iii ABSTRACT
BRYAN NURJAYANTI. Shorea Identification Using k-Nearest Neighbour Based on Morphological Characteristics of Leaves. Supervised by AZIZ KUSTIYO.
Dipterocarpaceae is a group of tropical plants that is used in a timber industry. One of Dipterocarpaceae clans is Shorea, that is the best timber-producing plant in the industrial world. Shorea is difficult to be identified because it has a lot of diversity. The inability to recognize Shorea in forest will enlarge the exploitation of Shorea that has a good timber quality, and silviculture work becomes less of the target because it is not known which Shorea species that will extinct.
Shorea tree is usually identified by using the stems, leaves, fruits, and flowers. However, leave is used for the identification in this research because it tends to be available as a source of observation at anytime. The leaves in this reasearch are the collection from Bogor Botanical Gardens. Data are obtained by manual calculating to get the characteristics of the leaves. The obtained data will be processed using k-Nearest Neighbor to get the closeness of new data and training data.
The leaves that are included in this research are Shorea multiflora, palembanica, balangeran, lepida and assamica, each one has 10 data. Each set of data has 10 attributes that support the leaf characteristics. From the whole data, Shorea are divided into five subsets including data training and data testing for each subset. This research has two experiments the first experiment without normalization produces 84% accuracy and the second experiment with a normalization produces 100% accuracy.
1 PENDAHULUAN
Latar Belakang
Dipterocarpaceae adalah sekelompok tumbuhan hutan hujan tropis yang dimanfaatkan dalam bidang perkayuan. Kelompok famili Dipterocarpaceae yang digunakan dalam perkayuan adalah meranti merah, meranti putih, dan meranti kuning dari jenis Shorea, Anisoptera dan Parashorea. Dipterocarpaceae
tumbuh dibagian barat Indonesia, Malaysia, Brunei, Filipina dan penyebarannya ke arah timur sampai dengan Nugini (Irian Jaya dan Papua Nugini).
Dipterocarpaceae sulit untuk diidentifikasi terutama di Kalimantan yang memiliki jenis terbanyak. Ketidakmampuan untuk mengenal individu Dipterocarpaceae di hutan mem-perbesar terjadinya eksploitasi Dipterocar-paceae khususnya jenis Shorea yang memiliki kualitas kayu yang baik dan pekerjaan silvikultur kurang menjadi sasaran karena tidak diketahui jenis Dipterocarpaceae yang akan punah (Newman et al.1999).
Shorea adalah salah satu marga tumbuhan penghasil kayu terbaik dalam dunia perindustrian. Dengan nilai ekonomi yang tinggi mengakibatkan eksploitasi besar-besaran pohon Shorea. Hal ini dapat berdampak kepunahan terhadap pohon Shorea dan menyebabkan kerusakan hutan.
Model identifikasi daun Shorea yang akan dikembangkan dapat digunakan untuk mengenal daun Shorea. Identifikasi ini dilakukan agar tidak menyebabkan kesalahan pemilihan kayu yang tidak tepat dan mengurangi pertumbuhan jenis kayu dengan sifat-sifat yang tidak diinginkan. Sifat-sifat itu misalnya kualitas kayu yang rendah, pertumbuhan lambat, tajuk lebar yang jarang mencapai ukuran kayu, atau jenis pilihan yang tidak cocok untuk kondisi tanah tertentu.
Penentuan identifikasi pohon Shorea, biasanya menggunakan batang, daun, buah, dan bunga. Namun penelitian ini menggunakan daun sebagai bahan identifikasi dikarenakan daun cenderung tersedia sebagai sumber pengamatan sepanjang waktu. Bila meng-gunakan batang, batang pohon akan berubah warna atau kedalaman alur sejalan dengan bertambahnya umur pohon.
Salah satu metode yang digunakan untuk membangun model klasifikasi dalam
mengidentifikasi daun Shorea adalah k-Nearest Neighbour. k-Nearest Neighbour merupakan teknik yang lebih fleksibel karena mampu menglasifikasikan data uji ke dalam kelas label dengan cara mencari data latih yang relatif sama dengan data uji (Tan et al. 2006).
Tujuan
Penelitian ini bertujuan untuk menerapkan k-nearest Neighbour dalam mengidentifikasi jenis Shorea.
Ruang Lingkup
Ruang lingkup penilitian ini meliputi :
1 Daun yang diteliti hanya daun Shorea multiflora, palembanica, balangeran, lepida dan assamica.
2 Difokuskan untuk mengidentifikasi daun Shorea dengan mengidentifikasi karakteristik morfologi daun.
3 Data yang digunakan adalah data hasil pengukuran manual terhadap daun Shorea. 4 Daun Shorea yang digunakan diambil dari
beberapa koleksi Kebun Raya Bogor. Manfaat
Model identifikasi daun Shorea diharapkan dapat membantu dalam mengidentifikasi jenis
Shorea.
TINJAUAN PUSTAKA
Shorea
Shorea adalah salah satu marga dari Dipterocarpaceae penghasil kayu terbaik dalam dunia perindustrian. Dengan nilai ekonomi yang tinggi mengakibatkan eksploitasi besar-besaran yang dapat berdampak kepunahan terhadap pohon Shorea dan menyebabkan kerusakan hutan.
Shorea memiliki sekitar 194 jenis. Persebarannya meliputi 1 jenis di Jawa, 1 atau 2 jenis di Sulawesi, 3 jenis di Maluku dan sisanya menyebar kearah timur sampai Maluku (Indonesia) dan tidak meluas ke Cina bagian selatan (Newman et al. 1999).
1 PENDAHULUAN
Latar Belakang
Dipterocarpaceae adalah sekelompok tumbuhan hutan hujan tropis yang dimanfaatkan dalam bidang perkayuan. Kelompok famili Dipterocarpaceae yang digunakan dalam perkayuan adalah meranti merah, meranti putih, dan meranti kuning dari jenis Shorea, Anisoptera dan Parashorea. Dipterocarpaceae
tumbuh dibagian barat Indonesia, Malaysia, Brunei, Filipina dan penyebarannya ke arah timur sampai dengan Nugini (Irian Jaya dan Papua Nugini).
Dipterocarpaceae sulit untuk diidentifikasi terutama di Kalimantan yang memiliki jenis terbanyak. Ketidakmampuan untuk mengenal individu Dipterocarpaceae di hutan mem-perbesar terjadinya eksploitasi Dipterocar-paceae khususnya jenis Shorea yang memiliki kualitas kayu yang baik dan pekerjaan silvikultur kurang menjadi sasaran karena tidak diketahui jenis Dipterocarpaceae yang akan punah (Newman et al.1999).
Shorea adalah salah satu marga tumbuhan penghasil kayu terbaik dalam dunia perindustrian. Dengan nilai ekonomi yang tinggi mengakibatkan eksploitasi besar-besaran pohon Shorea. Hal ini dapat berdampak kepunahan terhadap pohon Shorea dan menyebabkan kerusakan hutan.
Model identifikasi daun Shorea yang akan dikembangkan dapat digunakan untuk mengenal daun Shorea. Identifikasi ini dilakukan agar tidak menyebabkan kesalahan pemilihan kayu yang tidak tepat dan mengurangi pertumbuhan jenis kayu dengan sifat-sifat yang tidak diinginkan. Sifat-sifat itu misalnya kualitas kayu yang rendah, pertumbuhan lambat, tajuk lebar yang jarang mencapai ukuran kayu, atau jenis pilihan yang tidak cocok untuk kondisi tanah tertentu.
Penentuan identifikasi pohon Shorea, biasanya menggunakan batang, daun, buah, dan bunga. Namun penelitian ini menggunakan daun sebagai bahan identifikasi dikarenakan daun cenderung tersedia sebagai sumber pengamatan sepanjang waktu. Bila meng-gunakan batang, batang pohon akan berubah warna atau kedalaman alur sejalan dengan bertambahnya umur pohon.
Salah satu metode yang digunakan untuk membangun model klasifikasi dalam
mengidentifikasi daun Shorea adalah k-Nearest Neighbour. k-Nearest Neighbour merupakan teknik yang lebih fleksibel karena mampu menglasifikasikan data uji ke dalam kelas label dengan cara mencari data latih yang relatif sama dengan data uji (Tan et al. 2006).
Tujuan
Penelitian ini bertujuan untuk menerapkan k-nearest Neighbour dalam mengidentifikasi jenis Shorea.
Ruang Lingkup
Ruang lingkup penilitian ini meliputi :
1 Daun yang diteliti hanya daun Shorea multiflora, palembanica, balangeran, lepida dan assamica.
2 Difokuskan untuk mengidentifikasi daun Shorea dengan mengidentifikasi karakteristik morfologi daun.
3 Data yang digunakan adalah data hasil pengukuran manual terhadap daun Shorea. 4 Daun Shorea yang digunakan diambil dari
beberapa koleksi Kebun Raya Bogor. Manfaat
Model identifikasi daun Shorea diharapkan dapat membantu dalam mengidentifikasi jenis
Shorea.
TINJAUAN PUSTAKA
Shorea
Shorea adalah salah satu marga dari Dipterocarpaceae penghasil kayu terbaik dalam dunia perindustrian. Dengan nilai ekonomi yang tinggi mengakibatkan eksploitasi besar-besaran yang dapat berdampak kepunahan terhadap pohon Shorea dan menyebabkan kerusakan hutan.
