ABSTRAK
Teknologi web dan jumlah pengguna internet berkembang dengan sangat pesat. Perkembangan media online mendorong munculnya informasi tekstual yang tidak terbatas. Twitter merupakan salah satu media online yang memungkinkan pengguna untuk mengirimkan pesan. Pesan yang ada pada Twitter dapat digunakan untuk menganalisis sentimen konsumen terhadap suatu produk. Salah satu cara untuk melakukan analisis sentimen yaitu Naïve Bayes Classifier (NBC). NBC adalah salah satu teknik klasifikasi yang digunakan untuk mengklasifikasi kalimat menjadi positif, negatif, ataupun netral. Untuk membuat sebuah aplikasi analisis sentimen diperlukan data training dan data testing. Data yang digunakan yaitu tweets yang berhubungan dengan beberapa provider telekomunikasi di Indonesia. Tahap-tahap pembuatan data training dimulai dari pengambilan data pada Twitter, pre processing, manual judgment, dan yang terakhir selection. Data training yang digunakan ada 1457 tweet yang diambil antara 15 Mei 2015 sampai tanggal 22 Mei 2015. Ada beberapa data testing
yang digunakan salah satunya yaitu dengan menggunakan data training itu sendiri. Analisis sentimen pada aplikasi memiliki tingkat keakuratan sekitar 70%. Persentase tweets pada beberapa provider telekomunikasi cenderung lebih banyak tweets negatif dan netral daripada positif.
vi
UNIVERSITAS KRISTEN MARANATHA
ABSTRACT
Web technology and the number of Internet users growing very rapidly. The development of online media to encourage the emergence of textual information which is not limited. Twitter is one of the online media that allows users to send messages. Existing messages on Twitter can be used to analyze consumer sentiment to a product. One way to perform sentiment analysis that Naïve Bayes Classifier (NBC). NBC is one of the classification techniques are used to classify the sentence be positive, negative, or neutral. To create an application sentiment analysis required training data and data testing. The data used are tweets related to multiple telecommunications providers in Indonesia. The stages of manufacture of the training data starting from the collection of data on Twitter, pre-processing, manual judgment, and the final selection. Training data are used there in 1457 tweets were taken between May 15, 2015 until May 22, 2015. There are some data testing that used one of them is by using the training data itself. Sentiment analysis on the application have the accuracy level of about 70%. The percentage of tweets in some telecom providers tend to be more negative tweets and neutral rather than positive.
DAFTAR ISI
PERNYATAAN ORISINALITAS LAPORAN PENELITIAN ... ii
PERNYATAAN PUBLIKASI LAPORAN PENELITIAN ... iii
PRAKATA ... iv
ABSTRAK ... v
ABSTRACT ... vi
DAFTAR ISI ... vii
DAFTAR GAMBAR ... xii
DAFTAR TABEL ... xiv
DAFTAR NOTASI/LAMBANG ... xvi
BAB 1 PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 2
1.3. Tujuan ... 2
1.4. Batasan Masalah... 2
1.5. Sistematika Penyajian ... 3
BAB 2 KAJIAN TEORI ... 4
2.1. Data Mining ... 4
2.2. Analisis Sentimen ... 4
2.3. Konsep Klasifikasi ... 5
2.4. Mutual Information ... 5
2.5. Naïve Bayes Classifier ... 6
2.6. Tokenizing... 7
2.7. Formalization ... 8
2.8. Stopping ... 8
2.9. N-Grams ... 8
2.10. Twitter & Twitter API ... 8
2.11. Evaluasi Tingkat Keberhasilan ... 10
BAB 3 ANALISIS DAN DISAIN ... 12
viii
UNIVERSITAS KRISTEN MARANATHA
3.1.1. Contoh Penerapan Analisis ... 12
3.1.1.1. Tokenizing ... 13
3.1.1.2. Formalization ... 14
3.1.1.3. Stopping ... 14
3.1.1.4. N-Grams... 15
3.1.1.5. Mutual Information ... 18
3.1.1.6. Proses Training Naïve Bayes ... 19
3.1.1.7. Testing ... 21
3.2. Gambaran Keseluruhan ... 22
3.2.1. Persyaratan Antarmuka Eksternal ... 22
3.2.2. Antarmuka dengan Pengguna ... 22
3.2.3. Antarmuka Perangkat Keras ... 22
3.2.3.1. Spesifikasi Antarmuka Perangkat Keras Saat Pengembangan ... 23
3.2.3.2. Spesifikasi Antarmuka Perangkat Keras End-User ... 23
3.2.4. Antarmuka Perangkat Lunak... 23
3.3. Disain Perangkat Lunak ... 23
3.3.1. Pemodelan Perangkat Lunak ... 23
3.3.1.1. Arsitektur Perangkat Lunak ... 24
3.3.1.1.1 Arsitektur Pembuatan Data Training ... 24
3.3.1.1.2 Arsitektur Pemilihan Term ... 25
3.3.1.1.3 Arsitektur Analisis Sentimen ... 27
3.3.1.2. Use Case ... 28
3.3.1.3. Use Case Skenario ... 28
3.3.1.3.1 Use Case Do Manual Judgment ... 28
3.3.1.3.2 Use Case Preprocessing ... 29
3.3.1.3.3 Use Case Calculate Mutual Information ... 29
3.3.1.3.4 Use Case Get Tweets ... 29
3.3.1.3.5 Use Case Do Classification ... 30
3.3.1.4. Activity Diagram ... 31
3.3.1.4.1 Activity Diagram Get Tweets ... 31
3.3.1.4.2 Activity Diagram Pre Processing ... 32
3.3.1.4.4 Activity Diagram Calculate Mutual Information ... 34
3.3.1.4.5 Activity Diagram Do Classification ... 35
3.3.2. Disain Penyimpanan Data ... 36
3.3.2.1. Entity Relationship Diagram (ERD) ... 36
3.3.2.2. Transfofmasi ERD ke dalam Tabel ... 36
3.3.2.2.1 Tabel Topic ... 36
3.3.2.2.2 Tabel Data Training ... 36
3.3.2.2.3 Tabel Data Testing ... 37
3.3.3. Disain Antarmuka ... 38
3.3.3.1. Rancangan Halaman Menu ... 38
3.3.3.2. Rancangan Halaman Get Training Data ... 38
3.3.3.3. Rancangan Halaman Manual Judgment ... 39
3.3.3.4. Rancangan Halaman Select Training Data ... 40
3.3.3.5. Rancangan Halaman Pre Processing... 40
3.3.3.6. Rancangan Halaman Get Testing Data ... 41
3.3.3.7. Rancangan Halaman Analayze ... 42
3.3.3.8. Rancangan Halaman Streaming Tweets ... 42
BAB 4 PENGEMBANGAN PERANGKAT LUNAK ... 44
4.1. Implementasi Class ... 44
4.1.1. Class Pre Processing ... 45
4.1.1.1. Method Tokenizing ... 46
4.1.1.2. Method Formalization... 46
4.1.1.3. Method Stopping... 47
4.1.1.4. Method NGram ... 48
4.1.2. Class Mutual Information ... 49
4.1.3. Class Tweet ... 51
4.1.4. Class Attribute ... 52
4.1.5. Class Classification ... 52
4.1.6. Class Sentence ... 54
4.1.7. Class Gram ... 54
4.1.8. Class TestSentence ... 55
x
UNIVERSITAS KRISTEN MARANATHA
4.2.1. Halaman Menu ... 56
4.2.2. Halaman Get Training Data ... 57
4.2.3. Halaman Manual Judgment... 58
4.2.4. Halaman Select Training Data ... 58
4.2.5. Halaman Pre Processing ... 59
4.2.6. Halaman Pre Processing Sentence ... 60
4.2.7. Halaman Pre Processing Tokenization ... 60
4.2.8. Halaman Pre Processing Formalization ... 61
4.2.9. Halaman Pre Processing Stopping ... 61
4.2.10. Halaman Pre Processing N Gram ... 62
4.2.11. Halaman Pre Processing Result MI ... 62
4.2.12. Halaman Pre Processing Selection ... 63
