VISUALISASI DATA BERKELOMPOK DENGAN ANALISIS
KOMPONEN UTAMA KERNEL
SONNA ARIYANTO LOBO
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Visualisasi Data Berkelompok dengan Analisis Komponen Utama Kernel adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2015
Sonna Ariyanto Lobo
RINGKASAN
SONNA ARIYANTO LOBO. Visualisasi Data Berkelompok dengan Analisis Komponen Utama Kernel. Dibimbing oleh SISWADI dan TONI BAKHTIAR.
Visualisasi adalah rekayasa dalam pembuatan gambar, diagram atau animasi untuk penampilan suatu informasi. Visualisasi sering digunakan dalam analisis data eksplorasi untuk meringkas karakteristik utama dari data. Tujuan utamanya ialah untuk mengomunikasikan informasi dengan jelas bagi pengguna melalui grafik, plot dan tabel sehingga data yang kompleks menjadi mudah diakses, dimengerti dan digunakan. Dalam data berkelompok, visualisasi dapat dilakukan dengan memplot objek-objek data secara langsung pada bidang Cartesius. Untuk data yang memiliki peubah lebih dari tiga, maka hal ini menjadi tidak mungkin dilakukan. Karena itu digunakanlah Analisis Komponen Utama (AKU).
AKU digunakan untuk mereduksi data yang berdimensi tinggi menjadi data baru yang memiliki dimensi rendah, dalam hal ini berdimensi dua, sehingga data menjadi dapat divisualisasikan. Peubah-peubah baru ini dinamakan komponen utama. Sayangnya, AKU tidak dapat memodelkan data yang memiliki kompleksitas tinggi dengan hubungan taklinear antarpeubah. Oleh karena itu, dikembangkanlah Analisis Komponen Utama Kernel (AKU Kernel). Secara implisit, AKU Kernel merupakan bentuk taklinear dari AKU dengan memetakan data ke suatu ruang fitur yang berdimensi tinggi di mana pada ruang tersebut data memiliki hubungan linear antarpeubah sehingga AKU dapat diterapkan.
Penelitian ini bertujuan untuk membandingkan hasil visualisasi antara AKU dan AKU Kernel dalam memisahkan data secara linear. Pada AKU Kernel, fungsi kernel yang digunakan pada penelitian ini adalah fungsi kernel Gauss yang mengandung parameter . Parameter ini sangat menentukan hasil pemetaan yang dihasilkan pada ruang fitur. Karena itu, pada penelitian ini didahului dengan menentukan suatu metode untuk memilih parameter sehingga dihasilkan visualisasi dengan AKU Kernel yang meminimumkan salah klasifikasi. Pengklasifikasian yang digunakan adalah analisis diskriminan linear Fisher yang berguna untuk melihat keterpisahan kelompok data secara linear.
Dari hasil analisis terhadap dua kelompok data sintetis, yaitu Data Sintetis Wang dan Data Synthetic Control Chart Time Series dan dua kelompok data real world, yaitu Data Tanaman Iris dan Data Pengenalan Anggur diperoleh bahwa AKU Kernel memberikan hasil yang lebih baik dalam memvisualisasikan keterpisahan data secara linear dibandingkan dengan hasil yang diberikan oleh AKU. Nilai parameter pada fungsi kernel Gauss untuk AKU Kernel yang memberikan hasil visualisasi yang meminimumkan salah klasifikasi diusulkan untuk dipilih pada interval min
xixj
max
xixj
; i j.SUMMARY
SONNA ARIYANTO LOBO. Visualization of Classified Data with Kernel Principal Component Analysis. Supervised by SISWADI and TONI BAKHTIAR.
Visualization is engineered in making drawings, diagrams or animations to the appearance of an information. Visualization is often used in exploratory data analysis to summarize the main characteristic of the data. Its main goal is to communicate information clearly and effectively to users through graphs, plots, and tables so it makes the data to be more accessible, understood and used. For classified data, visualization can be done directly by plotting the data object in the ordinary space. But, for the data with dimension is greater than three, the visualization cannot be done directly. It can be done by using Principal Component Analysis (PCA).
PCA is used to reduce the dimensionality of the data to be the new data with smaller dimensions, in this case into 2-dimensional space, so it can be visualized. The new variables that represent the data are called principal components. However, PCA could not model the high complexity data with nonlinear relationships among variables. Therefore, Kernel PCA was developed as the generalization of ordinary PCA. Implicitly, Kernel PCA is a nonlinear form of ordinary PCA which maps the original data that have nonlinear relationships among variables into high-dimensional feature space. At the space, the data obtained has linear relationships among variables so that ordinary PCA can be applied.
This study aimed to compare the result of visualization between PCA and Kernel PCA in separating the data. In Kernel PCA, kernel function used in this study is Gaussian kernel function with as parameter. The ability of Gaussian kernel function to map the classified data into feature space to obtain the separation among classes is very dependent on the parameter. So that, before using Kernel PCA, we need to assess the selection method for parameter σ in Gaussian kernel function to visualize of classified data that minimize misclassification. The classification used Fisher linear discriminant analysis to show the separation of the data in the feature space.
By empirical study of the two synthetic data sets, namely Wang Synthetic Data set and Synthetic Control Chart Time Series Data set and two real world data sets, namely Iris Data set and Wine Data set, we obtained that Kernel PCA gave better results in visualizing the separation of the data compared with PCA. Parameter values in Gauss kernel function for Kernel PCA which provides results visualization to minimize misclassification is proposed to be selected in the interval
min i j , max i j ; i j.
x x x x
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Matematika Terapan
VISUALISASI DATA BERKELOMPOK DENGAN ANALISIS
KOMPONEN UTAMA KERNEL
SONNA ARIYANTO LOBO
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
Judul Tesis : Visualisasi Data Berkelompok dengan Analisis Komponen Utama Kernel
Nama : Sonna Ariyanto Lobo NIM : G551130181
Disetujui oleh Komisi Pembimbing
Prof Dr Ir Siswadi, MSc Ketua
Dr Toni Bakhtiar, MSc Anggota
Diketahui oleh
Ketua Program Studi Matematika Terapan
Dr Jaharuddin, MS
Dekan Sekolah Pascasarjana IPB
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yesus atas segala anugerah-Nya sehingga penulis dapat menyelesaikan tesis ini. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan September 2014 ini ialah visualisasi data, dengan judul Visualisasi Data Berkelompok dengan Analisis Komponen Utama Kernel.
Penulisan tesis ini merupakan salah satu syarat memperoleh gelar Magister Sains pada program studi Matematika Terapan Sekolah Pascasarjana Institut Pertanian Bogor. Terima kasih penulis ucapkan kepada:
1. Bapak Prof Dr Ir Siswadi, MSc selaku ketua komisi pembimbing.
2. Bapak Dr Toni Bakhtiar, MSc selaku anggota komisi pembimbing sekaligus Ketua Departemen Matematika Institut Pertanian Bogor.
3. Bapak Dr Jaharuddin, MS selaku Ketua Program Studi Matematika Terapan Institut Pertanian Bogor.
4. Bapak Dr Ir I Gusti Putu Purnaba, DEA selaku penguji luar komisi.
5. Seluruh dosen dan tenaga kependidikan Departemen Matematika Institut Pertanian Bogor.
6. Direktorat Pendidik dan Tenaga Kependidikan (Diktendik)-DIKTI sebagai sponsor Beasiswa Pendidikan Pascasarjana Dalam Negeri (BPP-DN).
7. Orang tua dan adik-adik serta seluruh keluarga yang selalu memberikan dorongan dan mendoakan untuk keberhasilan studi bagi penulis.
8. Nur Fajri yang selalu menemani dan menjadi teman diskusi penulis.
9. Sahabat-sahabat yang tidak dapat disebutkan satu persatu yang telah banyak membantu penulis dalam menyelesaikan studi.
