2011 International Conference
on Asian Language Processing
IALP 2011
Table of Contents
Message from the General Chair...x
Message from the Program Chairs...xi
Message from the Local Organizing Chair...xii
Conference Committees...xiii
Program Committee...xiv
Invited Talks...xvi
Phonology, Morphology, Syntax, and Language Model
A Simplified-Traditional Chinese Character Conversion Model Based on Log-Linear Models ...3Yidong Chen, Xiaodong Shi, and Changle Zhou Improving Chinese Dependency Parsing with Self-Disambiguating Patterns ...7
Likun Qiu, Lei Wu, Kai Zhao, Changjian Hu, and Lingpeng Kong Joint Decoding for Chinese Word Segmentation and POS Tagging Using Character-Based and Word-Based Discriminative Models ...11
Xinxin Li, Xuan Wang, and Lin Yao Natural Language Grammar Induction of Indonesian Language Corpora Using Genetic Algorithm ...15
Arya Tandy Hermawan, Gunawan, and Joan Santoso Error-Driven Adaptive Language Modeling for Chinese Pinyin-to-Character Conversion ...19
Jin Hu Huang and David Powers Theoretical Framework of Mongolian Word Segmentation Specification for Information Processing ...23
Tong Laga and Xiaobing Zhao Research on the Uyghur Information Database for Information Processing ...26
Yusup Ebeydulla, Hesenjan Abliz, and Azragul Yusup Sentence Boundary Detection in Colloquial Arabic Text: A Preliminary Result ...30
Afnan A. Al-Subaihin, Hend S. Al-Khalifa, and AbdulMalik S. Al-Salman A Study of the Classification and Arrangement Rule of Uygur Morphemes for Information Processing ...33
Graph-Based Language Model of Long-Distance Dependency ...37 Faguo Zhou and Xingang Yu
BASRAH: Arabic Verses Meters Identification System ...41 Zainab A. Khalaf, Maytham Alabbas, and Tien-Ping Tan
Semantics
WordNet Editor to Refine Indonesian Language Lexical Database ...47 Gunawan, Jessica Felani Wijoyo, I. Ketut Eddy Purnama, and Mochamad Hariadi
Two Ontological Approaches to Building an Intergrated Semantic Network
for Yami ka-Verbs ...51 Meng-Chien Yang, Si-Wei Huang, and D. Victoria Rau
Issues with the Unergative/Unaccusative Classification of the Intransitive Verbs ...55 Nitesh Surtani, Khushboo Jha, and Soma Paul
A Sentence-Level Semantic Annotated Corpus Based on HNC Theory ...59 Zhiying Liu, Yaohong Jin, and Chuanjiang Miao
An Exploration on the Modes of Word Meaning Extension Based on Metaphorical
and Metonymic Mechanisms ...63 Xiaofang Ouyang
On the Semantic Orientation and Computer Identification of the Chinese Adverb
cai ...67 Lin He and Pengbing Chen
Exploring Both Flat and Structured Features for Number Type Identification
of Chinese Personal Noun Phrases ...71 Jun Lang
Discourse
The Context Imperative Sentences of Modern Chinese ...77 Hao Zhao and Kaihong Yang
Research on Cross-Document Coreference of Chinese Person Name ...81 Ji Ni, Fang Kong, Peifeng Li, and Qiaoming Zhu
Research of Event Pronoun Resolution ...85 Ning Zhang, Fang Kong, and Peifeng Li
Co-reference Resolution in Vietnamese Documents Based on Support Vector
Machines ...89 Duc-Trong Le, Mai-Vu Tran, Tri-Thanh Nguyen, and Quang-Thuy Ha
Research of Noun Phrase Coreference Resolution ...93 Junwei Gao, Fang Kong, Peifeng Li, and Qiaoming Zhu
Discourse Structures of English Exposition ...97 Donghong Liu and Meizhen Liao
Text Understanding and Retrieval
The Comparison of Chinese Spam Filter Based on Generative Model
and Discriminative Model ...107 Yong Han, Yingying Wang, Huafu Ding, and Haoliang Qi
Applying Grapheme, Word, and Syllable Information for Language Identification
in Code Switching Sentences ...111 Yin-Lai Yeong and Tien-Ping Tan
An Integrated Approach Using Conditional Random Fields for Named Entity
Recognition and Person Property Extraction in Vietnamese Text ...115 Hoang-Quynh Le, Mai-Vu Tran, Nhat-Nam Bui, Nguyen-Cuong Phan,
and Quang-Thuy Ha
A Query Reformulation Model Using Markov Graphic Method ...119 Jiali Zuo and Mingwen Wang
