SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
NUR AZIZAH
10111609
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
kepada Allah SWT atas berkat, rahmat, taufik dan hidayah-Nya, penyusunan skripsi yang berjudul “PENERAPAN DATA MINING DALAM
PEREKOMENDASIAN PRODUKSI TAS DENGAN METODE
ASSOSIATION MINING RULES DI KARTIN COLLECTION” dapat diselesaikan dengan baik.
Adapun tujuan dari penyusunan skripsi ini adalah untuk memenuhi salah satu syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika Universitas Komputer Indonesia.
Penulis menyadari bahwa dalam proses penulisan skripsi ini banyak mengalami kendala, namun berkat bantuan, bimbingan, kerjasama dari berbagai pihak dan berkah dari Allah SWT sehingga kendala-kendala yang dihadapi dapat diatasi. Untuk itu penulis menyampaikan rasa hormat dan terima kasih sebesar-besarnya kepada :
1. Allah SWT yang telah mencurahkan rahmat dan hidayah-Nya hingga detik ini.
2. Bapak Alif Finandhita, S.Kom., M.T selaku dosen pembimbing yang telah meluangkan waktu, tenaga, pikiran, memberikan motivasi, arahan dan saran serta ilmu pengetahuannya kepada penulis dalam penyusunan skripsi ini. 3. Bapak Adam Muchair Bachtiar, S.Kom., M.T selaku dosen penguji 1 yang
telah memberikan saran serta kritiknya dalam penyusunan skripsi ini.
4. Ibu Dian Dharmayanti, S.T., M.Kom. selaku dosen penguji 2 yang telah memberikan saran serta kritiknya dalam penyusunan skripsi ini.
iv penghargaan yang setinggi-tingginya kepada :
1. Ibunda Kurniatin dan Ayahanda Agus Jaya serta kakak dan adik tercinta Eko Kurnia Dijaya, Titin Damayanti dan Dimas Kevin yang telah tulus selalu mendoakan, memberikan dorongan moril dan materil, masukan, perhatian, dukungan sepenuhnya, dan kasih sayang yang tidak ternilai dan tanpa batas yang telah kalian berikan.
2. Kepada teman-teman angkatan 2011 atas dukungan dan kebersamaannya, terutama untuk Yusep Rahadian dan Febi Nurafiah yang tanpa henti memberikan support dan telah bersedia meluangkan waktunya untuk berbagi pendapat dengan penulis dalam menyelesaikan skripsi ini.
3. Kepada teman-teman satu bimbingan Bapak Alif Finandhita, S.Kom., M.T atas dukungan dan kebersamaannya untuk penulis dalam menyelesaikan skripsi ini.
4. Semua pihak yang tidak dapat penulis sebut satu persatu yang telah membantu dalam penyelesaian penulisan skripsi ini.
Keterbatasan kemampuan, pengetahuan dan pengalaman penulis dalam pembuatan skripsi ini masih jauh dari kesempurnaan. Untuk itu penulis akan selalu menerima segala masukan yang ditujukan untuk menyempurnakan skripsi ini. Akhir kata penulis mengharapkan semoga skripsi ini dapat bermanfaat serta manambah wawasan pengetahuan baik bagi penulis sendiri maupun bagi pembaca pada umunya,
Bandung, 31 Januari 2016
v
ABSTRACT ... .... . ii
KATA PENGANTAR ... .... iii
DAFTAR ISI ... .... .. v
DAFTAR GAMBAR ... .... viii
DAFTAR TABEL ... ....xiii
DAFTAR SIMBOL ... ...xv
DAFTAR LAMPIRAN ... ..xviii
BAB PENDAHULUAN ... ...1
1.1 Latar Belakang Masalah ... ...1
1.2 Perumusan Masalah ... ...2
1.3 Maksud dan Tujuan ... ...2
1.3.1 Maksud ... ...2
1.3.2 Tujuan ... ...2
1.4 Batasan Masalah ... ...2
1.5 Metodologi Penelitian ... .... ..3
1.5.1 Metodologi Penelitian ... ...3
1.5.2 Metode Pembangunan Data Mining... ...3
1.6 Sistematika Penulisan ... ...6
BAB 2 TINJAUAN PUSTAKA ... ...7
2.1 Pofil Instansi ... ...7
2.1.1 Sejarah Kartin Collection ... ...7
vi
2.2.1 Data ... ...9
2.2.2 Basis Data ... ...10
2.2.3 Database Mangement System ... ...11
2.2.4 Data Mining ... ...11
2.2.5 Association Rule ... ...16
2.2.6. Algoritma FP-Growth ... ...17
2.2.7 Unified Modeling Language (UML) ... ....22
2.2.8 MySQL ... ....25
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... ....26
3.1 Analisis Sistem ... ....26
3.1.1 Analisis Masalah ... ....26
3.1.2 Analisis Penerapan Metode CRISP-DM ... ....27
3.1.3 Analisis Spesifikasi Kebutuhan Perangkat Lunak ... ....93
3.2 Perancangan Sistem ... ...122
3.2.1 Perancangan Class ... ...122
3.2.2 Perancangan Basis Data ... ...125
3.2.2 Perancangan Struktur Menu ... ...128
3.2.3 Perancangan Antar Muka ... ...129
3.2.4 Perancangan Pesan ... ...131
3.2.5 Jariangan Semantik ... ...132
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... ...133
vii
4.1.4 Implementasi Antarmuka ... ...136
4.2 Pengujian Sistem ... ...137
4.2.1 Pengujian Alpha ... ...137
4.2.1.2 Kesimpulan Pengujian Alpha ... ...139
4.2.2 Pengujian Beta ... ...139
4.2.2.1 Kesimpulan Pengujian Beta ... ...140
4.2.3 Pengujian Hasil ... ...140
4.2.3.1 Kesimpulan Pengujian Hasil ... ...144
BAB 5 KESIMPULAN DAN SARAN ... ...145
5.1 Kesimpulan ... ...145
5.2 Saran ... ...145
146
DAFTAR PUSTAKA
[1] Larose D, T., 2005, Discovering knowledge in data : an introduction to data mining, Jhon Wiley & Sons Inc.
[2] (sumber : An Introduction to Database System, Canada: ( Adision – Wessley Publishing Company, 181, Third Edition ), hal 237.)..
[3] R. W. Pate Chapman, 2000. [Online]. Available: http://the- modeling-agency.com/crisp-dm.pdf. [Diakses 25 September 2015].
[4] F. Buku Teks Komputer: Basis Data, 5th ed., Bandung: Informatika, 2004.
[5] H.A.Fajar, Data Mining. Andi, 2013.
[6] J. Simarmata and I. Prayuda, Basis Data, Yogyakarta: Andi Offset, 2006. [7] F. Buku Teks Komputer: Basis Data, 5th ed., Bandung: Informatika,
2004.
[8] Ramon A. Mata Toledeo, Pailine K. Cushman, Dasar-dasar Database Relasional. Jakarta: Airlangga, 2007.
[9] B. Santoso, Data Mining: Teknik Pemanfaatan Data Untuk Keperluan Bisnis, Yogyakarta: Graha Ilmu, 2007.
[10] J. Han and M. Kamber, Data Mining : Concept and Techniques, 2nd ed. San Fransisco: Morgan Kauffman, 2006.
[11] D. T. Larose, DATA MINING METHODS AND MODELS, New Jersey: John Wiley & Sons, Inc, 2006.
[12] K. and E. T. Luthfi, Algoritma Data Mining, Andi, 2009.
[13] Widiati, Elsa. 2014. Implementasi Data Mining Menggunakan Aturan association Rules Terhadap Penyusunan Layout Makanan dan Penentuan
1
Kartin collection merupakan salah satu home industri dalam bidang konveksi tas yang berlokasi di jalan Karang Tineung Dalam No.1 Bandung. Kartin collection telah banyak memproduksi berbagai macam produk tas dengan model yang beragam. Produk-produk tas yang diproduksi oleh kartin collection dipasarkan kebanyak toko-toko yang tersebar di Bandung. Selain itu Kartin Collection juga menerima konsumen yang secara langsung membeli eceran ke tempat produksi. Dari waktu ke waktu data penjualan yang ada semakin banyak dan hanya dijadikan arsip tanpa adanya pengolahan untuk medapatkan informasi didalamnya.
