4.1. Disain Penelitian
Disain dalam penelitian ini menggunakan metode penelitian eksplanatif kuantitatif, dimana data yang akan digunakan adalah data kuantitatif yang berbentuk angka atau data yang diangkakan. Menurut Sugiyono (2009), penelitian eksplanatif adalah penelitian yang bertujuan untuk menguji berbagai hipotesa yang tujuannya untuk membenarkan atau memperkuat hipotesa tersebut serta menentukan sifat hubungan antara satu atau lebih variabel terikat dengan satu atau lebih variabel bebas.
Tujuan pemilihan metode eksplanatif karena peneliti ingin menguji hipotesis hubungan antar variabel nilai hubungan (relationship value)yang terdiri dari: biaya produk langsung (direct product cost), kualitas produk, kinerja pengiriman, orientasi pelanggan(customer know-how), dukungan layanan(service support) dan interaksi pribadi (personal interaction) terhadap kepuasan dan dampaknya terhadap loyalitas sikap (attitudinal loyalty) dan perilaku (behavioral loyalty). Pengumpulan data dan informasi diambil dari sampel dengan menggunakan daftar pertanyaan (questioner), kemudian dianalisa untuk mendapatkan data yang akurat tentang fakta-fakta serta hubungan antara variabel penelitian.
4.2. Variabel Penelitian
Variabel dalam penelitian ini dibedakan menjadi 3, yaitu variabel eksogen, variabel endogen dan variabel endogen mediasi. Variabel eksogen adalah variabel yang tidak diprediksi oleh variabel lain dalam model. Variabel eksogen dikenal juga sebagai independent variable. Variabel endogen, yakni variabel yang diprediksikan oleh satu atau beberapa variabel yang lain dalam model. Variabel endogen dikenal juga sebagai dependent variable. Sedangkan variabel endogen mediasi disebut juga variabelintervening atau antara. Variabel bebas kejadiannya adalah mendahului variabel terikat. Menurut Diposumantri (2012), variabel independen merupakan variabel yang menentukan atau mempengaruhi variabel dependen yang nilainya dapat mempengaruhi atau menentukan variabel dependen. Variabel mediadi merupakan variabel yang secara teoritis mempengaruhi hubungan antara variabel independen dengan variabel dependen menjadi hubungan yang tidak langsung dan tidak dapat diamati dan diukur. Variabel ini merupakan variabel penyela atau antara variabel independen dengan variabel dependen, sehingga variabel independen tidak langsung mempengaruhi berubahnya atau timbulnya variabel dependen. Sementara variabel dependen merupakan variabel yang nilainya dapat berubah dikarenakan adanya perubahan variabel yang lain atau ditentukan oleh variabel independen, keterkaitan variabel independen dan dependen ditunjukan pada model persamaan fungsi atau model persamaan matematika tertentu yang menggambarkan hubungan sebab akibat.
Tabel 4.1. menunjukkan variabel eksogen (independent variable),variabel endogen mediasi (intervening variable) dan variabel endogen (dependent variable)dalam penelitian ini :
Tabel 4.1. Variabel Penelitian
No. Variabel eksogen Variabel endogen
mediasi Variabel endogen 1 Biaya produk langsung Kepuasan Pelanggan Loyalitas perilaku
2 Kualitas produk Loyalitas sikap
3 Kinerja pengiriman (Delivery performance) 4 Orientasi Pelanggan
(customer know how) 5 Dukungan layanan
(service support) 6 Interaksi pribadi
(personal interaction)
4.2.1. Definisi Konsep
Definisi konseptual dari variabel dalam penelitian ini adalah :
a. Biaya Produk Langsung (direct product cost), yaitu harga yang dikenakan oleh pemasok, sebagai kunci hubungan antara pemasok dan pelanggan. Biaya produk merupakan semua biaya yang dikeluarkan perusahaan untuk memproduksi sebuah produk.
b. Kualitas Produk, yaitu kemampuan suatu produk untuk melakukan fungsi-fungsinya, kemampuan itu meliputi daya tahan, keandalan, ketelitian yang dihasilkan, kemudahan dioperasikan dan diperbaiki, dan atribut lain yang berharga pada produk secara keseluruhan.
c. Kinerja Pengiriman,merupakan kemampuan produsen atau pemasok dalam memenuhi 3 hal, yaitu : ketepatan waktu dalam memenuhi jadwal pengiriman, fleksibilitas, artinya dapat menyesuaikan diri dengan perubahan jadwal pengiriman, dan akurasi, artinya secara konsisten mengirimkan barang sesesuai dengan pesanan.
d. Orientasi Pelanggan (customer know-how), mencakup pengetahuan pemasok tentang bagaimana cara membantu pelanggan dalam mengembangkan produk baik produk yang sudah ada maupun produk baru. e. Dukungan Layanan (service support), meliputi sikap responsif dalam
melayani pelanggan serta kapasitas untuk mengelola pertukaran informasi antara pelanggan dengan pemasok.
f. Interaksi Pribadi (personal interaction), adalah dengan mengetahui informasi detail mengenai pelanggan serta menjaga hubungan baik dengan pelanggan.
