PENERAPAN ALGORITME PREFIXSPAN DAN GSP UNTUK
MENCARI POLA SEKUENSIAL PADA DATA PEMINJAMAN
BUKU DI PERPUSTAKAAN IPB
ARINA PRAMUDITA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN SUMBER
INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi yang berjudul Penerapan Algoritme Prefixspan dan GSP untuk Mencari Pola Sekuensial Pada Data Peminjaman Buku di Perpustakaan IPB adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Januari 2014
ABSTRAK
ARINA PRAMUDITA. Penerapan Algoritme Prefixspan dan GSP untuk Mencari Pola Sekuensial pada Data Peminjaman Buku di Perpustakaan IPB. Dibimbing oleh IMAS SUKAESIH SITANGGANG dan BADOLLAHI MUSTAFA
Perpustakaan IPB sebagai unit penunjang belajar bagi mahasiswa memiliki peranan yang penting salah satunya memberikan layanan dalam peminjaman buku. Data yang diperoleh dari transaksi sirkulasi peminjaman akan menghasilkan pola peminjaman buku oleh pengguna perpustakaan. Penelitian ini menerapkan algoritme prefixspan dan generalized sequential pattern (GSP) yang bertujuan untuk memperoleh pola sekuensial. Dataset yang digunakan adalah data dengan jumlah 50 hingga 4104 dengan minimum support dari 5% sampai 20%. Hasil penelitian menunjukan bahwa algoritme GSP bekerja lebih baik pada minimum support yang tinggi sedangkan algoritme prefixspan bekerja lebih baik pada minimum support yang rendah. Pola sekuensial yang dihasilkan dari kedua algoritme menunjukan keterkaitan antar item yaitu kode buku 820 (sastra) dengan kode buku 027 (perpustakaan umum), kode buku 631 (pertanian secara umum) dengan kode buku 658 (manajemen, administrasi, organisasi komersial), dan kode buku 631 dengan kode buku 636 (bidang peternakan). Buku yang paling sering dipinjam dari seluruh dataset adalah buku dengan kode 658
Kata kunci: generalized sequential pattern (GSP), pola sekuensial, prefixspan
ABSTRACT
ARINA PRAMUDITA. Application of Prefixspan and GSP Algorithms to Find the Sequential Patterns on Loan Data Book in IPB’s Library. Supervised by IMAS SUKAESIH SITANGGANG and BADOLLAHI MUSTAFA.
IPB's library as a learning support unit for student has an important role such as book lending service. The data obtained from the circulation transaction will generate a certain pattern of books that are being borrowed by library user. This research applies the prefixspan algorithm and generalized sequential pattern (GSP) algorithm to obtain a sequential pattern. The amount of data used ranges from 50 to 4104 with the value of minimum support ranges from 5% to 20%. The results show that the GSP algorithm works better on high minimum support while prefixspan algorithm works better in low minimum support. The sequential patterns generated from the two algorithms show the relationships between item: book code 820 (literature) with 027 (general), book code 631 (agriculture) with 658 (management, administration, commercial organizations), and book code 631 with 636 (husbandry). The most frequently borrowed book from the entire dataset is the book code 658.
PENERAPAN ALGORITME PREFIXSPAN DAN GSP UNTUK
MENCARI POLA SEKUENSIAL PADA DATA PEMINJAMAN
BUKU DI PERPUSTAKAAN IPB
ARINA PRAMUDITA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul Skripsi : Penerapan Algoritme Prefixspan dan GSP untuk Mencari Pola Sekuensial pada Data Peminjaman Buku di Perpustakaan IPB Nama : Arina Pramudita
NIM : G64114022
Disetujui oleh
Dr Imas S Sitanggang, SSi MKom Pembimbing I
Drs Badollahi Mustafa, MLib Pembimbing II
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Alhamdulillahi rabbil' alamin, puji syukur penulis panjatkan ke hadirat Allah subhanahu wa Ta'ala atas berkat, rahmat, taufik, dan hidayah-Nya, penyusunan skripsi yang berjudul Penerapan Algoritme Prefixspan dan GSP untuk Mencari Pola Sekuensial pada Data Peminjaman Buku di Perpustakaan IPB dapat diselesaikan dengan baik. Sholawat serta salam semoga selalu tercurahkan kepada Nabi Muhammad shalallahu 'alaihi wassalam beserta keluarga, sahabat, dan para pengikutnya yang telah memberikan contoh dalam meraih kebahagiaan di dunia dan akhirat.
Penulis menyadari bahwa keberhasilan penulisan skripsi ini tidak terlepas dari bantuan berbagai pihak. Untuk itu penulis menyampaikan ucapan terima kasih dan penghargaan kepada Ibu Dr Imas S Sitanggang, SSi Mkom selaku pembimbing I dan Bapak Drs Badollahi Mustafa, MLib selaku pembimbing II yang telah membantu penulis dalam menyusun tugas akhir ini.
Selanjutnya ucapan terima kasih penulis sampaikan pula kepada:
1 Pak Hari Agung Adrianto, SKom MSi selaku moderator sekaligus penguji dalam tugas akhir
2 Pak Fery selaku staf Perpustakaan IPB yang telah membantu penulis untuk memperoleh data peminjaman buku IPB
3 Agus Anang, SKom yang telah banyak membantu dalam pengolahan data perpustakaan
4 Phillippe Fournier-Viger selaku associate professor Ilmu Komputer University of Moncton, Canada yang telah banyak memberikan saran dan membuka pandangan mengenai kinerja kedua algoritme yang digunakan dalam penelitian ini
5 Devi Meisita Khairunnisa selaku partner skripsi atas kerjasama dan dukungan motifasinya
6 Ayahanda John Daniel dan Ibunda Wati Ningsih atas semua doa, kasih sayang, semangat, harapan, dan dukungan kepada penulis
