PEMBOBOTAN NILAI ALPHA DINAMIS PADA PROTOKOL
ROUTING SIMBET
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Untuk Mendapatkan Gelar Sarjana Komputer
Program Studi Teknik Informatika
DISUSUN OLEH BALTASAR Y.S. SUDJONO
155314123
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
DYNAMICALLY ALPHA WEIGHTING ON SIMBET
ROUTING PROTOCOL
A THESIS
Presented as Partial Fulfillment of Requirements To Obtain Sarjana Komputer Degree In Informatics Engineering Department
By:
BALTASAR Y.S. SUDJONO 155314123
INFORMATICS ENGINEERING STUDY PROGRAM INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
YOGYAKARTA 2019
v MOTTO
“Logic will get you from A to B. Imagination will take you everywhere”
Albert Einstein
“Be not afraid of greatness. Some are born great, some achieve greatness, and others have greatness thrust upon them.”
William Shakespeare
“The greatest danger for most of us is not that our aim is too high and we miss it, but that it is too low and we reach it.”
Michelangelo
DON’T BE AFRAID OF BEING DIFFERENT BE AFRAID OF BEING LIKE EVERYONE ELSE
viii ABSTRAK
Pengiriman pesan dalam jaringan oportunistik menjadi sulit karena perubahan topologi jaringan yang disebabkan pergerakan node secara bebas dalam jaringan. Dalam beberapa tahun terakhir, semakin banyak penelitian yang memanfaatkan hubungan sosial. Hubungan sosial cenderung lebih stabil seiring berjalannya waktu sehingga dengan mempelajarinya, dapat membantu menentukan node yang baik dalam menitipkan pesan.
Dengan memanfaatkan popularitas node dalam jaringan dan kedekatan terhadap node tujuan, muncul protokol SimBet yang melakukan pembobotan antara kedua properti sosial ini dalam menentukan node relay terbaik. Dengan mengetahui kecenderungan pergerakan dalam suatu jaringan, pembobotannya akan menjadi lebih mudah ditentukan diawal simulasi untuk hasil yang optimal. Namun properti manakah yang menjadi prioritas dalam menentukan node relay menjadi suatu tantangan sendiri ketika berhadapan dengan suatu jaringan dengan kecenderungan pergerakan yang belum diketahui sebelumnya. Beberapa node dalam jaringan bisa saja mempunyai kecenderungan yang berbeda dari beberapa node lain sehingga dengan menentukan pembobotan secara menyeluruh untuk tiap pesan menjadi tidak begitu optimal dan memakan waktu yang banyak jika harus mencoba beberapa pembobotan yang berbeda-beda dalam pergerakan yang sama untuk mendapatkan hasil yang optimal.
Untuk mengatasinya, setiap node secara dinamis melakukan pembobotan untuk setiap pesan di jaringan dan memfokuskan untuk mencari node dengan kedekatan yang tinggi terhadap node tujuan, untuk mengurangi beban di jaringan dan tetap mempertahankan performa delivery dan delay pada pengiriman pesan dengan hasil yang baik. Sebagai tambahan, kami membandingkan protokol hasil SimBet dengan SimBet pembobotan dinamis dan menentukan bahwa SimBet pembobotan dinamis mampu beradaptasi di setiap dataset yang diuji.
ix ABSTRACT
Message delivery in opportunistic network is difficult due to the topology changes cause by nodes move freely in the network. In the past few years, more and more researches have make advantages of social relationship. Social relationship tends to be more stable over time and understanding it can help to determine which node is good to be a relay in forwarding messages.
By utilizing node popularity in the network and closeness to the destination node, SimBet protocol was proposed which works by weighting these two properties in determining best relay node. Knowledge to the movement tendency in a network will make the weighting easier which can be predetermined before the simulation starts for the optimal result. However, which property will be prioritized in determining the relay node is a challenge when facing an unknown network’s movement tendency. Some nodes may have different movement pattern than others and the same predetermined weight for every message is not optimal and take a lot of time to try different weights in the same movement for the optimal result.
To overcome this, every node dynamically performs the weighting for every message in the network and focuses on finding the node with higher closeness to the destination, to reduce the overhead in the network and keep the delivery performance and delay on the good result. Additionally, this research also compares the original SimBet protocol to the SimBet with dynamic weighting and show that the dynamic weighting SimBet can adapt in every examined dataset.
xi
DAFTAR ISI
PEMBOBOTAN NILAI ALPHA DINAMIS PADA PROTOKOL ROUTING
SIMBET ... i
DYNAMICALLY ALPHA WEIGHTING ON SIMBET ROUTING PROTOCOL ... ii
HALAMAN PERSETUJUAN ... iiii
HALAMAN PENGESAHAN ... iv
MOTTO ... v
PERNYATAAN LEMBAR KEASLIAN KARYA ... vi
LEMBAR PERSETUJUAN PUBLIKASI KARYA ILMIAH ... vii
ABSTRAK ... viiii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xiii
DAFTAR RUMUS ... xiv
BAB I ... 1.1 LATAR BELAKANG ... 2 1.2 RUMUSAN MASALAH ... 2 1.3 TUJUAN PENELITIAN ... 2 1.4 BATASAN MASALAH ... 2 1.5 METODE PENELITIAN ... 2 1.6 SISTEMATIKA PENULISAN ... 3 BAB II ... 4
2.1 MOBILE AD-HOC NETWORK(MANET) ... 4
2.2 JARINGAN OPORTUNISTIK ... 4
2.3 PROPERTI SOSIAL OPPNET ... 4
2.4 ROUTING BERDASARKAN NILAI BETWEENNESS CENTRALITY DAN SIMILARITY ... 8
xii
2.6 SIMULATOR ONE ... 10
2.7 METRIK UNJUK KERJA ... 11
BAB III ... 13 3.1 DATA ... 13 3.2 ALAT PENELITIAN ... 13 3.3 LANGKAH-LANGKAH PENELITIAN ... 14 BAB IV ... 17 4.1 HAGGLE 3 – INFOCOM 5 ... 17
4.2 HAGGLE 4 – CAMBRIDGE IMOTES ... 21
4.3 HAGGLE 4 – SASSY ... 25 BAB V ... 29 5.1 KESIMPULAN ... 29 5.2 SARAN ... 29 DAFTAR PUSTAKA ... 31 LAMPIRAN ... 32
xiii
DATA GAMBAR
Gambar 2.1 Korelasi egocentric betweenness dengan sociocentric betweenness ... 5
Gambar 2.2 Topologi Jaringan ... 6
Gambar 2.3 Gambar Kelompok Saling Terpisah ... 7
Gambar 2.4 Gambaran umum kelas pada simulator ONE ... 11
Gambar 4.1 Grafik delivery probability dataset Haggle 3 – Infocom 5 ... 17
Gambar 4.2 Grafik overhead ratio dataset Haggle 3 – Infocom 5 ... 18
Gambar 4.3 Grafik latency dataset Haggle 3 – Infocom 5 ... 19
Gambar 4.4 Grafik hop count dataset Haggle 3 – Infocom 5 ... 20
Gambar 4.5 Grafik delivery Centrality dataset Haggle 3 - Infocom 5 ... 21
Gambar 4.6 Grafik delivery probability Haggle 4 - Cambridge Imotes ... 22
Gambar 4.7 Grafik overhead Haggle 4 - Cambridge Imotes ... 23
Gambar 4.8 Grafik latency dataset Haggle 4 - Cambridge Imotes ... 23
Gambar 4.9 Grafik hop count dataset Haggle 4 - Cambridge Imotes ... 24
Gambar 4.10 Grafik delivery centrality dataset Haggle 4 - Cambridge Imotes ... 25
Gambar 4.11 Grafik delivery probability dataset Sassy ... 26
Gambar 4.12 Grafik overhead ratio dataset Sassy ... 26
Gambar 4.13 Grafik latency dataset Sassy ... 27
Gambar 4.14 Grafik hop count dataset Sassy ... 27
xiv DAFTAR RUMUS Rumus 2.1 ... 4 Rumus 2.2 ... 6 Rumus 2.3 ... 6 Rumus 2.4 ... 6 Rumus 2.5 ... 7 Rumus 2.6 ... 8 Rumus 2.7 ... 9 Rumus 2.8 ... 9 Rumus 2.9 ... 10 Rumus 2.10 ... 10 Rumus 2.11 ... 12 Rumus 2.12 ... 12
1 BAB I PENDAHULUAN 1.1. Latar belakang
Dalam beberapa tahun sebelumnya, berbagai jenis routing untuk Delay Tolerant Networks(DTN) atau Opportunistic Network(OppNet) sudah banyak dikembangkan [1]. Permasalahan yang ada dalam routing pada jaringan ini adalah bagaimana menentukan node terbaik untuk meneruskan suatu pesan. Relasi sosial antar node cenderung stabil dari waktu ke waktu dan dengan mempelajarinya, dapat memfasilitasi pengiriman pesan. Beberapa protokol routing digunakan dengan memanfaatkan relasi sosial antar node untuk membantu memutuskan node manakah sebuah pesan akan diteruskan. Protokol-protokol ini disebut social-aware routing protocols [1].