Akhirnya, semoga penulisan tesis ini dapat bermanfaat dan memperkaya pengalaman belajar dan wawasan kita semua.
Bogor, Agustus 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN vii
1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 2
1.3 Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 3
2.1 Fungsi Kernel 3
2.2 Analisis Komponen Utama Kernel 4
2.3 Analisis Diskriminan Linear Fisher 7
3 METODE PENELITIAN 11
3.1 Data Penelitian 12
3.2 Langkah Penelitian 13
3.2.1 Menyiapkan Alat Uji 15
3.2.2 Membandingkan Efektivitas Teknik Visualisasi 15
4 HASIL DAN PEMBAHASAN 19
4.1 Algoritma Pereduksian Data 19
4.1.1 Algoritma Analisis Komponen Utama 19
4.1.2 Algoritma Analisis Komponen Utama Kernel 19
4.2 Hasil Uji Coba dan Analisis 22
4.2.1 Data Sintetis Wang 22
4.2.2 Data Synthetic Control Chart Time Series 27
4.2.3 Data Tanaman Iris 32
4.2.4 Data Pengenalan Anggur 37
5 SIMPULAN DAN SARAN 43
5.1 Simpulan 43
5.2 Saran 43
DAFTAR PUSTAKA 44
LAMPIRAN 46
DAFTAR TABEL
3.1 Salah klasifikasi data 11
3.2 Deskripsi kelompok Data Sintetis Wang 12
3.3 Deskripsi kelompok Data SCCTS 12
3.4 Deskripsi kelompok Data Tanaman Iris 13
3.5 Deskripsi kelompok Data Pengenalan Anggur 13
4.1 Deskripsi Keragaman Data Sintetis Wang 23
4.2 Fungsi diskriminan linear untuk Data Sintetis Wang 23
4.3 Salah klasifikasi untuk Data Sintetis Wang 24
4.4 Fungsi diskriminan linear untuk dua KU dari Data Sintetis
Wang dengan AKU 25
4.5 Salah klasifikasi untuk dua KU dari Data Sintetis Wang dengan AKU 25 4.6 Fungsi diskriminan linear untuk dua KU dari Data Sintetis Wang
dengan AKU Kernel 27
4.7 Salah klasifikasi untuk dua KU dari Data Sintetis Wang
dengan AKU Kernel 27
4.8 Deskripsi keragaman Data SCCTS 27
4.9 Fungsi diskriminan linear untuk Data SCCTS 28
4.10 Salah klasifikasi untuk Data SCCTS 29
4.11 Fungsi diskriminan linear untuk dua KU dari Data SCCTS
dengan AKU 30
4.12 Salah klasifikasi untuk dua KU dari Data SCCTS dengan AKU 30 4.13 Fungsi diskriminan linear untuk dua KU dari Data SCCTS
dengan AKU Kernel 32
4.14 Salah klasifikasi untuk dua KU dari Data SCCTS dengan AKU Kernel 32
4.15 Deskripsi keragaman Data Tanaman Iris 33
4.16 Fungsi diskriminan linear untuk Data Tanaman Iris 33
4.17 Salah klasifikasi untuk Data Tanaman Iris 33
4.18 Fungsi diskriminan linear untuk dua KU dari Data Tanaman Iris
dengan AKU 34
4.19 Salah klasifikasi untuk dua KU dari Data Tanaman Iris dengan AKU 35 4.20 Fungsi diskriminan linear untuk dua KU dari Data Tanaman Iris
dengan AKU Kernel 36
4.21 Salah klasifikasi untuk dua KU dari Data Tanaman Iris
dengan AKU Kernel 36
4.22 Deskripsi keragaman Data Pengenalan Anggur 37
4.23 Fungsi diskriminan linear untuk Data Pengenalan Anggur 38 4.24 Salah klasifikasi untuk Data Pengenalan Anggur 39 4.25 Fungsi diskriminan linear untuk dua KU dari Data Pengenalan
Anggur dengan AKU 40
4.26 Salah klasifikasi untuk dua KU dari Data Pengenalan Anggur
dengan AKU 40
4.27 Fungsi diskriminan linear untuk dua KU dari Data Pengenalan
Anggur dengan AKU Kernel 42
4.28 Salah klasifikasi untuk dua KU dari Data Pengenalan Anggur
DAFTAR GAMBAR
3.1 Diagram alir penelitian 14
3.2 Skema visualisasi data berkelompok dengan AKU 16 3.3 Skema visualisasi data berkelompok dengan AKU Kernel 17
3.4 Skema langkah-langkah penelitian 18
4.1 Visualisasi fungsi kernel Gauss untuk beberapa 21
4.2 Data Sintetis Wang 22
4.3 Data Sintetis Wang yang telah distandardisasi 23
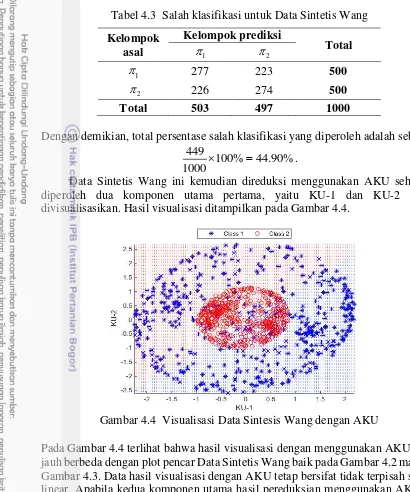
4.4 Visualisasi Data Sintetis Wang dengan AKU 24
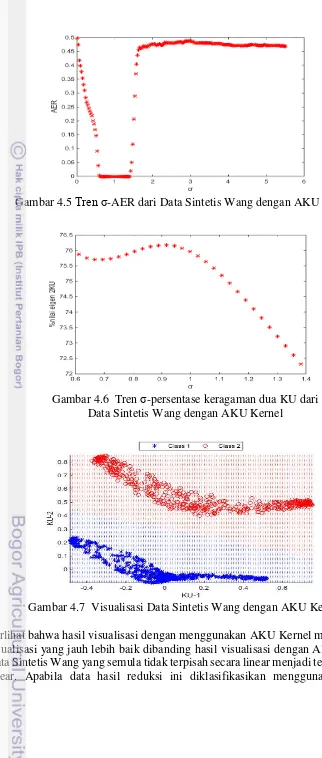
4.5 Tren -AER dari Data Sintetis Wang dengan AKU Kernel 26 4.6 Tren -persentase keragaman dua KU dari Data Sintetis Wang
dengan AKU Kernel 26
4.7 Visualisasi Data Sintetis Wang dengan AKU Kernel 26
4.8 Visualisasi Data SCCTS dengan AKU 29
4.9 Tren -AER dari Data SCCTS dengan AKU Kernel 31
4.10 Visualisasi Data SCCTS dengan AKU Kernel 31
4.11 Visualisasi Data Tanaman Iris dengan AKU 34
4.12 Tren -AER dari Data Tanaman Iris dengan AKU Kernel 35 4.13 Tren -persentase keragaman dua KU dari Data Tanaman Iris
dengan AKU Kernel 35
4.14 Visualisasi Data Tanaman Iris dengan AKU Kernel 36 4.15 Visualisasi Data Pengenalan Anggur dengan AKU 39 4.16 Tren -AER dari Data Pengenalan Anggur dengan AKU Kernel 41 4.17 Tren -persentase keragaman dua KU dari Data Pengenalan Anggur
dengan AKU Kernel 41
4.18 Visualisasi Data Pengenalan Anggur dengan AKU Kernel 41
DAFTAR LAMPIRAN
1 Algoritma Matlab AKU Kernel dengan fungsi kernel Gauss 46 2 Algoritma Matlab AKU Kernel dengan fungsi kernel linear 47 3 Algoritma Matlab untuk pemilihan parameter 48
4 Algoritma Matlab untuk visualisasi data 49
1
PENDAHULUAN
1.1Latar Belakang
Visualisasi adalah rekayasa dalam pembuatan gambar, diagram atau animasi untuk penampilan suatu informasi. Secara umum, visualisasi dalam bentuk gambar, baik yang bersifat abstrak maupun nyata, telah dikenal sejak awal dari peradaban manusia. Pada saat ini visualisasi telah berkembang dan banyak dipakai untuk keperluan ilmu pengetahuan, rekayasa, desain produk, pendidikan, multimedia interaktif, kedokteran dan lain-lain (Dostál 2008). Dalam statistika, visualisasi sering digunakan dalam analisis data eksplorasi yang diperkenalkan oleh John Tukey pada tahun 1977 sebagai pendekatan dalam menganalisis suatu himpunan data untuk meringkas karakteristik utama dari data tersebut (Chatfield 1995). Tujuan utama dari visualisasi data adalah untuk mengomunikasikan informasi dengan jelas dan efisien untuk pengguna melalui grafik, plot dan tabel. Hal ini membuat data yang kompleks menjadi lebih mudah diakses, dimengerti dan digunakan. Untuk data berdimensi lebih besar daripada tiga, visualisasi tidak dapat dilakukan secara langsung dengan memplot objek-objek data pada bidang Cartesius. Visualisasi dapat dilakukan dengan menggunakan Analisis Komponen Utama (AKU, Principal Component Analysis).