Search Results Clustering Based on a Linear Weighting Method of Similarity ...123 Dequan Zheng, Haibo Liu, and Tiejun Zhao
Extracting Pseudo-Labeled Samples for Sentiment Classification Using Emotion
Keywords ...127 Sophia Yat Mei Lee, Daming Dai, Shoushan Li, and Kathleen Ahrens
Imbalanced Sentiment Classification with Multi-strategy Ensemble Learning ...131 Zhongqing Wang, Shoushan Li, Guodong Zhou, Peifeng Li, and Qiaoming Zhu
Formalization and Rules for Recognition of Satirical Irony ...135 Lingpeng Kong and Likun Qiu
Summarization
An Automatic Linguistics Approach for Persian Document Summarization ...141 Hossein Kamyar, Mohsen Kahani, Mohsen Kamyar, and Asef Poormasoomi
Context-Based Persian Multi-document Summarization (Global View) ...145 Asef Poormasoomi, Mohsen Kahani, Saeed Varasteh Yazdi, and Hossein Kamyar
Centroid Integer Selection Model—A High Efficiency Method on Dynamic
Multi-document Summarization ...150 Meiling Liu, Dequan Zheng, Tiejun Zhao, and Yang Yu
Corpus Based Extractive Document Summarization for Indic Script ...154 P. Vijayapal Reddy, B. Vishnu Vardhan, and A. Govardhan
Research on Multi-document Summarization Model Based on Dynamic
Manifold-Ranking ...158 Meiling Liu, Honge Ren, Dequan Zheng, and Tiejun Zhao
Machine Translation
Improving Bilingual Lexicon Construction from Chinese-English Comparable
Corpora via Dependency Relationship Mapping ...169 Hua Xu, Dandan Liu, Longhua Qian, and Guodong Zhou
A Rule-Based Source-Side Reordering on Phrase Structure Subtrees ...173 Fangli Liang, Lei Chen, Miao Li, and Nasun-urtu
Automatic Acquisition of Chinese-Tibetan Multi-word Equivalent Pair
from Bilingual Corpora ...177 Minghua Nuo, Huidan Liu, Longlong Ma, Jian Wu, and Zhiming Ding
Character-Level System Combination: An Empirical Study for English-to-Chinese
Spoken Language Translation ...181 Jinhua Du
Mining Parallel Data from Comparable Corpora via Triangulation ...185 Thi-Ngoc-Diep Do, Eric Castelli, and Laurent Besacier
Using Rich Linguistic and Contextual Information for Tree-Based Statistical
Machine Translation ...189 Bui Thanh Hung, Nguyen Le Minh, and Akira Shimazu
Research on Element Sub-sentence in Chinese-English Patent Machine Translation ...193 Zhiying Liu, Yaohong Jin, and Yuhuan Chi
Lexical Word Similarity for Re-ranking in Vietnamese-English Named Entity Back
Transliteration ...197 Thi Hoang Diem Le and Ai Ti Aw
The Chinese-English Bilingual Sentence Alignment Based on Length ...201 Huafu Ding, Lili Quan, and Haoliang Qi
Optimal Translation Boundaries for BTG-Based Decoding ...205 Xiangyu Duan and Min Zhang
Spoken Language Processing
Acoustic Space in Motor Disorders of Speech: Two Case Studies ...211 Vaishna Narang, Deepshikha Misra, and Garima Dalal
Adopting Malay Syllable Structure for Syllable Based Speech Synthesizer for Iban
and Bidayuh Languages ...216 Sarah F. S. Juan, Vyonne Edwin, Chai Yeen Cheong, Jun Choi Lee, and Alvin W. Yeo
How Vietnamese Attitudes can be Recognized and Confused: Cross-Cultural
Perception and Speech Prosody Analysis ...220 Dang-Khoa Mac, Eric Castelli, Véronique Aubergé, and Albert Rilliard
Non-native Accent Pronunciation Modeling in Automatic Speech Recognition ...224 Basem H.A. Ahmed and Tien-Ping Tan
An In-car Chinese Noise Corpus for Speech Recognition ...228 Jue Hou, Yi Liu, Chao Zhang, and Shilei Huang
Development of Acoustic Space in 3 to 5 Years Old Hindi Speaking Children ...236 Vaishna Narang, Garima Dalal, and Deepshikha Misra
Design of a Query-by-Humming System for Hindi Songs Using DDTW Based
Approach ...240 Prakhar K. Jain, Robin Jain, Hemant A. Patil, and T.K. Basu
Linear Regression for Prosody Prediction via Convex Optimization ...244 Ling Cen, Minghui Dong, and Paul Chan
Analyzing the Relationship between Formants and Pitch for Singing Voice ...248 Hwee Teng Tan and Minghui Dong
Linguistic Resources and Tools
