Diajukan
Pada Fak
NUGRA
PRO
JURUSAN
FAKULTAS T
UNIVERSIT
SKRIPSI
an Untuk Menempuh Ujian Sarjana
Fakultas Teknik dan Ilmu Komputer
Oleh :
GRAHA IMAN SANTOSA
10109797
PROGRAM STUDI S1
USAN TEKNIK INFORMATIKA
AS TEKNIK DAN ILMU KOMPUTE
RSITAS KOMPUTER INDONESIA
2011
i
Oleh
Nugraha Iman Santosa 10109797
Mesin pencarian dokumen adalah program komputer yang dirancang untuk melakukan pencarian atas dokumen dalam koleksi dokumen. Hasil pencarian umumnya ditampilkan dalam bentuk daftar yang seringkali diurutkan menurut tingkat akurasi kesesuaian dokumen dengan kebutuhan pengguna. Pada skripsi kali ini akan mengimplementasikan suatu aplikasi pencarian dokumen di dalam aplikasi eBdesk Collaboration. Dimana pencarian dokumen dilakukan terhadap dokumen-dokumen yang dimasukkan pengguna pada aplikasi eBdesk Collaboration.
Ada 2 proses yang dilakukan pada aplikasi yang dibuat, antara lain : proses penentuan indeks dan proses pencarian. Proses penentuan indeks yaitu proses mengekstrak dokumen yang di-upload, melakukan pre-processing kemudian menyimpan hasilnya ke dalam database. Proses selanjutnya adalah pencarian, yaitu mencari dokumen dari database berdasarkan kata kunci dari pengguna, kemudian mengurutkan dokumen hasil pencarian dengan menggunakan metode tf-idf, sehingga dihasilkan daftar dokumen yang telah terurut.
Metode tf-idf adalah metode yang umum digunakan untuk mesin pencarian karena efisien dan sederhana. Pembobotan dokumen menggunakan tf-idf menunjukkan bahwa deskripsi terbaik dari dokumen terjadi ketika kata yang banyak muncul dalam dokumen tersebut dan sangat sedikit muncul pada dokumen yang lain.
ii
ABSTRACT
TF-IDF IMPLEMENTATION FOR DOCUMENTS SEARCHING (A case study in PT. eBdesk Indonesia)
by
Nugraha Iman Santosa 10109797
Document search engine is a computer program designed to search for documents in document collections. Search results are generally displayed in the form of lists that are often sorted by the accuracy of the document conformance to user needs. In this thesis will implement an application to search documents in the application eBdesk Collaboration. Where the document search conducted on the documents that user uploaded on the eBdesk Collaboration application.
There are two processes are performed on an application made, among others: the process of indexing and the searching process. The process of indexing is a process to extract the uploaded document, perform pre-processing and then save the results into the database. The next process is searching, which is seeking documents from database based on keyword from user, than rank the search result document using tf-idf method, so the result is list of documents that have been ranked.
Tf-idf method is a method commonly used for search engines because of its efficiency and its simplicity. Weighted using the tf-idf document shows that the best description of the document occurs when a word often appears in documents and very rarely appears on other documents.
iii
dilimpahkan kepada penulis sehingga pada akhirnya penulis dapat menyelesaikan laporan skripsi ini dengan judul “IMPLEMENTASI TF-IDF UNTUK
PENCARIAN DOKUMEN (STUDI KASUS DI PT. EBDESK
INDONESIA)”.
Skripsi ini disusun untuk memenuhi salah satu syarat dalam menyelesaikan jenjang pendidikan S1 Jurusan Teknik Informatika Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia. Tentu saja laporan ini tidak terselesaikan begitu saja, berbagai hambatan dan kesulitan penulis dapatkan. Karena itu dengan segala kerendahan hati, penulis ingin menyampaikan rasa hormat dan terima kasih sebesar-besarnya kepada :
1. Allah SWT yang telah memberikan kesehatan dan memberikan kemudahan dalam melaksanakan tugas akhir dan menyelesaikan laporan ini.
2. Kepada orang tua yang selalu memberi dukungan baik secara moril dan materil.
3. Bapak Dr. Ir. Eddi Soeryanto Soegoto, M.Sc. selaku Rektor Universitas Komputer Indonesia.
4. Bapak Dr. Arry Akhmad Arman selaku Dekan Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia.
iv
6. Ibu Janivita Joto Sudirham, ST.,MSc.,PhD. selaku dosen pembimbing yang telah meluangkan waktu, tenaga dan pikirannya untuk mebimbing dan memberikan saran serta ilmu pengetahuannya kepada penulis dalam penyusunan Skripsi ini.
7. Kepada seluruh dosen dan staff Jurusan Teknik Informatika Universitas Komputer Indonesia Bandung.
8. Penulis juga mengucapkan terima kasih kepada seluruh teman, sahabat dan semua pihak yang tidak dapat disebutkan satu persatu.
Penulis menyadari bahwa dalam penyusunan laporan skripsi ini masih terdapat kekurangan dan jauh dari kesempurnaan. Penulis mengharapkan saran dan kritik dari pembaca demi kemajuan pekerjaan penulis di masa yang akan datang.
Akhir kata, semoga laporan skripsi ini dapat memenuhi tujuan penulisannya serta bermanfaat bagi penulis dan kita semua.
Wassalamu'alaikum Wr. Wb.
Bandung, Maret 2012
v
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... xi
DAFTAR SIMBOL... xiii
DAFTAR LAMPIRAN ... xvi
BAB 1 ... 1
PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Identifikasi Masalah ... 3
1.3 Maksud dan Tujuan ... 3
1.4 Metodologi Penelitian ... 4
1.5 Batasan Masalah ... 5
1.6 Sistematika Penulisan ... 6
BAB 2 ... 8
TINJAUAN PUSTAKA ... 8
2.1 Tinjauan Tempat Penelitian ... 8
2.2 Istilah-istilah yang Digunakan Dalam Penulisan ... 9
vi
2.4.3 Inverted Index ... 21
2.5 Proses Pencarian ... 22
2.5.1 Ranking ... 23
2.6 Metode TF-IDF ... 24
2.7 Vector Space Model ... 27
2.8 Konsep Berorientasi Objek ... 29
2.8.1 Kelas ... 30
2.8.2 Objek ... 30
2.8.3 Atribut ... 30
2.8.4 Method ... 31
2.8.5 Constructor ... 31
2.8.6 Package ... 31
2.9 Unified Modelling Languange ... 31
2.9.1 Use Case Diagram ... 32
2.9.2 Sequence Diagram ... 33
2.9.3 Class Diagram ... 34
2.9.4 Activity Diagram ... 34
2.10JAVA ... 35
2.11MySQL Server 5 ... 38
vii
3.1.2 Use Case Aplikasi eBdesk Collaboration ... 42
3.1.3 Class Diagram Pada Pengelolaan Dokumen ... 43
3.2 Analisis Perangkat Lunak Yang Akan Dibangun ... 44
3.2.2 Deskripsi Umum Perangkat Lunak ... 44
3.3 Analisis Kebutuhan Sistem ... 46
3.3.2 Kebutuhan Fungsional ... 46
3.3.3 Use Case Diagram ... 46
3.3.4 Analisis Perangkat Lunak ... 52
3.3.5 Analisis Perangkat Keras ... 52
3.4 Perancangan Applikasi ... 52
3.4.1 Sequence Diagram ... 52
3.4.2 Diagram Aktivitas ... 56
3.4.3 Diagram Kelas ... 59
3.4.4 Skema Relasi ... 61
3.4.5 Struktur File ... 62
3.5 Perancangan Antarmuka ... 67
BAB 4 ... 72
IMPLEMENTASI DAN PENGUJIAN ... 72
4.1 Implementasi Aplikasi ... 72
viii
4.1.5 Implementasi Database ... 74
4.1.6 Aplikasi Pengelolaan Dokumen ... 76
4.1.7. Aplikasi Pencarian Dokumen ... 78
4.2 Pengujian ... 80
4.3 Pengujian Alpha ... 80
4.4 Pengujian Beta ... 93
BAB 5 ... 99
KESIMPULAN DAN SARAN ... 99
5.1 Kesimpulan ... 99
5.2 Saran ... 99
1
1.1 Latar Belakang Masalah
PT. eBdesk Indonesia adalah sebuah produsen piranti lunak yang telah berdiri sejak tahun 2000. Saat ini PT eBdesk sedang mengembangkan sebuah produk bernama Collaboration, yaitu berupa sebuah aplikasi yang memungkinkan penggunanya berkolaborasi untuk mencapai suatu tujuan. Beberapa fitur utama dalam aplikasi Collaboration adalah sharing dokumen, galeri, blog dan forum.
Dalam aplikasi Collaboration ini terdapat fasilitas untuk menyimpan dokumen. Proses pencarian dokumen yang dilakukan pada aplikasi collaboration saat ini baru sebatas mencari dokumen berdasarkan judul dan deskripsi singkat yang disimpan ke dalam database.
