1. Waktu Penelitian
Penelitian berfokus pada data Pagu dan Realisasi anggaran Satker-satker jajaran Polri, baik sumber dana maupun output, untuk periode 2012 – 2016. Pengambilan data-data penelitian dilakukan pada tanggal 1 Oktober 2016 – 30 Juni 2017.
2. Tempat Penelitian
Penelitian dilaksanakan pada kantor Direktorat Jenderal Anggaran, Kementerian Keuangan. Penulis akan mengunjungi beberapa unit kerja yang terkait bidang penelitian seperti Direktorat Sistem Penganggaran, Direktorat Penyusunan Anggaran Pendapatan Belanja Negara (APBN), Direktorat Anggaran Bidang Perekonomian dan Kemaritiman, Direktorat Anggaran Bidang Pembangunan Manusia dan Kebudayaan, Direktorat anggaran Bidang Politik, hukum, Pertahanan dan kemananan, dan Bagian Anggaran Bendahara Umum Negara.
B. Desain Penelitian
Desain penelitian ini adalah penelitian kausal yang bertujuan menguji hipotesis tentang pengaruh simultan yang terjadi antara tiga variabel eksogen terhadap satu variabel endogen. Penelitian akan menguji pengaruh variabel realisasi belanja pemerintah yang terdiri dari belanja pegawai, belanja barang, dan belanja modal terhadap kinerja pelaksanaan anggaran. Penelitian juga akan
menguji pengaruh blokir anggaran terhadap kinerja atas pelaksanaan anggaran. Pengaruh variabel revisi anggaran terhadap kinerja atas pelaksanaan anggaran juga menjadi salah satu fokus penelitian. Penelitian ini bertujuan menguji secara simultan hubungan realisasi belanja pemerintah, blokir anggaran, dan revisi anggaran belanja terhadap kinerja atas pelaksanaan anggaran.
C. Definisi dan Operasionalisasi Variabel 1. Definisi Variabel
Dalam penelitian pada umumnya dikenal istilah variabel independen (variabel bebas) dan variabel dependen (terikat). Menurut Sugiyono (2013: 59) Variabel terikat merupakan variabel yang dipengauhi atau yang menjadi akibat, karena adanya variabel bebas. Variabel bebas menurut Sugiyono (2013: 59) merupakan variabel yang mempengaruhi atau yang menjadi sebab perubahanya atau timbulnya variabel dependen (terikat). Dalam terminologi ini, nilai kinerja atas pelaksanaan RKA-K/L merupakan variabel dependen, sedangkan varians belanja pegawai, varians belanja barang, varians belanja modal, dan revisi anggaran belanja merupakan variabel independen.
Pada penelitian dengan metode Structural Equation Modeling (SEM), terminologi varibel merujuk pada konstruk. Konstruk berdasarkan sifat hubungannya terdiri dari konstruk eksogen dan konstruk endogen. Konstruk berdasarkan sifat keterukurannya terdiri dari konstruk laten dan konstruk manifest. Menurut Imam Ghozali (2014:13) Konstruk eksogen adalah variabel independen, sedangkan konstruk endogen adalah variabel dependen. Dalam bentuk grafis konstruk endogen menjadi target paling tidak satu anak panah (→)
atau hubungan regresi, sedangkan konstruk eksogen menjadi target garis dengan dua anak panah (↔) atau hubungan korelasi/kovarian. Konstruk endogen penelitian ini, yaitu kinerja atas pelaksanaan anggaran, varians belanja pegawai, varians belanja barang, dan varians belanja modal, sedangkan revisi anggaran belanja, merupakan konstruk eksogen. Keseluruhan variabel penelitian ini termasuk dalam konstruk manifest karena dapat diukur secara langsung.
