BAB II
TINJAUAN PUSTAKA
Bab ini menguraikan tentang teori-teori penunjang yang dipakai dalam melakukan penelitian data mining dengan metode asosiasi menggunakan algoritma apriori yang terdiri dari state of the art
, pengertian
data mining, aplikasi
data mining,
tahapan data mining, metode asosiasi serta teori tentang algoritma apriori.
2.1State of the Art
Penelitian ini didasarkan atas penelitian sebelumnya yang berhubungan dengan pengembangan data mining dengan metode asosiasi menggunakan algoritma apriori. Penelitian yang dilakukan R. Agrawal, et al pada tahun 1993 yang berjudul “Mining Association Rules Between Sets of Items in Large Databases” adalah awal
mula dikembangkannya data mining dengan metode asosiasi menggunakan algoritma apriori. Pada tahun 1994, R. Agrawal dan R. Srikant kembali melakukan penelitian mengenai metode asosiasi dengan judul “Fast Algorithms for Mining Association Rules”. Penelitian ini kemudian difokuskan untuk menyempurnakan algoritma apriori
yang sudah dikembangkan sebelumnya dan dari situlah algoritma apriori dikenal sebagai salah satu algoritma untuk metode asosiasi. Penelitian tentang metode apriori terus berkembang. Para peneliti terus mencoba untuk melakukan optimasi terhadap
metode apriori agar mendapatkan kinerja yang lebih cepat dan menemukan aturan asosiasi terbaik.
Jogi Suresh dan T. Ramanjaneyulu (2013) melakukan penelitian dengan judul “Mining Frequent Itemsets Using Apriori Algorithm”. Penelitian Suresh dan
Ramanjaneyulu menggunakan algoritma apriori klasik yang sudah dikembangkan sebelumnya dan belum menggunakan teknik optimasi untuk memperoleh aturan asosiasi yang lebih efisien.
Sheila A. Abaya pada tahun 2012 dalam penelitiannya yang berjudul “Association Rule Mining based on Apriori Algorithm in Minimizing Candidate Generation” melakukan improvisasi terhadap algoritma apriori. Improvisasi
dilakukan dengan cara menentukan “set size” dan “set size frequency”. Set size adalah jumlah item per transaksi sedangkan set size frequency adalah jumlah transaksi yang setidaknya memiliki “set size” item
.
Set size dan set size frequency ini digunakan untuk mengeliminasi kandidat kunci yang tidak signifikan.Jiao Yabing (2013) dalam penelitiannya dengan judul “Research of an Improved Apriori Algorithm in Data mining Association Rules” melakukan optimasi
terhadap algoritma apriori yaitu dengan cara mengurangi atau memangkas (pruning) jumlah calon kandidat frequent itemset pada kandidat itemset Ck.
Jaishree Singh, et al pada tahun (2013) melakukan penelitian dengan judul
Penelitian Singh, dkk ini melakukan improvisasi algoritma apriori dengan cara mengurangi jumlah transaksi (transaction reduction) yang jumlah item
pertransaksinya tidak memenuhi nilai batas yang ditentukan. Pengurangan transaksi
tersebut berdampak pada efisiensi waktu yang lebih cepat saat scanning database
.
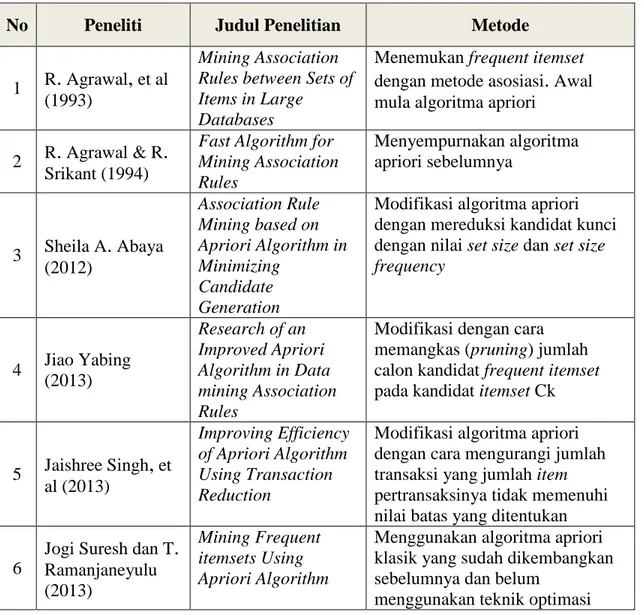
Tabel 2.
