masa berlaku mulai Vol. 1 No. 1 tahun 2017 s.d Vol. 5 No. 3 tahun 2021
Terbit online pada laman web jurnal: http://jurnal.iaii.or.id
JURNAL RESTI
(Rekayasa Sistem dan Teknologi Informasi)
Vol. 4 No. 5 (2020) 899 - 906
ISSN Media Elektronik: 2580-0760
Identifikasi Spesies Reptil Menggunakan Convolutional Neural Network
(CNN)
Olvy Diaz Annesa1, Condro Kartiko2, Agi Prasetiadi3
123Jurusan Teknik Informatika, Fakultas Informatika, Institut Teknologi Telkom Purwokerto 1[email protected], 2[email protected], 3[email protected] Abstract
Reptiles are one of the most common fauna in the territory of Indonesia. quite a lot of people who have an interest in knowing more about this fauna in order to increase knowledge. Based on previous research, Deep Learning is needed in particular the CNN method for computer programs to identify reptile species through images. This reseacrh aims to determine the right model in producing high accuracy in the identification of reptile species. Thousands of images are generated through data augmentation processes for manually captured images. Using the Python programming language and Dropout technique, an accuracy of 93% was obtained by this research in identifying 14 different types of reptiles.
Keywords: reptile, species identification, convolutional neural network, data augmentation, python
Abstrak
Reptil adalah salah satu fauna yang banyak terdapat di wilayah Indonesia. Tidak sedikit masyarakat yang memiliki ketertarikan untuk mengetahui lebih jauh mengenai fauna ini guna menambah pengetahuan. Berdasarkan penelitian sebelumnya, diperlukan
Deep Learning khususnya metode CNN bagi program komputer untuk mengidentifikasi spesies reptil melalui gambar.
Penelitian ini bertujuan untuk mengetahui model yang tepat dalam menghasilkan akurasi tinggi dalam identifikasi spesies reptil. Ribuan gambar dihasilkan melalui prosess augmentasi data terhadap gambar yang ditangkap secara manual. Menggunakan bahasa pemrograman Python dan teknik Dropout, akurasi sebesar 93% diperoleh penelitian ini dalam mengidentifikasi 14 jenis reptil yang berbeda.
Kata kunci: reptil, identifikasi spesies, jaringan saraf konvolusional, augmentasi data, python 1. Pendahuluan
Indonesia adalah salah satu negara pusat keanekaragaman hayati di dunia. Keanekaragaman hayati Indonesia menempati rangking kedua di dunia setelah Brazil. Reptil adalah salah satu fauna yang banyak terdapat di wilayah Indonesia. Persentase sebesar 8% dari jumlah jenis reptil dunia, lebih dari 723 jenis reptil terdapat di Indonesia [1]. Reptilia yang terbagi menjadi berbagai macam jenis buaya, kadal, ular dan kura-kura memiliki keunikan masing-masing sehingga sangat diminati oleh kalangan pencinta reptilia di berbagai belahan dunia, termasuk di Indonesia. Tidak sedikit masyarakat, bukan hanya dari kalangan pencinta reptil namun juga orang awam, yang memiliki ketertarikan untuk mengetahui lebih jauh mengenai fauna ini guna menambah pengetahuan.
Pada era digital ini, pertumbuhan data telah berkembang
objek dalam gambar pun banyak dikembangkan [2] . Berbeda dengan manusia dan hewan, mesin dan komputer tidak mampu mengenali objek dengan mudah. Perlu diciptakan kecerdasaan buatan bagi program komputer untuk melakukan pekerjaan layaknya manusia dimana spesies reptil dapat diidentifikasi berdasarkan pada beberapa karakteristik seperti bentuk kepala, pola tubuh, warna kulit, dan bentuk mata. Didasari oleh pemanfaatan banyak lapisan pengolahan informasi untuk ekstraksi fitur, pengenalan pola dan klasifikasi, maka dalam penelitian ini sebuah pendekatan bernama Deep Learning digunakan sebagai solusi dengan berperan sebagai sistem pembelajaran komputer [3]. Metode-metode berbasis pengenalan gambar merupakan teknik yang umum digunakan untuk memecahkan masalah tersebut. Salah satu metode yang cukup efisien untuk mengenali gambar adalah Convolutional Neural Network (CNN).
