SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
RAHAYU DWI PERMATASARI
10110397
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
v
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah ... 2
1.5 Metodologi Penelitian ... 3
1.6 Sistematika Penulisan ... 5
BAB 2 TINJAUAN PUSTAKA ... 7
2.1 Text Mining ... 7
2.2 Analisis Sentimen ... 7
2.3 Twitter ... 8
2.4 Naive Bayes ... 9
2.4.1 Naive Bayes untuk Klasifikasi ... 11
2.4.2 Karakteristik Naive Bayes ... 13
2.5 UML ... 13
2.5.1 Diagram UML ... 13
2.6 Cross Validation ... 15
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 17
3.1 Analisis Sistem ... 17
3.1.1 Analisis Masalah ... 17
3.1.3 Analisis Data Masukan ... 19
3.1.4 Analisis Metode / Algoritma ... 28
3.1.5 Analisis Kebutuhan Non Fungsional ... 41
3.1.6 Analisis Kebutuhan Fungsional ... 42
3.2 Perancangan Sistem ... 74
3.2.1 Perancangan Struktur Menu ... 74
3.2.2 Perancangan Antar Muka ... 75
3.2.3 Jaringan Semantik... 78
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... 79
4.1 Implementasi Sistem ... 79
4.1.1 Implementasi Perangkat Keras ... 79
4.1.2 Implementasi Perangkat Lunak ... 79
4.1.3 Implementasi Database ... 80
4.1.4 Implementasi Class ... 81
4.1.5 Implementasi Antarmuka ... 81
4.2 Pengujian Sistem ... 82
4.3 Kesimpulan Pengujian ... 88
BAB 5 KESIMPULAN DAN SARAN ... 89
5.1 Kesimpulan... 89
5.2 Saran ... 89
91
DAFTAR PUSTAKA
[1] Imam Fahrur Rozi, Sholeh Hadi Pramono, and Erfan Achmad Dahlan, "Implementasi Opinion Mining (Analisis Sentimen) untuk Ekstraksi Data Opini Publik pada Perguruan Tinggi," Jurnal EECCIS, vol. 6, Juni 2012. [2] Bing Liu, "Sentiment Analysis: A Multi-Faceted Problem," IEEE Intelligent
Systems, 2010.
[3] Eko Prasetyo, Data Mining Konsep dan Aplikasi menggunakan MATLAB, 1st ed., Nikodemus WK, Ed. Yogyakarta: Penerbit ANDI, 2012.
[4] Ni Wayan Sumartini Saraswati. (2011) Kumpulan Thesis Program
Pascasarjana Universitas Udayana. [Online].
http://www.pps.unud.ac.id/thesis/pdf_thesis/unud-209-236721286-tesis.pdf
[5] Ronen Feldman and James Sanger, The Text Mining Handbook Advanced Approaches in Analyzing Unstructured Data, 1st ed.: Cambridge University Press, 2006.
[6] Ian H Witten. ((diakses 23 Maret 2014 10:14)) Computer Science Department, University of Waikato. [Online]. www.cs.waikato.ac.nz
[7] Rosa A S and M Shalahuddin, Rekayasa Perangkat Lunak Terstruktur dan Berorientasi Objek. Bandung, Indonesia: Informatika, 2013.
[8] Ethem Alpaydin, Introduction to Machine Learning.: The MIT Press, 2010. [9] Francesco Camastra and Alessandro Vinciarelli, Machine Learning for
Audio, Image and Video Analysis Theory and Applications.: Springer, 2008.
[10] Trevor Hastie, Robert Tibshirani, and Jerome Friedman, The Elements of Statistical Learning Data Mining, Inference, and Prediction, 2nd ed.: Springer, 2008.
[11] Roger S Pressman, Software Engineering : A Practitioner's Approach, 7th ed.
[13] Ismail Sunni and Dwi Hendratmo Widyantoro, "Analisis Sentimen dan Ekstraksi Topik Penentu Sentimen pada Opini Terhadap Tokoh Publik," Jurnal Sarjana Institut Teknologi Bandung Bidang Teknik Elektro dan Informatika, vol. 1, Juli 2012.
iii
KATA PENGANTAR
Salam hangat,
Puji dan syukur penulis panjatkan kepada Allah SWT atas rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul
“Analisis Sentimen Nasabah Bank X menggunakan Pengklasifikasian Naive
Bayes”.
Penyusunan skripsi ini tidak akan terwujud tanpa mendapat dukungan, bantuan dan masukan dari berbagai pihak. Untuk itu, penulis ingin menyampaikan terima kasih yang sebesar – besarnya kepada :
1. Andy Subroto dan Maria Setiawati Pranata, selaku orang tua penulis, terima
kasih atas segala dukungan dan do’a yang dipanjatkan untuk kelancaran
penelitian penulis.
2. Sinta Tanuwidjojo, selaku oma dari penulis, yang telah menjadi sumber semangat bagi penulis untuk dapat menyelesaikan penelitian ini tepat pada waktunya.
3. Wulan Kartikasari, Rizky Tri Puspitasari, Dimas Surya Subrata dan Faragrina Prima Mustikasari, selaku kakak dan adik penulis, yang selalu mendukung dan memberikan semangat disaat penulis mengalami kejenuhan dalam mengerjakan penelitian.
4. Ibu Nelly Indriani, S.Si., M.T., selaku dosen pembimbing, yang tiada henti memberikan arahan dalam pengerjaan penelitian ini.
5. Bapak Adam Mukharil Bachtiar, S.Kom., M.T., selaku dosen reviewer, yang telah banyak memberi masukan yang amat berarti bagi penelitian ini. 6. Ibu Anna Dara Andriana, S.Kom., M.Kom., selaku dosen penguji, yang
telah memberikan saran bagi penelitian ini.