1 Penelitian yang Sudah Dilakukan SebelumnyaNo Peneliti Judul Penelitian Metode
1 R. Agrawal, et al (1993)
Mining Association Rules between Sets of Items in Large
Databases
Menemukan frequent itemset
dengan metode asosiasi. Awal mula algoritma apriori
2 R. Agrawal & R. Srikant (1994)
Fast Algorithm for Mining Association Rules Menyempurnakan algoritma apriori sebelumnya 3 Sheila A. Abaya (2012) Association Rule Mining based on Apriori Algorithm in Minimizing Candidate Generation
Modifikasi algoritma apriori dengan mereduksi kandidat kunci dengan nilai set size dan set size frequency 4 Jiao Yabing (2013) Research of an Improved Apriori Algorithm in Data mining Association Rules
Modifikasi dengan cara memangkas (pruning) jumlah calon kandidat frequent itemset
pada kandidat itemset Ck
5 Jaishree Singh, et al (2013) Improving Efficiency of Apriori Algorithm Using Transaction Reduction
Modifikasi algoritma apriori dengan cara mengurangi jumlah transaksi yang jumlah item
pertransaksinya tidak memenuhi nilai batas yang ditentukan
6
Jogi Suresh dan T. Ramanjaneyulu (2013)
Mining Frequent itemsets Using Apriori Algorithm
Menggunakan algoritma apriori klasik yang sudah dikembangkan sebelumnya dan belum
Inti dari semua penelitan-penelitian terdahulu mengenai optimasi terhadap algoritma apriori yang tercantum dalam tabel diatas adalah membatasi calon kandidat
frequent itemset yang dimunculkan. Pembatasan tersebut dilakukan dengan cara memangkas item, kombinasi dan transaksi serta pembatasan iterasi yang tidak diinginkan sehingga tidak terjadi perulangan scanning database yang berlebihan, dengan begitu akan menghasilkan aturan asosiasi secara tepat dan dalam waktu yang lebih cepat.
2.2Pengertian Data mining
Secara harfiah, data mining sebenarnya adalah kesalahan penamaan atau penyebutan. Jika mengacu kepada kegiatan penambangan emas dari sekumpulan batu atau pasir, aktivitas itu lebih disebut dengan penggalian emas daripada penggalian batu atau pasir. Jadi data mining seharusnya lebih pantas atau lebih cocok disebut
dengan penggalian pengetahuan dari data yang ada (knowledge mining from data). Tetapi penggalian pengetahuan (knowledge mining) mempunyai pengertian yang dangkal yang mungkin tidak mencerminkan kegiatan penggalian dari data yang berjumlah besar dengan menggunakan pola atau metode yang diterapkan. Mining
(penggalian) sendiri diartikan sebagai proses untuk menemukan sebagian kecil sesuatu yang sangat berharga dari sekumpulan material yang besar.
Han dan Kamber (2006) dalam bukunya yang berjudul “Data mining Concepts and Techniques” mengatakan, secara singkat data mining dapat diartikan sebagai mengekstraksi atau menggali pengetahuan dari data yang berjumlah besar. Sedangkan menurut Daniel T. Larose (2005) ada beberapa definisi dari Data mining
yang diambil dari beberapa sumber. Secara umum data mining dapat didefinisikan sebagai berikut :
- Data mining adalah proses menemukan sesuatu yang bermakna dari suatu korelasi baru, pola dan tren yang ada dengan cara memilah-milah data berukuran besar yang disimpan dalam repositori, menggunakan teknologi pengenalan pola serta teknik matematika dan statistik.
- Data mining adalah analisis pengamatan database untuk menemukan hubungan yang tidak terduga dan untuk meringkas data dengan cara atau metode baru yang dapat dimengerti dan bermanfaat kepada pemilik data.
- Data mining merupakan bidang ilmu interdisipliner yang menyatukan teknik pembelajaran dari mesin (machine learning), pengenalan pola (pattern recognition), statistik, database
, dan visualisasi untuk mengatasi masalah
ekstraksi informasi dari basis data yang besar.- Data mining diartikan sebagai suatu proses ekstraksi informasi berguna dan potensial dari sekumpulan data yang terdapat secara implisit dalam suatu basis data.
Analisa data mining berjalan pada data yang cenderung terus membesar dan teknik terbaik yang digunakan kemudian beorientasi kepada data berukuran sangat besar untuk mendapatkan kesimpulan dan keputusan paling layak. Data mining
memiliki beberapa sebutan atau nama lain yaitu : Knowledgediscovery in databases (KDD), ekstraksi pengetahuan (knowledge extraction), Analisa data/pola
(data/pattern analysis), kecerdasan bisnis (business intelligence), data archaeology
dan datadredging (Daniel T. Larose, 2005).