Kartin Collection mengalami penurunan dalam penjualan karena pemilihan model – model tas yang telah diproduksi tidak terjual seperti biasanya. Karena tidak adanya pertimbangan saat penentuan model tas yang harus diproduksi mengakibatkan melesetnya informasi model tas yang harus diproduksi, sehingga terjadi penumpukan barang digudang. Hal ini tentu akan mempengaruhi penjualan untuk beberapa waktu yang akan datang.
Salah satu teknik untuk memecahkan permasalahan ini adalah dengan metode data mining. Data mining adalah sebuah proses percarian informasi secara otomatis dalam tempat penyimpanan data berukuran besar[1]. Teknik data mining
digunakan untuk memeriksa basis data dari transaksi penjualan untuk menemukan pola yang baru dan berguna untuk pendukung keputusan dalam meningkatkan pelayanan dan penjualan tas di Kartin Collection. Salah satu metode yang digunakan dalam teknologi data mining adalah metode association rules.
Berdasarkan masalah yang dihadapi di Kartin Collection, maka perlu dilakukan suatu “ Penerapan Data Mining Dalam Perekomendasian Produksi Tas Dengan Metode Assosiation Mining Rules Di Kartin Collection” Agar dapat mengetahui pola pembelian dari pelanggan dan memberikan informasi kepada pihak Kartin Collection dalam menentukan model tas yang akan produksi.
1.2 Perumusan Masalah
Dari latar belakang diatas dapat disimpulkan perumusan masalah yaitu bagaimana cara menerapkan data mining dengan metode association rules untuk merekomendasikan model tas yang harus diproduksi oleh Kartin Collection.
1.3 Maksud dan Tujuan 1.3.1 Maksud
Maksud dari penelitian ini adalah untuk menerapkan data mining dalam perekomedasian produksi tas dengan metode association mining rules di Kartin Collection.
1.3.2 Tujuan
Adapun tujuan yang ingin dicapai adalah sebagai berikut :
1. Membantu pihak Kartin Collection dalam memanfaatkan data penjualan untuk mendapatkan informasi didalam data penjualan tersebut.
2. Membantu pihak Kartin Collection untuk mendapatkan informasi mengenai model tas apa saja yang harus diproduksi.
1.4 Batasan Masalah
Berdasarkan perumusan masalah diatas maka batasan masalah dapat disimpukan sebagai berikut :
1. Metode yang digunakan adalah metode association rules.[1] 2. Algoritma yang digunakan adalah algoritma Fp-Growth [1].
4. Aplikasi yang akan dibuat berbasis dekstop.
5. Metode analisis yang digunakan dalam pembangunan perangkat lunak ini menggunakan pendekatan analisis pemograman berorientasi objek.
1.5 Metodologi Penelitian
Metodologi penelitian yang digunakan adalah metodologi penelitian kuantitatif dengan metode penelitian eksperimental, yaitu metode penelitian yang bertujuan untuk membandingkan antara hasil penelitian yang dilakukan secara manual dengan hasil penelitian yang dilakukan melalui suatu sistem atau alat[3]. Metode penelitian ini dibagi menjadi 2 tahap, yaitu tahap pengumpulan data dan tahap pembangunan data mining.
1.5.1 Metodologi Penelitian
Metode pengumpulan data yang digunakan dalam penelitian ini adalah sebagai berikut :
1. Studi Literatur
Studi literatur adalah metode pengumpulan data yang dilakukan dengan cara mengumpulkan literatur, jurnal, paper, dan website yang ada kaitannya dengan judul penelitian.
2. Wawancara
Wawancara yang dilakukan langsung kepada pihak perusahaan untuk mendapatkan informasi tentang data transaksi penjualan dan meminta data transaksi tersebut.
3. Observasi
Teknik pengumpulan data dengan mengadakan penelitian dan peninjauan langsung terhadap permasalahan yang diambil..
1.5.2 Metode Pembangunan Data Mining
Untuk data yang dapat di proses dengan CRSP-DM ini, tidak ada ketentuan atau karakteristik tertentu, karena data tersebut akan diproses kembali pada fase-fase di dalamnya.
Gambar 1. 1 Cross Industri Standard for Data Mining(CRISP-DM)[3]
Berikut ini adalah tahapan-tahapan yang akan dilakukan dalam penelitian ini sesuai dengan CRISP-DM :
1. Business understanding
Tahap pertama adalah memahami tujuan dan kebutuhan dari sudut pandang bisnis, kemudian menterjemahkan pengetahuan ini kedalam pendefinisan masalah data mining, untuk menentukan bisnis perusahaan yang sedang berjalan di kartin collection.
2. Data understanding
data yang akan digunakan sebagai hipotesa untuk menemukan informasi yang tersembunyi.
3. Data preparation
Tahap ini meliputi semua kegiatan untuk membangun dataset akhir (data
yang akan diproses pada tahap pemodelan/modeling) dari data mentah. Pada tahap ini juga mencakup pemilihan tabel, record, dan atribut-atribut data, termasuk proses pembersihan untuk kemudian dijadikan masukan dalam tahap pemodelan (modeling).
4. Modeling
Dalam tahapan pemodelan ini akan menggunakan teknik metode data mining dengan metode association rule dengan cara menemukan aturan asosiatif atau pola kombinasi model tas berdasarkan hasil data transaksi, sehingga dapat diketahui model tas apa saja yang sering dibeli secara bersamaan oleh konsumen.
5. Evaluation
Pada tahap evaluasi ini akan dibandingkan hasil improved fp-growth
dilakukan oleh sistem dengan perhitungan manual, dengan mengambil beberapa sampel acak. Evaluasi ini ditujukan untuk mengukur apakah pemodelan yang dilakukan sesuai dengan tujuan pengimplementasian data mining pada sistem ini.
6. Deployment
1.6 Sistematika Penulisan
Sistematika penulisan yang digunakan dalam penyusunan laporan tugas akhir ini adalah sebagai berikut :
BAB I. PENDAHULUAN
Bab ini membahas mengenai Latar Belakang Masalah, Rumusan Masalah, Maksud dan Tujuan, Batasan Masalah, Metodologi Penelitian, dan Sistematika Penulisan yang digunakan.
BAB II. TINJAUAN PUSTAKA
Bab ini membahas tentang sejarah, logo, visi, misi, struktur organisasi dari Kartin Collection dan berbagai konsep dasar dan teori-teori yang berhubungan dengan judul penelitian, seperti pengertian data, datamining, associaiton rule algoritma improved fp-growth,UML.
BAB III. ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi tentang analisis dan perancangan sistem yang akan dibangun berdasarkan data penjualan yang diperoleh dari Kartin Collection dengan menggunakan data mining dengan metode associaiton rule menggunakan algoritma improved fp-growth.
BAB IV. IMPLEMENTASI DAN PENGUJIAN
Bab ini menjelaskan tentang implementasi dan pengujian terhadap tingkat kekuatan dan keakuratan aturan-aturan asosiasi yang telah didapatkan berdasarkan pola pembelian yang telah diterapkan sesuai dengan algoritma improved fp-growth.
BAB V. KESIMPULAN DAN SARAN
7 2.1.1 Sejarah Kartin Collection
Konveksi tas Kartin Collection didirikan oleh seorang wirausahawan yang bernama bapak Agus Supianto. Konveksi tersebut berdiri tahun 1990 di Jln. Karang Tineung No.1 Bandung . Tujuan pendirian usaha pembuatan tas dari bahan dolbi maupun bahan lain ini dilihat dari potensi masyarakat akan bersifat konsumtif, bapak Agus akhirnya mendirikan suatu konveksi pembuatan tas. Tidak hanya dilihat dari masyarakatnya saja pendirian usaha tersebut difungsikan untuk memenuhi kebutuhan keluarga bapak Agus. Akhirnya sampai saat ini konveksi tersebut dapat berkembang pesat dengan kiat-kiat seorang wirausaha yang dimiliki oleh bapak Agus yaitu percaya diri, optimis, dan tekad yang besar untuk menggapai suatu impian dalam berwirausaha. Ditambah etos kerja dan ulet dalam mengerjakan usaha yang digelutinya.
