STK511
Analisis Statistika
Pertemuan – 12
Hanya nama/lambang
Ordered: A>B>C>D>E
Hanya mengukur selisih tidak mampu mengukur Nisbah/rasio Mampu Mengukur Nisbah/rasio
12. Pengantar
Skala Pengukuran Nominal Ordinal Categorical Interval Ratio Numeric Data/VariabelPeubah
Kategorik
Numerik
Ditentukan oleh:
1. Skala pengukuran data/peubah 2. Jenis hubungan antar peubah
Causal relationship X
Y Numerik Kategorik
Numerik Regresi Linier ANOVA
Kategorik
Regresi Logistik, Diskriminan,
Classification and Regression Tree, Neural Network
Regresi Logistik Classification and
Regression Tree Neural Network
Peubah dan Metode Analisis
• Dalam analisis statistika (misal: uji hipotesis) tersedia pilihan prosedur : parametrik dan nonparametrik
• Prosedur parametrik mengasumsikan data memiliki sebaran teoritik tertentu dan nilai data itu sendiri yang digunakan dalam analisis (uji hipotesis)
• Prosedur nonparametrik tidak mengasumsikan data memiliki sebaran teoritik tertentu dan biasanya bukan nilai data itu sendiri (biasanya rangking) yang digunakan dalam analisis.
Parametrik vs Nonparametrik
• Keuntungan uji nonparametrik adalah mudah dan tidak perlu untuk memeriksa sebaran data.
• Namun, kuasa uji (kemampuan memdeteksi hipotesis H1 atau 1-) nonparametrik lebih rendah dibandingkan uji parametrik padanannya.
• Kelemahan lain uji nonparametrik adalah uji parametrik ternyata masih dapat digunakan pada data yang asumsi
sebarannya tidak dipenuhi (selama tidak jauh melenceng dari sebaran semula).
Uji - t dan ANOVA contohnya, masih dapat digunakan untuk Parametrik vs Nonparametrik
Pengujian hipotesis mengenai nilai tengah populasi Banyaknya
populasi Parametrik Nonparametrik
Satu Uji Z, Uji - t Uji Tanda, Wilcoxon
Dua Uji Z, Uji - t Mann-Whitney
Lebih ANOVA Kruskal-Wallis,
Friedman Parametrik vs Nonparametrik
Prosedur ini disebut uji tanda karena data yang akan dianalisis diubah menjadi serangkaian tanda plus dan minus, sehingga
statistik uji yang digunakan adalah jumlah tanda plus atau jumlah tanda minus.
Asumsi:
• Contoh yang tersedia merupakan contoh acak dari suatu populasi dengan median M yang belum diketahui.
• Peubah yang akan diamati sekurang-kurangnya ber-skala ordinal.
Hipotesis:
• H0 : M = M0 H1 : M M0 • H0 : M M0 H1 : M M0 • H : M M H1 : M M
Statistik uji
Pencatatan tanda dari n buah selisih, artinya mencatat (Xi - M0) dengan i = 1,2, ..., n.
Jika H0 benar kita berharap contoh acak memiliki tanda plus sama banyaknya dengan tanda minus. Jika kita mendapatkan suatu jumlah tanda (baik plus atau minus) yang cukup kecil maka H0 ditolak.
Kaidah Keputusan
Tolaklah H0 pada taraf nyata jika peluang untuk mendapatkan suatu tanda yang lebih sedikit dari pada tanda yang lainnya
dalam suatu conoth acak berukuran n adalah kurang dari atau sama dengan /2 (), jika H0 benar.
Ilustrasi :
Data1 : 2 3 4 5 6 7 8 3 4 5 6 7 4 3 2 5 6 7
Sign Test for Median: Data1
Sign test of median = 5.000 versus not = 5.000 N Below Equal Above P Median Data1 18 8 3 7 1.0000 5.000
Dalam uji Wilcoxon, kita menggunakan peringkat bertanda nilai-nilai selisih (Xi - M). Kita akan menghitung jumlah peringkat
bertanda negatif maupun jumlah peringkat bertanda positif.
