PEMODELAN
PERSAMAAN STRUKTURAL:
I. ANALISIS JALUR
Johan Harlan
Pusat Studi Informatika Kedokteran Universitas Gunadarma
Pemodelan Persamaan Struktural:
I. Analisis Jalur
Penulis : Johan Harlan
ISBN 978-602-9438-27-7
Cetakan Pertama, Juli 2013
Disain cover : Joko Slameto
Diterbitkan pertama kali oleh Gunadarma
Jl. Margonda Raya No. 100, Pondokcina, Depok 16424
Telp. +62-21-78881112, 7863819 Faks. +62-21-7872829
e-mail : [email protected]
Hak Cipta dilindungi undang-undang. Dilarang mengutip atau
memperbanyak dalam bentuk apapun sebagian atau seluruh isi buku tanpa
ijin tertulis dari penerbit.
v
KATA PENGANTAR
Pemodelan persamaan struktural (structural equation modeling; SEM) adalah suatu teknik analisis statistika yang terutama menekankan penilaian model, dapat dianggap sebagai perluasan General Linear Model, disebut juga sebagai second generation multivariate
analysis. Analisis SEM dapat dibedakan atas tiga tipe, analisis jalur, analisis faktor
konfirmatorik, dan model regresi struktural.
Buku ini merupakan buku pertama dalam seri SEM, yang akan membahas mengenai analisis jalur. Pembahasan analisis jalur di sini mencakup pembahasan tentang teori analisis jalur, praktek analisis jalur dengan program komputer statistik Stata, dan interpretasi hasilnya. Pembahasan teori analisis jalur bersifat mendasar, yaitu menyangkut pengetahuan teoretis minimum dari segi Statistika yang dibutuhkan seorang peneliti untuk melakukan analisis PA. Pengetahuan teoretis ini juga sangat penting dan diperlukan sebagai dasar bagi mereka yang ingin mempelajari kedua tipe SEM berikutnya, yaitu analisis faktor konfirmatorik dan model regresi struktural.
Praktek analisis jalur yang akan dibahas adalah analisis SEM dengan Stata, suatu paket komputer statistik. Analisis SEM dengan paket komputer statistik Stata ini dapat dilaksanakan dalam mode interaktif maupun mode grafik. Interpretasi hasil analisis jalur dengan Stata yang akan dibahas adalah pemahaman menurut aspek Statistika, sedangkan aspek substantif tetap harus dikaji oleh peneliti sendiri berdasarkan bidang keilmuannya masing-masing.
Sebagai prasyarat untuk mempelajari SEM, pembaca diharapkan telah memiliki pengetahuan dasar mengenai analisis regresi (untuk PA) dan analisis faktor (untuk CFA), walaupun dalam buku-buku seri SEM ini akan dibahas juga telaah ulang secara singkat mengenai konsep-konsep tersebut.
Jakarta, Juli 2012
vii
DAFTAR ISI
Kata Pengantar
v
Daftar Isi
vii
Bab 1 Pendahuluan
1
Pengertian Dasar SEM . . . 1
Struktur pada SEM . . . 3
Variabel Teramati dan Variabel Laten . . . 3
Variabel Endogen dan Eksogen . . . 3
Beberapa Karakteristik Kekhususan SEM . . . 4
Program Komputer untuk SEM . . . 5
Lambang SEM dalam Kepustakaan dan Stata . . . 6
Bab 2 Telaah Ulang Analisis Regresi
9
Model dan Persamaan Regresi . . . 9Data Tak-terstandardisasi dan Terstandardisasi . . . 11
Matriks Kovariansi dan Korelasi . . . 13
Analisis Regresi dangan Stata . . . 14
Bab 3 Konsep-konsep Dasar Analisis Jalur
19
Analisis Jalur dan Model Struktural . . . 19Asumsi dalam Analisis Jalur . . . 19
Parameter dan Derajat Bebas Model . . . 20
Tipe Model Jalur . . . 21
Identifikasi Model . . . 22
Ukuran Sampel . . . 23
Hubungan Antar-Variabel . . . 24
Bab 4 Estimasi Parameter
25
Parameter Model Jalur . . . 25Estimasi Efek pada Model Jalur . . . 28
viii
Uji Sobel . . . 32
Notasi Jalur SEM . . . 33
Estimasi Koefisien Jalur SEM dengan Stata . . . 34
Bab 5 Uji Hipotesis dan Penilaian Model
49
Uji Hipotesis pada SEM . . . 49Klasifikasi Statistik Suai . . . 49
Macam Statistik Suai . . . 50
Estimasi Statistik Suai SEM dengan Stata . . . 54
Model Ekivalen pada Analisis Jalur . . . 61
Bab 6 Pemodelan SEM dalam Mode Grafik pada Stata
63
Graphical User Interface pada Stata . . . 63Analisis SEM dengan Mode Grafik . . . 65
Bab 7 Model Struktural Non-Rekursif
68
Tipe Model Struktural Non-Rekursif . . . 68Identifikasi pada Mode Non-Rekursif . . . 68
Kondisi Order . . . 69
Kondisi Rank . . . 70
Efek Tak Langsung pada Model Non-Rekursif . . . 71
Korelasi Ganda Kuadrat . . . 72
Analisis Model Non-Rekursif dengan Stata . . . 74
Bab 8 Struktur Rerata
80
Analisis Nilai Rerata pada SEM . . . 80Identifikasi Struktur Rerata . . . 81
Estimasi Struktur Rerata . . . 82
Bab 9 Sampling Ganda
84
Penggunaan Sampling Ganda pada SEM . . . 84Analisis Sampel Ganda pada Stata . . . 85
ix
Kepustakaan
89
Lampiran 1 Koefisien Korelasi
90
Lampiran 2 Analisis Regresi Linear dengan Stata
97
Lampiran 3 Beberapa Nilai-Nilai Statistik Suai pada Analisis SEM
111
Bab 1. Pendahuluan
1
BAB 1
PENDAHULUAN
Pengertian Dasar SEM
Pemodelan persamaan struktural (structural equation modeling; SEM) bukan
merupakan suatu teknik statistika tunggal seperti analisis variansi, analisis regresi, dan sebagainya, melainkan mengacu kepada suatu kelompok prosedur yang saling berkaitan (a
family of related procedures). SEM dikenal pula sebagai „analisis multivariat generasi kedua‟
(second generation multivariate analysis). Istilah lain untuk SEM ialah pemodelan kausal (causal modeling). Dalam kenyataannya SEM hanyalah berguna untuk menunjang dugaan keberadaan hubungan kausal, karena tidak ada teknik statistika yang dapat membuktikan kausalitas dalam rancangan studi observasional. SEM umumnya digunakan untuk rancangan studi observasional, namun jika diperlukan dapat pula digunakan dalam rancangan studi eksperimental.
Dikenal dua tipe model dalam SEM yaitu model struktural dan model pengukuran.
Model struktural mengkaji struktur hubungan antara variabel teramati, sedangkan model pengukuran menekankan pengukuran variabel laten dengan menggunakan indikator.
Berdasarkan tipe pemodelan tersebut SEM dapat dibagi menjadi tiga bagian, yaitu analisis jalur, analisis faktor konfirmatorik, dan model regresi struktural. Analisis jalur (path
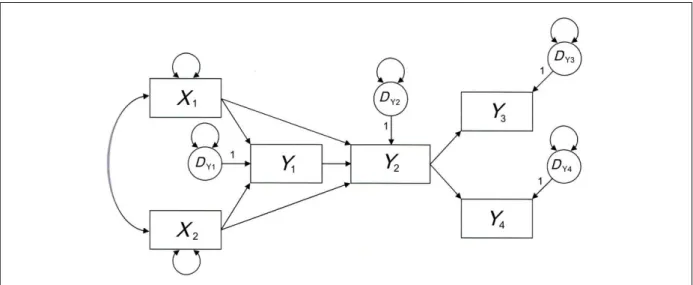
analysis; PA) merupakan model struktural untuk variabel teramati (lihat contoh pada diagram
1.1), sedang analisis faktor konfirmatorik (confirmatory factor analysis; CFA) adalah model pengukuran untuk variabel laten (contoh pada diagram 1.2). Model regresi struktural (structural regression model; model SR) adalah sintesis antara model struktural dengan model pengukuran, merupakan gabungan antara analisis jalur dengan CFA (contoh pada diagram 1.3).