g. Kepuasan Pelanggan (customer satisfaction) merupakan pengukuran yang merepresentasikan performa dari suatu perusahaan berdasarkan perspektif kebutuhan pelanggan. Pengukuran kepuasan pelanggan ini didasarkan kepada kualitas dari pelayanan yang disediakan oleh perusahaan. Pelanggan memberikan pandangan dan pendapat mereka tentang pelayanan yang diberikan perusahaan dengan memberikan penilaian terhadap aspek-aspek pelayanan yang ada berdasarkan pengalaman yang dialaminya.
h. Loyalitas Sikap (attitudinal loyalty), meliputi tingkat kecenderungan komitmen terhadap suatu merek oleh pelanggan, kata positif dari mulut,
kemauan untuk merekomendasikan kepada orang lain dan mendorong orang lain untuk menggunakan produk dan jasa perusahaan.
i. Loyalitas Perilaku (behavioural loyalty),merupakan pembelian ulang atau pembelian kembali suatu merek oleh pelanggan, konsep yang menekankan pada runtutan pembelian, proporsi pembelian dan probabilitas pembelian.
4.2.2. Definisi Operasional
Definisi operasional adalah suatu definisi yang didasarkan pada karakteristik yang dapat diobservasi dari apa yang sedang didefinisikan atau mengubah konsep-konsep yang berupa konstruk dengan kata-kata yang menggambarkan perilaku atau gejala yang dapat diamati dan yang dapat diuji dan ditentukan kebenarannya oleh orang lain (Young dalam Koentjaraningrat, 2002).
Tujuan adanya definisi operasional adalah untuk memudahkan didalam pengumpulan data dan menghindarkan perbedaan interpretasi serta membatasi ruang lingkup variabel. Selain itu adanya definisi operasional dapat mengukur definisi variabel secara operasional dan dapat dipertanggungjawabkan (referensi jelas)
Untuk memudahkan instrumen penelitian, maka peneliti menggunakan matrik pengembangan instrumen. Menurut Sugiyono (2009:120), matrik pengembangan instrumen adalah matrik yang digunakan untuk memudahkan penyusunan instrumen penelitian. Titik tolak dari penyusunan instrumen penelitian ini adalah variabel-variabel yang ditetapkan untuk diteliti. Dari variabel-variabel ini kemudian ditetapkan indikator-indikator dari setiap variabel,
yang selanjutnya dijabarkan menjadi butir-butir pertanyaan. Untuk bisa menetapkan indikator-indikator dari setiap variabel yang diteliti, maka peneliti mendasarkannya pada kajian teori-teori yang mendukung, hasil penelitian sebelumnya serta menganalisa data yang ada di lapangan. Penggunaan teori, hasil penelitian sebelumnya dan analisa data lapangan dilakukan secermat mungkin agar diperoleh indikator yang valid.
Berdasarkan kajian teori, hasil penelitian sebelumnya dan analisa data lapangan, maka peneliti menyusun matrik pengembangan instrumen atau biasa disebut juga dengan operasional variabel penelitian sebagai berikut :
Tabel 4.2. Variabel Operasional Penelitian
Variabel Dimensi Indikator Skala
Biaya produk langsung
(direct product cost) Harga produk Ordinal
Memberikan penawaran harga yang
menarik Ordinal
Biaya resiko barang cacat Ordinal Keamanan barang dalam pengiriman Ordinal Kualitas produk Kinerja Produk
(performance) Warna cerah dan tidak mudah pudar Ordinal Daya tutup cat yang baik Ordinal Daya sebar cat yang luas Ordinal Garansi dari pengaruh perubahan cuaca,
pertumbuhan jamur dan lumut Ordinal Fitur produk
(features) Varian warna cat Decorshield Ordinal Sumber: Diolah oleh penulis (2015)
Lanjutan Tabel 4.2. Variabel Operasional Penelitian
Variabel Dimensi Indikator Skala
Reliabilitas (reliability)
Cat yang diformulasikan untuk cat tembok eksterior
Ordinal Kesesuaian
(conformance)
Kualitas produk sesuai dengan ekspektasi pelanggan
Ordinal Daya tahan
(durability)
Jaminan waktu dalam penyimpanan barang
Ordinal Kinerja pengiriman
(delivery performance)
Pengiriman sesuai denganlead timeyang ditentukan
Ordinal Barang yang dikirim sesuai dengan
pesanan pelanggan
Ordinal Barang pesanan dapat dikirimkan lebih
cepat, dalam kondisi khusus sesuai dengan permintaan pelanggan
Ordinal
Orientasi pelanggan (customer know-how)
Keaktifan dalam pengembangan produk existingdi pemasar perantara
Ordinal Mengetahui potensi pengembangan
produk baru di pemasar perantara
Ordinal Dukungan layanan
(service support)
Tenaga pemasar memberikan informasi yang cepat ketika dibutuhkan pelanggan
Ordinal Tenaga pemasar memberikan informasi
yang tepat kepada pelanggan
Ordinal Interaksi pribadi
(personal interaction)
Mudah bekerja sama dengan pelanggan Ordinal Memiliki hubungan kerja yang baik
dengan pelanggan
Ordinal Kepuasan Pelanggan Expectation Kesesuaian produk dan kinerja dengan
harapan
Ordinal Adanya pengalaman positif dalam
bekerja sama
Ordinal Subjective
Disconfirmation
Adanya konfirmasi individu tentang produk dan layanan
Ordinal Performance
Outcomes
Adanya manfaat yang optimal dari produk dan layanan Ordinal Loyalitas Sikap (attitudinal loyalty) Sikap merekomendasikan
Word of mouth(WOM) positif Ordinal Kesediaaan merekomendasikan Ordinal Loyalitas perilaku
(behavioural loyalty)
Sikap pembelian ulang
Pembelian rutin produk pemasok Ordinal Hubungan kerjasama
jangka panjang
Kesediaan melakukan kerjasama jangka panjang
Ordinal
4.3. Populasi dan Sample Penelitian
4.3.1 Populasi
Populasi adalah wilayah generalisasi yang terdiri atas obyek atau subyek yang mempunyai kualitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulannya (Sugiyono, 2009:72).
