LANDASAN TEORI
3.1 Pengertian dan Kegunaan Peramalan
Peramalan(forecasting) adalah perkiraan tentang sesuatu yang akan terjadi pada waktu yang akan datang yang didasarkan pada data yang ada pada waktu sekarang dan waktu lampau (historical data). Dengan memahami arti peramalan,maka untuk membuat suatu peramalan yang baik, pertama kali kita harus mencari faktor-faktor yang dapat mempengaruhi variabel yang akan diramal.
Peramalan merupakan proses dari estimasi di dalam situasi yang tidak diketahui, mirip dengan memprediksi, tetapi lebih ke dalam istilah umum, dan biasanya mengacu pada estimasi dari time series, cross sectional atau longitudinal data.
(http://en.wikipedia.org/wiki/Time_series). Estimasi merupakan hasil dari perhitungan
hasil prakiraan yang dapat dipergunakan walaupun data dari input tidak lengkap, tidak jelas dan noisy. (http://en.wikipedia.org/wiki/Estimation)
Dalam melakukan analisa ekonomi atau analisa kegiatan usaha perusahaan, haruslah diperkirakan apa yang akan terjadi dalam bidang ekonomi atau dalam dunia usaha pada masa yang akan datang. Kegiatan untuk memperkirakan apa yang akan terjadi pada masa yang akan datang, kita kenal dengan apa yang disebut peramalan (forecasting). (Assauri, 1984, p1).
Bagaimanapun juga suatu peramalan tetaplah merupakan suatu perhitung berdasarkan data masa lampau dibantu dengan variable yang mempengaruhi, karena itu peramalan tetaplah peramalan sehingga hasil proyeksi dari peramalan tersebut tidaklah
dapat akan secara tepat menggambarkan kenyataan apa yang akan terjadi di masa mendatang.
Kegunaan dari peramalan sangat digunakan dan terlihat ketika mengambil suatu keputusan. Setiap orang akan selalu menghadapi suatu masalah dalam pengambilan keputusan, setiap orang akan selalu memikirkan suatu keputusan yang dipikirkannya dengan suatu perhitungan dan pertimbangan yang matang untuk menghasilkan suatu keputusan yang baik. Melalui peramalan setiap orang yang menghadapi masalah dalam pengambilan keputusan akan dimudahkan oleh hasil proyeksi yang didapat melalui peramalan. Dalam suatu perusahaan peramalan digunakan untuk membuat keputusan dalam kegiatan penjualan, persediaan barang, keuangan dan lain lain.
3.2 Jenis Peramalan
Jika dilihat dari jangka waktu ramalan yang disusun, maka peramalan dapat dibedakan atas dua macam, yaitu :
1) Peramalan jangka panjang, yaitu peramalan yang dilakukan untuk penyusunan hasil ramalan yang jangka wkatunya lebih dari satu setengah tahun atau tiga semester.
2) Peramalan jangka pendek, yaitu peramalan yang dilakukan untuk penyusunan hasil ramalan dengan waktu yang kurang dari satu setengah tahun, atau tiga semester.
Jika dilihat berdasarkan sifat ramalan yang telah disusun, maka peramalan dapat dibedakan atas dua macam, yaitu :
1) Peramalan model kualitatif yaitu metode peramalan yang tidak menggunakan perumusan matematis dan statistik, serta peramalan yang didasarkan atas data kualitatif pada masa lalu.
2) Peramalan model kuantitatif yaitu menggunakan perumusan matematis dan statistik, serta peramalan yang didasarkan atas data kuantitatif pada masa lalu.
3.3 Langkah-Langkah Peramalan
Peramalan yang baik adalah peramalan yang dilakukan dengan mengikuti
langkah atau suatu prosedur penyusunan yang baik dalam meramal yang akan menentukan kualitas dari hasil peramalan yang disusun dan akan diproyeksikan. Pada dasarnya terdapat tiga langkah atau prosedur peramalan yang penting, atau harus dilakukan untuk menghasilkan peramalan yang berkualitas, yaitu :
1) Menganalisa data yang lalu, tahap ini berguna untuk pola dari data-data yang terjadi pada masa lalu.
2) Menentukan metode yang digunakan. Metode peramalan yang baik adalah metode yang memberikan hasil ramalan yang tidak jauh berbeda atau setidaknya mendekati dengan data kenyataan yang terjadi.
3) Memproyeksikan data yang lalu dengan menggunakan metode peramalan yang dipergunakan, dan mempertimbangkan adanya beberapa faktor atau variabel yang mempengaruhi dan kemudian memproyeksikan hasil peramalannya menggunakan metode yang sudah dipilih tersebut.
3.4 Proses dan Metode Peramalan
Proses Peramalan dalam kasus ini dibagi menjadi dua metode, Peramalan Regresi Berganda dan MARIMA. Dimana kedua metode tersebut mempunyai variabel-variabel bebas yang mempengaruhi variabel-variabel tidak bebas (data keuntungan), tetapi variabel bebas dari masing-masing metode tidak berjumlah sama dan tentu saja hanya hal ini menyebabkan perbedaan data variabel bebas dari masing-masing metode. Pada dasarnya proses beserta variable-variable bebas dalam peramalan kasus ini dibagi menjadi dua, yaitu :
Metode Regresi Berganda menggunakan variabel data keuntungan sebagai variable tidak bebas, dan menggunakan beberapa variabel-variabel bebas seperti data penjualan dalam unit, pendapatan masyarakat, kurs dollar dan lain lain sebagai faktor yang mempengaruhi variabel tidak bebas tersebut.
Metode Fungsi Transfer atau MARIMA menggunakan variabel data keuntungan sebagai variabel tidak bebas (sebagai deret output), dan menggunakan variabel data investasi sebagai variabel bebas (deret input) yang mempengaruhi deret output tersebut. dalam kasus ini model fungsi transfer menggunakan data bivariate, yaitu hanya mempunyai dua deret data yang satu sebagai deret input dan deret output .
3.4.1 Metode Multiple Regression
Untuk memahami apa itu yang dimaksud dengan Regresi Berganda adalah dengan melihat variabel-variabel yang dinyatakan sebagai variabel yang dicari
(dependant variable) atau variabel yang menentukan (independent variable). Dalam bahasa indonesia biasa disebut sebagai variabel bebas dan variabel tidak bebas.
Regresi Berganda adalah peramalan dengan menggunakan analisa “cross section” atau “causal model” mendasarkan hasil ramalan yang disusun atas pola hubungan antara variabel yang dicari atau diramalkan dengan variabel-variabel yang mempengaruhi atau bebas yang bukan deret waktu.