7 Adiku Ega Haricandra yang selalu menjadi motifasi bagi penulis
8 Seluruh staf dan dosen Departemen Ilmu Komputer IPB atas segala bimbingan dan kemudahan layanan
9 Seluruh teman-teman Ilkom 6 atas kebersamaan dan semangatnya
10 Semua pihak lain yang telah membantu penulis, dan tidak dapat disebutkan satu persatu, jazakumullah khairan.
Bogor, Januari 2014
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 1
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE PENELITIAN 2
Data Peminjaman Buku Perpustakaan IPB 2
Spesifikasi Kebutuhan Perangkat Sistem 3
Tahapan Penelitian 4
Praproses 4
Perbandingan Kinerja Kedua Algoritme 7
Analisis Pola Sekuensial 7
HASIL DAN PEMBAHASAN 7
Praproses 7
Transformasi Data 7
Seleksi Data 7
Pembersihan Data 8
Pembuatan Pola Sekuensial 8
Penentuan Pola Sekuensial 9
Pola sekuensial 9
Itemset dan Dataset 9
Minimum support 9
Waktu eksekusi 9
Penggunaan Algoritme Prefixspan dan GSP pada Data Peminjaman Buku di
Perpustakaan IPB 9
Pemilihan Minimum support 9
Pemilihan Dataset 9
Perbandingan Kinerja Algoritme Prefixspan dan GSP 10
Analisis Pola Sekuensial 15
Perbedaan Urutan Hasil Pola Sekuensial 15
SIMPULAN DAN SARAN 18
Simpulan 18
Saran 19
DAFTAR PUSTAKA 19
LAMPIRAN 20
RIWAYAT HIDUP 22
DAFTAR TABEL
1 Field dalam data sirkulasi IPB 3
2 Kelas utama UDC 3
3 Contoh hierarki peminjaman buku perpustakaan 3
4 Prefix dan suffix dalam prefixspan 7
5 Contoh peminjaman buku setelah diubah ke dalam bentuk sekuensial 8 6 Contoh data transaksi perpustakaan IPB dengan format input SPMF 8 7 Data hasil eksekusi algoritme prefixspan dan GSP menggunakan SPMF 11 8 Perbedaan urutan pola sekuensial kedua algoritme 16
DAFTAR GAMBAR
1 Tahapan penelitian 4
2 Tahapan praproses 5
3 Proses algoritme GSP menghasilkan pola sekuensial 6 4 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset
50 12
5 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset
100 13
6 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset
500 13
7 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset
1000 13
8 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset
2000 13
9 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset
4104 14
10Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum
support 5% 14
11Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum
support 6% 14
12Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum
support 8% 14
13Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum
support 10% 15
14Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum
support 15% 15
15Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum
DAFTAR LAMPIRAN
1 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan
pada dataset 50 20
2 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan
pada dataset 100 20
3 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan
pada dataset 500 20
4 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan
pada dataset 1000 20
5 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan
pada dataset 2000 21
6 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan
1
PENDAHULUAN
Latar Belakang
Perpustakaan IPB sebagai salah satu unit penyedia penunjang kebutuhan belajar bagi mahasiswa mencatat data transaksi peminjaman buku yang banyak setiap hari. Transaksi tersebut menghasilkan kumpulan data yang besar. Tercatat sebanyak 18.669 transaksi peminjaman buku periode tahun 2003-2013. Angka tersebut diperoleh dari basisdata perpustakaan IPB yang sebelumnya sudah diseleksi dengan membuang beberapa data yang sudah tidak diperlukan agar dapat menghemat memori. Data tersebut akan menghasilkan informasi yang penting sebagai penunjang pengambilan keputusan bila dianalisis lebih lanjut. Salah satu informasi yang berguna adalah dapat memberikan rekomendasi kepada mahasiswa mengenai keterkaitan antar buku yang dipinjam
Analisis terhadap data sirkulasi pemninjaman buku lebih lanjut dapat dilakukan dengan menerapkan data mining. Data mining merupakan proses ekstraksi informasi atau pola yang penting dalam basis data berukuran besar (Han dan Kamber 2006). Penerapan data mining pada peminjaman buku di perpustakaan IPB diharapkan dapat digunakan sebagai penunjang pengambilan keputusan dengan cara melihat pola peminjaman buku.
Metode data mining yang akan digunakan pada penelitian ini adalah metode sequential pattern mining. Sequential pattern mining pertama kali diperkenalkan oleh (Agrawal dan Srikant 1995) yang ditujukan untuk mencari inter-transaction pattern yaitu kemunculan item yang diikuti oleh item lain yang terurut berdasarkan waktu transaksi. Sebagai contoh, seseorang meminjam buku
“Pengenalan Dasar Ilmu Komputer” pada dua bulan yang lalu mungkin juga akan
meminjam “Pemrograman dengan PHP ” pada bulan berikutnya.
Algoritme yang digunakan dalam penelitian ini adalah algoritme prefixspan dan generalized sequential pattern (GSP). Prefixspan menggunakan basisdata yang diproyeksikan, sehingga dalam menentukan pola peminjaman buku tidak diperlukan pembangkitan kandidat, sehingga dapat menghemat waktu eksekusi. Hal ini berbeda dengan GSP dalam menghasilkan pola peminjaman yang memerlukan pembangkitan kandidat, sehingga memerlukan waktu eksekusi yang lebih lama.
Tujuan Penelitian
Tujuan dari penelitian ini adalah sebagai berikut:
1 Menentukan pola sekuensial dari data peminjaman buku pada Perpustakaan IPB dengan dua algoritme yaitu prefixspan dan GSP.
