Fakultas Ilmu Komputer
Universitas Brawijaya
857
Peramalan Kenaikan Indeks Harga Konsumen/Inflasi Kota Malang
menggunakan Metode Support Vector Regression (SVR) dengan Chaotic
Genetic Algorithm-Simulated Annealing (CGASA)
Muhammad Maulana Sholihin Hidayatullah1, Imam Cholissodin2, Rizal Setya Perdana3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya
Email: 1maulshh@gmail.com, 2imam.cholissodin@gmail.com, 3rizalespe@ub.ac.id
Abstrak
Peramalan inflasi adalah hal yang rumit. Tingkat inflasi yang dihitung berdasarkan kenaikan indeks harga konsumen (IHK) dipengaruhi berbagai faktor mulai dari gejolak harga berbagai jenis barang yang tidak menentu, nilai tukar rupiah, tingkat inflasi dunia, kebijakan pemerintah, gejolak suplai barang dan permintaan masyarakat. Hibridasi algoritma support vector regression (SVR) dengan chaotic sequence dan algoritma genetika telah sukses diaplikasikan untuk meningkatkan akurasi peramalan dalam berbagai bidang. Tetapi masih belum banyak diekplorasi penggunaan algoritma ini dalam bidang ekonomi pasar yaitu peramalan inflasi. Jurnal ini akan menganalisa potensial dari algoritma hibridasi
yaitu chaotic genetic algorithm-simulated annealing algorithm (CGASA) dengan model SVR untuk
meningkatkan performa akurasi peramalan. Dengan tingkat keacakan yang kacau dari chaotic sequence akan mampu menghindarkan premature local optimum dan korvengensi dini, terlebih dengan adanya algoritma simulated annealing yang meningkatkan wilayah pencarian solusi. Hasil uji peramalan pada penelitian ini menunjukkan keakuratan yang lebih baik dibandingkan penelitian sebelumnya yang telah
dikaji yaitu Metode ensembel gabungan antara algoritma autoregressive integrated moving average
(ARIMA) dan jaringan syaraf tiruan (ANN).
Kata Kunci: peramalan inflasi, indeks harga konsumen, support vector regression (SVR), chaotic genetic algorithm-simulated annealing (CGASA)
Abstract
Inflation forecasting is complicated. Inflation rate calculated based on the rise in the consumer price index (CPI) is influenced by various factors ranging from volatile prices of various types of goods, rupiah exchange rate, world inflation rate, government policy, fluctuations in the supply of goods and demand. Hybridation algorithm of support vector regression (SVR) with chaotic sequences and genetic algorithms has been successfully applied to improve the accuracy of forecasting in various fields. But it has not been explored the usability of this algorithm in the field of market economy which is forecasting inflation. This journal will analyze the potential of hybridization algorithm that which is chaotic genetic algorithm-simulated annealing algorithm (CGASA) with SVR model to improve the performance of forecasting accuracy. With the chaotic sequence of chaotic sequences, it will be able to avoid premature local optimum and early convergention, especially with the simulated annealing algorithm that increases the search area of the solution. The results of the forecasting test in this study show better accuracy than the previous research which has been studied is the combined ensemble method between autoregressive integrated moving average (ARIMA) and artificial neural network (ANN) algorithm
.
Keywords: inflation forecasting, consumer price index, support vector regression (SVR), chaotic genetic algorithm-simulated annealing (CGASA)
1. PENDAHULUAN
Secara umum inflasi didefinisikan sebagai naiknya harga barang secara umum dan terus menerus. Inflasi tidak terjadi jika kenaikan harga
yang dialami hanya pada satu atau dua barang saja, kecuali bila kenaikan itu menyebar (atau mengakibatkan kenaikan harga) pada barang lainnya (Bank Indonesia, 2013). Indikator yang sering digunakan untuk mengukur tingkat inflasi
adalah Indeks Harga Konsumen (IHK).
Perubahan IHK dari bulan ke bulan
menunjukkan pergerakan harga dari paket barang dan jasa yang dikonsumsi masyarakat. Dalam upaya pengendalian inflasi di Indonesia, sejak tahun 2005 dibentuk Tim Pemantauan dan Pengendalian Inflasi (TPI) yang bertugas pada level pusat dan TPID pada level daerah (Bank Indonesia, 2013). Penelitian ini merupakan pengembangan peramalan IHK tiap kelompok pengeluaran pada tingkat daerah dengan studi kasus Kota Malang yang dapat memberikan input bagi TPID Kota Malang sebagai pertimbangan dalam pengambilan kebijakan.
Penelitian dalam bidang peramalan time-series adalah salah satu metode yang telah
digunakan dalam berbagai implementasi
dikarenakan oleh kemampuannya untuk
memprediksi nilai masa depan. Metode time-series yang sering digunakan dalam peramalan data non-linear antara lain Artificial Neural Networks (ANN), Threshold Autoregressive
(TAR), Autoregressive Conditional
Heteroscedastic (ARCH), dan Support Vector
Regression (SVR) (Alwee, et al., 2013). Support Vector Regression (SVR) adalah salah satu metode dalam memperkirakan data non-linear. Ide SVR didasarkan pada perhitungan fungsi regresi linear dalam ruang fitur dimensi tinggi
dimana input data dipetakan melalui sebuah
fungsi non-linear (Basak, et al., 2007). SVR telah diterapkan di berbagai bidang – time-series dan prediksi keuangan, pendekatan teknik analisis kompleks, pemrograman kurva konveks kuadrat, fungsi kemungkinan kerugian, dll (Basak, et al., 2007). SVR memiliki kegunaan terbesar saat dimensi dari ruang input dan urutan pendekatan yang menciptakan dimensi dari representasi ruang fitur yang lebih besar (Drucker, et al., 1996).