Shorea memiliki sekitar 194 jenis. Persebarannya meliputi 1 jenis di Jawa, 1 atau 2 jenis di Sulawesi, 3 jenis di Maluku dan sisanya menyebar kearah timur sampai Maluku (Indonesia) dan tidak meluas ke Cina bagian selatan (Newman et al. 1999).
2 penjulang di hutan hujan dari kawasan Paparan
Sunda, dapat tumbuh hingga ketinggian 500 m (Newman et al.1999).
Gambar 1 Pohon Shorea.
Ciri-ciri diagnostik utama pohon Shorea sangat besar dengan pepagan dalam berlapis-lapis atau berwarna coklat merah gelap. Daun menjangat, tidak berlipatan, tidak bentuk perisai, tidak berlukup, 4-18 x 2-8 cm, pangkal daun biasanya simetris, permukaan bawah daun bila mengering pudar, pertulangan sekunder bersirip, 7-25 pasang, terpisah permanen, pada permukaan bawah daun bila mengering warnanya sama seperti helai daun, atau lebih gelap pada Shorea javanica (Newman et al. 1999).
Penelitian ini menggunakan lima jenis Shorea, yaitu:
1 Shorea multiflora
Ciri-ciri utama umumnya berupa pohon kecil sampai sedang dengan buah tanpa sayap. Daun dengan ujung lancip panjang (meruncing), pangkal membundar (membulat), pertulangan daun tembus cahaya bila segar (Newman et al. 1999).
Gambar 2 Daun Shorea multiflora. 2 Shorea palembanica
Ciri-ciri utama habitat tepi sungai, perawakan berbonggol, daun besar, bila
mengering coklat merah (Newman et al. 1999).
Gambar 3 Daun Shorea palembanica. 3 Shorea balangeran
Ciri-ciri utama habitat hutan rawa gambut, ujung daun lancip (meruncing), pangkal daun membundar (membulat), permukaan atas daun bila mengering coklat agak lembayung, permukaan bawah bila mengering coklat kekuning-kuningan. Shorea balangeran merupakan salah satu Shorea yang terancam punah (Newman et al. 1999).
Gambar 4 Daun Shorea balangeran. 4 Shorea lepida
Ciri-ciri utama pohon dewasa memiliki daun agak tipis, lonjong dan runcing. Permukaan atas daun bila mengering coklat agak lembayung, coklat kuning pada tulang daun, coklat pudar pada permukaan bawah daun (Newman et al. 1999).
3 5 Shorea assamica
Ciri-ciri utama daun di bawah permukaan memunyai indumentums sisik-sisik kecil. Daun jorong atau bundar telur, ujung daun lancip pendek (tumpul), pangkal daun membundar, permukaan daun bila mengering coklat dan bila diraba licin (Newman et al. 1999).
Gambar 6 Daun Shorea assamica. K-Fold Cross Validation
Sebelum digunakan, sebuah sistem berbasis komputer harus dievaluasi dalam berbagai aspek. Di antara aspek-aspek ini, validasi kinerja bisa merupakan yang paling penting. (Fu 1994).
Metode k-fold cross validation membagi sebuah himpunan contoh secara acak menjadi k himpunan bagian lain (subset) yang paling bebas. Dilakukan ulangan sebanyak k kali untuk pelatihan dan pengujian. Pada setiap ulangan disisipkan setiap subset untuk pengujian dan subset lainnya untuk pelatihan (Stone 1974 diacu dalam Fu 1994).
Tingkat akurasi dihitung dengan membagi jumlah keseluruhan klasifikasi yang benar dengan jumlah semua instance pada data awal (Han & Kamber 2001).
∑ ∑
Normalisasi
Pada perhitungan jarak Euclidean, atribut berskala panjang dapat memunyai pengaruh lebih besar daripada atribut berskala pendek. Untuk mencegah hal tersebut perlu dilakukan
normalisasi terhadap nilai atribut (Larose 2005 diacu dalam Faiza 2009).
Salah satu metode normalisasi adalah min-max normalization yang diterapkan untuk fitur numerik. Formula untuk normalisasi atribut X adalah:
Dengan X* adalah nilai setelah dinormalisasi, X adalah nilai sebelum dinormalisasi, min(X) adalah nilai minimum dari fitur, dan max(X) adalah nilai maksimum dari suatu fitur.
Confusion Matrix
Evaluasi model klasifikasi berdasar pada proporsi antara data uji yang diprediksi secara tepat dengan total seluruh prediksi (Tan et al. 2006). Informasi mengenai klasifikasi sebenarnya (aktual) dengan klasifikasi hasil prediksi disajikan dalam bentuk tabel yang disebut confusion matrix seperti diperlihatkan pada Tabel 1.
Tabel 1 Confusion matrix dua kelas Kelas hasil prediksi Kelas aktual Kelas 1 Kelas 2
Kelas 1 a b
Kelas 2 c d
Jumlah baris dan kolom pada tabel bergantung pada banyaknya kelas target. Akurasi merupakan proporsi jumlah prediksi yang tepat. Contoh perhitungan akurasi untuk tabel tersebut adalah:
KNN (K-Nearest Neighbour)
K-Nearest Neighbour merepresentasikan setiap data sebagai titik dalam k-ruang dimensi. Jika ada sebuah data uji maka akan dihitung kedekatan titik data lainnya pada data latih untuk diklasifikasikan berdasarkan kedekatan-nya yang didefinisikan dengan ukuran jarak (Han & Kamber 2006).
4 fungsi jarak. Fungsi jarak yang umumnya
digunakan adalah jarak Euclidean dengan menggunakan rumus sebagai berikut (Larose 2005).
√∑ (
)
,
dengan
x = x1,x2, … , xm menyatakan data uji, y = y1,y2, … , ym menyatakan data latih dan xi-yi = selisih data uji dengan data latih.Penelitian ini, terdapat dua jenis data yang digunakan, yaitu data numerik dan data nominal. Data nominal atau sering disebut juga data kategori yaitu data yang diperoleh melalui pengelompokan objek berdasarkan kategori tertentu. Walaupun data nominal dapat dinyatakan dalam bentuk angka, namun angka tersebut tidak memiliki urutan atau makna matematis sehingga tidak dapat dibandingkan (Dharma, 2008).
Untuk data nominal atau yang disebut kategori, penggunaan jarak Euclidean tidak tepat, sebaliknya dapat didefinisikan dengan sebuah fungsi yang digunakan untuk membandingkan nilai data uji dan data latih. Untuk menghitung jarak nominal menggunakan rumus sebagai berikut (Larose 2005).
{
Yang berarti bahwa jika data latih sama dengan data uji maka jaraknya 0, selainnya jaraknya 1.
Untuk menggabungkan kedua jarak semua variabel, dilakukan aggregate ketidaksamaan berat rata-rata dari jarak masing-masing fitur dengan menggunakan rumus sebagai berikut (Teknomo, 2006).
∑ ∑
,
dengan k merupakan variabel fitur, ij selisih data latih dan data uji, Sijk merupakan kesamaan
dan ketidaksamaan antara objek dimana Wijk
bernilai 1 untuk nilai numerik dan 0.5 untuk nilai nominal. Nilai pembobotan ini diberikan agar jarak fitur nominal tidak terlalu mendominasi hasil perhitungan.
METODOLOGI PENELITIAN
Kerangka Penelitian
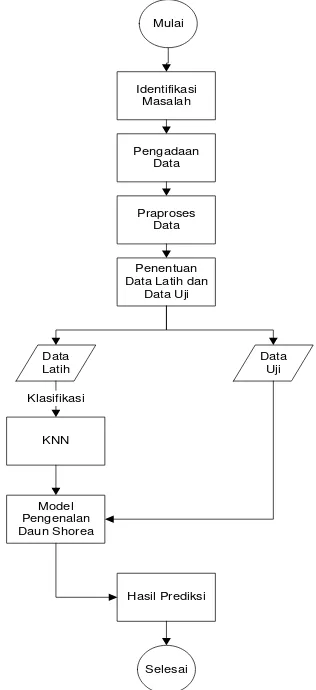
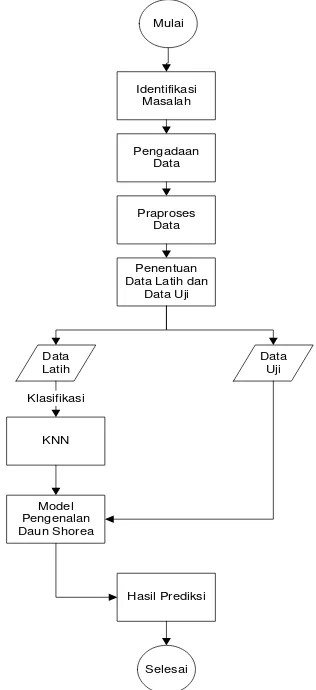
Penelitian ini memunyai beberapa tahapan untuk mengetahui tingkat akurasi yang diperoleh menggunakan algoritme k-Nearest Neighbour dalam pengidentifikasian daun Shorea. Tahapan proses tersebut akan disajikan pada Gambar 7.
Gambar 7 Diagram alur pembuatan sistem. Identifikasi Masalah
Tahap identifikasi permasalahan yang meliputi tahap pemilihan masalah, identifikasi, tujuan, dan sumber pengetahuan. Masalah yang ada saat ini pihak rimbawan atau pekerja di hutan masih mengalami kesulitan dalam mengidentifikasi daun Shorea. Kesalahan dalam mengidentifikasi ini dapat menyebabkan kesalahan pemilihan kayu yang tidak tepat.
