BAB II
TINJAUAN PUSTAKA
2.1. Penambangan Data (Data Mining)
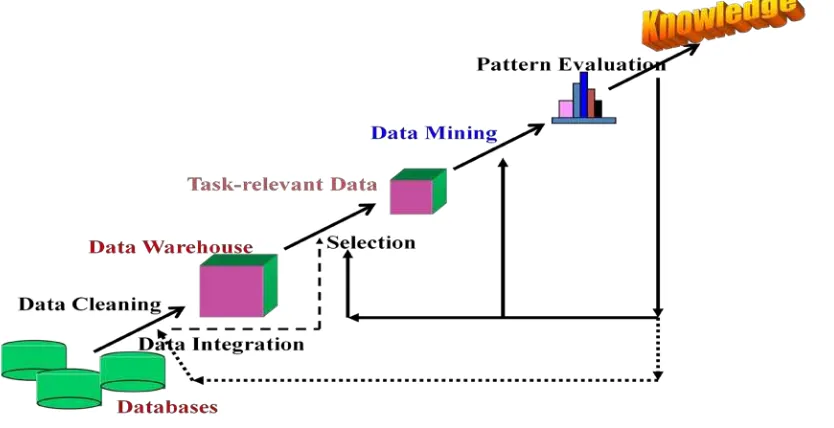
Penambangan data (Data Mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini tersembunyi dibalik data atau tidak diketahui secara manual (Iko Pramudiono, 2006). Proses untuk menggali nilai tambah dari sekumpulan data sering juga dikenal sebagai penemuan pengetahuan dari pangkalan data (Knowledge Discovery in Databases = KDD) yaitu tahap-tahap yang dilakukan dalam menggali pengetahuan dari sekumpulan data. Tahap-tahap yang dimaksud digambarkan seperti Gambar 2.1. berikut ini:
Gambar 2.1. Proses Menggali Pengetahuan Dari Pangkalan Data (Sumber; Han.J & Kember, 2006)
1. Data Selection
Pada proses ini dilakukan pemilihan himpunan data, menciptakan himpunan data target, atau memfokuskan pada subset variabel (sampel data) dimana penemuan akan melakukan. Hasil seleksi disimpan dalam satu berkas yang terpisah dari basis data operasional.
2. Pre-Processing
Pre-Processing dilakukan untuk membuang data yang tidak konsisten dan noise, duplikasi data,memperbaiki kesalahan data dan boleh juga diperkaya dengan data eksternal yang relevan.
3. Transformation
Proses ini mentransformasikan atau menggabungkan ke dalam data yang lebih tepat untuk melakukan proses mining dengan cara melakukan peringkasan.
4. Data Mining
Proses data mining yaitu proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik, metode atau algoritma tertentu.
5. Evaluasi
Proses untuk menterjemahkan pola-pola yang dihasilkan dari data mining. Mengevaluasi apakah pola atau informasi yang ditemukan bersesuaian atau bertentangan dengan fakta atau hipotesa sebelum nya.
himpunan data yang berukuran besar, output dari data mining dapat dipakai untuk memperbaiki pengambilan keputusan.
Pada dasarkan data mining berhubungan dengan analisis data dan penggunaan perangkat lunak untuk mencari pola dan kesamaan dalam sekelompok data. Ide dasarnya menggali sumber yang berharga dari tempat yang sama sekali tidak terduga, seperti perangkat lunak. Data mining mengekstrasi pola yang sebelumnya tidak terlihat atau tidak begitu jelas sehingga tidak terperhatikan sebelumnya. Analisis data mining berjalan pada data yang cenderung terus meningkat dan teknik terbaik yang digunakan kemudian berorientasi kepada data yang berukuran sangat besar untuk mendapatkan kesimpulan dan keputusan paling layak. Data mining memiliki beberapa sebutan antara lain yaitu : Knowledge Discovery (MiningI in Databases (KDD), ekstraksi pengetahuan (knowledge extraction), analisis data pola , kecerdasan bisnis (business intelligence).
Beberapa faktor yang mendukung perlunya data mining adalah : 1. Data telah mencapai jumlah dan ukuran yang sangat besar. 2. Telah dilakukan proses data warehousing.
3. Kemampuan komputasi yang semakin terjangkau. 4. Persaingan bisnis yang semakin ketat.
Secara sederhana data mining mengacu pada pengekstrakan suatu pengetahuan dari banyaknya data. Sehingga data mining dapat disebut secara tepat dengan data pengetahuan yang diambil dari data sangat besar. Mining itu sendiri berkarakteristik pada proses yang menemukan sekumpulan data kecil yang berharga dari sekian banyak data yang ada.
2.2 Klastering
2.2.1. Pengertian Klastering
”Klastering adalah proses pengelompokkan satu set benda-benda fisik atau abstrak ke dalam kelas objek yang sama” (Han and Kamber, 2006).