Dalam analisa atau model ini , diassumsikan bahwa faktor atau variabel yang diramalkan menunjukkan suatu hubungan pengaruh sebab akibat dengan beberapa variabel bebas. Sebagai contoh permintaan atau penjualan dipengaruhi oleh variabel-variabel pendapatan, harga, persaingan, dan variabel-variabel-variabel-variabel lainnya. Dan bentuk umum dari multiple regression adalah :
Y = a + b1 X1 + b2 X2 + . . . + bn Xn (3-1-1)
di mana Y adalah variabel yang diramalkan (dependent variabel ) dan X1 adalah variabel
bebas pertama yang mempengaruhi Y, X2 adalah variabel bebas kedua yang
mempengaruhi Y, Xn adalah variabel bebas ke n yang mempengaruhi variable yang
diramalkan dan a, b1, b2, . . . bn adalah parameter atau koeffision regressi.
Penggunaan teknik dan metode multiple regression ini dalam peramalan, hanya mungkin bila dikethui nilai atau besaran dari parameter (koeffisien) regresi a, b1, dan b2 dalam hubungan fungsional dan multiple regresion dengan bentuk fungsi linear Y = a + b1 X1 + b2 X2 (dalam contoh hanya ada dua variabel bebas). Pada prinsipnya teknik dan
metode yang ada, mendasarkan proses analisanya pada usaha untuk mendapatkan suatu persamaan regresi yang tepat dengan kesalahan ramalan (ei) yang terkecil. Kesalahan
ramalan diminimalisasikan dengan cara mengambil turunan parsial atau partial derivative dari jumlah kesalahan ramalan dan kemudian menyamakannya dengan 0
(nol). Metode ini dikenal dengan metode “least squares” atau biasa disebut LS. Proses pengerjaannya sebagai berikut (dengan menggunakan 2 variabel bebas) (Assauri, 1984, p69-72) :
o Persamaan regresi peramalan adalah Yˆ =a+b1X1+b2X2 (3-1-2) o Kesalahan ramalan ialah ei =Yi −Yˆ
o Kuadrat kesalahan ramalan menjadi
∑
ei =∑
(Y1 −Yˆ)2 Kemudian subtitusikan Yˆ dengan a + b1 X1 + b2 X2 maka diperoleh∑
∑
= − − − 2 2 2 1 1 ) (Y a b X b X ei i (3-1-3)Parsial derivative-nya adalah :
∑
∑
=− − − = ∂ ∂ 0 ) ( 2 ) ( 2 2 1 1 2 X b X b Y a e i i (3-1-4)∑
∑
=− − − − = ∂ ∂ 0 ) ( 2 ) ( 2 2 1 1 1 1 2 X b X b a Y X b e i i (3-1-5)∑
∑
=− − − − = ∂ ∂ 0 ) ( 2 ) ( 2 2 1 1 2 1 2 X b X b a Y X b e i i (3-1-6)Dari ketiga persamaan di atas (3-1-4) , (3-1-5) dan (3-1-6) dapat diperoleh hasil persamaan dibawah ini, yang juga merupakan pola umum dari “least square”, yaitu:
∑
∑
Yi=na+b1∑
X1 +b2 X2 (3-1-7)∑
∑
X1Yi=a∑
X1+b1∑
X21+b2 X1X2 (3-1-8)∑
∑
X2Yi=a∑
X2 +b1∑
X1X2 +b2 X22 (3-1-9)Yang akhirnya nilai-nilai dari persamaan di atas dapat diperoleh dengan cara mensubtitusikan untuk mendapatkan parameter a , b1 dan b2. Hal ini juga berlaku untuk
lebih dari dua variabel bebas yang mempengaruhi variabel tidak bebas tersebut.
Pembuatan model Multiple Regression dapat dilakukan dengan cara menggunakan Matrix yaitu dengan memasukan nilai X dan Y sebagai berikut (Neter, 1996, p225-226) : ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = 2 1 1 1 1 22 12 1 12 11 1 Xn Xn X X X X X M M M M (3-1-10) ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = Yn Y Y Y M M 2 1 (3-1-11)
Yang kemudian dari data Matrix X dan Matrix Y di atas digunakan lebih lanjut untuk perhitungan Matrix X’X dan X’Y. setelah mendapatkan kedua matrix, maka perhitungan untuk mendapatkan model dapat dilanjutkan dengan menghitung X’X invers atau (X’X)-1 . kemudian akan menghasilkan (X’X)-1X’Y yang dimana :
⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ = − 2 1 ' ) ' ( 1 b b a Y X X X (3-1-12)
Dimana dari Matrix di atas maka akan menghasilkan pemodelan Y = a + b1X1 + b2X2
Untuk metode Regresi Berganda diperlukan standarisasi dari setiap variabel-variabel bebas yang mempengaruhi variabel-variabel tidak bebas, dengan membakukan setiap nilai-nilai dari tiap variabel bebas menjadi nilai Z dengan rumus:
σ υ − = i i x Z (3-1-13)
dengan menggunakan bantuan rumus µ
n x n i i
∑
= = 1 υ (3-1-14)dan dengan rumus S
n x n i i
∑
= − = 1 ) ( υ σ (3-1-15)Pengecekan valid atau tidaknya suatu data di dalam Regresi Berganda sangatlah penting untuk dilaksanakan, di dalam regresi berganda haruslah melakukan pengecekan korelasi (hubungan) antara variabel-variabel bebas dengan variabel bebas lainnya, selain itu juga dilakukan pengecekan korelasi (hubungan) antara variabel tidak bebas dengan variabel bebas. Korelasi-korelasi yang sesuai akan dapat menghasilkan peramalan data yang sesuai dengan model Regresi Berganda.
Valid atau tidaknya data multivariate yang akan dijadikan variabel-variabel untuk peramalan menggunakan model Regresi Berganda akan dibahas lebih lanjut melalui Multikolinearitas dan uji Significant F dan uji t.
3.4.1.1 Multikoleniaritas
Jika dua titik vektor (kolom-kolom data) berada pada arah yang sama, mereka dikatakan kolinear. Pada analisis regresi, multikolinearitas adalah nama yang diberikan kepada satu atau beberapa kondisi berikut :
• Dua variabel-bebas berkorelasi sempurna ( oleh karena itu vektor-vektor yang menggambarkan variabel tersebut adalah kolinear).
• Dua variabel bebas hampir berkorelasi sempurna (misalnya korealasi antar mereka mendekati +1 atau -1).
• Kombinasi linear dari beberapa variabel bebas berkorelasi sempurna (atau mendekasi sempurna) dengan variabel bebas yang lain.