Untuk lebih menambah nilai jual dari aplikasi collaboration ini, oleh karena itu ingin dibuatkan sebuah fitur baru yaitu pencarian dokumen yang bisa menelusuri query pencarian sampai ke dalam isi dokumen yang di-upload nya itu sendiri.
Untuk menghasilkan dokumen yang relevan terhadap query pencarian maka diperlukan proses perangkingan pada dokumen hasil pencarian. Dengan melakukan perangkingan terhadap dokumen, dokumen yang telah didapatkan tersebut ditampilkan terurut dari dokumen yang memiliki tingkat relevansi lebih tinggi ke tingkat relevansi rendah.
Ada beberapa model yang digunakan dalam membuat aplikasi pencarian dokumen yaitu : Model Boolean, Model Ruang Vektor (Vector Space Model), dan Model Probabilistik. Namun dari ketiga model tersebut model ruang vektor adalah model yang paling popular dan umum digunakan karena mudah diimplementasikan dan mendukung adanya pemeringkatan / perangkingan dokumen.
Dalam model ruang vektor, metode yang digunakan untuk melakukan perangkingan adalah dengan menghitung bobot dokumen terhadap query. Pembobotan ini menghitung bobot frekuensi kemunculan kata dalam suatu dokumen (term frequency – tf ) diimbangi dengan frekuensi kemunculan kata pada koleksi dokumen(inverse document frequency - idf), yang dikenal dengan pembobotan tf-idf. Pembobotan menggunakan tf-idf menunjukkan bahwa deskripsi terbaik dari dokumen terjadi ketika kata yang banyak muncul dalam dokumen tersebut dan sangat sedikit muncul pada dokumen yang lain.
Berdasarkan uraian diatas, penulis ingin melakukan implementasi tf-idf dengan dengan membuat perangkat lunak. Perangkat lunak ini diharapkan bisa melakukan pembobotan atau perangkingan pada pencarian dokumen yang ada.
1.2 Identifikasi Masalah
Permasalahan yang akan diangkat dalam skripsi ini adalah :
1. Bagaimana membuat aplikasi pencarian dokumen yang bisa menelusuri
query ke dalam isi teks dokumen ?
2. Bagaimana mengimplementasikan metode tf-idf pada aplikasi pencarian dokumen tersebut ?
1.3 Maksud dan Tujuan
Maksud dari pembuatan skripsi ini yaitu untuk membuat sebuah aplikasi pencarian dokumen yang mengimplementasikan penggunaan metode tf-idf.
Tujuan yang akan dicapai dalam pembuatan skripsi ini adalah :
1. Membuat aplikasi yang bisa mencari dokumen dari koleksi dokumen berdasarkan query yang diinputkan pengguna, dan memberikan peringkat terhadap hasil pencarian tersebut supaya menghasilkan dokumen yang relevan terhadap query.
1.4 Metodologi Penelitian
Tahapan-tahapan yang akan dilalui dalam pelaksanaan skripsi ini adalah sebagai berikut :
a. Studi literatur
Mengumpulkan bahan-bahan referensi yang menunjang proses penelitian yaitu yang berhubungan dengan pengenalan search engine, penentuan indeks dan pencarian pada search engine dan pembobotan pada search engine.
b. Pengumpulan data di lapangan
Pengumpulan data ini dilakukan dengan dua cara, pertama dengan observasi langsung ketempat penelitian untuk mendapatkan data primer dan dokumen-dokumen yang diperlukan yang berkaitan dengan penelitian. Kedua, melakukan wawancara mendalam. Wawancara dilakukan untuk memperoleh data-data yang diperlukan penulis. Wawancara ini juga bertujuan untuk mencari tahu kondisi aplikasi yang saat ini berjalan di lapangan, dan masalah apa yang dihadapi.
c. Analisis
d. Perancangan
Pada tahap ini dilakukan perancangan terhadap sistem yang akan dibangun. Diantaranya adalah : membuat rancangan database, rancangan fungsionalitas, dan membuat rancangan antarmuka sistem.
e. Implementasi
Pada tahap ini dilakukan implementasi berdasarkan hasil rancangan. Adapun proses yang dilakukan pada tahap implementasi antara lain :
1. Pembangunan database berbasis MySQL. 2. Perancangan interface.
3. Pengimplementasian algoritma metode TF-IDF yang diintegrasikan dengan studi kasus.
f. Pengambilan kesimpulan dan saran
Pada tahap ini adalah tahap terakhir dari penelitian yang dilakukan yakni pengambilan kesimpulan dari beberapa tahap yang telah dilalui. Kemudian menyusun laporan dari penelitian yang dilakukan.
1.5 Batasan Masalah
Berdasarkan latar belakang dan identifikasi masalah yang diketahui, penulis membatasi ruang lingkupnya sebagai berikut :
2. Menambahkan proses penentuan indeks pada aplikasi upload dokumen dalam eBdesk Collaboration, untuk mendukung proses pencarian dokumen.
3. Pencarian dalam aplikasi ini berupa teks berbahasa Inggris dan pengujian dilakukan terhadap dokumen teks yang berisi kata (term). Dikarenakan aplikasi eBdesk Collaboration saat ini diimplementasikan pada proyek di Malaysia, dan diharapkan akan bisa diimplementasikan di negara tetangga lainnya seperti Singapura.
4. Pengideksan dan pencarian dilakukan terhadap dokumen yang berekstensi *.txt dan *.doc.
5. Ukuran file yang di-upload maksimal 4 MB.
1.6 Sistematika Penulisan
Sistematika penulisan laporan penelitian ini disusun untuk memberikan gambaran umum tentang penelitian yang dijalankan. Sistematika penulisan skripsi ini adalah sebagai berikut :
BAB 1 PENDAHULUAN
BAB 2 TINJAUAN PUSTAKA
Menjelaskan tentang konsep dasar aplikasi text mining, penentuan indeks (tokenizing, filtering, stemming, tagging), metode tf-idf, vector space model, perancangan sistem, basis data, tinjauan perangkat lunak, dan bahasa pemrograman yang digunakan untuk membangun aplikasi.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Membahas analisis terhadap kebutuhan aplikasi dengan menggunakan metode tf-idf, perancangan basis data, perancangan program aplikasi, perancangan input dan
output.
BAB 4 IMPLEMENTASI
Dalam bab ini membahas dan menampilkan aplikasi yang sudah dibangun berdasarkan perancangan yang telah dibuat dan menunjukkan hasil dari implementasi aplikasi terhadap data yang diolah. Aplikasi dibuat menggunakan bahasa pemrograman Java dan basis data MySQL.
BAB 5 KESIMPULAN DAN SARAN
8
Bab tinjuan pustaka berisi tentang tinjauan tempat penelitian, konsep dasar aplikasi text mining, penentuan indeks, metode tf-idf, vector space model, konsep berorientasi objek, basis data, tinjauan perangkat lunak, dan bahasa pemrograman JAVA yang digunakan untuk membangun aplikasi.
2.1 Tinjauan Tempat Penelitian
PT. eBdesk didirikan pada tahun 1998, sebagai perusahaan produsen perangkat lunak yang bergerak di bidang teknologi informasi. Ebdesk telah mengembangkan produk portal perusahaan, berdasarkan teknologi internet. Ebdesk tetap fokus untuk mengembangkan produk-produk yang berkelanjutan sesuai dengan perubahan teknologi dan tren. Ebdesk adalah salah satu perusahaan pertama yang mengembangkan corporate portal, yang mana corporate portal itu sendiri adalah sebuah konsep baru ketika eBdesk didirikan.
eBdesk Corporate Portal mengintegrasikan berbagai informasi dan aplikasi, dari perusahaan di dalam atau di luar, di antarmuka web pribadi tunggal. Ini adalah platform untuk menyebarkan sepenuhnya portal web interface yang memberikan koneksi mulus antara karyawan, manajer, pemilik, mitra, dan pelanggan.
yang komprehensif end-to-end dan layanan untuk berbagai segmen industri. Saat ini ada 6 anggota SAA termasuk XYBASE (Malaysia), eBdesk (Indonesia), Patimas (Malaysia), TMS, SSC Solution (Thailand), BlueBridge Software.
Saat ini PT eBdesk sedang mengembangkan sebuah produk bernama eBdesk Collaboration, yaitu berupa sebuah aplikasi yang memungkinkan penggunanya berkolaborasi untuk mencapai suatu tujuan. Beberapa fitur utama dalam aplikasi eBdesk Collaboration adalah sharing dokumen, galeri, blog dan forum.
Dalam aplikasi eBdesk Collaboration ini terdapat fasilitas untuk menyimpan dokumen. Untuk setiap dokumen bisa terdiri dari satu atau beberapa
file yang di-upload kedalam aplikasi, disimpan pula ke dalam database berupa judul dan deskripsi singkat mengenai dokumen yang dimasukkan oleh pengguna. Proses pencarian dokumen yang dilakukan pada aplikasi eBdesk Collaboration saat ini baru sebatas mencari dokumen berdasarkan judul dan deskripsi singkat yang disimpan ke dalam database.
