KAJIAN METODE PENDUGAAN PADA MODEL REGRESI
DENGAN PEUBAH PENJELAS BERSIFAT ACAK
MOCHAMMAD FACHROUZI ISKANDAR
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2014
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul Kajian Metode Pendugaan pada Model Regresi dengan Peubah Penjelas Bersifat Acak adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari skripsi saya kepada Institut Pertanian Bogor.
Bogor, Oktober 2014
Mochammad Fachrouzi Iskandar
ABSTRAK
MOCHAMMAD FACHROUZI ISKANDAR. Kajian Metode Pendugaan pada Model Regresi dengan Peubah Penjelas Bersifat Acak. Dibimbing oleh ITASIA DINA SULVIANTI dan INDAHWATI.
Analisis regresi merupakan metode statistika yang mengevaluasi hubungan antara satu peubah dengan peubah lainnya. Analisis regresi model I menggambarkan hubungan antara peubah X dan peubah Y hanya bersifat satu arah dengan nilai X sebagai peubah penjelas bernilai tetap atau diukur tanpa galat. Analisis regresi model I menggunakan metode pendugaan Metode Kuadrat Terkecil (MKT) sebagai metode pendugaan parameternya. Analisis regresi model II merupakan analisis model regresi dengan peubah penjelasnya peubah acak. Terdapat dua metode pendugaan pada analisis regresi model II yaitu metode
ordinary least product regression (Model IIA) dan metode major axis regression
(Model IIB). Kemudahan dalam menggunakan analisis regresi model I dengan metode pendugaan MKT menyebabkan banyak peneliti menggunakan model ini sebagai model untuk analisis regresi dengan peubah penjelas yang acak. Tujuan penelitian ini adalah untuk membandingkan analisis regresi model I (MKT) dengan analisis regresi model II (metode ordinary least product dan metode
major axis regression). Data yang digunakan pada penelitian ini merupakan data simulasi dengan peubah respon (Y) dan peubah penjelas (X) bersifat acak. Hasil dari penelitian ini menunjukkan bahwa untuk peubah penjelas yang bersifat acak, metode ordinary least product regression merupakan metode pendugaan yang terbaik di antara kedua metode pendugaan lainnya karena menghasilkan nilai bias dan nilai mean square error yang terkecil. Dalam kondisi ini, MKT masih baik digunakan untuk menduga parameter model regresi linier sederhana jika nilai korelasi antara peubah acak X dan Y tinggi (r ≥ 0.9).
Kata kunci: bias, korelasi, mean square error, Model I, Model IIA, Model IIB
ABSTRACT
MOCHAMMAD FACHROUZI ISKANDAR. The Study on Estimation Method of Regression Models with Predictors Variable is Random. Supervised by ITASIA DINA SULVIANTI and INDAHWATI.
Regression analysis is a statistical method to evaluate the relationship between a variable with other variables. Model I regression analysis describes the one-way relationship between variable X and variable Y with the value of X as fixed variable or measured without error. Model I regression analysis uses
Ordinary Least Square (OLS) as an estimation method. Model II regression analysis is a regression model with predictors variable that becomes a random variable. There are two estimation methods of model II regression analysis,
ordinary least product regression (Model IIA) and major axis regression (Model IIB). The convenience of using model I regression analysis with OLS estimation method causes many researchers to use this model as a model regression analysis with random predictor variables. The purpose of this study is to compare model I
regression analysis (OLS estimation method) and model II regression analysis (ordinary least product estimation method and major axis regression estimation method). The data used in this research are simulation data where response variable (Y) and predictor variable (X) are random. The result of this study showed for predictor variable is random, ordinary least product regression is the best estimation method compared to the other methods because it produces the smallest value of bias and the smallest value of mean square error. In this condition, OLScan be used for the estimate parameter of simple linier regression model if the correlation value between predictor variable (X) and response variable (Y) is high (r ≥ 0.9).
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
KAJIAN METODE PENDUGAAN PADA MODEL REGRESI
DENGAN PEUBAH PENJELAS BERSIFAT ACAK
MOCHAMMAD FACHROUZI ISKANDAR
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2014
Judul Skripsi: Kajian Metode Pendugaan pada Model Regresi dengan Peubah
Nama
NIM
Penjelas Bersifat Acak
: Mochammad Fachrouzi Iskandar : 014090089
Disetujui oleh
�
Dra ltasia Dina Sulvianti. MSi Pembimbing I
,{"
/1/
I.Diketahui oleh
Dr Anang Ku
f
ia. MSit
Ketua Depart em enTanggal Lulus:
.2 2 OCT 2014
C\r;
Dr lr
J:
hwati, MSi Pembimbing IIPRAKATA
Alhamdulillah, segala puji dan syukur penulis panjatkan kehadirat Allah SWT atas segala rahmat dan karunia-Nya sehingga skripsi ini berhasil diselesaikan. Skripsi ini berjudul Kajian Metode Pendugaan pada Model Regresi dengan Peubah Penjelas Bersifat Acak. Skripsi ini merupakan salah satu syarat mendapatkan gelar Sarjana Statistika pada Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Penulis mengucapkan terima kasih kepada semua pihak yang telah membantu dalam menyelesaikan skripsi ini, antara lain:
1.Ibu Dra Itasia Dina Sulvianti, MSi dan Ibu Dr Ir Indahwati, MSi atas bimbingan, arahan, dan kesabarannya selama penulis menyelesaikan skripsi ini.
