9
LANDASAN TEORI
2.1 Toserba
Toserba atau disebut juga departement store adalah toko retail yang memiliki beragam lini produk yang banyak serta dikelompokan sesuai kategori lini produknya, seperti pakaian, furniture, mainan, buku, peralatan olahraga, dan perabot rumah tangga (Sopiah dan Syihabudin dalam Lestari, 2009:15).
Seperti toko retail pada umumnya, departement store menggunakan sistem self display service dalam menjual produknya, hal ini memungkinkan konsumen dapat memilih langsung barang kebutuhannya. Setiap lini beroperasi sebagai suatu departemen tersendiri yang dikelola oleh pembeli atau pedagang khusus. Beberapa departement store yang masuk dalam industri ini kebanyakan memilki tipe relatif sama dengan retailer lainnya, dengan lebih menekankan pada harga rendah serta sedikit layanan (low-price few-services). Departement store telah mengubah keberadaan model layanan toko dan menambah beberapa layanan (counter). Kebanyakan dari toko tersebut membuka usaha dengan sistem sewa. Pemilik departement store menyewakan outlet kepada pengusaha mandiri, yang akan membayar kepada pihak departement strore berdasarkan persentase pendapatan.
2.2 Data Mining
Data mining merupakan ekstraksi informasi yang tersirat dalam sekumpulan data. Data mining juga dapat diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan (Prasetyo, 2012:2).
Penggalian data ini dilakukan pada sekumpulan data yang besar untuk menemukan pola atau hubungan yang ada dalam kumpulan data tersebut (Kusrini & Luthfi, 2009:3). Hasil penemuan yang diperoleh setelah proses penggalian data ini, kemudian dapat digunakan untuk analisis yang lebih lanjut, dalam kaitannya dengan pengambilan keputusan yang harus dilakukan pihak manajemen suatu organisasi atau untuk melakukan pengecekan, apakah tujuan organisasi telah tercapai atau belum.
Model data mining secara umum dapat dibagi menjadi dua bagian yaitu (IBM dalam Lestari, 2009:16).
a. Verification Model
Model ini menggunakan perkiraan dari pengguna, dan melakukan tes terhadap perkiraan yang diambil sebelumnya dengan menggunakan data-data yang ada. Penekanan terhadap model ini adalah terletak pada pengguna yang bertanggung jawab terhadap penyusunan perkiraan dan permasalahan pada data untuk meniadakan atau menegaskan hasil perkiraan yang diambil.
Sebagai contoh dalam bidang pemasaran, sebelum sebuah perusahaan mengeluarkan suatu item baru ke pasaran, perusahaan tersebut harus memiliki informasi tentang kecenderungan konsumen untuk membeli item yang akan dikeluarkan. Perkiraan dapat disusun untuk mengidentifikasi konsumen yang potensial dan karakteristik dari konsumen yang ada.
b. Discovery Model
Model ini berbeda dengan Verification model, dimana pada model ini sistem secara langsung menemukan informasi-informasi yang penting yang tersembunyi dalam suatu data yang besar. Data-data yang ada kemudian dipilih
untuk menemukan suatu pola, trend yang ada, dan keadaan umum pada saat itu tanpa adanya campur tangan dan tuntutan dari pengguna. Pada data-data yang ada selanjutnya diadakan proses pencarian tanpa adanya proses perkiraan sebelumnya. Sampai akhirnya semua konsumen dikelompokan berdasarkan karakteristik yang sama.
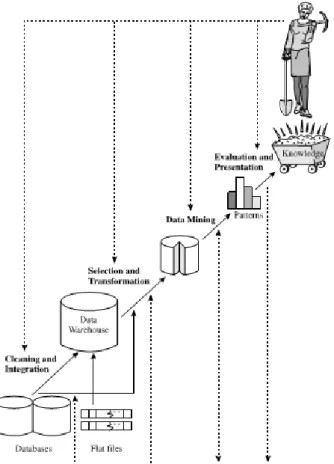
Data mining merupakan salah satu tahap dalam proses pencarian pengetahuan atau KDD (Knowledge Discovery in Database), dapat dilihat pada Gambar 2.1
Gambar 2.1 Data mining sebagai salah satu tahap dalam pencarian pengetahuan
(Sumber : Han, 2006 : 6)
Secara umum proses Knowledge Discoery in Database dapat dijelaskan sebagai berikut :
1. Data cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning atau pembersihan pada data yang menjadi fokus KDD. Proses cleaning meliputi antara lain memeriksa data yang tidak lengkap atau missing value dan mengurangi kerancuan / noisy.
2. Data integration
Menggabungkan berbagai sumber data yang dibutuhkan atau integration, kualitas data yang dimiliki akan sangat menentukan kualitas dari hasil data mining.
3. Data selection
Pemilihan atau seleksi data yang diperlukan dari sekumpulan sumber data sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi inilah yang akan digunakan untuk proses data mining. Disimpan dalam suatu berkas terpisah dari sumber data.