8. Teman – teman IF-9 2010, khususnya Mochamad Adhitya, Rachmat Setiawan, Al Yasser Noersyahid beserta Geng Hore, yang selalu ada disaat suka dan duka selama pengerjaan skripsi.
9. Teman – teman Analisis Sentimen, Pipit dan Iwan, yang telah banyak membagikan ilmu baru bagi penulis guna pengerjaan penelitian ini.
10. Teman – teman anak bimbingan Ibu Nelly, yang telah bersama – sama menghadapi manis pahit perjuangan skripsi.
11. Seluruh pihak yang telah memberikan kontribusi dan bantuannya bagi penulis dalam pengerjaan penelitian ini namun tidak dapat disebutkan satu persatu.
Akhir kata, semoga skripsi ini dapat bermanfaat bagi para pembaca.
Terima Kasih,
Bandung, Agustus 2014
1
BAB 1 PENDAHULUAN
1.1 Latar Belakang Masalah
Analisis sentimen atau opinion mining merupakan proses memahami, mengekstrak, dan mengolah data tekstual secara otomatis untuk mendapatkan suatu informasi sentimen yang terkandung dalam suatu kalimat opini [1]. Secara umum, analisis sentimen bertujuan untuk menentukan sikap pembicara atau penulis terhadap suatu topik atau keseluruhan polaritas kontekstual pada suatu dokumen. Sikap dapat berupa penilaian atau evaluasi, sisi emosional penulis pada saat menulis atau efek komunikasi emosional yang penulis inginkan terhadap pembacanya [2]. Twitter sebagai salah satu jejaring sosial yang interaktif memungkinkan penggunanya untuk mengkritisi suatu isu maupun sebuah fasilitas pelayanan secara real time. Masyarakat yang semula membutuhkan waktu lama untuk menyampaikan aspirasinya kini dapat melakukannya dengan mudah berkat kehadiran teknologi ini.
Bank X sebagai salah satu bank terkemuka di Indonesia tentulah memiliki jumlah nasabah yang cukup besar dan mencakup hampir seluruh lapisan masyarakat. Setiap nasabah memiliki tingkat kepuasan berbeda terhadap kinerja dari Bank X, sehingga selalu ada pro dan kontra berupa saran dan keluhan. Pemrosesan terhadap saran dan keluhan yang semula diterima melalui customer service secara man to man, kini dapat disampaikan secara real time melalui
Twitter sehingga Bank X dapat mengetahui tanggapan secara cepat tingkat kepuasan nasabah terhadap pelayanan yang diberikannya. Namun mengingat banyaknya jumlah nasabah Bank X, tak sedikit pula saran maupun keluhan dari Twitter yang harus diterima per hari.
Naive Bayes merupakan teknik prediksi berbasis probabilistik sederhana dengan asumsi independensi yang kuat pada fitur, dalam artian sebuah fitur pada sebuah data tidak berkaitan dengan ada atau tidaknya fitur lain dalam data yang sama [3]. Menurut penelitian yang telah dilakukan sebelumnya, Naive Bayes hanya memerlukan sejumlah kecil data pelatihan untuk mengestimasi parameter yang diperlukan untuk klasifikasi [4].
Berdasarkan permasalahan yang ada serta studi literatur yang telah dilakukan, maka penelitian ini bermaksud untuk melakukan Analisis Sentimen Nasabah Bank X menggunakan Pengklasifikasian Naïve Bayes.
1.2 Perumusan Masalah
Berdasarkan latar belakang masalah maka dapat dirumuskan masalah bagaimana tingkat kecocokan metode Naive Bayes dalam mengklasifikasikan kalimat sentimen ke dalam kelas positif dan negatif.
1.3 Maksud dan Tujuan
Berdasarkan permasalahan yang ada, maka maksud dari penelitian yang dilakukan adalah menerapkan metode Naive Bayes untuk mengklasifikasikan kalimat sentimen ke dalam kelas positif dan negatif.
Sedangkan tujuan yang ingin dicapai adalah mengetahui kecocokan metode Naive Bayes dalam mengklasifikasikan kalimat sentimen ke dalam kelas positif dan negatif.
1.4 Batasan Masalah
3
1. Data sentimen mengenai Bank X diperoleh dari akun twitter resmi Bank X @HaloBCA.
2. Data sentimen diklasifikasikan ke dalam dua kelas yaitu positif dan negatif.
3. Perangkat lunak yang dibangun bersifat simulator.
4. Pendekatan pembangunan perangkat lunak yang digunakan pada penelitian adalah pendekatan berorientasi objek.
1.5 Metodologi Penelitian
Metodologi yang digunakan dalam penelitian ini adalah deskriptif. Metode deskriptif merupakan suatu metode penelitian yang bertujuan untuk mendapatkan gambaran yang jelas tentang kebutuhan berlangsungnya penelitian dan berusaha menggambarkan serta menginterpretasi objek yang sesuai dengan fakta secara sistematis, faktual dan akurat.