2.Bapak Dr Ir M Nur Aidi, MSi selaku penguji atas saran dan kritikannya yang membangun.
3.Dosen pengajar Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor atas ilmu yang diberikan. 4.Ibu Markonah dan Tata Usaha Departemen Statistika, Fakultas Matematika
dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor atas bantuannya dalam kelancaran administrasi.
5.Bapak, ibu, kakak, dan adik di rumah yang senantiasa memberikan semangat.
6.Wenny Permata Sari dan teman-teman Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor angkatan 46 yang telah membantu dan menyemangati penulis dalam pembuatan skripsi ini.
Penulis menyadari masih banyak kekurangan dalam penulisan skripsi ini. Oleh karena itu, penulis menerima saran dan kritikan yang membangun dari berbagai pihak agar dapat meningkatkan pengetahuan penulis di masa yang akan datang. Penulis berharap semoga skripsi ini bermanfaat bagi penulis dan pembaca pada umumnya.
Bogor, Oktober 2014
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi PENDAHULUAN 1 Latar Belakang 1 Tujuan Penelitian 2Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 2
Model Hubungan Linier Fungsional 2
Model Hubungan Linier Struktural 2
Metode Kuadrat Terkecil 3
Metode Ordinary Least Product Regression 4
Metode Major Axis Regression 5
Penduga Tak Bias 6
Mean Square Error 7
METODE 7
Data 7
Metode 8
HASIL DAN PEMBAHASAN 8
Pembangkitan Data 8
Nilai Dugaan Parameter 9
Bias Penduga Parameter 11
Mean Square Error 12
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 14
DAFTAR TABEL
1. Kombinasi pembangkitan data 7
2. Hasil rata-rata dan simpangan baku dari pengulangan nilai ̂
sebanyak 10 kali 10
3. Hasil rata-rata dan simpangan baku dari pengulangan nilai ̂
sebanyak 10 kali 11
4. Rataan bias ̂ dari Model I, Model IIA, dan Model IIB 11 5. Rataan bias ̂ dari Model I, Model IIA, dan Model IIB 12
DAFTAR GAMBAR
1. Pendugaan dengan metode Ordinary Least Product 4 2. Nilai ̂0 dari Model I, Model IIA, dan Model IIB 9 3. Nilai ̂ dari Model I, Model IIA, dan Model IIB 10 4. MSE ̂0 dari Model I, Model IIA, dan Model IIB 12 5. MSE ̂ dari Model I, Model IIA, dan Model IIB 13
PENDAHULUAN
Latar Belakang
Analisis regresi merupakan metode statistika yang mengevaluasi hubungan antara satu peubah dengan peubah lainnya. Analisis regresi merupakan teknik statistika yang sangat berguna dibeberapa permasalahan. Analisis ini bertujuan untuk melihat hubungan antara peubah penjelas (X) dengan peubah respon (Y). Peubah penjelas merupakan peubah yang menentukan hasil pada peubah respon. Quinn dan Keough (2002) menyatakan bahwa tujuan analisis regresi ada tiga, yaitu mendeskripsikan hubungan linier antara peubah Y dan X, menjelaskan seberapa besar peubah Y dapat dijelaskan oleh peubah X, dan memprediksi nilai baru peubah Y dengan nilai baru peubah X.
Analisis regresi yang umum digunakan adalah analisis regresi model I dengan menggunakan Metode Kuadrat Terkecil (MKT) sebagai metode penduga parameternya. Pendugaan parameter menggunakan MKT mengasumsikan peubah penjelas (X) bernilai tetap. Nilai peubah penjelas yang tetap mudah didapatkan jika penelitian dilakukan di laboratorium namun sulit didapatkan jika penelitian berada di lapangan. Penelitian di lapangan menghasilkan peubah penjelas yang bernilai acak sehingga metode pendugaan MKT kurang tepat digunakan. Asumsi yang terlanggar akan menyebabkan bias pada penduga sehingga akan terjadi kesalahan pada prediksi nilai baru. Penyebab terjadinya sifat acak pada peubah penjelas tidak hanya karena acaknya data pada lapangan, namun kesalahan pada pengukuran juga mengakibatkan peubah penjelas menjadi peubah acak. Permasalahan tersebut dapat diatasi dengan menggunakan analisis regresi model II.
Ludbrook (1997) menyatakan analisis regresi model II dirancang untuk kasus data peubah respon Y dan peubah penjelas X yang keduanya merupakan peubah acak. Analisis ini meminimumkan penyimpangan nilai X dan nilai Y dari garis regresinya. Terdapat dua macam metode pendugaan parameter dalam analisis regresi model II yaitu metode ordinary least product regression (Model IIA) dan metode major axis regression (Model IIB) (Ludbrook 2012). Minat para peneliti untuk mendapatkan penduga parameter yang mendekati parameter menjadi hal yang perlu dipertimbangkan dalam menggunakan analisis regresi model II. Masih banyaknya para peneliti yang mengetahui bahwa data yang dimiliki peubah penjelasnya (X) bersifat acak namun masih tetap menggunakan analisis regresi model I disebabkan para peneliti tidak mengetahui dan kesulitan dalam melakukan analisis regresi model II.
