Abstrak —Transportation is one of the industrial that grow rapidly. The production and sales of cars and truck are increasing year by year in United States of America. There are some indicators to determine the price of vehicle. One of them is vehicle’s spesification. They are horsepower, wheel base, weight, length and widht. Those spesifications can classify the vehicle into some group. The data of vehicles’ name and their spesification in in United States of America on 2004 will be analyzed using clustering analysis. They are consist of single linkage, complete linkage and K-Means. The next step is choose the optimum cluster that can formed by each method using the value of pseudo f. After that is calculate the internal cluster dispersion rate (icdrate) of each method and choose the smallest one. The result from all of methods deliver the same conclusio. The optimum cluster that formed is two clusters but each method has different member of it cluster. The best method based on the value of icdrate is Single Linkage with two clusters.
Key word—Clustering, Complete Linkage, icdrate, K-Means, Pseudo f, Single Linkage, Vehicle.
I. PENDAHULUAN
alah satu industri yang paling berkembang saat ini adalah industri transportasi. Produksi dan penjualan mobil maupun truk sangat diperhatikan oleh industri transportasi ini. Penjualan kendaraan dari tahun ke tahun meningkat di berbagai negara, tak terkecuali Amerika Serikat. Indikator yang paling penting dalam menentukan harga kendaraan adalah spesifikasi kendaraan. Spesifikasi kendaraan tersebut meliputi horsepower, panjang dan lebar kendaraan, berat kendaraan, serta wheelbase. Beberapa spesifikasi yang ada pada kendaraan dapat digunakan untuk mengelompokkan ke dalam jenis apa kendaraan tersebut. Objek dalam suatu kelompok yang terbentuk diharapkan memiliki kemiripan dengan objek lain pada kelompok yang sama, tetapi sangat tidak mirip dengan objek pada cluster yang lain. Oleh karena itu, akan dilakukan pengelompokkan kendaraan dengan data penjualan kendaraan di Amerika Serikat pada tahun 2004 beserta spesifikasinya berdasarkan jenis kendaraannya dengan menggunakan metode clustering.
S
Analisis cluster digunakan untuk mengelompokkan obyek-obyek pengamatan menjadi beberapa kelompok sehingga akan diperoleh kelompok dimana obyek-obyek dalam satu kelompok tersebut mempunyai persamaan sedangkan dengan anggota kelompok lain mempunyai perbedaan [1]. Dalam mengembangkan metode clustering terdapat beberapa pendekatan, diantaranya dengan pendekatan hirarki dan pendekatan non-hirarki. Clustering dengan pendekatan non-hirarki dapat menggunakan metode K-means, mengelompokkan data dengan memilah-milah data yang dianalisa ke dalam cluster-cluster yang
ada. Clustering dengan pendekatan hirarki, mengelom-pokkan data dengan membuat suatu hirarki berupa dendo-gram (tree) dimana data yang mirip akan ditempatkan pada hirarki yang berdekatan dan yang tidak pada hirarki yang berjauhan. Tujuan dari laporan ini adalah pengelompokan jenis kendaraan berdasarkan data penjualan kendaaraan di Amerika Serikat pada tahun 2004 beserta spesifikasinya.
II. TINJAUAN PUSTAKA A. Analisis Cluster
Analisis cluster (analisis kelompok) adalah metode analisis yang digunakan untuk mengelompokkan obyek-obyek pengamatan menjadi beberapa kelompok sehingga akan diperoleh kelompok dimana obyek-obyek dalam satu kelompok tersebut mempunyai persamaan sedangkan dengan anggota kelompok lain mempunyai perbedaan [1]. Secara umun dalam melakukan analisis cluster terdapat dua metode yang digunakan, yaitu pengelompokan secara hirarki dan pengelompokan secara non-hirarki. Jarak yang digunakan adalah euclidean dengan rumus sebagai berikut.
d
(
i, k
)=
√
∑
j
(
x
ij−
x
kj)
2 (1) Di mana d(i,k) adalah jarak antara observasi i dengan k.B. Analisis Cluster Secara Hirarki
Analisis cluster merupakan teknik pengelompokan dimana belum diketahuinya asumsi berapa banyak grup atau struktur grup yang terbentuk. Pengelompokan dilakukan berdasarkan kemiripan atau ketidakmiripan [2]. Salah satu teknik clustering yang popular adalah dilakukan secara hirarki. Dinamakan hirarki sebab pengelompokan dilakukan secara bertahap dengan menggabungkan objek yang diamati kemiripannya ke dalam suatu cluster berdasarkan karakteristik tertentu. Terdapat beberapa jenis clustering secara hirarki, diantaranya yaitu Single Linkage, Complete Linkage, Average Linkage, dan Ward’s Hierarchical Clustering Method.