Pada penelitian ini yang menjadi populasi adalah seluruh perantara pemasaran(stockist)PT. Propan Raya di Jawa dan Sumatera yang berjumlah 2000 stockist. Jumlah ini adalah berdasarkan data jumlahstockistper Desember 2014.
4.3.2 Sample
Sampel adalah anggota populasi yang memberi keterangan yang hendak diselidiki dan dianggap bisa mewakili keseluruhan dari populasi (Sunyoto, 2011). Menurut Sugiyono (2006:73), sampel adalah bagian dari jumlah dan karakteristik yang dimiliki oleh populasi tersebut. Dengan kata lain, sampel merupakan bagian yang diambil dari populasi dalam suatu penelitian.
Penentuan lokasi penelitian didasarkan pada keterbatasan-keterbatasan yang dimiliki peneliti, sedangkan untuk mendapatkan sampel yang dapat menggambarkan populasi, maka dalam penentuan sampel penelitian ini digunakan rumus Slovin dalam Umar (2004), sebagai berikut :
Gambar 4.1. Rumus perhitungan sample menurut Slovin
Ket :
n = Jumlah sampel N = Jumlah Populasi
e = Batas toleransi kesalahan (error tolerance)
Populasi dalam penelitian ini adalah semua perantara pemasaran atau distributor cat retail yang menjual produk Decorshield dengan jumlah kurang lebih 2.000 stockist. Adapun besarnya sampel ditentukan dengan menggunakan rumus Slovin (Umar, 2004) adalah :
n = N/(1+Ne²)
n = 2.000/1+(2.000x0.08²)
n = 144.9 atau dibulatkan menjadi 145 responden.
Kuesioner diberikan langsung oleh peneliti dengan sebelumnya dijelaskan maksud dan tujuan penelitian agar tidak terjadidistorsidalam pengisian substansi kuesioner. Jika responden berkenan maka kuesioner dapat diisi langsung, tetapi jika waktu tidak memungkinkan karena kesibukan atau sesuatu hal bagi responden maka jawaban kuesioner di ambil dalam 1 atau 2 hari sesuai dengan kesepakatan.
Teknik pengambilan sampel pada penelitian ini menggunakan Non Probability Sampling, yaitu teknik sampling yang tidak diberikan peluang yang sama bagi setiap populasi untuk dipilih menjadi anggota sampel, sedangkan metode yang digunakan adalah Judgemental Sampling, yaitu cara pemilihan sampel atas dasar pertimbangan tertentu. Dalam metode ini, periset menggunakan pertimbangan tertentu terhadap elemen populasi yang dipilih sebagai sampel.
Anggota populasi yang dipilih ditentukan langsung oleh periset. Artinya, tidak ada peluang bagi anggota populasi yang lain untuk menjadi sampel bila di luar pertimbangan periset (Istijanto, 2009). Dalam hal ini periset menetapkan kriteria bahwa sampel harus menjual cat Decorshield, dengan demikian tidak semua toko cat ritel memiliki peluang yang sama untuk terpilih menjadi sampel (non-probability).
4.4. Jenis dan Sumber Data
Sumber data yang akan diperoleh dalam penelitian ini adalah sebagai berikut :
1) Sumber data primer, merupakan data primer yaitu merupakan data yang di dapat dari sumber pertama baik individu atau perorangan, seperti hasil wawancara atau pengisian kuesioner, dalam hal ini adalah perantara pemasaran (stockist) cat DecorshieldPT. Propan Raya
2) Dokumentasi atau arsip perusahaan, merupakan sumber data dalam bentuk informasi dan dokumen yang diperoleh dalam bentuk surat-surat, catatan atau laporan yang terkait dengan masalah penelitian yang telah tersusun dalam arsip pada PT. Propan Raya.
