MODEL ONTOLOGI PADA BIODIVERSITY
1Amelia Afrianti (50407085) 2
Prof. Dr. I Wayan Simri Wicaksana, SSi., MEng
1
Mahasiswa Teknik Informatika, Fakultas Teknologi Industri, Universitas Gunadarma, afriant_amel@yahoo.com
2
Dosen Tetap Universitas Gunadarma, iwayan@yahoo.com
ABSTRAKSI
Semakin berkembangnya dunia internet dan teknologi informasi membuat setiap kegiatan di dunia ini membutuhkan informasi sebagai referensi. Informasi yang didapatkan bisa berupa tingkat biodiversitas atau keanekaragaman hayati yang tinggi di kepulauan Indonesia. Keanekaragaman ini dapat menyebabkan jenis spesies dengan karakteristik yang beraneka ragam.
Melalui penulisan ini akan dibuat sebuah model ontology sebagai salah satu cara untuk menyelesaikan masalah keanekaragaman informasi mengenai perubahan taksonomi. Model ontology ini dapat menyajikan data sebagai informasi mengenai deskripsi data dan relasi antar takson sesuai dengan tingkatan taksonomi berdasarkan data yang didapatkan dari LIPI. Selain itu, untuk mengetahui tingkat kesamaan antara data taksonomi sebelum berubah dengan data taksonomi sesudah berubah dengan menggunakan algoritma similarity.
Kata Kunci : Ontology, Biodiversity, Taksonomi, Algoritma Similarity
ABSTRACT
The growing world of internet and information technology makes every activity in the world requires information as a reference. The information obtained can be a level of biodiversity or high biodiversity in the Indonesian archipelago. This diversity can lead to species with diverse characteristics.
Through this thesis will be made an ontology model as one way to solve the problem of information regarding changes in taxonomic diversity. This ontology model can present data as information concerning the description of the data and the relation between taxon according to the taxonomic level based on data obtained from LIPI. In addition, to determine the degree of similarity between taxonomic data before changing with taxonomic data after changing using similarity algorithms.
Keywords : Ontology, Biodiversity, taxonomy, Similarity Algorithm
1. PENDAHULUAN
Semakin berkembangnya dunia Internet dan teknologi informasi membuat setiap kegiatan di dunia ini membutuhkan informasi sebagai referensi. Hal ini menyebabkan sumber informasi dapat diakses tanpa ada batasan waktu dan geografi. Informasi yang dicari bukan hanya sebatas
teknologi yang sedang berkembang saat ini tapi juga dapat berupa informasi mengenai keanekaragaman makhluk hidup.
Kepulauan Indonesia memiliki tingkat biodiversitas atau kenakeragaman hayati yang tinggi. Oleh karena itu memiliki jenis spesies dengan karakteristik yang beraneka ragam. Jika suatu spesies dengan ciri-ciri yang sama terdapat di daerah lain dan ternyata kedua spesies tersebut memiliki keterkaitan maka informasi tersebut akan dilihat melalui pemetaan apakah spesies tersebut berada dalam hirarki yang sama.
Dalam hal informasi, tidak menjamin bahwa informasi dari sumber yang satu dengan sumber yang lain sama. Khususnya dalam hal taksonomi yang mengalami perubahan pada salah satu atau beberapa tingkatan. Hal-hal yang menyebabkan perubahan dalam taksonomi adalah penggabungan antara dua grup dalam satu takson yang sama. Selain itu, dengan ditemukannya spesies baru dan dengan adanya perubahan dalam salah satu tingkatan takson juga dapat menyebabkan perubahan dalam taksonomi. Sehingga informasi yang didapatkan sehubungan dengan perubahan taksonomi dapat beraneka ragam.
Tujuan penulisan skripsi ini adalah membentuk model ontology yang dapat menyajikan data sebagai informasi mengenai deskripsi data dan relasi antar takson sesuai dengan tingkatan taksonomi berdasarkan data yang didapatkan dari LIPI. Selain itu, untuk mengetahui tingkat kesamaan antara data taksonomi sebelum berubah dengan data taksonmomi sesudah berubah dengan menggunakan algoritma similarity.
2. LANDASAN TEORI
Pengertian Ontology Secara Umum
Pengertian ontology sangat beragam dan berubah sesuai dengan berjalannya waktu, ada beberapa definisi ontology. Neches dan rekannya memberikan definisi awal tentang ontology yaitu: "Sebuah ontology merupakan definisi dari pengertian dasar dan relasi vokabulari dari sebuah area sebagaimana aturan dari kombinasi istilah dan relasi untuk mendefinisikan vokabulari".