Penelitian tentang pengenalan objek sudah banyak dilakukan dan sudah banyak ditetapkan di berbagai bidang di Indonesia. Amiza Amir, dkk [4] melakukan penelitian dengan membandingkan akurasi dari metode decision tree J48, nearest neighbors, k-nearest neighbors (k-NN), backpropagation neural network, dan naïve Bayes pada sistem klasifikasi spesies ular. Tingkat akurasi yang dihasilkan dari pengujian ini adalah 75,64% untuk naif Bayes, 87,93% untuk backpropagation neural network, 89,22% untuk nearest neighbors, 80,34% untuk k-NN, dan 71,29% untuk J48.
Alex K., dkk [5] melakukan uji coba terhadap deep convolutional neural network dengan skala besar
untuk mengklasifikasikan 1,2 juta gambar resolusi tinggi dalam kontes ImageNet LSVRC-2010 ke dalam 1.000 kelas yang berbeda dengan menggunakan image classification dengan metode CNN dan metode regularisasi dropout. Tingkat akurasi kesalahan sebesar 15,3%.
Sumaiya D., dkk [6] melakukan penelitian guna
mendeteksi kanker payudara otomatis yang menggabungkan algoritma CNN dan image classification, menghasilkan tingkat akurasi prediksi penelitian hingga 99,86%.
Kiran S., dkk [7] menguji model Deep Learning untuk pengenalan gambar menggunakan TensorFlow dari perangkat lunak Dockers. Menggunakan algoritma CNN dan memperoleh hasil 99% pada tingkat akurasi untuk mengidentifikasi gambar uji.
Condro K., dkk [8] melakukan penelitian yang bertujuan untuk menghasilkan model CNN untuk mengenali spesies reptil. Hasil akurasi yang diperoleh sebesar 64,3% dalam mengidentifikasi 14 jenis spesies yang berdeda.
Dari beberapa perbandingan dari penelitian terkait, dapat disimpulkan bahwa penelitian ini dilakukan dalam bidang mengacu pada referensi dari penelitian bidang medis oleh Sumaiya D., dkk dimana tingkat akurasi penelitian tersebut mencapai 99%, serta penelitian bidang identifikasi reptil oleh Condro K., dkk dimana penelitian tersebut menggunakan dataset berupa spesies reptil. Selain itu kedua penelitian sama-sama menggunakan Deep Learning berupa metode CNN, bahasa pemograman Python dan kedua penelitian diterapkan ke dalam sistem deteksi serta identifikasi sehingga itu menjadi acuan utama pada penelitian ini.
1. Metode Penelitian
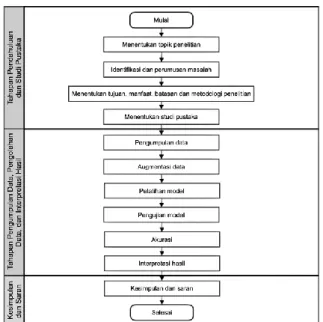
Perancangan arsitektur untuk sistem identifikasi spesies reptil pada penelitian ini dilakukan dalam beberapa tahap yang dapat dilihat dalam Gambar 1.
Gambar 1. Flowchart Penelitian
Gambar 1 menunjukkan bahwa proses penelitian diawali dengan tahap observasi dengan melakukan pengumpulan data berupa pengambilan gambar spesies reptil dari Ordo Crocodilian, Squamata dan Testudinata dari berbagai sudut yang dikumpulkan secara manual menggunakan kamera ponsel dari Taman Reptil Adiluhur, Kebumen. Reptil yang menjadi subjek penelitian berasal dari Ordo Crocodilian, Squamata dan Testudinata dapat dilihat pada Tabel 1.