4. Transformation
Data-data yang telah melalui proses cleaning, integration, dan selection tidak bisa langsung digunakan, tahap ini merupakan proses kreatif untuk merubah bentuk data kedalam bentuk yang dapat dieksekusi oleh program. Bentuk yang dibuat sangat tergantung dari informasi apa yang akan dicari dalam data tersebut. 5. Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
6. Interpretaion atau Evaluation
Pola-pola yang diidentifikasi oleh program kemudian diterjemahkan atau diinterpretasikan kedalam bentuk yang bisa dimengerti manusia untuk membantu dalam perencanaan strategi bisnis.
Pekerjaan yang berkaitan dengan data mining dapat dibagi menjadi empat kelompok (Prasetyo, 2012 : 5), yaitu :
1. Prediction modeling atau Model Prediksi
Model prediksi berkaitan dengan pembuatan sebuah model yang dapat melakukan pemetaan dari setiap himpunan variabel kesetiap targetnya, kemudian menggunakan model tersebut untuk memberikan nilai target pada himpunan baru yang didapat.
Misalnya, pekerjaan untuk melakukan deteksi jenis penyakit pasien berdasarkan sejumlah nilai parameter penyakit yang diderita.
2. Cluster analysis atau Analisis Kelompok
Analisis kelompok melakukan pengelompokan data-data kedalam sejumlah kelompok (cluster) berdasarkan kesamaan karakteristik masing-masing data.
Misalnya adalah untuk mengetahui pola pembelian barang oleh konsumen pada waktu-waktu tertentu.
3. Association analysis atau Analisis Asosiasi
Analisis asosiasi digunakan untuk menemukan pola yang menggambarkan kekuatan hubungan dalam data. Pola yang ditemukan biasanya merepresentasikan bentuk aturan implikasi.
Misalnya untuk mengetahui pola beli masyarakat dengan analisis keranjang belanja.
4. Anomaly detection atau Deteksi Anomali
Deteksi anomali berkaitan dengan pengamatan sebuah data dari sejumlah data yang secara signifikan mempunyai karakteristik yang berbeda dari sisa data yang lain.
Misalnya diterapkan pada sistem jaringan untuk mengetahui pola data yang memasuki jaringan sehingga penyusupan bisa ditemukan.
2.3 Perbedaan Data Mining dengan Data Warehouse
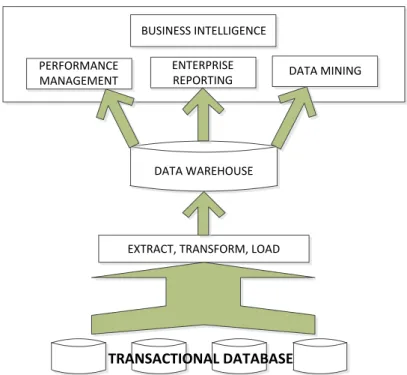
Perbedaan antara data mining dan data warehouse dapat dilihat pada Gambar 2.2
BUSINESS INTELLIGENCE PERFORMANCE
MANAGEMENT
ENTERPRISE
REPORTING DATA MINING
DATA WAREHOUSE
EXTRACT, TRANSFORM, LOAD
TRANSACTIONAL DATABASE
Gambar 2.2 Perbedaan data mining dengan data warehouse
(Sumber : Prasetyo, 2012 : 3)
dari gambar tersebut, dapat dilihat bahwa data mining adalah bidang yang sepenuhnya menggunakan apa yang dihasilkan oleh data warehouse, bersama
dengan bidang yang menangani masalah pelaporan dan manajemen data. Sementara, data warehouse sendiri bertugas untuk menarik atau melakukan query data dari basis data mentah untuk memberikan hasil data yang nantinya digunakan oleh bidang yang menangani manajemen, pelaporan, dan data mining.
Dengan data mining inilah, penggalian informasi baru dapat dilakukan dengan bekal data mentah yang diberikan oleh data warehouse. Hasil yang diberikan oleh ketiga bidang tersebut berguna untuk mendukung aktivitas bisnis cerdas (business intelligence) (Prasetyo, 2012 : 3).
2.4 Posisi Data Mining dalam Berbagai Disiplin Ilmu
Para ahli berusaha menentukan posisi bidang data mining diantara bidang-bidang yang lain. Hal ini dikarenakan ada kesamaan antara sebagian bahasan dalam data mining dengan bahasan dibidang lain. Memang tidak seratus persen sama, tetapi ada sejumlah kesamaan karakteristik dalam beberapa hal. Diantaranya adalah kesamaan bidang data mining dengan bidang statistik adalah penyampelan, estimasi, dan pengujian hipotesis. Kesamaan dengan kecerdasan buatan (artificial intelligence), pengenalan pola (pattern recognition), dan pembelajaran mesin (machine learning) adalah algoritma pencarian, teknik pemodelan dan teori pembelajaran. Kesamaan karakteristik ini dapat dilihat pada Gambar 2.3
Gambar 2.3 Posisi data mining diantara berbagai bidang ilmu
bidang lain yang juga mempengaruhi data mining adalah teknologi basis data, yang mendukung penyediaan penyimpanan yang efisien, pengindeksan, dan pemrosesan query. Teknik komputasi paralel sering digunakan untuk memberikan kinerja yang tinggi untuk ukuran set data yang besar, sedangkan komputasi terdistribusi dapat digunakan untuk menangani masalah ketika data tidak dapat disimpan disuatu tempat.