Dalam implementasi SVR terdapat
parameter-parameter yang menentukan yang berperan penting untuk meningkatkan akurasi
peramalan. Oleh karena itu digunakan
hibridisasi algoritma genetika dengan simulated annealing (GASA) dalam penentuan
parameter-parameter tersebut. Algoritma GASA
merupakan percobaan inovatif dengan
menerapkan kemampuan superior algoritma SA untuk mencapai solusi yang lebih ideal, dan dengan mempekerjakan proses mutasi GA untuk meningkatkan proses pencarian (Zhang, et al.,
2012). Lebih jauh lagi penggunaan chaotic
search yang dimasukkan dalam algoritma meta-heuristik dapat meningkatkan perilaku pencarian
algoritma dan melewati optima lokal
(Sheikholeslami & Kaveh, 2013).
Penelitian ini merupakan peramalan
kenaikan IHK pada tingkat daerah dengan studi kasus Kota Malang. Metode yang digunakan
adalah Support Vector Regression (SVR) yang
optimasi menggunakan metode Chaotic Genetic Algorithm Simulated Annealing (CGASA). Dengan metode yang telah diajukan diharapkan mampu memberikan hasil peramalan inflasi yang akurat bagi TPID Kota Malang sebagai pertimbangan dalam pengambilan kebijakan. 2. TINJAUAN PUSTAKA
2.1 Inflasi
Secara umum inflasi didefinisikan sebagai naiknya harga barang secara umum dan terus menerus. Inflasi tidak terjadi jika kenaikan harga yang dialami hanya pada satu atau dua barang saja, kecuali bila kenaikan itu menyebar (atau mengakibatkan kenaikan harga) pada barang lainnya (Bank Indonesia, 2013). Kebalikan dari inflasi disebut deflasi. Faktor yang dapat digunakan untuk mengukur tingkat inflasi adalah Indeks Harga Konsumen (IHK). Perubahan IHK dari seiring dengan waktu menunjukkan pergerakan harga dari paket barang dan jasa yang dikonsumsi masyarakat.
2.2 Support Vector Regression (SVR)
Support Vector Regression (SVR) sudah banyak digunakan diberbagai macam bidang peramalan seperti peramalan inflasi di Indonesia dan peramalan kebutuhan listrik. Support Vector Regression (SVR) memetakan data ke dalam dimensi fitur yang lebih tinggi, sehingga dapat menerima regresi linear. Daripada mendapatkan
empirical error, SVR bertujuan untuk
meminimalisir batas dari error. Berikut adalah tahapan Algoritma Sekuensial untuk regresi non-linear:
1. Inisialisasi parameter yaitu variable scalar
(𝜆), learning rate (𝛾), variable slack (𝐶),
epsilon (), dan iterasi maksimum.
2. Inisialisasi 𝛼𝑖 dan 𝛼𝑖∗ dengan nilai awal 0
untuk keduanya, dilanjutkan dengan
menghitung nilai matriks hessian.
[𝑅]𝑖𝑗= 𝐾(𝑥𝑖, 𝑥𝑗) + 𝜆2, 𝑖, 𝑗 = 1, … , 𝑙 (1)
3. Lakukan iterasi untuk setiap titik data
Fakultas Ilmu Komputer, Universitas Brawijaya
a. Lakukan pada stiap data latih dengan
persamaan berikut:
𝐸𝑖 = 𝑦𝑖 − ∑𝑙𝑗=1(𝛼𝑖∗− 𝛼𝑖)𝑅𝑖𝑗 (2)
b. Lakukan pada setiap data latih dengan
persamaan berikut:
𝛿𝛼𝑖∗= min {max[𝛾(−𝐸𝑖−
𝜀), −𝛼𝑖∗] , 𝐶 − 𝛼𝑖∗ (3)
𝛿𝛼𝑖 = min {max[𝛾(−𝐸𝑖−
𝜀), −𝛼𝑖] , 𝐶 − 𝛼𝑖} (4)
c. Setelah ditemukan nilai lagrange, tahap
berikutnya dalah lakukan pada setiap data latih pada persamaan 5 dan 6
𝛼𝑖= 𝛼𝑖+ 𝛿𝛼𝑖 (5)
𝛼𝑖∗= 𝛼𝑖∗+ 𝛿𝛼𝑖∗ (6)
4. Lakukan secara berulang langkah ketiga
hingga mencapai iterasi maksimum atau
max(|𝛿𝛼𝑖|) < 𝜀 dan max(|𝛿𝛼𝒊∗|) < 𝜀
5. Menghitung fungsi regresi
𝑓(𝑥) = ∑𝑙𝑖=1(𝛼𝑖∗−𝛼𝑖)𝐾(𝑥𝑖, 𝑥) + 𝜆2 (7) Keterangan:
[𝑅]𝑖𝑗 = matriks hessian
𝐾(𝑥𝑖, 𝑥𝑗) = fungsi kernel yang digunakan
𝜆2 = variabel skalar
𝑙 = banyak data yang digunakan
𝐸𝑖 = nilai eror ke-i
𝑦𝑖 = nilai aktual data latih ke-i
𝛼𝑖∗, 𝛼𝑖 = nilai Lagrange Multiplier
𝛿𝛼𝑖∗ , 𝛿𝛼𝑖 = perubahan nilai αi dan αi*
= nilai epsilon
γ = nilai learning rate
Ϲ = variabel slack
2.3 Chaotic Genetic Algorithm-Simulated
Annealing (CGASA)
Metode Chaotic Genetic
Algorithm-Simulated Annealing (CGASA) adalah gabungan dari Algoritma Genetika yang
menggunakan Chaotic Sequence dengan
Simulated Annealing. Penggabungan ini bertujuan untuk mendapatkan kelebihan dari masing-masing algoritma dan memberikan solusi optimal dalam penentuan variabel-variabel yang dibutuhkan pada SVR.
