Akmal Nasution
Sekolah Tinggi Manajemen Informatika dan Kompter (STMIK ROYAL) Kisaran Jalan Prof. H.M. Yamin No. 173 Kisaran Kab. Asahan
Pos-el : [email protected]
Abstract
Kecepatan dan ketepatan informasi merupakan salah satu faktor penentu keberhasilan perusahaan dalam memenuhi kebutuhan pelanggan. Pengolahan data dengan ilmu komputer sangat membantu segala kegiatan pada perusahaan/organisasi lebih efektif dan efisien. Data mining menjadi salah satu ilmu dari bidang komputer yang sangat berpengaruh dalam pengolahan data, dimana dengan menggunakan salah satu teknik data mining dalam pengolahan data, dapat diperoleh informasi-informasi penting untuk kemajuan perusahaan. Tidak terkecuali untuk pengolahan data pada asuransi jiwa. Tujuan utama dari penelitian ini adalah untuk pengolahan data asuransi jiwa berdasarkan tingkat kesadaran masyarakat pada PT. Jasaraharja Putera. Dari data tahun 2009 dan 2010 yang tersedia dapat diperoleh informasi bahwa terjadi peningkatan paket yang diambil dari paket Standard ke paket Exclusive. Hal ini menunjukkan kesadaran masyarakat dalam berasuransi sudah cukup tinggi. Dalam penelitian ini metode clustering dilakukan secara hirarki menggunakan metode pautan tunggal atau single linkage. Proses komputasi yang digunakan untuk mengolah data adalah aplikasi TANAGRA. Data di ambil dari PT Asuransi Jasaraharja Putera Padang Sumatera Barat yaitu data tentang Produk ASPRI.
1.
Pendahuluan
Pada masa sekarang ini perkembangan teknologi dan komunikasi dari waktu ke waktu dirasakan meningkat pesat, terlebih lagi perkembangan di bidang teknologi komputer yang mendorong penggunaan dan pemanfaatan perkembangan teknologi tersebut secara luas di berbagai bidang dan aspek kehidupan, sehingga memudahkan masyarakat pada umumnya dan individu pada khususnya dalam menunjang kegiatan mereka sehari-hari.
Salah satu contoh dari pemanfaatan dan
dengan konsep data mining, yang mana teknologi seperti ini diharapkan dapat mempermudah user untuk memahami kebiasaan masyarakat dalam berasuransi jiwa, sehingga akan diperoleh kesimpulan dan informasi yang berguna untuk kedepannya.
Berdasarkan uraian singkat diatas peninjauan sementara pada perusahaan yang bergerak dibidang bisnis ini pun tidak mau ketinggalan untuk memanfaatkan teknologi dalam penyelesaian pekerjaannya, termasuk untuk menganalisa pola dan kebiasaan masyarakat dalam berasuransi. Dengan memanfaatkan data pada tahun-tahun sebelumnya, dapat diperoleh informasi penting mengenai kebiasaan dan pola pikir masyarakat dalam berasuransi. Oleh karena itu dilakukanlah penelitian yang berjudul Analisa Tingkat Kesadaran Masyarakat Pengguna Asuransi Jiwa dengan Metode Clustering.
2.
Landasan Teori
2.1 Data Mining
Data Mining merupakan salah satu proses eksplorasi dan analisis data yang memiliki banyak metode yang sesuai dengan kegunannya. Clustering
dan AssosiationRules merupakan dua diantara metode tersebut. Proses Data Mining mencakup proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik, metode atau algoritma tertentu yang bervariasi. Secara sederhana data mining bisa dikatakan sebagai proses menyaring pengetahuan dari sejumlah data yang besar.
2.2 Metode dan Sifat Data Mining
Beberapa alat dan metode yang digunakan seperti:
1. Sampling : menyeleksi subset representatif dari populasi data yang besar.
2.
Transformation : memanipulasi data mentah untuk menghasilkan input tunggal.5. Feature Extraction : membuka spesifikasi data yang signifikan dalam konteks tertentu.
2.3 Clustering
Clustering juga dikenal sebagai unsupervised learning yang membagi data menjadi kelompok – kelompok atau cluster berdasarkan kemiripan atribut di antara data tersebut. Karakteristik dari tiap cluster tidak ditentukan sebelumnya melainkan tercermin dari kemiripan data yang terkelompok didalamnya. Selain digunakan sebagai metode yang independen dalam data mining, clustering juga digunakan dalam pra-premrosesan data sebelum data diolah dengan metode data mining lain untuk meningkatkan pemahaman terhadap domain data.