4.5. Teknik Pengumpulan Data
Untuk mengumpulkan data, penggunakan teknik pengumpulan data dilakukan melalui teknik sebagai berikut:
1) Angket atau kuesioner, yaitu pengumpulan data melalui daftar pertanyaan secara tertutup dalam bentuk daftar pertanyaan tentang masalah penelitian
yang harus diisi oleh reponden tanpa kehadiran peneliti. Untuk menghasilkan jawaban yang diharapkan, maka dalam angket diberikan panduan pengisian, bahasa yang sederhana, dan item pertanyaan sesuai dengan permasalahan kajian.
2) Wawancara atau interview merupakan proses yang dilakukan dengan melalui tanya jawab langsung dengan sejumlah objek penelitian untuk tujuan tertentu. Wawancara dapat dilakukan di rumah, kantor, ruangan publik ataupun telepon. Wawancara dapat dilakukan dengan memberikan pertanyaan secara verbal dan peneliti membuat catatan hasil dari jawaban dari wawancara tersebut.
3) Studi dokumentasi, yaitu mengumpulkan data dari sumber laporan, arsip, petunjuk yang berkaitan dengan objek/masalah penelitian.
4.6. Teknik Analisa Data
Alat ukur penelitian yang digunakan berbentuk daftar pertanyaan (quistioner) melalui angket. Kuesioner merupakan salah satu alat ukur yang dirancang dalam bentuk pertanyaan. Jawaban yang diharapkan bersifat tertutup, artinya pada setiap pertanyaan sudah diberikan pilihan-pilihan untuk menjawabnya. Tingkat pengukuran yang dipakai dalam penelitian ini adalah kuesioner yang dikonstruksi dalam bentuk skala bertingkat (rating scale) dengan menggunakan skala Likert, yang berisi pertanyaan yang berkaitan dengan masalah dan variabel penelitian. Responden diminta untuk memberikan jawaban terhadap setiap pertanyaan mengenai tingkat kesesuaian. Jawaban pada item terdiri atas
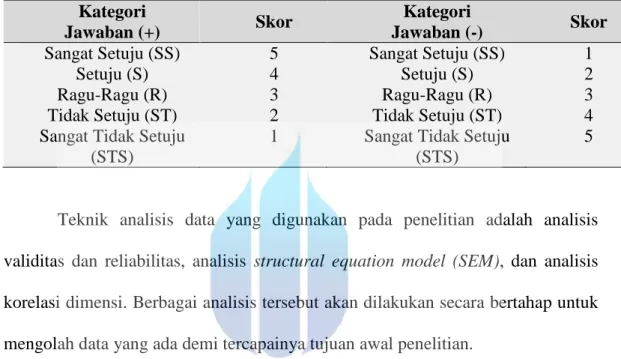
lima alternatif sebagaimana tersaji dalam tabel 4.3. Data yang diperoleh dari responden akan terbentang dalam suatu kontinum negatif sampai dengan positif (Friendenberg dalam Sugiyono 2008:197).
Tabel 4.3. Lima Alternatif Jawaban Responden Kategori Jawaban (+) Skor Kategori Jawaban (-) Skor Sangat Setuju (SS) Setuju (S) Ragu-Ragu (R) Tidak Setuju (ST) Sangat Tidak Setuju
(STS) 5 4 3 2 1 Sangat Setuju (SS) Setuju (S) Ragu-Ragu (R) Tidak Setuju (ST) Sangat Tidak Setuju
(STS) 1 2 3 4 5
Teknik analisis data yang digunakan pada penelitian adalah analisis validitas dan reliabilitas, analisis structural equation model (SEM), dan analisis korelasi dimensi. Berbagai analisis tersebut akan dilakukan secara bertahap untuk mengolah data yang ada demi tercapainya tujuan awal penelitian.
4.6.1. Uji Validitas, Uji Normalitas dan Reliabilitas Instrumen
4.6.1.1. Uji Validitas
Uji validitas berhubungan dengan apakah suatu variabel mengukur apa yang seharusnya diukur. Secara tradisional, validitas dapat dibedakan menjadi empat jenis yaitu: content validity, criterion validity, construct validty, dan convergent & discriminant validity.
Meskipun dengan cara yang berbeda-beda, masing-masing jenis tersebut berusaha menunjukkkan apakah sebuah ukuran berhubungan dengan sebuah konsep. Lebih lanjut menurut Doll, Xia dan Torkzadeh (1994) mengaplikasikan definisi
di atas untuk mengukur validitas variabel-variabel dalam Confirmatory Factor Analysis (CFA), sebagai berikut :
1) Pada first order model pengukuran, standard factor loadings (muatan faktor standar) variabel-variabel teramati (indicator) terhadap variabel laten (faktor) merupakan estimasi validitas variabel-variabel teramati tersebut.
2) Pada second or higher level model pengukuran, standard structural coefficients dari faktor-faktor (variabel-variabel laten) pada konstruk (variabel laten) yang lebih tinggi adalah estimasi validitas dari faktor-faktor tersebut.
Sementara itu, Igbariaet.al(1997) yang menggunakanguidelinesdari Hair et.al (1995) tentang relative importance and significant of the factor loading of each item menyatakan bahwa muatan faktor standar ≥ 0.50 adalah very significant.
