MAKALAH ANALISIS REGRESI TERAPAN
Pemilihan Model Regresi Terbaik Menggunakan Metode All Possible
Regression, Best Subset Regression, dan Sequensial Regression
Disusun oleh :
Kelompok 4
Nurinayah (14611070) Moh. Aliamsyah (14611076)
Andre Pratama (14611078)
Suri Islamiah (14611090)
Rifa Fitrianti (14611094)
Kelas C
JURUSAN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS ISLAM INDONESIA
Pemilihan Model Regresi Terbaik Menggunakan Metode All Possible Regression, Best Subset Regression, dan Sequensial Regression
Andre Pratama, Nurinayah, Moh. Aliamsyah, Rifa Fitrianti, Suri Islamiah (rifa.fitrianti@gmail.com)
Program Studi Statistika, Universitas Islam Indonesia, Yogyakarta
Abstrak
Analisis regresi seringkali digunakan untuk mengkaji hubungan antara beberapa variabel dan meramal suatu variabel. Agar diperoleh hasil analisis yang optimal, maka diperlukan model regresi terbaik. Pemilihan model regresi terbaik adalah penentuan peubah bebas mana yang akan dimasukkan dalam model regresi sehingga model tersebut dapat menjelaskan perilaku peubah tak bebas dengan baik. Metode yang umum digunakan antara lain all possible regression, best subset regression, the backward elimination, the stepwise regression procedure dan lain-lain. Penelitian ini bertujuan mengkaji metode pemilihan model regresi terbaik yang dapat di terapkan dalam analisis regresi. Dari metode-metode yang dibahas, metode yang merupa kan metode terbaik adalah metode Stepwise. Kemudia n untuk metode yang cukup memuaskan untuk diaplikasikan adalah metode the backward elimination, karena metode ini jauh lebih menghemat waktu dan tenaga dibandingkan dengan metode all possible regression. Sedangkan pada metode best subset regression sendiri memiliki beberapa kelemahan, seperti cenderung menghasilkan persamaan regresi dengan terlalu banyak peubah peramal.
Kata-kata Kunci : analisis regresi, all possible regression, best subset regression, the backward elimination, the stepwise regression procedure.
I. PENDAHULUAN
1.1. Latar Belakang
perilaku peubah tak bebas dengan sebaik-baiknya dengan memilih peubah-peubah bebas dari sekian banyak peubah bebas yang tersedia dalam data.
Untuk menentukan peubah bebas mana yang akan dimasukkan ke dalam model regresi, menurut Draper, ada dua kriteria yang saling bertentangan yaitu agar persamaannya bermanfaat untuk peramalan, biasanya ingin dimasukkan sebanyak mungkin peubah sehingga diperoleh nilai ramalan yang andal serta untuk memperoleh informasi dari banyak peubah serta pemantauannya sering kali diperlukan biaya yang tinggi, maka diinginkan persaman regresi yang mencakup sesedikit mungkin peubah. Kompromi diantara kedua kriteria itulah yang disebut pemilihan model regresi terbaik.
Untuk mengatasi kesulitan yang dihadapi dalam menentukan model terbaik dapat digunakan beberapa metode yaitu metode semua kombinasi yang mungkin (all possible regression), regresi himpunan bagian terbaik (best subset regression),
prosedur eliminasi langkah mundur (the backward elimination) dan prosedur regresi bertatar (the stepwise regression procedure). Metode yang sering digunakan adalah metode semua kombinasi yang mungkin (all possible regression). Namun metode yang biasanya direkomendasikan adalah metode the stepwise regression procedure, karena lebih menghemat waktu-komputer dibandingkan metode-metode yang lain, dan juga untuk mencegah masuknya peubah X daripada yang diperlukan sambil memperbaiki persamaannya pada setiap tahap.
1.2. Rumusan Masalah
Berdasarkan latar belakang masalah diatas, maka permasalahan yang akan dibahas dalam penulisan ini adalah sebagai berikut:
a. Apa saja metode-metode yang dapat digunakan dalam pemilihan model regresi terbaik ?
b. Bagaimana langkah-langkah menggunakan metode tersebut agar diperoleh model regresi terbainya ?
1.3. Tujuan
Tujuan yang ingin dicapai dalam penulisan ini adalah sebagai berikut:
a. Untuk mengetahui metode-metode yang digunakan dalam pemilihan model regresi terbaik.
b. Untuk mengetahui langkah-langkah dalam menggunakan metode tersebut. c. Untuk mengetahui penerapan metode-metode tersebut dalam sebuah kasus.
II. KAJIAN PUSTAKA
Penelitian mengenai pemilihan model terbaik dilakukan untuk mengetahui metode mana yang lebih mudah digunakan untuk memilih persamaan model terbaik dan bagaimana cara memilih persamaan model terbaik. Model regresi terbaik adalah model yang dapat menjelaskan perilaku peubah tak bebas dengan sebaik-baiknya dengan memilih peubah-peubah bebas dari sekian banyak peubah bebas yang tersedia dalam data. Pada tahap yang paling sederhana model bertujuan untuk pemerian, menerangkan suatu sistem, peubah apa saja yang besar pengaruhnya dalam sistem tersebut. Model juga berguna untuk tujuan prediksi maupun untuk pengendalian suatu sistem, serta penaksiran parameter regresi.
Kajian mengenai pemilihan model regresi terbaik antara lain dilakukan oleh Ferry Kondo Lembang. Hasil penelitiannya yaitu “Analisis Regresi Berganda dengan Metode Stepwise pada Data HBAT”. Hasil penelitiannya menjelaskan bahwa kepuasan pelanggan secara signifikan dipengaruhi oleh tanggapan terhadap komplain, kualitas produk, image dari sales aktivitas e-commarce, dan product line. Selain itu kajian menganai pemilihan model regresi terbaik juga dilakukan
oleh Herlina Hanum. Hasil penelitiannya yaitu “Perbandingan Metode Stepwise, Best Subset Regression, dan Fraksi dalam Pemilihan Model Regresi Berganda
tanpa ada masalah multikolinear. Penelitian lainnya juga dilakukan oleh Novelysa Samosir, Partano Siagian, dan Pengarapen Bangun. Mereka bersama-sama
melakukan penelitian tentang “Analisa Metode Backward dan Metode Forward untuk Menentukan Persamaan Regresi Linier Berganda” dengan studi kasus, Jumlah Kecelakaan Lalu Lintas di Kotamadya Medan dan masih banyak lagi penelitian lainnya berkaitan dengan pemilihan model regresi terbaik.
III. METODE PENELITIAN
Tulisan ini dibuat berdasarkan hasil analisis data menggunakan metode all possible regression, best subset regression, the backward elimination, forward
selection dan the stepwise regression procedure. Dalam Kajian ini digunakan data
Apendiks B, yang berasal dari buku A. Hald Statistical Theory with Engineering
Application yang diterbitkan oleh Wiley, New York, Pada 1952 yang memiliki 4
peubah bebas. Data tersebut memilki korelasi tinggi antar peubah bebasnya. Agar terlihat jelas perbandingan dari hasil kelima metode tersebut, penyajian dilakukan untuk masing-masing metode. Kemudian dipilih model terbaik dengan mengguna-kan masing-masing metode. Kajian difokusmengguna-kan pada bentuk dan sifat model terbaik yang dihasilkan dari kelima metode tersebut.