• Kombinasi linear dari satu sub-himpunan variabel bebas berkorelasi sempurna(atau mendekati) dengan suatu kombinasi linear dari sub-himpunan variabel bebas yang lain.
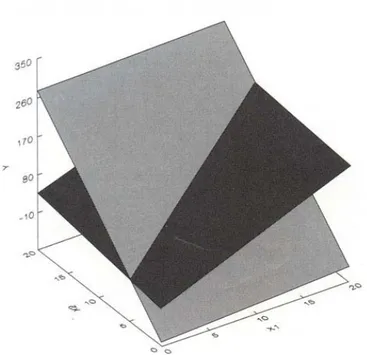
Multikolinearitas harus dihindari oleh model regresi karena hal ini dapat menyebabkan peramalan Y = a + bX (dan juga untuk regresi lebih dari 1 variabel) yang salah. Hal ini harus diperhatikan oleh pengguna model Regresi Berganda, karena pengguna model Regresi berganda merasa modelnya sudah benar, tetapi jika dicek lebih lanjut maka peramalan variabel tidak bebas akan menghasilkan peramalan yang salah .
Contoh: Y X1 X2 23 2 6 83 8 9 63 6 8 103 10 10
Dari data di atas akan terlihat korelasi yang sempurna antara X1 dan X2 yaitu 1 Dengan
model X2 = 5 + 0.5X1. Kemudian akan terjadi kekacauan karena seseorang telah
menemukan model regresi untuk data di atas yaitu : Ŷ = -87 + X1 + 18X2
Dan kemudian seseorang yang lain juga menemukan model regresi yaitu : Ŷ = -7 + 9X1 + 2X2 X1 X2 Ŷ = -7 + 9X1 + 2X2 Ŷ = -87 + X1 + 18X2 2 6 23 23 8 9 83 83 6 8 63 63 10 10 103 103
Terlihat Bahwa Kedua model tersebut menghasilkan Y yang sama, dengan menggunakan data dari X1 dan X2, dan menghasilkan peramalan Y yang berbeda jika X1
dan X2 nya dimasukan angka yang berbeda dari data di atas misalkan X1 = 12 danX2 =
12. karena itu lah Multikolinearitas haruslah dihindari di dalam model peramalan regresi.
Gambar 3.1 2 bidang yang bersinggungan di X2 = 5 + 0.5X1
3.4.1.2 Significant Test
Untuk Meneliti apakah regresi yang dipergunakan dalam penyusunan ramalan adalah benar linear atau tidak, di mana data observasi tepat berada di sekitar garis regresi linear , maka perlu dilakukan apa yang disebut dengan Significance test. Kalau ternyata dari hasil tes yang telah dilakukan diperolah hasil yang tidak significance , maka kurang tepatlah bila regresi linear yang dipergunakan dalam penyusunan ramalan tersebut.
Dalam significance tes ini, kita ingin mengetauhi apakah benar secara statistik (statistical valid) bahwa hubungan yang ada antara variabel yang diramalkan dengan variabel waktu adalah Y = a + bX. Untuk pengujian ini perlu dilakukan dua macam tes, yaitu:
• Test untuk mengetahui apakah koeffisien variabel bebas secara statistik berbeda dari 0 (nol), hal ini dikenal sebagai “F-test”
• Test untuk mengetahui apakah nilai estimasi dari a dan b dapat bervariasi karena pengaruh sampling dan/atau pengaruh random, dengan apa yang dikenal sebagai “t-test”
3.4.1.3 F-Test
Kita harus menentukan apakah untuk peramalan yang dilakukan dapat dipergunakan rata-rata atau garis regresi, sedangkan dari gambaran mengenai data observasi dapat dengan jelas atau tidak dapat terlihat dengan nyata. Oleh karena itu untuk maksud tersebut perlu dilakukan tes secara statistik dalam distribusi F, yang dikenal dengan “F-test”, yang menunjukkan apakah cara data atau pandangan statistik lebih baik digunakan rata-rata atau garis regresi untuk penggambaran data tersebut.
Distribusi F adalah ratio dari dua variance yaitu seperti persamaan (Assauri, 1984, p62-65) : k n Y Y k Y Y F − − − − =
∑
∑
2 2 ) ( 1 ) ( ) ) (3-2-1)atau menggunakan bantuan koeffisien penentu , R :
k n R k R F − −− = 2 2 1 1 (3-2-2)
dimana n = jumlah data dan k = jumlah variabel
Setelah nilai F ratio diperolah maka dilakukan perbandingan antara nilai F raito ini dengan F tabel , jika F ratio mempunyai nilai yang lebih kecil atau sama dengan nilai F tabel maka secara statistik koeffisien variabel bebas (contoh b di dalam Y = a + bX)
tidak significant berbeda dengan nol , sehingga dapat disimpulkan bahwa tidaklah tepat menggunakan model Y = a + bX atau tidaklah tepat menggunakan garis regresi
3.4.1.4 t-Test
Sebenarnya nilai a dan b yang diperoleh adalah merupakan hasil yang diperoleh dari suatu prosedur sample . Oleh karena itu nilai a dan b tersebut bukanlah merupakan nilai parameter dari riel (α dan β) , karena itu perlu menguji apakah benar nilai α dan β dapat diperoleh. T tes didasarkan atas nilai dari apa yang dikenal dengan “student-t distribution”, yang menunjukan seluruh nilai yang mungkin bahwa a dan b dapat diambil sebagai hasil dari sampling. Untuk pengetesan galat perlu dicari standard error dari a dan b . Standart error dari a diperoleh dengan formula (Assauri, 1984, p65-69) :
n
u aσ
σ
=
(3-3-1)Dimana σu adalah standard deviasi dari regresi , dan nilainya dicari dengan formula:
2 2 ) ( 2 2 − = − − =
∑
∑
n e n Y Yi i u )σ
(3-3-2)Standard error dari b diperoleh dengan menggunakan formula
∑
− = 2 ) (Xi X u bσ
σ
(3-3-3)Dengan menggunakan standar errod dari a(σa) dan standar error dari b(σb) , kita
dapat membuat selang kepercayaan dan tes hipotesis untuk ini , misalkan salah satu hipotesisnya tersebut menyatakan apakah nilai a (atau b) berbeda nyata atau significant dari 0(nol). Hipotesis ini dapat di tes menggunakan t distribution atau t test, dengan formula sebagai berikut:
a
a
a
test
t
σ
=
−
.
(3-3-4) dan bb
b
test
t
σ
=
−
.
