1
BAB I PENDAHULUAN
1.
1.1. Latar Belakang
Perkembangan infrastruktur dan penggunaan teknologi informasi memberikan dampak yang luas dalam bagaimana manusia menjalani hidupnya.
Salah satunya adalah perolehan dan penyebaran informasi yang menjadi mudah dilakukan dalam bentuk elektronis, baik yang berwujud teks, wicara, citra, ataupun video. Hal ini mengakibatkan informasi menjadi berlimpah tetapi nilai informasi yang dikandungnya tidak teruji dan sulit dipertanggungjawabkan, bahkan berpotensi mengandung unsur negatif, salah satunya dalam bentuk pornografi.
Seiring berjalannya waktu, masalah pornografi semakin sulit diatasi dan semakin banyak ekspos pornografi kepada pengguna internet. Survey menunjukkan bahwa 64 persen pengguna internet berusia 10 sampai dengan 19 tahun di Indonesia mengetahui keberadaan konten pornografi di internet (KOMINFO dan UNICEF, 2014).
Di Indonesia terdapat beberapa upaya yang telah dilakukan untuk
menanggulangi masalah pornografi di internet, salah satunya adalah melalui
peraturan pemerintah. Di dalam Pasal 1 Peraturan Menteri Komunikasi dan
Informatika Republik Indonesia (PERMENKOMINFO RI) Nomor 19 Tahun 2014
Tentang Penanganan Situs Internet Bemuatan Negatif dijelaskan bahwa jenis situs
internet yang ditangani adalah situs yang mengandung pornografi dan kegiatan
ilegal lainnya berdasarkan peraturan perundang-undangan. Serta di dalam Pasal 8 dijelaskan bahwa Penyelenggara Jasa Akses Internet (PJAI) wajib melakukan pemblokiran terhadap situs-situs yang terdapat dalam TRUST+. Sistem TRUST+
menerapkan mekanisme kerja dengan menyediakan server pusat yang akan menjadi acuan dan rujukan kepada seluruh layanan akses informasi publik (fasilitas bersama), serta menerima informasi-informasi dari fasilitas akses informasi publik untuk menjadi alat analisis dan profiling penggunaan internet di Indonesia dengan melakukan perlindungan terhadap top level domain, Uniform Resource Locator (URL), dan konten .
Perlindungan terhadap URL tidak lain adalah upaya pemblokiran translasi URL situs bermuatan negatif terhadap alamat Internet Protocol (IP) penyedia dalam Domain Name Service (DNS). Akan tetapi, jumlah situs yang mengandung unsur pornografi terus berkembang. Selain itu, peraturan ini hanya berlaku pada penyelenggara akses internet Indonesia. Dengan demikian, apabila pengguna internet menggunakan DNS luar negeri, maka situs porno tetap dapat diakses.
Dengan adanya kelemahan tersebut, maka perlu dilakukan upaya pemblokiran situs porno melalui proses pengenalan konten situs web secara otomatis dimana komputer memiliki kemampuan mengenali dan mengklasifikasikan konten yang mengandung pornografi, baik konten visual, teks, ataupun kombinasi keduanya.
Pengklasifikasian berbasis teks merupakan hal yang penting dalam proses klasifikasi konten pornografi. Hal ini karena dalam beberapa penelitian terdahulu, klasifikasi teks merupakan deteksi awal kandungan konten pornografi (Du, 2003;
Hu, 2007; Ahmadi, 2011). Bahkan, dalam penelitian lain, klasifikasi teks menjadi
proses tunggal untuk pengenalan dan penapisan konten pornografi (Abidin, 2014).
Akan tetapi, klasifikasi teks bergantung pada Bahasa yang digunakan. Penelitian klasifikasi konten teks berbahasa Indonesia yang telah dilakukan sebelumnya dilakukan oleh Abidin (2014).
Abidin (2014) membangun sistem penapis konten pornografi dalam situs web Bahasa Indonesia berbasis klasifikasi teks dengan metode Vector Space Model (VSM) dan Term Frequency – Inverse Document Frequency (TF-IDF). Hasil pengujian menunjukkan 82.80% situs web yang mengandung pornografi berhasil tertapis. Untuk meningkatkan akurasi, Abidin menyarankan upaya peningkatan model klasifikasi dengan penggunaan metode tokenisasi n-gram dan reduksi term dalam pra-proses teks.
Namun demikian, akurasi klasifikasi teks dipengaruhi oleh banyak faktor, diantaranya koleksi data (Korde & Mahender, 2012), corpus category (Dan, 2013), pemilihan metode pra-proses, seleksi fitur, jumlah term atau kata yang digunakan (García Adeva, 2014) dan pemilihan algoritme klasifikasi. Oleh karena itu, pada penelitian ini akan dicari kombinasi proses klasifikasi yang menghasilkan akurasi terbaik pada kasus klasifikasi konten pornografi berbasis teks Bahasa Indonesia.
Proses klasifikasi yang dimaksud dalam penelitian ini adalah kombinasi
kerja antara metode pra-proses dan metode klasifikasi. Metode klasifikasi yang
populer dan menunjukkan akurasi yang tinggi dalam kasus klasifikasi teks
diantaranya adalah Naïve Bayes Classifier (NBC) dan Support Vector Machine
(SVM). Oleh karena itu, dalam penelitian ini dilakukan pengujian beberapa metode
pra-proses dan metode SVM dan NBC.
1.2. Rumusan Masalah
Berdasarkan paparan pada bagian latar belakang, maka rumusan masalah pada penelitian ini adalah sebagai berikut:
1. Akurasi klasifikasi yang belum tinggi pada klasifikasi konten pornografi berbahasa Indonesia berbasis teks.
2. Belum dieksplorasinya proses-proses pra-proses dan pemilihan metode klasifikasi yang digunakan untuk klasifikasi teks pornografi berbahasa Indonesia.