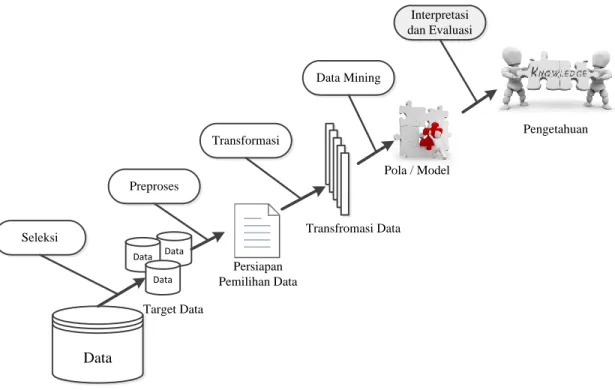
2.3Tahapan Data mining
Han dan Kamber (2006) mengatakan, bahwa data mining mempunyai pengertian yang sama dengan knowledge discovery from data atau KDD. Tahapan yang dilakukan pada proses data mining sama dengan proses yang dilakukan pada
knowledge discovery
. Tahapan dimulai dari seleksi data dari data sumber ke data
target, tahap preprocessing untuk memperbaiki kualitas data, transformasi, data mining serta tahap interpretasi dan evaluasi yang menghasilkan output berupa pengetahuan baru yang diharapkan memberikan kontribusi yang lebih baik.Data Data Data Data Seleksi Transformasi Data Mining Preproses Target Data Persiapan Pemilihan Data Transfromasi Data Pola / Model Interpretasi dan Evaluasi Pengetahuan
Gambar 2
.
1 Tahapan Data miningTahapan-tahapan yang terjadi pada proses data mining atau knowledge discovery menurut Kenneth Collier (1998) dibagi menjadi 5 tahapan yaitu :
1. Seleksi Data
Tujuan dari fase ini adalah ekstraksi dari gudang data yang besar menjadi data yang relevan dengan analisis data mining
. Proses ekstraksi data membantu
untuk merampingkan dan mempercepat proses.2. DataPreprocessing
Fase ini berkaitan dengan pembersihan data dan persiapan tugas yang diperlukan untuk memastikan hasil yang benar. Menghilangkan missing value
dalam data, memastikan bahwa nilai-nilai kode memiliki arti seragam dan memastikan bahwa tidak ada nilai data palsu adalah tindakan khas yang terjadi selama fase ini.
3. Transformasi Data
Tahap ini mengubah data ke dalam bentuk atau format yang sesuai untuk kebutuhan data mining
. Proses normalisasi biasanya diperlukan dalam tahap
data transformas.4. Data mining
Tujuan dari tahap data mining adalah untuk menganalisis database sesuai algoritma yang digunakan sehingga menemukan pola atau aturan yang bermakna serta menghasilkan model prediksi. Data mining adalah elemen inti dari siklus KDD.
5. Interpretasi dan Evaluasi
Sementara algoritma data mining memiliki potensi untuk menghasilkan jumlah yang tidak terbatas dari pola tersembunyi dalam data, banyak hasil dari proses tersebut mungkin tidak bermakna atau berguna. Tahap akhir ini bertujuan untuk memilih model-model yang valid dan berguna untuk membuat keputusan bisnis masa depan.
Proses KDD secara garis besar memang terdiri dari 5 tahap seperti yang telah dijelaskan sebelumnya. Akan tetapi, dalam proses KDD yang sesungguhnya, dapat saja terjadi iterasi atau pengulangan pada tahap-tahap tertentu. Pada setiap tahap dalam proses KDD, seorang analis dapat saja kembali ke tahap sebelumnya. Sebagai contoh, pada saat coding atau data mining
, analis menyadari proses
cleaning belum dilakukan dengan sempurna, atau mungkin saja analis menemukan data atau informasi baru untuk memperkaya data yang sudah ada sehingga harus mengulang proses sebelumnya.2.4Tugas Utama Data mining
Pada umumnya tugas utama data mining dibagi menjadi: deskripsi, prediksi, estimasi, klasifikasi, clustering dan asosiasi (Daniel T. Larose 2005).
