TUGAS INDIVIDU
METODE REGRESI
Analisis Data Pengaruh Usia Mahasiswa Saat Masuk S2
dan Fakultas Asal Mahsiswa Terhadap Nilai Tes Potensi
Akademik (TPA) Mahasiswa Program Magister ITS
Tahun 2006 Dengan Menggunakan Analisis Regresi
Dummy
Oleh:
Fausania Hibatullah
1313 030 018
Asisten Dosen:
Ardhian Bayu Firdauz
Program Studi Diploma III
Jurusan Statistika
Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Teknologi Sepuluh Nopember
Surabaya
1
BAB I
ANALISIS DAN PEMBAHASAN
1.1 Interpretasi Model Regresi Linier Berganda dengan Variabel
Prediktor Dummy
Pada penelitian ini, model regresi linier berganda bertujuan untuk meramalkan nilai TPA (Tes Potensi Akademik) dari mahasiswa program Magister ITS pada tahun 2006 berdasarkan faktor usia mahasiswa pada saat masuk S2 dan fakultas mahasiswa berasal. Terdapat 3 kategori fakultas yaitu FMIPA, FTK dan FTIf ITS. Berikut adalah koding yang dilakukan dalam analisis regresi linier berganda dengan variabel dummy pada data fakultas mahasiswa berasal.
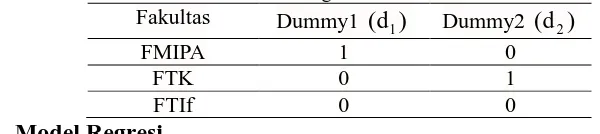
Tabel 1.1 Koding Pada Data Fakultas
Fakultas Dummy1 ( )
Berikut hasil persamaan model regresi linier berganda dengan variabel prediktor dummy dengan menggunakan Software Minitab.
Tabel 1.2 Model Regresi
Persamaan Regresi y6213.37x -7.9d1-54.1d2
R-Sq 30.5 %
Berdasarkan Tabel 1.2 dapat diketahui bahwa persamaan model regresi mampu menjelaskan sebesar 30.5% variabilitas yang dimiliki, sedangkan sisanya sebesar 69.5% dijelaskan oleh variabel lain yang tidak masuk dalam model.
A. Persamaan Regresi untuk Fakultas Fakultas Matematika dan Ilmu
Pengetahuan Alam (FMIPA)
2
sebesar 7.9 poin dibandingkan dengan nilai TOEFL dari mahasiswa program Magister FTIf ITS.
B. Persamaan Regresi untuk Fakultas Teknologi Kelautan (FTK)
2
Dari persamaan model diatas, dijelaskan bahwa nilai Tes Potensi Akademik (TPA) dari mahasiswa program Magister FTK ITS tahun 2006 lebih rendah sebesar 54.1 poin dibandingkan dengan nilai TOEFL dari mahasiswa program Magister FTIf ITS.
C. Persamaan regresi untuk Fakultas Teknologi Informasi (FTIf)
2
Dari persamaan model diatas, dijelaskan bahwa nilai Tes Potensi Akademik (TPA) dari mahasiswa program Magister FTIf ITS tahun 2006 lebih tinggi dibandingkan dengan nilai TOEFL dari mahasiswa program Magister FMIPA dan FTK ITS.
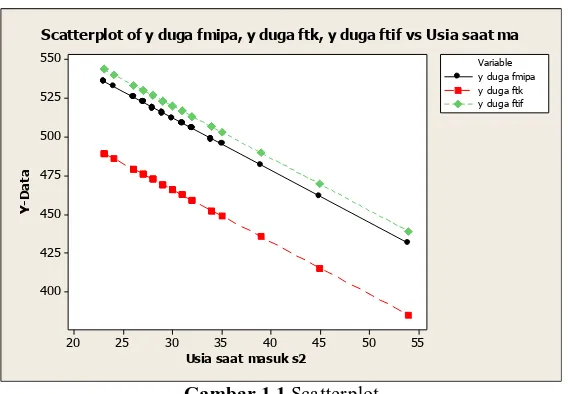
1.1.2 Scatterplot
3
Scatterplot of y duga fmipa, y duga ftk, y duga ftif vs Usia saat ma
Gambar 1.1 Scatterplot
Berdasarkan hasil persamaan model regresi dan Gambar 1.1, dapat diketahui bahwa nilai Tes Potensi Akademik (TPA) mahasiswa program Magister dari FTIf ITS tahun 2006 lebih tinggi sebesar 7.9 poin dibandingkan dengan mahasiswa program Magister dari FMIPA ITS dan lebih tinggi sebesar 54.1 poin dibandingkan dengan mahasiswa program Magister dari FTK ITS.
1.2 Analisis Regresi Linier Berganda dengan Variabel Prediktor Dummy
Pada analisis Regresi Linier Berganda dengan variabel prediktor dummy
akan dilakukan uji serentak sertauji parsial pada data nilai Tes Potensi Akademik (TPA) mahasiswa program Magister ITS tahun 2006 berdasarkan faktor usia mahasiswa saat masuk S2 dan fakultas mahasiswa berasal.
1.2.1 Uji Serentak
Uji serentak adalah pengujian untuk melihat signifikansi parameter secara bersama.
Hipotesis yang digunakan sebagai berikut.
:
0
H i 0 dimana i = 1, 2, 3 (semua variabel tidak berpengaruh signifikan
terhadap nilai TPA mahasiswa program Magister ITS)
: 1
H Minimal ada satu i 0 dimana i = 1, 2, 3 (Minimal ada satu variabel yang
berpengaruh signifikan terhadap nilai TPA mahasiswa program Magister ITS)
Taraf signifikan : 0.05
4
Tabel 1.3 Hasil Uji Serentak
Sumber Derajat Bebas
Jumlah Kuadrat
Kuadrat Tengah
F-hitung F0.05(3,26) P-value
Regresi 3 34248 11416 3.80 2.98 0,022
Galat 26 78039 3001
Total 29 112287
Berdasarkan Tabel 1.3 dapat diketahui bahwa nilai F hitung sebesar 3.80. Pada taraf 0.05, didapatkan nilai F tabel (F0.05(3,26)) sebesar 2.98 sehingga F
(3.80) > F0.05(3,26) (2.98) dan P-value (0.022) < α (0.05) maka keputusan yang
diambil adalah ditolak dan didapatkan kesimpulan bahwa minimal ada satu
variabel yang berpengaruh signifikan terhadap nilai Tes Potensi Akademik (TPA) dari mahasiswa program Magister ITS tahun 2006.
1.2.2 Uji Parsial
Uji parsial digunakan untuk mengetahui variabel/parameter mana dari memiliki pengaruh signifikan terhadap nilai Tes Potensi Akademik (TPA) mahasiswa program Magister ITS tahun 2006. Uji ini dilakukan pada masing-masing variabel prediktor dengan variabel respon sehingga menggunakan beberapa analisis.