2.4 Genetic Algorithm (GA)
Algoritma Genetika (GA) merupakan salah
satu cabang Evolutionary Algorithm (EA) yang
terkenal saat ini, pertama kali dicetuskan oleh
John Holland dalam bukunya yang berjudul “Adaptation in Natural and Artificial Systems” pada tahun 1975. Ide dasar algoritma genetika adalah menerapkan sebuah teori evolusi genetika yang dicetuskan oleh Darwin pada teknologi komputasi, dimana individu dapat mengalami perubahan genetik atau biasa disebut dengan mutasi untuk menyesuaikan diri dengan lingkungan sehingga dapat terus bertahan hidup (Gendreau and Potvin 2010). Algoritma genetika dikenal para peneliti sebagai algoritma karena
kemampuannya menangani berbagai
permasalahan yang memiliki ruang pencarian kompleks dengan model matematis sehingga cocok diterapkan pada berbagai bidang seperti pada pertanian, biologi, pendidikan, industri, pangan, militer, teknologi informasi, dan lain-lain (Mahmudy, 2013). Penerapan algoritma genetika yang umum antara lain untuk
menyelesaikan permasalahan penjadwalan
peristiwa (time-tabling), optimasi penyusunan rute atau travelling salesman problem (TSP), dan lain-lain. Secara umum, GA memiliki 3 tahap, yaitu: membuat populasi awal, mengevaluasi fungsi fitness, dan memproduksi populasi baru (Wu & Lu, 2012). Untuk menggunakan GA, ada beberapa hal yang harus diperhatikan sebagai berikut: (Zhang, et al., 2009)
1. Skema pemetaan
Ada dua bentuk pemetaan skema, yaitu
binary dan Real Coded Genetic Algorithm
(RCGA). Pemetaan binary merupakan pemetaan yang paling sering digunakan
dalam Genetic Algorithm. Sebagai contoh
pada pemetaan binary, jika solusi yang kita cari merupakan sebuah bilangan antara 0 sampai dengan 15, kita dapat menggunakan 4 digit biner sebagai representasi dari solusi
tersebut. Misalnya 0101 merupakan
representasi dari bilangan 3, dan 1001 merupakan representasi dari bilangan 9.
2. Ukuran populasi
Ukuran populasi akan mempengaruhi performa dari GA secara langsung. Jika ukuran terlalu kecil, populasi akan lebih mudah mencapai local minimization. Tetapi apabila ukuran populasi terlalu besar, itu akan menyebabkan banyak waktu yang diperlukan untuk melakukan kalkulasi. Berdasarkan pengalaman, ukuran yang paling sesuai selalu berada antara 50 dan 200.
3. Fungsi fitness
Fungsi fitness digunakan untuk
Pemilihan fungsi fitness adalah kunci dalam
pengaplikasian GA. Fungsi ini
menyesuaikan dengan permasalahan yang sedang diselesaikan. Sebagai contoh, untuk mencari nilai fitness pada penelitian ini digunakan persamaan
fitness = 1
1+MAPE (8)
4. Operator genetika
Operator genetika terbagi atas tiga operator dasar yaitu reproduksi, crossover, dan mutasi.
a. Reproduksi
Operator reproduksi terdiri dari operasi seleksi copy dan operasi seleksi survive. Pada operasi ini, metode survival digunakan untuk memilih individu
untuk generasi berikutnya. Ada
beberapa metode seleksi dalam Genetic Algorithm, seperti roulette wheel, replacement selection, dan binary tournament. Metode seleksi yang paling sering digunakan adalah seleksi roulette wheel.
𝑝𝑖 = 𝑓𝑖
∑𝑁𝑗=1𝑓𝑗 (9)
Dimana 𝑝𝑖 merupakan probabilitas
terpilihnya individu 𝑖 sebagai induk dari
individu baru, 𝑓𝑖 merupakan nilai fungsi
fitness untuk individu 𝑖, dan ∑𝑁𝑗=1𝑓𝑗
merupakan total seluruh nilai fitness dari semua individu. Metode seleksi yang digunakan dalam penelitian ini adalah metode seleksi roulette wheel.
b. Crossover
Operator crossover memilih 2
kromosom secara acak sesuai dengan
probabilitas crossover 𝑃𝑐, dan kemudian
secara acak menukar bagian dari gen
kromosom untuk menghasilkan 2
kromosom baru. Ada 4 operator crossover yang paling sering digunakan, yaitu one-point crossover, two-point crossover, multi-point crossover, dan uniform crossover. Crossover yang digunakan dalam penelitian ini adalah extended intermediate crossover, yang dapat dihitung dengan menggunakan persamaan berikut:
𝑥𝑐1= 𝑥𝑝1+ 𝑟𝑎𝑛𝑑𝑜𝑚 (𝑥𝑝2− 𝑥𝑝1) (10)
𝑥𝑐2= 𝑥𝑝2+ 𝑟𝑎𝑛𝑑𝑜𝑚 (𝑥𝑝1− 𝑥𝑝2) (11)
c. Mutasi
Operator mutasi dapat mempertahankan keberagaman dari populasi. Untuk skema binary encoding, operator mutasi
digunakan untuk mengubah gen
kromosom 1 menjadi 0, atau 0 menjadi
1 sesuai dengan probabilitas mutasi 𝑃𝑚.