Dilain pihak, analisis regresi linier sederhana yang hubungannya linier, keeratan hubungan antara peubah respon dengan peubah penjelas dapat dijelaskan dengan koefisien korelasi Pearson. Nilai korelasi Pearson yang mendekati 1 akan mengakibatkan model regresi mendekati model deterministik walaupun peubah penjelas dan peubah responnya bersifat acak. Berdasarkan hal tersebut perlu dikaji keakuratan MKT dalam menduga parameter regresi yang peubah penjelasnya acak. Penelitian ini dilakukan melalui kajian simulasi dengan cara membangkitkan data yang peubah respon dan peubah penjelasnya bersifat acak dengan nilai korelasi dari 0.100 hingga 0.901.
2
Tujuan Penelitian
Tujuan dari penelitian ini ialah membandingkan analisis regresi model I yang metode pendugaannya menggunakan MKT dengan analisis regresi model II yang metode pendugaannya menggunakan metode ordinary least product regression dan metode major axis regression.
Ruang Lingkup Penelitian
Penelitian ini dibatasi untuk koefisien korelasi antara peubah respon dengan peubah penjelas yang bernilai positif dan hanya dibatasi untuk model regresi linier sederhana, sehingga kesimpulan yang ada hanya mewakili data dengan korelasi bernilai positif dan hanya memiliki satu peubah penjelas (X) dan satu peubah respon (Y).
TINJAUAN PUSTAKA
Model Hubungan Linier Fungsional
Model hubungan linier fungsional menganggap bahwa peubah X dan Y merupakan peubah acak dengan E[X] = , E[Y] = , dan mengasumsikan hubungan fungsionalnya
Model untuk setiap (xi,yi), i = 1,...,n, yaitu
dengan nilai i merupakan peubah yang tidak diketahui besarannya dan bernilai
tetap, serta saling bebas.
Model Hubungan Linier Struktural
Model hubungan linier struktural merupakan model yang menganggap bahwa i merupakan contoh acak dari suatu populasi tertentu yang mempunyai
nilai harapan sama dengan dan ragam sama dengan , sehingga model yang memenuhi model hubungan linier struktural dapat dituliskan sebagai berikut:
0
0
3 dengan n saling bebas dan n bebas terhadap .
Metode Kuadrat Terkecil
Metode Kuadrat Terkecil (MKT) dirancang untuk menghasilkan penduga
0 n 1 dengan cara meminimumkan jumlah kuadrat galatnya. Persamaan
regresi linier sederhana dengan n pengamatan sebagai berikut: ̂0 ̂ , i = 1,2,3, ... , n
dengan ̂0 dan ̂ merupakan dugaan parameter regresi, yi merupakan nilai peubah
respon ketika peubah penjelas sama dengan xi, dan xi merupakan nilai peubah
penjelas. Persamaan tersebut digunakan untuk meminimumkan jumlah kuadrat sisaannya dengan melakukan penurunan parsial seperti berikut:
∑ n ∑ ̂0 ̂ ∑n 0 ∑ ̂0 ̂ n 0 ∑n ∑ ̂0 ̂ n 0
Setelah dilakukan penurunan pada persamaan tersebut, didapatkan persamaan berikut: n ̂0 ̂ ∑ n ∑ n ̂ 0∑ n ̂ ∑ n ∑ n
Persamaan di atas dapat dituliskan sebagai berikut:
̂ 0 ̅ ̂ ̅ ̂ ∑ ∑n ∑n n n ∑n ∑n n
4
Metode Ordinary Least Product Regression
Prinsip dalam pendugaan parameter menggunakan metode ordinary least product regression (OLP) ialah meminimumkan jumlah hasil kali simpangan x dan simpangan y terhadap garis regresinya (minimize ∑ ) (Ludbrook 2010). Asumsi dalam pendugaan OLP hampir sama dengan pendugaan MKT, yang berbeda hanya pada peubah penjelasnya bersifat acak. Selain itu, sebaran normal ganda antara peubah respon dengan peubah penjelas juga harus terpenuhi (Ludbrook 1997).
Gambar 1 Pendugaan dengan metode Ordinary Least Product
Metode ordinary least product regression menganggap bahwa X sebagai peubah penjelas dan Y sebagai peubah respon dengan persamaan regresi ̂ ̂ , dan dapat juga Y sebagai peubah penjelas serta X sebagai peubah respon dengan persamaan regresi ̂ ̂ . Dari kedua persamaan tersebut didapatkan ̂ sebagai berikut :
̂ [ ̂ ̂ ] ̂
merupakan ̂ dari pendugaan MKT dengan Y sebagai peubah respon dan X sebagai peubah penjelas. ̂ merupakan ̂ dari pendugaan MKT dengan X sebagai peubah respon dan Y sebagai peubah penjelas.
̂ [ ̂ ̂ ̂ ∑ ̂ ∑ ̂ ̂ ] ̂ ̂ [ ∑ ̂ ∑ ̂ ∑ ̂ ̂ ∑ ̂ ̂ ]
5
̂
̂ ∑ ̂ ∑( ̂)
∑ ̂ ̂
dengan menggunakan rumus korelasi Pearson:
r = ∑ - ̂ - ̂ ∑( - ̂) ∑( - ̂)
⁄
maka persamaan di atas dapat ditulis sebagai berikut:
̂ ̂
Selain dengan menggunakan persamaan korelasi Pearson, dapat juga disederhanakan sebagai berikut:
̂ ∑ ̂ ̂ ∑ ⁄ ̂ ∑ ̂ ̂ ⁄ ∑ ̂ ∑( ̂) ̂ ∑ ̂ ∑( ̂) ∑ ̂ ̂ ∑ ∑ n ∑ (∑ ) n ∑ ∑ n ̂ ∑ ∑ ∑ ∑ ̂
dengan Sy merupakan simpangan baku peubah respon Y dan Sx merupakan
simpangan baku peubah penjelas X.