4.2.13. Halaman Get Testing Data ... 63
4.2.14. Halaman Analyze ... 64
4.2.15. Halaman Streaming Tweets ... 65
BAB 5 TESTING DAN EVALUASI SISTEM ... 66
5.1.1. Halaman Menu ... 66
5.1.2. Halaman Get Training Data ... 67
5.1.3. Halaman Manual Judgment... 68
5.1.4. Halaman Select Training Data ... 69
5.1.5. Halaman Pre Processing ... 69
5.1.6. Halaman Get Testing Data ... 71
5.1.7. Halaman Analayze ... 72
5.1.8. Halaman Streaming Tweets ... 72
5.1.9. Hasil Manual Judgment Data Training ... 73
5.1.10. Hasil Testing Analisis Sentimen pada Data Training ... 76
5.1.11. Hasil Testing Analisis Sentimen pada Data Testing ... 76
5.1.12. Hasil Testing Analisis Sentimen pada Data Testing Stream ... 78
5.1.13. Hasil Testing Dengan Memperhitungkan Jumlah Keyword ... 79
5.2. Hasil Evaluasi Tingkat Keberhasilan ... 79
BAB 6 KESIMPULAN DAN SARAN ... 81
xii
UNIVERSITAS KRISTEN MARANATHA
DAFTAR GAMBAR
Gambar 2.1 Contoh Autentikasi Twitter API ... 9
Gambar 2.2 Data Uji dengan Dua Kelas ... 10
Gambar 2.3 Dua Contoh Data Uji ... 11
Gambar 3.1 Arsitektur Pengambilan Data Training ... 24
Gambar 3.2 Arsitektur Pemilihan Term ... 25
Gambar 3.3 Arsitektur Proses Analisis Sentimen ... 27
Gambar 3.4 Use Case ... 28
Gambar 3.5 Activity Diagram Get Tweets ... 31
Gambar 3.6 Activity Diagram Pre Processing ... 32
Gambar 3.7 Activity Diagram Manual Judgment ... 33
Gambar 3.8 Activity Diagram Mutual Information ... 34
Gambar 3.9 Activity Diagram Do Classification ... 35
Gambar 3.10 Entity Relationship Diagram (ERD) ... 36
Gambar 3.11 Rancangan Halaman Menu ... 38
Gambar 3.12 Gambar Rancangan Get Training Data ... 38
Gambar 3.13 Rancangan Halaman Manual Judgment ... 39
Gambar 3.14 Rancangan Halaman Select Training Data... 40
Gambar 3.15 Rancangan Halaman Pre Processing ... 40
Gambar 3.16 Rancangan Halaman Get Testing Data ... 41
Gambar 3.17 Rancangan Halaman Analyze ... 42
Gambar 3.18 Rancangan Halaman Streaming Tweet ... 42
Gambar 4.1 Class Diagram Sistem Analisis Sentimen Pada Twitter... 44
Gambar 4.2 Class Preprocessing ... 45
Gambar 4.3 Method Tokenizing ... 46
Gambar 4.4 Method Formalization ... 47
Gambar 4.5 Method Stopping ... 48
Gambar 4.6 Method Unigram ... 48
Gambar 4.7 Method Bigram ... 49
Gambar 4.9 Method CalculateMI ... 50
Gambar 4.10 Class Tweet ... 51
Gambar 4.11 Class Attribute ... 52
Gambar 4.12 Class Classification ... 52
Gambar 4.13 Method testingNaiveBayes ... 53
Gambar 4.14 Class Sentence ... 54
Gambar 4.15 Class Gram ... 54
Gambar 4.16 Class TestSentence ... 55
Gambar 4.17 Halaman Menu ... 56
Gambar 4.18 Halaman Get Training Data ... 57
Gambar 4.19 Halaman Manual Judgment ... 58
Gambar 4.20 Halaman Select Training Data ... 58
Gambar 4.21 Halaman Pre Processing ... 59
Gambar 4.22 Halaman Pre Processing Sentence ... 60
Gambar 4.23 Halaman Pre Processing Tokenization ... 60
Gambar 4.24 Halaman Pre Processing Formalization ... 61
Gambar 4.25 Halaman Pre Processing Stopping ... 61
Gambar 4.26 Halaman Pre Processing N Gram ... 62
Gambar 4.27 Halaman Pre Processing Mutual Information ... 62
Gambar 4.28 Halaman Pre Processing Selection ... 63
Gambar 4.29 Halaman Get Data Testing ... 63
Gambar 4.30 Halaman Analyze ... 64
xiv
UNIVERSITAS KRISTEN MARANATHA
DAFTAR TABEL
Tabel 2.1 Tabel Mutual Information ... 6
Tabel 3.1 Kumpulan Kalimat ... 13
Tabel 3.2 Kalimat setelah dilakukan Tokenizing ... 13
Tabel 3.3 Kalimat setelah proses Formalization ... 14
Tabel 3.4 Kalimat setelah proses Stopping ... 14
Tabel 3.5 Kalimat Setelah Proses Unigram dan Bigram... 15
Tabel 3.6 Tabel Unigram Positif ... 16
Tabel 3.7 Tabel Bigram Positif ... 17
Tabel 3.8 Tabel Unigram Negatif ... 17
Tabel 3.9 Tabel Bigram Negatif... 17
Tabel 3.10 Tabel N-grams Netral... 18
Tabel 3.11 Tabel Hasil Mutual Information Class Positif ... 18
Tabel 3.12 Tabel Hasil Mutual Information Class Negatif... 19
Tabel 3.13 Tabel Hasil Mutual Information Class Netral... 19
Tabel 3.14 Tabel Data Training Naïve Bayes ... 19
Tabel 3.15 Tabel Proses Naïve Bayes ... 20
Tabel 3.16 Tabel Nilai Probabilistik ... 20
Tabel 3.17 Tabel Hasil Nilai Probabilistik dengan Laplacian Smoothing ... 21
Tabel 3.18 Tabel Data Testing dalam Format Naïve Bayes ... 21
Tabel 3.19 Tabel Topic ... 36
Tabel 3.20 Tabel Data Training ... 37
Tabel 3.21 Tabel Data Testing ... 37
Tabel 4.1 Fungsi Method dari Kelas Pre Processing ... 45
Tabel 4.2 Fungsi Method pada Kelas Mutual Information ... 50
Tabel 4.3 Fungsi Method pada Kelas Tweet ... 51
Tabel 5.1 Blackbox Testing Halaman Menu... 66
Tabel 5.2 Blackbox Testing Halaman Get Training Data ... 67
Tabel 5.3 Blackbox Testing Halaman Manual Judgment ... 68
Tabel 5.5 Blackbox Testing Halaman Pre Processing ... 69
Tabel 5.6 Blackbox Testing Halaman Get Testing Data... 71
Tabel 5.7 Blackbox Testing Halaman Analyze... 72
Tabel 5.8 Blackbox Testing Halaman Streaming Tweets ... 72
Tabel 5.9 Contoh Retweet ... 73
Tabel 5.10 Contoh Tweets per Kategori ... 74
Tabel 5.11 Hasil Manual Judgment ... 75
Tabel 5.12 Hasil Persentase Manual Judgment... 75
Tabel 5.13 Persentase Terkategori ... 76
Tabel 5.14 Matrix Confusion ... 76
Tabel 5.15 Hasil Testing pada Data Testing ... 77
Tabel 5.16 Hasil Testing yang Tidak Sesuai ... 77
Tabel 5.17 Hasil Streaming Tweets ... 78
Tabel 5.18 Hasil Persentasi dengan Memperhitungkan Jumlah Keyword ... 79
Tabel 5.19 Perbandingan Hasil Persentase Manual Judgment oleh Tiga Evaluator .. 80
Tabel 5.20 Hasil Testing Manual Judgment Evaluator A ... 80
Tabel 5.21 Hasil Testing Manual Judgment Evaluator B ... 80
xvi
UNIVERSITAS KRISTEN MARANATHA
DAFTAR NOTASI/LAMBANG
Jenis Notasi/Lambang Nama Arti
ERD Entitas Menunjukkan sebuah
objek yang dapat
dibedakan dengan
objek lainnya
ERD Atribut Mendeskripsikan
karakter entitas
ERD Relasi Menunjukkan adanya
hubungan diantara
sejumlah entitas yang
berbeda
ERD Garis (one to
many)
Penghubung antar
relasi dan entitas
dimana satu entitas
dapat memiliki lebih
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Pada masa ini teknologi web dan jumlah pengguna internet berkembang dengan sangat pesat. Perkembangan media online mendorong munculnya informasi tekstual yang tidak terbatas. Informasi tekstual dibagi menjadi dua yaitu fakta dan opini. Fakta merupakan ekspresi objektif mengenai sesuatu kejadian sedangkan opini adalah ekspresi subjektif yang menggambarkan sentimen orang, pendapat atau perasaan. Salah satu media online yang paling banyak digunakan yaitu Twitter.