Untuk lebih menambah nilai jual dari aplikasi eBdesk Collaboration ini, oleh karena itu ingin dibuatkan sebuah fitur baru yaitu pencarian dokumen yang bisa menelusuri query pencarian sampai ke dalam isi file yang di-upload nya itu sendiri.
2.2 Istilah-istilah yang Digunakan Dalam Penulisan
b. File : berkas tertulis (surat, akta, dsb) dari waktu yang lampau, disimpan kedalam media elektronik, disimpan dan dipelihara di tempat khusus untuk referensi. Contoh : Kontrak Kerja PT A.docx
c. Dokumen : kumpulan / gabungan dari file. Sebagai contoh, dokumen pendukung skripsi, didalamnya terdapat file-file : Jadwal Kegiatan Proposal.docx, Kerangka Penulisan Skripsi.docx, Sistem Evaluasi dan Seleksi Proposal.docx, Syarat Pengajuan Proposal.docx, dll. rapkan dapat memenuhi keinginan pengguna dari kumpulan file yang ada
d. Query: pertanyaan yang dimasukkan pengguna ke dalam aplikasi untuk mencari file
2.3 Text Mining
Text mining adalah salah satu bidang khusus dari data mining. Text mining
dapat didefinisikan sebagai suatu proses menggali informasi dari data yang berupa teks dimana sumber data biasanya didapatkan dari dokumen. (Khodra, 2003). Tujuan dari text mining adalah untuk mendapatkan informasi yang berguna dari sekumpulan dokumen. Jadi, sumber data yang digunakan pada text mining adalah kumpulan teks yang memiliki format yang tidak terstruktur atau minimal semi terstruktur.
Algoritma yang digunakan pada text mining, biasanya tidak hanya melakukan perhitungan hanya pada dokumen, tetapi juga pada fitur. Empat macam fitur yang sering digunakan:
pembentuk semantik feature, seperti kata, term dan concept.Pada umumnya, representasi character-based ini jarang digunakan pada beberapa teknik pemrosesan teks.
b. Words adalah satuan kata yang digunakan untuk diproses.
c. Terms merupakan single word dan frasa multiword yang terpilih secara langsung dari corpus. Representasi term-based dari dokumen tersusun dari subset term dalam dokumen.
d. Concept merupakan feature yang digenerate dari sebuah dokumen secara manual, rule-based, atau metodologi lain. Pada tugas akhir ini, konsep digenerate dari argumen atau kata benda yang sudah diberi label pada suatu dokumen.
Text mining bisa juga diartikan sebagai proses analisis teks untuk menemukan informasi baru dari sekumpulan teks berbahasa alami yang tidak terstruktur. Singkatnya adalah pencarian pola tertentu pada suatu text. Dalam text mining ada 5 tahapan umum yang biasanya terdapat pada text mining yaitu
tokenizing, filtering, stemming, tagging dan Analyzing. (Harlian, 2006)
2.4 Proses Penentuan Indeks
Terdapat beberapa tahapan untuk melakukan proses penentuan indeks sampai tersimpan didalam basis data yaitu menyimpan ID file dan menyimpan
a. Tokenizing
Merupakan proses memecah (parsing) file menjadi token-token yaitu dengan memotong menjadi term. Contoh hasil tokenizing terlihat pada Gambar 2.1 sebagai berikut :
Gambar 2.1 Hasil Tokenizing [Milkha, 2006]
b. Filtering
Merupakan proses menghilangkan kata-kata umum yang sering ditampilkan dalam file seperti : is, for, in, dan sebagainya. Contoh hasil filtering terlihat pada Gambar 2.2 sebagai berikut :
Gambar 2.2 Hasil Filtering [Milkha, 2006]
management
management is a new concept in the business world. management
is
c. Stemming
Merupakan proses pembuangan prefix (awalan) dan suffix (imbuhan akhiran) secara morfologi dari suatu kata berimbuhan menjadi kata dasar. Sebelum dilakukan proses stemming, terlebih dahulu dilakukan pengecekan kedalam kamus kata dasar. Kata yang tidak ada dalam kamus akan dilakukan proses
stemming. Contoh hasil stemming terlihat pada Gambar 2.3 sebagai berikut :
Gambar 2.3 Hasil Stemming [Milkha, 2006]
d. Tagging
Tahapan tagging adalah tahap mencari bentuk awal/root kata dari tiap kata dalam bentuk lampau atau kata hasil stemming. Contoh hasil tagging terlihat pada Gambar 2.4 sebagai berikut :
Gambar 2.4 Hasil Tagging [Milkha, 2006]
Contoh dari proses penentuan indeks bisa dilihat pada ilustrasi dibawah ini : 1. Teks yang diproses adalah ”Text mining, sometimes alternately referred to
as text data mining”
2. Dilakukan proses tokenizing terhadap teks, maka dihasilkan daftar kata-kata sebagai berikut :
text
3. Setelah proses tokenizing, dilakukan proses filtering yang berfungsi untuk menghilangkan kata-kata umum. Dalam kasus ini yang menjadi kata umum adalah ”as” dan ”to”. Daftar kata-kata umum bisa dilihat pada lampiran. Setelah proses filtering maka dihasilkan daftar kata-kata sebagai berikut :
4. Selanjutnya dilakukan proses stemming. Sehingga dihasilkan hasil proses dari stemming sebagai berikut :
refer text data mine
5. Selain dilakukan proses stemming, untuk kata yang tidak ada dalam kamus maka dilakukan proses tagging. Sehingga dihasilkan daftar sebagai berikut:
6. Proses terakhir adalah menghitung term weighting dari kata-kata yang telah diproses. Sehingga dihasilkan hasil perhitungannya sebagai berikut :
Kata Frekuensi
Algoritma yang paling umum digunakan untuk melakukan stemming bahasa Inggris dan efektif digunakan adalah algoritma Porter (Porter 1980). Algoritma porter terdiri dari 5 tahap pemotongan kata, yang digunakan secara sekuensial. Dalam tiap tahap tersebut ada berbagai ketentuan untuk memotong kata. Aturan-aturan tersebut disimbolkan sebagai berikut :
Algoritma untuk menghitung m :
Function countM(input term: array[] of char) → integer
{mengembalikan nilai m}
2. *S adalah aturan bahwa kata diakhiri dengan huruf S 3. *v* adalah di dalam kata mengandung huruf vokal
4. *d adalah akhiran kata merupakan konsonan rangkap (double)
5. *o adalah kata berakhiran KVK (konsonan - vokal - konsonan), dimana huruf konsonan yang kedua bukan W, X, atau Y
Aturan dalam menghapus akhiran dituliskan dengan : (kondisi) S1 -> S2. Ini berarti jika kata berakhiran S1, dan sebelum S1 memenuhi kondisi yang diberikan maka S1 diganti dengan S2.
Tahap-tahap pada algoritma Porter Stemmer adalah sebagai berikut : 1. Menghapus akhiran dari kata jamak
a. SSES -> SS (caresses) b. IES -> I (ponies) c. SS -> SS (caress) d. S -> (cats)
2. Menghapus infleksi lisan
a. (m>0) EED -> EE (agreed, feed) b. (*v*) ED -> (plastered, bled) c. (*v*) ING -> (motoring, sing)
3. Jika melakukan penghapusan ED atau ING pada tahap ke 2, maka dilanjutkan dengan tahap ini
c. IZ -> IZE (sized)
d. (*d dan bukan (*L atau *S atau *Z)) -> (tann) e. (m=1 dan *o) -> E (filing, failing, slowing) 4. Mengganti akhiran Y dengan I
(*v*) Y -> I (happy, sky)
5. Menghapus satu akhiran dari beberapa akhiran a. (m>0) ATIONAL -> ATE (relational)
b. (m>0) TIONAL -> TION (conditional, rational) c. (m>0) ENCI -> ENCE (valenci)
d. (m>0) ANCI -> ANCE (hesitanci) e. (m>0) IZER -> IZE (digitizer)
f. (m>0) ABLI -> ABLE (conformabli) g. (m>0) ALLI -> AL (radically) h. (m>0) ENTLI -> ENT (differently) i. (m>0) ELI -> E (vilely)
r. (m>0) ALITI -> AL (formaliti) s. (m>0) IVITI -> IVE (sensitiviti) t. (m>0) BILITI -> BLE (sensibility) 6. Menghapus satu akhiran dari beberapa akhiran
a. (m>0) ICATE -> IC (triplicate) b. (m>0) ATIVE -> (formative) c. (m>0) ALIZE -> AL (formalize) d. (m>0) ICITI -> IC (electriciti) e. (m>0) ICAL -> IC (electrical) f. (m>0) FUL -> (hopeful) g. (m>0) NESS -> (goodness) 7. Menghapus akhiran terakhir
a. (m>1) AL -> (revival)
b. (m>1) ANCE -> (allowance, dance) c. (m>1) ENCE -> (inference, fence) d. (m>1) ER -> (airliner, employer) e. (m>1) IC -> (gyroscopic, electric)
f. (m>1) ABLE -> (adjustable, mov(e)able) g. (m>1) IBLE -> (defensible,bible)
h. (m>1) ANT -> (irritant,ant) i. (m>1) EMENT -> (replacement) j. (m>1) MENT -> (adjustment)
l. (m>1) OU -> ( homologous) m. (m>1) ISM -> (communism) n. (m>1) ATE -> (activate) o. (m>1) ITI -> (angulariti) p. (m>1) OUS -> (homologous) q. (m>1) IVE -> (effective) r. (m>1) IZE -> (bowdlerize) 8. Menghapus akhiran e
a. (m>1) E -> (probate, rate)
b. (m=1 dan bukan *o) E -> (cease) 9. Mengurangi akhiran L rangkap
(m>1 dan *LL) -> L (controll, roll) 2.4.2 Term Weigthing
Term adalah suatu kata atau suatu kumpulan kata yang merupakan ekspresi verbal dari suatu pengertian. Dalam information retrieval sebuah term
perlu diberi bobot, karena semakin sering suatu term muncul pada suatu file, maka kemungkinan term tersebut semakin penting dalam file.
