Penerapan algoritma K-Means untuk pengelompokan Sekolah Menengah Atas di Provinsi Daerah Istimewa Yogyakarta berdasarkan nilai daya serap ujian nasional Bahasa Indonesia
Bebas
187
0
0
Teks penuh
(2) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. THE IMPLEMENTATION OF K-MEANS ALGORITHM FOR CLUSTERING THE SENIOR HIGH SCHOOLS IN THE PROVINCE OF YOGYAKARTA SPECIAL REGION BASED ON THE ABSORPTION CAPACITY SCORE OF BAHASA INDONESIA NATIONAL EXAMINATION. A THESIS Present as Partial Fullfillment of the Requirements to Obtain the Sarjana Komputer Degree in Informatics Engineering Study Program. By : Desky Antonio Valdera Alatubir 125314096. INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATIC ENGINEERING FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY YOGYAKARTA 2017. ii.
(3) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI.
(4) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI.
(5) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. HALAMAN PERSEMBAHAN. “Segala perkara dapat kutanggung di dalam Dia yang memberi kekuatan kepadaku.” (Filipi 4:13). Karya ini kupersembahkan kepada : Tuhan Yesus Kristus Bunda Maria Keluarga. v.
(6) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI.
(7) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. ABSTRAK Ujian Nasional merupakan salah satu upaya pemerintah dalam rangka memacu peningkatan mutu pendidikan. Berbagai upaya pasti dilakukan setiap sekolah agar para peserta didiknya mampu memberikan hasil yang memuaskan. Untuk mendapatkan hasil ujian nasional yang memuaskan juga diperlukan upaya para guru dalam peningkatan kualitas belajar siswa. Kemampuan setiap siswa dalam memahami materi dapat diukur salah satunya dengan daya serap setiap pelajaran. Daya serap diukur dengan cara menghitung setiap kompetensi dari soal pada suatu mata pelajaran. Pada tugas akhir ini menggunakan metode pengelompokan Kmeans, metode ini dapat digunakan untuk mengelompokkan Sekolah Menengah Atas di Provinsi Daerah Istimewa Yogyakarta berdasarkan data nilai Daya Serap ujian nasional mata pelajaran Bahasa Indonesia. Dalam tugas akhir ini penulis akan melakukan penelitian dengan mencari jumlah cluster terbaik dari 4 dataset dengan jumlah data yang berbeda-beda (34, 68, 102, dan 137). Terdapat banyak cara dalam menentukan hal tersebut, salah satunya dengan metode Elbow. Penentuan metode ini dilihat dari grafik SSE (Sum Square Error) dari beberapa jumlah cluster. Kemudian dalam melakukan proses mengubah data mentah menjadi suatu informasi yang bermanfaat, penulis menggunakan proses Knowledge Discovery in Database (KDD) yang terdiri dari pembersihan data, seleksi data, panambangan data, evaluasi yang terbentuk dan presentasi pengetahuan. Hasil dari penelitian ini akan dijadikan dasar untuk penentuan jumlah cluster terbaik dari data nilai Daya Serap ujian nasional mata pelajaran Bahasa Indonesia di Provinsi Daerah Istimewa Yogyakarta.. Kata Kunci : K-means, metode Elbow, nilai daya serap, SSE (Sum Square Error). vii.
(8) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. ABSTRACT National Examination is one of the government’s efforts in improving the educational quality. Multiple efforts have certainly been pursued by each school in order that the students will be able to attain satisfying results. In order to attain the satisfying results in the National Examination, teacher should also improve the students’ learning quality. The students’ capacity in understanding the materials can be measured and one of the measures is the absorption capacity for each subject. The absorption capacity was measured by calculating the score of each competency in a subject. In relation to this final assignment, the researcher has implemented the K-Means clustering method; this method can be implemented in order to cluster the Senior High Schools in the Province of Yogyakarta Special Region based on the Absorption Capacity Score from the Bahasa Indonesia National Examination. In this final assignment, the researcher will conduct a study by looking for the best cluster of 4 dataset with different amount of data (34, 68, 102, and 137). There are many methods for clustering the data and one of the methods is the Elbow method. The selection of this method is seen from the SSE (Sum Square Error) method from several numbers of clusters. Then, in turning the raw data into beneficial information, the researcher has made use of Knowledge in Discovery Database (KDD) that consists of data cleaning, data selection, data mining, evaluation that has been formed, and knowledge presentation. The results of this study will be the basis for determining the best cluster from the data of Absorption Capacity Test Score in the Bahasa Indonesia National Examination conducted in the Province of Yogyakarta Special Region.. Keyword: K-means, Elbow method, absorption capacity score, SSE (Sum Square Error). viii.
(9) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI.
(10) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. KATA PENGANTAR Puji dan Syukur kepada Tuhan Yang Maha Esa, karena pada akhirnya penulis dapat menyelesaikan penelitian tugas akhir ini yang berjudul “PENERAPAN ALGORITMA. K-MEANS. UNTUK. PENGELOMPOKAN. SEKOLAH. MENENGAH ATAS DI PROVINSI DAERAH ISTIMEWA YOGYAKARTA BERDASARKAN NILAI DAYA SERAP UJIAN NASIONAL BAHASA INDONESIA. ” Dalam menyelesaikan seluruh penyusunan tugas akhir ini, penulis tak lepas dari doa, bantuan, dukungan, dan motivasi dari banyak pihak. Oleh karena itu, penulis ingin mengucapkan banyak terima kasih kepada : 1. Tuhan Yesus Kristus dan Bunda Maria yang selalu memberikan berkat dan kekuatan sehingga penulis dapat menyelesaikan tugas akhir ini. 2. Kedua orang tua penulis, Hendrikus Alatubir dan Sara Selfi Labiran atas doa, kasih sayang, perhatian, kepercayaan, dukungan baik moral maupun finansial yang diberikan kepada penulis. 3. Adik penulis, Sela Alatubir, Karina Alatubir, dan Kiki Alatubir yang selalu mendoakan dan memberi semangat dalam menyusun tugas akhir. 4. Bapak Sudi Mungkasi, S.Si., M.Math.Sc.,Ph.D selaku Dekan Fakultas Sains dan Teknologi. 5. Ibu Dr. Anastasia Rita Widiarti selaku ketua Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta. 6. Ibu Paulina Heruningsih Prima Rosa, S.Si.,M.Sc. selaku Dosen Pembimbing yang telah dengan sabar membimbing, memberikan waktu, nasehat dan memberikan motivasi kepada penulis. 7. Bapak Eko Hari Parmadi S.Si., M.Kom. selaku Dosen Pembimbing Akademik penulis. 8. Seluruh Dosen dan Karyawan jurusan Teknik Informatika Universitas Sanata Dharma Yogyakarta, yang telah membimbing dan membantu selama proses perkuliahan.. x.
(11) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 9. Kakak sepupu Ramsi dan adik sepupu Rio terima kasih atas doa, bantuan dan dukungan kalian bagi penulis. 10. Triesti Shindu Lakmi yang selalu mendukung, menyemangati, mendoakan, dan selalu menemani dalam suka dan duka. 11. Teman-teman kontrakan yang selalu memberikan semangat dan dukungan kepada penulis. 12. Teman-teman Program Studi Teknik Informatika angkatan 2012 untuk dukungan semangat dan kebersamaan selama menjalani masa perkuliahan ini. 13. Serta semua pihak yang telah membantu dalam penyusunan tugas akhir ini yang tidak dapat disebutkan satu persatu.. Penulis menyadari bahwa masih banyak kekurangan yang perlu diperbaiki dalam tugas akhir ini, untuk itu penulis mengharapkan masukan dan kritik, serta saran dari berbagai pihak untuk menyempurnakannya. Semoga tugas akhir ini dapat bermanfaat, bagi penulis maupun pembaca. Terima kasih.. Yogyakarta, 02 Agustus 2017 Penulis,. Desky Antonio Valdera Alatubir. xi.
(12) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. DAFTAR ISI HALAMAN JUDUL ................................................................................................................. i TITLE PAGE ............................................................................................................................. ii HALAMAN PERSETUJUAN................................................................................................. iii HALAMAN PENGESAHAN.................................................................................................. iv HALAMAN PERSEMBAHAN ............................................................................................... v PERNYATAAN KEASLIAN KARYA .................................................................................. vi ABSTRAK .............................................................................................................................. vii ABSTRACT............................................................................................................................. viii LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH .................... ix KATA PENGANTAR .............................................................................................................. x DAFTAR ISI........................................................................................................................... xii DAFTAR GAMBAR ............................................................................................................. xvi DAFTAR TABEL................................................................................................................. xvii BAB I PENDAHULUAN ......................................................................................................... 1 1. 1 LATAR BELAKANG ................................................................................................... 1 1.2 RUMUSAN MASALAH ................................................................................................ 3 1.3 BATASAN MASALAH ................................................................................................. 3 1.4 TUJUAN DAN MANFAAT PENELITIAN .................................................................. 3 1.5 METODOLOGI PENELITIAN ...................................................................................... 4 1.6 SISTEMATIKA PENULISAN ....................................................................................... 5 BAB II LANDASAN TEORI ................................................................................................... 7 2.1 Penambangan Data (Data Mining) ................................................................................. 7. xii.
(13) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 2.1.1 Pengertian Penambangan Data (Data Mining) ........................................................ 7 2.1.2 Fungsi Penambangan Data (Data Mining)............................................................... 7 2.2 Knowledge Discovery in Database (KDD) ................................................................... 10 2.3 Analisis Clustering........................................................................................................ 12 2.3.1 Pengertian Clustering............................................................................................. 12 2.3.2 Tipe Clustering ...................................................................................................... 12 2.3.3 K-means ................................................................................................................. 13 2.3.4 Distance Space ....................................................................................................... 16 2.4 Metode Elbow ............................................................................................................... 17 2.4.1 Pengertian Metode Elbow ...................................................................................... 17 2.4.2 Contoh penerapan Metode Elbow .......................................................................... 19 BAB III METODOLOGI PENELITIAN ............................................................................... 20 3.1 Sumber Data.................................................................................................................. 20 3.2 Spesifikasi Alat ............................................................................................................. 22 3.3 Tahap – Tahap Penelitian.............................................................................................. 23 3.3.1 Studi Kasus ............................................................................................................ 23 3.3.2 Penelitian Pustaka .................................................................................................. 23 3.3.3 Knowledge Discovery in Database (KDD) ............................................................ 23 3.3.4 Pengembangan Perangkat Lunak ........................................................................... 24 3.3.5. Analisis hasil clustering .................................................................................. 25. 3.3.6. Pembuatan Laporan......................................................................................... 26. BAB IV PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA ..................................................................................................... 27 4.1 Pemrosesan Awal .......................................................................................................... 27. xiii.