IV. LANDASAN TEORI
Pada bagian ini akan dijabarkan definisi maupun teorema sebagai dasar pengertian untuk mempermudah pembahasan pada bagian selanjutnya. Landasan teori yang digunakan adalah sebagai berikut:
4.1. Regresi Berganda
bersama-sama berpengaruh secara signifikan terhadap variabel dependen (Y). Persamaan regresi berganda sebagai berikut:
= + + + + ⋯ + + � [4.1]
Keterangan:
Y = Variabel dependen (nilai yang diprediksikan) X1, X2, X3 = Variabel independen
= Konstanta (nilai Y apabila X1, X2…..Xn = 0)
= Koefisien regresi (nilai peningkatan ataupun penurunan)
� = Galat acak yang berdistribusi � , �
4.2. Variabel Dependen
Variabel dependen (variabel respon) yaitu variabel yang keberadaannya dipengaruhi oleh variabel lainnya dan dinotasikan dengan variabel Y.
4.3. Variabel Independen
Variabel independen disebut juga dengan variabel prediktor yaitu variabel yang bebas (tidak dipengaruhi oleh variabel lainnya) dan dinotasikan dengan X.
4.4. Nilai F
Dalam hal yang lebih umum, misal akan dibandingkan
= + + � [4.2] Keterangan:
Y = Variabel dependen (nilai yang diprediksikan) X1, X2 = Variabel independen
= Koefisien regresi (nilai peningkatan ataupun penurunan)
� = Galat acak yang berdistribusi � , �
�ℎ �� = / �−− / [4.3]
Keterangan:
Fhitung = Nilai F yang diperoleh dari proses matematis (hitung) JKS = Jumlah kuadrat sisa (variansi karena sisa)
� = Banyaknya sampel
= Banyaknya parameter dalam model
= Banyaknya parameter dalam model
Dalam hal nilai Fhitung besar, artinya lebih besar dari � , − , yang diperoleh dari tabel-F, maka kita akan memilih model yang lengkap, sedangkan bila nilai Fhitung kecil maka pilih model yang lebih sederhana.
4.5. Korelasi
Korelasi adalah derajat hubungan linear antara dua variabel atau lebih dari data hasil pengamatan. Dua variabel dikatakan berkorelasi apabila perubahan dalam satu variabel diikuti oleh perubahan variabel lain, baik yang searah maupun tidak. Berdasarkan hubungan antar variabel yang satu dengan variabel lainnya dinyatakan
dengan koefisien korelasi yang disimbolkan dengan ”r”. Besarnya korelasi berkisar antara − ≤ ≤ . Jika dua variabel berkorelasi negatif maka nilai koefisien korelasinya akan mendekati -1, jika dua variabel tidak berkorelasi maka nilai koefisien korelasinya akan mendekati 0, sedangkan jika dua variabel berkorelasi positif maka nilai koefisien korelasinya akan mendekati 1.
4.6. Nilai �̅�
� , maka uji-F tidak lagi banyak menolong. Dalam hal ini penggunaan R2 lebih sesuai. Hubungan yang lebih umum dari R2 ditentukan dengan rumus:
= % = (∑�= �̂ −�̅
JKR = Jumlah kuadrat regresi (variansi karena regresi) JKT = Jumlah kuadrat total (variansi total)
Salah satu kelemahan R2 ialah bahwa besarnya dipengaruhi oleh banyaknya peubah bebas dalam model, R2 membesar bersama banyaknya parameter dalam model, sehingga sulit menyatakan beberapa R2 yang optimum. Akan tetapi bila model yang ingin dibandingkan mempunyai banyaknya parameter dalam model yang sama maka R2 mudah digunakan, kemudian pilih model dengan R2 terbesar. Suatu cara mengatasi kelemahan R2 tersebut diatas ialah dengan menggunakan apa yang disebut dengan R2-disesuaikan, lambang ̅ . Penyesuaian dikerjakan dengan membagi JKS dan JKT masing-masing dengan derajat kebebasannya pada rumus R2. Nilai R2 dapat dirumuskan sebagai berikut:
̅ = − / �−
R2 = Nilai koefisien determinasi
JKS = Jumlah kuadrat sisa (variansi karena sisa) JKT = Jumlah kuadrat total (variansi total)
� = Banyaknya sampel
= Banyaknya parameter dalam model
4.7. Rataan Kuadrat Sisa, S2
Salah satu patokan yang digunakan dalam menilai kecocokan suatu model dengan data ialah dengan rataan kuadrat sisa , makin kecil nilai akan semakin baik model. Ukuran ini memperhitungkan banyaknya parameter dalam model melalui pembagian dengan derajat kebebasannya. Rataan kuadrat sisa, , mungkin membesar bila penuruanan dalam JKS akibat pemasukan suatu peubah tambahan kedalam model tidak dapat mengimbangi penurunan dalam derajat kebabasannya (sebesar 1). Penambahan peubah bebas ke dalam model akan menurunkan JKS dan derajat kebebasannya, keduanya menuju ke nol jika p menuju ke n. akan sulit mera-malkan apa tepatnya yang terjadi dengan = / � − . Pada umumnya akan mengecil kesuatu minimum kemudian mungkin bergelombang di sekitar nilai tersebut bila p membesar. berkaitan erat dengan ̅2, apabila mengecil maka
̅2 membesar. Nilai dirumuskan sebagai berikut:
= = �− − [4.6]
Keterangan:
= Rataan kuadrat sisa (KTS)
JKS = Jumlah kuadrat sisa (variansi karena sisa)
� = Banyaknya sampel
= Banyaknya parameter dalam model
4.8. Metode R2 Maksimum (MAXR)
salah satu peubah dalam model dengan yang lainnya yang berada diluar. Model yang memberikan terbesar adalah model terbaik dari kelompok model dengan dua peubah. Peubah ketiga kemudian dipilih yang memberikan terbesar, dengan cara mengganti suatu peubah dalam model dengan yang lainnya yang berada diluar dipilih model tiga peubah yang memberikan terbesar. Metode ini dilanjutkan sehingga diperoleh model dengan tiga peubah dengan terbesar dan seterusnya.
4.9. Statistik Cp-Mallows
Statistik Cp-Mallows merupakan nilai dugaan yang didapat dari persamaan regesi berdasarkan sebagian peubah bebas pada umumnya bias. Model statistik Cp-Mallows dengan parameter adalah:
� = �− � −
[4.7]
Keterangan:
JKSp = Jumlah kuadrat sisaan dari model yang ditentukan = Estimasi variansi sisaan
� = Banyaknya observasi
= Banyaknya parameter dalam model
Perhatikan bahwa pada persamaan (4.7) diambil dari model yang lengkap sehingga untuk model ini selalu diperoleh � = , seolah-olah model tersebut tidak
bias. Nilai Cp berkaitan sangat erat dengan R2-disesuaikan, sehingga apabila R2 -disesuaikan maka Cp juga dengan sendirinya dapt dihitung sehingga tidak ada tambahan informasi yang diberikan Cp. Jika ketiga patokan yang telah diberikan, R2-disesuaikan, rataan kuadrat sisa dan Cp ternyata berkaitan erat satu sama lain
sehingga sesungguhnya ketiganya memberikan informasi yang sama.