2.4.1 Deskripsi
Deskripsi bertujuan untuk mengidentifikasi pola yang muncul secara berulang pada suatu data dan mengubah pola tersebut menjadi aturan dan kriteria yang dapat mudah dimengerti oleh para ahli pada domain aplikasinya. Aturan yang dihasilkan harus mudah dimengerti agar dapat dengan efektif meningkatkan tingkat pengetahuan (knowledge) pada sistem. Tugas deskriptif merupakan tugas data mining yang sering dibutuhkan pada teknik postprocessing untuk melakukan validasi dan menjelaskan hasil dari proses data mining
.
Postprocessing merupakan proses yang digunakanuntuk memastikan hanya hasil yang valid dan berguna yang dapat digunakan oleh pihak yang berkepentingan.
2.4.2 Prediksi
Prediksi memiliki kemiripan dengan klasifikasi, akan tetapi data diklasifikasikan berdasarkan perilaku atau nilai yang diperkirakan pada masa yang akan datang. Contoh dari tugas prediksi misalnya untuk memprediksikan adanya pengurangan jumlah pelanggan dalam waktu dekat dan prediksi harga saham dalam tiga bulan yang akan datang.
Beberapa metode dan teknik yang digunakan untuk klasifikasi dan estimasi juga dapat digunakan untuk prediksi dalam kondisi yang tepat. Hal ini termasuk metode statistik tradisional dari estimasi titik dan interval keyakinan estimasi, simple linear regression dan korelasi (correlation), dan multiple regression
, serta metode
data mining dan knowledge discovery seperti jaringan saraf, decision tree
, dan
metode k-nearestneighbor.
2.4.3 Estimasi
Estimasi hampir sama dengan prediksi, kecuali variabel target estimasi lebih ke arah numerik dari pada ke arah kategori. Model dibangun menggunakan record
Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilkan model estimasi.
Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya. Bidang analisis statistik memberikan beberapa metode estimasi yang bernilai dan banyak digunakan. Hal Ini termasuk estimasi titik dan interval keyakinan estimasi, simple linear regression dan korelasi (correlation), dan multipleregression
.
2.4.4 Klasifikasi
Klasifikasi merupakan proses menemukan sebuah model atau fungsi yang mendeskripsikan dan membedakan data ke dalam kelas-kelas. Klasifikasi melibatkan proses pemeriksaan karakteristik dari objek dan memasukkan objek ke dalam salah satu kelas yang sudah didefinisikan sebelumnya (Han dan Kamber, 2006).
Menurut Han dan Kamber (2006) secara umum, klasifikasi terdiri dari dua tahap. Tahap pertama yaitu learning (proses belajar), merupakan sebuah model dibuat untuk menggambarkan himpunan kelas atau konsep data yang telah ditentukan sebelumnya. Model tersebut dibangun dengan menganalisa record-record pada basis
data yang digambarkan dalam bentuk atribut. Setiap record diasumsikan masuk ke dalam suatu kelas yang telah ditentukan sebelumnya, yang dinamakan atribut kelas.
Model itu sendiri bisa berupa aturan IF-THEN
,
decisiontree, formula matematis atau
neuralnetwork.
Namun terkadang klasifikasi perlu didasarkan pada prediksi yang berbeda, membutuhkan plot banyak dimensi. Oleh karena itu, perlu dilakukan peralihan ke model yang lebih canggih untuk melakukan tugas klasifikasi. Metode data mining
yang umum digunakan untuk klasifikasi adalah k-nearestneighbor
,
decisiontree, dan
jaringan saraf (neuralnetwork).2.4.5 Clustering
Clustering merupakan pengelompokan data tanpa berdasarkan kelas data tertentu ke dalam kelas objek yang sama. Sebuah kluster adalah kumpulan record
yang memiliki kemiripan suatu dengan yang lainnya dan memiliki ketidakmiripan dengan record dalam kluster lain. Tujuannya adalah untuk menghasilkan
pengelompokan objek yang mirip satu sama lain dalam kelompok-kelompok. Semakin besar kemiripan objek dalam suatu cluster dan semakin besar perbedaan tiap
Clustering berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengelompokkan. Clustering tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan dengan record dalam kelompok lain akan bernilai minimal.
Clustering sering dilakukan sebagai langkah awal dalam proses data mining
,
dengan kluster yang dihasilkan digunakan sebagai masukan lebih lanjut ke hilir teknik yang berbeda, seperti neural network. Beberapa metode
clustering adalahk-means clustering dan Kohonennetworks.
2.4.6 Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang
belanja (market basket analisys). Tugas asosiasi berusaha untuk mengungkap aturan untuk mengukur hubungan antara dua atau lebih atribut.
