besar dibandingkan dengan istilah yang berada pada description.
Lingkup Implemental
Lingkungan implementasi yang akan digunakan adalah sebagai berikut:
Perangkat Lunak :
• Sistem operasi Windows XP Professional • Java 1.6
• Apache Tomcat 6 • MySQL 5 Perangkat Keras :
• Processor Intel dual core 1.6 GB • RAM 1 GB
HASIL DAN PEMBAHASAN Koleksi Dokumen
Penelitian ini menggunakan koleksi dokumen RSS versi 2.0 yang didapatkan dari beberapa situs berita berbahasa Indonesia di antaranya situs berita Antara, Detik, Kompas, Liputan6, Okezone, dan Tempointeraktif, yang diunduh pada tanggal 22, 23 dan 27 Agustus 2009. Contoh dari salah satu dokumen RSS berita dapat dilihat pada Lampiran 1.
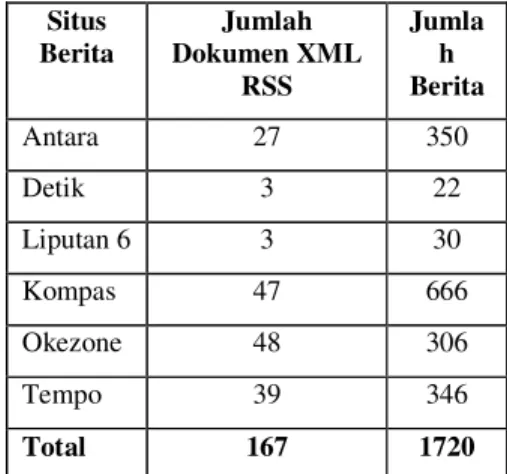
Untuk menguji kinerja sistem temu kembali informasi digunakan koleksi dokumen sebanyak 173 dokumen RSS. Dari 173 dokumen RSS yang dipergunakan hanya 167 dokumen yang terindeks oleh sistem dan diperoleh 1720 buah berita (Tabel 3). Hal ini dikarenakan beberapa dokumen RSS tidak memenuhi aturan penulisan XML yang benar.
Untuk melakukan uji coba, dibentuk daftar pasangan kueri dan jumlah dokumen yang relevan yang akan dipergunakan untuk mengukur kinerja sistem temu kembali informasi yang dibuat. Adapun daftar kueri yang akan diujikan terhadap dokumen dapat dilihat pada Tabel 4.
Tahap-tahap Penelitian
Text Operation
1. Parsing
Dokumen masukan diproses secara sekuensial dan menghasilkan sebuah token. Proses parsing dilakukan dalam dua tahapan yaitu:
Tabel 3 Situs berita dan jumlah RSS yang diunduh Situs Berita Jumlah Dokumen XML RSS Jumla h Berita Antara 27 350 Detik 3 22 Liputan 6 3 30 Kompas 47 666 Okezone 48 306 Tempo 39 346 Total 167 1720
Tabel 4 Daftar kueri untuk pengujian sistem
No Kueri Dokumen Relevan 1 Kebakaran 7 2 Gempa bumi 5 3 Inter Milan 15 4 Kebakaran hutan 5 5 Nuklir Iran 4 6 Pembunuhan Nasrudin 5 7 Tari pendet 29 8 Virus komputer 6 9 Pemakaman Michael Jackson 7 10 Pemilu di Afghanistan 7 a. Parsing tahap satu
Proses parsing tahap satu adalah sebagai berikut:
• Dokumen dimuat ke dalam memori, dengan menggunakan JDOM (external library yang digunakan dalam Java), kemudian dilakukan proses pembacaan secara sekuensial untuk mendapatkan setiap token berita yang ada di dalam dokumen RSS. Sebuah berita dalam dokumen RSS direpresentasikan dalam sebuah elemen item (Gambar 4) sehingga proses parsing dilakukan berdasarkan elemen tersebut untuk mendapatkan berita yang terdapat pada dokumen RSS.
Gambar 4 Representasi berita dalam dokumen RSS.
• Setiap token berita yang diperoleh dibentuk sebuah identitas yang unik yang akan digunakan sebagai nama berkas dari token berita tersebut dengan menggunakan teknik enkripsi MD5. Nama file dan token berita disimpan ke dalam basis data. Hasil dari proses parsing tahap satu dapat dilihat pada Lampiran 2.