Twitter merupakan salah satu media sosial yang memiliki banyak pengguna di Indonesia. Indonesia menjadi pengguna twitter ke lima terbanyak di seluruh dunia pada Maret 2013 dengan jumlah pengguna 29.000.000 diikuti peringkat diatasnya ada U.K., Japan, Brazil, USA dengan jumlah pengguna secara berurutan 32.000.000 pengguna, 34.000.000 pengguna, 41.000.000 pengguna, 143.000.000 pengguna. Dan Jakarta yang merupakan ibukota negara Indonesia adalah kota dengan jumlah Tweet terbanyak yaitu 2,4 % dari 10,6 milliar Tweet yang ada di seluruh dunia pada Maret 2013 (data di ambil dari socialbreakers.com dan mediabistro.com). Sangat banyaknya opini pada sosial media yang beredar setiap harinya, pengolahan data text dalam jumlah besar sangat diperlukan.
Perkembangan data mining yang pesat tidak terlepas dari perkembangan tekonologi informasi yang memungkinkan data tekstual yang berjumlah besar terakumulasi. Proses untuk memahami, mengekstrak, dan mengolah data tekstual untuk mendapatkan informasi sentimen disebut dengan analisis sentimen. Analisis sentimen biasa digunakan untuk menganalisis tiap pernyataan di media online, apakah kalimat tersebut menyatakan aspek positif, negatif, ataupun netral. Seiring dengan semakin dibutuhkannya data mining, muncul beberapa algoritma untuk mengklasifikasi data tekstual dalam jumlah besar, salah satunya yaitu algoritma Naïve Bayes.
2
UNIVERSITAS KRISTEN MARANATHA berdasarkan pengalaman di masa sebelumnya. Kelebihan Naïve Nayes adalah sederhana dan cepat, tetapi memiliki akurasi yang cukup tinggi.
1.2. Rumusan Masalah
Berdasarkan latar belakang pada bagian 1.1, maka dirumuskan masalah sebagai berikut:
1. Bagaimana cara kerja metode Naive Bayes Classifier yang digunakan dalam analisis sentimen terhadap opini berbahasa Indonesia yang diambil dari Twitter ?
2. Bagaimana perbandingan hasil analisis sentimen dari beberapa provider telekomunikasi?
3. Bagaimana cara melakukan analisis sentimen provider telekomunikasi pada Twitter secara otomatis ?
1.3. Tujuan
Berdasarkan rumusan masalah pada bagian 1.2, maka tujuan dari penelitian ini adalah membuat aplikasi analisis sentimen terhadap provider telekomunikasi pada twitter secara otomatis dengan menggunakan metode klasifikasi Naïve Bayes.
1.4. Batasan Masalah
Untuk memfokuskan permasalahan yang dibahas, dilakukan pembatasan ruang lingkup permasalahan yang dibahas, yaitu:
1. Opini hanya terbatas pada bahasa Indonesia.
2. Data training yang digunakan adalah opini terhadap provider X dan Y, yang diambil dari Tweet pengguna provider antara tanggal 15 Mei 2015 sampai tanggal 22 Mei 2015.
3
1.5. Sistematika Penyajian
Sistematika pembahasan dari penyusunan laporan ini adalah sebagai berikut:
BAB I. Pendahuluan
Bab ini berisi tentang pendahuluan yang terdiri dari latar belakang, rumusan masalah, tujuan, batasan masalah, dan sistematika penyajian laporan tugas akhir.
BAB II. Kajian Teori
Bab ini berisi tentang penjelasan teori-teori yang berkaitan dengan pembuatan dan pendukung perangkat lunak.
BAB III. Analisis dan Disain
Bab ini berisi tentang penjelasan analisis, gambaran arsitektur keseluruhan, dan disain perangkat lunak.
BAB IV. Pengembangan Perangkat Lunak
Bab ini berisi tentang penjelasan perencanaan tahap implementasi modul, penjelasan mengenai analisis dyari algoritma yang digunakan, dan implementasi antarmuka.
BAB V. Testing dan Evaluasi Sistem
Bab ini berisi tentang penjelasan rencana pengujian perangkat lunak yang akan dilakukan.
BAB VI. Kesimpulan dan Saran
12
UNIVERSITAS KRISTEN MARANATHA
BAB 3
ANALISIS DAN DISAIN
Pada bab ini akan dijelaskan mengenai analisis, gambaran arsitektur keseluruhan, dan disain sistem analisis sentimen.
3.1. Analisis
Aplikasi ini merupakan aplikasi untuk menganalisis Tweet terhadap provider telekomunikasi, apakah masuk dalam kategori positif, negatif ataupun netral. Tweet yang diklasifikasi hanya terbatasa pada bahasa Indonesia, dan data akan diambil dengan menggunakan Twitter API.
Terdapat dua tipe data yaitu data training dan data testing. Data training yaitu kumpulan Tweet tentang provider x dan y yang diambil pada jangka waktu tertentu kemudian dilakukan klasifikasi secara manual (manual judgment). Sistem telah menyediakan sebuah form untuk memudahkan user untuk melakukan klasifikasi secara manual. Manual judgment dilakukan oleh tiga orang dan hasilnya akan dibandingkan. Data testing yaitu data yang diperoleh dari Twitter, dan data tersebeut akan digunakan untuk melakukan testing klasifikasi secara otomatis.
Ada beberapa tahapan pada untuk membentuk data training, diantaranya yaitu manual tagging, pre-processing, selelction. Pada tahap awal, kalimat – kalimat dikategorikan kedalam 3 file teks yang berbeda. Setelah itu dilakukan tahap pre-processing pada setiap kalimat di masing - masing file teks dan akan menghasilkan term-term. Lalu dilanjutkan dengan proses selection, pada proses ini kumpulan term tersebut akan dihitung dengan rumus dan akan diurutkan dari yang terbesar. Hasilnya akan diambil sebanyak n terbesar dan akan menjadi atribut pada data trainig.
3.1.1. Contoh Penerapan Analisis
13
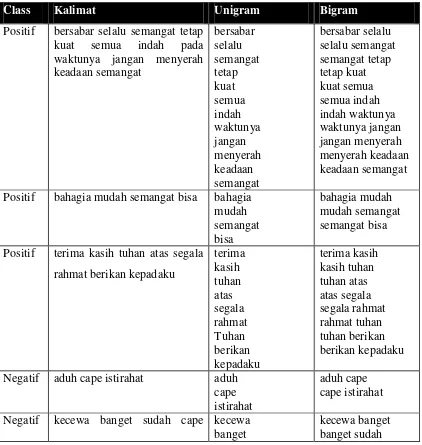
Tabel 3.1 Kumpulan Kalimat
Positif bersabar, selalu semangat, tetap kuat, dan semua akan indah pada waktunya.. Jgn menyerah dengan keadaan semangat!!
bahagia itu mdh. Semangat!! Bisa!!
Terima kasih Tuhan atas segala rahmat yang telah Tuhan berikan kepadaku.
Negatif Aduh....Cape istirahat dlu
kecewa banget, udah cape2 ngerjain tetapi hasil tdk sesuai.. ga ada niat bljr
Netral Selamat siang
Setelah sekumpulan kalimat tersebut telah dikategorikan secara manual atau yang biasa disebut dengan manual tagging, maka langkah selanjutnya yaitu proses pre-processing. Pre-processing terdiri dari beberapa proses yaitu tokenizing, formalization, stopping, dan n-grams.
3.1.1.1. Tokenizing
Pada proses tokenizing setiap kalimat akan dibagi menjadi beberapa bagian (token). Tidak hanya itu, dalam tahap ini semua tanda baca akan dihapus. Dan juga setiap kata yang berawalan dengan huruf kapital akan diubah menjadi huruf kecil. Tabel 3.2 merupakan hasil kalimat setelah dilakukan tokenizing.