A. Uji Parsial Pengaruh Usia Mahasiswa Saat Masuk S2 Terhadap Nilai
TPA Mahasiswa Program Magister ITS
Hipotesis yang digunakan adalah sebagai berikut.
: 0
H 1 0 (Usia saat masuk S2 tidak berpengaruh signifikan terhadap nilai
TPA mahasiswa program Magister ITS)
: 1
H 1 0 (Usia saat masuk S2 berpengaruh signifikan terhadap nilai TPA
mahasiswa program Magister ITS) Taraf signifikan : 0.05
Daerah penolakan : Tolak H0 jika |t|t/2(n(p1))
Statistik uji :
Tabel 1.4 Uji Parsial X terhadap Y
Prediktor t-hitung t0.025(26) P-value
Usia saat masuk S2
-2.15 2.056 0.041
Berdasarkan Tabel 1.4 dapat diketahui bahwa nilai |t-hitung| sebesar 2.15. Pada taraf 0.05, didapatkan nilai t tabel (t0.025(26)) sebesar 2.056 sehingga |t|
(2.15) > t0.025(26) (2.056) dan P-value (0.041) < α (0.05) maka keputusan yang
5
diambil adalah ditolak dan didapatkan kesimpulan bahwa usia mahasiswa
saat masuk S2 berpengaruh signifikan terhadap nilai Tes Potensi Akademik (TPA) mahasiswa program Magister ITS
B. Uji Parsial Pengaruh Variabel Dummy Terhadap Nilai TPA
Mahasiswa Program Magister ITS
Hipotesis yang digunakan adalah sebagai berikut.
: 0
H 2 3 0(Asal fakultas dari FMIPA dan FTK ITS tidak berpengaruh
signifikan terhadap nilai TPA mahasiswa program Magister ITS)
: 1
H Minimal ada satu i 0 dimana i = 2,3 (Minimal ada satu asal fakultas yang
berpengaruh signifikan terhadap nilai TPA mahasiswa program Magister ITS)
Berdasarkan hasil perhitungan diatas dapat diketahui bahwa nilai F-hitung sebesar 2.819. Pada taraf 0.05, didapatkan nilai F tabel (F0.05(3,26)) sebesar 2.98
sehingga F (2.819) < F0.05(3,26) (2.98) maka keputusan yang diambil adalah H0 gagal
ditolak dan didapatkan kesimpulan bahwa asal fakultas dari FMIPA dan FTK ITS tidak berpengaruh signifikan terhadap nilai TPA mahasiswa program Magister ITS.
C. Uji Parsial Ada Tidaknya Perbedaan Antara Mahasiswa Dengan
Fakultas Asal FMIPA dan FTIf ITS
Hipotesis yang digunakan adalah sebagai berikut.
:
0
H 2 0 (Mahasiswa yang berasal dari FMIPA ITS tidak memiliki perbedaan yang signifikan dengan mahasiswa yang berasal dari FTIf ITS)
: 1
H 2 0 (Mahasiswa yang berasal dari FMIPA ITS memiliki perbedaan yang
signifikan dengan mahasiswa yang berasal dari FTIf ITS) Taraf signifikan : 0.05
6
Daerah penolakan : Tolak H0 jika |t|t/2(n(p1))
Statistik uji :
Tabel 1.5 Uji Parsial Kategori 1 dan 3
Prediktor t-hitung P-value FMIPA ITS -0.32 0,752
Berdasarkan Tabel 1.5 dapat diketahui bahwa nilai |t-hitung| sebesar 0.32. Pada taraf 0.05, didapatkan nilai t tabel (t0.025(26)) sebesar 2.056 sehingga |t|
(0.32) < t0.025(26) (2.056) dan P-value (0.752) > α (0.05) maka keputusan yang
diambil adalah gagal ditolak dan didapatkan kesimpulan bahwa mahasiswa
yang berasal dari FMIPA ITS tidak memiliki perbedaan yang signifikan dengan mahasiswa yang berasal dari FTIf ITS.
D. Uji Parsial Ada Tidaknya Perbedaan Antara Mahasiswa Dengan
Fakultas Asal FTK dan FTIf ITS
Hipotesis yang digunakan adalah sebagai berikut. :
0
H 3 0 (Mahasiswa yang berasal dari FTK ITS tidak memiliki perbedaan yang signifikan dengan mahasiswa yang berasal dari FTIf ITS)
: 1
H 30 (Mahasiswa yang berasal dari FTK ITS memiliki perbedaan yang
signifikan dengan mahasiswa yang berasal dari FTIf ITS) Taraf signifikan : 0.05
Daerah penolakan : Tolak H0 jika |t|t/2(n(p1))
Statistik uji :
Tabel 1.6 Uji Parsial Kategori 2 dan 3
Prediktor t-hitung P-value
FTK ITS -2.19 0,038
Berdasarkan Tabel 1.6 dapat diketahui bahwa nilai |t-hitung| sebesar 2.19. Pada taraf 0.05, didapatkan nilai t tabel (t0.025(26)) sebesar 2.056 sehingga |t|
(2.19) > t0.025(26) (2.056) dan P-value (0.038) < α (0.05) maka keputusan yang
diambil adalah ditolak dan didapatkan kesimpulan bahwa mahasiswa yang
berasal dari FTK ITS memiliki perbedaan yang signifikan dengan mahasiswa yang berasal dari FTIf ITS.
E. Uji Parsial Ada Tidaknya Perbedaan Antara Mahasiswa Dengan
Fakultas Asal FTI dan FTSP ITS
Hipotesis yang digunakan adalah sebagai berikut.
0 H
7 :
0
H 2 3 (Mahasiswa yang berasal dari FMIPA dan FTK ITS memberikan respon yang sama terhadap nilai TPA mahasiswa program Magister di ITS)
:
Berdasarkan hasil perhitungan diatas dapat diketahui bahwa nilai |t-hitung| sebesar 1.886. Pada taraf 0.05, didapatkan nilai t tabel (t0.025(26)) sebesar 2.056
sehingga |t| (1.886) < t0.025(26) (2.056) maka keputusan yang diambil adalah
gagal ditolak dan didapatkan kesimpulan bahwa mahasiswa yang berasal dari FMIPA dan FTK ITS memberikan respon yang sama terhadap nilai TPA mahasiswa program Magister di ITS.