a. Variabel Endogen
1) Nilai Kinerja atas Pelaksanaan Rencana Kerja dan Anggaran Kementerian/ Lembaga (RKA-K/L)
Anggaran yang dimaksud pada penelitian ini mengacu pada dokumen Rencana Kerja dan Anggaran Kementerian/ Lembaga (RKA-K/L). Nilai Kinerja atas pelaksanaan RKA-K/L ini berdasarkan data yang tercatat pada Aplikasi SMART periode 2012 – 2016. Peraturan Menteri Keuangan (PMK) Nomor 249 tahun 2011 menjelaskan tentang mekanisme penilaian kinerja. Nilai Kinerja dihitung dengan menjumlahkan perkalian nilai aspek implementasi dan aspek manfaat dengan bobot masing-masing. Rumus perhitungan tersebut, yaitu:
NK = (I × WI) + (CH × WCH)
dengan
I = (P × WP) + (K × WK) + (PK × WPK) + (NE × WE)
Keterangan:
NK : Nilai Kinerja
I : Nilai aspek implementasi P : Penyerapan anggaran
K : Konsistensi antara perencanaan dan implementasi PK : Pencapaian Keluaran
NE : Nilai Efisiensi CH : Capaian Hasil
WI : Bobot aspek implementasi
WCH : Bobot capaian hasil
WP : Bobot penyerapan anggaran
WK : Bobot konsistensi antara perencanaan dan implementasi
WPK : Bobot pencapaian Keluaran
WE : Bobot efisiensi
Hasil penilaian kinerja dikelompokkan dalam lima kategori sebagaimana disebutkan dalam Pasal 13 ayat (7) PMK Nomor 249 tahun 2011 sebagai berikut:
a. Nilai Kinerja lebih dari 90% sampai dengan 100% dikategorikan dengan Sangat Baik.
b. Nilai Kinerja lebih dari 80% sampai dengan 90% dikategorikan dengan Baik.
c. Nilai Kinerja lebih dari 60% sampai dengan 80% dikategorikan dengan Cukup atau Normal.
d. Nilai Kinerja lebih dari 50% sampai dengan 60% dikategorikan dengan Kurang.
e. Nilai Kinerja sampai dengan 50% dikategorikan dengan Sangat Kurang.
b. Variabel Eksogen
1) Realisasi Belanja Pemerintah
Realisasi belanja pemerintah merupakan bagian realisasi anggaran. Menurut Bastian (2010) realisasi anggaran merupakan pelaksanaan segala sesuatu yang telah direncanakan dan dianggarkan oleh organisasi publik. Rumusan realisasi
belanja dihitung dengan pendekatan varians belanja yang digunakan pada penelitian Paat (2013) dan Assidiqi (2014) sebagai berikut:
RB = 𝑅𝐵𝐴𝐵𝑡
𝑡
Keterangan:
RR : Persentase realisasi belanja pemerintah 𝑅𝐵𝑡 : Realisasi belanja pemerintah tahun ke-t
𝐴𝐵𝑡 : Anggaran belanja awal (sesuai Perpres Rincian APBN) tahun ke-t 2) Revisi anggaran belanja
Penelitian-penelitian terdahulu yang terkait revisi anggaran belanja tidak secara spesifik menyebutkan tentang rumus untuk menghitung besaran revisi anggaran belanja. Revisi anggaran belanja dalam penelitian ini merujuk pada perubahan rincian anggaran yang disebabkan oleh penambahan atau pengurangan pagu anggaran dan perubahan atau pergeseran rincian anggaran dan/atau pergeseran anggaran dalam hal pagu anggaran tetap. Penelitian ini akan merumuskan revisi anggaran sebagai berikut:
Rev_Ang = ∆𝐴𝐵𝑃𝑖 + ∆𝐴𝐵𝐵𝑖 + ∆𝐴𝐵𝑀𝑖 Keterangan:
Rev_Ang : Revisi anggaran
∆𝐴𝐵𝑃𝑖 : Perubahan anggaran belanja pegawai tahun ke-i ∆𝐴𝐵𝐵𝑖 : Perubahan anggaran belanja barang tahun ke-i ∆𝐴𝐵𝑀𝑖 : Perubahan anggaran belanja modal tahun ke-i
3) Blokir Anggaran
Penelitian-penelitian terdahulu yang terkait perubahan anggaran belanja tidak secara spesifik menyebutkan tentang rumus untuk menghitung besaran blokir anggaran. Berdasarkan Lampiran VI Peraturan Menteri Keuangan (PMK) Nomor 163/PMK.02/2016 dirumuskan besaran blokir sebagai berikut:
BA = BA1 + BA2 + BA3
Keterangan:
BA : Blokir anggaran
BA1 : Blokir anggaran karena masih harus dilengkapi dengan dokumen sebagai
dasar pengalokasian anggaran.