2 Membandingkan kinerja prefixspan dan GSP dalam memperoleh pola sekuensial pada data peminjaman buku Perpustakaan IPB.
2
Manfaat Penelitian
Penelitian ini diharapkan memberi manfaat sebagai berikut:
1 Memberikan gambaran alur kerja prefixspan dan GSP dalam mengolah data peminjaman buku di Perpustakaan IPB.
2 Mengetahui pola peminjaman buku di Perpustakaan IPB.
3 Memudahkan pihak perpustakaan untuk mengambil keputusan dalam manejemen stok buku.
4 Menemukan kode buku tertentu yang memiliki keterkaitan paling kuat.
5 Memberikan rekomendasi peminjaman buku kepada mahasiswa dengan cara melihat hubungan buku yang dipinjam dengan buku lainnya.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah sebagai berikut:
1 Penelitian ini membandingan dua metode sequential pattern mining yaitu prefixspan dan GSP.
2 Penelitian ini menggunakan data transaksi peminjaman buku mulai tahun 2003-2013.
3 Penelitian ini menggunakan perangkat lunak bantu yaitu SPMF (Viger 2013) untuk memperoleh pola sekuensial.
METODE PENELITIAN
Data Peminjaman Buku Perpustakaan IPB
Data yang digunakandalam penelitian ini adalah data transaksi peminjaman (sirkulasi) buku pada Perpustakaan IPB periode tahun 2003-2013. Data tersebut diperoleh dalam format CDS/ISIS (circ.mst) yang terdiri atas 18.669 record dan 14 field yang sebelumnya telah diseleksi oleh pihak perpustakaan dengan membuang beberapa record yang sudah tidak diperlukan lagi, guna menghemat memory. Deskripsi field data transaksi peminjaman buku di Perpustakaan IPB dapat dilihat pada Tabel 1.
Perpustakaan IPB mengklasifikasikan buku berdasarkan Universal Decimal Classification (UDC) dari system Dewey Decimal Classification (DDC). UDC adalah sistem klasifikasi bahan perpustakaan yang dikembangkan oleh pakar biliografi Belgia, Paul Otlet dan Henri La Fontaine. Sistem klasifikasi UDC menggunakan tanda-tanda baca tertentu yang membagi ilmu pengetahuan ke dalam sepuluh kelompok. Ke-sepuluh kelompok tersebut dapat dilihat pada Tabel 2.
3
Tabel 1 Field dalam data Sirkulasi IPB
No Nama field Tipe data
1 No.identitas peminjam Alphanumeric
2 Kategori peminjam Alphanumeric
3 No. Registrasi buku Alphanumeric
4 Judul buku Alphanumeric
5 Kelas buku yang dipinjam Alphanumeric
6 Kondisi buku yang dipinjam Alphanumeric
7 Tanggal peminjaman Alphanumeric
8 Kode tanggal peminjaman Alphanumeric
9 Tanggal buku harus kembali Alphanumeric 10 Tanggal buku dikembalikan Alphanumeric
11 Jenis peminjaman Alphanumeric
12 Operator transaksi buku Alphanumeric
13 Nama peminjam Alphanumeric
14 Jenis koleksi Alphanumeric
Tabel 2 Kelas utama UDC Kelas utama
UDC Keterangan
0 Sains dan pengetahuan. Organisasi. Ilmu komputer. Dokumentasi. Kepustakawanan. Lembaga. Publikasi 1 Filsafat. Psikologi
2 Agama.Teologi
3 Ilmu Sosial
4 (Tidak digunakan) 5 Matematika. Ilmu Alam
6 Applied Science. Kedokteran.Teknologi 7 Seni. Rekreasi. Entertainment. Olahraga 8 Bahasa. Linguistik. Literatur
9 Geografi. Biografi. Sejarah Sumber: http://www.udcc.org/udcsummary/php/index.php
Tabel 3 Contoh hierarki peminjaman buku perpustakaan Kode kelas Kelas buku yang dipinjam
500 Matematika. Ilmu Alam
570 Ilmu-ilmu hayati pada umumnya
574 Ekologi dan biodiversitas umum
Spesifikasi Kebutuhan Perangkat Sistem
Implementasi sistem menggunakan komputer personal yang memiliki spesifikasi perangkat keras dan perangkat lunak sebagai berikut:
Perangkat keras
Processor Intel Core i3-2367M CPU @ 1.40Hz
4
Sistem operasi: Windows 7 Ultimate 32-bit
Harddisk 500 GB
Keyboard dan mouse
Monitor
Perangkat lunak
Microsoft Excel 2010 sebagai lembar kerja (worksheet) dalam pengolahan data
Java Platform SE 7 U21 versi 7.0.210.11
PostgreSQL sebagai sistem manajemen basis data
SPMF versi 0.94 sebagai perangkat lunak yang digunakan untuk menghasilkan pola sekuensial dari data peminjaman buku perpustakaan IPB
Tahapan Penelitian
Prefixspan dan GSP adalah dua metode dalam data mining yang dapat digunakan untuk memperoleh pola sekuensial dengan berbagai tahapan. Tahapan tersebut dapat dilihat pada Gambar 1.
Gambar 1 Tahapan penelitian
Praproses
5
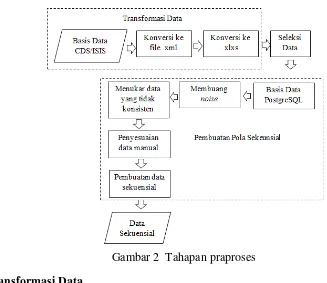
Gambar 2 Tahapan praproses
Transformasi Data
Transformasi data merupakan tahap untuk mengubah format data dalam format yang sesuai agar data dapat diproses. Format koleksi data dari perpustakaan dikonversi dari format CDS/ISIS (circ.mst) menjadi format Microsoft Excel (.xlxs) kemudian dikonversi kembali ke format data sekuensial dalam (.txt) agar dapat dibaca oleh software SPMF.
Seleksi Data
Seleksi data merupakan proses untuk menentukan data yang akan diproses lebih lanjut untuk dianalisis. Pada tahapan ini juga akan dipilih field atau atribut yang dibutuhkan sebagai input untuk masing-masing algoritme. Data yang digunakan meliputi No. Identitas Peminjam, Tanggal peminjaman, dan Kelas buku yang dipinjam. Data peminjaman buku Perpustakaan IPB memiliki 3 kelas buku. Dalam penelitian ini digunakan hanya kelas 3 saja untuk memperoleh pola sekuensial.
Pembersihan Data
Pembersihan data merupakan tahap pembersihan data dari noise, nilai kosong, dan data yang tidak konsisten dari koleksi data yang akan diproses.