AKU merupakan analisis tertua dan diketahui merupakan teknik terpopuler dalam analisis peubah ganda. Ide pokok dari AKU ialah mengurangi dimensi dengan menggantikan peubah dalam data peubah ganda dengan sejumlah peubah turunan yang lebih sedikit (Jolliffe 2002). AKU juga dikatakan sebagai transformasi Hotelling yang merupakan sebuah teknik untuk menyederhanakan suatu himpunan data, dengan mereduksi dimensi himpunan data menjadi lebih kecil untuk analisis dengan tetap mempertahankan sebanyak mungkin tampilan variasi dalam himpunan data asal. Peubah baru yang merepresentasikan data dengan dimensi yang lebih kecil disebut komponen utama (KU). Secara aljabar, komponen utama yang diperoleh merupakan kombinasi linear dari semua peubah asal yang memiliki varians terbesar secara berurutan dan tidak berkorelasi dengan komponen utama sebelumnya. Namun, karena AKU menggunakan kombinasi linear untuk menginterpretasikan data maka AKU tidak dapat memodelkan data yang memiliki kompleksitas tinggi dengan hubungan taklinear antarpeubah. Oleh karena itu, dikembangkan metode yang merupakan perumuman dari AKU yang disebut dengan Analisis Komponen Utama Kernel (AKU Kernel).
2
digunakan. Salah satu fungsi kernel yang sering digunakan ialah fungsi kernel Gauss yang berbentuk
,
exp 2 2 ,2
i j i j
x x
x x
dengan x adalah vektor objek data dan adalah parameter (Schölkopf & Smola 2002). Keberhasilan dari fungsi kernel Gauss dalam memetakan data berkelompok ke dalam ruang fitur sehingga diperoleh data yang terpisah sangat bergantung pada parameter ini. Banyak penelitian telah dilakukan menggunakan metode AKU Kernel dengan fungsi kernel Gauss untuk mereduksi data. Setiap penelitian tersebut memiliki metode tersendiri dalam memilih parameter bergantung pada objektivitas penelitiannya dan memberikan nilai yang berbeda-beda, meskipun terkadang digunakan untuk objektivitas yang sama. Oleh karena itu, proses penentuan parameter ini masih menjadi topik penelitian yang terus berlanjut dengan hasil yang belum jelas hingga saat ini (Widjaja et al. 2012).
1.2Perumusan Masalah
Untuk memudahkan langkah-langkah penelitian dan metode penelitian, maka dibuat rumusan penelitian sebagai berikut:
1. Bagaimana metode untuk menduga parameter dari AKU Kernel sehingga diperoleh hasil visualisasi dengan salah klasifikasi terkecil.
2. Bagaimana efektivitas AKU Kernel dibandingkan dengan AKU dalam memvisualisasikan data berkelompok untuk melihat keterpisahan kelompok data secara linear.
1.3Tujuan Penelitian
Berdasarkan permasalahan di atas, maka penelitian ini bertujuan untuk: 1. Mengkaji suatu metode pemilihan parameter pada parameter Gauss dalam
memvisualisasikan data berkelompok yang meminimumkan salah klasifikasi. 2. Membandingkan efektivitas metode AKU Kernel dalam memvisualisasikan
keterpisahan secara linear data berkelompok dibandingkan dengan metode AKU berdasarkan salah klasifikasi yang diperoleh.
3
2
TINJAUAN PUSTAKA
2.1Fungsi Kernel
Fungsi kernel dapat diartikan sebagai hasil kali dalam baku dari objek data pada ruang fitur. Misalkan
x adalah fungsi yang memetakan objek data dari ruang asal ke ruang fitur, maka fungsi kernel dapat dituliskan sebagai
, ,
.
i j i j
T i j
x x x x
x x
Dua sifat yang harus dipenuhi oleh fungsi kernel ialah: 1. Simetrik
,
,
,
, x z x z z x z x 2. Memenuhi ketaksamaan Cauchy-Schwarz
2 2 2 2 , , , , , , x z x z
x z
x x z z
x x z z
Fungsi-fungsi kernel umumnya dibagi menjadi dua kelompok (Nielsen & Canty 2008). Pertama, fungsi kernel stasioner yang hanya bergantung pada hasil kali dalam antarobjek di ruang asal. Sebagai contoh, fungsi-fungsi kernel yang tergolong fungsi kernel stasioner ialah
1. kernel linear :
x xi, j
x xTi j 2. kernel pangkat :
x xi, j
x xTi j
p 3. kernel polinomial :
x xi, j
x xTi jh0
pKedua, fungsi kernel homogen atau Radial Basic Function (RBF) yang hanya bergantung pada jarak Euclid antarobjek pada ruang asal. Sebagai contoh, fungsi-fungsi kernel yang tergolong RBF ialah
1. kernel multikuadratik :
1 2 2 20 ,
i j i j h
x x x x
2. kernel invers multikuadratik :
1 2 2 20 ,
i j i j h
x x x x
3. kernel Gauss :
x xi, j
exp
xi xj 2
2h02
dengan h0 adalah parameter yang harus dipilih. Pemilihan parameter ini sangat menentukan hasil pemetaan dari ruang asal ke ruang fitur. Oleh karena itu, pemilihan parameter h0 menentukan pula hasil pereduksian peubah dengan menggunakan AKU Kernel.
(2)
(3)
4
Salah satu fungsi yang sering digunakan dalam AKU Kernel adalah fungsi kernel Gauss. Banyak metode telah digunakan untuk memilih parameter h0 pada fungsi kernel Gauss ini. Sebagai contoh misalkan diberikan data dengan p peubah dan n observasi maka Rathi et al. (2006) menggunakan
2 2
0 1min ; 1, 2, ,
p
i j i j i
c
h j p
p
x x dengan c adalah parameter kontrol. Widjaja et al. (2012) memilih nilai parameter 0
h pada interval 2 2 2 0 ˆ ˆ 100 100 h
; dengan 2 2
1 ˆ p i i n s p
di mana si2 adalah varians data peubah ke-i, kemudian memilih nilai pada interval (6) yang memaksimumkan perbedaan antara nilai eigen pertama dengan jumlah nilai eigen lainnya. Yang terbaru, Alam & Fukumizu (2014) menggunakan metode Leave One Out Cross Validation untuk memilih parameter h0 yang meminimumkan jarak Euclid antara objek x dengan pre-image xˆ. Wang (2014a) menggunakan 0 1 n NN i i c h d n
dengan diNN adalah jarak Euclid terdekat dari objek data xi ke objek data terdekatnya.