2.4 Hierarchical Clustering
Kategori algoritma clustering yang banyak dikenal adalah Hierarchical Clustering. Hierarchical Clustering adalah salah satu algoritma clustering yang dapat digunakan untuk meng-cluster dokumen (document clustering). Dari teknik hierarchical clustering, dapat dihasilkan suatu kumpulan partisi yang berurutan, dimana dalam kumpulan tersebut terdapat :
a. Cluster – cluster yang mempunyai poin – poin individu. Cluster – cluster ini berada di level yang paling bawah.
b. Sebuah cluster yang didalamnya terdapat poin – poin yang dipunyai semua cluster didalamnya.
Single cluster ini berada di level yang paling atas.
2.5 Metode Single Lingkage
Input untuk algoritma singlelinkage bisa berujud jarak atau similarities antara pasangan-pasangan dari objek-objek. Kelompok-kelompok dibentuk dari entities individu dengan menggabungkan jarak paling pendek atau similarities (kemiripan) yang paling besar. Pada awalnya, kita harus menemukan jarak terpendek dalam D = {dik} dan menggabungkan
objek-objek yang bersesuaian misalnya, U dan V , untuk mendapatkan cluster (UV). Untuk langkah (3) dari algoritma di atas jarak-jarak antara (UV) dan cluster W yang lain dihitung dengan cara
d
(UV)W= min {d
UW, d
VW}
Di sini besaran-besaran dUW dan dVW berturut-turut adalah jarak terpendek antara cluster
-cluster U dan W dan juga cluster-cluster V dan W.
3.
Analisa dan Pembahasan
3.1 Analisis Data dan Cluster
Tahap analisa merupakan tahap yang penting dalam pengolahan data, untuk itu perlu adanya gambaran lengkap mengenai sistem yang dipakai dan gambaran lengkap mengenai data yang akan diolah. Perlu juga dianalisis hubungannya dengan masyarakat di kota Padang pada umumnya, untuk memperoleh hasil analisis yang sesuai dengan tujuan.
.
3.1.1 Analisa Data
Kesadaran masyarakat di kota padang dalam berasuransi khususnya asuransi jiwa, penulis telah mendapatkan data dari sebuah asuransi yang bernaung di kota padang yaitu P.T JasaRaharja Putera yang merupakan anak dari perusaahan JasaRaharja. Jasa Raharja Putera adalah perseroan yang sudah ada sejak tahun 1997 dan memiliki cabang di berbagai kota. JasaRaharja Putera memiliki berbagai macam produk dan yang digunakan dalam penelitian ini khusus pada produk yang berhubungan dengan jiwa yaitu produk ASPRI.
Dari data yang ada, terdapat data nasabah yang berupa tanggal mereka berasuransi, pemilihan paket asuransi serta jangka waktunya. Dengan data yang ada tersebut bisa di olah dengan menggunakan metode data mining untuk mencari kesimpulan, pola tersembunyi serta pengetahuan yang nanti nya sangat berguna.
3.1.2 Analisis Cluster
Tujuan dari Analisis Cluster adalah mengelompokkan obyek berdasarkan kesamaan karakteristik di antara obyek-obyek tersebut. Langkah pengelompokan dalam analisis cluster mencakup 3 hal berikut :
1. Mengukur kesamaan jarak 2. Membentuk cluster secara hirarkis 3. Menentukan jumlah cluster.
Konsep dari metode hirarkis ini dimulai dengan menggabungkan 2 obyek yang paling mirip, kemudian gabungan 2 obyek tersebut akan bergabung lagi dengan satu atau lebih obyek yang paling mirip lainnya. Proses
menjadi satu cluster besar yang mencakup semua
obyek. Metode ini disebut juga sebagai ”aglomerative”
yang digambarkan dengan dendogram.
Langkah-langkah dalam algoritma clustering
hirarki agglomerative untuk mengelompokkan N objek (item/variabel) :
1. Mulai dengan N cluster, setiap cluster mengandung entiti tunggal dan sebuah matriks simetrik dari jarak (similarities) D = {dik} dengan tipe NxN.
2. Cari matriks jarak untuk pasangan cluster yang terdekat (paling mirip). Misalkan jarak antara cluster U dan V yang paling mirip adalah duv.
3. Gabungkan cluster U dan V. Label cluster yang baru dibentuk dengan (UV). Update entries pada matrik jarak dengan cara :
a. Hapus baris dan kolom yang bersesuaian dengan cluster U dan V
b. Tambahkan baris dan kolom yang memberikan jarak-jarak antara cluster (UV) dan cluster-cluster yang tersisa.
4. Ulangi langkah 2 dan 3 sebanyak (N-1) kali. (Semua objek akan berada dalam cluster tunggal setelah algoritma berahir). Catat identitas dari cluster yang digabungkan dan tingkat-tingkat (jarak atau similaritas) di mana penggabungan terjadi.