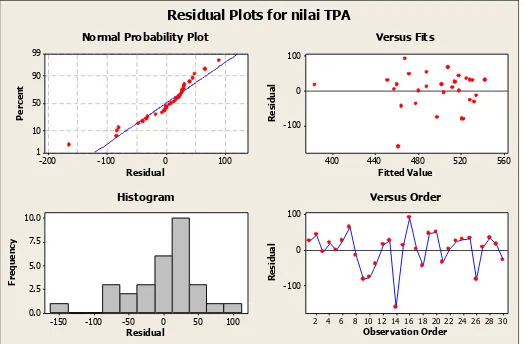
1.3 Pemeriksaan Asumsi Residual IIDN
Setelah melakukan analisis Regresi Linier Berganda dengan variabel prediktor dummy, selanjutnya akan dilakukan pemeriksaan asumsi residual IIDN yaitu residual independen, residual identik, dan residual berdistribusi normal.
100
Gambar 1.2 Pemeriksaan Asumsi Residual IIDN
8
9
BAB II
KESIMPULAN DAN SARAN
2.1 Kesimpulan
Berdasarkan analisis dan pembahasan pada Bab I dapat diperoleh kesimpulan sebagai berikut.
1. Model regresi linier menunjukkan bahwa nilai nilai Tes Potensi Akademik (TPA) mahasiswa program Magister dari FTIf ITS tahun 2006 lebih tinggi sebesar 7.9 poin dibandingkan dengan mahasiswa program Magister dari FMIPA ITS dan lebih tinggi sebesar 54.1 poin dibandingkan dengan mahasiswa program Magister dari FTK ITS.
2. Uji serentak pada analisis regresi linier berganda dengan variabel prediktor
dummy menunjukkan bahwa minimal ada satu variabel yang berpengaruh signifikan terhadap nilai TPA mahasiswa program Magister ITS, sehingga dilanjutkan ke uji parsial. Uji parsial menunjukkan bahwa usia mahasiswa saat masuk S2 berpengaruh signifikan terhadap nilai TPA mahasiswa program Magister ITS, asal fakultas dari FMIPA dan FTK ITS tidak berpengaruh signifikan terhadap nilai TPA mahasiswa program Magister ITS, mahasiswa yang berasal dari FMIPA ITS tidak memiliki perbedaan yang signifikan dengan mahasiswa yang berasal dari FTIf ITS, mahasiswa yang berasal dari FTK ITS memiliki perbedaan yang signifikan dengan mahasiswa yang berasal dari FTIf ITS, mahasiswa yang berasal dari FMIPA dan FTK ITS memberikan respon yang sama terhadap nilai TPA mahasiswa program Magister di ITS.
3. Pemeriksaan asumsi residual IIDN menunjukkan bahwa data nilai TPA mahasiswa program Magister ITS tahun 2006 memenuhi asumsi residual identik dan independen namun tidak berdistribusi normal.
2.2 Saran
LAMPIRAN
Lampiran 1 Nilai TPA Mahasiswa Program Magister ITS Tahun 2006
Berdasarkan Usia Saat Masuk S2 dan Fakultas.
No Nilai TPA Usia saat masuk s2 Fakultas D1 D2
1 540 29 FMIPA 1 0
2 560 28 FMIPA 1 0
3 500 32 FMIPA 1 0
4 480 45 FMIPA 1 0
5 480 39 FMIPA 1 0
6 560 24 FMIPA 1 0
7 575 31 FMIPA 1 0
8 520 23 FMIPA 1 0
9 440 27 FMIPA 1 0
10 420 34 FMIPA 1 0
11 440 26 FTK 0 1
12 400 54 FTK 0 1
13 480 34 FTK 0 1
14 300 31 FTK 0 1
15 500 23 FTK 0 1
16 560 29 FTK 0 1
17 460 32 FTK 0 1
18 420 30 FTK 0 1
19 520 28 FTK 0 1
20 540 23 FTK 0 1
21 500 26 FTIf 0 0
22 520 30 FTIf 0 0
23 540 31 FTIf 0 0
24 560 27 FTIf 0 0
25 575 23 FTIf 0 0
26 440 29 FTIf 0 0
27 520 32 FTIf 0 0
28 560 28 FTIf 0 0
29 520 35 FTIf 0 0
30 500 27 FTIf 0 0
Keterangan :
D1 = Fakultas Matematika dan Ilmu Pengetahuan Alam ITS (FMIPA ITS)
Lampiran 2 Output Model Regresi
Lampiran 3 Output Regresi Linier Berganda Uji Serentak dan Uji Parsial
Lampiran 4
Lampiran 4 Varians β
The regression equation is
nilai TPA = 621 - 3.37 Usia saat masuk s2 - 7.9 FMIPA - 54.1 FTK
S = 54.7858 R-Sq = 30.5% R-Sq(adj) = 22.5%
Analysis of Variance
Source DF SS MS F P Regression 3 34248 11416 3.80 0.022 Residual Error 26 78039 3001
Total 29 112287
Source DF Seq SS Usia saat masuk s2 1 17330 FMIPA 1 2578 FTK 1 14340
Predictor Coef SE Coef T P Constant 620.62 48.36 12.83 0.000 Usia saat masuk s2 -3.372 1.568 -2.15 0.041 FMIPA -7.91 24.79 -0.32 0.752 FTK -54.08 24.74 -2.19 0.038
Data Display
Matrix M5
TUGAS INDIVIDU
METODE REGRESI
Pengujian Asumsi Residual IIDN, Pendeteksian
Multikonlinearitas dan Pemilihan Model Terbaik
pada
Data Faktor-Faktor yang Diduga Mempengaruhi Jumlah
Kasus Kanker Serviks di Tiap Kabupaten/Kota di
Provinsi Jawa Timur Tahun 2010
Oleh:
Fausania Hibatullah
1313 030 018
Asisten Dosen:
Ardhian Bayu Firdauz
Program Studi Diploma III
Jurusan Statistika
Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Teknologi Sepuluh Nopember
Surabaya
1
BAB I
ANALISIS DAN PEMBAHASAN
1.1 Statistika Deskriptif
Statsistika deskriptif merupakan langkah analisis yang harus dilakukan pertama kali untuk mengetahui dan memberikan keterangan tentang karakteristik data dari hasil pengamatan yang telah dilakukan dalam praktikum. Perhitungan statistika deskriptif tersebut diolah menggunakan software Minitab. Berikut merupakan hasil perhitungan statistika deskriptif data mengenai jumlah kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur.