(3-3-5)yang kemudian hasil dari t test ini dibandingkan dengan tabel t. Jika perhitungan t tes lebih besar dari nilai yang diperoleh dari t tabel maka dengan tingkat kepercayaan tertentu maka dapat disimpulkan bahwa nilai koeffisien regresi yaitu a ( atau b ) secara statistik berbeda nyata dari 0(nol). Dengan perkataan lain adalah tepat atau benar jika kita menggunakan persamaan multiple regresi bentuk linear yaitu Y = a + bx1.
Pengujian t-test dapat tidak dilakukan jika dari awal pengecekan multikolinearitas sudah dilakukan, hal ini karena hampir samanya pengetesan antara T-test dengan multikolinearitas yaitu untuk mencari hubungan antara variabel variabelnya.
3.4.2 Metode Tranfer Function (MARIMA)
Kunci untuk memahami metodologi MARIMA didapat dari perasaan tentang apa itu fungsi transfer. Seperti yang disebutkan sebelumnya dalam kasus ini model yang digunakan adalah MARIMA data bivariate yaitu data dari suatu deret input (Xt) dan deret
Output(Yt) yaitu suatu fungsi transfer dari data deret input yang kemudian di proses
dengan fungsi transfer, dan dengan tambahan deret output maka akan menghasilkan suatu peramalan deret output di masa mendatang. Fungsi transfer atau MARIMA disebut sebagai analisa deret waktu, karena deret ini mendasarkan hasil ramalan yang disusun atas pola hubungan yang dicari atau diramalkan dengan variabel waktu yang ditambah dengan variabel deret input.
Untuk deret input(Xt) dan deret Output(Yt) tertentu dalam bentuk data mentah,
terdapat empat tahap utama dan beberapa sub-tahap di dalam proses lengkap dari pembentukan model Fungsi Transfer atau MARIMA, sebagai berikut (Makridakis, 1999, p531-573) :
1. Identifikasi Bentuk Model
1.1 Mempersiapkan deret input dan output 1.2 Pemutihan deret input
1.3 “Pemutihan” deret output
1.4 Penghitungan korelasi-silang(cross corelation) dan autokolerasi untuk deret input dan deret output yang telah diputihkan
1.5 Penaksiran langsung bobot respons impuls
1.6 Penetapan(r,s,b) untuk model fungsi transfer yang menghubungkan deret input dan output
1.7 Penaksiran awal deret gangguan(nt) dan perhitungan autokolerasi, parsial
dan spektrum garis untuk deret ini
1.8 Penetapan (pn,qn) untuk Model ARIMA (pn,0,qn) dari deret gangguan (nt)
2. Penaksiran Parameter-Parameter Model Fungsi Transfer / MARIMA 2.1 Taksiran Awal parameter
2.2 Taksiran akhir parameter 3. Uji Diagnosis Model Fungsi Transfer
3.1 Penghitungan autokolerasi untuk nilai sisa model(r,s,b) yang menghubungkan deret input dan output
3.2 Penghitungan korelasi silang antara nilai sisa yang disebutkan dalam 3.1 dengan deret gangguan yang telah diputihkan
4. Penggunaan Model Fungsi Transfer untuk Peramalan
4.1 Peramalan nilai-nilai yang akan datang dengan menggunakan model fungsi transfer yang telah dibuat
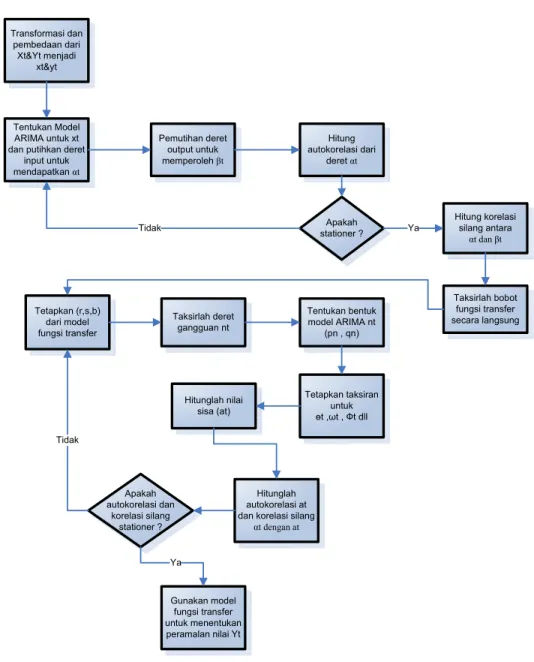
Ke empat tahap atau sub-tahap dalam penggunaan metode MARIMA dapat dilihat dengan lebih mudah dengan menggunakan bagan atau diagram berikut di bawah ini : Transformasi dan pembedaan dari Xt&Yt menjadi xt&yt Tentukan Model ARIMA untuk xt dan putihkan deret
input untuk mendapatkan αt Pemutihan deret output untuk memperoleh βt Hitung autokorelasi dari deret αt Apakah stationer ? Hitung korelasi silang antara αt dan βt Taksirlah bobot fungsi transfer secara langsung Tetapkan (r,s,b) dari model fungsi transfer Taksirlah deret gangguan nt Tentukan bentuk model ARIMA nt (pn , qn) Tetapkan taksiran untuk өt ,ωt , Фt dll Hitunglah nilai sisa (at) Hitunglah autokorelasi at dan korelasi silang
αt dengan at Apakah autokorelasi dan korelasi silang stationer ? Gunakan model fungsi transfer untuk menentukan peramalan nilai Yt Ya Tidak Tidak Ya
Gambar 3.2 Tahap-tahap proses metode MARIMA (Makridakis, 1999, p533-534, dimodifikasi)
3.4.2.1 Identifikasi Bentuk Model
• Mempersiapkan Deret Input dan Output
Tahap ini dianggap sebagai suatu tahap untuk menetapkan :
1. apakah tansformasi terhadap data input dan output perlu dilakukan atau tidak .
2. berapa tingkat pembedaan yang seharusnya diterapkan untuk deret input maupun output agar mereka menjadi stasioner.
3. apakah deret input dan output perlu dihilangkan pengaruh musimannya Deret Data yang telah ditransformasi dan yang telah sesuai , kemudian kita sebut xt dan yt. Atau bisa disimpulkan bahwa di tahap ini perlu diadakan
pengecekan kestationeran atau kestatisan (akan dijelaskan lebih lanjut di bagian 3.4.2.5) untuk melanjutkan ke tahap selanjutnya , yaitu dengan melakukan pembedaan terhadap nilai Xt dan Yt menjadi xt dan yt dengan persamaan :
(1-B) Xt = xt (3-4-1A)
(1-B) Yt = yt (3-4-1B)
• Pemutihan Deret Input (Xt)
Sebelum pemutihan Deret Input dilaksanakan , maka diperlukan suatu pencarian model ARIMA dari data xt, melalui perhitungan autokorelasi dan korelasi partial (akan dijelaskan lebih lanjut di bagian 3.4.2.5 dan 3.4.2.6) untuk menaksirkan atau menduga nilai θ dan Φ yang akan digunakan untuk
mendapatkan nilai pemutihan baik untuk deret input sebagai αt dan deret
output sebagai βt.