2.5 Data, Informasi, dan Pengetahuan (Knowledge)
Data adalah segala fakta, angka, atau teks yang dapat diproses oleh komputer. Saat ini, akumulasi pertumbuhan jumlah data berjalan dengan cepat dalam format dan basis data yang berbeda. Data-data tersebut, antara lain adalah
1. Data operasional atau transaksional, seperti penjualan, inventaris, penggajian, akuntansi, dan sebagainya.
2. Data non-operasional, seperti industri penjualan (supermarket), peramalan, dan data ekonomi-makro.
3. Metadata adalah data mengenai data itu sendiri, seperti desain logika basis data atau definisi kamus data.
Sementara informasi adalah pola, asosiasi, atau hubungan antara semua data yang dapat memberikan informasi. Sebagai contoh, analisis titik eceran (retail point) data transaksi penjualan dapat menghasilkan informasi mengenai produk apa yang sebaiknya dijual dan kapan menjualnya.
Informasi dapat dikonversi menjadi pengetahuan mengenai pola-pola historis dan tren masa depan. Misalnya, ringkasan informasi tentang penjualan eceran supermarket dapat dianalisis sehubungan dengan upaya promosi untuk memberikan pengetahuan mengenai perilaku konsumen dalam membeli.
Dengan demikian produsen atau pengecer dapat menentukan item yang paling rentan terhadap upaya promosi.
2.6 Association Rule
Aturan asosiasi (Association rules) atau analisis afinitas (afinity analysis) berkenaan dengan studi tentang ‘apa bersama apa’. Ini bisa berupa studi transaksi di supermarket, misalnya seseorang yang membeli shampoo juga membeli sabun mandi. Disini berarti shampoo bersama dengan sabun mandi. Karena awalya berasal dari studi tentang database transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama produk apa, maka aturan asosiasi juga sering dinamakan market basket analysis (Santoso, 2007:225).
Strategi umum yang diadopsi oleh banyak algoritma penggalian aturan asosiasi adalah memecah masalah kedalam dua pekerjaan utama (Prasetyo 2012 : 5), yaitu :
a. Frequent itemset generation
Tujuannya adalah mencari semua itemset yang memenuhi ambang batas atau minimum support. Itemset ini disebut frequent itemset (itemset yang sering muncul). Nilai support ini diperoleh dengan rumus dapat dilihat pada Rumus 2.1
( )
Rumus 2.1 Rumus mencari nilai support
(Sumber : Kusrini, 2009 : 150)
Rumus 2.1 menjelaskan bahwa nilai support diperoleh dengan cara membagi jumlah transaksi yang mengandung item A dengan jumlah seluruh transaksi.
b. Rule generation
Tujuannya adalah mencari aturan atau pola dengan confidence tinggi dari frequent itemset yang ditemukan dalam langkah itemset generation. Aturan ini kemudian disebut aturan yang kuat (strong rule).
Rumus untuk menghitung confidence dapat dilihat pada Rumus 2.2 ( )
Rumus 2.2 Rumus mencari nilai confidence
(Sumber : Kusrini, 2009 : 151)
Rumus 2.5 menjelaskan bahwa untuk mencari nilai confidence itemset A,B yaitu dengan membagi jumlah transaksi yang mengandung item A dan B dengan seluruh transaksi yang mengandung item A.
Ketersediaan database mengenai catatan tranksaksi pembelian para pelanggan suatu supermarket atau tempat lain, telah mendorong pengembangan teknik-teknik yang secara otomatis menemukan asosiasi produk atau item-item yang tersimpan dalam database tersebut. Sebagai contoh adalah data mengenai transaksi yang terkumpul dari scanner barcode dalam supermarket. Database transaksi ini seperti ini mengandung record dalam jumlah sangat besar. Setiap record mendaftar semua item yang dibeli oleh seorang pelanggan dalam suatu transaksi pembelian.
Para manajer ingin tahu apakah suatu kelompok item selalu dibeli secara bersama-sama. Para manajer bisa menggunakan informasi tersebut untuk membuat layout supermarket sehingga penyusunan item-item tersebut bisa optimal satu sama lain. Aturan asosiasi ingin memberikan informasi tersebut
dalam bentuk hubungan ‘if-then’, ‘jika-maka’, atau ‘If antecendent, then consequent’.