Pembuatan Pola Sekuensial
6
Pencarian Pola Sekuensial
Pola sekuensial adalah suatu pola yang menunjukan urutan transaksi dalam suatu periode. Pola ini dapat digunakan untuk menganalisis hubungan antar item. Dalam penelitian ini item yang dimaksud adalah buku.
a Pencarian Pola Sekuensial dengan GSP
Generalized sequential pattern (GSP) merupakan salah satu algoritme untuk penyelesaian masalah sequential pattern. GSP didesain untuk data transaksi, dimana setiap pola merupakan kumpulan dari transaksi setiap waktu dan setiap transaksi berupa item (Ahola 2001). Algoritme ini bekerja menemukan pola sekuensial dengan cara membangkitkan candidates yang sesuai dengan minimum support yang ditentukan.
GSP memeriksa semua basisdata untuk menghitung single item ( 1-sequences). Item yang frequent akan membentuk dua item (2-sequences). Item yang frequent pada 2-sequences akan digunakan untuk men-generate candidate dari 3 item (3-sequences). Proses ini akan berhenti sampai tidak ada frequentitem yang ditemukan (Zaki 1997). Proses algoritme GSP dalam membangkitkan candidate dapat dilihat pada Gambar 3.
Gambar 3 Proses algoritme GSP menghasilkan pola sekuensial
b Pencarian Pola Sekuensial dengan Prefixspan
7
Tabel 4 Prefix dan suffix dalam prefixspan
Prefix Suffix (prefix-based-projection)
<a> <(abc)(ac)d(cf)> dari kinerja algoritme akan dicatat dalam tabel untuk kemudian dianalisis lebih lanjut.
Analisis Pola Sekuensial
Pada tahap ini akan dilakukan analisis hasil pola sekuensial yang dihasilkan oleh kedua algoritme baik dari pola sekuensial yang diperoleh maupun waktu eksekusi yang dibutuhkan pada setiap minimum support dan dataset.
HASIL DAN PEMBAHASAN
Praproses
Data peminjaman buku Perpustakaan IPB harus melalui tahapan praproses terlebih dahulu untuk dapat menghasilkan pola sekuensial. Praproses ini dilakukan agar data masukan (input) valid dan sesuai denga format input perangkat lunak yang digunakan. Tahapan praproses dapat dilihat pada Gambar 1.
Transformasi Data
Data peminjaman buku Perpustakaan IPB yang diperoleh dari basisdata CDS/ISIS memiliki format CIRC (.mst). Data tersebut dapat diolah lebih lanjut dengan cara mentransformasikan format yang semula (.mst) ke dalam format (.xlxs). Data kemudian diseleksi dan dibersihkan agar terbebas dari noise. Proses transformasi data dilakukan dengan dua tahap
a Data dikonversi ke dalam bentuk XML.
b Data yang telah ditransformasikan dalam format xml, kemudian kembali ditransformasikan ke dalam format .xlxs.
Seleksi Data
8
Pembersihan Data
Proses seleksi data menghasilkan tiga atribut. Atribut ini kemudian dimasukan ke dalam DBMS PostgreSQL untuk dibersihkan. Pada pembersihan data awal ditemukan ada 3000 data yang tidak memenuhi standar UDC karena mengandung noise (tanda selain angka seperti . (titik), ‘ (kutip), dan – (strip)). Proses ini melibatkan query dimana noisediasumsikan sebagai angka ‘0’.
Pembersihan data selanjutnya dilakukan dengan menukar kelas yang salah dalam klasifikasi. Misalnya KLS1 bernilai 631 dan KLS3 bernilai 630 maka tukar kedua kelas tersebut sehingga KLS1 bernilai 630 dan KLS3 bernilai 631.
Pembersihan data selanjutnya dilakukan dengan mencocokan data yang ketiga kelasnya bersifat umum secara manual dengan mencocokan kelas dan judul buku pada format pengklasifikasian UDC.
Pembuatan Pola Sekuensial
Untuk menentukan pola sekuensial dengan metode prefixspan dan GSP dilakukan dengan bantuan perangkat lunak (SPMF). Perangkat lunak ini membaca input berupa data dalam bentuk sekuensial. Pada awalnya data peminjaman buku perpustakaan IPB masih dalam format .xlxs dimana No. identitas peminjam masih diperlukan. Format data dalam bentuk sekuensial dapat dilihat pada Tabel 5.
Tabel 5 Contoh peminjaman buku setelah diubah ke dalam bentuk sekuensial
Identitas peminjam Pola sekuensial D14202024 <(637 664 637) 664> A151050241 <658>
Setiap tanda kurung menggambarkan buku yang dipinjam bersamaan pada waktu yang sama sedangkan kode yang tidak ditulis dalam tanda kurung menggambarkan kode buku yang dipinjam pada waktu yang berbeda. Untuk setiap kode buku yang sama dan dipinjam secara bersamaan pada waktu yang sama cukup ditulis satu kali.
SPMF tidak membaca karakter ‘(’ (kurung buka) ‘)’ (kurung tutup) ‘<’
(lebih kecil) ’>’ (lebih besar), maka karakter harus diubah. Untuk setiap
perbedaan waktu transaksi dipisahkan dengan tanda ‘-1’ dan diakhiri dengan
tanda ‘-1 -2’. Pola transaksi pada Tabel 5 akan diubah ke dalam format yang dapat
dibaca oleh SPMF. Perubahan bentuk sekuensial diperlihatkan pada Tabel 6. Tabel 6 Contoh data transaksi Perpustakaan IPB dengan
format input SPMF
Identitas peminjam Pola sekuensial
D14202024 637 664 637 -1 664 -1 -2
A151050241 658 -1 -2
9
Penentuan Pola Sekuensial
Metode data mining yang digunakan pada penelitian ini adalah metode sequential pattern mining dengan menggunakan algoritme prefixspan dan GSP. Beberapa istilah digunakan dalam metode sequential pattern mining. Istilah tersebut di antaranya:
1 Pola sekuensial
Pola sekuansial yang dimaksud adalah pola yang dibentuk dari kode buku berdasarkan urutan transaksi peminjaman buku. No id peminjam menjadi atribut unik untuk mengelompokan kode-kode buku yang dipinjam dalam satu transaksi. Kemudian transaksi tersebut diurutkan berdasarkan waktu dari yang paling lama hingga yang terbaru. Semakin panjang pola sekuensial dihasilkan maka semakin banyak transaksi peminjaman yang dilakukan.