2.4.3 Inverted Index
Ide dasar dari inverted index adalah membuat dictionary dari term-term
(Manning, 2008). Untuk setiap term, terdapat list yang merekam file dimana term
tersebut berada yang disebut dengan posting dan list dari posting disebut posting list.
Didalam file koleksi, setiap file memiliki serial number yang unik, yang disebut dengan file identifier (fileID), dimana fileID dinyatakan dengan bilangan
integer yang bertambah. Input dari proses penentuan indeks merupakan list dari
token yang telah dinormalisasi dari setiap file, dimana list merupakan pasangan antar term dan fileID. Inti dari tahap proses penentuan indeks adalah melakukan pengurutan term secara alphabetis dan setiap posting list diurutkan berdasarkan docID. Kemunculan term yang sama dari satu file digabungkan dan kemunculan
term yang sama dari file yang berbeda dikelompokkan (Manning, 2008). Contoh
inverted index dapat dilihat pada Gambar 2.5.
Gambar 2.5 menunjukkan list dari inverted index. Setiap list terdiri dari
term dan posting list, dimana setiap posting list berisi fileID dan frekuensi kemunculan term dari term yang berada didalam fileID. Nilai frekuensi dari kemunculan term dalam file dituliskan dengan simbol tfd,t. Terlihat di gambar ada
4 term yaitu : abacus, actor, aspen, dan atoll. Untuk posting list abacus file dengan ID = 3, memiliki frekuensi kemunculan term abacus sebesar 94 kali, atau dengan kata lain tf3,abacus= 94; tf19,abacus= 7; tf20,abacus= 212; tf22,abacus= 56. Dan begitu pun
seterusnya untuk term yang lain.
2.5 Proses Pencarian
Setelah proses penentuan indeks, tahap selanjutnya adalah proses pencarian. Proses pencarian merupakan suatu proses mencari ke dalam basis data berdasarkan kata kunci yang dimasukkan oleh pengguna. Tahapan dalam proses pencarian adalah :
a. Tokenizing
Tahap awal dalam melakukan pencarian adalah memecah (tokenizing) query,
keyword yang dimasukkan pengguna dijadikan sebagai query untuk melakukan pencarian kedalam database.
b. Filtering
c. Stemming
Setelah query tersebut melewati proses filtering, kemudian query tersebut melalui proses stemming yaitu suatu proses membuang awalan, akhiran dari kata. Hal ini dilakukan karena yang disimpan di dalam indeks database adalah kata dasar saja. Sebelum dilakukan proses stemming, terlebih dahulu dilakukan pengecekan kedalam kamus kata dasar.
d. Tagging
Setelah query tersebut melewati proses stemming, kemudian query tersebut melalui proses tagging adalah tahap mencari bentuk awal/root kata dari tiap kata dalam bentuk lampau atau kata hasil stemming.
e. Ranking
Tahap yang terakhir adalah melakukan perangkingan, dari file-file yang didapatkan. Perangkingan disusun berdasarkan bobot masing masing file
terhadap kata kunci, file yang paling besar bobotnya menjadi file dengan
ranking teratas. 2.5.1 Ranking
Ranking (perangkingan) merupakan pencarian file-file yang relevan terhadap query dan mengurutkan file tersebut berdasarkan kesesuaiannya dengan
query.
dilakukan dengan menghitung bobot masing-masing file terhadap query. Cara menghitung bobot masing-masing file terhadap query adalah dengan menggunakan metode tf-idf. Setelah dilakukan pembobotan, file hasil pencarian akan ditampilkan sesuai bobot dari file.
2.6 Metode TF-IDF
Metode tf-idf adalah suatu metode atau formula yang digunakan untuk menghitung bobot masing-masing file terhadap kata kunci (Harlian, Milkha. 2006). Metode TF/IDF dikenal sebagai algorithma yang sederhana namun relevan dalam melakukan pencocokan kata pada sebuah dokumen. Karena kelebihan itulah metode tf-idf banyak digunakan untuk pemberian bobot. Term frequency * inverse document frequency atau biasa disingkat dengan tf-idf.
Term frequency (tf) adalah frekuensi dari kemunculan sebuah term dalam
file yang bersangkutan. Oleh sebab itu, tf memiliki nilai yang bervariasi dari suatu
file ke file yang lain bergantung pada tingkat kepentingan sebuah term dalam sebuah file yang diberikan.
Inverse document frequency (idf) adalah suatu statistik yang mengkarakteristikkan sebuah term dalam keseluruhan koleksi file. Idf merupakan sebuah perhitungan dari bagaimana term didistribusikan secara luas pada koleksi
koleksi tidak berguna untuk membedakan file berdasarkan topik tertentu. Nilai idf
dalam sebuah termt dirumuskan dalam persamaan berikut:
.m = log m
(2.1)
ϒ .m , =ϒ ,∙ .m (2.2)
Keterangan:
N : Jumlah file
dft : Jumlah file yang mengandung term yang bersangkutan
ϒ , : Frekuensi kemunculan term pada file yang bersangkutan, dimana frekuensi ini sudah dihitung pada proses sebelumnya dan disimpan ke dalam basis data, lihat sub bab 2.4.3 Inverted Index
.m : Nilai invers document frequency (idf) dari sebuah
term. Yaitu statistik yang mengkarakteristikkan sebuah term dalam keseluruhan koleksi file
ϒ .m , : Bobot sebuah term setelah dihitung menggunakan
metode tf*idf
Perhitungan bobot dari term tertentu dalam sebuah file dengan menggunakan tf*idf menunjukkan bahwa deskripsi terbaik dari file adalah term
yang banyak muncul dalam file tersebut dan sangat sedikit muncul pada file yang lain. Demikian juga sebuah term yang muncul dalam jumlah yang sedang dalam porsi yang cukup dalam file koleksi yang diberikan menjadi deskriptor yang baik. Bobot terendah akan di berikan pada yang yang muncul sangat jarang pada beberapa file dan term yang muncul pada hampir atau seluruh file.
Jika hasil dari proses pembobotan tf*idf menunjukkan bahwa ada file-file
menentukan peringkat dari file-file yang memiliki nilai sama. Perhitungan tersebut dilakukan dengan menggunakan metode vector space model. Dimana metode ini mengukur kemiripan antara suatu file dengan suatu query.
Contoh simulasi perhitungan nilai tf*idf bisa dilihat pada bagian dibawah ini :
Hitung term frekuensi(tf)
ant bee cat dog eel fox gnu hog
f1 2 1
f2 1 1 4 1
f3 1 1 1 1 1
Hitung document frequency (df)
term df
Hitung invers document frequency (idf)
Maka, nilai tf-idf berdasarkan query diatas adalah : f1 : 0,334
f2 : 0,88 f3 : 0,176
2.7 Vector Space Model
Vector space model merupakan solusi atas permasalah yang dihadapi jika menggunakan metode tf-idf. Karena pada metode tf-idf terdapat kemungkinan antar file memiliki bobot yang sama, sehingga ambigu untuk diurutkan.
Vector space model merupakan model yang digunakan untuk mengukur kemiripan antara suatu file dengan suatu query. Pada model ini, query dan file
dianggap sebagai vektor-vektor pada ruang n-dimensi, dimana n adalah jumlah dari seluruh term tunggal. (Harjono & David, 2005).
Inti perhitungan dari metode ini adalah dengan menghitung nilai cosinus sudut dari dua vektor, yaitu bobot dari tiap file dan bobot dari query. Menggunakan consine similiarity untuk mengukur kemiripan file terhadap query.