4 fungsi jarak. Fungsi jarak yang umumnya
digunakan adalah jarak Euclidean dengan menggunakan rumus sebagai berikut (Larose 2005).
√∑ (
)
,
dengan
x = x1,x2, … , xm menyatakan data uji, y = y1,y2, … , ym menyatakan data latih dan xi-yi = selisih data uji dengan data latih.Penelitian ini, terdapat dua jenis data yang digunakan, yaitu data numerik dan data nominal. Data nominal atau sering disebut juga data kategori yaitu data yang diperoleh melalui pengelompokan objek berdasarkan kategori tertentu. Walaupun data nominal dapat dinyatakan dalam bentuk angka, namun angka tersebut tidak memiliki urutan atau makna matematis sehingga tidak dapat dibandingkan (Dharma, 2008).
Untuk data nominal atau yang disebut kategori, penggunaan jarak Euclidean tidak tepat, sebaliknya dapat didefinisikan dengan sebuah fungsi yang digunakan untuk membandingkan nilai data uji dan data latih. Untuk menghitung jarak nominal menggunakan rumus sebagai berikut (Larose 2005).
{
Yang berarti bahwa jika data latih sama dengan data uji maka jaraknya 0, selainnya jaraknya 1.
Untuk menggabungkan kedua jarak semua variabel, dilakukan aggregate ketidaksamaan berat rata-rata dari jarak masing-masing fitur dengan menggunakan rumus sebagai berikut (Teknomo, 2006).
∑ ∑
,
dengan k merupakan variabel fitur, ij selisih data latih dan data uji, Sijk merupakan kesamaan
dan ketidaksamaan antara objek dimana Wijk
bernilai 1 untuk nilai numerik dan 0.5 untuk nilai nominal. Nilai pembobotan ini diberikan agar jarak fitur nominal tidak terlalu mendominasi hasil perhitungan.
METODOLOGI PENELITIAN
Kerangka Penelitian
Penelitian ini memunyai beberapa tahapan untuk mengetahui tingkat akurasi yang diperoleh menggunakan algoritme k-Nearest Neighbour dalam pengidentifikasian daun Shorea. Tahapan proses tersebut akan disajikan pada Gambar 7.
Gambar 7 Diagram alur pembuatan sistem. Identifikasi Masalah
Tahap identifikasi permasalahan yang meliputi tahap pemilihan masalah, identifikasi, tujuan, dan sumber pengetahuan. Masalah yang ada saat ini pihak rimbawan atau pekerja di hutan masih mengalami kesulitan dalam mengidentifikasi daun Shorea. Kesalahan dalam mengidentifikasi ini dapat menyebabkan kesalahan pemilihan kayu yang tidak tepat.
5 akuisisi pengetahuan pakar dan pustaka yang
mendukung. Pengadaan Data
Daun Shorea yang digunakan didapatkan dari Kebun Raya Bogor. Penelitian ini menggunakan beberapa atribut yang mencirikan bentuk morfologi daun Shorea. Data yang digunakan merupakan data dari perhitungan manual beberapa jenis daun Shorea.
Data dalam penelitian ini memunyai beberapa fitur, yaitu:
1 Panjang daun, yaitu panjang daun diukur dari pangkal daun hingga ujung daun. 2 Lebar daun, yaitu lebar daun diukur
berdasarkan permukaan daun paling lebar.
Gambar 8 Lebar dan panjang daun 3 Bentuk tulang daun, yaitu susunan tulang
cabang pada daun. Bentuk tulang daun dapat dibedakan menjadi :
a Menempel : ujung tulang cabang bagian dalam sebelah kanan bertemu dengan ujung tulang cabang bagian dalam sebelah kiri.
b Tidak menempel : ujung tulang cabang bagian dalam sebelah kanan tidak bertemu dengan ujung tulang cabang bagian dalam sebelah kiri.
4 Permukaan daun, yaitu keadaan permukaan daun bagian atas dan bawah, seperti : a Atas bawah halus
b Atas halus bawah kasar c Atas bawah kasar d Atas kasar bawah halus
5 Ujung daun, yaitu bentuk ujung daun. Beberapa bentuk ujung daun di antaranya: a Runcing, jika kedua tepi daun di kanan
kiri ibu tulang sedikit demi sedikit menuju ke atas dan pertemuannya pada puncak daun melancip.
b Meruncing, seperti pada ujung yang runcing, tetapi titik pertemuan kedua tepi daunnya jauh lebih tinggi dari dugaan, hingga ujung daun nampak sempit panjang dan runcing.
c Tumpul, tepi daun yang semula masih agak jauh dari ibu tulang membentuk sudut yang tumpul.
d Membulat, seperti pada ujung yang tumpul, tetapi tidak terbentuk sudut sama sekali, hingga ujung daun merupakan semacam suatu busur.
Gambar 9 Ujung daun
6 Pangkal daun, yaitu bentuk pangkal daun.
Gambar 10 Pangkal daun.
7 Keliling daun, yaitu keliling tepi daun yang diukur dengan menggunakan benang.
6 daun kemudian dibagi empat. Contoh
pengukuran luas :
9 Sudut antar tulang daun, yaitu sudut antara ibu tulang daun dengan tulang cabang daun sebelah kanan atau kiri yang diukur menggunakan busur.
10 Jumlah tulang daun, yaitu jumlah tulang cabang daun sebelah kanan dan tulang cabang daun sebelah kiri.
Praproses Data
Tahapan yang dilakukan dalam praproses di antaranya pengolahan data dengan fitur nominal menggunakan nominal distance seperti bentuk ujung daun, permukaan daun, bentuk tulang daun dan bentuk pangkal daun. Praproses data juga dilakukan pada tahap awal normalisasi data numerik agar didapatkan range antara nol hingga satu. Hal ini dilakukan untuk menghindari perbedaan range yang terlalu besar antar fitur.
Penentuan Data Latih dan Data Uji
Pada penelitian ini pembagian data latih dan data uji akan dilakukan dengan menggunakan teknik k-fold cross validation dengan nilai k = 5.
Klasifikasi
Teknik klasifikasi yang akan digunakan menggunakan k–Nearest Neighbour. Teknik k– Nearest Neighbour mencari jarak terdekat antara data yang akan dievaluasi dengan k
tetangga (neighbour) terdekatnya dalam data pelatihan.
Model Daun Shorea
Tahapan ini merupakan tahapan yang paling penting karena pada tahap ini teknik klasifikasi diaplikasikan terhadap data yang sudah diperoleh. Teknik klasifikasi yang digunakan menggunakan k–Nearest Neighbour. Langkah-langkah pada metode tersebut yaitu:
Hitung jarak Euclidean: pada tahap ini setiap data uji akan dihitung jaraknya ke setiap data latih untuk mengetahui ukuran kedekatan atau ukuran kesamaan antara data uji dengan data latih.
Hitung jarak nominal: pada tahap ini dilakukan proses pengubahan beberapa fitur yang bersifat nominal dilambangkan dengan nilai numerik sehingga mempermudah perbandingan data uji terhadap data latih.
Aggregate (menggabungkan) data: pada tahap ini data pengolahan nominal dan pengolahan menggunakan Euclidean digabungkan.
Penentuan nilai k: pada k–Nearest Neighbour penentuan nilai k yang tepat sangat penting untuk menunjukkan jumlah tetangga terdekat. Setelah didapatkan hasil identifikasi, selanjutnya dilakukan evaluasi klasifikasi yang dihasilkan metode k-Nearest Neighbour. Hasil Prediksi
Pada tahap akhir ini diharapkan data testing yang dimasukan akan terklasifikasi pada kelas yang benar.
Lingkungan Pengembangan
Perangkat lunak yang digunakan dalam penelitian yaitu :
Windows XP Home Edition Service Pack 3
XAMPP Version 1.7.1
Notepad v5.1.1
Microsoft Office Excel 2007
Perangkat keras yang digunakan dalam penelitian yaitu :
Processor Intel Atom 1.66 GHz
RAM 1.00 GB
Harddisk kapasitas 150 GB Gambar 11 Sudut daun
7 HASIL DAN PEMBAHASAN
Praproses
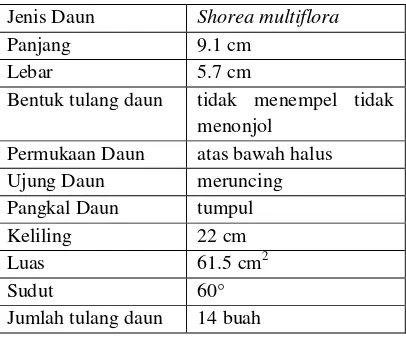
Data yang digunakan pada penelitian ini merupakan data hasil perhitungan manual fitur-fitur morfologi daun Shorea yang diambil dari beberapa koleksi di Kebun Raya Bogor. Berikut disajikan contoh data hasil perhitungan manual dan fitur-fitur yang diperlihatkan pada Tabel 2. Tabel 2 Data daun
Jenis Daun Shorea multiflora
Panjang 9.1 cm
Lebar 5.7 cm
Bentuk tulang daun tidak menempel tidak menonjol
Permukaan Daun atas bawah halus
Ujung Daun meruncing
Pangkal Daun tumpul
Keliling 22 cm
Luas 61.5 cm2
Sudut 60°
Jumlah tulang daun 14 buah
Proses pengambilan data ini dilakukan selama satu bulan. Data yang didapat sebanyak 50 data dari perhitungan manual berdasarkan fitur-fitur yang telah ditetapkan sesuai dengan morfologi daun. Data yang digunakan sebanyak 50 data meliputi 10 data Shorea multiflora, 10 data Shorea palembanica, 10 data Shorea balangeran, 10 data Shorea assamica, dan 10 data Shorea lepida.