Tabel 1.Tabel Data Spesies Reptil No Ordo Spesies
1 Crocodilian Buaya Siam
2 Gavial 3 4 5 6 7 8 9 10 11 12 13 14 Squamata Testudinata Air Albino Biawak Blue Insularis Cincin Emas Cincin Perak Gekko Gonyosoma Iguana Jali Sanca Burma Sanca Kembang Kura-kura
Tabel 1 menunjukkan data bahwa spesies Buaya Siam dan Gavial termasuk dalam Ordo Crocodilian. Spesies Ular Air Albino, Biawak, Ular Blue Insularis, Ular Cincin Emas, Ular Cincin Perak, Gekko, Ular Gonyosoma, Iguana, Ular Jali, Ular Sanca Burma dan Ular Sanca Kembang termasuk dalam Ordo Squamata. Sedangkan Kura-kura termasuk dalam Ordo Testudinata.
Beberapa instrumen penelitian yang digunakan dalam penelitian ini dibagi menjadi dua, yaitu untuk perangkat keras berupa Laptop MacBook Air 2019 dengan
spesifikasi: Processor: 1,6 GHz Dual-Core Intel Core i5, Memory: 8,00 GB, Kamera Single 13 MP, f/1.9, AF, SD card 128GB. Serta perangkat lunak dengan Operating System macOS Catalina, Jupyter Notebook, menggunakan Python versi 3.7 dengan library berupa Tensorflow, Numpy, Keras dan OpenCV.
Gambar 2. Flowchart Pengolahan Data
Gambar 2 menjunjukkan bahwa dataset yang akan digunakan pada tahap augmentasi dibagi menjadi 3 jenis, yang pertama adalah Dataset 1 dengan jumlah 9 spesies. Pelatihan tidak dilakukan menggunakan seluruh 14 spesies sekaligus, hal ini dilakukan agar penggunaan resource komputer menjadi lebih optimal. Sehingga ketika hasil yang diperoleh telah sesuai, barulah jumlah model dapat ditingkatkan menjadi 14 spesies. Dataset 1 berisi 1 gambar dari masing-masing spesies sehingga menghasilkan total 9 gambar asli untuk digunakan sebagai data train dan data test. Selanjutnya ada Dataset 2, model yang digunakan dalam data ini meningkat menjadi 14 spesies, menghasilkan total 14 gambar asli untuk masing-masing digunakan sebagai data train dan data test. Sedangkan pada Dataset 3 sama-sama menggunakan 14 model, namun yang membedakan adalah jumlah gambar asli yang digunakan tidak hanya 1 namun berbeda pada tiap spesiesnya, dengan rincian pada Tabel 2.
Tabel 2.Tabel Jumlah Data Gambar Asli Dataset 3 Spesies Jumlah Gambar Asli Buaya Siam 13 Gavial 25 Air Albino Biawak Blue Insularis Cincin Emas Cincin Perak Gekko Gonyosoma Iguana Jali Sanca Burma Sanca Kembang Kura-kura 104 101 61 15 140 21 102 37 61 18 69 202
Tabel 3. menunjukkan bahwa Testudinata menggunakan data dengan jumlah gambar asli terbanyak dengan jumlah 202, sedangkan Albino hanya menggunakan 13 gambar data asli. Dataset 1, Dataset 2 dan Dataset 3 selanjutnya memasuki proses augmentasi data dimana dalam proses tersebut dilakukan banyak perubahan dan peningkatan jumlah data.
Augmentasi dilakukan terhadap data gambar yang akan digunakan agar data gambar tidak sebesar gambar asli, sehingga meringankan beban komputer pada saat proses pelatihan. Sehingga sebelum memasuki proses augmentasi, resolusi gambar asli telah diubah menjadi 400 x 400 piksel.
Gambar-gambar dari 14 spesies tersebut kemudian melalui proses augmentasi dengan diperbanyak menjadi 3000 gambar tiap kategorinya dengan tambahan proses seperti random distorsion, rotate, zoom random, crop random, resize menjadi 64 x 64 piksel, flip random, rotate 90o dan rotate 270o dengan tujuan menjadikan gambar satu dengan yang lain terlihat berbeda.