3.2 Pembahasan Metode Single Linkage
Input untuk algoritma single linkage bisa berwujud jarak atau similarity antara pasangan-pasangan dari objek-objek. Kelompok-kelompok dibentuk dari entities individu dengan menggabungkan jarak paling pendek atau similarity (kemiripan) yang paling besar.
Pada awalnya, kita harus menemukan jarak terpendek dalam D = {dik} dan menggabungkan objek-objek yang bersesuaian misalnya, U dan V , untuk mendapatkan cluster (UV). Untuk langkah (3) dari algoritma di atas jarak-jarak antara (UV) dan cluster W yang lain dihitung dengan cara
d(UV)W = min {dUW, dVW }
Di sini besaran-besaran dUW dan dVW berturut-turut adalah jarak terpendek antara cluster-cluster U dan W dan juga cluster-cluster-cluster-cluster V dan W .
3.3 Struktur Data Set
Dari file yang diperoleh, terdapat beberapa record dan field, serta attribute-atribute untuk setiap fieldnya yang dipakai dalam pengolahan data ini. Ada 12 field dalam laporan penerimaan PA pada
JP-Insurance ini yang akan menjadi landasan pengolahan data, yaitu tanggal penerbitan/tanggal setor, nomor polis, nomor regis, nama tertanggung, PA HP A, PA HP B, PA HP D, ND (natural dead), premi, premi ND, periode awal asuransi, dan periode akhir asuransi.
4.
Implementasi dan Pengujian
4.1 Perkenalan Tanagra
Tanagra adalah software DATA MINING untuk keperluan akademik dan riset. Di dalamnya disediakan beberapa metoda data mining mulai dari mengekplorasi analisis data, pembelajaran statistik, pembelajaran mesin, dan database.
4.2 Hasil Pengujian Data dengan Tanagra
Dalam penggunaan Tanagra, terlebih dahulu sediakan file masukannya atau datasetnya. Dalam hal ini digunakan file berformat xls (Excel) sesuai dengan data yang tersedia (gambar 1).
Gambar 1 Pilih Dataset
Informasi awal tentang dataset yang pilih akan ditampilkan. Terlihat bahwa dataset (Data Tahun 2009) terdiri dari 12 attribute dan 444 example (gambar 2).
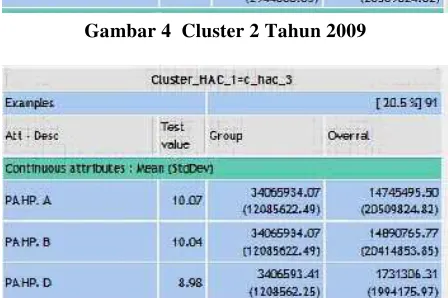
Kemudian diperoleh laporan akhirnya dalam 3 buah cluster, lihat gambar 3, gambar 4, dan gambar 5.
Gambar 3 Cluster 1 Tahun 2009
Gambar 4 Cluster 2 Tahun 2009
Gambar 5 Cluster 3 Tahun 2009
Dari laporan Data Tahun 2009 yang diperoleh, dapat disimpulkan bahwa, Cluster pertama (C_HAC_1) menyatakan paket tertinggi masyarakat dalam berasuransi di kota Padang (Paket Exclusive Platinum). Hal ini terlihat dari PA HP.B dan PA HP.A yang tinggi, mencapai 100 juta, sedangkan PA HP.D 10 juta. Sesuai dengan pembahasan sebelumnya, bahwa paket exclusive Platinum adalah 100 juta HP.A, 100 juta
HP.B, 10 juta HP.D. Semua paket dalam cluster ini, 53% nya diterbitkan pada akhir bulan.
Cluster kedua (C_HAC_2) menyatakan paket terendah masyarakat dalam berasuransi di kota Padang (Paket Standard). Hal ini terlihat dari rata-rata PA HP.D yang hanya 900 ribu-an dan rata-rata PA HP.B, PA HP.A hanya sekitar 6 juta. Sesuai dengan pembahasan sebelumnya, bahwa Paket Standard tertinggi adalah 10 juta HP.A, 10 juta HP.B, 1 juta HP.D sedangkan paket Standard terkecil adalah 2,5 juta HP.A, 2,5 juta HP.B, dan 0,25 juta HP.D. Sementara itu semua paket dalam cluster ini, 33,7% nya diterbitkan pada awal bulan.