Dalam buku ini pembahasan selanjutnya adalah mengenai analisis jalur. Walaupun analisis jalur hanya merupakan sebagian dari keseluruhan metode statistika yang ada dalam SEM dan juga merupakan teknik statistika yang tertua dalam SEM, pemahaman mengenai analisis jalur sangat penting dan merupakan dasar utama untuk mempelajari SEM secara keseluruhan.
Bab 1. Pendahuluan
2
Gambar 1.1 Contoh model jalur
Gambar 1.2 Contoh model analisis faktor konfirmatorik
Bab 1. Pendahuluan
3
Struktur pada SEM
Bagian model persamaan struktural yang merepresentasikan hipotesis tentang variansi dan kovariansi adalah struktur kovariansi, sedangkan jika rerata juga dianalisis bersama dengan kovariansi, maka model persamaan struktural memiliki baik struktur kovariansi maupun struktur rerata, dengan struktur rerata merepresentasikan estimasi rerata faktor.
Salah satu kelebihan SEM ialah dapat diestimasinya rerata variabel laten, yang tak dapat dilakukan pada teknik analisis statistik lainnya. Misalnya dalam ANOVA (analisis variansi), estimasi hanya dapat dilakukan untuk rerata variabel teramati. Walaupun demikian, dalam kebanyakan analisis SEM struktur rerata tak dibutuhkan dan rerata tak dianalisis.
Variabel Teramati dan Variabel Laten
Variabel dalam SEM dibedakan menjadi variabel teramati dan variabel laten. Variabel
teramati (observed variable) adalah variabel yang nilai datanya dapat diukur secara langsung
oleh peneliti dan nilainya ada pada basis-data penelitian. Contohnya antara lain yaitu tinggi badan, berat badan, dan sebagainya. Variabel teramati dapat berupa variabel kategorik nominal, kategorik ordinal, ataupun kontinu. Dalam contoh pada gambar 1.1, X1, X2, Y1, Y2
, Y3, dan Y4adalah variabel-variabel teramati.
Variabel laten (variabel tak-teramati; unobserved variable) yang adakalanya disebut
juga sebagai konstruk (construct) atau faktor, adalah variabelnya yang nilai datanya tidak diperoleh melalui pengukuran langsung oleh peneliti, tetapi diukur secara tidak langsung melalui beberapa variabel teramati yang disebut juga sebagai indikator. Misalnya untuk variabel laten prestasi belajar (achievement) siswa SD, indikatornya adalah (hasil tes) kemampuan membaca, kemampuan menulis, dan kemampuan berhitung. Variabel laten dalam SEM selalu merupakan variabel kontinu. Dalam contoh pada gambar 1.2, A dan B adalah variabel-variabel laten. Variabel laten tak digunakan dalam analisis jalur yang akan dibahas di sini. Konstruk dapat menjadi variabel teramati jika nilai-nilainya diperoleh dari
indikator-tunggal (single-indicator).
Variabel Endogen dan Eksogen
Variabel eksogen (variabel independen) adalah variabel yang sama sekali tidak menerima efek variabel lain, sedangkan variabel endogen adalah variabel yang menerima efek satu atau lebih variabel lain. Efek antar variabel ini dapat terjadi dari suatu variabel
Bab 1. Pendahuluan
4
eksogen ke suatu variabel endogen ataupun dari suatu variabel endogen ke variabel endogen lain. Dalam pengertian ini variabel mediator (variabel perantara) dianggap sebagai variabel endogen, sedangkan suku pengganggu (disturbance) adalah variabel eksogen. Tiap variabel endogen memiliki suku pengganggu, yang selalu merupakan variabel laten. Variabel endogen dalam SEM dapat berperan sebagai variabel dependen maupun independen. Dalam contoh pada gambar 1.1, X1 dan X2 adalah variabel eksogen, sedangkan Y1, Y2, Y3, dan Y4
adalah variabel endogen. Y1 dan Y2 merupakan variabel mediator.
Istilah variabel eksogen (independen) menyatakan bahwa nilai-nilai variabel ini dapat bervariasi dengan bebas sehingga memiliki nilai variansi tertentu, sedangkan variabel endogen tidak dapat bervariasi dengan bebas sehingga tidak memiliki variansi. Dalam contoh pada gambar 1.1 tampak bahwa hanya variabel eksogen X1 dan X2 yang memiliki
variansi. Variabel endogen Y1, Y2, Y3, dan Y4 tidak memiliki variansi, yang memiliki variansi adalah suku pengganggu (disturbances) untuk keempat variabel endogen tersebut.
Suku pengganggu pada model struktural SEM merepresentasikan galat pengukuran (measurement error) variabel endogennya beserta variabel independen yang tak diperhitungkan (omitted causes) dalam model.
Dua variabel eksogen yang memiliki asosiasi tak-teranalisis (unanalyzed association) dapat bervariasi bersama (ber-kovariansi), sehingga pasangan variabel eksogen demikian memiliki nilai kovariansi tertentu. Pada contoh gambar 1.1 diperlihatkan adanya korelasi antara variabel eksogen X1 dan X2. Perhatikan bahwa dalam SEM semua variabel eksogen
dianggap saling berkorelasi walaupun tak digambarkan dalam model.
Beberapa Karakteristik Kekhususan SEM
SEM memiliki beberapa karakteristik khusus yang membedakannya dari teknik statistika lainnya, yaitu:
- SEM bukan merupakan teknik statistika tunggal, namun merupakan kumpulan sejumlah teknik statistika yang berkaitan, terutama analisis regresi dan analisis faktor. - SEM mengkaji model a priori, yaitu model yang sudah harus ada dan dibuat peneliti
sebelum dimulainya pengumpulan dan analisis data. Model boleh diperbaiki dalam tahap analisis, tetapi tidak boleh baru dibuat setelah data ada dan sepenuhnya dikembangkan hanya berdasarkan data yang diperoleh peneliti. Implikasinya yaitu peneliti harus memiliki dasar yang kokoh dalam bidang substansi keilmuannya.
Bab 1. Pendahuluan
5
- Dalam tahap analisis jika diperlukan untuk memenuhi persyaratan statistika, model boleh direvisi, tetapi proses revisi model tidak boleh bertentangan dengan pengetahuan teoretis di bidang substansi penelitian.
- SEM dapat mengkaji lebih daripada satu model dan model yang ternyata dapat menjelaskan data dengan baik berdasarkan analisis SEM juga mungkin lebih daripada satu.
- SEM dapat menganalisis variabel teramati maupun variabel laten. Sebagian besar teknik statistika dibuat untuk menganalisis variabel teramati. Ada juga teknik statistika yang dikhususkan untuk menganalisis variabel laten, tetapi SEM dapat menganalisis kedua tipe variabel tersebut bersama-sama.
- SEM adalah teknik sampel besar. Untuk memperoleh hasil yang terpercaya, ukuran sampel minimum ideal yang dianjurkan adalah 20 kali jumlah parameter, misalnya model dengan 10 parameter dianjurkan menggunakan sampel berukuran 200.
- Estimasi pada SEM umumnya dilakukan dengan metode maximum likelihood (ML) yang merupakan metode informasi-penuh (full-information method) yang menganalisis seluruh persamaan dalam model sekaligus, berbeda misalnya dengan metode kuadrat terkecil yang dapat dianggap sebagai metode informasi-parsial (partial-information
method) karena dalam tiap tahap hanya menganalisis satu persamaan.
- SEM kurang memberi penekanan pada uji statistik dalam pengertian sebagai uji parameter dalam Statistika Umum. Didapatkan berbagai alasan yang menyebabkan uji statistik demikian menjadi kurang penting dalam SEM, yang terutama yaitu karena SEM dimaksudkan untuk meng-evaluasi keseluruhan model secara global, sedangkan uji statistik sebagai uji parameter hanya menyangkut detil spesifik dalam model. Alasan teknis lainnya yaitu karena SEM merupakan teknik sampel besar, sedangkan secara teoretis sampel besar dapat mengakibatkan efek trivial dapat menjadi „sangat bermakna‟ secara statistik. Uji statistik yang lazim dilakukan dalam SEM memiliki tujuan berbeda, yaitu „pengujian model‟ antara lain dengan memperbandingkan matriks kovariansi data dengan matriks kovariansi yang diprediksi oleh model yang diajukan peneliti, walaupun ada juga uji statistik untuk pengujian parameter yang dianggap kurang penting.