Mutasi yang digunakan dalam penelitian ini adalah random mutation, dimana anak diperoleh dengan menggunakan persamaan berikut:
𝑥𝑐 = 𝑥𝑝+ 𝑟𝑎𝑛𝑑𝑜𝑚 (𝑏𝑎𝑡𝑎𝑠𝑚𝑎𝑘𝑠−
𝑏𝑎𝑡𝑎𝑠𝑚𝑖𝑛) (12)
2.5 Chaotic Sequence
Metode optimasi Chaos adalah teknik
optimasi yang muncul dalam beberapa tahun
terakhir dan memiliki sifat seperti chaotic
ergodicity dan sensitivitas nilai awal sebagai mekanisme optimasi global (Zhang, et al., 2012). Logistic map, salah satu yang paling simple dari urutan kacau merupakan pemetaan polinomial pangkat dua, dengan fungsi sebagai berikut:
𝑥(𝑖+1)= 𝜇𝑥(𝑖)(1 − 𝑥(𝑖)) (13)
𝑥(𝑖)∈ (0,1) , 𝑖 = 0, 1, 2, … (14)
2.6 Chaotic Genetic Algorithm (CGA)
Saat ini Algoritma Genetika (GA) telah
digunakan dalam berbagai permasalahan
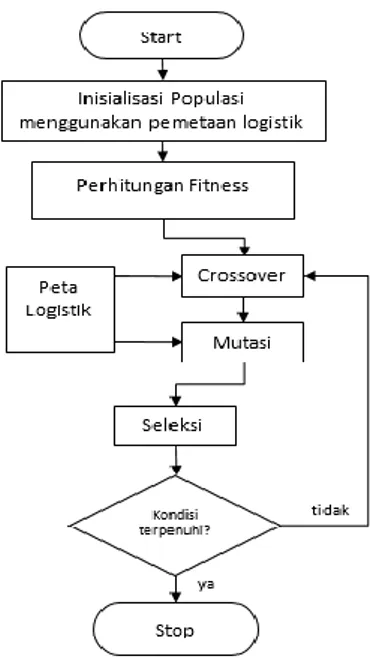
optimasi kompleks. Namun, metode ini memiliki kelemahan dalam jumlah iterasi yang besar dalam mencapai solusi optimum global dan titik konvergensi yang tersebar merupakan masalah utama dalam GA (Javidi & Hosseinpourfard, 2015). Dalam metode GA, populasi awal yang dihasilkan oleh pendekatan random mungkin tidak merata dan jauh dari solusi optimal. Oleh karena itu, digunakan distribusi seragam pemetaan logistic untuk menghasilkan populasi awal. Kemudian, pada penelitian ini juga
menggunakan output peta logistik pada
crossover dan mutasi setiap kali nomor acak diperlukan. Flowchart dari metode yang diusulkan ditunjukkan dalam gambar berikut:
Fakultas Ilmu Komputer, Universitas Brawijaya Gambar 1 - Diagram alir chaotic genetic algorithm
2.7 Simulated Annealing
Algoritma simulated annealing (SA)
diilhami dari annealing yakni teknik
pembetukan kristal dalam suatu materi dimana dilakukan pemanasan sampai suhu tertentu agar atom-atom pada materi tersebut dapat bergerak secara bebas kemudian dilakukan pendinginan secara bertahap agar atom-atom yang tadinya bergerak secara bebas, dapat menemukan tempat yang optimum. Dalam prosedur SA, dengan memilih suatu solusi awal kemudian dilakukan perubahan pada struktur solusinya, apabila solusi baru lebih baik maka akan langsung diterima sebagai solusi yang lebih optimal. Dan jika solusi baru dinyatakan lebih buruk maka akan dilakukan pemilihan solusi dengan probability acceptance. Ada empat hal yang perlu diperhatikan dalam penggunaan algoritma SA (Kirkpatrick, et al., 1983):
a. Konfigurasi sistem yang dan representasi
masalah sesederhana mungkin
b. Bagaimana cara memodifikasi kandidat
solusi pada proses modifikasi
c. Fungsi untuk menghitung seberapa optimal
suatu kandidat solusi
d. Kapan parameter T mulai diturunkan, dan
banyak iterasi yang dibutuhkan
2.8 Chaotic Genetic Algorithm-Simulated
Annealing (CGASA)
CGASA adalah algoritma pencarian
gabungan dengan menggabungkan dua
algoritma pencarian yakni algoritma genetika
yang menggunakan chaotic sequence dan
simulated annealing. Penggabungan kedua algoritma ini bertujuan untuk saling menutupi kekurangan dari masing-masing algoritma dan memanfaatkan kelebihan agar mendapatkan solusi yang lebih optimal (Al-Milli, 2011). Algoritma genetika dikenal karena pencariannya yang luas namun sering terperangkap pada local
optimum sehingga membutuhkan simulated
annealing untuk mendapatkan solusi yang
diharapkan mendekati global optimum.
Simulated annealing pun dapat memanfaatkan kelebihan algoritma genetika karena pada simulated annealing tidak mempertimbangkan solusi terdahulu dan hanya terfokus pada satu solusi terbaik saat ini, padahal terdapat kemungkinan solusi terbaik didapat dari solusi terdahulu. Dengan algoritma genetika, akan didapatkan lebih banyak pilihan solusi yang dapat diproses pada perulangan selanjutnya.
Gambar 2 – Alur Algoritma CGASA
2.9 Normalisasi Data
Sebelum melakukan proses peramalan nilai inflasi ini, akan dilakukan proses pengolahan data terlebih dahulu. Proses pengolahan data yang dilakukan adalah normalisasi data.
Normalisasi pada data bertujuan untuk
mengubah data agar berada pada jarak tertentu dan menyamakan standar dari semua data yang digunakan dalam proses perhitungan. Proses normalisasi yang digunakan adalah Min-Max Normalisasi. Rumus perhitungan Min-Max Normalization dapat dilihat pada persamaan berikut:
𝑥′ = 𝑥−𝑥𝑚𝑖𝑛
𝑥𝑚𝑎𝑥−𝑥𝑚𝑖𝑛 (15)
Sedangkan untuk melakukan proses
denormalisasi data, yaitu proses untuk
mengembalikan nilai data menjadi nilai yang sebenarnya (nilai sebelum dinormalisasi), adalah
dengan mencari nilai 𝑥. Proses pencarian nilai 𝑥
dapat dilakukan dengan menggunakan
persamaan berikut:
𝑥 = 𝑥𝑚𝑖𝑛+ (𝑥′(𝑥𝑚𝑎𝑥− 𝑥𝑚𝑖𝑛)) (16)
2.10 Nilai Evaluasi
Nilai evaluasi merupakan sebuah nilai yang digunakan dalam melakukan pengujian dan pengukuran terhadap sebuah peramalan. Nilai evaluasi ini seringkali diukur dalam bentuk tingkat kesalahan atau error rate. Nilai error rate
yang digunakan adalah Mean Absolute
Percentage Error (MAPE) (Mathaba, et al., 2014). Rumus untuk MAPE dapat dituliskan sebagai persamaan berikut:
𝑀𝐴𝑃𝐸 = ∑ |(𝑦𝑖−𝑦𝑖′) 𝑦𝑖 | × 100 𝑛 𝑛 𝑖=1 (17)
MAPE digunakan dalam penelitian ini karena MAPE memberikan hasil yang relatif terhadap
nilai yang sebenarnya sehingga tingkat error
yang didapatkan lebih stabil pada batasan persentase.