Berdasarkan fitur-fitur yang digunakan terdapat 4 fitur yang bersifat nominal, yaitu fitur bentuk tulang daun, permukaan daun, ujung daun, dan pangkal daun. Fitur-fitur ini memiliki selang nilai yang berbeda. Pada Tabel 3 disajikan selang nilai yang terdapat di setiap fitur.
Tabel 3 Selang nilai fitur daun No Nama Fitur
1 Bentuk Tulang Daun
a. tidak menempel tidak menonjol b. menempel, tidak menonjol
c. tidak menempel, bagian bawah menonjol bernilai nominal dilambangkan dengan angka untuk memudahkan perhitungan algoritme. Pada Tabel 4 disajikan konversi fitur-fitur nominal.
Tabel 4 Konversi fitur-fitur nominal
No Nama Fitur
Nilai Konversi
1 Bentuk Tulang Daun -
a. tidak menempel, tidak menonjol
1
b. menempel, tidak menonjol
2
c. tidak menempel, bagian bawah menonjol
8 Contoh normalisasi untuk record pertama
berdasarkan rumus normalisasi adalah:
Percobaan pertama (tanpa normalisasi) Dari banyaknya data yang diperoleh sebanyak 50 record, dibagi menjadi 5 subset yang setiap subset berisi 2 record dari setiap jenis daun.
Percobaan pertama menggunakan 40 record sebagai data latih yang berisi subset 1, 2, 3, dan 4. Subset 5 yang berisi 10 record dijadikan data uji. Percobaan terus dilakukan hingga setiap subset pernah menjadi data uji. Susunan data latih dan data uji pada percobaan disajikan pada Tabel 5.
Tabel 5 Susunan data latih dan data Uji Iterasi Pelatihan Pengujian Iterasi pertama S2,S3,S4,S5 S1 Iterasi kedua S1,S3,S4,S5 S2 Iterasi ketiga S1,S2,S4,S5 S3 Iterasi keempat S1,S2,S3,S5 S4 Iterasi kelima S1,S2,S3,S4 S5
Data tersebut kemudian diterapkan dalam metode k-Nearest Neighbour melalui tahap-tahap berikut ini:
1 Setiap record data uji dihitung jaraknya ke setiap record data latih untuk mengetahui kedekatan antara data uji dengan data latih. Untuk data bertipe numerik, selisih antara data uji dengan data latih adalah pengurangan nilai data uji dengan nilai data latih. Untuk data bertipe nominal, data diolah menggunakan nominal distance. Bila data uji sama dengan data latih maka bernilai nol dan bila data uji berbeda dengan data latih maka bernilai 1.
2 Digabungkan hasil perhitungan yang menggunakan jarak Euclidean dan nominal distance dengan menggunakan rumus aggregate. Memberikan bobot 1 pada hasil perhitungan Euclidean dan bobot 0.5 pada hasil perhitungan nominal. Pemberian bobot 0.5 pada perhitungan nominal agar tidak mendominasi hasil perhitungan. 3 Penentuan nilai k tetangga terdekat pada
percobaan pertama dilakukan dengan
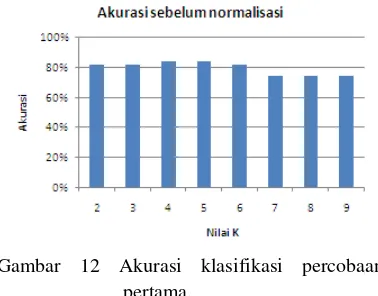
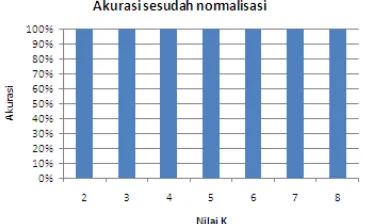
mencoba nilai k mulai dari 2 sampai 9 dalam metode k-Nearest Neighbour. Akurasi klasifikasi untuk nilai k=2 sampai k=9 diperlihatkan pada Gambar 12.
Gambar 12 Akurasi klasifikasi percobaan pertama.
Berdasarkan gambar tersebut (Gambar 12) akurasi terbesar yang diperoleh adalah 84% dengan nilai k=4 dan k=5. Untuk mengetahui record yang salah diklasifikasikan digunakan confusion matrix yang diperlihatkan pada Tabel 6.
9 salah diidentifikasi sebagai kelas 3 sebanyak 1
record. Kelas 5 (Shorea Assamica) yang tepat diklasifikasi sebagai kelas 5 sebanyak 10 record, dan tidak ada kelas 1 yang salah diklasifikasi sebagai kelas 2, kelas 3, kelas 4 dan kelas 1. Berdasarkan rumus confusion matrix, besarnya akurasi adalah:
Hasil akurasi setiap iterasi dapat dilihat pada Gambar 13.
Gambar 13 Hasil iterasi tanpa normalisasi. Berdasarkan percobaan pertama dapat disimpulkan iterasi ketiga dan keempat memiliki hasil akurasi paling kecil pada setiap nilai k nya. Kesalahan identifikasi terdapat ketika Shorea palembanica teridentifikasi sebagai Shorea assamica pada iterasi ketiga dan Shorea lepida sebagai Shorea palembanica pada iterasi keempat. Hal ini terjadi karena dipengaruhi kemiripan luas dan panjang data uji terhadap data latih.
Hasil jarak kedekatan diperlihatkan pada Tabel 7 dengan menggunakn iterasi ketiga sebagai contoh.
Tabel 7 Perhitungan jarak tanpa normalisasi
Jarak Kelas Urutan 24.13 Shorea palembanica 9 17.90 Shorea assamica 6 18.12 Shorea assamica 7 Pada perhitungan di atas dapat disimpulkan bahwa Shorea palembanica diidentifikasi sebagai Shorea assamica. Dari percobaan
pertama dapat disimpulkan nilai k terbaik adalah 3 dengan akurasi tertinggi 84%.
Percobaan kedua (dengan normalisasi) Percobaan kedua menggunakan 40 record sebagai data latih yang berisi subset 1, 2, 3, dan 4. Subset 5 yang berisi 10 record dijadikan data uji. Percobaan terus dilakukan hingga setiap subset pernah menjadi data uji. Susunan data latih dan data uji pada percobaan disajikan pada Tabel 5.
Data tersebut kemudian diterapkan dalam metode k-Nearest Neighbour melalui tahap-tahap berikut ini:
1 Normalisasi dilakukan pada setiap fitur hingga didapatkan range antara 0 sampai 1 pada seluruh data. Hal ini dilakukan untuk mengcegah data uji yang nilainya lebih besar dari data latih. Setelah didapatkan hasil normalisasi, lakukan langkah satu seperti percobaan pertama.
2 Digabungkan hasil perhitungan yang menggunakan euclid dan nominal dengan menggunakan rumus aggregate. Memberikan bobot 1 pada hasil perhitungan Euclidean dan bobot 0.5 pada hasil perhitungan nominal. Pemberian bobot 0.5 pada perhitungan nominal agar tidak mendominasi hasil perhitungan. 3 Penentuan nilai k tetangga terdekat pada
percobaan kedua dilakukan dengan mencoba nilai k mulai dari 2 sampai 9 dalam metode k-Nearest Neighbour. Akurasi klasifikasi untuk nilai k=2 sampai k=9 diperlihatkan Gambar 14.
Gambar 14 Akurasi klasifikasi percobaan kedua Berdasarkan gambar tersebut (Gambar 14) akurasi terbesar yang diperoleh adalah 100%. Hal ini disebabkan karena penggunaan
10 normalisasi yang menyamakan range setiap
fitur.
Hasil jarak kedekatan diperlihatkan pada Tabel 8 dengan menggunakan iterasi ketiga sebagai contoh.
Tabel 8 Hasil perhitungan dengan normalisasi
Jarak Kelas Urutan
0.49 Shorea palembanica 2 0.58 Shorea palembanica 3
1.23 Shorea lepida 9
0.62 Shorea palembanica 5 0.69 Shorea palembanica 8 0.58 Shorea palembanica 4 0.67 Shorea palembanica 7 0.63 Shorea palembanica 6 0.39 Shorea palembanica 1 Berdasarkan percobaan kedua dihasilkan akurasi 100% pada setiap nilai k. Hal ini dikarenakan perbedaan bentuk morfologi daun yang memang berbeda dan fitur-fiturnya memang mewakili morfologi daun.
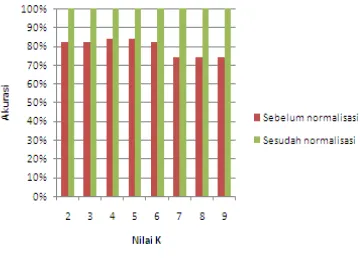
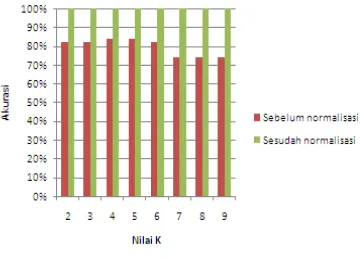
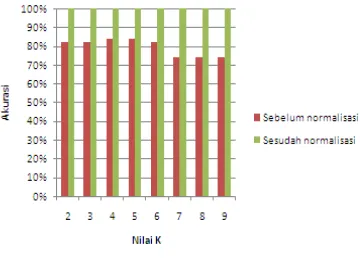
Perbandingan akurasi sebelum dan sesudah normalisasi diperlihatkan pada Gambar 15.
