8
LANDASAN TEORI 2.1 Teori Umum
2.1.1 Perancangan Sistem
Perancangan sistem merupakan penguraian suatu sistem informasi yang utuh ke dalam bagian komputerisasi yang dimaksud, mengidentifikasi dan mengevaluasi permasalahan, menentukan kriteria, menghitung konsistensi terhadap kriteria yang ada, serta mendapatkan hasil atau tujuan dari masalah tersebut (Lucas, 1993).
Tahapan perancangan memiliki tujuan mendesign sistem baru yang dapat menyelesaikan masalah-masalah yang dihadapi perusahaan yang diperoleh dari pemilihan alternative sistem yang terbaik. Kegiatan yang dilakukan dalam tahap perancangan ini meliputi perancangan input, output, dan file. Berikut ini adalah proses dalam perancangan sistem yang terbagi menjadi dua, yaitu:
a. Relationship Diagram
Bagi perancang basis data, Entity Relationship Diagram (ERD) berguna untuk memodelkan sistem yang nantinya akan dikembangkan basis datanya. Model ini juga membantu perancang basis data pada saat melakukan analisis dan perancangan basis data karena model ini dapat menunjukkan macam data yang dibutuhkan dan kerelasian antar data di dalamnya. Bagi pemakai, model ini sangat membantu dalam hal pemahaman model sistem dan rancangan basis data yang akan dikembangkan oleh perancang basis data (Sutanta, 2004). Sebuah ERD tersusun atas 3 komponen yaitu:
1. Entitas (entity).
Entitas menunjukkan obyek–obyek dasar yang terkait di dalam sistem. Obyek dasar dapat berupa orang, benda, atau hal yang keterangannya perlu disimpan di dalam basis data.
2. Atribut.
Atribut sering disebut sebagai properti yang merupakan keterangan – keterangan yang terkait pada sebuah entitas yang perlu disimpan sebagai basis data. Atribut berfungsi sebagai penjelas sebuah entitas.
3. Kerelasian antar entitas.
Kerelasian antar entitas mendefinisikan hubungan antar dua buah entitas. Kerelasian antar entitas dapat dikelompokkan dalam tiga jenis yaitu kerelasian jenis satu ke satu, kerelasian jenis banyak ke satu dan kerelasian jenis banyak ke banyak.
b. Data Flow Diagram
Data Flow Diagram (DFD) digunakan untuk menggambarkan suatu sistem yang telah ada atau sistem baru yang akan dikembangkan secara logika tanpa mempertimbangkan lingkungan fisik di mana data itu mengalir (misalnya lewat telepon, surat) atau lingkungan fisik di mana data itu akan disimpan (misalnya file kartu, tape, disket). DFD merupakan alat yang digunakan pada metodologi pengembangan sistem yang terstruktur. DFD juga merupakan alat yang cukup populer sekarang ini, karena dapat menggambarkan arus data di dalam sistem dengan terstruktur dan jelas (Kendall dan Kendall, 2005:243).
1. Simbol DFD
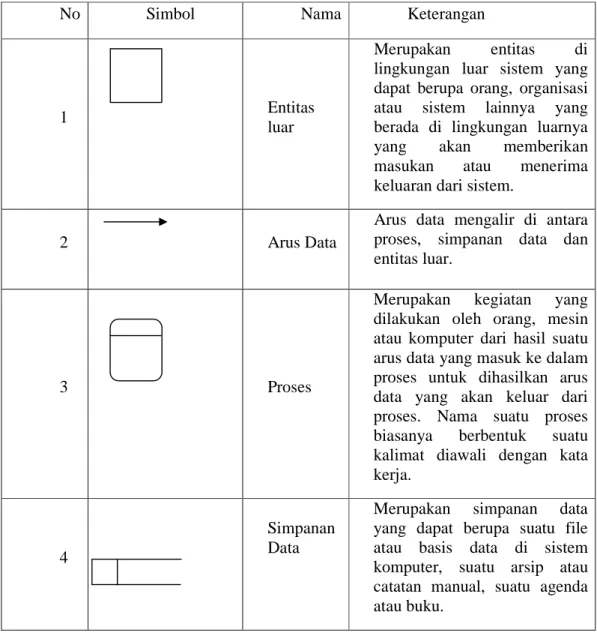
Ada empat simbol pokok di dalam menggambar suatu DFD dapat dilihat pada Tabel 1, dengan menggunakan simbol Gane & Sarson (Kendall dan Kendall, 2005:243).
