54 BAB 4
ANALISIS DAN HASIL PENELITIAN
1.1 Analisis Hasil Penelitian 1.1.1 Analisis Deskriptif Statistik
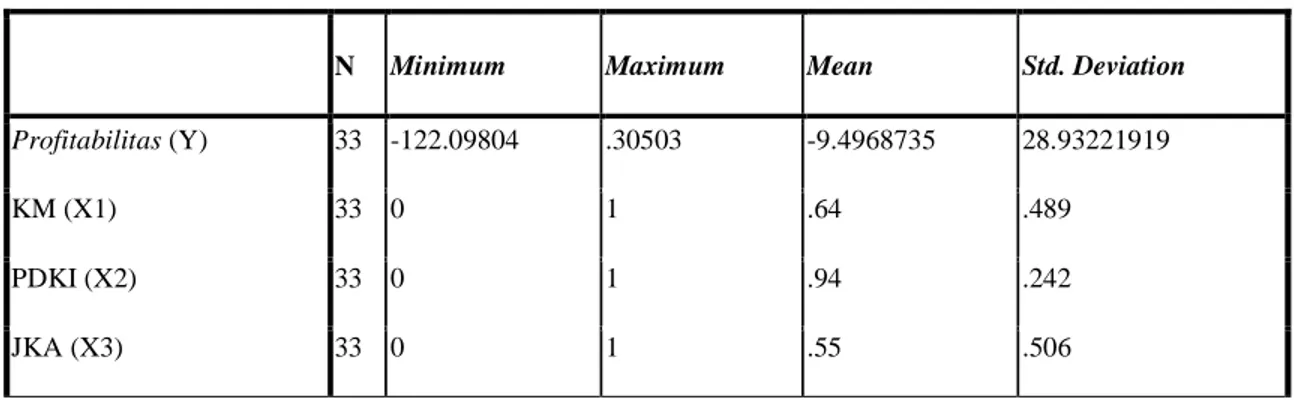
Penggunaan analisis statistik deskriptif untuk memberikan gambaran data yang akan dijadikan sampel yang dilakukan dengan menganalisis data kuantitatif. Dalam melakukan analisis statistik deskriptif harus mengukur nilai maksimum (max), nilai minimum (min), nilai rata-rata (mean), dan standar deviasi. Maksimum menyatakan jumlah atribut paling banyak dan minimum menyatakan jumlah atribut paling sedikit. Nilai rata-rata (mean) berguna untuk mengetahui nilai rata-rata variabel yang dianalisis. Standar deviasi merupakan penggambaran berupa angka yang berasal dari adanya sebaran data terhadap nilai rata-rata. Hasil dari analisis deskriptif statistik penelitian tersebut sebagai berikut ini:
Tabel 1 Hasil Descriptive Statistics
N Minimum Maximum Mean Std. Deviation
Profitabilitas (Y) 33 -122.09804 .30503 -9.4968735 28.93221919
KM (X1) 33 0 1 .64 .489
PDKI (X2) 33 0 1 .94 .242
JKA (X3) 33 0 1 .55 .506
Dari adanya hasil tabel di atas yang merupakan hasil analisis deskriptif statistik yang membahas mengenai adanya variable-variabel yang digunakan oleh peneliti dalam penelitian ini. Untuk variabel profitabilitas menyatakan jumlah datanya sebanyak 33, nilai minimumnya sebesar 122,09804, nilai maksimumnya sebesar 0,30503, nilai rataratanya (mean) sebesar
-55 9.4968735, serta standar deviasinya sebesar 28,93221919. Standar deviasi yang sering dikenal dengan simpangan baku merupakan nilai sebaran data yang digunakan untuk mengetahui nilai-nilai data yang tersebar. Dalam penelitian ini menyatakan nilai standar deviasi sebesar 28,93221919 yang artinya nilai sebaran data dari rata-rata 1 standar deviasi sebesar 28,93221919.