2.1.2 Logo
Berikut ini adalah logo dari konveksi tas Kartin Collection yang dapat dilihat pada gambar 2.1 dibawah ini :
2.1.3 Struktur Organisasi
Berikut ini adalah struktur organisasi konveksi tas kartin Collection yang dapat dilihat pada gambar 2.2 dibawah ini :
Gambar 2. 2 Struktur Organisasi kartin Collection
Job description :
1. Pemilik bertanggung jawab penuh terhadap Kartin Collection, tugas dan tanggung jawabnya sebagai berikut:
a. Membuat perencanaan, strategi dan kebijakan yang menyangkut operasi Kartin Collection.
b. Menyusun anggaran kebutuhan persediaan bahan baku. c. Melakukan kontrol secara keseluruhan di Kartin Collection.
d. Memegang kendali atas keputusan penting yang bersifat umum berkaitan dengan keuangan.
2. Bagian Gudang memiliki tugas dan tanggung jawab sebagai berikut : a. Mengecek ketersedian bahan baku.
b. Membeli persedian bahan baku.
c. Memberikan bahan baku kepada pekerja.
3. Pekerja memeliki tugas dan tanggung jawab sebagai berikut: a. Membuat tas sesuai perintah.
b. Menyelesaikan pembuatan tas tepat waktu. Pemilik
Bagian Gudang
Pekerja Adm
Keuangan
4. Bagian Adm keuangan bertugas terhadap transaksi pelanggan, tugas dan tanggung jawab sebagai berikut :
a. Bertanggung jawab terhadap hal-hal yang menyangkut keuangan. b. Menghitung pemasukan dan pengeluaran setiap bulannya.
5. Bagian pemasaran memeliki tugas dan tanggung jawab untuk memasarkan dan memdistribusikan produk tas kepada pelanggan.
2.1.4 Visi dan Misi
Visi dari Kartin Collection ini adalah menjadikan perusahaan konveksi yang terbaik, dengan pengerjaan pesanan yang tepat waktu dan mampu melayani permintaan pesanan sesuai dengan apa yang diinginkan oleh setiap konsumen. baik dari segi pelayanan, kualitas, maupun kuantitas yang memuaskan, sedangkan misinya adalah Mengutamakan pelayanan pada kepuasan yang optimal bagi para pelanggan. Berperan aktif untuk meningkatkan kualitas dan produktivitas yang dapat memberikan kepuasan para pelanggan, karyawan dan mitra bisnis. mengembangkan sumber daya untuk dapat menghasilkan produk yang berkualitas dan memiliki mutu yang konsisten.
2.2 Landasan teori
Landasan teori yang berkaitan dengan materi atau teori yang digunakan sebagai acuan melakukan penenlitian. Landasan teori yang diuraikan merupakan hasil studi literatur, buku-buku, maupun situs internet.
2.2.1 Data
Data adalah representasi fakta dunia nyata yang mewakili suatu objek seperti manusia (pegawai, siswa, pembeli, pelanggan), barang, hewan, peristiwa, konsep, keadaan, dan sebagainya, yang direkam dalam bentuk angka, huruf, simbol, teks, gambar, bunyi, atau kombinasinya [5]. Data dapat digunakan sebagai input dan menghasilkan sebuah informasi. Data juga merupakan sesuatu yang belum memiliki arti dan masih membutuhkan suatu pengolahan. Dalam data
sebagai variabel, field, karakteristik atau fitur. Salah satu himpunan data adalah
recorddata, yaitu data yang terdiri dari sekumpulan record, yang masing-masing terdiri dari satu set atribut yang tetap. Salah satu yang termasuk dalam tipe data record yaitu data transaksi. Data transaksi merupakan sebuah tipe khusus dari
record data, dimana tiap record (transaksi) meliputi satu setitem [6]. 2.2.2 Basis Data
Basis data adalah mekanisme yang digunakan untuk menyimpan informasi atau data. Informasi adalah sesuatu yang kita gunakan sehari-hari untuk berbagai alasan. Dengan basis data, pengguna dapat menyimpan data secara terorganisasi. Setelah data disimpan, informasi harus mudah diambil. Kriteria dapat digunakan untuk mengambil informasi. Cara data disimpan dalam basis data menentukan seberapa mudah mencari informasi berdasarkan banyak kriteria. Data pun harus mudah ditambahkan ke dalam basis data, dimodifikasi, dan dihapus [7].
Menurut Fathansyah [8], basis data sendiri dapat didefinisikan dalam sejumlah sudut pandang seperti :
1. Himpunan kelompok data (arsip) yang saling berhubungan yang diorganisasi sedemikian rupa agar kelak dapat dimanfaatkan kembali dengan cepat dan mudah.
2. Kumpulan data yang saling berhubungan yang disimpan secara bersama sedemikian rupa dan tanpa pengulangan (redudansi) yang tidak perlu, untuk memenuhi berbagai kebutuhan.
3. Kumpulan file/ tabel/ arsip yang saling berhubungan yang disimpan dalam media penyimpanan elektronis.
2.2.2.1 Data pada Basis Data dan Hubungannya Ada 3 jenis data pada sistem database, yaitu [9] :
1. Data operasional dari suatu organisasi, berupa data yang tersimpan dalam basis data
3. Data kelauran (output data), berupa laporan melalui peralatan output sebagai hasil dari dalam sistem yang mengakses data operasional.
2.2.2.2 Keuntungan dan Kerugian Pemakaian Sistem Database
Keuntungan [9] :
1. Terpeliharanya keselarasan data
2. Data dapat dipakai secara bersama-sama.
3. Memudahkan penerapan standarisaasi dan batas-batas pengamanan. 4. Terpeliharanya keseimbangan atas perbedaan kebutuhan data dari setiap aplikasi.
5. Program /data independent. Kerugian :
1. Mahal dalam implementasinya. 2. Rumit
3. Penanganan proses recoverybackup sulit.
4. Kerusakan pada sistem basis data dapat mempengaruhi. 2.2.3 Database Mangement System
Kumpulan atau gabungan database dengan perangkat lunak aplikasi yang berbasis database tersebut dinamakan Database Management System (DBMS). DBMS
merupakan koleksi terpadu dari database dan program–program komputer (utilitas) yang digunakan untuk mengakses dan memelihara database. Program-program tersebut menyediakan berbagai fasilitas operasi untuk memasukan, melacak, dan memodifikasi data kedalam database, mendefinisikan data baru, serta mengolah data menjadi informasi yang dibutuhkan (DBMS = Database + Program Utilitas) [8].
2.2.4 Data Mining
Secara umum, definisi data mining dapat diartikan sebagai berikut [11]: 1. Proses penemuan pola yang menarik dari data yang tersimpan dalam
jumlah besar.
2. Ekstrasi dari suatu informasi yang berguna atau menarik (non-trivial, implisit, sebelumnya belum diketahui potensi kegunaannya) pola atau pengetahuan dari data yang di simpan dalam jumlah besar.
3. Eksplorasi dari analisa secara otomatis atau semiotomatis terhadap data data dalam jumlah besar untuk mencari pola dan aturan yang berarti.
2.2.4.1 Konsep Data Mining
Data mining sangat diperlukan terutama dalam mengelola data yang sangat besar untuk memudahkan aktifitas recording suatu transaksi dan untuk proses data warehousing agar dapat memberikan informasi yang akurat bagi bagi pengguna data mining. Alasan utama data mining sangat dibutuhkan dalam industri informasi karena tersedianya data dalam jumlah yang besar dan semakin besarnya kebutuhan untuk mengubah data tersebut menjadi informasi dan pengetahuan yang berguna karena sesuai fokus bidang ilmu ini yaitu melakukan kegiatan mengekstraksi atau menambang pengetahuan dari data yang berukuran atau berjumlah besar. Informasi iniliah yang nantinya sangat berguna untuk pengembangan. Berikut adalah langkah-langkah dalam data mining [10] :
1. Data cleaning yaitu untuk menghilangkan noise data yang tidak
konsisten.
