proses pengerjaan algoritma apriori adalah sebagai berikut :
1. Tentukan nilai minimum support. 2. Tentukan nilai minimum confidence.
3. Cari data kandidat itemset ke-k (Ck) dan hitung frequent itemset-nya. 4. Tentukan nilai support-nya.
5. Hilangkan data yang nilai support-nya kurang dari nilai minimum support. 6. Setelah mendapatkan data yang nilai support-nya lebih dari nilai minimum
support (frequent), gabungkan data-data tersebut sehingga menciptakan
k-itemset.
7. Ulangi langkah 3 sampai dengan langkah 6 sampai proses penggabungan data tidak menghasilkan data baru.
9. Hilangkan data yang nilai confidence-nya kurang dari nilai minimum confidence.
Metode Apriori yang akan digunakan pada penelitian ini, mempunyai beberapa kelebihan :
a. Menggunakan pendekatan apriori untuk mencari maksimal frequent itemset.
b. Membutuhkan hanya sedikit pembacaan database dan meminimalkan pengunaan I/O
Faktor-faktor yang dapat mengakibatkan kompleksitas pada algoritma apriori adalah sebagai berikut :
1. Pemilihan minimum support
a. Dengan menurunkan batas minimum support dapat menyebabkan semakin banyaknya frequent itemset yang didapatkan.
b. Hal ini juga menyebabkan peningkatan jumlah kandidat dan panjang maksimum dari frequent itemset.
2. Dimensi atau jumlah item pada data set
a. Lebih banyak ruang yang dibutuhkan untuk menyimpan hitungan support
untuk setiap item.
b. Jika jumlah pada frequent item juga meningkat, baik komputasi dan I/O cost mungkin juga akan meningkat.
3. Besarnya ukuran database
a. Algoritma akan meningkat dengan jumlah dari transaksi
II.2.6 Basis Data (Database)
yang direkam dalam bentuk angka, huruf, simbol, teks, gambar, bunyi, atau kombinasinya[5].
Database adalah kumplan data yang saling berkaitan, berhubungan yang disimpan secara bersama-sama sedemikian rupa tanpa pengulangan yang tidak perlu, untuk memenuhi berbagai kebutuhan. Data-data ini harus mengandung semua informasi untuk mendukung semua kebutuhan sistem. Proses dasar yang dimiliki oleh database ada empat, yaitu:
1. Pembuatan data-data baru (create database)
2. Penambahan data (insert)
3. Mengubah data (update)
4. Menghapus data (delete).
Database merupakan salah satu komponen yang penting dalam sistem informasi, karena merupakan basis dalam menyediakan informasi pada para pengguna. Basis data (database) menjadi penting karena munculnya beberapa masalah bila tidak menggunakan data yang terpusat, seperti adanya duplikasi data, hubungan antar data tidak jelas, organisasi data dan update menjadi rumit. Jadi tujuan dari pengaturan data dengan menggunakan basis data adalah :
a. Menyediakan penyimpanan data untuk dapat digunakan oleh organisasi saat sekarang dan masa yang akan datang.
b. Cara pemasukan data sehingga memudahkan tugas operator dan menyangkut pula waktu yang diperlukan oleh pemakai untuk mendapatkan data serta hak-hak yang dimiliki terhadap data yang ditangani.
c. Pengendalian data untuk setiap siklus agar data selalu up-to-date dan dapat mencerminakan perubahan spesifik yang terjadi di setiap sistem.
d. Pengamanan data terhadap kemungkinan penambahan, modifikasi, pencurian dan gangguan-gangguan lain.
Merupakan bahasa definisi data yang digunakan untuk membuat dan mengelola objek database seperti database, tabel dan view.
b. DML (Data Manipulation Language)
Merupakan bahasa manipulasi data yang digunakan untuk memanipulasi data pada objek database seperti tabel.
c. DCL (Data Control Language)
Merupakan bahasa yang digunakan untuk mengendalikan pengaksesan data.
Penyusunan basis data meliputi proses memasukkan data kedalam media penyimpanan data, dan diatur dengan menggunakan perangkat Sistem Manajemen Basis Data (Database Management System / DBMS).
II.2.7 Database Management System(DBMS)
“Managemen Sistem Basis Data (Database Management System /DBMS)
adalah perangkat lunak yang di desain untuk membantu dalam hal pemeliharaan
dan utilitas kumpulan data dalam jumlah besar”[5].
