Hal 185
Klustering Data Ekspresi Gen dengan Metoda-metoda
Berbasis Dekomposisi Nilai Singular
Studi Kasus: Data Ekspresi Gen Kanker Paru
Evi Noviani
1, Yoga Satria Putra
1, Kuntjoro Adji Sidarto
21
FMIPA Universitas Tanjungpura Pontianak
2
FMIPA Institut Teknologi Bandung [email protected]
Abstrak.Pada penelitian ini telah dikelompokkan data ekspresi gen kanker paru dengan
memanfaatkan dekomposisi nilai singular. pasien kanker yang tergolong pada sub tipe kanker paru yang sama dikelompokkan pada cluster yang sama berdasarkan data ekpresi gen yang berupa matriks berukuran puluhan ribu sampai ratusan ribu. Pembentukan
cluster dilakukan dengan terlebih dahulu memodelkan ke dalam permasalahan optimisasi
yaitu meminimumkan kesalahan penempatan pasien pada suatu kelompok, atau maksimumkan ketepatan dalam menempatkan pasien pada suatu kelompok. Masalah minimisasi/maksimisasi tersebut dapat diselesaikan dengan mengambil nilai singular kanan pertama dari dekomposisi nilai singular matriks data yang telah dinormalisasi. Dari proses ini didapatkan beberapa kelompok penderita kanker paru. Data ekspresi gen kanker paru telah dikelompokkan juga dengan menggunakan SVD-gaps. SVD-gaps ini mengambil k vektor singular kanan pertama, yang kemudian dicari selisih antara elemen vektor singular yang telah diurutkan. Dengan toleransi tertentu, maka selisih ini akan menentukan apakah dibentuk kelompok baru atau tidak. SVD-gaps menghasilkan 11 kelompok pasien kanker paru-paru.
Kata Kunci.SVD-gaps, Dekomposisi Nilai Singular, Data Ekspresi Gen, Klustering.
PENDAHULUAN
Rangkaian Deoxyribonucleic acid (DNA) merekam setiap karakteristik dan sifat setiap mahluk hidup. Gen yang dikodekan dalam DNA berperan sebagai pesan di dalam sel yang memberitahu bagaimana sel berperilaku. Gen yang berbeda memberitahu sel bagaimana membuat protein yang berbeda. Satu kode gen untuk satu protein. Setiap sel memiliki banyak gen dan karena itu dapat membuat banyak protein yang berbeda. Beberapa protein mengontrol bagaimana sel berperilaku. Contohnya protein yang memberitahu sel untuk mereproduksi dengan membagi dirinya menjadi dua[1].
Dewasa ini informasi yang terkandung dalam DNA yang nantinya akan menghasilkan protein tertentu dapat diukur oleh teknologi microarray. Data microarrayini menyajikan data tingkat ekspresi gen yang direpresentasikan melalui titik-titik warna.Satu sampel pada data microarrayterdiri dari ribuan atau
puluhan ribu gen. Pada pengolahan data microarrayinilah menjadi hal yang menarik manakala didapatkan informasi penting dari data yang berukuran besar.
Data ekspresi gen yang dihasilkan dari data microarray juga dapat mengukur ekspresi manakala terjadi mutasi pada gen. Mutasi pada gen berarti bahwa gen tersebut telah rusak atau hilang. Sebuah mutasi dapat berarti bahwa terlalu banyak protein dibuat atau protein tidak dibuat sama sekali[1]. Seringkali,
mutasi yang menyebabkankanker adalah mutasi padagen-gen yangmengatur pertumbuhan sel[2].
Data level ekspresi gen manusia berukuran relatif besar, sesuai dengan jumlah gen pada manusia. Jadi melalui level ekspresi setiap gen ini diperlukan suatu metoda sedemikian sehingga data microarray manusia yang memiliki puluhan ribu gen tersebut dapat terbaca karakteristiknya.Beberapa pasien dikelompokan menjadi satu kelompok jika
Hal 186
mereka mempunyai karakteristik yang sama dan akan terbagi dalam kelompok yang berbeda manakala karakteristiknya berbeda.