2. Data integration yaitu menggabungkan beberapa file atau
database.
3. Data selection yaitu data yang relevan dengan tugas analisis dikembalikan ke dalam database untuk proses data mining.
4. Data transformation yaitu data berubah atau bersatu menjadi bentuk yang tepat untuk menambang dengan ringkasan performa atau operasi agresi.
5. Data mining yaitu proses esensial dimana metode yang intelejen digunakan untuk mengekstrak pola data.
6. Knowledge disccovery yaitu proses esential dimana metode yang intelejen digunakan untuk mengekstrak pola data.
7. Pattern evolution yaitu untuk mengidentifikasi pola yang benar-benar menarik yang mewakili pengetahuan berdasarkan atas beberapa tindakan yang menarik.
8. Knowledge presentation yaitu gambaran teknik visualisasi dan pengetahuan digunakan untuk memberikan pengetahuan yang telah ditambah kepada user.
2.2.4.2 Metode Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu [12] :
1. Deskripsi
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih kearah numerik daripada ke arah kategori. Model dibangun dengan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada dimasa mendatang. Contoh prediksi dalam bisnis dan penelitian adalah :
1. Prediksi harga beras dalam tiga bulan yang akan datang.
2. Prediksi persentase kenaikan kecelakaan lalu lintas tahun depan
jika batas bawah dinaikan. 4. Klasifikasi
Dalam klasifikasi, terdapat terget variabel kategori. sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori yaitu: pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. Contoh lain klasifikasi dalam bisnis dan penelitian adalah :
1. Menentukan apakah suatu transaksi kartu kredit merupakan
transaksi yang curang atau bukan.
2. Mendiagnosis penyakit seorang pasien untuk mendapatkan
termasuk kategori penyakit apa. 5. Pengklusteran
dengan yang lainnya dan tidak memiliki kemiripan dengan record-record
dalam kluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengklusteran. pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari
variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keselurahan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan
record dalam suatu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal. Contoh pengklusteran dalam bisnis dan penelitian adalah :
1. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk sebuah perusahaan yang tidak memiliki dana pemasaran yang besar.
2. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilaku finansial dalam baik maupun mencurigakan.
3. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang pasar. Contoh asosiasi dalam bisnis dan penelitian adalah :
1. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respon positif terhadap penawaran upgrade layanan yang diberikan.
2.2.5 Association Rule
Aturan asosiasi (Association rule) adalah salah satu teknik tentang ‘apa
bersama apa’. Ini bisa berupa transaksi di supermarket, misalnya seseorang yang
membeli susu bayi juga membeli sabun mandi. Di sini berarti susu bayi bersama sabun mandi. Karena awalnya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan asosiasi juga sering dinamakan Market Basket [13].
Untuk mencari association rule dari suatu kumpulan data, tahap pertama yang harus dilakukan adalah mencari frequent itemset terlebih dahulu. Frequent itemset adalah sekumpulan item yang sering muncul secara bersamaan. Setelah semua pola frequent itemset ditemukan, barulah mencari aturan asosiatif atau aturan keterkaitan yang memenuhui syarat yang telah ditentukan.
Jika diasumsikan bahwa barang yang dijual di swalayan adalah semesta, maka setiap barang akan memiliki Boolean variable yang akan menunjukan keberadaannya atau tidak barang tersebut dalam satu transaksi atau satu keranjang belanja. Pola Boolean yang didapat digunakan untuk menganalisa barang yang dibeli secara bersamaan. Pola tersebut dirumuskan dalam sebuah association rule.
Sebagai contoh konsumen biasanya akan membeli kopi dan susu yang ditujukan sebagai berikut :
Kopi → susu [support = 2%, confidence = 60%]
Nilai support 2% menunjukan bahwa keseluruhan dari total transaksi konsumen membeli kopi dan susu secara bersamaan yaitu sebanyak 2%. Sedangkan confidence 60% yaitu menunjukan bila konsumen membeli kopi dan pasti membeli susu sebesar 60%.
Penting tidaknya suatu aturan asosiatif dapat diketahui dengan dua parameter, yaitu support dan confidence. Support (nilai penunjang) adalah presentase kombinasi item tersebut dalam database, sedangkan confidence (nilai kepastian) adalah kuatnya hubungan antar-item dalam aturan asosiasi.
a. Support : suatu ukuran yang menunjukan seberapa besar tingkat dominasi suatu
itemset dari keseluruhan transaksi. Ukuran ini menentukan apakah suatu
itemset layak untuk dicari confidence-nya ( misal, dari keseluruhan transaksi yang ada, seberapa besar tingkat dominasi suatu item yang menunjukan bahwa
item A dan item B dibeli bersamaan).
b. Confidence : suatu ukuran yang menunjukan hubungan antara 2 item secara
conditional (misal, menghitung kemungkinan seberapa sering item B dibeli oleh pelanggan jika pelanggan tersebut membeli sebuah item A).
Kedua ukuran ini nantinya berguna dalam menentukan kekuatan suatu pola dengan membandingkan pola tersebut dengan nilai minimum kedua parameter tersebut yang ditentukan oleh pengguna. Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan asosiasi yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk
confidence (minimum confidence).
Nilai support sebuah item diperoleh dengan rumus sebagai berikut[6] :
x100%….. Persamaan (2.1)
Sementara itu, nilai support dari 2 item diperoleh dari rumus berikut:
x100%..Persamaan (2.2) Sedangkan nilai confidence dapat dicari setelah pola frekuensi munculnya sebuah
item ditemukan. Rumus untuk menghitung confidence adalah sebagai berikut:
x100%…..Persamaan(2.3)
2.2.6 Algoritma FP-Growth
descending dari frekuensi yang ada dataset tersebut. Masing-masing item yang tidak mencapai kebutuhan minimum dari threshold tidak dimasukkan kedalam pohon, tapi dikeluarkan secara efektif dari dataset.
FP-Tree merupakan struktur penyimpanan data yang dimampatkan. FP-Tree dibangun dengan memetakan setiap data transaksi ke dalam setiap lintasan tertentu dalam FP-Tree. Karena dalam setiap transaksi yang dipetakan, mungkin ada transaksi yang memiliki item yang sama, maka lintasannya memungkinkan untuk saling menimpa. Semakin banyak data transaksi yang memiliki item yang sama, maka proses pemampatan dengan struktur data FP-Tree semakin efektif. Kelebihan dari FP-Tree adalah hanya memerlukan dua kali pemindaian data transaksi yang terbukti sangat efisien. FP-Growth dapat dibagi menjadi 3 tahapan utama yaitu sebagai :
1. Tahap Pembangkitan conditional pattern base.
Conditional Pattern Base merupakan sub database yang berisi prefix path dan suffix pattern. Pembangkitan conditinal pattern base
didapatkan melalui FP-Tree yang telah dibangun sebelumnya. 2. Tahap Pembangkitan Conditional FP-Tree
Pada tahap ini, support count dari setiap item pada setiap conditional pattern base dijumlahkan, lalu setiap item yang memiliki jumlah
support count lebih besar atau sama dengan minimum support count ξ
akan dibangkitkan dengan conditional FP-Tree. 3. Tahap Pencarian frequent pattern
Apabila conditional FP-Tree merupakan lintasan tunggal (single path), maka didapatkan frequent itemset dnegan melakukan kombinasi item untuk setiap conditional FP-Tree. Jika bukan lintasan tunggal, maka dilakukan pembangkitan FP-Growth secara rekursif.