3. METODOLOGI
Tahapan yang dilakukan dalam penelitian ini ditunjukkan pada gambar 3 berupa diagram alir metodologi penelitian
3.1 Data Penelitian
Dalam melakukan implementasi peramalan inflasi kota Malang, data latih yang diperlukan berupa nilai IHK kota Malang. Data tersebut berbentuk nilai per bulan selama 6 tahun terakhir (Januari 2011 –Mei 2017) yang didapatkan dari website BPS Malang.
4. PERANCANGAN
Pada bagian perancangan diberikan
penjelasan tentang penyelesaian permasalahan
peramalan kenaikan indeks harga
konsumen/inflasi kota malang menggunakan metode support vector regression (SVR) dengan chaotic genetic algorithm-simulated annealing (cgasa).
Gambar 3 – Diagram Alir Metodologi Penelitian Tahap perancangan sistem ini terdiri dari dua proses utama yaitu pelatihan SVR dan optimasi parameter SVR menggunakan metode CGASA. Proses pelatihan SVR menggunakan data inflasi
selama beberapa tahun terakhir untuk
mendapatkan variabel peramalan nilai inflasi berdasarkan fitur data yang telah diketahui. Fitur data yang digunakan adalah data inflasi pada bulan-bulan sebelumnya yang membentuk time series. Dari data time series inflasi yang terjadi di Kota Malang akan diekstraksi menjadi data training dan data testing untuk mengetahui akurasi.
Perancangan perangkat lunak yang akan dibuat terdiri dari dua fitur, yaitu pelatihan dan peramalan SVR. Masing-masing fitur tersebut memiliki alur proses-proses yang dirancang sedemikian rupa untuk memenuhi tujuan dari penelitian. Alur proses tiap fitur lebih jelas dapat dilihat pada subbab berikutnya. Sedangkan aliran data pada aplikasi yang dibangun secara detail dapat dilihat pada gambar berikut
Fakultas Ilmu Komputer, Universitas Brawijaya Gambar 4 - Aliran data pada perancangan aplikasi
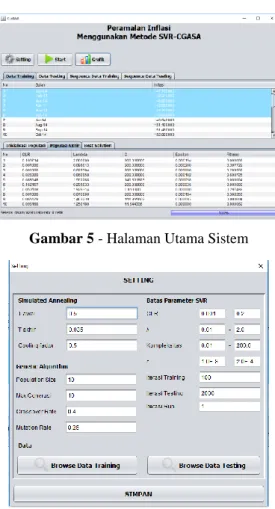
5. IMPLEMENTASI
Implementasi antarmuka yang digunakan
pada peramalan kenaikan indeks harga
konsumen/inflasi kota malang menggunakan metode support vector regression (SVR) dengan chaotic genetic algorithm-simulated annealing (cgasa) terdiri atas halaman utama dan halaman pengaturan.
Gambar 5 - Halaman Utama Sistem
Gambar 6 - Halaman Pengaturan Sistem
6. PENGUJIAN
Pengujian yang dilakukan meliputi
pengujian batas parameter CLR, nilai λ (lambda), nilai C (complexity), nilai epsilon, pengujian ukuran populasi, pengujian jumlah generasi, pengujian tingkat crossover, pengujian tingkat mutasi, pengujian temperatur awal SA, pengujian temperatur akhir, pengujian cooling factor, pengujian jumlah iterasi SVR, serta pengujian variasi data latih dan uji.
6.1 Pengujian Batas Parameter CLR
Berdasarkan grafik uji coba pada Gambar 7, terlihat bahwa rerata fitness paling besar didapatkan pada batas CLR 0.0001-0.2. Constant learning rate (CLR) yang berkisar pada jangkauan tersebut mampu menghasilkan nilai error MAPE yang paling kecil. CLR merupakan
konstanta yang digunakan dalam laju
pembelajaran. Semakin kecil nilai CLR, proses learning akan berjalan lebih lambat, namun akan mendapatkan hasil yang lebih konvergen. Sebaliknya, semakin besar nilai CLR, hasil yang didapatkan lebih divergen (Vijayakumar & Wu, 1999).
Gambar 7 - Grafik Hasil Pengujian Batas Epsilon
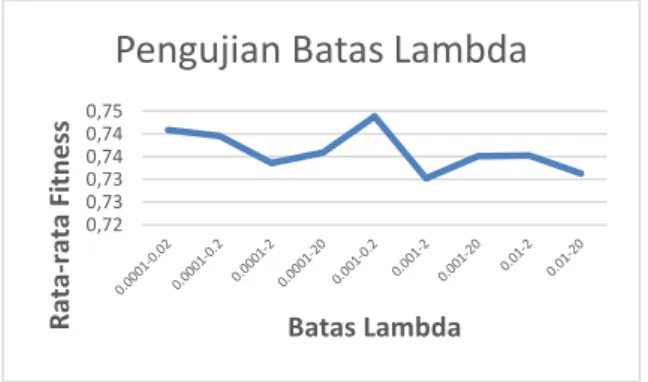
6.2 Pengujian Batas Lamda
Pada Gambar 8, terlihat bahwa nilai Lambda yang paling optimal adalah pada batas 0.001-0.2. Lambda berhubungan erat dengan faktor penambahan, nilai ini berhubungan dengan jarak dalam matriks hessian. Lambda itu sendiri dapat
didefinisikan sebagai ukuran besarnya
penskalaan ruang pemetaan kernel pada SVR (Vijayakumar and Wu 1999) 0,68 0,70 0,72 0,74 0,76 R ata -r ata Fi tn e ss Batas CLR
Pengujian Batas CLR
Gambar 8 - Halaman Utama Sistem
6.3 Pengujian Batas Kompleksitas
Pada Gambar 9, dapat dilihat bahwa batas Complexity yang paling optimal adalah 0.0001-20. Nilai Complexity (C) merupakan sebuah variabel untuk menampung nilai pelanggaran toleransi berupa batas atas deviasi pada fungsi regresi. Semakin besar nilai C, maka regresi yang terbentuk semakin jauh dari batas deviasi, sedangkan semakin kecil nilai C, maka regresi yang terbentuk akan mendekati batas deviasinya.