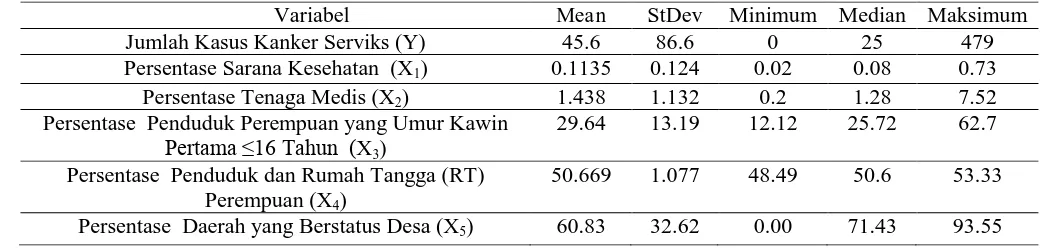
Tabel 1.1 Statistika Deskriptif
Berdasarkan Tabel 1.1, dapat diketahui bahwa nilai rata-rata dari jumlah kasus kanker serviks di tiap kabupaten/kota provinsi Jawa Timur pada tahun 2010 sebesar 45.6 kasus, nilai maksimum sebesar 479 kasus dan nilai minimum sebesar 0 kasus dengan nilai keragaman sebesar 86.6. Setengah dari data jumlah kasus kanker serviks di tiap kabupaten/kota provinsi Jawa Timur mempunyai nilai diatas 25 kasus, sedangkan setengah lainnya mempunyai nilai dibawah 25 kasus. Nilai rata-rata dari persentase sarana kesehatan di tiap kabupaten/kota provinsi Jawa Timur pada tahun 2010 sebesar 0.1135 persen dengan nilai keragaman sebesar 0.124. Nilai rata-rata dari persentase tenaga medis di tiap kabupaten/kota provinsi Jawa Timur pada tahun 2010 sebesar 1.438 persen dengan nilai keragaman sebesar 1.132. Nilai rata-rata dari persentase penduduk perempuan yang umur
Variabel Mean StDev Minimum Median Maksimum
Jumlah Kasus Kanker Serviks (Y) 45.6 86.6 0 25 479
Persentase Sarana Kesehatan (X1) 0.1135 0.124 0.02 0.08 0.73
Persentase Tenaga Medis (X2) 1.438 1.132 0.2 1.28 7.52
Persentase Penduduk Perempuan yang Umur Kawin
Pertama ≤16 Tahun (X3)
29.64 13.19 12.12 25.72 62.7 Persentase Penduduk dan Rumah Tangga (RT)
Perempuan (X4)
2
kawin pertama ≤16 tahun di tiap kabupaten/kota provinsi Jawa Timur pada tahun 2010 sebesar 29.64 persen dengan nilai keragaman sebesar 13.19. Nilai rata-rata dari persentase penduduk dan RT perempuan di tiap kabupaten/kota provinsi Jawa Timur pada tahun 2010 sebesar 50.669 persen dengan nilai keragaman sebesar 1.077. Nilai rata-rata dari persentase daerah yang berstatus desa di tiap kabupaten/kota provinsi Jawa Timur pada tahun 2010 sebesar 60.83 persen dengan nilai keragaman sebesar 32.62, sehingga variabel prediktor persentase daerah yang berstatus desa di tiap kabupaten/kota provinsi Jawa Timur pada tahun 2010 mempunyai nilai rata-rata dan nilai keragaman terbesar.
1.2 Pemeriksaan dan Pengujian Asumsi Residual IIDN
Pemeriksaan asumsi residual IIDN (Identik, Independen dan Distribusi Normal) ini dilakukan untuk mengetahui apakah data dalam percobaan ini memenuhi asumsi residual identik, independen dan berdistribusi normal dengan memeriksa residualnya. Berikut merupakan pemeriksaan secara visual beserta pengujiannya.
1.2.1 Pemeriksaan dan Pengujian Asumsi Residual Identik
Berikut merupakan hasil pemeriksaan asumsi residual identik pada data yang telah diperoleh dengan software minitab.
300 250
200 150
100 50
0 400
300
200
100
0
-100
Fitted Value
R
e
s
id
u
a
l
Versus Fits (response is y)
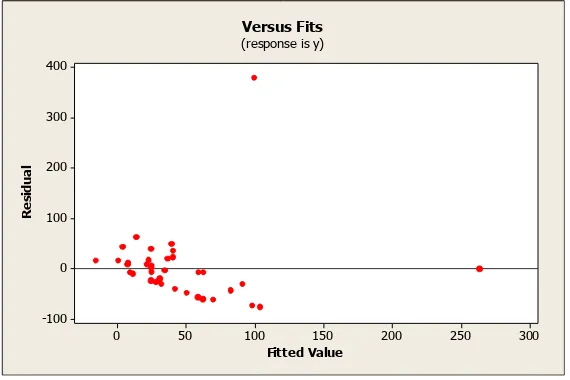
Gambar 1.1 Pemeriksaan Asumsi Residual Identik
3
Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur telah memenuhi asumsi residual identik. Untuk mengetahui lebih tepat apakah data telah memenuhi asumsi identik, maka dilakukan pengujian Glejser.
Hipotesis yang digunakan adalah sebagai berikut.
H0 : σ12= σ22= σ32 = σ42 = σ52 = σ2 (residual memenuhi asumsi identik)
H1 : σ12= σ22= σ32 = σ42 = σ52≠σ2 (residual tidak memenuhi asumsi identik)
Taraf Signifikan : α = 0,05
Daerah Kritis: Tolak H0 jika Fhitung > Ftabel
Statistik Uji:
Tabel 1.2 ANOVA Uji Glejser
Source DF SS MS F Ftabel P
Regression 5 27286 5457 1.55 2.52 0.205
Residual Error 31 109452 3531
Total 36 136737
Berdasarkan Tabel 1.2 dapat diketahui bahwa nilai Fhitung (1.55) < Ftabel
(2.52) maka keputusan yang didapat adalah gagal tolak H0. Selain itu dapat dilihat
dari nilai Pvalue (0.205) > α (0,05) maka dapat diambil keputusan bahwa H0 gagal
ditolak dan didapatkan kesimpulan bahwa residual data pada jumlah kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur telah memenuhi asumsi residual identik.
1.2.2 Pemeriksaan dan Pengujian Asumsi Residual Independen
4
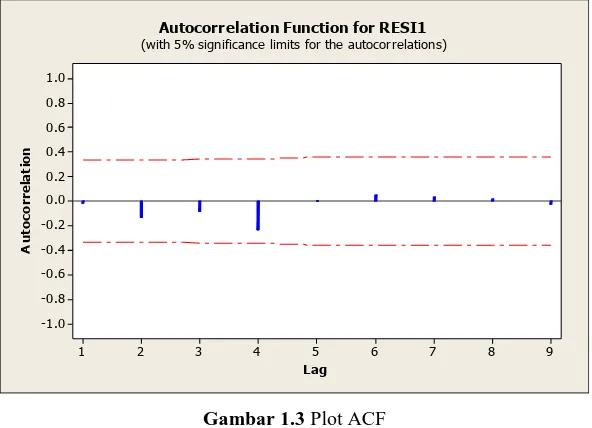
Gambar 1.2 Pemeriksaan Asumsi Residual Independen
Gambar 1.2 secara visual dapat dilihat plot-plot telah menyebar secara acak dan tidak membentuk suatu pola tertentu, sehingga dapat disimpulkan bahwa residual data pada jumlah kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur telah memenuhi asumsi residual independen, kemudian dilakukan uji independensi residual dengan pemeriksaan pada plot ACF sebagai berikut.