Aturan asosiasi adalah bentuk "Jika pendahuluan, maka konsekuen," (If
antecedent
,
then consequent) dengan ukuran dukungan dan kepercayaan yang berhubungan dengan aturan. Sebagai contoh, supermarket tertentu mungkinmenemukan bahwa dari 1000 pelanggan yang berbelanja pada Kamis malam, 200 membeli popok dan 50 membeli bir. Dengan demikian, aturan asosiasi menjadi "Jika membeli popok, kemudian membeli bir" dengan dukungan 200/1000 = 20% dan kepercayaan 50/200 = 25%.
Contoh asosiasi dalam bisnis dan penelitian adalah:
a. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respon positif terhadap penawaran upgrade
layanan yang diberikan.
b. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli bersamaan.
2.5Aplikasi Data mining
Sebagai cabang ilmu baru di bidang sistem informasi cukup banyak penerapan yang dapat dilakukan oleh data mining
. Apalagi ditunjang kekayaan dan
keanekaragaman berbagai bidang ilmu (artificial intelligence,
database, statistik,
pemodelan matematika, pengolahan citra dsb.) membuat penerapan data miningmenjadi makin luas. Salah satu penerapan proses data mining adalah pada Costumer
berhubungan dengan manajemen pelanggan pada suatu proses transaksi. Informasi tersebut nantinya dapat digunakan untuk meningkatkan pelanggan.
2.5.1 Penerapan Data mining pada CRM
Pelanggan (Customer) adalah aset paling penting dari suatu perusahaan. Tidak akan terjadi prospek bisnis jika tanpa adanya pelanggan yang merasa puas dan tetap setia menjalin hubungan dengan suatu organisasi. Itulah mengapa suatu organisasi harus merencanakan dan menerapkan strategi yang jelas untuk memperlakukan pelanggan. CRM (Customer Relationship Management) adalah strategi untuk membangun, mengelola, dan memperkuat hubungan pelanggan yang setia dan bertahan lama. CRM harus dilakukan dengan pendekatan Customer-centric
berdasarkan wawasan pelanggan (Tsiptsis dan Chorianopoulos 2009).
Sistem CRM merupakan alat yang digunakan untuk mendukung strategi efektif mengelola pelanggan. Untuk melakukan sistem CRM tersebut organisasi perlu mendapatkan informasi tentang pelanggan, seperti kebutuhan dan keinginan mereka melalui analisis data. Di sinilah data mining dapat membantu dalam retensi pelanggan karena memungkinkan identifikasi tepat waktu terhadap pelanggan yang dianggap berharga (setia) dengan kemungkinan pelanggan yang akan pergi. Hal ini dapat mendukung pengembangan pelanggan dengan mencocokkan produk dengan
pelanggan dan penargetan yang lebih baik dari kampanye promosi produk. Hal ini juga dapat membantu untuk mengungkapkan segmen pelanggan yang berbeda, memfasilitasi pengembangan produk baru disesuaikan dan penawaran produk yang lebih baik mengatasi preferensi khusus dan prioritas dari pelanggan.
Menurut Tsiptsis dan Chorianopoulos (2009) data mining bertujuan untuk mengekstrak pengetahuan dan wawasan melalui analisis data dalam jumlah besar dengan menggunakan teknik pemodelan yang canggih. Data mining mengubah data menjadi pengetahuan dan informasi yang ditindaklanjuti. Data yang akan dianalisis mungkin berada dan terorganisir dalam data pasar dan gudang data atau dapat diekstraksi dari berbagai sumber data terstruktur. Sebuah prosedur data mining
memiliki banyak tahapan. Prosedur ini biasanya melibatkan manajemen data yang luas sebelum dilakukan penerapan algoritma pembelajaran statistik dan pengembangan model yang tepat.
2.5.2 Data mining dalam Kerangka CRM
Data mining dapat memberikan wawasan pelanggan yang sangat penting untuk membangun strategi CRM yang efektif. Hal ini dapat menyebabkan interaksi personal dengan pelanggan, maka kepuasan meningkat. Hal ini dapat mendukung manajemen terhadap pelanggan serta dioptimalkan pada seluruh tahapan siklus hidup dari pelanggan tersebut, baik dari akuisisi dan pembentukan hubungan yang kuat
sehingga dapat mencegah pengurangan pelanggan atau kembali memenangkan pelanggan yang telah hilang. Retailer berusaha untuk mendapatkan pangsa pasar yang lebih besar dan pelanggan yang lebih besar dari target yang mereka tetapkan. Lebih khusus, kegiatan pemasaran yang dapat didukung dengan penggunaan data mining meliputi topik-topik berikut (Tsiptsis dan Chorianopoulos, 2009).