1.3. Batasan Masalah
Beberapa batasan yang dilakukan dalam penelitian ini adalah sebagai berikut:
1. batasan subyek penelitian, menggunakan kumpulan teks Bahasa Indonesia hasil ekstraksi dari situs-situs web yang telah digunakan pada penelitian Content Filtering oleh Abidin (2014), dan
2. batasan sistem, penelitian menggunakan perangkat lunak Weka versi 3.6.11 untuk pengolahan dan analisis data. Metode klasifikasi yang digunakan adalah Support Vector Machine (SVM) dengan kernel polinomial dan Naïve Bayes Classifier (NBC).
1.4. Pertanyaan Penelitian
1. Bagaimana penerapan metode SVM dan NBC pada proses klasifikasi teks
berbahasa Indonesia yang mengandung pornografi?
2. Apakah penggunaan metode tokenisasi yang berbeda dapat mempengaruhi proses klasifikasi teks berbahasa Indonesia yang mengandung pornografi?
3. Apakah penggunaan metode tokenisasi dan nilai C yang berbeda pada SVM dan NBC dapat mempengaruhi proses klasifikasi teks berbahasa Indonesia yang mengandung pornografi?
4. Apakah penggunaan metode tokenisasi, nilai C pada SVM dan NBC, dan stop word list yang berbeda dapat mempengaruhi proses klasifikasi teks berbahasa Indonesia yang mengandung pornografi?
1.5. Tujuan Penelitian
Tujuan dilakukannya penelitian ini adalah sebagai berikut:
1. mempelajari penerapan metode SVM dan NBC pada klasifikasi teks pada kasus klasifikasi teks Bahasa Indonesia yang mengandung konten pornografi,
2. melakukan analisis performa dan mengetahui tingkat akurasi algoritme SVM dan NBC dalam klasifikasi teks Bahasa Indonesia yang mengandung konten ponografi, dan
3. mengetahui pengaruh penggunaan metode-metode pra-proses dan nilai C yang digunakan terhadap akurasi klasifikasi menggunakan SVM dan NBC.
1.6. Manfaat Penelitian
Penelitian ini diharapkan dapat menjadi dasar dalam pengembangan sistem pengklasifikasi teks yang mengandung unsur pornografi yang lebih akurat.
Keberadaan sistem pengklasifikasi teks pornografi diharapkan dapat menjadi tapis
dari situs yang berisi konten pornografi baik yang berjalan di mesin client maupun berbasis proxy. Hasil penelitian ini diharapkan pula dapat dijadikan sebagai dasar dan pertimbangan dalam penelitian-penelitian yang terkait klasifikasi teks di masa depan.
1.7. Keaslian Penelitian
Penelitian ini merupakan kelanjutan dari penelitian ”System of Negative Indonesian Website Detection Using TF-IDF and Vector Space Model” yang telah dilakukan oleh Abidin (2014). Penilitian tersebut menggunakan metode TF-IDF dan Vector Space Model (VSM). Penelitian tersebut telah memperoleh akurasi klasifikasi sebesar 82.80%. Penelitian ini berupaya menghasilkan model klasifikasi terbaik yang merupakan kombinasi dari metode pra-proses dan metode klasifikasi yang digunakan.
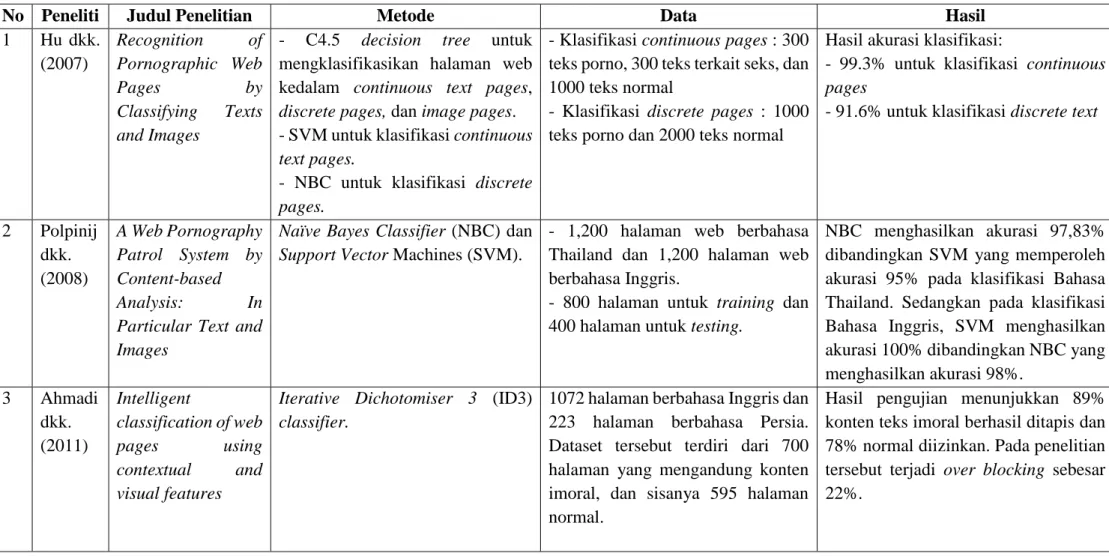
Beberapa penelitian mengenai klasifikasi konten teks untuk penapis konten
pornografi lainnya dapat diamati dalam Tabel 1.1.
Tabel 1.1 Ringkasan Penelitian Tentang Klasifikasi Teks Pornografi