Asumsi:
• Contoh yang tersedia merupakan contoh acak dari suatu populasi dengan median M yang belum diketahui.
• Peubah yang akan diamati sekurang-kurangnya ber-skala interval.
• Populasi simetrik dan antar pengamatan saling bebas.
Hipotesis:
• H0 : M = M0 H1 : M M0 • H0 : M M0 H1 : M M0 • H0 : M M0 H1 : M M0
Statistik uji
1. Hitung : Di = Xi – M0
2. Beri peringkat dari selisih terkecil hingga terbesar tanpa memperhatikan tandanya.
3. Tandai setiap peringkat dari tanda selisih (Di)
4. Tentukan jumlah peringkat bertanda positif, misalkan dinotasikan dengan T+ dan jumlah peringkat bertanda negatif , T-.
Kaidah Keputusan
• Terima H0 jika T+ = T-.
• Aproksimasi untuk contoh besar
T n(n 1)/4
Ilustrasi :
Data1 : 2 3 4 5 6 7 8 3 4 5 6 7 4 3 2 5 6 7
Wilcoxon Signed Rank Test: Data1
Test of median = 5.000 versus median not = 5.000 N
for Wilcoxon Estimated N Test Statistic P Median Data1 18 15 53.0 0.712 5.000
Asumsi:
• Data terdiri atas dua gugus contoh acak yang saling bebas : X1, X2…Xn dan Y1, Y2…Yn. Contoh pertama ditarik dari suatu populasi dengan median Mx dan contoh kedua dari populasi dengan median My.
• Skala pengukuran paling sedikit adalah ordinal.
• Kedua populasi memiliki bentuk sebaran yang sama.
• Fungsi sebaran dari kedua populasi hanya berbeda pada lokasinya (mean).
Hipotesis:
H0 : Mx = My
H1 : Mx My (H1 : Mx > My, H1 : Mx < My)
Statistik Uji
• Gabungkan kedua contoh, kemudian beri peringkat dari yang terkecil hingga yang terbesar.
• Jumlahkan peringkat-peringkat dari populasi 1.
Jika parameter lokasi dari populasi 1 lebih kecil, kita
mengharapkan jumlah peringkat contoh yang ditarik dari
popuasi 1 akan lebih kecil dari jumlah peringkat contoh yang ditarik dari populasi 2. Begitu juga sebaliknya.
• Statistik uji didasarkan pada jumlah peringkat yang cukup kecil atau cukup besar dari amatan-amatan contoh yang berasal
dari populasi 1.
• , dengan S adalah jumlah peringkat untuk contoh dari populasi 1 2
1) (n
n S
T 1 1
Kaidah Keputusan
• H1 : Mx My
Tolak H0 jika Thitung < w/2 atau Thitung w1-/2. • H1 : Mx < My
Tolak H0 jika Thitung < w • H1 : Mx > My
Tolak H0 jika Thitung > w1-. Catatan : w1- = n1n2 - w
Aproksimasi untuk n besar
1 2 1 2 1 2 T n n /2 z ~ 0,1 n n (n n 1)/12 N Ilustrasi :