(14) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 4.1.1 Pembersihan Data (Data Cleaning) ....................................................................... 27 4.1.2 Integrasi Data (Data Integration)........................................................................... 27 4.1.3 Seleksi Data (Data Selection) ................................................................................ 27 4.1.4 Transformasi Data (Data Transformation) ............................................................ 28 4.2 Perancangan Perangkat Lunak Penambangan Data ...................................................... 28 4.2.1 Perancangan Umum ............................................................................................... 28 4.2.2 Diagram Usecase ................................................................................................... 31 4.2.3 Diagram Aktifitas (Activity Diagram) ................................................................... 31 4.2.4 Diagram Kelas (Class Diagram)............................................................................ 32 4.2.5 Diagram Sekuen (Sequence Diagram) ................................................................... 32 4.2.6 Perancangan Struktur Data..................................................................................... 32 4.2.7 Perancangan Antarmuka ........................................................................................ 34 BAB V IMPLEMENTASI PENAMBANGAN DATA DAN ANALISIS HASIL ................ 37 5.1 Implementasi Rancangan Perangkat Lunak Penambangan Data .................................. 37 5.1.1 Implementasi Kelas ................................................................................................ 37 5.1.2 Implementasi Listing Program K-Means ............................................................... 48 5.1.3 Implementasi Listing Program Elbow ................................................................... 50 5.2 Analisis Hasil ................................................................................................................ 51 5.2.1 Analisis Pengujian Validitas Perangkat Lunak (Black Box) .................................. 51 5.2.2 Pengujian Perbandingan Hasil Hitung Manual dengan Hasil Perangkat. Lunak . 52. 5.3 Kelebihan dan Kekurangan Perangkat Lunak ............................................................... 59 5.3.1 Kelebihan Perangkat Lunak ................................................................................... 59 5.3.2 Kekurangan Perangkat Lunak ................................................................................ 59. xiv.
(15) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB VI PENUTUP ................................................................................................................ 61 6.1 Kesimpulan ................................................................................................................... 61 6.2 Saran ............................................................................................................................. 62 DAFTAR PUSTAKA ............................................................................................................. 63 Lampiran 1 Contoh Perhitungan Metode Elbow..................................................................... 65 Lampiran 2 Rencana Pengujian Black Box / Kasus Uji .......................................................... 69 Lampiran 3 Contoh Input dan Data Ujinya ............................................................................. 72 Lampiran 4 Proses Perhitungan Manual K-Means Serta Analisis Cluster metode Elbow ...... 85 Lampiran 5 Perhitungan Menggunakan Perangkat Lunak ................................................... 134 Lampiran 6 Tabel Hasil Uji Perbandingan Anggota Tiap Cluster Secara Manual dan Menggunakan Perangkat Lunak............................................................................................ 142 Lampiran 7 Diagram Aktifitas (Activity Diagram) ............................................................... 166 Lampiran 8 Diagram Kelas (Class Diagram) ....................................................................... 168 Lampiran 9 Diagram Sekuen (Sequence Diagram) .............................................................. 169. xv.
(16) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Daftar Gambar. Gambar 2.1 Tahap-tahap di dalam proses Knowledge Discovery in Database (Han&Kamber, 2006) .............................................................................................. 10 Gambar 2.2 Grafik metode Elbow (Kodinariya & Makwana, 2013) ....................... 18 Gambar 4.1 Diagram Konteks .................................................................................. 29 Gambar 4.2 Diagram Flowchart .............................................................................. 30 Gambar 4.3 Diagram Usecase.................................................................................. 31 Gambar 4.4 Ilustrasi konsep ArrayList .................................................................... 33 Gambar 4.5 Perancangan ArrayList ......................................................................... 34 Gambar 4.6 Antarmuka halaman awal ..................................................................... 34 Gambar 4.7 Antarmuka halaman Data ..................................................................... 35 Gambar 4.8 Antarmuka halaman About .................................................................. 36 Gambar 5.1 Implementasi Antarmuka Kelas Awal ................................................. 39 Gambar 5.2 Implementasi Antarmuka Kelas Utama Tab Data ............................... 47 Gambar 5.3 Implementasi Antarmuka Kelas Utama Tab About ............................. 47 Gambar 5.4 Grafik Metode Elbow dengan dengan total data 34. ............................ 54 Gambar 5.5 Grafik Metode Elbow dengan dengan total data 68. ............................ 55 Gambar 5.6 Grafik Metode Elbow dengan dengan total data 102 ........................... 56 Gambar 5.7 Grafik Metode Elbow dengan dengan total data 137 ........................... 57. xvi.
(17) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Daftar Tabel Tabel 3.1 Atribut Data data daya serap ujian nasional mata pelajaran Bahasa Indonesia tahun ajaran 2014/2015 ........................................................................... 20 Tabel 4.1 Atribut yang tidak digunakan pada data daya serap ................................ 28 Tabel 5.1 Implementasi kelas awal .......................................................................... 37 Tabel 5.2 Implementasi Kelas Utama ...................................................................... 39 Tabel 5.3 Implementasi kelas KMeans .................................................................... 48 Tabel 5.4 Rencana Pengujian Black Box.................................................................. 51 Tabel 5.7 Hasil pengujian dataset dengan menggunakan metode Elbow dengan total data 34. ............................................................................................ 54 Tabel 5.8 Hasil pengujian dataset dengan menggunakan metode Elbow dengan total data 68 ............................................................................................. 55 Tabel 5.9 Hasil pengujian dataset dengan menggunakan metode Elbow dengan total data 102 ........................................................................................... 56 Tabel 5.10 Hasil pengujian dataset dengan menggunakan metode Elbow dengan total data 137 ........................................................................................... 57 Tabel 5.11 Rangkuman hasil uji coba ke 4 Dataset ................................................. 59. xvii.
(18) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB I PENDAHULUAN 1. 1 LATAR BELAKANG Ujian Nasional merupakan salah satu upaya pemerintah dalam rangka memacu peningkatan mutu pendidikan. Ujian Nasional selain berfungsi untuk mengukur dan menilai pencapaian kompetensi lulusan dalam mata pelajaran tertentu, serta pemetaan mutu pendidikan pada tingkat pendidikan dasar dan menengah, juga berfungsi sebagai motivator bagi pihak-pihak terkait untuk bekerja lebih baik guna mencapai hasil ujian yang baik. Selain itu hasil dari ujian nasional juga berguna sebagai bahan pertimbangan seleksi masuk untuk pendidikan selanjutnya. Berbagai upaya pasti dilakukan setiap sekolah agar para peserta didiknya mampu memberikan hasil yang memuaskan. Untuk mendapatkan hasil ujian nasional yang memuaskan juga diperlukan upaya para guru dalam peningkatan kualitas belajar siswa. Kemampuan setiap siswa dalam memahami materi dapat diukur salah satunya dengan daya serap setiap pelajaran. Daya serap diukur dengan cara menghitung setiap kompetensi dari soal pada suatu mata pelajaran. Daya serap ujian nasional memberikan banyak manfaat bagi banyak pihak, terutama sekolah sebagai tempat siswa belajar. Daya serap ujian nasional ini memberikan informasi seberapa besar daya serap peserta ujian, dapat mengetahui kemampuan dan kelemahan dalam suatu kompetensi, dan dapat mengetahui keberhasilan guru dalam menyampaikan pelajaran. Informasi tentang hasil daya serap ujian nasional ini telah disediakan pada website resmi milik Puspendik Balitbang Kemdikbud yang dapat diakses melalui alamat http://litbang.kemdikbud.go.id dalam beberapa bentuk data yaitu statistik, grafik, daftar dan daya serap. Dalam penelitian ini bentuk informasi yang akan digunakan adalah daya serap. Pada informasi ini berisi berbagai data, diantaranya data laporan daya serap ujian nasional siswa Sekolah Menengah Atas (SMA) dari jurusan IPA untuk mata pelajaran Bahasa Indonesia yang memiliki 21 indikator pencapaian 1.
(19) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. kompetensinya. Dari data tersebut nantinya akan dilakukan pengelompokan SMA berdasarkan setiap indikator pencapaian kompetensi mata pelajaran Bahasa Indonesia. Nantinya hasil pengelompokan tersebut dapat memberikan informasi peta mutu pendidikan yang bisa di manfaatkan oleh berbagai macam instansi pendidikan dalam memperbaiki metode pengajaran yang diberikan para guru terhadap siswanya guna meningkatkan mutu dan kualitas pendidikan di provinsi Daerah Istimewa Yogyakarta (DIY). Algoritma K-means merupakan algoritma pengelompokan iteratif yang melakukan partisi set data ke dalam sejumlah K cluster yang sudah ditetapkan di awal. Secara historis, K-means menjadi salah satu algoritma yang paling penting dalam bidang data mining (Wu dan Kumar, 2009). Algoritma K-means ini memiliki potensi sebagai teknik yang dapat di pakai untuk melakukan pengelompokan data, sehingga penulis menggunakan teknik ini untuk mengelompokkan data daya serap ujian nasional SMA jurusan IPA diprovinsi DIY, dalam mata pelajaran Bahasa Indonesia dengan 21 indikator pencapaian kompetensinya. Pada penelitian ini, penulis mengkhususkan memilih untuk mengelompokkan mata pelajaran Bahasa Indonesia. Hal ini didasari karena Bahasa Indonesia merupakan salah satu identitas Bangsa Indonesia. Bahasa Indonesia mempunyai kedudukan yang sangat penting dalam kehidupan berbangsa dan negara. Selain itu juga mempelajari Bahasa Indonesia dapat membantu kita dalam berkomunikasi serta menambah keterampilan berbahasa Indonesia yang baik dan benar. Berdasarkan hal diatas, maka penulis tertarik untuk melakukan pengelompokan data daya serap ujian nasional SMA jurusan IPA, dalam mata pelajaran Bahasa Indonesia dengan 21 indikator pencapaian kompetensinya khususnya pada provinsi DIY dengan menggunakan algoritma K-means, sehingga penulis mengangkat judul tugas akhir yaitu “Penerapan algoritma K-means untuk pengelompokan Sekolah Menengah Atas di provinsi Daerah Istimewa Yogyakarta berdasarkan nilai daya serap ujian nasional Bahasa Indonesia.”. 2.