Secara umum, ontology digunakan pada Artificial Intelligence (AI) dan persentasi pengetahuan. Segala bidang ilmu yang ada di dunia, dapat menggunakan metode ontology untuk dapat berhubungan dan saling berkomunikasi dalam hal pertukaran informasi antara sistem-sistem yang berbeda.
Pengertian Ontology Mapping
Mapping atau matching adalah operasi penting dalam domain aplikasi, seperti semantik web, skema/ontologi terintegrasi, data warehouses, e-commerce, query mediation, dan lain-lain. Ontology mapping atau pemetaan ontologi merupakan salah satu dari ontologi penelitian. Ontology mapping juga merupakan upaya untuk meningkatkan pemetaan semantik yaitu digunakan untuk menemukan korespondensi semantik antara elemen yang sama dari ontologi yang berbeda.
Metode pada Ontology Mapping
Ontology mapping atau pemetaan ontologi merupakan sebuah metode untuk memetakan komponen (kelas atau atribut) dari ontologi untuk komponen ontology lainnya. Kalfoglou dan
Schorlemme mengembangkan metode otomatis untuk pemetaan ontologi, yaitu IF-Map, berdasarkan teori information flow Barwise- Seligman. Metode mereka mengacu pada dasar pembuktian teoritis dari teori channel Barwise dan Seligman dan menyediakan cara sistematis dan mekanis untuk menyebarkan pada sebuah lingkungan terdistribusi untuk melakukan pemetaan ontologi antara berbagai ontologi yang berbeda.
Tools berdasarkan ontology mapping adalah MAFRA - MApping FRAmework mendefinisikan struktur pemetaan spesifik dan fungsi transformasi untuk mentransfer dari satu ontologi ke ontologi yang lain. Arsitektur MAFRA didasarkan pada infrastruktur KAON. OntoMapper adalah pemetaan antara dua ontology berdasarkan kombinasi dari IR (information retrieval) berdasarkan klasifikasi teks dan inferensi Bayesian. Pendekatan SKAT - A Semantic Knowledge Articulation Tool berfokus pada identifikasi artikulasi yang lebih dari dua ontologi, yaitu istilah dimana hubungan terjadi di antara sumber-sumber. SKAT didasarkan pada simple lexical dan structural matching untuk interaksi dua sumber web.
Approach pada Skema Mapping
Skema mapping merupakan metode untuk mengembangkan relasi atau pemetaan dari skema sumber ke skema target. Contoh tools atau approach dari skema mapping adalah sebagai berikut: COMA (COmbining MAtch algorithm) didasarkan pada penggabungan algoritma dengan cara yang fleksibel. CUPID merupakan algoritma yang mengacu hanya berdasarkan skema. S-Match mengusulkan metode SAT sebagai approach untuk semantik level. Berikut ini tabel approach pada skema mapping.
Tabel 1. Approach pada Skema Mapping
Approach Element Syntatic Element- External Structure- Syntactic Structure- Semantic Lainnya
CUPID string based, language based, data types, key properties auxiliary thesauri, synonyms, hypernyms, abbreviations tree matching weighted by leaves hybrid, heuristic
COMA string based, language based, data type auxiliary thesauri, synonyms, hypernyms, abbreviations, alignment reuse DAG matching with a bias towards of leaf or children structures, paths hybrid, heuristic
S-Match string based, language based WordNet: sense based, gloss based propositional SAT hybrid, heuristic and formal
3. PEMBAHASAN
Pengertian dan Manfaat Biodiversity
Keanekaragaman hayati (biodiversitas) adalah keanekaragaman organisme yang menunjukkan keseluruhan atau totalitas variasi gen, jenis, dan ekosistem pada suatu daerah. Keseluruhan gen, jenis dan ekosistem merupakan dasar kehidupan di bumi. Mengingat pentingnya keanekaragaman hayati bagi kehidupan maka keanekaragaman hayati perlu dipelajari dan dilestarikan. Tingginya tingkat keanekaragaman hayati di permukaan bumi mendorong ilmuwan mencari cara terbaik untuk mempelajarinya, yaitu dengan klasfikasi.