Sistem Manajemen Basis data (Database Management System) merupakan sistem pengoperasian dan sejumlah data pada komputer. Dengan sistem ini dapat merubah data, memperbaiki data yang salah dan menghapus data yang tidak dapat dipakai. Sistem manajemen database merupakan suatu perluasan software
sebelumnya mengenai software pada generasi komputer yang pertama. Dalam hal ini data dan informasi merupakan kesatuan yang saling berhubungan dan berkerja sama yang terdiri dari: peralatan, tenaga pelaksana dan prosedur data. Sehingga pengolahan data ini membentuk sistem pengolahan data. Peralatan dalam hal ini berupa perangakat keras (hardware) yang digunakan, dan prosedur data yaitu berupa perangakat lunak (software) yang digunakan dan dipakai untuk mengalokasikan dalam pembuatan sistem informasi pengolahan database.
menyembunyikan informasi mengenai bagaimana data disimpan dan dirawat, tetapi data tetap dapat diambil dengan efisien.
Pertimbangan efisiensi yang digunakan adalah bagaimana merancang struktur data yang kompleks, tetapi tetap dapat digunakan oleh pengguna yang masih awam, tanpa mengetahui kompleksitas stuktur data. Sistem manajemen
database atau database management system (DBMS) adalah merupakan suatu sistem software yang memungkinkan seorang user dapat mendefinisikan, membuat, dan memelihara serta menyediakan akses terkontrol terhadap data.
Database sendiri adalah sekumpulan data yang berhubungan dengan secara logika dan memiliki beberapa arti yang saling berpautan. DBMS yang utuh biasanya terdiri dari :
1. Hardware
Hardware merupakan sistem komputer aktual yang digunakan untuk menyimpan dan mengakses database. Dalam sebuah organisasi berskala besar,
hardware terdiri : jaringan dengan sebuah server pusat dan beberapa program
client yang berjalan di komputer desktop.
2. Software beserta utility Software adalah DBMS yang aktual. DBMS memungkinkan para user untuk berkomunikasi dengan database. Dengan kata lain DBMS merupakan mediator antara database dengan user. Sebuah
database harus memuat seluruh data yang diperlukan oleh sebuah organisasi. 3. Prosedur
Bagian integral dari setiap sistem adalah sekumpulan prosedur yang mengontrol jalannya sistem, yaitu praktik-praktik nyata yang harus diikuti
user untuk mendapatkan, memasukkan, menjaga, dan mengambil data. 4. Data
Data adalah jantung dari DBMS. Ada dua jenis data. Pertama, adalah kumpulan informasi yang diperlukan oleh suatu organisasi. Jenis data kedua adalah metadata, yaitu informasi mengenai database.
Ada sejumlah user yang dapat mengakses atau mengambil data sesuai dengan kebutuhan penggunaan aplikasi-aplikasi dan interface yang disediakan oleh DBMS, antara lain adalah :
a. Database administrator adalah orang atau group yang bertanggungjawab mengimplementasikan sistem database di dalam suatu organisasi.
b. Enduser adalah orang yang berada di depan workstation dan berinteraksi secara langsung dengan sistem.
c. Programmer aplikasi, orang yang berinteraksi dengan database melalui cara yang berbeda.
II.2.8 Entity Realtionship Diagram(ERD)
ERD adalah suatu model jaringan yang menggunakan susunan data yang disimpan dalam sistem secara abstrak[6]. Basis data Relasional adalah kumpulan dari relasi-relasi yang mengandung seluruh informasi berkenaan suatu entitas/ objek yang akan disimpan di dalam database. Tiap relasi disimpan sebagai sebuah file tersendiri. Perancangan basis data merupakan suatu kegiaatan yang setidaknya bertujuan sebagai berikut:
a. Menghilangkan redundansi data.
b. Meminimumkan jumlah relasi di dalam basis data.
c. Membuat relasi berada dalam bentuk normal, sehingga dapat meminimumkan permasalahan berkenaan dengan penambahan, pembaharuan dan penghapusan.
ERD adalah suatu pemodelan dari basis data relasional yang didasarkan atas persepsi di dalam dunia nyata, dunia ini senantiasa terdiri dari sekumpulan objek yang saling berhubungan antara satu dengan yang lainnya. Suatu objek disebut entity dan hubungan yang dimilikinya disebut relationship. Suatu entity bersifat unik dan memiliki atribut sebagai pembeda dengan entity lainnya.