Berikut ini prosedur untuk melakukan pembentukan cluster secara hirarki
a. Mendapatkan matriks jarak D = {dik} dan menetapkan
akan ada sebanyak N cluster yang dapat terbentuk, dimana N adalah banyak objek yang diamati.
b. Menentukan matriks jarak untuk kedekatan antar cluster.
c. Menggabungkan cluster yang terbukti memiliki kedekatan.
d. Mengulang langkah c sebanyak N-1 kali hingga dipero-leh banyaknya cluster yang terbentuk dan seberapa dekat jarak antar cluster tersebut.
Hasil penggabungan tersebut dapat diuraikan atau
Analisis
Cluster
pada Data
American New Cars and
Truk
tahun 2014 dengan Metode Hirarki dan
Non-Hirarki
Ikacipta Mega Ayuputri, M. Alifian Nuriman, Ratna Juwita, M. Alfan AlfianRiyadi, Dr. Bambang W. Otok Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Teknologi Sepuluh Nopember Jl. Arief Rahman Hakim, Surabaya 60111 Indonesia
dijelaskan dengan baik secara visual oleh dendrogram. 1. Single Linkage
Single linkage merupakan metode untuk mengelompokkan objek ke dalam cluster berdasarkan kedekatan dengan objek lainnya. Berdasarkan prosedur pembentukan cluster di atas, metode ini menggunakan kriteria berikut.
d
(UV)W=
min
{
d
UW, d
VW}
(2) dimana jarak antara cluster (UV) dan cluster W merupakan jarak minimal antara cluster U dan W atau antara cluster V dan W [2].2. Complete Linkage
Complete linkage merupakan metode untuk mengelompokkan objek ke dalam cluster berdasarkan ketidakmiripan dengan objek lainnya. Berdasarkan prosedur pembentukan klaster di atas, metode ini menggunakan kriteria berikut.
d
(UV)W=
max
{
d
UW, d
VW}
(3)dimana jarak antara cluster (UV) dan cluster W merupakan jarak paling jauh antara cluster U dan W atau antara klaster V dan W [2].
C. Analisis Cluster Secara Non-Hirarki
Teknik clustering dengan metode non-hirarki menempatkan obyek ke dalam kelompok dimana jumlah cluster ditentukan. Salah satu metode cluster non-hirarki adalah K-means [2].
Prosedur metode K-means adalah dengan mempartisi atau mengelompokan data ke dalam jumlah cluster yang telah ditentukan peneliti. Kemudian secara iterative melakukan pemindahan pengamatan pada antar cluster, sampai beberapa kriteria numerik terpenuhi. Kriteria menentukan tujuan yang berhubungan dengan meminimalkan jarak pengamatan dari satu sama lain dalam sebuah cluster dan memaksimalkan jarak antara cluster [3]
Algoritma pada metode clostering menggunakan K-Means adalah sebagai berikut.
1. Partisi data ke dalam K cluster sebagai inisiasi
2. Lanjutkan melalui daftar data, dengan melalui data yang terdekat dengan mean. Hitung kembali mean unruk cluster yang menerima maupun kehilangan data. 3. Ulangi langkah kedua hingga tidak ada penugasan yang
terjadi [2].
D. Calinski-Harabasz Pseudo F-Statistics Pseudo F-statistics adalah salah satu metode yang umum digunakan untuk menentukan banyaknya kelompok yang optimum [4]. Rumus Pseudo F-statistics ditulis dalam persamaan berikut.