Adapun pengumpulan data dan pengembangan perangkat lunak dalam penelitian ini menggunakan metode sebagai berikut :
1. Metode Pengumpulan Data
Metode yang digunakan dalam pengumpulan data pada penelitian ini adalah sebagai berikut :
a. Studi Literatur
Pengumpulan data dengan cara mempelajari sumber kepustakaan diantaranya hasil penelitian, jurnal, paper, buku referensi, dan bacaan – bacaan yang ada kaitannya dengan Analisis Sentimen serta Naive Bayes.
b. Observasi
2. Metode Pembangunan Perangkat Lunak
Metode yang digunakan dalam pembuatan perangkat lunak pada penelitian ini adalah Waterfall, adapun tahapan metode Waterfall seperti terlihat pada Gambar 1.1
Gambar 1.1 Waterfall menurut Roger S. Pressman
Berikut adalah penjelasan dari tiap tahapan pada model Waterfall : a. Communication
Tahapan ini merupakan tahap awal pengumpulan kebutuhan dari perangkat lunak yang akan dibangun dengan melakukan pengumpulan data dengan cara observasi terhadap data yang akan digunakan, serta mengumpulkan data – data pendukung lainnya melalui sumber kepustakaan.
b. Planning
Tahapan ini merupakan lanjutan dari tahap Communication, dimana setelah dilakukan pengumpulan terhadap kebutuhan perangkat lunak, maka mulai dilakukan penjadwalan terhadap pembangunan perangkat lunak.
c. Modeling
5
d. Construction
Tahapan ini merupakan tahap pembangunan perangkat lunak dengan menerjemahkan hasil dari pemodelan perangkat lunak ke dalam bentuk kode yang dapat dimengerti oleh komputer. Setelah perangkat lunak dibangun dilakukan pengujian terhadap logika dari perangkat lunak untuk mencari celah kesalahan pada perangkat lunak agar didapatkan perangkat lunak yang sesuai dengan kebutuhan.
e. Deployment
Tahapan ini merupakan tahap akhir dalam pembangunan perangkat lunak. Dimana perangkat lunak siap untuk digunakan sesuai dengan kebutuhannya serta dilakukan pemeliharaan terhadap perangkat lunak seperti penyesuaian akan perubahan keadaan sebenarnya yang ada di lingkungan.
1.6 Sistematika Penulisan
Sistematika penulisan tugas akhir ini disusun untuk memberikan gambaran secara umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB 1 PENDAHULUAN
Bab 1 berisi dasar pemikiran atas dilakukannya penelitian, meliputi latar belakang masalah yang melandasi dilakukannya penelitian, perumusan masalah yang ada, maksud dan tujuan yang akan dicapai, batasan masalah, metodologi penelitian, serta sistematika penulisan yang digunakan dalam penelitian.
BAB 2 TINJAUAN PUSTAKA
Bab 2 berisi konsep dasar serta teori – teori yang berkaitan dengan Analisis Sentimen, seperti Text Mining, Naive Bayes juga penjelasan singkat mengenai Twitter, UML serta Teori Validasi dan Evaluasi.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab 4 berisi hasil Implementasi dan Pengujian Sistem yang dibangun dengan menggunakan metode cross validation dan confusion matrix untuk mengetahui ketepatan dari analisis yang telah dilakukan.
BAB 5 KESIMPULAN DAN SARAN
7
BAB 2
TINJAUAN PUSTAKA
2.1 Text Mining
Text mining adalah suatu bidang baru yang sedang berkembang yang
mencoba untuk mengumpulkan informasi yang memiliki arti dari teks bahasa alami [5]. Bidang ini mungkin lebih dikenali sebagai proses dalam menganalisis teks untuk mengekstrak informasi yang berguna untuk suatu tujuan tertentu. Dibandingkan dengan jenis data yang tersimpan dalam database, text mining menggunakan data teks yang tidak terstruktur, tidak memiliki bentuk yang jelas dan sulit untuk diuraikan dengan pendekatan algoritma. Namun, dalam budaya modern, teks adalah perantara yang paling umum untuk pertukaran secara formal dari informasi. Bidang text mining biasanya berkaitan dengan teks yang memiliki fungsi untuk komunikasi dari informasi yang faktual atau opini, dan keinginan untuk mencoba mengekstrak informasi dari sebuah teks secara otomatis merupakan hal yang menarik meskipun tingkat keberhasilan yang diperoleh hanyalah sebagian [6].
Text mining umumnya digunakan untuk menunjukkan sistem yang
menganalisis sejumlah besar teks bahasa alami dan mendeteksi pola penggunaan leksikal atau bahasa dalam upaya untuk mengekstrak informasi yang mungkin berguna [6].
2.2 Analisis Sentimen
Sentiment analysis atau opinion mining mengacu pada penggunaan
emosional penulis pada saat menulis atau efek komunikasi emosional yang penulis inginkan terhadap pembacanya [2].
Tugas dasar dalam analisis sentimen adalah mengklasifikasikan polaritas dari teks yang ada dalam dokumen, kalimat, atau fitur/tingkat aspek – apakah pendapat yang dikemukakan dalam dokumen, kalimat atau fitur entitas/aspek bersifat positif, negatif atau netral. Lebih lanjut manfaat lain dari analisis sentimen adalah dapat mengklasifikasikan ungkapan emosional seperti sedih, gembira, atau marah.
Ekspresi atau sentimen mengacu pada fokus topik tertentu, pernyataan pada satu topik mungkin akan berbeda makna dengan pernyataan yang sama pada subjek yang berbeda. Sebagai contoh, adalah hal yang baik untuk mengatakan alur film tidak terprediksi, tapi adalah hal yang tidak baik jika „tidak terprediksi‟ dinyatakan pada kemudi dari kendaraan. Bahkan pada produk tertentu, kata – kata yang sama dapat menggambarkan makna kebalikan, contoh adalah hal yang buruk untuk waktu start-up pada kamera digital jika dinyatakan “lama”, namun jika “lama” dinyatakan pada usia baterai maka akan menjadi hal positif. Oleh karena itu pada beberapa penelitian, terutama pada review produk, pekerjaan didahului dengan menentukan elemen dari sebuah produk yang sedang dibicarakan sebelum memulai proses opinion mining [4].