Terdapat beberapa metode untuk mengklusterkan data dengan ukuran relatif besar. Diantaranya adalah matrix Factorisation[3], dan Dekomposisi Nilai Singular (Singular Value Decomposition/ SVD)[4,5, 6, 7]. Pada pencitraan digital, dekomposisi nilai singular telah digunakan. Pada pengiriman citra digital, reduksi dimensi pada data, sehingga hanya beberapa data saja yang digunakan akan tetapi gambar yang dikirim hampir sama dengan gambar asli, sangat menguntungkan terutama pada pemakaian memori.
Pada penelitian ini data ekspresi gen yang berukuran relatif besar akan diklusterkan dengan teknik-teknik yang menggunakan dekomposisi nilai singular. Algoritma akan diimplementasikan pada data ekspresi gen pasien kanker paru-paru[8].Garber mengelompokan data microarray pasienkanker paru dengan menggunakan teknik hierarchical clustering. Data yang dipublikasikan oleh Garber inilah yang akan disimulasikan dengan menggunakan teknik yang menggunakan dekomposisi nilai singular.
METODE PENELITIAN
Misalkan diberikan suatu matriks data ekspresi gen, sebut , dengan ukuran . Dengan menyatakan banyaknya gen dan menyatakan banyaknya pasien yang akan dikelompokkan. Elemen matriks pada baris dan kolom , ,
menyatakan level ekspresi gen pada pasien
Data ekspresi gen dapat dinyatakan ke dalam graf bipartit dengan gen dan sampel masing-masing di kelompok titik yang berbeda [6].Bobot pada sisi yang menghubungkan antara gen dan sampel bernilai positif jika gen i relatif
over-expressed di sampel j, dan bernilai negatif jika gen i relatif under-expressed di sampel j.
Tujuan graf-bipartit tersebut adalah ingin membagi himpunan G(gen) kedalam 2 atau lebih grup, dan membagi himpunan S(sampel) kedalam 2 atau lebih grup, sehingga untuk masing-masing grup dan sampel level ekspresinya memiliki sifat hampir sama. Hal ini dikarenakan gen berkaitan yang terlibat dalam suatu proses akan aktif di himpunan sampel tertentu yang memiliki sifat hampir sama[6].
Misalkan adalah vektor indikator apakah gen i dimasukkan ke G1 ( )atau G2 ( ). Dan
misalkan pula adalah vektor indikator apakah sampel j dimasukkan ke S1 ( ) atau S2 ( ).Tujuan
dari pengelompokkan ini adalah diinginkan ketika
, dan diinginkan , maka , ,dan . Dengan klustering ini diharapkan dapat memaksimalkan ketepatan dalam menempatkan gen dan sampel pada grup yang sesuai. Secara matematis dapat dituliskan sebagai berikut:
{ }
{ }
∑ ∑ (1)
Ketika aij> 0 maka tempatkan gen i
dan sampel j di grup yang sama piqi= 1.
Dan ketika aij< 0 maka tempatkan gen i
dan sampel j di grup lain yang berbeda piqi= -1.Dengan dimana
( ) ∑ | | dan
dengan (
) ∑ | |. Matriks
menunjukkan setiap entri di dipangkatkan . Untuk selanjutnya,
menunjukkan setiap elemennya dipangkatkan k, yaitu .
Sehingga masalah optimisasi (1) tersebut dapat dituliskan sebagai berikut:
Hal 187 Pada pengolahan data selanjutnya
digunakan normalisasi data terlebih dahulu, yakni dan
. Secara biologi, normalisasi data dapat menghilangkan efek karena adanya perbedaaan kondisi saat eksperimen dan dilakukan sedemikian sehingga penekanan ada pada pengelompokan(bi-clustering) data [9].
HASIL DAN PEMBAHASAN
Pada penelitian ini akan dibahas implementasi dengan menggunakan algoritma dengan memanfaatkan hasil dari solusi analitik yang dibuat Higham, untuk selanjutnya disebut sebagai algoritma Higham. Untuk selanjutnya akan dibahas juga klustering dengan SVD-gaps pada data kanker paru-paru. SVD gaps pertama kali diperkenalkan oleh Douglas [5], yang menggunakannya untuk mengklusterkan data Yahoo!.