Orang semakin menyadari bahwa manfaat keanekaragaman hayati bagi peningkatan kesejahteraan manusia sangat besar. Biodiversity atau keanekaragaman hayati ini memiliki beberapa manfaat bagi manusia, diantaranya adalah nilai biologi, nilai pendidikan, nilai estetika dan budaya, nilai ekologi, serta nilai religius.
Pengertian dan Manfaat Taksonomi
Kegiatan klasifikasi tidak lain adalah pembentukan kelompok-kelompok makhluk hidup dengan cara mencari keseragaman ciri atau sifat di dalam keanekaragaman ciri yang ada pada makhluk hidup tersebut. Makhluk hidup sangat banyak jumlahnya dan sangat beranekaragam ciri dan sifatnya. Untuk mempelajarinya perlu dicari cara yang paling baik, yaitu dengan melakukan pengelompokan atau klasifikasi makhluk hidup. Jadi tujuan klasifikasi makhluk hidup adalah menyederhanakan obyek kajian, sekaligus mempermudah dalam mengenali keanekaragaman makhluk hidup.
Setiap kelompok yang terbentuk dari hasil klasifikasi makhluk hidup, disebut Takson. Lahirlah istilah taksonomi (takson = kelompok, nomos = hukum), atau juga disebut sistematika (susunan dalam suatu sistem). Taksonomi yaitu ilmu tentang kelompok organisme berdasarkan perbedaan kategori menurut karakter fisiknya. Pengelompokan atau karakterisasi akan dikelompokan didasarkan kesamaannya yang biasanya diwariskan kepada keturunannya dari nenek moyangnya. Dalam biologi, taksonomi merupakan cabang ilmu tersendiri yang mempelajari penggolongan atau sistematika makhluk hidup. Berikut adalah tingkatan dalam taksonomi :
Kerajaan (Kingdom) Tumbuhan/Hewan (Divisio/Phyllum) Kelas (Classis) Bangsa (Ordo) Suku (Familia) Marga (Genus) Jenis (Spesies)
Langkah Pembuatan Ontology
Dalam pembuatan ontology secara teori memiliki beberapa langkah, yaitu menentukan domain, membuat klasi kasi, membuat taksonomi, mengisi property, melihat glossary, dan melihat semantik.
Menentukan domain Membuat klasifikasi Membuat taksonomi Mengisi property Melihat glossary Melihat Semantik Algoritma Similarity
Algoritma similarity digunakan untuk mencari kesamaan antara data saat taksonominya belum berubah dengan data yang taksonominya telah berubah. Dalam hal ini algoritma yang digunakan memiliki cara kerja dengan mencocokan antara satu kelas dengan kelas yang lainnya atau yang disebut juga dengan text similarity. Jika hasilnya menujukkan kesamaan maka diberi nilai 1 dan jika hasilnya berbeda maka diberi nilai 0. Dengan menghitung total dari nilai kesamaan yang dibagi dengan jumlah data yang ada maka didapatkan nilai similarity-nya. Input yang diberikan untuk algoritma ini adalah set of superclass yang merupakan hasil dari eksekusi perintah Sparql.
Input
1: Sparql ! Set of superclass 2: Text Similarity
3: Treshold/Limit Value
Steps
1: for i = 1 to 10 do 2: for j = 1 to 10 do 3: if sup 1 [i] = sup 2 [j] 4: m = m+1
5: if sup 1 [i] ! = sup 2 [i] 6: k [i] = get table name 7: end if
8: end if 9: end for 10: end for
11: calculate : set sim = m/10
Output :
1: Sim = m/10 2: k [i] = table name
Penjelasan dari algoritma similarity di atas adalah diberikan tiga input yang terdiri dari set of superclass yang didapatkan dari hasil eksekusi Sparql, kemudian input yang kedua adalah Text Similarity. Selanjutnya, untuk input yang ketiga adalah Treshold atau Limit Value yang
merupakan batasan untuk similarity yang didapatkan. Kemudian untuk langkah-langkahnya yang pertama adalah digunakan dua perulangan menggunakan variabel i dan j. for i = 1 to 10 do digunakan untuk mengambil data sebelum perubahan taksonomi dari data pertama sampai data kesepuluh. Pada setiap pengambilan data dilanjutkan dengan perulangan kedua, yaitu for j = 1 to 10 do untuk mengambil data setelah perubahan taksonomi dari data pertama sampai data kesepuluh. Kemudian terdapat kondisi if sup 1 [i] = sup 2 [j] yang digunakan untuk menentukan kesamaan antara data pada perulangan satu yang dimasukkan pada variabel sup 1 ke i dengan data pada perulangan kedua pada variabel sup 2 ke j. Variabel sup 1 menjelaskan set of superclass dari data saat taksonomi sebelum berubah dan variabel sup 2 menjelaskan set of superclass dari data taksonomi setelah berubah.