Metode-metode tersebut memiliki objektivitas yang berbeda-beda sesuai masalah pada penelitiannya masing-masing. Karena itu, nilai h0 yang diberikan pun berbeda-beda, meskipun terkadang digunakan untuk objektivitas yang sama.
2.2Analisis Komponen Utama Kernel Misalkan diberikan matriks data
1, 2, ,
,T
nXp x x xn dengan xi adalah vektor objek data yang berdimensi .p Diberikan pula fungsi
x sebagai fungsi yang digunakan untuk memetakan vektor objek data ke ruang fitur yang berdimensi, F
p sehingga diperoleh matriks data pada ruang fitur sebagai berikut
1 , 2 , ,
. FT nΦp x x xn Vektor rataan pada ruang fitur ialah
1 1 . n i i n
xDengan demikian, vektor objek data yang terkoreksi terhadap nilai tengahnya pada ruang fitur ialah
i
i . x x
Matriks kovarians pada ruang fitur untuk data yang telah terkoreksi terhadap nilai tengah kemudian didefinisikan sebagai
1 1 1 n T i i in
C x x
5 yang berukuran pFpF.
Seperti pada AKU linear, komponen utama diperoleh dengan menyelesaikan persamaan eigen
Cv v
(Jolliffe 2002). Namun, karena pF bisa jadi sangat besar bahkan umumnya fungsi
x belum tentu dapat diketahui, maka akan menjadi sangat sulit untuk menghitung matriks C dan menyelesaikan persamaan eigennya secara langsung. Karena itu, lebih mudah jika diselesaikan secara tidak langsung dengan menggunakan persamaan eigen kernel.
Perhatikan persamaan eigen (12) pada ruang fitur. Karena C adalah matriks semi-definit positif, maka m 0; m1, 2, ,r untuk rrank
X dan1 2 r 0.
Dengan mendefinisikan hasil kali dalam pada ruang fitur sebagai hasil kali dalam baku, v v1, 2 pF berlaku
1, 2 1 2, T
v v v v maka m berlaku
1 1 1 1 1 1 1 1 , 1m m m
n T
i i m
i
n T
i i m
i n
i m i i n n n
v Cvx x v
x x v
x v x
sehingga diperoleh
1 , 1n i m
m i i
m n
x vv x .
Misalkan mi
xi ,vm
m
n1 ,
maka diperoleh vektor eigen vm pada (13) sebagai kombinasi linear dari
x1 , x2 , ,
xn
atau dapat juga ditulis sebagai
1n
m
i mi iv x .
Dengan menggunakan persamaan (11) dan (14), persamaan eigen (12) pada ruang fitur, j 1, ,n, ekuivalen dengan
j , m
j , m m x Cv x v
1 1
, ,
1
n T
j i i i m j m m
n
x x x v x v
1
1
, , ,
1
n
j i i m i j m m
n x
x v x x v
1
1
1
1
, , ,
1
n n n
j i i k mk k i m j k mk k
n x
x
x x x
x
1 1 1
1
, , ,
1
n n n
j i mk k i m j mk k
i k k
n
x x x x
x x(12)
(13)
6
1 1 1
1
, , ,
1
n n n
mk j i k i m mk j k
i k k
n
x x x x
x x
1 1 1
1
, , ,
1
n n n
mk i k j i m mk j k
i k k
n
x x x x
x x .Didefinisikan Ksebagai matriks Kernel atau matriks Gram yang berukuran n n
di mana
2
1 1 1 1
, ,
,
, , , ,
1 1 1
, , , , .
ij i j
i j
i j
i i i j
n n n n
i j i j i j i j
j i i j
n n n
K x x
x x
x x
x x x x
x x x x x x x x
(Bishop 2006). Dengan menggunakan persamaan (16), persamaan (15) dapat ditulis dalam bentuk persamaan eigen kernel sebagai
2 1
1 m m m
n K α Kα
yang ekuivalen dengan
1
1 m m m
n Kα α
di mana αm
m1, m2, ,mn
T.Komponen utama diperoleh melalui hasil kali dalam antara vektor eigen yang telah dinormalisasi dengan vektor objek data pada ruang fitur. Karena matriks C bersifat simetri, maka vektor eigen vm bersifat ortogonal. Dengan demikian, vektor eigen
m
v akan bersifat ortonormal apabila memenuhi
1 1 1 1 1 1 , 1 , 1 1 , , , , , , , , 11 , 1 .
m m
n n
mi i mj j
i j
n n
mi i mj j i j
n n
mi mj i j i j
n
mi mj i j i j
n
mi mj i j i j
m m m
m m
m m m m
n n n
v v x x x x x x x x x x α Kα α α α αDengan demikian, vektor eigen vm yang telah ortonormal dapat ditulis sebagai (15)
(16)
(17)
(18)
7
1 1 1 1 nm mi i
i m n
mi i i
n
v x xdi mana mi mi
n1
m
1 2. Koefisien proyeksi pada vektor eigen vm untuk vektor uji x ialah
1 1 1 , , , , nm mk k
k n mk k k n mk k k
v x x x
x x
x x
(Schӧlkopf et al.1998) sehingga komponen utama taklinearnya dapat ditulis sebagai
,
ΦV KA
di mana pFVr
v v1, 2, ,vr
dan nAr
α α1, 2, ,αr
(Nielsen & Canty 2008), sedangkan komponen utama taklinear untuk data yang tidak terkoreksi pada nilai tengah pada ruang fitur dapat ditulis sebagai
ΦV KA
di mana Kij
x xi, j
.2.3Analisis Diskriminan Linear Fisher
Analisis diskriminan adalah bagian dari statistika peubah ganda yang bertujuan untuk menggambarkan ciri-ciri suatu pengamatan dari bermacam-macam populasi yang diketahui, baik secara grafis maupun aljabar dengan membentuk fungsi diskriminan. Dengan kata lain, analisis diskriminan digunakan untuk mengklasifikasikan individu ke dalam salah satu dari dua kelompok atau lebih. Dalam hal ini, mengklasifikasikan vektor input x dan menempatkannya ke dalam salah satu dari K kelompok data k; k 1, 2, , .K Umumnya, kelompok-kelompok tersebut dibuat terpisah sehingga setiap input hanya boleh berada dalam salah satu kelompok saja. Kelompok-kelompok tersebut dipisahkan oleh bidang pembatas yang berdimensi
p1
untuk input yang berdimensi p. Bidang pembatas yang dibentuk dari sebuah fungsi linear disebut bidang hiper.Misalkan diberikan n objek data latih
1, 2, ,
, T n
X x x x p
i
x dan
terdiri atas K kelompok data. Untuk setiap kelompok data didefinisikan
k
f x = fungsi kepadatan peluang untuk data pada kelompok k k
p = peluang sebarang objek x tergolong ke dalam kelompok k
(20)
(21) (22)
8
|c k i = biaya sebarang objek x pada kelompok i yang kemudian
dikelompokkan ke dalam kelompok k. Untuk k i, maka
| 0c i i
k
R = daerah yang diklasifikasikan ke dalam kelompok k
|P i k = peluang sebarang objek pada kelompok k yang kemudian
dikelompokkan ke dalam kelompok i
=
i k R f d
x xdengan
1
| 1 |
i k K i
P i i P i k
.Ekspektasi biaya salah klasifikasi (ECM, Expected Cost of Misclassification) sebarang objek pada kelompok k yang kemudian dikelompokkan ke dalam kelompok 1, 2, ,i, , atau K untuk ik ialah
11
ECM | |
| i k i i k K i K k i R
k P i k c i k
c i k f d
x xsedangkan total ekspektasi biaya salah klasifikasi (TECM) dapat dihitung sebagai
1 1 1 1 1 TECM ECM | | . i i k i i k K k k K K k kk i R
K K
k k
k i R
p k
p c i k f d
p c i k f d
x x x xPengklasifikasian dipilih berdasarkan daerah R R1, 2, ,RK yang meminimumkan TECM (Johnson & Wichern 2007). Dalam Anderson (2003), karena fi
x adalah fungsi kepadatan peluang sehingga fi
x 0; x, maka pengklasifikasian pada persamaan (25) ekuivalen dengan mengalokasikan setiap objek x ke dalam kelompok k yang memenuhi
1 1,2, , argmin | i k K k i i k Kk p f c i k
x .Persamaan (26) ekuivalen dengan memilih k, i k yang berlaku
|
|k k i i
p f x c i k p f x c k i
atau
ln p fk k x c i k| ln p fi i x c k i| .Jika data latih yang diberikan nilai pi dan c k i
| tidak diketahui, maka kedua nilai tersebut dapat diasumsikan bernilai sama untuk setiap kelompok data, sehingga pemilihan sebarang objek x untuk digolongkan ke dalam kelompok k dapat dipilih berdasarkan kelompok k yang memenuhi
k i
f x f x ; i k
(24)
(25)
(26)
9 atau
ln fk x ln fi x ; i k.
