BAB III
METODE PENELITIAN
A. Waktu dan Tempat Penelitian
Penelitian ini dilakukan dengan mengunduh data dari Bursa Efek Indonesia (BEI), dengan memilih perushaan yang terdaftar di LQ45 selama 5 tahun berturut-turut, dari tahun 2010-2015.
B. Desain Penelitian
Penelitian ini merupakan penelitian kausal yang melakukan pengujian hipotesis tentang pengaruh satu atau beberapa variabel terhadap variabel lainnya, dan bertujuan untuk memperoleh bukti empiris tentang pengaruh keputusan investasi, keputusan pendanaan, dan kebijakan dividen terhadap nilai perusahaan.
C. Definisi dan Operasional Variabel 1. Variabel Independen
Variabel independen dalam penelitian ini adalah keputusan investasi, keputusan pendanaan dan kebijakan dividen.
a. Keputusan Investasi
Keputusan investasi yang didefinisikan sebagai kombinasi antara aktiva yang dimiliki (assets in place) dan pilihan investasi di masa yang akan datang dengan net present value positif (Myers, 1977 dalam Wijaya dan Wibawa, 2010). Keputusan investasi dalam penelitian ini
diproksikan dengan PER (Price Earning Ratio), dimana PER menunjukkan perbandingan antara closing price dengan laba per lembar saham (earning per share). PER dirumuskan dengan : (Wijaya dan Wibawa, 2010)
Keterangan :
PER = Price Earning Ratio EPS = Earning Per Share
b. Keputusan Pendanaan
Keputusan pendanaan didefinisikan sebagai keputusan yang menyangkut komposisi pendanaan yang dipilih oleh perusahaan (Hasnawati, 2005 dalam Wijaya dan Wibawa, 2010). Keputusan pendanaan dalam penelitian ini diproksikan dengan Debt to Equity Ratio (DER), dimana rasio ini menunjukkan perbandingan antara pembiayaan dan pendanaan melalui hutang dengan pendanaan melalui ekuitas. DER dirumuskan dengan : (Wijaya dan Wibawa, 2010)
c. Kebijakan Dividen
Keputusan kebijakan dividen adalah keputusan tentang seberapa banyak laba saat ini yang akan dibayarkan sebagai dividen daripada
ditahan untuk diinvestasikan kembali dalam perusahaan (Brigham dan Houston, 2001 dalam Wijaya dan Wibawa, 2010). Kebijakan dividen dalam penelitian ini diproksikan dengan Yield, yaitu Dividen dalam rupiah dibagi harga saham penutupan.
2. Variabel Dependen
Variabel dependen dalam penelitian ini adalah nilai perusahaan, dimana nilai perusahaan didefinisikan sebagai nilai pasar karena nilai perusahaan dapat memberikan kemakmuran pemegang saham secara maksimum apabila harga saham perusahaan meningkat (Hasnawati, 2005 dalam Wijaya dan Wibawa, 2010). Nilai perusahaan dalam penelitian ini diproksikan dengan Price Book Value (PBV). PBV mengukur nilai yang diberikan pasar keuangan kepada manajemen dan organisasi perusahaan sebagai sebuah perusahaan yang terus tumbuh. PBV dirumuskan dengan : (Wijaya dan Wibawa, 2010)
D. Populasi dan Sampel
Populasi dalam penelitian ini adalah perusahaan LQ45 yang terdaftar di Bursa Efek Indonesia (BEI) pada periode 2010-2015. Yaitu sebanyak 23 perusahaan. Sampel penelitian ini diperoleh dengan metode
purposive sampling. purposive sampling adalah pengambilan sampel secara sengaja sesuai dengan persyaratan sampel yang diperlukan. peneliti menentukan sendiri sampel yang diambil karena ada pertimbangan tertentu. Adapun kriteria yang digunakan untuk memilih sample pada penelitian ini adalah sebagai berikut :
1. Perusahaan LQ45 yang terdaftar di Bursa Efek Indonesia (BEI) dan mempublikasikan laporan keuangan berturut-turut dari tahun 2010 sampai 2015.