Dari berbagai routing social-aware yang ada, peneliti tertarik untuk melakukan penelitian untuk protokol SimBet [1]. Protokol ini melakukan pembobotan terhadap nilai Centrality Betweenness dan Similarity dengan nilai yang sama untuk setiap pengiriman pesan. Pembobotan ini berpengaruh pada performa SimBet dan tidak bisa ditentukan secara sepele karena sesungguhnya pembobotan yang optimal tergantung pada kecenderungan pergerakan node suatu jaringan yang bersangkutan. Maka dari itu dibutuhkan algoritma agar pembobotan terhadap kedua metric SimBet untuk setiap pengiriman pesan bisa dilakukan secara dinamis oleh tiap-tiap node. Pada penelitian ini, penulis akan melakukan pengukuran seberapa efisien performa SimBet jika pembobotan dilakukan secara dinamis oleh tiap-tiap node.
1.2. Rumusan Masalah
Berdasarkan latar belakang, maka rumusan masalah yang didapat adalah seberapa efisien performa protokol SimBet dengan pembobotan nilai Centrality Betweenness dan Similarity yang dinamis pada tiap pengiriman pesan dalam jaringan dibandingkan dengan SimBet yang melakukan pembobotan secara menyeluruh untuk semua pesan di awal simulasi.
1.3. Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk mengetahui seberapa efisien kinerja protokol SimBet ketika pembobotan dilakukan pada setiap pengiriman pesan.
1.4. Batasan Masalah
Batasan masalah dalam penelitian ini adalah: 1. Menggunakan protokol routing SimBet.
2. Pergerakan yang diamati adalah pergerakan sosial oportunistik. 3. Pengujian dilakukan menggunakan Simulator ONE.
4. Metrik unjuk kerja yang akan digunakan untuk menilai unjuk kerja protokol routing SimBet adalah delivery probability, overhead ratio, hop count, latency average, dan delivery centrality.
1.5. Metode Penelitian
Metode yang dilakukan dalam penelitian ini meliputi: 1. Studi Pustaka
Mempelajari teori-teori yang berkaitan dengan protokol SimBet, node centrality, node similarity.
2. Pengumpulan Bahan Penelitian
Menggunakan data traces pergerakan mobile yang sudah tersedia di Internet pada alamat http://www.shigs.co.uk/index.php?page=traces. 3. Pembuatan Alat Uji
Sistem dirancang dari mengidentifikasi apa yang dilakukan oleh protokol sehingga dapat menghasilkan data hasil simulasi yang dapat dianalisis.
4. Pengujian
Membuat implementasi dari protokol routing yang akan digunakan dalam penelitian.
5. Analisis Hasil Pengujian
Dalam tahap ini data yang telah dikumpulkan akan diproses menggunakan simulator dan diamati untuk dianalisis berdasarkan parameter kinerja yang sudah ditentukan.
1.6. Sistematika Penulisan BAB I: PENDAHULUAN
Bab ini berisi penjelasan tentang latar belakang masalah, rumusan masalah, tujuan penelitian, manfaat penelitian, batasan masalah, metode penelitian, dan sistematika penulisan.
BAB II: LANDASAN TEORI
Bab ini berisi tentang teori tentang centrality degree, node similarity, dan protokol routing SimBet yang digunakan sebagai dasar dalam mengukur unjuk kerja protokol routing.
BAB III: METODE PENELITIAN
Bab ini berisi tentang data penelitian, alat penelitian, langkah-langkah pengujian.
BAB IV: PENGUJIAN DAN ANALISIS
Bab ini berisi tentang tahap pengujian, yaitu simulasi, dan analisis hasil data simulasi.
BAB V: KESIMPULAN DAN SARAN
Bab ini berisi tentang kesimpulan hasil penelitian dan saran dari penulis untuk penelitian selanjutnya.
4 BAB II
LANDASAN TEORI 2.1. Mobile Ad-Hoc Network (MANET)
MANET merupakan jaringan wireless mobile yang dinamis. Node-node bergerak dengan bebas dan sewenang-wenang mengorganisir dirinya masing-masing. Walaupun demikian, routing pada jaringan ini tetap bisa dilakukan karena jalur dari source ke destination.
2.2. Jaringan Oportunistik
Jaringan oportunistik (Opportunistic Network/OppNet) merupakan jenis dari MANET yang mana pada OppNet ini tidak selalu tersedia jalur dari source ke destination karena topologi jaringan yang sering berubah-ubah, dan menjadikan routing dalam jaringan ini menjadi sulit dan mempunyai delay yang tinggi pada tiap pengiriman pesan.
Jaringan Sosial Oportunistik
Karakteristik sosial menjadi pertimbangan baru dalam routing di OppNet. Dalam berbagai kasus OppNet, alat komunikasi dibawa oleh manusia yang kelakuannya dideskripsikan dalam bentuk sosial. Ikatan sosial antar manusia cenderung stabil dari waktu ke waktu yang kemudian dengan mempelajarinya bisa membantu untuk membuat forwarding decision yang lebih baik di OppNet.
2.3. Properti Sosial OppNet Betweenness Centrality Rumus 2.1. 𝐶𝐵(𝑝𝑖) = ∑ ∑ 𝑔𝑗𝑘(𝑝𝑖) 𝑔𝑗𝑘 𝑗−1 𝑘=1 𝑁 𝑗=1
𝑔𝑗𝑘= jumlah total jalur terpendek yang menghubungkan
𝑝𝑖 dan 𝑝𝑘
𝑔𝑗𝑘(𝑝𝑖) = jumlah total jalur terpendek yang menghubungkan 𝑝𝑗
Nilai betweenness centrality merepresentasikan seberapa pentingnya sebuah node dalam menjadi penghubung antar node lainnya untuk saling berkomunikasi. Semakin tinggi nilai betweenness centrality maka sebuah node akan dianggap node yang paling populer dan mampu memfasilitasi interaksi antar node-node yang terhubung dengan node tersebut.