4.6.1.2. Uji Normalitas
Untuk data melihat apakah asumsi normalitas data terpenuhi atau tidak sehingga dapat diolah lebih lanjut dalam permodelan SEM, sebaran data harus dianalisis terlebih dahulu. Distribusi data dikatakan normal pada tingkat signifikansi 0.01 jika Critical Ratio (CR), Skewenes (kemiringan), atau CR Curtosis (keruncingan) tidak lebih dari ± 2.58 (Santoso, 2007: 74). Hasil uji normalitasunivariatedan multivariatedata dalam penelitian menunjukkan bahwa untuk kedua syarat nilai CR seperti yang dijelaskan pada bab sebelumnya tidak
terpenuhi, tetapi salah satu dari kriteria tersebut terpenuhi yakni dengan menggunakan kriteria Critical Ratio Kurtois (CR) ± 2.58. Dengan demikian secara keseluruhan dapat dikatakan bahwa data yang digunakan dalam penelitian ini berdistribusi normal.
4.6.1.3. Uji Reliabilitas
Reliabilitas adalah konsistensi suatu pengukuran. Reliabilitas tinggi menunjukkan bahwa indikator-indikator mempunyai konsistensi tinggi dalam mengukur konstruk latentnya. Menurut Sinuraya (2009: 25) reliabilitas merupakan ukuran mengenai konsistensi internal dari indikator-indikator sebuah konstruk yang menunjukkan derajat sampai dimana masing-masing indikator itu mengindikasikan sebuah konstruk yang umum. Uji reliabilitas juga digunakan untuk menguji instrumen penelitian yang bila digunakan beberapa kali untuk mengukur objek yang sama, akan menghasilkan data yang sama (Sugiyono, 2010: 121).
Dalam analisis SEM uji reliabilitas yang paling tepat adalah dengan menggunakan construct reliability bukan dengan cronbrach alpha (Shook dkk., 2006: 400). Perbedaan paling mendasar antara construct reliability dengan cronbrach alpha adalah adanya asumsi equivalency, atau dengan kata lain construct reliability tidak berasumsi bahwa tiap item/observed variable mempunyai kontribusi (loadings) yang sama terhadap variabel laten (construct) seperti dalam cronbrach alpha. Ghozali (2008:137) lebih lanjut menjelaskan bahwa penggunaan cronbrach alpha sebagai pengukuran reliabilitas dalam
kenyataannya memberikan reliabilitas yang lebih rendah (under estimate) bila dibandingkan denganconstruct reliability.
Shook dkk. (2006: 400) dan Ghozali (2008:69) menyatakan nilaiconstruct reliability ≥ 0.70 menunjukkan reliabilitas yang baik, sedangkan untuk menghitungconstruct reliabilitydapat menggunakan rumus sebagai berikut:
Construct Reliability =
(∑ Standar Loading)2
(∑ Standar Loading)2
+∑ Kesalahan Pengukuran
Gambar 4.1. Rumus menghitung Construct Reliability 4.6.2 AnalisisStructural Equation Model (SEM)
Pengujian terhadap model penelitian ini dilakukan dengan menggunakan structural equation model (SEM). Selain dikenal dengan analysis of moment structures, analisis statistik ini digunakan untuk mengestimasi beberapa regresi yang terpisah tetapi saling berhubungan secara bersamaan (simultaneously).
Berbeda dengan analisis regresi, dengan SEM bisa terdapat beberapa variabel dependen dan variabel dependen ini bisa menjadi variabel independen bagi variabeldependenlain. Dengan kata lain,SEMdapat digunakan untuk model penelitian yang didalamnya terdapat variabel intervening seperti pada penelitian ini.
Menurut Hair et. al dalam Sofyan Yamin dan Kurniawan (2009), SEM adalah sebuah teknik statistic multivariate yang menggabungkan aspek-aspek dalam regresi berganda (yang bertujuan untuk menguji hubungan dependen) dan analisis faktor (yang menyajikan unmeasured concept factors with multiple
variable) yang digunakan untuk memperkirakan serangkaian hubungan dependen yang saling mempengaruhi secara bersama-sama.
Teknik pengolahan data SEM dengan metode confirmatory analysis digunakan dalam penelitian ini. Observed variable menggambarkan satu latent variable tertentu. Sebagai suatu metode pengujian yang menggabungkan analisis faktor, analisis lintasan dan regresi, SEM lebih merupakan metode confirmatory dari padaexplanatoryyang bertujuan untuk mengevaluasiproposed dimensionally yang diajukan yang berasal dari penelitian sebelumnya.
SEM memiliki dua elemen atau model, yaitu model struktural dan model pengukuran.
4.6.2.1 Asumsi-asumsiStructural Equation Model (SEM)
Asumsi-asumsi yang harus dipenuhi dalam prosedur pengumpulan dan pengolahan data yang dianalisis dengan pemodelan SEM sebagai berikut.
1) Ukuran sampel
Ukuran sampel yang harus dipenuhi dalam pemodelan ini adalah minimum berjumlah 100 dan selanjutnya menggunakan perbandingan 5 observasi untuk setiap estimated parameter. Karena itu bila kita mengembangkan model dengan 20 parameter, maka minimum sampel yang harus digunakan adalah sebanyak 100 sampel.