2.3 Twitter
Twitter adalah jejaring sosial online dan layanan microblogging yang memungkinkan penggunanya untuk mengirim dan membaca pesan berbasis teks yang dibatasi sebanyak 140 karakter dikenal dengan sebutan tweet. Pengguna yang terdaftar dapat membaca dan mencatat tweet, sedangkan pengguna yang tidak terdaftar hanya dapat membacanya. Pengguna mengakses Twitter melalui tampilan situs, pesan singkat, atau melalui aplikasi untuk perangkat selular.
9
juta pengguna terdaftar pada tahun 2012 yang mencatat 340 juta tweet per harinya. Layanan Twitter juga menangani 1,6 milyar kata kunci pencarian per harinya. Twitter menjadi satu dari sepuluh situs yang paling sering dikunjungi dan dikenal dengan sebutan “Pesan singkat melalui Internet”.
Tingginya popularitas Twitter menyebabkan layanan ini telah dimanfaatkan untuk berbagai keperluan dalam berbagai aspek, misalnya sebagai sarana protes, kampanye politik, sarana pembelajaran, dan sebagai media komunikasi darurat. Twitter juga dihadapkan pada berbagai masalah dan kontroversi seperti masalah keamanan dan privasi pengguna, gugatan hukum, dan penyensoran.
2.4 Naive Bayes
Bayes merupakan teknik prediksi berbasis probabilistik sederhana yang berdasar pada penerapan teorema Bayes dengan asumsi independensi (ketidaktergantungan) yang kuat (naif) [3].
Dalam Bayes (terutama Naive Bayes), maksud independensi yang kuat pada fitur adalah bahwa sebuah fitur pada sebuah data tidak berkaitan dengan ada atau tidaknya fitur lain dalam data yang sama. Contohnya pada kasus klasifikasi hewan dengan fitur penutup kulit, melahirkan, berat dan menyusui. Dalam dunia nyata, hewan yang berkembang biak dengan cara melahirkan dipastikan juga menyusui. Disini ada ketergantungan pada fitur menyusui karena hewan yang menyusui biasanya melahirkan, atau hewan yang bertelur biasanya tidak menyusui. Dalam Bayes, hal tersebut tidak dipandang sehingga masing – masing fitur seolah tidak memiliki hubungan apa pun [3].
Prediksi Bayes didasarkan pada teorema Bayes dengan persamaan umum seperti terlihat pada Persamaan 2.1
| |
Keterangan :
P(H|E) = Probabilitas akhir bersyarat (conditional probability) suatu hipotesis H terjadi jika diberikan bukti (evidence) E terjadi. P(E|H) = Probabilitas sebuah bukti E akan mempengaruhi hipotesis H P(H) = Probabilitas awal (priori) hipotesis H terjadi tanpa memandang
bukti apapun
P(E) = Probabilitas awal (priori) bukti E terjadi tanpa memandang hipotesis/bukti yang lain
Ide dasar dari aturan Bayes adalah bahwa hasil dari hipotesis atau peristiwa (H) dapat diperkirakan berdasarkan pada beberapa bukti (E) yang diamati. Ada beberapa hal penting dari aturan Bayes tersebut, yaitu
1. Sebuah probabilitas awal/priori H atau P(H) adalah probabilitas dari suatu hipotesis sebelum bukti diamati.
2. Sebuah probabilitas akhir H atau P(H|E) adalah probabilitas dari suatu hipotesis setelah bukti diamati.
Tergantung pada situasi yang tepat dari model probabilitas, Naive Bayes dapat dilatih sangat efisien dalam supervised learning. Dalam aplikasi praktis, parameter estimasi untuk model Naive Bayes menggunakan metode likelihood maksimum, dengan kata lain, seseorang dapat bekerja dengan model Naïve Bayes tanpa mempercayai probabilitas Bayesian atau menggunakan metode Bayesian lainnya [4].
11
2.4.1 Naive Bayes untuk Klasifikasi
Kaitan antara Naive Bayes dengan klasifikasi, korelasi hipotesis, dan bukti dengan klasifikasi adalah bahwa hipotesis dalam teorema Bayes merupakan label kelas yang menjadi target pemetaan dalam klasifikasi, sedangkan bukti merupakan fitur – fitur yang menjadi masukan dalam model klasifikasi. Jika X adalah vektor masukan yang berisi fitur dan Y adalah label kelas, Naive Bayes dituliskan dengan P(Y|X). Notasi tersebut berarti probabilitas label kelas Y didapatkan setelah fitur – fitur X diamati. Notasi ini disebut juga probabilitas akhir (posterior probability) untuk Y, sedangkan P(Y) disebut probabilitas awal (prior probability) Y [3].
Selama proses pelatihan harus dilakukan pembelajaran probabilitas akhir P(Y|X) pada model untuk setiap kombinasi X dan Y berdasarkan informasi yang didapat dari data latih. Dengan membangun model tersebut, suatu data uji X‟ dapat diklasifikasikan dengan mencari nilai Y‟ dengan memaksimalkan nilai P(Y‟|X‟) yang didapat [3].
Formulasi Naive Bayes untuk klasifikasi seperti dapat dilihat pada Persamaan 2.2
| ∏ |
(2. 2)
Keterangan
P(Y|X) = Probabilitas data dengan vektor X pada kelas Y. P(Y) = Probabilitas awal kelas Y.