Program Komputer untuk SEM
Program statistik komputer untuk SEM telah dikenal sejak paruh kedua 1970-an, walaupun pada waktu itu program SEM yang dikenal secara luas hanyalah LISREL (Linear
Bab 1. Pendahuluan
6
Structural Relationships) yang dikembangkan oleh Jöreskog & Sörbom yang menggunakan
mode interaktif. Dalam perkembangan selanjutnya dikenal pula AMOS (Analysis of Moment
Structures) yang dikembangkan oleh SPSS Inc sebagai program aplikasi yang berdiri sendiri.
AMOS memiliki kemudahan karena dapat dijalankan dalam mode grafik dengan menggunakan GUI (Graphical User Interface), walaupun dapat juga dijalankan dengan mode
batch.
Sekarang dikenal juga berbagai prosedur SEM yang merupakan bagian program statistik komputer komprehensif, misalnya:
- Prosedur CALIS/TCALIS (Covariance Analysis and Linear Structural Equations) pada SAS/STAT
- Prosedur RAMONA (Reticular Action Model or Near Approximation) pada SYSTAT. - Prosedur SEPATH (Structural Equation Modeling and Path Analysis) pada
STATISTICA.
Berbagai prosedur ini umumnya harus dijalankan dalam mode batch (kecuali SEPATH). Prosedur terbaru yang dibahas dalam buku ini yaitu prosedur sem (structural
equation modeling) yang didapatkan pada program statistik STATA. Prosedur sem ini baru
didapatkan pada STATA versi 12 yang diluncurkan pada tahun 2011. Prosedur sem pada STATA 12 ini dapat dijalankan dengan mode grafik maupun interaktif.
Lambang SEM dalam Kepustakaan dan Stata
Berikut ini diperlihatkan beberapa lambang yang lazim dipergunakan untuk notasi SEM dalam kepustakaan dan dipergunakan pula dalam Stata:
1. Variabel:
a. Variabel teramati:
Variabel teramati dinyatakan dengan lambang empat persegi panjang (“ ”) atau
bujur sangkar (“ ”). Nama variabel dituliskan dalam empat persegi panjang atau
bujur sangkar itu. Seluruh variabel yang ada pada basis-data adalah variabel teramati.
Pada Stata, nama variabel teramati seluruhnya ditulis dengan huruf kecil. b. Variabel laten:
Variabel laten digambarkan dengan lambang elips (“ ”) atau lingkaran (“ ”). Nama variabel dituliskan dalam elips atau lingkaran itu. Pada model jalur, hanya suku pengganggu yang merupakan variabel laten.
Bab 1. Pendahuluan
7
Pada Stata, penulisan nama variabel laten diawali dengan huruf besar, kecuali untuk suku pengganggu (butir 1.c)
c. Suku pengganggu:
Suku pengganggu ada untuk setiap variabel endogen, merupakan variabel laten yang memiliki variansi, sedangkan variabel endogen itu sendiri tidak memiliki variansi.
Pada Stata, variabel laten untuk sebuah variabel endogen dinamakan sebagai “e.nama_var_endogen”, misalnya untuk variabel endogen “sistolik”, nama suku pengganggunya adalah “e.sistolik”. Walaupun merupakan variabel laten, penulisan nama suku pengganggu tidak diawali dengan huruf besar.
2. Efek antar-variabel: a. Efek searah:
Efek searah suatu variabel terhadap variabel lainnya dinyatakan dengan lambang
anak panah searah (“→”). Misalnya, efek searah variabel X terhadap variabel Y
dinyatakan sebagai X → Y. Nilai yang dituliskan dekat anak panah pada model awal menyatakan nilai kendala yang ditentukan peneliti pada penyusunan model ataupun estimasi yang diperoleh dari data sampel sebagai koefisien regresi atau koefisien
jalur.
Pada pemodelan Stata, efek searah variabel X terhadap Y dituliskan sebagai “sem (Y <− X)” atau “sem (X −> Y)”.
b. Efek resiprokal:
Efek resiprokal antar dua variabel dinyatakan dengan lambang anak panah
bolak-balik (“ ”). Misalnya, efek resiprokal antar variabel Y1 dan Y2 dinyatakan sebagai
1
Y Y2.
Pada pemodelan Stata, hubungan resiprokal antar variabel Y1 dan Y2 dituliskan
sebagai “sem (Y2 <− Y1) (Y1 <− Y2)” 3. Variansi:
Variansi suatu variabel eksogen dinyatakan dengan lambang anak panah
berkepala-ganda, yang berawal dan berakhir pada variabel yang sama (“ ”).
Dalam SEM, semua variabel eksogen dan suku pengganggu memiliki variansi, sedangkan variabel endogen tidak memiliki variansi.
Bab 1. Pendahuluan
8
Pada pemodelan Stata dengan mode interaktif, keberadaan variansi tidak perlu dicantumkan, walaupun diasumsikan semua variabel eksogen dan suku pengganggu memiliki variansi.
4. Kovariansi dan korelasi:
Kovariansi atau korelasi dinyatakan dengan lambang anak panah berkepala-ganda, yang berawal dan berakhir pada dua variabel berbeda (“ ”).
Kovariansi diasumsikan selalu ada antar variabel eksogen, walaupun tidak digambarkan dalam model. Selain itu, kovariansi mungkin ada (tidak selalu, tergantung model peneliti) antar suku pengganggu. Kovariansi tidak ditemukan antar variabel
endogen. Secara statistik, kovariansi dalam SEM disebut sebagai asosiasi tak-teranalisis (unanalyzed association) atas dasar asumsi bahwa pada kovariansi antar dua
variabel terdapat variabel ketiga yang tak diketahui dan tak dianalisis yang menimbulkan efek terhadap kedua variabel yang berkovariansi sekaligus.
Pada Stata, kovariansi dituliskan sebagai “cov(var1*var2), misalnya kovariansi antar variabel eksogen “usia” dan “pendidikan” dituliskan sebagai “cov(usia*pendidikan), sedangkan kovariansi antar suku pengganggu “e.sistolik” dan “e.kolesterol” dituliskan sebagai “cov(e.sistolik*e.kolesterol).
Bab 2. Telaah Ulang Analisis Regresi
9
BAB 2
TELAAH ULANG ANALISIS REGRESI
Model dan Persamaan Regresi
Pemahaman tentang analisis regresi merupakan prasyarat untuk mempelajari analisis jalur (path analysis; PA). Analisis regresi adalah suatu teknik statistika untuk mengkaji hubungan antara satu atau lebih variabel independen kontinu dengan satu variabel dependen kontinu. Analisis regresi dapat berupa regresi sederhana (simple regression) jika hanya ada satu variabel independen atau regresi ganda (multiple regression) jika didapatkan lebih daripada satu variabel independen. Kadang-kadang analisis regresi juga digunakan untuk variabel independen yang berskala kategorik, yang dinyatakan dalam bentuk variabel
indikator yang hanya bernilai nol atau satu.
Model dan persamaan garis regresi sederhana masing-masing dinyatakan sebagai: i
y = 0 + 1 x + i i (2.1)
dan ˆy= 0 + 1 x (2.2)
0
: intersep (intercept); konstante
1
: kemiringan (slope); koefisien regresi i
x : variabel independen; regresor; prediktor
i
y : variabel dependen; outcome; kriterion
i
: suku galat (error); residual
Estimasinya yang diperoleh dari data sampel masing-masing adalah: i
y = b + 0 b1x + i e i (2.1.a)
dan ˆy= b + 0 b1 x (2.2.a)
dengan b sebagai estimator untuk 0 0 (ˆ0 = b ) dan0 b1 sebagai estimator untuk1
ˆ1b1
.Model dan persamaan garis regresi ganda (dengan 2 variabel independen X1 dan X ) 2
masing-masing dinyatakan sebagai: i
y = 0 + 1 x + 1i 2 x +2i i (2.3)
Bab 2. Telaah Ulang Analisis Regresi
10 Estimasinya masing-masing adalah:
i
y = b + 0 b1x + 1i b2 x + 2i e i (2.3.a)
dan ˆy= b + 0 b1 x +1 b2 x 2 (2.4.a)
Estimasi koefisien regresi pada regresi sederhana maupun ganda dilakukan dengan metode kuadrat terkecil (ordinary least square; OLS). Salah satu asumsi yang penting bagi OLS ialah tidak adanya korelasi antara variabel independen dengan suku residual variabel dependen.