Dari proses parsing tahap satu dihasilkan 1720 berita dari 167 dokumen RSS. b. Parsing tahap dua
Setiap token berita yang diperoleh dari tahap satu diproses kembali, parsing di sini bertujuan untuk mendapatkan token istilah (satuan perkata) dari token berita.
Tidak semua informasi yang ada pada token berita dipergunakan, hanya informasi yang tersimpan dalam elemen title dan description yang diolah, di mana elemen title dan description merepresentasikan judul dan deskripsi berita. Berikut ini adalah proses parsing tahap dua:
• Dengan menggunakan JDOM isi dari elemen item dan description diambil. • Proses pengambilan token istilah dengan
cara membaca satu persatu karakter. Sebuah karakter dapat berupa salah satu dari tiga jenis berikut:
o whitespace, berarti karakter ini merupakan karakter pemisah token o alphanumeric, berarti karakter ini
merupakan huruf atau angka
o other, berarti karakter ini tidak termasuk jenis-jenis di atas.
• Jika karakter yang ditemukan merupakan huruf atau angka maka karakter tersebut menjadi karakter pertama dari istilah. • Karakter-karakter selanjutnya menjadi
bagian dari istilah tersebut hingga ditemukan karakter whitespace atau akhir dari istilah.
Istilah yang didapatkan dari hasil parsing tahap kedua disebut token istilah, yang kemudian diubah ke dalam bentuk lower case (Ridha 2002).
2. Stemming
Mekanisme stemming digunakan untuk mengatasi masalah variasi dalam bentuk kata yang sebenarnya memiliki makna yang sama. Penelitian ini menggabungkan metode Tala stemmer yang telah diadopsi dengan penggunaan kamus kata dasar bahasa Indonesia dan gugus konsonan.
Beberapa fungsi pendukung yang digunakan dalam stemming antara lain a. isBasicWord(s), mengembalikan true bila
kata s adalah kata dasar selainnya false; b. isVocal(c), mengembalikan true bila
karakter c termasuk ke dalam huruf vokal (a, i, u, e, o) selainya false;
c. substring(i, n), mengembalikan potongan karakter dimulai dari indeks ke i sampai indeks ke n dari karakter token istilah; d. numberOfVocals(s), mengembalikan
jumlah huruf vokal dalam kata.
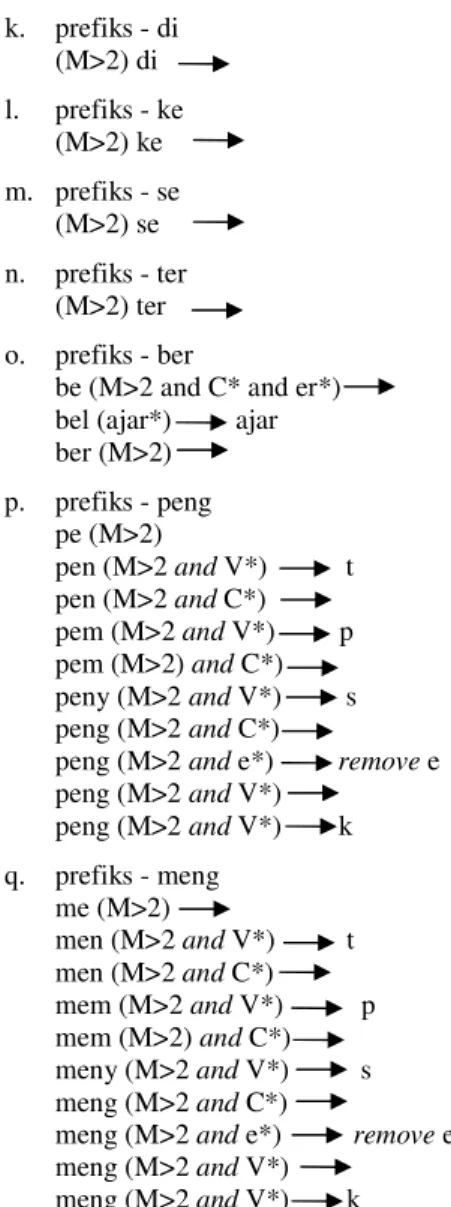
berikut adalah aturan dan proses pemotongan untuk tiap imbuhan yang diadopsi dari aturan pemotongan pada penelitian Aries (2005): a. partikel - lah (M>2) lah b. partikel - kah (M>2) kah c. partikel - tah (M>2) tah d. partikel - pun (M>2) pun
e. kata ganti kepunyaan - ku (M>2) ku
f. kata ganti kepunyaan - mu (M>2) mu
g. kata ganti kepunyaan - nya (M>2) nya h. sufiks - i (M>2) i i. sufiks - an (M>2) an j. sufiks - kan (M>2) kan
k. prefiks - di (M>2) di l. prefiks - ke (M>2) ke m. prefiks - se (M>2) se n. prefiks - ter (M>2) ter o. prefiks - ber
be (M>2 and C* and er*) bel (ajar*) ajar ber (M>2) p. prefiks - peng pe (M>2) pen (M>2 and V*) t pen (M>2 and C*) pem (M>2 and V*) p pem (M>2) and C*) peny (M>2 and V*) s peng (M>2 and C*)
peng (M>2 and e*) remove e peng (M>2 and V*) peng (M>2 and V*) k q. prefiks - meng me (M>2) men (M>2 and V*) t men (M>2 and C*) mem (M>2 and V*) p mem (M>2) and C*) meny (M>2 and V*) s meng (M>2 and C*)
meng (M>2 and e*) remove e meng (M>2 and V*)
meng (M>2 and V*) k
Dalam hal ini V* : diawali dengan huruf vokal, C* : diawali dengan huruf konsonan, dan e* : diawali dengan huruf e, dan M adalah jumlah minimal ukuran hasil stem.
