BAB IV PEMBAHASAN
1.1. Data Pengamatan
Data yang digunakan dalam laporan ini adalah data nilai inflasi bulanan, inflasi tahun kalender dan inflasi tahunan pada bulan Agustus 2015 di 26 kota IHK di Indonesia (lampiran 1). Objek dari data adalah data 82 kabupaten/kota di Indonesia, sedangkan 3 komponen inflasi, yaitu data inflasi bulanan, inflasi tahun kalender dan inflasi tahunan bertindak sebagai variabel. Data pengamatan diolah dengan menggunakan software SPSS 17 untuk membantu menyelesaikan metode clusterK-Means.
1.2. Metode Cluster K-Means Cluster
Metode K-Means digunakan sebagai alternatif metode cluster untuk data dengan ukuran yang besar karena memiliki kecepatan yang lebih tinggi dibandingkan metode hirarki. Mac Queen menyarankan bahwa penggunaan K-Means untuk menjelaskan algoritma dalam penentuan suatu objek ke dalam cluster tertentu berdasarkan rataan terdekat sebagaimana telah dijelaskan sebelumnya bahwa metode K-Means Cluster ini jumlah cluster ditentukan sendiri. Oleh karena itu, berikut ini langkah-langkah yang harus dilakukan dalam menggunakan metode K-Means Cluster dalam aplikasi program SPSS. Perlu diingat bahwa bahan analisis bukan lagi data asli, namun data hasil transformasi/standardisasi (lampiran 2). Asumsi yang harus dipenuhi dalam Analisis Cluster yaitu :
Sampel yang diambil benar-benar dapat mewakili populasi yang ada (representativeness of the sample)
Multikolinieritas sehingga dalam pengklasteran dapat menggunakan jarak Euclidian.
a) Menentukan k sebagai jumlah cluster yang ingin dibentuk pada metode K-Means.
b) Menentukan Centroid dan Jarak Setiap Objek dengan Setiap Centroid pada metode K-Means hingga nilai pusat cluster tidak berubah lagi pada metode K-Means.
Banyaknya cluster yang akan dibentuk (k) pada proses peng-cluster-an dengan metode
K-Means adalah tiga buah sehingga terdapat tiga buah centroid (pusat cluster) dimana c1 (centroid cluster 1), c2 (centroid cluster 2), c3 (centroid cluster 3) dengan bantuan SPSS, nilai centroid dapat dilihat pada tampilan initial cluster center sehingga diperoleh:
Cluster
1 2 3
Zscore(inf_bulanan) -1.40374 -1.87362 1.50956
Zscore(inf_kalender) -2.71270 2.25242 4.28615
[image:2.595.149.415.215.318.2] [image:2.595.155.355.446.576.2]Zscore(inf_tahunan) -.87977 1.58771 4.47836 Tabel 4.1 Initial cluster center
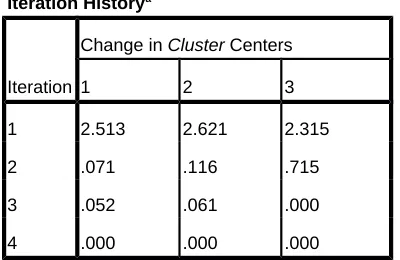
Tabel diatas merupakan tampilan pertama proses clustering data sebelum dilakukan iterasi. Untuk mendeteksi berapa kali proses iterasi yang dilakukan dalam proses clustering dari 82 obyek yang diteliti, dapat dilihat dari tampilan output berikut ini :
Iteration Historya
Iteration
Change in Cluster Centers
1 2 3
1 2.513 2.621 2.315
2 .071 .116 .715
3 .052 .061 .000
4 .000 .000 .000
a. Convergence achieved due to no or small change in cluster centers. The maximum absolute coordinate change for any center is . 000. The current iteration is 4. The minimum distance between initial centers is 4.893.
Tabel 4.2 Iteration history
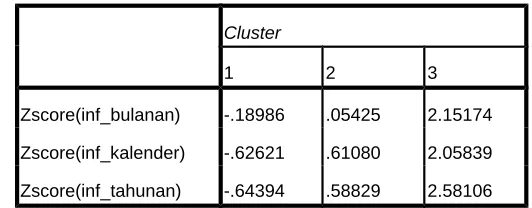
Ketika nilai dari ketiga centroid tersebut sudah tetap atau tidak mengalami perubahan, maka proses peng-cluster-an berhenti. Nilai dari ketiga centroid baru dapat dilihat dalam output SPSS final cluster centers. Adapun hasil akhir dari proses clustering digambarkan berikut ini :
Cluster
1 2 3
Zscore(inf_bulanan) -.18986 .05425 2.15174
Zscore(inf_kalender) -.62621 .61080 2.05839
[image:3.595.144.410.182.286.2]Zscore(inf_tahunan) -.64394 .58829 2.58106 Tabel 4.3 Final Cluster Centers
c) Interpretasi Cluster pada Metode K-Means.
Pada Output Final Cluster Centers masih terkait dengan proses standardisasi data sebelumnya, yang mengacu pada z-score dengan ketentuan sebagai berikut :
Nilai negatif (-) berarti data berada di bawah rata-rata total.