∏ | = Probabilitas independen kelas Y dari semua fitur dalam vektor X.
sebagai kelas yang dipilih sebagai hasil prediksi. Sementara probabilitas independen ∏ | tersebut merupakan pengaruh semua fitur dari data terhadap setiap kelas Y, yang dinotasikan dengan Persamaan 2.3
| ∏ |
(2. 3)
Setiap set fitur X= { terdiri atas q atribut (q dimensi). Umumnya, Bayes mudah dihitung untuk fitur bertipe kategoris seperti pada kasus klasifikasi hewan dengan fitur “penutup kulit” dengan nilai {bulu, rambut, cangkang}, atau kasus fitur “jenis kelamin” dengan nilai {pria, wanita}. Namun untuk fitur dengan tipe numerik (kontinu) ada perlakuan khusus sebelum dimasukkan dalam Naive Bayes [3]. Caranya adalah :
1. Melakukan diskretisasi pada setiap fitur kontinu dan mengganti nilai fitur kontinu tersebut dengan nilai interval diskret. Pendekatan ini dilakukan dengan mentransformasi fitur kontinu ke dalam fitur ordinal.
2. Mengasumsikan bentuk tertentu dari distribusi probabilitas untuk fitur kontinu dan memperkirakan parameter distribusi dengan data pelatihan. Distribusi Gaussian biasanya dipilih untuk merepresentasikan probabilitas bersyarat dari fitur kontinu pada sebuah kelas | , sedangkan distribusi Gaussian dikarakteristikkan dengan dua parameter : mean, µ, dan varian, . Untuk setiap kelas , probabilitas bersyarat kelas untuk fitur seperti terlihat pada Persamaan 2.4
|
√
(2. 4)
13
2.4.2 Karakteristik Naive Bayes
Klasifikasi dengan Naive Bayes bekerja berdasarkan teori probabilitas yang memandang semua fitur dari data sebagai bukti dalam probabilitas. Hal ini memberikan karakteristik Naive Bayes sebagai berikut :
1. Metode Naive Bayes teguh (robust) terhadap data – data yang terisolasi yang biasanya merupakan data dengan karakteristik berbeda (outlier). Naive Bayes juga dapat menangani nilai atribut yang salah dengan mengabaikan data latih selama proses pembangunan model dan prediksi.
2. Tangguh menghadapi atribut yang tidak relevan.
3. Atribut yang mempunyai korelasi bisa mendegradasi kinerja klasifikasi Naive Bayes karena asumsi independensi atribut tersebut sudah tidak ada [3].
2.5 UML
UML (Unified Modeling Language) merupakan standarisasi bahasa pemodelan untuk pembangunan perangkat lunak yang dibangun dengan menggunakan teknik pemrograman berorientasi objek. UML muncul karena adanya kebutuhan pemodelan visual untuk menspesifikasikan, menggambarkan, membangun, dan dokumentasi dari sistem perangkat lunak. UML merupakan bahasa visual untuk pemodelan dan komunikasi mengenai sebuah sistem dengan menggunakan diagram dan teks – teks pendukung [7].
2.5.1 Diagram UML
Pada UML terdapat 13 macam yang dikelompokkan ke dalam 3 kategori berikut :
a. Structure Diagram
Kumpulan diagram yang digunakan untuk menggambarkan suatu struktur statis dari sistem yang dimodelkan. Terdiri atas Class Diagram, Object Diagram, Component Diagram, Composite Structure Diagram, Package
b. Behavior Diagram
Kumpulan diagram yang digunakan untuk menggambarkan kelakuan sistem atau rangkaian perubahan yang terjadi pada sebuah sistem. Terdiri atas Use Case Diagram, Activity Diagram dan State Machine Diagram.
c. Interaction Diagram
Kumpulan diagram yang digunakan untuk menggambarkan interaksi sistem dengan sistem lain maupun interaksi antar subsistem pada suatu sistem. Terdiri atas Sequence Diagram, Communication Diagram, Timing Diagram dan Interaction Overview Diagram.
Adapun dari 13 diagram tersebut yang akan digunakan pada sistem yang dibangun adalah sebagai berikut :
2.5.1.1Use Case Diagram
Merupakan pemodelan untuk kelakuan (behavior) sistem yang akan dibuat. Use Case mendeskripsikan sebuah interaksi antara satu atau lebih aktor dengan
sistem yang akan dibuat. Secara kasar, Use Case digunakan untuk mengetahui fungsi apa saja yang ada di dalam sebuah sistem dan siapa saja yang berhak menggunakan fungsi – fungsi itu.
2.5.1.2Activity Diagram
Menggambarkan workflow (aliran kerja) atau aktivitas dari sebuah sistem atau proses bisnis atau menu yang ada pada perangkat lunak. Menggambarkan aktivitas dari sistem bukan apa yang dilakukan aktor.
2.5.1.3Class Diagram
15
Gambar 2. 1 Contoh Class Diagram
2.5.1.4Sequence Diagram
Menggambarkan kelakuan objek pada Use Case dengan mendeskripsikan waktu hidup objek dan message yang dikirimkan dan diterima antar objek.
2.6 Cross Validation
Untuk tujuan replikasi, yang dibutuhkan adalah mendapatkan jumlah dari data latih dan pasangan data uji dari dataset X (setelah lebih dahulu memisahkan sebagian data sebagai data uji). Untuk mendapatkannya, jika sampel X cukup besar, kita dapat membaginya secara acak kedalam K bagian, lalu secara acak memisahkan masing-masing bagian ke dalam 2 kelompok dan menggunakan setengah data pertama untuk data latih dan setengah data lainnya untuk data uji. Pengujian ini dilakukan berulang dengan menggunakan data split yang berbeda, dinamakan cross validation.
K-fold cross-validation adalah sebuah pengujian dimana dataset X dibagi
secara acak kedalam K bagian dengan ukuran yang sama, Xi, i=1,...,K. Untuk memproses tiap pasangnya, diambil terlebih dahulu salah satu bagian dari K bagian sebagai data tes, dan mengkombinasikan sisanya sebanyak K-1 bagian sebagai data latih. Proses pengujian dilakukan sebanyak K kali [8]. Nilai K yang umum digunakan adalah 5 atau 10 [9] [10].