Pseudo F
−
statistics
=
R
2k
−
1
1
−
R
2n
−
k
(4)
R
2=
SST
−
SSW
SST
(5)SST
=
∑
i=1
n
∑
j=1
c
∑
k=1
p
(
x
ijk−´
x
j)
2 (6)SSW
=
∑
i=1
n
∑
j=1
c
∑
k=1
p
(
x
ijk−´
x
jk)
2 (7)E. Internal Cluster Dispersion Rate
Beberapa macam metode untuk membandingkan hasil pengelompokan dapat dilakukan berbagai cara dan rumusan. Salah satunya dengan menghitung performansi cluster dengan menghitung nilai SSB dari hasil pengolahan data dan menghitung persebaran (internal cluster dispersion rate) dalam masing-masing klaster yang telah terbentuk. Semakin kecil nilai icdrate maka semakin baik hasil pengelompokkannya. Membandingkan metode cluster yang terbaik dengan nilai persebaran data-data dalam cluster (internal cluster dispersion rate) didefinisikan dengan persamaan berikut [5].
icdrate
=
1
−
SSB
SST
(8)SSB
=
∑
j=1
c
∑
k=1
p
(
x
jk− ´
x
j)
2 (9)III. METODOLOGI PENELITIAN A. Sumber Data
Sumber data yang digunakan adalah data sekunder. Data yang diperoleh berasal dari http://www.idvbook.com/ dengan judul “2004 Cars and Trucks” dan diambil pada tanggal 29 April 2017 pukul 14.00 WIB [6].
B. Variabel Penelitian
Variabel yang digunakan pada penelitian ini sebanyak 6 variabel dengan 40 tipe kendaraan yang diamati. Berikut ini tabel yang memuat variabel pada penelitian ini.
Tabel 1. Variabel Penelitian
No. Variabel Keterangan
1 X1 Reatail price (US$)
2 X2 Horsepower
3 X3 Weight (pound)
4 X4 Wheel Base (inches)
5 X5 Length (inches)
6 X6 Width (inches)
Satuan yang digunakan antar variabel memiliki perbedaan sehingga perlu dilakukan standardize pada variabel penelitian.
C. Langkah Analisis
Langkah analisis yang digunakan pada penelitian ini adalah sebagai berikut.
1. Mengidentifikasi masalah dan tujuan penelitian. 2. Mengumpulkan data penjualan cars and trucks di
Amerika pada tahun 2004.
3. Melakukan analisis cluster dengan metode hirarki (single linkage dan complete linkage).
4. Melakukan analisis cluster dengan metode non-hirarki (K-means).
5. Membandingkan hasil analisis cluster dengan menggunakan Pseudo F-statistics.
6. Menguji kebaikan model dari analisis cluster dengan icdrate.
IV. HASIL DAN PEMBAHASAN A. Pengecekan Missing Value
Analisis cluster dapat dilakukan pada data yang tidak mengandung missing value. Apabila terdapat data yang missing maka harus diatasi sebelum dianalisis lebih lanjut. Berikut adalah tabel yang digunakan untuk mendeteksi apakah pada data American new cars and trucks terdapat missing value atau tidak.
Tabel 2. Pengecekan Missing Value
Valid Missing Total
N Percent N Percent N Percent
40 100 0 0 40 100
Tabel 2 menunjukkan bahwa data berjumlah 40 dan tidak ada missing value sehingga data dapat dianalisis lebih lanjut dengan analisis cluster.
B. Analisis Cluster dengan Single Linkage
Hasil olahan analisis cluster menggunakan metode single linkage berdasarkan iterasi jarak Euclidian yang terdiri dari minimum 2 cluster hingga maksimum 28 cluster.
Berikut merupakan dendogram pengelompokan data menggunakan metode single linkage:
Gambar 1. Grafik dendogram untuk Single Linkage
Dilihat dari grafik rescaled distance cluster combine pada scale distance 25 menunjukkan 2 cluster yang mengelompokkan data. Pada scale distance 20 menunjuk-kan 2 cluster, pada scale distance 10 menunjukmenunjuk-kan 3 clus-ter dan seclus-terusnya sampai menunjukkan 28 cluster yang mengelompokkan data. Kemudian dipilih pengelompokkan 2 cluster.
Tabel 3. Pengelompokkan dengan 2 Cluster
Cluster Jumlah
1 39
2 1
Berdasarkan Tabel 3 terlihat bahwa jumlah anggota pada cluster satu lebih banyak dibandingingkan cluster dua. Terdapat 39 tipe mobil masuk pada cluster satu dan hanya satu tipe mobil masuk pada cluster dua. Selain
menggunakan dendogram, jumlah cluster bisa ditentukan menggunakan pseudo f-statistics. Berikut ini merupakan hasil perhitungan pseudo f-statistics pada metode single linkage.