Aturan ini dihitung dari data yang sifatnya probabilistik. Dalam sistem rekomendasi seperti yang diterapkan oleh toko buku online Amazon.com, ketika seseorang melihat suatu item, akan direkomendasikan untuk membeli item yang lain yang biasanya dibeli oleh pelanggan lain secara bersama-sama. Misalnya seseorang sedang memeriksa atau melihat CD tentang lagu Deep Purple diwebsitenya Amazon.com, maka akan ditunjukan juga CD musik lain yang biasanya secara bersama dibeli, misalnya CD musik Rainbow, Led Zeppelin, Genesis dan lain-lain (Santosa : 2007 : 226).
2.7 Bentuk Dasar Association Rule
Association Rule ditentukan oleh dua parameter, yaitu :
a. Support
Suatu nilai yang menunjukan seberapa besar tingkat persentase kombinasi item dari keseluruhan transaksi.
b. Confidence
Suatu nilai yang menunjukan kuatnya hubungan antar item dalam suatu pola.
Kedua nilai ini sangat berguna dalam menentukan kekuatan suatu pola yang ditemukan. Semakin tinggi kedua nilai ini maka semakin kuat pula pola beli konsumen yang ditemukan yang sering disebut strong rule atau aturan yang kuat. association rule biasanya dinyatakan dalam bentuk :
Yang berarti dari seluruh jumlah transaksi, 50% mengandung shampoo dan sabun mandi dan dari seluruh transaksi yang mengandung shampoo, 80% juga mengandung sabun mandi. Dapat pula dirubah kedalam bahasa yang lebih mudah dimengerti yaitu “Seorang konsumen yang membeli shampoo kemungkinan 80% akan membeli sabun mandi. Pola ini cukup akurat karena mewakili 50% transaksi”.
2.8 Algoritma
Algoritma adalah prosedur yang berisi langkah-langkah logis untuk menyelesaikan suatu masalah (Munir, 2007:4). Misalkan saja algoritma aktifitas pagi hari sebelum berangkat kerja secara berurutan yaitu :
1. Turun dari tempat tidur 2. Melepas piama
3. Mandi 4. Berpakaian 5. Makan pagi 6. Pergi kerja
Secara umum proses algoritma dapat dilihat pada gambar 2.4.
ALGORITMA MASALAH
SOLUSI
Gambar 2.4 Proses algoritma
Istilah algoritma berasal dari nama seorang ilmuan muslim berkebangsaan arab bernama Ja’fat Mohammed bin Musa al Khowarizmi (tahun 790-840), yang sangat terkenal dengan sebutan bapak Aljabar.
2.9 Frequent Pattern Tree (FP-Tree)
FP-Tree adalah struktur penyimpanan data yang dipadatkan. FP-Tree dibangun dengan memetakan setiap data transaksi kedalam setiap lintasan tertentu dalam FP-Tree (Chandrawati dalam Suprasetyo, 2012:15). Karena dalam setiap transaksi yang dipetakan mungkin ada yang memiliki item yang sama, maka lintasannya memungkinkan untuk saling menimpa, semakin banyak data transaksi yang memiliki item yang sama, maka proses pemadatan dengan FP-Tree akan semakain efektif. FP-Tree memerlukan dua kali scanning atau penelusuran database untuk menemukan Frequent itemsets (Bharat dalam Suprasetyo, 2012:16). Penelusuran pertama untuk menghitung nilai support masing-masing item dan menyeleksi item yang memenuhi minimum support. Sedangkan penelusuran kedua untuk membentuk frequent itemsets dengan membaca FP-Tree yang diawali dengan membaca lintasan yang memiliki item dengan nilai frequensi terkecil.
FP-Tree adalah sebuah pohon dengan definisi sebagai berikut :
a. FP-Tree dibentuk oleh sebuah akar yang diberi label null, sekumpulan sub-tree yang beranggotakan item-item tertentu dan sebuah tabel frequent header.
b. Setiap simpul dalam FP-Tree mengandung tiga informasi penting, yaitu label item menginformasikan jenis item yang direpresentasikan simpul tersebut, support count merepresentasikan jumlah lintasan transaksi yang melalui simpul tersebut dan pointer penghubung yang menghubungkan simpul-simpul dengan label item sama antar-lintasan, ditandai dengan garis panah putus-putus. (Chandrawati dalam Suprasetyo, 2012:16).