Ego Network – Egocentric Betweenness Centrality
Pada jaringan sosial oportunistik tidak ada topologi jaringan yang terbentuk sehingga sangat tidak dimungkinkan untuk mengumpulkan informasi seluruh jaringan. Oleh karena itu, pada penelitian ini akan digunakan konsep “ego network” yang hanya terdiri dari satu node (ego node) beserta node-node yang terhubung dengan ego node dan link antar node yang terbentuk [2].
Gambar 2.1. Korelasi egocentric betweenness dengan sociocentric betweenness (Marsden, 2002)
Berdasarkan penelitian yang dilakukan oleh Marsden, pada penerapannya egocentric betweenness dan sociocentric betweenness dapat menghasilkan peringkat popularitas yang hampir sama. Oleh karena itu, konsep ego network dapat diterapkan dalam metode penghitungan centrality pada jaringan sosial oportunistik [2].
Penghitungan Egocentric Betweenness Centrality
Secara matematis, node-node yang sudah ditemui ego node dapat direpresentasikan dalam bentuk matriks adjacency. Matriks yang terbentuk adalah
Rumus 2.4. matriks simetris yang akan memiliki orde n x n, n merupakan jumlah node yang sudah ditemui oleh ego node.
Rumus 2.2. 𝐴𝑖𝑗= {
1, jika node i dan j pernah bertemu 0, sebaliknya
𝐴 = matriks adjacency dari sebuah ego node A
Rumus 2.3.
𝐸𝐵𝐶(𝐴) = ∑ 1
𝐴2[1 − 𝐴] 𝑖,𝑗
𝐸𝐵𝐶(𝐴) = nilai egocentric betweenness centrality sebuah ego node 𝐴
𝐴2= kuadrat dari matriks adjacency A
Karena matriks yang terbentuk adalah matriks simetris, hanya nilai di atas diagonal dan tidak bernilai 0 yang perlu diperhatikan. Ketika ego node bertemu dengan node baru yang belum termasuk dalam daftar node-node yang ditemuinya, ego node akan melakukan pembaharuan daftar node dan orde matriks adjacency. Pada ego network, node yang diperhitungkan adalah node yang ditemui ego node secara langsung maka hanya daftar node milik contact node (node yang ditemui ego node) yang sama-sama ditemui oleh ego node dan contact node saja yang dimasukkan ke dalam matriks adjacency.
Contoh: 𝐸𝐵𝐶(𝑤8) = ∑1 3= 1 3
Node Similarity
Jaringan sosial dapat menunjukkan adanya derajat transitivity yang sangat tinggi. Transitivity adalah relasi antara 3 node, jika ada hubungan antara node 1 dan node 2, node 2 dan node 3, maka secara tidak langsung node 1 dan node 3 juga berhubungan. Semakin tinggi nilai transitivity antara node 1 dan node 3 maka probabilitas untuk bertemu akan meningkat. Hal ini biasa disebut dengan pengelompokan (clustering). Dalam sebuah jaringan, semakin banyak teman yang sama yang dimiliki oleh dua buah node yang tidak saling terhubung maka semakin tinggi probabilitas kedua node ini saling terhubung.
Gambar 2.3. Kelompok yang saling terpisah
Probabilitas dari penghitungan di bawah dapat menggambarkan adanya ‘node similarity’ dari node x dan node y pada sebuah topologi jaringan. Semakin banyak kesamaan himpunan node tetangga yang sama antara node x dan y, maka semakin tinggi probabilitas kedua buah node untuk saling bertemu.
Rumus 2.5. 𝑃(𝑥, 𝑦) = |𝑁(𝑥) ∩ 𝑁(𝑦)|
𝑃(𝑥, 𝑦) = probabilitas node x dan node y terhubung 𝑁(𝑥) = himpunan node yang terhubung dengan x 𝑁(𝑦) = himpunan node yang terhubung dengan y
Contoh:
Matriks pertemuan yang telah
terbentuk pada penyimpanan lokal node w8.
Matriks n x m (matriks pertemuan node w5 dengan seluruh node yang sudah ditemui node w8
Jumlah node yang masuk irisan node yang sama-sama pernah ditemui menunjukan nilai node similarity w8 ke w5
𝑃(𝑤8, 𝑤5) = 1
2.4. Routing Berdasarkan Nilai Betweenness Centrality dan Similarity
Utilitas SimBet menggunakan dua metric penghitungan yaitu node similarity dan betweenness centrality yang sudah dijelaskan sebelumnya. Node yang terpilih sebagai node relay adalah node yang memiliki nilai utilitas tertinggi dalam menyampaikan pesan ke node destination. Nilai utilitas SimBet didapatkan dari penghitungan nilai utilitas node similarity dan utilitas betweenness dari ego node (n) untuk mengirim pesan ke node destination (d) dibandingkan dengan node relay (m). Penghitungan Nilai Utilitas SimBet
Rumus 2.6. 𝑆𝑖𝑚𝑈𝑡𝑖𝑙𝑛(𝑑) =
𝑆𝑖𝑚𝑛(𝑑)
𝑆𝑖𝑚𝑛(𝑑) + 𝑆𝑖𝑚𝑚(𝑑)
𝑆𝑖𝑚𝑈𝑡𝑖𝑙𝑛(𝑑) = nilai utilitas node similarity node n terhadap node d
𝑆𝑖𝑚𝑛(𝑑) = nilai node similarity node n terhadap node d
𝑆𝑖𝑚𝑚(𝑑) = nilai node similarity node m terhadap node d
irisan node yang sama-sama ditemui oleh node w8 dan w5
Rumus 2.7. 𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛=
𝐵𝑒𝑡𝑛
𝐵𝑒𝑡𝑛+ 𝐵𝑒𝑡𝑚
𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛= nilai utilitas betweenness node n
𝐵𝑒𝑡𝑛= nilai betweenness node n
𝐵𝑒𝑡𝑚 = nilai betweenness node m
Nilai utilitas SimBet node n ke node d dapat diukur dengan mengombinasikan nilai utilitas node similarity dan utilitas betweenness yang telah diukur sebelumnya.
Rumus 2.8. 𝑆𝑖𝑚𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛(𝑑) = 𝛼𝑆𝑖𝑚𝑈𝑡𝑖𝑙𝑛(𝑑) + 𝛽𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛
𝑆𝑖𝑚𝐵𝑒𝑡𝑈𝑡𝑖𝑙𝑛(𝑑) = nilai utilitas SimBet node n ke node d
𝛼 + 𝛽 = 1
Nilai α dan β merupakan parameter yang berubah-ubah pada tiap pengiriman pesan tergantung pada perhitungan tiap node untuk memutuskan nilai utilitas mana yang lebih dominan untuk digunakan dalam meneruskan pesan yang bersangkutan.