4.10. Identifikasi Model Regresi
mempe-ngaruhi atau bahkan menghambat dalam proses analisis regresi. Proses identifikasi bertujuan untuk menentukan metode serta langkah-langkah yang sesuai diterapkan pada data penelitian yang tersedia.
4.11. Estimasi Model Regresi
Metode yang digunakan untuk mengestimasi fungsi regresi adalah metode pendekatan kuadrat terkecil (least square approach). Melalui metode ini peneliti bermaksud memperkecil jumlah kuadrat error yang terjadi (error total merupakan selisih antara nilai aktual dengan nilai yang diprediksi melalui model regresi). Estimasi model dimulai dengan menentukan variabel independen yang akan masuk dalam persamaan regresi. Salah satu pendekatan yang dapat dan sering digunakan dalam pemilihan model terbaik adalah pendekatan sequensial regression. Selain itu ada dua pendekatan lain yaitu all possible regression dan best subset regression. Metode-metode yang biasa digunakan dalam penentuan model regresi terbaik adalah sebagai berikut:
4.11.1.Semua Kemungkinan Regresi (All Possible Regression)
Metode semua kombinasi yang mungkin adalah metode yang umumnya digunakan. Di dalam metode tersebut ada beberapa kriteria yang digunakan yaitu R2 yang disesuaikan, S2 (rataan kuadrat sisa)dan Cp Mallows. Penentuan persamaan mana yang terbaik untuk dipilih dilakukan melalui evaluasi pola-pola yang teramati. Pilih model terbaik diantara semua kemungkinan berdasarkan berbagai suatu kriteria tertentu. Untuk menentukan model yang terbaik dapat digunakan kombinasi dari beberapa kriteria. Namun prosedur ini cenderung tidak praktis karena harus memeriksa semua kemungkinan, itu juga berarti bahwa kita harus memeriksa sejumlah besar persamaan regresi yang ada.
4.11.2.Regresi “Himpunan Bagian Terbaik” (Best Subset Regression)
Cp Mallows. Prosedur Best Subset Regression memiliki beberapa kelemahan: (1) Cenderung menghasilkan persamaan regresi dengan terlalu banyak peramal. (2) Jika K diambil terlalu kecil, persamaan regresi yang paling masuk akal untuk dipilih
mungkin malah tidak muncul dalam himpunan ‘K terbaik’, meskipun mengkin
muncul ditempat lain. (3) Belum ada informasi tercetak yang dengan mudah dapat diperoleh mengenai bagaimana berbagai himpunan bagian tersebut diperoleh.
4.11.3.Prosedur Eliminasi Langkah Maju (Forward Elimination Procedure)
Metode seleksi maju adalah langkah maju di mana peubah bebas dimasukkan satu demi satu menurut urutan besar pengaruhnya terhadap model, dan berhenti bila semua yang memenuhi syarat telah masuk. Dimulai dengan memeriksa matriks korelasi kemudian mengambil peubah bebas yang menghasilkan koefisien korelasi maksimum, dan tidak dipersoalkan apakah korelasi positif atau negatif karena yang diperhatikan hanyalah eratnya hubungan antara suatu peubah bebas dengan Y sedangkan arah hubungan tidak menjadi persoalan. Bila nilai Fhitung lebih kecil dari yang ditetapkan untuk pemasukan peubah bebas ke dalam model maka tidak jadi masuk, begitu juga sebaliknya.
Persamaannya dari prosedur eliminasi langkah maju adalah sebagai berikut:
� = ( , )| = ( , )−( , ) ( ) [4.8]
Keterangan:
JKR = Jumlah kuadrat regresi = Rataan kuadrat sisa
, = Peubah bebas ke i dan ke j
4.11.4.Prosedur Eliminasi Langkah Mundur (The Backward Elimination)
Metode eliminasi langkah mundur lebih ekonomis dibandingkan dengan metode ‘semua kemungkinan regresi’ dalam pengertian bahwa metode ini mencoba memeriksa hanya regresi terbaik yang mengandung sejumlah tertentu peubah primal. Langkah-langkah pokok dalam prosedur ini adalah sebagai berikut:
b. Menghitung nilai-F parsial untuk setiap peubah peramal, seolah-olah ia merupakan peubah terakhir yang dimasukan ke dalam persamaan regresi. c. Membandingkan nilai-F parsial terendah, misalnya FL, dengan nilai-F
bertaraf nyata dari tabel, misalnya F0. Jika FL < F0, dibuang peubah ZL, yang menghasilkan FL dari persamaan regresi dan kemudian hitung kembali persamaan regresi tanpa menyertakan peubah tersebut; selanjutnya kembali ke langkah (b). Sedangkan jika FL > F0 ambilah persamaan regresi itu.
4.11.4.Prosedur Regresi Bertatar (The Stepwise Reggression Procedure)
Prosedur regresi Stepwise adalah salah satu metode untuk mendapatkan model terbaik dari sebuah analisis regresi. Secara definisi adalah gabungan antara metode forward dan backward, variabel yang pertama kali masuk adalah variabel yang korelasinya tertinggi dan signifikan dengan variabel dependen, variabel yang masuk kedua adalah variabel yang korelasi parsialnya tertinggi dan masih signifikan, setelah variabel tertentu masuk ke dalam model maka variabel lain yang ada di dalam model dievaluasi, jika ada variabel yang tidak signifikan maka variabel tersebut dikeluarkan.
4.11.5.Metode PRESS (Prediction Sum of Square)
Metode PRESS (Prediction Sum of Square) merupakan bentuk cross-validasi yang digunakan dalam analisis regresi untuk memberikan ukuran ringkasan fit dari model untuk sampel pengamatan yang sendiri tidak digunakan untuk
memperkirakan model. Hal ini dihitung sebagai jumlah kuadrat dari residual prediksi untuk pengamatan mereka. Penggunaan pengamatan dengan pengecualian pengamatan ke i untuk memprediksikan respons pengamatan ke i dan yi, selanjutnya selisih antara yi dengan prediksi dikuadratkan lalu jumlahkan untuk i = 1,2, ... , n (Allen,1974). Lambang PRESSP menyatakan bahwa model dengan p parameter yang digunakan. Adapun rumusnya yaitu:
Model yang baik adalah model yang menghasilkan PRESSP yang kecil dalam kelompok p parameter. Sesunggunya metode ini merupakan gabungan dari semua kombinasi yang mungkin, prediksi dan analisis sisa.
4.12. Validasi Model Regresi
a. Melakukan uji asumsi klasik
Uji asumsi klasik meliputi uji normalitas dengan mempertimbagkan hasil uji Kolmogorov Smirnov, uji autokorelasi dengan membertimbangkan nilai Durbin Watson (DW), uji heteroskedastisitas dengan melakukan uji glesjer, serta uji multikolinieritas dengan menghitung nilai Variance Inflating Factor (VIF).
b. Menerapkan model ini ke dalam sampel lainnya.