Gambar 15 Perbandingan akurasi. Pada Gambar 16 dapat dilihat bahwa setelah data dinormalisasi memberikan pengaruh yang cukup besar hingga mencapai akurasi 100%.
KESIMPULAN DAN SARAN
Kesimpulan
Dari beberapa percobaan yang dilakukan terhadap data daun Shorea dengan metode k-Nearest Neighbour, diperoleh kesimpulan sebagai berikut:
1. Akurasi terbesar adalah 100% pada percobaan kedua dengan melakukan normalisasi data, sedangkan pada
percobaan pertama tanpa melakukan normalisasi menghasilkan akurasi 84%. 2. Metode k-Nearest Neighbour dapat
diterapkan pada pengidentifikasian daun Shorea.
Saran
Penelitian ini masih memunyai beberapa kekurangan yang dapat diperbaiki pada penelitian selanjutnya. Beberapa saran itu di antaranya:
1. Menganalisis fitur-fitur untuk mengetahui fitur mana yang paling mempengaruhi proses identifikasi jenis Shorea.
2. Memperbanyak jenis daun Shorea agar lebih bervariasi.
3. Memperbanyak fitur-fitur yang digunakan seperti jarak antara daun, arah tulang daun pertama ke kanan atau ke kiri, perbandingan luas daun kanan dan kiri, jumlah tulang daun kanan dan kiri, memperbaiki perhitungan sudut, perhitungan luas dan keliling menggunakan regresi linear.
4. Menyempurnakan perhitungan pada data nominal.
DAFTAR PUSTAKA
Dharma Surya. 2008. Pengolahan dan Analisis Data Penelitian. Jakarta: Direktorat Tenaga Kependidikan, Departemen Pendidikan Nasional.
Faiza Ninon N. 2009. Prediksi Tingkat Keberhasilan Mahasiswa Tingkat I IPB Dengan Metode k-Nearest Neighbour [Skripsi]. Bogor : Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Freivalds R, Ozols M, Mancinska L. 2009. Theoritical Computer Science. Latvia : University of Latvia.
Fu L. 1994. Neural Networks in Computers Intelligence. Singapura: McGraw-Hill.
10 normalisasi yang menyamakan range setiap
fitur.
Hasil jarak kedekatan diperlihatkan pada Tabel 8 dengan menggunakan iterasi ketiga sebagai contoh.
Tabel 8 Hasil perhitungan dengan normalisasi
Jarak Kelas Urutan
0.49 Shorea palembanica 2 0.58 Shorea palembanica 3
1.23 Shorea lepida 9
0.62 Shorea palembanica 5 0.69 Shorea palembanica 8 0.58 Shorea palembanica 4 0.67 Shorea palembanica 7 0.63 Shorea palembanica 6 0.39 Shorea palembanica 1 Berdasarkan percobaan kedua dihasilkan akurasi 100% pada setiap nilai k. Hal ini dikarenakan perbedaan bentuk morfologi daun yang memang berbeda dan fitur-fiturnya memang mewakili morfologi daun.
Perbandingan akurasi sebelum dan sesudah normalisasi diperlihatkan pada Gambar 15.
Gambar 15 Perbandingan akurasi. Pada Gambar 16 dapat dilihat bahwa setelah data dinormalisasi memberikan pengaruh yang cukup besar hingga mencapai akurasi 100%.
KESIMPULAN DAN SARAN
Kesimpulan
Dari beberapa percobaan yang dilakukan terhadap data daun Shorea dengan metode k-Nearest Neighbour, diperoleh kesimpulan sebagai berikut:
1. Akurasi terbesar adalah 100% pada percobaan kedua dengan melakukan normalisasi data, sedangkan pada
percobaan pertama tanpa melakukan normalisasi menghasilkan akurasi 84%. 2. Metode k-Nearest Neighbour dapat
diterapkan pada pengidentifikasian daun Shorea.
Saran
Penelitian ini masih memunyai beberapa kekurangan yang dapat diperbaiki pada penelitian selanjutnya. Beberapa saran itu di antaranya:
1. Menganalisis fitur-fitur untuk mengetahui fitur mana yang paling mempengaruhi proses identifikasi jenis Shorea.
2. Memperbanyak jenis daun Shorea agar lebih bervariasi.
3. Memperbanyak fitur-fitur yang digunakan seperti jarak antara daun, arah tulang daun pertama ke kanan atau ke kiri, perbandingan luas daun kanan dan kiri, jumlah tulang daun kanan dan kiri, memperbaiki perhitungan sudut, perhitungan luas dan keliling menggunakan regresi linear.
4. Menyempurnakan perhitungan pada data nominal.
DAFTAR PUSTAKA
Dharma Surya. 2008. Pengolahan dan Analisis Data Penelitian. Jakarta: Direktorat Tenaga Kependidikan, Departemen Pendidikan Nasional.
Faiza Ninon N. 2009. Prediksi Tingkat Keberhasilan Mahasiswa Tingkat I IPB Dengan Metode k-Nearest Neighbour [Skripsi]. Bogor : Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Freivalds R, Ozols M, Mancinska L. 2009. Theoritical Computer Science. Latvia : University of Latvia.
Fu L. 1994. Neural Networks in Computers Intelligence. Singapura: McGraw-Hill.
ii
IDENTIFIKASI SHOREA MENGGUNAKAN k-NEAREST NEIGHBOUR
BERDASARKAN KARAKTERISTIK MORFOLOGI DAUN
BRYAN NURJAYANTI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Program Studi Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
10 normalisasi yang menyamakan range setiap
fitur.
Hasil jarak kedekatan diperlihatkan pada Tabel 8 dengan menggunakan iterasi ketiga sebagai contoh.
Tabel 8 Hasil perhitungan dengan normalisasi
Jarak Kelas Urutan
0.49 Shorea palembanica 2 0.58 Shorea palembanica 3
1.23 Shorea lepida 9
0.62 Shorea palembanica 5 0.69 Shorea palembanica 8 0.58 Shorea palembanica 4 0.67 Shorea palembanica 7 0.63 Shorea palembanica 6 0.39 Shorea palembanica 1 Berdasarkan percobaan kedua dihasilkan akurasi 100% pada setiap nilai k. Hal ini dikarenakan perbedaan bentuk morfologi daun yang memang berbeda dan fitur-fiturnya memang mewakili morfologi daun.
Perbandingan akurasi sebelum dan sesudah normalisasi diperlihatkan pada Gambar 15.
Gambar 15 Perbandingan akurasi. Pada Gambar 16 dapat dilihat bahwa setelah data dinormalisasi memberikan pengaruh yang cukup besar hingga mencapai akurasi 100%.
KESIMPULAN DAN SARAN
Kesimpulan
Dari beberapa percobaan yang dilakukan terhadap data daun Shorea dengan metode k-Nearest Neighbour, diperoleh kesimpulan sebagai berikut:
1. Akurasi terbesar adalah 100% pada percobaan kedua dengan melakukan normalisasi data, sedangkan pada
percobaan pertama tanpa melakukan normalisasi menghasilkan akurasi 84%. 2. Metode k-Nearest Neighbour dapat
diterapkan pada pengidentifikasian daun Shorea.
Saran
Penelitian ini masih memunyai beberapa kekurangan yang dapat diperbaiki pada penelitian selanjutnya. Beberapa saran itu di antaranya:
1. Menganalisis fitur-fitur untuk mengetahui fitur mana yang paling mempengaruhi proses identifikasi jenis Shorea.
2. Memperbanyak jenis daun Shorea agar lebih bervariasi.
3. Memperbanyak fitur-fitur yang digunakan seperti jarak antara daun, arah tulang daun pertama ke kanan atau ke kiri, perbandingan luas daun kanan dan kiri, jumlah tulang daun kanan dan kiri, memperbaiki perhitungan sudut, perhitungan luas dan keliling menggunakan regresi linear.
4. Menyempurnakan perhitungan pada data nominal.
DAFTAR PUSTAKA
Dharma Surya. 2008. Pengolahan dan Analisis Data Penelitian. Jakarta: Direktorat Tenaga Kependidikan, Departemen Pendidikan Nasional.
Faiza Ninon N. 2009. Prediksi Tingkat Keberhasilan Mahasiswa Tingkat I IPB Dengan Metode k-Nearest Neighbour [Skripsi]. Bogor : Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Freivalds R, Ozols M, Mancinska L. 2009. Theoritical Computer Science. Latvia : University of Latvia.
Fu L. 1994. Neural Networks in Computers Intelligence. Singapura: McGraw-Hill.
11 Kahramanli Humar. 2010. A Novel Distance
Measure For Data Vectors with nominal feature values. USA: World Scientific and Engineering Academy and Society.
Larose Daniel T. 2005. Discovering Knowledge in Data: An Introduction to Data Mining. John Wiley & Sons, Inc.
li Cen, Biswas G. 2002. Unsupervised Learning with Mixed Numeric and Nominal Data. Vol 14. no.4. IEEE Transaction on knowledge and data engineering.
Newman et al. 1999. Pedoman Identifikasi Pohon-Pohon Dipterocarpaceae Jawa sampai Niugini. Bogor : PROSEA INDONESIA.
Tan Pang-Ning, et al. 2006. Introduction to Data Mining. Boston: Pearson Education, Inc.