Tabel 3.2 Kalimat setelah dilakukan Tokenizing
Positif bersabar selalu semangat tetap kuat dan semua akan indah pada waktunya jgn menyerah dengan keadaan semangat
bahagia itu mdh semangat bisa
terima kasih tuhan atas segala rahmat yang telah tuhan berikan kepadaku Negatif aduh cape istirahat dlu
kecewa banget udah cape ngerjain tetapi hasil tdk sesuai ga ada niat bljr
14
UNIVERSITAS KRISTEN MARANATHA
3.1.1.2. Formalization
Proses selanjutnya yaitu proses formalization. Pada tahap ini setiap token dengan kata yang tidak baku akan diubah menjadi kata baku. Misalnya kata „jgn‟
diubah menjadi „jangan‟, kata „ga‟ diubah menjadi „tidak‟. Kamus formalization yang digunakan didapat dari sebuah library natural language processing Tim Lab Grafika dan Intelegensia Buatan dari Sekolah Teknik Elektro dan Informatika Institut Teknologi Bandung khusus untuk metode “IndonesianSentenceFormalization” serta ditambahkan beberapa kata yang perlu ditambahkan untuk penelitian seperti kata
„trobel‟ menjadi „masalah‟ atau misalkan kata „lemot‟ menjadi „lambat. Tabel 3.3 merupakan hasil setelah dilakukan proses formatlization.
Tabel 3.3 Kalimat setelah proses Formalization
Positif bersabar selalu semangat tetap kuat dan semua akan indah pada waktunya jangan menyerah dengan keadaan semangat
bahagia itu mudah semangat bisa
terima kasih tuhan atas segala rahmat yang telah tuhan berikan kepadaku Negatif aduh cape istirahat dulu
kecewa banget sudah cape ngerjain tetapi hasil tidak sesuai tidak ada niat belajar
Netral selamat siang
3.1.1.3. Stopping
Tahap selanjutnya yaitu stopping. Pada tahap akan menghapus seluruh kata penghubung, artinya setiap kata-kata yang tidak bermakna akan dihapus. Kata-kata
yang akan dihapus yaitu „dan‟, „akan‟, „pada‟, „dengan‟, „itu‟, „yang‟, „kau‟, „banget‟,
„tetapi‟, „telah‟, „dulu‟ dan „makin‟. Tabel 3.4 merupakan hasil dari proses stopping. Tabel 3.4 Kalimat setelah proses Stopping
Positif bersabar selalu semangat tetap kuat semua indah pada waktunya jangan menyerah keadaan semangat
bahagia mudah semangat bisa
15
kecewa banget sudah cape ngerjain hasil tidak sesuai tidak ada niat belajar
Netral selamat siang
3.1.1.4. N-Grams
Proses selanjutnya yaitu n-grams. Pada tahap ini sistem akan mengambil sejumlah n kata sebagai suatu term dan menghitung berapa banyak kata itu muncul. N-grams yang digunakan yaitu bigram dan unigram. Hasil n-grams dapat dilihat pada tabel 3.5.
Tabel 3.5 Kalimat Setelah Proses Unigram dan Bigram
Class Kalimat Unigram Bigram
Positif bersabar selalu semangat tetap kuat semua indah pada waktunya jangan menyerah keadaan semangat Positif bahagia mudah semangat bisa bahagia
mudah Negatif aduh cape istirahat aduh
16
UNIVERSITAS KRISTEN MARANATHA
Class Kalimat Unigram Bigram
ngerjain hasil tidak sesuai sudah cape
Negatif tidak ada niat belajar tidak ada
Netral selamat siang selamat
siang
selamat siang
Tabel 3.5 merupakan hasil setelah dilakukan bigram dan unigram. Setelah itu, term akan dihitung sesuai dengan kemunculan di setiap dokumen. Pada tabel di bawah ini merupakan hasil frekuensi yang muncul pada setiap term.
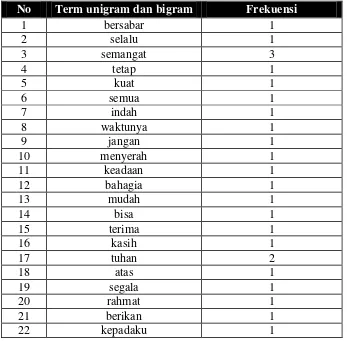
Tabel 3.6 Tabel Unigram Positif
No Term unigram dan bigram Frekuensi
17
Tabel 3.7 Tabel Bigram Positif
No Term unigram dan bigram Frekuensi
1 selalu semangat 1
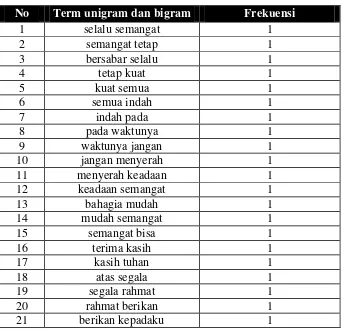
Tabel 3.8 Tabel Unigram Negatif
No Term unigram dan bigram Frekuensi
1 aduh 1
Tabel 3.9 Tabel Bigram Negatif
No Term unigram dan bigram Frekuensi
18
UNIVERSITAS KRISTEN MARANATHA
No Term unigram dan bigram Frekuensi
2 cape istirahat 1
Tabel 3.10 Tabel N-grams Netral
No Term unigram dan bigram Frekuensi
1 selamat 1
2 siang 1
3 selamat siang 1
3.1.1.5. Mutual Information
Pada sub bab ini akan menjelaskan tahap selanjutnya setelah tahap preprocessing. Setelah frekuensi kemunculan setiap term diketahui, maka akan dilakukan penyeleksian term. Caranya dengan menghitung berapa banyak jumlah term x di class y dan class non y. Lalu dimasukkkan ke dalam rumus mutual information. Contoh untuk term „semangat‟, jumlah term „semangat‟ pada class
„positif‟ ada 3, sedangkan pada class selain positif (negatif, netral) ada 0. Sehingga nilai N11 dan N10 pada rumus MI secara berurutan adalah 3 dan 0. Untuk mencari nilai N01 dengan cara menghitung jumlah term selain term „semangat‟ pada class positif, sedangkan N00 menghitung jumlah term selain term „semangat‟ pada class selain positif yaitu pada class negatif dan netral. Nilai N01 dan N00 secara berurutan yaitu 43 dan 30. Lalu setiap variabel tersebut akan dimasukkan ke dalam rumus MI. Tujuan dari MI yaitu memilih term yang mempunyai peranan penting dalam setiap class.
Tabel 3.11 Tabel Hasil Mutual Information Class Positif
Term Hasil MI
19
Term Hasil MI
tuhan 0.003773987
indah 0.00053165
Tabel 3.12 Tabel Hasil Mutual Information Class Negatif
Term Hasil MI
cape 0.023696812
tidak 0.023696812
kecewa 0.01070534
Tabel 3.13 Tabel Hasil Mutual Information Class Netral
Term Hasil MI
selamat 0.074252384
siang 0.074252384
selamat siang 0.074252384
Tabel 3.11 , 3.12, dan 3.13 merupakan hasil dari penghitungan mutual information yang sudah diambil tiga terbesar dari masing-masing class. Jadi term yang paling berperan pada class positif yaitu „semangat‟ dan „tuhan‟, pada class
negatif yaitu „cape‟ dan ‟tidak‟, serta pada netral yaitu „siang‟dan „selamat siang‟.
3.1.1.6. Proses Training Naïve Bayes
Term yang sudah terseleksi digunakan untuk keyword pada proses training Naïve Bayes. Tabel 3.14 merupakan tabel untuk proses training Naïve Bayes dengan mengambil dua teratas pada setiap class.
Tabel 3.14 Tabel Data Training Naïve Bayes
20
UNIVERSITAS KRISTEN MARANATHA Sistem akan memeriksa setiap kalimat untuk setiap term. Jika sebuah kalimat mengandung keyword makan akan diberi nilai 1 sedangkan jika tidak mengandung keyword maka akan diberi nilai 0. Berikut contoh-contoh kalimat dalam pembentukan data training :
1. Mendapat pencerahan dari Tuhan mebuatku menjadi semangat kembali. 2. Cape banget sih kuliah, banyak sekali yang harus diselesaikan.
