KLASIFIKASI NOVEL SESUAI DENGAN GENRE MENGGUNAKAN TF-IDF
SKRIPSI
RUDYANTO BUDIMAN P 091402084
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
KLASIFIKASI NOVEL SESUAI DENGAN GENRE
MENGGUNAKAN TF-IDF
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Teknologi Informasi
RUDYANTO BUDIMAN P 091402084
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
ii
PERSETUJUAN
Judul : KLASIFIKASI NOVEL SESUAI DENGAN GENRE
MENGGUNAKAN TF-IDF
Kategori : SKRIPSI
Nama : RUDYANTO BUDIMAN P
Nomor Induk Mahasiswa : 091402084
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI (FASILKOM-TI) UNIVERSITAS SUMATERA UTARA
Diluluskan di Medan, Juni 2015
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Baihaqi Siregar, S.Si.,M.T Mohammad Fadly Syahputra, B.Sc, M.Sc.IT
NIP. 197902082010121002 NIP. 198301292009121003
Diketahui / Disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
PERNYATAAN
KLASIFIKASI NOVEL SESUAI DENGAN GENRE MENGGUNAKAN TF-IDF
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Juni 2015
RUDYANTO BUDIMAN P
iv
UCAPAN TERIMA KASIH
Segala puji dan syukur penulis panjatkan kepada Tuhan Yesus Kristus atas segala berkat dan pengasihanNya yang sungguh berlimpah, sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Teknologi Informasi Program Studi S1 Teknologi Informasi Universitas Sumatera Utara.
Penyelesaian skripsi ini tidak terlepas dari bantuan dari berbagai pihak, untuk itu, penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Kedua orangtua penulis yang telah memberikan dukungan moril dan spiritual, alm Ir.Nelson Eddy Siahaan.(+) dan almh Dra.Bonur Rulyanna Sitorus.(+) yang terlebih dahulu meninggalkan dunia saat masa akhir perkuliahan penulis, kedua adik saya Stephany Novianty Siahaan SE, dan Silvia Pratiwi Yunisari Siahaan yang terus memberikan motivasi dan dukungan.
2. Bapak M.Fadly Syahputra B.Sc.,M.Sc.,IT dan Bapak Baihaqi Siregar,S.Si.,MT selaku pembimbing yang telah banyak meluangkan waktu dan pikirannya, memotivasi dan memberikan kritik dan saran kepada penulis.
3. Bapak M. Anggia Muchtar ST.,MM.IT dan Bapak Dani Gunawan,ST.,M.T yang telah bersedia menjadi dosen pembanding yang telah memberikan kritik dan saran kepada penulis.
4. Ketua dan Sekretaris Program Studi Teknologi Informasi, Bapak M. Anggia Muchtar, ST.,MM.IT dan Bapak M. Fadly Syahputra, B.Sc.,M.Sc.IT.
5. Seluruh Dosen dan Staff pegawai di Program Studi S1 Teknologi Informasi
6. Terima kasih juga penulis ucapkan kepada teman-teman: Fernando, Alex, Christop, Alman, Andi, Suando, Tony, Leo, Ranap, Juki, Salman, Icha, Amira, Fadullah, Fadli, Yanna, seluruh teman angkatan 09 Teknologi Informasi, seluruh abang kakak dan adik di jurusan Teknologi Informasi yang tidak dapat disebutkan satu per satu, Vanesa Felicia, Bruno, Karina, Mewati, J.sirait. Junnie hutabarat, dan Leonardi sitanggang,
ABSTRAK
Novel memiliki beberapa genre antara lain genre romantis, horror, misteri, inspiratif dan masih banyak lagi. Namun pada saat ini pengklasifikasian novel kedalam genre-genre masih dilakukan secara manual. Oleh sebab itu dibutuhkan suatu sistem yang dapat mengklasifikasikan novel kedalam genrenya masing-masing secara otomatis. Hal ini dilakukan karena banyaknya genre dari novel tersebut, sehingga sistem ini nantinya dapat membantu pembaca, penerbit dan penulis yang hendak membuat dan membaca novel untuk mengetahui secara singkat genre novel yang sedang dibaca atau ditulisnya. Penelitian ini menggunakan text mining dan TF-IDF untuk proses pengklasifikasian novel. Text
mining dapat diartikan sebagai penemuan informasi yang baru yang sebelumnya
tidak diketahui oleh komputer dengan mengekstrak informasi secara otomatis dari sumber yang berbeda. Sedangkan data resource digunakan sebagai acuan dalam mengklasifikasi novel. Pada penelitian ini novel dibagi menjadi 4 kategori: horor,inspiratif,misteri dan romantis. Text yang dimasukan berupa judul, penulis, dan sinopsis. Sinopsis inilah yang akan diproses untuk menghasilkan klasifikasi genre novel. Proses pertama adalah proses persiapan dokumen dan seleksi dokumen. Kemudian dilanjutkan dengan proses pembobotan kata menggunakan
TF-IDF, kemudian klasifikasi dilakukan dengan membandingkan nilai kemiripan
diantara teks dan sebuah node yang ada di data resource. Teks yang diperoleh akan diklasifikasikan dalam sebuah genre atau node yang ada jika memiliki nilai kemiripan paling tinggi di salah satu node di data resource. Pengujian sistem dilakukan dengan mengambil 100 sinopsis novel online secara acak dan menghasilkan tingkat akurasi sebesar 75%.
vi
NOVEL CLASSIFICATION BASED ON GENRE USING TF-IDF
ABSTRACT
Novel has many genres such as romantic, horror, mystery, inspirational, and many more. However, today the classification of novel into genre is done manually. Therefore, we need a novel classification system which can classify novels into their each genre automatically. A novel classification system is needed because novel has many genres, so this system will help the reader, the publisher, and the writer who writing and reading a novel to know shortly about the genre of novel that they read or write. This research is using text mining method with TF-IDF method for classifying the novel. Text mining is a process to discover new information which is not known by the computer before by extracting the information automatically from the different sources. Whereas, data resource is used a as reference for classifying novel. This research will divide novel into four categories : horror, inspirational, mystery, and romantic. The text which is entered into the program such as title, writer, and synopsis. The synopsis will be processed to classify the genre of novel. The first step is preparing the document and selecting the document. The next step is giving a weight into word using TF-IDF
method, then comparing the similarity between text and a node in data resource to do the classification process. The text that has been obtained will be classified into a genre or an existing node if it has the highest similarity value in one node in data
resource. The system testing collects randomly 100 synopsis from electronic novel
and the result is 75% accuracy rate from the testing.