2 Itemset dan Dataset
Itemset adalah sekumpulam Item dalam satu transaksi. Item dalam penelitian ini adalah kode buku perpustakaan yang sudah diklasifikasikan berdasarkan standar UDC dimana beberapa judul buku bisa diklasifikasikan dalam satu kode UDC. Item ini digunakan sebagai input pada perangkat lunak SPMF.
Dataset adalah kumpulan dari itemset. Dataset mengandung informasi peminjaman yang dikelompokan berdasarkan kriteria tertentu.
3 Minimum support
Minimum support adalah jumlah minimum yang dicapai suatu itemset yang frequent. Semakin tinggi minimum support maka semakin erat keterkaitan antar item.
4 Waktu eksekusi
Waktu eksekusi adalah waktu yang diperlukan oleh suatu algoritme dalam membentuk pola sekuensial. Waktu ini akan dibandingkan untuk memperoleh kesimpulan kinerja kedua algoritme dalam menghasilkan pola sekuensial.
Penggunaan Algoritme Prefixspan dan GSP pada Data Peminjaman Buku di Perpustakaan IPB
Pemilihan minimum support
Minimum support yang digunakan dalam penelitian ini adalah 5%, 6%, 8%, 10%, 15% dan 20%. Ke-enam minimum support tersebut dipilih agar mudah mengamati perbedaan kedua algoritme dalam menghasilkan pola sekuensial. Di atas 20% sudah tidak diperoleh pola sekuensial yang frequent.
Pemilihan dataset
10
Perbandingan Kinerja Algoritme Prefixspan dan GSP
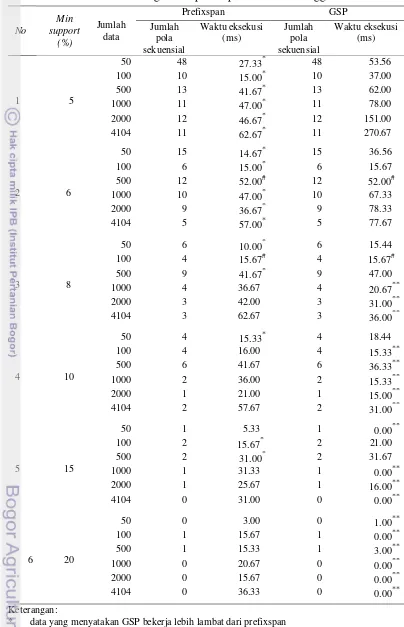
Perbedaan alur kerja dari prefixspan dan GSP dalam menghasilkan pola sekuensial akan mempengaruhi jumlah pola sekuensial yang dihasilkan dan waktu eksekusi yang diperlukan. Hasil eksekusi kedua algoritme dengan SPMF dapat dilihat pada Tabel 7.
Data peminjaman buku Perpustakaan IPB dengan masing-masing minimum support dan dataset di uji sebanyak tiga kali. Hal ini dilakukan karena masing-masing algoritme menghasilkan waktu eksekusi yang berbeda pada setiap pengulangan pengujian. Menurut Viger (2013) hal ini disebabkan oleh hal-hal sebagai berikut:
1 Waktu eksekusi yang dihasilkan oleh algoritme GSP adalah waktu eksekusi untuk menulis file output saja. Waktu eksekusi untuk membaca file input dan mengidentifikasi single frequent item tidak dihitung sedangkan waktu eksekusi algoritme prefixspan adalah waktu eksekusi untuk menulis file output dan lain-lain. Waktu eksekusi untuk membaca file input tidak dihitung.
2 Kinerja komputer saat program dijalankan (dalam kasus ini hanya dijalankan SPMF saja).
Data dari tiga kali pengulangan kemudian dirata-ratakan dan dicatat hasilnya pada Tabel 7 sementara data lengkap dari tiga percobaan per dataset disajikan pada Lampiran 1 sampai Lampiran 6. Beberapa informasi yang diperoleh dari Tabel 7 adalah sebagai berikut:
1 Berdasarkan jumlah pola sekuensial yang dihasilkan
Prefixspan dan GSP menghasilkan jumlah pola sekuensial yang sama pada setiap dataset dan minimum support.
2 Berdasarkan waktu eksekusi
Terdapat 18 data yang menyatakan bahwa GSP bekerja lebih cepat dari prefixspan yang diberi tanda (**), 2 data yang menyatakan GSP bekerja sama cepatnya dengan prefixspan yang diberi tanda (#), 16 data yang menyatakan GSP bekerja lebih lambat dari prefixspan yang diberi tanda (*).
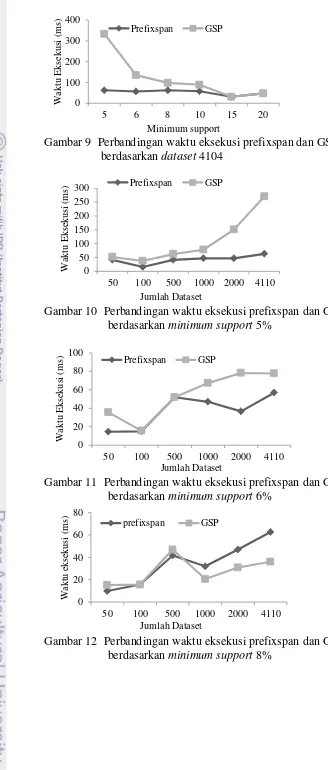
Gambar 4 sampai Gambar 9 merupakan perbandingan antara minimum support dan waktu eksekusi yang dikelompokan berdasarkan dataset. Gambar tersebut menunjukan pada setiap dataset, prefixspan memiliki waktu eksekusi yang lebih cepat pada minimum support yang rendah sedangkan GSP memiliki waktu eksekusi yang cepat pada minimum support yang tinggi. Beberapa alasan terkait hal tersebut diantaranya:
1 Kondisi data yang seragam
GSP menghasilkan pola sekuensial dengan cara membangkitkan kandidat. Masalah yang ditimbulkan dalam algoritme GSP adalah pembangkitan kandidat yang ternyata tidak ada di basisdata, hal ini yang menyebabkan GSP memerlukan waktu yang lama dalam memperoleh pola sekuensial.