Berikut ini adalah tahapan untuk menghitung nilai similarity :
1 Hitung Length :
2 Hitung Inner Product : x1.x2 = x11.x21 + x12.x22 + ... x1n.x2n 3 Hitung nilai Cosine of the
angle
: x1, x2, x3… xn = term
x1.x2 = term yang sesuai dengan query
Contoh sudut antara vektor query dan vektor dokumen dapat dilihat pada gambar 2.6.
Gambar 2.6 Representasi grafis sudut vector dokumen dan query
Contoh perhitungan nilai cosinus similarity bisa dilihat pada bagian dibawah ini :
query
q ant dog
document text terms
f1 ant ant bee ant bee
f2 dog bee dog hog dog ant dog ant bee dog hog
f3 cat gnu dog eel fox cat dog eel fox gnu
Hitung Length
ant bee cat dog eel fox gnu hog length
q 1 1 √2
f1 2 1 √5
f2 1 1 4 1 √19
f3 1 1 1 1 1 √5
Hitung Inner Product f1 1*2 + 1*0 = 2 f2 1*1 + 1*4 = 5 f3 1*0 + 1*1 = 1
Hitung nilai Cosine of the angle
f1 f2 f3
q 2 / √10 = 0,63 5 / √38 = 0,81 5 / √10 = 0,32
2.8 Konsep Berorientasi Objek
mempermudah pemeliharaan, mempertinggi kemampuan dalam modifikasi dan meningkatkan penggunaan kembali software. (JEDI, 2007)
Dalam konsep berorientasi objek dikenal beberapa istilah sebagai berikut:
2.8.1 Kelas
Kelas adalah cetak biru (rancangan) dari objek. Ini berarti kita bisa membuat banyak objek dari satu macam kelas. Kelas mendefinisikan sebuah tipe dari objek. Di dalam kelas kita dapat mendeklarasikan variabel dan menciptakan objek (instansiasi). Sebuah kelas mempunyai anggota (member) yang terdiri atas atribut dan method. (Common Labz, 2008)
2.8.2 Objek
Objek secara lugas dapat diartikan sebagai instansiasi atau hasil ciptaan dari suatu kelas yang telah dibuat sebelumnya. Dalam pengembangan program orientasi objek lebih lanjut, sebuah objek dapat dimungkinkan terdiri atas objek-objek lain. Seperti halnya objek mobil terdiri atas mesin, ban, kerangka mobil, pintu, karoseri dan lain-lain. Atau, bisa jadi sebuah objek merupakan turunan dari objek lain sehingga mewarisi sifat-sifat induknya. ( Common Labz, 2008)
2.8.3 Atribut
2.8.4 Method
Method dikenal juga sebagai suatu fungsi dan prosedur. Dalam OOP,
method digunakan untuk memodularisasi program melalui pemisahan tugas dalam suatu class. Pemanggilan method menspesifikasikan nama method
dan menyediakan informasi (parameter) yang diperlukan untuk melaksanakan tugasnya. (Common Labz, 2008)
2.8.5 Constructor
Constructor adalah tipe khusus method yang digunakan untuk menginstansiasi atau menciptakan sebuah objek. Nama constructor adalah sama dengan nama kelasnya. Selain itu, constructor tidak bisa mengembalikan suatu nilai (not return value) bahkan void sekalipun. (Common Labz, 2008)
2.8.6 Package
Package menunjuk pada pengelompokkan kelas dan/atau sub package. Strukturnya dapat disamakan dengan direktorinya. (JEDI, 2007)
2.9 Unified Modelling Languange
Unified Modelling Language (UML) adalah sebuah "bahasa" yang telah menjadi standar dalam industri untuk visualisasi, merancang dan mendokumentasikan sistem piranti lunak. UML menawarkan sebuah standar untuk merancang model sebuah sistem. (Common Labz, 2008)
sistem operasi dan jaringan apapun, serta ditulis dalam bahasa pemrograman apapun. Tetapi karena UML juga menggunakan class dan operation dalam konsep dasarnya, maka ia lebih cocok untuk penulisan piranti lunak dalam bahasa-bahasa berorientasi objek seperti C++, Java, C# atau VB.NET. (Darwiyanti & Wahono, 2003)
Pada UML dikenal beberapa diagram, diantaranya sebagai berikut:
2.9.1 Use Case Diagram
Use case diagram menggambarkan fungsionalitas yang diharapkan dari sebuah sistem. Yang ditekankan adalah “apa” yang diperbuat sistem, dan bukan “bagaimana”. Sebuah use case merepresentasikan sebuah interaksi antara aktor dengan sistem. Use case merupakan sebuah pekerjaan tertentu, misalnya login ke sistem, meng-create sebuah daftar belanja, dan sebagainya. Seorang/sebuah aktor adalah sebuah entitas manusia atau mesin yang berinteraksi dengan sistem untuk melakukan pekerjaan-pekerjaan tertentu. (Darwiyanti & Wahono, 2003)
2.9.2 Sequence Diagram
Sequence diagram menggambarkan interaksi antar objek di dalam dan di sekitar sistem (termasuk pengguna, display, dan sebagainya) berupa
message yang digambarkan terhadap waktu. Sequence diagram terdiri atas dimensi vertikal (waktu) dan dimensi horizontal (objek-objek yang terkait).
Sequence diagram biasa digunakan untuk menggambarkan skenario atau rangkaian langkah-langkah yang dilakukan sebagai respons dari sebuah event untuk menghasilkan output tertentu. Diawali dari apa yang
men-trigger aktivitas tersebut, proses dan perubahan apa saja yang terjadi secara internal dan output apa yang dihasilkan. (Darwiyanti &Wahono, 2003)
2.9.3 Class Diagram
Class (Kelas) adalah sebuah spesifikasi yang jika diinstansiasi akan menghasilkan sebuah objek dan merupakan inti dari pengembangan dan desain berorientasi objek. Kelas menggambarkan keadaan (atribut/properti) suatu sistem, sekaligus menawarkan layanan untuk memanipulasi keadaan tersebut (metoda/fungsi).
Diagram kelas menggambarkan struktur dan deskripsi kelas, paket dan objek beserta hubungan satu sama lain seperti containment, pewarisan, asosiasi, dan lain-lain. (Darwiyanti & Wahono, 2003)
Gambar 2.9 Contoh diagram kelas
2.9.4 Activity Diagram
Activity diagram menggambarkan berbagai alir aktivitas dalam sistem yang sedang dirancang, bagaimana masing-masing alir berawal, decision
juga dapat menggambarkan proses paralel yang mungkin terjadi pada beberapa eksekusi.
Activity diagram merupakan state diagram khusus, di mana sebagian besar state adalah action dan sebagian besar transisi di-trigger oleh selesainya state sebelumnya (internal processing). Oleh karena itu activity diagram tidak menggambarkan perlakuan internal sebuah sistem (dan interaksi antar subsistem) secara eksak, tetapi lebih menggambarkan proses-proses dan jalur-jalur aktivitas dari level atas secara umum. (Darwiyanti &Wahono, 2003)
Gambar 2.10 Contoh activity diagram
2.10 JAVA
motivasi untuk membuat sebuah bahasa pemrograman yang bersifat portable dan
platform independent (tidak tergantung mesin dan sistem operasi) yang dapat digunakan untuk membuat piranti lunak yang dapat ditanamkan (embedded) pada berbagai macam peralatan elektronik consumer biasa, seperti microwave, remote control, telepon, card reader dan sebagainya. (Common Labz, 2008)
Java adalah bahasa pemogramman yang sederhana dan tangguh. Berikut ini adalah beberapa karakteristik dari Java sesuai dengan definisi Sun.
1. Sederhana. Bahasa pemrograman Java menggunakan sintaks mirip dengan C++ namun sintaks pada Java telah banyak diperbaiki terutama menghilangkan penggunaan pointer yang rumit dan multiple inheritance. Java juga menggunakan automatic memory allocation dan memory garbage collection.
2. Berorientasi objek. Java mengunakan pemrograman berorientasi objek yang membuat program dapat dibuat secara modular dan dapat dipergunakan kembali. Pemrograman berorientasi objek memodelkan dunia nyata kedalam objek dan melakukan interaksi antar objek-objek tersebut.
3. Dapat didistribusi dengan mudah. Java dibuat untuk membuat aplikasi terdistribusi secara mudah dengan adanya libraries networking yang terintegrasi pada Java.
dikompilasi menjadi Java bytecodes dapat dijalankan pada platform yang berbeda-beda.
5. Robust. Java mempuyai reliabilitas yang tinggi. Compiler pada Java mempunyai kemampuan mendeteksi error secara lebih teliti dibandingkan bahasa pemrograman lain. Java mempunyai runtime-Exception handling
untuk membantu mengatasi error pada pemrograman.
6. Aman. Sebagai bahasa pemrograman untuk aplikasi internet dan terdistribusi, Java memiliki beberapa mekanisme keamanan untuk menjaga aplikasi tidak digunakan untuk merusak sistem komputer yang menjalankan aplikasi tersebut.