DAFTAR ISI
Hal
Persetujuan ii
Pernyataan iii
Ucapan Terima Kasih iv
Abstrak v
Abstract vi
Daftar Isi vii
Daftar Tabel x
Daftar Gambar xi
Bab 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 3
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 4
1.5 Manfaat Penelitian 4
1.6 Metodologi Penelitian 4
1.7 Sistematika Penulisan 5
Bab 2 LANDASAN TEORI
2.1 Text Mining 7
2.1.1 Tahapan Text mining 7
viii
2.4 Novel 13
2.5 Tesaurus Bahasa Indonesia 14
2.6 Penelitian Terdahulu 15
Bab 3 ANALISIS DAN PERANCANGAN
3.1 Analisis Data 17
3.1.1 Novel 17
3.1.2 Data Resource 18
3.2 Analisis Sistem 19
3.2.1 Data Set 20
3.2.2 Proses Persiapan dan seleksi dokumen 21
3.3.2.1 Tokenisasi 21
3.3.2.2 Pembuangan Stopword 23
3.3.2.3 Stemming 27
3.3.3 Pembobotan Kata dengan TF-IDF 30
3.3 Perancangan Tampilan Antarmuka 35
3.3.1 Rancangan Tampilan Halaman Utama 35
3.3.2 Rancangan Tampilan Halaman Data Resource 36
3.3.3 Rancangan Tampilan Halaman About 36
3.3.4 Rancangan Tampilan Halaman Proses 37
Bab 4 IMPLEMENTASI DAN PENGUJIAN
4.1 Implementasi Sistem 39
4.1.1 Spesifikasi perangkat keras dan perangkat lunak 39
4.1.2 Tampilan Halaman Utama 40
4.1.3 Tampilan Halaman Data Resource 40
4.1.4 Tampilan Halaman About 41
4.1.5 Tampilan Halaman Proses 42
4.2 Hasil Pengujian Sistem 44
Bab 5 KESIMPULAN DAN SARAN
5.2 Saran 54
x
DAFTAR TABEL
Hal
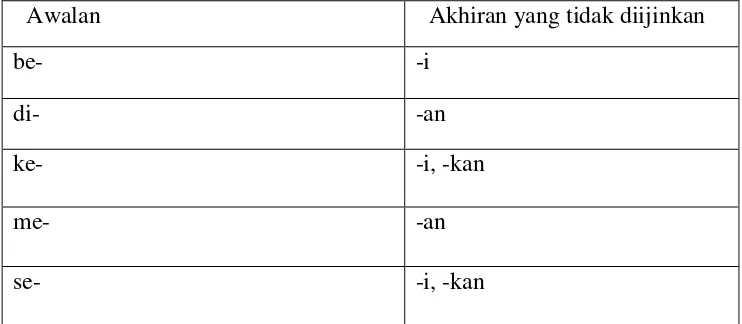
Tabel 2.1 Tabel kombinasi awalan akhiran yang tidak diijinkan 10
Tabel 2.2 Tabel aturan peluruhan kata dasar 10
Tabel 2.3 Tabel Penelitian Terdahulu 16
Tabel 3.1 Tabel Data Resource 18
Tabel 3.2 Tabel Tokenisasi 22
Tabel 3.3 Stopword list 24
Tabel 3.4 Hasil Filtering Proses Stopword 26
Tabel 3.5 Tahapan Hasil Stemming 30
Tabel 3.6 Hasil Pembobotan Kata 31
Tabel 3.7 Hasil Pengklasifikasian Genre Novel 33
DAFTAR GAMBAR
Halaman
Gambar 3.1 Arsitektur Umum 20
Gambar 3.2 Input Sinopsis Novel 20
Gambar 3.3 Flowchart Proses Tokenisasi 21
Gambar 3.4 Flowchart Proses Stopword 24
Gambar 3.5 Flowchart Proses Steeming 27
Gambar 3.6 Rancangan Tampilan Halaman Utama 35
Gambar 3.7 Rancangan Tampilan Data Resource 36
Gambar 3.8 Rancangan Tampilan Halaman About 36
Gambar 3.9 Rancangan Tampilan Halaman Proses 37
Gambar 3.10 Rancangan Tampilan Halaman Hasil Proses 38
Gambar 3.11 Rancangan Tampilan Halaman Detail Proses 38
Gambar 4.1 Tampilan halaman utama 40
Gambar 4.2 Tampilan Halaman Data Resource 41
Gambar 4.3 Tampilan halaman about 41
Gambar 4.4 Tampilan halaman proses 42
Gambar 4.5 Tampilan halaman hasil proses 43
v
ABSTRAK
Novel memiliki beberapa genre antara lain genre romantis, horror, misteri, inspiratif dan masih banyak lagi. Namun pada saat ini pengklasifikasian novel kedalam genre-genre masih dilakukan secara manual. Oleh sebab itu dibutuhkan suatu sistem yang dapat mengklasifikasikan novel kedalam genrenya masing-masing secara otomatis. Hal ini dilakukan karena banyaknya genre dari novel tersebut, sehingga sistem ini nantinya dapat membantu pembaca, penerbit dan penulis yang hendak membuat dan membaca novel untuk mengetahui secara singkat genre novel yang sedang dibaca atau ditulisnya. Penelitian ini menggunakan text mining dan TF-IDF untuk proses pengklasifikasian novel. Text
mining dapat diartikan sebagai penemuan informasi yang baru yang sebelumnya
tidak diketahui oleh komputer dengan mengekstrak informasi secara otomatis dari sumber yang berbeda. Sedangkan data resource digunakan sebagai acuan dalam mengklasifikasi novel. Pada penelitian ini novel dibagi menjadi 4 kategori: horor,inspiratif,misteri dan romantis. Text yang dimasukan berupa judul, penulis, dan sinopsis. Sinopsis inilah yang akan diproses untuk menghasilkan klasifikasi genre novel. Proses pertama adalah proses persiapan dokumen dan seleksi dokumen. Kemudian dilanjutkan dengan proses pembobotan kata menggunakan
TF-IDF, kemudian klasifikasi dilakukan dengan membandingkan nilai kemiripan
diantara teks dan sebuah node yang ada di data resource. Teks yang diperoleh akan diklasifikasikan dalam sebuah genre atau node yang ada jika memiliki nilai kemiripan paling tinggi di salah satu node di data resource. Pengujian sistem dilakukan dengan mengambil 100 sinopsis novel online secara acak dan menghasilkan tingkat akurasi sebesar 75%.
NOVEL CLASSIFICATION BASED ON GENRE USING TF-IDF
ABSTRACT
Novel has many genres such as romantic, horror, mystery, inspirational, and many more. However, today the classification of novel into genre is done manually. Therefore, we need a novel classification system which can classify novels into their each genre automatically. A novel classification system is needed because novel has many genres, so this system will help the reader, the publisher, and the writer who writing and reading a novel to know shortly about the genre of novel that they read or write. This research is using text mining method with TF-IDF method for classifying the novel. Text mining is a process to discover new information which is not known by the computer before by extracting the information automatically from the different sources. Whereas, data resource is used a as reference for classifying novel. This research will divide novel into four categories : horror, inspirational, mystery, and romantic. The text which is entered into the program such as title, writer, and synopsis. The synopsis will be processed to classify the genre of novel. The first step is preparing the document and selecting the document. The next step is giving a weight into word using TF-IDF
method, then comparing the similarity between text and a node in data resource to do the classification process. The text that has been obtained will be classified into a genre or an existing node if it has the highest similarity value in one node in data
resource. The system testing collects randomly 100 synopsis from electronic novel
and the result is 75% accuracy rate from the testing.
BAB I
PENDAHULUAN
1.1 Latar Belakang
Di zaman yang serba teknologi seperti saat ini, informasi menjadi salah satu kebutuhan
yang sangat penting bagi masyarakat. Perkembangan akan informasi tersebut menuntut
adanya suatu media penyedia informasi yang dapat diakses dan dinikmati oleh setiap orang
secara mudah, tepat, dan cepat. Informasi tersebut biasanya dapat kita peroleh dari
beberapa sumber, seperti media cetak maupun media eletronik.
Media cetak biasanya kita peroleh melalui koran, majalah, dan lain lain. Sedangkan
untuk media eletronik biasanya dapat kita peroleh dari televisi, radio, internet, dan lain
lain. Salah satu media pencarian informasi yang paling populer saat ini adalah penggunaan
internet. Internet sering digunakan dalam pencarian informasi mengenai jurnal, artikel
ilmiah, komik, novel dan lain-lain.
Kata novel berasal dari bahasa Italia, novella, yang berarti "sebuah kisah atau sepotong berita". Dalam Kamus Besar Bahasa Indonesia novel adalah karangan prosa yang
panjang mengandung rangkaian cerita kehidupan seseorang dengan orang di sekelilingnya
dengan menonjolkan watak dan sifat tiap pelaku. Penulis novel disebut dengan novelis
.
memiliki beberapa genre antara lain genre romantis, horror, misteri,, inspiratif dan
masih banyak lagi. Namun didalam membagi novel kedalam genre-genre tersebut saat
ini masih dilakukan secara manual. Oleh sebab itu dibutuhkan suatu sistem yang dapat
mengklasifikasikan novel kedalam genrenya masing-masing secara otomatis
dikarenakan banyaknya genre dari novel tersebut, sehingga nantinya dapat membantu
pembaca, penerbit dan penulis yang hendak membuat novel untuk mengetahui secara
singkat genre novel yang sedang dibaca atau ditulisnya.
Beberapa penelitian telah dilakukan untuk sistem pengklsifikasian antara lain
metode Ontologi (Basnur Wira Prajna.,Sensuse Indra Dana.,2010, Pengklasifikasian
otomatis berbasis Ontologi untuk artikel berita berbahasa Indonesia), metode Naive
Bayes (Kurniawan, B, dkk. 2012, Klasifikasi konten berita dengan metode text
mining), (Wibisono, Y.,2005,Klasifikasi berita berbahasa indonesia menggunakan
Naïve Bayes classifier internal). Pada sistem yang akan dibangun, penulis
menggunakan metode TF-IDF.
Dari latar belakang di atas, maka penulis akan membangun suatu sistem yang
berfungsi untuk mengklasifikasikan novel sesuai genre nya masing-masing memakai
TF-IDF , dengan judul “Klasifikasi Novel Sesuai Dengan Genre Menggunakan
TF-IDF”. Diharapkan sistem yang akan dibuat dapat menghemat waktu dan dapat
memudahkan pembaca, penulis novel dan penerbit dalam mengklasifikasikan novel
3
1.2 Rumusan Masalah
Dengan banyaknya genre novel, maka proses pengklasifikasian novel sesuai genre
akan semakin sulit. Maka diperlukan cara untuk menglasifikasikan novel sesuai
dengan genrenya secara otomatis.
1.3 Batasan Masalah
Batasan masalah pada penelitian ini yaitu :
1. Genre dibatasi 4 jenis genre yaitu genre horror, inspiratif, misteri, romantis.
2. Novel yang digunakan adalah novel dalam Bahasa Indonesia.
3. Novel yang diambil dari media novel online.
4. Text yang akan dimasukan berupa judul, nama penulis, dan sinopsis dari novel
tersebut.