9
(with 5% significance limits for the autocorrelations)
Gambar 1.3 Plot ACF
5
kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur tidak memiliki autokorelasi atau independen.
Untuk mengetahui lebih tepat apakah data telah memenuhi asumsi independen, maka dilakukan uji Durbin Watson dengan pengujian dua sisi.
Hipotesis yang digunakan adalah sebagai berikut. H0: ρ = 0 (residual data memenuhi asumsi independen)
H1: ρ ≠ 0 (residual data tidak memenuhi asumsi independen)
Taraf signifikan: α = 0,05
Daerah Kritis: Tolak H0 jika d < dU
Statistik Uji:
Tabel 1.3 Nilai Durbin Watson
Durbin-Watson statistic dU
2.02816 1,79
Berdasarkan Tabel 1.3 dapat diketahui bahwa nilai Durbin-Watson statisic
sebesar 2.02816, sehingga dapat diambil keputusan bahwa H0 gagal ditolak dan
didapatkan kesimpulan bahwa residual data pada jumlah kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur telah memenuhi asumsi residual independen.
1.2.3 Pemeriksaan dan Pengujian Asumsi Residual Beristribusi Normal
6
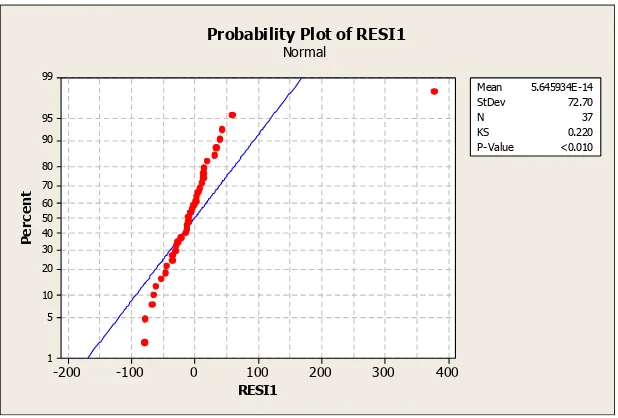
Gambar 1.4 Pemeriksaan Asumsi Residual Distribusi Normal
Berdasarkan Gambar 1.4 dapat diketahui bahwa plot-plot residual tidak mengikuti dan menyebar secara acak pada garis normal, sehingga secara visual didapatkan kesimpulan bahwa residual data pada jumlah kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur tidak memenuhi asumsi residual berdistribusi normal.
Untuk lebih jelasnya, pembahasan akan berlanjut pada uji Kolmogorov Smirnov untuk mengetahui apakah residual berdistribusi normal.
Hipotesis yang digunakan adalah sebagai berikut. H0 : residual data berdistribusi normal
H1 : residual data tidak berdistribusi normal
Taraf signifikan : α = 0,05
Daerah Kritis: Tolak H0 jika D>Dtabel
7
-58.9569 1 5 0.135135 -0.81092 0.208707 0.073571553 -51.2759 1 6 0.162162 -0.70527 0.240321 0.078159256 -43.9837 1 7 0.189189 -0.60497 0.2726 0.08341054 -42.5439 1 8 0.216216 -0.58517 0.279218 0.063001976 -33.6239 1 9 0.243243 -0.46248 0.32187 0.078626479 -33.0508 1 10 0.27027 -0.45459 0.324701 0.054430627 -28.461 1 11 0.297297 -0.39146 0.347727 0.050430084 -26.3403 1 12 0.324324 -0.36229 0.358566 0.034241512 -25.3595 1 13 0.351351 -0.34881 0.363618 0.012266396 -20.6137 1 14 0.378378 -0.28353 0.388386 0.01000721 -12.1991 1 15 0.405405 -0.16779 0.433374 0.027968514 -10.5687 1 16 0.432432 -0.14537 0.442211 0.009778562 -10.2796 1 17 0.459459 -0.14139 0.443781 0.01567828 -9.16279 1 18 0.486486 -0.12603 0.449855 0.036631851 -7.987 1 19 0.513514 -0.10986 0.456262 0.057251856 -5.26453 1 20 0.540541 -0.07241 0.471138 0.069402931 -1.5751 1 21 0.567568 -0.02166 0.491358 0.076209789 -0.17234 1 22 0.594595 -0.00237 0.499054 0.09554026 4.120685 1 23 0.621622 0.056678 0.522599 0.099022648 4.982244 1 24 0.648649 0.068528 0.527317 0.121331402 6.659471 1 25 0.675676 0.091597 0.536491 0.139184783 10.01841 1 26 0.702703 0.137797 0.5548 0.147903064 13.43022 1 27 0.72973 0.184725 0.573277 0.156452232 14.37834 1 28 0.756757 0.197765 0.578386 0.178371068 15.51851 1 29 0.783784 0.213448 0.584511 0.199272619 16.711 1 30 0.810811 0.22985 0.590896 0.219915085 21.9087 1 31 0.837838 0.301341 0.618423 0.219415071 33.5559 1 32 0.864865 0.461541 0.677795 0.187070016 36.09519 1 33 0.891892 0.496468 0.690218 0.201674144 41.54001 1 34 0.918919 0.571358 0.716121 0.202797436 46.13517 1 35 0.945946 0.634562 0.737143 0.208803127 59.90816 1 36 0.972973 0.824001 0.79503 0.17794251
378.8678 1 37 1 5.2111 1 0
D = Sup |Fn(X)-F0(X)| = 0.219915085 = 0.22
Berdasarkan Tabel 1.4 dapat diketahui bahwa nilai D sebesar 0.22 dengan P-value kurang dari 0.01. Nilai D (0.22) > Dtabel (0.196) dan Pvalue (<0,010) < α
(0,05) maka dapat diambil keputusan H0 ditolak, sehingga didapatkan kesimpulan
8
pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur tidak memenuhi asumsi residual berdistribusi normal.
1.3 Pendeteksian Multikolinieritas
Identifikasi multikolinieritas pada variable-variabel prediktor dapat dilakukan dengan melihat nilai VIF (Variance Inflation Factor) pada masing-masing variabel prediktor. Berikut adalah nilai VIF dari setiap variabel prediktor yang didapatkan dengan menggunakan Software Minitab.