Dalam statistika terapan, untuk pengklasifikasian, umumnya populasi diasumsikan berdistribusi normal karena kesederhanaan dan keakuratan dari distribusi ini yang cukup tinggi pada berbagai model populasi. Karena itu, untuk setiap data latih yang tidak diketahui distribusi data kelompoknya, maka data kelompok tersebut diasumsikan berdistribusi normal dengan vektor rataan yang berbeda-beda untuk setiap kelompoknya, sehingga fungsi kepadatan peluang untuk setiap kelompok data dapat ditulis sebagai
1
2 2 1 1 1 exp 2 2 p T
k k k k
k f
x x μ Σ x μ
Σ ; k1, 2, ,K,
dengan μk dan Σk adalah vektor rataan dan matriks kovarians kelompok k yang kemudian diestimasi dengan menggunakan penaksir maximum likelihood xk dan
k
S . Sk merupakan matriks kovarians kelompok k yang anggotanya adalah
1 1
; 1, 2, , ; 1, 2, , , 1
m
ij k ki i kj j
s x x x x i p j p
m
di mana m adalah banyaknya objek pada kelompok k. Fungsi diskriminan kelompok k dapat diperoleh melalui
1 2 2 1 1 ln 1 1 ln exp 2 2 1 1ln 2 ln .
2 2 2
p Q
k k
T
k k k
k
T
k k k
d f p x x
x μ Σ x μ
Σ
Σ x μ Σ x μ
Karena suku
p 2 ln 2
bernilai sama untuk setiap kelompok data, maka nilai tersebut dapat diabaikan sehingga persamaan (31) dapat ditulis sebagai
1
1 1 1
1 1 1
1 1
ln
2 2
1 1 1
ln
2 2 2
1 1 1
ln .
2 2 2
T Q
k k k k k
T T T
k k k k k k k
T T T
k k k k k k k
d
x Σ x μ Σ x μ
x Σ x μ Σ x μ Σ μ Σ
x Σ x μ Σ x μ Σ μ Σ
Untuk data yang keragaman setiap kelompoknya sama
Σk Σj Σ;jk
, maka nilai
1 2 xTΣ xk1
1 2 ln Σk
juga dapat diabaikan karena bernilai sama untuk setiap kelompok data sehingga diperoleh fungsi diskriminan linear
1
10 1 2 ,
T T
k k k k
T k k d w
x μ Σ x μ Σ μ
w x
dengan Σ adalah matriks kovarians gabungan yang diestimasi dengan
10
1 1 1 K k k k gab K k k n n K
SS ; Sk matriks kovarians kelompok k.
Persamaan (33) kemudian dikenal dengan nama Fungsi Diskriminan Linear Fisher. Berdasarkan persamaan (28), maka pengalokasian untuk sebarang vektor objek x
ke dalam kelompok k dapat dipilih berdasarkan
1,2, , argmax k k K k d xsedangkan fungsi bidang hiper yang memisahkan antara kelompok j dan k,
,
j k
ialah
0k j
d x d x
0 0
0T
k j wk wj
w w x
1 1
1 1 1 10
2 2
T T T T
k j k k j j
μ Σ μ Σ x μ Σ μ μ Σ μ
1
1
1
0 2
T T
k j k j k j
μ μ Σ x μ μ Σ μ μ
1 1
0 2
T
k j k j
μ μ Σ x μ μ .
Fungsi bidang hiper pada persamaan (36) dikenal dengan nama fungsi pengklasifikasian Anderson. Data input yang terpisah oleh bidang hiper disebut data yang terpisah secara linear.
(34)
(35)
11
3
METODE PENELITIAN
Langkah-langkah yang digunakan untuk membahas permasalahan yang diambil dalam penelitian dibahas pada bab ini. Di bagian ini juga disebutkan metode yang digunakan untuk melakukan pereduksian data berkelompok menjadi dua komponen utama atau visualisasi data dengan menggunakan AKU dan AKU Kernel.
Penelitian ini menggunakan studi literatur dan kemudian mengimplementasikan AKU dan AKU Kernel untuk memvisualisasikan data berkelompok ke dalam program komputer menggunakan software Matlab yang meminimumkan total proporsi salah klasifikasi. Untuk pengklasifikasian, digunakan analisis diskriminan linear Fisher guna melihat keterpisahan data secara linear. Pada AKU Kernel, sebelum melakukan visualisasi terhadap data berkelompok, pertama-tama dibuatkan sebuah algoritma untuk menentukan nilai parameter untuk fungsi Kernel Gauss. Parameter ini kemudian digunakan dalam melakukan pereduksian data dengan AKU Kernel. Selain itu pada penelitian ini, metode visualisasi data dengan AKU dan AKU Kernel juga diterapkan pada beberapa data sekunder berkelompok yang populer dan sering digunakan sebagai contoh dalam pengklasifikasian data. Tujuan dari langkah ini adalah untuk mengetahui apakah dengan menggunakan nilai yang tepat, AKU Kernel dapat memberikan visualisasi yang lebih baik jika dibandingkan dengan AKU berdasarkan total proporsi salah klasifikasi yang dihasilkan.
Total proporsi salah klasifikasi (AER, Apparent Error Rate) yang digunakan sebagai evaluasi pada penelitian ini merupakan perbandingan banyaknya objek yang memperoleh kelompok prediksi yang berbeda dengan kelompok asal terhadap banyaknya objek data. Salah klasifikasi untuk setiap kelompok data dapat diperoleh melalui Tabel 3.1
Tabel 3.1 Salah klasifikasi data Kelompok
asal
Kelompok prediksi
Total 1
2 K 1
n11 n12 n1K n1
n21 n22 n2K n2
K
nK1 nK2 nKK nK
Total n1 n2 nK n n
di mana njk adalah banyaknya anggota kelompok j yang kemudian diklasifikasikan ke dalam kelompok k.
Dengan demikian, total salah klasifikasi (SK) dapat ditulis sebagai 1
SK K kk
k
n n
sedangkan total proporsi salah klasifikasi (AER) dapat ditulis sebagai
12
1
AER
K kk k
n n
n
sehingga total persentase salah klasifikasi data dapat diperoleh melalui AER 100% .
3.1Data Penelitian
Data yang digunakan pada penelitian ini terdiri dari dua kelompok data sintetis dan dua kelompok data dari kehidupan nyata (real-world). Data-data tersebut diunduh dari UCI Machine Learning Repository, kecuali Data Sintetis Wang yang diunduh dari Matlab Central. Deskripsi kelompok dari data-data tersebut adalah sebagai berikut:
1. Data Sintetis Wang (Wang 2014b) yang terdiri atas 1000 objek data dengan 3 peubah dan 2 kelompok data. Banyaknya objek tiap kelompok ditunjukkan pada Tabel 3.2.