Selanjutnya untuk m = m+1 merupakan perhitungan yang digunakan untuk mencari total nilai variabel sup 1 yang sama dengan variabel sup 2. Nilai dari variabel m dapat digunakan sebagai nilai untuk mencari teks similarity antara data taksonomi sebelum berubah dengan data taksonomi setelah berubah. Kemudian if sup 1 [i]!= sup 2 [i] merupakan suatu kondisi yang digunakan untuk mencari nilai variabel sup 1 yang tidak sama dengan variabel sup 2. Jika ditemukan nilai variabel sup 1 yang tidak sama dengan variabel sup 2 maka diambil tabel name yang dimasukkan pada variabel k. Hal ini ditunjukkan pada sintaks berikut k [i] = get table name. Kemudian setelah seluruh proses perulangan selesai, dilakukan penghitungan untuk mencari similarity antara data taksonomi sebelum berubah dengan data taksonomi setelah berubah dengan sintaks sebagai berikut calculate : set sim= m/10. Calculate digunakan untuk menunjukkan proses penghitungan pada variabel sim. Variabel ini digunakan untuk menyimpan hasil pembagian antara total teks similarity dibagi dengan banyaknya data yaitu sepuluh level class. Hasil dari algoritma similarity ini terdapat output, yaitu nilai similarity pada variabel sim dan table name pada variabel k. Nilai variabel sim harus sesuai dengan batasan nilai atau treshold yang diberikan yaitu antara 0 sampai 1. Semakin besar nilai similarity pada variabel sim maka semakin besar kesamaan data antara taksonomi sebelum berubah dengan taksonomi sesudah berubah. Sedangkan nilai dari variabel k merupakan kumpulan dari data taksonomi yang berbeda, untuk melihat letak perbedaan data pada tingkatan taksonominya.
4. HASIL DAN ANALISIS
Data Taksonomi
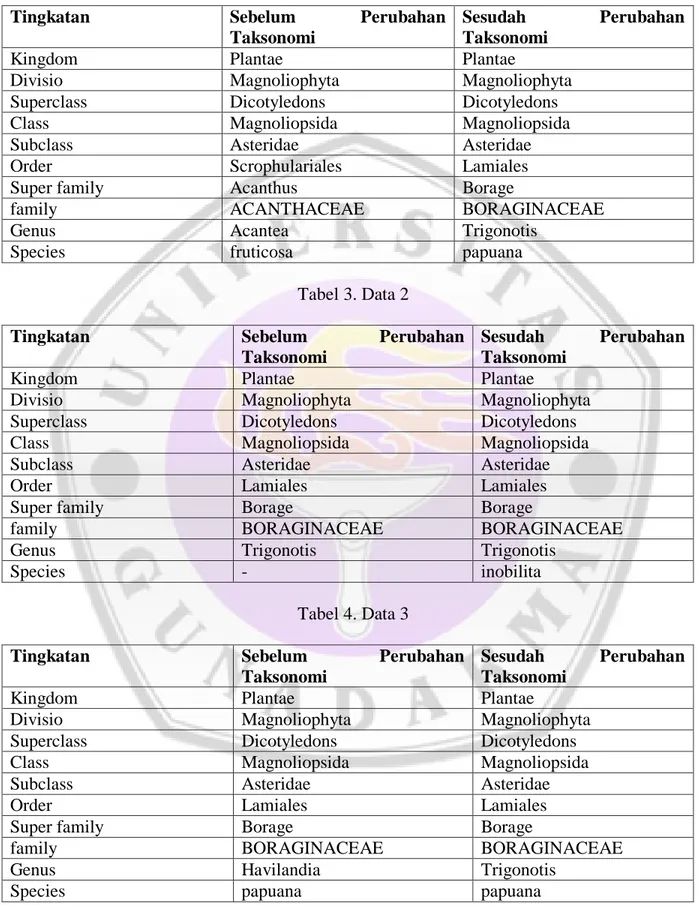
Data taksonomi yang dipergunakan meliputi sepuluh level class yang terdiri dari kingdom, divisio, superclass, class, subclass, order, superfamily, family, genus, dan species. Data ini diambil dari Lembaga Ilmu Pengetahuan Indonesia (LIPI) dan merupakan taksonomi dalam dunia tumbuhan atau disebut dengan plantae. Kesepeluh level class ini terbagi menjadi empat instances, dimana berdasarkan hasil penelusuran terhadap individual pada data ditemukan 4 instances yang mengalami perubahan pada salah satu atau lebih pada level class-nya yang dapat dilihat pada tabel 4.1 - 4.4. Empat instances tersebut adalah empat jenis data yang dikelompokkan berdasarkan spesies yang memiliki tingkat taksonomi yang berbeda-beda.