Contoh 2.1:
Misalkan dimiliki data hipotetis seperti terlihat pada tabel 2.1. Hasil regresi yterhadap 1
x diperlihatkan pada tabel 2.2.a, sedangkan hasil regresi y terhadap x1 dan x diperlihatkan 2
pada tabel 2.2.b.
Tabel 2.1 Contoh data hipotetis untuk analisis regresi
No y 1 x x 2 1 116 49 240 2 152 48 209 3 134 55 210 4 132 49 171 5 130 50 255 6 118 52 232 7 136 48 147 8 108 59 268 9 108 59 231 10 128 52 199 Rerata y= 126.2 x = 52.1 1 x = 216.2 2 SD sy= 13.77 s = 4.23 1 s = 37.18 2
Tabel 2.2 Hasil analisis regresi untuk data hipotetis tabel 2.1 a. Model regresi sederhana: y = 0 + 1 x + 1
b SE(b) B t Nilai-p
Konstante 245.42 42.84 5.73 < 0.001
1
x –2.29 0.82 –0.70 –2.79 0.024
Bab 2. Telaah Ulang Analisis Regresi
11
b. Model regresi ganda: y = 0 + 1 x + 1 2x + 2
b SE(b) B t Nilai-p Konstante 242.97 43.15 5.63 0.001 1 x –1.81 0.97 –0.55 –1.87 0.104 2 x –0.11 0.11 –0.28 –0.96 0.371 n = 10; 2 R = 0.55
Data Tak-terstandardisasi dan Terstandardisasi
Data seperti pada tabel 2.1 dinyatakan sebagai sebagai data dalam bentuk tak-terstandardisasi (unstandardized). Data tak-standardisasi x dapat diubah menjadi data terstandardisasi (standardized) z yang memiliki rerata nol dan standar deviasi satu dengan rumus transformasi:
z = x
(2.5)
Misalkan zy adalah bentuk terstandardisasi untuk variabel y dan z adalah bentuk 1
terstandardisasi untuk variabel x , maka regresi 1 zy terhadap z akan menghasilkan model 1
dan persamaan garis regresi:
yi
z = B1 z + 1i zei (2.6)
dan z = ˆy B1 x 1 (2.7)
B (beta) : Koefisien regresi untuk bentuk terstandardisasi
Garis regresi untuk bentuk terstandardisasi ini selalu melalui titik pangkal [0 ; 0], sehingga suku konstante selalu bernilai sama dengan nol (tidak ada suku konstante). Nilai k dan estimasinya b dalam analisis regresi dinamakan koefisien regresi, sedangkan nilai k B k
(beta) dalam analisis jalur disebut koefisien jalur (ada yang menyebutnya hanya sebagai path / jalur). Perhatikan bahwa ada kepustakaan yang menamakan k juga sebagai koefisien jalur, namun di sini istilah koefisien jalur hanya digunakan untuk B (beta). k
Untuk model regresi ganda dengan 2 prediktor seperti pada tabel 2.2.b, beta dapat diperoleh dari persamaan:
1 B = b1 1 y s s dan B = 2 b2 2 y s s (2.8)
Bab 2. Telaah Ulang Analisis Regresi 12 1 s : standar deviasi x 1 2 s : standar deviasi x 2 Contoh 2.2:
Lihat kembali data hipotetis pada tabel 2.1. Dengan transformasi zy=
y y y s ;z =1 1 1 1 x x s ; danz =2 2 2 2 x x s
diperoleh data terstandardisasi seperti terlihat pada tabel 2.3.
Berdasarkan hasil analisis regresi pada tabel 2.2, diperoleh model regresi tak-standardisasi dan tertak-standardisasi seperti yang ditampilkan pada tabel 2.4.
Tabel 2.3 Contoh data dalam bentuk tak-terstandardisasi dan bentuk terstandardisasi
No y x 1 x 2 zy z 1 z 2 1 116 49 240 –0.74 –0.73 0.64 2 152 48 209 1.87 –0.97 –0.19 3 134 55 210 0.57 0.69 –0.17 4 132 49 171 0.42 –0.73 –1.22 5 130 50 255 0.28 –0.50 1.04 6 118 52 232 –0.60 –0.02 0.42 7 136 48 147 0.71 –0.97 –1.86 8 108 59 268 –1.32 1.63 1.39 9 108 59 231 –1.32 1.63 0.40 10 128 52 199 0.13 –0.02 –0.46 Rerata 126.2 52.1 216.2 0.00 0.00 0.00 SD 13.77 4.23 37.18 1.00 1.00 1.00
Tabel 2.4 Model regresi untuk data tak-terstandardisasi dan terstandardisasi beserta estimasinya Tak-terstandardisasi Terstandardisasi Regresi sederhana Model y = 0 + 1 x + 1 zy=B1 z + 1 z Estimasi y = 245.42– 2.29x + e 1 y z = –0.70z + 1 ze Regresi ganda Model y = 0 + 1 x + 1 2 x + 2 y z =B1 z + 1 B2 z + 2 z Estimasi y = 242.97– 1.81x1– 0.11x + e 2 zy= –0.55z1– 0.28z + 2 ze
Bab 2. Telaah Ulang Analisis Regresi
13
Matriks Kovariansi dan Korelasi
Variansi variabel random x dan kovariansi antara variabel random x dan y masing-masing adalah:
Var x = E
xx
2 (2.8)
;
Cov x y = E
x
x
y
y (2.9) Estimasi dari data sampel adalah:
ˆ Var x =
2 1 i i x x n
(2.8.a)
ˆ ; Cov x y =
1 i i i x x y y n
(2.9.a)Jika variabel random x dan y masing-masing dikonversi menjadi bentuk terstandardisasi x
z dan zy , maka korelasi antara x dan y sama dengan kovariansi antara z dan x zy :
;
Corr x y = Cov z
x ; zy
(2.10) Korelasi antara x dan y dapat juga diperoleh dari persamaan:
;
Corr x y =
;
x y
Cov x y
(2.11)
Estimasi dari data sampel adalah:
ˆ ; Corr x y = ˆ
;
x y Cov x y s s (2.11.a) Contoh 2.3:Lihat data hipotetis pada tabel 2.1 dan bentuk terstandardisasinya pada tabel 2.3. Matriks kovariansi dan korelasinya untuk data tak-standardisasi diperlihatkan pada tabel 2.5, sedangkan matriks kovariansi dan korelasi untuk data terstandardisasi disajikan pada tabel 2.6. Perhatikan bahwa untuk data terstandardisasi, matriks kovariansinya identik dengan matriks korelasi.
Bab 2. Telaah Ulang Analisis Regresi
14
Tabel 2.5 Matriks kovariansi dan korelasi untuk data tak-terstandardisasi
Matriks kovariansi Matriks korelasi
y x1 x2 y x1 x2 y 189.73 y 1.00 1 x –40.91 17.88 x1 –0.70 1.00 2 x –293.60 82.20 1382.40 x2 –0.57 0.52 1.00
Tabel 2.6 Matriks kovariansi dan korelasi untuk data terstandardisasi
Matriks kovariansi Matriks korelasi
y z z1 z2 zy z1 z2 y z 1.00 zy 1.00 1 z –0.70 1.00 z1 –0.70 1.00 2 z –0.57 0.52 1.00 z2 –0.57 0.52 1.00
Analisis Regresi dengan Stata
Terdapat beberapa cara untuk membuat file data Stata, cara yang termudah ialah dengan membuat file basis-data dalam Excel, yang kemudian di-“import” ke dalam Stata.
Selanjutnya akan diperlihatkan prosedur analisis regresi dalam Stata dengan perintah regress.
Contoh 2.4 (Membuat file data Stata):
Masukkan data hipotetis hubungan antara tekanan darah sistolik (y), usia (x1), dan kadar kolesterol serum (x2) yang ada pada tabel 2.1 pada lembar isian (spreadsheet) Excel. Simpan data pada folder D:\SEM\Data dengan nama sistolik.xls.