Langkah selanjutnya, gambar dibagi dengan perbandingan 9:1 dimana data train diperbanyak 2700 kali sedangkan untuk data test sebanyak 300 kali, sehingga menghasilkan 24300 data train dan 2709 data test. Sampel data gambar asli 9 spesies dari Dataset 1 yang digunakan untuk model ke-1 hingga ke-3 dapat dilihat dalam Gambar 3.
Gambar 3. Sampel Data Asli 9 Spesies
Model ke-4 hingga ke-6 menggunakan keseluruhan data dari 14 spesies, 14 spesies, yang kemudian melalui proses augmentasi menghasilkan 37800 data train dan 4214 data test. Sedangkan model ke-7 dan ke-8 menggunakan keseluruhan data gambar asli yang telah terkumpul yang kemudian menjalani proses augmentasi, sehingga menghasilkan 38741 data train dan 5155 data test. Sampel data gambar asli dari Dataset 2 dan Dataset 3 yang digunakan untuk model ke-4 hingga ke-8 dapat dilihat dalam Gambar 4.
Gambar 4. Sampel Data Asli 14 Spesies Kode Program Augmentasi Data import Augmentor
import os
def perbanyak_(ini, sebanyak_ini): source_dir = ini
output_dir = "."
p=Augmentor.Pipeline(source_directory=source_d ir, output_directory=output_dir)
p.random_distortion(probability=1,
grid_width=4, grid_height=4, magnitude=1) p.rotate(probability=0.7,max_left_rotation=13, max_right_rotation=13) p.zoom_random(probability=0.5,percentage_area= 0.9) p.crop_random(probability=0.6,percentage_area= 0.9)
p.resize(probability=1.0, width=64, height=64) p.flip_random(probability=0.7) p.rotate90(probability=0.5) p.rotate270(probability=0.5) p.sample(sebanyak_ini) perbanyak_("dataset/test/albino", 300) perbanyak_("dataset/test/biawak", 300) perbanyak_("dataset/test/blue", 300) perbanyak_("dataset/test/burma", 300) perbanyak_("dataset/test/emas", 300) perbanyak_("dataset/test/gavial", 300) perbanyak_("dataset/test/gekkonidae", 300) perbanyak_("dataset/test/gonyosoma", 300) perbanyak_("dataset/test/green", 300) perbanyak_("dataset/test/jali", 300) perbanyak_("dataset/test/kembang", 300) perbanyak_("dataset/test/perak", 300) perbanyak_("dataset/test/siamensis", 300) perbanyak_("dataset/test/testudinata", 300) perbanyak_("dataset/train/albino", 2700) perbanyak_("dataset/train/biawak", 2700) perbanyak_("dataset/train/blue", 2700) perbanyak_("dataset/train/burma", 2700) perbanyak_("dataset/train/emas", 2700) perbanyak_("dataset/train/gavial", 2700) perbanyak_("dataset/train/gekkonidae", 2700) perbanyak_("dataset/train/gonyosoma", 2700) perbanyak_("dataset/train/green", 2700) perbanyak_("dataset/train/jali", 2700) perbanyak_("dataset/train/kembang", 2700) perbanyak_("dataset/train/perak", 2700) perbanyak_("dataset/train/siamensis", 2700) perbanyak_("dataset/train/testudinata", 2700)
Ketika augmentasi data telah dilakukan, maka selanjutnya dataset melewati proses pelatihan berdasarkan pembagian model yang telah ditentukan. Rincian dari arsitektur model tersebut terlampir dalam Tabel 3.