1.1.2 Uji Asumsi Klasik
Uji asumsi klasik dilakukan sebelum melakukan pengujian hipotesis. Uji asumsi klasik dapat dijabarkan sebagai berikut:
1.1.2.1 Hasil Uji Normalitas Data
Uji normalitas berguna untuk mengetahui apakah populasi yang terdapat dalam penelitian berdistribusi normal atau tidak. Dalam analisis grafik dilihat dengan normal probability plot dimana apabila data menyebar pada sekitar garis diagonal dan juga mengikuti arah garis diagonal atau grafik maka dapat dinyatakan data tersebut berdistribusi normal sedangkan apabila data menyebar jauh dari garis diagonal dan juga tidak mengikuti arah garis diagonal atau grafik maka dapat dinyatakan data tersebut berdistribusi tidak normal. Dalam analisis statistik untuk menguji normalitas maka digunakan uji Kolmogorov-Smirnov (K-S) dengan α = 5%, apabila nilai signifikansi < 0,05 maka dapat dinyatakan data tersebut tidak berdistribusi normal sebaliknya apabila nilai signifikansi > 0,05 maka dapat dinyatakan data ini berdistribusi normal. Hasil dari uji normalitas penelitian ini sebagai berikut ini:
Metode Grafik
56 Gambar 2 Chart Normal P-P Plot
Dengan melihat dari hasil gambar grafik di atas berupa titik-titik yang menyebar mendekati garis diagonal serta mengikuti arah garis diagonal ini maka dapat dinyatakan bahwa data yang digunakan dalam penelitian ini berdistribusi normal.
Meskipun pada awalnya data yang digunakan dalam penelitian ini tidak berdistribusi normal tetapi setelah menggunakan log maka data penelitian ini berdistribusi normal.
Tabel 2 One-Sample Kolmogorov-Smirnov Test
Profitabilitas KM (X1) PDKI (X2)
JKA (X3)
57
Normal Parametersa,b Mean -2,2530 ,64 ,94 ,55
Std. Deviation 1,03392 ,489 ,242 ,506 Most Extreme Differences Absolute ,155 ,408 ,538 ,361 Positive ,151 ,267 ,401 ,314 Negative -,155 -,408 -,538 -,361 Kolmogorov-Smirnov Z ,677 2,344 3,091 2,074
Asymp. Sig. (2-tailed) ,749 ,000 ,000 ,000
Diketahui nilai signifikansi (Asym.sig 2 tailed) untuk empat variabel dan nilai residual > 5% maka dapat dinyatakan data tersebut berdistribusi normal.
1.1.2.2 Hasil Uji Autokorelasi
Apabila data yang digunakan dalam penelitian ini ialah data yang pengumpulannya berdasarkan time series maka akan terdapat uji autokorelasi dalam penelitian ini. Dalam data time series data yang selanjutnya merupakan fungsi dari data yang sebelumnya atau data yang selanjutnya mempunyai suatu korelasi yang tinggi terhadap adanya data sebelumnya. Pendeteksian pada uji autokorelasi dapat dilakukan dengan tes Durbin Watson. Pendeteksian autokorelasi yang digunakan dengan tes Durbin Watson yang dapat ditarik kesimpulan apabila telah melihat koefisien korelasi Durbin Watson test (Algifari, 1997) yang diuraikan berikut:
Tabel 3 Durbin Watson test Tingkat Autokorelasi uji Durbin Watson Kesimpulan
Kurang dari 1,10 Ada autokorelasi
1,10 – 1,54 Tidak ada kesimpulan
1,55 – 2,46 Tidak ada autokorelasi
2,47 – 2,90 Tidak ada kesimpulan
Lebih dari 2,91 Ada autokorelasi
58 Tabel 4 Hasil Uji Autokorelasi
Model Durbin-Watson
1 2,143
a. Predictors: (Constant), JKA (X3), KM (X1), PDKI (X2) b. Dependent Variable: Profitabilitas
Hasil uji autokorelasi menyatakan nilai Durbin-Watson sebesar 2,143 yang berada pada rentang 1,55 – 2,46 yang artinya tidak ada masalah autokorelasi.