Berikut ini merupakan contoh kasus penerapan metode association rule
menggunakan Algoritma FP-Growth :
Tabel 2.1 Data Transaksi
TID Items
1 B
2 B, D
3 A, C, D, E
4 A, D, E
5 B, C
6 A, C
7 A
Yang mana nilai support count didapat dari :
x 100% = 2.14 ≈ 2
Frekuensi kemunculan tiap item dapat dilihat pada tabel berikut:
Tabel 2.2 Frekuensi Kemunculan Tiap Karakter
Item Frekuensi
A 4
B 3
C 3
D 3
E 2
Selanjutnya pada gambar di bawah ini memberikan ilustrasi mengenai pembentukan FP-Tree setelah pembacaan TID 2
Gambar 2.5 Hasil Pembentukan FP-Tree setelah pembacaan TID 5
Gambar 2.6 Hasil pembentukan FP-Tree setelah pembacaan TID 7 Diberikan 7 data transaksi dengan 5 jenis item seperti pada tabel di atas. Gambar 5-7 menunjukan proses terbentuknya FP-Tree setiap TID dibaca. Setiap simpul pada FP-Tree mengandung nama sebuah item dan counter support yang berfungsi untuk menghitung frekuensi kemunculan item tersebut dalam tiap lintasan transaksi.
a. Tahap pembangkitan conditional pattern base
Merupakan subdata yang berisi prefix path (lintasan awal) dan suffix pattern
(pola akhiran). Pembangkitan conditional pattren base didapatkan melalui FP-Tree yang telah dibangun sebelumnya.
b. Tahap pembangkitan conditional FP-Tree
Pada tahap ini, support count dari setiap item pada setiap conditional pattern base dijumlahkan, lalu setiap item yang memiliki jumlah support count lebih besar atau sama dengan minimum support count akan dibangkitkan dengan
conditionalFP-Tree.
Tabel 2. 3 Hasil Perhitungan Conditional Pattern Base dan Conditional FP-Tree
Item Conditional Pattern Base ConditionalFP Tree
E {{A,C,D:1}, {A,D:1}} {<A:2,D:2>} D {{B:1}, {A,C:1}, {A:1}} {A:2}
C {B:1}, {A:2} {A:2}
c. Tahap pencarian frequent itemset.
Apabila conditional FP-Tree merupakan lintasan tunggal(single-path), maka didapatkan frequent itemset dengan melakukan kombinasi item untuk setiap
conditional FP-Tree. Jika bukan lintasan tunggal, maka dilakukan pembangkitan FP-Growth secara rekursif (proses memanggil dirinya sendiri) seperti contoh pada tabel 2.3 dibawah ini :
Tabel 2. 4 Hasil Frequent Itemset
Suffix Frequent Itemset
E E, A-E, D-E, A-D-E
D D, A-D
Tabel 2.5 Hasil Generate Rule
Rule Support Confidence (%)
A → E 2 (2/4)*100 = 50
E → A 2 (2/2)*100 = 100
A → D 2 (2/4)*100 = 50
D → A 2 (2/3)*100 = 66.67
A → C 2 (2/4)*100 = 50
C → A 2 (2/3)*100 = 66.67
D → E 2 (2/3)*100 = 66.67
E → D 2 (2/2)*100 = 100
A- D →E 2 (2/2)*100 = 100
D- E →A 2 (2/2)*100 = 100
2.2.7 Unified Modeling Language (UML)
Unified Modeling Language (UML) adalah himpunan struktur dan teknik untuk pemodelan desain program berorientasi objek serta aplikasinya. Berikut adalah beberapa model yang digunakan dalam perancangan Data Mining
Pemaketan Produk di Minimarket Warga Tunggal untuk menggambarkan sistem dalam UML:
1. Diagram Use Case 2. Diagram Aktivity
3. Diagram Class
4. Diagram Sequence
2.2.7.1 Diagram Use Case
Diagram use case adalah model fungsional sebuah sistem yang menggunakan aktor dan use case. Use case adalah layanan (services) atau fungsi–fungsi yang disediakan oleh sistem untuk penggunanya.
1. Sebuah use case adalah dimana sistem digunakan untuk memenuhi satu atau lebih kebutuhan pemakai.
2. Use case merupakan awal yang sangat baik untuk setiap fase
pengembangan berbasis objek, design testing, dan dokumentasi. 3. Use case menggambarkan kebutuhan sistem dari sudut pandang di
luar sistem.
4. Use case menentukan nilai yang diberikan sistem kepada pemakainya.
5. Use case hanya menetapkan apa yang seharusnya dikerjakan oleh sistem, yaitu kebutuhan fungsional sistem.
6. Use case tidak untuk menentukan kebutuhan nonfungsional, misal: sasaran kerja, bahasa pemrograman.
2.2.7.2 Diagram Class
Diagram kelas adalah diagram UML yang menggambarkan kelas-kelas dalam sebuah sistem dan hubungannya antara satu dengan yang lain, serta dimasukkan pula atribut dan operasi. Tahapan dari diagram kelas adalah sebagai berikut:
1. Mengidentifikasi objek dan mendapatkan kelas-kelasnya. 2. Mengidentifikasi atribut kelas-kelas.
3. Mulai mengkonstruksikan kamus data. 4. Mengidentifikasi operasi pada kelas-kelas.
5. Mengidentifikasikan hubungan antar kelas dengan menggunakan
asosiasi, agregasi, dan inheritance (pewarisan).
2.2.7.3 Diagram Aktifitas
2.2.7.4 Diagram Objek
Sequence diagram (diagram urutan) adalah suatu diagram yang memperlihatkan atau menampilkan interaksi-interaksi antar objek di dalam sistem yang disusun pada sebuah urutan atau rangkaian waktu. Interaksi antar objek tersebut termasuk pengguna, display, dan sebagainya berupa pesan/message. Sequence Diagram digunakan untuk menggambarkan skenario atau rangkaian langkah-langkah yang dilakukan sebagai sebuah respon dari suatu kejadian/even untuk menghasilkan output tertentu. Sequence Diagram diawali dari apa yang me-trigger aktivitas tersebut, proses dan perubahan apa saja yang terjadi secara internal dan output apa yang dihasilkan.
2.2.8 MySQL
MySQL adalah multiuser database yang menggunakan bahasa structured Query Language (SQL). MySQL dalam operasi client server melibatkan server daemon MySQL di sisi server dan berbagai macam program serta library yang berjalan di sisi client. MySQL mampu menangani data yang cukup besar. Perusahaan yang mengembangkan MySQL yaitu TcX, mengaku bahwa MySQL yang mampu menyimpan data lebih dari 40 database, 10.000 tabel dan sekitar 7 juta baris, totalnya kurang lebih 100 Gigabyte data [2].
25
Analisis sistem adalah penguraian dari suatu informasi yang utuh kedalam bagian-bagian komponennya dengan maksud untuk mengidentifikasi dan mengevaluasi permasalahan, kesempatan, hambatan yang terjadi dan kebutuhan yang diharapkan sehingga dapat diusulkan perbaikan. Analisis Sistem ini bertujuan untuk menjelaskan permasalahan yang muncul pada saat pembangunan sistem, hal ini bertujuan untuk membantu ketika proses perancangan sistem berlangsung. Tugas utama analisis sistem dalam tahap ini adalah menemukan kelemahan-kelemahan dari sistem yang berjalan sehingga dapat diusulkan perbaikannya. Dalam analisis sistem ini meliputi beberapa bagian, yaitu :
1. Analisis Masalah
2. Analisis Penerepan Metode CRISP-DM
3. Analisis Spesifikasi Kebutuhan Perangkat Lunak 3.1.1 Analisis Masalah
Analisis masalah yang dilakukan adalah melihat dan mengidentifikasi permasalahan atau kendala di dalam penelitian yang dilakukan. Masalah dapat diartikan sebagai suatu pernyataan yang menyatakan tentang situasi yang memerlukan pemecahan. Perlu ada analisis masalah melalui rumusan masalah yang sudah ditentukan sebelumnya. Berdasarkan hasil pengamatan, diketahui bahwa analisis masalahnya adalah sebagai berikut :
1. Kartin Collection masih mengalami masalah dalam penentuan model tas yang akan diproduksi
3.1.2 Analisis Penerapan Metode CRISP-DM
Metode pembangunan perangkat data mining yang digunakan dalam penelitian ini adalah Cross-Industry Standard Process for Data Mining (CRISP-DM).
3.1.2.1 Pemahaman Bisnis
Tahapan pemahaman bisnis merupakan tahapan pertama dilakukan dalam kerangka kerja CRISP-DM. Dalam tahapan bisnis ini terdapat beberapa tahapan lainnya, yaitu :
1. Tujuan Bisnis
Dalam proses bisnisnya Kartin Collection mempunyai tujuan bisnis yaitu untuk meningkatkan mutu kualitas tas sesuai dengan permintaan dari pelanggan tetap.