7. Architecture Neutral. Program Java merupakan platform independent. Program cukup mempunyai satu buah versi yang dapat dijalankan pada platform yang berbeda dengan Java Virtual Machine.
8. Portabel.Source code maupun program Java dapat dengan mudah dibawa ke platform yang berbeda-beda tanpa harus dikompilasi ulang.
9. Performance. Performance pada Java sering dikatakan kurang tinggi. Namun performance Java dapat ditingkatkan menggunakan kompilasi Java lain seperti buatan Inprise, Microsoft ataupun Symantec yang menggunakan Just In Time Compilers (JIT).
11.Dinamis. Java didesain untuk dapat dijalankan pada lingkungan yang dinamis. Perubahan pada suatu class dengan menambahkan properties ataupun method dapat dilakukan tanpa menggangu program yang menggunakan class tersebut.
2.11 MySQL Server 5
MySQL adalah salah satu Relational Database Management System (RDBMS) yang didistribusikan secara gratis di bawah lisensi GPL (General Public License) yang dibuat oleh MySQLAB. MySQL merupakan turunan dari konsep database SQL (Structured Query Languange) untuk pemilihan/seleksi dan pemasukan data yang memungkinkan pengoperasian data dikerjakan dengan mudah secara otomatis.
Pada MySQL terdapat beberapa storage engine (mesin penyimpanan data) yang berbeda-beda dan dapat ditentukan oleh proggramer database tersebut. Gambar di bawah ini merupakan arsitektur MySQL:
Kelebihan MySQL:
1. Portability. Berjalan stabil pada berbagai sistem operasi (Windows,Linux, Mac OS, Solaris dsb)
2. Free dan Open Source. Didistribusikan secara gratis dan open source. 3. Multiuser. dapat digunakan oleh beberapa pengguna dalam waktu yang
bersamaan tanpa mengalami masalah atau konflik
4. Performance Tuning. Memiliki kecepatan yang baik dalam menangani
5. Column Types. memiliki tipe kolom yang kompleks, seperti : signed/unsigned integer, float, double, char, varchar, blob, time, datetime, timestamp, year, set serta enum
6. Command dan Functions. memiliki operator dan fungsi secara penuh yang mendukung perintah SELECT dan WHERE dalam query
7. Security. memiliki lapisan sekuritas, seperti level subnetmask, nama host
dan izin akses pengguna disertai dengan password enkripsi.
8. Scalability dan Limits. Mampu menangani basis data dalam skala besar dengan jumlah records lebih dari 50 juta dan 60 ribu tabel serta 5 miliar baris.
9. Connectivity. Dapat melakukan koneksi dengan client menggunakan protokol TCP/IP, Unix soket atau Named Pipes.
10.Localization. Dapat mendeteksi pesan kesalah (error code) pada client
dengan menggunakan lebih dari dua puluh bahasa.
11.Interface. Memiliki interface terhadap berbagai aplikasi dan bahasa pemrograman dengan fungsi API (Application Programming Interface). 12.Clients dan Tools. dilengkapi dengan berbagai tool yang dapat digunakan
untuk administrasi database
40
Bab analisis dan perancangan perangkat lunak berisi analisis aplikasi yang sudah ada serta analisis dan perancangan dari perangkat lunak yang akan dibangun. Pada bab ini akan ditentukan pula kebutuhan dan pemodelan dari perangkat lunak yang akan dibangun, dimana pemodelan menggunakan Unified Modeling Language (UML).
3.1 Analisis Aplikasi eBdesk Collaboration
Pada sub bab ini akan dijelaskan mengenai perangkat lunak yang sudah ada sebelumnya, dalam hal ini adalah aplikasi eBdesk Collaboration, dimana aplikasi pencarian dokumen akan diletakkan pada eBdesk Collaboration.
3.1.1 Deskripsi Sistem
Aplikasi eBdesk Collaboration adalah sebuah aplikasi yang ditujukan sebagai sarana untuk berkolaborasi antar pegawai dalam sebuah perusahaan. Beberapa fitur utama dalam aplikasi eBdesk Collaboration adalah sharing
dokumen, galeri, blog, kegiatan dan forum. Berikut ini akan dijelaskan secara singkat fungsi dari masing-masing fitur yang ada :
1. Pengaturan Profile
foto, mengedit personal informasi pengguna baik itu berupa nama depan, nama lengkap, alamat rumah, alamat email dan sebagainya.
2. Pengelolaan Dokumen
Pada modul dokumen, pengguna dapat mengelola dokumen seperti mengupload dokumen, mengisi informasi terhadap dokumen yang diupload, mendownload file yang ada dalam dokumen.
3. Pengelolaan Galeri
Pada modul galeri , pengguna dapat mengelola galeri seperti membuat galeri foto baru, menambahkan foto ke galeri yang sudah ada, mendownload foto yang ada di dalam suatu galeri, memberikan komentar terhadap foto yang sudah di upload.
4. Pengelolaan Kegiatan
Pada modul kegiatan, pengguna dapat melihat kegiatan yang ada, membuat kegiatan baru, menambah informasi pada kegiatan dan memberikan suatu komentar terhadap event.
5. Pengelolaan Blog
Pada modul blog, pengguna dapat mengelola blog seperti membuat blog baru, mengedit dan menghapus blog, dan memberikan komentar terhadap blog yang telah dibuat.
6. Pengelolaan Forum
3.1.2 Use Case Aplikasi eBdesk Collaboration
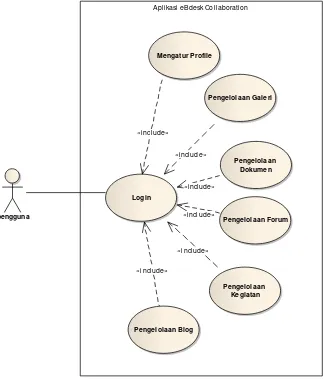
Gambar 3.1 Use Case Aplikasi eBdesk Collaboration
Gambar 3.1 menjelaskan diagram use case dari aplikasi eBdesk Collaboration. Dalam diagram use case ini hanya terdapat satu jenis aktor, sehingga bisa disebut pengguna. Dalam diagram ini, terdapat tujuh proses yang bisa dilakukan pengguna yaitu : Login, Mengatur Profile, Pengelolaan Galeri,
Aplikasi eBdesk Collaboration
pengguna
Pengelolaan Forum
Pengelolaan Kegiatan
Pengelolaan Blog
Pengelolaan Dokumen Mengatur Profile
Pengelolaan Galeri
Login
«include»
«include»
«include»
«include»
«include»
Pengelolaan Dokumen, Pengelolaan Forum, Pengelolaan Kegiatan, dan Pengelolaan Blog.
3.1.3 Class Diagram Pada Pengelolaan Dokumen
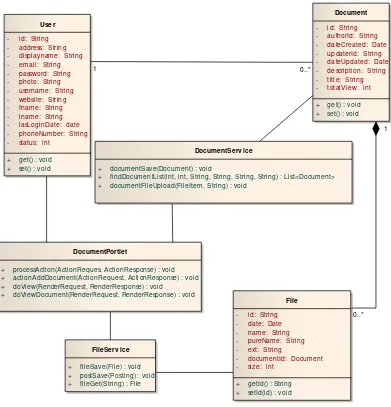
Gambar 3.2 Class diagram pada pengelolaan dokumen
Diagram kelas dalam Gambar 3.2 diatas ini memberikan gambaran keterkaitan antara kelas-kelas pada aplikasi pengelolaan dokumen. Seperti terlihat
File
- documentId: Document - size: int - dateCreated: Date - updaterId: String - dateUpdated: Date - description: String - title: String - totalView: int
+ get() : void + set() : void
DocumentServ ice
+ documentSave(Document) : void
+ findDocumentList(int, int, String, String, String, String) : List<Document> + documentFileUpload(FileItem, String) : void
DocumentPortlet
+ processAction(ActionReques, ActionResponse) : void + actionAddDocument(ActionRequest, ActionResponse) : void + doView(RenderRequest, RenderResponse) : void
+ doViewDocument(RenderRequest, RenderResponse) : void
FileServ ice
+ fileSave(File) : void + postSave(Posting) : void + fileGet(String) : File
User
pada Gambar 3.2 bahwa adanya keterhubungan kelas-kelas antara lain : DocumentPortlet, DocumentService, FileService, User, Document, dan File.
3.2 Analisis Perangkat Lunak Yang Akan Dibangun
Pada analisis perangkat lunak ini akan dijelaskan mengenai deskripsi umum dari perangkat lunak yang akan dibangun yaitu aplikasi pencarian dokumen, use case model berupa use case diagram serta use case skenario, realisasi use case dan activity diagram.