Klustering Dengan Algoritma Higham
Masalah klustering (2) dapat diselesaikan dengan teorema berikut[7]:
Teorema
Masalah ‖ ‖ ‖ ‖dapat
diselesaikan dengan mengambil
( ) dan
( ) dengan dan adalah vektor singular kiri dan kanan kesatu dari
( ) ( ) .[7]
Berdasarkan teorema tersebut, didapat algoritma sebagai berikut[10]:
1. Input matriks
2. Hitung jumlah total ekspresi dari nilai mutlak dari elemen di setiap baris
( ) dan setiap kolom ( ).
3. Bentuk vektor dari jumlah total ekspresi baris ( ) dan kolom ( ) 4. Bentuk matriks diagonal dengan
elemen diagonal utama adalah akar entri dari vektor dan , yang dinotasikan dan
5. Hitung matriks .
6. Hitung bentuk dekomposisi nilai singular dari , ambil vektor singular kiri dan kanan Pertama. Hitung dan sebagai solusi dari masalah
clustering.Plot atau juga melibatkan singular kedua dan ketiga sebagai visualisasi hasil pengelompokan sampel data.
Penyelesaian di atas berlaku untuk matriks ekspresi gen dengan elemen positif, negatif atau nol. Sedangkan khusus untuk matriks dengan elemen tak negatif, telah disimulasikan oleh Noviani,et. Al pada kankerkanker Leukemia[11].
Klustering Dengan Svd-Gaps
Matriks data ekspresi gen, , dinormalisasi terlebih dahulu, baru kemudian dicari dekomposisi nilai singularnya. SVD yang digunakan adalah truncated SVD, yakni hasil dekomposisinya hanya diambil vektor saja. Nilai ditentukan yaitu pada saat nilai singular mengalami lengkungan (elbow).Hal ini berarti bahwa hanya diambil vektor singular yang memiliki pengaruh cukup besar terhadap data.Berikut algoritma SVD gaps yang digunakan pada penelitian ini:
1. Tentukan [ ] 2. Untuk i = 1 : k, 3. Untuk , pisahkan dan
tentukan selisih(gaps) diantara vektor singular kananyang telah diurutkan.. 4. Jika gaps antara baris dan dari
cukup besar, lebih dari sama dengan toleransi, maka bagi A dengan baris yang sesuai (columns).
5. Buat vektor kolom yang mengandung nama-nama cluster numerik dari untuk semua kolom. 6. Setelah menemukan untuk semua
, bandingkan pola nama cluster untuk baris .
Hal 188
Jika kolom dan memiliki pola nama cluster yang sama dalam , maka kolom dan termasuk kedalam cluster yang sama. Toleransi yang digunakan untuk penentuan kluster baru pada penelitian ini adalah zscore dari selisih antara nilai vektor singular yang telah diurutkan lebih dari 3,5.
Implementasi Algoritma
Algoritma Higham dan SVD gaps pertama-tama diimplementasikan pada matriks dengan aturan sebagai berikut:
{
jik d n jik d n jik 1 d n | | sel inn
Notasi rand menyatakan nilai yang dipilih secara random dengan menggunakan distribusi uniform ( ).Sedangkan menyatakan nilai yang dipilih secara random mengikuti distribusi normal dengan rataan 0 dan standar deviasi 1.
Matriks di atas kemudian diacak kolom dan barisnya, kemudian diterapkan algoritma Higham dan SVD-gaps. Hasil algoritma tersebut dapat dilihat pada Gambar 1.
Gambar 4Hasil algoritma higham dan svd-gaps pada data simulasi
Pada Gambar 1 (a) disajikan matriks awal yang dibentuk ( ).