Pada data perpustakaan diperoleh data dengan item yang sedikit namun pola yang panjang seperti 027 1 820 1 027 1 027 1 027 1 027 1 027 1 027 1
-2. Kode ‘027’ muncul beberapa kali. Hal tersebut menggambarkan transaksi
dilakukan dengan meminjam kode buku yang sama pada waktu yang berbeda beberapa kali. Bila item yang dihasilkan sedikit maka pembangkitan kandidat tidak akan lama. Hal inilah yang menyebabkan GSP bekerja lebih cepat.
11
Tabel 7 Data hasil eksekusi algoritme prefixspan dan GSP menggunakan SPMF
No
12
Di sisi lain prefixspan bekerja dengan proyeksi ke basisdata. Untuk menghasilkan pola sekuensial pada setiap length, prefixspan harus melakukan scan terhadap basisdata terus menerus. Hal ini yang menyebabkan prefixspan bekerja lebih lambat pada kasus diatas.
2 Minimum support yang diterapkan
Penentuan minimum support akan mempengaruhi waktu eksekusi dari kedua algoritme. Semakin tinggi minimum support maka candidate yang dihasilkan oleh GSP semakin sedikit. Hal inilah yang menyebabkan GSP bekerja lebih cepat pada minimum support yang tinggi.
Di sisi lain prefixspan bekerja dengan melakukan scan terhadap basisdata. Pada minimum support yang rendah prefixspan bekerja lebih cepat dibandingkan GSP yang akan membangkitkan kandidat semakin banyak.
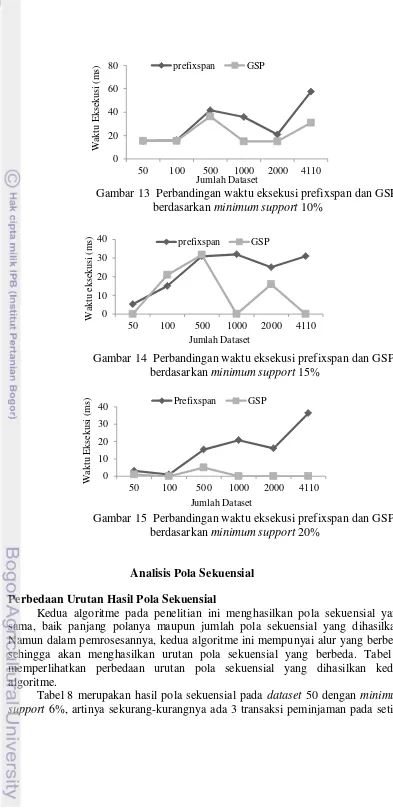
Analisis akan dilanjutkan dengan membandingkan kinerja kedua algoritme berdasarkan minimum support. Gambar 10 sampai Gambar 15 merupakan perbandingan antara waktu eksekusi dan dataset yang dikelompokan berdasarkan minimum support. Dari Gambar 10 sampai Gambar 15 dapat diperoleh informasi bahwa prefixspan bekerja lebih cepat pada minimum support yang lebih kecil (5% dan 6%). Semakin rendah minimum support yang digunakan dan semakin besar dataset, prefixspan bekerja lebih cepat. GSP bekerja lebih cepat pada minimum support yang tinggi. Semakin tinggi minimum support yang diterapkan, GSP akan semakin sedikit dalam membangkitkan kandidat dalam setiap dataset, hal inilah yang menyebabkan GSP bekerja lebih cepat pada minimum support yang tinggi.
Pada minimum support 5%, 6%, 8% dengan dataset 50, prefixspan bekerja lebih cepat dari GSP namun ketika minimum support dinaikan menjadi 10% kinerja prefixspan menurun sehingga memiliki waktu eksekusi yang sama dengan GSP. Ketika minimum support dinaikan kembali menjadi 15% dan 20% prefixspan bekerja lebih lambat dari GSP. Penentuan minimum support ini sangat mempengaruhi waktu eksekusi kedua algoritme untuk menghasilkan pola sekuensial.
Gambar 4 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset 50
13
Gambar 5 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset 100
Gambar 6 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset 500
Gambar 7 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset 1000
Gambar 8 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset 2000
14
Gambar 9 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan dataset 4104
Gambar 10 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum support 5%
Gambar 11 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum support 6%
Gambar 12 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum support 8%
0
50 100 500 1000 2000 4110
W
50 100 500 1000 2000 4110
W
50 100 500 1000 2000 4110
15
Gambar 13 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum support 10%
Gambar 14 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum support 15%
Gambar 15 Perbandingan waktu eksekusi prefixspan dan GSP berdasarkan minimum support 20%
Analisis Pola Sekuensial
Perbedaan Urutan Hasil Pola Sekuensial
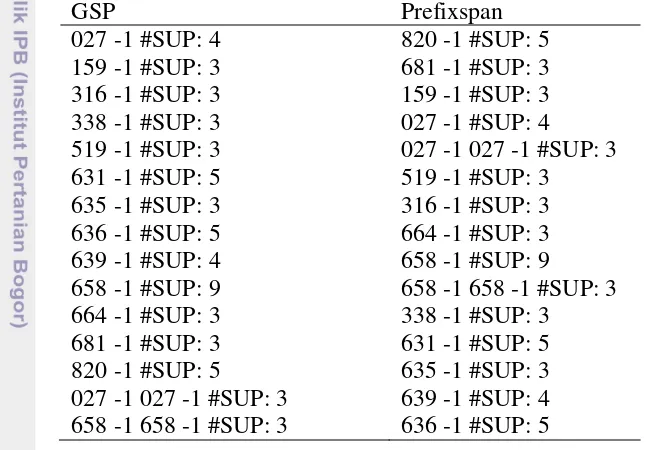
Kedua algoritme pada penelitian ini menghasilkan pola sekuensial yang sama, baik panjang polanya maupun jumlah pola sekuensial yang dihasilkan. Namun dalam pemrosesannya, kedua algoritme ini mempunyai alur yang berbeda sehingga akan menghasilkan urutan pola sekuensial yang berbeda. Tabel 8 memperlihatkan perbedaan urutan pola sekuensial yang dihasilkan kedua algoritme.