Dalam tahap pemutihan ini adalah “Hilangkan seluruh pola yang diketahui” supaya yang tertinggal adalah “white noise”. Ambil sebagai contoh, deret input xt. Apabila ia dapat dimodelkan sebagai proses ARIMA ,
misalnya ARIMA (px, 0, qx) maka ia dapat didefinisikan :
Φx(B)xt = θx(B)αt (3-4-2)
Dimana Φx(B) adalah operator autoregresi, operator rata-rata bergerak dan αt
adalah galat acak, yaitu white noise. Dengan menyusun kembali suku-suku pada sub-tahap (1-1) kita dapat merubah xt ke dalam deret nilai αt, sebagai
berikut : t t x x x B B α θ φ = ) ( ) ( (3-4-3)
inilah yang dimaksud dengan pemutihan deret xt
• “Pemutihan” Deret Output(Yt)
Sama dengan pemutihan deret input yaitu :
t t x x x B B β θ φ = ) ( ) ( (3-4-4)
Deret yt yang telah diputihkan akan disebut deret βt
• Penghitungan korelasi-silang(cross corelation) dan autokolerasi untuk deret input dan deret output yang telah diputihkan
Kovarian antara dua variabel X dan Y ditetapkan sebagai berikut (rumus di sub-tahap ini menggunakan x dan y sebagai pengganti α dan β) :
)} )(
{(X X Y Y E
Cxy= − −
Kita dapat menggunakan bentuk ini untuk mendapatkan dua ragam yaitu Cxx dan Cyy . Sekarang dengan memasang subskrip waktu di bawah variabel X dan Y dan dengan memisalkan k sebagai time lag (beda waktu setiap pasangan data), kita dapat menentukan kovarians silang Cxy(k) dan Cyx(k), sebagai berikut )} )( { ) (k E Xt x Yt k y Cxy = −μ + −μ (3-4-5) )}Cyx(k)=E{(Yt −μy)(Xt+k −μx (3-4-6) dimana k = 0,1,2,3... dan seterusnya. Di dalam persamaan 3-4-5 X memberikan petunjuk pada Y berdasarkan periode k, sama halnya untuk persamaan 3-4-6 Y yang memberikan petunjuk kepada Y berdasarkan periode k.
Persamaan 3-4-5 dan 3-4-6 didefiniskan sebagai ekspektasi. Dalam praktek, taksiran kovarians-silang dihitung dengan rumus sebagai berikut :
∑
− = + − − = n k t t t k Y Y X X n k Cxy 1 ) )( ( 1 ) ( (3-4-7)∑
− = + − − = n k t k t t Y X X Y n k Cyx 1 ) )( ( 1 ) ( (3-4-8)Rumus ini juga dapat digunakan untuk menetapkan auto kovarians yaitu dengan mensubtitusikan X untuk Y atau Y untuk X dan menetapkan varians sederhana yaitu dengan mensubtitusikan X untuk Y dan Y untuk X dan membuat k = 0.
Kovarian silang kemudian diubah menjadi korelasi silang dengan membagi kovarians tersebut oleh dua standar deviasi sebagai berikut :
y x xy xy S S k Cxy Cyy Cxx k Cxy k k r ( ) ) 0 ( ) 0 ( ) ( ) ( ˆ ) ( =ρ = = (3-4-9)
Penghitungan korelasi silang digunakan untuk penentuan nilai b pada model fungsi transfer. sedangkan perhitungan autokorelasi dari αt diperlukan
untuk mengetahui kestatisan data deret αt. jika ternyata data αt menghasilkan
ketidakstatisan maka tahap akan kembali ke sub-tahap 1-2 untuk menentukan model ARIMA lagi dan kembali mencari nilai dari αt dan βt.
• Penaksiran Langsung Bobot Repons Impuls
Di tahap ini dilakukan penaksiran langsung untuk masing-masing Bobot Respon impuls, dengan rumus sebagai berikut :
α β αβ
υ
S S k r k ) ( = (3-4-10)• Penetapan (r,s,b) untuk Model Fungsi Transfer
Tiga Parameter kunci di dalam model fungsi transfer adalah (r, s, b), dimana r menunjukkan derajat fungsi δ(B), s menunjukkan derajat fungsi ω(B), dan b menunjukkan keterlambatan sebelum deret input mulai mempengaruhi deret output.
Parameter b mungkin merupakan yang paling sederhana untuk dihadapi . Apabila korelasi silang diuji dan rαβ(0)= rαβ (1)= rαβ (2), tetapi rαβ (3)=0,5
maka kita mengetahui bahwa b=3. dengan kata lain terdapat lag absolute sebesar 3 periode sebelum deret input α mulai mempengaruhi deret input β.
Terdapat 3 prinsip petunjuk dalam pembentukan nilai (r, s, b) yang tepat. 1. Sampai lag waktu ke b , korelasi silang tidak akan berbeda dari nol
secara signifikan
2. Untuk s time lah selanjutnya, korelasi sialng tidak akan memperlihatkan pola yang jelas
3. Untuk r time lag selanjutnya, korelasi-silang akan memperlihatkan suatu pola yang jelas.
Kenyataan dari persoalan diatas adalah jarang untuk menguji diagaram korelasi silang dan membuat ketiga nilai (r, s, b) tersebut menampakan diri secara jelas.
• Pengujian Pendahuluan Deret Gangguan (Noise Series)
pada tahap 1.5, bobot υ diukur secara langsung dan ini memungkinkan dilakukannya penghitungan nilai taksiran pendahuluan dari deret gangguan nt
Karena
yt = υ(B)xt + nt maka
nt = yt – υ0xt – υ1xt-1- υ2xt-2- . . . . – vgxt-g (3-4-11)
dimana g merupakan nilai praktis yang dipilih oleh orang yang meramalkan. Fungsi υ(B) mempunyai jumlah suku tidak terbatas , akan tetapi pada sub-tahap 1-5 hanya 5 atau 10 atau 15 bobot υ yang akan dihitung, dan ini sudah
dianggap memuaskan sebagai analisis pendahuluan dari deret gangguan (noise series).