Tabel 4. Hasil Perhitungan Pseudo f-statistics pada Metode Single Linkage
Metode Hirarki Pseudo F-Statistics
Single Linkage (5 cluster) 4,838
Single Linkage (4 cluster) 5,552
Single Linkage (3 cluster) 5,164
Single Linkage (2 cluster) 6,158
Berdasarkan Tabel 4 hasil perhitungan manual dan pada analisis cluster hirarki dengan metode Single Linkage memiliki nilai pseudo f-statistics yang terbesar adalah metode Single Linkage dengan jumlah cluster sebanyak 2 cluster. Hal ini dapat dikatakan bahwa pengelompokkan yang optimum adalah sebesar 2 cluster. Hal ini juga diperkuat dengan selisih dari banyak data (n) dengan stage yang memiliki lompatan tertinggi pada coefficient dalam Lampiran 1 yang apabila dihitung adalah sebesar 40 – 38 sama dengan 2 cluster.
C. Analisis Cluster dengan Complete Linkage
Berikut merupakan dendogram pengelompokan data menggunakan metode complete linkage dengan iterasi jarak Euclidean.
Gambar 2. Dendogram untuk Complete Linkage
Berdasarkan rescaled distance cluster combine pada gambar 2, scale distance 25 menunjukkan 2 cluster yang terbentuk dalam mengelompokkan data. Pada scale distance 15 menunjukkan 4 cluster yang terbentuk, dan seterusnya hingga menunjukkan 10 cluster yang mengelompokkan data. Kemudian dipilih pengelompokkan 2 cluster dengan hasil sebagai berikut.
Tabel 5. Pengelompokkan 2 Cluster dengan Complete Linkage
Cluster Jumlah
1 27
Tabel 5 menunjukkan bahwa anggota cluster satu lebih banyak dibandingkan cluster dua. Terdapat 27 tipe mobil pada cluster satu dan 13 tipe mobil pada cluster dua. Selain menggunakan dendogram, jumlah cluster dapat ditentukan melalui pseudo f-statistics. Berikut ini hasil perhitungan pseudo f-statistics dengan menggunakan metode complete linkage.
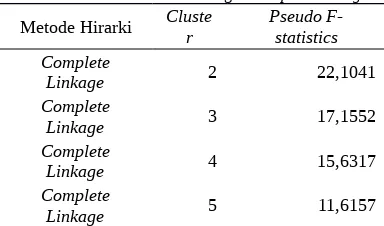
Tabel 6. Pseudo F-statistics dengan Complete Linkage
Metode Hirarki Cluster Pseudo F-statistics
Complete
Linkage 2 22,1041
Complete
Linkage 3 17,1552
Complete
Linkage 4 15,6317
Complete
Linkage 5 11,6157
Berdasarkan tabel 6, dapat diketahui bahwa nilai pseudo f-statistics terbesar pada metode complete linkage adalah pada 2 cluster. Hal ini dapat dikatakan bahwa pengelompokkan yang optimum dengan metode complete linkage adalah sebesar 2 cluster. Hal ini juga diperkuat dengan selisih dari banyak data (n) dengan stage yang memiliki lompatan tertinggi pada coefficient dalam lampiran 4 yang apabila dihitung adalah sebesar 40 – 38 sama dengan 2 cluster.
D. Analisis Cluster dengan K-Means Method
Pada analisis cluster menggunakan metode K-Means jumlah cluster yang diinginkan adalah sebanyak 2,3,4 dan 5 yang selanjutnya ditentukan jumlah cluster yang optimum. Jumlah cluster optimum pada metode K-Means bisa ditentukan menggunakan pseudo f-statistics. Berikut ini merupakan hasil perhitungan pseudo f-statistics untuk keempat clustering.
Tabel 7. Penentuan Jumlah Cluster Optimum menggunakan Pseudo f
Metode Non Hirarki Pseudo f
K-Means dua cluster 25,228
K-Means tiga cluster 13,660
K-Means empat cluster 21,130
K-Means lima cluster 18,109
Berdasarkan hasil pada Tabel 7 didapatkan nilai pseudo f terbesar adalah pada metode K-Means dengan dua cluster yang berarti bahwa jumlah cluster optimum sebanyak dua.
Setelah mendapatkan cluster optimum dilakukan perhitungan MANOVA untuk mengetahui variabel yang signifikan pada pengelompokkan K-Means dengan dua cluster. Hasil yang didapatkan adalah sebagai berikut.