2. Penentuan Sasaran Data Mining
Tujuan dari penerapan data mining nya adalah untuk mementukan model tas apa saya yang akan diproduksi, sesuai dengan permintaan pelangan tetap atau pelanggan lainnya.
3.1.2.2 Pemahaman Data
Tabel 3. 1 Struktur Data Transaksi Keterangan
Fungsi Untuk mengetahui jenis produk –produk yang paling sering terjual oleh customer
Format Microsoft Excel (.xlsx)
Atribut No No urut
Tgl Tanggal proses pembelian
Lokasi Tempat pembelian
Tuan/Toko Nama pemilik yang melayani No Transaksi Nomor pembelian
Banyaknya Banyaknya barang yang dibeli Kode Barang Kode dari setiap barang Nama Barang Nama barang yang dibeli
Hitam Warna hitam dari setiap nama barang Abu Warna abu dari setiap nama barang Cream Warna cream dari setiap nama barang Merah Warna merah dari setiap nama
barang
Coklat Warna coklat dari setiap nama barang Denim Hitam Warna denim hitam dari setiap nama
barang
Denim Biru Warna biru dari setiap nama barang Harga Harga barang yang dibeli
3.1.2.3 Persiapan Data
Sebelum dilakukan proses data mining harus dipersiapkan karena tidak semua data atau atribut dalam data digunakan pada proses mining. Proses ini dilakukan agar data dapat digunakan sesuai kebutuhan. Adapun tahapan – tahapan persiapan data adalah sebagai berikut :
1. Ekstraksi Data
Ekstraksi Data adalah proses pengambilan data transaksi penjualan dikartin collection dari sumber data yang berasal dari file berformat microsoft excel. Data yang telah diekstrak akan disimpan kedalam database, untuk melanjutkan proses pengolahan data ke tahap selanjutnya. Berikut adalah
data transaksi penjualan yang terjadi di kartin collection dapat dilihat pada lampiran E.
2. Pemilihan atribut
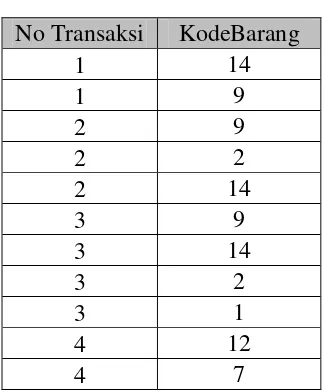
Berdasarkan imformasi yang ingin didapat oleh pengguna mengenai model produk yang dibeli secara bersamaan, maka atribut yang digunakan dalam data transaksi diatas adalah No Transaksi dan Kode Barang. No transaksi adalah ID dari transaksi dan atribuit Kode Barang adalah jenis barang yang dibeli. Ini bertujuan untuk proses mining, karena tidak semua data yang digunakan dalam data transaksi digunakan untuk proses mining. Berikut dibawah ini table proses pemilihan atribut dapat dilihat pada tabel 3.2 :
Tabel 3. 2Pemilihan atribut No Transaksi KodeBarang
No Transaksi KodeBarang
3. Pembersihan Data
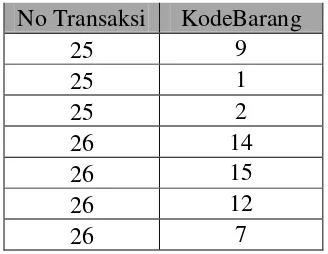
Pembersihan Data merupakan proses menghilangkan data dari hasil pemilihan atribut pada tabel 3.2. Data yang dihilangkan adalah ata pada satu transaksi yang hanya terdapat satu pembelian model tas, karena data tersebut tidak memiliki hubungan assosiasi dengan Item lain. data yang telah dibersihkan dapat dilihat pada tabel 3.3 :
Tabel 3. 3 Hasil Pembersihan Data
No Transaksi KodeBarang
4. Penyiapan Data awal
Setelah proses semua dilakukan dan data telah siap di mining, maka data
transaksi sudah dapat digunakan proses selanjutnya yaitu pemodelan.
3.1.2.4 Pemodelan
Pemodelan merupakan tahap untuk membuat model atau desain sistem yang akan dibangun. Data yang digunakan untuk pengolahan data ini adalah data
yang terdapat dalam table 3.3. Didalam tahap ini metode yang dipakai adalah metode association rule dengan algoritma fp-growth.
Metode assosiation rules terbagi menjadi dua tahap yaitu mencari pola frekuensi dan pembentukan atau perhitungan aturan asosiasi. Pencarian frekuensi adalah tahap mencari nilai frekuensi dari setiap Item, sedangkan pembentukan
asosiasi adalah proses perhitungan untuk mencari pola Item yang memenuhi nilai
minimum support.
Nilai minimum support yang digunakan adalah 10% dari 26 sampel data
transaksi yaitu 2.6 3. yang bertujuan untuk melihat banyaknya variasi data yang terjadi dalam proses pencarian hasil akhir yaitu rule.
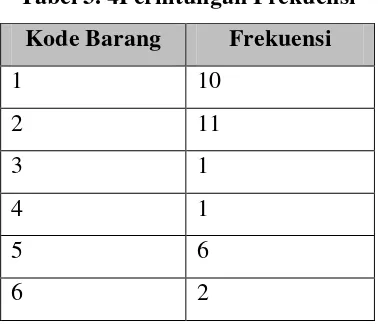
Berikut adalah tahap pencarian frekuensi dari setiap Item yaitu menuliskan setiap kode barang dan memberikan nilai frekuensi dengan cara menghitung kemunculan setiap barang. Hasil pencarian frekuensi dapat dilihat pada tabel 3.4 :
Tabel 3. 4Perhitungan Frekuensi Kode Barang Frekuensi
1 10
2 11
3 1
4 1
5 6
Kode Barang Frekuensi
7 9
8 2
9 12
10 3
11 1
12 8
14 18
15 10
16 1
Adapun tahapan dalam proses pencarian selanjutnya adalah sebagai berikut :
1. Langkah pertama menghilangkan data yang tidak memenuhi minimum support yang sudah ditentukan sebelumnya yaitu 3, berikut data yang memenuhi nilai minimum support dapat dilihat pada tabel 3.5 :
Tabel 3. 5 Data Yang Memenuhi Minimum Support
Kode Barang Support count
1 10
2 11
5 6
7 9
9 12
10 3
12 8
14 18
2. Langkah kedua adalah memberikan nilai priority untuk setiap Item. Setelah mendapatkan data yang memenuhi nilai minimum support seperti pada tabel 3.5 diatas, selanjutnya melakukan proses pengurutan secara ascending dari kemunculan setiap support count yang muncul dan memberikan priority
sebagai tanda dari setiap Item yang memiliki support count paling besar sampai dengan terkecil. Jika terdapat kode barang dengan support count yang sama maka yang akan didahulukan adalah kode barang yang kemunculannya lebih awal pada data transaksi dibandingkan yang lainnya. Berikut adalah hasil pengurutan berdasarkan prioritydapat dilihat pada tabel 3.6 :
Tabel 3. 6 Pengurutan Secara Ascending
Kode Barang Support Count Priority
14 18 1
9 12 2
2 11 3
1 10 4
15 10 5
7 9 6
12 8 7
5 6 8
10 3 9
3. Langkah ketiga setelah semua Item mendapatkan nilai priority maka data
transaksi yang memenihi minimum support akan diurutkan berdasarkan
priority. Pada tahap ini Item yang memiliki nilai priority tertinggi pada satu transaksi akan didahulakan penulisannya. Hasil pengurutan berdasarkan
Tabel 3. 7 Pengurutan Data Berdasarkan Priority
No Transaksi Kode Barang
1 14
1 9
2 14
2 9
2 2
3 14
3 9
3 2
3 1
4 2
4 1
4 15
4 7
4 12
4 5
4 10
5 14
5 9
5 1
5 15
5 7
5 12
5 5
6 14
6 9
6 2
6 15
No Transaksi Kode Barang
6 5
6 10
7 14
7 9
7 2
8 14
8 9
9 2
9 1
10 7
10 12
11 14
11 2
11 1
12 9
12 5
14 7
14 12
14 5
15 14
15 15
16 14
16 2
16 1
17 7
17 12
18 15
18 10
No Transaksi Kode Barang
19 9
20 14
20 9
20 1
20 15
20 7
20 12
20 5
21 14
21 2
21 1
21 15
22 14
22 2
22 15
23 14
23 1
23 15
23 7
23 12
24 14
24 9
25 14
25 9
25 2
25 1
26 14
26 15
No Transaksi Kode Barang
26 12
4. Langkah keempat adalah membuat fp-tree. Berikut proses pembentukan FP-Tree dibawah ini :
1. Transaksi 1 : 14,9
1) Lakukan pembacaan pada data transaksi pertama yang akan diproses.