Tabel 2.1 Simbol pokok di dalam menggambar DFD
No Simbol Nama Keterangan
1 Entitas
luar
Merupakan entitas di lingkungan luar sistem yang dapat berupa orang, organisasi atau sistem lainnya yang berada di lingkungan luarnya yang akan memberikan masukan atau menerima keluaran dari sistem.
2 Arus Data
Arus data mengalir di antara proses, simpanan data dan entitas luar.
3 Proses
Merupakan kegiatan yang dilakukan oleh orang, mesin atau komputer dari hasil suatu arus data yang masuk ke dalam proses untuk dihasilkan arus data yang akan keluar dari proses. Nama suatu proses biasanya berbentuk suatu kalimat diawali dengan kata kerja.
4
Simpanan Data
Merupakan simpanan data yang dapat berupa suatu file atau basis data di sistem komputer, suatu arsip atau catatan manual, suatu agenda atau buku.
2. Bentuk DFD
Terdapat dua bentuk DFD yaitu physical data flow diagram (PDFD) dan logical data flow diagram (LDFD) (Kendall dan Kendall, 2005:251).
PDFD lebih menekankan pada bagaimana proses dari sistem diterapkan sedang LDFD lebih menekankan pada proses apa yang terdapat di sistem.PDFD lebih tepat digunakan untuk menggambarkan sistem yang ada (sistem yang lama). Penekanan dari PDFD adalah bagaimana proses– proses dari sistem diterapkan (dengan cara apa, oleh siapa dan di mana) termasuk proses manual. LDFD lebih tepat digunakan untuk menggambarkan sistem yang akan diusulkan (sistem yang baru). LDFD tidak menekankan pada bagaimana sistem diterapkan, tetapi penekanannya hanya pada logika dari kebutuhan sistem yaitu proses apa secara logika yang dibutuhkan oleh sistem yang biasanya proses yang digambarkan hanya merupakan proses secara komputer saja.
3. Pembuatan DFD
Untuk memulai membuat DFD dari suatu sistem daftarkan semua komponen yang terlibat (entitas luar, proses, arus data dan simpanan data). Setelah semua teridentifikasi maka dilanjutkan dengan melakukan langkah berikut (Kendall dan Kendall, 2005:245):
a. Pembuatan context diagram
Context diagram adalah level tertinggi dalam sebuah DFD dan hanya berisi satu proses yang merupakan representasi dari suatu sistem. Proses dimulai dengan penomeran ke – 0 dan tidak berisi simpanan data.
b. Pembuatan diagram level 0
Diagram level 0 merupakan hasil pemecahan dari Context diagram menjadi bagian yang lebih terinci yang terdiri dari beberapa proses. Sebaiknya jumlah proses pada level ini maksimal
9 proses untuk menghindari diagram yang sulit untuk dimengerti. Setiap proses diberikan penomeran dengan sebuah bentuk integer. Simpanan data mulai ditampilkan pada level ini.
c. Pembuatan child diagram
Setiap proses pada diagram level 0 dipecah lagi agar didapat level yang lebih terinci lagi (child diagram). Proses pada level 0 yang dipecah lebih terinci lagi disebut parent process. Child diagram tidak menghasilkan keluaran atau menerima masukan yang mana parent process juga tidak menghasilkan keluaran atau menerima masukan. Semua arus data yang menuju ke atau keluar dari parent process harus ditampilkan lagi pada child diagram.
d. Pengecekan kesalahan
Pengecekan kesalahan pada diagram digunakan untuk melihat kesalahan yang terdapat pada sebuah DFD. Kesalahan yang umum terjadi dalam pembuatan DFD yaitu:
1. Sebuah proses tidak mempunyai masukan atau keluaran. 2. Simpanan data dengan entitas luar dihubungkan secara
langsung tanpa melalui suatu proses.