Data1 : 2 3 4 5 6 7 8 3 4 5 6 7 4 3 2 5 6 7 Data2 : 7 4 5 6 8 7 8 9 5 7 7 8 8 9 4 5 6 7
Mann-Whitney Test and CI: Data1, Data2 N Median
Data1 18 5.000 Data2 18 7.000
Point estimate for ETA1-ETA2 is -2.000
95.2 Percent CI for ETA1-ETA2 is (-3.000,-1.000) W = 245.0
Test of ETA1 = ETA2 vs ETA1 not = ETA2 is significant at 0.0056
• Uji nilai tengah beberapa populasi berdasarkan data contoh yang saling bebas
• Pengujian dilakukan dengan memberi peringkat pada data gabungan contoh
• Idenya, bila tidak ada perbedaan antar populasi, peringkat data masing-masing contoh akan memiliki kecenderungan yang sama
• Ilustrasi: pengujian kesamaan tingkat konsumsi rumah tangga antara tiga wilayah
• Langkah-langkah:
1. Penyusunan hipotesis:
H0: Tidak ada perbedaan konsumsi antar ketiga populasi H1: Ada perbedaan konsumsi antar ketiga populasi
No Wil 1 Rank 1 Wil 2 Rank 2 Wil 3 Rank 3 1 1 5 2 17 4 45 2 2 17 3 31 4 45 3 2 17 4 45 3 31 4 2 17 4 45 4 45 5 2 17 1 5 4 45 6 5 56.5 2 17 5 56.5 7 1 5 4 45 3 31 … … … … 20 2 17 2 17 5 56.5
2. Pemberian peringkat pada data gabungan
3. Penghitungan jumlah peringkat untuk masing-masing contoh
R1 = 391.5 R2 = 539.5 R3 = 899
4. Penghitungan statistik uji
k = banyaknya populasi H = 23.432
k 1 i i 2 i1)
3(N
n
R
1)
N(N
12
H
5. Evaluasi Uji
Tolak H0 bila H > 2
(db = k-1;) atau nilai-p <
Untuk data ilustrasi, dengan menggunakan Minitab diperoleh nilai-p = 0.000
untuk = 0.05 H0 ditolak
ada perbedaan konsumsi antar ketiga wilayah
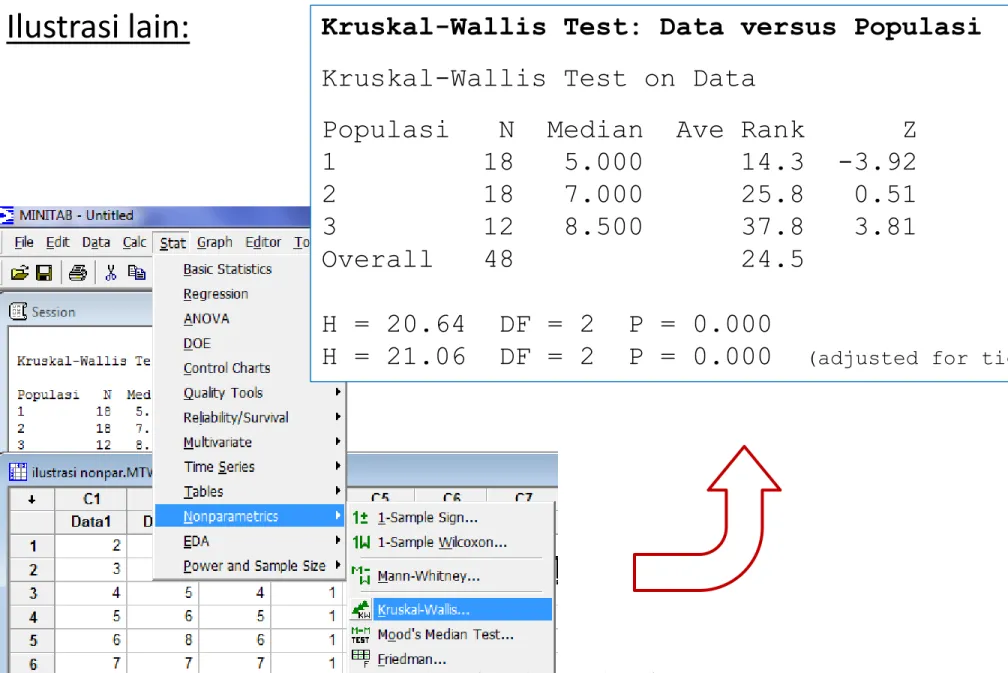
Kruskal-Wallis Test: Data versus Populasi
Kruskal-Wallis Test on Data
Populasi N Median Ave Rank Z 1 18 5.000 14.3 -3.92 2 18 7.000 25.8 0.51 3 12 8.500 37.8 3.81 Overall 48 24.5
H = 20.64 DF = 2 P = 0.000
H = 21.06 DF = 2 P = 0.000 (adjusted for ties)
Ilustrasi lain:
• Uji nilai tengah beberapa populasi berdasarkan data contoh yang saling terkait (kelompok)
• Pengujian dilakukan dengan memberi peringkat data pada masing-masing objek
• Idenya, bila tidak ada perbedaan antar populasi, peringkat data pada masing-masing contoh akan memiliki
kecenderungan yang sama
Suatu penelitian dilakukan untuk mengetahui pengaruh warna kertas (biru, hijau, oranye) terhadap tingkat respons bagi
kuesioner-kuesioner yang disebarkan dengan cara ditempelkan di kaca depan mobil yang diparkir di tempat parkir toko
swalayan.