2.5. Penentuan nilai 𝜶
Penentuan nilai 𝛼 tergantung pada hasil perhitungan nilai rasio tertinggi antara kedekatan carrier terhadap node destinasi atau nilai popularitas node carrier dalam jaringan dibandingkan terhadap node yang menjadi calon relay pesan. Pembobotan Nilai α dengan Prioritas Kedekatan Node terhadap Node Destinasi
Jika hasil rasio kedekatan node similarity terhadap popularitas node tersebut dibanding calon node relay lebih tinggi maka pembobotan α akan diutamakan terhadap nilai kedekatan node terhadap destinasi dengan menggunakan rasio antara kedekatan dan popularitas node.
Rumus 2.9.
𝛼= 𝑐𝑎𝑟𝑟𝑖𝑒𝑟𝑆𝑖𝑚
𝑐𝑎𝑟𝑟𝑖𝑒𝑟𝑆𝑖𝑚 + 𝑐𝑎𝑟𝑟𝑖𝑒𝑟𝐵𝑒𝑡 𝑐𝑎𝑟𝑟𝑖𝑒𝑟𝑆𝑖𝑚 = nilai node similarity node n terhadap node d 𝑐𝑎𝑟𝑟𝑖𝑒𝑟𝐵𝑒𝑡 = nilai betweenness node n
Pembobotan Nilai α dengan Prioritas Popularitas Node dalam Jaringan
Jika hasil rasio popularitas node carrier dan calon node relay lebih baik dari similarity node tersebut maka pembobotan α akan diutamakan terhadap nilai popularitas node dalam jaringan menggunakan rasio antara kedekatan dan popularitas node.
Rumus 2.10.
𝛼= 𝑐𝑎𝑟𝑟𝑖𝑒𝑟𝐵𝑒𝑡
𝑐𝑎𝑟𝑟𝑖𝑒𝑟𝑆𝑖𝑚 + 𝑐𝑎𝑟𝑟𝑖𝑒𝑟𝐵𝑒𝑡 𝑐𝑎𝑟𝑟𝑖𝑒𝑟𝑆𝑖𝑚 = nilai node similarity node n terhadap node d 𝑐𝑎𝑟𝑟𝑖𝑒𝑟𝐵𝑒𝑡 = nilai betweenness node n
2.6. Simulator ONE (Opportunistic Networking Environment)
Simulator ONE merupakan sebuah simulator yang dikembangkan menggunakan bahasa pemrograman Java dan digunakan untuk melakukan simulasi komunikasi pada OppNet. Simulator ONE bisa melakukan generate pergerakan node menggunakan model pergerakan yang berbeda-beda, melakukan routing pengiriman pesan antar node dengan berbagai algoritma routing OppNet yang berbeda-beda dan mampu menampilkan mobilitas dan pertukaran pesan secara real time menggunakan user interface [2].
Gambar 2.4. Gambaran umum kelas pada simulator ONE 2.7. Metrik Unjuk Kerja
Untuk mengetahui performa dari sebuah protokol routing, dibutuhkan beberapa metrik unjuk kerja jaringan. Dalam penelitian ini, ada 5 metrik unjuk kerja jaringan yang akan digunakan. Kelima metrik unjuk kerja jaringan yang digunakan adalah delivery probability, overhead ratio, latency average, hop count average, dan delivery centrality.
Cara menghitung nilai metrik unjuk kerja delivery probability, overhead ratio, latency average, hop count average sudah diimplementasikan dalam method messageTransferred(), pada kelas MessageStatsReport pada simulator ONE versi 1.4.1 yang dapat diunduh pada laman https://www.netlab.tkk.fi/tutkimus/dtn/. Sedangkan cara menghitung delivery centrality, sudah diimplementasikan pada kelas DeliveryCentralityReport dan dapat diunduh pada laman https://github.com/knightcode/the-one-pitt.
a. Delivery Probability
Delivery probability merupakan metrik unjuk kerja jaringan yang digunakan untuk mengetahui probabilitas pesan berhasil dikirimkan ke tujuan yaitu node destination. Semakin tinggi nilai delivery probability yang dihasilkan maka unjuk kerja protokol routing dapat dikatakan baik.
b. Latency Average
Latency average merupakan metrik unjuk kerja jaringan yang digunakan untuk mengetahui jumlah rata-rata waktu yang dibutuhkan sebuah pesan untuk mencapai node destination sejak pesan dibuat. Semakin tinggi nilai latency average yang dihasilkan maka unjuk kerja protokol routing dapat dikatakan buruk.
Rumus 2.11
𝐿𝑎𝑡𝑒𝑛𝑐𝑦 𝑎𝑣𝑒𝑟𝑎𝑔𝑒 =𝑠𝑢𝑚 𝑜𝑓 𝑙𝑎𝑡𝑒𝑛𝑐𝑦 𝑜𝑓 𝑑𝑒𝑙𝑖𝑣𝑒𝑟𝑒𝑑 𝑚𝑒𝑠𝑠𝑎𝑔𝑒𝑠 𝑡𝑜𝑡𝑎𝑙 𝑔𝑒𝑛𝑒𝑟𝑎𝑡𝑒𝑑 𝑛𝑒𝑤 𝑚𝑒𝑠𝑠𝑎𝑔𝑒𝑠
c. Hop Count Average
Hop count average merupakan metrik unjuk kerja jaringan yang digunakan untuk mengetahui jumlah rerata lompatan yang dilalui oleh sebuah pesan untuk mencapai node destination. Semakin tinggi nilai rerata hop count yang dihasilkan maka unjuk kerja protokol routing dapat dikatakan buruk.
d. Overhead Ratio
Overhead ratio merupakan metrik unjuk kerja jaringan yang digunakan untuk mengetahui perbandingan antara total copy pesan dalam jaringan dengan jumlah pesan yang sampai ke node destination. Semakin tinggi nilai overhead ratio yang dihasilkan maka unjuk kerja protokol routing dapat dikatakan buruk.
Rumus 2.12
𝑂𝑣𝑒𝑟ℎ𝑒𝑎𝑑 𝑟𝑎𝑡𝑖𝑜 = 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑟𝑒𝑙𝑎𝑦𝑒𝑑 𝑚𝑒𝑠𝑠𝑎𝑔𝑒𝑠 − 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑑𝑒𝑙𝑖𝑣𝑒𝑟𝑒𝑑 𝑚𝑒𝑠𝑠𝑎𝑔𝑒𝑠 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑑𝑒𝑙𝑖𝑣𝑒𝑟𝑒𝑑 𝑚𝑒𝑠𝑠𝑎𝑔𝑒𝑠
e. Delivery Centrality
Delivery centrality merupakan metrik unjuk kerja jaringan yang digunakan untuk mengetahui sebaran pesan yang diterima pada setiap node. Semakin tinggi nilai delivery centrality yang dihasilkan oleh setiap node maka unjuk kerja protokol routing dapat dikatakan buruk.
13 BAB III
METODE PENELITIAN 3.1. Data
Data yang digunakan adalah dataset encounter traces yang dicatat menggunakan alat komunikasi wireless dari berbagai eksperimen. Encounter time antar dua alat komunikasi wireless bisa dikatakan sebagai waktu yang dicatat ketika sebuah device menyadari adanya device yang lain. Dataset yang diteliti yakni Infocom 5, Infocom 6, Cambridge Imotes, dan Sassy. Tiap-tiap dataset memiliki waktu simulasi, jumlah device, dan kecenderungan pergerakan sosial yang berbeda-beda.