3. Kesalahan dalam penamaan pada proses atau pada arus data. 4. Memasukkan lebih dari sembilan proses dalam sebuah
diagram yang akan menyebabkan kebingungan dalam pembacaan.
Membuat ketidaksesuaian decomposition pada child diagram. Setiap child diagram harus mempunyai masukan dan keluaran yang sama dengan parent process.
c. Flowchart
Flowchart adalah penyajian yang sistematis tentang proses dan logika dari kegiatan penanganan informasi atau penggambaran secara grafik dari langkah-langkah dan urut-urutan prosedur dari suatu program. Flowchart menolong analis dan programmer untuk memecahkan masalah kedalam segmen-segmen yang lebih kecil dan menolong dalam menganalisis alternatif-alternatif lain dalam pengoperasian (Anharku, 2009).
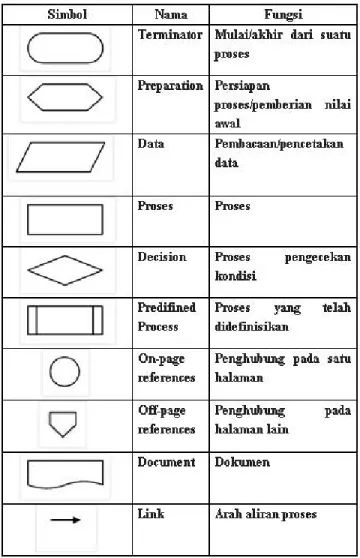
Beberapa simbol khusus yang sering digunakan untuk flowchart adalah sebagai berikut (Sutanta, E. 2004):
Gambar 2.1 Simbol Simbol Flowchart
2.1.2 C-sharp
C# adalah bahasa pemrograman baru yang diciptakan oleh Microsoft yang dikembangkan dibawah kepemimpinan Anders Hejlsberg yang telah menciptakan berbagai macam bahasa pemrograman termasuk Borland Turbo C++ dan orland Delphi. Bahasa C# juga telah di standarisasi secara internasional oleh ECMA. Seperti halnya bahasa pemrograman yang lain, C# bisa digunakan untuk membangun berbagai macam jenis aplikasi, seperti aplikasi berbasis windows (desktop) dan aplikasi berbasis web serta aplikasi berbasis web services.
Beberapa kelebihan dari bahasa C#
1. Termasuk bahasa pemrograman .NET dengan demikian user dapat menggunakan komponen-komponen yang dibangun dengan bahasa pemrograman .NET lainnya (integrasi antar bahasa)
2. Bahasa pemrograman C# memiliki language integrated query (LINQ) yang merupakan sintaks query yang dapat digunakan pada setiap kumpulan data.
3. Windows presentation foundation (WPF) dapat digunakan untuk membuat tampilan aplikasi dengan sangat kreatif
4. Microsoft memberikan IDE (Software yang digunakan untuk membangun sebuah program) secara gratis, yaitu Microsoft Visual Studio Express inilah yang akan digunakan untu membangun aplikasi C#.
2.2 Teori Khusus 2.2.1 Optimasi
Optimasi merupakan masalah yang berhubungan dengan keputusan yang terbaik, maksimum, minimum dan memberikan cara penentuan solusi yang memuaskan. Permasalahan yang berkaitan dengan optimisasi sangat kompleks dalam kehidupan sehari-hari. Nilai optimal yang didapat dalam optimisasi dapat berupa besaran panjang, waktu, jarak, dan lain-lain. Berikut ini adalah termasuk beberapa persoalan optimisasi:
1. Menentukan lintasan terpendek dari suatu tempat ke tempat yang lain. 2. Menentukan jumlah pekerja seminimal mungkin untuk melakukan suatu
proses produksi agar pengeluaran biaya pekerja dapat diminimalkan dan hasil produksi tetap maksimal.
4. Mengatur routing jaringan kabel telepon agar biaya pemasangan kabel tidak terlalu besar dan penggunaannya tidak boros.
2.2.2 Algoritma Ant Colony
Ant Colony Optimization (ACO) diadopsi dari perilaku koloni semut yang dikenal sebagai sistem semut (Dorigo, et.al, 1996). Semut mampu mengindera lingkungannya yang kompleks untuk mencari makanan dan kemudian kembali ke sarangnya dengan meninggalkan zat Pheromone pada rute-rute yang mereka lalui.