• Penetapan (pn,qn) untuk Model ARIMA (pn,0,qn) dari deret gangguan
(nt)
Setelah menggunakan persamaan 3-4-11 untuk mengukur deret gangguan, kemudian nilai-nilai nt dianalisis dengan cara ARIMA biasa untuk
menemukan apakah terdapat Model ARIMA (pn,0,qn) yang tepat untuk
menjelaskan mereka. Autokorelasi, spektrum garis ditetapkan dan selanjutnya nilai pn dan qn untuk autoregresi dan proses rata-rata bergerak,
berturut-turut dipilih. Dengan cara ini Φ n(B) dan θn(B) untuk nt diperoleh,
untuk mendapatkan : Φ n(B) nt = θn(B)αt
Atau untuk lebih memudahkan dapat dihitungan dengan perhitungan autokorelasi dan korelasi partial (akan dijelaskan lebih lanjut di bagian 3.4.2.5 dan 3.4.2.6).
3.4.2.2 Penaksiran Parameter Model Fungsi Tranfer / MARIMA
Setelah mendapatkan model fungsi MARIMA dari ARIMA dan model MARIMA dari deret noise maka akan dapat menghasilkan suatu model Fungsi transfer secara tentatif. Sebagai contoh suatu model fungsi dengan model fungsi transfer (2, 2, 2) dan ARIMA(2, 0, 1) untuk deret noise, maka menghasilkan model sebagai berikut :
t t t a B B B x B B B B y ) 1 ( ) 1 ( ) 1 ( ) ( 2 2 1 1 2 2 2 1 2 2 1 0 φ φ θ δ δ ω ω ω − − − + − − − − = − (3-4-12)
di tahap inilah nilai nilai dari ωn , δn , Φn dan θn akan ditaksirkan dengan taksiran.
Taksiran didapat dengan cara mensubtitusikan persamaan khusus seperti berikut: υj = 0 untuk j < b
υj = δ1υj-1 + . . . + δrυj-r + ω0 untuk j =b (3-4-13)
υj = δ1υj-1 + . . . + δrυj-r + ωj-b untuk j =b+1 , . . . , b+s
υj = δ1υj-1 + . . . + δrυj-r untuk j > b+s
dan jika rumus ini digunakan dengan menggunakan contoh dari model fungsi transfer dari model persamaan 3-4-12 jika nilai r = 2 , s = 2 dan b = 2, maka akan menghasilkan rumus : υ0 = 0 (1) υ1 = 0 (2) υ2 = δ1υ1 + δ2υ0 + ω0 (3) υ3 = δ1υ2 + δ2υ1 – ω1 (4) υ4 = δ1υ3 + δ2υ2 – ω2 (5) (3-4-14) υ5 = δ1υ4 + δ2υ3 (6) υ6 = δ1υ5 + δ2υ4 (7) υ7 = δ1υ6 + δ2υ5 (8)
dengan menggunakan pembobot impuls, maka akan didapat nilai nilai parameter yang diperlukan dengan cara mensubtitusikannya .
3.4.2.3 Pemeriksaan Diagnostik pada Model
Disini kita perlu mengecek deret nilai sisa akhir at dan hubungan deret at dengan
αt. Deret αt yang sudah didapat melaui tahap 1-2, secara umum bentuk prosedurnya
t b t t a B B x B B y ) ( ) ( ) ( ) ( φ θ δ ω + = −
bila dikalikan dengan δ(B)φ(B)kita peroleh
t b t t B B x B B a y B B) ( ) ( ) ( ) ( ) ( ) ( φ δ φ δ φ δ = − +
Dengan pengembangan perkalian dan pengaturan kembali, kita dapat mengekspresikan at sebagai sebuah fungsi dari bermacam-macam nilai y, nilai x dan nilai a sebelumnya. Berikut adalah tahap-tahap penguraian menjadi persamaan at dari model fungsi transfer
(1, 1, b)(1,1) : t t t a B B x B B y ) 1 ( ) 1 ( ) 1 ( ) ( 1 1 1 1 1 0 φ θ δ ω ω − − + − − = −
yang lanjutkan dengan mengkalikan tiap parameternya menjadi
t b t t B B x B B a y B B)(1 ) (1 )( ) (1 )(1 ) 1 ( −δ1 −φ1 = −φ1 ω0 −ω1 − + −δ1 −φ1 kemudian dengan melakukan pengaturan perkalian maka menjadi
yt = (δ1+Φ 1) yt-1 – (δ1Φ 1)yt-2
+ (ω0) x t-b – (ω0Φ 1+ω1) x t-b-1 + (Φ1ω1) xt-b-2 (3-4-15A)
+ at – (δ1+ θ 1) at-1 + (δ1θ1) at-2
Pada akhirnya Persamaan 3-4-15A dapat digunakan untuk peramalan , tetapi masih ada parameter yang kurang yang harus dicari yaitu at , sehingga melalui pengaturan kembali ,
maka persamaan at dapat dicari.
at = yt – (δ1+Φ 1) yt-1 + (δ1Φ 1)yt-2
– (ω0) x t-b + (ω0Φ 1+ω1) x t-b-1 – (Φ1ω1) xt-b-2 (3-4-15B)
Contoh menggunakan persamaan fungsi transfer (2, 2, b) (2, 0, 1) yang kita kerjakan adalah : at = yt + d1yt-1 + d2yt-2 + d3yt-3 + d4yt-4 - e0xt-b – e1xt-b-1 – e2xt-b-2 - e3xt-b-3 – e4xt-b-4 (3-4-16A) - f1at-1 – f2at-2 – f3at-3 di mana d1 = -δ1 - Φ 1 d2 = -δ2 - Φ 2 + δ1 Φ 1 d3 = δ1 Φ 2 + δ2 Φ 1 d4 = δ2 Φ 2 e0 = ω0 e1 = - ω1 - ω0Φ1 (3-4-16B) e2 = -ω0 Φ 2 – ω2 + ω1Φ1 e3 = ω1 Φ 2 + ω2 Φ 1 e4 = ω2 Φ 2 f1 = -δ1 - θ 1 f2 = -δ1 Φ 1 – δ2 f3 = θ 1δ2
Pengecekan deret nilai sisa akhir at (menggunakan persamaan 3-4-17A) dan hubungan
deret at denganαt (menggunakan persamaan 3-4-17B) dapat dilakukan dengan uji X2 Box
Pierce (menurut persamaan masing-masing) atau dengan pengecekan kestationeran atau kestatisan (perhitungan kestationeran atau kestatisan akan dijelaskan lebih lanjut di bagian 3.4.2.5).