3.2. Alat Penelitian a. Hardware
Sistem operasi : Windows 10 Home Single Language 64-bit (10.0, Build 17134)
Pabrikan sistem : Micro-Star International Co., Ltd. Model sistem : GL63 8RC
Prosesor : Intel(R) Core(TM) i7-8750U CPU @ 2.20GHz (12 CPUs), ~2.2GHz
Memori : 8192MB RAM b. Software
1. Eclipse
Eclipse merupakan sebuah Integrated Development Environment (IDE) yang digunakan dalam pemrograman, dan sudah banyak digunakan oleh banyak programmer. Eclipse sendiri lebih banyak ditulis menggunakan bahasa pemrograman Java tujuan penggunaanya adalah untuk Java juga, tetapi juga bisa digunakan untuk melakukan pemrograman dalam bahasa lainnya misalnya yang sudah terkenal seperti C, C++, JavaScript dan beberapa bahasa lainnya.
2. Simulator ONE
Penjelasan tentang simulator ONE sudah ditulis dalam landasan teori Simulator ONE, BAB II.
3.3. Langkah-Langkah Penelitian 1. Studi Pustaka
Studi pustaka dilakukan dengan membaca jurnal yang berkaitan dengan protokol routing simulator ONE, SimBet, centrality, betweenness centrality, node similarity.
2. Pengumpulan Bahan Penelitian
Data human contact datasets sudah tersedia online di Internet http://www.shigs.co.uk/index.php?page=traces. Peneliti hanya perlu mengunduh data pada link yang tersedia.
3. Pembuatan Alat Uji a. Analisis Kebutuhan
Analisis kebutuhan pada alat uji yang digunakan sudah ditulis dalam landasan teori Simulator ONE, BAB II.
b. Desain Alat Uji
Alat uji yang digunakan merupakan implementasi protokol SimBet di Simulator ONE dengan bahasa pemrograman Java.
i. Perhitungan nilai 𝛼
Algoritma perhitungan nilai 𝜶
1: Ambil nilai SimUtil Carrier dan BetUtil Carrier 2: Ambil property sosial carrier dari nilai utility terbaik 3: Nilai 𝛼 dihitung dengan rasio dari property telah diambil 4: Update nilai 𝛼 untuk perhitungan SimBetUtil
ii. Pseudo-code algoritma pemberian property 𝛼 pada tiap message Pseudo-code penambahan property 𝜶
while NA is in contact with NB do
receive neighboursNode(NB)
update betweenness_centrality(NA)
update node_similarity(NA)
while ∃ m ∈ buffer(NA) do
my_SimBetUtil = count SimBet_Util(NA)
peer_SimBetUtil = count SimBet_Util(NB)
if (my_SimUtil > my_BetUtil)
𝛼 = my_SimUtil/(my_SimUtil+ my_BetUtil) else 𝛼 = my_BetUtil /( my_SimUtil+ my_BetUtil) if (messageAlpha! =null) if(alpha>messageAlpha) updateMessageAlpha(𝛼); else alpha=messageAlpha; else putMessageAlpha if (peer_SimBetUtil > my_SimBetUtil OR NB = destination) then forward(m, NB) end if end while end while
4. Pengujian
a. Skenario Pengujian
Parameter yang diteliti yaitu menerapkan algoritma pembobotan dinamis nilai node similarity dan betweenness pada protokol routing SimBet untuk tiap pengiriman pesan yang kemudian dibandingkan hasilnya dengan protokol SimBet asli dengan parameter α bervariasi mulai dari 0, 0.1, 0.3, 0.6, 0.85, 1.
b. Desain Cara Melakukan Pengujian dengan Alat Uji
Pengujian dilakukan dengan cara menjalankan simulasi sebanyak 1 kali untuk setiap skenario yang diuji pada setiap dataset yang digunakan.
5. Analisis Hasil Pengujian
Menentukan nilai metrik unjuk kerja yang dibutuhkan untuk menganalisis unjuk kerja SimBet, yaitu delivery probability, overhead ratio, latency average, hop count average, dan delivery centrality.
a. Delivery Probability
Langkah untuk menghitung delivery probability sudah ditulis dalam landasan teori Metrik Unjuk Kerja Jaringan, BAB II.
b. Latency Average
Langkah untuk menghitung latency average sudah ditulis dalam landasan teori Metrik Unjuk Kerja Jaringan, BAB II.
c. Hop Count Average
Langkah untuk menghitung hop count average sudah ditulis dalam landasan teori Metrik Unjuk Kerja Jaringan, BAB II.
d. Overhead Ratio
Langkah untuk menghitung overhead ratio sudah ditulis dalam landasan teori Metrik Unjuk Kerja Jaringan, BAB II.
e. Delivery Centrality
Langkah untuk menghitung delivery centrality sudah ditulis dalam landasan teori Metrik Unjuk Kerja Jaringan, BAB II.
17 BAB IV
PENGUJIAN DAN ANALISIS
Untuk mengevaluasi unjuk kerja algoritma pembobotan nilai 𝛼 dinamis pada protokol routing SimBet, dilakukan simulasi dengan skenario yang telah dirancang pada Bab III, pada dataset Haggle 3 - Infocom 5, Haggle 4 - Cambridge Imotes, dan Sassy. Data hasil simulasi diperoleh dari report yang dibangkitkan ketika simulasi berjalan.
4.1. Haggle 3 – Infocom 5
Dataset ini berisi data pertemuan antar partisipan pada konferensi IEEE Infocom di Miami. Setiap partisipan diberi device (iMotes) yang digunakan untuk mencatat data pertemuan antar partisipan. Dari 50 partisipan yang dipilih, device yang menghasilkan data yang valid dan dapat digunakan untuk melakukan penelitian sebanyak 41 device. Durasi simulasi pada dataset ini adalah 254150 detik, sekitar 2.94 hari.
Gambar 4.1. Grafik delivery probability dataset Haggle 3 – Infocom 5 Pada grafik di atas, bisa dilihat bahwa nilai delivery probability tertinggi pada dataset ini adalah 𝛼=0.1 dan 𝛼=0.3. Pergerakan pada dataset ini cenderung tidak membentuk kelompok sehingga apabila pembobotannya lebih
0.76 0.78 0.8 0.82 0.84 0.86 0.88 0.1 0.3 0.6 0.85 1 De li v ery p ro b ab il it y
Delivery Probability : Haggle3-Infocom5
cenderung untuk menggunakan node similarity, yakni dengan meningkatkan nilai 𝛼 maka nilai delivery probability-nya akan menurun.
Nilai 𝛼 yang dinamis pada dataset ini menghasilkan delivery probability yang lebih rendah dari pada nilai 0<𝛼<1. Hal ini dikarenakan untuk tetap menjaga beban dan latency yang tidak terlalu tinggi pada jaringan dengan menghasilkan delivery probability yang layak, maka algoritma melakukan pembobotan yang cenderung menggunakan node similarity yang hasilnya berpengaruh pada penggunaan beban dalam jaringan yang lebih rendah namun tidak mengabaikan node-node popular.
Gambar 4.2. Grafik overhead ratio dataset Haggle 3 – Infocom 5 Dari grafik di atas dapat dilihat bahwa nilai 𝛼 dinamis pada dataset ini menghasilkan overhead ratio yang rendah mendekati layaknya ketika pembobotan sepenuhnya hanya menggunakan node similarity namun dengan nilai delivery probability yang lebih tinggi dari 𝛼=1. Hal ini dikarenakan algoritma yang memungkinkan setiap node memelihara nilai 𝛼 untuk setiap pesan dan akan terus meningkat jika ada perhitungan baru yang menghasilkan nilai 𝛼 lebih tinggi dari nilai sebelumnya.