3. Siang ini mendapat dukungan dari teman-teman membuatku menjadi semangat.
4. Basket dilapangan terbuka pada siang hari membuat menjadi cepat cape. 5. Selamat siang para hadirin sekalian.
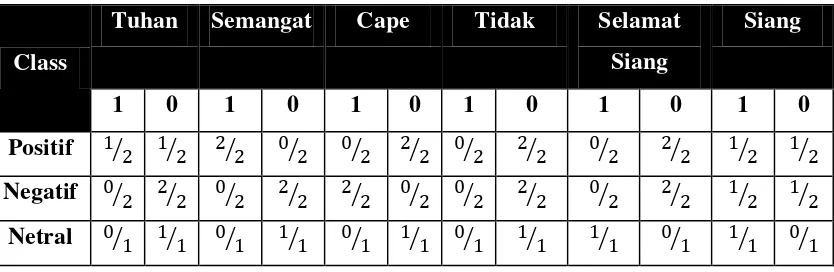
Tabel 3.15 Tabel Proses Naïve Bayes
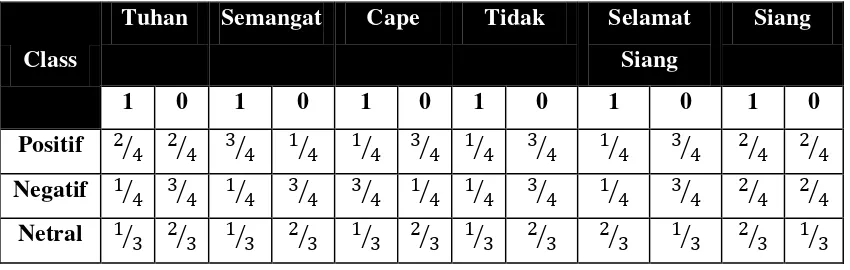
No Tuhan Semangat Cape Tidak Selamat Siang Siang Class
Langkah selanjutnya, sistem akan menghitung total kemunculan masing-masing keyword pada setiap class, lalu dibagi dengan total keseluruhan kemunculan atribut dari masin-masin class. Sehingga didapatkan nilai probabilistik sebagai berikut:
Tabel 3.16 Tabel Nilai Probabilistik
21
Pada tabel 3.16 terdapat nilai probabilistik yang bernilai 0. Oleh karena itu perlu dilakukan penambahan agar tidak ada nilai probabilistik yang bernilai nol. Proses penambahan jika terdapat nilai 0 disebut dengan Laplacian Smoothing. Setiap nilai akan ditambahkan satu. Berikut hasil dari proses Laplacian Smoothing pada tabel 3.17 :
Tabel 3.17 Tabel Hasil Nilai Probabilistik dengan Laplacian Smoothing
Class
Setelah proses training selesai maka akan dilakukan pengujian. Data yang digunakan pada saat testing yaitu data yang berasal dari twitter. Setiap kalimat dari data testing akan dimasukkan ke dalam kategori positif, negatif atau netral. Berikut adalah contoh kalimat untuk data testing:
“Semangat untuk teman-teman yang bertanding pada siang hari ini, Tuhan sertai kalian!”
Langkah pertama yaitu mengubah kalimat testing ini ke dalam format Naïve Bayes dan dihitung menggunakan rumus | | * P(Y). Berikut proses testing:
Tabel 3.18 Tabel Data Testing dalam Format Naïve Bayes
Semangat Tuhan Cape Tidak Selamat Siang Siang
1 1 0 0 0 1
Lalu cari nilai P(Y) pada masing-masing class: a) P(„Positif‟) = ⁄ = 0.4
22 netral secara berurutan bernilai 0.0125 dan 0.014815.
3.2. Gambaran Keseluruhan
Pada bagian ini akan dijelaskan mengenai fitur pada aplikasi yang akan dibangun.
3.2.1. Persyaratan Antarmuka Eksternal
Perangkat lunak ini memiliki persyaratan-persyaratan antar muka eksternal sebagai berikut:
1. Dibutuhkan koneksi internet untuk mengambil data dari Twitter. 2. Data kalimat yang diambil harus berbahasa Indonesia
3.2.2. Antarmuka dengan Pengguna
Pada bagian ini akan dijelaskan tentang persyaratan antarmuka dengan pengguna atau user:
1. User dapat melihat hasil dari setiap tahap dalam preprocessing 2. User dapat melakukan klasifikasi secara otomatis.
3.2.3. Antarmuka Perangkat Keras
23
3.2.3.1. Spesifikasi Antarmuka Perangkat Keras Saat Pengembangan
Antarmuka Perangkat Keras yang digunakan saat pengembangan aplikasi memiliki spesifikasi sebagai berikut :
1. Processor Intel i5-2410M, 2.3Ghz 2. RAM 4GB.
3. Harddisk 1 TB. 4. Mouse
5. Keyboard
3.2.3.2. Spesifikasi Antarmuka Perangkat Keras End-User
Antarmuka Perangkat Keras minimal yang digunakan untuk end-user untuk penggunaan aplikasi adalah sebagai berikut :
1. Microsoft Windows 7. 2. RAM 2GB.
3. Hard Disk 80 GB.
4. Processor Intel Core 2 Duo. 5. Monitor
6. Epson TM-u220 Series. 7. Mouse
8. Keyboard
3.2.4. Antarmuka Perangkat Lunak
Di bagian ini akan dijelaskan antarmuka perangkat lunak yang diperlukan untuk menjalankan perangkat lunak ini sebagai berikut :
1. Sistem operasi Windows 7 (direkomendasikan)/ Windows 8 2. Visual Studio 2012
3. SQL Server Management Studio
3.3. Disain Perangkat Lunak
Disain Perangkat Lunak terdiri atas pemodelan perangkat lunak, disain penyimpanan data dan disain antarmuka, dengan penjelasan sebagai berikut :
3.3.1. Pemodelan Perangkat Lunak
24
UNIVERSITAS KRISTEN MARANATHA
3.3.1.1. Arsitektur Perangkat Lunak
Arsitektur pada sistem analisis sentimen terhadap provider akan dibagi menjadi tiga bagian yaitu arsitektur pengambilan data training, arsitekur pemilihan term, dan arsitektur sistem analisis.
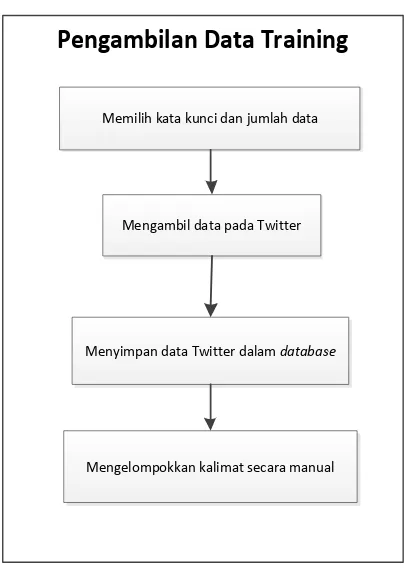
3.3.1.1.1 Arsitektur Pembuatan Data Training
Mengambil data pada Twitter Memilih kata kunci dan jumlah data
Menyimpan data Twitter dalam database
Mengelompokkan kalimat secara manual
Pengambilan Data Training
Gambar 3.1 Arsitektur Pengambilan Data Training
Gambar 3.1 menunjukkan arsitektur proses dalam pengambilan data training yang akan dibuat pada sistem. Langkah-langkah proses pengambilan data training adalah sebagai berikut :
1. User memilih kata kunci dan jumlah data yang akan diambil dalam pencarian Tweets.
2. Sistem akan mengambil data pada Twitter dengan menggunakan Twitter API. Diperlukan consumer key, consumer secret, access token, dan access token secret.