1.4 Tujuan Penelitian
Penelitian ini bertujuan untuk menghasilkan suatu sistem yang berfungsi untuk
mengklasifikasikan novel sesuai dengan genre menggunakan Metode TF-IDF. Sistem
ini nantinya diharapkan dapat membantu dan mempermudah bagi seorang penulis
maupun seorang pembaca dalam hal penentuan genre novel yang sedang ditulis atau
dibacanya.
1.5 Manfaat Penelitian
Manfaat penelitian ini adalah sebagai berikut :
1. Mempermudah dalam pengklasifikasian novel berdasarkan genre
2. Sistem yang dibangun dapat meminimkan waktu untuk menentukan genre dari
suatu novel tanpa harus membaca novel secara keseluruhan.
1.6 Metodologi Penelitian
Tahapan - tahapan yang akan dilakukan pada penulisan skripsi ini adalah sebagai
berikut :
1. Studi Literatur
Studi literatur dilakukan dengan cara mengumpulkan bahan referensi yaitu
berupa buku, artikel, paper, jurnal, makalah, maupun situs-situs dari internet.
Studi literatur yang dilakukan berkaitan dengan sistem klasifikasi dan metode
TF-IDF yang berkaitan dengan judul skripsi.
2. Identifikasi Masalah
Pada tahap ini, dilakukan identifikasi masalah yang akan diselesaikan pada
aplikasi yang akan dibangun.
3. Analisis dan Perancangan
Pada tahap ini dilakukan analisis dan perancangan terhadap permasalahan
yang ada dan batasan masalah
4. Implementasi Sistem
Pada tahap ini dilakukan proses implementasi pengkodean program dalam
aplikasi komputer menggunakan bahasa pemrograman yang telah dipilih yang
5
5. Pengujian sistem
Pada tahap ini dilakukan proses pengujian dan percobaan terhadap sistem
sesuai dengan kebutuhan yang ditentukan sebelumnya serta memastikan
program yang dibuat berjalan seperti yang diharapkan.
6. Dokumentasi
Pada tahap ini dilakukan pembuatan dokumentasi dalam bentuk laporan tugas
akhir.
1.7Sistematika Penulisan
Penulisan skripsi ini terdiri dari lima bab dengan masing-masing bab secara singkat
dijelaskan sebagai berikut:
Bab 1 : Pendahuluan
Bab ini berisi berisikan latar belakang, rumusan masalah, batasan masalah, tujuan
penelitian, manfaat penelitian, metodologi penelitian, dan sistematika penulisan.
Bab 2 : Landasan Teori
Pada bab ini dibahas mengenai teori-teori pendukung penelitian skrispsi yaitu teori
Text Mining dan metode TF-IDF
Bab 3 : Analisis dan Perancangan Sistem
Pada bab ini berisikan paparan analisis terhadap permasalahan dan penyelesaian
persoalan terhadap metode TF-IDF serta identifikasi kebutuhan perancangan sistem.
Bab 4 : Implementasi dan Pengujian Sistem
Pada bab ini berisi implementasi perancangan sistem dari hasil analisis dan
perancangan yang sudah dibuat, serta menguji sistem untuk menemukan kelebihan
Bab 5 : Kesimpulan dan Saran
Pada bab ini berisikan kesimpulan yang didapatkan terhadap hasil penelitian skripsi
BAB 2
LANDASAN TEORI
Bab ini akan membahas landasan teori, penelitian terdahulu, kerangka pikir, dan
hipotesis yang mendasari penyelesaian permasalahan dalam pengklasifikasian novel
menggunakan TF-IDF.
2.1Text mining
Text mining dapat diartikan sebagai penemuan informasi yang baru yang sebelumnya
tidak diketahui oleh komputer dengan mengekstrak informasi secara otomatis dari
sumber yang berbeda. Kunci dari proses ini adalah menggabungkan informasi yang
berhasil diekstraksi dari berbagai sumber (Hearst, 2003). Sedangkan menurut
(Harlian, 2006) text mining didefinisikan sebagai data yang berupa teks yang biasanya
sumber data didapatkan dari dokumen, dengan tujuan adalah mencari kata-kata yang
dapat mewakili isi dari dokumen tersebut yang nantinya dapat dilakukan analisa
hubungan antar dokumen.
2.1.1 Tahapan Text mining
Tahapan text mining secara umum dibagi menjadi beberapa tahapan umum (Triawati,
2009).
1. Text Preprocessing
Text Preprocessing merupakan tahapan awal dari text mining yang bertujuan
mempersiapakan teks menjadi data yang akan mengalami pengolahan pada tahap
selanjutnya. Pada text mining, data mentah yang berisi informasi memiliki struktur
terstruktur sesuai kebutuhan, yaitu biasanya akan mejadi nilai-nilai numerik. Proses
ini disebut Text Preprocessing (Triawati, 2009).
Pada tahap ini, tindakan yang dilakukan adalah toLowerCase, dengan
mengubah semua karakter huruf menjadi huruf kecil, dan tokenizing yaitu proses
penguraian deskripsi yang semula berupa kalimat mejadi kata-kata kemudian
menghilangkan delimiter-delimiter seperti tanda koma (,), tanda titik (.), spasi, dan
karakter angka yang terdapat pada kata tersebut.(Weiss et al, 2005).
2. Seleksi fitur (Feature Selection)
Pada tahap ini akan dilakukan seleksi dengan mengurangi jumlah kata-kata
yang dianggap tidak penting dalam dokumen tersebut untuk menghasilkan proses
pengklasifikasian yang lebih efektif dan akurat (Do et al, 2006., Feldman &
Sanger,2007., Berry et al ,2007). Tahapan ini adalah dengan melakukan penghilangan
stopword dan juga mengubah kata-kata kedalam bentuk dasar terhadap kata yang
berimbuhan (Berry et al, 2010), (Feldman et al, 2007)
Stopword merupakan kosakata yang bukan merupakan ciri atau kata unik dari
suatu dokumen seperti kata sambung (Dragut et al, 2009). Yang termasuk stopword
yaitu “ di”, “pada”, ”sebuah”, ”karena”, ”oleh” dan sebagainya. Sebelum memasuki
tahapan penghilang stopword, daftar stopword harus dibuat terlebih dahulu. Jika
kata-kata yang termasuk stopword masuk dalam stoplist, maka kata tersebut akan dihapus
dari deskripsi sehingga sisanya dianggap sebagai kata-kata yang mencirikan isi
dokumen atau keywords. Setelah melalui tahap penghilangan stopword, tahap
selanjutnya adalah stemming. Stemming adalah proses pemetaan dan penguraian
berbagai bentuk dari suatu kata menjadi kata dasarnya (Tala, 2003). Tujuan
dilakukannya proses stemming adalah menghilangkan imbuhan-imbuhan berupa
prefix, suffix, maupun konfiks yang terdapat pada setiap kata. Apabila imbuhan tadi
tidak dihilangkan maka setiap kata akan disimpan didalam database, sehingga
nantinya akan menjadi beban di dalam database. Bahasa Indonesia memiliki aturan
morfologi maka proses stemming harus berdasarkan aturan morfologi bahasa
9
Proses stemming biasanya menggunakan algoritma. Algoritma stemming telah
dikembangkan untuk beberapa bahasa, seperti Algoritma Porter untuk teks bahasa
Inggris, Algoritma Porter untuk teks bahasa Indonesia, dan Algoritma Nazief dan
Adriani untuk teks bahasa Indonesia (Nazief & Adriani, 1996). Algoritma Nazief &
Adriani memiliki keakuratan yang lebih besar dibandingkan Algoritma Porter untuk
stemming dalam bahasa Indonesia (Agusta, 2009).
2.2Algoritma Nazief & Adriani
Algoritma Nazief & Adriani adalah salah satu algoritma untuk stemming bahasa
Indonesia. Adapun tahapan yang dimiliki dalam algoritma ini adalah (Nazief &
Adriani,1996):
1. Cari kata yang akan di stemming didalam kamus. Jika ditemukan maka
diasumsikan kata tersebut adalah root word maka algoritma berhenti.