Metode Major Axis Regression
Prinsip dari metode major axis regression yaitu meminimumkan jumlah kuadrat pada jarak yang tegak lurus terhadap garis regresinya (Ludbrook 2010). Syarat untuk menggunakan metode ini ialah garis kemiringan sama dengan 1, ragam dari nilai peubah penjelas X dan ragam nilai peubah respon Y bernilai sama,
6
dan skala pengukuran nilai peubah penjelas X dan nilai peubah respon Y harus sama.
Metode pendugaan major axis regression mengasumsikan nilai ,
tetap dan diketahui. Pendekatan melalui data merupakan cara lain untuk mendapatkan nilai t u m ng ngg p n l . Pendugaan parameter menggunakan metode major axis regression menggunakan metode kemungkinan maksimum. Metode major axis regression mengasumsikan sebaran normal dari model hubungan fungsional yaitu:
( ) n ( ) n
dengan peubah acak X dan peubah acak Y saling bebas. Fungsi kemungkinannya adalah ( . n | ) n n p[ ∑ ( ) n ] p[ ∑( ) n ]
Persamaan kemungkinan tersebut dihitung nilai maksimumnya sehingga didapatkan ̂ dan ̂0 seperti berikut:
̂ ( ) √( )
̂
0 ̅ ̂ ̅
dengan nilai adalah .
Penduga Tak Bias
Salah satu ukuran untuk menentukan penduga yang terbaik ialah dengan melihat nilai bias. Umumnya ̂ merupakan penduga tak bias jika nilai harapan ̂ sama dengan . Pernyataan tersebut sama dengan rata-rata sebaran peluang ̂ atau rata-rata sebaran contoh ̂ sama dengan (Montgomery dan Runger 2003). ̂ merupakan penduga tak bias dari parameter jika:
( ̂)
dengan demikian besarnya nilai bias dari penduga dapat dituliskan sebagai berikut:
7
Mean Square Error
Selain melihat penduga tak bias, Mean Square Error (MSE) merupakan pertimbangan dalam mendapatkan penduga terbaik. Definisi MSE adalah sebagai berikut:
(̂) (̂ )
(̂) [̂ (̂)] [ (̂)]
(̂) (̂)
Ini menunjukkan bahwa MSE pada ̂ merupakan ragam ̂ yang ditambah bias kuadrat. Penduga yang baik memiliki nilai MSE yang minimum.
METODE
Data
Data yang digunakan pada penelitian ini merupakan hasil bangkitan melalui simulasi menggunakan perangkat lunak Rstudio versi 0.98.507 dengan menggunakan paket MASS, MethComp, dan mvnormtest. Pembangkitan data dilakukan dengan menggunakan model hubungan linier struktural. Spesifikasi data yang dibangkitkan dapat dilihat pada Tabel 1. Sebaran yang digunakan dalam membangkitkan data adalah sebaran normal ganda. Pengulangan dilakukan sebanyak 10000 kali pada setiap rentang korelasi.
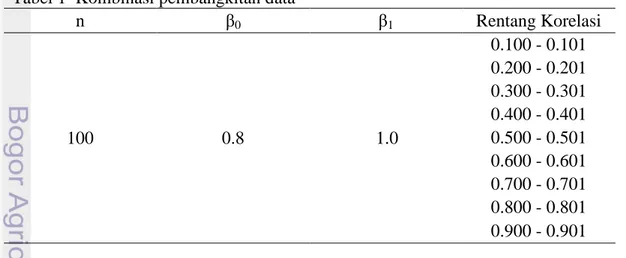
Tabel 1 Kombinasi pembangkitan data
n 0 1 Rentang Korelasi 100 0.8 1.0 0.100 - 0.101 0.200 - 0.201 0.300 - 0.301 0.400 - 0.401 0.500 - 0.501 0.600 - 0.601 0.700 - 0.701 0.800 - 0.801 0.900 - 0.901
8
Metode
Penelitian ini melalui beberapa tahapan, yaitu simulasi, pemodelan, dan pembandingan metode.
1. Simulasi pembangkitan data
1) M n ntuk n n l p r m t r 0 yaitu 0.8 n 1 yaitu 1.
2) Menentukan nilai ragam respon Y ( ) dan nilai ragam penjelas X ( ). 3) Menentukan nilai ragam Phsi ( ) dan nilai tengah Phsi ( ).
4) Membangkitkan contoh acak berukuran 100 untuk peubah X dan Y dengan menggunakan sebaran normal ganda seperti berikut (Casella dan Berger 2002).
( ) ([ ] *
+)
5) Mengulangi langkah 1 hingga 4 sebanyak 10000 kali. 6) Memilih data yang memenuhi:
a) Rentang korelasi tertentu.
b) Sebaran normal ganda dengan menggunakan Shapiro Wilk multivariate normality test.
7) Mengambil secara acak pasangan data yang terpilih sebanyak seperempat dari data terpilih.
8) Mengulangi langkah 7 sebanyak sepuluh kali. 2. Pemodelan dan pembandingan metode
1) Menghitung nilai korelasi pada data yang terpilih di tiap rentang korelasi. 2) l kuk n p n ug n p r m t r 0 n 1 pada tiap rentang korelasi
dengan menggunakan metode MKT, metode ordinary least product, dan metode major axis regression.