Sampel lainnya di sini dapat diperoleh dari sampel baru atau sampel yang diambil sebagai bagian dari sampel terdahulu. Jika data-data baru sukar untuk diperoleh, peneliti dapat menggunakan data awal dengan membagi dua data tersebut secara random. Dengan demikian, sebelum analisis regresi dilakukan akan terdapat dua set data. Set data pertama digunakan untuk membangun model, sedangkan set data kedua digunakan untuk menguji validitas model.
c. Membandingkan beberapa model regresi
Cara ini dilakukan dengan membandingkan suatu model regresi terhadap model-model regresi lainnya dengan jumlah variabel independen dan atau ukuran sampel yang berbeda. Perbandingan dilakukan berdasarkan nilai adjusted R2.
4.13. Interpretasi Model Regresi
V. PEMBAHASAN
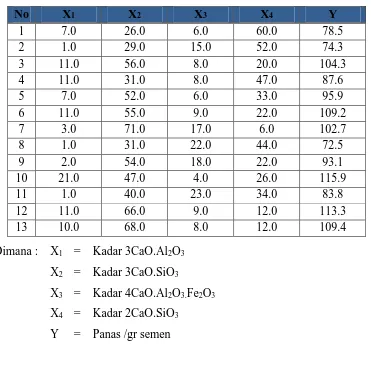
Dalam penelitian ini, data yang digunakan adalah data Apendiks B, yang berasal dari buku A. Hald Statistical Theory with Engineering Application yang diterbitkan oleh Wiley, New York, Pada 1952. Dimana data tersebut bertujuan untuk meneliti pengaruh beberapa senyawa kimia terhadap tingkat panas semen per gram. Data tersebut memiliki empat peubah peramal (X1, X2, X3 dan X4). Masalah ini terutama dipilih karena mengilustrasikan beberapa kesulitan tipikal yang biasanya terjadi dalam masalah regresi. Oleh karenanya, pada bagian pembahasan ini, penulis akan menjabarkan bagaimana menentukan model regresi terbaik dari data yang ada dengan menggunakan beberapa metode pemilihan model regresi terbaik. Beberapa metode yang digunakan yaitu All Possible Regression, Best Subset Regression dan Sequensial Regression. Data Apendiks B termuat pada
Tabel 4.1 berikut:
Tabel 4.1 Data Penelitian Apendiks B
5.1. Semua Kemungkinan Regresi (All Possible Regression)
Metode ini mengharuskan pengecekan kombinasi peubah yang dapat dibuat. Pemilihan model regresi terbaik dengan metode All Possible Regression, tidak mungkin dilakukan tanpa bantuan komputer. Karena untuk dapat mengambil kesimpulan terhadap pemilihan model terbaik baru bisa dilakukan ketika kriteria-kriteria pada metode All Possible Regression sudah diperoleh nilainya. Dalam menilai kebaikan suatu kombinasi atau peubah bebas biasanya sering menggunakan kriteria R2 yang disesuaikan (̅ , kuadrat tengah galat (s2) dan Cp dari Mallows. Setelah nilai dari setiap kriteria sudah didapatkan, penentuan model terbaik diperoleh dengan cara melakukan evaluasi seluruh kemungkinan model. Pilih model terbaik diantara semua kemungkinan berdasarkan berbagai suatu kriteria tertentu. Berdasarkan data tabel 4.1, nilai kriteria dari setiap peubah terlihat seperti
Tabel 4.2 berikut:
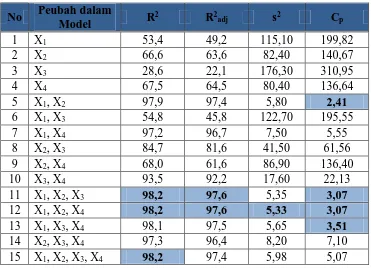
Tabel 4.2 Kriteria All Possible Regression
No Peubah dalam dalam model. Untuk menentukan peubah mana yang masuk model, maka dilakukan evaluasi dari seluruh kemungkinan. Untuk menentukan peubah yang masuk pada model berdasarkan kriteria R2 dan R2adj ditentukan dengan mencari nilai R2 dan R2
terbesar dari seluruh observasi. Sedangkan untuk menentukan peubah yang masuk model berdasarkan kriteria s2 dan Cp ditentukan dengan cara mencari nilai s2 dan Cp terkecil dari observasi yang ada. Pada tabel 4.2 dapat disimpulkan bahwa X1, X2,
dan X4 adalah peubah-peubah yang masuk model berdasarkan metode All Possible Regression. Jadi, model terbaik dari data Apendiks B nantinya adalah model yang
mengandung peubah X1, X2, dan X4. Secara umum, analisis All Possible Regression sangat tidak dianjurkan. Karena harus memeriksa semua kemungkinan. Hal tersebut memerlukan waktu dan tenaga yang cukup banyak. Oleh sebab itu, penggunaan metode ini jarang dilakukan dalam memilih model regresi terbaik.
5.2. Regresi “Himpunan Bagian Terbaik” (Best Subset Regression)
Pemilihan model regresi terbaik dengan menggunakan metode Best Subset Regression biasanya berdasarkan 3 (tiga) kriteria, yaitu nilai R2 maksimum, nilai R2 terkoreksi maksimum dan statistik Cp-Mallows. Untuk menentukan himpunan mana yang termasuk pada model terbaik dapat dilakukan dengan menggunakan data yang diperoleh pada metode All Possible Regression, kemudian tentukan peubah yang masuk kriteria berdasarkan banyaknya peubah dalam model seperti
Tabel 4.3 berikut:
Tabel 4.3 Kriteria Best Subset Regression
Banyak Peubah
Tabel 4.3 diatas. Seperti halnya memilih persamaan regresi terbaik dengan
menggunakan metode All Possible Regression, untuk menentukan peubah yang masuk pada model berdasarkan kriteria R2 dan R2adj ditentukan dengan mencari nilai R2 dan R2
adjterbesar dari seluruh observasi. Sedangkan untuk menentukan peubah yang masuk model berdasarkan kriteria s2 dan Cp ditentukan dengan cara mencari nilai s2 dan Cp terkecil dari observasi yang ada. Pada Tabel 4.3 dapat disimpulkan bahwa ada 3 (tiga) peubah yang akan masuk model yaitu X1, X2, dan X4 berdasarkan metode Best Subset Regression.
5.3. Metode Sekuesial
Metode sekuesial pada memilihan model regresi terbaik memuat 3 (tiga) prosedur didalamnya. Ketiga prosedur sekuesial yang dimaksud yaitu prosedur eliminasi langkah maju (The Backward Elimination Procedure), prosedur eliminasi langkah mundur (The Forward Elimination Procedure), dan prosedur regresi bertatar (The Stepwise Regression Procedure).