1. Segmentasi Pelanggan
Segmentasi pelanggan adalah proses membagi basis pelanggan ke dalam kelompok-kelompok yang berbeda dan homogen dalam rangka untuk mengembangkan strategi pemasaran yang berbeda sesuai dengan karakteristik pelanggan. Ada beberapa jenis segmentasi yang berbeda yaitu berdasarkan kriteria tertentu atau atribut yang digunakan untuk segmentasi. Dalam segmentasi perilaku, pelanggan dikelompokkan berdasarkan karakteristik perilaku dan penggunaan. Algoritma clustering dapat digunakan untuk menganalisis data perilaku serta mengidentifikasi kelompok alami dari pelanggan, dan menyarankan solusi yang didasarkan pada pola data yang diamati. Data mining juga dapat digunakan untuk pengembangan skema segmentasi berdasarkan situasi saat ini yang diharapkan atau perkiraan dari nilai pelanggan. Segmen ini diperlukan dalam rangka untuk memprioritaskan penanganan pelanggan dan intervensi pemasaran sesuai dengan pentingnya setiap pelanggan.
2. Segmentasi Kampanye Pemasaran Langsung
Retailer menggunakan kampanye pemasaran langsung untuk melakukan
komunikasi dengan pelanggan mereka melalui surat, internet, e-mail, telepon, dan saluran langsung lainnya. Hal ini dilakukan untuk mendorong akuisisi pelanggan dan pembelian produk lainnya pada retailer tersebut. Lebih khusus lagi, kampanye akuisisi bertujuan menarik pelanggan baru yang memiliki potensi yang besar terhadap produk. Kampanye Cross-/deep-/up-selling
diterapkan untuk menjual produk tambahan, bisa lebih baik dari produk yang sebelumnya, atau produk alternatif yang menguntungkan kepada pelanggan yang ada. Akhirnya, kampanye bertujuan untuk mencegah retensi pelanggan berharga dari mengakhiri hubungan mereka dengan retailer
.
Data mining dan klasifikasi (kecenderungan) model pada khususnya dapat mendukung pengembangan kampanye pemasaran bertarget. Mereka menganalisis karakteristik pelanggan dan mengenali profil dari target pelanggan. Kasus baru dengan profil serupa kemudian diidentifikasi, diberi skor kecenderungan yang tinggi, dan termasuk dalam daftar target. Model klasifikasi digunakan untuk mengoptimalkan kampanye pemasaran dapat dijelaskan sebagai berikut:
a. Model Akuisisi: model ini digunakan untuk mengenali calon pelanggan yang berpotensi menguntungkan dengan mencari “clones” dari pelanggan
yang sudah ada dalam daftar kontak eksternal,
b. Model Cross-/deep-/up-selling: model digunakan untuk mengungkapkan potensi pembelian dari pelanggan yang sudah ada.
c. Model Pengurangan Sukarela (Voluntary attrition): model ini digunakan untuk mengidentifikasi awal pelanggan dan melihat para pelanggan tersebut dengan kemungkinan peningkatan untuk meninggalkan suatu organisasi secara sukarela.
3. Segementasi MarketBasket dan SequenceAnalysis
Data mining dan model asosiasi pada khususnya dapat digunakan untuk mengidentifikasi produk-produk terkait yang biasanya dibeli bersama-sama. Model ini dapat digunakan untuk analisis market basket dan untuk mengungkapkan jenis produk atau jasa yang dapat dijual bersama-sama dengan produk yang dibeli oleh pelanggan. Model urutan (SequenceAnalysis) dilakukan dengan memperhitungkan urutan tindakan atau pembelian dari pelanggan serta dapat mengidentifikasi urutan peristiwa yang akan terjadi.
2.6Metode Asosiasi
Analisis asosiasi adalah teknik data mining untuk menemukan hubungan menarik antara suatu kombinasi item yang tersembunyi dalam suatu database
.
Hubungan ini dapat direpresentasikan dalam suatu bentuk aturan asosiasi (Tan, Steinbach, Kumar, 2004). Analisis asosiasi akan berusaha mengungkap asosiasi antara atribut, yaitu berusaha untuk mengungkap aturan untuk mengukur hubungan antara dua atau lebih atribut. Secara umum aturan asosiasi mempunyai bentuk :𝑰𝑭 𝒂𝒏𝒕𝒆𝒄𝒆𝒅𝒆𝒏𝒕 𝑻𝑯𝑬𝑵 𝒄𝒐𝒏𝒔𝒆𝒒𝒖𝒆𝒏𝒕
Kekuatan hubungan suatu aturan asosiatif dapat diukur dengan dua parameter yaitu support dan confidence
.