Tabel 1.5 Nilai VIF
Variabel Nilai VIF Persentase Sarana Kesehatan (X1) 9.733
Persentase Tenaga Medis (X2) 7.953
Persentase Penduduk Perempuan yang
Umur Kawin Pertama ≤16 Tahun (X3)
1.825 Persentase Penduduk dan Rumah
Tangga (RT) Perempuan (X4)
1.135 Persentase Daerah yang Berstatus
Desa (X5)
2.518
Berdasarkan Tabel 1.5, dapat diketahui bahwa pada variabel bebas X1, X2,
X3, X4 dan X5 tidak terdeteksi adanya multikolinieritas karena semua nilai nilai
VIF dari ke-5 variabel prediktor tersebut nilainya kurang dari 10, sehingga dapat disimpulkan bahwa tidak terdapat kasus multikolinieritas pada data jumlah kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur.
1.4 Pemilihan Model Terbaik dengan Metode All Possible Regression
Metode All Possible Regression digunakan untuk memilih persamaan penduga yang terbaik dengan mempertimbangkan kriteria nilai R2 yang dicapai, nilai S2 atau jumlah kuadrat sisa regresi, nilai Statistik Cp. Hasil output dari
9
kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur adalah sebagai berikut.
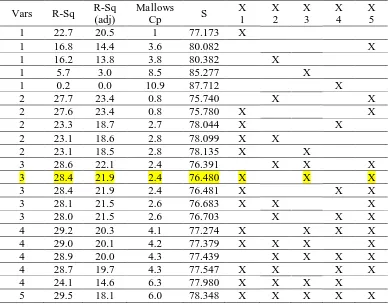
Tabel 1.6 Hasil Metode All Possible Regression Antara Variabel Respon Dengan Variabel Prediktor
Berdasarkan Tabel 1.6 dapat diketahui bahwa terdapat beberapa model dari prosedur All Possible Regression yang dapat digolongkan menjadi persamaan regresi terbaik. Salah satu model regresi yang terbaik antara variabel respon dan variabel prediktor yaitu antara Y dengan X1, X3, dan X5. Nilai R-Sq dan R-Sq (adj)
cukup tinggi yaitu 28.4 dan 21.9. Memiliki nilai S (kuadrat tengah sisa) yang kecil yaitu sebesar 76.480. Sedangkan nilai Cp-Mallows sebesar 2.4 yang hampir mendekati jumlah banyaknya variabel prediktor yang ditambah dengan intercept. Sehingga dalam hal ini model regresi terbaik dengan metode All Possible Regression adalah antara jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1), persentase penduduk perempuan yang umur kawin
pertama ≤16 tahun (X3) dan persentase daerah yang berstatus desa (X5).
Model regresi terbaik dengan metode All Possible Regression adalah
10
1.5 Pemilihan Model Terbaik dengan Metode Best Subset Regression
Pemilihan model regresi terbaik dengan metode best subset regression
tidak jauh beda dengan all possible regression. Pada metode best subset, hanya ditampilkan persamaan regresi terbaik yang terpilih dengan kriterianya masing-masing. Hasil output dari metode best subset regression pada d data jumlah kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur adalah sebagai berikut.
Tabel 1.7 Hasil Metode Best Subset Regression Antara Variabel Respon Dengan Variabel Prediktor
Berdasarkan Tabel 1.7 dapat diketahui bahwa terdapat beberapa model dari prosedur Best Subset Regression yang dapat digolongkan menjadi persamaan regresi terbaik. Salah satu model regresi yang terbaik antara variabel respon dan variabel prediktor yaitu antara Y dengan X1, X3, dan X5. Nilai R-Sq dan R-Sq (adj)
cukup tinggi yaitu 28.4 dan 21.9. Memiliki nilai S (kuadrat tengah sisa) yang kecil yaitu sebesar 76.480. Sedangkan nilai Cp-Mallows sebesar 2.4 yang hampir mendekati jumlah banyaknya variabel prediktor yang ditambah dengan intercept. Sehingga dalam hal ini model regresi terbaik dengan metode Best Subset Regression adalah antara jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1), persentase penduduk perempuan yang umur kawin
pertama ≤16 tahun (X3) dan persentase daerah yang berstatus desa (X5). Model
regresi terbaik dengan metode Best Subset Regression adalah
11
1.6 Pemilihan Model Terbaik dengan Metode Forward Selection
Pemilihan model terbaik dengan metode forward selection yaitu dengan menambahkan satu per satu variabel prediktor yang paling signifikan pada model. Berikut merupakan analisis untuk menentukan model regresi terbaik dengan menggunakan metode forward selection pada data jumlah kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur.
Tabel 1.8 Hasil Metode Forward Selection Antara Variabel Respon Dengan Variabel Prediktor
Persentase Sarana Kesehatan (X1)
Constant 7.934
X1 332
P-value 0.003
S 77.2
R-Sq 22.73
R-Sq (adj) 20.52
Mallows Cp 1
Berdasarkan Tabel 1.8 dapat diketahui bahwa pada metode forward selection tahap pertama, nilai yang paling signifikan adalah X1 dengan P-value
sebesar 0.003, sehingga dalam hal ini model regresi terbaik dengan metode
forward selection adalah antara jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1). Model regresi terbaiknya adalah
1
332X 7.934
y .
1.7 Pemilihan Model Terbaik dengan Metode Backward Elimination
12
perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur.
Tabel 1.9 Hasil Metode Backward Elimination Antara Variabel Respon Dengan Variabel Prediktor
Step 1 2 3 4 5
X1
P-value 0.613 0.026 0.028 0.031 0.003 X2
P-value 0.722
X3
P-value 0.559 0.572 0.542 X4
P-value 0.648 0.582 X5
P-value 0.136 0.124 0.124 0.139
S 78.3 77.3 76.5 75.8 77.2
R-sq 29.46 29.17 28.45 27.62 22.73
Mallows Cp 6 4.1 2.4 0.8 1
Berdasarkan Tabel 1.9 dapat diketahui bahwa pada metode backward elimination tahap pertama, variabel yang paling tidak signifikan adalah X2 dengan
P-value sebesar 0.722 sehingga X2 dikeluarkan dari model. Pada metode
backward elimination tahap kedua, variabel yang paling tidak signifikan adalah X4 dengan P-value sebesar 0.582 sehingga X4 dikeluarkan dari model. Pada
metode backward elimination tahap ketiga, variabel yang paling tidak signifikan adalah X3 dengan P-value sebesar 0.542 sehingga X3 dikeluarkan dari model. Pada
metode backward elimination tahap keempat, variabel yang paling tidak signifikan adalah X5 dengan P-value sebesar 0.139 sehingga X5 dikeluarkan dari
model. Pada tahap terakhir, nilai yang signifikan adalah X1 dengan P-value
sebesar 0.003. Oleh karena itu, dengan menggunakan metode backward elimination variabel yang masuk ke dalam model terbaik adalah jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1). Model regresi
terbaiknya adalah y7.934332X1.