2. Data Synthetic Control Chart Time Series (SCCTS, Alcock 1999) yang terdiri atas 600 objek dengan 60 peubah dan 6 kelompok data. Banyaknya objek tiap kelompok ditunjukkan pada Tabel 3.3.
3. Data Tanaman Iris (Fisher 1998) yang terdiri atas 150 objek data dengan 4 peubah dan 3 kelompok data. Banyaknya objek tiap kelompok ditunjukkan pada Tabel 3.4.
Tabel 3.2 Deskripsi kelompok Data Sintetis Wang Kelompok Banyaknya objek
nk1
500
2
500
Tabel 3.3 Deskripsi kelompok data SCCTS
Kelompok Banyaknya objek
nk1
100
2
100
3
100
4
100
5
100
6
100
(38)
13
4. Data Pengenalan Anggur (Forina & Aeberhard 1991) yang terdiri atas 178 objek dengan 13 peubah dan 3 kelompok data. Banyaknya objek tiap kelompok ditunjukkan pada Tabel 3.5.
3.2Langkah Penelitian
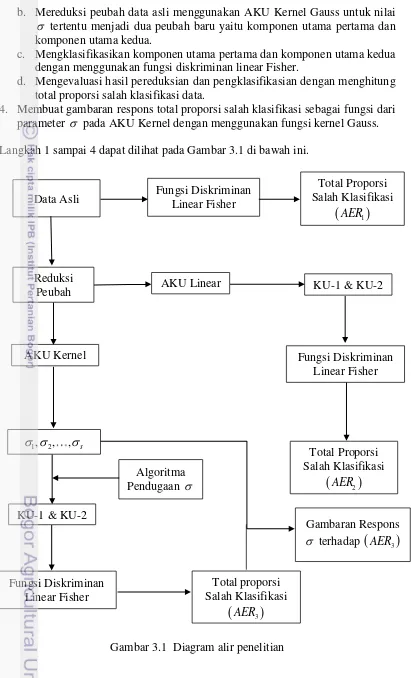
Langkah-langkah dalam penelitian ini terdiri atas dua tahap. Tahap pertama ialah menyiapkan alat uji berupa program yang disusun menggunakan bahasa pemrograman Matlab. Tahap kedua ialah membandingkan hasil visualisasi data berkelompok dengan menggunakan AKU dan AKU Kernel berdasarkan total proporsi salah klasifikasi yang diperoleh. Langkah-langkah dalam tahap dua dapat disusun sebagai berikut:
1. Data asli
Mengklasifikasikan data asli dengan menggunakan fungsi diskriminan linear Fisher.
Mengevaluasi hasil pengklasifikasian dengan menghitung total proporsi salah klasifikasi data.
2. AKU linear
Mereduksi peubah data asli menggunakan AKU linear menjadi dua peubah baru yaitu komponen utama pertama dan komponen utama kedua.
Mengklasifikasikan komponen utama pertama dan komponen utama kedua dengan menggunakan fungsi diskriminan linear Fisher.
Mengevaluasi hasil pereduksian dan pengklasifikasian dengan menghitung total proporsi salah klasifikasi data.
3. AKU Kernel
a. Menyusun algoritma pendugaan parameter fungsi kernel Gauss sehingga diperoleh hasil pereduksian dengan AKU Kernel yang memiliki total proporsi salah klasifikasi yang minimum.
Tabel 3.4 Deskripsi kelompok Data Tanaman Iris Kelompok Banyaknya objek
nkIris setosa (1) 50
Iris virginica (2) 50
Iris versicolor (3) 50
Tabel 3.5 Deskripsi kelompok Data Pengenalan Anggur Kelompok Banyaknya objek
nk1
59
2
71
3
14
b. Mereduksi peubah data asli menggunakan AKU Kernel Gauss untuk nilai
tertentu menjadi dua peubah baru yaitu komponen utama pertama dan komponen utama kedua.
c. Mengklasifikasikan komponen utama pertama dan komponen utama kedua dengan menggunakan fungsi diskriminan linear Fisher.
d. Mengevaluasi hasil pereduksian dan pengklasifikasian dengan menghitung total proporsi salah klasifikasi data.
4. Membuat gambaran respons total proporsi salah klasifikasi sebagai fungsi dari parameter pada AKU Kernel dengan menggunakan fungsi kernel Gauss. Langkah 1 sampai 4 dapat dilihat pada Gambar 3.1 di bawah ini.
Gambar 3.1 Diagram alir penelitian Data Asli
Fungsi Diskriminan Linear Fisher AKU Kernel
1, 2, , s
Total Proporsi Salah Klasifikasi
AER2
Fungsi DiskriminanLinear Fisher
Total Proporsi Salah Klasifikasi
AER1
Reduksi
Peubah AKU Linear
KU-1 & KU-2
Algoritma Pendugaan
KU-1 & KU-2
Gambaran Respons
terhadap
AER3
Fungsi Diskriminan Linear Fisher
Total proporsi Salah Klasifikasi
15 3.2.1 Menyiapkan Alat Uji
Pada tahap ini, dilakukan langkah-langkah sebagai berikut: 1. Mengidentifikasi masalah
Masalah pada penelitian ini adalah bagaimana metode untuk menduga parameter pada fungsi kernel Gauss sehingga diperoleh visualisasi data berkelompok yang terpisah secara linear dan meminimumkan salah klasifikasi dengan menggunakan AKU Kernel. Hasil visualisasi ini kemudian juga dibandingkan dengan hasil visualisasi yang diperoleh dengan menggunakan AKU berdasarkan salah klasifikasi yang diperoleh.
2. Menentukan tujuan
Tujuan dari penelitian ini adalah mengkaji suatu metode pemilihan parameter
pada fungsi kernel Gauss yang digunakan pada AKU Kernel dalam memvisualisasikan data berkelompok yang terpisah secara linear dan meminimumkan salah klasifikasi. Selain itu, penelitian ini juga bertujuan untuk membandingkan hasil visualisasi dengan AKU Kernel dengan hasil visualisasi dengan AKU berdasarkan salah klasifikasi yang diperoleh. 3. Studi literatur
Studi literatur dilakukan untuk mengkaji metode pereduksian data dengan menggunakan AKU dan AKU Kernel. Dalam bagian ini juga dikaji tentang Analisis Diskriminan Linear Fisher untuk mengklasifikasikan data.
4. Menyusun algoritma
Setelah melakukan studi literatur, langkah selanjutnya adalah menyusun algoritma visualisasi data dengan menggunakan AKU dan AKU Kernel. Untuk AKU Kernel, disusun pula algoritma untuk menduga parameter pada fungsi kernel Gauss yang meminimumkan salah klasifikasi.
5. Menyusun program komputer
Algoritma yang telah disusun kemudian diimplementasikan ke dalam salah satu bahasa pemograman komputer yaitu Matlab. Matlab dipilih karena fungsi-fungsi yang berkaitan dengan analisis diskriminan linear Fisher telah tersedia dan siap digunakan. Program yang disusun diharapkan menerima
input berupa matriks data berkelompok dan parameter untuk fungsi kernel Gauss. Setelah dijalankan, program memberikan output berupa plot pencar sebagai hasil visualisasi dari AKU Kernel yang paling meminimumkan salah klasifikasi.
Selain program utama, disusun juga script Matlab lain yang digunakan untuk menentukan nilai parameter yang paling meminimumkan salah klasifikasi dalam memvisualisasikan data dengan AKU Kernel.
3.2.2 Membandingkan Efektivitas Teknik Visualisasi
Pertama dijelaskan terlebih dahulu mengenai langkah memperoleh visualisasi dari data berkelompok menggunakan program yang telah disusun.