Tabel 3.Tabel Arsitektur Model Layer (Type) Output Shape M.1 M.2 M.3 M.4 M.5 M.6 M.7 M.8 Conv2D 62,6 2,16 30,3 0,8 62,62 ,32 62,62 ,32 62,62 ,32 60,60 ,32 64,64 ,32 64,64 ,32 MaxPoo ling2D 31,3 1,16 15,1 5,8 31,31 ,32 31,31 ,32 31,31 ,32 30,30 ,32 32,32 ,32 32,32 ,32 Conv2D 13,1 3,16 29,29 ,64 29,29 ,64 29,29 ,64 28,28 ,64 32,32 ,64 32,32 ,64 MaxPoo ling2D 6,6, 16 12,12 ,128 12,12 ,128 14,14 ,64 14,14 ,64 16,16 ,64 16,16 ,64 Conv2D 6,6,1 28 6,6,1 28 12,12 ,128 12,12 ,128 16,16 ,128 16,16 ,128 MaxPoo ling2D 6,6,1 28 6,6,1 28 8,8,1 28 8,8,1 28 Conv2D 4,4,2 56 4,4,2 56 8,8,2 56 8,8,2 56 SpatialD ropOut 8,8,2 56 MaxPoo ling2D 2,2,2 56 2,2,2 56 4,4,2 56 4,4,2 56 Flatten 153 76 576 4609 4608 1024 1024 4096 4096 Dense (ReLU) 10 10 10 10 10 10 10 10 Dense (Softmax ) 9 9 9 14 14 14 14 14
Tabel 3 menunjukkan bahwa Model M.1 menggunakan 1 lapisan konvolusi dan aktivasi Softmax sejumlah 9 didasari oleh jumlah spesies yang digunakan. Selanjutnya dilakukan penambahan lapisan pada Model M.2 menjadi 2 lapisan konvolusi dan Model M.3 menjadi 3 lapisan konvolusi. Pada Model M.4 jumlah spesies mengalami peningkatan menjadi 14 spesies sehingga terdapat perubahan pada Softmax menjadi 14. Selanjutnya Model M.5 menggunakan 4 lapisan konvolusi dan terus diterapkan hingga Model M.8. Namun berbeda dengan arsitektur yang lain, terjadi penambahan Dropout pada layer ke-4 pada Model M.8 sebesar 0,5.
3. Hasil dan Pembahasan
Dataset 1, Dataset 2 dan Dataset 3 yang telah melalui proses augmentasi menghasilkan data berupa gambar baru dengan bentuk berbeda satu dengan lain. Beberapa sampel hasil augmentasi data dapat dilihat pada Gambar 5.
Pelatihan model dilakukan berdasarkan arsitektur pada Tabel 3. Pada tahap pelatihan Model M.1 dilakukan dengan 100step/epoch dan 100 epoch. Epoch pertama menghasilkan akurasi validasi sebesar 9,44% dan membutuhkan waktu 841ms/step. Sedangkan epoch ke-100 menghasilkan akurasi validasi sebesar 72,97% dan membutuhkan waktu 656ms/step. Hasil tersebut dapat dilihat pada Gambar 6.
Gambar 5. Sampel Data Gambar Hasil Augmentasi
Gambar 6. Hasil Pelatihan Model M.1
Pada tahap pelatihan Model M.2 dilakukan dengan 100step/epoch dan 100 epoch. Epoch pertama menghasilkan akurasi validasi sebesar 28,35% dan membutuhkan waktu 743ms/step. Sedangkan epoch ke-100 menghasilkan akurasi validasi sebesar 99,72% dan membutuhkan waktu 601ms/step. Hasil tersebut dapat dilihat pada Gambar 7.
Gambar 7. Hasil Pelatihan Model M.2
Pada tahap pelatihan Model M.3 dilakukan dengan 100step/epoch dan 100 epoch. Epoch pertama menghasilkan akurasi validasi sebesar 16,15% dan membutuhkan waktu 2s/step. Sedangkan epoch ke-100 menghasilkan akurasi validasi sebesar 99,62% dan membutuhkan waktu 1s/step. Hasil tersebut dapat dilihat pada Gambar 8.