Teknomo Kardi. Similarity Measurement. http:\\people.revoledu.com\kardi\
tutorial\Similarity\ [22 Februari 2011] Tjitrosoepomo Gembong. 2005. Morfologi
iii ABSTRACT
BRYAN NURJAYANTI. Shorea Identification Using k-Nearest Neighbour Based on Morphological Characteristics of Leaves. Supervised by AZIZ KUSTIYO.
Dipterocarpaceae is a group of tropical plants that is used in a timber industry. One of Dipterocarpaceae clans is Shorea, that is the best timber-producing plant in the industrial world. Shorea is difficult to be identified because it has a lot of diversity. The inability to recognize Shorea in forest will enlarge the exploitation of Shorea that has a good timber quality, and silviculture work becomes less of the target because it is not known which Shorea species that will extinct.
Shorea tree is usually identified by using the stems, leaves, fruits, and flowers. However, leave is used for the identification in this research because it tends to be available as a source of observation at anytime. The leaves in this reasearch are the collection from Bogor Botanical Gardens. Data are obtained by manual calculating to get the characteristics of the leaves. The obtained data will be processed using k-Nearest Neighbor to get the closeness of new data and training data.
The leaves that are included in this research are Shorea multiflora, palembanica, balangeran, lepida and assamica, each one has 10 data. Each set of data has 10 attributes that support the leaf characteristics. From the whole data, Shorea are divided into five subsets including data training and data testing for each subset. This research has two experiments the first experiment without normalization produces 84% accuracy and the second experiment with a normalization produces 100% accuracy.
ii
IDENTIFIKASI SHOREA MENGGUNAKAN k-NEAREST NEIGHBOUR
BERDASARKAN KARAKTERISTIK MORFOLOGI DAUN
BRYAN NURJAYANTI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Program Studi Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
iv Judul Penelitian Identifikasi Shorea Menggunakan k-Nearest Neighbour Berdasarkan
Karakteristik Morfologi Daun
Nama Bryan Nurjayanti
NRP G64086022
Menyetujui :
Pembimbing
Aziz Kustiyo, S.Si., M.Kom. NIP 19700719 199802 1 001
Mengetahui : Ketua Departemen
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
v RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 8 September 1987. Anak pertama dari 2 bersaudara, dari pasangan Bapak Abdi Iskandar dan Ibu Susilowati.
Pada tahun 2005 penulis lulus dari SMU Negeri 89 Jakarta, kemudian melanjutkan pendidikan Diploma III pada Program Studi Manajemen Informatika, Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB. Lulus Diploma pada Tahun 2008 penulis melanjutkan studi di Institut Pertanian Bogor Jurusan Ilmu Komputer (ekstensi) untuk memperoleh gelar sarjana.
vi PRAKATA
Puji dan syukur penulis panjatkan kehadirat Allah SWT yang telah memberikan rahmat dan hidayah-Nya sehingga penulis dapat menyelesaikan karya ilmiah ini. Terima kasih penulis ucapkan kepada Bapak Aziz Kustiyo, S.Si, M.Kom selaku pembimbing. Adapun penulis mengucapkan terima kasih kepada:
1. Kedua orang tua dan kakak yang telah memberikan dukungan, perhatian, dan doa sehingga penulis dapat menyelesaikan studi di Departemen Ilmu Komputer IPB.
2. Dosen penguji Bapak Toto Haryanto, S.Kom, M.Si dan Bapak Mushthofa, S.Kom, M.Sc atas saran dan bimbingannya.
3. Pihak Kebun Raya Bogor atas sample daun Shorea. 4. Pihak Biotrop atas literatur tentang Shorea.
5. Seluruh dosen pengajar dan civitas akademika Departemen Ilmu Komputer FMIPA IPB. 6. Asep yang telah banyak membantu dalam pembuatan penelitian ini.
7. Dewi ”Meong” teman seperjuangan semasa kuliah. 8. Teman-teman satu bimbingan atas kerjasamanya.
9. Teman-teman Ekstensi ILKOM angkatan 3, atas kerjasamanya selama perkuliahan. 10.Semua pihak yang telah membantu yang belum disebutkan di atas.
Semoga penelitian ini dapat bermanfaat bagi semua pihak yang membutuhkan.
Bogor, Juni 2011
vii DAFTAR ISI
viii DAFTAR GAMBAR
1 Pohon Shorea. ... 2 2 Daun Shorea multiflora. ... 2 3 Daun Shorea palembanica. ... 2 4 Daun Shorea balangeran. ... 2 5 Daun Shorea lepida. ... 2 6 Daun Shorea assamica... 3 7 Diagram alur pembuatan sistem... 4 8 Lebar dan panjang daun ... 5 9 Ujung daun ... 5 10 Pangkal daun. ... 5 11 Sudut daun ... 6 12 Akurasi klasifikasi percobaan pertama. ... 8 13 Hasil iterasi tanpa normalisasi. ... 9 14 Akurasi klasifikasi percobaan kedua... 9 15 Perbandingan akurasi. ... 10
DAFTAR TABEL
1 Confusion matrix dua kelas ... 3 2 Data daun ... 7 3 Selang nilai fitur daun ... 7 4 Konversi fitur-fitur nominal ... 7 5 Susunan data latih dan data uji... 8 6 Confusion matrix percobaan pertama ... 8 7 Perhitungan jarak tanpa normalisasi ... 9 8 Hasil perhitungan dengan normalisasi ... 10
DAFTAR LAMPIRAN
1 Tabel data penelitian daun Shorea. ... 13 2 Contoh hasil perhitungan Euclidean sebelum normalisasi. ... 14 3 Contoh hasil perhitungan Euclidean sesudah normalisasi. ... 15 4 Contoh hasil perhitungan nominal. ... 16 5 Contoh hasil penggabungan kedua jarak sebelum normalisasi. ... 17 6 Contoh hasil penggabungan kedua jarak sesudah normalisasi. ... 18 7 Confusion matrix dengan nilai k=2. ... 19 8 Confusion matrix dengan nilai k=3 ... 19 9 Confusion matrix dengan nilai k=5 ... 19 10 Confusion matrix dengan nilai k=6 ... 20 11 Confusion matrix dengan nilai k=7 ... 20 12 Confusion matrix dengan nilai k=8 ... 20 13 Confusion matrix dengan nilai k=9 ... 21 Halaman
Halaman
1 PENDAHULUAN
Latar Belakang
Dipterocarpaceae adalah sekelompok tumbuhan hutan hujan tropis yang dimanfaatkan dalam bidang perkayuan. Kelompok famili Dipterocarpaceae yang digunakan dalam perkayuan adalah meranti merah, meranti putih, dan meranti kuning dari jenis Shorea, Anisoptera dan Parashorea. Dipterocarpaceae
tumbuh dibagian barat Indonesia, Malaysia, Brunei, Filipina dan penyebarannya ke arah timur sampai dengan Nugini (Irian Jaya dan Papua Nugini).
Dipterocarpaceae sulit untuk diidentifikasi terutama di Kalimantan yang memiliki jenis terbanyak. Ketidakmampuan untuk mengenal individu Dipterocarpaceae di hutan mem-perbesar terjadinya eksploitasi Dipterocar-paceae khususnya jenis Shorea yang memiliki kualitas kayu yang baik dan pekerjaan silvikultur kurang menjadi sasaran karena tidak diketahui jenis Dipterocarpaceae yang akan punah (Newman et al.1999).
Shorea adalah salah satu marga tumbuhan penghasil kayu terbaik dalam dunia perindustrian. Dengan nilai ekonomi yang tinggi mengakibatkan eksploitasi besar-besaran pohon Shorea. Hal ini dapat berdampak kepunahan terhadap pohon Shorea dan menyebabkan kerusakan hutan.
Model identifikasi daun Shorea yang akan dikembangkan dapat digunakan untuk mengenal daun Shorea. Identifikasi ini dilakukan agar tidak menyebabkan kesalahan pemilihan kayu yang tidak tepat dan mengurangi pertumbuhan jenis kayu dengan sifat-sifat yang tidak diinginkan. Sifat-sifat itu misalnya kualitas kayu yang rendah, pertumbuhan lambat, tajuk lebar yang jarang mencapai ukuran kayu, atau jenis pilihan yang tidak cocok untuk kondisi tanah tertentu.
Penentuan identifikasi pohon Shorea, biasanya menggunakan batang, daun, buah, dan bunga. Namun penelitian ini menggunakan daun sebagai bahan identifikasi dikarenakan daun cenderung tersedia sebagai sumber pengamatan sepanjang waktu. Bila meng-gunakan batang, batang pohon akan berubah warna atau kedalaman alur sejalan dengan bertambahnya umur pohon.
Salah satu metode yang digunakan untuk membangun model klasifikasi dalam
mengidentifikasi daun Shorea adalah k-Nearest Neighbour. k-Nearest Neighbour merupakan teknik yang lebih fleksibel karena mampu menglasifikasikan data uji ke dalam kelas label dengan cara mencari data latih yang relatif sama dengan data uji (Tan et al. 2006).
Tujuan
Penelitian ini bertujuan untuk menerapkan k-nearest Neighbour dalam mengidentifikasi jenis Shorea.