1.1.2.3 Hasil Uji Multikolinearitas
Peneliti mengunakan uji multikolinearitas untuk mengetahui apakah terjadi hubungan linear yang sempurna pada semua variabel bebas dalam fungsi linear. Apabila fungsi linear yang sempurna terjadi pada beberapa atau semua variabel independen dalam fungsi linear maka data ini mengandung multikolinearitas. Cara tepat dilakukan untuk mengetahui ada atau tidaknya gejala multikoliniearitas dengan melihat nilai Variance Inflation Factor (VIF) dan Tolerance. Apabila nilai Variance Inflation Factor kurang dari 10 dan Tolerance lebih dari 0,1 maka dalam data tersebut tidak terjadi multikoliniearitas (Ghozali, 2001). Hasil dari uji multikolinearitas dapat diuraikan sebagai berikut ini:
Tabel 5 Hasil Uji Multikolinearitas
Model Collinearity Statistics
Tolerance VIF 1 (Constant) 1,170 1,234 1,170 KM (X1) 0,854 PDKI (X2) 0,810 JKA (X3) 0,854
a. Dependent Variable: Profitabilitas
Hasil dari uji multikolinearitas menyatakan nilai Variance Inflation Factor (VIF) kurang dari 10 dan Tolerance lebih dari 0,1 yang artinya bahwa model regresi yang digunakan dalam penelitian ini tidak terjadi masalah multikolinearitas.
59 1.1.2.4 Hasil Uji Heteroskedastisitas
Uji heteroskedastisitas berguna untuk dapat mengetahui adanya ketidaksamaan varian dari residual untuk semua pengamatan pada model regresi. Pendeteksian mengenai ada tidaknya heteroskedastisitas dengan melakukan Uji Glejser. Uji Glejser tersebut dapat dilakukan dengan meregresikan adanya variable-variabel bebas terhadap nilai absolute residual. Residual dalam penelitian ini merupakan selisih nilai observasi dengan nilai prediksi, dan absolut merupakan nilai mutlaknya. Dinilai tidak terjadi heteroskedastisitas apabila nilai signifikansi tentang variabel bebas dengan residual lebih dari 0,05.(Ghozali, 2006). Hasil dari uji heteroskedastisitas dalam penelitian ini dapat berupa sebagai berikut ini:
Tabel 6 Hasil Uji Heteroskedastisitas
Model Sig. 1 (Constant) 1,000 KM (X1) ,208 PDKI (X2) ,665 JKA (X3) ,390
a. Dependent Variable: ABS_RES
Hasil dari uji heteroskedastisitas dengan variabel terikatnya berupa ABS_RES maka nilai signifikansi yang dipunyai oleh KM (X1), PDKI (X2), dan JKA (X3) lebih dari 5% yang artinya KM (X1), PDKI (X2), dan JKA (X3) terbebas dari masalah heteroskedastisitas. 1.1.3 Hasil Pengujian Hipotesis
1.1.3.1 Hasil Uji Regresi Linier Berganda
Tabel 7 Hasil Uji Regresi Linier Berganda
Model Unstandardized Coefficients
B Std. Error 1 (Constant) 1,617 1,098 KM (X1) ,333 ,586 PDKI (X2) ,699 1,253 JKA (X3) ,371 ,586
60 Melihat hasil uji regresi linier berganda di atas maka dapat dinyatakan bahwa:
Hasil konstanta sebesar 1,617. Hasil KM (X1) sebesar 0,333. Hasil PDKI (X2) sebesar 0,699. Hasil JKA (X3) sebesar 0,371.
1.1.3.2 Hasil Uji Signifikansi Simultan atau Uji Statistik F
Peneliti menggunakan uji Signifikansi Simultan atau Uji Statistik F yang disertai dengan bantuan program SPSS untuk dapat mengetahui apakah variabel independen secara bersama-sama berpengaruh terhadap variabel dependen, apabila pada tingkat probabilitas lebih kecil dari 5% atau 0,05 yang artinya semua variabel independen secara serentak mempengaruhi variabel dependen. Apabila F hitung > F tabel dan tingkat signifikansi (α) < 0,05 maka semua variabel bebas serentak mempengaruhi secara signifikan kepada variabel terikat. Apabila F hitung < F tabel dan tingkat signifikansi (α) > 0,05 maka semua variabel bebas serentak tidak mempengaruhi kepada variabel terikat. Hasil dari uji Signifikansi Simultan atau Uji Statistik F dapat dijabarkan sebagai berikut ini:
Tabel 10 Hasil Uji Signifikansi Simultan atau Uji Statistik F
Model F
1
Regression 0,324
Residual Total
a. Dependent Variable: Profitabilitas
b. Predictors: (Constant), JKA (X3), KM (X1), PDKI (X2)
61 H0 = 0 (Artinya KM, PDKI, dan JKA secara bersama-sama tidak berpengaruh terhadap profitabilitas).
Ha ≠ 0 (Artinya KM, PDKI, dan JKA secara bersama-sama berpengaruh terhadap profitabilitas).