Using HTML Tags to Improve Parallel Resources Extraction ...255 Yanhui Feng, Yu Hong, Wei Tang, Jianmin Yao, and Qiaoming Zhu
Automatic Labeling and Phonetic Assessment for an Unknown Asian Language:
The Case of the “Mo Piu” North Vietnamese Minority (early results) ...260 Geneviève Caelen-Haumont, Sethserey Sam, and Eric Castelli
Automatic Construction of Chinese-Mongolian Parallel Corpora from the Web
Based on the New Heuristic Information ...264 Zede Zhu, Miao Li, Lei Chen, and Shouguo Zheng
Developing Bengali Speech Corpus for Phone Recognizer Using Optimum Text
Selection Technique ...268 Sandipan Mandal, Biswajit Das, Pabitra Mitra, and Anupam Basu
Polarity Shifting: Corpus Construction and Analysis ...272 Xiaoqian Zhang, Shoushan Li, Guodong Zhou, and Hongxia Zhao
Building a Rule-Based Malay Text Segmentation Tool ...276 Bali Ranaivo-Malançon
Language Learning
The Phoneme-Level Articulator Dynamics for Pronunciation Animation ...283 Sheng Li, Lan Wang, and En Qi
The Effect of Arabic Language on Reading English for Arab EFL Learners: An
Eye Tracking Study ...287 Kholod S. Al-Khalifah and Hend S. Al-Khalifa
A Study on Eye Movement of Thai Students Reading Chinese Texts with
or without Marks for Word Boundaries ...291 Yumei Jiao and Peng Yu
Games for Academic Vocabulary Learning through a Virtual Environment ...295 Kiran Pala, Anil Kumar Singh, and Suryakanth V. Gangashetty
WordNet Editor to Refine Indonesian Language Lexical Database
Gunawan*,**), Jessica Felani Wijoyo**), I Ketut Eddy Purnama*), Mochamad Hariadi*)
*) Department of Electrical Engineering Faculty of Industrial Technology Institut Teknologi Sepuluh November
Surabaya, East Java, Indonesia **) Department of Computer Science
Sekolah Tinggi Teknik Surabaya Surabaya, East Java, Indonesia
[email protected], [email protected], ketut@ee_its.ac.id, mochar@ee_its.ac.id
Abstract—This paper describes an approach for editing Indonesian Language Lexical Database especially noun category and its relations. The purpose of this editor is to refine Indonesian Lexical Database that was developed in our previous researches. The visualization of the editor is using graph library with some modifications and additions. Furthermore, this editor will be web based so that everyone can participate to improve Indonesian Language Lexical Database. There is an administrator role that had to accept or reject any suggestion for the changes suggested by any member. We believe that this editing approach can also be used to improve WordNet developed in other languages.
Keywords-editor; visualization; Indonesian Language; lexical database; WordNet
I. INTRODUCTION
WordNet [1] is an English lexical database developed by Princeton University. The smallest unit in WordNet is synonym set (synset) that has a meaning/sense. This lexical database has two kinds of relations, those are semantic relation between synsets and lexical relation between words. One example of semantic relations is hypernymy-hyponymy relation, whereas one example of lexical relations is antonymy. Indonesian WordNet or Indonesian Lexical Database will have the same structure as English WordNet. In this paper, we will use Indonesian WordNet term instead of Indonesian Lexical Database.
Indonesian WordNet has been developed in our previous researches. This WordNet contains synset, gloss/sense, hypernymy-hyponymy relation, and holonymy-meronymy relation. The Synset was built using monolingual lexical resources [2], hypernymy-hyponymy relation was built for noun category [3], gloss extraction from web to append definition from Kamus Besar Bahasa Indonesia (KBBI) [4], and the last is holonymy-meronymy relation that was built for noun category. All of them are done automatically so that sometimes they are incomplete and still contain mistakes. Therefore, it is necessary to build an editor for this Indonesian WordNet.