∑
= − − = − − − − m k aa qn pn m n r s b r k 1 2 ) ( 2 ( 1 ) ( ) χ (3-4-17A)∑
= − − = − − m k a qn pn m n n r k 1 2 ) ( 2 ( 1 *) ( ) α χ (3-4-17B)3.4.2.4 Penggunaan Model Fungsi Transfer dalam Peramalan
Untuk memudahkan pemodelan MARIMA dari fungsi 3-4-16A di atas maka persamaan tersebut disederhanakan menjadi :
yt = - d1yt-1 - d2yt-2 - d3yt-3 - d4yt-4
+ e0xt-b + e1xt-b-1 + e2xt-b-2 + e3xt-b-3 + e4xt-b-4 (3-4-18)
+ f0at + f1at-1 + f2at-2 + f3at-3
Yang akhirnya persamaan 3-4-18 akan digunakan untuk meramalkan deret output dengan memasukan data sesuai dengan persamaan di atas. Untuk persamaan 3-4-15A juga merupakan persamaan yang sudah dapat digunakan untuk peramalan dengan model fungsi transfer (1, 1, b) (1, 1) .
3.4.2.5 Analisis Autokorelasi pengecekan Stationarity dan Nilai MA
Autokorelasi dapat dipergunakan untuk menentukan apakah suatu himpunan (set) data adalah acakan (random). Apabila seluruh koeffesien autokorelasi itu berada dalam batas-batas garis tingkat keyakinan, maka data tersebut adalah acakan. Untuk mengetahui seberapa jauh nilai acakan atau besarnya autokorelasi maka dilakukan perhitungan autokorelasi dengan time lag 1 sampai dengan n (biasanya n = 10). Berikut dibawah ini adalah rumus perhitungan korelasi (Assauri, 1984, p176-182) :
∑
∑
∑
∑
∑
−∑ ∑
− − = 2 2 2 2 ( ) ( ) ) )( ( Y Y n X X n Y X XY n rxy (3-4-19)Di dalam model ARIMA (p, d, q) terdapat 3 variabel atau nilai yang harus dicari dalam menentukan model. p variabel sebagai variabel AR, d variabel sebagai differential dan q model sebagai MA. Dengan menggunakan autokorelasi maka akan dapat menentukan nilai q atau MA .
Seperti yang disebutkan diatas bahwa nilai koeffesien korelasi harus di periksa lebih lanjut melalui perbandingan terhadap nilai garis batas melalui rumus batas dibawah ini ) 1 ( ) 1 ( n Z r n Z ≤ k ≤ − (3-4-20)
dengan menggunakan 95% tingkat kepercayaan maka akan dapat diketahui nilai Z melalui tabel Z.
Pengecekan nilai MA dapat dengan mudah diketahui dengan melihat koeffesien autokorelasi yang didapat dengan membandingkan nilai di timelag ke 1 sampai ke 10, jika melihat ternyata terdapat autokorelasi yang melebihi garis batas sampai ke timelag ke n, maka nilai q atau MA akan sama dengan nilai n tersebut. Dan jika tidak terdapat sama sekali nilai korelasi yang melebihi batas maka nilai q atau MA dinyatakan dengan 0.
Kestatisan dapat dengan mudah pula diperiksa oleh koeffesien autokorelasi dan garis batas, autokorelasi dari data yang statis akan menjadi nol atau mendekasi nol setelah timelag ke 2 atau ke 3, sedangkan untuk deret data yang tidak statis, autokorelasinya berbeda dari nol untuk beberapa periode waktu, atau akan melewati garis batas tingkat kepercayaan.
3.4.2.6 Analisis Partial Autokorelasi pengecekan nilai AR
Partial Autokorelasi adalah sebagai lanjutan dari perhitungan autokorelasi, tetapi dengan tambahan penggunaan persamaan untuk menghitung (Φ) yang menjadikannya partial dan akhirnya dapat digunakan untuk menghitung nilai AR dalam model ARIMA. berikut adalah persamaan-persamaan untuk mencari nilai dari partial autokorelasi (Assauri, 1984, p144-148) : p k p k k k k =φ ρ − +φ ρ − +φ ρ − +φ ρ − ρ 1 1 2 2 3 3 (3-4-21) untuk k = 1 , 2 , 3 , . . . , p Bila k = 1 : 0 1 1 φ ρ ρ = dan φ1 = ρ1 (3-4-22) jika ρ0 = 1, sedangkan ρ1 adalah koeffisien autokorelasi dari satu time lag .
Bila k =2 : 1 2 1 1 φ φ ρ ρ = + dan ρ2=φ1ρ1 +φ2 (3-4-23A) atau 2 1 1 2 2 1 ρ ρ ρ φ − − = dan 2 1 2 1 1 ) 1 ( 1 ρ ρ ρ φ − − = (3-4-23B) Bila k =3 : 3 3 1 2 1 1 φ φ ρ φ ρ ρ = + + 1 3 2 1 1 2 φ ρ φ φ ρ ρ = + + (3-4-24) 3 1 2 2 1 3 φ ρ φ ρ φ ρ = + +
Pensubstitusian r1 = ρ1 , r2 = ρ2 dan r3 = ρ3, dan pemecahan persamaan 3-4-24
susunan dari proses AR. Demikian pula halnya untuk k=p, kita dapat menghitung Φp dengan menggunakan p partial autokorelasi dari suatu kumpulan data deret waktu .
3.5 Analisis Error
Error adalah suatu hal yang mutlak dan selalu ada di dalam peramalan , karena peramalan tidak dapat secara pasti atau 100% menghasilkan data peramalan yang sama dengan hasil data fakta. Oleh karena itu, di dalam peramalan terdapat suatu perhitungan untuk menentukan seberapa besar error atau galat kesalahan peramalan yang dibuat jika dibandingkan dengan data faktanya.
Di dalam statistik peramalan terdapat dua rumus yang paling sering digunakan untuk menghitung error atau galat yang dihasilkan oleh peramalan,yaitu rumus MSE dan MAPE untuk menghitung error atau galat dari kesalahan peramalan metodenya.
Berikut adalah rumus MSE dan MAPE (Makridakis, 1999, p57-64) : MSE : n e n i i / 1 2
∑
= (3-5-1) keterangan : ¾ ei = error ¾ n = jumlah data MAPE n PE n i i / 1∑
= (3-5-2)Setelah menghitung galat menggunakan MSE dan MAPE, maka akan terlihat metode manakah yang lebih baik antara metode Regresi Berganda dan MARIMA.