Tabel 8. Hasil MANOVA Dua Cluster
Variabel F p-value
Retail Price 2,200 0,146
Horsepower 3,217 0,081
Weight 29,929 0,000
Wheel Base 54,468 0,000
Length 47,029 0,000
Width 81,974 0,000
Berdasarkan nilai p-value pada Tabel 8 terlihat bahwa variabel weight, wheel base, length dan width memiliki nilai < α sehingga diputuskan tolak H0. Hal ini berarti
bahwa keempat variabel tersebut yang memiliki kontribusi signifikan dalam mempengaruhi hasil pengelompokkan dua cluster. Adapun jumlah anggota untuk masing-masing cluster dengan metode K-Means dua cluster adalah sebagai berikut.
Tabel 9. Jumlah Anggota pada Pengelompokkan Dua Cluster
Cluster Jumlah
1 23
2 17
Pada pengelompokkan dua cluster 40 data tersebut sudah masuk di dalam cluster dan tidak ditemukan missing value dengan jumlah anggota pada cluster 1 lebih banyak dibandingkan cluster 2 (Tabel 9 ).
E. Metode Terbaik
Kriteria pemilihan model terbaik adalah dengan melihat nilai icdrate terkecil. Berikut merupakan nilai icdrate dari setiap cluster pada setiap metode.
Tabel 10. Hasil icdrate Model Hirarki dan Non Hirarki
Cluster Single Linkage Complete Linkage K-Means
2 0,863 0,976 0,979
Dari Tabel 12, diketahui nilai icdrate terkecil terdapat pada metode Single Linkage dengan 2 cluster, sehingga model pengelompokan dari metode tersebut paling baik diterapkan untuk kasus ini.
V. KESIMPULAN DAN SARAN A. Kesimpulan
Berdasarkan analisis dan pembahasan di atas diperoleh kesimpulan sebagai berikut. Pada dendogram metode clustering hirarki single linkage menghasilkan dua cluster dengan anggota pertama sebanyak 39 kendaraan dan satu kendaraan untuk cluster 2. Selanjutnya pada metode complete linkage juga menghasilkan dua cluster dengan anggota pertama sebanyak 27 kendaraan dan 13 kendaraan pada cluster 2. Keputusan yang sama juga terlihat dari perhitungan pseudo f terbesar yaitu pada dua cluster yang berarti sebagai jumlah cluster optimum. Pada metode non hirarki K-Means menggunakan pseudo f didapatkan kesimpulan yang sama. Jumlah cluster optimum yang terbentuk sebanyak dua cluster dengan variabel yang berkontribusi signifikan dalam pengelompokkan adalah weight, wheel base, length dan width. Pada penentuan model terbaik berdasarkan nilai icdrate terkecil disimpulkan bahwa metode single linkage dengan dua cluster adalah metode terbaik.
B. Saran
Berdasarkan penelitian yang telah dilakukan, saran yang dapat diberikan untuk penelitan selanjutnya adalah melakukan standarisasi data terlebih dahulu jika data yang digunakan memiliki stauan yang berbeda-beda agar clustering yang dihasilkan tepat.
DAFTAR PUSTAKA
[1] Rencher, Alvin C. 2002. Methods of Multivariate Analysis, Second Edition. Canada: John Wiley & Sons, Inc.
[2] Johnson, Richard. 2007. Applied Multivariate Statistical Analysis. Madison : Pearson Prentice Hall. [3] Rencher, Alvin C. 2002. Methods of Multivariate
Analysis, Second Edition. Canada: John Wiley & Sons, Inc.
[4] Santoso, Singgih. 2010. Statistik Multivariat, Konsep dan Aplikasi dengan SPSS. Jakarta: PT Elex Media Komputindo.