The rest of this paper is organized as follows. Section 2 is an explanation about Indonesian WordNet used in this editor. Section 3 presents the editing approach to refine Indonesian WordNet. Section 4 discusses about the result of the editing that has been done. Finally, section 5 and 6 give some conclusions and further research.
II. INDONESIAN WORDNET
In this section, the detailed information about Indonesian WordNet with some examples of its mistakes are presented. Each example will be equipped with the reason why it is considered wrong.
Table 1 presents the detailed data of Indonesian WordNet. This data are obtained from our previous researches as described in section I. It shows that there are 69830 synsets with each gloss, 9427 pairs hypernymy-hyponymy relations, and 2489 pairs holonymy-meronymy relations .
The 2489 pairs holonymy-meronymy relations are categorized into 3 types, those are part, substance, and member. Detailed of those types are described as follows.
1. If constituent object has different function, shape, and position then it is a part. For example, kaki (foot) is a part meronym for tubuh (body).
2. If constituent object is a substance (the content of other object) then it is a substance. For example,
oksigen (oxygen) is a substance meronym for
udara (air).
3. If constituent object has same function then it is a
member. For example, raja (king) is a member
meronym for istana (palace).
Table 2 shows the detailed data for each type of those relations according to the total number of holonymy-meronymy relations in table 1.
TABLE II. THREE CATEGORIES OF HOLONYMY-MERONYMY
pengganti akar gigi tiruan dan umumnya terbuat dari
Titanium atau paduan Titanium (artificial tooth root
replacement and usually made of Titanium or Titanium composite). Actually, gigi (tooth) has definition tulang keras dan kecil-kecil berwarna putih yang tumbuh tersusun berakar di dalam gusi dan kegunaannya untuk
mengunyah atau menggigit (hard bone and various small
things composed grow rooted in the gum and used for chewing or biting).
Wrong Gloss
gigi pengganti akar gigi tiruan dan umumnya terbuat dari Titanium atau paduan Titanium
tooth artificial tooth root replacement and usually made of Titanium or Titanium composite
Figure 1. Example of Wrong Gloss or Definition
An example of wrong hyponymy-hypernymy relation in Indonesian WordNet can be seen in figure 2. Synset {las} (which is equal to {weld} in English) has synset
{herba, tumbuhan_terna} (which is equal to {herb, herb
plant} in English) as a hypernym. {Weld} is an action while {herb, herb plant} is a kind of plant so that it is not correct that action can have a kind of plant as its hypernym. Because of that, this relation will be deleted.
Wrong Hypernymy-Hyponymy Relation
Hyponym :
las penyambungan (besi dan sebagainya) dengan cara membakar;
weld grafting (iron, etc) by burning
Hypernym :
herba, tumbuhan_terna tumbuhan terna
herb, herb plant herb plant
Figure 2. Example of Wrong Hypernymy-Hyponymy Relation
Another example is a wrong holonymy-meronymy relation (figure 3) which is gulai (curry) has duri (thorn) as its part. Gulai (curry) is one of Indonesian cuisine that does not have duri (thorn) as its part.
Wrong Holonymy-Meronymy Relation
Part Holonym :
gulai sayur berkuah santan dan diberi kunyit serta bumbu khusus (biasanya dicampur dengan ikan, daging kambing, daging sapi, dan sebagainya); salah satu masakan tradisional Indonesia yang berasal dari Sumatera Barat dan terkenal dengan kelezatannya karena mengandung berbagai macam rempah-rempah sebagai penyusun bumbu
curry vegetable with coconut milk sauce and will be given turmeric along with special seasoning (usually mixed with fish, mutton, etc.); one of Indonesian traditional cuisine comes from Sumatera Barat and popular with its delicious taste because it contains various spices as flavor constituents
Part Meronym :
duri gloss
thorn gloss
Figure 3. Example of Wrong Holonymy-Meronymy Relation
If we look at some examples of wrong data in Indonesian WordNet then it can be known that automatic data extraction will usually have imperfect data. Therefore, we need a manual correction using an editor.