3. Data yang sudah diambil tersebut akan disimpan pada database.
25
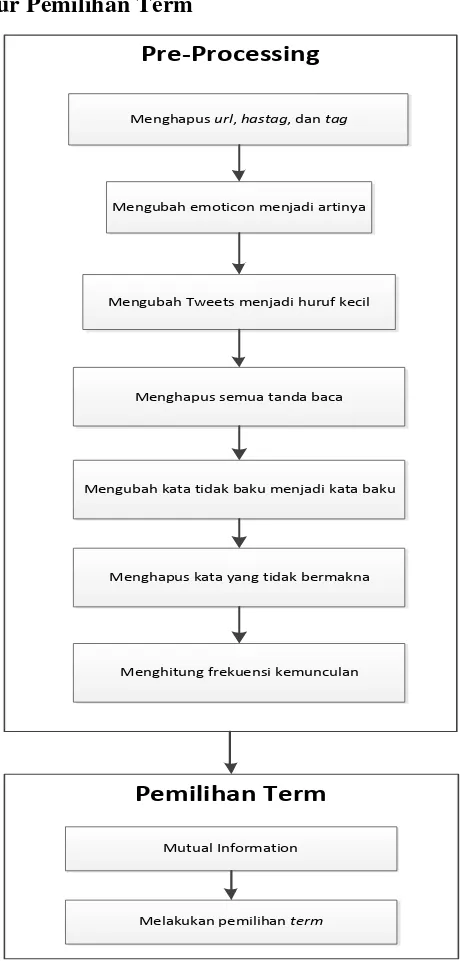
3.3.1.1.2 Arsitektur Pemilihan Term
Mengubah emoticon menjadi artinya Menghapus url, hastag, dan tag
Mengubah Tweets menjadi huruf kecil
Menghapus semua tanda baca Pre-Processing
Mengubah kata tidak baku menjadi kata baku
Menghapus kata yang tidak bermakna
Menghitung frekuensi kemunculan
Pemilihan Term
Mutual Information
Melakukan pemilihan term
Gambar 3.2 Arsitektur Pemilihan Term
Gambar 3.2 menunjukan arsitektur pemilihan term yang akan dibuat dalam sistem. Langkah-langkah proses pemilihan term adalah sebagai berikut:
1. Sebelum proses pemilihan term dilakukan preprocessing pada data training yang sudah dikelompokkan menjadi tiga kategori. Berikut tahap-tahap pada preprocessing :
26
UNIVERSITAS KRISTEN MARANATHA b. Mengubah emoticon pada Tweets sesuai dengan arti dalam
emoticon tersebut.
c. Mengubah semua huruf kapital menjadi huruf kecil pada Tweets. d. Menghapus semua tanda baca atau karakter khusus selain huruf
dan angka. Seperti koma, kutip, tanda seru, tanda tanya, titik dua, kutip, dan lain-lain.
e. Mengubah semua kata tidak baku menjadi kata baku. Misalnya
kata „ngga‟, „ga‟, „gak‟, „kaga‟ menjadi kata „tidak‟.
f. Menghapus semua kata-kata yang tidak memiliki makna maupun kata-kata yang paling sering muncul tetapi tidak memiliki peran dalam masing-masing kategori.
g. Setiap kata akan dihitung berdasarkan frekuensi kemunculannya pada masing-masing class(positif, negtif, netral).
2. Pemilihan term dibagi menjadi dua tahap, yaitu:
a. Menghitung mutual information pada seluruh kata.
27
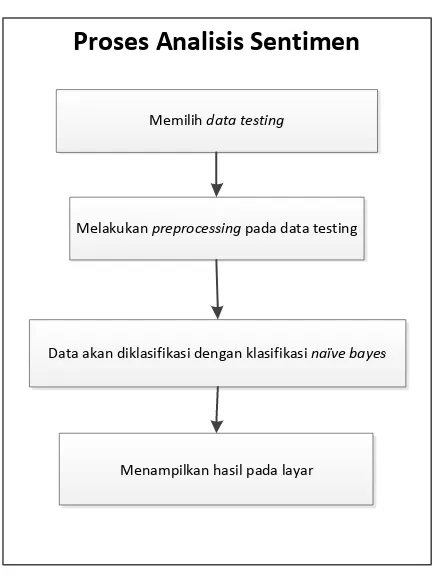
3.3.1.1.3 Arsitektur Analisis Sentimen
Melakukan preprocessing pada data testing Memilih data testing
Data akan diklasifikasi dengan klasifikasi naïve bayes
Menampilkan hasil pada layar
Proses Analisis Sentimen
Gambar 3.3 Arsitektur Proses Analisis Sentimen
Gambar 3.3 menunjukan arsitektur proses analisis sentimen yang akan diterapkan dalam sistem. Tahap-tahap analisis sentimen sebagai berikut:
1. Sistem menyediakan dua macam data testing yaitu, data testing yang diambil secara manual lalu disimpan dalam database dan data testing yang diambil secara otomatis dalam jangka waktu tertentu.
2. Sebelum dilakukan pengklasifikasian, data testing akan melalui tahap preprocessing sampai atribut-atribut tersebut bisa dibandingkan dengan term yang sudah dipilih pada data training.
3. Sistem akan melakukan perhitungan dengan metode naïve bayes. Lalu masing-masing kalimat akan dimasukkan ke dalam kelas yang nilai probabilitasnya paling besar.
28
UNIVERSITAS KRISTEN MARANATHA
3.3.1.2. Use Case
Pada sub bab ini akan menjelaskan tentang use case diagram dari sistem utama. Gambar 3.4 merupakan gambaran use case sistem.
User
Gambar 3.4 Use Case
3.3.1.3. Use Case Skenario
Pada sub bab ini akan menjelakan use case skenario dari use case pada bab 3.3.1.2 di atas.
3.3.1.3.1 Use Case Do Manual Judgment
Use-Case : Do Manual Judgment
Description : User mengklasifikasi kalimat secara manual ke dalam kategori positif, negatif, atau netral.
Participating Actor : User
Quality Requirement : User dapat mengklasifikasikan kalimat secara manual.
Main Course : Sistem akan menyimpan kategori tiap teks sesuai yang sudah diklasifikasi oleh user.
Pre-Condition : Menampilkan data Tweets yang sudah diambil sesuai dengan Id yang dipilih.
Post-Condition : Mengubah kategori setiap kalimat sesuai dengan pilihan user lalu disimpan di database agar bisa dilakukan preprocessing pada data training.
29
3.3.1.3.2 Use Case Preprocessing
Use-Case : Pre-processing
Description : Sistem akan melakukan tahap pre-processing pada suatu file.
Participating Actor : Sistem
Quality Requirement : Sistem berhasil melakukan pre-processing
Main Course : Sistem menampilkan setiap term beserta frekuensi kemunculannya.
Pre-Condition : Menampilkan kalimat sebelum dilakukan tahap pre-processing.
Post-Condition : Data term beserta frekuensi kemunculannya akan digunakan pada tahap mutual information.
3.3.1.3.3 Use Case Calculate Mutual Information
Use-Case : Calculate Mutual Information
Description : Sistem akan menghitung nilai dari setiap term. Participating Actor : Sistem
Quality Requirement : Sistem berhasil menghitung nilai setiap term dengan tepat.
Main Course : Sistem melakukan penyeleksian setiap term.
Pre-Condition : Hasil term pada tahap pre-processing akan digunakan pada tahap mutual information.
Post-Condition : Hasil dari mutual information akan digunakan pada tahap klasifikasi dengan naïve bayes.
3.3.1.3.4 Use Case Get Tweets
Use-Case : Get Tweet
Description : User mengambil data dari Twitter dengan menggunakan Twitter API sesusai topik yang dipilih.
Participating Actor : User
30
UNIVERSITAS KRISTEN MARANATHA Main Course : Sistem mengambil data dan menampilkan data-data
yang berhasil diambil. Setelah itu sistem menyimpan data tersebut ke dalam database. Pre-Condition : User memilih berapa banyak data yang akan
diambil beserta dengan topik nya.
Post-Condition : Sistem menyimpan data dalam database lalu menampilkan data.
3.3.1.3.5 Use Case Do Classification
Use-Case : Do Classification
Description : Memisahkan setiap term menjadi keyword dengan probabilistik nya masing-masing.
Participating Actor : Sistem
Quality Requirement : Sistem berhasil menyeleksi term menjadi sebuah keyword.
Main Course : Setiap term pada setiap kelas akan diseleksi menjadi sebuah keyword.
Pre-Condition : Hasil term pada tahap mutual information akan diurutkan dari yang terbesar hingga yang terkecil. Post-Condition : N teratas akan dijadikan sebuah keyword dan setiak
31
3.3.1.4. Activity Diagram
Pada sub bab ini akan dibahas mengenai acitvity diagram pada yang diambil dari use case pada bab 3.3.1.2.
3.3.1.4.1 Activity Diagram Get Tweets
User Sistem
Memilih kata kunci pencarian Masuk pada halaman Get Tweet
Sistem melakukan validasi dari hasil pencarian
Data akan disimpan dalam database
Sistem akan menampilkan data yang tersimpan
Dapat memilih kata kunci untuk mengurutkan data
Sistem mengurutkan data sesuai pilihan user Menentukan berapa banyak data yang dicari
Menekan tombol 'Get'
Gambar 3.5 Activity Diagram Get Tweets
32
UNIVERSITAS KRISTEN MARANATHA menyimpan Tweet yang memiliki “ID_Tweet” yang sudah ada dalam database. Kedua sistem tidak menyimpan semua retweet (RT), sehingga Tweet dengan dua
karakter pertama “RT” tidak akan disimpan dalam database. Dan yang ketiga sistem
tidak akan menyimpan Tweets dari provider tertentu.
