1
Teks penuh
Gambar
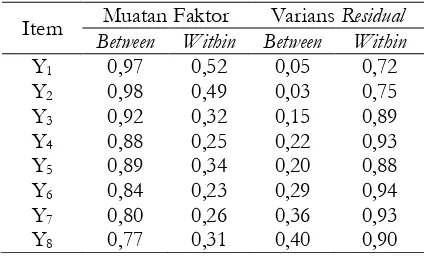
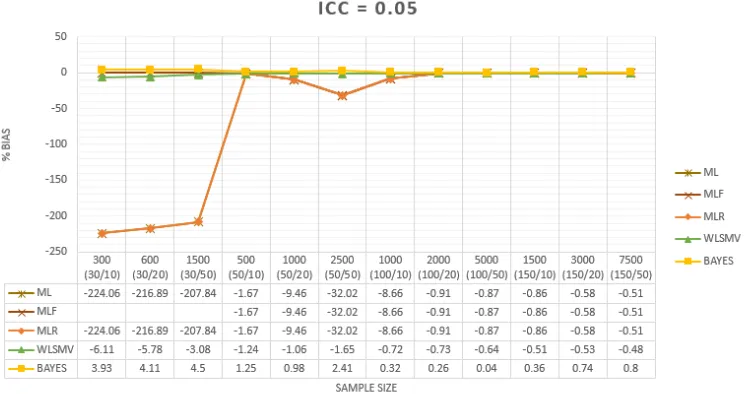
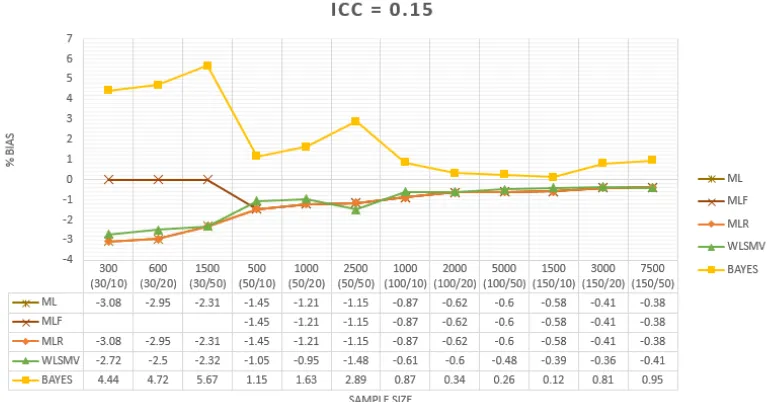
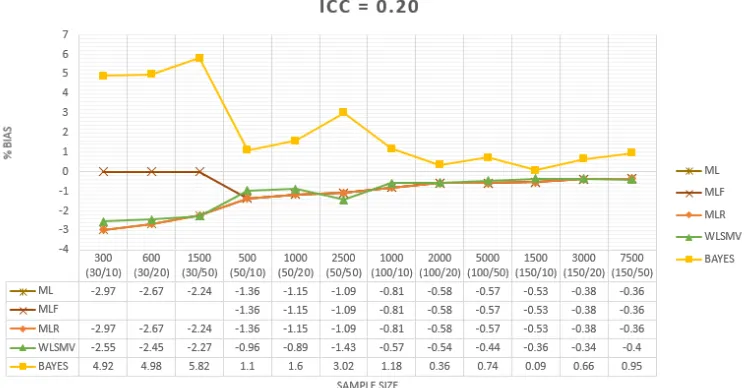
Garis besar
Dokumen terkait
Berdasarkan hasil wawancara dengan para informan tentang tanggapan masyarakat mengenai kecakapan petugas dalam memberikan pelayanan kepada masyarakat penulis melihat
Paper ini merupakan kajian analisis dinamik terhadap model pertumbuhan logistik suatu populasi dengan mengasumsikan bahwa daya dukung (carrying capacity) juga tumbuh
• Bahwa saksi mengetahui pemohon dan termohon adalah suami istri yang telah menikah sekitar bulan Desember 2006 di Kabupaten Lombok Barat karena saksi turut
Penurunan viabilitas bakteri selain disebabkan faktor nutrisi yang ada pada media pembawa, juga bisa disebabkan oleh bahan yang digunakan untuk mengaktifkan kembali sel
Secara keseluruhan di Kawasan Wisata Pusuk yang memiliki intensitas curah hujan yang tinggi, tanah longsor terjadi pada daerah dengan kemiringan lereng terjal
Hasil analisis TN, TP, NH4-N, N-NO3, N-NO2 dan PO4-P di daerah Linggai, inlet PLTA, Sungai Tampang, Bayur, Sungai Batang dan Sigiran menunjukkan nilai yang cukup
Temali: Jurnal Pembangunan Sosial, Volume 3 Nomor 1 Tahun 2020 183 pengairan untuk mencegah pengalihan pemanfaatan lahan produktif dengan meningkatkan peran serta masyarakat
Penelitian yang dilakukan oleh Agusti (2014) yang berjudul pengaruh profitabilitas , leverage , dan good corporate governance terhadap tax avoidance (studi empiris pada