(20) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 1.2 RUMUSAN MASALAH Berdasarkan latar belakang diatas, maka rumusan masalah yang penulis bahas adalah : 1.. Bagaimana menerapan algoritma K-means untuk mengelompokkan Sekolah Menengah Atas di provinsi Daerah Istimewa Yogyakarta berdasarkan data daya serap ujian nasional mata pelajaran Bahasa Indonesia ?. 2.. Bagaimana. analisis hasil clustering menggunakan metode Elbow untuk. menentukan nilai K yang sesuai bagi data daya serap ujian nasional Bahasa Indonesia tahun ajaran 2014/2015 ?. 1.3 BATASAN MASALAH Batasan masalah dalam tugas akhir ini adalah : 1.. Algoritma yang digunakan dalam penelitian ini adalah algoritma K-Means.. 2.. Data yang digunakan adalah data daya serap ujian nasional mata pelajaran Bahasa Indonesia jurusan IPA di provinsi Daerah Istimewa Yogyakarta tahun ajaran 2014/2015.. 3.. Atribut yang digunakan dalam proses clustering meliputi atribut nama sekolah dan ke 21 indikator pencapaian kompetensinya.. 1.4 TUJUAN DAN MANFAAT PENELITIAN Tujuan dari penelitian ini adalah yang pertama menerapkan algoritma K-means pada data daya serap ujian nasional untuk melakukan pengelompokan sekolah di provinsi. DIY,. sehingga. mempermudah. dalam. mengetahui. informasi. pengelompokan setiap sekolah di provinsi DIY secara cepat. Lalu yang kedua dapat menentukan jumlah cluster ideal dari data daya serap ujian nasional di provinsi DIY dengan menggunakan metode Elbow.. 3.
(21) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Manfaat dari penelitian ini adalah menjadi sebuah evaluasi untuk Sekolah Menengah Atas yang berada di provinsi DIY agar bisa semakin meningkatkan lagi mutu dan kualitas mata pelajaran bahasa indonesia untuk siswanya. Penelitian ini juga bisa berguna sebagai referensi untuk siapa saja, yang berkaitan dengan pengelompokan sekolah.. 1.5 METODOLOGI PENELITIAN Metodologi penelitian yang digunakan dalam menyelesaikan tugas akhir ini adalah sebagai berikut :. 1.. Penelitian Pustaka Pada tahap ini merupakan proses penulis melakukan pengumpulan semua informasi yang terkait dengan teori-teori dan algoritma yang akan digunakan untuk melakukan teknik pengelompokan data dari berbagai referensi yang tersedia.. 2.. Knowledge Discovery in Database (KDD) Pada tahap ini merupakan tahap dimana akan dilakukan proses KKD untuk mendapatkan sebuah informasi dari data daya serap ujian nasional bahasa indonesia di provinsi DIY. Di dalam proses ini daya serap ujian nasional Bahasa Indonesia akan dilakukan proses KDD diantaranya adalah pembersihan data, seleksi data, panambangan data, evaluasi yang terbentuk dan presentasi pengetahuan. Pada tahap penambangan data akan dibuat perangkat lunak sebagai alat uji dengan menggunakan metodologi waterfall. Metodologi tersebut terdiri dari analisa terhadap kebutuhan sistem, desain sistem, pemrograman dan yang terakhir adalah pengujian. Hasil yang didapat akan dianalisa untuk memperoleh informasi yang berguna dan bermanfaat.. 4.
(22) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 3.. Analisis Hasil Pada tahap ini akan dilakukan analisis pengujian validitas perangkat lunak, pengujian nilai K yang sesuai, dan pengujian anggota cluster.. 4.. Pembuatan Laporan Dari analisis dan pengujian hasil pengelompokan data daya serap ujian nasional dengan menggunakan algoritma K-means tersebut akan digunakan dalam penyusunan sebuah laporan tugas akhir.. 1.6 SISTEMATIKA PENULISAN Sistematika penulisan tugas akhir ini adalah sebagai berikut :. 1.. BAB I : Pendahuluan Bab ini berisi tentang latar belakang, rumusan masalah, batasan masalah, tujuan dan manfaat, metodologi penelitian, dan sistematika penulisan.. 2.. BAB II : Landasan Teori Bab ini berisi tentang teori-teori yang berkaitan dengan judul/masalah tugas akhir.. 3.. BAB III : Metodologi Penelitian Bab ini akan menjelaskan gambaran umum penelitian, data, spesifikasi alat, dan tahap-tahap penelitian.. 4.. BAB IV : Pemrosesan Awal dan Perancangan Perangkat Lunak Penambangan Data. 5.
(23) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Pada Bab ini akan membahas tentang bagaimana data daya serap ujian nasional akan di proses serta perancangan pembuatan perangkat lunak.. 5.. BAB V : Implementasi Penambangan Data dan Analisis Hasil Bab ini berisi tentang implementasi sistem yang dibangun, pengujian sistem, dan analisis hasil output sistem yang telah di buat.. 6.. BAB VI : Penutup Bab ini berikan tentang kesimpulan dan saran yang diperoleh dari pembuatan sistem yang telah dibuat.. LAMPIRAN. 6.
(24) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB II LANDASAN TEORI 2.1 Penambangan Data (Data Mining) 2.1.1 Pengertian Penambangan Data (Data Mining) Penambangan data (data mining) adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah suatu proses yang menggunakan teknik statistik, matematika, kecedarsan tiruan dan machine-learning untu mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database yang besar (Turban, dkk, 2005). Data mining adalah proses yang mempekerjakan satu atau lebih teknik pembelajaran komputer (machine learning) untuk manganalisis dan mengekstraksi pengetahuan (knowledge) secara otomatis (Hermawati, 2013).. 2.1.2 Fungsi Penambangan Data (Data Mining) Fungsionalitas penambangan data digunakan untuk menentukan jenis pola yang dapat ditemukan dalam tugas-tugas penambangan data. Secara umum tugas dari penambangan data adalah data dapat di klasifikasikan ke dalam dua kategori: deskriptif dan Prediktif. Tugas penambangan deskriptif yaitu mengkarakterisasi sifat umum dari data dalam basis data. Sedangkan penambangan Prediktif yaitu melakukan inferensi pada data saat ini untuk membuat prediksi. Fungsi penambangan data (data mining) dan jenis pola yang ditemukan, yaitu :. 7.
(25) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. a.. Konsep / Deskripsi Kelas: Karakterisasi dan Diskriminasi Data dapat dikaitkan dengan kelas atau konsep. Deskripsi seperti dari kelas atau konsep yang disebut deskripsi kelas / konsep. Deskripsi dapat diturunkan melalui karakterisasi data, dengan merangkum data dari kelas yang diteliti (sering disebut kelas target) secara umum, atau diskriminasi data, dengan perbandingan dari kelas target dengan satu atau set kelas komparatif (sering disebut kelas kontras), atau keduanya karakterisasi data dan diskriminasi.. b.. Penambangan Kemunculan Pola, Asosiasi, dan Korelasi Pola yang sering muncul (frequent) adalah pola yang sering terjadi di data. Jenis pola yang dimaksud yaitu itemset, subsequences, dan substructure. Sebuah itemset biasanya mengacu pada satu set item yang muncul bersamasama dalam satu set data transaksional. Sebuah subsequence contohnya seperti pola pelanggan yang cenderung membeli komputer, diikuti oleh kamera digital, dan kemudian kartu memori. Sebuah substructure dapat merujuk ke bentuk struktural yang berbeda, seperti grafik, tree, atau kisi, yang dapat dikombinasikan dengan itemset atau subsequences. Substructure yang sering terjadi disebut pola terstruktur. Penambangan pola mengarah pada penemuan asosiasi menarik dan korelasi dalam data.. c.. Klasifikasi dan Prediksi Klasifikasi. adalah. proses. menemukan. model. atau. fungsi. yang. menggambarkan dan membedakan kelas data atau konsep. Tujuannya untuk memprediksi kelas dari objek yang label kelas nya tidak diketahui. Prediksi digunakan untuk memprediksi hilang atau tidak tersedianya data nilai numerik pada label kelas. Analisis regresi adalah metodologi statistik yang paling sering digunakan untuk prediksi numerik. Prediksi juga mencakup identifikasi tren distribusi berdasarkan data yang tersedia. Klasifikasi dan prediksi mungkin. 8.
(26) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. perlu didahului dengan analisis relevansi untuk mengidentifikasi atribut yang tidak memberikan kontribusi pada proses klasifikasi atau prediksi.. d.. Analisis Cluster Analisis cluster yaitu menemukan kumpulan objek hingga objek-objek dalam satu kelompok sama (atau punya hubungan) dengan yang lain dan berbeda (atau tidak berhubungan) dengan objek-objek dalam kelompok lain. Tujuan dari analisis cluster adalah meminimalkan jarak di dalam. cluster dan. memaksimalkan jarak antar cluster.. e.. Analisis Outlier Database mungkin berisi data objek yang tidak sesuai dengan perilaku umum atau model data. Obyek data outlier. Sebagian besar metode data mining membuang outlier sebagai noise atau pengecualian. Namun, dalam beberapa aplikasi seperti deteksi penipuan, peristiwa langka bisa lebih menarik dari pada peristiwa yang sering terjadi. Outlier dapat dideteksi menggunakan uji statistik yang mengasumsikan distribusi atau model probabilitas data, atau menggunakan pendekatan jarak di mana objek yang berbeda dari setiap klaster lainnya dianggap outlier.. f.. Analisis Evolution Analisis evolusi menggambarkan data dan model keteraturan atau tren untuk objek yang perilakunya berubah dari waktu ke waktu. Meskipun termasuk dalam karakterisasi, diskriminasi, asosiasi dan analisis korelasi, klasifikasi, prediksi, atau pengelompokan data, fitur yang berbeda dari analisis tersebut meliputi analisis data time-series, urutan atau periodisitas pencocokan pola, dan analisis data berbasis kesamaan.. 9.