Gambar 8. Hasil Pelatihan Model M.3
Pada tahap pelatihan Model M.4 dilakukan dengan 100step/epoch dan 100 epoch. Epoch pertama menghasilkan akurasi validasi sebesar 9,50% dan membutuhkan waktu 1s/step. Sedangkan epoch ke-100 menghasilkan akurasi validasi sebesar 99,44% dan membutuhkan waktu 840ms/step. Hasil tersebut dapat dilihat pada Gambar 9.
Gambar 9. Hasil Pelatihan Model M.4
0 1 1 9 17 25 33 41 49 57 65 73 81 89 97
M.1
TRAIN TEST 0 1 2 1 7 13 19 25 31 37 43 49 55 61 67 73 79 85 91 97M.2
TRAIN TEST 0 1 2 1 7 13 19 25 31 37 43 49 55 61 67 73 79 85 91 97M.3
TRAIN TEST 0 0.5 1 1.5 1 7 13 19 25 31 37 43 49 55 61 67 73 79 85 91 97M.4
TRAIN TESTPada tahap pelatihan Model M.5 dilakukan dengan 100step/epoch dan 100 epoch. Epoch pertama menghasilkan akurasi validasi sebesar 7,56% dan membutuhkan waktu 2s/step. Sedangkan epoch ke-100 menghasilkan akurasi validasi sebesar 100% dan membutuhkan waktu 911ms/step. Hasil tersebut dapat dilihat pada Gambar 10.
Gambar 10. Hasil Pelatihan Model M.5
Pada tahap pelatihan Model M.6 dilakukan dengan 100step/epoch dan 100 epoch. Epoch pertama menghasilkan akurasi validasi sebesar 7,12% dan membutuhkan waktu 1s/step. Sedangkan epoch ke-100 menghasilkan akurasi validasi sebesar 99,94% dan membutuhkan waktu 904ms/step. Hasil tersebut dapat dilihat pada Gambar 11.
Gambar 11. Hasil Pelatihan Model M.6
Pada tahap pelatihan Model M.7 dilakukan dengan 100step/epoch dan 388 epoch. Epoch pertama menghasilkan akurasi validasi sebesar 6,47% dan membutuhkan waktu 1s/step. Sedangkan epoch ke-388 menghasilkan akurasi validasi sebesar 98,41% dan membutuhkan waktu 1s/step. Hasil tersebut dapat dilihat pada Gambar 12.
Gambar 12. Hasil Pelatihan Model M.7
Pada tahap pelatihan Model M.8 dilakukan dengan 100step/epoch dan 388 epoch. Epoch pertama menghasilkan akurasi validasi sebesar 90,31% dan membutuhkan waktu 2s/step. Sedangkan epoch ke-388 menghasilkan akurasi validasi sebesar 98,84% dan membutuhkan waktu 1s/step. Hasil tersebut dapat dilihat pada Gambar 13.
Gambar 13. Hasil Pelatihan Model M.8
Hasil dari pelatihan setiap model disimpan menjadi berkas dengan format .h5 untuk selanjutnya dilakukan proses pengujian model. Penggunaan memori pada setiap pelatihan model dapat dilihat pada Tabel 4.
Tabel 4.Tabel Arsitektur Model
Model Jumlah Lapisan Penggunaan Memori M.1 1 0,635 MB M.2 2 0,049 MB M.3 3 0,582 MB M.4 3 0,582 MB M.5 4 1,6 MB M.6 4 1,6 MB M.7 4 2,4 MB M.8 4 2,4 MB
Tabel 4 menunjukkan hasil pelatihan bahwa model yang menggunakan memori teringan adalah Model M.2 dengan memori sebesar 49kB sedangkan memori terberat adalah Model M.7 dan M.8 yaitu sebesar 2,4MB.
Tahap selanjutnya merupakan pengujian model yang dilakukan dengan memasukkan kode uji spesies reptile. Dari hasil tersebut prediksi dapat diketahui melalui tabel Confusion Matrix seperti pada Tabel 6.