Menentukan F hitung
Berdasarkan tabel di atas diperoleh F hitung sebesar 0,324. Menentukan F tabel
Hasil F tabel sebesar 2,934. Kriteria pengujian
Apabila F hitung< F tabel maka menerima H0. Apabila F hitung > F tabel maka menolak H0. Membandingkan thitung dengan ttabel.
Nilai F hitung < F tabel (0,324 < 2,934), maka menerima H0. Menyatakan kesimpulan
Karena F hitung < F tabel (0,324 < 2,934), maka menerima H0 artinya bahwa KM, PDKI, dan JKA secara bersama-sama tidak berpengaruh terhadap profitabilitas.
1.1.3.3 Hasil Uji Signifikansi Parsial atau uji statistik t
Peneliti menggunakan Uji Signifikansi Parsial atau sering dikenal dengan t-test agar peneliti dapat mengetahui sejauh mana variabel bebas yang digunakan dalam penelitian ini mempengaruhi variabel terikat yang digunakan dalam penelitian ini. Apabila t hitung > t tabel, berarti secara parsial variabel bebas berpengaruh terhadap variabel terikat. Apabila t
62 hitung≤ t tabel, berarti secara parsial variabel bebas tidak berpengaruh terhadap variabel terikat. Hasil uji t dapat diuraikan sebagai berikut ini:
Tabel 11 Hasil Uji Signifikansi Parsial atau uji statistik t
Model t 1 (Constant) 1,474 KM (X1) ,568 PDKI (X2) ,558 JKA (X3) ,633
a. Dependent Variable: Profitabilitas
Menentukan hipotesisnya
H0 = 0 (KM, PDKI, dan JKA secara parsial tidak berpengaruh terhadap profitabilitas). Ha ≠ 0 (KM, PDKI, dan JKA secara parsial berpengaruh terhadap profitabilitas ). Menentukan t tabel dengan menggunakan α = 0,05
Hasil ttabel adalah +2,045 / -2,045. Kriteria pengujian
Apabila -t hitung≥ -t tabel atau t hitung≤ t tabel maka menerima H0. Apabila -t hitung< -t tabel atau t hitung > t tabel maka menolak H0. Menyatakan kesimpulan
KM mempunyai nilai t hitung ≤ t tabel (0,568 ≤ 2,045) maka KM secara parsial tidak berpengaruh terhadap profitabilitas.
PDKI mempunyai nilai t hitung≤ t tabel (0,558 ≤ 2,045) maka PDKI secara parsial tidak berpengaruh terhadap profitabilitas.
63 JKA mempunyai nilai t hitung ≤ t tabel (0,633 ≤ 2,045) maka JKA secara parsial tidak berpengaruh terhadap profitabilitas.
1.1.3.4 Hasil Analisis Koefisien Determinasi (R2)
Peneliti menggunakan analisis determinasi dalam penelitian ini berguna untuk mengetahui untuk mengetahui presentase sumbangan pengaruh variabel bebas secara serentak terhadap variabel terikat yang menyatakan seberapa besar presentase variabel bebas yang digunakan dalam model mampu menjelaskan variabel terikat. Apabila artinya variabel bebas tidak memberikan pengaruh sedikitpun terhadap variabel terikat. Sedangkan apabila artinya variabel bebas memberikan pengaruh yang sempurna terhadap variabel terikat. (Priyatno, 2010).