Tabel 2. 1 Confusion Matrix
Tested Class
Predicted Class Positive Negative Total
Positive
True Positive : Hasil diprediksi bernilai True, dan pengujian menghasilkan True
False Positive : Hasil diprediksi bernilai False, dan pengujian
menghasilkan True
False Negative : Hasil diprediksi bernilai True, dan pengujian menghasilkan False
True Negative : Hasil diprediksi bernilai False, dan pengujian
menghasilkan False.
Setelah hasil pengujian menggunakan k-fold cross validation dievaluasi menggunakan confusion matrix, selanjutnya dapat dihitung nilai error dari keseluruhan iterasi dengan Persamaan 2.5
79
BAB 4
IMPLEMENTASI DAN PENGUJIAN SISTEM
4.1 Implementasi Sistem
Tahap implementasi sistem merupakan tahap pembangunan perangkat lunak, tahap lanjut dari tahap perancangan sistem. Tahap yang dilakukan untuk menerjemahkan perancangan berdasarkan hasil analisis dalam bahasa yang dimengerti oleh komputer serta penerapan perangkat lunak pada keadaan yang sebenarnya.
4.1.1 Implementasi Perangkat Keras
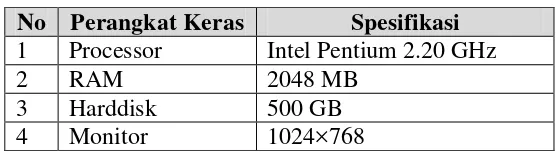
Spesifikasi perangkat keras (hardware) yang digunakan untuk membangun Analisis Sentimen terhadap PT. X menggunakan Pengklasifikasian Naive Bayes seperti dapat dilihat pada Tabel 4.1.
Tabel 4. 1 Implementasi Perangkat Keras
No Perangkat Keras Spesifikasi
1 Processor Intel Pentium 2.20 GHz
2 RAM 2048 MB
3 Harddisk 500 GB
4 Monitor 1024×768
4.1.2 Implementasi Perangkat Lunak
Spesifikasi perangkat lunak (software) yang digunakan untuk membangun Analisis Sentimen terhadap PT. X menggunakan Pengklasifikasian Naive Bayes seperti dapat dilihat pada Tabel 4.2
Tabel 4. 2 Implementasi Perangkat Lunak
No Perangkat Lunak Spesifikasi
1 Operating System Windows 7 2 Bahasa Pemrograman C#
3 Database MySQL
4 Web Server WampServer 2.0
5 Pemodelan StarUML
4.1.3 Implementasi Database
Pembuatan basis data (database), dilakukan dengan menggunakan MySQL. Implementasi basis data (database) dalam bahasa SQL adalah seperti dapat dilihat pada Tabel 4.3.
Tabel 4. 3 Implementasi Database
No Proses SQL
1 Pembuatan Database CREATE DATABASE
db_analisis_sentimen_bca; 2 Tabel “tb_m_reserve_tag” CREATE TABLE
`tb_m_reserve_tag` PRIMARY KEY (`tweet_id`) )
4 Tabel “tweetbca” CREATE TABLE `tweetbca`
( `tweet` VARCHAR(200) NOT NULL,
81
4.1.4 Implementasi Class
Implementasi class merupakan implementasi dari analisis kelas yang ada pada class diagram. Deskripsi implementasi class pada sistem yang dibangun dapat dilihat pada Tabel 4.4
Tabel 4. 4 Implementasi Class
No Nama Class Nama File Executable
1 KamusPembelajaran KamusPembelajaran.cs
2 SentimentAppDBConnection SentimentAppDBConnection.cs
3 PieDiagramBox PieDiagramBox.cs
4 Corpus Corpus.cs
5 KelasRekap KelasRekap.cs
6 ReserveTag ReserveTag.cs
7 TokenHasilKelasifikasi TokenHasilKelasifikasi.cs
8 Tweet Tweet.cs
9 TweetAndClass TweetAndClass.cs
4.1.5 Implementasi Antarmuka
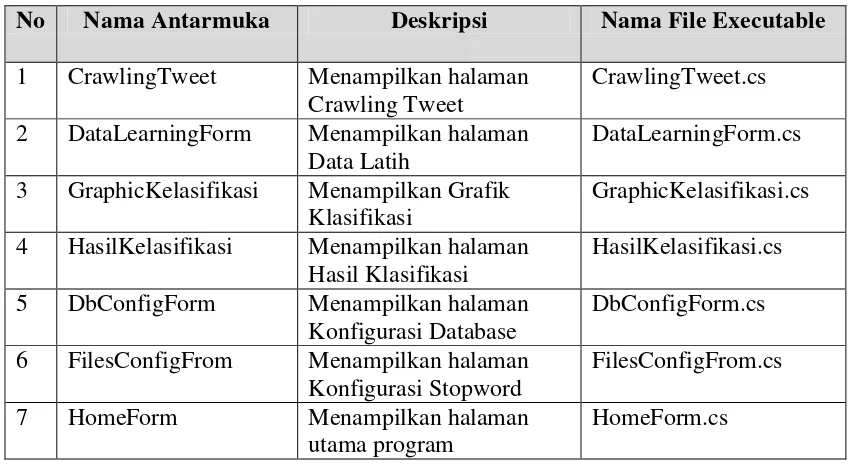
Implementasi antarmuka dilakukan untuk setiap tampilan program yang dibangun dalam bentuk file code. Deskripsi implementasi antarmuka pada sistem yang dibangun dapat dilihat pada Tabel 4.5
Tabel 4. 5 Implementasi Antarmuka
No Nama Antarmuka Deskripsi Nama File Executable
1 CrawlingTweet Menampilkan halaman Crawling Tweet
CrawlingTweet.cs 2 DataLearningForm Menampilkan halaman
Data Latih
DataLearningForm.cs 3 GraphicKelasifikasi Menampilkan Grafik
Klasifikasi
GraphicKelasifikasi.cs 4 HasilKelasifikasi Menampilkan halaman
Hasil Klasifikasi
HasilKelasifikasi.cs 5 DbConfigForm Menampilkan halaman
Konfigurasi Database
DbConfigForm.cs 6 FilesConfigFrom Menampilkan halaman
Konfigurasi Stopword
FilesConfigFrom.cs
7 HomeForm Menampilkan halaman
utama program
4.2 Pengujian Sistem
Pengujian ditujukan untuk mengukur tingkat kesesuaian antara hasil klasifikasi terhadap data sentimen secara manual dengan hasil klasifikasi menggunakan Naive Bayes. Adapun pengujian yang dilakukan menggunakan k-fold cross validation dengan nilai k = 10. Nilai 10 menunjukkan jumlah k-fold data,
dimana masing – masing subset memiliki data yang berbeda. Iterasi pengujian akan dilakukan sebanyak 10 kali.