Pergerakan pada dataset ini yang cenderung tidak berkelompok, maka dari itu untuk menghasilkan delivery probability yang tinggi pada pergerakan ini,
0 5 10 15 20 25 30 35 0.1 0.3 0.6 0.85 1 Ov erh ea d ra ti o
Overhead Ratio : Haggle3-Infocom5
pembobotan yang optimal adalah ketika lebih kuat pada penggunaan betweenness centrality namun berdampak pada overhead yang lebih tinggi dari pada ketika pembobotan lebih kuat menggunakan node similarity. Pada dataset ini, overhead juga berdampak terhadap latency, yang mana ketika pembobotan lebih kuat terhadap nilai betweenness centrality maka nilai latency akan lebih kecil dibandingkan ketika pembobotan lebih menggunakan node similarity.
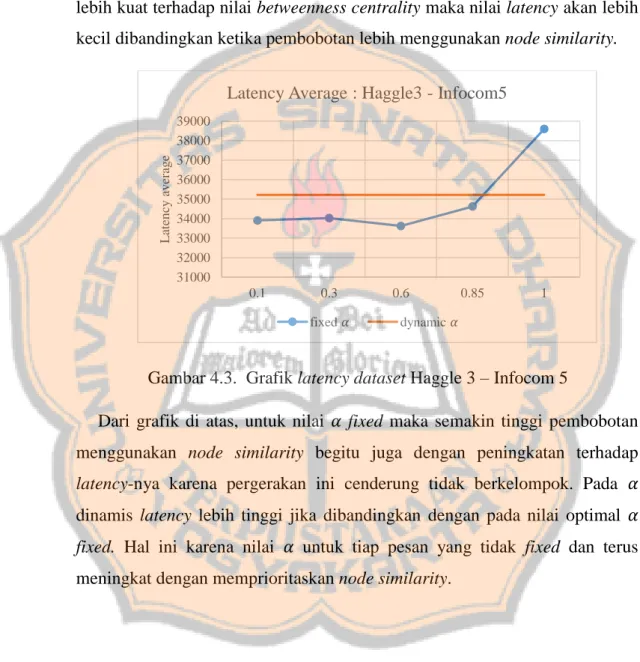
Gambar 4.3. Grafik latency dataset Haggle 3 – Infocom 5
Dari grafik di atas, untuk nilai 𝛼 fixed maka semakin tinggi pembobotan menggunakan node similarity begitu juga dengan peningkatan terhadap latency-nya karena pergerakan ini cenderung tidak berkelompok. Pada 𝛼 dinamis latency lebih tinggi jika dibandingkan dengan pada nilai optimal 𝛼 fixed. Hal ini karena nilai 𝛼 untuk tiap pesan yang tidak fixed dan terus meningkat dengan memprioritaskan node similarity.
31000 32000 33000 34000 35000 36000 37000 38000 39000 0.1 0.3 0.6 0.85 1 L aten cy a v era g e
Latency Average : Haggle3 - Infocom5
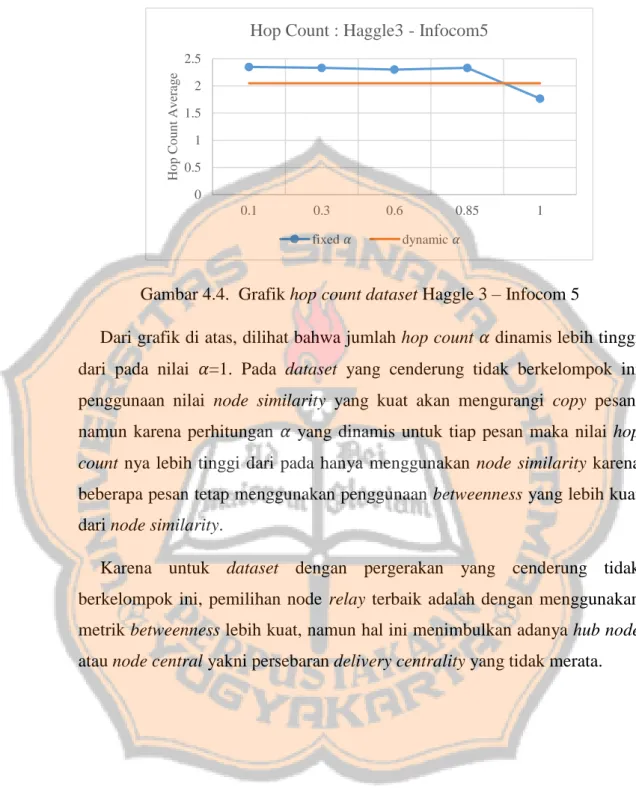
Gambar 4.4. Grafik hop count dataset Haggle 3 – Infocom 5
Dari grafik di atas, dilihat bahwa jumlah hop count 𝛼 dinamis lebih tinggi dari pada nilai 𝛼=1. Pada dataset yang cenderung tidak berkelompok ini penggunaan nilai node similarity yang kuat akan mengurangi copy pesan, namun karena perhitungan 𝛼 yang dinamis untuk tiap pesan maka nilai hop count nya lebih tinggi dari pada hanya menggunakan node similarity karena beberapa pesan tetap menggunakan penggunaan betweenness yang lebih kuat dari node similarity.
Karena untuk dataset dengan pergerakan yang cenderung tidak berkelompok ini, pemilihan node relay terbaik adalah dengan menggunakan metrik betweenness lebih kuat, namun hal ini menimbulkan adanya hub node atau node central yakni persebaran delivery centrality yang tidak merata.
0 0.5 1 1.5 2 2.5 0.1 0.3 0.6 0.85 1 Ho p Co u n t A v era g e
Hop Count : Haggle3 - Infocom5
Gambar 4.5. Grafik delivery centrality dataset Haggle 3 – Infocom 5 Bisa dilihat pada grafik di atas bahwa pada dataset ini, penggunaan metrik betweenness yang lebih kuat akan meningkatkan beban hub node. Pada nilai 𝛼 dinamis, nilai delivery centrality lebih merata jika dibandingkan dengan ketika nilai 𝛼=0.1. Berbeda dari pembobotan yang sepenuhnya menggunakan metrik similarity yang menghasilkan nilai delivery centrality yang lebih merata, pada pembobotan 𝛼 yang dinamis pada tiap pesan maka pemilihan node relay tidak hanya terhadap yang memiliki kedekatan terhadap destinasi tetapi juga terhadap node-node yang popular dalam jaringan sesuai hasil perhitungan algoritma.