Proses stemming dilakukan dengan langkah-langkah sebagai berikut :
a. Kata yang akan di-stemming pertama kali dicari ke dalam kamus. Jika kata tersebut ditemukan, maka kata tersebut adalah kata dasar, dan proses stemming dihentikan, b. Kata asli, kata hasil pemotongan dan
imbuhan yang dipotong dicatat ke dalam koleksi hasil potong,
c. Daftar kata pada koleksi hasil potong diiterasi untuk proses pengecekan dan pemotongan imbuhan,
d. Penghilangan partikel. Langkah ini dilakukan untuk menghilangkan partikel,
e. Penghilangan kata ganti kepunyaan. Langkah ini dilakukan untuk menghilangkan kata ganti kepunyaan,
f. Penghilangan sufiks. Langkah ini dilakukan untuk menghilangkan sufiks,
g. Penghilangan prefiks. Untuk prefiks terdapat tambahan aturan berupa penyisipan dan penghilangan karakter. Dilanjutkan dengan pemeriksaan apakah masih ada prefiks yang tersisa, jika ada maka dihilangkan. Jika tidak ada lagi maka lakukan langkah selanjutnya, h. Setelah tidak ada lagi imbuhan yang tersisa,
kemudian kata-kata yang ada pada koleksi hasil potong dicari ke dalam kamus kata dasar, urutan pengecekan dilakukan berdasarkan ukuran pemotongan imbuhan yang terbesar. Jika kata dasar tersebut ditemukan maka kata hasil proses stemming tersebut dikembalikan dan proses dihentikan,
i. Jika semua langkah telah dilakukan tetapi kata dasar tersebut tidak ditemukan pada kamus maka kata asli sebelum dilakukan proses stemming yang akan dikembalikan.
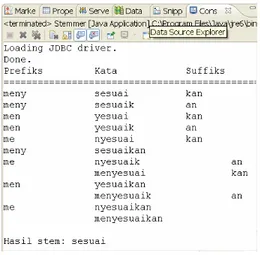
Sebelum menggunakan stemming istilah unik yang dihasilkan oleh proses Indexing sebesar 10.053. Hal ini berbeda ketika stemming ditambahkan pada saat proses pengindexan ke dalam sistem, jumlah istilah unik menjadi sebesar 7.459. Hasil pengujian menunjukkan bahwa stemming dapat mengurangi jumlah token istilah dalam penelitian sebesar 25.08 %. Contoh penerapan stemming yang telah diurutkan berdasarkan ukuran imbuhan yang terbesar dapat dilihat pada Gambar 5 dan 6.
Gambar 6 Stemming dengan penyisipan huruf.
Indexing
Proses pengindeksan dokumen dilakukan sebagai berikut:
1. proses pengekstrakan token-token istilah yang didapat dari hasil text operation, 2. jika token istilah termasuk ke dalam daftar
kata buang maka token dilewati,
3. token istilah diubah ke dalam bentuk kata dasar (stemming),
4. untuk setiap pasang token istilah dan token berita, ditambahkan informasi ke dalam posting (Gambar 7) dan dictionary (Gambar 8) yang bersesuaian,
5. proses token item berikutnya hingga seluruh dokumen dalam koleksi ditambahkan ke dalam indeks,
6. setelah semua dokumen terindeks proses pembobotan tf-idf dilakukan terhadap masing-masing pasangan token istilah dan token berita. Untuk token istilah yang terdapat pada tubuh berita pembobotan dilakukan secara normal, sedangkan untuk token istilah yang merupakan bagian dari judul dilakukan pembobotan dengan memodifikasi nilai frekuensi. Contoh hasil dari pembobotan yang dilakukan terhadap token istilah yang telah terindeks dapat dilihat pada Gambar 9.