5.3.1. Prosedur Eliminasi Langkah Mundur (The Backward Elimination)
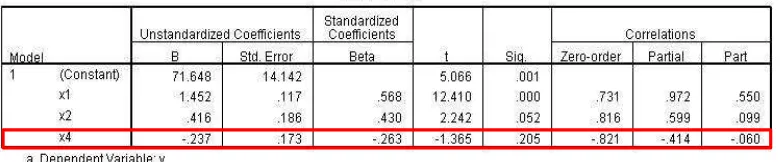
Metode Backward bekerja dengan mengeluarkan satu per satu variabel prediktor yang tidak signifikan dan dilakukan terus menerus sampai tidak ada variabel prediktor yang tidak signifikan. Untuk menentukan persamaan model terbaik dari data Apendiks B, peneliti mengujinya menggunakan metode Enter pada SPSS yang bertujuan agar dapat diketahui proses pemilihan variabel peubah mana saja yang masuk pada model regresi secara satu per satu. Variabel bebas yang memiliki nilai sigifikansi terbesar dan koefisien korelasi parsial terkecil akan diuji pertama kali apakah akan dieliminasi atau tetap dipertahankan di dalam model.
Gambar 4.1 Nilai Coefficients X1, X2, X3 dan X4
model adalah X1, X2, dan X4. Kemudian dilakukan analisis regresi tanpa menambahkan X3. Sehingga diperoleh tabel anova X1, X2, dan X4 berikut:
Gambar 4.2 Tabel Anova X1, X2, dan X4
Hipotesis model regresi X1, X2, dan X4:
1. Hipotesis = H0: β0 = β1 = β2= β4 = 0 (model tidak signifikan)
H1 : Ada minimal satu i dimana βi ≠ 0 , i = 1,2,4 (model signifikan)
2. Tingkat Signifikasi = 95% atau α = 0.05
3. Daerah Kritis = Tolak H0 jika sig.≤ α atau [Fhitung > Ftabel] 4. Statistik Uji = Fhitung = 166.832 > Ftabel = 3.86
Sig. (2-tiled) [0.000] < α (0.05)
5. Keputusan = Karena nilai Fhitung > Ftabel dan olak H0 sig. < 0.05 maka keputusan tolak H0
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa model regresi Y terhadap X1, X2 dan X3 signifikan.
Hipotesis anova X1, X2, dan X4 menunjukan bahwa model yang terdiri dari variabel bebas X1, X2, dan X4 merupakan model yang signifikan. Namun karena masih terdapat variabel yang memiliki nilai signifikansi terbesar diantara variabel bebas yang lain maka pemilihan model terbaik masih harus dilanjutkan. Nilai coefficients dari X1, X2, dan X4 terlihat seperti Gambar 4.3 berikut:
Setelah X1, X2, dan X4 dilakukan analisis regresi, nilai coefficient-nya mengalami perubahan seperti yang terlihat pada Gambar 4.3. Berdasarkan
Gambar 4.3 ternyata masih terdapat variabel bebas yang memiliki korelasi parsial
yang kecil, yaitu X4. Karena X4 memiliki korelasi terkecil dan nilai signifikansi terbesar maka X4 dieliminasi dari model regresi. Untuk melihat apakah apakah variabel X1 dan X2 signifikan maka dilakukan hipotesis berdasarkan tabel anova berikut:
Gambar 4.4 Tabel Anova X1, dan X2
Hipotesis model regresi X1, dan X2 :
1. Hipotesis = H0: β0 = β1 = β2 = 0 (model tidak signifikan) H1: Ada minimal satu i dimana βi ≠ 0
i = 1,2 (model signifikan) 2. Tingkat Signifikasi = 95% atau α = 0.05
3. Daerah Kritis = Tolak H0 jika sig.≤ α atau [Fhitung > Ftabel] 4. Statistik Uji = Fhitung = 229.504 > Ftabel = 4.10
Sig. (2-tiled) [0.000] < α (0.05)
5. Keputusan = Karena nilai Fhitung > Ftabel dan olak H0 sig. < 0.05 maka keputusan tolak H0
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa model regresi Y terhadap X1 dan X2 signifikan.
Nilai coefficient yang terbentuk setelah dilakukan analisis regresi Y terhadap X1 dan X2, maka diperoleh hasil analisis seperti Gambar 4.5 berikut:
Uji Konstanta β0berdasarkan nilai Coefficient :
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa konstanta model regresi adalah signifikan.
Uji Koefisien β1berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β1 = 0 (koefisien X1 tidak signifikan)
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa koefisien regresi X1 adalah signifikan.
Uji Koefisien β2berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β2 = 0 (koefisien X2 tidak signifikan)
Setelah X3 dan X4 dikeluarkan dari model regresi, ternyata model menjadi signifikan ketika model regresi hanya terdiri dari variabel bebas X1 dan X2, dengan demikian model regresi terbaik yang diperoleh dengan Backward Elimination Procedure adalah sebagai berikut:
̂ = . + . + .
Nilai konstanta sebesar 52.577. Hal ini berarti bahwa jika jumlah kadar 3CaO.Al2O3 (X1) dan jumlah kadar 3CaO.SiO2 (X2) tetap atau tidak mengalami penambahan atau pengurangan, maka panas semen per gram (Y) memiliki nilai sebesar 52.577. Nilai koefisien jumlah kadar 3CaO.Al2O3 (X1) sebesar 1.468. Hal ini mengandung arti bahwa setiap kenaikan panas semen per gram (Y) akan naik sebesar 1.468 dengan asumsi bahwa variabel bebas yang lain dari model regresi adalah tetap. Begitu halnya dengan nilai koefisien jumlah kadar 3CaO.SiO2 (X2) sebesar 0.662. Hal ini mengandung arti bahwa setiap kenaikan panas semen per gram (Y) akan naik sebesar 0.662 dengan asumsi bahwa variabel bebas yang lain dari model regresi adalah tetap.
5.3.2. Prosedur Eliminasi Langkah Maju (Forward Elimination Procedure)
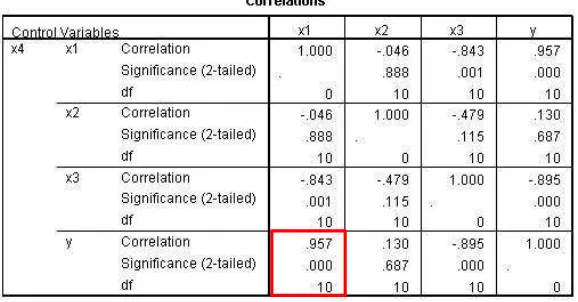
Kebalikan dari metode Backward Elimination Procedure, metode Forward adalah pemodelan dimulai dari nol peubah (empty model), kemudian satu persatu peubah dimasukan sampai kriteria tertentu terpenuhi. Untuk menentukan variabel mana yang akan masuk pertama pada model, maka diuji korelasinya terlebih dahulu. Hasil uji korelasi X1, X2, X3, dan X4 terlihat seperti gambar berikut:
Dari hasil analisis korelasi diatas diketahui bahwa variabel bebas yang mempunyai korelasi paling besar dengan variabel dependen adalah X4, maka X4 akan di regresikan dengan Y untuk menentukan apakah masuk dalam model atau tidak. Hasil uji regresi terlihat sebagai berikut:
Gambar 4.7 Tabel Anova dan Nilai Coefficient X4 terhadap Y
Hipotesis model regresi X4 berdasarkan tabel Anova :
1. Hipotesis = H0 : β4 = 0 (model tidak signifikan) Hi : β4 ≠ 0 (model signifikan) 2. Tingkat Signifikasi = 95% atau α = 0.05
3. Daerah Kritis = Tolak H0 jika sig.≤ α atau [Fhitung > Ftabel] 4. Statistik Uji = Fhitung = 22.799 > Ftabel = 4.92
Sig. (2-tiled) [0.010] < α (0.05)
5. Keputusan = Karena nilai Fhitung > Ftabel dan tolak H0 sig. < 0.05 maka keputusan tolak H0
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa model regresi Y terhadap X4 signifikan, maka X4 masuk dalam model.