3.2.2 Deskripsi Umum Perangkat Lunak
Perangkat lunak yang akan dibangun adalah perangkat lunak yang mampu melakukan proses penentuan indeks dan proses pencarian. Input dari perangkat lunak ini berupa file text yang disimpan dalam jenis file *.txt dan *.doc. Dan
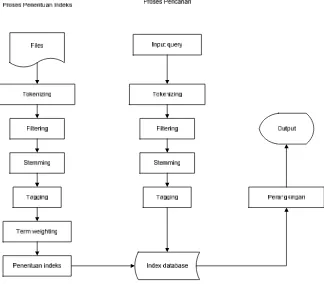
Gambar 3.3 Perangkat Lunak Aplikasi Pencarian Dokumen
Gambar 3.3 memperlihatkan gambaran perangkat lunak yang akan dibangun, untuk proses penentuan indeks dimulai dengan mengubah isi setiap file
yang terdapat di dalam file koleksi menjadi term, proses ini disebut tokenizing. Setiap term yang dihasilkan dari setiap file akan dilakukan proses filtering,
stemming dan tagging, lalu dari setiap term tersebut akan diberikan bobot (term weighting). Term yang telah mengalami proses tokenizing, filtering, stemming, tagging dan term weighting merupakan term yang akan menjadi indeks dari file
koleksi. Pada proses pencarian pengguna memasukkan query, lalu query tersebut dipecah (parse query), hasil dari parse query tersebut akan dilakukan proses
selanjutnya akan dilakukan perangkingan. Perangkingan disusun berdasarkan bobot masing-masing file terhadap query pencarian.
3.3 Analisis Kebutuhan Sistem
3.3.2 Kebutuhan Fungsional
Kebutuhan fungsional pada sistem ini adalah : 1. Upload file dari pengguna
2. Proses penentuan index
3. Input kata kunci dari pengguna 4. Load data dari database
5. Proses pembobotan menggunakan metode tf-idf 6. Tampilkan hasil ke pengguna.
7. Download file yang dipilih pengguna
3.3.3 Use Case Diagram
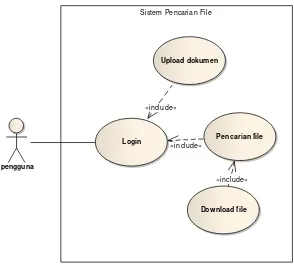
Gambar 3.4 Use case diagram
Gambar 3.4 menjelaskan diagram use case dari sistem pencarian file. Dalam diagram use case ini hanya terdapat satu jenis aktor, sehingga bisa disebut pengguna. Dalam diagram ini, terdapat empat proses yang bisa dilakukan pengguna yaitu : Login, Upload dokumen, Pencarian file, dan Download file. Proses login yaitu melakukan otentikasi pengguna yang akan masuk ke aplikasi. Proses upload dokumen yaitu melakukan upload file, dan mengindeks file ke dalam basis data. Proses pencarian file yaitu melakukan pencarian terhadap file
dan melakukan perangkingan terhadap dokumen hasil pencarian. Proses download file yaitu melakukan proses download terhadap file yang dipilih. Untuk mengetahui penjelasan lebih detail dari use case pada Gambar 3.4 bisa dilihat melalui skenario use case pada tabel 3.1 – 3.4 berikut ini :
Sistem Pencarian File
pengguna
Upload dokumen
Pencarian file
Dow nload file Login
«include»
«include»
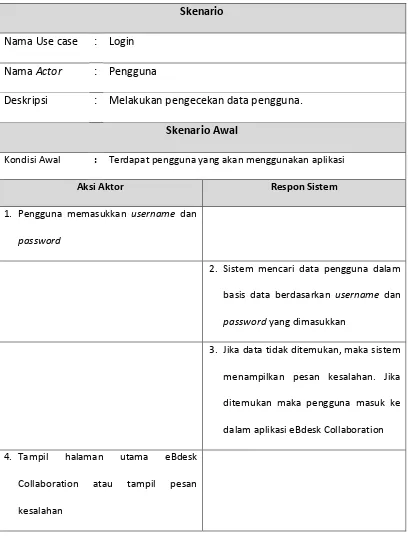
Tabel 3.1 Skenario use case login
Skenario
Nama Use case : Login
Nama Actor : Pengguna
Deskripsi : Melakukan pengecekan data pengguna.
Skenario Awal
Kondisi Awal : Terdapat pengguna yang akan menggunakan aplikasi
Aksi Aktor Respon Sistem
1. Pengguna memasukkan username dan
password
2. Sistem mencari data pengguna dalam
basis data berdasarkan username dan
password yang dimasukkan
3. Jika data tidak ditemukan, maka sistem
menampilkan pesan kesalahan. Jika
ditemukan maka pengguna masuk ke
dalam aplikasi eBdesk Collaboration
4. Tampil halaman utama eBdesk
Collaboration atau tampil pesan
Tabel 3.2 Skenario use case upload dokumen
Skenario
Nama Use case : Upload Dokumen
Nama Actor : Pengguna
Deskripsi : Melakukan upload file, dan mengindeks file ke dalam basis
data.
Skenario Awal
Kondisi Awal : Terdapat file yang belum diindeks
Terdapat form untuk meng-upload dokumen
Aksi Aktor Respon Sistem
1. Pengguna memasukkan judul dan
deskripsi singkat dokumen
2. Pengguna mengunggah file untuk
diindeks ke dalam sistem
3. Sistem menyimpan judul dan deskripsi
ke dalam basis data
4. Sistem membaca isi file kemudian
melakukan proses tokenizing, filtering,
stemming, tagging, dan term weighting
5. Sistem menyimpan data indeks ke basis
data.
6. Pengguna mendapatkan pesan berhasil
Tabel 3.3 Skenario use case pencarian file
Skenario
Nama Use case : Pencarian File
Nama Actor : Pengguna
Deskripsi : Melakukan pencarian terhadap file dan melakukan
perangkingan terhadap dokumen hasil pencarian.
Skenario Awal
Kondisi Awal : Tersedia form pencarian untuk memasukkan kata kunci
pencarian yang diinginkan oleh pengguna.
Aksi Aktor Respon Sistem
1. Pengguna memasukkan kata kunci
pencarian terhadap file.
2. Sistem kata kunci kemudian
melakukan proses tokenizing, filtering,
stemming, tagging terhadap kata
kunci
3. Server akan mengambil file dari
database yang isinya mengandung
kata kunci pencarian
4. Setelah query berhasil dieksekusi dan
file telah difilter lalu dokumen diproses
dihasilkan dokumen yang relevan
terhadap query
5. Sistem menampilkan file sesuai dengan
kata kunci pencarian.
6. Pengguna mendapatkan file sesuai
dengan kata kunci pencarian.
Tabel 3.4 Skenario use casedownload file
Skenario
Nama Use case : DownloadFile
Nama Actor : Pengguna
Deskripsi : Melakukan proses download terhadap file yang dipilih.
Skenario Awal
Kondisi Awal : Tersedia tampilan daftar dokumen hasil pencarian.
Aksi Aktor Respon Sistem
1. Pengguna memilih file yang akan di
download
2. Sistem mencari file fisik yang akan
di-download
3. Setelah file ditemukan sistem
menampilkan popup download
4. Pengguna mendapatkan file yang
3.3.4 Analisis Perangkat Lunak
Pembangunan sistem menggunakan beberapa perangkat lunak sebagai berikut:
1. Sistem Operasi : Windows 7 Ultimate 2. Bahasa Pemrograman : Java
3. Web Server: Apache Tomcat 6.0.26 4. Netbeans IDE 6.8 sebagai editor
5. Database : MySQL 6. Library
a. Spring 2.6 b. Hibernate 3.1 c. MySQL Connector d. POI 3.0
3.3.5 Analisis Perangkat Keras
Adapun daftar spesifikasi perangkat keras yang digunakan dalam pembangunan sistem adalah sebagai berikut.