2. Perusahaan LQ45 yang menerbitkan dividen secara berturut-turut dari tahun 2010-2015.
3. Tersedia laporan keuangan perusahaan secara lengkap selama tahun 2010-2015, baik secara fisik maupun melalui website.
Tabel 1.1
Jumlah Sampel Penelitian
No Kriteria Jumlah Perusahaan
1
Jumlah perusahaan LQ45 yang terdaftar di Bursa Efek Indonesia (BEI) tahun 2010 – 2015
23
2
Jumlah perusahaan LQ45 yang bersangkutan tidak membayar dividen secara konsisten selama periode 2010 – 2015
(15)
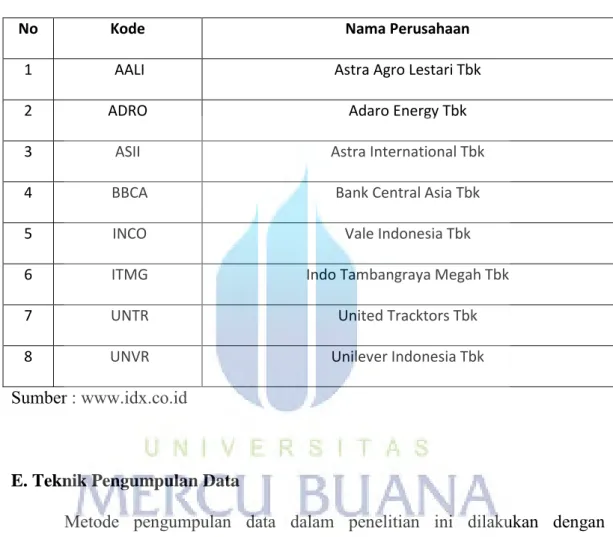
Berikut ini adalah daftar nama perusahaan LQ45 yang menjadi sample penelitian :
Tabel 3.2 Daftar Perusahaan
No Kode Nama Perusahaan
1 AALI Astra Agro Lestari Tbk
2 ADRO Adaro Energy Tbk
3 ASII Astra International Tbk
4 BBCA Bank Central Asia Tbk
5 INCO Vale Indonesia Tbk
6 ITMG Indo Tambangraya Megah Tbk
7 UNTR United Tracktors Tbk
8 UNVR Unilever Indonesia Tbk
Sumber : www.idx.co.id
E. Teknik Pengumpulan Data
Metode pengumpulan data dalam penelitian ini dilakukan dengan mengunduh data laporan tahunan perusahaan LQ45 di BEI. Jenis data yang digunakan dalam penelitian ini adalah data sekunder. Data penelitian diambil dari laporan tahunan perusahaan yang telah diaudit dan dipublikasikan. Data diperoleh antara lain dari :
F. Metode Analisis
Dalam penelitian ini metode analisis yang dilakukan adalah model analisis regresi data panel dengan bantuan software Eviews 6, dan untuk mengetahui tingkat signifikansi masing-masing koefisien regresi antara variabel independen terhadap variabel dependen, maka digunakan uji statistik sebagai berikut:
1. Uji Stasioneritas
Tujuan dari uji stasioneritas adalah untuk melihat apakah rata-rata varians data konstan sepanjang waktu dan kovarian antara dua atau lebih data dalam runtun waktu hanya tergantung pada kelambanan antara dua atau lebih periode waktu tersebut. (Gujarati, 2004).
Menurut Nachrowi (2006:339) disebutkan bahwa data time series merupakan sekumpulan nilai suatu variabel yang diambil pada waktu yang berbeda. Data time series memiliki permasalahan yaitu otokorelasi. Otokorelasi tersebut merupakan penyebab data menjadi tidak stasioner. Untuk menguji apakah data bersifat stasioner atau tidak, maka dalam penelitian ini akan digunakan uji Augmented Dickey-Fuller Unit Root Test (ADF-Unit Root Test) atau Phillips Peron. Kriteria pengujian adalah sebagai berikut:
H0 : data bersifat stasioner
Nilai absolut t-Statistic < nilai kritis uji pada tabel McKinnon pada berbagai tingkat kepercayaan (1%, 5%, dan 10%) atau Nilai Probability > tingkat signifikansi (0.05), maka secara statistic mampu menolak H0.
2. Analisis Regresi Data Panel
Menurut Nachrowi dan Usman (2006) bahwa data panel merupakan gabungan antara data berkala (time series) dan data individual (cross section). Data time series adalah data yang dikumpulkan dari waktu ke waktu terhadap suatu individu. Sedangkan data cross section merupakan data yang dikumpulkan dalam satu waktu terhadap banyak individu.