2. Infection suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”) dibuang. Jika
berupa partikel (“-lah”, “-kah”, “-tah”, atau “-pun”) maka langkah ini diulangi untuk menghapus Passive Pronouns(“-ku”, “-mu”, atau “-nya”), jika ada
3. Hapus derivation suffixes (“-i”, “-an”, atau “-kan”). Jika kata ditemukan
dikamus, maka algoritma berhenti. Jika tidak, maka dilanjutkan ke langkah 3a
a. Jika “-an” telah dihapus dalam huruf terakhir dari kata tersebut
ditemukan dalam kamus, maka algoritma berhenti. Jika tidak, akan
dilanjutkan ke langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an”, atau “-kan”) dikembalikan ke tahap
4. Hapus derivation prefix. 9”di-“ ,”ke-“, “se-“, “te-“, “be-“, dan “me-“) jika
pada langkah 3 ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak
pergi ke langkah 4b.
a. Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan seperti
pada tabel 2.1. jika ditemukan, maka algoritma berhenti, jika tidak
pergi ke langkah 4b.
b. For I=1 to 3, tentukan tipe awalan kemudian hapus awalan dan
lakukan perubahan pada kata dasar sesuai tabel peluruhan 2.2 jika root
algoritma berhenti. Jika awalan kedua sama dengan awalan pertama
maka algoritma berhenti.
5. Melakukan recoding.
6. Jika semua langkah selesai tetapi masih tidak berhasil, maka kata awal
diasumsikan sebagai root word. Proses selesai.
Tabel 2.1 Tabel kombinasi awalan akhiran yang tidak diijinkan (Adriani et al, 2007)
Awalan Akhiran yang tidak diijinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
Tabel 2.2 Tabel aturan peluruhan kata dasar (Adriani et al, 2007)
Aturan Awalan Peluruhan
1 berV... ber-V..| be-rV..
2 belajar bel-ajar
3 berClerC2 Be-ClerC2.. dimana C1!= {'r'|'l'}
4 terV... ter-V... | te-rV...
5 terCer... ter-Cer... dimana C!==’r’
6 teClerC2 te-CleC2... dimana C1!=’r’
7 me{I|r|w|y}V... me-{I|r|w|y}V...
8 mem{b|f|v}... mem-{b|f|v}...
9 Mempe... m-pe...
11
11 men{c|d|j|z} men-{c|d|j|z}...
12 menV... me-nV...|me-tV...
13 meng{g|h|q|k}... meng-{g|h|q|k}...
14 mengV... meng-V...|meng-kV...
15 mengeC Meng-C
21 pem{rV|V}... pe-m{rV|V}...|pe-p{rV|V}
22 pen{c|d|j|z}... pen-{c|d|j|z}...
23 penV... pe-nV... | pe-tV...
24 Peng{g|h|q} peng-{g|h|q}
25 pengV peng-V |peng-kV
26 penyV pe-nya|peny-sV
27 pelV pe-IV...; kecuali untuk kata “pelajar”
28 PeCP pe-CP...dimana C!={r|w|y|I|m|n}
dan P!=’er’
29 perCerV per-CerV... dimana C!={r|w|y|I|m|n}
Untuk mengatasi keterbatasan pada algoritma di atas, maka ditambahkan
bentuk tunggal, contoh: kata “ berbalas-balasan”, “berbalas” dan “balasan”
memiliki root word yang sama yaitu “balas”, maka root wood “berbalas
-balasan” adalah “balas”. Sebaliknya, pada kata “bolak-balik”, “bolak” dan
“balik” memiliki root word yang berbeda, maka root word-nya adalah
“bolak-balik”.
2. Tambahan bentuk awalan dan akhiran serta aturannya.
a. Tipe awalan “mem-“, kata yang diawali dengan awalan “ memp-“ memiliki
tipe awalan “mem-“.
b. Tipe awalan “meng-“, kata yang diawali dengan awalan “mengk-“
memiliki tipe awalan “meng-“..
2.3 Term Frequency-Inverse Document Frequency (TF-IDF)
TF-IDF (Term Frequency-Inverse Document Frequency) merupakan metode statistic
numeric yang mencerminkan seberapa pentingnya sebuah kata dalam sebuah
dokumen atau korpus (Rajaraman et al, 2011). Hal ini sering digunakan sebagai faktor
bobot dalam pencarian informasi dan penambangan teks (text mining). Nilai TF-IDF
meningkat secara proporsional berdasarkan jumlah atau banyaknya kata yang muncul
pada dokumen, tetapi diimbangi dengan frekuensi kata dalam korpus. Variasi dari
skema pembobotanTF-IDFsering digunakan oleh mesin pencari sebagai alat utama
dalam mencetak nilai (scoring) dan peringkat (ranking) sebuah relevansi dokumen
yang diberikan user.
Term Frequency-Inverse document frequency (TF-IDF) adalah suatu metode
pembobotan kata dengan menghitung nilai TF dan juga menghitung kemunculan
sebuah kata pada dokumen teks. Pada pembobotan ini, jika kemunculan term pada
sebuah dokumen teks tinggi dan kemunculan term tersebut pada dokumen teks yang
lain rendah, maka bobotnya akan semakin besar. Sedangkan jika kemunculan term
pada dokumen teks lain tinggi, maka bobotnya akan semakin kecil. Tujuan
penghitungan IDF adalah untuk mencari kata-kata yang benar-benar
13
(1)
Dengan tf(i,j) adalah frekuensi kemunculan term j pada dokumen teks d i D*, dimana i = 1,2,3,...,N, df(j) adalah frekuensi dokumen yang mengandung term j
dari semua koleksi dokumen, dan N adalah jumlah seluruh dokumen yang ada di
koleksi dokumen. Berdasarkan rumus diatas berapapun besarnya nilai tf(i,j), apabila
N= df(j) maka akan didapatkan hasil 0 (nol) untuk perhitungan idf. Untuk itu dapat
ditambahkan nilai 1 pada sisi idf, sehingga perhitungan untuk pembobotan dapat
dilihat pada rumus persamaan 2.
+1) (2)
2.4 Novel
Dari sekian banyak bentuk karya sastra yang ada saat ini seperti esai, novel, cerpen
dan lain-lain. Novel merupakan karya sastra yang paling populer, novel selalu
memiliki penggemar, baik itu remaja hingga dewasa, Menurut Kamus Besar Bahasa
Indonesia (KBBI), novel adalah karangan prosa yang panjang, mengandung rangkaian
cerita kehidupan seseorang dengan orang di sekelilingnya dengan menonjolkan watak
dan sifat setiap pelaku. Orang yang menulis novel adalah novelis. Novel memiliki
beberapa ciri yang paling utama, yaitu :
1. Memiliki alur/plot yang kompleks. Berbagai peristiwa dalam novel
ditampilkan saling berkaitan sehingga novel dapat bercerita panjang lebar,
membahas persoalan secara luas, dan lebih mendalam.
2. Tema dalam novel tidak hanya satu, tetapi muncul tema-tema sampingan.
Oleh karena itu, pengarang novel dapat membahas hampir semua segi
persoalan.
Genre merupakan cara penerbit, pembaca, atau penulis, membagi karya seni
berdasarkan kategori tertentu yang telah disepakati. Penerbit membutuhkan genre agar
mereka mudah menentukan pangsa pasar, serta bagaimana memasarkan sebuah buku.
Setiap genre mempunyai kategori masing-masing, serta formulanya yang berbeda satu
sama lain. Novel dibagi kedalam beberapa genre dintaranya (Forbes, Jamie M, 1998)
a. Horror adalah novel yang satu ini berisi cerita yang menegangkan, seram, dan
membuat pembaca berdebar-debar, pada umumnya bercerita tentang hal-hal
yang mistis atau seputar dunia gaib.
b. Inspiratif adalah adalah novel yang ceritanya mampu menginspirasi banyak
orang. Pada umumnya novel ini mempunyai pesan moral atau hikmah tertentu
yang dapat diambil oleh si pembaca novel. Sehingga pembaca akan termotivasi
atau mempunyai dorongan untuk melakukan hal yang lebih baik.
c. Misteri adalah sebuah novel yang memiliki cerita lebih rumit karena akan
menimbulkan rasa penasaran oleh si pembaca hingga akhir cerita.
d. Romantis adalah novel yang berceritakan seputar percintaan dan kasih sayang
dari awal cerita hingga akhir cerita.
2.5 Tesaurus Bahasa Indonesia
Kata tesaurus berasal dari bahasa Yunani, thesauros yang bermakna ‘khazanah’. Tesaurus mengalami perkembangan makna yakni ‘buku yang dijadikan sumber informasi’. Di dalam buku “Tesaurus Bahasa Indonesia Pusat Bahasa”, tesaurus berisi
seperangkat kata yang saling berhubungan maknanya. Pada dasarnya tesaurus
merupakan sarana yang digunakan untuk mengalihkan gagasan ke dalam sebuah kata
atau sebaliknya. Oleh sebab itu, tesaurus disusun berdasarkan gagasan atau tema.
Namun, untuk memudahkan pengguna dalam pencarian kata, tesaurus pun
berkembang, dan kini banyak tesaurus yang dikemas berdasarkan abjad.