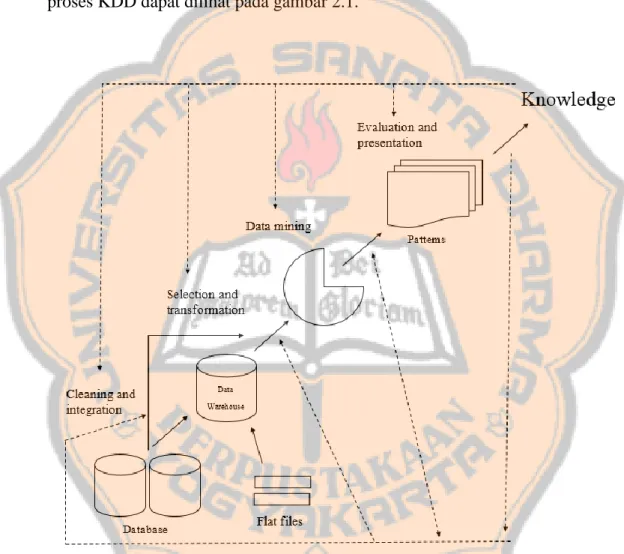
(27) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 2.2 Knowledge Discovery in Database (KDD) Menurut Han dan Kamber (2006), penambangan data tidak dapat dipisahkan dari proses knowledge discovery in database (KDD). Proses KDD merupakan sebuah proses mengubah data mentah menjadi suatu informasi yang berguna. Illustrasi proses KDD dapat dilihat pada gambar 2.1.. Gambar 2.1 Tahap-tahap di dalam proses Knowledge Discovery in Database (Han&Kamber, 2006).. Knowledge discovery sebagai suatu proses digambarkan dalam Gambar 2.1 dan terdiri dari urutan berulang dari langkah-langkah berikut :. 10.
(28) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 1.. Pembersihan Data (Data Cleaning) Tahap ini merupakan proses menghilangkan data yang tidak dibutuhkan (noise) dan data yang tidak konsisten. 2.. Integrasi Data (Data Integration) Tahap ini merupakan proses menggabungkan bermacam-macam data dari berbagai sumber.. 3.. Seleksi Data (Data Selection) Tahap ini merupakan proses menganalisis data yang relavan dari dalam database.. 4.. Transformasi Data (Data Transformation) Tahap ini merupakan proses data diubah (transformasi) atau digabungkan sehingga menjadi tepat untuk dilakukan penambangan data.. 5.. Penambangan Data (Data Mining) Tahap ini merupakan proses penting dimana metode cerdas dilakukan untuk menggali pola dari data.. 6.. Evaluasi Pola (Pattern Evaluation) Tahap ini merupakan proses untuk mengidentifikasi pola-pola yang benarbenar menarik yang mewakili pengetahuan berdasarkan beberapa langkah penting.. 7.. Presentasi Pengetahuan (Knowledge Presentation) Tahap ini merupakan proses teknik visualisasi dan representasi pengetahuan digunakan untuk menyajikan pengetahuan hasil penambangan kepada pengguna. 11.
(29) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 2.3 Analisis Clustering 2.3.1 Pengertian Clustering Clustering yaitu menemukan kumpulan obyek hingga obyek-obyek dalam satu kelompok sama (atau punya hubungan) dengan yang lain dan berbeda (atau tidak berhubungan) dengan obyek-obyek dalam kelompok lain. Tujuan dari clustering adalah untuk meminimalkan jarak di dalam cluster dan memaksimalkan jarak antar cluster (Hermawati, 2013). Clustering terbagi menjadi dua, yaitu hierarki dan partisi. Dalam pengelompokan berbasis hierarki (hierarchical clustering), satu data tunggal bisa dianggap sebuah cluster, dua atau lebih cluster kecil dapat bergabung menjadi sebuah cluster besar, begitu seterusnya hingga semua data dapat bergabung menjadi sebuah cluster. Di sisi lain, pengelompokan berbasis partisi membagi set data ke dalam sejumlah cluster yang tidak bertumpang-tindih antara satu cluster dengan cluster yang lain, artinya setiap data hanya menjadi anggota satu cluster saja (Prasetyo, 2014).. 2.3.2 Tipe Clustering Clustering merupakan suatu kumpulan dari keseluruhan cluster. Beberapa tipe penting dari clustering adalah (Hermawati, 2013) :. 1.. Partitional vs Hierarchical Partitional clustering adalah pembagian obyek data ke dalam subhimpunan (cluster) yang tidak overlap sedemikian hingga tiap obyek data berada dalam tepat satu sub-himpunan. Hierarchical clustering merupakan sebuah himpunan cluster bersarang yang diatur sebagai suatu pohon hirarki. Tiap simpul (cluster) dalam pohon (kecuali simpul daun) merupakan gabungan dari anaknya (subcluster) dan simpul akar berisi semua obyek.. 12.
(30) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 2.. Exclusive vs non-exclusive Exclusive clustering yaitu jika setiap obyek yang ada berada tepat di dalam satu cluster. Overlapping atau non-exclusive clustering yaitu bila sebuah obyek dapat berada di lebih dari satu cluster secara bersamaan.. 3.. Fuzzy vs non-fuzzy Dalam fuzzy clustering, sebuah titik termasuk dalam setiap cluster dengan suatu nilai bobot antara 0 dan 1. Jumlah dari bobot-bobot tersebut sama dengan 1. Clustering probabilitas mempunyai karakteristik yang sama.. 4.. Partial vs complete Dalam complete clustering, setiap obyek ditempatkan dalam sebuah cluster. Tetapi dalam partial clustering, tidak semua obyek ditempatkan dalam sebuah cluster. Kemungkinan ada obyek yang tidak tepat untuk ditempatkan di salah satu cluster, misalkan berupa outlier atau noise.. 2.3.3 K-means Algoritma K-means merupakan algoritma pengelompokan iteratif yang melakukan partisi set data ke dalam sejumlah K cluster yang sudah ditetapkan di awal. Secara historis, K-means menjadi salah satu algoritma yang paling penting dalam bidang data mining (Wu dan Kumar, 2009). K-means dapat diterapkan pada data yang direpresentasikan dalam r-dimensi ruang tempat. K-means mengelompokkan set data r-dimensi, X = {xi|i=1, …, N}, di mana xi d yang menyatakan data ke-i sebagai “titik data”. Algoritma K-means mengelompokkan semua titik data dalam X sehingga setiap titik xi hanya jatuh dalam satu dari K partisi. Yang perlu diperhatikan adalah titik berada dalam cluster yang mana, dilakukan dengan cara memberi setiap titik sebuah ID cluster. Titik dengan ID cluster yang sama berarti berada dalam satu cluster yang sama,. 13.
(31) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. sedangkan titik dengan ID cluster yang berbeda berada dalam cluster yang berbeda. Untuk menyatakan hal ini, biasanya dilakukan dengan vektor keanggotaan cluster m dengan panjang N, di mana mi bernilai ID cluster titik xi. Parameter yang harus dimasukkan ketika menggunakan algoritma K-means adalah nilai K. Nilai K yang digunakan biasanya didasarkan pada informasi yang di ketahui sebelumnya tentang sebenarnya berapa banyak cluster data yang muncul dalam X, berapa banyak cluster yang dibutuhkan untuk penerapannya, atau jenis cluster dicari dengan mengeksplorasi/melakukan percobaan dengan beberapa nilai K. Berapa nilai K yang dipilih tidak perlu memahami bagaimana K-means mempartisi set data X. Dalam K-means, setiap cluster dari K cluster diwakili oleh titik tunggal dalam d . set representatif cluster dinyatakan C = {cj|j=1, …, K}. Sejumlah K representatif cluster tersebut disebut juga sebagai cluster means atau cluster centroid (atau centroid saja).. Untuk set data dalam X dikelompokan bersadarkan konsep. kedekatan atau kemiripan. Pada saat data sudah dihitung ketidakmiripan terhadap setiap centroid, maka selanjutnya dipilih ketidakmiripan yang paling kecil sebagai cluster yang akan diikuti sebagai relokasi data pada cluster disebuah iterasi. Relokasi sebuah data dalam cluster yang diikuti dapat dinyatakan dengan nilai keanggotaan yang bernilai a yang benilai 0 atau 1. Nilai 0 jika tidak menjadi anggota sebuah cluster dan 1 jika menjadi anggota sebuah cluster. K-means mengelompokkan secara tegas data hanya pada satu cluster, maka dari nilai a sebuah data pada semua cluster, hanya satu yang benilai 1, sedangkan lainnya 0 yang dinyatakan pada persamaan berikut :. aij. 1 arg min {𝑑(𝑥𝑖 , 𝑐𝑗 )} …………………...........……………. (2.1). ={ 0 𝑙𝑎𝑖𝑛𝑛𝑦𝑎. Keterangan : a = nilai keanggotaan. 14.
(32) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. i = index data j = cluster ke j aij = data i yang masuk ke cluster j d(xi, cj) = ketidakmiripan (jarak) dari data ke-i ke cluster cj.. lalu pada relokasi centroid untuk mendapatkan titik centroid C didapatkan dengan menghitung rata-rata setiap fitur dari semua data yang tergabung dalam setiap cluster. Rata-rata sebuah fitur dari semua data dalam sebuah cluster dinyatakan oleh persamaan berikut :. cj =. 1 𝑁𝑘. ∑𝑁𝑘 𝑖=1 𝑥𝑗𝑖 ………………………….......................………. (2.2). Keterangan : j = cluster j xji = anggota cluster ke-k Nk = jumlah data yang tergabung dalam sebuah cluster.. Buat meminimalkan fungsi objektif/fungsi biaya non-negatif, seperti dinyatakan oleh persamaan berikut :. 2. 𝐾 J = ∑𝑁 𝑖=1 ∑𝑙=1 𝑎𝑖𝑐 𝑑(𝑥𝑖 , 𝑐𝑙 ). Keterangan : K = jumlah cluster N = jumlah data. 15. ……………………………………. (2.3).