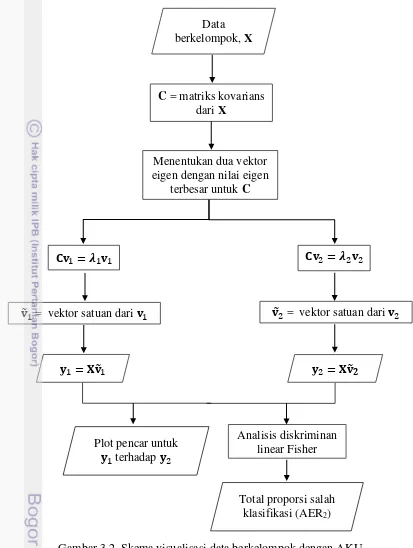
1. Visualisasi data berkelompok dengan AKU
Pada tahap ini akan diterapkan AKU terhadap data berkelompok. Tahap visualisasi data berkelompok menggunakan AKU dapat dilihat pada flowchart
16
Gambar 3.2 Skema visualisasi data berkelompok dengan AKU
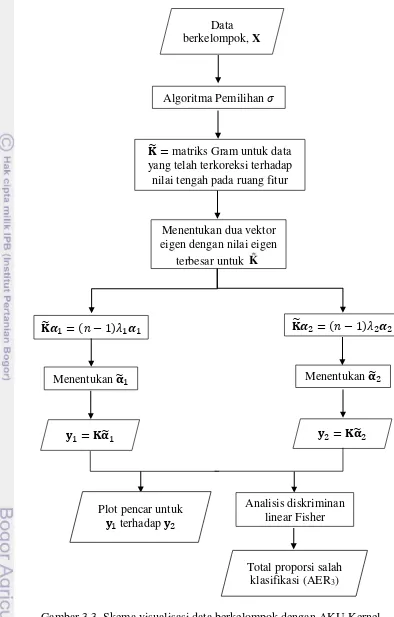
2. Visualisasi data berkelompok dengan AKU Kernel
Pada tahap ini akan diterapkan AKU Kernel terhadap data berkelompok. Tahap visualisasi data berkelompok menggunakan AKU Kernel dapat dilihat pada
flowchart pada Gambar 3.3 berikut. Data berkelompok, X
C = matriks kovarians dari X
� = �
Menentukan dua vektor eigen dengan nilai eigen
terbesar untuk C
� = �
= vektor satuan dari
� = � � = � �
Analisis diskriminan linear Fisher Plot pencar untuk
� terhadap �
Total proporsi salah klasifikasi (AER2)
17
Gambar 3.3 Skema visualisasi data berkelompok dengan AKU Kernel Hasil visualisasi untuk kedua metode tersebut diberikan oleh plot pencar KU-1
y1 terhadap KU-2
y2 . Untuk menentukan kualitas hasil visualisasi dari masing-masing metode digunakan total proporsi salah klasifikasi yangData berkelompok, X
� = matriks Gram untuk data yang telah terkoreksi terhadap nilai tengah pada ruang fitur
� � = � − 1 � �
Menentukan dua vektor eigen dengan nilai eigen
K terbesar untuk
� � = � − 1 � �
Menentukan �
� = �� � = ��
Menentukan �
Analisis diskriminan linear Fisher Algoritma Pemilihan �
Total proporsi salah klasifikasi (AER3)
18
dihitung menggunakan AER. Semakin kecil nilai AER yang diperoleh, semakin baik hasil visualisasi yang diberikan dalam menggambarkan keterpisahan dari data berkelompok secara linear.
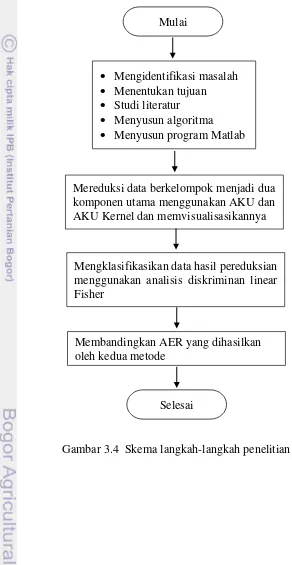
[image:32.595.107.399.167.732.2]Dari uraian di atas, digambarkan langkah-langkah yang dilakukan dalam penelitian ini seperti pada Gambar 3.4 berikut.
Gambar 3.4 Skema langkah-langkah penelitian
Mengidentifikasi masalah
Menentukan tujuan
Studi literatur
Menyusun algoritma
Menyusun program Matlab
Mereduksi data berkelompok menjadi dua komponen utama menggunakan AKU dan AKU Kernel dan memvisualisasikannya
Mengklasifikasikan data hasil pereduksian menggunakan analisis diskriminan linear Fisher
Membandingkan AER yang dihasilkan oleh kedua metode
Mulai
19
4
HASIL DAN PEMBAHASAN
Bab ini menjelaskan tentang hasil uji coba yang telah dilakukan untuk menjawab pertanyaan yang diberikan pada perumusan masalah. Selain itu, diberikan pula algoritma pereduksian data menjadi KU-1 dan KU-2 atau visualisasi data dengan menggunakan AKU maupun AKU Kernel dengan fungsi kernel Gauss kemudian membandingkan hasilnya berdasarkan salah klasifikasi yang diperoleh. Metode pengklasifikasian yang digunakan ialah analisis diskriminan linear Fisher.
4.1Algoritma Pereduksian Data 4.1.1 Algoritma Analisis Komponen Utama
Pada dasarnya cara kerja algoritma AKU ialah mereduksi data yang telah direpresentasikan dalam bentuk matriks dengan cara mentransformasi data menjadi komponen utama kemudian mengambil sejumlah komponen utama pertama sebagai data hasil reduksi dengan tetap mempertahankan kontribusi varians data sebesar mungkin.
Sebelum direduksi, biasanya data distandardisasi terlebih dahulu untuk menghilangkan dominasi varians dari peubah tertentu kemudian ditentukan matriks kovarians dari data. Langkah berikutnya adalah menghitung vektor eigen ortonormal dari matriks kovarians. Vektor eigen diurutkan berdasarkan nilai eigen taknol, mulai dari yang terbesar sampai yang terkecil. Matriks komponen utama diperoleh dengan cara mengalikan matriks data dengan matriks berkolom vektor eigen yang telah diurutkan. Banyaknya komponen utama biasanya dipilih berdasarkan persentase kontribusi keragaman yang diberikan. Untuk visualisasi, hanya digunakan komponen utama pertama (KU-1) dan komponen utama kedua (KU-2) untuk digambar sebagai hasil visualisasi data dalam bentuk plot pencar. Algoritma 1 Metode Visualisasi dengan AKU
1. Membentuk matriks data
2. Menghitung matriks kovarians data
3. Menghitung vektor eigen dari matriks kovarians data 4. Menormalkan vektor eigen
5. Mengurutkan vektor eigen data berdasarkan nilai eigen mulai dari terbesar hingga terkecil
6. Mengalikan matriks data dengan matriks berkolom vektor eigen 7. Menggambar dua komponen utama pertama dalam bentuk plot pencar.
4.1.2 Algoritma Analisis Komponen Utama Kernel
20
berdasarkan nilai eigen terbesar. Banyaknya komponen utama biasanya dipilih berdasarkan persentase kontribusi keragaman yang diberikan. Untuk visualisasi, hanya komponen utama pertama (KU-1) dan komponen utama kedua (KU-2) yang digunakan untuk digambar sebagai hasil visualisasi dari data dalam bentuk plot pencar.