3.6 Rekayasa Piranti Lunak
Rekayasa Peranti Lunak adalah aplikasi sistimatic, desain, pengembangan, maintaince dan dokumentasi dari peranti lunak yang digabungkan dengan teknologi dari computer science, management proyek, engineering,aplikasi, domain, desain tampulan, management asset digital dan field-field lainnya, yang bisa disimpulkan kegunaannya untuk membuat aplikasi dari rekayasa pembuatan piranti lunak.
Menurut Pressman (1992, p20-21), dalam perancangan piranti lunak, dikenal linear sequential model atau yang lebih dikenal dengan sebutan classic life cycle atau waterfall model. Model ini merupakan salah satu model terbaik yang digunakan dalam perancangan piranti lunak. Berikut adalah penjelasan singkat mengenai metode Waterfall melalui aktifitasnya :
1. System Engineering and Modeling (Model dan sistem Piranti Lunak)
Tahap ini adalah tahap penetapan kebutuhan dari semua elemen sistem yang akan dibuat, yaitu suatu proses yang besar yang dibuat berdasarkan requirement (permintaan) dari berbagai element dan kemudian mengalokasikan permintaan tersebut ke piranti lunak. Pandangan dari sistem ini adalah piranti lunak harus mempunyai interface dari berbagai element, seperti hardware, pengguna dan lainnya .
2. Software Requirement Analysis (Analisa Permintaan Piranti Lunak)
Yang dilakukan pada tahap ini adalah analisa atau penelitian guna mengetahui kebutuhan, sumber informasi, fungsi-fungsi yang dibutuhkan, kemampuan dan antarmuka dari sebuah piranti lunak yang akan direkayasa.
3. System Analysis and Design (Analisa Desain)
Tahap ini menekankan pada empat atribut program, yaitu struktur data, arsitektur piranti lunak, rincian prosedur dan karakter antarmuka. Pada tahap ini juga kita menerjemahkan kebutuhan ke dalam sebuah representasi perangkat lunak yang dapat dinilai kualitasnya sebelum dilakukan pengkodean.
4. Code Generation (pengkodean)
Di dalam tahap ini , desain yang sudah jadi di code untuk dapat menghasilkan piranti lunak yang diinginkan oleh permintaan dari analisis perancangan. penggunaan bahasa pemrograman yang tepat dapat membuat pembuatan piranti lunak menjadi lebih baik.
5. Testing
Tahap pengujian bertujuan untuk menguji atau memastikan output yang dihasilkan oleh program yang sudah dibuat sesuai dengan output yang kita harapkan. Tahap pengujian ini dapat dilakukan per unit, elemen atau secara keseluruhan.
6. Maintaince (Pemeliharaan)
Tahap pemeliharaan dilakukan dengan tujuan mengantisipasi kebutuhan pemakai terhadap fungsi-fungsi baru yang dapat timbul sebagai akibat munculnya sistem operasi baru, teknologi baru dan hardware baru.
Gambar 3.3 Waterfall Model [Pressman, 1992, p25]
3.6.1 Diagram Alir (FlowChart)
FlowChart adalah gambaran sistematis dari algoritma atau proses, yang biasa digunakan dalam bisnis/ekonomi presentasi untuk membantu pendengar menvisualisasikan isinya menjadi lebih baik. Secara umum diagram alir berisi tentang mulai dan berakhirnya suatu proses, masukan dan pengeluaran data, proses dan keputusan dalam mengetahui suatu proses atau dari suatu sistem. (http://en.wikipedia.org/wiki/Flowchart)
Berikut ini adalah tabel yang menjelaskan tentang komponen-komponen dari diagram alir : System Engineering Coding Analysis Design Maintenance Testing
Tabel 3.1 Tabel Simbol Diagram Alir
(http://www.smartdraw.com/tutorials/flowcharts/tutorial_02.htm)
Simbol Keterangan Dokumen
Simbol ini digunakan untuk menggambarkan semua jenis dokumen, yang merupakan formulir untuk merekam data terjadinya suatu transaksi.
Keputusan (Decision)
Simbol ini menggambarkan keputusan yang harus dibuat dalam proses pengolahan data. Keputusan yang dibuat ditulis dalam simbol.
Garis Alir
Simbol ini menggambarkan arah proses pengolahan data.
Masukan/Keluaran (Input/Output)
Simbol ini menggambarkan materi atau informasi yang masuk atau keluar dari sistem, seperti costumer order(masukan) atau produk(keluaran).
On Page Connector
Simbol ini menggambarkan penghubung jika masih di dalam satu halaman.
Simbol Keterangan
Off Page Connector
Simbol ini menggambarkan sebagai penghubung jika halamannya berbeda.
Proses
Simbol ini untuk menunjukkan tempat-tempat dalam sistem informasi yang mengolah atau mengubah data yang diterima menjadi data yang mengalir keluar. Nama pengolahan data ditulis didalam simbol.
Subroutine
Simbol ini menggambarkan rangkaian kejadian yang melakukan tugas tertentu yang dilekatkan kepada proses yang lebih besar.
Manual input
Input secara Manual dari pengguna atau user
Mulai / Berakhir (terminal)
Simbol ini untuk menggambarkan awal dan akhir suatu sistem akuntansi
3.6.2 Diagram Transisi (State Transition Diagram)
State Transition Diagram atau diagram transisi merupakan suatu alat perancangan yang menggambarkan sistem untuk mempengaruhi keaddan yang dinamis (Pressman,
1992, p217-234). Keadaan disini dapat difokuskan dan dihubungkan dalam berbagai cara untuk merepresentasikan sifat yang sekuensial dan concurrent(bersamaan). Transisi diantara dua keadaan umum disebabkan oleh suatu kondisi. Simbol-simbol yang digunakan di dalam STD adalah :
1. Modul
Simbol Lingkaran yang mewakili modul yang dipanggil apabila terjadi suatu tindakan.
Gambar 3.4 Gambar Notasi Modul 2. State (Tampilan Kondisi)
Merupakan layar yang ditampilkan menurut keadaan atau atribut, untuk mengetahui suatu dindakan pada waktu tertentu yang mewakili suatu bentuk keberadaan atau kondisi tertentu.
Gambar 3.5 Gambar Notasi Tampilan 3. State Transition (Tindakan)
Menggunakan simbol anak panah disertai keterangan tindakan yang dilakukan.
4. Kondisi dan Aksi
Kondisi bersifat mengubah state dan aksi adalah aksi yang dilakukan sistem ketika state berubah. Kondisi dan aksi digambarkan dengan anak panah yang menghubungkan dua keadaan yang berkaitan.
![Gambar 3.3 Waterfall Model [Pressman, 1992, p25]](https://thumb-ap.123doks.com/thumbv2/123dok/4578957.3334926/32.918.213.772.101.445/gambar-waterfall-model-pressman-p.webp)