Perintah Stata:
Ambil file Excel sistolik.xls untuk dibuka dalam format Stata, selanjutnya simpan data dalam format data Stata:
. import excel using “D:\SEM\Data\sistolik.xls”, firstrow . label variable y "tekanan darah sistolik"
. label variable x1 "usia"
. label variable x2 "kadar kolesterol serum" . save “D:\SEM\Data\sistolik.dta”
Bab 2. Telaah Ulang Analisis Regresi
15
Perintah “import” adalah perintah Stata untuk mengambil file data dalam format non-Stata (umumnya file Excel) dan dibuka dalam format Stata. Perintah “label” adalah perintah untuk memberi „label‟ bagi variabel tertentu. Setelah itu file masih harus disimpan dalam format Stata dengan perintah “save” untuk memudahkan penggunaannya pada sesi lebih lanjut.
Contoh 2.5 (Analisis regresi dengan Stata):
Perintah Stata:
. use “D:\SEM\Data\sistolik.dta”, clear . regress y x1
y Coef. Std. Err. t P > | t | [ 95% Conf. Interval]
x1 −2.288378 .8197659 −2.79 0.024 −4.178762 −.3979942
_cons 245.4245 42.8362 5.73 0.000 146.644 344.2049
Perintah “regress” adalah perintah Stata untuk melaksanakan analisis regresi linear, baik sederhana maupun ganda. Perintah “regress” diikuti oleh nama variabel dependen, dan selanjutnya disusul oleh nama variabel independen.
. regress y x1 x2
y Coef. Std. Err. t P > | t | [ 95% Conf. Interval]
x1 −1.805473 .9670317 −1.87 0.104 −4.09214 .4811937
x2 −.1050276 .1099716 −0.96 0.371 −.3650691 .155014
Bab 2. Telaah Ulang Analisis Regresi
16
Contoh 2.6 (Analisis regresi terstandardisasi dengan Stata):
Perintah Stata:
. use “D:\SEM\Data\sistolik.dta”, clear . regress y x1, beta
y Coef. Std. Err. t P > | t | Beta
x1 −2.288378 .8197659 −2.79 0.024 −.7024456
_cons 245.4245 42.8362 5.73 0.000 .
Perintah “use” adalah perintah Stata untuk membuka file data Stata (file dengan ekstensi *.dta). Opsi “,clear” pada perintah “use” setelah nama dan jalur (path) file yang akan dibuka merupakan perintah untuk menghapus semua isi file data Stata terakhir yang masih terbuka dan ada dalam memori komputer. Opsi “, beta” pada perintah “regress” setelah nama variabel independen merupakan perintah untuk menampilkan koefisien beta, yaitu koefisien regresi terstandardisasi.
. regress y x1 x2, beta
y Coef. Std. Err. t P > | t | Beta
x1 −1.805473 .9670317 −1.87 0.104 −.554212
x2 −.1050276 .1099716 −0.96 0.371 −.283497
_cons 242.9721 43.14995 5.63 0.001 .
Contoh 2.7 (Regresi linear, contoh pada manual Stata):
File data: auto.dta Variabel:
variable name variable label
weight foreign mpg Weight (lbs.) Cartype Miliage (mpg)
Bab 2. Telaah Ulang Analisis Regresi
17
Model:
Persamaan:
mpg = α + β1weight + β2weight2 + β3foreign + ε1
Perintah regress (analisis regresi linear):
. sysuse auto
. regress mpg weight c.weight#c.weight foreign
Source SS df MS Number of obs = 74
F(3,70) = 52.25
Model 1689.15372 3 563.05124 Prob > F = 0.0000
Residual 754.30574 70 10.7757963 R-squared = 0.6913
Adj R-squared = 0.6781
Total 2443.45946 73 33.4720474 Root MSE = 3.2827
mpg Coef. Std. Err. t P>|t| [95% Conf. Interval]
weight −.0165729 .0039692 −4.18 0.000 −.0244892 −.0086567
c.weight#c.weight 1.59e-06 6.25e-07 2.55 0.013 3.45e-07 2.84e-06
foreign −2.2035 1.059246 −2.08 0.041 −4.3161 −.0909002
_cons 56.53884 6.197383 9.12 0.000 44.17855 68.89913
. regress, beta
mpg Coef. Std. Err. t P>|t| Beta
weight −.0165729 .0039692 −4.18 0.000 −2.226321 1.32654 −.17527 .
c.weight#c.weight 1.59e-06 6.25e-07 2.55 0.013
foreign −2.2035 1.059246 −2.08 0.041
_cons 56.53884 6.197383 9.12 0.000
Perintah “sysuse” adalah perintah untuk membuka file data Stata yang dipasok oleh provider Stata dan disimpan dalam basis-data Stata pada saat meng-install program Stata. Dengan perintah “sysuse” cukup dituliskan nama file yang akan dibuka tanpa perlu menuliskan jalurnya. Pada perintah “regress” pertama di atas nama variabel dependen dan independennya harus ditulis lengkap, namun dalam perintah “regress” kedua yang
Bab 2. Telaah Ulang Analisis Regresi
18
disertai opsi “, beta” nama-nama variabel tidak usah dituliskan lagi, asal perintah “regress” kedua langsung diberikan setelah perintah “regress” pertama tanpa diselingi perintah Stata lainnya.
Pembahasan lebih rinci tentang perintah-perintah Stata untuk analisis regresi linear dapat dilihat pada Lampiran 2.
Bab 3. Konsep-konsep Dasar Analisis Jalur
19
BAB 3
KONSEP-KONSEP DASAR ANALISIS JALUR
Analisis Jalur dan Model Struktural
Model struktural dalam SEM adalah model yang menggambarkan struktur hubungan
antara sejumlah variabel teramati. Variabel teramati (observed variables) adalah variabel yang nilainya ada dalam himpunan-data (dataset). Dalam model ini tidak dipentingkan cara pengukuran yang dilakukan untuk memperoleh nilai-nilai untuk variabel tersebut.
Berdasarkan arahnya, efek antar-variabel dibedakan menjadi efek searah dan efek resiprokal. Efek searah adalah efek yang terjadi secara searah antara variabel kausal (sebab) dengan variabel efek (akibat), misalnya efek searah variabel X terhadap variabel Y (X → Y).
Efek resiprokal adalah efek yang terjadi secara dua-arah antar dua variabel, misalnya efek
resiprokal antara variabel Y1 dan Y2(Y1 Y2). Pada efek resiprokal ini tidak dapat dibedakan
variabel mana yang merupakan variabel kausal atau variabel efek.
Asumsi dalam Analisis Jalur
Asumsi-asumsi dalam analisis jalur dapat dibagi menjadi dua kelompok: 1. Asumsi teoretis:
Asumsi kausalitas yang tergantung pada terpenuhinya persyaratan berikut: a. Model dispesifikasikan dengan benar.
b. Ada hubungan teramati dan dapat diukur (observed and measurable relationship) antara variabel independen X dan variabel dependen Y (ada korelasi antara X dan Y). c. Ada urutan temporal: variabel independen X secara temporal harus terjadi
mendahului variabel dependen Y.
d. Tidak ada hubungan palsu (nonspurious relationship) antara variabel independen X dan variabel dependen Y (hubungan teramati, dapat diukur, dan temporal antara X dan Y tidak hilang dengan pengendalian terhadap efek variabel-variabel lain).
2. Asumsi statistika:
a. Asumsi yang terkait dengan regresi ganda: asumsi normalitas, homoskedastisitas, dan linearitas.
Bab 3. Konsep-konsep Dasar Analisis Jalur
20
b. Besar hubungan antara dua variabel independen yang berkorelasi satu sama lain dan tak-teranalisis direpresentasikan oleh koefisien korelasinya.
c. Pengukuran variabel endogen sekurang-kurangnya berskala interval. d. Pengukuran variabel eksogen bersifat bebas-galat.
e. Arah hubungan kausal terspesifikasi dengan benar: apakah X menyebabkan Y (X →
Y), Y menyebabkan X (Y → X), atau terdapat hubungan resiprokal (X Y).
f. Bentuk distribusi diketahui: Bentuk distribusi probabilitas parameter dispesifikasikan.
Parameter dan Derajat Bebas Model
Pada model struktur kovariansi (SEM tanpa analisis rerata), parameter-nya adalah efek langsung terhadap variabel endogen serta variansi dan kovariansi variabel eksogen. Efek langsung yang dimaksud adalah efek yang besarnya yaitu nilai parameternya harus diestimasi. Dengan demikian maka jumlah parameter q dapat ditentukan dengan menghitung jumlah lambang →, , dan dalam diagram SEM, yaitu jumlah efek langsung searah (koefisien regresi), variansi, dan kovariansi.