2) Lakukan pengecekan pada root yang diinisialisasikan dengan Null, jika root belum mempunyai anak (child), maka data yang dibaca tadi menjadi anak pertama dari
root. Dan support count dari masing masing node
bertambah 1, kecuali root.
NUll
14:1
9:1
Gambar 3. 1 Tree No transaksi
2. Transaksi 2 : 14,9,2
1) Lakukan pembacaan pada data transaksi kedua yang akan diproses.
NUll
14:2
9:2
2:1
Gambar 3. 2 Tree No transaksi 2
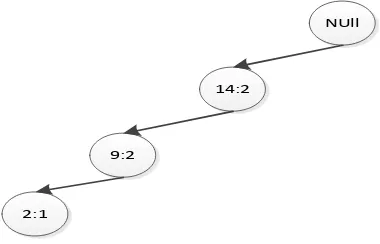
3. Transaksi 3 : 14,9,2,1
1) Lakukan pembacaan pada data transaksi ketiga yang akan diproses.
2) Jika data yang keluar berikutnya sama dengan data yang pertama, maka itu bukan anak kedua dari root, tetapi tetap anak dari root yang sebelumnya keluar, yang berubah adalah
support count-nya menjadi bertambah 1.
NUll
14:3
9:3
2:2
1:1
4. Transaksi 4 : 2,1,15,7,12,5,10
1) Lakukan pembacaan pada data transaksi keempat yang akan diproses.
2) Jika data yang dibaca atau data yang keluar berbeda dengan
data yang kelaur sebelumnya maka itu menjadi anak terakhir dari root dan menjadi sibling dari node data pertama. Dan
support count dari node tersebut bertambah1.
NUll
14:3
9:3
2:2
1:1
2:1
1:1
15:1
10:1 7:1
12:1
5:1
Gambar 3. 4 Tree No transaksi 4
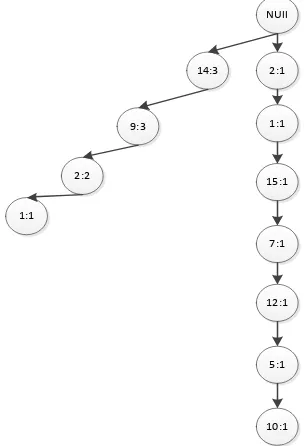
5. Transaksi 5 : 14,9,1,15,7,12,5
1) Lakukan pembacaan pada data transaksi kelima yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
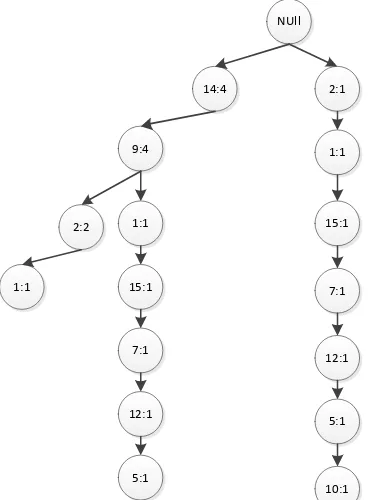
14:4
9:4
2:2
1:1
2:1
1:1
15:1
10:1 7:1
12:1
5:1 1:1
15:1
7:1
12:1
5:1
Gambar 3. 5 Tree No transaksi 5
6. Transaksi 6: 14,9,2,15,7,5,10
1) Lakukan pembacaan pada data transaksi keenam yang akan diproses.
NUll
14:5
9:5
2:3
1:1
2:1
1:1
15:1
10:1 7:1
12:1
5:1 1:1
15:1
7:1
12:1
5:1 15:1
7:1
5:1
10:1
Gambar 3. 6 Tree No transaksi 6
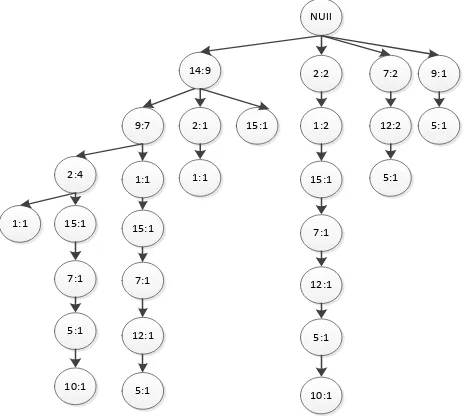
7. Transaksi 7 : 14,9,2
1) Lakukan pembacaan pada data transaksi ketujuh yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
14:6
9:6
2:4
1:1
2:1
1:1
15:1
10:1 7:1
12:1
5:1 1:1
15:1
7:1
12:1
5:1 15:1
7:1
5:1
10:1
Gambar 3. 7 Tree No transaksi 7
8. Transaksi 8 : 14,9
1) Lakukan pembacaan pada data transaksi kedelapan yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
14:7
9:7
2:4
1:1
2:1
1:1
15:1
10:1 7:1
12:1
5:1 1:1
15:1
7:1
12:1
5:1 15:1
7:1
5:1
10:1
Gambar 3. 8 Tree No transaksi 8
9. Transaksi 9 : 2,1
1) Lakukan pembacaan pada data transaksi kesembilan yang akan diproses.
NUll
1) Lakukan pembacaan pada data transaksi kesepuluh yang akan diproses.
2) Jika data yang dibaca atau data yang keluar berbeda dengan
data yang kelaur sebelumnya maka itu menjadi anak terakhir dari root dan menjadi sibling dari node data pertama. Dan
11.Transaksi 11 : 14,2,1 saja yang bertambah support count-nya.
NUll
1) Lakukan pembacaan pada data transaksi kedua belas yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
1) Lakukan pembacaan pada data transaksi kedelapan belas yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
1) Lakukan pembacaan pada data transaksi kesembilan belas yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasanmaka node pada lintasan yang lain tidak bertambah
NUll
19.Transaksi 20 : 14,9,1,15,7,12,5
1) Lakukan pembacaan pada data transaksi kedua puluh yang akan diproses.
NUll
20.Transaksi 21 : 14,2,1,15
1) Lakukan pembacaan pada data transaksi kedua puluh satu yang akan diproses.
NUll
21.Transaksi 22 : 14,2,15
1) Lakukan pembacaan pada data transaksi keduapuluh dua yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
Gambar 3. 21 Tree No transaksi 22
22.Transaksi 23 : 14,1,15,7,12
1) Lakukan pembacaan pada data transaksi keduapuluh tiga yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah support count-nya, hanya data yang dibaca sama saja yang bertambah support count-nya.
NUll yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
24.Transaksi 25 : 14,9,2,1
1) Lakukan pembacaan pada data transaksi keduapuluh lima yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
25.Transaksi 26 : 14,15,7,12
1) Lakukan pembacaan pada data transaksi kedua puluh enam yang akan diproses.