Data yang sudah disimpan pada database akan ditampilkan oleh sistem. User dapat mengurutkan data sesuai kata kunci yang sudah disediakan oleh sistem. Kata kunci tersebut tersedia dalam bentuk combo box yang berisi “ID”, “Author”, “Text”,
“Date”, dan “Category”.
3.3.1.4.2 Activity Diagram Pre Processing
Sistem User
User menekan tombol "Start Processing" Memisahkan kalimat ke dalam 3 class
Mengubah kalimat menjadi kumpulan token
Menyimpan sekumpulan token dalam teks
Mengubah semua token menjadi kata baku
Menghapus token yang tidak bermakna
Menghitung kemunculan tiap token dengan n-grams
Menyimpan hasil proses n-grams
33
Gambar 3.6 adalah gambaran acvitiy diagram pada proses preprocessing. Pertama-tama user memisahkan kalimat-kalimat ke dalam 3 class yaitu positif, negatif, dan netral secara manual. Lalu user menenakan tombol “Start Processing”, sistem akan mengubah seluruh kalimat menjadi sekumpulan token dan akan disimpan menurut class-nya masing-masing. Setelah proses tokenizing selesai, sekumpulan token yang bukan merupakan kata baku akan diubah menjadi kata baku. Pada tahap pre-processing ini sistem akan menghapus setiap token (kata) yang tidak memiliki makna, seperti kata penghubung. Proses terakhir pada preprocessing adalah n-grams. Sistem akan menghitung setiap frekuensi kemunculan masing-masing token pada setiap kelas, lalu hasil preprocessing akan disimpan dalam sistem.
3.3.1.4.3 Activity Diagram Manual Judgment
User Sistem
Memasukkan ID
Masuk pada halaman 'Manual Judgment'
Sistem akan menampilkan kalimat sesuai dengan ID
Menekan tombol sesuai kategori yang dipilih
Sistem akan menyimpan kategori yang dipilih
Sistem akan penambahan satu pada ID
Sistem akan menampilkan kalimat sesuai dengan ID
34
UNIVERSITAS KRISTEN MARANATHA Pada gambar 3.7 menunjukan activity diagram pada proses manual judgment. Pertama-tama user masuk pada halaman “Manual Judgment”. User dapat memilih id data yang akan dilakukan pemilihan kategori. Sistem akan menampilkan teks sesuai id yang dimasukan. User dapat membaca teks tersebut lalu dapat memilih data tersebut masuk dalam kategori mana. Terdapat empat tombol untuk melakukan manual judgment diantara lain, tombol “Positive”, “Negative”, “Netral”, dan “Skip”.
Tombol “Positive”, “Negative”, dan “Netral” digunakan untuk memilih kategori. Jika tombol ditekan maka id akan bertambah satu secara otomatis, lalu sistem akan menampilkan data sesuai dengan id.
3.3.1.4.4 Activity Diagram Calculate Mutual Information
Sistem
Membaca file hasil pre processing
Menghitung term x pada kelas y
Menghitung term x pada kelas non y
Menghitung dengan rumus mutual information
35
Gambar 3.8 merupakan activity diagram pada proses mutual information. Setiap term akan dihitung akan dihitung frekuensi kemunculannya pada class y maupun kelas non y. Sistem akan menghitung setiap term dengan rumus mutual information.
3.3.1.4.5 Activity Diagram Do Classification
Sistem User
User menekan tombol "Start" Memilih metode klasifikasi "Naive Bayes"
Membaca hasil dari mutual information
Mengambil n nilai tertinggi
Mengubah ke dalam format naive bayes
Menghitung nilai probabilistik setiap term
Melakukan laplacian smoothing jika terdapat nilai 0 Menghitung dengan rumus Naive Bayes
[terdapat probabilistik bernilai 0] [ tidak terdapat probabilistik bernilai 0]
Gambar 3.9 Activity Diagram Do Classification
36
UNIVERSITAS KRISTEN MARANATHA proses ini disebut dengan laplacian smoothing. Setelah itu akan dilakukan perhitungan dengan rumus Naïve Bayes.
3.3.2. Disain Penyimpanan Data
Disain peyimpanan data dijelaskan melalui ERD dan ditransformasikan dalam tabel.
3.3.2.1. Entity Relationship Diagram (ERD)
Pada sub bab ini akan menggambarkan ERD pada sistem. Gambar ERD ditunjukan pada gambar 3.10.
Topic mempunyai
Gambar 3.10 Entity Relationship Diagram (ERD)
3.3.2.2. Transfofmasi ERD ke dalam Tabel
Pada sub bab ini akan menjelaskan tentang transformasi ERD pada bab
3.3.2.1. Akan dijelaskan melalui tabel dengan heading atribut, tipe data, dan
keterangan. Berikut tabel-table hasil transformasi ERD pada bab 3.3.2.1
3.3.2.2.1 Tabel Topic
Tabel 3.19 merupakan hasil dari transformasi ERD pada tabel topic. Tabel topic memiliki atribut “ID_topic” sebagai primary key dan “topic”. Tipe data setiap atribut bisa dilihat pada tabel 3.19.
Tabel 3.19 Tabel Topic
Atribut Tipe Data Keterangan
ID_Topic int Primary Key
Topic Nvarchar(50)
3.3.2.2.2 Tabel Data Training
37
“Text”, “Date”, “Date_Tweet”, “Category”, “Status”, dan “ID_Topic” sebagai foreign key dari tabel “topic”. Tipe data setiap atribut bisa dilihat pada tabel 3.20.
Tabel 3.20 Tabel Data Training
Atribut Tipe Data Keterangan
ID int Primary Key
ID_Tweet bigint
Author nvarchar(50)
Text nvarchar(200)
Date datetime
Date_Tweet datetime
Category varchar(10)
Status varchar(5)
ID_Topic int Foreign key
3.3.2.2.3 Tabel Data Testing
Tabel 3.21 merupakan hasil dari transformasi ERD pada tabel tweet. Tabel data testing memiliki atribut “ID” sebagai primary key, “ID_Tweet”, “Author”,
“Text”, “Date”, ”Date_Tweet”, “Category”, “Status”, dan “ID_Topic” sebagai foreign key dari tabel “topic”. Tipe data setiap atribut bisa dilihat pada tabel 3.21.
Tabel 3.21 Tabel Data Testing
Atribut Tipe Data Keterangan
ID int Primary Key
ID_Tweet bigint
Author nvarchar(50)
Text nvarchar(200)
Date datetime
Date_Tweet datetime
Category varchar(10)
Status varchar(5)
38
UNIVERSITAS KRISTEN MARANATHA
3.3.3. Disain Antarmuka
Berikut ini adalah disain antarmuka pada sistem analisis sentimen.
3.3.3.1. Rancangan Halaman Menu
Menu
Get Training Data
Sentiment Analysis Twitter
Select Training Data
Get Data Testing Data Training :
Gambar 3.11 Rancangan Halaman Menu
Gambar 3.11 merupakan rancangan pada halaman “Menu”. Terdapat 3 buah button yaitu, “Get Training Data”, “Select Data Training”, dan “Get Data Testing”.
3.3.3.2. Rancangan Halaman Get Training Data
Get Training Data
Get
Topic: Sort
Manual Judgment
Export to .Txt Add
Filter :
From
To
39
Gambar 3.12 merupakan rancangan disain pada halaman “Get Tweets”. Halaman ini merupakan halaman untuk mengambil Tweets. Pada bagian atas
halaman terdapat “numeric up down” untuk menentukan jumlah data yang dipilih dan sebuah combo box yang digunakan untuk memilih topic apa yang akan dipilih. Selain itu ada “combo box sort” yang digunakan untuk mengurutkan data sesuai kata yang user pilih. Dalam combo box terdapat kata kunci “ID”, “Author”, “Text”,
“Date”, dan “Category”.