Parameter model dapat bersifat bebas, terfiksasi, ataupun terkendala. Parameter bebas (free parameter) harus diestimasi berdasarkan data yang ada. Parameter terfiksasi (fixed
parameter) dispesifikasikan nilainya sama dengan konstante tertentu. Parameter terkendala
(constrained parameter) harus diestimasi dalam batasan tertentu, namun nilainya tidak terfiksasi sama dengan konstante tertentu. Dalam perhitungan jumlah parameter di atas, parameter terfiksasi tidak diikutsertakan. Dua parameter yang dikendalakan memiliki nilai yang sama tetapi tidak difiksasikan besar nilainya, diperhitungkan sebagai satu parameter dalam menghitung jumlah parameter. Dalam pembahasan selanjutnya, istilah „terfiksasi‟ dan „terkendala‟ ini akan seringkali saling dipertukarkan dengan pengertian yang sama.
Jika menyatakan jumlah variabel teramati dalam model, maka banyak nilai pada diagonal matriks kovariansi dan di bawahnya, yang menyatakan banyak nilai variansi dan kovariansi tak-berulang (nonredundant covariances; kovariansi unik) adalah:
+ (− 1) + (− 2) + . . . + 1
Banyak nilai ini dinamakan juga sebagai jumlah titik data (number of data points) untuk model struktur kovariansi, yaitu:
p =
1
2
Bab 3. Konsep-konsep Dasar Analisis Jalur
21
p : jumlah pengamatan
: jumlah variabel teramati dalam model
Selisih antara jumlah titik data dengan jumlah parameter merupakan derajat bebas
model, yaitu:
M
df = p – q (3.2)
M
df : derajat bebas model
q : jumlah parameter yang diestimasi
Jumlah titik data p merupakan jumlah parameter maksimal yang dapat diestimasi dalam suatu model persamaan struktural. Kline (2005) menamakan jumlah titik data ini sebagai
jumlah pengamatan (number of observations) bagi struktur kovariansi yang berbeda dengan ukuran sampel n. Ada pula yang menyebutkannya sebagai jumlah moment sampel
(number of sample moments). Pada program Stata istilah „jumlah pengamatan‟ memiliki pengertian yang sama dengan „ukuran sampel‟ N (lambang ukuran sampel pada Stata), sedangkan jumlah titik data dinamakan sebagai momen derajat-dua (second-order moments).
Tipe Model Jalur
Didapatkan dua tipe dasar model jalur yaitu model rekursif dan model non-rekursif.
Model rekursif adalah model jalur dengan seluruh hubungan antar-variabelnya bersifat
searah (efek searah) yang tidak membentuk loop tertutup dan seluruh suku pengganggunya tak saling berkorelasi. Contoh model rekursif diperlihatkan pada gambar 3.1.a.
Model non-rekursif adalah model jalur yang memiliki sekurang-kurangnya satu loop
tertutup atau hubungan antar-variabel dua-arah (efek resiprokal) dan/atau suku pengganggu yang saling berkorelasi. Contoh model non-rekursif diperlihatkan pada gambar 3.1.b. Selain itu masih didapatkan model jalur yang bersifat rekursif parsial (gambar 3.2).
Bab 3. Konsep-konsep Dasar Analisis Jalur
22
Gambar 3.1 (a) Contoh model rekursif (kiri); (b) Contoh model non-rekursif (kanan)
Gambar 3.2 Contoh model rekursif parsial: (a) Pola bebas-busur (dianggap rekursif; kiri) dan (b) Pola busur (dianggap non-rekursif; kanan)
Pola bebas-busur (bow-free pattern) seperti pada gambar 3.2 kiri adalah pola dengan korelasi antara dua suku pengganggu tanpa adanya jalur antara variabel endogennya. Dalam estimasi parameter, pola ini dapat diperlakukan seperti model rekursif. Pada pola busur (bow
pattern; gambar 3.2 kanan), korelasi antara dua suku pengganggu disertai dengan jalur antara
kedua variabel endogennya.
Identifikasi Model
Sebuah model jalur dikatakan teridentifikasi (identified) jika secara teoretis
dimungkinkan untuk memperoleh estimasi yang unik bagi setiap parameter.
Persyaratan untuk identifikasi model SEM ialah: (1) Jumlah titik data lebih besar atau sama dengan jumlah parameter yang diestimasi (dfM> 0), dan (2) Variabel laten (tidak ada yang
Bab 3. Konsep-konsep Dasar Analisis Jalur
23
dianalisis pada model jalur) sekurang-kurangnya berskala interval. Berdasarkan status identifikasinya, model jalur dibedakan menjadi:
1. Kurang-teridentifikasi (under-identified): dfM < 0 2. Tepat-teridentifikasi (just-identified): dfM = 0 3. Lebih-teridentifikasi (over-identified): dfM > 0
Model yang tepat-teridentifikasi, yang disebut juga sebagai model jenuh hanya
memiliki sedikit kegunaan, walaupun sesuai sempurna dengan data. Kegunaannya yaitu
hanya untuk mengestimasi koefisien regresi dan koefisien jalur. Jika model kurang-teridentifikasi, estimasi parameter tak dapat dilakukan dan peneliti dianjurkan untuk
memperbaiki model dengan mengurangi jumlah parameter yang hendak diestimasi. Hanya pada model yang lebih-teridentifikasi analisis SEM disarankan diteruskan.
Model rekursif secara teoretis akan selalu teridentifikasi, namun dapat menjadi
kurang teridentifikasi secara empirik (empirical under-identified) karena adanya multikolinearitas. Estimasi parameter untuk model kurang-teridentifikasi dengan program statistik komputer akan menyebabkan berlangsungnya proses iteratif secara terus menerus tanpa konvergensi. Cara mengatasinya adalah menghentikan program dan mengulangi proses estimasi dengan terlebih dahulu menentukan batasan jumlah iterasi.
Adakalanya tidak mudah untuk menentukan status identifikasi bagi model yang rumit. Dalam hal ini Brown (2006) menganjurkan untuk menjalankan program statistik komputer dan membiarkan program komputer yang menentukan status identifikasi model.
Ukuran Sampel
Perhatikan bahwa pada sebagian literatur tentang SEM, istilah „ukuran sampel‟ (jumlah anggota sampel) memiliki pengertian yang berbeda dengan istilah „jumlah pengamatan„ (Kline, 2005). Seperti halnya dengan teknik statistika lainnya, sampel besar akan menghasilkan estimasi dengan galat sampling (sampling error) lebih kecil daripada yang dihasilkan oleh sampel kecil. Perhitungan ukuran sampel minimum yang dibutuhkan dapat dilakukan berdasarkan analisis kekuatan (power analysis) yang diinginkan, namun secara kasar ukuran sampel dapat dibedakan menjadi:
- Sampel kecil: N < 100
- Sampel sedang: 100 < N < 200 - Sampel besar: N > 200
Bab 3. Konsep-konsep Dasar Analisis Jalur
24
Ukuran sampel minimum yang dibutuhkan juga dapat dihitung secara kasar dengan rasio 10 : 1 terhadap jumlah parameter yang diestimasi, misalnya model jalur dengan 20 parameter akan membutuhkan ukuran sampel minimum sebesar 200 kasus. Jackson (2003) menganjurkan rasio ukuran sampel minimum ideal : parameter model sebesar 20 : 1 untuk estimasi maximum likelihood.
Hubungan Antar-Variabel
Hubungan antara variabel terdiri atas efek kausal dan asosiasi non-kausal. Efek kausal adalah efek yang diasumsikan menyatakan kausalitas (hubungan sebab-akibat) antar dua variabel, dapat berupa efek langsung ataupun efek tak-langsung.
Efek langsung (direct effect) adalah efek kausal hipotetis suatu variabel terhadap
variabel kedua yang terjadi secara langsung tanpa melalui variabel ketiga. Efek searah suatu variabel terhadap variabel lainnya dinyatakan dengan lambang anak panah (“→”). Misalnya, efek langsung variabel X terhadap variabel Y dinyatakan sebagai X → Y. Besarnya efek searah dinyatakan sebagai koefisien regresi (tak-terstandardisasi) atau koefisien jalur (terstandardisasi).