(33) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. i = data ke i aic = data i yang masuk pada cluster c d(xi, cj) = ketidakmiripan (jarak) dari data ke-i ke cluster cj.. Berikut merupakan prosedur Algoritma pengelompokan K-means menurut Prasetyo (2014) : 1.. Inisialisasi : tentukan nilai k sebagai jumlah cluster yang diinginkan dan metrik ketidakmiripan (jarak) yang diinginkan. jika perlu tetapkan ambang batas perubahan fungsi objektif dan ambang batas perubahan posisi centroid.. 2.. Pilih K data dari set data x sebagai centroid.. 3.. Alokasikan semua data ke centroid terdekat dengan metrik jarak yang sudah ditetapkan (memperbarui cluster ID setiap data).. 4.. Hitung kembali centroid C berdasarkan data yang mengikuti cluster masingmasing.. 5.. Ulangi langkah 3 dan 4 hingga kondisi konvergen tercapai, yaitu (a) perubahan fungsi objektif sudah dibawah ambang batas yang diinginkan atau (b) tidak ada data yang berpindah cluster, atau (c) perubahan posisi centroid sudah dibawah ambang batas yang ditetapkan.. 2.3.4 Distance Space Distance Space adalah proses penghitungan jarak antara suatu dokumen dengan dokumen lainnya. Untuk menguhitung Distance Space rumus yang dapat digunakan adalah Euclidean distance. Rumus Euclidean distance sebagai berikut (Handoyo, dkk, 2014) : ......................…. (2.4). 16.
(34) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Keterangan : d(i,j) = jarak antara data ke i dan data ke j xi1 = nilai atribut ke satu dari data ke i xj1 = nilai atribut ke satu dari data ke j n = jumlah atribut yang di gunakan.. 2.4 Metode Elbow 2.4.1 Pengertian Metode Elbow Metode Elbow merupakan suatu metode yang digunakan untuk menghasilkan informasi dalam menentukan jumlah cluster terbaik dengan cara melihat persentase hasil perbandingan antara jumlah cluster yang akan membentuk siku pada suatu titik (Madhulatha, T.S., 2012). Metode ini memberikan ide/gagasan dengan cara memilih nilai cluster dan kemudian menambah nilai cluster tersebut untuk dijadikan model data dalam penentuan cluster terbaik.Selain itu persentase perhitungan yang dihasilkan menjadi pembanding antara jumlah cluster yang ditambah. Hasil persentase yang berbeda dari setiap nilai cluster dapat ditunjukkan dengan menggunakan grafik sebagai sumber informasinya. Jika nilai cluster pertama dengan nilai cluster kedua memberikan sudut dalam grafik atau nilainya mengalami penurunan paling besar maka nilai cluster tersebut yang terbaik (Bholowalia, dkk. 2014). Untuk mendapatkan perbandingannya adalah dengan menghitung SSE (Sum of Square Error) dari masing-masing nilai cluster. Karena semakin besar jumlah cluster K maka nilai SSE akan semakin kecil. Rumus SSE pada K-Means (Kodinariya & Makwana, 2013).. 2 𝑊 (𝑆, 𝐶 ) = ∑𝐾 𝐾=1 ∑𝑖𝑆𝑘 || 𝑦𝑖 − 𝐶𝑘 ||. 17. ……...............……… (2.4).
(35) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Keterangan : S = K-cluster yang telah terbentuk yi = data y pada indeks ke i ck = rata – rata K-cluster pada nilai k (k=1,2,…K).. Setelah dilihat akan ada beberapa nilai K yang mengalami penurunan paling besar dan selanjutnya hasil dari nilai K akan turun secara perlahan-lahan sampai hasil dari nilai K tersebut stabil. Misalnya nilai cluster K=2 ke K=3, kemudian dari K=3 ke K=4, terlihat penurunan drastis membentuk siku pada titik K=3 maka nilai cluster k yang ideal adalah K=3 (Kodinariya & Makwana, 2013).. Gambar 2.2 Grafik metode Elbow (Kodinariya & Makwana, 2013). 18.
(36) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Algoritma Metode Elbow dalam menentukan nilai K pada K-Means (Bholowalia, dkk. 2014).: 1.. Mulai. 2.. Inisialisasi awal nilai K. 3.. Naikkan nilai K. 4.. Hitung hasil sum of square error dari tiap nilai K. 5.. Melihat hasil sum of square error dari nilai K yang turun secara drastis. 6.. Tetapkan nilai K yang berbentuk siku. 7.. Selesai. 2.4.2 Contoh penerapan Metode Elbow Berikut adalah contoh penerapan metode Elbow pada data daya serap ujian nasional mata pelajaran bahasa indonesia, yang telah melewati proses pengelompokan dengan menggunakan algoritma K-means. Di sini nilai K yang ditetapkan sebagai inisialisasi jumlah cluster adalah 2. Kemudian hanya mengambil 21 indikator pencapaian kompetensinya, serta data daya serap yang digunakan sebanyak 34 data. Contoh perhitungan penerapan metode Elbow diatas terlampir pada lampiran 1.. 19.
(37) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB III METODOLOGI PENELITIAN 3.1 Sumber Data Data yang digunakan untuk penelitian ini adalah data file yang berformat .xls yang diperoleh dari website milik Kementrian Pendidikan dan Kebudayaan yang dapat di akses melalui alamat http://litbang.kemdikbud.go.id/. Data ini merupakan data daya serap ujian nasional mata pelajaran Bahasa Indonesia jurusan IPA tahun ajaran 2014/2015, dengan memiliki 21 indikator pencapaian kompetensinya. Berikut ini adalah atribut yang dimiliki dan nilai kompetensi data daya serap ujian nasional mata pelajaran Bahasa Indonesia :. Tabel 3.1 Atribut Data data daya serap ujian nasional mata pelajaran Bahasa Indonesia tahun ajaran 2014/2015. Atribut. Keterangan. KODE SEKOLAH. Kode Sekolah. NAMA SEKOLAH. Nama Sekolah. JNS SEK. Jenis Sekolah (SMA/NA). STS SEK. Status Sekolah (Negeri/Swasta). BIND1. Melengkapi berbagai bentuk dan jenis paragraf dengan kalimat yang padu. BIND2. Melengkapi dialog drama. BIND3. Melengkapi larik puisi lama/baru (dengan kata kias/berlambang/ berima/bermajas. 20.
(38) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BIND4. Melengkapi paragraf dengan kata baku, kata serapan, kata berimbuhan, kata ulang, ungkapan, peribahasa. BIND5. Melengkapi teks pidato Menentukan isi dan simpulan grafik,. BIND6. diagram atau tabel Menentukan isi paragraf: fakta, opini, pernyataan/ jawaban pertanyaan sesuai isi, tujuan penulis, arti kata/istilah, isi biografi. BIND7. Menentukan isi puisi lama, pantun, BIND8. gurindam. BIND9. Menentukan kalimat resensi. BIND10. Menentukan kalimat kritik. BIND11. Menentukan opini penulis dan pihak yang dituju dalam tajuk rencana/editorial. BIND12. Menentukan unsur-unsur intrinsik dan ekstrinsik sastra Melayu klasik/hikayat. BIND13. Menentukan unsur-unsur intrinsik puisi. BIND14. Menulis paragraf padu. BIND15. Menentukan unsur-unsur intrinsik/ ekstrinsik novel/cerpen/drama. BIND16. Menentukan unsur-unsur paragraf, ide pokok, kalimat utama, kalimat penjelas. 21.
(39) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Menulis judul sesuai EYD. BIND17. Menulis karya ilmiah (latar belakang BIND18. dan rumusan masalah) Menulis surat resmi. BIND19. Menyunting kalimat dalam surat BIND20. resmi Menyunting penggunaan kalimat/frasa/kata penghubung/istilah dalam paragraf. BIND21. Pada data daya serap diatas, atribut yang akan dipakai dalam penelitian ini berjumlah 22 yaitu atribut nama sekolah, BIND1, BIND2, BIND3, BIND4, BIND5, BIND6, BIND7, BIND8, BIND9, BIND10, BIND11, BIND2, BIND13, BIND4, BIND5, BIND16, BIND17, BIND18, BIND19, BIND20, dan BIND21. Sehingga ketiga atribut yang sisa akan dihapus.. 3.2 Spesifikasi Alat Sistem akan dibangun menggunakan hardware dan software sebagai berikut : a.. Spesifikasi Hardware. 1.. Prosesor : intel core i3-2350M 2.30GHz. 2.. Memori : 2 GB. 3.. Harddisk : 500 GB. b.. Spesifikasi Software. 1.. Sistem Operasi Microsoft Windows 8.1. 2.. Compiler IDE NetBeans 8.1 untuk membuat interface dan source code sistem.. 22.
(40) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 3.3 Tahap – Tahap Penelitian 3.3.1 Studi Kasus Ujian Nasional merupakan salah satu upaya pemerintah dalam rangka memacu peningkatan mutu pendidikan. Ujian Nasional selain berfungsi untuk mengukur dan menilai pencapaian kompetensi lulusan dalam mata pelajaran tertentu, serta pemetaan mutu pendidikan pada tingkat pendidikan dasar dan menengah, juga berfungsi sebagai motivator bagi pihak-pihak terkait untuk bekerja lebih baik guna mencapai hasil ujian yang baik. Selain itu hasil dari ujian nasional juga berguna sebagai bahan pertimbangan seleksi masuk untuk pendidikan selanjutnya, berbagai upaya pasti dilakukan setiap sekolah-sekolah agar para peserta didiknya mampu memberikan hasil yang memuaskan. Untuk mendapatkan hasil ujian nasional yang memuaskan juga diperlukan upaya para guru dalam peningkatan kualitas belajar siswa, kemampuan masing-masing siswa dalam memahami materi bergantung pada daya serap setiap pelajaran. Daya serap merupakan kemampuan setiap siswa dalam menerima pelajaran dengan batas yang telah di tentukan. Daya serap dapat diperoleh oleh guru setelah selesai pembelajaran dan melakukan sebuah tes.. 3.3.2 Penelitian Pustaka Pada tahap ini peneliti melakukan studi literatur untuk memperoleh informasi tentang teori-teori teknik penambangan data khususnya tentang Algoritma K-means, yang dapat menunjang dan mendukung penelitian ini. Informasi yang digunakan berasal dari buku-buku, jurnal, dan karya ilmiah.. 3.3.3 Knowledge Discovery in Database (KDD) Pada Proses ini bertujuan untuk mengubah sebuah data mentah menjadi sebuah informasi yang berguna dan bermanfaat. Di Sini penulis menggunakan proses Knowledge Discovery in Database (KDD) diantaranya adalah pembersihan data, integrasi data, seleksi data, transformasi data, penambangan data, evaluasi pola, dan. 23.