Baskoro (2010) menyatakan bahwa :
Klastering adalah satu diantara alat bantu pada data mining yang bertujuan untuk mengelompokkan objek-objek ke dalam klaster-klaster. Klaster adalah sekelompok atau sekumpulan objek-objek data yang similar satu sama lain dalam klaster yang sama dan disimilar terhadap objek-objek data yang berbeda klaster. Objek-objek yang akan dikelompokkan ke dalam satu atau lebih klaster sehingga objek-objek yang berada dalam suatu klaster akan mempunyai kesamaan yang tinggi antara satu dengan yang lainnya. Objek-objek dikelompokkan berdasarkan prinsip memaksimalkan kesamaan objek pada klaster yang sama dan memaksimalkan ketidaksamaan pada klaster yang berbeda. Kesamaan objek biasanya diperoleh dari nilai-nilai atribut yang menjelaskan objek data, sedangkan objek-objek data biasanya direpresentasikan sebagai sebuah titik dalam ruang multidimensi.
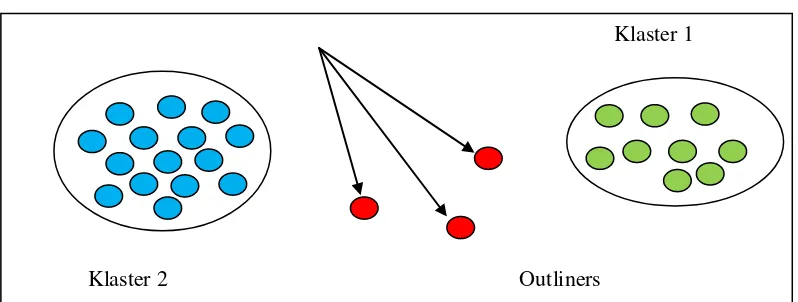
Klaster 1
Klaster 2 Outliners
Gambar 2.2 Contoh Klastering(Baskoro 2010)
Adapun tujuan dari data Klastering ini adalah untuk meminimalisasikan
objective function yang diset dalam proses Klastering, yang pada umumnya
berusaha meminimalisasikan variasi di dalam suatu Klaster dan
memaksimalisasikan variasi antar Klaster.
2.2.2. Metode Klastering.
Secara garis besar, terdapat beberapa metode clusterisasi data. Pemilihan metode clusterisasi bergantung pada tipe data dan tujuan clusterisasi itu sendiri. Metode-metode beserta algoritma yang termasuk didalamnya meliputi (Baskoro, 2010): Sadaaki et. al. (2008) menyatakan :
Sebelum memutuskan berapa jumlah cluster yang akan dibentuk bahwa
terdapat dua pendekatan yang dapat digunakan yaitu :
a. supervised (jika jumlah cluster ditentukan).
b. unsupervised (jika jumlah cluster tidak ditentukan/alami).
2.3. Dokumen Klastering.
“Dokumen Klastering merupakan suatu teknik untuk mengelompokkan
dokumen-dokumen berdasarkan kemiripannya dengan tujuan mendapatkan sekumpulan
dokumen yang tepat” (Widyawati, 2010). Dokumen-dokumen tersebut dikelompokan
ke dalam klaster berdasarkan tingkat kemiripannya. Suatu klaster dapat dikatakan
bagus apabila tingkat kemiripan antar anggota klaster sangat tinggi dan tingkat Klaster 1
kemiripan antar klaster sangat rendah. Sedangkan kualitas suatu klasterdapat diukur
melalui kemampuannya dalam menemukan pola-pola yang tersembunyi.