After analyzing Indonesian WordNet data, there are 5924 wrong hypernymy-hyponymy relations and 1099 holonymy-meronymy relations to be deleted. After deleting those relations, the hypernymy-hyponymy relations got are 9427 - 5924 = 3503 relations and total holonymy-meronymy relations are 2489 - 1099 = 1390 relations. Besides those deletions, there are also additions for those relations to complete them. Detailed additions for hypernymy-hyponymy relations and holonymy-meronymy relations are 349 and 77 relations. The final Indonesian WordNet data can be seen in final column in table 3.
III. EDITING APPROACH
This editing approach uses a graph visualization to visualize Indonesian WordNet data. The purpose of this editor is not only to correct wrong Indonesian WordNet data but also to append it with antonymy relations for noun category. The graph drawing method used in this editor is Force Directed Graph so that it can produce graph with a good aesthetic. All suggestions correction data from member will be managed by a website administrator. Besides that, administrator has a responsibility to form a lexical database using grinder in Linux Operating System.
A. Indonesian WordNet Database Structure
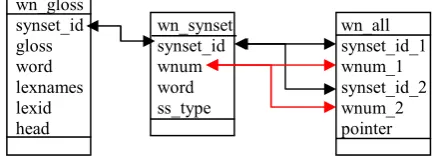
Structure of Indonesian WordNet database can be seen in figure 4. Wn_gloss is a table for all senses/definitions of synsets, wn_synset is a table for all synsets existing in Indonesian Language, and wn_all is a table for all relations whether semantic or lexical relations. WordNet in languages other than Indonesian Language can also be edited using this editor if their database are converted into a structure like figure 4.
wn_gloss
synset_id wn_synset wn_all
gloss synset_id synset_id_1
word wnum wnum_1
lexnames word synset_id_2
lexid ss_type wnum_2
head pointer
Figure 4. Indonesian WordNet Database Structure
B. Preprocessing
Before the editor uses Indonesian WordNet as input data, there are some preprocessing steps needed. This is because Indonesian WordNet was obtained automatically in our previous researches as explained before. The preprocessing steps are listed below.
1. Remove all special symbols in synset and gloss 2. Remove all tags (< >) and “gloss” keywords 3. Remove twin words
preprocessing Indonesian WordNet, we get total 69827 synsets with each gloss and no change in the number of relations.
C. Force Directed Graph
Force Directed Graph method [5] is one of graph drawing method that produces a graph with as few as crossing edges as possible. Graph created using this method is simulated as if it were physical system by assigning attractive and repulsive forces between nodes. This process is done continuously to find the optimal layout by minimizing the energy of the system. Most WordNet data visualization uses this method, synonym [6] for example. In this paper, the implementation of this method uses springy and springyui libraries. Those two libraries are used because the number of synonym words in Indonesian WordNet synsets are varied and sometimes too many.
D. Visualization and Editing
Editor web page explained here has two main areas, those are editing menus located at the left (area 1) and graph drawing canvas (area 2). Figure 5 shows how the design of this editor web page. Editing menus consist of word searching, graph setting, colors description, node description, and graph changing. Graph changing menu will be only available if members are in editing mode (by pressing “change” button in the change graph option in the word searching menu).
Figure 5. Editor Web Page
In graph changing menu (figure 6a), there are 4 types of data (sense, word in synset, semantic relation, and lexical relation) that can be managed and option to save the suggestion data to server database or not. If administrator agrees with that suggestion then the changes will be applied to Indonesian WordNet and vice versa. Figure 6b is the design of the form to add a new sense.
(a) (b)
Figure 6. Graph Changing Menu (a) and Add New Sense Form (b)
Indonesian WordNet data in this editor will be presented in graph elements as follows. Sense and word in each synset will be represented in node form, while all relations whether semantic or lexical relations will be represented in edge form. A sense is represented by its synset number, whereas a word in synset is represented by the word itself. Each WordNet category (noun, verb, adjective, adverb) and relation will have different colors which can be managed using graph setting menu. Description of those colors can be seen in colors description menu in figure 7.
Figure 7. Colors Description Menu
An example of WordNet data visualization (using colors setting in figure 7) can be seen in figure 8. Node with green color is a sense with noun category. Edge with orange color is a synonym relation. Manusia (human being) has 5 different noun senses/definitions/meanings in Indonesian WordNet. In figure 8, manusia (human being)
and penunggu dunia (world watchman) are synonym in
sense number 40927.