Keunggulan regresi data panel menurut Wibisono (2005) antara lain : a. Data panel mampu memperhitungkan heterogenitas individu secara
ekspilisit dengan mengizinkan variabel spesifik individu.
b. Kemampuan mengontrol heterogenitas ini selanjutnya menjadikan data panel dapat digunakan untuk menguji dan membangun model perilaku lebih kompleks.
c. Data panel mendasarkan diri pada observasi cross-section yang berulang-ulang (time series), sehingga metode data panel cocok digunakan sebagai study of dynamic adjustment.
d. Tingginya jumlah observasi memiliki implikasi pada data yang lebih informatif, lebih variatif, dan kolinieritas (multiko) antara data semakin berkurang, dan derajat kebebasan (degree of freedom/df) lebih tinggi sehingga dapat diperoleh hasil estimasi yang lebih efisien.
e. Data panel dapat digunakan untuk mempelajari model-model perilaku yang kompleks.
f. Data panel dapat digunakan untuk meminimalkan bias yang mungkin ditimbulkan oleh agregasi data individu.
Permodelan menggunakan teknik regresi data panel dapat dilakukan dengan tiga pendekatan alternatif, yaitu: metode Common Effect (pooled least square), metode Fixed Effect (FE), dan metode Random Effect (RF). a. Common Effect (pooled least square)
Metode Common Effect adalah metode yang hanya menggabungkan data tanpa melihat perbedaan waktu dan individu. Model ini menganggap bahwa dan slop dari setiap variabel sama untuk setiap obyek observasi. Kelemahan model ini adalah ketidaksesuaian model dengan keadaan yang sebenarnya. Kondisi tiap obyek dapat berbeda dan kondisi suatu obyek satu waktu dengan waktu yang lain dapat berbeda. Model Common Effect dapat diformulasikan sebagai berikut:
= +
Dimana:
= Variabel dependen di waktu t untuk unit cross section i
= intersep
= parameter untuk variabel ke-j
= variabel bebas j di waktu t untuk unit cross section i = komponen error di waktu t untuk unit cross section j
I = urutan perusahaan yang diobservasi t = Time series (urutan waktu)
j = urutan variabel
b. Fixed Effect (FE)
Metode Fixed Effect adalah metode yang mengestimasi data panel dengan menggunakan variabel dummy untuk menangkap adanya perbedaan intersep. Metode ini mengasumsikan bahwa koefisien regresi (slope) tetap antar individu dan antar waktu.(Widarjono, 2007). Namun intersepnya berbeda antar perusahaan namun sama antar waktu (time invariant). Akan tetapi metode ini membawa kelemahan yaitu berkurangnya derajat kebebasan (degree of freedom) yang pada akhirnya mengurangi efisiensi parameter.
Berikut adalah permodelan Fixed Effect :
Dimana:
D2i = 1 dummy untuk perusahaan 2, 0 jika bukan; D3i = 1 dummy untuk perusahaan 3, 0 jika bukan; dan seterusnya.
Karena penelitian ini menggunakan 8 perusahaan maka kita menggunakan 7 dummy guna menghindari perangkap variable dummy (dummy variable trap), yaitu situasi dimana terjadi kolinearitas sempurna.
c. Random Effect (RE)
Metode Random Effect adalah metode yang akan mengestimasi data panel dimana variabel gangguan mungkin saling berhubungan antar waktu dan antar individu. (Widarjono, 2007). Teknik yang digunakan dalam metode Random Effect adalah dengan menambahkan variabel gangguan (error terms) yang mungkin saja akan muncul pada hubungan antar waktu dan antar data perusahaan. Model Random Effect secara umum dituliskan sebagai berikut:
= + = +
Dimana:
– ) = komponen cross section error – ) = komponen time series error
– ) = komponen time series error dan cross section error
3. Pemilihan Model
Untuk memilih model yang paling tepat digunakan dalam mengelola data panel, terdapat beberapa pengujian yang dapat dilakukan, yaitu:
a. Uji Chow
Chow test digunakan untuk mementukan apakah model data panel regresi dengan metode Common Effect atau dengan metode Fixed Effect, apabila dari hasil uji tersebut di tentukan bahwa metode Common Effect yang digunakan, maka tidak perlu diuji kembali dengan Uji Hausman.