1.8 Pemilihan Model Terbaik dengan Metode Stepwise Regression
Stepwise merupakan gabungan antara metode forward dengan metode
13
adalah variabel yang korelasi parsialnya paling tinggi dan masih signifikan, setelah variabel tertentu masuk kedalam model maka variabel yang lain yang ada didalam model dievaluasi. Jika ada variabel yang tidak signifikan maka variabel tersebut dikeluarkan. Berikut merupakan analisis untuk menentukan model regresi terbaik dengan menggunakan metode stepwise regression pada data jumlah kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur.
Tabel 1.10 Uji Korelasi Antara Y dan Variabel Prediktor
X1 X2 X3 X4 X5 Berdasarkan Tabel 1.10 dapat diketahui bahwa korelasi yang paling siginifikan dengan nilai korelasi tertinggi adalah antara jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1) dengan nilai Pearson
Correlation sebesar 0.477 dan P-value sebesar 0.003. Oleh karena itu, di lanjutkan pada uji korelasi parsial untuk mengetahui apakah ada variabel prediktor lain yang signifikan dengan menggunakan persentase sarana kesehatan (X1) sebagai
variabel kontrol.
Tabel 1.11 Uji Korelasi Parsial
Variabel Kontrol X2 X3 X4 X5
variabel kontrol. Oleh karena itu, dengan menggunakan metode stepwise regression, variabel yang masuk ke dalam model terbaik adalah jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1). Model regresi
14
BAB II
KESIMPULAN DAN SARAN
2.2 Kesimpulan
Berdasarkan analisis dan pembahasan pada Bab I dapat diperoleh kesimpulan sebagai berikut.
1. Nilai rata-rata dari jumlah kasus kanker serviks di tiap kabupaten/kota provinsi Jawa Timur pada tahun 2010 sebesar 45.6 kasus, nilai maksimum sebesar 479 kasus dan nilai minimum sebesar 0 kasus dengan nilai keragaman sebesar 86.6. Variabel prediktor persentase daerah yang berstatus desa di tiap kabupaten/kota provinsi Jawa Timur memiliki nilai rata-rata dan nilai keragaman terbesar.
2. Pemeriksaan dan pengujian asumsi residual IIDN menunjukkan bahwa residual data pada jumlah kasus kanker serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur telah memenuhi asumsi residual identik dan independen namun tidak memenuhi asumsi residual berdistribusi normal. 3. Tidak terdapat kasus multikolinieritas pada data jumlah kasus kanker
serviks di setiap kabupaten/kota di Jawa Timur tahun 2010 berdasarkan faktor persentase sarana kesehatan, persentase tenaga medis, persentase penduduk perempuan yang umur kawin pertama ≤16 tahun, persentase penduduk dan Rumah Tangga (RT) perempuan dan persentase daerah yang berstatus desa di tiap kabupaten/kota di Jawa Timur.
4. Model regresi terbaik dengan metode All Possible Regression adalah antara jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1), persentase penduduk perempuan yang umur kawin
pertama ≤16 tahun (X3) dan persentase daerah yang berstatus desa (X5).
Model regresi terbaik dengan metode All Possible Regression adalah
5 3
1 0.8X 0.851X
266X 5
.
43
15
5. Model regresi terbaik dengan metode Best Subset Regression adalah antara jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1), persentase penduduk perempuan yang umur kawin
pertama ≤16 tahun (X3) dan persentase daerah yang berstatus desa (X5).
Model regresi terbaik dengan metode Best Subset Regression adalah
5 3
1 0.8X 0.851X
266X 5
.
43
y .
6. Model regresi terbaik dengan metode Forward Selection adalah jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1). Model
regresi terbaiknya adalah y7.934332X1.
7. Model regresi terbaik dengan metode Backward Elimination adalah jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1).
Model regresi terbaiknya adalah y7.934332X1.
8. Model regresi terbaik dengan metode Stepwise Regression adalah jumlah kasus kanker serviks (Y) dengan persentase sarana kesehatan (X1). Model
regresi terbaiknya adalah y7.934332X1.
2.2 Saran
LAMPIRAN
Lampiran 1 Data Jumlah Kasus Kanker Serviks di Tiap Kabupaten/Kota Provinsi
Jawa Timur Tahun 2010 dengan Variabel Prediktornya
No Kabupaten/Kota Y X1 X2 X3 X4 X5
1 Pacitan 0 0.02 0.92 21.78 49.87 88.89
2 Ponorogo 25 0.12 1.15 24.82 51.12 78.36
3 Trenggalek 19 0.06 1.08 30.48 50.1 82.17
4 Tulungagung 75 0.16 1.28 22.34 50.85 66.42
5 Blitar 15 0.06 1.14 22.95 49.16 78.63
6 Kediri 11 0.1 1.88 20.71 50.43 69.48
7 Malang 51 0.24 2.14 30.05 49.62 70
8 Lumajang 18 0.1 1.71 34.5 50.79 86.63
9 Jember 0 0.2 2.07 40.79 50.67 74.6
10 Banyuwangi 30 0.14 1.73 31.04 49.16 71.43
11 Bondowoso 54 0.06 1.62 58.78 50.49 84.93
12 Situbondo 0 0.04 0.2 62.7 50.33 75.74
13 Probolinggo 86 0.08 1.06 59.27 50.14 77.27
14 Pasuruan 0 0.06 1.55 33.63 50.97 70.96
15 Sidoarjo 26 0.32 2.19 13.92 49.31 24.08
16 Mojokerto 0 0.16 1.55 24.31 50.25 66.45
17 Jombang 0 0.14 2.03 22.28 50.69 52.94
18 Nganjuk 0 0.12 1.34 24.59 49.4 69.72
19 Madiun 74 0.02 1.4 29.47 51.41 81.07
20 Magetan 39 0.04 1.04 24.76 51.91 69.79
21 Ngawi 46 0.04 1.37 25.72 51.75 93.09
22 Bojonegoro 61 0.12 1.45 36.35 50.29 86.51
23 Tuban 0 0.06 1.01 34.67 50.57 86.28