Tabel 2. Data 1
Tingkatan Sebelum Perubahan
Taksonomi
Sesudah Perubahan Taksonomi
Kingdom Plantae Plantae
Divisio Magnoliophyta Magnoliophyta
Superclass Dicotyledons Dicotyledons
Class Magnoliopsida Magnoliopsida
Subclass Asteridae Asteridae
Order Scrophulariales Lamiales
Super family Acanthus Borage
family ACANTHACEAE BORAGINACEAE
Genus Acantea Trigonotis
Species fruticosa papuana
Tabel 3. Data 2
Tingkatan Sebelum Perubahan
Taksonomi
Sesudah Perubahan Taksonomi
Kingdom Plantae Plantae
Divisio Magnoliophyta Magnoliophyta
Superclass Dicotyledons Dicotyledons
Class Magnoliopsida Magnoliopsida
Subclass Asteridae Asteridae
Order Lamiales Lamiales
Super family Borage Borage
family BORAGINACEAE BORAGINACEAE
Genus Trigonotis Trigonotis
Species - inobilita
Tabel 4. Data 3
Tingkatan Sebelum Perubahan
Taksonomi
Sesudah Perubahan Taksonomi
Kingdom Plantae Plantae
Divisio Magnoliophyta Magnoliophyta
Superclass Dicotyledons Dicotyledons
Class Magnoliopsida Magnoliopsida
Subclass Asteridae Asteridae
Order Lamiales Lamiales
Super family Borage Borage
family BORAGINACEAE BORAGINACEAE
Genus Havilandia Trigonotis
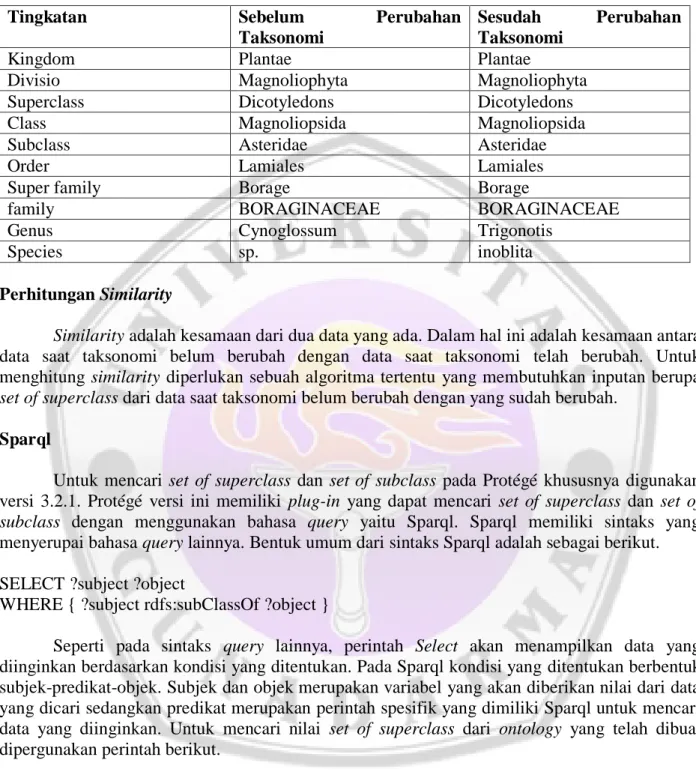
Tabel 5. Data 4
Tingkatan Sebelum Perubahan
Taksonomi
Sesudah Perubahan Taksonomi
Kingdom Plantae Plantae
Divisio Magnoliophyta Magnoliophyta
Superclass Dicotyledons Dicotyledons
Class Magnoliopsida Magnoliopsida
Subclass Asteridae Asteridae
Order Lamiales Lamiales
Super family Borage Borage
family BORAGINACEAE BORAGINACEAE
Genus Cynoglossum Trigonotis
Species sp. inoblita
Perhitungan Similarity
Similarity adalah kesamaan dari dua data yang ada. Dalam hal ini adalah kesamaan antara data saat taksonomi belum berubah dengan data saat taksonomi telah berubah. Untuk menghitung similarity diperlukan sebuah algoritma tertentu yang membutuhkan inputan berupa set of superclass dari data saat taksonomi belum berubah dengan yang sudah berubah.