Gambar 2.3. berikut ini menunjukkan contoh data yang akan dilakukan
klastering :
Gambar 2.3 Data Sebelum dilakukan proses pengelompokkan
Jika data dilakukan klastering (pengelompokkan) berdasarkan warna, maka
pengelompokkannya seperti yang terlihat pada gambar 2.4 :
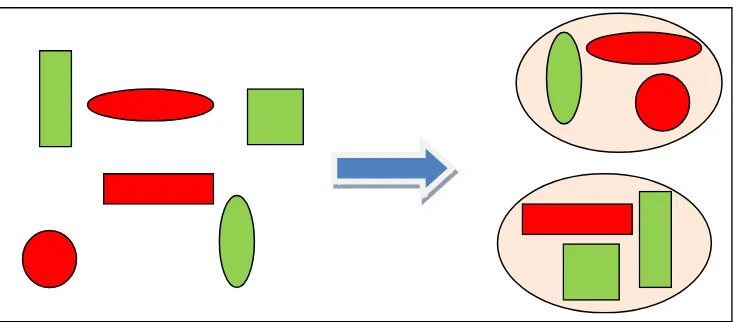
Jika data dilakukan klastering berdasarkan bentuk, maka pengelompokkan
seperti terlihat gambar 2.5 :
Gambar 2.5 Pengelompokkan berdasarkan kesamaan bentuk
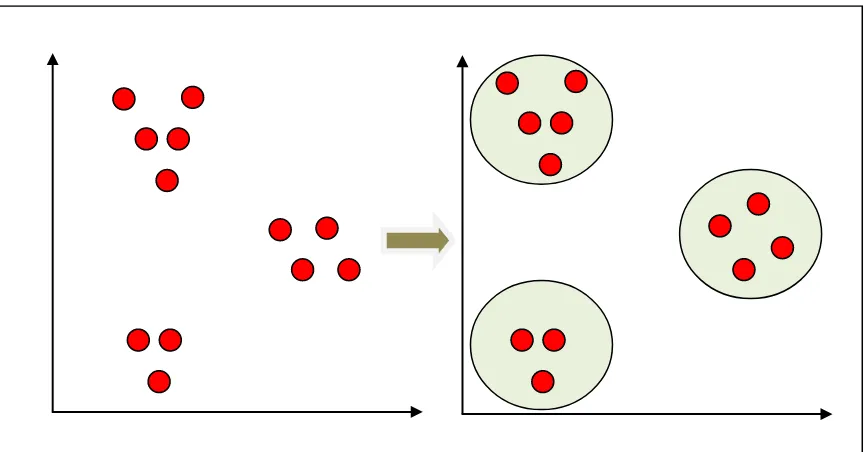
Pengelompokkan bisa juga bisa dilakukan dengan kesamaan jarak
Gambar 2.6 Pengelompokkan berdasarkan kesamaan jarak
Teknik analisis data yang bertujuan untuk mengelompokkan individu / objek
kedalam beberapa kelompok yang memiliki sifat berbeda antar kelompok, sehingga
Ukuran data yang bias digunakan adalah jarak euclidius (euiclidean) antara dua objek.
Jika objek pertama yang diamati adalah X =[ x1, x2, m, xp,]’ dan Y = [y1, y2,m, yp]’
adalah :
d(𝑥𝑥+𝑦𝑦) = √ �𝑝𝑝𝑗𝑗=1(Xy−Yj) 2 ……….2.1
analisi klaster diukur dengan menggunakan nilai variance, variance digunakan
untuk mengukur nilai penyebarandari data-data hasil klastering. Pada dasarnya
variance pada klastering ada 2 yaitu variance dalam klaster (Vw) dan variance antar
klaster (Vb). klaster disebut ideal jika memiliki nilai Vw seminimal mungkin Vb
semaksimal mungkin.
Untuk menghitung nilai variance dari semua data setiap klaster digunakan
rumus :
Sedangkan untuk menghitung variance didalam klaster digunakan rumus
sebagai berikut :
1
1
Sedangkan untuk menghitung variance antar klaster digunakan rumus
sebagai berikut :
untuk mendapat nilai variance dari semua klaster dilakukan dengan cara
membagi nilai variance dalam klaster dengan variance antar klaster. Semakin kecil
nilai tersebut maka semakin klaster yang dihasilkan.
2.4. Support Vector Clustering (SVC)
Support vector clustering merupakan metode clustering dengan menggunakan probabilitas kepadatan titik memakai kernel jarak pada dimensi tinggi (Ben-hur et al, 2001 ) Dua tahapan dari SVC adalah pelatihan data untuk menentukan jarak dan pelabelan kluster.
Pada metode ini, data dipetakan ke dalam dimensi yang lebih tinggi dengan kernel jarak. Pada ruang dimensi yang baru, dilakukan kluster data terlihat sebagai bentuk bola. Untuk mendapatkan kluster data yang sesuai, dilakukan pencarian bentuk bola yang minimal (minimal sphere) .
Dimana merupakan fungsi transformasi non linear Xj dari dimensi rendah ke dimensi tinggi.
Sehingga persamaan diatas dapat diubah menjadi
………..2.5 Dimana :
a merupakan titik tengah bola minimal R merupakan radius bola minimal
Variabel slack untuk pinalty term bentuk bola yang tidak selalu ideal, dimana j
>= 0.
Untuk dapat menyelesaikan permasalah bola minimal, diperkenalkan Langrangian
……….2.6
Untuk setiap titik xj dengan $j =0 merupakan titik yang berada di permukaan atau di dalam bola. Dimana $j >=0 dan μj>=0 merupakan
Langrangian Multiplier yang bisa didapatkan dengan mengubah ke bentuk Dual problem (W):
………..2.7 Dengan konstrain
Dengan mengeset turunan dari Langrarian menghasilkan a=
Bola minimal yang telah didapat kemudian dipetakan kembali ke dimensi awal (rendah) dengan menjadi kontur yang secara eksplisit memperlihatkan bentuk kluster. Seluruh titik yang berada pada kontur tersebut diasosiasikan sebagai anggota kluster tersebut.