3) Melakukan pengulangan pada langkah 1 hingga 2 sebanyak sepuluh kali. 4) Menghitung nilai bias ̂ dan ̂ untuk setiap metode pendugaan di setiap
rentang korelasi.
5) Menghitung nilai MSE ̂ dan ̂ untuk setiap metode pendugaan di setiap rentang korelasi.
6) Melakukan pengulangan langkah 2 hingga 5 sebanyak sepuluh kali.
HASIL DAN PEMBAHASAN
Pembangkitan Data
Model hubungan linier struktural digunakan sebagai model awal dalam membangkitkan data. Pemilihan model linier struktural disebabkan kemudahan untuk mengubah nilai korelasi antara peubah penjelas (X) dan peubah respon (Y). Kemudahan tersebut disebabkan oleh model linier struktural yang berupa sebaran normal ganda (Casella dan Berger 2002).
9 Tujuan dilakukannya simulasi karena kemudahan untuk membandingkan ketiga metode tersebut. Simulasi juga memudahkan data yang didapatkan sudah menyebar normal ganda serta mendapatkan data yang sesuai dengan korelasi yang diinginkan. Korelasi yang berbeda-beda digunakan untuk melihat kebaikan metode pendugaan pada rentang korelasi tertentu.
Awal pembangkitan yakni m n ntuk n n l 0 n 1 yang akan
dibandingkan dengan dengan nilai ̂ dan nilai ̂ dari masing-masing metode pendugaan. l 0 r 0.8 n 1 sebesar 1. Kemudian membangkitkan nilai
ragam respon Y ( ) dan ragam penjelas X ( ) serta nilai ragam Phsi ( ) dan nilai tengah Phsi ( ). Penentuan nilai ragam respon Y, ragam penjelas X, nilai ragam Phsi, dan nilai tengah Phsi tidak dapat sembarang nilai karena ada kriteria korelasi pada masing-masing bangkitan. Pembangkitan nilai n sebanyak 100 yang diulang sebanyak 10000 kali untuk masing-masing peubah penjelas (X) dan peubah respon (Y) yang menyebar normal ganda. Banyaknya 10000 pasangan peubah penjelas (X) dan peubah respon (Y) dilanjutkan dengan pengujian korelasi dan pengujian sebaran normal ganda. Pengujian korelasi menggunakan korelasi Pearson dan pengujian sebaran normal ganda menggunakan uji Shapiro Wilk multivariate normality test dengan taraf nyata sebesar 5%.
Nilai Dugaan Parameter
Setelah memperoleh data simulasi yang telah memenuhi syarat korelasi dan uji normalitas ganda maka dilanjutkan dengan melakukan pendugaan dengan ketiga metode pendugaan yaitu Model I dengan menggunakan metode pendugaan MKT, Model IIA dengan menggunakan metode pendugaan ordinary least product regression, dan Model IIB dengan metode pendugaan major axis regression. Pendugaan yang hanya dilakukan sekali tidak cukup memberikan informasi bahwa hasil dugaan mendekati parameter, maka dilakukan pengulangan. Hasil dari pengulangan tersebut dicari nilai rataan dan simpangan bakunya. Gambar 2 menunjukkan contoh nilai ̂ dari setiap metode pendugaan. Hasil menunjukkan
0.000 0.500 1.000 1.500 2.000 2.500 3.000 3.500 4.000 0.100 -0.101 0.200 -0.201 0.300 -0.301 0.400 -0.401 0.500 -0.501 0.600 -0.601 0.700 -0.701 0.800 -0.801 0.900 -0.901 N ilai D u gaan Rentang Korelasi Model I Model IIA Model IIB
10
dengan menggunakan Model I, nilai ̂ mendekati parameter 0 seiring dengan
korelasi yang semakin mendekati 1. Nilai ̂ dari Model IIA dan Model IIB menunjukkan hasil yang mendekati parameter 0 di setiap rentang korelasi.
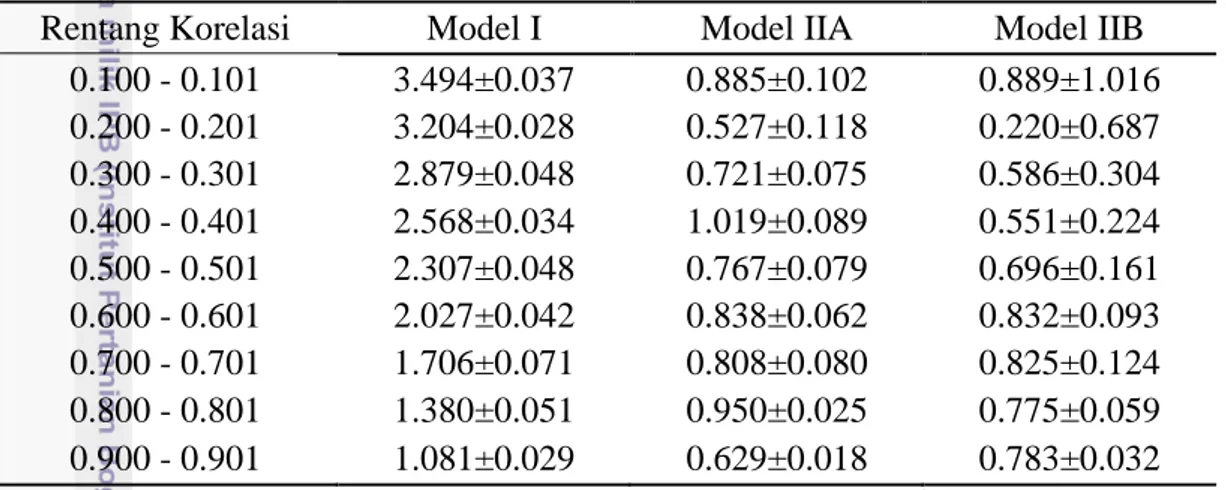
Pengulangan nilai ̂ dilakukan untuk melihat keberagaman nilai dugaan yang disajikan pada Tabel 2. Model I dan Model IIA menunjukkan nilai ̂ yang tidak beragam di setiap rentang korelasi. Model IIB merupakan metode pendugaan yang menghasilkan dugaan yang keberagamannya tinggi pada rentang korelasi 0.100 – 0.101 dan 0.200 – 0.201 karena simpangan bakunya yang besar. Ini menunjukkan bahwa metode pendugaan dengan menggunakan Model IIB tidak baik pada rentang korelasi tersebut.