Kemudian matriks diacak baris dan kolomnya dan disajikan dalam Gambar 1(b). Matriks hasil acak inilah yang akan diterapkan algoritmaHigham dan SVD-gaps. Dapat dilihat pada Gambar 1 (c) dan (d) matriks data dapat diurutkan kembali. Matriks terdiri dari tiga submatriks yang relatif berbeda dengan entri yang lain. Gambar 1(c) merupakan matriks hasil
pengurutan kembali dengan menggunakan algoritma Higham. Sedangkan Gambar 1(d) merupakan matriks hasil pengurutan dengan menggunakan SVD-gaps.
Pada Gambar 1 dapat terlihatbahwa dengan algoritma Higham dan SVD-gaps, blok matriks dapat disusun kembali menjadi tiga. Hal ini menunjukkan bahwa dari data yang ada dapat dikelompokkan menjadi tiga kluster.
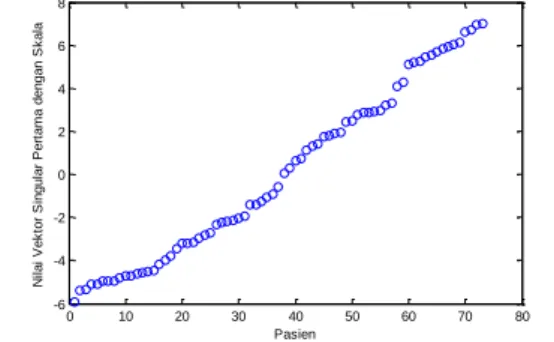
Untuk selanjutnya, dilakukan simulasi pada data kanker paru-paru. Data ekspresi gen kanker paru-paru yang akan diolah, terlebih dahulu diubah menjadi bentuk matriks data. Entri pada baris i dan kolom j matriks tersebut menunjukkan ekspresi gen i pada pasien j. Pada Gambar 2 dapat dilihat hasil simulasi dengan menggunakan algoritma Higham.
Gambar 5Nilai vektor singular pertama yang telah diurutkan dengan algoritma higham
Gambar 2 menyatakan nilai vektor singular pertama dari data ekspresi gen kanker paru yang telah diurutkan. Dari sini terlihat belum adanya ketentuan pasien mana tergolong pada kluster apa. Pembentukan kluster baru terbatas dengan subjektifitas seseorang dalam melihat pengelompokannya. Jika nilai vektor singular pertama dan kedua diplot, maka akan didapatkan seperti pada Gambar 3.
(a) 5 10 15 5 10 15 20 (b) 5 10 15 5 10 15 20 (c) 5 10 15 5 10 15 20 (d) 5 10 15 5 10 15 20 0 10 20 30 40 50 60 70 80 -6 -4 -2 0 2 4 6 8x 10 -3 Pasien N ila i V e k to r S in g u la r P e rt a m a d e n g a n S k a la
Hal 189 Gambar6Nilai vektor Singular Pertama
yang telah diurutkan dengan algoritma Higham
Jika diperhatikan, data-data pada Gambar 3 akan sulit untuk menentukan pasien termasuk kluster mana. Oleh karena itu, selanjutnya klustering dicoba dengan menggunakan SVD-gaps.
Dengan menggunakan algoritma pada SVD-gaps dapat diketahui bahwa pasien kanker paru-paru terbagi menjadi 11 kluster. Pasien normal termasuk dalam satu kluster. Sedangkan kluster 3 didominasi oleh pasien Adenocarsinoma. Hasil penghitungan dapat dilihat pada Tabel 1.