Tesaurus berbeda dengan kamus, jika pada kamus informasi yang didapat
adalah tentang makna kata, sedangkan pada tesaurus sendiri dapat dicari kata yang
akan digunakan untuk mengungkapkan gagasan pengguna. Dengan demikian tesaurus
dapat membantu penggunanya dalam mengekspresikan atau mengungkapkan gagasan
sesuai dengan apa yang dimaksud. Sebagai contoh, pencarian kata lain untuk kata
“hewan”, pengguna tesaurus dapat mencari pada lema hewan.
Hewan n binatang, dabat,fauna,sato,satwa
Kata diatas tersebut merupakan sederetan kata yang terdapat pada kata hewan,
15
ini berguna juga dalam pengajaran bahasa. Di dalam buku tesaurus bahasa indonesia
pusat bahasa ini, hiponim dicantumkan pula karena didalam tesaurus biasanya
memuat makna yang saling bertalian atau berhubungan. Sehingga, pengguna dapat
dengan mudah memperoleh kata yang tepat sesuai dengan yang dikehendaki sehingga
pengguna dapat memanfaatkan kata itu untuk keperluan pragmatis.
2.6 Penelitian Terdahulu
Dalam melakukan penelitian, penulis membutuhkan beberapa bahan penelitian yang
sudah pernah dilakukan peneliti-peneliti lainnya mengenai masalah teknik
pengklasifikasian dan metode Ontologi.
(Februariyanti, 2012) berhasil mengimplementasikan metode ontologi dan
hasil eksperimen didapat struktur direktory dan struktur halaman web sesuai dengan
struktur ontology.
(Kurniawan, 2012) berhasil melakukan proses klasifikasi data berita secara
otomatis dan proses klasifikasi semakin akurat jika data latih yang digunakan dalam
pembelajaran berjumlah banyak. Untuk penelitian yang dilakukan oleh peneliti
Tabel 2.3.Tabel Penelitian Terdahulu
No Peneliti Tahun Judul penelitian Keterangan
1 Herny
Februariyanti
2012 Klasifikasi dokumen
berita teks bahasa
Indonesia
menggunakan
Ontologi
- klasifikasi menggunakan
TF-IDF dengan menghitung nilai
similaritas dengan file yang
ada pada file ontologi
- hasil dari pengklasifikasian
disimpan di directory local
dengan mengikuti struktur
ontology.
2 Bambang
Kurniawan
2012 Klasifikasi Konten Berita Dengan Metode Text Mining
- Klasifikasi data berita secara
otomatis dan proses klasifikasi
semakin akurat jika data latih
yang digunakan dalam
pembelajaran berjumlah
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Dalam bab ini berisi beberapa hal diantaranya seperti data yang digunakan, penerapan
algoritma dan analisis perancangan sistem dalam mengimplementasikan TF-IDF
dalam pengklasifikasian novel.
3.1. Analisis Data
Dalam penelitian ini data yang digunakan adalah data yang berhubungan dengan
novel seperti judul, sinopsis, dan pengarang novel tersebut. Dalam penelitian ini data
sinopsis dari novel tersebut akan diproses untuk menghasilkan klasifikasi novel
berdasarkan genre, seperti horor, misteri, romantis, dan inspiratif dengan
menggunakan TF-IDF. Data yang digunakan dalam penelitian ini adalah data yang
didapat dari media novel online dan Kamus Tesaurus Pusat Bahasa sebagai data
resource.
3.1.1. Novel
Novel merupakan karangan prosa yang panjang, mengandung rangkaian cerita
kehidupan seseorang dengan orang di sekelilingnya dengan menonjolkan watak dan
sifat setiap pelaku. Novel juga merupakan karya sastra yang paling populer dibaca.
Novel memiliki banyak genre, diantaranya adalah horor, inspiratif, misteri dan
romantis. Genre merupakan pengkategorian tanpa batas-batas yang jelas yang dibuat
oleh penerbit untuk mengkategorikan novel-novel yang ada
Novel dipilih karena novel merupakan karya sastra yang paling populer dari
karya sastra yang lain sehingga layak untuk dijadikan domain dalam penelitian ini.
Untuk data yang di input pada penelitian ini adalah berupa sinopsis novel, judul novel,
3.1.2. Data resource
Data resource digunakan sebagai keyword atau kata kunci dalam proses hitung
kemiripan yang berupa kata dasar. Keyword atau kata kunci didapat dari Tesaurus
Bahasa Indonesia Pusat Bahasa sebagai acuan untuk mencari kata-kata yang dapat
mewakili dari genre-genre novel yang diteliti. Berikut daftar kata kunci yang dapat
mewakili dari genre-genre novel yang didapat dari Tesaurus Bahasa Indonesia Pusat
Bahasa. Data resource dapat dilihat pada tabel 3.1.
Tabel 3.1Data Resource
2 inspirasi Ahli,ajar,akal,ambisi,andai,baik,belajar,benak,bijak,,budi,
capai,cemerlang, cendikiawan, cerdas, cerdik, cita, citra, coba,
damba,dapat, didik,diri, gagah, gagasan, gemar, genius, harap, ,hasil,
hasrat, ide,ideologi, ilham, ilmu, imajinatif, impi, impresi, ingat,
ingin,inpresi,intelek, inisiatif, inspirasi, intensi, jadi, jago, jalan, juara,
jujur,kabul, kenang, kesan, khayal,kiat,kompak, konsep,kreasi,
kreatif, kreativitas,kunci,lihai,logika,luang,lulus, mahir, masalah,
master, mau, menang, mimpi, niat, opini,paham,pakar, pandai,
pandang, patuh, persepsi,
pikir,pimpin,pintar,prakarsa,prestasi,prinsip,profesional,prospek,
rencana,rintang,sarjana,semangat,sempat,serah,setia,simpati,solid,
spesialis,sukses,taat,tabah, teguh,tekad,teknikus, teliti, tuju,
19
durhaka, enigma, hebat, hilang, hukum, ikhtiar,intai, isyarat,
jadi,jahat,jasus,jelek,kasus, kejam, kode, komplikasi,kondisi,
kriminal, kunci, malam, mirakel, misteri, mistik,
muslihat,pelaku,periksa ,peristiwa,perkara,primitif,problem,
rahasia,residivis, rongsok, rusak,sandi,siasat,skandal,soa,
sulit,susah,suluk,taktik, tebak,terjadi,trik, tuduh,urus
4 Romantis Akad,asih, asmara, bahagia, berahi, ceria, cerita, cinta, emosional,
hasrat, hati, hubung, iba, ikat, ingin, ikhlas, jalin, jodoh, jujur, juwita,
kagum, kangen, kasih, kasmaran, kawin, kekasih, kisah, komitmen,
komunikasi, kontak, manis, mesra, minat, nafsu naksir, pacar, pasang,
pesona, pikat, polos,prihatin,puja,putih,putus,rajut, rayu, rela, rindu,
risau, roman,sayang,sedih,sejati, senang,sentuh, setia, sosok, suci,
suka, teman,temu,tulus
3.2. Analisis Sistem
Analisis sistem bertujuan untuk mengindentifikasi permasalahan yang ada pada
sistem. Analisis ini sangat diperlukan sebagai dasar perancangan sistem. Yang
tercakup dalam analisis sistem adalah desain data, deskripsi data, deskripsi sistem, dan
implementasi desain. Sebelum masuk ke dalam tahap perancangan sebuah sistem,
perlu dilakukan analisis sistem yang akan dibangun. Analisis sistem merupakan istilah
yang secara kolektif mendeskripsikan fase-fase awal pengembangan sistem. Analisis
sistem bertujuan untuk mengindentifikasi permasalahan yang ada pada sistem. Dalam
tahap ini menjabarkan kebutuhan-kebutuhan yang berguna untuk perancangan sistem
agar sistem yang dibangun sesuai dengan masalah yang akan diselesaikan.
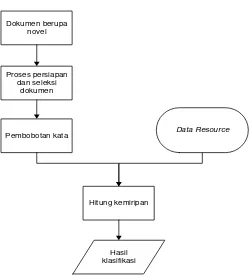
Penelitian ini memiliki beberapa tahapan yaitu input novel, Text Processing
(Tokenisasi, pembuangan stopword, dan proses stemming), pembobotan kata (term),
dan mengklasifikasikannya dengan menghitung nilai similaritas termnya dengan data
yang ada pada data resource. Berikut rancangan sistem yang ditampilkan dalam
Dokumen berupa
Gambar 3.1 Arsitektur Umum
Keterangan gambar 3.1 dapat dilihat dibawah ini:
1. Data Set
Pada bagian ini data yang dimasukan adalah berupa judul novel, penulis novel dan
sinopsis novel. Namun data yang diproses nantinya adalah data yang diperoleh dari
sinopsis novel tersebut. Input sinopsis novel dapat dilihat pada gambar 3.2
Gambar 3.2 Input Sinopsis Novel
21
2. Proses Persiapan dan seleksi dokumen
Pada bagian ini sinopsis yang sudah diinput akan melalui proses persiapan dan seleksi
dokumen dimana tahapan ini bertujuan untuk mempersiapkan text menjadi data yang
akan mengalami pengolahan menjadi data untuk proses pengklasifikasian. Tahapan ini
memiliki beberapa tahapan yaitu: tokenisasi (tokenization), pembuangan
stopword(stopword removal) dan yang terahir proses stemming.