Tabel 2 Hasil rata-rata dan simpangan baku dari pengulangan nilai ̂ sebanyak 10 kali
Rentang Korelasi Model I Model IIA Model IIB
0.100 - 0.101 3.494±0.037 0.885±0.102 0.889±1.016 0.200 - 0.201 3.204±0.028 0.527±0.118 0.220±0.687 0.300 - 0.301 2.879±0.048 0.721±0.075 0.586±0.304 0.400 - 0.401 2.568±0.034 1.019±0.089 0.551±0.224 0.500 - 0.501 2.307±0.048 0.767±0.079 0.696±0.161 0.600 - 0.601 2.027±0.042 0.838±0.062 0.832±0.093 0.700 - 0.701 1.706±0.071 0.808±0.080 0.825±0.124 0.800 - 0.801 1.380±0.051 0.950±0.025 0.775±0.059 0.900 - 0.901 1.081±0.029 0.629±0.018 0.783±0.032
Proses simulasi juga digunakan untuk pendugaan nilai ̂ . Proses simulasi yang dilakukan tidak jauh berbeda dengan proses pendugaan paramater 0.
Gambar 3 menunjukkan contoh nilai ̂ dari setiap metode pendugaan. Model I menunjukkan bahwa nilai ̂ semakin mendekati parameternya dengan semakin tingginya rentang korelasinya. Hasil dari Model IIA dan Model IIB tidak saling
0.000 0.200 0.400 0.600 0.800 1.000 1.200 0.100 -0.101 0.200 -0.201 0.300 -0.301 0.400 -0.401 0.500 -0.501 0.600 -0.601 0.700 -0.701 0.800 -0.801 0.900 -0.901 N ilai D u gaan Rentang Korelasi Model I Model IIA Model IIB
11 berbeda, kedua metode pendugaan mampu mendekati parameter pada setiap rentang korelasi. Tabel 3 menyajikan keberagaman nilai ̂ melalui rata-rata dan simpangan baku. Ketiga metode pendugaan menunjukkan hasil yang tidak beragam pada setiap rentang korelasi karena simpangan baku yang kecil.
Tabel 3 Hasil rata-rata dan simpangan baku dari pengulangan nilai ̂ sebanyak 10 kali
Rentang Korelasi Model I Model IIA Model IIB
0.100 - 0.101 0.097±0.003 0.961±0.034 0.953±0.325 0.200 - 0.201 0.204±0.008 1.019±0.041 1.206±0.237 0.300 - 0.301 0.303±0.008 1.009±0.026 1.069±0.093 0.400 - 0.401 0.411±0.012 1.026±0.031 1.083±0.080 0.500 - 0.501 0.507±0.014 1.013±0.029 1.033±0.056 0.600 - 0.601 0.599±0.011 0.998±0.019 1.001±0.031 0.700 - 0.701 0.697±0.019 0.995±0.028 0.995±0.039 0.800 - 0.801 0.808±0.008 1.009±0.009 1.012±0.012 0.900 - 0.901 0.903±0.006 1.002±0.007 1.003±0.007
Bias Penduga Parameter
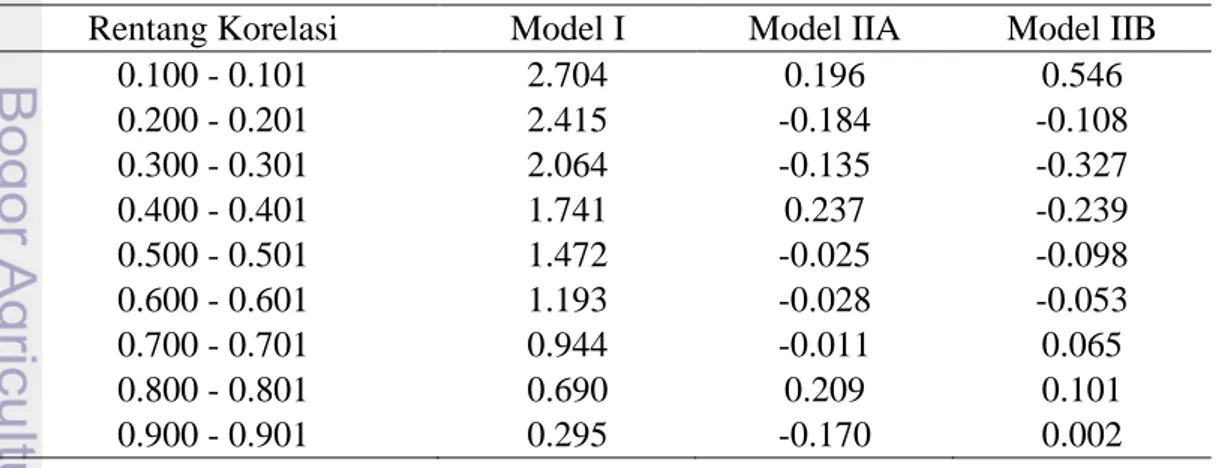
Tanda negatif pada nilai bias mengindikasikan bahwa nilai dugaan berbias ke bawah, sedangkan nilai positif pada nilai bias mengindikasikan nilai dugaan berbias ke atas. Nilai bias yang dihasilkan dari masing-masing metode pendugaan disajikan pada Tabel 4. Model I menghasilkan nilai ̂ cenderung berbias ke atas di setiap rentang korelasi. Model I menghasilkan nilai bias mutlak yang paling tinggi dibandingkan Model IIA dan Model IIB di setiap rentang korelasi. Nilai bias mutlak pada Model I semakin mendekati 0 dengan rentang korelasi mendekati 1. Model IIA dan Model IIB menghasilkan nilai bias mutlak yang kecil di setiap rentang korelasi.