Uji Konstanta β0berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β0 = 0 (konstanta tidak signifikan) H1 : β0 ≠ 0 (konstanta signifikan) 2. Tingkat Signifikasi = 95% atau α = 5%
4. Statistik Uji = Sig. (2-tiled) [0.000] < α (0.05)
5. Keputusan = Karena nilai sig. < 0.05 maka tolak H0
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa konstanta model regresi adalah signifikan.
Uji Koefisien β4berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β4 = 0 (koefisien X4 tidak signifikan) H1 : β4 ≠ 0 (koefisien X4 signifikan) 2. Tingkat Signifikasi = 95% atau α = 5%
3. Daerah Kritis = Tolak H0 jika sig.(2-tiled) ≤ α 4. Statistik Uji = Sig. (2-tiled) [0.001] < α (0.05)
5. Keputusan = Karena nilai sig. < 0.05 maka tolak H0
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa koefisien regresi X4 adalah signifikan.
Kemudian proses pemilihan model regresi terbaik dari data Apendiks B dilanjutkan dengan menguji korelasi dengan X4 sebagai variabel kontrol. Hasil uji korelasinya dalah sebagai berikut:
Gambar 4.8 Nilai Korelasi X1, X2, X3 terhadap X4
Gambar 4.9 Tabel Anova dan Nilai Coefficient X1 dan X4 terhadap Y
Hipotesis model regresi X1 dan X4 berdasarkan tabel Anova:
1. Hipotesis = H0 : βi = 0 (model tidak signifikan) Hi : Ada minimal satu i dimana βi ≠ 0 i = 1,4 (model signifikan)
2. Tingkat Signifikasi = 95% atau α = 0.05
3. Daerah Kritis = Tolak H0 jika sig.≤ α atau [Fhitung > Ftabel] 4. Statistik Uji = Fhitung = 176.672 > Ftabel = 4.10
Sig. (2-tiled) [0.010] < α (0.05)
5. Keputusan = Karena nilai Fhitung > Ftabel dan tolak H0 sig. < 0.05 maka keputusan tolak H0
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa model regresi Y terhadap X1 dan X4 signifikan, maka X1 dan X4 masuk dalam model.
Uji Konstanta β0berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β0 = 0 (konstanta tidak signifikan) H1 : β0 ≠ 0 (konstanta signifikan) 2. Tingkat Signifikasi = 95% atau α = 5%
5. Keputusan = Karena nilai sig. < 0.05 maka tolak H0
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa konstanta model regresi adalah signifikan.
Uji Koefisien β1berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β1 = 0 (koefisien X1 tidak signifikan)
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa koefisien regresi X1 adalah signifikan.
Uji Koefisien β4 berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β4 = 0 (koefisien X2 tidak signifikan)
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa koefisien regresi X4 adalah signifikan.
Gambar 4.10 Nilai Korelasi X2, X3 terhadap X4 dan X1
Dengan memperhatikan korelasi diatas, maka X2 akan masuk pada pengujian selanjutnya karena X2 memiliki korelasi terbesar jika dibandingkan dengan X3. Berikut hasil pengujian regresi Y terhadap X1, X2 dan X4 :
Gambar 4.11 Hasil Analisis Regresi Y terhadap X1, X2, dan X4
Hipotesis model regresi X1, X2 dan X4 berdasarkan tabel Anova :
1. Hipotesis = H0: βi = 0 (model tidak signifikan) Hi: Ada minimal satu i dimana βi ≠ 0 i = 1,2,4 (model signifikan)
2. Tingkat Signifikasi = 95% atau α = 0.05
3. Daerah Kritis = Tolak H0 jika sig.≤ α atau [Fhitung > Ftabel] 4. Statistik Uji = Fhitung = 166.832 > Ftabel = 3.86
Sig. (2-tiled) [0.010] < α (0.05)
5. Keputusan = Karena nilai Fhitung > Ftabel dan tolak H0 sig. < 0.05 maka keputusan tolak H0
X2 dan X4 signifikan, maka X1, X2 dan X4 masuk dalam model.
Setelah X1, X2, dan X4 dilakukan analisis regresi, nilai coefficient-nya mengalami perubahan seperti yang terlihat pada Gambar 4.11. Untuk mengetahui koefisien X1, X2, dan X4 signifikan terhadap model maka dilakukan analisis berikut:
Uji Konstanta β0berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β0 = 0 (konstanta tidak signifikan)
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa konstanta model regresi adalah signifikan.
Uji Koefisien β1berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β1 = 0 (koefisien X1 tidak signifikan)
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa koefisien regresi X1 adalah signifikan.
Uji Koefisien β2berdasarkan nilai Coefficient :
2. Tingkat Signifikasi = 95% atau α = 5%
3. Daerah Kritis = Tolak H0 jika sig.(2-tiled) ≤ α Gagal tolak H0 jika sig.(2-tiled)> α 4. Statistik Uji = Sig. (2-tiled) [0.052] > α (0.05)
5. Keputusan = Karena nilai sig. > 0.05 maka gagal tolak H0 6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan
kesimpulan bahwa koefisien regresi X2 adalah tidak signifikan.
Uji Koefisien β4berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β4 = 0 (konstanta tidak signifikan)
5. Keputusan = Karena nilai sig. > 0.05 maka gagal tolak H0 6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan
kesimpulan bahwa koefisien regresi X4 adalah tidak signifikan.
Dengan hasil diatas terlihat ketika X2 masuk pada model regresi, nilai koefisien menjadi berubah dan membuat koefisien yang telah masuk sebelumnya menjadi tidak signifikan. Oleh sebab itu maka proses terhenti, sehingga tidak perlu dilanjutkan untuk penguji variabel X3. Jadi model terbaik dari data Apendiks B menurut metode Forward Regression adalah
̂ = . + . + . − .
per gram (Y) akan naik sebesar 1.452 dengan asumsi bahwa variabel bebas yang lain dari model regresi adalah tetap. Begitu halnya dengan nilai koefisien jumlah kadar 3CaO.SiO2 (X2) sebesar 0.416. Hal ini mengandung arti bahwa setiap kenaikan panas semen per gram (Y) akan naik sebesar 0.416 dengan asumsi bahwa variabel bebas yang lain dari model regresi adalah tetap. Sedangkan nilai koefisien untuk jumlah kadar 2CaO.SiO2 (X4) sebesar 0.237 dan bernilai negatif, hal ini menunjukan bahwa jumlah kadar 2CaO.SiO2 (X4) mempunyai hubungan yang berlawanan arah dengan variabel panas semen per gram (Y). Koefisien jumlah kadar 2CaO.SiO2 (X4) berarti bahwa setiap kenaikan panas semen per gram (Y) akan turun sebesar 0.237 dengan asumsi bahwa variabel bebas yang lain dari model regresi adalah tetap (konstan).