Ciri titik berada di dalam kontur adalah jarak titik tersebut dengan pusat kluster lebih kecil atau sama dengan radius bola.
……….2.8
……….2.9
Sehingga bentuk kluster dapat dilihat dengan melihat titik –titik support vector dari kluster tersebut. Untuk menentukan titik masuk ke kluster mana diperlukan pengujian jarak titik tersebut dengan titik yang lain. Misal terdapat titik i dan j maka i dan j termasuk dalam kluster yang sama jika jarak seluruh titik-titik antara i dan j dalam garis lurus lebih kecil atau sama dengan radius bola minima. Cara diatas mengharuskan dibuatnya matrik ketetanggan antar titik dimana Aij=1 jika titik i dan j terletak dalam 1 kluster dan Aij=0 jika i dan j tidak terletak dalam 1 kluster.
2.5. Algoritma Support Vector Clustering 1. Lakukan inisialisasi data.
2. Lakukan pencarian nilai beta melalui optimasi persamaan linear dual
wolfe dengan konstrain 0< βj < C dan ∑βj=1
2.6. Algoritma K-Medoids
Pengelompokkan merupakan proses pengumpulan beberapa objek ke dalam
kelompok sehingga setiap objek dalam satu kelompok adalah mirip namun tidak
mirip dengan kelompok yang lain. Metode K-Means telah diketahui sehingga teknik
yang baik untuk pengelompokan. Namun, metode K-Means ini sensitive terhadap
adanya outlier, alternatifnya yang sering digunakan adalah metode K-Medoids
(Park dan Jun, 2009). K-Medoids ini mirip dengan K-Mean, namun yang menjadi
center klaster adalah datum, bukan mean data.
Park dan Jun (2009) menawarkan algoritma K-Medoids dimana menurut
penelitiannya algoritma ini menghasilkan kinerja yang baik dibandingkan K-Means
dan dengan waktu yang lebih cepat.
Algoritma K-Medoids tersebut adalah sebagai berikut :
1. Tahap pertama (pilih inisial medoid)
1-1 Hitung dij , jarak di antara setiap pasangan objek berdasarkan ukuran jarak
tertentu, misalnya Euclidean
𝑑𝑑𝑖𝑖𝑗𝑗 = �∑𝑝𝑝𝑎𝑎=1(𝑥𝑥𝑖𝑖𝑎𝑎 − 𝑥𝑥𝑗𝑗𝑎𝑎)2 = �(x𝑖𝑖 − x𝑗𝑗)′(x𝑖𝑖−x𝑗𝑗) ( 2.10 )
dimana i=1,…..,n; j=1,…..,n dan p adalah banyak variable, serta V adalah matrik varian kovarian.
1-2 Hitung vj untuk setiap objek j dimana
1-3 Urutkan vj dari terkecil ke terbesar. Pilih objek terkecil sebanyak k
sebagai inisial medoid.
Cari medoid baru pada setiap kelompok dimana jarak antar objek minimal. Update medoid setiap kelompok yang ada dengan medoid yang baru.
3 Tahap Ketiga (menghubungkan objek pada medoid)
3-1 Hitung jarak semua objek ke setiap medoid dan dihasilkan kelompok baru berdasarkan jarak minimal.
3-2 Hitung jarak semua ke medoid kelompoknya. Jika jumlahnya sama dengan jumlah sebelumnya, hentikan algoritma. Jika tidak kembali ke tahap 2.
2.7. Riset-Riset Terkait
Terdapat beberapa riset yang telah dilakukan banyak peneliti berkaitan dengan
domain pendidikan, seperti yang akan dijelaskan dibawah ini :
1. Muchammad Juniarto (2009) menjelaskan bahwa metode SVC lebih baik
daripada K-Means dalam pengelompokkan data.
2. Kusrini (2001) menjelaskan bahwa algoritma data mining.
3. Jayanti Diah Basuki (2008) menjelaskan implementasi tentang algoritma
K-Medoids untuk Clustering dokumen teks.
4. Karhendana, A (2008) menjelaskan tentang pemanfaatan dokumen
2.8. Kontribusi Riset
Penelitian ini memberikan kontribuasi pada pemahaman tentang hubungan data tugas akhir mahasiswa AMIK Tunas Bangsa Pematangsiantar untuk mengetahui perbandingan ke dua algoritma yang mana yang lebih cepat dalam pengclasteran dokumen. Beberapa kemungkinan lain yang dianggap penting adalah bahwa perguruan tinggi dapat menggunakan informasi dalam hal pengelompokkan data di perguruan tinggi tersebut, untuk membuat agar dapat diketahui model algoritma mana yang lebih baik dalam pengklasteran dokumen.
2.9. Analisis dan Interpretasi