Pheromone adalah zat kimia yang berasal dari kelenjar endokrin dan digunakan oleh makhluk hidup untuk mengenali sesama jenis, individu lain, kelompok, dan untuk membantu proses reproduksi. Berbeda dengan hormon, Pheromone menyebar ke luar tubuh dan hanya dapat mempengaruhi dan dikenali oleh individu lain yang sejenis (satu spesies).
Proses peninggalan Pheromone ini dikenal sebagai stigmery, yaitu sebuah proses memodifikasi lingkungan yang tidak hanya bertujuan untuk mengingat jalan pulang ke sarang, tetapi juga memungkinkan para semut berkomunikasi dengan koloninya.
Seiring waktu, bagaimanapun juga jejak Pheromone akan menguap dan akan mengurangi kekuatan daya tariknya. Lebih cepat setiap semut pulang pergi melalui rute tersebut, maka Pheromone yang menguap lebih sedikit. Begitu pula sebaliknya jika semut lebih lama pulang pergi melalui rute tersebut, maka Pheromone yang menguap lebih banyak.
Filosofi dari Algoritma Ant Colony adalah:
1. Pemecahan masalah merupakan pemodelan dari realita koloni semut dalam mencari makanan
2. Jumlah alternatif solusi sebagai pemecahan masalah adalah merupakan jumlah semut di dalam koloni tersebut
3. Populasi dari jumlah alternatif solusi adalah masing-masing waktu koloni pergi mencari makanan dan kembali ke sarang mereka.
Manfaat algoritma koloni semut selain digunakan untuk mencari sebuah path / jalur yang optimal (baik jarak, waktu dan biaya), di dalam sebuah jaringan distribusi barang, pun algoritma ini dapat dimanfaatkan untuk mencari nilai optimal lain yang terjadi di lapangan, seperti permasalahan kombinasi, nilai produksi dan juga dapat digunakan untuk forecasting.
Secara jelasnya cara kerja semut menemukan rute terpendek dalam ACO adalah sebagai berikut : Secara alamiah semut mampu menemukan rute terpendek dalam perjalanan dari sarang ke tempat-tempat sumber makanan. Koloni semut dapat menemukan rute terpendek antara sarang dan sumber makanan berdasarkan jejak kaki pada lintasan yang telah dilalui. Semakin banyak semut yang melalui suatu lintasan, maka akan semakin jelas bekas jejak kakinya. Hal ini akan menyebabkan lintasan yang dilalui semut dalam jumlah sedikit, semakin lama akan semakin berkurang kepadatan semut yang melewatinya, atau bahkan akan tidak dilewati sama sekali. Sebaliknya lintasan yang dilalui semut dalam jumlah banyak, semakin lama akan semakin bertambah kepadatan semut yang melewatinya, atau bahkan semua semut akan melalui lintasan tersebut (Dorigo, M., Maniezzo, V., dan Colorni, A., 1991a).
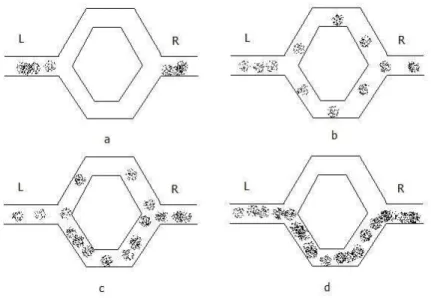
Gambar 2.2. Perjalanan Semut dari Sarang ke Sumber Makanan.