Nilai positif (+) berarti data berada di atas rata rata total. Rumus umum yang digunakan yaitu :
X Z
Dimana :
X : rata-rata sampel (variabel dalam cluster)
: rata-rata populasi
Z : nilai standardisasi : standar deviasi
Sebagai contoh, apabila ingin diketahui rata-rata tingkat inflasi bulanan di cluster-1 yaitu :
(rata-rata inflasi bulanan ) + (-0,18986 x standar deviasi rata-rata inflasi bulanan) = 0,1962 + (-0,18986x 0, 63845)
= 0,074983883
tabel output Final Cluster Centers, dengan ketentuan yang telah dijabarkan diatas pula, dapat didefinisikan sebagai berikut :
Cluster-1
Dalam cluster-1 ini berisikan kota-kota yang mempunyai tingkat inflasi bulanan, inflasi tahun kalender dan inflasi tahunan yang kurang dari rata-rata populasi kota yang diteliti. Hal ini terbukti dari nilai positif (-) yang terdapat pada tabel Final Cluster Centers dalam keseluruhan variabel. Dengan demikian, dapat diduga bahwa cluster-1 ini merupakan pengelompokan dari kota-kota yang mempunyai tingkat inflasi rendah.
Cluster-2
Karakteristik kota yang masuk dalam pengelompokan cluster-2 yaitu memiliki rata-rata tingkat inflasi bulanan, inflasi tahun kalender dan inflasi tahunan yang melebihi rata-rata populasi kota yang diteliti. Untuk instrumen variabel yang lain kota-kota di cluster-2 ini berada di atas ratarata populasi. Dengan demikian, dapat diduga sekumpulan kota-kota menengah berada pada cluster-2.
Cluster-3
Sedangkan karakteristik di cluster-3 berisikan kota-kota yang mempunyai tingkat inflasi bulanan, inflasi tahun kalender dan inflasi tahunan yang lebih dari rata-rata populasi kota yang diteliti. Hal ini terbukti dari nilai positif (+) yang terdapat pada tabel Final Cluster
Centers dalam keseluruhan variabel. Dengan demikian, dapat diduga bahwa cluster-1 ini merupakan pengelompokan dari kota-kota yang mempunyai tingkat inflasi paling tinggi.
Selanjutnya untuk mengetahui jumlah anggota masing-masing cluster yang terbentuk dapat dilihat pada tabel output berikut ini:
Cluster 1 44.000
2 35.000
3 3.000
Valid 82.000
[image:4.595.189.354.553.658.2]Missing .000
Tabel 4.4 Number of Cases in each Cluster
memberi ciri spesifik untuk menggambarkan isi cluster tersebut maka diperoleh sebagai berikut:
1) Cluster 1 beranggotakan kota IHK Meulaboh, Banda Aceh, Lhoksemawe, Pematang Siantar, Padang Sidempuan, Padang, Bukit Tinggi, Tembilahan, Pekanbaru, Bungo, Jambi, Metro, Tanjung Pandang, Tanjung Pinang, Sukabumi, Cirebon, Depok, Tasikmalaya, Cilacap, Purwokerto, Kudus, Surakarta, Semarang, Yogyakarta, Jember, Banyuwangi, Sumenep, Kediri, Probolinggo, Madiun, Mataram, Bima, Maumere, Kupang, Palangkaraya, Palu, Bulukumba, Watampone, Pare-Pare, Palopo, Kendari, Manokwari, Merauke dan Jayapura.
2) Cluster 2 beranggotakan kota IHK Sibolga, Medan, Dumai, Palembang, Lubuk Linggau, Bandar Lampung, Pangkal Pinang, Batam, Jakarta, Bogor, Bandung, Bekasi, Tegal, Malang, Surabaya, Tangerang, Cilegon, Serang, Singaraja, Denpasar, Pontianak, Singkawang, Sampit, Tanjung, Banjarmasin, Balikpapan, Samarinda, Tarakan, Manado, Makassar, Bau-Bau, Gorontalo, Mamuju, Ambon dan Sorong.
3) Cluster 3 beranggotakan kota IHK Bengkulu, Tual dan Ternate.
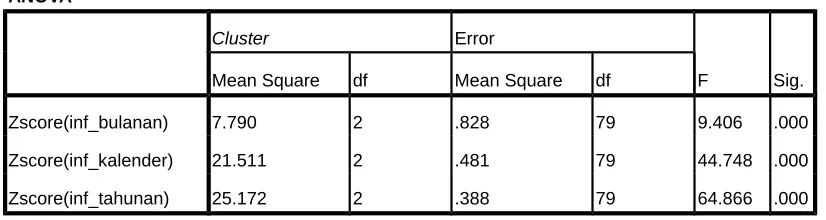
d) Melakukan Validasi Cluster.
Tahapan selanjutnya yang perlu dilakukan yaitu melihat perbedaan variabel pada
cluster yang terbentuk. Dalam hal ini dapat dilihat dari nilai F dan nilai probabilitas (sig) masing-masing variabel, seperti tampak dalam tabel berikut:
ANOVA
Cluster Error
F Sig.
Mean Square df Mean Square df
Zscore(inf_bulanan) 7.790 2 .828 79 9.406 .000
Zscore(inf_kalender) 21.511 2 .481 79 44.748 .000
[image:5.595.69.482.509.619.2]Zscore(inf_tahunan) 25.172 2 .388 79 64.866 .000
Tabel 4.4 ANOVA
Zscore(inf_kalender) dan F=64.866 untuk Zscore(inf_tahunan) dengan sig = 0,000 sedangkan
0.05
, k 1,n k F ,2,79 3.11226
F sehiingga F.Hipotesis:
H0: variabel inflasi bulanan bukan variabel pembeda dalam peng-cluster-an.
H1: variabel inflasi bulanan merupakan variabel pembeda dalam peng-cluster-an
Karena F (Zscore(inf_bulanan)) >F0.05,2,79 3.11226 maka tolak H
0, berarti variabel inflasi
bulanan merupakan variabel pembeda dalam peng-cluster-an.