2.1. Tokenisasi
Sebelum kata dipisahkan dari kalimat, terlebih dahulu dibersihkan dari tanda baca, tag
html dan angka. Proses ini dilakukan sebelum proses tokenisasi supaya dapat
memperkecil hasil dari tokenisasi tersebut. Pada proses tokenisasi akan dibaca
dokumen berupa teks yang selanjutnya akan dilakukan proses pemotongan string
input berdasarkan tiap kata yang menyusunnya. Umumnya setiap kata akan
terpisahkan dengan kata yang lain oleh karakter spasi, sehingga proses tokenisasi
mengandalkan karakter spasi pada dokumen teks tersebut untuk melakukan pemisahan
kata.
start
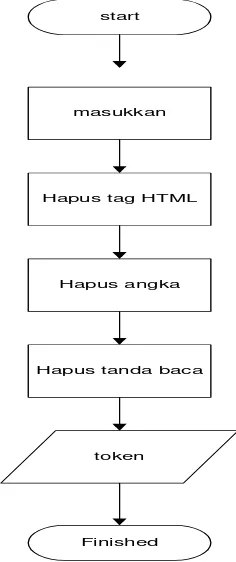
masukkan
Hapus tag HTML
Hapus angka
Hapus tanda baca
token
Finished
Seperti pada gambar 3.5 proses tokenisasi, semua term dalam dokumen teks
yang di masukan akan dihapus tag htmlnya, kemudian term yang sudah dihapus tag
htmlnya akan dicek lagi untuk menghapus angka yang ada pada teks tersebut,
kemudian proses terakhir dari tokenisasi adalah dilakukannya penghapusan tanda
baca. Sehingga hasilnya adalah term menjadi token-token yang terpisah. Hasil proses
tokenisasi dapat dilihat pada tabel 3.4
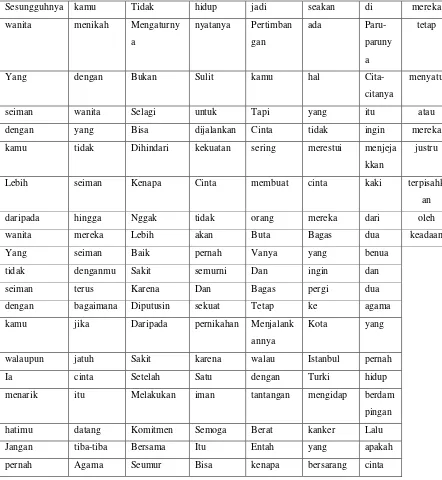
Tabel 3.2 Tokenisasi
kamu tidak Dihindari kekuatan sering merestui menjeja
kkan
justru
Lebih seiman Kenapa Cinta membuat cinta kaki terpisahk
an
dengan bagaimana Diputusin sekuat Tetap ke agama
kamu jika Daripada pernikahan Menjalank
annya
Kota yang
walaupun jatuh Sakit karena walau Istanbul pernah
Ia cinta Setelah Satu dengan Turki hidup
menarik itu Melakukan iman tantangan mengidap berdam
pingan
hatimu datang Komitmen Semoga Berat kanker Lalu
Jangan tiba-tiba Bersama Itu Entah yang apakah
23
2.2.Pembuangan Stopword
Sebelum dilakukan stopword harus dilakukan normalisasi dengan mengubah semua
huruf kapital menjadi huruf kecil. Proses pembuangan stopword merupakan proses
pembuangan term yang tidak memiliki arti atau relevan. Term tersebut diperoleh
setelah tahap tokenisasi, kemudian dicek kedalam daftar stopword, jika kata tersebut
masuk ke dalam daftar stopword maka kata tersebut tidak akan diproses lebih lanjut.
Sedangkan jika sebuah kata tidak termasuk ke dalam daftar stopword maka kata
tersebut akan masuk ke proses berikutnya. Dalam penelitian ini daftar stopword yang
digunakan adalah daftar stopword yang digunakan oleh (Tala, 2003) . flowchart
Start
Arrray term/ token
Inisialisasi awal i = 0 Ambil term ke-i
Term i = stopword
Tambahkan term i ke array hasil
i= (len array -1)
Return array hasil
Stop
ya
tidak
tidak
ya
i + 1
Gambar 3.4 Flowchart Proses Stopword
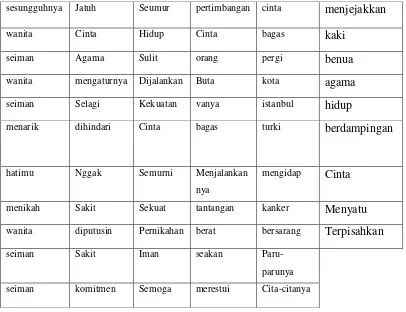
Sedangkan tabel stopword yang diperoleh dapat dilihat pada tabel 3.5.dan hasil
filtering dari proses stopword dapat dilihat pada tabel 3.6.
Tabel 3.3 stopword list
dengan tiba-tiba dan apakah
kamu Selagi tetap atau
lebih Bisa walau mereka
daripada Kenapa dengan justru
25
dengan Karena yang keadaan
kamu Daripada tidak
walaupun Setelah mereka
ia Melakukan yang
jangan Bersama ingin
pernah Untuk ke
yang Tidak yang
tidak Akan itu
hingga Pernah ingin
mereka Dan dari
dengan Karena dua
terus Satu dan
bagaimana Itu dua
jika Bisa yang
itu Tapi pernah
Tabel 3.4 Hasil Filtering Proses Stopword
sesungguhnya Jatuh Seumur pertimbangan cinta menjejakkan
wanita Cinta Hidup Cinta bagas kaki
seiman Agama Sulit orang pergi benua
wanita mengaturnya Dijalankan Buta kota agama
seiman Selagi Kekuatan vanya istanbul hidup
menarik dihindari Cinta bagas turki berdampingan
hatimu Nggak Semurni Menjalankan
nya
mengidap Cinta
menikah Sakit Sekuat tantangan kanker Menyatu
wanita diputusin Pernikahan berat bersarang Terpisahkan
seiman Sakit Iman seakan
Paru-parunya
27
Penghapusan afiks 1 Penghapusan afiks 2 Penghapusan afiks 3 Start
Stop
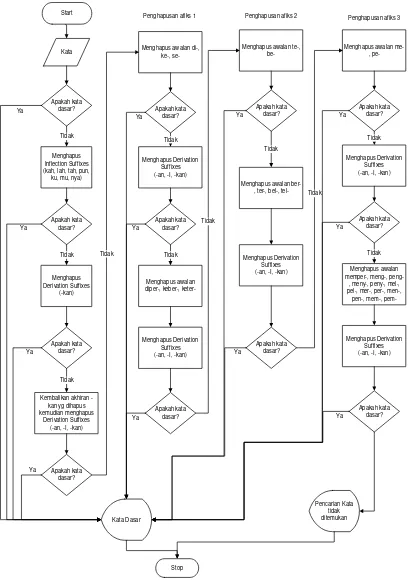
Stemming bertujuan untuk menghasilkan bentuk dasar dari sebuah term atau
kata. Term yang sudah melewati proses pembuangan stopword yang akan menjadi
input dalam proses ini. Algoritma yang digunakan dalam proses stemming ini adalah
algoritma Nazief & Andriani. Algoritma ini digunakan karena algoritma Nazief &
Andriani memiliki keakuratan yang baik dalam proses stemming Bahasa Indonesia.
Berikut penjelasan dari flowchart proses stemming menggunakan algoritma Nazief &
Andriani:
1. Pertama-tama adalah kata yang diterima dalam proses stemming dicek apakah kata
tersebut terdapat didalam list kata dasar. Jika kata tersebut terdapat dalam list kata
dasar maka proses berhenti tetapi jika tidak proses berlanjut.
2. Proses selanjutnya adalah melakukan penghapusan Inflection Suffix. Akhiran ini
berupa akhiran –lah, -kah, -mu, -ku, -tah, -pun dan –nya. Setelah dihapus, maka
dilakukan pengecekan kembali apakah kata tersebut terdapat di list kata dasar. Jika
ada, maka proses berhenti jika tidak berlanjut ke point ke-3.