2) Jika data yang keluar sama setelah pembacaan, namun berbeda lintasan maka node pada lintasan yang lain tidak bertambah
NUll
Setelah pembuatan fp-tree dilakukan langkah selanjutnya adalah tahap Pembangkitan Conditional Pattern Base, Tahap Pembangkitan Conditional FP-Tree dan pencarian Frequent Pattern. Adapun langkahnya yaitu :
a. Tahap Pembangkitan Conditional Pattern Base
Mencari support count terkecil dari setiap Item sampai dengan terbesar berdasarkan hasil pembentukan fp-tree sebelumnya . Berikut ini adalah
support count terkecil sampai dengan terbesar dapat dilihat pada tabel 3.8 :
Tabel 3. 8 Condiitonal Pattern Base
Item Conditonal Pattern Base
10 14,9,2,15,7,5:1 2,1,15,7,12,5:1 15:1
2,1,15,7,12:1 7,12:1 9:1
12 14,9,1,15,7:2 14,15,7:1 14,1,15,7:1 2,1,15,7:1 7:3
7 14,9,2,15:1
14,9,1,15:2 14,15:1 14,1,15:1 2,1,15:1
15 14,9,2:1
14,9,1:2 14,2,1:1 14,2:1 14:2 14,1:1 2,1:1
1 14,9,2:2
14,9:2 14,2:3 14:1 2:2
2 14,9:5
14:4
b. Tahap Pembangkitan Conditional FP-Tree
Pada tahap ini setiap Item-Itemakan dibuat conditional fp-tree, dan apabila ada Item yang memenuhi minimum support atau sama dengan 3, maka Item tersebut akan dibangkitkan lagi untuk mencari frequent pattern. Berikut adalah conditional fp-tree dari tiap Item.
1. Conditional FP-Tree Item 10:
Tahap pembentukan Conditional FP-Tree untuk Item10 dengan
Conditional pattern base
{14,9,2,15,7,5:1},{2,1,15,7,12,5:1},{15:1}
Gambar 3. 26 Conditional FP-Tree Item
Karena support count Item 10 memenuhi minimum support maka Item10 akan dibangkitkan dengan conditional fp-tree, berikut langkah langkahnya :
1. Item {10} akan dihilangkan dan support count yang satu lintasan dengan {10} akan sama dengan support count {10} sebelumnya.
2. Apabila dalam suatu lintasan melintasi satu atau dua lintasan, maka
NUll
14:1
9:1
2:1
2:1
1:1
15:1
7:1
12:1
5:1 15:1
7:1
5:1
15:1
Gambar 3. 27 Conditional FP-TreeItem 10 setelah dibangkitkan
3. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequent pattern yang memenuhi minimum support.{15:3} adalah Item
yang keluar yang dapat memenuhi minimum support.
Null
15:3
Gambar 3. 28 Conditional FP-Tree 10,15:3 Hasil Frequent Pattern
2. Conditional FP-Tree untuk Item 5 dengan conditional pattern base
NUll
Gambar 3. 29 Conditional FP-Tree Item 5
Karena support count Item 5 memenuhi minimum support maka Item 5 akan dibangkitkan dengan conditional fp-tree, berikut langkah langkahnya :
1. Item {5} akan dihilangkan dan support count yang satu lintasan dengan {5} akan sama dengan support count {5} sebelumnya.
2. Apabila dalam suatu lintasan melintasi satu atau dua lintasan, maka
support count-nya akan selalu bertambah 1.
NUll
3. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequent pattern yang memenuhi minimum support.
{14:3},{9:4},{1:3},{15:4},{7:5},{12:4} adalah Item yang keluar yang dapat memenuhi minimum support.
Null
14:3
Gambar 3. 31 Conditional FP-Tree 5,14:3 Hasil Frequent pattern Null
9:4
Gambar 3. 32 Conditional FP-Tree 5,9:4 Hasil FrequentPattertn Null
1:3
Gambar 3. 33 Conditional FP-Tree 5,1:3 Hasil Frequent Pattern Null
15:4
Gambar 3. 34 Conditional FP-Tree 5,15:4 Hasil FrequentPattertn
Null
7:5
Null
12:4
Gambar 3. 36 Conditional FP-Tree 5,12:4 Hasil FrequentPattertn
3. Conditional FP-Tree untuk Item 12 dengan conditional pattern base
{14,9,1,15,7:2} {14,15,7:1} {14,1,15,7:1} {2,1,15,7:1} {7,:3} NUll
14:18
9:11
2:2
1:2
15:1
7:1
12:1 1:2
15:2
7:2
12:2
7:3
12:3
15:2 1:1
15:1
7:1
12:1 7:1
12:1
Gambar 3. 37 Conditional FP-TreeItem 12
Karena support count Item 12 memenuhi minimum support maka Item 12 akan dibangkitkan dengan conditional fp-tree, berikut langkah langkahnya :
1. Item {12} akan dihilangkan dan support count yang satu lintasan dengan {12} akan sama dengan support count {12} sebelumnya.
2. Apabila dalam suatu lintasan melintasi satu atau dua lintasan, maka
NUll
14:4
9:2
2:1
1:1
15:1
7:1 1:2
15:2
7:2
7:3
15:1
1:1
15:1
7:1 7:1
Gambar 3. 38 Conditional FP-Tree Item 12 setelah dibangkitkan
3. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequen patterns harus memenuhi minimum support.
{14:4},{1:4},{15:5},{7:8} adalah Item yang memenuhi minimum support.
Null
14:4
Gambar 3. 39 Conditional FP-Tree 12,14:4 Hasil Frequent Pattertn Null
1:4
Gambar 3. 40 Conditional FP-Tree 12,1:4 Hasil Frequent Pattertn Null
15:5
Null
7:8
Gambar 3. 42 Conditional FP-Tree 12,7:8 Hasil Frequent Pattertn
4. Conditional FP-Tree untuk tem 7 dengan conditional pattern base
{14,9,2,15:1 } {14,9,1,15:2} {14,15:2} {14,1,15:1} {2,1,15:1}
NUll
14:18
9:11
2:5
2:2
1:2
15:1
7:1 1:2
15:2
7:2 15:1
7:1
15:2 1:1
15:1
7:1 7:1
Gambar 3. 43 Conditional FP-TreeItem 7
Karena support count Item 7 memenuhi minimum support maka Item 7 akan dibangkitkan dengan conditional fp-tree, berikut langkah langkahnya :
1. Item {7} akan dihilangkan dan support count yang satu lintasan dengan {7} akan sama dengan support count {7} sebelumnya.
2. Apabila dalam suatu lintasan melintasi satu atau dua lintasan, maka
NUll
14:5
9:3
2:1
2:1
1:1
15:1 1:2
15:2 15:1
15:1
1:1
15:1
Gambar 3. 44 Conditional FP-Tree Item 7 setelah dibangkitkan
3. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequen patterns harus memenuhi minimum support.{14:5},{9:3}, {15:6},{1:4} adalah Item yang memenuhi minimum support.
Null
14:6
Gambar 3. 45 Conditional FP-Tree 7,14:5 Hasil Frequent Pattertn
Null
9:3
Gambar 3. 46 Conditional FP-Tree 7,9:3 Hasil Frequent Pattertn Null
15:6
Null
1:4
Gambar 3. 48 Conditional FP-Tree 7,1:4 Hasil Frequent Pattertn
5. Conditional FP-Tree untuk Item15 dengan conditional pattern base
{14,9,2:1} {14,9,1:2} {14,2:2} {14:2} {14,1:1} {2,1:1}
NUll
14:18
9:11
2:5
2:2
1:2
15:1 1:2
15:2 15:1
2:4 15:2
15:1
15:1
1:1
15:1 1:3
15:1
Gambar 3. 49 Conditional FP-TreeItem 15
Karena support count Item 15 memenuhi minimum support maka Item 15 akan dibangkitkan dengan conditional fp-tree, berikut langkah langkahnya :
1. Item {15} akan dihilangkan dan support count yang satu lintasan dengan {15} akan sama dengan support count {15} sebelumnya.
NUll
14:8
9:3
2:1
2:1
1:1
1:2
2:2
1:1
1:1
Gambar 3. 50 Conditional FP-Tree Item 15 setelah dibangkitkan
3. Setelah proses pembangkitan, maka proses terakhir adalah mencari
frequen patterns harus memenuhi minimum support.
{14:8},{9:3},{2:4},{1:5} adalah Item yang memenuhi minimum support.
Null
14:8
Gambar 3. 51 Conditional FP-Tree 15,14:8 Hasil Frequent Pattertn
Null
9:3
Gambar 3. 52 Conditional FP-Tree 15,9:3 Hasil Frequent Pattertn
Null
2:4