LAMPIRAN
1. Data retail price, horsepower, dan weight berdasarkan penjualan tipe mobil di Amerika Serikat tahun 2004
Vehicle Name X1 X2 X3
Acura RSX Type S 2dr 23820 200 2778
Audi A4 3.0 4dr 31840 220 3462
Audi A4 3.0 Quattro 4dr auto 34480 220 3627
Audi A6 2.7 Turbo Quattro 4dr 42840 250 3836
Audi A6 3.0 4dr 36640 220 3561
Audi A6 3.0 Quattro 4dr 39640 220 3880
Audi A8 L Quattro 4dr 69190 330 4399
Audi S4 Avant Quattro 49090 340 3936
BMW 325i 4dr 28495 184 3219
BMW 330Ci convertible 2dr 44295 225 3616
BMW 545iA 4dr 54995 325 3814
BMW X3 3.0i 37000 225 4023
Buick Century Custom 4dr 22180 175 3353
Buick Park Avenue 4dr 35545 205 3778
Cadillac Deville 4dr 45445 275 3984
Chevrolet Astro 26395 190 4605
Chevrolet Corvette 2dr 44535 350 3246
Chevrolet Corvette convertible 2dr 51535 350 3248
Chevrolet Impala 4dr 21900 180 3465
Chevrolet Malibu Maxx LS 22225 200 3458
Chevrolet Tahoe LT 41465 295 5050
Chrysler 300M 4dr 29865 250 3581
Chrysler Concorde LXi 4dr 26860 232 3548
Chrysler Sebring Touring 4dr 21840 200 3222
CMC Yukon 1500 SLE 35725 285 5042
Dodge Durango SLT 32235 230 4987
Dodge Grand Caravan SXT 32660 215 4440
Dodge Intrepid SE 4dr 22035 200 3469
Ford Escape XLS 22515 201 3346
Ford Freestar SE 26930 193 4275
GMC Safari SLE 25640 190 4309
GMC Yukon XL 2500 SLT 46265 325 6133
Honda Accord EX V6 2dr 26960 240 3294
Honda CR-V LX 19860 160 3258
Honda Odyssey LX 24950 240 4310
Hyundai Accent GL 4dr 11839 103 2290
Hyundai Elantra GT 4dr 15389 138 2635
Infiniti FX45 36395 315 4309
Infiniti G35 4dr 32445 260 3677
Isuzu Rodeo S 20449 193 3836
2. Data wheel base, length, dan width berdasarkan penjualan tipe mobil di Amerika Serikat tahun 2004
Vehicle Name X4 X5 X 6
Acura RSX Type S 2dr 101 172 68
Audi A4 3.0 4dr 104 179 70
Audi A4 3.0 Quattro 4dr auto 104 179 70
Audi A6 2.7 Turbo Quattro 4dr 109 192 71
Audi A6 3.0 4dr 109 192 71
Audi A6 3.0 Quattro 4dr 109 192 71
Audi A8 L Quattro 4dr 121 204 75
Audi S4 Avant Quattro 104 179 70
BMW 325i 4dr 107 176 69
BMW 330Ci convertible 2dr 10 17 6
7 7 9
BMW 545iA 4dr 114 191 73
BMW X3 3.0i 110 180 73
Buick Century Custom 4dr 109 195 73
Buick Park Avenue 4dr 114 207 75
Cadillac Deville 4dr 115 207 74
Chevrolet Astro 111 190 78
Chevrolet Corvette 2dr 105 180 74
Chevrolet Corvette convertible 2dr 105 180 74
Chevrolet Impala 4dr 111 200 73
Chevrolet Malibu Maxx LS 112 188 70
Chevrolet Tahoe LT 116 197 79
Chrysler 300M 4dr 113 198 74
Chrysler Concorde LXi 4dr 113 208 74
Chrysler Sebring Touring 4dr 108 191 71
CMC Yukon 1500 SLE 116 199 79
Dodge Durango SLT 119 201 76
Dodge Grand Caravan SXT 119 201 79
Dodge Intrepid SE 4dr 113 204 75
Ford Escape XLS 103 173 70
Ford Freestar SE 121 201 77
GMC Safari SLE 111 190 78
GMC Yukon XL 2500 SLT 130 219 79
Honda Accord EX V6 2dr 105 188 71
Honda CR-V LX 103 179 70
Honda Odyssey LX 118 201 76
Hyundai Accent GL 4dr 96 167 66
Hyundai Elantra GT 4dr 103 178 68
Infiniti FX45 112 189 76
Infiniti G35 4dr 112 187 69