Tabel 8 merupakan hasil pola sekuensial pada dataset 50 dengan minimum support 6%, artinya sekurang-kurangnya ada 3 transaksi peminjaman pada setiap
0 20 40 60 80
50 100 500 1000 2000 4110
W
50 100 500 1000 2000 4110
W
50 100 500 1000 2000 4110
16
kode buku yang diperoleh dari 50 dataset. Perbedaan terlihat pada cara kedua algoritme tersebut menampilkan output.
GSP bekerja dengan cara membangkitkan kandidat. Terlihat pada Tabel 8, GSP menyelesaikan terlebih dahulu setiap itemset per-length. GSP tidak dapat menghasilkan length-2 sequential pattern bila length-1 sequential pattern belum selesai di-buat begitupun seterusnya hingga tidak diperoleh lagi pola yang memenuhi minimum support.
Prefixspan bekerja dengan menggunakan proyeksi basisdata. Dapat dilihat pada Tabel 8 bahwa prefixspan bekerja per-prefix. Artinya prefixspan dapat membuat length-n per-prefix tanpa harus menyelesaikan semua sesuai urutan, seperti pada GSP. Contohnya dapat dilihat pada Tabel 8, kode buku 658 memenuhi minimum support pada length-1, pada kode tersebut prefixspan dapat langsung mencari hingga length-ntanpa harus mencari kandidat yang lain.
Tabel 8 Perbedaan urutan pola sekuensial kedua algoritme
GSP Prefixspan
Item Buku yang Dipinjam
Tabel 8 menunjukan kode ‘658’ muncul sebanyak 9 kali pada length-1
artinya buku dengan kode ‘658’ banyak dipinjam tanpa meminjam buku yang lain.
Tabel 8 juga memberi hasil keterkaitan antar kode buku sampai peminjaman 2 item , yaitu ada sebanyak tiga kali transaksi peminjaman pada kode buku ‘027’
yang dipinjam berurutan dengan kode buku ‘027’ pada waktu yang berbeda dan
kode buku ‘658’ yang dipinjam berurutan dengan kode buku ‘658’ pada waktu
17
Pola yang Dihasilkan dari Data Peminjaman Buku Perpustakaan IPB
Terdapat beberapa pola yang dapat dianalisis pada beberapa dataset. Pola tersebut menggambarkan kode buku yang sering dipinjam dan kode buku yang saling terkait satu dengan yang lain.
1 Dataset 50
Pada dataset 50 diperoleh pola menarik yaitu pada minimum support 5% artinya ada sekurang-kurangnya 2 dari 50 transaksi peminjaman. Pola tersebut adalah sebagai berikut.
Pada pola diatas diperoleh pola terpanjang yang masing-masing dipinjam sebanyak dua kali yaitu pada length-2 ( pola yang memiliki keterkaitan sampai dua item) yaitu item <820 027>, <027 820>, <(027 820)>,<(631 658)>,<(631 636)> dimana ada dua dari 50 data transaksi yang menggambarkan seseorang akan meminjam buku dengan kode 820 (sastra) kemudian 027 (perpustakaan umum) secara terpisah pada waktu yang berbeda, begitu juga sebaliknya, selain itu ada juga yang meminjam kode buku 027 dan 820 secara bersamaan di waktu yang sama. Keterkaitan kuat lainnya adalah ketika seseorang meminjam buku dengan kode buku 631 (pertanian secara umum) dan 658 (Manajemen, administrasi bisnis. Organisasi komersial) yang dipinjam bersamaan, dan 631 dan 636 ( peternakan dan pengembangbiakan ternak secara umum. Pemeliharaan ternak. Pembibitan hewan domestik) yang dipinjam bersamaan.
2 Dataset 100
Pada dataset 100 diperoleh pola yang menunjukan keterkaitan kode buku yang sama yaitu pada minimum support 10%, polanya adalah sebagai berikut.
658 -1 #SUP: 11 631 -1 #SUP: 34
631 -1 631 -1 #SUP: 16
631 -1 631 -1 631 -1 #SUP: 12
18
3 Dataset 4104 (seluruh data peminjaman buku periode 2003-2013)
Pada dataset 4104 (seluruh data transaksi peminjaman buku) diperoleh pola yang menunjukan keterkaitan kode buku yang sama yaitu pada minimum 10%, pola tersebut adalah sebagai berikut.
631 -1 #SUP: 435 658 -1 #SUP: 458
Pola diatas menjelaskan dari 4104 peminjam buku, 435 diantaranya meminjam buku dengan kode 631 (pertanian secara umum) dan 458 diantaranya meminjam buku dengan kode 658 (Manajemen, administrasi bisnis. Organisasi komersial). Dari pola diatas dapat diambil kesimpulan bahwa dari seluruh transaksi peminjaman buku pada Perpustakaan IPB kode buku yang paling banyak dipinjam adalah 658 (Manajemen, administrasi bisnis. Organisasi komersial).
SIMPULAN DAN SARAN
Simpulan
Dari hasil analisis yang telah dilakukan diperoleh beberapa kesimpulan terkait kinerja kedua algoritme dalam menghasilkan pola sekuensial pada data Peminjaman Buku Perpustakaan IPB periode 2003-2013.