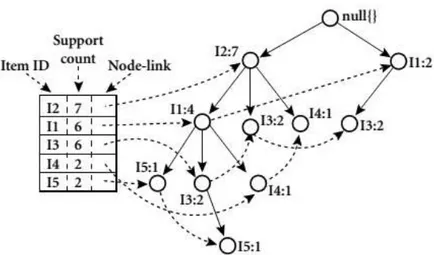
Contoh sebuah FP-Tree dapat dilihat pada Gambar 2.5
Gambar 2.5 FP-Tree (Sumber : Han, 2006 : 244) 2.10 Algoritma Frequent Pattern Growth (FP-Growth)
Algoritma PF-Growth merupakan salah satu algoritma association rule yang cukup sering dipakai. Algoritma FP-Growth merupakan salah satu solusi dari algoritma apriori yang memiliki beberapa masalah seperti pada tahap frequent itemset candidate generation dalam menentukan frequent itemset harus melakukan pattern matching / scanning database secara berulang-ulang yang menyebabkan proses mining menjadi lama dan untuk data yang besar menghasilkan kombinasi yang banyak.
Algoritma FP-Growth dapat menentukan frequent itemset tanpa perlu melakukan candidate generation. Growth menggunakan struktur data FP-Tree. Dengan menggunakan cara ini scanning database hanya dilakukan sebanyak dua kali, tidak perlu berulang-ulang. Data akan direpresentasikan dalam bentuk FP-Tree.
Setelah FP-Tree terbentuk, digunakan pendekatan divide and conquer untuk memperoleh frequent itemset. FP-Tree merupakan struktur data yang baik sekali untuk frequent pattern mining. Struktur ini memberikan informasi yang lengkap untuk membentuk frequent pattern. Item-item yang tidak frequent (tidak sering muncul) sudah tidak ada lagi dalam FP-Tree.
Algoritma FP-Growth dibagi menjadi tiga langkah utama, yaitu :
a. Tahap Pembangkitan Conditional Pattern Base.
Conditional Pattern Base merupakan subdata yang berisi prefix path (lintasan awal) dan suffix pattern (pola akhiran). Pembangkitan conditional pattern base didapatkan melalui FP-Tree yang telah dibangun sebelumnya.
b. Tahap Pembangkitan Conditional FP-Tree
Pada tahap ini, support count dari setiap item pada setiap conditional pattern base dijumlahkan, lalu setiap item yang memiliki jumlah support count lebih besar atau sama dengan minimum support count akan dibangkitkan dengan conditional FP-Tree.
c. Tahap Pencarian Frequent itemset
Apabila Conditional FP-Tree merupakan lintasan tunggal (single path), maka didapatkan frequent itemset dengan melakukan kombinasi untuk setiap conditional FP-Tree. Jika bukan lintasan tunggal, maka dilakukan pembangkitan FP-Growth secara rekursif. (Chandrawati dalam Suprasetyo, 2012:17).
Secara umum algoritma frequent pattern growth dalam mencari frequent itemset dapat dlihat pada Gambar 2.6
Input:
1. D, a transaction database;
2. min_sup, the minimum support count threshold. Output: The complete set of frequent patterns.
Method:
1. The FP-Tree is constructed in the following steps:
a. Scan the transaction database D once. Collect F, the set of frequent items, and their support counts. Sort F in support count descending order as L, the list of frequent items.
b. Create the root of an FP-Tree, and label it as “null”. For each transaction Trans in D do the following. Select and sort the frequent items in Trans according to the order of
L. Let the sorted frequent item list in Trans be[p|P], where p is the first element and P
is the remaining list. Call insert_tree ([p|P], T], which is performed as follows. If T has a child N such that N.item-name = p.item-name, then increament N’s count by 1; else create a new node N, and let its count be 1, its parent link be linked to T, and its node-link to the nodes with the same item-name via the node-node-link structure. If P is
nonempty, call insert_tree(P,N) recurcively.
2. The FP-Tree is mined by calling FP_growth(FP_tree, null), which is impelemented as follows.
Procedure FP_growth(Tree, α)
(1). if Tree contains a single path P then
(2). for each combinations (denoted as β) of the nodes in the path P
(3). generate pattern β U α with support_count = minimum support count of nodes in β;
(4). else for each ai in the header of Tree {
(5). generate pattern β = ai U α with support count = ai.support_count; (6). construct β's conditional pattern base and the β's conditional FP_tree
Treeβ; (7). if Treeβ ≠ ∅ then
(8). call FP-growth(Treeβ,β);}
Gambar 2.6 Algoritma Frequent Pattern Growth
Sumber (Han, 2006:246)
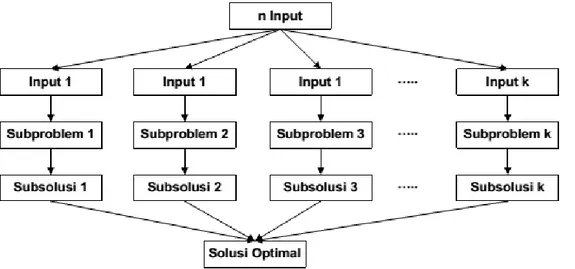
2.11 Divide and Conquer
Divide and Conquer merupakan metode yang berprinsip memecah permasalahan yang besar menjadi beberapa bagian kecil sehingga lebih mudah untuk diselesaikan. Langkah-langkah umum metode Divide and Conquer yaitu :
a. Divide
Membagi masalah menjadi beberapa sub-masalah yang memiliki kemiripan dengan masalah semula namun berukuran lebih kecil
b. Conquer
Memecahkan atau menyelesaikan masing-masing sub-masalah secara rekursif.
c. Combine
Menggabungkan solusi masing-masing sub-masalah sehingga membentuk solusi masalah semula (Pranowo dalam Suprasetyo, 2012:19).