(41) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. presentasi pengetahuan. Di sini Khusus pada tahap pembersihan data dan integrasi data, penulis akan menlakukannya secara manual menggunakan software microsoft excel. Kemudian tahap selanjutnya yaitu seleksi data, transformasi data, penambangan data, serta evaluasi pola akan dilakukan menggunakan sistem yang akan penulis bangun sebagai alat bantu untuk melakukan tahap-tahap tersebut. Lalu untuk tahap presentasi pengetahuan penulis akan menjelaskan hasil evaluasi sehingga informasi yang diperoleh dapat diterima oleh pihak-pihak yang membutuhkan.. 3.3.4 Pengembangan Perangkat Lunak Pada tahap seleksi data, transformasi data, dan penambangan data di dalam proses Knowledge Discovery in Database (KDD), penulis mengembangkan perangkat lunak sebagai alat untuk mengolah Dataset yang penulis miliki untuk mendapatkan informasi yang berguna. Metode yang digunakan oleh penulis dan pengembang sistem adalah metode waterfall. Metode ini merupakan metode yang paling sering digunakan oleh para pengembang perangkat lunak. Metode ini menggunakan sistem linier yaitu apa yang dilakukan pada tahap sebelumnya akan mempengaruhi tahap selanjutnya. Metode waterfall mempunyai langkah-langkah sebagai berikut:. 1.. Analisa Pada langkah ini analisa terhadap kebutuhan sistem. Pengumpulan data dalam tahap ini bisa dilakukan melalui sebuah penelitian, wawancara atau studi literatur. Seorang sistem analis bertugas dalam mencari informasi sebanyak mungkin dari user sehingga sistem yang dibuat dapat sesuai dengan kebutuhan user. Pada tahapan ini menghasilkan dokumen user requirement yang dapat digunakan sistem analis untuk menerjemahkan ke dalam bahasa pemrograman.. 24.
(42) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 2.. Desain Pada proses desain akan menerjemahkan syarat kebutuhan ke sebuah perancangan perangkat lunak yang dapat dapat diperkirakan sebelum diubah ke dalam bahasa pemrograman. Fokus dari proses ini pada struktur data, arsitektur perangkat lunak, representasi interface, dan detail algoritma. Tahapan ini akan menghasilkan dokumen yang disebut software requirement. Dokumen ini yang digunakan seorang programmer untuk membangun sistemnya.. 3.. Pemrograman Pemrograman. merupakan. penerjemahan. design. ke. dalam. bahasa. pemrograman. Pada tahap ini programmer akan mengubah proses transaksi yang diinginkan user ke dalam sistem yang dibangun.. 4.. Pengujian Perangkat Lunak Pada tahap pengujian perangkat lunak dilakukan setelah pemrograman selesai. Pengujian yang digunakan adalah membandingkan perhitungan manual dengan hasil yang diperoleh dari perangkat lunak. Tujuan pengujian ini adalah untuk menemukan Kesalahan-kesalahan yang terdapat pada perangkat lunak tersebut agar kemudian dapat diperbaiki.. 3.3.5. Analisis hasil clustering. Pada tahap ini akan dilakukan analisis pengujian validitas dengan membuat rencana pengujian Black Box untuk memeriksa semua fungsi pada perangkat lunak. Tahap berikutnya adalah pengujian anggota cluster dengan perhitungan manual dan menggunakan perangkat lunak. Tahap pengujian yang terakhir akan dilakukan pengujian nilai K untuk mendapatkan nilai K yang ideal dari data daya serap ujian nasional Bahasa Indonesia jurusan IPA tahun ajaran 2014/2015 menggunakan metode Elbow.. 25.
(43) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 3.3.6. Pembuatan Laporan Pada tahap ini merupakan tahap pembuatan laporan dari hasil analisis hasil. clustering ke dalam sebuah laporan tugas akhir.. 26.
(44) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB IV PEMROSESAN AWAL DAN PERANCANGAN PERANGKAT LUNAK PENAMBANGAN DATA. 4.1 Pemrosesan Awal 4.1.1 Pembersihan Data (Data Cleaning) Pembersihan data merupakan sebuah proses membersihkan data dari noise, contohnya data daya serap yang tidak terisi nilai apapun serta data-data yang tidak konsisten. Pada penelitian ini terdapat beberapa data daya serap yang tidak memiliki nilai apapun sehingga data seperti itu akan dihapus.. 4.1.2 Integrasi Data (Data Integration) Pada tahap integrasi ini merupakan tahap penggabungan data dari berbagai sumber. Data yang peneliti gunakan didapat dari situs Kemdikbud berupa data daya serap ujian nasional Bahasa Indonesia jurusan IPA tahun ajaran 2014/2015, beserta 21 indikator pencapaian kompetensinya. Data tersebut masih persekolah sehingga akan digabungkan menjadi 1 file excel berekstensi .xls.. 4.1.3 Seleksi Data (Data Selection) Pada tahap ini merupakan tahapan pemilihan (seleksi) data dari sekumpulan data, tahap ini harus dilakukan sebelum masuk kedalam proses KDD. Berikut merupakan daftar atribut yang tidak akan dipakai dalam proses clustering :. 27.
(45) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Tabel 4.1 Atribut yang tidak digunakan pada data daya serap No.. Nama Atribut. Keterangan. 1. KODE SEKOLAH. Kode sekolah. 2. JNS SEK. Jenis sekolah. 3. STS SEK. Status sekolah. Pada ketiga Atribut diatas merupakan atribut pendukung yang tidak digunakan dalam proses clustering. Sehingga hasil seleksi atribut dari data daya serap ujian nasional Bahasa Indonesia jurusan IPA tahun ajaran 2014/2015 yang akan digunakan dalam penelitian ini berjumlah 22 yaitu Nama sekolah dan ke 21 atribut indikator pencapaian kompetensinya.. 4.1.4 Transformasi Data (Data Transformation) Pada proses ini transformasi data yang dilakukan yaitu untuk data yang telah melewati tahap seleksi sehingga data tersebut dapat di proses pada penambangan data. Data yang tadi diseleksi akan dilakukan transformasi data dengan menyimpan data tersebut ke dalam bentuk array yang nantinya siap untuk masuk pada tahap penambangan data.. 4.2 Perancangan Perangkat Lunak Penambangan Data 4.2.1 Perancangan Umum 4.2.1.1 Input Masukan untuk sistem ini adalah data daya serap yang besal dari file yang berekstensi .xls yang dapat dipilih oleh pengguna. Pada sistem ini pengguna juga. 28.
(46) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. berperan untuk memilih atribut kompetensi yang nantinya digunakan dalam proses clustering, serta pengguna juga memasukkan nilai K pada textfield yang telah disediakan.. Data daya serap, atribut yang dipilih, tentukan nilai K. Clustering Menggunakan K-Means. Pengguna Hasil pengelompokan data daya serap. Gambar 4.1 Diagram Konteks. 4.2.1.2 Proses Proses pada sistem yang akan dibangun terdiri dari beberapa tahapan yang akan dilewati untuk dapat mengelompokkan data daya serap ujian nasional bahasa indonesia jurusan IPA tahun ajaran 2014/2015. Berikut adalah tahapannya : 1.. Pengambilan data daya serap yang telah melewati tahap preprocessing untuk digunakan pada proses penambangan data.. 2.. Memilih atribut kompetensi yang akan digunakan.. 3.. Menentukan nilai K.. 4.. Proses pengelompokan data menggunakan Algoritma K-Means.. 5.. Menganalisa hasil pengelompokan untuk masing-masing nilai K yang telah dijalankan dengan menggunakan metode Elbow.. 29.
(47) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Start. A. B Masukkan file. Tentukan centroid. Tampilkan Hasil Clustering. TIDAK Hitung jarak objek ke titik awal. File excel berekstensi .xls ?. Simpan Hasil Clustering YA. TIDAK. Kelompokkan objek untuk jarak terkecil. Cek data. File excel berektensi .xls. YA Tentukan centroid baru. End Data numerik ?. YA. Terdapat selisi pusat cluster lama dan baru?. TIDAK. B. Proses seleksi Atribut. Masukkan nilai K.. Proses Clustering K-Means. A. Gambar 4.2 Diagram Flowchart. 4.2.1.3 Output Hasil output yang diperoleh dari sistem yang akan dibangun adalah data hasil pengelompokan menggunakan Algoritma K-Means berdasarkan nilai K yang sebelumnya telah di tetapkan oleh pengguna.. 30.
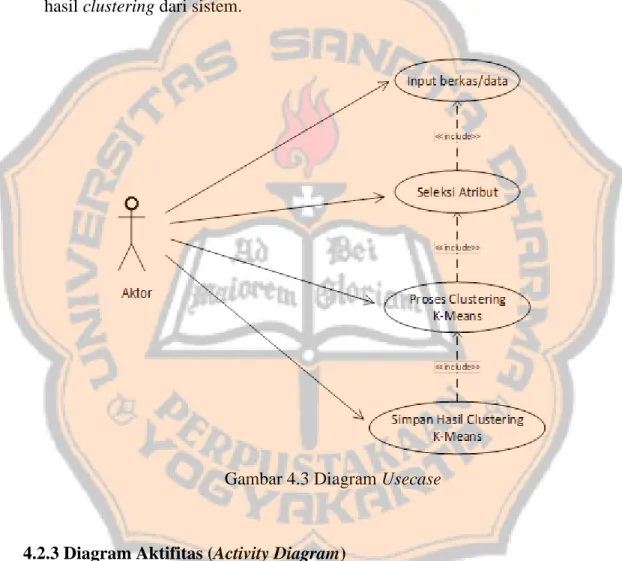
(48) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 4.2.2 Diagram Usecase Diagram Usecase merupakan sebuah gambaran interaksi antara pengguna (aktor) dengan sistem. Pada sistem yang akan dibangun pengguna (aktor) dapat memasukkan berkas/data yang akan dikelompokan, melakukan seleksi atribut yang akan di gunakan, melakukan proses clustering, dan melakukan proses penyimpanan hasil clustering dari sistem.. Gambar 4.3 Diagram Usecase. 4.2.3 Diagram Aktifitas (Activity Diagram) Diagram Aktifitas digunakan untuk mengambarkan aktivitas yang dilakukan oleh pengguna (user) dan sistem pada setiap usecase yang disebutkan pada gambar 4.3. Gambaran diagram aktivitas dari setiap usecase terlampir pada lampiran 7.. 31.