1. Processor Intel(R) Core(TM) 2 Duo processor 2.5GHz 2. Memori 3072MB
3. Hardisk 296GB 4. Monitor 14`
5. Keyboard dan Mouse
3.4 Perancangan Applikasi
3.4.1 Sequence Diagram
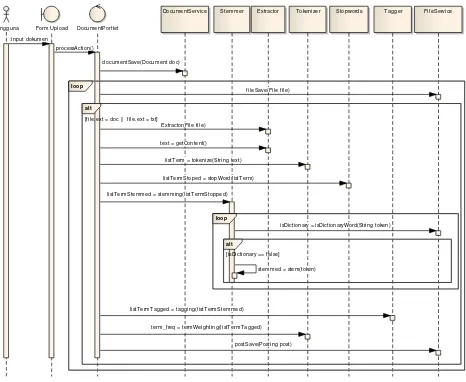
Gambar 3.5 Sequence diagram upload dokumen
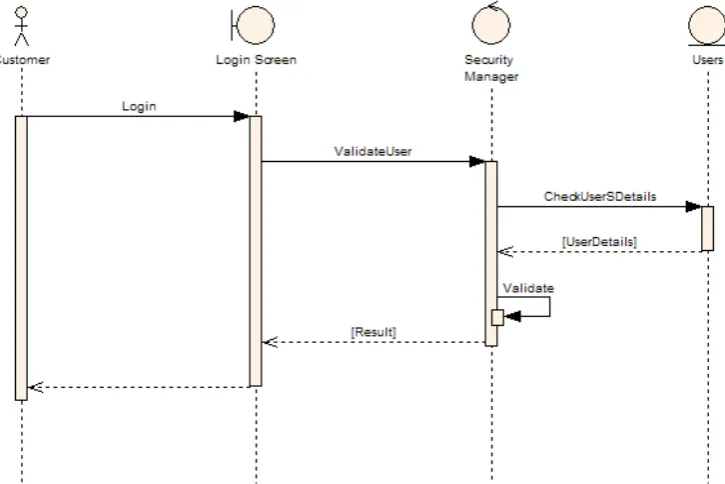
Sequence diagram dalam Gambar 3.5 memberikan gambaran pada saat terjadinya use case upload dokumen. Pada awalnya pengguna memasukkan judul, deskripsi singkat, dan file-file untuk disimpan ke dalam sistem. Kemudian kelas DocumentPortlet bertugas untuk mengatur urutan proses-proses yang harus dilakukan mulai dari menyimpan data dokumen ke dalam database, memanggil kelas-kelas Extractor, Tokenizer, Stopwords, Stemmer, Tagger untuk mengolah teks, dan yang terakhir menyimpan data posting ke dalam database.
Pengguna
listT erm = tokenize(String text)
3.4.1.2 Sequence diagram pencarian file
Sequence diagram dalam Gambar 3.6 dibawah ini memberikan gambaran pada saat terjadinya use case pencarian file. Pada awalnya pengguna memasukkan kata kunci pencarian di form pencarian. Lalu sistem akan mengolah query sehingga dihasilkan kata dasar dari masing-masing term. Mengirim parameter kata kunci pencarian dan akan memproses query
ke database.
Gambar 3.6 Sequence diagram pencarian file
3.4.1.3 Sequence diagram download file
Sequence diagram dalam Gambar 3.7 dibawah ini memberikan gambaran pada saat terjadinya use case download file. Pada awalnya terdapat daftar file hasil dari proses pencarian. Kemudian pengguna memilih
file mana yang akan di download. Sistem akan menampilkan popup untuk proses download file.
Stemmer Stopwords
T okenizer SearchingService
SearchDocumentPortlet Form Pencarian
Pengguna
Tagger FileService
loop
alt
[isDictionary == false] :input query
processAction()
listTerm = tokenize(String query)
listT ermStoped = stopWord(listTerm)
listTermStemmed = stemming(listT ermStopped)
isDictionary = isDictionaryWord(String token)
stemmed = stem(token)
listTermTagged = tagging(listTermStemmed)
listFile = findByKeyword(listTermTagged, start, limit) :tampilkan
Gambar 3.7 Sequence diagram download file
3.4.2 Diagram Aktivitas
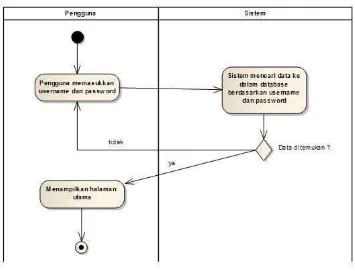
Gambar 3.8 menjelaskan mengenai diagram aktivitas login, dimana aktivitas awalnya adalah pengguna memasukkan username dan password. Kemudian sistem memproses dengan melakukan pencarian data user ke database berdasarkan username dan password. Jika data ditemukan maka pengguna diarahkan ke halaman utama. Jika tidak maka kembali ke halaman login dan menampilkan pesan.
Gambar 3.9 Diagram aktivitas upload file
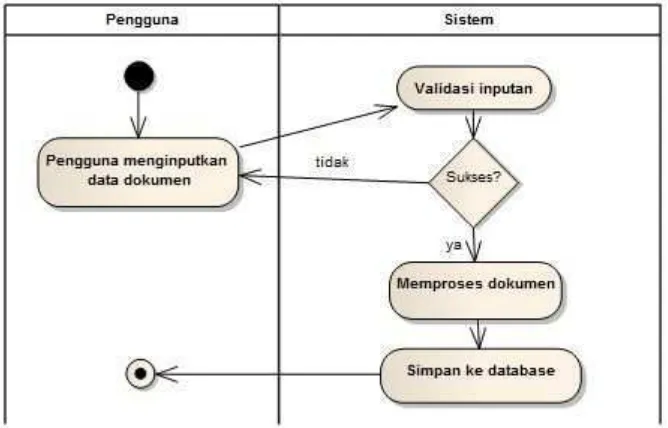
Gambar 3.9 menjelaskan mengenai diagram aktivitas upload dokumen, dimana aktivitas awalnya adalah pengguna memasukkan data dokumen beserta
penentuan indeks, kemudian hasil dari penentuan indeks tersebut disimpan ke dalam basis data.
Gambar 3.10 Diagram aktivitas pencarian
dari pencarian tersebut, maka sistem melakukan proses perangkingan terhadap
file-file hasil pencarian. Selanjutnya file hasil yang telah di-ranking ditampilkan kepada pengguna. Jika pengguna ingin mengunduh file, maka sistem mengambil
file fisik yang tersimpan untuk diberikan kepada pengguna.
3.4.3 Diagram Kelas
Gambar 3.11 Class diagram aplikasi pencarian dokumen
Tokenizer
+ tokenize(text) : List<String>
+ termWeighting(tokens) : Map<String, Integer>
Stopw ords
- stopWordList: Li st<String> + checkStopwords(word) : boolean + i nitWordList() : void
+ stopWord(List<String>) : List<String>
Stemmer
+ stemming(List<String>) : List<String> + stem(String) : String
+ removePluralSuffixation(Stri ng) : String + removeVerbalInflection(String) : String + lastProcessVerbalInflection(String) : String + replaceLastYT oI(Stri ng) : void
+ removeSuffixFromMultipleSuffixes(String) : String + continueRemoveSuffixFromMultipleSuffixes(String) : void + removeLastSuffix(String) : String
+ removeE(String) : String + reduceLL(String) : String + isDoubleC(String) : boolean + isEndCVC(String) : boolean + isContaintVowel(String) : boolean + isVowel(String) : boolean + countM(String) : int
Dictionary
- term: String - Postings: Posting + getT erm() : String + setTerm(term) : void + setPostings(Postings) : void + getPostings() : List<Posting>
Posting
- id: int - fileId: File - dictId: Dictionary - freq: int
+ getDocId() : Document + setDocId(docId) : void + getFreq() : i nt + setFreq(freq) : void
File - documentId: Document - size: int - dateCreated: Date - updaterId: String - dateUpdated: Date - description: String - title: String - totalView: int + get() : void + set() : void
DocumentServ ice
+ documentSave(Document) : void
+ findDocumentLi st(int, int, String, String, String, String) : List<Document> + documentFileUpload(FileItem, String) : void
DocumentPortlet
+ processAction(ActionReques, Acti onResponse) : void + actionAddDocument(ActionRequest, ActionResponse) : void + doView(RenderRequest, RenderResponse) : void + doViewDocument(RenderRequest, RenderResponse) : void + indexingController(Fi le) : void
Tagger
- verbMap: Map<String, String> + getTaggedWord(String) : String + initVerbList() : void + tag(List<String>) : List<String>
Extractor
- content: String + Extractor(file) + getContent() : String + textExtractor() : void + wordExtractor() : voi d
FileServ ice
+ fileSave(File) : void + postSave(Posting) : void + fileGet(String) : File
User
- id: String - address: String - displayname: String - email: String - lasLoginDate: date - phoneNumber: String - status: int + get() : void + set() : void
SearchingServ ice
+ findByKeyword(List<String>, int, int) : List<File>
SearchingDocumentPortlet
+ doView(RenderRequest, RenderResponse) : void + serveResource(ResourceRequest, ResourceResponse) : voi d
Diagram kelas dalam Gambar 3.11 diatas ini memberikan gambaran keterkaitan antara kelas-kelas pada aplikasi pencarian dokumen. Seperti terlihat pada bagian 3.4.1.1 dan 3.4.1.2, bahwa adanya keterhubungan kelas-kelas antara lain : DocumentPortlet, DocumentService, FileService, Extractor, Tokenizer, Stemmer, Tagger, Stopwords, Dictionary, Posting, Document, File, SearchingPortlet, dan SearchingService
3.4.4 Skema Relasi
Gambar 3.12 Skema relasi subsistem pencarian dokumen
3.4.5 Struktur File
Sistem aplikasi membutuhkan spesifikasi file yang dimaksudkan untuk memudahkan sistem kerja komputer dalam melakukan pengaturan dan pencarian data. Struktur file digunakan dalam perancangan sistem untuk menentukan struktur fisik database dengan menjelaskan rincian dari setiap file (nama file,
User FK documentId: VARCHAR(36)