Tabel 4 Rataan bias ̂ dari Model I, Model IIA, dan Model IIB
Rentang Korelasi Model I Model IIA Model IIB
0.100 - 0.101 2.704 0.196 0.546 0.200 - 0.201 2.415 -0.184 -0.108 0.300 - 0.301 2.064 -0.135 -0.327 0.400 - 0.401 1.741 0.237 -0.239 0.500 - 0.501 1.472 -0.025 -0.098 0.600 - 0.601 1.193 -0.028 -0.053 0.700 - 0.701 0.944 -0.011 0.065 0.800 - 0.801 0.690 0.209 0.101 0.900 - 0.901 0.295 -0.170 0.002
12
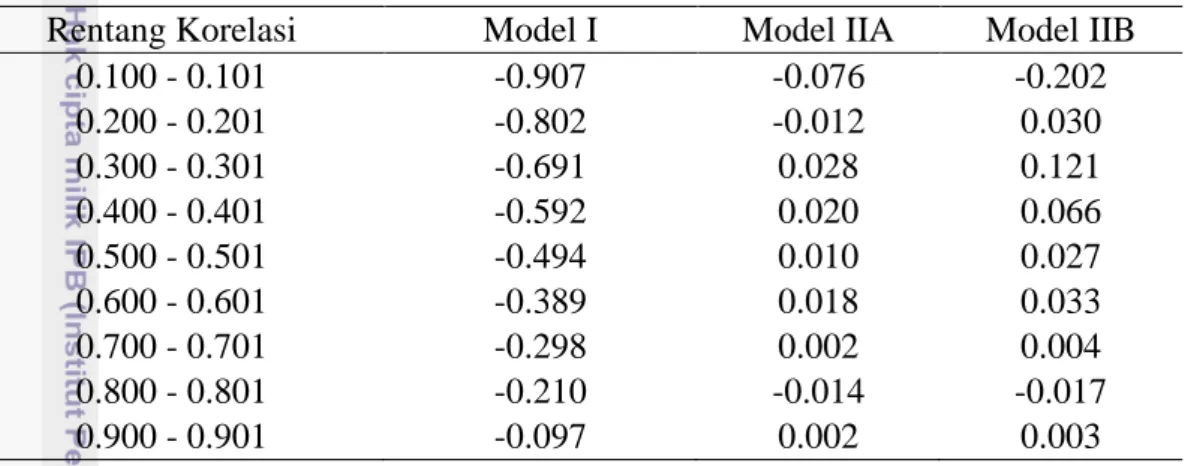
Tabel 5 menyajikan nilai bias dari ̂ dengan menggunakan masing-masing metode pendugaan. Model I menghasilkan nilai ̂ yang cenderung berbias ke bawah di setiap rentang korelasi. Nilai bias mutlak pada Model I merupakan nilai bias mutlak yang paling tinggi dibandingkan Model IIA dan Model IIB di setiap rentang korelasi. Nilai bias mutlak pada Model I semakin mendekati 0 dengan rentang korelasi mendekati 1. Model I mengalami penurunan nilai bias mutlak yang paling tinggi terjadi pada rentang korelasi 0.900 – 0.901. Model IIA dan Model IIB menghasilkan nilai bias mutlak yang kecil di setiap rentang korelasi. Tabel 5 Rataan bias ̂ dari Model I, Model IIA, dan Model IIB
Rentang Korelasi Model I Model IIA Model IIB
0.100 - 0.101 -0.907 -0.076 -0.202 0.200 - 0.201 -0.802 -0.012 0.030 0.300 - 0.301 -0.691 0.028 0.121 0.400 - 0.401 -0.592 0.020 0.066 0.500 - 0.501 -0.494 0.010 0.027 0.600 - 0.601 -0.389 0.018 0.033 0.700 - 0.701 -0.298 0.002 0.004 0.800 - 0.801 -0.210 -0.014 -0.017 0.900 - 0.901 -0.097 0.002 0.003
Mean Square Error
Mean Square Error (MSE) mempertimbangkan keragaman nilai dugaan dari beberapa metode pendugaan. Metode pendugaan yang mendapatkan nilai MSE terkecil atau mendekati 0 maka metode pendugaan tersebut dapat dikatakan baik. Gambar 4 menunjukkan nilai MSE dari nilai ̂ dengan menggunakan metode pendugaan Model I, Model IIA, dan Model IIB. Model I mengalami penurunan nilai MSE dengan rentang korelasi yang mendekati 1 dan nilai MSE yang paling kecil dengan rentang korelasi 0.900 – 0.901. Model IIA dapat
0.000 2.000 4.000 6.000 8.000 10.000 12.000 14.000 0.100 -0.101 0.200 -0.201 0.300 -0.301 0.400 -0.401 0.500 -0.501 0.600 -0.601 0.700 -0.701 0.800 -0.801 0.900 -0.901 M SE Rentang Korelasi Model I Model IIA Model IIB
13 dikatakan metode pendugaan yang paling baik karena di setiap rentang korelasi, nilai MSE nya sangat rendah. MSE yang dihasilkan dari Model IIB menunjukkan yang paling besar di rentang korelasi 0.100 – 0.101 dan mengalami penurunan nilai MSE dengan rentang korelasi yang mendekati 1.