Figure 8. The Visualization of Manusia (Human Being)
Several functions and methods are added to the springy and springyui libraries and also some modifications are made to those two libraries so that they can meet the needs of this editor. In this paper, only some of the additional functions and methods are shown. These additional functions and methods can be seen in figure 9.
Synonym
Word
area 2 area 1
Hyponym to Hypernym
modify sense
modify all the categories of words in the synset modify a word in the synset
delete all lexical relations delete all words in the synset delete a certain word in the synset get a node by its label
add new or delete existing semantic relation add new or delete existing lexical relation add new sense to existing word
get the status of the graph get the total number of nodes
add new edge with certain type to the graph create new node with certain type
create new edge with certain type
Figure 9. Some Additional Functions and Methods
E. Editor Website Management and Lexical Database
Formation
This editor system needs an administrator role to manage all suggestions suggested by members. Every suggestion that is accepted will change Indonesian WordNet data and vice versa.
Before converting the database to a lexical database model, the database will be converted into lexicographer files. In this editor we use lexicographer file generator that was created in our previous research. Afterward, Indonesian WordNet will be created using grinder in Linux Operating System by administrator (local/not web based).
IV. RESULT
In this section, an explanation about the result that we get after editing Indonesian WordNet data is given. Table 3 shows information about the initial state and the final state. Initial state is state after preprocessing Indonesian WordNet data, whereas final state is the final state after correcting the data. Actually, between these two states there are some editing phases with more than 85 volunteers in correcting this Indonesian WordNet data.
TABLE III. INDONESIAN WORDNET RESULT
Data Initial Final
Gloss 69827 69827
Synset 69827 69827
Antonymy 0 78
Substance 179 146
Member 209 180
We also compare the statistic of Indonesian WordNet to English WordNet. Table 4 shows the comparison of words and synsets for both languages. Both languages have most definitions in noun category. We can see here that Indonesian WordNet is more compact than English WordNet. It can be seen from the total number of words and synsets for Indonesian WordNet which are fewer than English WordNet. Words Synsets Words Synsets
Noun 53529 41272 117798 82115
Verb 30211 20798 11529 13767
Adjective 12375 7104 21479 18156
Adverb 1455 653 4481 3621
Total 97570 69827 155287 117659
V. CONCLUSIONS
Indonesian WordNet correction needs a fairly large number of Volunteers. This is due to the amount of Indonesian WordNet data that is quite a lot as explained before. Besides that, knowledge about WordNet as a lexical database that consists of 4 categories (noun, verb, adjective, and adverb) with semantic and lexical relations is extremely important. This is due at the time of correcting data by volunteers, many of them are still not familiar with WordNet and confused with the purpose of each relationship and term.
Visualization and editing Indonesian WordNet data visually make user enjoy the editing process. Representation of WordNet data in a text based can not attract users in the process of correcting data. This editor also shows only one relation at a time while visualizing Indonesian WordNet data to make it clear and understandable.
The most important thing is this editing approach, as already described before, is probably applicable to all WordNet with other languages than Indonesian Language. Using this editing approach, WordNet developed in other languages can also be refined.
VI. FURTHER RESEARCH
Based on this editor, we find an enhancement that can be done. The enchancement is to improve the editor so that it can handle other Indonesian WordNet categories with their relations besides noun category.
ACKNOWLEDGMENT
We would like to thank STTS students that had already become volunteers to correct Indonesian WordNet data using this editor. We also hope that this Indonesian Wordnet can be helpful for developing Indonesian Natural Language Processing, Text Mining, and Web Mining applications.
REFERENCES
[1] Christiane Fellbaum, “WordNet: An Electronic Lexical Database”, Cambridge, MA: MIT Press, 1998.
[2] Gunawan and Andy Saputra, “Building Synsets for Indonesian WordNet with Monolingual Lexical Resources”, Proc. IALP conference, Harbin, China, 2010.
[3] Gunawan and Erick Pranata, “Acquisition of Hypernymy-Hyponymy Relation between Nouns for WordNet Building”, Proc. IALP conference, Harbin, China, 2010.
[4] Tim Pusat Bahasa, Kamus Bahasa Indonesia, Jakarta : Pusat Bahasa Departemen Pendidikan Nasional, 2008.
[5] Yi Fan Hu, “Efficient and High Quality Force-Directed Graph Drawing”, The Mathematica Journal, 10 (37-71), 2005.