Contoh : entity Mahasiswa, mempunyai atribut nama, umur, alamat, dan nim.
a. Kotak persegi panjang, menggambarkan himpunan entitas. b. Elips, menggambarkan atribut-atribut entitas.
c. Diamon, menggambarkan hubungan antara himpunan entitas d. Garis, yang menghubungkan antar objek dalam diagram E-R
E-R Diagram merupakan suatu bahasa pemodelan dimana posisinya dapat dianalogikan dengan story board dalam industri film, blue print arsitektur suatu bangunan, miniatur, dan lain-lain. Dalam praktiknya, membangun suatu sistem terlebih dahulu dilakukannya suatu perencanaan. Pemodelan merupakan suatu sub bagian dari perencanaan secara keseluruhan sebagai salah satu upaya feedback
evaluasi perampungan suatu perencanaan. E-R Diagram sebagai suatu pemodelan setidaknya memiliki beberapa karakteristik dan manfaat sebagai berikut:
a. Memudahkan untuk dilakukannya analisis dan perubahan sistem sejak dini, bersifat murah dan cepat
b. Memberikan gambaran umum akan sistem yang akan di buat sehingga memudahkan developer.
c. Menghasilkan dokumentasi yang baik untuk client sebagai bahan diskusi dengan bentuk E-R Diagram itu sendiri, dan
d. Kamus data bagi bagi para pengembang database.
Struktur dari E-R Diagram secara umum ialah terdiri dari:
a. Entitas merupakan objek utama yang informasi akan disimpan, iasanya berupa kata benda, ex; Mahasiswa, Dosen, Nasabah, Mata Kuliah, Ruangan, dan lain-lain. Objek dapat berupa benda nyata maupun abstrak.
b. Atribut merupakan deskripsi dari objek yang bersangkutan.
c. Relationship merupakan suatu hubungan yang terjalin antara dua entitas yang ada.
sedangkan derajat minimum disebut dengan modalitas. Kardinalitas yang terjadi diantara dua himpunan entitas (misal A dan B) dapat berupa :
a. OnetoOne, satu record dipetakan dengan satu record di entitas lain. Contoh: satu nasabah punya satu account.
b. OnetoMany, Satu record dapat dipetakan menjadi beberapa record di entitas lain. Contoh: satu nasabah dapat punya lebih dari satu account.
c. Manyto Many, Beberapa record dapat dipetakan menjadi beberapa record di entitas lain. Contoh: satu nasabah dapat memiliki lebih dari satu account. Satu account dapat dimiliki lebih dari satu nasabah (joinaccount).
II.2.9 Data Dlow Diagram(DFD)
DFD adalah suatu model logika data atau proses yang dibuat untuk menggambarkan dari mana asal data dan kemana tujuan data yang keluar dari sistem, dimana data disimpan, proses apa yang menghasilkan data tersebut dan interaksi antara data yang tersimpan dan proses yang dikenakan pada data tersebut.
DFD sering digunakan untuk menggambarkan suatu sistem yang telah ada atau sistem baru yang akan dikembangkan secara logika tanpa mempertimbangkan lingkungan fisik dimana data tersebut mengalir atau dimana data tersebut akan disimpan.
DFD merupakan alat yang digunakan pada metodologi pengembangan sistem yang terstruktur. Kelebihan utama pendekatan aliran data, yaitu :
a. Kebebasan dari menjalankan implementasi teknis sistem.
b. Pemahaman lebih jauh mengenai keterkaitan satu sama lain dalam sistem dan subsistem.
b. Mengkomunikasikan pengetahuan sistem yang ada dengan pengguna melalui diagram aliran data.
c. Menganalisis sistem yang diajukan untuk menentukan apakah data-data dan proses yang diperlukan sudah ditetapkan.
a. Dapat digunakan sebagai latihan yang bermanfaat bagi penganalisis, sehingga bisa memahami dengan lebih baik keterkaitan satu sama lain dalam sistem dan subsistem.
b. Membedakan sistem dari lingkungannya dengan menempatkan batas-batasnya.
c. Dapat digunakan sebagai suatu perangkat untuk berinteraksi dengan pengguna.
d. Memungkinkan penganalisis menggambarkan setiap komponen yang digunakan dalam diagram.
DFD terdiri dari context diagram dan diagram rinci (DFD Levelled).
Context diagram berfungsi memetakan model lingkungan (menggambarkan hubungan antara entitas luar, masukan dan keluaran sistem), yang direpresentasikan dengan lingkaran tunggal yang mewakili keseluruhan sistem. DFD levelled menggambarkan sistem sebagai jaringan kerja antara fungsi yang berhubungan satu sama lain dengan aliran dan penyimpanan data, model ini hanya memodelkan sistem dari sudut pandang fungsi.
II.2.10 Kamus Data (Data Dictionary)
Merupakan katalog (tempat penyimpanan) dari elemen-elemen yang berada dalam satu sistem. Kamus data mempunyai fungsi yang sama dalam pemodelan sistem dan juga berfungsi membantu pelaku sistem untuk mengerti aplikasi secara detail, dan me-reorganisasi semua elemen data yang digunakan dalam sistem sehingga pemakai dan penganalisa sistem punya dasar pengertian yang sama tentang masukan, keluaran, penyimpanan dan proses[6].