Ruang Lingkup
Ruang lingkup penilitian ini meliputi :
1 Daun yang diteliti hanya daun Shorea multiflora, palembanica, balangeran, lepida dan assamica.
2 Difokuskan untuk mengidentifikasi daun Shorea dengan mengidentifikasi karakteristik morfologi daun.
3 Data yang digunakan adalah data hasil pengukuran manual terhadap daun Shorea. 4 Daun Shorea yang digunakan diambil dari
beberapa koleksi Kebun Raya Bogor. Manfaat
Model identifikasi daun Shorea diharapkan dapat membantu dalam mengidentifikasi jenis
Shorea.
TINJAUAN PUSTAKA
Shorea
Shorea adalah salah satu marga dari Dipterocarpaceae penghasil kayu terbaik dalam dunia perindustrian. Dengan nilai ekonomi yang tinggi mengakibatkan eksploitasi besar-besaran yang dapat berdampak kepunahan terhadap pohon Shorea dan menyebabkan kerusakan hutan.
Shorea memiliki sekitar 194 jenis. Persebarannya meliputi 1 jenis di Jawa, 1 atau 2 jenis di Sulawesi, 3 jenis di Maluku dan sisanya menyebar kearah timur sampai Maluku (Indonesia) dan tidak meluas ke Cina bagian selatan (Newman et al. 1999).
2 penjulang di hutan hujan dari kawasan Paparan
Sunda, dapat tumbuh hingga ketinggian 500 m (Newman et al.1999).
Gambar 1 Pohon Shorea.
Ciri-ciri diagnostik utama pohon Shorea sangat besar dengan pepagan dalam berlapis-lapis atau berwarna coklat merah gelap. Daun menjangat, tidak berlipatan, tidak bentuk perisai, tidak berlukup, 4-18 x 2-8 cm, pangkal daun biasanya simetris, permukaan bawah daun bila mengering pudar, pertulangan sekunder bersirip, 7-25 pasang, terpisah permanen, pada permukaan bawah daun bila mengering warnanya sama seperti helai daun, atau lebih gelap pada Shorea javanica (Newman et al. 1999).
Penelitian ini menggunakan lima jenis Shorea, yaitu:
1 Shorea multiflora
Ciri-ciri utama umumnya berupa pohon kecil sampai sedang dengan buah tanpa sayap. Daun dengan ujung lancip panjang (meruncing), pangkal membundar (membulat), pertulangan daun tembus cahaya bila segar (Newman et al. 1999).
Gambar 2 Daun Shorea multiflora. 2 Shorea palembanica
Ciri-ciri utama habitat tepi sungai, perawakan berbonggol, daun besar, bila
mengering coklat merah (Newman et al. 1999).
Gambar 3 Daun Shorea palembanica. 3 Shorea balangeran
Ciri-ciri utama habitat hutan rawa gambut, ujung daun lancip (meruncing), pangkal daun membundar (membulat), permukaan atas daun bila mengering coklat agak lembayung, permukaan bawah bila mengering coklat kekuning-kuningan. Shorea balangeran merupakan salah satu Shorea yang terancam punah (Newman et al. 1999).
Gambar 4 Daun Shorea balangeran. 4 Shorea lepida
Ciri-ciri utama pohon dewasa memiliki daun agak tipis, lonjong dan runcing. Permukaan atas daun bila mengering coklat agak lembayung, coklat kuning pada tulang daun, coklat pudar pada permukaan bawah daun (Newman et al. 1999).
3 5 Shorea assamica
Ciri-ciri utama daun di bawah permukaan memunyai indumentums sisik-sisik kecil. Daun jorong atau bundar telur, ujung daun lancip pendek (tumpul), pangkal daun membundar, permukaan daun bila mengering coklat dan bila diraba licin (Newman et al. 1999).
Gambar 6 Daun Shorea assamica. K-Fold Cross Validation
Sebelum digunakan, sebuah sistem berbasis komputer harus dievaluasi dalam berbagai aspek. Di antara aspek-aspek ini, validasi kinerja bisa merupakan yang paling penting. (Fu 1994).
Metode k-fold cross validation membagi sebuah himpunan contoh secara acak menjadi k himpunan bagian lain (subset) yang paling bebas. Dilakukan ulangan sebanyak k kali untuk pelatihan dan pengujian. Pada setiap ulangan disisipkan setiap subset untuk pengujian dan subset lainnya untuk pelatihan (Stone 1974 diacu dalam Fu 1994).
Tingkat akurasi dihitung dengan membagi jumlah keseluruhan klasifikasi yang benar dengan jumlah semua instance pada data awal (Han & Kamber 2001).
∑ ∑
Normalisasi
Pada perhitungan jarak Euclidean, atribut berskala panjang dapat memunyai pengaruh lebih besar daripada atribut berskala pendek. Untuk mencegah hal tersebut perlu dilakukan
normalisasi terhadap nilai atribut (Larose 2005 diacu dalam Faiza 2009).
Salah satu metode normalisasi adalah min-max normalization yang diterapkan untuk fitur numerik. Formula untuk normalisasi atribut X adalah:
Dengan X* adalah nilai setelah dinormalisasi, X adalah nilai sebelum dinormalisasi, min(X) adalah nilai minimum dari fitur, dan max(X) adalah nilai maksimum dari suatu fitur.
Confusion Matrix
Evaluasi model klasifikasi berdasar pada proporsi antara data uji yang diprediksi secara tepat dengan total seluruh prediksi (Tan et al. 2006). Informasi mengenai klasifikasi sebenarnya (aktual) dengan klasifikasi hasil prediksi disajikan dalam bentuk tabel yang disebut confusion matrix seperti diperlihatkan pada Tabel 1.
Tabel 1 Confusion matrix dua kelas Kelas hasil prediksi Kelas aktual Kelas 1 Kelas 2
Kelas 1 a b
Kelas 2 c d
Jumlah baris dan kolom pada tabel bergantung pada banyaknya kelas target. Akurasi merupakan proporsi jumlah prediksi yang tepat. Contoh perhitungan akurasi untuk tabel tersebut adalah:
KNN (K-Nearest Neighbour)
K-Nearest Neighbour merepresentasikan setiap data sebagai titik dalam k-ruang dimensi. Jika ada sebuah data uji maka akan dihitung kedekatan titik data lainnya pada data latih untuk diklasifikasikan berdasarkan kedekatan-nya yang didefinisikan dengan ukuran jarak (Han & Kamber 2006).
4 fungsi jarak. Fungsi jarak yang umumnya
digunakan adalah jarak Euclidean dengan menggunakan rumus sebagai berikut (Larose 2005).
√∑ (
)
,
dengan
x = x1,x2, … , xm menyatakan data uji, y = y1,y2, … , ym menyatakan data latih dan xi-yi = selisih data uji dengan data latih.Penelitian ini, terdapat dua jenis data yang digunakan, yaitu data numerik dan data nominal. Data nominal atau sering disebut juga data kategori yaitu data yang diperoleh melalui pengelompokan objek berdasarkan kategori tertentu. Walaupun data nominal dapat dinyatakan dalam bentuk angka, namun angka tersebut tidak memiliki urutan atau makna matematis sehingga tidak dapat dibandingkan (Dharma, 2008).
Untuk data nominal atau yang disebut kategori, penggunaan jarak Euclidean tidak tepat, sebaliknya dapat didefinisikan dengan sebuah fungsi yang digunakan untuk membandingkan nilai data uji dan data latih. Untuk menghitung jarak nominal menggunakan rumus sebagai berikut (Larose 2005).
{
Yang berarti bahwa jika data latih sama dengan data uji maka jaraknya 0, selainnya jaraknya 1.
Untuk menggabungkan kedua jarak semua variabel, dilakukan aggregate ketidaksamaan berat rata-rata dari jarak masing-masing fitur dengan menggunakan rumus sebagai berikut (Teknomo, 2006).
∑ ∑
,
dengan k merupakan variabel fitur, ij selisih data latih dan data uji, Sijk merupakan kesamaan
dan ketidaksamaan antara objek dimana Wijk
bernilai 1 untuk nilai numerik dan 0.5 untuk nilai nominal. Nilai pembobotan ini diberikan agar jarak fitur nominal tidak terlalu mendominasi hasil perhitungan.
METODOLOGI PENELITIAN
Kerangka Penelitian
Penelitian ini memunyai beberapa tahapan untuk mengetahui tingkat akurasi yang diperoleh menggunakan algoritme k-Nearest Neighbour dalam pengidentifikasian daun Shorea. Tahapan proses tersebut akan disajikan pada Gambar 7.
Gambar 7 Diagram alur pembuatan sistem. Identifikasi Masalah
Tahap identifikasi permasalahan yang meliputi tahap pemilihan masalah, identifikasi, tujuan, dan sumber pengetahuan. Masalah yang ada saat ini pihak rimbawan atau pekerja di hutan masih mengalami kesulitan dalam mengidentifikasi daun Shorea. Kesalahan dalam mengidentifikasi ini dapat menyebabkan kesalahan pemilihan kayu yang tidak tepat.
5 akuisisi pengetahuan pakar dan pustaka yang
mendukung. Pengadaan Data
Daun Shorea yang digunakan didapatkan dari Kebun Raya Bogor. Penelitian ini menggunakan beberapa atribut yang mencirikan bentuk morfologi daun Shorea. Data yang digunakan merupakan data dari perhitungan manual beberapa jenis daun Shorea.
Data dalam penelitian ini memunyai beberapa fitur, yaitu:
1 Panjang daun, yaitu panjang daun diukur dari pangkal daun hingga ujung daun. 2 Lebar daun, yaitu lebar daun diukur
berdasarkan permukaan daun paling lebar.