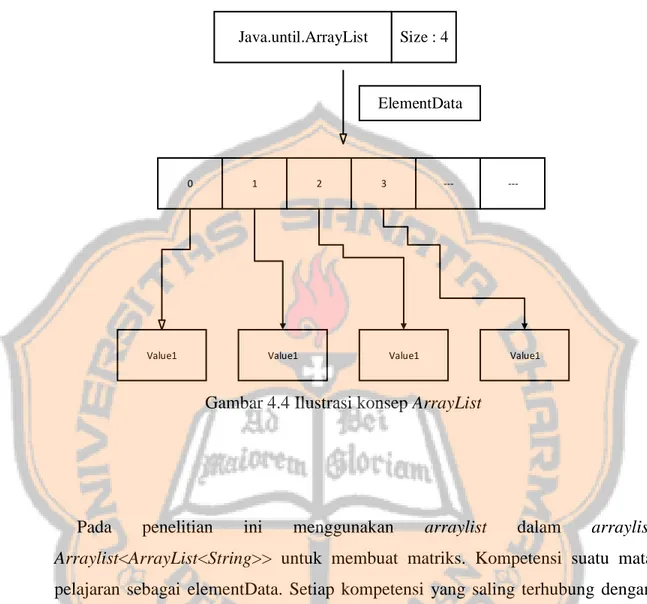
(49) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 4.2.4 Diagram Kelas (Class Diagram) Diagram kelas berguna untuk mengambarkan hubungan antar kelas dalam sistem, diagram kelas yang dibangun pada sistem ini terlampir pada lampiran 8.. 4.2.5 Diagram Sekuen (Sequence Diagram) Diagram sekuen adalah diagram yang memperlihatkan interaksi antar objek didalam sistem. Diagram sekuen pada sistem ini terdiri dari 4 sesuai dengan usecase. Diagram sekuen dapat dilihat pada lampiran 9.. 4.2.6 Perancangan Struktur Data Pada sistem pengelompokan data daya serap menggunakan metode K-means ini membutuhkan suatu tempat penyimpanan data yang tidak membutuhkan memori yang terlalu banyak dan tidak menghabiskan waktu yang cukup banyak ketika sistem dijalankan kerena dapat mengubah data dengan lebih efisien. Berdasarkan kebutuhan diatas penelitian ini akan mengunakan konsep struktur data arraylist. ArrayList adalah sebuah kelas yang dapat melakukan menyimpanan data berupa list object berbentuk array yang ukurannya dapat berubah secara dinamis sesuai dengan jumlah data yang dimasukkan. Berikut ilustrasi arrayList pada gambar 4.4 dibawah ini :. 32.
(50) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Size : 4. Java.until.ArrayList. ElementData. 0. 1. Value1. 2. 3. Value1. ---. Value1. ---. Value1. Gambar 4.4 Ilustrasi konsep ArrayList. Pada. penelitian. ini. menggunakan. arraylist. dalam. arraylist. Arraylist<ArrayList<String>> untuk membuat matriks. Kompetensi suatu mata pelajaran sebagai elementData. Setiap kompetensi yang saling terhubung dengan kompetensi lainnya akan berada dalam index yang sama pada arraylist. Objek arraylist akan selalu dibuat untuk setiap kode sekolah yang berbeda. Setelah membuat objek arraylist untuk setiap kode sekolah maka akan dibuat objek arraylist untuk menyatukan semua arraylist sebelumnya. Sebagai contoh perancangan dijelaskan pada gambar 4.5 dibawah ini :. 33.
(51) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Size : 4. Java.until.ArrayList. ElementData : kompetensi mapel. 0. 1. 3. Nama Sekolah. Nama Sekolah. Nama Sekolah. Nama Sekolah. 1. 2. 3. 4. 0. Nama Sekolah. 2. KOM1. 1. 1. Nama Sekolah. 2. KOM1. 3. Nama Sekolah. 2. KOM1. Nama Sekolah. 3. KOM1. 4. dst.... Gambar 4.5 Perancangan ArrayList. 4.2.7 Perancangan Antarmuka 4.2.6.1 Halaman Awal Perancangan antarmuka halaman awal dapat dilihat pada gambar 4.6 berikut ini :. Gambar 4.6 Antarmuka halaman awal. 34.
(52) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Halaman ini merupakan halaman yang akan pertama kali muncul saat program dijalankan, setelah itu akan menampilkan halaman data.. 4.2.5.2 Halaman Data Perancangan antarmuka halaman data dapat dilihat pada gambar 4.7 berikut ini :. Gambar 4.7 Antarmuka halaman Data. Halaman ini merupakan halaman utama dari sistem yang berfungsi sebagai sarana untuk memasukan data, seleksi atribut yang hendak digunakan, serta berfungsi untuk memberikan nilai K buat proses clustering K-Means. Pada halaman ini juga nantinya akan berfungsi untuk menampilkan hasil clustering K-Means dan melakukan proses penyimpanan.. 35.
(53) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 4.2.5.3 Halaman About Perancangan antarmuka halaman data dapat dilihat pada gambar 4.8 berikut ini :. Gambar 4.8 Antarmuka halaman Data Halaman ini merupakan halaman untuk menampilkan informasi tentang sistem.. 36.
(54) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. BAB V IMPLEMENTASI PENAMBANGAN DATA DAN ANALISIS HASIL 5.1 Implementasi Rancangan Perangkat Lunak Penambangan Data Perangkat lunak pengelompokan data daya serap ini menggunakan metode clustering K-Means memiliki 3 buah kelas.. 5.1.1 Implementasi Kelas Berikut ini merupakan setiap detail dari kelas untuk antarmuka pada perangkat lunak pengelompokan data daya serap, dapat dilihat pada tabel 5.1 dibawah ini. Tabel 5.1 Implementasi kelas awal ID Object. Jenis. Teks. Keterangan. judul_index1. Jlabel. Penerapan Algoritma K-. Judul perangkat. Means Untuk. lunak. Pengelompokan Sekolah Menengah Atas (Sma) judul_index2. Jlabel. Di Provinsi Diy. Judul perangkat. Berdasarkan Nilai Daya. lunak. Serap Ujian Nasional judul_index3. label_logo. Jlabel. Bahasa Indonesia. Judul perangkat. 2014/2015.. lunak. Jlabel. Logo perangkat lunak. 37.
(55) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. progress_bar. Jprogressbar. Bar proses dari parangkat lunak. judul_index4. Jlabel. Fakultas Sains Dan. Informasi. Teknologi Universitas. fakultas dan. Sanata Dharma. universitas pembuat perangkat lunak. judul_index5. Jlabel. Yogyakarta 2016/2017. Informasi fakultas dan universitas pembuat perangkat lunak. judul_index6. Jlabel. Desky Antonio Valdera. Informasi nama. Alatubir | Nim :. dan nim. 125314096. pembuat perangkat lunak. 38.
(56) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Implementasi antarmuka dari kelas awal yang merupakan halaman awal yang akan muncul saat perangkat lunak dijalankan, dapat dilihat pada gambar 5.1 berikut ini. :. Gambar 5.1 Implementasi Antarmuka Kelas Awal. Spesifikasi detail dari kelas Utama dapat dilihat pada tabel 5.2 berikut ini.. Tabel 5.2 Implementasi Kelas Utama ID Object. Jenis. Teks. Keterangan. label_judul_atas. Jlabel. Penerapan. Judul. Algoritma K-Means. perangakat. Untuk. lunak. Pengelompokan. 39.
(57) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Sekolah Menengah Atas (Sma) label_judul_tengah. Jlabel. Di Provinsi Diy. Judul. Berdasarkan Nilai. perangakat. Daya Serap Ujian. lunak. Nasional label_judul_bawah. Jlabel. Bahasa Indonesia. Judul. 2014/2015.. perangakat lunak. logo_kiri. Jlabel. Logo sebelah kiri. logo_kanan. Jlabel. Logo sebelah kanan. utama_tab. Jtabbedpane. Inisialisasi 2 tab Data dan About. table. Jtable. Tabel utama perangkat lunak. label_lokasi_file. Jlabel. Lokasi File. Keterangan lokasi file. tombol_browse. Jbutton. Browse. Tombol browse file pada perangkat lunak, bila di. 40.
(58) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. klik akan menampilkan direktori buat memilih file. kolom_lokasi_file. Jtextfield. Kolom keterangan lokasi file. jumlah_dt. Jlabel. Keterangan jumlah file yang tersedia. tableseleksiatribut. Jtable. Tabel yang berisi sejumlah atribut dari data yang diinputkan. label_seleksi_atribut. Jlabel. Seleksi Atribut. Judul seleksi atribut pada perangkat lunak. table_atribut2. Jtable. Tabel untuk sejumlah atribut yang dipilih.. tombol_pilih_atribut. Jbutton. -->. Keterangan pilih atribut. 41.
(59) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. ke kanan, bila di klik akan menambahkan atribut yang dipilih ke dalam tabel atribut terpilih. tombol_prosesing. Jbutton. Preprosesing. Tombol preposesing untuk melakukan proses seleksi atribut yang telah terpilih, bila di klik akan menampilan atribut yang telah terpilih pada tabel utama perangkat lunak.. tombol_hapus_atribut Jbutton. <--. Keterangan pilih atribut ke kiri, bila di. 42.
(60) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. klik akan menghapus atribut yang dipilih. label_proses. Jlabel. Keterangan bila proses preprosesing selesai.. textarea_hasil. Jtextarea. Menampilkan hasil proses clustering dari perangkat lunak.. kolom_nilai_k. Jtextfield. Untuk memasukkan jumlah cluster. tombol_proses. Jbutton. Proses. Tombol memulai proses clustering pada perangkat lunak.. label_nilaik. Jlabel. Nilai K :. Keterangan untuk nilai K. 43.