Proses Divide and Conquer dapat dilihat pada Gambar 2.7.
Gambar 2.7 Proses Divide and Conquer
(Sumber : Astuti, 2008 : 1)
2.12 State Of The Art
Penelitian sebelumnya yang berhubungan dengan judul ini dapat dilihat pada Tabel 2.1
Tabel 2.1 Tabel State Of The Art
No. Peneliti / Tahun Tujuan Metode Hasil
1. Kusumo, dkk. (2003)
Mencari asosiasi dalam data dan membandingkan 2 teknik pe rhitungan support yaitu K-way dan 2 Group-By Apriori, K-way, dan 2 Group-by Metode K-way lebih baik daripada 2 Group-by
Lanjutan Tabel 2.1 Tabel State Of The Art
No. Peneliti / Tahun Tujuan Metode Hasil
2. Sholichah (2009) Mencari pola
hubungan keterkaitan antar data dalam pembiayaan Murabahah Association Rule Pengajuan pembiayaan dengan plafond 20 s.d. 40 juta, margin 2% s.d. 2,2%, lama 19 s.d. 28 bulan sebanyak 100% 3. Huda (2010) Mencari informasi
tingkat kelulusan dengan data induk mahasiswa
Apriori Aplikasi Data Mining dapat digunakan untuk mengetahui hubungan data kelulusan dengan data induk mahasiswa 4. Amiruddin, dkk. (2010) Mencari pola hubungan atribut-atribut dan frequent itemset dalam database NUPTK Apriori Ditemukan 184 rule penting yang tersembunyi dalam database NUPTK 5. Suprasetyo (2012)
Mencari pola beli konsumen dalam data transaksi untuk digunakan dalam strategi bisnis yaitu tata letak dan promosi
Frequent Pattern Growth / FP-Growth Ditemukan pola terkuat yaitu jika membeli telur ayam maka akan membeli mie instant dengan support 3,13% dan confident 72,72%
Pada penelitian terakhir (Suprasetyo, 2012) menggunakan algoritma FP-Growth untuk mencari pola beli konsumen dalam data transaksi. Namun dalam penerapannya proses data preprocessing tidak dijelaskan secara detail dan tidak adanya matrik pola beli konsumen, sehingga akan menyulitkan pengguna dalam memahami pola beli konsumen.
2.13 Unified Modeling Language (UML)
Unified Modeling Language (UML) adalah standar bahasa pemodelan visual yang digunakan untuk menentukan, menggambarkan, dan mendokumentasikan sebuah sistem perangkat lunak (Rumbaugh, 2004:3).
Dengan menggunakan UML kita dapat membuat model untuk semua jenis aplikasi perangkat lunak, dimana aplikasi tersebut dapat berjalan pada piranti keras, sistem operasi dan jaringan apapun, serta ditulis dalam bahasa pemrograman apapun.
Karena UML menggunakan class dan method dalam konsep dasarnya, maka bahasa berorientasi objek lebih cocok digunakan seperti VB.Net.
UML memiliki beberapa tipe diagram yaitu usecase diagram, class diagram, dan sequence diagram.
A. Use Case Diagram
Use Case diagram menggambarkan fungsionalitas yang diharapkan dari sebuah sistem, yang ditekankan adalah “apa” yang diperbuat sistem, dan bukan “bagaimana”. Sebuah use case mempresentasikan sebuah interaksi antara actor dengan sistem. Use case menggambarkan kata kerja seperti login ke sistem, maintenance user dan sebagainya.
use case a
use case a.1
Komponen Use Case Diagram dapat dilihat pada Tabel 2.2
Tabel 2.2 Komponen Use Case Diagram
No. Simbol Keterangan
1 Actor menggambarkan pengguna
software aplikasi (user). Actor membantu memberikan suatu gambaran jelas tentang apa yang harus dikerjakan software atau aplikasi.
2 Use Case menggambarkan perilaku
software aplikasi, termasuk didalamnya interaksi antara actor dengan software aplikasi tersebut.
3 Asosiasi, yaitu hubungan statis
antar element. Umumnya menggambarkan element yang memiliki atribut berupa element lain, <<include>>: termasuk didalam use case lain yang diharuskan (required) <<extend>> : perluasan dari use case lain jika kondisi atau syarat terpenuhi.