Gambar 9 - Grafik Hasil Pengujian Batas Kompleksitas
6.4 Pengujian Batas Epsilon
Pada Gambar 10, dapat dilihat bahwa nilai Epsilon yang paling optimal berada pada batas 1E-8 s.d 0.0009. Nilai Epsilon menunjukkan tingkat ketelitian dalam regresi. Semakin kecil nilai Epsilon, mengindikasikan bahwa tingkat ketelitian dalam regresi semakin besar sehingga menghasilkan hasil yang lebih baik.
Gambar 10 - Grafik Hasil Pengujian Batas Epsilon
6.5 Pengujian Ukuran Populasi GA
Berdasarkan grafik uji coba pada Gambar 11, terlihat bahwa pada pengujian ukuran populasi, nilai rata-rata fitness mengalami peningkatan. Hal ini disebabkan karena sifat algoritma yang stochastic, yang berarti bahwa
nilai fitness masih bergantung pada
pembangkitan individu secara acak pada inisialisasi populasi awal. Jumlah populasi yang terlalu kecil akan mengakibatkan kurangnya keberagaman dalam populasi awal.
Gambar 11 - Grafik Hasil Pengujian Ukuran Populasi GA
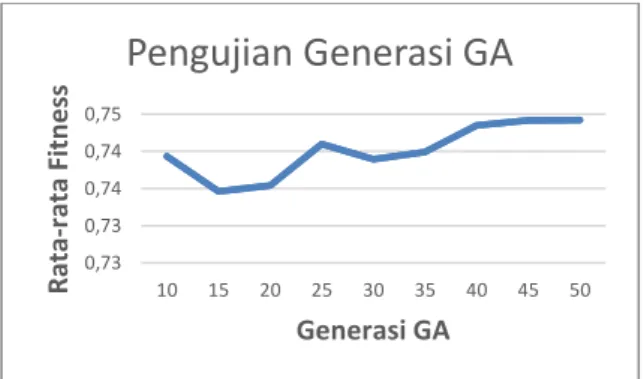
6.6 Pengujian Generasi GA
Berdasarkan grafik uji coba pada Gambar 12, terlihat bahwa pada pengujian banyak generasi, terjadi peningkatan rata-rata nilai fitness. 0,72 0,73 0,73 0,74 0,74 0,75 R ata -r ata Fi tn e ss Batas Lambda
Pengujian Batas Lambda
0,58 0,68 0,78 R ata -r ata Fi tn e ss Batas Kompleksitas
Pengujian Batas
Kompleksitas
0,72 0,73 0,73 0,74 0,74 1E-7 s.d 0.0009 1E-7 s.d 0.009 1E-7 s.d 0.09 1E-6 s.d 0.0009 1E-6 s.d 0.009 1E-6 s.d 0.09 1E-8 s.d 0.0009 1E-8 s.d 0.009 1E-8 s.d 0.09 R ata -r ata Fi tn e ss Batas EpsilonPengujian Batas Epsilon
0,72 0,73 0,74 0,75 10 15 20 25 30 35 40 45 50 R ata -r ata Fi tn e ss Ukuran Populasi GA
Pengujian Ukuran Populasi
GA
Fakultas Ilmu Komputer, Universitas Brawijaya Gambar 12 - Grafik Hasil Pengujian Generasi GA 6.7 Pengujian Tingkat Crossover
Berdasarkan grafik uji coba pada Gambar 13, terlihat bahwa semakin besar tingkat crossover, tidak menjamin nilai fitness akan meningkat. Hal ini disebabkan karena tingkat crossover hanya memperluas area pencarian di dalam populasi itu sendiri. Tingkat crossover
yang tinggi memungkinkan GA untuk
melakukan eksploitasi terhadap area tetangga yang memiliki kualitas lebih baik, sedangkan
tingkat crossover yang rendah akan
mengakibatkan GA hanya bergantung pada proses mutasi.
Gambar 13 - Grafik Hasil Pengujian Tingkat Crossover
6.8 Pengujian Tingkat Mutasi
Berdasarkan grafik uji coba pada Gambar 14, terlihat bahwa semakin besar tingkat mutasi, tidak menjamin nilai fitness akan meningkat. Hal ini disebabkan karena tingkat mutasi hanya memperluas area pencarian di luar populasi itu
sendiri. Semakin tinggi tingkat mutasi
memungkinkan GA untuk melakukan eksplorasi area baru pada ruang pencarian, sedangkan tingkat mutasi yang rendah akan mengakibatkan keberagaman populasi pada GA menjadi menurun.
Gambar 14 - Grafik Hasil Pengujian Tingkat Mutasi
6.9 Pengujian Temperatur Awal SA
Berdasarkan grafik uji coba pada Gambar 15, terlihat bahwa semakin besar temperatur awal, tidak menjamin nilai fitness akan
meningkat. Hal ini disebabkan karena
temperatur awal hanya berperan dalam
menentukan batas awal temperatur pada SA. Semakin besar nilai temperatur awal, maka ruang pencarian SA akan menjadi semakin lebar, sedangkan semakin kecil nilai temperatur awal menjadikan ruang pencarian SA yang kecil mengakibatkan mudah terjebak pada local optimum.