3. Proses ini akan melakukan penghapusan Derivation Suffix. Akhirannya berupa
akhiran –i, -an, -kan.
a. Pertama-tama akan dihapus akhiran –kan kemudian dicek dalam list kata
dasar. Jika ditemukan di list kata dasar, maka proses berhenti jika tidak,
akhiran –kan yang dihapus dikembalikan dan dilanjutkan dengan penghapusan
akhiran –i dan –an. Jika ditemukan di list kata dasar, proses berhenti jika tidak
dilanjutkan ke point 3.b.
b. Akhiran yang sudah dihapus dikembalikan ke kata sebelumnya dan dilanjutkan
ke point 4.
4. Selanjutnya akan dilakukan proses penghapusan Derivation Prefix. Proses ini
memiliki 3 tahap penghapusan prefiks. Jika pada langkah sebelumnya ada sufiks
yang dihapus, maka proses dilanjutkan ke point 4a.
a. Periksa apakah kata memiliki imbuhan yang terdapat dalam daftar kombinasi
awalan dan imbuhan yang tidak diizinkan. Jika ditemukan maka proses
berhenti jika tidak dilanjutkan.
b. Dilakukan proses penghapusan afiks yang pertama. Awalan yang dihapus
29
i. Pertama-tama awalan di-, ke-, se- dihapus kemudian dicek apakah kata
tersebut terdapat dalam list kata dasar. Jika ditemukan, proses berhenti, jika
tidak dilanjukan.
ii. Dilakukan proses penghapusan derivation suffix kembali. Jika kata tersebut
adalah kata dasar proses berhenti jika tidak bentuk kata dikembalikan ke
semula dan proses dilanjutkan.
iii. Dilakukan proses penghapusan awalan diper-, keber, keter- dan dilanjutkan
dengan penghapusan derication suffix. Kemudian kata dicek kembali
apakah kata tersebut kata dasar. Jika ya, proses berhenti jika tidak kata
dikembalikan ke bentuk semula dan proses dilanjutkan.
c. Dilakukan proses penghapusan afiks yang kedua. Awalan yang akan dihapus
adalah awalan te- dan be-.
i. Pertama-tama dilakukan penghapusan awalan te- dan ber- kemudian dicek
apakah kata tersebut kata dasar. Jika ya, proses berhenti jika tidak, kata
dikembalikan ke bentuk semula dan proses dilanjutkan.
ii. Dilakukan penghapusan awalan ber-, bel-, ter-, tel- dan dilanjutkan dengan
penghapusan derivation suffix. Jika kata adalah kata dasar, proses berhenti
jika tidak kata dikembalikan ke bentuk semula dan proses dilanjutkan.
d. Dilakukan prose penghapusan afiks yang ketiga. Awalan yang akan dihapus
adalah awalan me- dan pe-. Awalan ini adalah awalan yang memilik banyak
perubahan bentuk awalan jika digabungkan dengan kata dasar. Oleh sebab itu
akan banyak dilakukan pengecekan terhadap seluruh perubahan awalan.
i. Pertama-tama dilakukan penghapusan awalan me- dan pe- kemudian dicek
apakah kata tersebut kata dasar. Jika iya, proses berhenti, jika tidak proses
dilanjutkan.
ii. Dilakukan penghapusan derivation suffix dan kemudian dicek kembali
apakah kata tersebut kata dasar. Jika ya, maka proses berhenti, jika tidak
kata dikembalikan ke bentuk semula dan proses dilanjutkan.
Dilakukan proses penghapusan awalan yang mengalami perubahan bentuk
seperti memper-, meng-, meny-, mel-, mer-, men-, mem-, peng-, peny-, pel, per-, pen-,
pem-. Kemudian proses dilanjutkan dengan penghapusan derivation suffix dan dicek
apakah kata tersebut adalah kata dasar, jika maka proses berhenti jika tidak kata
Hasil dari proses stemming ditunjukan pada tabel 3.7
Tabel 3.5 Tahapan Hasil Stemming
sungguh jatuh Sulit cinta bagas kaki
3. Pembobotan kata dengan TF-IDF
Proses pembobotan kata adalah proses pemberian nilai atau bobot ke sebuah kata
berdasarkan kemunculannya pada suatu dokumen teks (Baeza-Yates et al, 1999). Pada
proses sebelumnya atau proses Text Processing akan didapat kumpulan kata atau term
yang kemudian direpresentasikan kedalam sebuah terms vector. Terms vector suatu
dokumen teks a adalah tuple bobot semua term pada a. Nilai bobot sebuah term inilah
yang nantinya akan merepresentasikan dokumen teks. Pada penelitian ini proses
pembobotan kata menggunakan metode Term Frequency-Inverse Document
Frequency (TF-IDF).
Term Frequency-Inverse document frequency (TF-IDF) adalah suatu metode
pembobotan kata dengan menghitung nilai TF dan juga menghitung kemunculan
sebuah kata pada dokumen teks. Pada pembobotan ini, jika kemunculan term pada
sebuah dokumen teks tinggi dan kemunculan term tersebut pada dokumen teks yang
lain rendah, maka bobotnya akan semakin besar. Sedangkan jika kemunculan term
pada dokumen teks lain tinggi, maka bobotnya akan semakin kecil. Tujuan
31
paling baik dalam perolehan informasi (Khodra et al, 2005). Adapun rumus dari
TF-IDF dapat di lihat pada persamaan berikut (Salton, 1983).
(1)
Dengan tf(i,j) adalah frekuensi kemunculan term j pada dokumen teks d i
D*, dimana i = 1,2,3,...,N, df(j) adalah frekuensi dokumen yang mengandung term j
dari semua koleksi dokumen, dan N adalah jumlah seluruh dokumen yang ada di
koleksi dokumen. Berdasarkan rumus diatas berapapun besarnya nilai tf(i,j), apabila
N= df(j) maka akan didapatkan hasil 0 (nol) untuk perhitungan idf. Untuk itu dapat
ditambahkan nilai 1 pada sisi idf, sehingga perhitungan untuk pembobotan dapat
dilihat pada rumus persamaan 2.
+1) (2)
Pada penelitian ini, proses klasifikasi dokumen text berupa novel dilakukan
setelah melakukan pembobotan kata.. Proses klasifikasi dilakukan dengan memetakan
kata pada novel ke daftar kata yang mewakili dari genre yang ada di dalam data
resource, kemudian dihitung nilai kemiripan kata yang didapat dari proses TF-IDF
dengan menjumlahkan bobot setiap kata yang sama dengan daftar kata pada data
resource,dan Kemudian akan diklasifikasikan tepat ke salah satu genre yang memiliki
nilai kemiripan tertinggi atau terbesar. Hasil dari tahapan pembobotan kata
menggunakan TF-IDF dapat dilihat pada tabel 3.8 dan hasil pengklasifikasian dapat
dilihat pada tabel 3.9.
Tabel 3.6 Hasil Pembobotan Kata.
33
Tabel 3.7 Hasil Pengklasifikasian Genre Novel.
35
Dari hasil tabel 3.7 dapat dilihat hasil dari pengklasifikasian genre dengan
menghasilkan genre romantis sebagai hasil dari pengklasifikasian,karena memiliki
nilai tertinggi dari hasil kemiripan antara TF-IDF dengan dataresource.
3.3.Perancangan Tampilan Antarmuka
Perancangan tampilan antarmuka bertujuan untuk menggambarkan ide tampilan dari
sistem yang dibuat.
3.3.1. Rancangan tampilan halaman utama.
Rancangan halaman utama ini berfungsi untuk menampilkan halaman utama yang
berisikan menubar, seperti home, data resource,about. Dibagian atas terdapat sliding
picture dan button lanjut proses untuk masuk ke halaman proses. Pada rancangan
halaman utama ini nantinya akan terdapat penjelasan singkat tentang novel dan
penjelasan stemming dan TF-IDF. Dapat dilihat pada gambar 3.6.
Gambar 3.6 Rancangan Tampilan Halaman Utama
Selamat Datang
Penjelasan
Novel
Penjelasan
TF-IDF
Penjelasan
Stemming
Footer
Lanjut Proses
Title Menu Bar 1 Menu Bar 2 Menu Bar 3
3.3.2. Rancangan tampilan halaman dataresource.
Rancangan tampilan data resource berfungsi untuk menampilkan kata-kata yang
mewakili dari setiap genre yang ada. Kemudian ditampilkan dalam bentuk tree.
Rancangan tampilan halaman dataresource dapat dilihat pada gambar 3.9.
Gambar 3.7 Rancangan Halaman Data Resource
3.3.3. Rancangan tampilan halaman about.
Rancangan tampilan halaman about berfungsi untuk menampilkan perkenalan singkat
pembuat sistem serta penjelasan singkat tentang sistem tersebut. Rancangan halaman
about dapat dilihat pada gambar 3.10
Gambar 3.8 Rancangan Tampilan Halaman About. Sub Menu
Data Resource
Title Menu bar
1
Menu bar 2
Menu bar 3
Footer
Description of
picture
pictures
Footer
37
3.3.4. Rancangan tampilan halaman proses.
Rancangan tampilan proses berfungsi untuk melakukan proses serta melihat hasil
proses. Pada halaman ini terdapat form untuk mengisi judul novel, pengarang novel,
dan sinopsis dari novel tersebut dan terdapat juga tombol submit untuk melakukan
proses setelah mengisi semua form. Rancangan tampilan halaman proses dapat dilihat
pada gambar 3.11. setelah melakukan pengisian form dan menekan tombol submit
maka akan diproses untuk mendapatkan hasil. Rancangan tampilan hasil proses dapat
dilihat pada gambar 3.12 dan rancangan tampilan halaman detail hasil dapat dilihat
pada gambar 3.13.