5.3.3. Prosedur Regresi Bertatar (The Stepwise Regression Procedure)
Stepwise Regression Procedure dimulai dengan memasukan variabel bebas
yang mempunyai korelasi paling kuat dengan variabel dependen. Kemudian setiap kali pemasukan variabel bebas yang lain, dilakukan pengujian untuk tetap memasukan variabel bebas atau mengeluarkannya. Korelasi dari variabel dependen dan independen adalah sebagai berikut:
Gambar 4.12 Korelasi X1, X2, X3 dan X4
Gambar 4.13 Nilai Regresi X4 terhadap Y
Hipotesis model regresi X4 berdasarkan tabel Anova :
1. Hipotesis = H0 : β4 = 0 (model tidak signifikan) H1 : β4 ≠ 0 (model signifikan) 2. Tingkat Signifikasi = 95% atau α = 0.05
3. Daerah Kritis = Tolak H0 jika sig.≤ α atau [Fhitung > Ftabel] 4. Statistik Uji = Fhitung = 22.799 > Ftabel = 4.75
Sig. (2-tiled) [0.001] < α (0.05)
5. Keputusan = Karena nilai Fhitung > Ftabel dan olak H0 sig. < 0.05 maka keputusan tolak H0
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa model regresi X4 terhadap Y signifikan, maka X4 masuk dalam model.
Setelah dinyatakan bahwa variabel X4 masuk pada model regresi, kemudian proses pemilihan model regresi terbaik dari data Apendiks B dilanjutkan dengan menguji korelasi X1, X2, X3 dan Y dengan X4 sebagai variabel kontrol. Hasil /uji korelasinya dalah sebagai berikut:
Berdasarkan hasil korelasi parsial diatas, variabel yang masuk kedua adalah variabel X1, karena korelasi parsialnya tertinggi dan signifikan terhadap Y, X1 dan X4 yang masuk pada model kemudian diregresikan terhadap Y. Hasil regresi X1 dan X2 adalah sebagai berikut:
Gambar 4.15 Hasil Regresi X1, X4 terhadap Y
Hipotesis model regresi X1, X4 berdasarkan tabel Anova :
1. Hipotesis = H0: βi = 0 (model tidak signifikan) Hi : Ada minimal satu i dimana βi ≠ 0 i = 1,4 (model signifikan)
2. Tingkat Signifikasi = 95% atau α = 0.05
3. Daerah Kritis = Tolak H0 jika sig.≤ α atau [Fhitung > Ftabel] 4. Statistik Uji = Fhitung = 176.627 > Ftabel = 4.10
Sig. (2-tiled) [0.000] < α (0.05)
5. Keputusan = Karena nilai Fhitung > Ftabel dan tolak H0 sig. < 0.05 maka keputusan tolak H0
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa model regresi X1 dan X4 terhadap Ysignifikan, maka X1 dan X4 masuk dalam model.
Gambar 4.16 Nilai Korelasi Parsial X2, X3, Y
Hasil korelasi parsial X2 dan X3 dengan variabel kontrol X4 dan X1 mem- perlihatkan bahwa korelasi X2 lebih besar dari X3. Sehingga X2 akan diuji regresi bersama X1, X4 terhadap Y. Hasil regresinya adalah sebagai berikut:
Gambar 4.17 Hasil Regresi X1, X2 dan X4 terhadap Y
Hipotesis model regresi X1, X2 dan X4 berdasarkan tabel Anova :
1. Hipotesis = H0: βi = 0 (model tidak signifikan) Hi: Ada minimal satu i dimana βi ≠ 0 i = 1,2,4 (model signifikan)
2. Tingkat Signifikasi = 95% atau α = 0.05
3. Daerah Kritis = Tolak H0 jika sig.≤ α atau [Fhitung > Ftabel] 4. Statistik Uji = Fhitung = 166.832 > Ftabel = 3.86
Sig. (2-tiled) [0.000] < α (0.05)
5. Keputusan = Karena nilai Fhitung > Ftabel dan tolak H0 sig. < 0.05 maka keputusan tolak H0
Uji Konstanta β0berdasarkan nilai Coefficient :
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa konstanta model regresi adalah signifikan.
Uji Konstanta β1berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β1 = 0 (koefisien X1 tidak signifikan)
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa koefisien regresi X1 adalah signifikan.
Uji Konstanta β2 berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β2 = 0 (koefisien X2 tidak signifikan)
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa koefisien regresi X2 adalah tidak signifikan.
Uji Konstanta β4 berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β4 = 0 (konstanta tidak signifikan) H1 : β4 ≠ 0 (konstanta signifikan) 2. Tingkat Signifikasi = 95% atau α = 5%
3. Daerah Kritis = Tolak H0 jika sig.(2-tiled) ≤ α Gagal tolak H0 jika sig.(2-tiled)> α 4. Statistik Uji = Sig. (2-tiled) [0.205] > α (0.05)
5. Keputusan = Karena nilai sig. > 0.05 maka gagal tolak H0 6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan
kesimpulan bahwa koefisien regresi X4 adalah tidak signifikan.
Dari hasil hipotesis diatas, dapat disimpulkan bahwa ketika X2 masuk pada model, maka koefisien X2 dan X4. Menjadi tidak signifikan. Maka diantara kedua variabel tersebut harus dikeluarkan dari model. Untuk menentukan variabel mana yang akan keluar model dapat dilihat dari nilai signifikansi dan korelasi parsialnya. Variabel yang dikeluarkan dari model adalah variabel yang memiliki tingkat signifikansi terbesar dan memiliki korelasi parsial terkecil. Dari kedua variabel tersebut, X4 memiliki nilai sigifikansi terbesar dan korelasi parsial terkecil, maka X4 dikeluarkan dari model. Kemudian variabel yang tersisa yaitu X1 dan X2 di regresikan lagi terhadap Y sehingga diperoleh hasil berikut:
Hipotesis model regresi X1, dan X2 berdasarkan tabel Anova :
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa model regresi X1 dan X4 terhadap Ysignifikan, maka X1 dan X4 masuk dalam model.
Uji Konstanta β0berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β0 = 0 (konstanta tidak signifikan)
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa konstanta model regresi adalah signifikan.
Uji Konstanta β1berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β1 = 0 (koefisien X1 tidak signifikan) H1 : β1 ≠ 0 (koefisien X1 signifikan) 2. Tingkat Signifikasi = 95% atau α = 5%
5. Keputusan = Karena nilai sig. < 0.05 maka tolak H0
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa koefisien regresi X1 adalah signifikan.