Cluster ketiga (C_HAC_3) menyatakan paket menengah masyarakat dalam berasuransi dikota Padang (Paket Exclusive Gold dan Silver). Hal ini terlihat dari rata-rata PA HP.A dan PA HP.B yang mencapai 34 juta-an dan PA HP.D mencapai 3,5 juta. Sesuai dengan pembahasan sebelumnya, bahwa Paket Exclusive Gold, maksimumnya adalah 50 juta HP.A, 50 juta HP.B, 5 juta HP.D sedangkan paket Exclusive Silver, maksimumnya adalah 25 juta HP.A, 25 juta HP.B, dan 2,5 juta HP.D. Sementara itu semua paket dalam cluster ini, 16,5% nya diterbitkan pada pertengahan bulan. Hal yang sama juga dilakukan untuk data tahun 2010.
5.
Penutup
Setelah semua data (laporan 2009 dan 2010) diproses, diperoleh poin-poin penting sebagai berikut : 1. Proses cluster secara hirarki dengan menggunakan
metode single linkage mampu menunjukkan tingkatan paket asuransi yang di ambil oleh masyarakat kota Padang.
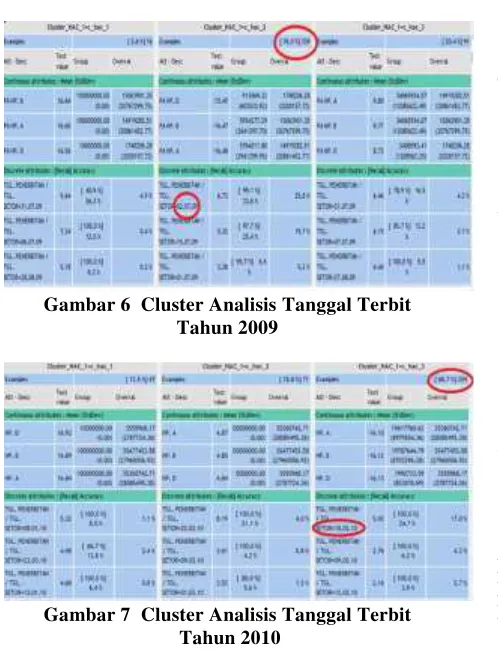
2. Dari hasil cluster analisis data tahun 2009 dapat disimpulkan nasabah lebih cenderung berasuransi di awal bulan daripada di akhir atau di tengah bulan. Hal tersebut menggambarkan tingkat kesadaran masyarakat cukup tinggi dalam berasuransi dengan menjadikan asuransi sebagai kebutuhan pokok, lihat gambar 6.
Gambar 6 Cluster Analisis Tanggal Terbit Tahun 2009
Gambar 7 Cluster Analisis Tanggal Terbit Tahun 2010
4. Dari hasil cluster analisis data tahun 2009, sekitar 76% masyarakat kota Padang yang berasuransi di Jasaraharja Putera mengambil paket Standard seperti terlihat pada gambar 8.
Gambar 8 Cluster Analisis Paket Asuransi Tahun 2009
5. Dari hasil cluster analisis data tahun 2010, sekitar 68,7% masyarakat kota Padang yang berasuransi di Jasaraharja Putera mengambil paket Exclusive
Silver ke bawah (Standard Melati, Standard Mawar, Standard Cempaka).
6. Dari data tahun 2009 dan 2010 nasabah lebih cenderung mengambil paket Standard dengan Premi yang relative lebih murah. Hal ini menggambarkan tingkat ekonomi menengah kebawah lebih banyak bersuransi dan menjadikan asuransi sebagai kebutuhan pokok.
7. Dari perbandingan data tahun 2009 dan 2010 dapat disimpulkan bahwa tingkat kesadaran masyarakat kota padang dalam berasuransi sudah cukup tinggi, hal ini terlihat dari peningkatan paket yang diambil antara tahun 2009 dan 2010. Pada 2009, kebanyakan mengambil paket standard kebawah saja, sedangkan pada 2010, telah banyak yang mengambil paket exclusive dan standard.
6.
References
[1]Han, Jiawei, Micheline Kamber, 2001, Data Mining : Concepts and Techniques. Morgan Kaufmann. [2]Johan Oscar Ong, "Implementasi Algoritma K-Means Clustering Untuk Menentukan Strategi Marketing President University," Jurnal Ilmiah Teknik Industri, vol. 12, no. 1, pp. 10-13, Juni 2013.
[3]Larose, Daniel T, Discovering Knowledge in Data: An Introduction to Data Mining.: John Willey & Sons. Inc, 2005.
[4] Rendy Handoyo, dkk, “Perbandingan Metode Clustering Menggunakan Metode Single Linkage dan K - Means pada Pengelompokan Dokumen”, Jurnal Sifo Mikroskil, Vol. 15, No.2, 2014.