Pembobotan terhadap token istilah yang merupakan bagian dari judul adalah sebagai berikut : j i freq i title i freq title i freq j i freq j i tf , max ) 2 , ( ) , , ( , × + − = ,
di mana besaran angka dua adalah asumsi penulis untuk memboboti token istilah yang
terdapat pada judul, dengan asumsi bahwa token istilah yang terdapat pada judul berita dianggap lebih penting dari pada tubuh berita. Untuk token istilah yang tidak berada pada judul maka nilai freqi,tittle=0.
Gambar 7 Tabel posting.
Gambar 8 Tabel dictionary.
Gambar 9 Hasil pembobotan tf-idf. Untuk pengindeksan teks kueri digunakan tahap satu, dua, empat dan lima. Tahap tiga dilewati karena pada saat pengindeksan teks kueri tidak akan dimasukkan ke dalam tabel posting dan dictionary, pengindeksan disini hanya bertujuan untuk mendapatkan frekuensi istilah. Untuk tahap lima berbeda dengan pengindeksan dokumen, di sini teks kueri
diboboti dengan menggunakan pembobotan sebagai berikut: × × + = t df N q i freq i q i freq q i w log , max , 5 . 0 5 . 0 , . Searching
Pada tahap ini dilakukan pencarian kata kueri ke dalam inverted index untuk menemukan dokumen mana saja yang mengandung kata kueri.
Setelah ditemukan, kemudian dilakukan proses pengukuran tingkat kedekatan antara kueri dan dokumen dengan menggunakan ukuran kesamaan cosine, sehingga setiap dokumen memiliki nilai kedekatan dengan kueri. Contoh hasil penghitungan nilai cosine sebelum diurutkan dengan menggunakan kueri uji coba ”nuklir Iran” dapat dlihat pada Gambar 10.
Gambar 10 Nilai cosine untuk kueri uji coba ”nuklir Iran".
Gambar 11 Daftar dokumen dan nilai cosine yang telah terurut berdasarkan kueri
masukan ”nuklir Iran”.
Ranking
Pengurutan atau ranking dilakukan berdasarkan nilai kesamaan yang dimiliki setiap dokumen dari hasil penghitungan cosine pada tahap searching. Pengurutan nilai kesamaan tersebut dilakukan secara asscending untuk mendapatkan urutan dokumen yang memiliki tingkat kesamaan mulai dari yang paling tinggi sampai yang terendah.
Hasil dari pengurutan inilah yang akan dikembalikan kepada pengguna sebagai hasil dari pencarian berdasarkan teks kueri yang diinputkan oleh pengguna.
Pengurutan yang dilakukan oleh sistem berdasarkan nilai cosine hasil dari tahap searching dapat dilihat pada Gambar 11.
User Interface
User interface dari sistem temu kembali pada penelitian ini dapat dilihat pada Gambar 12.
Gambar 12 User interface dari sistem temu kembali.
Evaluasi sistem temu kembali informasi Evaluasi yang digunakan dalam penelitian ini adalah evaluasi untuk mengukur keefektifan sistem dalam menemukan dokumen yang relevan terhadap kueri masukan pengguna.
Pengujian dilakukan sebanyak dua kali, pengujian pertama dilakukan dengan memberikan bobot lebih pada judul dan yang kedua adalah pengujian dengan menggunakan pembobotan secara normal.
Dari hasil pengujian (Lampiran 3), dapat dilihat bahwa jumlah dokumen relevan dan jumlah dokumen yang ditemukembalikan pada masing-masing pembobotan hasilnya sama.
Perbedaan dapat terjadi pada urutan dokumen relevan yang ditemukembalikan oleh sistem. Hal ini dikarenakan dokumen yang tidak relevan tetapi mengandung kata kueri pada judul dokumen, dapat memiliki nilai cosine yang lebih tinggi dari pada dokumen yang relevan tetapi tidak mengandung kata kueri pada judul.