Gambar 15 Grafik Hasil Pengujian Temperatur Awal SA
6.10 Pengujian Temperatur SA
Berdasarkan grafik uji coba pada Gambar 16, terlihat bahwa semakin besar temperatur akhir, tidak menjamin nilai fitness akan
meningkat. Hal ini disebabkan karena
temperatur akhir hanya berperan dalam
menentukan batas bawah dari temperatur pada SA. Semakin tinggi nilai temperatur akhir pada SA akan mengakibatkan ruang pencarian yang semakin sempit. 0,73 0,73 0,74 0,74 0,75 10 15 20 25 30 35 40 45 50 R ata -r ata Fi tn e ss Generasi GA
Pengujian Generasi GA
0,73 0,73 0,74 0,74 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 R ata -r ata Fi tn e ss Tingkat CrossoverPengujian Tingkat Crossover
0,73 0,73 0,73 0,73 0,74 0,74 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 R ata -r ata Fi tn e ss Tingkat Mutasi
Pengujian Tingkat Mutasi
0,73 0,73 0,74 0,74 0,50 0,75 1,00 1,25 1,50 1,75 2,00 2,25 2,50 R ata -r ata Fi tn e ss Temperatur Awal SA
Pengujian Temperatur Awal
SA
Gambar 16 - Grafik Hasil Pengujian Temperatur Akhir SA
6.11 Pengujian Cooling Factor SA
Berdasarkan grafik uji coba pada Gambar 17, terlihat bahwa semakin besar cooling factor, maka nilai fitness juga akan meningkat. Hal ini disebabkan karena jumlah iterasi berpengaruh terhadap rata-rata yang dihasilkan. Hal ini disebabkan karena cooling factor hanya berperan
dalam menentukan kecepatan penurunan
temperatur pada SA.
Gambar 17 - Grafik Hasil Pengujian Cooling Factor SA
6.12 Pengujian Jumlah Iterasi SVR Berdasarkan grafik uji coba pada Gambar 18, terlihat bahwa semakin besar jumlah iterasi SVR, maka nilai fitness juga akan meningkat. Hal ini disebabkan karena jumlah iterasi SVR berpengaruh terhadap presisi dari SVR yang dihasilkan. Semakin banyak iterasi SVR yang digunakan akan menghasilkan nilai peramalan
yang semakin baik, namun dengan
bertambahnya jumlah iterasi SVR, waktu komputasi yang diperlukan juga meningkat secara eksponensial.
Gambar 18 - Grafik Hasil Pengujian Jumlah Iterasi SVR
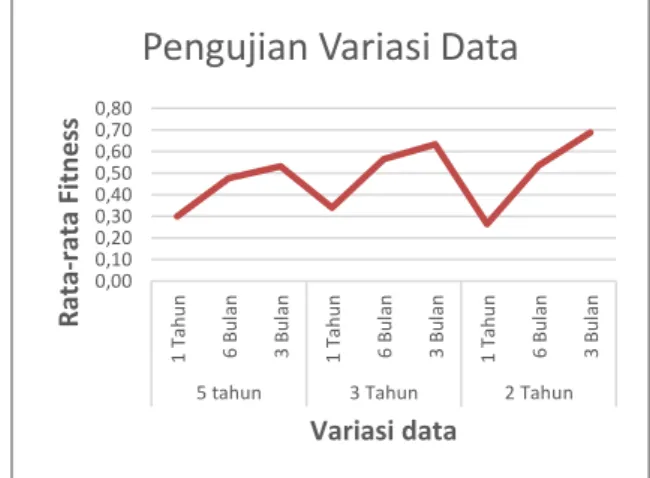
6.13 Pengujian Variasi Data
Berdasarkan grafik uji coba pada Gambar 19, terlihat bahwa nilai fitness terbesar dihasilkan oleh peramalan dengan menggunakan 2 tahun. Dari grafik tersebut juga dapat disimpulkan bahwa semakin banyak jumlah data training yang digunakan, tidak menjamin bahwa nilai fitness akan meningkat. Namun dengan bertambahnya jumlah data training yang digunakan, waktu komputasi yang diperlukan juga meningkat
Gambar 19 - Grafik Hasil Pengujian Variasi Data
7. KESIMPULAN
Kesimpulan yang diambil dari penelitian yang telah dilakukan tentang peramalan indeks harga konsumen Kota Malang menggunakan metode support vector regression (SVR) dengan chaotic genetic algorithm-simulated annealing (CGASA) adalah:
1. Metode SVR dengan CGASA dapat
diterapkan dalam kasus peramalan kenaikan IHK/inflasi Kota Malang dengan cara sebagai berikut: 0,73 0,73 0,74 0,74 R ata -r ata Fi tn e ss Temperatur Akhir SA
Pengujian Temperatur Akhir
SA
0,72 0,73 0,73 0,74 0,74 0,75 0,75 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 R ata -r ata Fi tn e ss Cooling factor SAPengujian Cooling factor SA
0,45 0,55 0,65 0,75 0,85 0,95 R ata -r ata Fi tn e ss Jumlah Iterasi SVR
Pengujian Jumlah Iterasi SVR
0,00 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 1 T ah u n 6 B u la n 3 B u la n 1 T ah u n 6 B u la n 3 B u la n 1 T ah u n 6 B u lan 3 B u la n
5 tahun 3 Tahun 2 Tahun
R ata -r ata Fi tn e ss Variasi data
Fakultas Ilmu Komputer, Universitas Brawijaya
a. SVR merupakan metode pemodelan
regresi non-linear yang digunakan untuk
meramalkan nilai indeks harga
konsumen menggunakan time-series pada bulan sebelumnya sebagai input.
b. Untuk mendapatkan SVR yang bekerja
secara baik dilakukan optimasi
menggunakan metode CGASA.