1 Prefixspan dan GSP menghasilkan pola sekuensial yang sama baik panjang polanya maupun jumlah pola sekuensial yang dihasilkan meskipun alur kerja algoritme ini berbeda. Pada dataset 50 dengan minimum support 5% diperoleh transaksi peminjaman yang menarik dengan pola <820 027> dimana buku dengan kode 820 (sastra) akan dipinjam berurutan pada waktu yang berbeda dengan kode buku 027 (perpustakaan umum) begitupun sebaliknya, <(027 820)> dimana kode buku 027 akan dipinjam bersamaan dengan kode buku 820, <(631 658)> dimana kode buku 631 (pertanian secara umum) akan dipinjam bersamaan dengan kode buku 658 (Manajemen, administrasi bisnis. Organisasi komersial), <(631 636)> dimana kode buku 631 akan dipinjam bersamaan dengan kode buku 636 ( peternakan dan pengembangbiakan ternak secara umum. Pemeliharaan ternak. Pembibitan hewan domestik). Pada seluruh dataset yang merupakan seluruh transaksi peminjaman buku diperoleh kesimpulan bahwa buku dengan kode 658 dipinjam sebanyak 458 kali. Hal ini berarti bahwa buku yang paling sering dipinjam di Perpustakaan IPB adalah buku dengan kode 658 (Manajemen, administrasi bisnis. Organisasi komersial). 2 GSP bekerja lebih cepat pada minimum support yang tinggi karena akan
19
minimum support dan dataset yang digunakan GSP bekerja lebih cepat pada data peminjaman buku Perpustakaan IPB periode 2003-2013.
Saran
Penelitian selanjutnya diharapkan dapat menghasilkan korelasi yang kuat dan pola sekuensial yang lebih baik pada minimum support yang tinggi serta dapat mengelompokan data berdasarkan fakultas atau departemen agar bisa melihat pola peminjaman buku pada setiap fakultas atau departemen.
DAFTAR PUSTAKA
Ahola J. 2001. Mining sequential pattern (version 1.0) [Internet]. [diunduh 2013 Okt 31]. Tersedia pada: http://www.vtt.fi/inf/julkaisut/muut /2001.
Agrawal R, Srikant R. 1995. Mining sequential pattern. Di dalam International Conference on Data Engineering; 1995 Mar; Taipei, Taiwan. hlm 3-14. Han J, Kamber M. 2006. Data Mining Concepts and Techniques. Ed ke-2. San
Fransisco (US): Morgan Kaufmann.
Pei J, Han J, Mortazawi-Asl B, Wang J, Pinto H, Chen Q, Dayal U, Hsu M. 2004. Mining sequential patterns by pattern-growth: the prefixspan approach. IEEE Transactions on Knowledge and Data Engineering. 16(11):1424-1440. Zaki MJ. 1997. Fast mining of sequential patterns in very large databases
[technical report]. NewYork (US): University of Rochester.
Viger PF. 2013. Sequential pattern mining framework (SPMF) versi 0.94 [internet]. [diunduh 2013 Agu 6]. Tersedia pada:http://www.philippe-fournier-viger.com/spmf.
20
LAMPIRAN
Lampiran 1 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan pada dataset 50
Minsup Jml
sekuen
Waktu Eksekusi Prefixspan (ms) Waktu Eksekusi GSP (ms)
I1 I2 I3 Rataan I1 I2 I3 Rataan
Lampiran 2 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan pada dataset 100
Minsup Jml
sekuen
Waktu Eksekusi Prefixspan (ms) Waktu Eksekusi GSP (ms)
I1 I2 I3 Rataan I1 I2 I3 Rataan
Lampiran 3 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan pada dataset 500
Minsup Jml
sekuen
Waktu Eksekusi Prefixspan (ms) Waktu Eksekusi GSP (ms)
I1 I2 I3 Rataan I1 I2 I3 Rataan
Lampiran 4 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan pada dataset 1000
Minsup Jml
sekuen
Waktu Eksekusi Prefixspan (ms) Waktu Eksekusi GSP (ms)
21
Lampiran 5 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan pada dataset 2000
Minsup Jml sekuen
Waktu Eksekusi Prefixspan (ms) Waktu Eksekusi GSP (ms)
I1 I2 I3 Rataan I1 I2 I3 Rataan
5 12 47.00 47.00 46.00 46.67 156.00 156.00 141.00 151.00
6 9 31.00 32.00 47.00 36.67 94.00 63.00 78.00 78.33
8 3 32.00 47.00 47.00 42.00 31.00 31.00 31.00 31.00
10 1 16.00 16.00 31.00 21.00 15.00 15.00 15.00 15.00
15 1 31.00 31.00 15.00 25.67 16.00 16.00 16.00 16.00
20 0 16.00 15.00 16.00 15.67 0.00 0.00 0.00 0.00
Lampiran 6 Data perolehan jumlah sekuen dan waktu eksekusi pada tiga pengulangan pada dataset 4104
Minsup Jml sekuen
Waktu Eksekusi Prefixspan (ms) Waktu Eksekusi GSP (ms)
I1 I2 I3 Rataan I1 I2 I3 Rataan
5 11 62.00 63.00 63.00 62.67 266.00 265.00 281.00 270.67
6 5 62.00 62.00 47.00 57.00 62.00 93.00 78.00 77.67
8 3 47.00 78.00 63.00 62.67 31.00 31.00 46.00 36.00
10 2 63.00 47.00 63.00 57.67 31.00 31.00 31.00 31.00
15 0 31.00 31.00 31.00 31.00 0.00 0.00 0.00 0.00
22
RIWAYAT HIDUP
Penulis lahir di Yogyakarta 31 Desember 1989, anak pertama dari dua bersaudara. Putri dari Bapak John Daniel dan Ibu Wati ningsih. Penulis menyelesaikan Sekolah Menengah Atas (SMA) di SMA Negeri 4 Bogor lalu kemudian diterima sebagai mahasiswa USMI Diploma IPB jurusan Manajemen Informatika. Penulis Menyelesaikan study di diploma IPB lalu kemudian lulus dan melanjutkan study pada Ilmu Komputer IPB untuk meraih gelar Sarjana Komputer.
Pada masa sekolah hingga menjadi mahasiswa penulis aktif dalam kegiatan kemahasiswaan seperti terlibat dalam beberapa kepanitian (OMDI, MPKMB). Penulis juga sering mengikuti seminar-seminar yang dapat menambah pengetahuan dan rekan kerja.