Tabel 5.Tabel Hasil Pengujian Model M.1
0 1 2 1 7 13 19 25 31 37 43 49 55 61 67 73 79 85 91 97
M.5
TRAIN TEST 0 0.5 1 1.5 1 7 13 19 25 31 37 43 49 55 61 67 73 79 85 91 97M.6
TRAIN TEST 0 1 2 1 24 47 70 93 116 139 162 185 208 231 254 277 300 323 346 369M.7
TRAIN TEST 0 0.5 1 1.5 1 24 47 70 93 116 139 162 185 208 231 254 277 300 323 346 369M.8
TRAIN TESTTabel 5 menujukkan bahwa spesies yang memiliki data aktual terendah adalah Siamensis dengan perolehan sebanyak 3 dari total 301. Sedangkan spesies yang memiliki data aktual tertinggi adalah Green dengan perolehan sebanyak 272 dari total 301.
Tabel 6.Tabel Hasil Pengujian Model M.2
Tabel 6 menujukkan bahwa spesies yang memiliki data aktual terendah adalah Burma dengan perolehan sebanyak 260 dari total 301. Sedangkan spesies yang memiliki data aktual tertinggi adalah Siamensis, Green, Kembang dan Testudinata dengan perolehan sebanyak 301 dari total 301.
Tabel 7.Tabel Hasil Pengujian Model M.3
Tabel 7 menujukkan bahwa spesies yang memiliki data aktual terendah adalah Burma dengan perolehan sebanyak 293 dari total 301. Sedangkan spesies yang memiliki data aktual tertinggi adalah Siamensis, Green dan Kembang dengan perolehan sebanyak 301 dari total 301.
Tabel 8.Tabel Hasil Pengujian Model M.4
Tabel 8 menujukkan spesies yang memiliki data aktual terendah adalah Blue, Gekkonidae, Gonyosoma dan
Green dengan perolehan sebanyak 0 dari total 301. Sedangkan spesies yang memiliki data aktual tertinggi adalah Testudinata dengan perolehan sebanyak 301 dari total 301.
Tabel 9.Tabel Hasil Pengujian Model M.5
Tabel 9 menujukkan bahwa hanya Albino, Siamensis dan Testudinata yang memiliki sejumlah data aktual dengan Testudinata sebagai spesies yang memiliki data aktual tertinggi sebanyak 301 dari total 301.
Tabel 10.Tabel Hasil Pengujian Model M.6
Tabel 10 menujukkan bahwa spesies yang memiliki data aktual terendah adalah Burma dengan perolehan 0 dari total 301. Sedangkan spesies yang memiliki data actual tertinggi adalah Testudinata dengan perolehan sebanyak 301 dari total 301.
Tabel 11.Tabel Hasil Pengujian Model M.7
Tabel 11 menujukkan bahwa spesies yang memiliki data aktual terendah adalah Albino dengan perolehan
sebanyak 249 dari total 312. Sedangkan spesies yang memiliki data aktual tertinggi adalah Burma dengan perolehan sebanyak 400 dari total 400.
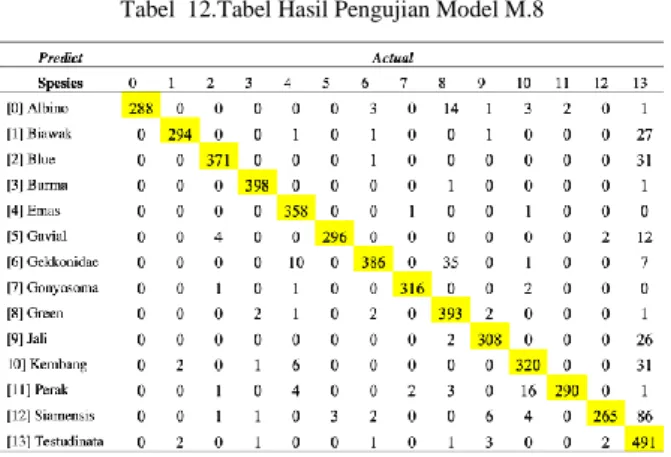
Tabel 12.Tabel Hasil Pengujian Model M.8
Tabel 12 menujukkan bahwa spesies yang memiliki data aktual terendah adalah Siamensis dengan perolehan 265 dari total 368. Sedangkan spesies yang memiliki data aktual tertinggi adalah Burma dengan perolehan sebanyak 398 dari total 400.