BA2 : Blokir anggaran karena alokasi anggaran yang masih terpusat.
BA2 : Blokir anggaran karena output cadangan.
2. Operasionalisasi variabel
Operasional variabel penelitian menguraikan tentang indikator dan skala untuk setiap variabel. Penjelasan terperinci mengenai operasional variabel disajikan dalam Tabel 3.1.
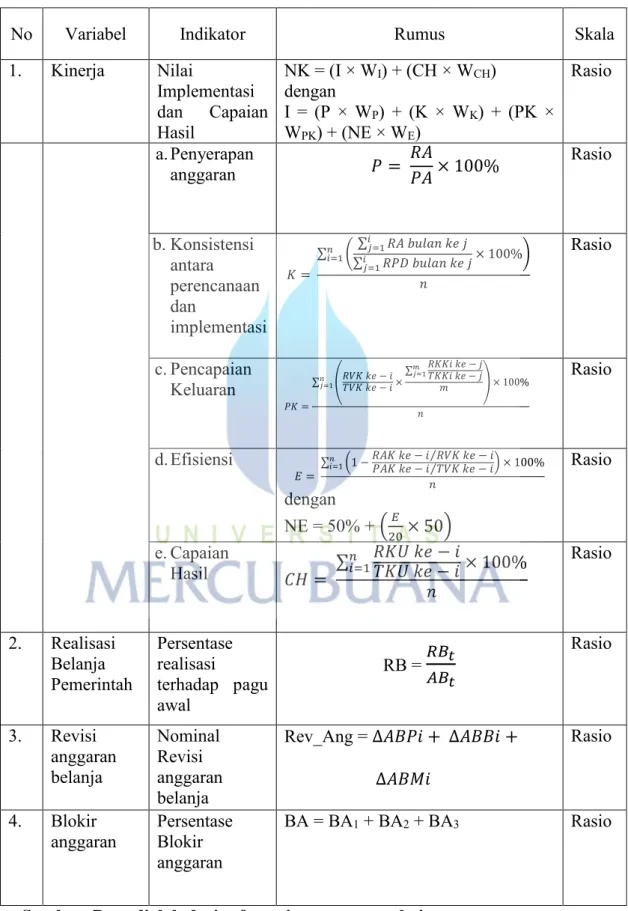
TABEL 3.1 OPERASIONALISASI VARIABEL
No Variabel Indikator Rumus Skala
1. Kinerja Nilai Implementasi dan Capaian Hasil NK = (I × WI) + (CH × WCH) dengan I = (P × WP) + (K × WK) + (PK × WPK) + (NE × WE) Rasio a. Penyerapan anggaran 𝑃 = 𝑅𝐴𝑃𝐴× 100% Rasio b. Konsistensi antara perencanaan dan implementasi 𝐾 = ∑ (∑ 𝑅𝐴 𝑏𝑢𝑙𝑎𝑛 𝑘𝑒 𝑗 𝑖 𝑗=1 ∑𝑖 𝑅𝑃𝐷 𝑏𝑢𝑙𝑎𝑛 𝑘𝑒 𝑗 𝑗=1 × 100%) 𝑛 𝑖=1 𝑛 Rasio c. Pencapaian Keluaran 𝑃𝐾 = ∑ (𝑅𝑉𝐾 𝑘𝑒 − 𝑖𝑇𝑉𝐾 𝑘𝑒 − 𝑖 ×∑ 𝑅𝐾𝐾𝑖 𝑘𝑒 − 𝑗 𝑇𝐾𝐾𝑖 𝑘𝑒 − 𝑗 𝑚 𝑗=1 𝑚 ) × 100% 𝑛 𝑗=1 𝑛 Rasio d. Efisiensi 𝐸 = ∑𝑛 (1 − 𝑅𝐴𝐾 𝑘𝑒 − 𝑖 𝑅𝑉𝐾 𝑘𝑒 − 𝑖𝑃𝐴𝐾 𝑘𝑒 − 𝑖 𝑇𝑉𝐾 𝑘𝑒 − 𝑖⁄⁄ ) × 100% 𝑖=1 𝑛 dengan NE = 50% + (20𝐸 × 50) Rasio e. Capaian Hasil 𝐶𝐻 = ∑𝑛𝑖=1𝑅𝐾𝑈 𝑘𝑒 − 𝑖𝑇𝐾𝑈 𝑘𝑒 − 𝑖 × 100% 𝑛 Rasio 2. Realisasi Belanja Pemerintah Persentase realisasi terhadap pagu awal RB = 𝑅𝐵𝐴𝐵𝑡 𝑡 Rasio 3. Revisi anggaran belanja Nominal Revisi anggaran belanja Rev_Ang = ∆𝐴𝐵𝑃𝑖 + ∆𝐴𝐵𝐵𝑖 + ∆𝐴𝐵𝑀𝑖 Rasio 4. Blokir
anggaran Persentase Blokir anggaran
BA = BA1 + BA2 + BA3 Rasio
D. Populasi dan Sampel Penelitian 1. Populasi
Berdasarkan data referensi Aplikasi SMART (Sistem Monitoring dan Evaluasi Terpadu, Kementerian Keuangan) dengan alamat domain
http://monev.anggaran.kemenkeu.go.id/smart/ pada tahun 2016, terdapat 88 Kementerian/ Lembaga (K/L). Yang ditetapkan sebagai populasi pada penelitian ini adalah 88 Kementerian/ Lembaga (K/L) selama periode 2012 – 2016.
2. Sampel
Pemilihan sampel ditentukan mengunakan Purposive sampling untuk menentukan sampel. Dari 88 Kementerian/ Lembaga (K/L) yang terdaftar, penulis akan memilih 88 Kementerian/ Lembaga (K/L) yang akan dijadikan sampel dengan kriteria sebagai berikut :