Sparql
Untuk mencari set of superclass dan set of subclass pada Protégé khususnya digunakan versi 3.2.1. Protégé versi ini memiliki plug-in yang dapat mencari set of superclass dan set of subclass dengan menggunakan bahasa query yaitu Sparql. Sparql memiliki sintaks yang menyerupai bahasa query lainnya. Bentuk umum dari sintaks Sparql adalah sebagai berikut.
SELECT ?subject ?object
WHERE { ?subject rdfs:subClassOf ?object }
Seperti pada sintaks query lainnya, perintah Select akan menampilkan data yang diinginkan berdasarkan kondisi yang ditentukan. Pada Sparql kondisi yang ditentukan berbentuk subjek-predikat-objek. Subjek dan objek merupakan variabel yang akan diberikan nilai dari data yang dicari sedangkan predikat merupakan perintah spesifik yang dimiliki Sparql untuk mencari data yang diinginkan. Untuk mencari nilai set of superclass dari ontology yang telah dibuat dipergunakan perintah berikut.
SELECT * WHERE {
?species rdfs:subClassOf (:nama_class_genus) . ?species rdfs:subClassOf ?genus .
?genus rdfs:subClassOf ?family . ?family rdfs:subClassOf ?superfamily. ?superfamily rdfs:subClassOf ?ordo .
?ordo rdfs:subClassOf ?subclass . ?subclass rdfs:subClassOf ?class . ?class rdfs:subClassOf ?superclass . ?superclass rdfs:subClassOf ?divisio . ?filum rdfs:subClassOf ?kingdom }
Pada sintaks di atas terdapat tiga jenis variabel, yaitu tabel Name, predikat dan variable class. Tabel name ditandai dengan lambang tanda tanya (?) di depan nama variabel. Predikat yang dipergunakan adalah rdfs:subClassOf, yang digunakan untuk mencari nilai subclass dari sebuah class sedangkan variabel class yang digunakan sebagai acuan dalam pencarian data diawali dengan lambang titik dua (:) di depan nama variabel nya. Jika variabel pada kondisi pertama diganti dengan nama class :Acanthea maka akan didapatkan set of superclass seperti gambar berikut.
Gambar 1. Hasil Eksekusi Sparql
Hasil Perhitungan Tabel
Dalam melakukan perhitungan kesamaan data yang ada pada tabel, setiap data takson yang sama sebelum perubahan taksonomi dengan sesudah perubahan taksonomi diberi nilai 1. Sedangkan untuk data takson yang tidak sama sebelum perubahan taksonomi dengan sesudah perubahan taksonomi diberi nilai 0. Data takson yang sama akan dimasukkan ke dalam variabel S dan untuk data takson yang berbeda dimasukkan ke dalam variabel B. Perhitungan dilakukan dengan menggunakan total nilai dari setiap data takson yang sama sebelum dan sesudah perubahan taksonomi. Dengan total nilai tersebut dibagi dengan banyaknya data maka didapatkan nilai similarity antara kedua data yang dimasukkan ke dalam variabel Sim.