Kamus data mendefinisikan elemen data dengan fungsi sebagai berikut : a. Menjelaskan arti aliran data dan penyimpanan dalam DFD.
b. Mendeskripsikan komposisi paket data yang bergerak melalui aliran misalnya alamat diuraikan menjadi kota, negara dan kode pos.
c. Mendeskripsikan komposisi penyimpanan data.
d. Menspesifikasikan nilai dan satuan yang relevan bagi penyimpanan dan aliran data.
e. Mendeskripsikan hubungan detail antar penyimpanan yang akan menjadi titik perhatian dalam Diagram Keterhubungan Entitas (E-R).
II.2.11 MySQL
MySQL adalah sebuah program database server yang mampu menerima dan mengirimkan datanya dengan sangat cepat, multi user serta menggunakan perintah standar SQL (structure Query Language). MySQL merupakan sebuah
database server yang free, artinya kita bebas menggunakan database ini untuk keperluan pribadi atau usaha tanpa harus membeli atau membayar lesensinya[7].
MySQL sendiri adalah sebuah database server yang mampu menangani beberapa user didalamnya. Dengan demikian, MySQL juga mampu menangani beberapa instruksi sekaligus dalam setiap waktu akses. Di dalam sistemnya, MySQL merekam semua data user dalam sebuah tabel user yang berada pada
database yang bernama mysql. Dalam tabel user tersebut demua akses dan hak akses user mampu ditangani dengan baik.
1. Local Client
MySQL sebagai sebuah Server database, juga dapat berfungsi sebagai client
yang dijalankan pada komputer lokal dimana MySQL itu berjalan.
2. Remote Client
Dapat diakses melalui komputer jaringan dengan cara remote. 3. Remote Login
Dapat diakses dengan menggunakan program MySQL yang berada pada komputer lain.
4. Web Browser
Dapat diakses menggunakan program yang dibuat dengan sebuah program yang berbasis server site yang berjalan di bawah Web Browser.
5. Scripting Language
Dapat diakses melalui programaplikasi client yang kita ciptakan sendiri dengan menggunakan pemrograman visual maupun non visual yang berjalan di dalam jaringan.
II.2.12 Sekilas Tentang Microsoft Visual Studio .Net Dan C#
Visual studio .Net adalah sekumpulan alat pengembangan software yang diperuntukkan bagi .Net platform[8]. Microsoft Visual Studio merupakan sebuah perangkat lunak lengkap (suite) yang dapat digunakan untuk melakukan pengembangan aplikasi, baik itu aplikasi bisnis, aplikasi personal, ataupun komponen aplikasinya, dalam bentuk aplikasi console, aplikasi Windows, ataupun aplikasi Web. Microsoft Visual Studio dapat digunakan untuk mengembangkan aplikasi dalam native code (dalam bentuk bahasa mesin yang berjalan di atas Windows) ataupun managed code (dalam bentuk Microsoft Intermediate Language di atas .NET Framework).
1
BAB I
PENDAHULUAN
I.1 Latar Belakang Masalah
Kalvin Socks Production adalah sebuah perusahaan perseorangan yang bergerak di bidang industri produksi kaos kaki dan telah beroperasi sejak tahun 1987. Hingga kini, Kalvin Socks Production telah melayani sekian banyak transaksi pesanan produksi yang melibatkan 53 jenis kaos kaki. Banyak data yang terlibat dalam setiap transaksi penjualan ini, seperti nomor transaksi, data item
yang dibeli, waktu pembelian dan jumlah item yang dibeli. Saat ini pemanfaatan data yang dimiliki belum maksimal, hanya sebatas arsip, laporan bagi perusahaan dan tidak dimanfaatkan untuk pertimbangan jenis kaos kaki yang akan diproduksi. Kalvin Sock Production memproduksi kaos kaki berdasarkan dua hal, yaitu permintaan agen tetap dan history penjualan banyaknya jenis barang yang sering dijual secara langsung atau eceran. Penentuan produksi berdasarkan history
penjualan jenis barang yang sering dijual, mengakibatkan banyak melesetnya informasi jenis barang yang harus diproduksi, sehingga terjadi penumpukan barang di gudang.
Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan terkait dari berbagai basis data besar [1]. Salah satu metode yang seringkali digunakan dalam teknologi data mining adalah metode asosiasi atau association rule mining. Association rule
merupakan teknik data mining untuk menemukan aturan asosiasi antara suatu kombinasi item[1]. Data mining algoritma asosiasi dapat membantu dalam proses penjualan dengan memberikan hubungan antar data penjualan sehingga akan didapat pola pembelian pelanggan dalam suatu transaksi.
dianalisisnya data penjualan produk kaos kaki ini dapat mengetahui pola pembelian dari pelanggan dan mengetahui jenis produk apa saja yang harus pihak perusahaan sediakan, yang mana semua informasi ini dapat digunakan oleh pihak perusahaan dalam pertimbangan jenis kaos kaki yang akan diproduksi.
I.2 Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan diatas, diperoleh titik permasalahan dalam penilitian ini adalah :
“Bagaimana cara menerapkan data mining pada penjualan produk kaos kaki di Kalvin Socks Production menggunakan metode association”.
I.3 Maksud Dan Tujuan
Maksud penelitian ini adalah untuk Menerapkan data mining pada penjualan produk kaos kaki di Kalvin Socks Production menggunakan metode association.
Sedangkan tujuan dalam penelitian ini adalah:
1. Membantu pihak perusahaan mengetahui pola pembelian dari pelanggan. 2. Membantu pihak perusahaan mengetahui jenis-jenis, ukuran dan warna kaos
kaki apa saja yang sering dipesan secara bersamaan oleh pelanggan.
I.4 Batasan Masalah
Dalam penelitian ini, penulis membatasi masalah sebagai berikut :
1. Data yang akan dianalisis merupakan data transaksi penjualan produk kaos kaki.
2. Penentuan produk yang paling banyak dipesan berdasarkan jenis, ukuran dan warna kaos kaki.
3. Algoritma yang digunakan dalam metode association yang dilakukan adalah Algoritma Apriori.
4. Hasil dari analisis adalah diketahuinya jenis kaos kaki sebagai pertimbangan produksi di Kalvin Socks Production.
6. Perangkat lunak database yang digunakan adalah MySql 7. Aplikasi dibangun menggunakan bahasa pemrograman C#.
I.5 Metodologi Penelitian
Metodologi penelitian yang digunakan dalam penulisan tugas akhir ini adalah menggunakan metode penelitian deskriptif, yaitu menggambarkan secara sistematis fakta dan karakteristik objek dan subjek yang diteliti secara tepat.
Pengumpulan data dan pembangunan perangkat lunak dalam penelitian ini menggunakan metode sebagai berikut:
1. Metode Pengumpulan Data
Metode yang digunakan pada saat mengumpulkan data sebagai berikut: a. Wawancara
Teknik pengumpulan data dengan cara berinteraksi atau berkomunikasi secara langsung kepada responden dengan mengajukan pertanyaan yang sesuai dengan topik yang diambil. Wawancara dilakukan terhadap wakil pimpinan di Kalvin Socks Production.
b. Observasi
Teknik pengumpulan data dengan cara mengamati objek secara langsung pada proses-proses yang sedang berjalan. Observasi dilakukan terhadap sistem yang sedang berjalan di Kalvin Socks Production.
c. Studi Literatur
2. Metode Pembangunan Perangkat Lunak
Perangkat lunak ini akan dibangun menggunakan model air terjun (waterfall). Model waterfall memacu tim pengembang untuk merinci apa yang seharusnya perangkat lunak lakukan (mengumpulkan dan menentukan kebutuhan sistem) sebelum sistem tersebut dikembangkan. Tahap-tahap utama dari model ini memetakan kegiatan-kegiatan pembangunan dasar yaitu:
a. Analisis dan definisi persyaratan
Pelayanan, batasan, dan tujuan sistem ditentukan melalui konsultasi dengan
user sistem. Persyaratan ini kemudian didefinisikan secara rinci dan berfungsi sebagaispesifikasi sistem.
Adapun metode untuk menganalisis data yang digunakan dalam penelitian ini adalah dengan menggunakan data mining. Tahapan dari data mining sebagai berikut [2] :
1. Data selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing / cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses
cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah
3. Transformation
Coding adalah proses pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining adalah mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
b. Perancangan sistem dan perangkat lunak
Proses perancangan sistem membagi persyaratan dalam sistem perangkat keras atau perangkat lunak. Kegiatan ini menentukan arsitektur sistem secara keseluruhan. Perancangan perangkat lunak melibatkan identifikasi dan deskripsi abstraksi sistem perangkat lunak yang mendasar dan hubungan-hubungannya. c. Implementasi dan pengujian unit
Pada tahap ini, perancangan perangkat lunak direalisasikan sebagai serangkaian program atau unit telah memenuhi spesifikasinya.
d. Integrasi dan pengujian sistem