2) Normalitas dan linearitas
Sebaran data harus dianalisis untuk melihat apakah asumsi normalitas dipenuhi sehingga data dapat diolah lebih lanjut untuk pemodelan SEM ini. Normalitas dapat diuji dengan melihat gambar histogram data atau dapat diuji dengan
metode-metode statistik uji normalitas ini perlu dilakukan baik untuk normalitas terhadap data tunggal maupun normalitas multivariat di mana beberapa variabel digunakan sekaligus dalam analisis akhir. Uji linearitas dapat dilakukan dengan mengamati scatterplots dari data yaitu dengan memilih pasangan data dan dilihat pola penyebarannya untuk menduga ada tidaknya linearitas.
3) Outliers
Outliers adalah observasi yang muncul dengan nilai-nilai ekstrim baik secara univariat maupun multivariat yaitu yang muncul karena kombinasi karakteristik unik yang dimilikinya dan terlihat sangat jauh berbeda dari observasi lainnya. Selain itu, dapat diadakan perlakuan khusus pada outliers ini asal diketahui bagaimana munculnya outliersitu.Outlierspada dasarnya dapat muncul dalam empat kategori yaitu :
a. outliers muncul karena kesalahan prosedur seperti kesalahan dalam memasukkan data atau kesalahan dalam mengkoding data. Misalnya nilai 7 diketik 70 sehingga jauh berbeda dengan nilai-nilai lainnya dalam sebuah rentang jawaban responden antara 1 - 10. Bila hal semacam ini lolos dalam pengetikan data untuk pengolahan melalui komputer, maka angka 70 dapat menjadi sebuah nilai ekstrim;
b. outliers dapat saja muncul karena keadaan yang benar-benar khusus yang memungkinkan profit datanya lain daripada yang lain, tetapi peneliti mempunyai penjelasan mengenai apa penyebab munculnya nilai ekstrim itu.
c. outliers dapat muncul karena adanya sesuatu alasan tetapi peneliti tidak dapat mengetahui apa penyebabnya atau tidak ada penjelasan mengenai sebab-sebab munculnya nilai ekstrim itu;
d. outliers dapat muncul dalam range nilai yang ada, tetapi bila dikombinasi dengan variabel lainnya, kombinasinya menjadi tidak lazim atau sangat ekstrim. Inilah yang disebut dengan multivariate outliers.
4) Multikolinearitas dan singularitas
Multikolinearitas dapat dideteksi dari determinan matriks kovarians. Nilai determinan matriks kovarians yang sangat kecil (extremely small) memberi indikasi adanya problem multikolinearitas atau singularitas. Pada umumnya program-program komputer SEM telah menyediakan fasilitas"warning" setiap kali terdapat indikasi multikolinearitas atau singularitas. Bila muncul pesan itu, telitilah ulang data yang digunakan untuk mengetahui apakah terdapat kombinasi linear dari variabel yang dianalisis. Perlakukan data (data treatment) yang dapat diambil adalah keluarkan variabel yang menyebabkan singularitas itu. Bila singularitas dan multikolinearitas ditemukan dalam data yang dikeluarkan itu, salah satu treatment yang dapat diambil adalah dengan menciptakan "composite variables", lalu gunakan composite variables itu dalam analisis selanjutnya.
Setelah asumsi-asumsi SEM dilihat, hal berikutnya adalah menentukan kriteria yang akan digunakan untuk mengevaluasi model dan pengaruh-pengaruh yang ditampilkan dalam model. Hair, et. al (Ferdinand, 2002) mengemukakan
bahwa dalam analisis SEM tidak ada alat uji statistik tunggal untuk mengukur atau menguji hipotesis mengenai model. Umumnya terhadap berbagai jenis fit index yang digunakan untuk mengukur derajat kesesuaian antara model yang dihipotesiskan dengan data yang disajikan. Peneliti diharapkan melakukan pengujian dengan menggunakan beberapa fit index untuk mengukur "kebenaran" model yang diajukannya.
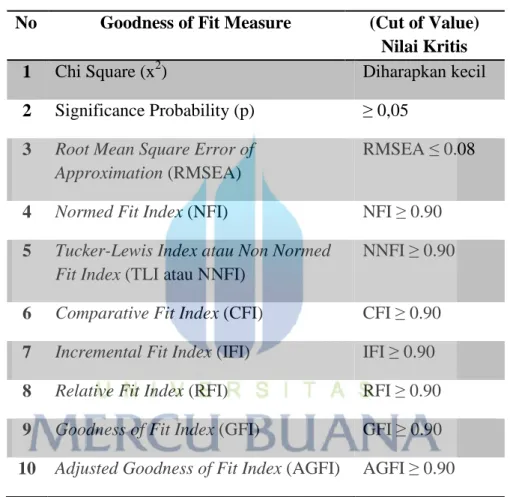
Dalam penilaian model, indeks TLI dan CFI sangat dianjurkan untuk digunakan karena indeks-indeks ini relatif tidak sensitif terhadap besarnya sampel dan kurang dipengaruhi pula oleh kerumitan model. Tabel 4.3 menunjukkan indeks-indeks yang dapat digunakan untuk menguji kelayakan sebuah model.