Lima tempat parkir toko swalayan dipilih dan ketiga warna
kuesioner tersebut ditempelkan secara acak pada mobil-mobil yang diparkir di lima tempat parkir
Ilustrasi:
1. Penyusunan hipotesis
H0: Tidak ada perbedaan respon pengembalian kuesioner untuk ketiga warna
H1: Ada perbedaan respon pengembalian kuesioner untuk ketiga warna
2. Pemberian peringkat pada data respon pengembalian kuesioner untuk masing-masing toko swalayan
3. Penghitungan jumlah peringkat untuk masing-masing warna kuesioner
Langkah-langkah:
Tempat Parkir Warna Kuesioner
Biru Hijau Oranye
1 28 (2) 34 (3) 27 (1)
2 26 (2) 29 (3) 25 (1)
3 31 (2) 35 (3) 29 (1)
4 29 (2) 31 (3) 27 (1)
5 30 (3) 29 (2) 28 (1)
Rbiru=11 Rhijau=14 Roranye=5
4. Penghitungan statistik uji b = banyaknya objek = 5 k = banyaknya populasi = 3 2 = 8.400
k 1 j 2 j 2 rR
3b(k
1)
1)
bk(k
12
χ
Langkah-langkah:5. Evaluasi Uji
Tolak H0 bila H > 2(db = k-1;) atau nilai-p <
Untuk data ilustrasi, dengan menggunakan Minitab diperoleh nilai-p = 0.015
untuk = 0.05 H0 ditolak
ada perbedaan respon pengembalian kuesioner untuk ketiga warna
Langkah-langkah:
Minitab
12. Uji Friedman RAK
Friedman Test: Respon versus Warna blocked by Parkir
S = 8.40 DF = 2 P = 0.015 Sum of Warna N Est Median Ranks Biru 5 28.667 11.0 Hijau 5 31.333 14.0 Oranye 5 27.000 5.0
Uji Khi-Kuadrat
Dari data yang dimiliki, seringkali diinginkan untuk dievaluasi adakah keterkaitan atau hubungan antar peubah-peubah
yang ada.
Peubah numerik korelasi Peubah kategorik asosiasi
Beberapa ilustrasi asosiasi antar peubah
• Hubungan antara pendapatan yang diterima dengan kepuasan kerja yang dirasakan
• Hubungan antara keputusan pembelian suatu produk tertentu dikaitkan dengan jenis kelamin atau tingkat pendapatan
konsumen
• Hubungan antara status kredit nasabah (lancar atau macet) dengan status rumah (sendiri atau kontrak) dan lokasi tinggal (desa atau kota)
Asosiasi
Peubah A
Peubah B
Total
Kategori 1 Kategori 2 ... Kategori q
Kategori 1 O11 O12 ... O1q B1
Kategori 2 O21 O22 ... O2q B2
... ... ... ... ... ...