Support (nilai penunjang) adalah persentase kombinasi item tersebut dalam database dan confidence (nilai kepastian) yaitu kuatnya hubungan antar item dalam aturan asosiatif.Metode analisis asosiasi, juga dikenal sebagai market basket analysis
, yaitu
analisis yang sering dipakai untuk menganalisa isi keranjang belanja konsumen dalam suatu pasar swalayan. Contoh penerapan dari aturan asosiatif adalah analisa pembelian produk pada sebuah toko alat tulis, pada analisa itu misalkan dapat diketahui berapa besar kemungkinan seorang pelanggan membeli pensil bersamaan dengan membeli penghapus. Penerapan aturan asosiasi dalam kasus tersebut dapat membantu pemilik toko untuk dipakai sebagai pendukung keputusan dalam penjualanseperti mengatur penempatan barang, mengatur persediaan atau membuat promosi pemasaran dengan menerapkan diskon untuk kombinasi barang tertentu.
Analisis asosiasi didefinisikan sebagai suatu proses untuk menemukan semua aturan asosiasi yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence (minimum confidence). Dasar analisis asosiasi terbagi menjadi dua tahap, yaitu:
1. Analisa pola frekuensi tinggi, pada tahap ini dicari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database
. Nilai
supportsebuah item diperoleh dengan rumus berikut :
𝑆𝑢𝑝𝑝𝑜𝑟𝑡 (𝐴) =𝐽𝑢𝑚𝑙𝑎ℎ 𝑇𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖 𝑢𝑛𝑡𝑢𝑘 𝐴
𝑇𝑜𝑡𝑎𝑙 𝑇𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖 ... (2.1)
Keterangan :
- Support A adalah nilai penunjang persentase kombinasi item A dalam
database.
- Jumlah transaksi untuk A adalah kemunculan item A dalam keseluruhan transaksi.
- Total transaksi adalah jumlah total transaksi yang ada dalam database.
𝑆𝑢𝑝𝑝𝑜𝑟𝑡 (𝐴
,
𝐵) = 𝑃 (𝐴 ∩ 𝐵)... (2.2)
𝑆𝑢𝑝𝑝𝑜𝑟𝑡 (𝐴
,
𝐵) = ∑ 𝑇𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖 𝑢𝑛𝑡𝑢𝑘 𝐴 𝑑𝑎𝑛 𝐵 ∑ 𝑇𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖Keterangan :
- Support A,B adalah nilai penunjang (persentase) kombinasi dari dua item
yaitu item A dan item B dalam database.
- Ʃ transaksi untuk A dan B adalah jumlah kemunculan kombinasi item A dan B dalam keseluruhan transaksi.
- Ʃ transaksi adalah jumlah total transaksi yang ada dalam database.
2. Pembentukan aturan Asosiasi, setelah semua pola frekuensi tinggi ditemukan, barulah dicari aturan asosiasi yang memenuhi syarat minimum untuk confidence
dengan menghitung nilai confidence aturan assosiatif A B.
Nilai confidence dari aturan A B diperoleh dari rumus sebagai berikut:
𝐶𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒 = 𝑃(𝐵|𝐴) =∑ 𝑇𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖 𝑢𝑛𝑡𝑢𝑘 𝐴 𝑑𝑎𝑛 𝐵
∑ 𝑇𝑟𝑎𝑛𝑠𝑎𝑘𝑠𝑖 𝑢𝑛𝑡𝑢𝑘 𝐴 ... (2.3)
Keterangan :
- Confidence P(A|B) adalah nilai kepastian kuatnya hubungan antar item A dan
item B dalam aturan asosiatif atau berapa kali item A muncul bersamaan dengan item B.
- Ʃ transaksi untuk A dan B adalah jumlah kemunculan kombinasi item A dan B dalam keseluruhan transaksi.
- Ʃ transaksi untuk A adalah jumlah total transaksi item A dalam keseluruhan transaksi
.
2.7Algoritma Apriori
Algoritma apriori termasuk jenis aturan asosiasi pada data mining yang dikembangkan pertama kali oleh R. Agrawal dan R. Srikant pada tahun 1994. Algoritma ini didasarkan pada fakta bahwa apriori menggunakan pengetahuan sebelumnya dari suatu itemset dengan frekuensi kemunculan yang sering atau disebut
frequent itemset
. Apriori menggunakan pendekatan iteratif dimana k-
itemsetdigunakan untuk mengeksplorasi (k+1)-itemset berikutnya (Han&Kamber, 2006). Prinsip metode apriori adalah jika suatu itemset sering muncul (frequent), maka semua subset dari itemset tersebut juga harus sering muncul dalam suatu database
(Tan, Steinbach, Kumar, 2004).