Isuzu Rodeo S 106 178 70
3. Agglomeration Schedule dengan metode Single Linkage
Stage Cluster Combined Coefficients Cluster 1 Cluster 2
1 2 3 ,320
2 16 31 ,417
3 5 6 ,512
4 21 25 ,541
6 4 5 ,580
7 17 18 ,592
8 20 24 ,790
9 13 28 ,802
10 13 23 ,816
11 13 20 ,820
12 29 34 ,896
13 27 30 ,918
14 13 22 ,929
15 9 29 ,941
16 9 40 ,948
17 2 9 ,959
18 13 33 ,964
19 27 35 ,977
20 13 14 ,981
21 2 13 1,007
22 2 10 1,007
23 1 2 1,030
24 4 39 1,149
25 26 27 1,149
26 1 37 1,168
27 1 4 1,187
28 1 12 1,206
29 21 26 1,388
30 1 21 1,483
31 1 15 1,516
32 8 17 1,520
33 1 38 1,706
34 1 16 1,712
35 1 36 1,727
36 1 11 1,825
37 1 8 1,923
38 1 7 2,182
39 1 32 3,264
4. Hasil pengelompokkan Single Linkage dua cluster
Cluste
r Tipe Mobil
1
Acura RSX Type S 2dr, Audi A4 3.0 4dr, Audi A4 3.0 Quattro 4dr , Audi A6 2.7 Turbo Quattro 4drauto, Audi A6 3.0 4dr, Audi A6 3.0 Quattro 4dr, Audi S4 Avant Quattro, BMW 325i 4dr, BMW 330Ci convertible 2dr, BMW X3 3.0i, Buick Century Custom 4dr, Buick Park Avenue 4dr, Chevrolet Corvette 2dr, Chevrolet Corvette convertible 2dr, Chevrolet Impala 4dr, Chevrolet Malibu Maxx LS, Chrysler 300M 4dr, Chrysler Concorde LXi 4dr, Chrysler Sebring Touring 4dr, Dodge Intrepid SE 4dr, Ford Escape XLS, Honda Accord EX V6 2dr, Honda CR-V LX, Hyundai Accent GL 4dr, Hyundai Elantra GT 4dr, Infiniti G35 4dr, Isuzu Rodeo S, Audi A8 L Quattro 4dr, BMW 545iA 4dr, Cadillac Deville 4dr, Chevrolet Astro, Chevrolet Tahoe LT, CMC Yukon 1500 SLE, Dodge Durango SLT, Dodge Grand Caravan SXT, Ford Freestar SE, GMC Safari SLE, Honda Odyssey LX, dan Infiniti FX45
2 GMC Yukon XL 2500 SLT
5. Agglomeration Schedule dengan metode Complete Linkage
Stage Cluster Combined Coefficients Cluster 1 Cluster 2
1 2 3 ,320
2 16 31 ,417
3 5 6 ,512
4 21 25 ,541
5 13 19 ,548
6 17 18 ,592
7 20 24 ,790
8 23 28 ,816
9 4 5 ,825
10 29 34 ,896
11 27 30 ,918
12 29 40 1,086
13 2 9 1,142
14 26 35 1,149
15 22 23 1,231
16 14 22 1,259
17 4 39 1,272
18 26 27 1,324
19 13 20 1,370
20 1 37 1,414
21 10 12 1,505
22 2 33 1,535
23 8 17 1,556
24 4 10 1,627
25 2 29 1,717
26 21 38 1,762
27 11 15 1,825
28 16 26 2,079
29 1 36 2,297
30 13 14 2,474
31 7 11 2,494
32 16 21 2,810
33 4 8 2,965
34 2 13 3,812
35 2 4 4,426
36 7 16 4,864
37 7 32 5,396
38 1 2 6,232
39 1 7 10,525
6. Hasil pengelompokkan Complete Linkage dua cluster
Cluste
r Tipe Mobil
1
Acura RSX Type S 2dr, Audi A4 3.0 4dr, Audi A4 3.0 Quattro 4dr , Audi A6 2.7 Turbo Quattro 4drauto, Audi A6 3.0 4dr, Audi A6 3.0 Quattro 4dr, Audi S4 Avant Quattro, BMW 325i 4dr, BMW 330Ci convertible 2dr, BMW X3 3.0i, Buick Century Custom 4dr, Buick Park Avenue 4dr, Chevrolet Corvette 2dr, Chevrolet Corvette convertible 2dr, Chevrolet Impala 4dr, Chevrolet Malibu Maxx LS, Chrysler 300M 4dr, Chrysler Concorde LXi 4dr, Chrysler Sebring Touring 4dr, Dodge Intrepid SE 4dr, Ford Escape XLS, Honda Accord EX V6 2dr, Honda CR-V LX, Hyundai Accent GL 4dr, Hyundai Elantra GT 4dr, Infiniti G35 4dr, dan Isuzu Rodeo S
2