TABEL 3Hasil klustering pasien kanker paru
Nomor Pasien Nomor Baru Hasil Pengacakan Cluster Diagnosa Awal(Garber, 2001) Nomor Pasien Nomor Baru Hasil Pengacakan Cluster Diagnosa Awal(Garber, 2001) 28 12 1 306-99_normal 43 43 3 139-97_LCLC 29 10 1 219-97_normal 44 1 3 219-97_SCC 30 4 1 222-97_normal 45 40 3 75-95_combined 31 16 1 315-99_normal 46 57 3 166-96_SCC 32 13 1 314-99_normal 47 45 3 246-97_SCC_c 53 17 1 157-96_SCC 48 36 3 246-97_SCC_p 62 46 2 315-99_SCLC 49 60 3 42-95_SCC Nomor Pasien Nomor Baru Hasil Pengacakan Cluster Diagnosa Awal(Garber, 2001) Nomor Pasien Nomor Baru Hasil Pengacakan Cluster Diagnosa Awal(Garber, 2001) 1 53 3 181-96_Adeno 51 20 3 245-97_SCC 2 71 3 132-95_Adeno 52 59 3 239-97_SCC 3 58 3 198-96_Adeno 54 2 3 69-96_Adeno 4 67 3 156-96_Adeno 55 5 3 232-97_node 5 50 3 187-96_Adeno 56 22 3 232-97_SCC 6 15 3 180-96_Adeno 57 19 3 220-97_node 7 49 3 199-97_Adeno_p 58 3 3 220-97_SCC 8 47 3 199-97_Adeno_c 59 9 3 3-00_SCC 9 56 3 12-00_Adeno 60 29 3 58-95_SCC 10 51 3 137-96_Adeno 63 48 3 230-97_SCLC 11 21 3 68-96_Adeno 65 64 3 207-97_SCLC 12 34 3 257-97_Adeno 66 72 3 299-99_Adeno 13 55 3 204-97_Adeno 67 66 3 161-96_Adeno 14 39 3 11-00_Adeno 68 31 3 6-00_LCLC 15 68 3 320-00_Adeno_c 72 38 3 147-96_Adeno 16 11 3 320-00_Adeno_p 73 61 3 237-97_Adeno 17 63 3 319-00PT_Adeno 39 24 4 184-96_node 18 52 3 313-99MT_Adeno 41 65 5 234-97_Adeno 19 18 3 313-99PT_Adeno 22 7 6 306-99_node 20 44 3 185-96_Adeno 23 37 6 306-99_Adeno 21 32 3 178-96_Adeno 24 70 6 226-97_Adeno 26 41 3 165-96_Adeno 25 28 6 222-97_Adeno 27 6 3 fetal_lung 64 30 6 314-99_SCLC 33 23 3 319-00MT2 40 27 7 184-96_Adeno 34 8 3 319-00MT1 69 62 8 256-97_LCLC 35 73 3 218-97_Adeno 71 42 8 248-97_LCLC 36 35 3 223-97_Adeno 70 25 9 191-96_Adeno 37 26 3 80-96_Adeno 61 54 10 315-99_node -6 -4 -2 0 2 4 6 8 x 10-3 -10 -8 -6 -4 -2 0 2 4 6x 10
Nilai Vektor Singular Kanan Pertama
N ila i V e k to r S in g u la r K a n a n K e d u a 1 23 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 4950 51 52 53 54 55 56 57 58 59 60 61 62 63 64 6566 67 68 69 70 71 72 73
Hal 190 Nomor Pasien Nomor Baru Hasil Pengacakan Cluster Diagnosa Awal(Garber, 2001) Nomor Pasien Nomor Baru Hasil Pengacakan Cluster Diagnosa Awal(Garber, 2001) 38 14 3 265-98_Adeno 50 69 11 245-97_node 42 33 3 59-96_SCC
Dari Tabel 1 dapat terlihat bahwa pasien normal terkelompokkan menjadi satu kelompok. Sedangkan kluster 3 didominasi oleh pasien adenocarsinoma. Kluster 8 hanya terdiri dari pasien LCLC.
Pada pembagian kluster dengan SVD-gaps tersebut, dapat terlihat pada Tabel 1 terdapat kluster yang hanya terdiri dari satu anggota.Terdapat pasien SCC tergolong pada kluster 3 yang anggota klusternya didominasi pasien Adeno. Yang menyebabkan hal ini terjadi sangat dipengaruhi oleh penentuan toleransi yang digunakan untuk pembentukan suatu kluster. Pada penelitian ini digunakan nilai zscore 3,5. Selain penentuan toleransi gaps, hasil klustering juga dipengaruhi pemilihan nilai k pada saat penentuan truncated-SVD.