Dari tabel recall precision kesepuluh kueri pada Lampiran 4 dan grafik average precision pada Lampiran 5 terlihat bahwa 90% hasil pencarian mengembalikan recall sebesar 100%, salah satunya pada kueri pengujian kesatu, dan recall terendah sebesar 85,71% pada kueri pengujian ke sepuluh.
Penurunan recall ini terjadi pada kueri kesepuluh yaitu ”pemilu di Afghanistan” setelah dilakukan pengamatan, yang menjadi faktor penyebabnya adalah dari sisi penulisan. Masalah penulisan terjadi pada saat dokumen relevan yang tidak ditemukembalikan memiliki cara penulisan nama negara yang berbeda dengan kueri, pada dokumen relevan yang tidak dapat ditemukembalikan oleh sistem tertulis ”Afganistan” hal ini tentunya akan dianggap berbeda dengan kata ”Afghanistan” pada kueri.
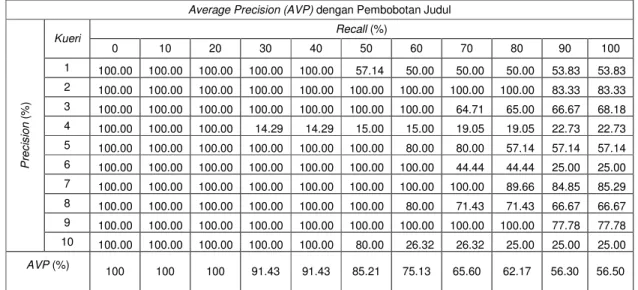
Untuk melihat kinerja sistem berdasarkan nilai average precision masing-masing pengujian dapat dilihat pada Tabel 5, dan
grafik average precision pada Gambar 13. Pada tabel dan grafik average precision terlihat bahwa dengan pembobotan normal pada tingkat recall 30% sampai dengan 50% dan 70% sampai dengan 100%, sistem memiliki tingkat precision rata-rata lebih tinggi dibandingkan dengan yang menggunakan pembobotan lebih pada judul, hanya pada saat tingkat recall 60% sistem dengan pembobotan lebih pada judul memiliki nilai precision rata-rata lebih tinggi dari pembobotan normal. Dengan demikian dapat disimpulkan bahwa penggunaan pembobotan normal memberikan hasil yang lebih baik dari pada penggunaan pembobotan judul.
Tabel 5 Average precision dengan pembobotan judul
Average Precision (AVP) dengan Pembobotan Judul Recall (%) Kueri 0 10 20 30 40 50 60 70 80 90 100 1 100.00 100.00 100.00 100.00 100.00 57.14 50.00 50.00 50.00 53.83 53.83 2 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 83.33 83.33 3 100.00 100.00 100.00 100.00 100.00 100.00 100.00 64.71 65.00 66.67 68.18 4 100.00 100.00 100.00 14.29 14.29 15.00 15.00 19.05 19.05 22.73 22.73 5 100.00 100.00 100.00 100.00 100.00 100.00 80.00 80.00 57.14 57.14 57.14 6 100.00 100.00 100.00 100.00 100.00 100.00 100.00 44.44 44.44 25.00 25.00 7 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 89.66 84.85 85.29 8 100.00 100.00 100.00 100.00 100.00 100.00 80.00 71.43 71.43 66.67 66.67 9 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 77.78 77.78 P rec is ion ( %) 10 100.00 100.00 100.00 100.00 100.00 80.00 26.32 26.32 25.00 25.00 25.00 AVP (%) 100 100 100 91.43 91.43 85.21 75.13 65.60 62.17 56.30 56.50
Tabel 6 Average precision dengan pembobotan normal
Average Precision (AVP) dengan pembobotan normal Recall (%) Kueri 0 10 20 30 40 50 60 70 80 90 100 1 100.00 100.00 100.00 100.00 100.00 57.14 50.00 50.00 30.00 30.43 30.43 2 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 3 100.00 100.00 100.00 100.00 100.00 100.00 100.00 84.62 80.00 70.00 71.43 4 100.00 100.00 100.00 28.57 28.57 21.43 21.43 25.00 25.00 27.78 27.78 5 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 50.00 50.00 50.00 6 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 29.41 29.41 7 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 90.32 87.88 8 100.00 100.00 100.00 100.00 100.00 100.00 57.14 45.45 45.45 50.00 50.00 9 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 100.00 Pre c is ion ( %) 10 100.00 100.00 100.00 100.00 100.00 100.00 21.74 21.74 22.22 22.22 22.22 AVP (%) 100 100 100 92.86 92.86 87.86 75.03 72.68 65.27 57.02 56.92