Gambar 8 Lebar dan panjang daun 3 Bentuk tulang daun, yaitu susunan tulang
cabang pada daun. Bentuk tulang daun dapat dibedakan menjadi :
a Menempel : ujung tulang cabang bagian dalam sebelah kanan bertemu dengan ujung tulang cabang bagian dalam sebelah kiri.
b Tidak menempel : ujung tulang cabang bagian dalam sebelah kanan tidak bertemu dengan ujung tulang cabang bagian dalam sebelah kiri.
4 Permukaan daun, yaitu keadaan permukaan daun bagian atas dan bawah, seperti : a Atas bawah halus
b Atas halus bawah kasar c Atas bawah kasar d Atas kasar bawah halus
5 Ujung daun, yaitu bentuk ujung daun. Beberapa bentuk ujung daun di antaranya: a Runcing, jika kedua tepi daun di kanan
kiri ibu tulang sedikit demi sedikit menuju ke atas dan pertemuannya pada puncak daun melancip.
b Meruncing, seperti pada ujung yang runcing, tetapi titik pertemuan kedua tepi daunnya jauh lebih tinggi dari dugaan, hingga ujung daun nampak sempit panjang dan runcing.
c Tumpul, tepi daun yang semula masih agak jauh dari ibu tulang membentuk sudut yang tumpul.
d Membulat, seperti pada ujung yang tumpul, tetapi tidak terbentuk sudut sama sekali, hingga ujung daun merupakan semacam suatu busur.
Gambar 9 Ujung daun
6 Pangkal daun, yaitu bentuk pangkal daun.
Gambar 10 Pangkal daun.
7 Keliling daun, yaitu keliling tepi daun yang diukur dengan menggunakan benang.
6 daun kemudian dibagi empat. Contoh
pengukuran luas :
9 Sudut antar tulang daun, yaitu sudut antara ibu tulang daun dengan tulang cabang daun sebelah kanan atau kiri yang diukur menggunakan busur.
10 Jumlah tulang daun, yaitu jumlah tulang cabang daun sebelah kanan dan tulang cabang daun sebelah kiri.
Praproses Data
Tahapan yang dilakukan dalam praproses di antaranya pengolahan data dengan fitur nominal menggunakan nominal distance seperti bentuk ujung daun, permukaan daun, bentuk tulang daun dan bentuk pangkal daun. Praproses data juga dilakukan pada tahap awal normalisasi data numerik agar didapatkan range antara nol hingga satu. Hal ini dilakukan untuk menghindari perbedaan range yang terlalu besar antar fitur.
Penentuan Data Latih dan Data Uji
Pada penelitian ini pembagian data latih dan data uji akan dilakukan dengan menggunakan teknik k-fold cross validation dengan nilai k = 5.
Klasifikasi
Teknik klasifikasi yang akan digunakan menggunakan k–Nearest Neighbour. Teknik k– Nearest Neighbour mencari jarak terdekat antara data yang akan dievaluasi dengan k
tetangga (neighbour) terdekatnya dalam data pelatihan.
Model Daun Shorea
Tahapan ini merupakan tahapan yang paling penting karena pada tahap ini teknik klasifikasi diaplikasikan terhadap data yang sudah diperoleh. Teknik klasifikasi yang digunakan menggunakan k–Nearest Neighbour. Langkah-langkah pada metode tersebut yaitu:
Hitung jarak Euclidean: pada tahap ini setiap data uji akan dihitung jaraknya ke setiap data latih untuk mengetahui ukuran kedekatan atau ukuran kesamaan antara data uji dengan data latih.
Hitung jarak nominal: pada tahap ini dilakukan proses pengubahan beberapa fitur yang bersifat nominal dilambangkan dengan nilai numerik sehingga mempermudah perbandingan data uji terhadap data latih.
Aggregate (menggabungkan) data: pada tahap ini data pengolahan nominal dan pengolahan menggunakan Euclidean digabungkan.
Penentuan nilai k: pada k–Nearest Neighbour penentuan nilai k yang tepat sangat penting untuk menunjukkan jumlah tetangga terdekat. Setelah didapatkan hasil identifikasi, selanjutnya dilakukan evaluasi klasifikasi yang dihasilkan metode k-Nearest Neighbour. Hasil Prediksi
Pada tahap akhir ini diharapkan data testing yang dimasukan akan terklasifikasi pada kelas yang benar.
Lingkungan Pengembangan
Perangkat lunak yang digunakan dalam penelitian yaitu :
Windows XP Home Edition Service Pack 3
XAMPP Version 1.7.1
Notepad v5.1.1
Microsoft Office Excel 2007
Perangkat keras yang digunakan dalam penelitian yaitu :
Processor Intel Atom 1.66 GHz
RAM 1.00 GB
Harddisk kapasitas 150 GB Gambar 11 Sudut daun
7 HASIL DAN PEMBAHASAN
Praproses
Data yang digunakan pada penelitian ini merupakan data hasil perhitungan manual fitur-fitur morfologi daun Shorea yang diambil dari beberapa koleksi di Kebun Raya Bogor. Berikut disajikan contoh data hasil perhitungan manual dan fitur-fitur yang diperlihatkan pada Tabel 2. Tabel 2 Data daun
Jenis Daun Shorea multiflora
Panjang 9.1 cm
Lebar 5.7 cm
Bentuk tulang daun tidak menempel tidak menonjol
Permukaan Daun atas bawah halus
Ujung Daun meruncing
Pangkal Daun tumpul
Keliling 22 cm
Luas 61.5 cm2
Sudut 60°
Jumlah tulang daun 14 buah
Proses pengambilan data ini dilakukan selama satu bulan. Data yang didapat sebanyak 50 data dari perhitungan manual berdasarkan fitur-fitur yang telah ditetapkan sesuai dengan morfologi daun. Data yang digunakan sebanyak 50 data meliputi 10 data Shorea multiflora, 10 data Shorea palembanica, 10 data Shorea balangeran, 10 data Shorea assamica, dan 10 data Shorea lepida.
Berdasarkan fitur-fitur yang digunakan terdapat 4 fitur yang bersifat nominal, yaitu fitur bentuk tulang daun, permukaan daun, ujung daun, dan pangkal daun. Fitur-fitur ini memiliki selang nilai yang berbeda. Pada Tabel 3 disajikan selang nilai yang terdapat di setiap fitur.
Tabel 3 Selang nilai fitur daun No Nama Fitur
1 Bentuk Tulang Daun
a. tidak menempel tidak menonjol b. menempel, tidak menonjol
c. tidak menempel, bagian bawah menonjol bernilai nominal dilambangkan dengan angka untuk memudahkan perhitungan algoritme. Pada Tabel 4 disajikan konversi fitur-fitur nominal.
Tabel 4 Konversi fitur-fitur nominal
No Nama Fitur
Nilai Konversi
1 Bentuk Tulang Daun -
a. tidak menempel, tidak menonjol
1
b. menempel, tidak menonjol
2
c. tidak menempel, bagian bawah menonjol
8 Contoh normalisasi untuk record pertama
berdasarkan rumus normalisasi adalah:
Percobaan pertama (tanpa normalisasi) Dari banyaknya data yang diperoleh sebanyak 50 record, dibagi menjadi 5 subset yang setiap subset berisi 2 record dari setiap jenis daun.
Percobaan pertama menggunakan 40 record sebagai data latih yang berisi subset 1, 2, 3, dan 4. Subset 5 yang berisi 10 record dijadikan data uji. Percobaan terus dilakukan hingga setiap subset pernah menjadi data uji. Susunan data latih dan data uji pada percobaan disajikan pada Tabel 5.
Tabel 5 Susunan data latih dan data Uji Iterasi Pelatihan Pengujian Iterasi pertama S2,S3,S4,S5 S1 Iterasi kedua S1,S3,S4,S5 S2 Iterasi ketiga S1,S2,S4,S5 S3 Iterasi keempat S1,S2,S3,S5 S4 Iterasi kelima S1,S2,S3,S4 S5
Data tersebut kemudian diterapkan dalam metode k-Nearest Neighbour melalui tahap-tahap berikut ini:
1 Setiap record data uji dihitung jaraknya ke setiap record data latih untuk mengetahui kedekatan antara data uji dengan data latih. Untuk data bertipe numerik, selisih antara data uji dengan data latih adalah pengurangan nilai data uji dengan nilai data latih. Untuk data bertipe nominal, data diolah menggunakan nominal distance. Bila data uji sama dengan data latih maka bernilai nol dan bila data uji berbeda dengan data latih maka bernilai 1.
2 Digabungkan hasil perhitungan yang menggunakan jarak Euclidean dan nominal distance dengan menggunakan rumus aggregate. Memberikan bobot 1 pada hasil perhitungan Euclidean dan bobot 0.5 pada hasil perhitungan nominal. Pemberian bobot 0.5 pada perhitungan nominal agar tidak mendominasi hasil perhitungan. 3 Penentuan nilai k tetangga terdekat pada
percobaan pertama dilakukan dengan
mencoba nilai k mulai dari 2 sampai 9 dalam metode k-Nearest Neighbour. Akurasi klasifikasi untuk nilai k=2 sampai k=9 diperlihatkan pada Gambar 12.
Gambar 12 Akurasi klasifikasi percobaan pertama.
Berdasarkan gambar tersebut (Gambar 12) akurasi terbesar yang diperoleh adalah 84% dengan nilai k=4 dan k=5. Untuk mengetahui record yang salah diklasifikasikan digunakan confusion matrix yang diperlihatkan pada Tabel 6.