c. GA merupakan metode heuristik untuk
menemukan parameter terbaik pada SVR sehingga mampu menghasilkan nilai akurasi tertinggi.
d. SA merupakan proses perubahan solusi
agar mampu mencoba pilihan solusi yang lebih luas dan menjaga GA agar tidak terjebak dalam konvergensi dini. e. Chaotic sequence digunakan sebagai
metode pembangkitan angka yang digunakan dalam proses GA dan SA.
f. Parameter algoritma SVR CGASA yang
didapatkan berdasarkan hasil analisis adalah sebagai berikut:
i. Batas CLR: 0.0001 – 0.2
ii. Batas Lambda: 0.001 – 0.2
iii. Batas Complexity: 0.01 – 20
iv. Batas Epsilon: 1E-8 – 0.0009
v. Generasi GA: 45
vi. Populasi GA: 50
vii. Crossover rate: 0.3
viii. Mutation rate: 0.4
ix. Temperatur awal SA: 1.25
x. Temperatur akhir: 0.008
xi. Cooling factor: 0.9
xii. Iterasi SVR: 50000
xiii. Data Latih: 3 tahun
xiv. Data Uji: 6 bulan
2. Hasil peramalan menggunakan parameter
yang didapatkan pada proses analisis dan pengujian menghasilkan nilai error terkecil sebesar 0.304462 dan fitness sebesar 0.7666. Tingkat error ini dirasa terlalu besar dan masih tidak dapat terlalu diandalkan dalam meramalkan nilai IHK di Kota Malang. Namun hasil ini lebih baik dibandingkan penelitian yang sebelumnya dikaji yaitu peramalan inflasi menggunakan metode ensembel error sebesar 0.34.
DAFTAR PUSTAKA
Al-Milli, N. R. 2011. "Hybrid Genetic
Algorithms with Simulating Annealing for
University Course Timetabling
Problems." Zarqa University College. Alwee, R., S. M. H. Shamsuddin, and R.
Sallehuddin. 2013. "Hybrid Support
Vector Regression and Autoregressive Integrated Moving Average Models
Improved by Particle Swarm
Optimization for Property Crime Rates Forecasting with Economic Indicators." The Scientific World Journal 1-11.
Bank Indonesia. 2013. Pengenalan Inflasi -
Bank Sentral Republik Indonesia. diakses
pada 25 Juli 2016.
http://www.bi.go.id/id/moneter/inflasi/pe ngenalan/Contents/Default.aspx.
Basak, Debasish, Srimanta Pal, and Dipak Chandra Patranabis. 2007. "Support Vector Regression." Neural Information Processing – Letters and Reviews 11: 203-224.
Drucker, Harris, Chris J.C. Burges, Linda Kaufman, Alex Smola, and Vladimir Vapnik. 1996. Support Vector Regression Machines. West Long Branch: Bell Labs. Gendreau, Michel, and Jean-Yves Potvin, . 2010.
Handbook of Metaheuristics. 2nd. New York: Springer.
Heidari-Bateni, G., and A. McGillem. 1994.
"Chaotic Direct-sequence Spread
Spectrum Communication System." IEEE Transaction on Communication 42 (2): 1524-1527.
Javidi, Mohammad, and Roghiyeh
Hosseinpourfard. 2015. "Chaos Genetic
Algorithm Instead Genetic Algorithm." The International Arab Journal of Information Technology 12 (2): 163-168. Kirkpatrick, S., C. D. Gelatt, and M. P. Vecchi.
1983. Optimization by Simulated
Annealing. Science.
Mahmudy, Wayan Firdaus. 2013. Algoritma
Evolusi. Malang: Program Teknologi Informasi dan Ilmu Komputer (PTIIK) Universitas Brawijaya.
Mathaba, T., X. Xia, and J. Zhang. 2014. "Analysing the Economic Benefit of Electricity Price Forecast in Industrial
Load Scheduling." Electric Power
Systems Research 116: 158-165.
Norozi, A., M. K. A. Ariffin, N. Ismail, and F. Mustapha. 2011. "An Optimization
Technique Using Hybrid GA-SA
Problem." Scientific Research and Essays 6(8): 1720-1731.
Rajkumar, N., and P. Jaganathan. 2013. "A New RBF Kernel Based Learning Method Applied to Multiclass Dermatology
Diseases Classification." Conference on
Information and Communication Technologies.
Ren, Y., and G. Bai. 2010. "Determination of Optimal SVM Parameters by Using GA/PSO." Journal of Computers 8 (3). Sheikholeslami, R., and A. Kaveh. 2013. "A
Survet of Chaos Embedded
Meta-Heuristic." International Journal of
Optimization in Civil Engineering 3 (Civil Eng): 617-633.
Silfiani, Mega, and Suhartono. 2013. "Aplikasi Metode Ensembel untuk Peramalan
Inflasi di Indonesia." Institut Teknologi
Sepuluh Nopember (ITS).
TPID. 2014. Buku Petunjuk TPID. Jakarta: Kementerian Dalam Negeri Republik Indonesia.
Vijayakumar, S., and S. Wu. 1999. "Sequential Support Vector Classifiers and Regression." International Conference on Soft Computing 610-619.
Wu, J., and Z. Lu. 2012. "A Novel Hybrid Genetic Algorithm and Simulated Annealing for Feature Selection and
Kernel Optimization in Support Vector
Regression." Information Reuse and Integration 401-406.
Zhang, Q., G. Shan, X. Duan, and Z. Zhang.
2009. "Parameters Optimization of
Support Vector Machine based on Simulated Annealing and Genetic Algorithm." International Conference on Robotic and Biometrics 1302-1306. Zhang, Wen Yu, Wei-Chiang Hong, Yucheng
Dong, Gary Tsai, Jing-Tian Sung, and Guo-feng Fan. 2012. "Application of SVR
with chaotic GASA algorithm in cyclic
electric load forecasting." Energy 45: 850-858.