Beberapa indeks kesesuaian dan cut-off value-nya yang digunakan dalam menguji apakah sebuah model dapat diterima atau ditolak seperti diuraikan berikut ini.
1) Chi-Square Statistic (x2)
Chi-square statistic merupakan alat uji paling fundamental untuk mengukur overall fit. Chi-square ini bersifat sangat sentitif terhadap besarnya sampel yang digunakan. Karena itu bila jumlah sampel adalah cukup besar yaitu lebih dari 200 sampel, maka statistik chi-square ini harus didampingi oleh alat uji lainnya menurut Hair, et. al (Ferdinand, 2002). Model yang diuji akan dipandang baik atau memuaskan bila nilai chi-squarenya rendah. Menurut Hulland et. al dalam Ferdinand (2002) bahwa semakin kecil nilai x2 semakin baik model itu karena dalam uji beda chi-square, x2 = 0, berarti benar-benar tidak ada perbedaan (Ho
diterima) berdasarkan probabilitas dengan cut off value sebesar p>0.05 atau p>0.10.
2) RMSEA(The Root Mean Square Error of Approximatian)
RMSEA adalah sebuah indeks yang dapat digunakan untuk menkompensasi chi-square statistic dalam sampel yang besar. Nilai RMSEA menunjukkan goodness-of-fit yang dapat diharapkan bila model diestimasi dalam populasi. Menurut Browne & Cudeck (Ferdinand, 2002) bahwa nilai RMSEA yang lebih kecil atau sama dengan 0.08 merupakan indeks untuk dapat diterimanya model yang menunjukkan sebuah close fit dari model itu berdasarkandegrees offreedom.
3) GFI(Goodness of Fit Index)
Indeks kesesuaian(fit index)ini akan menghitung proporsi tertimbang dari varians dalam matriks kovarians sampel yang dijelaskan oleh matriks kovarians populasi yang terestimasikan menurut Bentley, et. al (Ferdinand, 2002). GFI adalah sebuah ukuran non-statistikal yang mempunyai rentang nilai antara 0(poor fit)sampai dengan 1,0(perfect fit). Nilai yang tinggi dalam indeks ini menunjukkan sebuah"better fit".
4) AGFI(Adjusted Goodness-of-Fit Index)
Tanaka & Huba (Ferdinand, 2002) menyatakan bahwa GFI adalah anolog dari R2 dalam regresi berganda. Fit Index ini disesuaikan terhadapdegrees of freedom yang tersedia untuk menguji diterima tidaknya model (Arbuckle,1999).Menurut Hair, et. al (Ferdinand, 2002) bahwa tingkat penerimaan yang direkomendasikan adalah bila AGFI mempunyai nilai
sama dengan atau lebih besar dari 0.90. Perlu diketahui bahwa baik GFI maupun AGFI adalah kriteria yang memperhitungkan proporsi tertimbang dari varians dalam sebuah matriks kovarians sampel. Nilai sebesar 0.95 dapat diinterpretasikan sebagai tingkatan yang baik good overall modelfit (baik) sedangkan besaran nilai antara 0.90 – 0.95 menunjukkan tingkatan cukup(adequate fit).
5) CMIN/DF
Indeks fit ini merupakan the minimum sample discrepancy function (CMIN) dibagi dengan degree of freedom-nya akan menghasilkan indeks CMIN/DF. Umumnya para peneliti melaporkannya sebagai salah satu indikator untuk mengukur tingkat fitnya sebuah model. Dalam hal ini CMIN/DF tidak lain adalah statistik chi-square, C2 dibagi DF-nya sehingga disebut chi square relatif. Nilai C2 relatif kurang dari 2.0 atau bahkan kadang kurang dari 3.0 menunjukkan antara model dan data fit. 6) TLI(Tucker Lewis Index)
TLI merupakan sebuah alternatif incremental fit index yang membandingkan sebuah model yang diuji terhadap sebuah baseline model. Nilai yang direkomendasikan sebagai acuan untuk diterimanya sebuah model adalah penerimaan ≥ 0.90 dan nilai yang sangat mendekati 1 menunjukkana very good fit.
7) CFI(Comparative Fit Index)
Indeks ini mempunyai rentang nilai antara 0 sampai dengan 1. Semakin mendekati 1, mengindikasikan adanya a very good fit. Nilai yang
direkomendasikan adalah CFI ≥ 0.90. Indeks ini besarannya tidak dipengaruhi oleh ukuran sampel, karena itu sangat baik untuk mengukur tingkat penerimaan sebuah model.