Jumlah data yang digunakan sebanyak 540 data, data ini merupakan data hasil tahap preprocessing yang telah dikelompokkan sebelumnya ke dalam kelas positif dan negatif secara manual dengan jumlah sebesar 270 data untuk masing – masing kelasnya. Tiap fold terdiri dari 54 data. Data tweet dapat dilihat pada bagian Lampiran C.
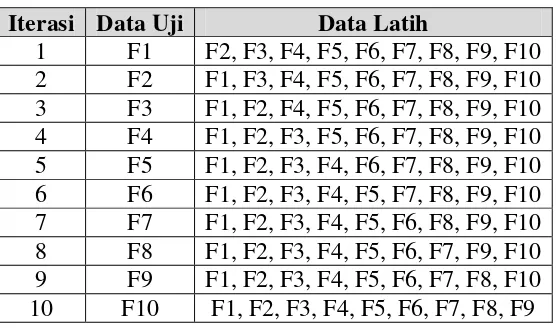
Percobaan pengujian dilakukan sebanyak 10 kali, dimana tiap fold akan secara bergantian menjadi data latih dan data uji. Berikut adalah kombinasi fold yang digunakan seperti dapat dilihat pada Tabel 4.6.
Tabel 4. 6 Kombinasi FoldCross Validation
Iterasi Data Uji Data Latih
83
1. Iterasi Satu
Digunakan 486 data sebagai data latih dan 54 data sebagai data uji. Adapun data latih yang digunakan adalah fold 2, fold 3, fold 4, fold 5, fold 6, fold 7, fold 8, fold 9 dan fold 10, sedangkan data yang akan diuji
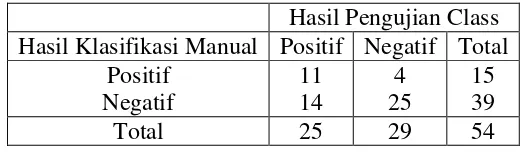
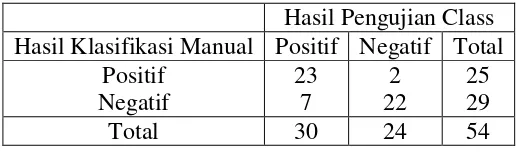
adalah fold 1. Hasil pengujian fold pertama dengan menggunakan 10-Fold Cross Validation seperti dapat dilihat pada Tabel 4.7.
Tabel 4. 7 Hasil Pengujian Cross Validation pada Fold 1
Hasil Pengujian Class Hasil Klasifikasi Manual Positif Negatif Total
Positif fold 6, fold 7, fold 8, fold 9 dan fold 10, sedangkan data yang akan diuji
adalah fold 2. Hasil pengujian fold pertama dengan menggunakan 10-Fold Cross Validation seperti dapat dilihat pada Tabel 4.8.
Tabel 4. 8 Hasil Pengujian Cross Validation pada Fold 2
Hasil Pengujian Class Hasil Klasifikasi Manual Positif Negatif Total
3. Iterasi Tiga
Digunakan 486 data sebagai data latih dan 54 data sebagai data uji. Adapun data latih yang digunakan adalah fold 1, fold 2, fold 4, fold 5, fold 6, fold 7, fold 8, fold 9 dan fold 10, sedangkan data yang akan diuji
adalah fold 3. Hasil pengujian fold pertama dengan menggunakan 10-Fold Cross Validation seperti dapat dilihat pada Tabel 4.9.
Tabel 4. 9 Hasil Pengujian Cross Validation pada Fold 3
Hasil Pengujian Class Hasil Klasifikasi Manual Positif Negatif Total
Positif fold 6, fold 7, fold 8, fold 9 dan fold 10, sedangkan data yang akan diuji
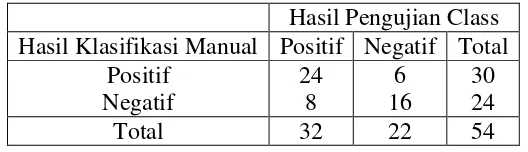
adalah fold 4. Hasil pengujian fold pertama dengan menggunakan 10-Fold Cross Validation seperti dapat dilihat pada Tabel 4.10.