Di bagian tengah halaman terdapat “data grid view Tweet” untuk melihat data-data yang sudah tersimpan dalam database. Terdapat tujuh buah kolom yaitu,
“ID”, “ID_Tweet”, “Author”, “Text”, “Date”, “Category”, dan “Status”. Di sebelah terdapat dua buah tombol, yang pertama tombol “Manual Judgment” yang berfungsi untuk masuk pada halaman “Manual Judgment”. Yang kedua tombol “Export to .Txt” yang berfungsi untuk mengexport data yang ada dalam database ke dalam sebuah file .txt yang nantinya akan digunakan dalam pelatihan data training.
3.3.3.3. Rancangan Halaman Manual Judgment
Manual Judgment
Netral
Positive
Negative
Netral
Skip
Category : Get Skip ID
Gambar 3.13 Rancangan Halaman Manual Judgment
40
UNIVERSITAS KRISTEN MARANATHA
sebelah kanan halaman. Tombol “Positive” berguna untuk mengubah kategori menjadi kategori positif, sedangkan tombol “Negative” dan “Netral” secara berurutan berguna untuk merubah kategori menjadi negatif dan netral. Pada sebelah kiri atas halaman terdapat sebuah text box yang berguna untuk meninformasikan
kategori data. Tombol “Skip ID” berfungsi untuk mencari id mana yang belum terklasfikasi secara manual.
3.3.3.4. Rancangan Halaman Select Training Data
Select Training Data
OK Topic
Cancel
Gambar 3.14 Rancangan Halaman Select Training Data
Gambar 3.14 merupakan rancangan disain pada halaman “Select Training Data”. Pada halaman ini terdapat sebuah combo box yang berisi seluruh topik yang terdapat pada aplikasi. Terdapat dua buah button yaitu “OK” dan “Cancel”.
3.3.3.5. Rancangan Halaman Pre Processing
Pre Processing
Sentence Tokenization Formalization Stopping N Gram Result MI Selection Category
Status: Pos: Neg: Net: Total Tweet: All
Gambar 3.15 Rancangan Halaman Pre Processing
41
“Tokenization”, “Formalization”, “Stopping”, “N Gram”, “Result MI”, dan
“Selection”. Masing-masing data gridview menampilkan hasil dari setiap tahap pre processing sampai tahap selection.
Terdapat sebuah combo box “Category” yang berisi kata “All”, “Positive”,
“Negative”, dan “Netral”. Combo box ini berfungsi untuk menyaring data yang ditampilkan oleh sistem. Pada sebuah kanan halaman terdapat label yang akan memberikan informasi terhadap user tentang berapa banyak tweets dari masing kategori.
3.3.3.6. Rancangan Halaman Get Testing Data
Get Testing Data
Sort
Analyze
Stream Tweet Get
Topic:
Gambar 3.16 Rancangan Halaman Get Testing Data
Pada gambar 3.16 merupakan rancangan disain pada halaman “Get Testing Data”. Halaman ini hampir mirip dengan halaman “Get Tweet”. Bedanya halaman ini digunakan untuk mengambil data dari Twitter untuk data testing. Sedangkan
halaman “Get Tweet” digunakan untuk mengambil data dari Twitter yang digunakan untuk data training. Terdapat tombol “Analyze” dan “Stream Tweet” pada sebelah kanan halaman. Tombol “Analyze” berguna untuk masuk ke halaman “Analyze”
42
UNIVERSITAS KRISTEN MARANATHA
3.3.3.7. Rancangan Halaman Analayze
Analyze
Start
Gambar 3.17 Rancangan Halaman Analyze
Pada gambar 3.17 merupakan rancangan disain pada halaman “Analyze”. Halaman ini digunakan untuk melihat hasil data testing yang diambil secara manual
pada halaman “Get Data Testing”. Terdapat sebuah data gridview yang memiliki kolom “Sentence” dan “Result”. Sistem akan menampilkan hasil dari masing-masing
kalimat jika tombol “Start” sudah ditekan.
3.3.3.8. Rancangan Halaman Streaming Tweets
Stream Tweets
25 May 2015 12:11:12 AM Start
Stop
Result (12 Tweet) Pos : 15% Neg :30% Net : 40%
Uncategorized : 15 %
Start Time : 25 May 2015 12:11:12 AM End Time : 25 May 2015 12:11:12 AM
Export to Txt X:
Y:
Gambar 3.18 Rancangan Halaman Streaming Tweet
43
untuk bagian “Y”. Sistem akan mengambil data dari Twitter sesuai kata yang dimasukan pada text box, setelah user menekan tombol “Start”. Pada halaman ini terdapat sebuah data gridview yang memiliki kolom “Sentence” dan “Result”. Data gridview ini akan menampilkan data yang diambil dari Twitter beserta hasil klasifikasi secara otomatis. Tombol “Stop” digunakan apabila user ingin
81
UNIVERSITAS KRISTEN MARANATHA
BAB 6
KESIMPULAN DAN SARAN
Pada bab ini akan dibuat kesimpulan rancangan pembuatan aplikasi serta pembahasan terhadap pengujian aplikasi.
6.1. Kesimpulan
Dari hasil analisis ini dapat diambil kesimpulan mengenai pembuatan aplikasi, antara lain:
1. Aplikasi dapat melakukan analisis sentimen terhadap opini berbahasa Inodensia tentang provider telekomunikasi pada Twitter. Dengan mengklasifikasikan kalimat ke dalam kelas positif, negatif, dan netral. 2. Setelah melakukan pengambilan tweets tentang beberapa provider
telekomunikasi di Indonesia, persentase tweets positif cenderung lebih sedikit daripada tweets negatif maupun netral. Dapat dilihat dari hasil manual judgment, persentase tweets positif, negatif dan netral secara berurutan adalah 13.7%, 44.3%, dan 41.8%.
3. Dari hasil testing terhadap data training, persentase hasil tweets yang dapat dikategorikan sekitar 85% dan memiliki keakuratan sekitar 78%. 4. Dari hasil lima percobaan dengan menggunakan jumlah keyword yang
berbeda (positif (30) negatif (30) netral(60), top 10, top 30, hasil MI di atas rata-rata, dan semua keyword), tingkat akurasi tertinggi yaitu 78 % dengan menggunakan 30 kata positif, 30 kata negatif, dan 60 kata netral. 5. Hasil rata-rata persentase tingkat akurasi dari hasil manual judgment yang
82
6.2. Saran
Adapun saran yang diberikan untuk aplikasi analisis sentimen ini, yaitu : 1. Fitur stemming dapat ditambahkan pada proses pre processing untuk
mengurangi keragaman dari bentukan kata.
2. Kamus emoticon, stopword dan formalization dapat dilengkapi untuk meningkatkan akurasi pada analisis sentimen.
3. Melakukan translate pada kata-kata berbahasa inggris yang terdapat dalam kalimat berbahasa Indonesia.
4. Melakukan analisis sentimen dengan metode selain Naïve Bayes, seperti Support Vector Machine atau K- Nearest Neighbor.
83
UNIVERSITAS KRISTEN MARANATHA
DAFTAR PUSTAKA
Cambridge University Press. (2009). http://nlp.stanford.edu. Retrieved Novermber 15, 2014, from http://nlp.stanford.edu/IR-book/pdf/13bayes.pdf
Huma Lodhi, C. S.-T. (2002). Text Classificaition using String Kernels. Journal of Machine Learning Research , 419-444.
Jiawei Han, M. K. (2012). Data Mining : Concepts and Techniques. Waltham: Elsevier Inc.
Kaplan, R. M. (2005). A Method for Tokenizing Text. Inquiries into Words, Constraints and Contexts., 55-64.
Liu, B. (2012). Sentiment Analysis and Opinion Mining. Morgan & Claypool Publishers.
Pang, B., & Lee, L. (2008). Opinion Mining and Sentiment Analysis. Foundations and Trends in Information Retrieval.
Popov, I., & Nikolaev, K. (2012). Formalization of a Natural Language.
Prasetyo, E. (2012). Data Mining : Konsep dan Aplikasi Menggunakan MATLAB. Yogyakarta: ANDI.
Stefan Buttcher, C. L. (2010). Informarion Retreieval : Implementing and Evaluating Search Engines. London: The MIT Press.
Twitter. (n.d.). Retrieved Juli 8, 2015, from dev.twitter: https://dev.twitter.com/rest/public
Witten, I., Frank, E., & Hall, M. (2011). Data Mining Practical Machine Learning Tools and Techniques. Elsevier.