KESIMPULAN
Data ekspresi gen telah dapat dikelompokkan dengan menggunakan teknik dekomposisi nilai singular. Dengan menggunakan algoritma Higham belum ada aturan mekanisme suatu pasien termasuk kluster mana, akan tetapi penentuan kluster dilakukan secara subjektif dengan melihat plot nilai vektor singular kanan pertama. Hal ini akan efektif ketika data yang diteliti nilai vektor singular kanannya antara kluster yang satu dengan yang lainnya terpisah sangat jelas. Tetapi untuk data kanker paru pada penelitian ini hampir tidak dapat dibedakan antara kluster yang satu dengan yang lain. Berbeda halnya dengan algoritma Higham, pada algoritma SVD-gaps sudah ada kriteria penentuan suatu kluster, yaitu melalui besarnya toleransi pada selisih antara nilai vektor singular kanan. Setiap pasien sudah ditetapkan termasuk kluster mana. Namun demikian,
untuk memperbaiki ketepatan dalam menentukan kluster diperlukan kajian mengenai besarnya toleransi ini dan penentuan sampai dimensi berapa harus dihitung truncated-SVDnya.
UCAPAN TERIMA KASIH
Penelitian ini merupakan bagian dari Penelitian Pekerti tahun 2012 yang dibiayai Dikti.Terima kasih penulis ucapkan kepada Jurusan Matematika dan Fakultas MIPA Universitas Tanjungpura dan Dept. Matematika FMIPA ITB serta Dirjen Dikti yang telah mendukung penulis.
DAFTAR PUSTAKA
_____, How Cancer Start.
http://www.cancerresearchuk.org/cancer- help/about-cancer/what-is-cancer/cells/how-cancer-starts#how_starts. Akses tanggal 30 April 2013
_____, The Relationship Between DNA
and Cancer.
http://www.foundationmedicine.com/patients-dna-cancer.php. Akses tanggal 30 April 2013
Brunet, JP., Pablo Tamayo, T.R. Golub, & J.P. Mesirov. (2004). Metagenes and Molecular Pattern Discovery Using Matrix Factorization. Procidings of The National Academy of Sciences:
101.p. 4164-4169.
Noviani, Evi & Putra,Y. S., (2010), Pengklasteran Pasien Kanker Leukemia Berdasarkan Data Ekspresi Gen dengan Menggunakan Dekomposisi Nilai Singular. Journal of Mathematics and Its Applications (Limits): 7, p. 49-56 Douglas, E.P. (2008), Clustering datasets
with Singular Value Decomposition, Thesis Master of Science in
Hal 191 Mathematics, The Graduate school of
the college of charleston.
Higham, Desmond J, Gabriela K., J. Keith Vass. 2005. Analysis of the singular value decomposition as a tool for processing
microarray expression data. In: Proceedings of
ALGORITMY 2005, 13-18 March 2005, p.250-259, Podbanské, Slovakia.
Higham, Desmond J, Gabriela K., J. Keith Vass. 2007. Spectral Analysis of Two-signed Microarray Expression Data. Mathematical Medicine and Biology:
24, p. 131-148
Garber, M. E., et.al.,(2001). Diversity of Gene Expression in Adenocarcinoma of The Lung. Procidings of The
National Academy of Sciences: 98, p. 13784–13789.
Kluger, Y., R Basri, J.T Chang, et al.(2003). Spectral Biclustering of Microarray Data: Coclustering Genes and Conditions. Genome
Research.13, 703-716.
Noviani, Evi, K. A. Sidarto, Y. S. Putra, (2012). Pengelompokan Pasien Kanker Liver Berdasarkan Data Ekspresi Gen dengan Struktur Papan Catur. Prosiding KNM XVI- 3-6 Juli 2012- UNPAD, Jatinangor.
Noviani, E. dan Putra, Y.S., (2010) Pengklasteran Pasien Kanker Leukemia Berdasarkan Data Ekspresi Gen dengan Menggunakan Dekomposisi Nilai Singular. Limits. 7, 49-55.