Data tabel 1
S={(Plantae,Plantae), (Magnoliophyta, Magnoliophyta), (Dicotyledons, Dicotyledons), (Magnoliopsida, Magnoliopsida), (Asteridae, Asteridae)}
B = {(Scrophulariales, Lamiales), (Achantus, Borage), (Acanthaceae, Boraginaceae), (Acantea, Trigonotis), (Fruticosa, Papuana)}
Sim = Total Anggota Himpunan S Banyaknya Data
Sim = 5/10 Sim = 0.5
Data tabel 2
S={(Plantae,Plantae), (Magnoliophyta, Magnoliophyta), (Dicotyledons, Dicotyledons), (Magnoliopsida, Magnoliopsida), (Asteridae, Asteridae), (Lamiales, Lamiales), (Borage, Borage), (Boraginaceae, Boraginaceae), (Trigonotis, trigonotis)}
B = {(-, Inobilita)}
Sim = Total Anggota Himpunan S Banyaknya Data
Sim = 9/10 Sim = 0.9
Data tabel 3
S={(Plantae,Plantae), (Magnoliophyta, Magnoliophyta), (Dicotyledons, Dicotyledons), (Magnoliopsida, Magnoliopsida), (Asteridae, Asteridae), (Lamiales, Lamiales), (Borage, Borage), (Boraginaceae, Boraginaceae), (Papuana, Papuana)}
B = {(Havilandia, Trigonotis)}
Sim = Total Anggota Himpunan S Banyaknya Data
Sim = 9/10 Sim = 0.9
Data tabel 4
S={(Plantae,Plantae), (Magnoliophyta, Magnoliophyta), (Dicotyledons, Dicotyledons), (Magnoliopsida, Magnoliopsida), (Asteridae, Asteridae), (Lamiales, Lamiales), (Borage, Borage), (Boraginaceae, Boraginaceae)}
B = {(Cynoglossum, Trigonotis), (sp., inobilita)}
Sim = Total Anggota Himpunan S Banyaknya Data
Sim = 8/10 Sim = 0.8 5. PENUTUP
Kesimpulan
Penulisan ini berisi pembuatan model ontology pada keanekaragaman hayati atau biodiversity yang dibuat pada Protégé versi 3 (tiga) dan 4 (empat) dengan menggunakan data yang didapatkan dari Lembaga Ilmu Pengentahuan Indonesia (LIPI). Dari model ontology yang dibuat, dihasilkan struktur hirarki taksonomi sesuai dengan tingkatan taksonominya. Selain itu, dihasilkan juga property yang berupa deskripsi data dan relasi yang terjadi antar takson dalam taksonomi. Dalam penyajian data taksonomi ini dibutuhkan atribut class, individual, object property, dan data property yang dihubungkan dalam property assertions pada Protégé.
Kemudian terdapat suatu algoritma yang digunakan untuk mencari kesamaan antar data sebelum perubahan taksonomi dengan data sesudah perubahan taksonomi yang disebut dengan algoritma similarity. Algoritma similarity ini menggunakan hasil eksekusi dari Sparql yang berupa set of superclass sebagai input-an dari tabel data. Algoritma ini akan menghasilkan nilai kesamaan data dari data sebelum perubahan taksonomi dan sesudah perubahan taksonomi, dimana semakin besar nilai tersebut maka semakin besar juga tingkat kesamaan antar takson dan begitu juga sebaliknya. Selain itu, dengan algoritma ini dapat diketahui letak perbedaan takson pada masing-masing tingkatan taksonomi yang dikumpulkan pada sebuah himpunan.
Saran
Pembuatan model ontology ini masih sangat sederhana karena adanya keterbatasan data. Selain itu, data yang digunakan hanya berasal dari satu sumber saja yaitu didapatkan dari LIPI. Kemudian data yang didapatkan ini pun tidak sepenuhnya lengkap, penulis hanya dapat membaca beberapa data saja terlebih lagi hanya orang dalam bidang biologi yang dapat mengerti cara membaca data ini. Untuk pengembangan model ontology ini, maka sebaiknya dibuat model ontology dengan menggunakan data yang lebih lengkap dan dapat dimengerti secara umum. Selain itu, algoritma yang dibuat masih sangat sederhana dengan menghasillkan dua output, yaitu nilai similarity atau kesamaan data dan letak perbedaan takson pada tingkatan taksonomi. Oleh karena itu, penulis menyarankan kepada siapa saja yang membaca penulisan ini, agar dapat mengembangkan dan menyempurnakan model ontology dan algoritma similarity agar lebih baik lagi.
DAFTAR PUSTAKA
[1] J. Barwise dan J. Seligman, Information Flow: The Logic of Distributed Systems, ser. Cambridge Tracts in Theoretical Computer Science. Cambridge University Press, 1997, vol. 44.
[2] A. Bernaras, I. Laresgoiti, dan J. Corera, “Building and reusing ontologies for electrical network applications,” in Proceedings of the 12th European Conference on Artificial Intelligence, 1996, pp. 298-302.
[3] W. N. Borst, “Construction of engineering ontologies for knowledge sharing and reuse,” PhD thesis, University of Twente, Netherland, 5 September 1997.
[4] G. D. G. D. Calvanese dan M. Lenzerini, “Ontology of integration and integration of ontologies,” in Proceedings of the 9th International Conference on Conceptual Structures (ICCS'01), Stanford, CA, USA, August 2001.