Tabel 4. 10 Hasil Pengujian Cross Validation pada Fold 4
Hasil Pengujian Class Hasil Klasifikasi Manual Positif Negatif Total
85
5. Iterasi Lima
Digunakan 486 data sebagai data latih dan 54 data sebagai data uji. Adapun data latih yang digunakan adalah fold 1, fold 2, fold 3, fold 4, fold 6, fold 7, fold 8, fold 9 dan fold 10, sedangkan data yang akan diuji
adalah fold 5. Hasil pengujian fold pertama dengan menggunakan 10-Fold Cross Validation seperti dapat dilihat pada Tabel 4.11.
Tabel 4. 11 Hasil Pengujian Cross Validation pada Fold 5
Hasil Pengujian Class Hasil Klasifikasi Manual Positif Negatif Total
Positif fold 5, fold 7, fold 8, fold 9 dan fold 10, sedangkan data yang akan diuji
adalah fold 6. Hasil pengujian fold pertama dengan menggunakan 10-Fold Cross Validation seperti dapat dilihat pada Tabel 4.12.
Tabel 4. 12 Hasil Pengujian Cross Validation pada Fold 6
Hasil Pengujian Class Hasil Klasifikasi Manual Positif Negatif Total
7. Iterasi Tujuh
Digunakan 486 data sebagai data latih dan 54 data sebagai data uji. Adapun data latih yang digunakan adalah fold 1, fold 2, fold 3, fold 4, fold 5, fold 6, fold 8, fold 9 dan fold 10, sedangkan data yang akan diuji
adalah fold 7. Hasil pengujian fold pertama dengan menggunakan 10-Fold Cross Validation seperti dapat dilihat pada Tabel 4.13.
Tabel 4. 13 Hasil Pengujian Cross Validation pada Fold 7
Hasil Pengujian Class Hasil Klasifikasi Manual Positif Negatif Total
Positif fold 5, fold 6, fold 7, fold 9 dan fold 10, sedangkan data yang akan diuji
adalah fold 8. Hasil pengujian fold pertama dengan menggunakan 10-Fold Cross Validation seperti dapat dilihat pada Tabel 4.14.
Tabel 4. 14 Hasil Pengujian Cross Validation pada Fold 8
Hasil Pengujian Class Hasil Klasifikasi Manual Positif Negatif Total
87
9. Iterasi Sembilan
Digunakan 486 data sebagai data latih dan 54 data sebagai data uji. Adapun data latih yang digunakan adalah fold 1, fold 2, fold 3, fold 4, fold 5, fold 6, fold 7, fold 8 dan fold 10, sedangkan data yang akan diuji
adalah fold 9. Hasil pengujian fold pertama dengan menggunakan 10-Fold Cross Validation seperti dapat dilihat pada Tabel 4.15.
Tabel 4. 15 Hasil Pengujian Cross Validation pada Fold 9
Hasil Pengujian Class Hasil Klasifikasi Manual Positif Negatif Total
Positif Fold Cross Validation seperti dapat dilihat pada Tabel 4.16.
Tabel 4. 16 Hasil Pengujian Cross Validation pada Fold 10
Hasil Pengujian Class Hasil Klasifikasi Manual Positif Negatif Total
Setelah dilakukan iterasi sebanyak 10 kali, didapat hasil pengujian seperti dapat dilihat pada Tabel 4.17.
Tabel 4. 17 Nilai Error Pengujian
Hasil Pengujian
Data Uji Nilai error
Iterasi 1 27,78%
Iterasi 2 33,33%
Iterasi 3 25,93%
Iterasi 4 16,67%
Iterasi 5 24,07%
Iterasi 6 25,93%
Iterasi 7 18,52%
Iterasi 8 22,22%
Iterasi 9 18,52%
Iterasi 10 29,63%
Rata – rata Error 24,26%
4.3 Kesimpulan Pengujian
89
BAB 5
KESIMPULAN DAN SARAN
Pada bab ini akan dikemukakan kesimpulan yang diperoleh dari pembahasan bab – bab sebelumnya serta saran untuk perbaikan dan pengembangan sistem yang lebih lanjut.
5.1 Kesimpulan
Berdasarkan hasil yang didapat dalam penelitian dan penyusunan skripsi ini serta disesuaikan dengan tujuan, maka diperoleh kesimpulan bahwa dengan sistem yang dibangun diketahui nilai error yang diberikan metode Naive Bayes dalam mengklasifikasikan kalimat sentimen ke dalam kelas positif dan negatif sebesar 24,26%. Dengan nilai error yang diberikan, dapat disimpulkan bahwa metode Naive Bayes sesuai untuk dipergunakan dalam melakukan pengklasifikasian terhadap kalimat sentimen.
5.2 Saran
Dari hasil penelitian yang telah dilakukan, sistem yang dibangun masih memiliki kekurangan baik dari segi fungsionalitas maupun data yang dimiliki. Oleh karena itu agar didapat sistem yang lebih handal dan akurat perlu dilakukan pengembangan dan penyempurnaan lebih lanjut. Adapun saran agar sistem dapat berfungsi dengan lebih baik lagi yaitu :
1. Penambahan fitur yang memungkinkan penambahan data hasil crawling tweet ke dalam data latih.
2. Proses penentuan kelas dari hasil crawling tweet baru.
DAFTAR RIWAYAT HIDUP
Nama Lengkap : Rahayu Dwi Permatasari Tempat/Tanggal Lahir : Bandung, 13 Mei 1993
Jenis Kelamin : Perempuan
Agama : Islam
Alamat Lengkap : Jl Pasirluyu No 73/205A RT 02/02 Kel.Pasirluyu Kec.Regol Bandung 40254
Email : heyrahoy@gmail.com
PENDIDIKAN
1998-2004 : SD Negeri Nilem 3 Bandung
2004-2007 : SMP Negeri 28 Bandung
2007-2010 : SMA Negeri 11 Bandung