3.9 Rancangan Tampilan Halaman Proses
Title Menu Bar 1 Menu Bar 2 Menu Bar 3
Footer Input Judul Novel
Input Pengarang
Input Sinopsis
3.10 Rancangan Tampilan Halaman Hasil Proses
3.11 Rancangan Tampilan Halaman Detail Proses
Pada rancangan tampilan halaman detail proses diatas, terdapat kolom-kolom yang
menunjukan genre dari hasil klasifikasi, disini juga terdapat kolom untuk
menampilkan perhitungan dari hasil klasifikasi yang didapat tersebut.
result
horror inspiratif misteri romantis
no kata TF-IDF horror inspirasi misteri romantis
keluar ok
Judul Pengara Sinopsis
Genre Horor
Horror Inspiratif Misteri Romantis
keluar ok AAAA
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Tahapan yang dilakukan setelah analisis dan perancangan sistem adalah implementasi
dan pengujian sistem. Tahapan ini diperlukan untuk mengetahui apakah media
Teknologi Informasi tersebut berhasil atau tidak. Berikut merupakan hasil
implementasi dan pengujian dari sistem yang sudah dibangun.
4.1Implementasi Sistem
Sesuai dengan hasil analisis dan perancangan sistem yang telah dibuat, dilakukan
implementasi perancangan menjadi aplikasi pembelajaran yang ditujukan untuk
membantu pengklasifikasian novel sesuai dengan genre menggunakan metode
TF-IDF, dengan bahasa pemrograman C#.
4.1.1 Spesifikasi Perangkat Keras dan Perangkat Lunak yang Digunakan
Sistem dibuat di dalam lingkungan perangkat keras yang memiliki spesifikasi sebagai
berikut:
1. Processor intel® Core(TM)2 Solo CPU U3500 @1.40GHz
2. Memory RAM yang digunakan 4 GB.
3. Kapasitas Hardisk 500 GB.
Selain perangkat keras, sistem juga dibuat dalam lingkungan spesifikasi perangkat
lunak sebagai berikut:
1. Windows 7 Ultimate.
2. Software Microsoft Visual Studio 2010.
3. Bahasa pemrograman C#, menggunakan framework ASP.NET MVC.net versi 3
4.1.2 Tampilan Halaman utama
Tampilan halaman utama aplikasi merupakan tampilan desain user interface ketika
aplikasi dijalankan. Pada tampilan utama terdapat 3 menu bar yaitu home, data
resource, dan about. Pada halaman ini terdapat juga image slider dimana terdapat
button lanjut proses untuk masuk ke halaman input data novel. Pada halaman ini juga
terdapat penjelasan mengenai novel, TF-IDF dan stemming. tampilannya dapat dilihat
pada gambar 4.1.
Gambar 4.1 Tampilan Halaman Utama
4.1.3 Tampilan halaman data resource
Pada halaman data resource terdapat sebuah tree yang berisikan kata-kata yang
mewakili dari setiap genre novel yang diperoleh dari Kamus Tesaurus Pusat Bahasa.
41
4.2Tampilan Halaman Data Resource
4.1.4 Tampilan halaman about
Pada halaman ini berisikan tentang profil dari pembuat sistem klasifikasi novel
berdasarkan genre. Tampilannya dapat dilihat pada gambar 4.3.
4.1.5 Tampilan halaman proses
Pada halaman ini terdapat form untuk menginput data novel berupa judul novel,
pengarang dan sinopsis dari novel. Pengguna harus mengisi form judul, pengarang
dan sinopsis novel dengan lengkap untuk selanjutnya diproses oleh sistem dengan
menekan tombol submit. Tampilan halaman proses dapat dilihat pada gambar 4.4
Gambar 4.4 Tampilan Halaman Proses
Setelah semua form terisi dan tombol submit ditekan maka hasilnya akan
ditampilkan secara pop up. Pada halaman ini terdapat empat kotak yang merupakan
genre dari novel. Hasil klasifikasi genre yang dimaksud akan ditunjukan oleh kotak
yang berwarna hijau. Dan terdapat hasil perhitungan dari jumlah kata dasar pada
sinopsis yang mewakili dari genre tersebut. Tampilan hasil dapat dilihat pada gambar
43
Gambar 4.5 Tampilan Hasil Proses
Setelah tampilan hasil proses muncul, maka kita dapat melihat detail dari hasil
tersebut dengan mengklik point yang terdapat pada panel hasil yang terpilih sebagai
hasil genre (panel yang berwarna hijau). Berikut tampilan detail hasil pada gambar
4.6.
4.2Hasil Pengujian Sistem
Pengujian sistem dilakukan dengan mengambil 100 novel online secara acak, Setelah
diproses maka diperoleh hasil berupa genre novel. Hasil pengujian dapat dilihat pada
tabel 4.1
51
94 00:00 Saat Hantu Muncul
Horror 2 0 0 0 True
95 Hantu Penari Horror 6 0 0 2 True
96 Pasien Terakhir
Horror 7 0 0 0 True
97 The Bastard Legacy; Warisan Legendaris para Bedebah
Horror 12 4 16 7 False
98 Death on Camera
Horror 8 0 4 2 True
99 Berikutnya Kau yang Mati
Horror 13 2 0 4 True
100 R.I.S.A.R.A Horror 11 0 2 7 True
Dari tabel 4.1 terlihat bahwa hasil klasifikasi tidak sepenuhnya akurat. Rata-rata
tingkat akurasi keberhasilan klasifikasi dapat dilihat dengan perhitungan :
BAB 5
KESIMPULAN DAN SARAN
8.1Kesimpulan
Dari hasil analisis dan pengujian yang dilakukan pada aplikasi dari bab sebelumnya,
dapat disimpulkan bahwa :
1. Metode TF-IDF dapat digunakan dalam membentuk pengklasifikasian novel
berdasarkan genre.
2. Text Mining dengan gabungan metode TF-IDF dapat menghitung nilai
similaritas dengan genre yang ada didalam data resource. Untuk menghasilkan
pengklasifikasian novel sesuai genre.
3. Hasil klasifikasi genre novel sangat bergantung pada daftar kata yang ada pada
data resource. Kata-kata yang tidak mewakili genre dengan baik dapat
menghasilkan klasifikasi yang salah.
8.2Saran
Adapun saran-saran yang untuk penelitian maupun pengembangan berikutnya adalah :
1. Dalam menginput kata yang mewakili genre harus menggunakan
kata-kata yang sangat spesifik agar hasil dari pengklasifikasian dapat lebih baik
lagi.
2. Ada baiknya untuk penelitian selanjutnya pengklasifikasian genre tidak hanya
dilakukan berdasarkan sinopsis saja.
3. Pada penelitian selanjutnya juga dapat diterapkan teknik-teknik yang lain
untuk dapat mendukung pengklasifikasian novel sesuai genre yang ada dengan
DAFTAR PUSTAKA
Agusta, L. 2009 . Perbandingan Algoritma Stemming Porter Dengan Algoritma
Nazief dan Adriani untuk Stemming Dokumen Teks Bahasa Indonesia.
KonferensiNasional Sistem dan Informatika 31:196-198.
Berry, M.W. & Kogan, J. 2010. Text Mining Aplication and theory. WILEY: United
Kingdom.
Do, D. T., Hui, C. S., & Fong, A.C.M. 2006. Associative Feature Selection for Text
Mining. International Journal of Information Technology 12(4): 59-58.
Februariyanti, Herny. 2012. Klasifikasi Dokumen Berita Teks Bahasa Indonesia
Menggunakan Ontologi.
Feldman, R & Sanger, J. 2007. The Text Mining Handbook: Advanced Approaches
In Analyzing Unstructured Data. Cambridge University Press: New York.
Forbes, Jamie M. (1998). "Fiction Dictionary". In Herman, Jeff, Writer's Guide to
Book Editors, Publishers, and Literary Agents 1999–2000, pp. 861–871.
Rocklin, California: Prima Publishing.
Harlian, Milka. 2006. Machine Learning Text Kategorization. Austin : University of
Texas.
Hearst, Marti. 2003. What Is Text Minning?. SIMS,UC Berkeley.
http://www.sims.berkeley.edu/~hearst/text.mining.html . Diakses tanggal 25