4 Pewarisan, yaitu hubungan hirarkis
antar element. Element dapat diturunkan dari element lain dan mewarisi semua atribut dan metoda element asalnya dan menambahkan fungsionalitas baru, sehingga iadisebut anak dari element yang diwarisinya. Kebalikan dari pewarisan adalah generalisasi.
5 Dependency atau ketergantungan
adalah suatu jenis hubungan yang menandakan bahwa satu element, atau kelompok element, bertindak sebagai klien tergantung pada unsur lain atau kelompok element yang berlaku sebagai penyalur.
Actor
Use Case
Cari pola Bentuk FP-Tree
<<include>>
Cari asosiasi tiap node
<<extend>>
Actor
Bentuk FP-Tree
B. Class Diagram
Class adalah sebuah spesifikasi yang jika diinstansiasi akan menghasilkan sebuah objek dan merupakan inti dari pengembangan berorientasi objek. Class menggambarkan keadaan (attribute/property) suatu sistem, sekaligus menawarkan layanan untuk memanipulasi keadaan tersebut (metode/fungsi).
Class diagram menggambarkan struktur dan deskripsi class, packed dan objek beserta hubungan satu sama lain seperti containment, pewarisan, asosiasi dan lainnya.
Class memiliki tiga area pokok : 1. Nama class
2. Atribut
3. Metoda (operasi)
Atribut dan metoda dapat memiliki salah satu sifat berikut :
1. Private, tidak dapat dipanggil dari luar class yang bersangkutan. 2. Protected, hanya dapat dipanggil oleh class yang bersangkutan dan
anak-anak yang mewarisinya.
3. Public, dapat dipanggil oleh siapa saja.
4. Package, Atribut‐atribut dan metoda‐metodapackage (di Teknologi Java) dapat diakses dari metoda di kelas lain yang disimpan di dalam package yang sama.
Contoh class diagram dapat dilihat pada Gambar 2.8
Gambar 2.8 Class diagram C. Sequence Diagram
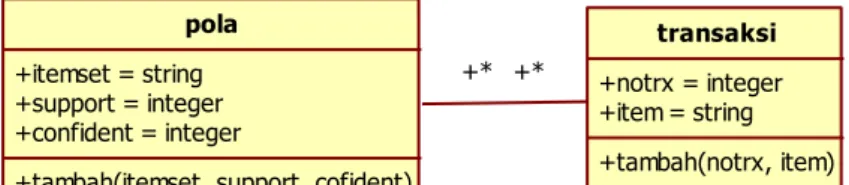
Diagram ini menjelaskan bagaimana objek berinteraksi dengan lainnya dengan cara mengirim dan menerima pesan. Sequence diagram memiliki dua sumbu yaitu sumbu vertikal dan sumbu horizontal.
Sumbu vertikal putus-putus merepresentasikan “lifetime” objek dan sumbu horizontal menunjukan sekumpulan objek. Diagram ini juga menyatakan interaksi khusus diantara objek yang terjadi pada beberapa tempat selama fungsi tertentu dijalankan.
Komunikasi diantara objek direpresentasikan dengan garis horizontal disertai dengan nama operasinya, dapat dilihat pada gambar 2.9
pola +itemset = string +support = integer +confident = integer
+tambah(itemset, support, cofident)
transaksi +notrx = integer +item = string +tambah(notrx, item) +* +*
Gambar 2.9 Sequence Diagram 2.14 Visual Studio 2010
Microsoft Visual Basic.NET atau yang sering dikenal dengan nama VB.NET adalah salah satu tools untuk mengembangkan dan membangun aplikasi di bawah .NET Framework dengan menggunakan bahasa BASIC.
BASIC adalah singkatan dari Beginner’s All-purpose Symbolic Instruction Code adalah sebuah kelompok bahasa pemrograman tingkat tinggi. Secara harfiah, BASIC memiliki arti kode instruksi simbolis semua tujuan yang dapat digunakan oleh para pemula.
Microsoft Visual Studio 2010 merupaka versi terbaru dari Visual Basic. Visual Studio sangat cocok untuk digunakan programmer pemula karena
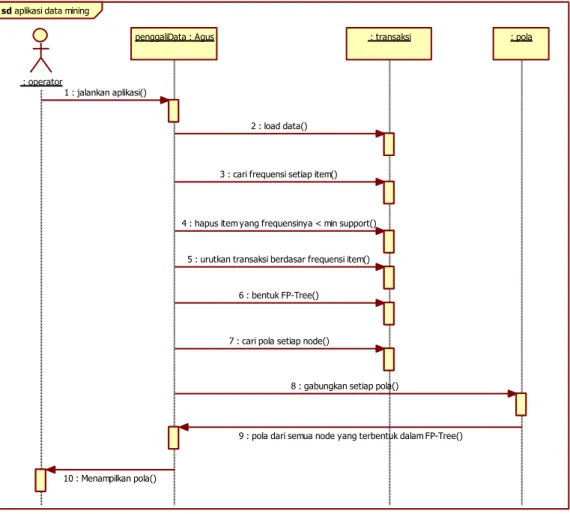
aplikasi data mining
sd penggaliData : Agus : operator : transaksi : pola 1 : jalankan aplikasi() 2 : load data()
3 : cari frequensi setiap item()
4 : hapus item yang frequensinya < min support() 5 : urutkan transaksi berdasar frequensi item()
6 : bentuk FP-Tree()
7 : cari pola setiap node()
8 : gabungkan setiap pola()
9 : pola dari semua node yang terbentuk dalam FP-Tree()
bahasanya mudah dipahami dan tidak terlalu banyak aturan khusus. Misalnya pada bahasa pemrograman Pascal, kita harus menambahkan titik koma (;) ditiap baris program dan akan error jika kita melewatkan salah satu baris saja.