4.2. Haggle 4 – Cambridge Imotes
Dataset ini berisi data pertemuan antar pelajar di Universitas Cambridge. Jumlah partisipan yang digunakan dalam simulasi ini sebanyak 36 orang. Lokasi pengambilan data berada di Kota Cambridge, Inggris. Selain dibawa 36 orang mahasiswa Cambridge, iMotes juga diletakkan di beberapa tempat yang sering dikunjungi partisipan, yaitu laboratorium komputer Universitas Cambridge, toko penjual bahan makanan, pub, supermarket, pusat perbelanjaan di Kota Cambridge. Durasi simulasi pada dataset ini adalah 987529, sekitar 11.43 hari. 0 5 10 15 20 25 30 35 40 45 50 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 31 33 35 37 39 Node ID
Delivery Centrality: Haggle3 - Infocom5
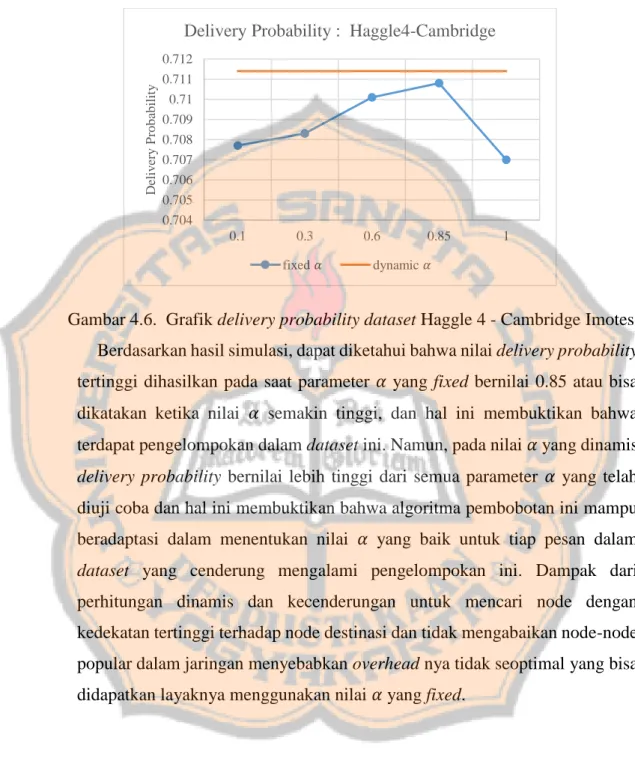
Gambar 4.6. Grafik delivery probability dataset Haggle 4 - Cambridge Imotes Berdasarkan hasil simulasi, dapat diketahui bahwa nilai delivery probability tertinggi dihasilkan pada saat parameter 𝛼 yang fixed bernilai 0.85 atau bisa dikatakan ketika nilai 𝛼 semakin tinggi, dan hal ini membuktikan bahwa terdapat pengelompokan dalam dataset ini. Namun, pada nilai 𝛼 yang dinamis delivery probability bernilai lebih tinggi dari semua parameter 𝛼 yang telah diuji coba dan hal ini membuktikan bahwa algoritma pembobotan ini mampu beradaptasi dalam menentukan nilai 𝛼 yang baik untuk tiap pesan dalam dataset yang cenderung mengalami pengelompokan ini. Dampak dari perhitungan dinamis dan kecenderungan untuk mencari node dengan kedekatan tertinggi terhadap node destinasi dan tidak mengabaikan node-node popular dalam jaringan menyebabkan overhead nya tidak seoptimal yang bisa didapatkan layaknya menggunakan nilai 𝛼 yang fixed.
0.704 0.705 0.706 0.707 0.708 0.709 0.71 0.711 0.712 0.1 0.3 0.6 0.85 1 De li v ery P ro b ab il it y
Delivery Probability : Haggle4-Cambridge
Gambar 4.7. Grafik overhead dataset Haggle 4 - Cambridge Imotes Pada grafik di atas bisa dilihat bahwa overhead ratio yang dihasilkan berkurang seiring nilai 𝛼 yang juga mengecil yang dikarenakan pengaruh kecenderungan similarity pada dataset ini. Untuk nilai 𝛼 dinamis overhead yang dihasilkan tidak sebagus ketika nilai 𝛼 cenderung diboboti terhadap similarity namun hampir setara dengan ketika 𝛼 bernilai 0.6. Hal dikarenakan nilai 𝛼 yang berbeda untuk tiap pesan dari hasil perhitungan saat pertemuan antar node.
Gambar 4.8. Grafik latency dataset Haggle 4 - Cambridge Imotes Untuk nilai fixed 0<𝛼<1, dengan menggunakan kombinasi metrik node similarity dan betweenness centrality untuk menentukan node relay terbaik, maka nilai latency yang dihasilkan lebih kecil dibandingkan protokol routing SimBet yang hanya menggunakan metrik betweenness centrality yang lebih kuat. Hal ini disebabkan karena karakteristik antar node pada dataset Haggle
18 19 20 21 22 23 24 0.1 0.3 0.6 0.85 1 Ov erh ea d ra ti o
Overhead Ratio : Haggle4-Cambridge
fixed 𝛼 dynamic 𝛼 84000 86000 88000 90000 92000 94000 0.1 0.3 0.6 0.85 1 L aten cy A v era g e Latency : Haggle4-Cambridge fixed 𝛼 dynamic 𝛼
4 - Cambridge Imotes ini memiliki nilai keterhubungan yang cukup tinggi. Sebagaimana nilai 𝛼 yang dinamis memiliki hasil yang menunjukkan kesesuaian dengan jenis pergerakan cenderung berkelompok pada dataset ini yakni hasil latency yang dihasilkan rendah namun dengan nilai delivery probability yang baik.
Gambar 4.9. Grafik hop count dataset Haggle 4 - Cambridge Imotes Pada grafik di atas, bisa dilihat bahwa karena pergerakan yang cenderung berkelompok ini nilai hop count 𝛼 lebih tinggi dari pada ≤𝛼≤1 karena pergerakan yang cenderung berkelompok dan algoritma yang mengutamakan untuk mencari node dengan nilai kedekatan yang lebih tinggi terhadap node tujuan untuk pesan yang bersangkutan. Waktu simulasi yang lama pada dataset ini menyebabkan nilai 𝛼 untuk pesan mempunyai peluang lebih tinggi untuk terjadi perubahan nilai 𝛼 yang lebih sering sehingga semakintinggi hop count suatu pesan. 2.2 2.25 2.3 2.35 2.4 2.45 2.5 2.55 0.1 0.3 0.6 0.85 1 Ho p Co u n t A v era g e
Hop Count : Haggle4 - Cambridge
Gambar 4.10. Grafik Delivery Centrality dataset Haggle4-Cambridge Pergerakan dataset yang cenderung berkelompok ini menyebabkan penyebaran pesan merata baik ketika pembobotan lebih kuat menggunakan metrik similarity maupun betweenness. Pembobotan dinamis pun tidak menunjukkan perbedaan yang jauh pada grafik di atas.
4.3. Sassy
Dataset ini berisi data pertemuan antar pelajar undergraduate, pelajar postgraduate, dan staff di Universitas St. Andrew. Jumlah partisipan yang digunakan dalam simulasi ini sebanyak 22 pelajar undergraduate, 3 pelajar postgraduate, dan 2 orang staff. Lokasi penelitian berada di dalam dan di luar Kota St. Andrew. Dari 27 partisipan, hanya 25 device yang datanya valid dan bisa digunakan untuk melakukan penelitian. Durasi simulasi pada dataset ini adalah sekitar 79 hari.
0 50 100 150 200 250 300 0 1 2 3 4 5 6 8 9 1011121314151617181920212223242526272829303132333435
Delivery Centrality : Haggle4 - Cambridge
Gambar 4.11. Grafik delivery probability dataset Sassy
Berdasarkan hasil simulasi, dapat diketahui bahwa nilai 𝛼=0.6 merupakan pembobotan fixed yang menghasilkan delivery probability tertinggi, yang artinya pergerakan pada dataset ini seimbang dalam penggunaan metrik similarity dan betweenness. Nilai 𝛼 dinamis menghasilkan nilai delivery probability yang lebih rendah. Hal ini dikarenakan algoritma pembobotan dinamis ini cenderung menggunakan metrik similarity yang ketika diterapkan pada pergerakan yang tidak berkelompok ini akan mengalami penurunan.