Algoritma 2 Metode Visualisasi dengan AKU Kernel 1. Membentuk matriks data
2. Menghitung matriks Kernel untuk data pada ruang fitur yang telah terkoreksi terhadap nilai tengah
3. Menghitung vektor eigen dari matriks Kernel untuk data pada ruang fitur yang telah dikoreksi terhadap nilai tengah
4. Menormalkan vektor eigen
5. Mengurutkan vektor eigen data berdasarkan nilai eigen mulai dari terbesar hingga terkecil
6. Mengalikan matriks Kernel untuk data pada ruang fitur dengan matriks berkolom vektor eigen
7. Menggambar dua komponen utama pertama dalam bentuk plot pencar.
Namun, sebelum menggunakan Algoritma 2 di atas, ada satu hal yang harus diperhatikan terlebih dahulu, yaitu pada langkah 2. Untuk dapat melakukan langkah 2, yang pertama-tama yang harus dilakukan adalah memilih fungsi kernel. Pada penelitian ini, seperti yang telah dibicarakan terlebih dahulu pada pendahuluan, fungsi yang akan digunakan adalah fungsi kernel Gauss. Tetapi perlu diingat bahwa fungsi kernel Gauss ini mengandung sebuah paramater, yaitu parameter yang harus dipilih terlebih dahulu. Banyak penelitian untuk pereduksian data telah dilakukan dengan menggunakan metode AKU Kernel dengan fungsi kernel Gauss. Namun, sampai saat ini proses penentuan parameter ini masih menjadi topik penelitian yang terus berlanjut dengan hasil yang belum jelas. Salah satu permasalahannya adalah pemilihan parameter sangat bergantung pada objektivitas dari penelitian itu sendiri.
Fungsi kernel Gauss, berbentuk
2 2
, exp 2
i j i j
x x x x dengan
x adalah vektor objek data dan 2
adalah varians. Fungsi kernel Gauss dapat divisualisasikan dengan menggunakan fungsi
exp 22 2x g x
,
di mana x xi xj . Fungsi ini memiliki 3 titik kritis, yaitu x0, x dan
x di mana titik x0 adalah titik maksimum sedangkan titik x dan
x adalah titik belok. Andaikan diberikan x
10,10 ,
x , maka diperoleh visualisasi fungsi kernel Gauss untuk 1, 5, 10, 12 dan100
seperti pada Gambar 4.1.
21
Gambar 4.1 Visualisasi fungsi kernel Gauss untuk beberapa
Gambar kurva yang memperlihatkan bentuk visualisasi dari kurva fungsi kernel Gauss diperoleh pada nilai yang berada pada selang
0, max
x . Ketika nilai
max x , maka kurva yang diperoleh menjadi seperti kurva fungsi kuadratis bahkan untuk yang cukup besar, kurva menjadi seperti kurva fungsi linear.
Selain itu dalam AKU Kernel, fungsi kernel Gauss digunakan untuk menghitung matriks Kernel yang merupakan bentuk dual dari matriks kovarians pada ruang fitur (Nielsen & Canty 2008). Karena itu pemilihan nilai parameter sangat menentukan keragaman data pada ruang fitur tersebut. Pemilihan parameter
yang terlalu besar dibanding jarak antarobjek data akan mengakibatkan matriks Kernel yang terbentuk adalah matriks satuan, sehingga objek-objek data pada ruang fitur menjadi terkonsentrasi pada satu titik. Begitu pula, jika dipilih parameter yang terlalu kecil dibanding jarak antarobjek data, maka matriks Kernel yang terbentuk adalah matriks identitas sehingga mengakibatkan peubah-peubah pada ruang fitur tidak memiliki korelasi sehingga AKU menjadi tidak layak untuk diterapkan. Hal ini mengakibatkan nilai yang terlalu besar dibanding jarak antarobjek akan membuat peubah pada ruang fitur makin kehilangan keragaman, sedangkan makin kecil , makin kecil pula korelasi antarpeubah pada ruang fitur. Oleh karena itu, pada penelitian ini pemilihan parameter dilakukan pada selang min xixj , max xixj ; i j. Selang interval ini kemudian dipartisi dan setiap titiknya diuji untuk mendapatkan titik yang memberikan nilai parameter dengan total proporsi salah terkecil. Banyaknya titik pada selang dipilih berdasarkan lebar selang interval. Pada penelitian ini, setiap selang interval dibagi menjadi 200 partisi. Algoritma untuk memilih parameter yang meminimumkan salah klasifikasi pada interval min xixj , max xi xj ; i j diberikan pada Algoritma 3.
Algoritma 3 Pemilihan :
Input: data berkelompok
Output:
1. Menghitung jarak antarobjek pada data
2. Mendefinisikan interval dari jarak terdekat hingga jarak terjauh
3. Melakukan pereduksian menggunakan AKU Kernel sesuai pers. (23) dengan fungsi kernel Gauss pada pers. (1) untuk setiap nilai pada interval
22
5. Menghitung total proporsi salah klasifikasi (AER) dengan menggunakan pers. (38)
6. Memilih yang meminimumkan SK
7. Jika ada beberapa titik yang memiliki AER minimum, maka dipilih pada titik-titik tersebut yang memaksimalkan persentase keragaman varians yang diberikan oleh dua komponen utama pertama.
4.2Hasil Uji Coba dan Analisis
Algoritma 1, algoritma 2 dan algoritma 3 di atas kemudian diaplikasikan pada beberapa data seperti yang tertera pada subbab 3.1. Data-data tersebut divisualisasi menggunakan AKU dan AKU Kernel dan kemudian diklasifikasikan menggunakan fungsi diskriminan linear Fisher untuk melihat keterpisahan secara linear antarkelompok data.
4.2.1 Data Sintetis Wang
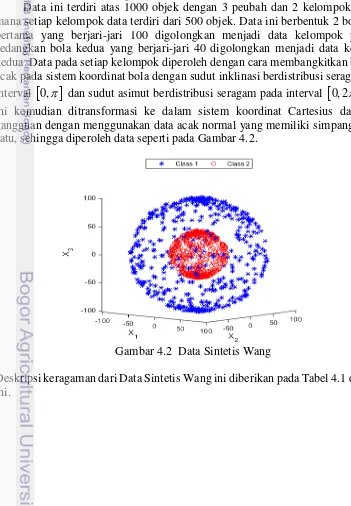
[image:36.595.90.441.304.810.2]Data ini terdiri atas 1000 objek dengan 3 peubah dan 2 kelompok data, di mana setiap kelompok data terdiri dari 500 objek. Data ini berbentuk 2 bola. Bola pertama yang berjari-jari 100 digolongkan menjadi data kelompok pertama, sedangkan bola kedua yang berjari-jari 40 digolongkan menjadi data kelompok kedua. Data pada setiap kelompok diperoleh dengan cara membangkitkan bilangan acak pada sistem koordinat bola dengan sudut inklinasi berdistribusi seragam pada interval
0, dan sudut asimut berdistribusi seragam pada interval
0, 2
. Data ini kemudian ditransformasi ke dalam sistem koordinat Cartesius dan diberi gangguan dengan menggunakan data acak normal yang memiliki simpangan baku satu, sehingga diperoleh data seperti pada Gambar 4.2.Gambar 4.2 Data Sintetis Wang
23 Tabel 4.1 Deskripsi keragaman Data Sintetis Wang
Peubah Varians
� 1354.5
� 1601.0
� 2835.7
Data kemudian distandardisasi menjadi data pada Gambar 4.3 untuk menghilangkan dominasi keragaman dari peubah tertentu.
[image:37.595.171.394.224.414.2]Gambar 4.3 Data Sintetis Wang yang telah distandardisasi
[image:37.595.114.461.531.676.2]Gambar 4.2 dan Gambar 4.3 menunjukkan bahwa kedua kelompok tersebut tidak dapat dipisahkan oleh garis linear apapun. Apabila data sintetis ini diklasifikasikan menggunakan analisis diskriminan linear Fisher, maka akan diperoleh fungsi diskriminan linear Fisher seperti yang diberikan pada Tabel 4.2.
Tabel 4.2 Fungsi diskriminan linear untuk Data Sintetis Wang Kelompok Fungsi diskriminan linear
Fisher
1
1
0.0352
0.0272 0.0021 0.0227
T
d
x x
2
2
0.0352
0.0272 0.0021 0.0227
T
d
x x
24
<