Hasil dari analisis koefisien determinasi (R2) dalam penelitian tersebut dapat diuraikan sebagai berikut:
Tabel 12 Hasil Analisis Koefisien Determinasi (R2)
Model R R Square Adjusted R Square
1 ,247a ,061 -,127
a. Predictors: (Constant), JKA (X3), KM (X1), PDKI (X2) b. Dependent Variable: Profitabilitas
Adanya hasil tabel di atas maka dapat dilihat bahwa nilai R Square sebesar 0,061 yang artinya variabel KM, PDKI, dan JKA memberikan pengaruh sebesar 6,1% terhadap profitabilitas, sedangkan sisanya dipengaruhi oleh variabel lain yang tidak diteliti oleh peneliti dalam penelitian ini.
Pada hasil adjusted R square menyatakan hasil negatif yang berarti bahwa model yang digunakan dalam penelitian ini tidak cocok.
64 1.1.4 Uji Beda
1.1.4.1 Hasil Analisis Uji Homogenitas
Sebelum melakukan analisis Independent Samples T Test maka terlebih dahulu harus melakukan uji asumsi varian atau uji homogenitas yang berguna untuk mengetahui apakah varian yang dalam penelitian tersebut sama atau berbeda. Apabila varian sama maka uji t menggunakan nilai Equal Variance Assumed (diasumsikan varian sama). Apabila varian berbeda maka uji t menggunakan nilai Equal Variance Not Assumed (diasumsikan varian berbeda).
(1) Menentukan hipotesis nol dan hipotesis alternatif
H0 : Kelompok data profitabilitas antara perusahaan di Indonesia dengan perusahaan di Australia mempunyai varian yang sama.
Ha : Kelompok data profitabilitas antara perusahaan di Indonesia dengan perusahaan di Australia mempunyai varian yang berbeda.
(2) Pengambilan keputusan
Apabila Signifikansi > 0,05 maka menerima H0 (varian sama). Apabila Signifikansi < 0,05 maka menolak H0 (varian berbeda).
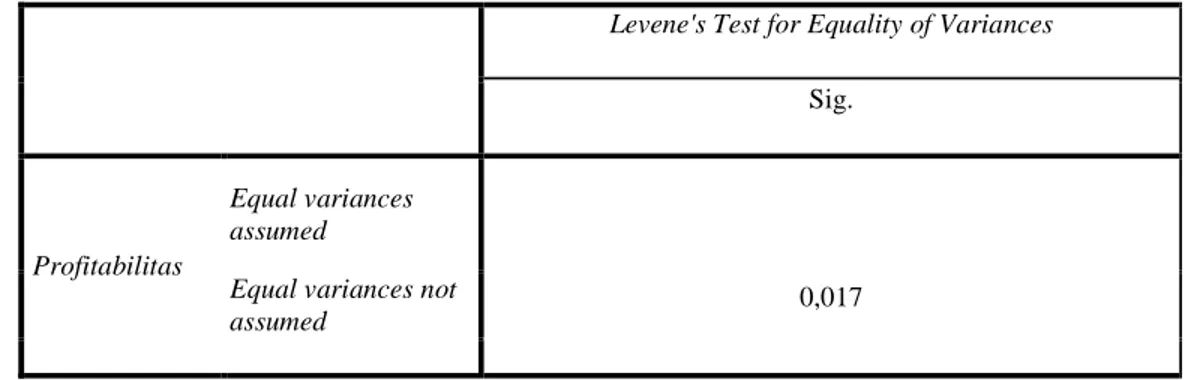
Tabel 13 Hasil Analisis Uji Homogenitas
Levene's Test for Equality of Variances Sig.
Profitabilitas
Equal variances assumed
0,017 Equal variances not
65 (3) Menyatakan kesimpulan
Diketahui nilai signifikansi dari uji Levene’s sebesar 0,017 yang artinya nilai signifikansi lebih kecil dari 0,05 maka menolak H0. Hal ini menyatakan kelompok data profitabilitas antara perusahaan di Indonesia dengan perusahaan di Australia mempunyai varian yang berbeda maka independent samples t test menggunakan nilai yang equal variance not assumed.
1.1.4.2 Hasil Analisis Uji Independent Samples T Test
Uji independent sample t test atau uji t sampel bebas berguna untuk menguji perbedaan adanya rata-rata dua kelompok data independen.
(1) Menentukan hipotesis nol dan hipotesis alternatifnya
H0 : Tidak ada perbedaan profitabilitas antara perusahaan di Indonesia dengan perusahaan di Australia.