Pengujian yang dilakukan dengan Chow-test atau Likelihood ratio test, dengan asumsi yaitu:
H0 : model mengikuti Pool H1 : model mengikuti Fixed
b. Uji Hausman
Hausman test adalah pengujian statistik untuk memilih apakah model Fixed Effect atau Random Effect yang paling tepat digunakan. Apabila dari hasil Uji Chow tersebut ditentukan bahwa metode Fixed Effect yang digunakan, maka harus ada uji lanjutan dengan Uji Hausman untuk memilih antara metode Fixed Effect atau metode Random Effect yang akan digunakan untuk mengestimasi regresi data panel. Pengujian yang dilakukan menggunakan Hausman test dengan asumsi sebagai berikut:
H0 : model mengikuti Random Effect
H1 : model mengikuti Fixed Effect
Pengujian ini untuk mengetahui apakah model regresi yang digunakan layak (fit) untuk melakukan pengujian hipotesis dalam penelitian ini. Pengujian ini dilakukan dengan alat bantuan program Eviews versi 7. Kriteria pengujiannya adalah sebagai berikut:
1) H0 diterima dan Ha ditolak apabila value > 0,05 atau bila nilai signifikansi lebih dari nilai alpha 0,05 berarti model regresi dalam penelitian ini tidak layak (fit) untuk digunakan dalam penelitian.
2) H0 ditolak dan Ha diterima apabila value < 0,05 atau bila nilai signifikansi kurang dari nilai alpha 0,05 berarti model regresi dalam penelitian ini layak (fit) untuk digunakan dalam penelitian.
4. Uji Statistik F
Menurut Ghozali (2011:98) uji statistik F pada dasarnya menunjukkan apakah semua variabel independen atau bebas yang dimasukkan dalam model mempunyai pengaruh secara bersama-sama terhadap variabel dependen/terikat. Hipotesis nol (Ho) yang hendak diuji adalah apakah semua parameter dalam model sama dengan nol, atau:
Ho : b1 = b2 = ……..= bk = 0
Artinya, apakah semua variabel independen bukan merupakan penjelas yang signifikan terhadap variabel dependen. Hipotesis alternatifnya (HA) tidak semua parameter secara simultan sama dengan nol, atau:
HA : b1 ≠ b2 ≠ ……….≠ bk ≠ 0
Keterangan :
Jk
reg =a
1Σ x
1i .y
i+ a
2Σ x
2i. y
iJk
res =Σ (Y
i-
i)
2Artinya. Semua variabel independen secara simultan merupakan penjelas yang signifikan terhadap variabel dependen.
Untuk menguji hipotesis ini digunakan statistik F dengan kriteria pengambilan keputusan sebagai berikut:
a. Quick look : bila nilai F lebih besar daripada 4 maka Ho dapat ditolak pada derajat kepercayaan 5%., Dengan kata lain kita menerima hipotesis alternatif, yang menyatakan bahwa semua variabel independen secara serentak dan signifikan secara serentak dan signifikan mempengaruhi variabel dependen.
b. Membandingkan nilai F hasil perhitungan dengan nilai F menurut tabel. Bila nilai F hitung lebih besar daripada nilai F tabel, maka Ho ditolak dan menerima HA.
5. Uji Statistik t (Uji Parsial)
Menurut Ghozali (2011:98) uji statistik t pada dasarnya menunjukkan seberapa jauh pengaruh satu variabel penjelas/independen secara individual dalam menerangkan variasi variabel dependen. Hipotesis nol (Ho) yang hendak diuji adalah apakah suatu parameter (bi) sama dengan nol, atau:
Ho : bi = 0
Artinya apakah suatu variabel independen bukan merupakan penjelas yang signifikan terhadap variabel dependen. Hipotesis alternatifnya (HA) parameter suatu variabel tidak sama dengan nol, atau:
HA : bi ≠ 0
Artinya, variabel tersebut merupakan penjelas yang signifikan terhadap variabel dependen.
Keterangan :
b = Koefisien Regresi Seb = Standar Error b
Cara melakukan uji t adalah sebagai berikut:
a. Quick look : bila jumlah degree of freedom (df) adalah 20 atau lebih, dan derajat kepercayaan sebesar 5%, maka Ho yang menyatakan bi = 0 dapat ditolak bila nilai t lebih besar dari 2 (dalam nilai absolut). Dengan kata lain kita menerima hipotesis alternatif, yang menyatakan bahwa suatu variabel independen secara individual mempengaruhi variabel dependen. b. Membandingkan nilai statistik t dengan titik kritis menurut tabel. Apabila
nilai statistik t hasil perhitungan lebih tinggi dibandingkan nilai t tabel, kita menerima hipotesis alternatif yang menyatakan bahwa suatu variabel independen secara individual mempengaruhi variabel dependen.