Efek tak-langsung (indirect effect) adalah efek kausal hipotetis suatu variabel terhadap
variabel kedua yang terjadi melalui satu atau lebih variabel mediator (intervening variables). Misalnya, efek tak langsung variabel X terhadap variabel Y2 yang terjadi melalui variabel mediator Y1 dinyatakan sebagai X → Y1 → Y2. Jika bX1 menyatakan koefisien regresi X terhadap Y1 dan b12 menyatakan koefisien regresi Y1 terhadap Y2, maka besar efek
tak-langsung (tak-terstandardisasi) X terhadap Y2 adalah bX1.b12. Dalam bentuk terstandardisasi jika pX1 menyatakan koefisien jalur X terhadap Y1 dan p12 menyatakan koefisien jalur Y1
terhadap Y2, maka besar efek tak-langsung terstandardisasi X terhadap Y2 adalah pX1.p12.
Asosiasi non-kausal adalah hubungan suatu variabel dengan variabel kedua yang
terjadi melalui variabel ketiga yang berkorelasi namun asosiasinya tak-teranalisis dengan variabel pertama, dinyatakan sebagaiX1 X2→Y atauX1 X2→ Y1 → . . . → Yk
25
BAB 4
ESTIMASI PARAMETER
Parameter Model Jalur
Untuk menjelaskan dasar-dasar perhitungan estimasi pada SEM, digunakan contoh model jalur Illness oleh Roth et al (1989) yang dalam bentuk penyederhanaan dapat diperlihatkan seperti pada gambar 4.1.
Gambar 4.1 Contoh model jalur Illness (Roth et al, 1989)
Dengan teknik statistika regresi ganda, model di atas dapat diuraikan menjadi tiga model regresi ganda:
Fit = A3+B13Exe + B23Hard + D3 (4.1)
Str = A4+B14Exe + B24Hard + B34Fit + D4 (4.2)
Ill = A5+B15Exe + B25Hard + B35Fit + B45Str + D5 (4.3) Keterangan:
1-Exe: Exercise; 2-Hard: Hardiness; 3-Fit: Fitness; 4-Str: Stress; 5-Ill: Illness.
Dalam notasi SEM, gambaran model jalur di atas biasanya disajikan lebih lengkap seperti terlihat pada gambar 4.2, dengan beberapa tambahan:
a. Variansi untuk tiap variabel eksogen (Exe dan Hard) b. Korelasi antar variabel eksogen (antara Exe dengan Hard)
c. Suku pengganggu (disturbance) untuk tiap variabel endogen (DFi,DSt, dan DIl). d. Variansi untuk tiap suku pengganggu (variansi DFi,DSt, dan DIl).
26
e. Koefisien jalur tiap suku pengganggu ke variabel endogennya yang terfiksasi menjadi bernilai sama dengan 1 (DFi→ Fit,DSt→ Str, dan DIl→ Ill).
Anak panah yang terputus-putus dimaksudkan untuk menyatakan perkiraan bahwa koefisien regresi atau koefisien jalurnya bernilai sama dengan nol.
Gambar 4.2 Contoh model jalur Illness dalam notasi SEM
Estimasi matriks kovariansi dan korelasi data Illness yang diperoleh dengan metode ML (maximum likelihood) dari sampel yang terdiri atas 373 orang mahasiswa diperlihatkan pada tabel 4.1. Perhatikan bahwa dengan teknik statistika standar, variansi populasi 2 diestimasikan dengan variansi sampel s2=
2 1 i x x n
, tetapi dengan metode ML variansipopulasi 2 diestimasikan sebagai S2=
2 ix x n
. Untuk sampel besar, nilai 2s dan S2
dapat dianggap sama, namun untuk sampel kecil S2 merupakan estimator yang bias negatif bagi variansi populasi 2. Juga untuk kovariansi sampel, estimasi tak biasnya adalah
1 2 ( ; ) cov x x =
1 1
2 2
1 i i x x x x n
, namun dengan metode ML kovariansi populasidiestimasikan sebagai Cov x x( ;1 2)=
x1i x1
x2i x2
n
27 Akibat penggunaan S2=
2 i x x n
sebagai estimasi variansi populasi yaitu:- Nilai estimasi rerata variabel terstandardisasi tidak sama dengan nol.
- Untuk model regresi terstandardisasi, nilai estimasi intersep tidak sama dengan nol.
Tabel 4.1 Estimasi matriks kovariansi dan korelasi data Illness a. Matriks kovariansi
Variabel Exe Hard Fit Str Ill
1. Exe 4422.25 2. Hard –75.81 1444.00 3. Fit 954.41 97.89 1354.24 4. Str –222.78 –585.58 –320.53 4489.00 5. Ill –332.39 –379.88 –666.79 1423.29 3903.75 b. Matriks korelasi
Variabel Exe Hard Fit Str Ill
1. Exe 1.00 2. Hard –0.03 1.00 3. Fit 0.39 0.07 1.00 4. Str –0.05 –0.23 –0.13 1.00 5. Ill –0.08 –0.16 –0.29 0.34 1.00 SD 66.50 38.00 36.80 67.00 62.48
Perhatikan bahwa kedua matriks ini saling berkaitan, dari matriks kovariansi dapat diperoleh matriks korelasi, sebaliknya dari matrik korelasi dan nilai-nilai standar deviasi dapat dihitung matriks kovariansi.
Contoh 4.1:
Dari nilai Cov (Exe ; Fit) = 954.41, Var (Exe) = 4422.25, dan Var (Fit) = 1354.24 dapat dihitung nilai Corr (Exe ; Fit):
Corr (Exe ; Fit) =
;
Cov Exe Fit SD Exe SD Fit
=
954.41
4422.25 1354.24 = 0.39
Atau nilai Cov (Hard ; Str) dapat dihitung dari Corr (Hard ; Str) = –0.23, SD (Hard) = 38.00, dan SD (Str) = 67.00:
28
Cov (Hard ; Str) = Corr (Hard ; Str) . SD (Hard) . SD (Str)
= (–0.23)(38.00)(67.00) = –585.58
Estimasi Efek pada Model Jalur
Estimasi nilai-nilai koefisien jalur yang dilakukan dengan metode maximum likelihood memerlukan proses iteratif, sehingga umumnya tak dapat dilakukan secara manual, tetapi membutuhkan program komputer untuk menyelesaikannya. Pada program statistik komputer demikian, sebagai masukan (input) dapat diisikan nilai-nilai tiap variabel teramati yang ada pada dataset, namun dapat juga diberikan matriks kovariansi atau korelasi (disertai standar deviasi tiap variabel).
Gambar 4.3 Model jalur Illness dengan nilai-nilai estimasi koefisien regresi (atas) dan koefisien jalurnya (bawah)
29
Sebagai contoh, untuk data Illness di atas menghasilkan estimasi nilai-nilai koefisien regresi (tak-terstandardisasi; atas) dan koefisien korelasi (terstandardisasi; bawah) seperti terlihat pada gambar 4.3, sedangkan hasil penilaian kemaknaannya diperlihatkan pada tabel 4.2.
Tabel 4.2 Estimasi parameter tak-terstandardisasi dan terstandardisasi model jalur Illness
a. Efek langsung Parameter bij SE b
ij pij Exe → Fit .217** .026 .392 Hard → Fit .079 .046 .082 Exe → Str –.014 .055 −.014 Hard → Str –.393** .089 −.223 Fit → Str –.198 .099 −.109 Exe → Ill .032 .048 .034 Hard → Ill –.121 .079 −.074 Fit → Ill –.442** .087 −.260 Str → Ill .271** .045 .291b. Variansi dan kovariansi
Parameter Var (X) SE (X) Var (Z)
Exe 4410.39** 323.39 1.000 Hard 1440.13** 105.60 1.000 Exe Hard −75.607 130.73 −.030 Fit D 1136.16** 83.31 .841 Str D 4181.00** 306.57 .934 Ill D 3178.98** 233.09 .817 *: p < .05; **: p < .01 Sumber: Roth et al (1989); N = 373
Interpretasi terhadap nilai-nilai estimasi pada model jalur Illness tersebut ialah:
1. Besar efek langsung adalah sama dengan koefisien regresi pada model tak-terstandardisasi dan koefisien jalur (nilai beta) pada model tak-terstandardisasi.