a. terdaftar secara konsisten pada aplikasi SMART periode 2012 – 2016; dan b. hasil evaluasi kinerja mendapat predikat minimal Cukup sebanyak tiga kali
atau lebih selama periode 2012 – 2016.
Berdasarkan kriteria yang telah ditetapkan, jumlah sampel dirinci sebagai berikut.
TABEL 3.2 RINCIAN SAMPEL
No. Uraian Jumlah
1. Kementerian/ Lembaga (K/L) se-Indonesia 88 2. Kementerian/ Lembaga (K/L) yang tidak terdaftar secara Konsisten
dalam Referensi Aplikasi SMART periode 2012 - 2016 (4) 3. Kementerian/ Lembaga (K/L) yang hasil evaluasi kinerjanya tidak
mendapat predikat minimal Cukup sebanyak tiga kali atau lebih selama periode 2012 – 2016
(15)
4. Kementerian/ Lembaga (K/L) yang memenuhi kriteria untuk
E. Teknik Pengumpulan Data
Teknik pengumpulan data yang dilakukan meliputi dua metode yaitu:
1. Teknik dokumentasi dari sumber data sekunder dengan mengumpulkan, mencatat, dan mengolah data yang berkaitan dengan penelitian. Data bersumber dari data-data yang diperoleh pada Direktorat Jenderal Anggaran, Kementerian Keuangan.
2. Teknik wawancara dengan pihak-pihak terkait dan berkompeten dalam bidang anggaran, yaitu Pejabat di lingkungan Direktorat Sistem Penganggaran dan Direktorat anggaran Bidang Politik, hukum, Pertahanan dan kemananan, dan Bagian Anggaran Bendahara Umum Negara (Dit. Polhukhankam dan BA BUN), Kementerian Keuangan.
F. Metode Analisis 1. Statistik Deskriptif
Menurut Sugiyono (2013: 206) Statistik deskriptif adalah statistik yang digunakan untuk menganalisis data dengan cara mendiskripsikan atau menggambarkan data yang telah terkumpul sebagaimana adanya tanpa bermaksud membuat kesimpulan yang berlaku untuk umum atau generalisasi. Data dari sampel yang terkumpul dapat disajikan dalam bentuk tabel, grafik, diagram lingkaran, piktogram, perhitungan mean, median, modus, perhitungan desil, persentil, perhitungan penyebaran data melalui perhitungan rata-rata dan standar deviasi. Statistik deskriptif akan diterapkan pada seluruh variabel penelitian ini
guna mendapatkan gambaran umum maupun penjelasan terinci tentang fenomena yang akan dianalisis.
