Big Data Computational Intelligence Networking 4 pdf pdf
Teks penuh
Gambar
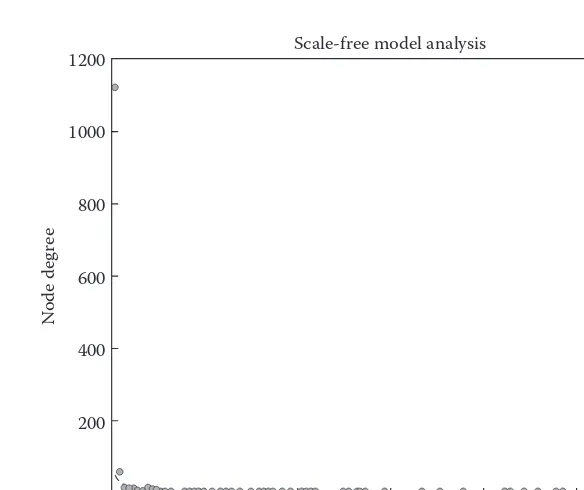
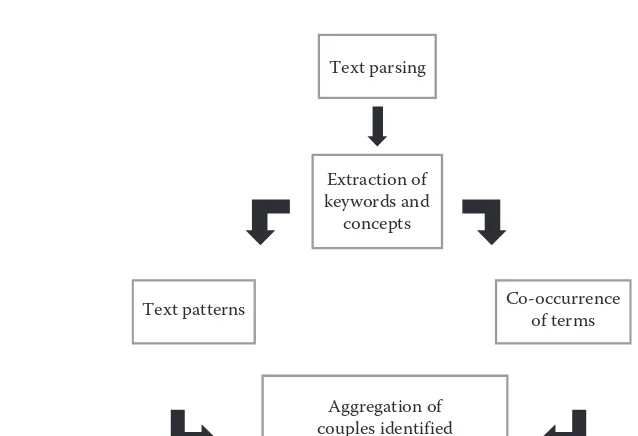
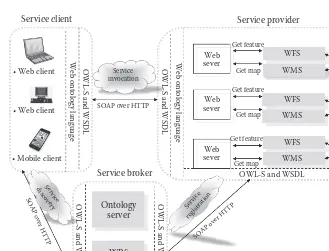

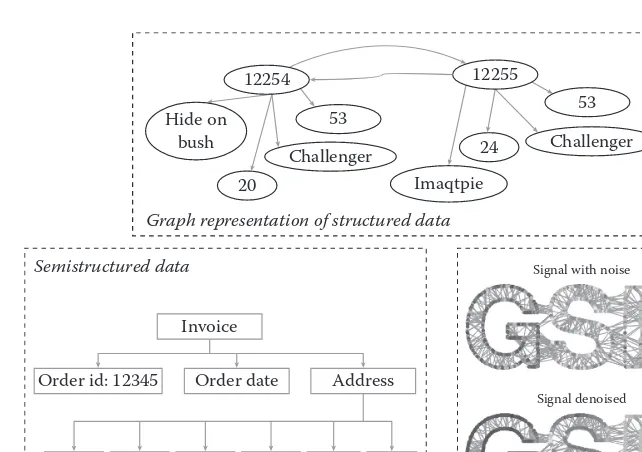
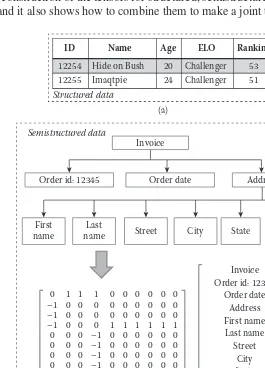
Dokumen terkait
Selama kegiatan diskusi kelompok berlangsung, tiap siswa diharapkan aktif untuk saling berbagi ide dalam menganalisis dan membuat katagori dari unsur- unsur
CHAPTER IV FINDING OF THE RESEARCH 4.1 The Reading Comprehension of Recount Text of the Eighth Grade Students of SMP NU Al Ma’ruf Kudus in Academic Year 2012/2013
Dari hasil pengujian didapatkan hasil sebagian besar responden memberikan motif yang mengarahkan pada kateori tinggi baik pada motif kognitif dan motif identitas personal,
Atas dasar pemikiran di atas, maka perlu diadakan penelitian mengenai Faktor-Faktor Yang Mempengaruhi Pengambilan Keputusan Nasabah Dalam Memilih Produk Bank
Table 3.. The body size also describes the uniqueness of the SenSi-1 Agrinak chicken as male line of native broiler chicken. Table 6 presents adult body weight and
2013.An Analysis of Speech Function In The Transcript Of Face 2 Face Interview Of Desi Anwar With Richard Gere on July 23, 2011.Skripsi.English Education Department,
Penelitian ini bertujuan untuk mengetahui pengaruh corporate social responsiblity terhadap citra perusahaan dan berdampak pada minat beli konsumen Yamaha Vega ZR New di
“…bahwa asas hukum bukan merupakan hukum kongkrit, melainkan merupakan pikiran dasar yang umum dan abstrak, atau merupakan latar belakang peraturan yang kongkrit