Kategori p Op1 Op2 ... Opq Bp
Total K K ... K N
Eksplorasi asosiasi antar peubah biasa diawali dengan tabulasi silang antar kedua peubah
Tabulasi Silang
• Pada evaluasi ada tidaknya asosiasi antar peubah, hipotesis yang diuji adalah:
H0: Tidak ada asosiasi antar peubah H1: Ada asosiasi antar peubah
• Apabila H0 benar, maka semestinya frekuensi masing-masing sel (frekuensi harapan) pada tabulasi silang adalah
Hipotesis
x
i j ijB
K
E
N
• Semakin jauh nilai frekuensi sebenarnya (Oij) dengan frekuensi harapan (Eij), maka semakin besar kemungkinan hipotesis H0 salah atau tidak didukung data
• Dari ide ini disusun statistik uji untuk pengujian asosiasi sebagai berikut 2 p q 2 i 1 j 1
(
ij ij)
hitung ijO
E
E
Statistik Uji• Jika H0 benar, maka 2
hitung menyebar 2 dengan
db = (p-1)(q-1) • H0 ditolak bila: 2 hitung > 2[db=(p-1)(q-1);] nilai-p < Kriteria Penolakan H0
• Ilustrasi: asosiasi antara pendapatan yang diterima dengan kepuasan kerja yang dirasakan
Pendapatan Kepuasan kerja Total
1 2 3 1 6 13 3 22 2 9 37 12 58 3 3 13 8 24 Total 18 63 23 104 Ilustrasi
• Nilai Harapan E11 = (22)x(18)/(104) = 3.81 E21 = (58)x(18)/(104) = 10.04 … E33 = (24)x(23)/(104) = 5.31 • Statistik uji 2=4.094
5.31
5.31)
(8
...
10.04
10.04)
(9
3.81
3.81)
(6
χ
2 2 2 2
Ilustrasi• Evaluasi uji
Tolak H0 bila 2 > 2
[db = (B-1)(K-1);] atau bila nilai-p <
dengan menggunakan Minitab diperoleh nilai-p = 0.393
untuk = 0.05 H0 diterima
Tidak ada asosiasi antara pendapatan yang diterima dengan kepuasan kerja yang dirasakan
Ilustrasi
12. Hubungan Antar Peubah
Minitab
Tabulated statistics: Pendapatan, Kepuasan Kerja Rows: Pendapatan Columns: Kepuasan Kerja
1 2 3 All 1 6 13 3 22 3.81 13.33 4.87 22.00 2 9 37 12 58 10.04 35.13 12.83 58.00 3 3 13 8 24 4.15 14.54 5.31 24.00 All 18 63 23 104 18.00 63.00 23.00 104.00 Cell Contents: Count
Expected count
Pearson Chi-Square = 4.094, DF = 4, P-Value = 0.393
Likelihood Ratio Chi-Square = 3.877, DF = 4, P-Value = 0.423 * NOTE * 3 cells with expected counts less than 5
C o n t i n u o u s
C a t e g o r i c a l
L i n e a r
R e g r e s s i o n
A n a l y s i s
12. Regresi Logistik
OverviewMasalah :
• Var(Yi/ni) = i(1 - i) /ni (tidak konstan) MKT terboboti • Masih memungkinan - < i < padahal 0 < i < 1
• Solusi : menggunakan canonical parameter / link function log [i/(1 - i)] = X
Yi ~ Binomial (ni, i) E(Yi) = ni i, Var(Yi) = ni i (1 - i) Model :
E(Yi/ni) = i = X MKT
Modeling Data Biner
Model Linear:
yi ~ N(i, 2) dengan
i = 1x1i + 2x2i + 3x3i + … + pxpi
Komponen dalam GLM:
(tidak harus normal, asal keluarga eksponensial)
1. Komponen acak y1, y2, …, yn contoh acak dimana yi ~ (i, 2)
2. Komponen sistematik merupakan fungsi dari peubah penjelas : i = ix1i + ix2i + ix3i + … + ixpi
3. Fungsi hubung menghubungkan antara fungsi dari nilai tengah komponen acak dengan komponen sistematik : g(i) = i
GLM: Pengembangan Model Linear
• Suatu peubah acak Y termasuk dalam keluarga eksponensial jika fkp/fmp dapat dibentuk sbb Y ~ E(, )
dengan = E(Y) = b’(), 2 = Var(Y) = b’’() a().