2. Analisis Structural Equation Modeling (SEM)
Structural Equation Modeling (SEM) merupakan gabungan dari dua metode statistik yang terpisah, yaitu analisis faktor (factor analysis) yang dikembangkan di ilmu psikologi dan psikometri serta model persamaan simultan (simultaneous equation modeling) yang dikembangkan di ekonometrika. (Ghozali, 2016: 3). Menurut Ferdinand (dalam Atmaja, 2011: 51) Jika dilihat dari penyusunan model serta cara kerjanya, SEM adalah gabungan dari analisis faktor dan analisis regresi yang dapat menjelaskan hubungan antar banyak variabel. Menganalisis model penelitian dengan SEM dapat mengidenfikasi dimensi-dimensi sebuah konstruk dan pada saat yang sama dapat mengukur pengaruh atau derajat hubungan antar faktor yang telah diidentifikasikan dimensi-dimensinya itu. Hair et al. (dalam Ghozali, 2016: 61) mengajukan tahapan analisis persamaan sttruktural menjadi 7 (tujuh) langkah yaitu: (1) pengembangan model secara teoritis; (2) menyusun diagram jalur (path diagram); (3) mengubah diagram jalur menjadi persamaan struktural; (4) memilih matrik input untuk analisis data; (5) menilai identifikasi model; (6) mengevaluasi estimasi model; dan (7) interprestasi terhadap model.
Penjelasan detail masing-masing tahapan permodelan SEM sebagai berikut. a. Pengembangan model secara teoritis
Langkah pertama dalam pegembangaan model SEM adalah pencarian atau pengembangan sebuah model yang mempunyai justifikasi teoris yang kuat.
Spesifisilkasi model dilakukan dengan membuat model yang merepresentasikan masalah yang menjadi obyek penelitian berdasarkan kerangka teoretis pada bab II. b. Penyusunan diagram jalur (path diagram)
Model teoritis yang telah dibanggun pada langkah pertama akan digambarkan dalam sebuah path diagram. Peneliti, pada penelitian terkait SEM, umumnya bekerja dengan konstruk atau faktor, yang merupakan konsep-konsep yang memiliki pijakan teoritis yang cukup untuk menjelaskan berbagai bentuk hubungan. Pada Diagram 3.1 akan disajikan diagaram alur dari penelitian indikatornya.
c. Pengubahan diagram jalur menjadi persamaan struktural
Peneliti akan mengkonversi spesifikasi model tersebut kedalam rangkaian persamaan setelah teori atau model teoritis dikembangkan dan digambarkan dalam sebuah diagram alur. Menurut Atmaja (2011 :59) Persamaan yang dibangun terdiri dari :
1) Persamaan-persamaan struktural (structural equations). Persamaan ini dirumuskan untuk menyatakan hubungan kausalitas antar berbagai konstruk. Persamaan struktural pada dasarnya dibangun dengan pedoman sebagai berikut: Variabel Endogen = Variabel Eksogen + Error.
DIAGRAM 3.1 MODEL PENELITIAN
2) Persamaan spesifikasi model pengukuran (measurement model). Pada spesifikasi itu peneliti menentukan variabel mana mengukur konstruk mana, serta menentukan serangkaian matriks yang menunjukkan korelasi yang dihipotesakan atar konstruk atau variabel.
Persamaan yang dibangun dalam penelitian ini adalah sebagai berikut: Y =
γ
1.2x1 +γ
1.3 x2 +γ
1.3x3+
e1 (1)dengan: Y = Nilai kinerja atas pelaksanaan RKA-K/L x1= Realisasi belanja pemerintah
x2= Revisi anggaran belanja x3= Blokir anggaran
e1 = error peramalan observasi
d. Pemilihan matrik input untuk analisis data
Matriks input penelitian ini dalam pengujian teori adalah matriks konvarians/varians, sebab lebih memenuhi asumsi dan metodologi, dimana standard error yang dilaporkan akan menunjukan angka yang lebih akurat
dibandingkan dengan menggunakan matriks korelasi. Ukuran sampel yang direkomendasikan untuk metode Maximum Likelihood (ML) antara 100 sampai 200. Ketika sampel menjadi besar (di atas 400 sampai 500), maka metode ML menjadi sangat sensitif dan selalu menghasilkan perbedaan secara signifikan sehingga ukuran Goodness-of-fit menjadi jelek (Ghozali, 2014: 64). Estimasi model menggunakan program SPSS versi 20, SPSS AMOS versi 21, dan Lisrel versi 8.8.