Gambar 2.2.a di atas menunjukkan ada dua kelompok semut yang akan melakukan perjalanan. Satu kelompok bernama L yaitu kelompok yang berangkat dari arah kiri yang merupakan sarang semut dan kelompok lain yang bernama kelompok R yang berangkat dari kanan yang merupakan sumber makanan. Kedua kelompok semut dari titik awal keberangkatan sedang dalam posisi pengambilan keputusan jalan sebelah mana yang akan diambil. Kelompok semut L membagi dua kelompok lagi. Sebagian melalui jalan atas dan sebagian melalui jalan bawah. Hal ini juga berlaku pada kelompok semut R. Gambar 2.14.b dan gambar 2.14.c menunjukkan bahwa kelompok semut berjalan pada kecepatan yang sama dengan meninggalkan Pheromone (jejak kaki semut) di jalan yang telah dilalui. Pheromone yang ditinggalkan oleh semut - semut yang melalui jalan atas telah mengalami banyak penguapan karena semut yang melalui jalan atas berjumlah lebih sedikit dari pada jalan yang di bawah. Hal ini dikarenakan jarak yang
ditempuh lebih panjang daripada jalan bawah. Sedangkan Pheromone yang berada di jalan bawah, penguapannya cenderung lebih lama. Karena semut yang melalui jalan bawah lebih banyak daripada semut yang melalui jalan atas. Gambar 2.14.d menunjukkan bahwa semut-semut yang lain pada akhirnya memutuskan untuk melewati jalan bawah karena Pheromone yang ditinggalkan masih banyak. Sedangkan Pheromone pada jalan atas sudah banyak menguap sehingga semut-semut tidak memilih jalan atas tersebut. Semakin banyak semut yang melalui jalan bawah maka semakin banyak semut yang mengikutinya.
Demikian juga dengan jalan atas, semakin sedikit semut yang melalui jalan atas, maka Pheromone yang ditinggalkan semakin berkurang bahkan hilang. Dari sinilah kemudian terpilihlah rute terpendek antara sarang dan sumber makanan.
Kelebihan Algoritma Ant Colony terletak pada beberapa hal yang membedakan algoritma ini dengan yang lainnya yaitu :
1. Algoritma ini bekerja dengan umpan balik yang positif dalam penemuan dan pencapaian solusi yang baik. Dimana pada suatu titik tertentu suatu kelompok memilih option yang berbeda dan salah satu memberikan hasil yang baik, lalu di masa yang akan datang pilihan tersebut akan selalu digunakan.
2. Algoritma ini mempunyai sifat sinergi yang tinggi. Keefektifan pencarian ditunjukkan dengan memberikan sejumlah semut yang saling bekerja sama dan setiap kerja sama akan saling independen.
3. Pengunaan struktur yang luas dalam algoritma semut membantu dalam menemukan solusi yang dapat diterima pada tahap awal proses penelitian.
4. Kebagusan dari algoritma ini untuk diaplikasikan pada versi yang sama untuk masalah kombinasi optimasi yang berbeda, seperti dalam ATSP (Asymmetric Travelling Salesman Problem).
5. Algoritma ini dapat diaplikasikan untuk masalah kombinasi optimalisasi yang lain.
Tahapan-tahapan algoritma semut yang digunakan dalam penelitian ini adalah sebagai berikut:
1. Tahap inisialisasi harga parameter dan node pertama setiap semut.
Pada tahap ini dilakukan inisialisasi harga parameter yang akan digunakan dala perhitungan algoritma semut selanjutnya. Parameter ini secara langsung mempunya pengaruh terhadap perhitungan probabilitas node yang akan dikunjungi. Parameter yang digunnakan antara lain
a. N adalah banyak kota
b. X dan Y adalah koordinat atau d adalah jarak antar kota (namun pada penulisan ini tidak menggunakan koordinat X dan Y dikarenakan dipenulisan ini menggunakan d jarak antara rumah ke rumah)
c. Q adalah tetapan siklus semut.
d. α adalah tetapan pengendali intesitas jejak semut.
f. M adalah jumlah semut.
g. ρ adalah tetapan penguapan jejak semut.
h. NCmax adalah jumlah siklus maksimum.
i. τij adalah intensitas jejak semut antar rumah.
2. Inisialisasi node pertama setiap semut.
Pada tahap ini menentuka nilai node pertama pada semut menentukan jumlah semut dan lain nya.
3. Pengisian node pertama ke dalam tabu list.
Tahap ini adalah node-node petama setiap semua hasil inisialisasi langkah 1 harus diisikan sebagai elemen pertama tabu list. Tabu list digunakan untuk menyimpan daftar urutan node-node yang sudah dikunjungi setiap semut. Kemudian setiap kali seekor semut berkunjung ke suatu kota, elemen tabu list bertambah satu, demikian seterusnya sampai tabu list penuh atau mempunyai banyak elemen yang sama dengan semua node yang harus dikunjungi.