• Untuk tetap,
• Score function dan Fisher information function : dan
GLM: Sebaran Keluarga Eksponensial
Y
e
s
N
o
B i n a r y
T w o
C a t e g o r i e s
N
o
m
i
n
a
l
O
r
d
i
n
a
l
T h r e e
o r
M o r e
C a t e g o r i e s
Binary
Jenis Regresi Logistik
12. Regresi Logistik
Menggambarkan hubungan antara peluang “beli” vs “tidak Kurva Regresi Logistik
P
iP r e d i c t o r
P r e d i c t o r
L o g i t
T r a n s f o r m
Asumsi12. Regresi Logistik
Transformasi fungsi peluang
Model:
logit (pi) = 0 + 1X1
Transformasi dan Model Regresi Logistik
1 1 0 1 1 01
1
x xe
e
Y
P
logit
log
1
i i ip
p
p
12. Regresi Logistik
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 1 > 0 1 < 0
Transformasi dan Model Regresi Logistik
Statistik uji-G adalah uji rasio kemungkinan (likelihood ratio test) yang digunakan untuk menguji peranan peubah penjelas di dalam model secara bersama-sama (Hosmer & Lemeshow, 1989).
Rumus umum uji-G untuk menguji hipotesis : H0 : 1 = 2 = … = k = 0
H1 : minimal ada satu yang tidak sama dengan 0 adalah
Statistik G ini, secara teoritis mengikuti sebaran 2 dengan derajat bebas k. bebas peubah dengan likelihood bebas peubah pa likelihood G 2ln tan
Uji Hipotesis: Simultan
Sementara itu, uji Wald digunakan untuk menguji parameter i secara parsial. Hipotesis yang diuji adalah:
H0 : i = 0 H1 : i 0
Formula statistik Wald adalah:
Secara teori, statistik W ini mengikuti sebaran normal baku jika H0 benar. ) ˆ ( ˆ i i SE W
Uji Hipotesis: Parsial
Odd (ukuran asosiasi pada regresi logistik) rasio peluang kejadian sukses dengan kejadian tidak sukses dari peubah respon.
Adapun rasio odd mengindikasikan seberapa lebih mungkin, dalam kaitannya dengan nilai odd, munculnya kejadian sukses pada suatu kelompok dibandingkan dengan kelompok lainnya. Sebagai contoh, seberapa lebih besar peluang wanita untuk membeli produk dengan harga tertentu dibandingkan dengan pria.
Odd dan Rasio Odd
Rasio odd antara pria dengan wanita adalah: Odd dan Rasio Odd
12. Regresi Logistik
Jenis kelamin Membeli produk Total Ya Tidak Pria 10 90 100 Wanita 20 60 80 Total 30 150 180 0.11 0.9 0.1 membeli) P(tidak P(membeli) Oddpria 0.33 0.75 0.25 membeli) P(tidak P(membeli) Oddwanita 0.33 0.33 0.11 Odd Odd Odd Rasio wanita pria Ilustrasi
Binary Logistic Regression: purchase versus JK Link Function: Logit
Response Information Variable Value Count
purchase 1 162 (Event) 0 269
Total 431
Logistic Regression Table
Odds 95% CI Predictor Coef SE Coef Z P Ratio Lower Upper Constant -0.319353 0.130749 -2.44 0.015
JK -0.437307 0.202931 -2.15 0.031 0.65 0.43 0.96
12. Regresi Logistik
Tabulated statistics: JK, purchase Rows: JK Columns: purchase
0 1 All 0 139 101 240 1 130 61 191 All 269 162 431