Pada algoritma ini calon (k+1)-itemset dihasilkan oleh penggabungan dua
itemset pada domain / ukuran k. Calon (k+1)-itemset yang mengandung frekuensi
subset yang jarang muncul atau dibawah threshold akan dipangkas dan tidak dipakai dalam menentukan aturan asosiasi (Tan, Steinbach, Kumar, 2004). Sesuai dengan aturan asosiasi, algoritma apriori juga menggunakan minimum support dan minimum
confidence untuk menentukan aturan itemset mana yang sesuai untuk digunakan dalam pengambilan keputusan.
1-itemset digunakan untuk menemukan 2-itemset yaitu kombinasi item yang berjumlah 2, contohnya if buy pensil then buy penghapus
, 2-
itemset digunakan untuk menemukan 3-itemset yaitu kombinasi item yang berjumlah 3, contohnya if buy pensil and buy pulpen then buy penghapus dan seterusnya sampai tidak ada lagifrequent k-itemset yang bisa ditemukan (Han&Kamber, 2006). 2.7.1 Struktur Kombinasi
Struktur dari itemset disini adalah mengikuti suatu bentuk dari kombinasi. Pengertian kombinasi adalah menggabungkan beberapa objek dari suatu grup tanpa memperhatikan urutan (Wikipedia, 2016). Di dalam kombinasi, urutan objek tidak diperhatikan sebagai contoh dimana {1,2,3} adalah sama dengan {2,3,1} dan {3,1,2}.
Kombinasi dapat dibagi menjadi dua yaitu kombinasi dengan pengulangan dan kombinasi tanpa pengulangan. Kombinasi tanpa pengulangan ketika urutan tidak diperhatikan akan tetapi setiap objek yang ada hanya bisa dipilih sekali maka jumlah kombinasi yang ada adalah:
𝑛!
𝑟!(𝑛−𝑟)!
= (
𝑛Dimana n adalah jumlah objek yang bisa dipilih dan r adalah jumlah yang harus dipilih. Sebagai contoh, terdapat 5 pensil warna dengan warna yang berbeda yaitu; merah, kuning, hijau, biru dan ungu. Pensil warna tersebut hanya boleh dipilih dua warna. Banyak cara untuk mengkombinasikan pensil warna yang ada dengan menggunakan rumus di atas adalah 5!/(5-2)!(2)! = 10 kombinasi.
Kombinasi dengan pengulangan jika urutan tidak diperhatikan dan objek bisa dipilih lebih dari sekali, maka jumlah kombinasi yang ada adalah ditunjukkan pada rumus berikut : (𝑛+𝑟−1)! 𝑟!(𝑛−1)!
= (
𝑛+𝑟−1 𝑟) = (
𝑛+𝑟−1 𝑛−1)
... (2.5)Di mana n adalah jumlah objek yang bisa dipilih dan r adalah jumlah yang harus dipilih. Sebagai contoh adalah terdapat 10 jenis kue donat berbeda pada suatu toko donat. Kombinasi yang dihasilkan jika ingin untuk membeli tiga buah donat adalah (10+3-1)!/3!(10-1)! = 220 kombinasi.
Kombinasi yang digunakan dalam algoritma apriori pada penelitian ini adalah kombinasi tanpa pengulangan. Urutan item dalam kombinasi yang dibentuk tidak diperhatikan akan tetapi setiap item yang ada hanya boleh digunakan sekali dalam satu kombinasi atau itemset
.
2.7.2 Perhitungan Waktu Iterasi
Algoritma apriori melakukan scaning database berulang kali untuk menemukan frequent itemset dalam membentuk aturan asosiasi. Waktu iterasi yang ditempuh algoritma dapat dihitung dari waktu berakhirnya algoritma sampai mendapatkan aturan asosiasi dikurangi dengan waktu awal algoritma dijalankan sesuai dengan rumus berikut.
𝑡_𝑙𝑎𝑚𝑎 = 𝑡_𝑎𝑘ℎ𝑖𝑟 − 𝑡_𝑎𝑤𝑎𝑙 ... (2.6)
Dimana
t_awal = mencatat waktu awal mulainya proses iterasi. t_akhir = mencatat waktu berakhirnya proses iterasi.