Teknik estimasi yang tersedia dalam AMOS versi 21 antara lain: 1) Maximum Likehood Estimation (ML)
2) General Least Square Estimation (GLS) 3) Unweighted Least Square Estimation (ULS) 4) Scale Free Least Square Estimation (SLS) 5) Asymtotically Least Square Estimation (ADF)
Dalam memilih jenis estimasi memerlukan beberapa pertimbangan terutama dari sisi jumlah sampel dan hasil pengujian atas asumsi normalitas. Penelitian ini akan menggunakan Maximum Likehood Estimation (ML) dengan pertimbangan asumsi normalitas dipenuhi dan ukuran sampel antara 200 – 250.
e. Penilaian identifikasi model
Menurut Ghozali (2014: 65) Cara melihat ada tidaknya problem identifikasi adalah dengan melihat hasil estimasi yang meliputi:
1) Adanya nilai standard error yang besar untuk satu atau lebih koefisien. 2) Ketidakmampuan program untuk invert information matrix.
4) Adanya nilai korelasi yang sangat tinggi (>0,90) antar koefisien estimasi. Menurut Hair et al. (dalam Yudanto, 2009) Untuk tujuan identifikasi, perbedaan besaran koefisien korelasi dan kovarian yang diusulkan dengan besaran aktual koefisien model struktural, dikenal dengan degree of freedom (df). Besaran degree of freedom dapat diperhitungkan dengan persamaan berikut ini:
df = ½[( p + q)(p + q + 1)]- t
Keterangan:p = the number of endogenous indicators q = the number of exogenous indicators
t = the number of estimated coefficients in the proposed model f. Penilaian kriteria Goodness-of-fit
Langkah pertama dalam menilai estimasi model adalah evaluasi atas pemenuhan asumsi-asumsi SEM. Menurut Atmaja (2011: 61) Asumsi-asumsi yang harus dipenuhi dalam prosedur pengumpulan dan pengolahan data yang dianalisis dengan pemodelan SEM adalah sebagai berikut:
1) Ukuran sampel
Ukuran sampel yang harus dipenuhi dalam pemodelan ini adalah minimum berjumlah 100 dan selanjutnya menggunakan perbandingan 5 observasi untuk setiap estimated parameter. Karena itu bila kita mengembangkan model dengan 14 paremeter, maka sampel maksimum yang harus digunakan adalah sebanyak 140 sampel.
2) Normalitas dan Linearitas
Sebaran data harus dianalisa untuk melihat apakah asumsi normalitas dipenuhi sehingga data dapat diolah lebih lanjut untuk pemodelan SEM ini. Normalitas dapat diuji dengan melihat gambar histogram data atau dapat diuji dengan metode-metode statistik. Uji normalitas ini perlu dilakukan baik untuk normalitas untuk data tunggal maupun normalitas multivariate dimana beberapa variabel digunakan sekaligus dalam analisis akhir. Uji linearitas dapat dilakukan dengan mengamati scarplot dari data yaitu dengan memilih pasangan data dan dilihat pola penyebarannya untuk menduga ada tidaknya linearitas.