Berdasarkan Confusion Matrix yang telah dibuat, maka diperoleh hasil probabilitas akurasi pada Tabel 13.
Tabel 13.Tabel Hasil Total Probabilitas Akurasi Dataset 1
Tabel 13 menunjukkan bahwa dari 3 model pada pengujian Dataset 1, diperoleh hasil bahwa Model M.3 memiliki akurasi tertinggi dengan jumlah 99%. Maka proses selanjutnya yaitu mengimplementasikan arsitektur Model M.3 pada Dataset 2.
Tabel 14.Tabel Hasil Total Probabilitas Akurasi Dataset 1 dan Dataset 2
Tabel 14 menunjukkan bahwa arsitektur Model M.3 yang diimplementasikan pada Model M.4 menunjukkan total probabilitas akurasi yang rendah yaitu hanya sebesar 37%. Maka dilakukan pengembangan arsitektur untuk model M.5 dan M.6 dimana model M.6 memiliki akurasi lebih tinggi sehingga dilakukan uji coba pengimplementasian pada jumlah data yang lebih banyak yaitu pada model M.7.
Dapat dilihat pada hasil Model M.7 mengalami peningkatan dengan total probabilitas akurasi sebesar 91%. Dalam pengujian model M.8 dimana teknik Dropout sebesar 0,5 digunakan pada layer ke-4, terjadi peningkatan sebanyak 2%, menghasilkan total probabilitas akurasi sebesar 93%.
4. Kesimpulan
Berdasarkan hasil analisis yang telah dilakukan dalam penelitian ini, maka diperoleh kesimpulan bahwa penggunaan teknik Dropout sebesar 0,5 yang diterapkan pada pengujian Model M.8 berpengaruh dalam peningkatan hasil akurasi sehingga menghasilkan probabilitas akurasi tertinggi dalam penelitian ini yaitu sebesar 93%.
Daftar Rujukan
[1] BAPPENAS, Indonesian Biodiversity Strategy and Action Plan (IBSAP) 2015-2020. 2016.
[2] I. S. Abdurrazaq, S. Suyanto, and D. Q. Utama, “Image-Based Classification of Snake Species Using Convolutional Neural Network,” 2019 2nd Int. Semin. Res. Inf. Technol. Intell. Syst. ISRITI 2019, pp. 97–102, 2019, doi: 10.1109/ISRITI48646.2019.9034633.
[3] S. R. Dewi, “Deep Learning Object Detection Pada Video menggunakan Tensorflow dan Convolutional Neural Network,” Univ. Islam Indones., 2018.
[4] A. Amir, N. A. H. Zahri, N. Yaakob, and R. B. Ahmad, “Image Classification for Snake Species Using Machine Learning Techniques,” Adv. Intell. Syst. Comput., vol. 532, pp. 52–59, 2017, doi: 10.1007/978-3-319-48517-1_5.
[5] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Commun. ACM, vol. 60, no. 6, pp. 84–90, 2017, doi: 10.1145/3065386.
[6] S. Dabeer, M. M. Khan, and S. Islam, “Cancer Diagnosis in Histopathological Image: CNN Based Approach,” Informatics Med. Unlocked, vol. 16, no. May, p. 100231, 2019, doi: 10.1016/j.imu.2019.100231.
[7] K. Seetala, W. Birdsong, and Y. B. Reedy, “Image Classification Using TensorFlow,” Adv. Intellegent Syst. Comput. 800, no. ITNG, pp. 485–488, 2019, doi: https://doi.org/10.1007/978- 3- 030- 14070- 0_67.
[8] C. Kartiko, A. Prasetiadi, and E. Usada, “Reptile Recognition based on Convolutional Neural Network,” Int. J. Innov. Technol. Explor. Eng., vol. 9, no. 3S, pp. 112–115, 2020, doi: 10.35940/ijitee.c1026.0193s20.z