4. Penyusunan rute kunjungan setiap semut ke setiap node.
Setelah semut terdistribusi ke sejumlah atau setiap node, semut-semut akan mulai melakukakn perjalan dari node pertama sebagai node asal dan salah satu node-node lain nya sebagai tujuan. Kemudian semut akan memlilih salah satu dari node tujuan berikutnya, demikian seterusnya sampai semua node dikunjungin. Maka untuk menentukan kode tujuan ini digunakan persamaan dinamai randomproportional rule (Dorigo, M.,
Maniezzo, V., dan Colorni, A., 1996), yang ditunjukkan oleh persamaan
di bawah ini. merupakan probabilitas dari semut k pada titik r yang memilih untuk menuju ke titik s.
Dimana :
(a) : jumlah Pheromone yang terdapat pada edge antara titik r dan titik s (b)
(
)
) ( 1 ) ( rs d rsn = : visibility (invers dari jarak d(rs))
(c) α adalah sebuah parameter yang mengontrol bobot (weight) relatif dari Pheromone
(d) β adalah parameter pengendali jarak (α > 0 dan β < 0).
Persamaan diatas menunjukkan besarnya kebolehjadian suatu node untuk dipilih sebagai node tujuan. Semakin besar harga probabilitas semakin besar pula kebolehjadian untuk dipilih sebagai node tujuan.
5. Menghitung panjang rute semut dan perhitungan perubahan harga intensitas jejak kaki semut antar node.
Pada tahap ini dilakukan perhitungan jarak antara tiap node. Dengan dij sebagai jarak antara node i ke node j yang dihitung berdasarkan persamaan :
Persamaan ini digunakan untuk menetukan jarak apabila diketahui mengguanakan koordinat. Tetapi pada penulisan ini menggunakan jarak antara rumah sehingga tidak menggunakan rumus ini. Perjalanan semut antar node akan meninggalkan jejak kaki pada semua lintasan yang dilaluinya. Adanya penguapan menyebabkan terjadinya perubahan harga intensitas jejak kaki antar node. Persamaan perubahan ini adalah :
Dengan ij Dt adalah perubahan harga intensitas jejak kaki semut antar node setiap semut yang dihitung berdasarkan persamaan :
6. Perhitungan harga intensitas jejak kaki semut antarnode untuk siklus berikutnya dan reset harga perubahan intensitas jejak kaki semut antarnode.
Semut lintasan antarnode yang dijadikan jalur perjalanan setiap semut mempunyai kemungkinan untuk dilewati semut-semut pada siklus berikutnya. Karena adanya penguapan feromon tersebut dan intesitasnya juga mengalami perubahan tergantung pada semut-semut yang
melewatinya, maka di mata semut yang akan lewat pada lintasan tersebut untuk siklus berikutnya, harga intensitas sudah berubah. Harga intensitas jejak kaki semut antar node untuk siklus berikutnya dihitung dengan persamaan:
.
Selanjutnya untuk siklus berikutnya perubahan harga intesitas jejak semua antar node perlu di reset kembali agar berharga sama dengan nol.
7. Pengosongan tabu list
Apabila belum tercapai jumlah siklus maksimum atau belum terkonvergensi, maka algoritma perlu diulang lagi dari langkah ke 2 dengan harga parameter intensitas jejak kaki semut antar node yang sudah di perbaharui. Disamping itu tabu list perlu dikosongkan untuk diisi lagi dengan urutan node yang baru pada siklus berikutnya.
Proses ini berlangsung sampai perjalanan mencapai jumlah maksimum pada jalur NCMax atau semua semut membuat pola perjalanan yang sama. Hal ini disebut dengan stagnation behavior karena hal ini digunakan pada situasi di mana titik algoritma mencapai solusi alternatif.
8. Hasil pengolahan data menggunakan algoritma semut
Dai hasil pengolahan data dengan menggunakan algoritma semut, maka diperoleh panjang rute pipa terpendek.