[5] F.-B. dan Martínes-Béjar, “A cooperative framework for integrating ontologies,” Journal, International Journal of Human-Computer Studies, 2002.
[6] H. Enderton, A Mathematical Introduction to Logic, 2nd edisi. Academic Press, January 2001.
[7] F. Giunchiglia, P. Shvaiko, dan M. Yatskevich, “S-match: An algorithm and an implementation of semantic matching,” Technical Report DIT-04-015, Univeristy of Trento, Trento-Italy, February 2004, also: In Proceedings of the European Semantic Web Symposium, LNCS 3053, pp. 61-75, 2004.
[8] T. R. Gruber, ”A translation approach to portable ontology specifications,” Knowledge Acquisition, vol. 5, no. 2, pp. 199-220, 1993.
[9] N. Guarino, “Formal ontology and information systems,” in Proceedings of FOIS. Amsterdam: IOS Press, 1998, pp. 3-15.
[10] H. hai Do dan E. Rahm, “Coma - a system for flexible combination of schema matching approaches,” in VLDB, 2002.
[11] Y. Kalfoglou dan M. Schorlemmer, “Information-flow-based ontology mapping,” in On the Move to Meaningful Internet Systems 2002: CoopIS, DOA, and ODBASE., ser. Lecture Notes in Computer Science, vol. 2519. Springer, 2002, pp. 1132-1151.
[12] R. Kent, “The information flow foundation for conceptual knowledge organization,” in Proceedings of the 6th International Conference of the International Society for Knowledge Organization (ISKO), Toronto, Canada, August 2000.
[13] A. Kiryakov, K. Simov, dan M. Dimitrov, “Ontomap: Portal for upper-level ontologies,” in Proceedings of the 2nd International Conference on Formal Onto- logy in Information Systems (FOIS'01), Ogunquit, Maine, USA, October 2001.
[14] M. Lacher dan G. Groh, “Facilitating the exchange of explicit knowledge through ontology mappings,” in Proceedings of the 14th International FLAIRS conference, Key West, FL, USA, May 2001.
[15] J. Madhavan, P. Bernstein, P. Domingos, dan A. Halevy, “Representing and reasoning about mappings between domain models,” in Proceedings of the 18th National Conference on Artificial Intelligence (AAAI'02), Edmonton, Alberta, Canada, August 2002.
[16] J. Madhavan, P. A. Bernstein, dan E. Rahm, “Generic schema matching with cupid,” in Proceedings of the 27th International Conference on Very Large Data Bases, 2001, pp. 49-58.
[17] A. Maedche dan S. Staab, “Semi-automatic engineering of ontologies from texts,” in Proceedings of the 12th International Conference on Software Engineering and Knowledge Engineering (SEKE 2000), Chicago, IL, USA, July 2000, pp. 231-239.
[18] K. T. S. Michael C. Daconta, Leo J. Obrst, The Semantic Web: A guide to the future of XML, Web Services and Knowledge Management. Indianapolis, Indiana: Wiley Publishing, 2003.
[19] P. Mitra, G. Wiederhold, dan J. Jannink, “Semi-automatic integration of knowledge sources,” in Proc. of the 2nd Int. Conf. On Information FUSION'99, 1999.
[20] R. Neches, R. Fikes, T. Finin, T. Gruber, R. Patil, T. Senator, dan W. Swartout, “Enabling technology for knowledge sharing,” AI Magazine, 1991.
[21] N. F. Noy, “Semantic integration: a survey of ontology-based approaches,” in Proc. of Workshop on Semantic Integration at SWC-2003, Sanibel Island, FL, 2003.
[22] S. Prasad, Y. Peng, dan T. Finin, “Using explicit information to map between two ontologies,” in Proceedings of the AAMAS 2002 Wokshop on Ontologies in Agent Systems (OAS'02), Bologna, Italy, July 2002.
[23] N. Silva dan J. Rocha, Ontology Mapping for Interoperability in Semantic Web, 2003. [24] R. Studer, V. R. Benjamins, dan D. Fensel, “Knowledge engineering: Principles and
methods,” Data and Knowledge Engineering, vol. 25, pp. 161-197, 1998.
[25] I. W. S. Wicaksana, “Survei dan evaluasi metode pengembangan ontologi (survey and evaluation of methodology of ontology development),” in Proc. Of KOMMIT 2004, Jakarta&Depok, Agustus 2004, university Gunadarma.