Selain bahasanya yang mudah dipahami, Visual Studio juga mempunyai fitur intellisense. Dengan adanya intelisense kita dapat menulis program dengan mudah. Misalnya untuk membuat suatu Prosedur kita hanya tinggal mengetikan Sub <nama_prosedur> lalu kita tekan enter maka kerangka program otomatis dibuatkan. Selain itu intelisense akan memberitahu kita apa saja nama variable yang sudah digunakan. Biasanya para programmer lupa apa saja nama variable yang sudah dibuat karena terlalu banyak.
Visual Studio juga tidak hanya bisa memakai bahasa VB saja tetapi bisa juga memakai bahasa C++, C# dan F#. Hal ini membuat para programmer yang telah lama memakai bahasa C++, C# dan F# tidak perlu mempelajari bahasa VB itu sendiri. Project yang bisa dibuat dengan Visual Studo 2010 juga sangan banyak. Misalnya untuk pemrograman desktop (Windows) ada Windows Form, Console, dll. Ada juga untuk pemrograman web, cloud, dll.
2.15 Dotnetbar 10.3
Dotnetbar 10.3 adalah sekumpulan toolbox (Add-on Visual Studio) yang terdiri dari 56 komponen yang menarik untuk membuat user interface professional dengan sangat mudah. Selama lebih dari 9 tahun Dotnetbar telah banyak membantu pengembang aplikasi untuk memuat tampilan user interface Windows Forms yang cantik dan professional dengan sangat mudah.
Dotnetbar adalah komponen toolbox pertama di dunia dalam memperkenalkan feature secara penuh tampilan yang dimiliki oleh Office 2010, Windows 7 dan Office 2007.
2.16 Database
Basisdata atau Database adalah kumpulan data yang secara logic berkaitan dalam merepresentasikan fenomena atau fakta secara terstruktur dalam domain tertentu untuk mendukung aplikasi pada sistem tertentu.
Adapun sistem manajemen basis data atau DBMS (Database Management System) adalah perangkat lunak untuk mendefinisikan, menciptakan, mengelola dan mengendalikan pengaksesan basisdata. Fungsi sistem manajemen basisdata saat ini yang paling penting adalah menyediakan basisdata untuk sistem informasi manajemen.
Contoh produk DBMS atau sekarang telah berkembang dan lebih dikenal dengan RDMBS (Relational Database Manajemen System) yaitu SQL Server, Oracle dan MySQL. Setiap produk mempunyai kelebihan dan kekurangannya masing-masing.
Jadi dalam penggunaannya harus mempertimbangkan dengan matang produk RDMS mana yang akan digunakan yang paling sesuai dengan kebutuhan dan kemampuan.
2.17 Pengujian Black-Box
Merupakan uji coba terhadap program yang telah dikerjakan. Metode yang digunakan untuk testing adalah Black Box. Pengujian pada black box berfokus pada persyaratan fungsional perangkat lunak.
Dengan demikian, pengujian black box memungkinkan rekayasa perangkat lunak mendapatkan serangkaian kondisi input yang sepenuhnya menggunakan semua persyaratan fungsional suatu program.
Pengujian black box berusaha menemukan kesalahan dalam kategori sebagai berikut:
a. Fungsi-fungsi yang tidak benar atau hilang b. Kesalahan interface
c. Kesalahan dalam struktur data atau akses database eksternal d. Kesalahan kinerja.
e. Inisialisasi dan kesalahan terminasi
Pengujian yang dilakukan black box pada awal proses cenderung diaplikasikan selama tahap akhir pengujian. Karena pengujian black box memeperhatikan struktur kontrol maka perhatian berfokus pada domain informasi. Pengujian didesain untuk menjawab pertanyaan-pertanyaan berikut:
a. Bagaimana validitas fungsional diuji?
b. Kelas input apa yang akan membuat test case menjadi baik? c. Apakah sistem sensitif terhadap harga input tersebut?
d. Bagaimana batasan dari suatu data diisolasi?
e. Kecepatan data apa dan volume data apa yang dapat ditolelir oleh sistem?