3) Outliers
Outliers adalah observasi yang muncul dengan nilai-nilai ekstrim baik secara univariat maupun multivariate yaitu yang muncul karena kombinasi karakteristik unik yang dimilikinya. Dapat diadakan treatment khusus pada outliers ini asal diketahui bagaimana munculnya outliers itu. Outlier pada dasarnya dapat muncul dalam empat kategori, yaitu:
a) Outlier muncul karena kesalahan prosedur, seperti kesalahan dalam memasukan data atau kesalahan dalam mengkoding data.
b) Outlier muncul karena adanya yang benar-benar khusus memungkinkan profit datanya lain dari pada yang lain, tetapi peneliti mempunyai penjelasan mengenai apa penyebab munculnya nilai ekstrim itu.
c) Outlier dapat muncul karena adanya sesuatu alasan tetapi peneliti tidak dapat mengetahui apa penyebabnya atau tidak ada penjelasan mengenai sebab-sebab munculnya nilai ekstrim itu.
d) Outlier dapat muncul dalam range nilai yang ada, tetapi bila dikombinasi dengan variabel lainnya, kombinasinya menjadi tidak lazim, atau sangat ekstrim. Inilah yang disebut dengan multivariate Outliers.
4) Multicollinearity dan singularity
Multicollinearitas dapat dideksi dari determinan matriks kovarians. Nilai determinan matriks kovarians yang sangat kecil (extremely small) member indikasi adanya problem multikolinearitas. Pada umumnya program-program komputer SEM telah menyediakan fasilitas warning, setiap kali terdapat indikasi multikoloniaritas atau singularitas. Bila muncul pesan itu data yang digunakan harus diteliti lagi untuk mengetahui apakah terdapat kombinasi linier dari variabel yang dianalisis. Tindakan yang dapat diambil adalah mengeluarkan variabel yang menyebabkan singularitas itu. Bila singularitas dan multikolinearitas ditemukan dalam data yang dikeluarkan itu, salah satu treatment yang dapat diambil adalah dengan menciptakan composit variables, lalu gunakan composite variables itu dalam analisis selanjutnya.
Setelah pengujian atas asumsi-asumsi dasar SEM, langkah berikutnya adalah mengevaluasi kriteria goodness of fit. Menurut Ghozali (2014: 66) ada tiga jenis ukuran dalam goodness-of-fit yaitu:
a. Absolut Fit Measures
Absolut Fit Measures mengukur model fit secara keseluruhan (baik model secara structural maupun secara bersama).
b. Incremental fit measures
Incremental fit measures membandingkan proposed model dengan baseline model yang sering disebut dengan null model. Mengukur Incremental fit measures menggunakan kriteria sebagai berikut:
c. Parsimonious fit measures
Ukuran ini menghubungkan goodness-of-fit model dengan sejumlah koefisien estimasi yang diperlukan untuk mencapai level fit. Prosedur ini mirip dengan adjustment nilai R2 dalam multiple regression.
Untuk analisis regresi berganda, kriteria goodness of fit yang ditekankan hanya Absolut Fit Measures. Pengukuran Absolut Fit Measures dengan menggunakan kriteria:
1. Chi-Square
Chi-Square digunakan untuk menguji perbedaan antara matrik kovarians sampel. Nilai Chi-Square yang relatif tinggi terhadap degree of freedom menunjukkan bahwa matrik kovarian atau korelasi yang diobservasi dengan yang diprediksi berbeda secara nyata dan ini menghasilkan probabilitas (p) lebih kecil dari tingkat signifikansi (α) dan sebaliknya. Peneliti harus mencari nilai Chi-Square yang tidak signifikan karena mengharapkan model yang diusulkan cocok atau fit dengan data observasi.
2. CMIN
CMIN mengambarkan perbedaan antara unrestricted sample covariance matrix S dan restricted covariance matrix ∑(θ) atau secara esensi menggambarkan likelihood ratio test yang umumnya dinyatakan dalam Chi-Square (χ2) statistic.
Nilai statistik ini sama dengan (N – 1) Fmin (ukuran besar besar sampel dikurangi 1 dan dikalikan dengan minimum fit function). Jika nilai Chi-Square signifikan, maka dianjurkan untuk mengabaikannya dan melihat ukuran goodness of fit lainnya.
3. CMIN/DF
Rasio ini untuk mengukur fit yang diperoleh dari nilai Chi-Square dibagi dengan degree of freedom. Menurut Wheaton (1977) nilai rasio 5 (lima) atau kurang dari 5 (lima) merupakan ukuran yang reasonable. Menurut Byrne mengemukakan nilai rasio ini < 2 merupakan fit.