Untuk contoh di atas, efek langsung b13 = 0.217 pada gambar 4.3 atas adalah estimasi koefisien regresi Exe ke Fit (Exe → Fit), sedangkan efek langsung p13 = 0.392 pada gambar 3 bawah adalah estimasi koefisien jalur Exe ke Fit.
30
2. Variansi suku pengganggu pada model tak terstandardisasi merupakan estimasi bagi variansi variabel endogen yang berkaitan yang tak dijelaskan oleh variabel eksogen yang merupakan prediktornya.
Untuk contoh pada gambar 4.3 atas, variansi suku pengganggu DFi sebesar 1136.16 adalah estimasi variansi Fit yang tak dijelaskan oleh Exe dan Hard. Estimasi variansi Fit seluruhnya, termasuk yang dijelaskan oleh Exe dan Hard, adalah 1354.24 (matriks 1.a). 3. Untuk model terstandardisasi, variansi variabel eksogen selalu sama bernilai 1,
sedangkan variansi suku pengganggu merupakan estimasi proporsi variansi variabel endogen yang berkaitan yang tak dijelaskan oleh variabel eksogen prediktornya.
Untuk contoh pada gambar 4.3 bawah, variansi suku pengganggu DFi sebesar 0.841 adalah estimasi proporsi variansi Fit yang tak dijelaskan oleh Exe dan Hard. Nilai ini sama besarnya dengan 1 – RFi2 , RFi2 adalah koefisien determinasi Fit pada regresinya terhadap Exe dan Hard.
Dekomposisi Efek
Koefisien korelasi adalah ukuran kekuatan hubungan terstandardisasi antara dua variabel kontinu. Pada SEM, hubungan antara variabel dapat dibedakan menjadi efek kausal dan asosiasi non-kausal. Efek kausal adalah efek yang diasumsikan menyatakan kausalitas (hubungan sebab-akibat) antar dua variabel, dapat berupa efek langsung ataupun efek tak-langsung.
Efek langsung (direct effect) adalah efek kausal hipotetis suatu variabel terhadap
variabel kedua yang terjadi secara langsung tanpa melalui variabel ketiga. Efek searah suatu variabel terhadap variabel lainnya dinyatakan dengan lambang anak panah (“→”). Misalnya, efek langsung variabel x terhadap variabel y digambarkan sebagai x → y. Besarnya efek searah dinyatakan sebagai koefisien regresi (tak-terstandardisasi) atau koefisien jalur (terstandardisasi).
Efek tak-langsung (indirect effect) adalah efek kausal hipotetis suatu variabel terhadap
variabel kedua yang terjadi melalui satu atau lebih variabel mediator (intervening variables). Efek tak langsung variabel x terhadap variabel y2 yang terjadi melalui variabel mediator y1
dalam hubungan x → y1 → y2adalah: 2
x
31
2
x
b : efek tak-langsung (tak-terstandardisasi) x terhadap y2 1
x
b : efek langsung (tak-terstandardisasi) x terhadap y1 (koefisien regresi x key1 )
12
b : efek langsung (tak-terstandardisasi) y1terhadap y2 (koefisien regresi y1 ke y2) Dengan kondisi yang sama, untuk bentuk terstandardisasi diperoleh:
2
x
p = px1.p12 (4.5)
2
x
p : efek tak-langsung (terstandardisasi) x terhadap y2 1
x
p : efek langsung (terstandardisasi) x terhadap y1 (koefisien jalur x key1 ) 12
p : efek langsung (terstandardisasi) y1 terhadap y2 (koefisien jalury1 ke y2)
Asosiasi non-kausal adalah hubungan suatu variabel dengan variabel kedua yang
terjadi melalui variabel ketiga yang berkorelasi namun asosiasinya tak-teranalisis dengan variabel pertama, digambarkan sebagai ataux1 x2→ y1 → . . . → yk. Dalam hubungan x1
2
x → y, asosiasi non kausal antarax1 dengan y adalah: 1y
a = r12.p2y (4.6) 1y
a : asosiasi non-kausal antara x1dengan y 12
r : korelasi (asosiasi tak-teranalisis) antara x1 dengan x2
2y
p : efek langsung (terstandardisasi) x2 terhadap y (koefisien jalur x2 ke y )
Contoh 4.2:
Hubungan antara Exe dengan Ill (terstandardisasi) dapat dijabarkan sebagai berikut:
1. Efek kausal langsung (Exe → Ill): 0.0340
2. Efek kausal tak-langsung:
- Exe → Fit → Ill : (0.392)(–0.260) = –0.1019 - Exe → Str → Ill : (–0.014)(0.291) = –0.0041 - Exe → Fit → Str → Ill : (0.392)(–0.109)(0.291) = –0.0124
Jumlah efek kausal tak-langsung –0.1184
32 3. Asosiasi non-kausal:
- Exe Hard → Ill : (–0.030)(–0.074) = 0.0022
- Exe Hard → Fit → Ill : (–0.030)(0.082)(–0.260) = 0.0006 - Exe Hard → Str → Ill : (–0.030)(–0.223)(0.291) = 0.0019 - Exe Hard → Fit → Str → Ill : (–0.030)(0.082)(–0.109)(0.291) = 0.0001
Jumlah asosiasi non-kausal 0.0049
Besar hubungan seluruhnya antara Exe dengan Ill adalah: –0.0795 Hubungan antara Exe dengan Ill sebesar –0.0795 ini adalah sama dengan koefisien korelasi antara Exe dengan Ill, yaitu –0.08 (dengan pembulatan, tabel 4.1.b).
Uji Sobel
Uji Sobel adalah uji statistik untuk efek tak-langsung tak terstandardisasi antar dua
variabel yang terjadi melalui satu variabel mediator. Misalkan dalam hubungan x → y1 → 2
y , b1 menyatakan koefisien regresi x ke y1 dengan standard errorSE1 dan b2 menyatakan koefisien regresi y1 ke y2 dengan standard error SE2, maka statistik penguji untuk uji hipotesis H0: 12 = 0 adalah: uji Z = 12 12 b SE (4.7)
yang berdistribusi Z (normal standar) dengan:
12
SE =
b2 2 SE1 2 b1 2 SE2
2 (4.8)12
b =b b1. 2 : Efek tak-langsung (tak-terstandardisasi) x terhadap y2 12
SE : Standard error (b b1. 2)
Uji Sobel ini memiliki akurasi yang memadai untuk sampel berukuran besar.
Contoh 4.3:
Lihat kembali model jalur Illness pada gambar 4.3. Misalkan hendak diuji hipotesis H0
: 12 = 0 dengan 12 menyatakan efek tak-langsung (tak-terstandardisasi) Exe terhadap Ill melalui Exe → Fit → Ill dalam populasi. Estimasinya dari data sampel adalah b12 yang nilainya diperoleh sebagai hasil perkalian b b1 2, b1 menyatakan koefisien regresi Fit terhadap
33
1
b = 0.217 b2 = –0.442
1
SE = 0.026 SE2= 0.087
(Nilai SE1dan SE2 diperoleh dari keluaran program statistik komputer)
12 b = (b1)(b2) = (0.217)(–0.442) = –0.096 12 SE =
b2 2 SE1 2 b1 2 SE2
2 =
0.442
2 0.026
2 0.217
2 0.087
2 = 0.022 uji Z = 12 12 b SE = 0.096 0.022 = –4.34Notasi Jalur SEM
“sem path notation” merupakan sintaks perintah untuk diagram jalur (command syntax
for path diagrams). Sintaks-nya adalah:
sem paths . . . [, covariance() variance() means() [group()]] Jalur (paths) menspesifikasikan arah jalur antar variabel model peneliti.
Model yang akan disesuaikan sepenuhnya dideskripsikan oleh “paths, covariance(), variance(), and means()”.
Sintaks unsur-unsur ini dimodifikasikan (digeneralisasikan) apabila opsi “group()” dispesifikasikan.
Jalur untuk regresi sederhana dituliskan sebagai: (vardep <− varind) atau (varind −>vardep)
vardep : variabel dependen
varind : variabel independen Misalnya:
(y <− x) atau (x −> y) Perhatikan bahwa:
- Variabel laten dinamai dengan huruf besar untuk huruf pertamanya - Variabel teramati dinamai dengan huruf kecil untuk huruf pertamanya