Gambar 5 menunjukkan nilai MSE untuk ̂ dari ketiga metode pendugaan. Hal yang sama terlihat dengan Gambar 4. Model I menunjukkan nilai MSE yang semakin kecil dengan rentang korelasi yang mendekati 1 dan nilai MSE yang paling terkecil pada rentang korelasi 0.900 – 0.901. Model IIA menunjukkan nilai MSE yang kecil di setiap rentang korelasinya. Model IIB mengalami penurunan nilai MSE seiring dengan bertambahnya rentang korelasi dan nilai MSE paling tinggi pada rentang korelasi 0.100 – 0.101.
SIMPULAN DAN SARAN
Simpulan
Analisis regresi model II dengan menggunakan metode pendugaan ordinary least product merupakan metode pendugaan yang terbaik dibandingkan dengan kedua metode pendugaan lainnya yaitu MKT dan major axis regression dengan peubah penjelas yang bersifat acak. Analisis regresi model I dengan metode pendugaan MKT masih baik digunakan untuk menduga model regresi linier sederhana yang peubah penjelasnya acak jika antara peubah penjelas dan peubah respon memiliki hubungan yang linier dengan nilai korelasi tinggi (r ≥ 0.9).
0.000 0.200 0.400 0.600 0.800 1.000 1.200 1.400 0.100 -0.101 0.200 -0.201 0.300 -0.301 0.400 -0.401 0.500 -0.501 0.600 -0.601 0.700 -0.701 0.800 -0.801 0.900 -0.901 M SE Rentang Korelasi Model I Model IIA Model IIB
14
Saran
Kondisi simulasi yang dicobakan dalam penelitian ini hanya mempertimbangkan besaran nilai korelasi yang positif antara peubah respon dan peubah penjelas. Agar mendapatkan kesimpulan yang lebih luas, pada penelitian selanjutnya dapat dipertimbangkan beberapa kondisi simulasi, misalnya perbedaan ukuran contoh n l p r m t r ≠ 1, atau besaran nilai korelasi yang negatif.
DAFTAR PUSTAKA
Casella G, Berger RL. 2002. Statistical Inference. 2nd Ed. New York(US): Duxbury.
Ludbrook J. 1997. Comparing Methods of Measurement. Clinic Experiment Pharmacol Physiol [Internet]. [diunduh pada 2013 mei 22]; 24:193-203. Tersedia pada: http://www.molecularlab.it/.
Ludbrook J. 2010. Linear Regression Analysis for Comparing Two Measurers or Methods of Measurement: But Which Regression?. Clinic Experiment Pharmacol Physiol [Internet]. [diunduh pada 2013 mei 22]; 37:692-699. doi:10.1111/j.1440-1681.2010.05376.x. Tersedia pada: http://content.ebscohost.com/.
Ludbrook J. 2012. A Primer for Biomedical Scientist on How to Execute Model II Linear Regression Analysis. Clinic Experimen Pharmacol Physiol [Internet]. [diunduh pada 2013 mei 20]; 39:329-335. doi:10.1111/j.1440-1681.2011.05643.x. Tersedia pada: http://content.ebscohost.com/.
Montgomery DC, Runger GC. 2003. Applied Statistics and Probability for Engineers. 3rd ed. New York (US): John Wiley & Sons.
Quinn GP, Keough MJ. 2002. Experimental Design and Data Analysis for Biologists. New York (US): Cambridge University Pr.
15
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 7 Mei 1991 sebagai anak kedua dari empat bersaudara dari pasangan Bapak Sofyan dan Ibu Barkah. Tahun 2006 penulis lulus dari Sekolah Menengah Pertama Negeri 2 Pamulang. Tahun 2009 penulis lulus dari Sekolah Menengah Atas Negeri 1 Ciputat dan pada tahun yang sama penulis diterima di Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur Ujian Talenta Masuk (UTM) IPB.
Selama mengikuti perkuliahan, penulis aktif sebagai pengurus pada beberapa organisasi yaitu himpunan mahasiswa pertanian satu ciputat IPB (HISPAN1C), anggota Departemen Human and Resource 2011, dan Statistics Center. Penulis juga aktif dalam kepanitiaan seperti Statistika Ria 2011, Pesta Sains 2012, dan Welcome Ceremony of Statistics (WCS) 2011. Penulis melaksanakan praktik lapang di Balai Penelitian Tanaman Rempah dan Obat bagian Hama dan Proteksi Tanaman pada bulan Februari – April 2013.