Tugas presentasi system terdistribusi Kelas Jumat Tiap Kelompok terdiri dari 3-4 orang
Teks penuh
Gambar
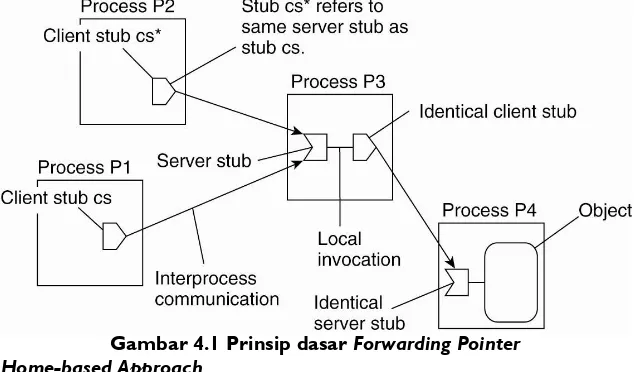
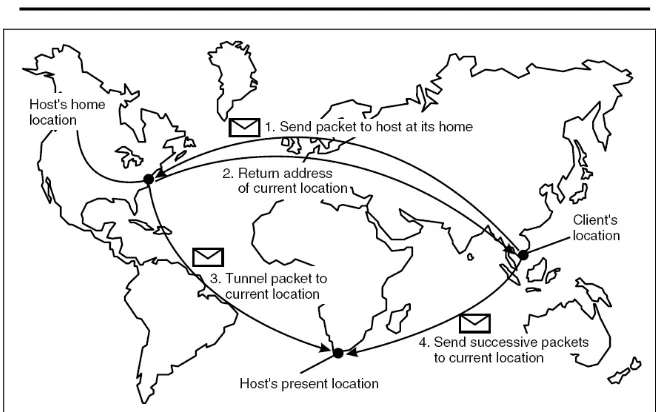
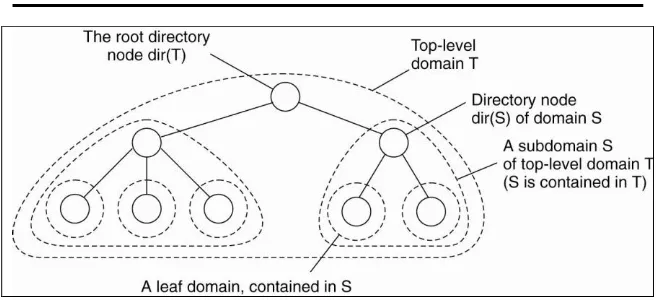
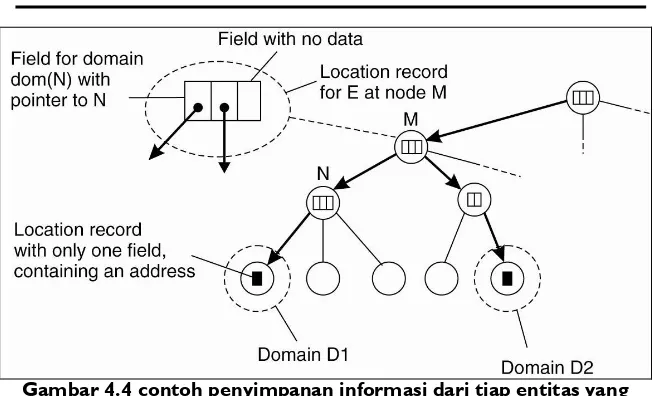
Dokumen terkait
Sari Alam Sumber Selat (PT. SASS) Plaza Gani Jemaat Lt. Cut Mutiah No. Cikini Raya No. Bumi Mandiri Jl. Sari Kembang Jl. Agus Salim No. Taman Amir Hamzah No. Fambali DKI Jakarta
Hal ini dapat terjadi karena faktor risiko lain yaitu indeks massa tubuh rendah dan jumlah paritas lebih dari atau sama dengan tiga, karena osteoporosis disebabkan oleh banyak
2 Angka Kemiskinan Jika program raskin dihentikan dan diganti uang (e-money), maka banyak keluarga yang status sosial-ekonominya rendah (miskin) akan kesulitan memenuhi
Teknik, USU Medan Sumut 2007 Karyawan Bank Riau Jl... Mahasiswa angkatan (semester
[r]
During that stage, which lasts four to five days, young adult worker bees called nurses (for obvious reasons) feed the larvae royal jelly and bee bread—a fermented mix of
Allah Subhanahu wa Ta „ala telah melebihkan kurma dari buah -buahan yang lain, Alloh Subhanahu wa Ta „ala menyebutnya di 20 tempat yang berbeda di dalam Al- Qur‟an dengan
Eksistensialisme adalah aliran yang memandang segala sesuatu berdasarkan eksistensinya atau bagaimana manusia berada dalam dunia.Secara etimologi eksistensialisme