Gambar 4.12. Grafik overhead dataset Sassy
Pada grafik di atas bisa dilihat bahwa overhead ratio yang dihasilkan menunjukan perbedaan yang tidak begitu signifikan antara nilai 𝛼 fixed
0.186 0.188 0.19 0.192 0.194 0.196 0.198 0.1 0.3 0.6 0.85 1 Deliv er y P ro b ab ilit y
Delivery Probability : Sassy
fixed 𝛼 dynamic 𝛼 0 2 4 6 8 10 0.1 0.3 0.6 0.85 1 Ov er h ea d r atio
Overhead Ratio : Sassy
maupun dinamis. Penggunaan metrik similarity yang semakin kuat semakin meningkatkan overhead ratio dalam jaringan. Ketika pembobotan hanya menggunakan metrik similarity, nilai overhead ratio mengalami penurunan.
Gambar 4.13. Grafik latency dataset Sassy
Pada grafik di atas, kita bisa melihat pengaruh pembobotan nilai 𝛼 fixed terhadap latency yang terendah pada nilai 0.6. Penggunaan pengaruh metrik similarity dan betweenness pada pergerakan yang tidak memiliki pola tertentu ini mengurangi latency sehingga membantu pesan untuk lebih cepat sampai ke node tujuan.
Gambar 4.14. Grafik hop count dataset Sassy
Pada grafik hop count average di atas, bisa dilihat bahwa semakin tinggi pengaruh metrik similarity yang digunakan maka semakin banyak pesan melalui node-node relay sebelum mencapai tujuan. Pada pergerakan yang
580000 590000 600000 610000 620000 0.1 0.3 0.6 0.85 1 L aten cy av er ag e Latency : Sassy fixed 𝛼 dynamic 𝛼 1.8 1.85 1.9 1.95 2 2.05 0.1 0.3 0.6 0.85 1 Ho p Co u n t A v era g e
Hop Count : Sassy
tidak memiliki pola tertentu ini, pergerakan yang ada membentuk kelompok-kelompok namun tidak tetap sehingga tingkat keterhubungan antar node menjadi rendah pada dataset ini. Ketika pembobotan hanya menggunakan metrik similarity maka rantai pertemanan menjadi lebih kecil. Untuk nilai 𝛼 dinamis rantai pertemanan sangat tinggi karena kecenderungan menggunakan metrik similarity namun dengan tetap menggunakan pengaruh metrik betweenness.
Gambar 4.15. Grafik Delivery Centrality dataset Sassy
Pergerakan dataset yang cenderung tidak berpola ini menyebabkan persebaran delivery centrality yang tidak jauh berbeda antra kecenderungan pembobotan baik terhadap metrik betweenness maupun similarity. Pada grafik di atas, hanya terlihat satu node yang memiliki beban lebih tinggi dari node-node yang lainnya karena lebih menggunakan metrik betweenness dan juga peda pembobotan nilai 𝛼 dinamis.
0 100 200 300 400 500 600 0 1 2 3 4 5 6 7 8 10 11 12 13 14 17 20 21 23 24 Delivery Centrality : Sassy
29 BAB V
KESIMPULAN DAN SARAN 5.1. Kesimpulan
Dari hasil pengujian dengan simulasi beserta analisis hasil simulasi maka didapat kesimpulan bahwa protokol SimBet dengan nilai 𝛼 yang dinamis mampu beradaptasi pada dataset yang memiliki pergerakan cenderung berkelompok maupun tidak berkelompok dengan kekurangan dan kelebihannya masing-masing. Untuk dataset dengan pergerakan yang cenderung tidak berkelompok maka hasil delivery probability tidak lebih baik dari 0<𝛼<1 namun kelebihannya yakni walaupun delivery probability untuk 𝛼 dinamis ini cenderung menyamai 𝛼=1 namun untuk hasil overhead lebih rendah dari pada 0<𝛼<1 yang juga cenderung menyamai nilai 𝛼 =1 namun yang berbeda yakni dengan latency yang jauh lebih rendah dibandingkan dengan nilai 𝛼 =1 dikarenakan hasil pembobotan dinamis yang menghasilkan banyak nilai 𝛼 untuk penggunaan metrik node similarity lebih kuat daripada metrik betweenness namun dengan beberapa nilai 𝛼 yang rendah maka tetap menjaga beban dan delay pada pengiriman pesan dalam jaringan.
Untuk dataset dengan pergerakan yang cenderung berkelompok, delivery probability nilai 𝛼 dinamis mengungguli nilai 0≤𝛼≤1 namun dengan overhead yang menunjukkan bahwa nilai 𝛼 dinamis mendekati keseimbangan antara pembobotan terhadap node similarity dan betweenness dan dengan latency yang baik seakan menggunakan 𝛼 lebih memprioritaskan node similarity.
5.2. Saran
Pada penelitian selanjutnya perlu diteliti metode perhitungan untuk bisa mendeteksi kecenderungan pergerakan secara menyeluruh dalam satu jaringan dan bisa menentukan prioritas hasil untuk lebih mengutamakan delivery probability setinggi mungkin tanpa memikirkan beban jaringan atau hasil delivery probability yang layak dengan beban yang rendah. Perlu juga ada penelitian yang menggunakan pembobotan dinamis pada protokol SimBet digabungkan dengan
matriks node similarity yang tidak hanya fixed bernilai 0 dan satu tetapi juga dinamis terhadap kesegaran hubungan antar node.
DAFTAR PUSTAKA
[1] Daly, Elizabeth dan Mads Haar. Social Network Analysis for Routing in Disconnected Delay-Tolerant MANETs. IEEE Transactions on Mobile Computing (Volume: 8, Issue: 5, May 2009). DOI: 10.1109/TMC.2008.161. [2] Ari Keränen, Jörg Ott and Teemu Kärkkäinen. The ONE Simulator for DTN Protocol Evaluation. SIMUTools'09: 2nd International Conference on Simulation Tools and Techniques. Rome, March
2009. URL:https://www.netlab.tkk.fi/tutkimus/dtn/theone/pub/the_one_simutools. pdf. Diakses: 18 Februari 2019.
[3] Everett, Martin dan Stephen P. Borgatti. 2005. Ego Network Betweenness. Social Networks 27 (2005) 31–38.
URL:https://pdfs.semanticscholar.org/01eb/fdb48fdf2cd286260db3789a221ffda87 a44.pdf. Diakses: 15 Februari 2019.
[4] Greg Bigwood, Tristan Henderson, Devan Rehunathan, Martin Bateman, Saleem Bhatti, CRAWDAD dataset st_andrews/sassy (v. 2011-06-03), diunduh dari http://crawdad.org/st_andrews/sassy/20110603,
https://doi.org/10.15783/C7S59X, Jun 2011.
[5] James Scott, Richard Gass, Jon Crowcroft, Pan Hui, Christophe Diot, Augustin Chaintreau, CRAWDAD dataset cambridge/haggle (v. 2009-05-29), diunduh dari http://crawdad.org/cambridge/haggle/20090529,
LAMPIRAN