Tabel 4.4. Goodness of Fit Index
No Goodness of Fit Measure (Cut of Value) Nilai Kritis
1 Chi Square (x2) Diharapkan kecil
2 Significance Probability (p) ≥0,05 3 Root Mean Square Error of
Approximation(RMSEA)
RMSEA≤0.08
4 Normed Fit Index(NFI) NFI≥0.90 5 Tucker-Lewis Index atau Non Normed
Fit Index(TLI atau NNFI)
NNFI≥0.90
6 Comparative Fit Index(CFI) CFI≥0.90 7 Incremental Fit Index(IFI) IFI≥0.90 8 Relative Fit Index(RFI) RFI≥0.90 9 Goodness of Fit Index(GFI) GFI≥0.90 10 Adjusted Goodness of Fit Index(AGFI) AGFI≥0.90 Sumber : Ferdinand (2002)
8) NFI (Normed Fit Index)
Nilai NFI berkisar antara 0 sampai 1. Nilai NFI≥0.90 menunjukkan good fit, sedangkan nilai 0.80≤NFI < 0.90 sering disebut sebagai marginal fit. 9) IFI (Incremental Fit Index)
Nilai IFI berkisar antara 0 sampai 1. Nilai IFI ≥ 0.90 menunjukkan good fit, sedangkan nilai 0.80≤IFI < 0.90 sering disebut sebagai marginal fit.
10) RFI (Relative Fit Index)
Nilai IFI berkisar antara 0 sampai 1. Nilai IFI ≥ 0.90 menunjukkan good fit, sedangkan nilai 0.80≤IFI < 0.90 sering disebut sebagai marginal fit.
4.6.2.2 Prosedur SEM (Structural Equation Model)
Menurut Hair et. al (1995) prosedur SEM terdiri dari 7 tahapan pembentukan dan analisis SEM yaitu :
1) Membentuk model teori sebagai dasar model SEM yang mempunyai justifikasi teoritis yang kuat. Merupakan suatu model kausal atau sebab akibat yang menyatakan hubungan antar dimensi atau variabel.
2) Membangun path diagramdari hubungan kausal yang dibentuk oleh teori dasar. Path diagram tersebut memudahkan peneliti untuk melihat hubungan-hubungan kausalitas yang diujinya
3) Membagi path diagram tersebut menjadi satu set dari model pengukuran (measurement modeldanstructural model)
4) Pemilihan matrik data input dan mengestimasi model yang diajukan. Perbedaan SEM dengan teknik multivariat lainya adalam dalam hal input data yang digunakan dalam permodelan dan estimasinya SEM hanya menggunakan matrik varian/kovarian atau matrik korelasi sebagai data input untuk keseluruhan estimasi yang dilakukan.
5) Menentukan the identification of the structural model. Langkah ini untuk model yang dispesifikasikan bukan model yang identified/underidentified. Problem identifikasi dapat muncul melalui :
a) Standarderroruntuk satu/beberapa koefisien adalah sangat besar. b) Program ini mampu menghasilkan matrik informasi yang
seharusnya disajikan
c) Muncul angka-angka yang aneh seperti adanya error varian yang negatif
d) Muncul korelasi yang sangat tinggi antar korelasi estimasi yang didapat.
6) Mengevaluasi kriteria dari goodness of fit atau uji kecocokan. Pada tahap ini kesesuaian model dievaluasi melalui penelaahan terhadap berbagai kriteriagoodness of fitsebagai berikut :
a) Ukuran sampel minimal 160 dan dengan perbandingan 5 observasi untuk setiap parameterestimate
b) Normalitas dan linearitas c) Multicolinearity & singularity
7) Menginterpretasikan hasil yang didapat dan mengubah model jika diperlukan.
4.6.2.3 Pengujian Hipotesis
Setelah model tersebut memenuhi syarat, maka yang perlu dilakukan selanjutnya adalah uji regression weight/loading faktor. Uji ini dilakukan sama dengan uji t terhadapregression weight /loadingfaktor/ koefisien model).
Pengujian ini dilakukan terhadap:
Parameter Lambda (), yaitu parameter yang berkenaan dengan pengukuran variabel latent berdasarkan variabel manifest (berkaitan dengan validitas instrumen).
Hipotesis yang di uji:
H0 :i = 0 (tidak signifikan) H1 :i > 0 (signifikan)
2) Hipotesis mengenaistructural model:
a. Parameter Beta (), yaitu parameter pengaruh variabel eksogen terhadap variabel endogen dalamstructural model.
Hipotesis yang di uji:
H0 :i = 0 (tidak signifikan) H1 :i0 (signifikan)
b. Parameter Gama (), yaitu parameter pengaruh variabel endogen terhadap variabel endogen dalamstructural model.
Hipotesis yang di uji:
H0 :i = 0 (tidak signifikan) H1 :i0 (signifikan)
Uji ini sama dengan uji t (uji parsial) dalam multiple regression, uji ini dilakukan dengan cara membandingkan nilai t hitung dengan t tabel, engan ketentuan:
jika t hitung > t tabel berarti variabel tersebut signifikan dan jika t hitung≤t tabel berarti variabel tersebut tidak signifikan
Ferdinand (2002:75) menjelaskan bahwa t hitung identik dengan C.R (critical ratio) yang diuji dengan nilai probabilitas p, dimana jika p < 0.05 menunjukkan pengaruh yang signifikan dan jika p > 0.05 menunjukkan tidak signifikan.