Ha : Ada perbedaan profitabilitas antara perusahaan di Indonesia dengan perusahaan di Australia.
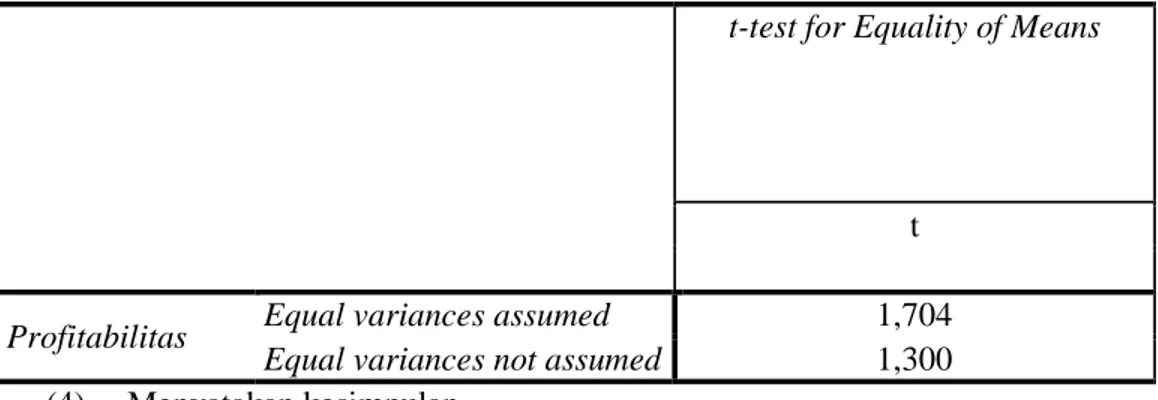
(2) Menentukan t hitung dan t tabel
t hitung sebesar 1,300 (lihat pada tabel independent samples test yang kolom Equal variances not assumed).
t tabel dapat dicari dengan menggunakan program Ms. Excel yaitu pada signifikansi 0,05 : 2 = 0,025 (uji 2 sisi) dengan derajat kebebasan df = 9,750, hasil diperoleh untuk t tabel sebesar +2,262 / -2,262.
(3) Pengambilan keputusan
66 Apabila t hitung > t tabel atau –t hitung < -t tabel maka menolak H0.
Tabel 14 Hasil Analisis Uji Independent Samples T Test t-test for Equality of Means
t
Profitabilitas Equal variances assumed 1,704
Equal variances not assumed 1,300
(4) Menyatakan kesimpulan
Dapat diketahui bahwa t hitung < t tabel (1,300 < 2,262) maka menerima H0. Hal tersebut artinya tidak ada perbedaan profitabilitas antara perusahaan di Indonesia dengan perusahaan di Australia.
Penelitian ini mempunyai satu sumber referensi utama yaitu jurnal akuntansi yang ditulis oleh Abdul Rahim Sangadji tahun 2012 yang berjudul “Pengaruh Faktor-faktor Corporate Governance Terhadap Profitabilitas Perusahaan Publik Yang Tercatat Di Bursa Efek Indonesia Tahun 2011 (Studi Empiris 50 Perusahaan)” tetapi penelitian ini berbeda dengan penelitian tersebut selain mempunyai judul yang berbeda, perbedaannya juga terletak di banyak perbedaan antara lain penelitian ini menggunakan kepemilikan manajerial, proporsi dewan komisaris independen, dan jumlah komite audit sebagai mekanisme pengukur GCG, menggunakan perhitungan NPM sebagai pengukur profitabilitas perusahaan, dengan bantuan SPSS 20 serta menggunakan sampel berupa perusahaan yang terdaftar di bursa efek Indonesia dan bursa efek Australia sedangkan penelitian tersebut menggunakan komisaris independen, komite audit, auditor eksternal, dan kepemilikan asing sebagai mekanisme pengukur GCG, menggunakan ROA sebagai pengukur profitabilitas serta menggunakan bantuan SPSS 17 serta menggunakan sampel berupa perusahaan yang
67 terdaftar di bursa efek Indonesia saja. Perbedaan-perbedaan ini untuk menghasilkan hasil penelitian yang unik serta menarik minat orang untuk membaca karena penggunaan negara lain.