(61) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. label_nilaisse. Jlabel. Untuk nilai SSE metode Elbow. tombol_simpan. Jbutton. Simpan. Tombol untuk melakukan proses penyimpanan hasil clustering.. tombol_reset. Jbutton. Reset Sistem. Tombol untuk melakukan reset perangkat lunak.. notif_tersimpan. Jlabel. Untuk menampilkan status dari hasil yang penyimpanan perangkat lunak.. label_nama1. Jlabel. 44. Fakultas Sains Dan. Informasi. Teknologi. fakultas dan. Universitas Sanata. universitas. Dharma. pembuat.
(62) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. perangkat lunak label_nama2. Jlabel. Yogyakarta. Informasi. 2016/2017. fakultas dan universitas pembuat perangkat lunak. label_nama3. Jlabel. Desky Antonio. Informasi. Valdera Alatubir. nama Dan NIM Pembuat Perangkat Lunak. label_nama4. Jlabel. Nim : 125314096. Informasi nama Dan NIM Pembuat Perangkat Lunak. textarea_about. Jtextarea. Infomasi tentang perangkat lunak. label_nama_about1. Jlabel. 45. Fakultas Sains Dan. Informasi. Teknologi. fakultas dan. Universitas Sanata. universitas. Dharma. pembuat.
(63) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. perangkat lunak label_nama_about2. Jlabel. Yogyakarta. Informasi. 2016/2017. fakultas dan universitas pembuat perangkat lunak. label_nama_about3. Jlabel. Desky Antonio. Informasi. Valdera Alatubir. nama Dan NIM Pembuat Perangkat Lunak. label_nama_about4. Jlabel. Nim : 125314096. Informasi nama Dan NIM Pembuat Perangkat Lunak. Implementasi antarmuka dari kelas Utama untuk halaman utama yang terdiri dari 2 tab yaitu tab Data dan About, dapat dilihat pada gambar 5.2 dan 5.3 berikut.. 46.
(64) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Gambar 5.2 Implementasi Antarmuka Kelas Utama Tab Data. Gambar 5.3 Implementasi Antarmuka Kelas Utama Tab About. 47.
(65) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. Spesifikasi detail dari kelas KMeans dapat dilihat pada tabel 5.3 berikut ini.. Tabel 5.3 Implementasi kelas KMeans Id object. Jenis. findcentroidbaru() Float. Keterangan Untuk menentukan centroid baru. sequentialsearch() Int. Untuk mencari index nilai yang terkecil. min(). Static. Untuk menentukan nilai yang paling kecil. centroid(). Arraylist. Untuk menentukan centroid awal. 5.1.2. Implementasi Listing Program K-Means List<Float[]> listCtr_01 = new ArrayList<Float[]>(); public void KMeans(ArrayList<ArrayList<String>> arr, int jumlahCentroid, List<Float[]> listCtr) throws SQLException { int l = 0; listCtr_01 = listCtr; while (l == 0) { List<Double[]> listHasilHitung = new ArrayList<Double[]>(); boolean status = true; //hitungJarak listHasilHitung = hitungJarak(listCtr_01); int[] datacluster = new int[arrTampgindeksSekolah.size()]; datacluster = MenentukanCluster(listHasilHitung, arr); List<Float[]> listCtrBaru = new ArrayList<Float[]>(); Float[] ctrBaru = new Float[jumlahCentroid]; int index;. 48.
(66) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. for (int i = 0; i < listCtr_01.size(); i++) { ctrBaru = new Float[jumlahCentroid]; index = 0; for (int j = 0; j < listCtr_01.get(i).length; j++) { ctrBaru[index] = KMeans.getKmeans().findCentroidBaru(arr, datacluster, j, i); index++; } listCtrBaru.add(ctrBaru); } System.out.println("\nIterasi ke " + jmliterasi + "\n+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++"); for (int i = 0; i < listCtrBaru.size(); i++) { System.out.println("\n_____________________\n"); for (int j = 0; j < listCtrBaru.get(i).length; j++) { String satu = String.valueOf(listCtrBaru.get(i)[j]); String dua = String.valueOf(listCtr_01.get(i)[j]); System.out.print(satu + "\n" + dua + "\n\n"); // cetak perbandingan 2 nilai rata2 cluster sblum dan baru if (satu.equalsIgnoreCase(dua)) { status = true; } else { status = false; } } System.out.println("\n_____________________\n"); } System.out.println("\n+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ++++++"); //bandingin centroid lama sama centroid baru if (status == false) { jmliterasi++; //menambahkan nilai iterasi l = 0; listCtr_01 = listCtrBaru; //menyimpan nilai centroid lama } else { break;}}}. 49.
(67) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 5.1.3. Implementasi Listing Program Elbow double nilaiSSE = 0; for (int i = 0; i < TampungindeksSekolah.size(); i++) { double tambah2cluster = 0; System.out.println("Cluster " + i); System.out.println("_________________________________________________"); for (int n = 0; n < arrNilaiSekolah.size(); n++) { double sum = 0, rata2 = 0; int nilaiN = 0; for (int j = 0; j < TampungindeksSekolah.get(i).size(); j++) { System.out.println(arrTampgNilaiSekolah.get(TampungindeksSekolah.get(i).get(j)).get(n)); sum += Double.parseDouble(arrTampgNilaiSekolah.get(TampungindeksSekolah.get(i).get(j)).get(n)); nilaiN += 1; } rata2 = sum / nilaiN; double pankat = 0, sumpangkat = 0; for (int j = 0; j < TampungindeksSekolah.get(i).size(); j++) { pankat = Math.pow((Double.parseDouble(arrTampgNilaiSekolah.get(TampungindeksSekolah.get(i).get(j)).get(n)) - rata2), 2); sumpangkat += pankat; } System.out.println("-------------------"); System.out.print("sum = " + sumpangkat); System.out.println("\n"); tambah2cluster += sumpangkat; } System.out.println("_________________________________________________"); System.out.println("sum total cluster " + i + " = " + tambah2cluster); System.out.println("_________________________________________________\n"); nilaiSSE += tambah2cluster; } System.out.println("\n_________________________________________________"); System.out.println("Nilai SSE dengan K " + kolom_nilai_K.getText() + " = " + nilaiSSE); System.out.println("_________________________________________________\n");. 50.
(68) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 5.2 Analisis Hasil 5.2.1 Analisis Pengujian Validitas Perangkat Lunak (Black Box) 5.2.1.1 Rencana Pengujian Black Box Pada tabel 5.4 dibawah ini akan menjelaskan rencana pengujian dengan menggunakan metode black box.. Tabel 5.4 Rencana Pengujian Black Box No. Use Case. Butir Uji Pengujian input berkas data dari file. 1. Input Berkas/Data. Kasus Uji UC1-01. bertipe .xls Pengujian input berkas data dari file. UC1-02. selain bertipe .xls Pengujian memilih atribut yang 2. Seleksi Atribut. UC2-01. digunakan untuk clustering. Pengujian membatalkan pemilihan. UC2-02. atribut dengan menekan tombol “” 3 4. Proses Clustering K-Means. Pengujian melakukan proses clustering. UC3-01. K-Means. Simpan Hasil. Pengujian menyimpan hasil clustering. Clustering K-. K-Means ke dalam file bertipe .xls. UC4-01. Means. 5.2.1.2 Prosedur Pengujian Black Box dan Kasus Uji Setelah menyusun rencana pengujian pada tabel 5.4, maka akan dilakukan prosedur pengujian serta kasus uji yang terlampir pada lampiran 2.. 51.
(69) PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI. 5.2.1.3 Evaluasi Pengujian Black Box Seluruh hasil pengujian black box yang terlampir pada lampiran 2 menunjukan bahwa perangkat lunak sudah dapat berjalan dengan baik dan telah sesuai dengan perancangan yang sudah dibuat. Hal ini dapat dilihat dari semua fungsi yang telah berjalan sesuai dengan yang diharapkan. Perangkat lunak juga mampu menampilkan berbagai pesan kesalahan baik dari user maupun dari perangkat lunak sendiri.. 5.2.2 Pengujian Perbandingan Hasil Hitung Manual dengan Hasil Perangkat Lunak Data uji yang akan digunakan untuk perhitungan manual dan menggunakan perangkat lunak yaitu memakai 22 atribut dengan data sebanyak 137. Data uji ini diambil dari data daya serap ujian nasional Bahasa Indonesia SMA jurusan IPA di Provinsi DIY tahun ajaran 2014/2015. Uji coba akan dilakukan dalam 4 kali pengujian dengan jumlah data yg berbeda-beda. Contoh input data ujinya terlampir pada lampiran 3.. 5.2.2.1 Perhitungan Manual Pengujian Perhitungan manual menggunakan data daya serap ujian nasional Bahasa Indonesia SMA jurusan IPA di Provinsi DIY tahun ajaran 2014/2015. Proses perhitungan manual dilakukan dengan menggunakan aplikasi Microsoft Excel. Dalam proses perhitungan ini akan menetapkan nilai K = 2 sampai 3, untuk uji coba dengan jumlah data 34, 68, 102, dan 137. Proses perhitungan manual berserta dengan hasilnya terlampir pada lampiran 4.. 52.
Gambar


+7




Garis besar
Dokumen terkait
Pada saat uji oleh ahli materi ada catatan penting berkaitan dengan kemampuan komu- nikasi matematis siswa yang dapat difasilitasi oleh LKPD yang dikem- bangkan, dimana
Skripsi ini mengambil judul “PEREKRUTAN DAN PENAMPUNGAN PEREMPUAN DESA UNTUK DIPERDAGANGKAN SEBAGAI TENAGA KERJA INDONESIA: SEBELUM DAN SETELAH BERLAKUNYA UU NOMOR 21
Berdasarkan penelitian yang dilakukan, dapat ditarik kesimpulan bahwa aplikasi sistem rekomendasi dan monitoring pengerjaan servis mobil dibangun dengan menggunakan
Puji syukur kepada Tuhan Yang Maha Esa atas rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan skripsi dengan judul : Hubungan Antara Kesulitan Target
Dengan demikian pendidikan kewarganegaraan di perguruan tinggi saat ini dapat dijadikan sebagai sintesis antara “civic education”, “democracy education”,
Dari hasil tersebut dapat disimpulkan bahwa senyawa flavonoid hasil isolasi pada konsentrasi 0,6% dan 0,8% memiliki aktivitas mukolitik yang setara dengan
Museum Learning via Social and Mobile Technologies: (How) can online interactions enhance the visitor experience?, British Journal of Educational Technology,
Istirahat..