24 Lamongan 30 0.08 1.47 37.44 51.84 89.24
25 Gresik 63 0.12 1.78 22.16 50.07 60.96
26 Bangkalan 27 0.02 1.01 37.43 53.33 86.48
27 Sampang 15 0.02 0.74 47.45 51.39 93.55
28 Pamekasan 0 0.02 0.98 41.8 51.21 86.77
29 Sumenep 4 0.04 1.09 47.79 53.12 89.46
30 Kota Kediri 58 0.16 0.83 12.12 50.66 0
31 Kota Blitar 53 0.08 0.49 14.98 48.49 0
32 Kota Malang 479 0.18 1.36 17.75 50.6 5.26 33
Kota
36 Kota Madiun 23 0.11 0.85 13.32 53.12 0 37 Kota Surabaya 262 0.73 7.52 12.16 50.38 0
Keterangan :
Y = Jumlah kasus kanker serviks di tiap kabupaten/kota provinsi Jawa Timur X1 = Persentase sarana kesehatan di tiap kabupaten/kota provinsi Jawa Timur
X2 = Persentase tenaga medis di tiap kabupaten/kota provinsi Jawa Timur
X3 = persentase penduduk perempuan yang umur kawin pertama ≤16 tahun di
tiap kabupaten/kota provinsi Jawa Timur
X4 = Persentase penduduk dan Rumah Tangga (RT) perempuan di tiap
kabupaten/kota provinsi Jawa Timur
X5 = Persentase daerah yang berstatus desa di tiap kabupaten/kota provinsi Jawa
Timur
Lampiran 2 Output Statistika Deskriptif
Lampiran 3 Output Uji Glejser
Descriptive Statistics: y, x1, x2, x3, x4, x5
Variable N Mean StDev Minimum Median Maximum y 37 45.6 86.6 0.0 25.0 479.0 x1 37 0.1135 0.1243 0.0200 0.0800 0.7300 x2 37 1.438 1.132 0.200 1.280 7.520 x3 37 29.64 13.19 12.12 25.72 62.70 x4 37 50.669 1.077 48.490 50.600 53.330 x5 37 60.83 32.62 0.00 71.43 93.55
Regression Analysis: residual abs versus x1, x2, x3, x4, x5
The regression equation is
residual abs = - 194 + 105 x1 - 16.6 x2 + 0.31 x3 + 5.62 x4 - 0.820 x5
Analysis of Variance
Source DF SS MS F P Regression 5 27286 5457 1.55 0.205 Residual Error 31 109452 3531
Lampiran 4 Output Durbin Watson Statistic
Lampiran 5 Output VIF
Lampiran 6 Output Metode All Possible Regression
Regression Analysis: y versus x1, x2, x3, x4, x5
Durbin-Watson statistic = 2.02816
Regression Analysis: y versus x1, x2, x3, x4, x5
The regression equation is
y = - 257 + 168 x1 + 11.7 x2 + 0.79 x3 + 6.0 x4 - 0.973 x5
Predictor Coef SE Coef T P VIF Constant -256.5 655.3 -0.39 0.698
x1 167.6 327.7 0.51 0.613 9.733 x2 11.66 32.52 0.36 0.722 7.953 x3 0.790 1.338 0.59 0.559 1.825 x4 5.96 12.91 0.46 0.648 1.135 x5 -0.9732 0.6352 -1.53 0.136 2.518
Best Subsets Regression: y versus x1, x2, x3, x4, x5
Response is y
Mallows x x x x x Vars R-Sq R-Sq(adj) Cp S 1 2 3 4 5 1 22.7 20.5 1.0 77.173 X
Lampiran 7 Output Metode Best Subset Regression
Lampiran 8 Output Metode Forward Selection
Best Subsets Regression: y versus x1, x2, x3, x4, x5
Response is y
Mallows x x x x x Vars R-Sq R-Sq(adj) Cp S 1 2 3 4 5 1 22.7 20.5 1.0 77.173 X
1 16.8 14.4 3.6 80.082 X 2 27.7 23.4 0.8 75.740 X X 2 27.6 23.4 0.8 75.780 X X 3 28.6 22.1 2.4 76.391 X X X 3 28.4 21.9 2.4 76.480 X X X 4 29.2 20.3 4.1 77.274 X X X X 4 29.0 20.1 4.2 77.379 X X X X 5 29.5 18.1 6.0 78.348 X X X X X
Stepwise Regression: y versus x1, x2, x3, x4, x5
Forward selection. Alpha-to-Enter: 0.05
Response is y on 5 predictors, with N = 37
Step 1 Constant 7.934
x1 332 T-Value 3.21 P-Value 0.003
Lampiran 9 Output Metode Backward Elimination
Lampiran 10 Output Uji Korelasi
Correlations
Y x1 x2 x3 x4 x5
y Pearson Correlation 1 .477** .402* -.238 -.043 -.410*
Sig. (2-tailed) .003 .014 .157 .801 .012
N 37 37 37 37 37 37
x1 Pearson Correlation .477** 1 .901** -.388* -.235 -.444**
Sig. (2-tailed) .003 .000 .018 .162 .006
N 37 37 37 37 37 37
x2 Pearson Correlation .402* .901** 1 -.240 -.110 -.190
Sig. (2-tailed) .014 .000 .152 .518 .260
Stepwise Regression: y versus x1, x2, x3, x4, x5
Backward elimination. Alpha-to-Remove: 0.05
Response is y on 5 predictors, with N = 37
Step 1 2 3 4 5 Constant -256.525 -313.445 43.512 56.445 7.934
x1 168 277 266 256 332 T-Value 0.51 2.34 2.30 2.26 3.21 P-Value 0.613 0.026 0.028 0.031 0.003
x2 12 T-Value 0.36 P-Value 0.722
x3 0.8 0.8 0.8 T-Value 0.59 0.57 0.62 P-Value 0.559 0.572 0.542
x4 6 7 T-Value 0.46 0.57 P-Value 0.648 0.582
x5 -0.97 -0.86 -0.85 -0.66 T-Value -1.53 -1.58 -1.58 -1.52 P-Value 0.136 0.124 0.124 0.139
N 37 37 37 37 37 37
x3 Pearson Correlation -.238 -.388* -.240 1 .184 .659**
Sig. (2-tailed) .157 .018 .152 .274 .000
N 37 37 37 37 37 37
x4 Pearson Correlation -.043 -.235 -.110 .184 1 .180
Sig. (2-tailed) .801 .162 .518 .274 .287
N 37 37 37 37 37 37
x5 Pearson Correlation -.410* -.444** -.190 .659** .180 1
Sig. (2-tailed) .012 .006 .260 .000 .287
N 37 37 37 37 37 37
Lampiran 11 Output Uji Korelasi Parsial
Correlations
Control Variables Y x2 x3 x4 x5
x1 y Correlation 1.000 -.072 -.065 .081 -.252
Significance (2-tailed) . .678 .707 .639 .139
df 0 34 34 34 34
x2 Correlation -.072 1.000 .274 .241 .539
Significance (2-tailed) .678 . .106 .156 .001
df 34 0 34 34 34
x3 Correlation -.065 .274 1.000 .104 .590
Significance (2-tailed) .707 .106 . .546 .000
df 34 34 0 34 34
x4 Correlation .081 .241 .104 1.000 .087
Significance (2-tailed) .639 .156 .546 . .614
df 34 34 34 0 34
x5 Correlation -.252 .539 .590 .087 1.000
Significance (2-tailed) .139 .001 .000 .614 .