Handbook of Big Data Technologies
Teks penuh
Gambar
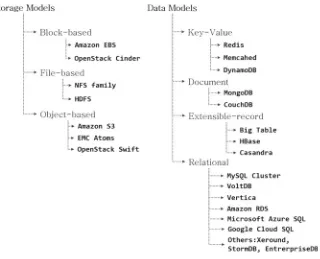
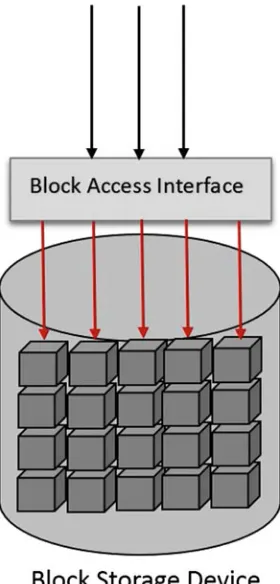
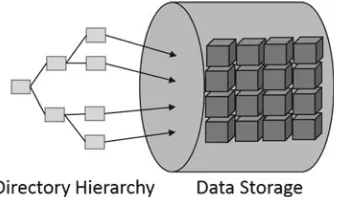
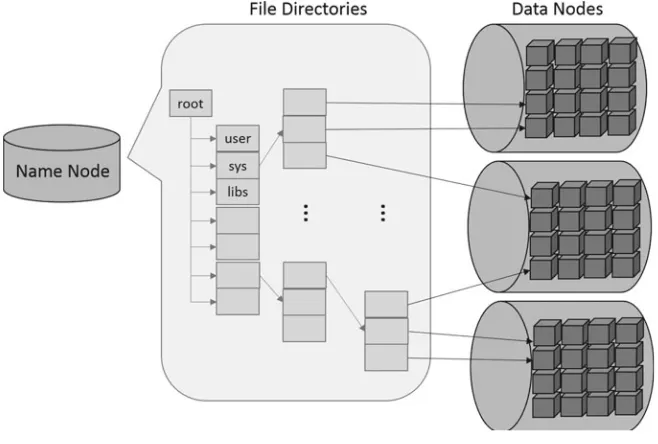
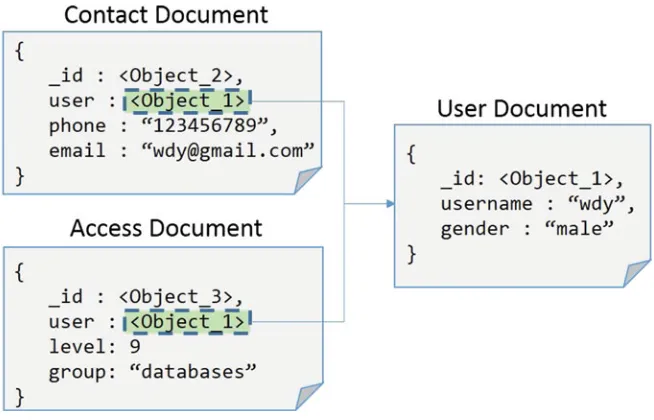

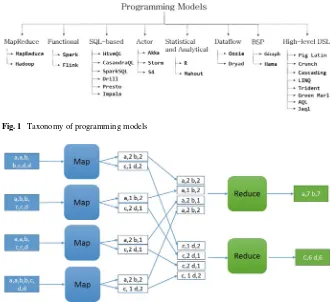

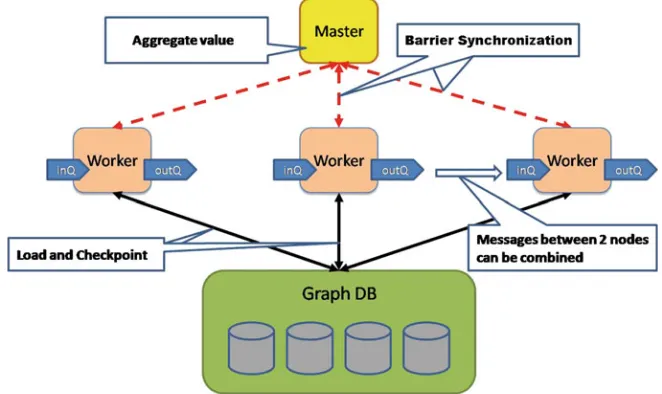
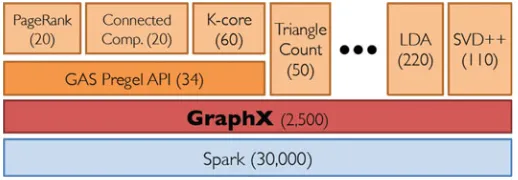
Garis besar
Dokumen terkait
Dalam rangka pemenuhan operasional RTRW provinsi, maka pada tahun 2014 ini Pemerintah Provinsi SULUT melaksanakan kegiatan penyusunan Studi Awal Rencana Tata Ruang
Seperti pada penjumlahan dua pecahan campuran, maka pengurangan pecahan campuran dapat dilakukan dengan cara mengurangkan bagian bilangan cacah terpisah dari bagian
[r]
mengumumkan Rencana Umum Pengadaan Barang/Jasa untuk pelaksanaan kegiatan tahun anggaran 2013, seperti tersebut dibawah ini:. JENIS PENGADAAN
Berdasarkan hasil evaluasi terhadap file upload penawaran (dokumen penawaran harga, administrasi dan teknis) serta dokumen kualifikasi yang telah dilaksanakan oleh Panitia
Peserta yang memasukan Penawaran dapat menyampaikan sanggahan secara tertulis atas Penetapan Pemenang kepada Panitia Pengadaan Barang dan Jasa dalam waktu 3 (Tiga) hari kerja
Kompetensi Umum Setelah mengikuti matakuliah ini mahasiswa mampu menerapkan paradigma baru pendidikan dan pembelajaran Ilmu Pengetahuan Sosial (PIPS) di sekolah
Pemahaman yang seperti inilah yang dijalankan Nabi kita Muhammad SAW dalam menjalankan dakwah Islamiyah untuk meninggalkan pengaruh masyarakat pra-sejarah Islam ( jahiliyah ) menuju