4. GFI (Goodness of fit index)
GFI adalah ukuran non statistik yang nilainya berkisar dari 0 (poor fit) sampai 1,0 (perfect fit). Nilai GFI tingi menunukkan fit yang lebih baik dan beberapa nilai GFI yang dapat diterima sebagai nilai yang layak belum ada standarnya, tetapi banyak peneliti menganjurkan nilai di atas 90% sebagai ukuran good fit.
5. RMSEA (Root Mean Square error of Approximation)
RMSEA adalah ukaran yang digunakan untuk memperbaiki kecenderungan nilai Chi-square untuk menolak model dengan sampel besar. Nilai yang diterima dalam pengukuran ini berkisar antara 0,05 sampai 0,08.
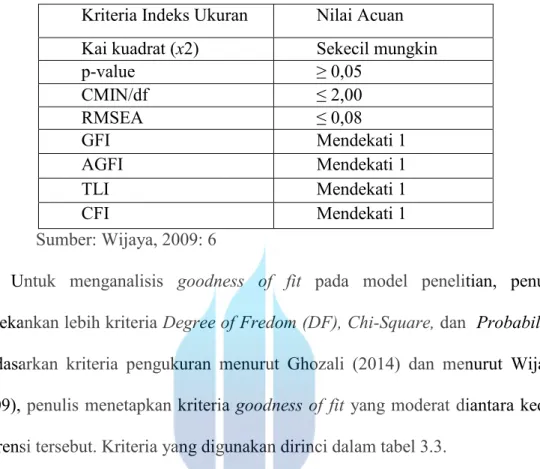
Sedangkan menurut Wijaya (2009:6) tujuan utama SEM adalah untuk menguji kesesuaian atau menguji fit suatu model yaitu menguji kesesuaian model teoritik dengan model empirik. Kriteria goodness of fit adalah sebagai berikut:
TABEL 3.4 KRITERIA GOODNESS OF FIT Kriteria Indeks Ukuran Nilai Acuan Kai kuadrat (x2) Sekecil mungkin
p-value ≥ 0,05 CMIN/df ≤ 2,00 RMSEA ≤ 0,08 GFI Mendekati 1 AGFI Mendekati 1 TLI Mendekati 1 CFI Mendekati 1 Sumber: Wijaya, 2009: 6
Untuk menganalisis goodness of fit pada model penelitian, penulis menekankan lebih kriteria Degree of Fredom (DF), Chi-Square, dan Probability. Berdasarkan kriteria pengukuran menurut Ghozali (2014) dan menurut Wijaya (2009), penulis menetapkan kriteria goodness of fit yang moderat diantara kedua referensi tersebut. Kriteria yang digunakan dirinci dalam tabel 3.3.
TABEL 3.5 PERBANDINGAN KRITERIA GOODNESS OF FIT Goodness-of-Fit
Index Ghozali (2014) Wijaya (2009) Cut off Value Penelitian
Degree of Fredom
(DF) Positif (+) - Positif (+)
Chi – Square Diharapkan kecil Sekecil mungkin Diharapkan kecil
Probability ≥ 0,05 ≥ 0,05 ≥ 0,05
Sumber: Wijaya, 2009: 6 dan Ghozali, 2014: 66, diolah g. Interprestasi terhadap model
Langkah terakhir dari SEM adalah melakukan interpretasi bila model yang dihasilkan sudah diterima. Sedangkan modifikasi model diperlukan karena tidak fitnya hasil yang diperoleh pada tahap keenam. Namun segala modifikasi harus memperhatikan atau berdasarkan teori yang mendukung.
3. Uji Hipotesis
Pengujian hipotesis didasarkan atas pengolahan data penelitian dengan menggunakan analisis SEM, dengan cara menganalisis nilai regresi menurut output aplikasi AMOS. Pengujian hipotesis dilakukan dengan menganalisis nilai C.R dan nilai P hasil olah data, dibandingkan dengan batasan statistik yang disyaratkan, yaitu C.R.≤-1,96 atau C.R.≥ 1,96 untuk nilai C.R. dan dibawah 0,05 untuk nilai P. Apabila hasil olah data menunjukkan nilai yang memenuhi syarat tersebut, maka hipotesis penelitian yang diajukan dapat diterima. Jika hasil olah data tidak memenuhi kriteria yang dipersyaratkan, hipotesis penelitian ditolak.