Uji Konstanta β2berdasarkan nilai Coefficient :
1. Hipotesis = H0 : β2 = 0 (koefisien X2 tidak signifikan)
6. Kesimpulan = Jadi, dengan nilai signifikansi 0.05 didapatkan kesimpulan bahwa koefisien regresi X2 adalah signifikan.
Setelah X4 dikeluarkan dari model regresi, ternyata model menjadi signifikan ketika model regresi hanya terdiri dari variabel bebas X1 dan X2. Karena X4 tidak signifikan, maka proses pemilihan model terbaik regresi tidak perlu dilanjutkan untuk menguji variabel X3, dengan demikian model regresi terbaik yang diperoleh dengan Backward Elimination Procedure adalah sebagai berikut:
̂ = . + . + .
Setelah model terbaik dari data Apendiks B diperoleh. Langkah selanjutnya dilakukan validasi model yang diperoleh dengan melakukan uji asumsi. Uji asumsi merupakan persyaratan yang harus dipenuhi dalam analisis regresi linier berganda yang berbasis ordinary least square (OLS). Tujuan pengujian asumsi klasik adalah untuk memberikan kepastian atau validasi bahwa persamaan regresi yang didapat-kan memiliki ketepatan dalam estimasi, tidak bias dan konsisten. Perlu diketahui, terdapat kemungkinan data aktual tidak memenuhi semua asumsi klasik ini. Beberapa perbaikan, baik pengecekan kembali data outlier maupun recollecterror data dapat dilakukan. Uji asumsi klasik meliputi uji multikolinearitas, uji autokorelasi, uji heteroskedastisitas, dan uji normalitas.
a. Uji Asumsi Multikolinieritas
Tujuan digunakannya uji multikolinieritas adalah untuk menguji apakah pada model regresi ditemukan adanya korelasi antar variabel independen. Jika terdapat atau terjadi korelasi, maka dinamakan terdapat problem multikolinieritas (multiko). Model regresi yang baik seharusnya tidak terjadi korelasi di antara variabel independen. Dari data Apendiks B yang menganalisa pengaruh beberapa senyawa kimia terhadap tingkat panas semen per gram, analisis uji asumsi multi-kolinearitasnya adalah sebagai berikut:
Gambar 4.19 Hasil Coefficients
Coefficients menunjukkan angka 1.055. Dengan demikian dapat disimpulkan bahwa model pada penelitian ini memenuhi syarat untuk menjadi model regresi yang baik karena tidak terjadi korelasi antar variabel independen.
b. Uji Asumsi Autokorelasi
Uji autokorelasi bertujuan untuk menguji apakah dalam model regresi linear ada korelasi antara kesalahan pengganggu pada periode t dengan kesalahan pengganggu pada periode sebelumnya (t-1). Jika terjadi korelasi, maka dinamakan ada problem autokorelasi. Analisisnya adalah sebagai berikut:
Gambar 4.20 Hasil Coefficients
Data Apendiks B sebanyak 13 sampel untuk setiap variabel (n) dengan 2 variabel independen (k) yang masuk kedalam model, maka diperoleh hipotesis berikut:
1. Hipotesis = Ho : Tidak terdapat autokorelasi Hi : Terdapat autokorelasi 2. Tingkat Signifikasi = 95% atau α = 5%
3. Daerah Kritis = Tolak H0 jika 0 < DW <d1 atau 4 – dl < DW < 4 Terima H0 jika du < DW < 4 - du
Tidak ada keputusan jika 0 < DW <du atau 4 – du < DW < 4 - dl
4. Statistik Uji = du < DW < 4 - du
1.5621 < 1.922 < 2.4379 --- Terima H0 5. Keputusan = Terima H0
c. Uji Asumsi Normalitas
Uji ini bertujuan untuk menguji apakah dalam sebuah model regresi, variabel independen, variabel dependen, atau keduanya mempunyai distribusi normal atau tidak. Suatu model regresi yang baik adalah yang memiliki distribusi data normal atau mendekati normal. Secara eksplorasi, pemeriksaan terhadap asumsi kenormalan dapat dilakukan dengan histogram maupun plot normal. Jika kurva normal setangkup atau plot normal mendekati garis lurus, maka sisaan menyebar normal, seperti gambar berikut:
Gambar 4.21 Grafik Histogram dari Data Apendiks B
Gambar 4.22 Grafik P-Plot dari Data Apendiks B
Dengan melihat tampilan grafik Histogram maupun grafik Normal P-Plot of Regression Standardized Residual dapat disimpulkan bahwa grafik histogram
regresi yang baik karena merupakan model regresi yang memiliki distribusi data normal atau mendekati normal. Pengujian lain yang dapat dilakukan yaitu dengan uji Kolmogorov Smirnov, berikut adalah hasil pengujian Kolmogorov Smirnov terlihat seperti gambar berikut:
Gambar 4.23 Hasil Uji Kolmogorov Smirnov
Berdasarkan Gambar 4.23 hasil uji kolmogorov Smirnov maka diperoleh hipotesis berikut:
1. Hipotesis = Ho : Sisaan menyebar normal Hi : Sisaan tidak menyebar normal 2. Tingkat Signifikasi = 95% atau α = 5%
3. Daerah Kritis = Tolak Ho jika sig.(2-tiled) ≤ α 4. Statistik Uji = sig.[0.335]> 0.05
5. Keputusan = Gagal Tolak H0
6. Kesimpulan = Dengan signifikansi 0.05 gagal tolak H0 karena nilai sig. [0.335] > 0.05 artinya sisaan dari model regresi menyebar normal.
d. Uji Asumsi Heteroskedastisitas
Gambar 4.24 Scatterplot dari Data Apendiks B
Dari grafik Scatterplot terlihat bahwa titik-titik menyebar secara acak. Uji asumsi heteroskedastisitas tidak hanya dapat dilakukan dengan melihat hasil Scatterplot, namun dapat dilakukan juga dengan uji Glejser. Hasil Coefficient baru
dari uji Glejser adalah sebagai berikut:
Gambar 4.25 Hasil Coefficients Baru
Uji Koefisien β1 berdasarkan nilai Coefficient :
1. Hipotesis = Ho : Terjadi heteroskedositas Hi : Tidak terjadi heteroskedositas 2. Tingkat Signifikasi = 95% atau α = 5%
3. Daerah Kritis = Tolak Ho jika sig.(2-tiled) ≤ α 4. Statistik Uji = Sig. (2-tiled) [0.811] > α (0.05) 5. Keputusan = Gagal tolak H0
6. Kesimpulan = Dengan signifikansi 0.05, terlihat bahwa nilai sig.X1 > α. Jadi dapat disimpulkan bahwa model regresi mengandung adanya heteroskedositas.
Uji Koefisien β2 berdasarkan nilai Coefficient :
2. Tingkat Signifikasi = 95% atau α = 5%
3. Daerah Kritis = Tolak Ho jika sig.(2-tiled) ≤ α 4. Statistik Uji = Sig. (2-tiled) [0.807] > α (0.05) 5. Keputusan = Gagal tolak H0
6. Kesimpulan = Dengan signifikansi 0.05, terlihat bahwa nilai sig.X2 > α. Jadi dapat disimpulkan bahwa model regresi mengandung adanya heteroskedositas.
Berdasarkan hasil validasi dengan menggunakan uji asumsi klasik, model terbaik untuk data Apendiks B adalah ̂ = . + . + . , dimana pada uji asumsi klasik diatas menyatakan bahwa persamaan tersebut tidak terdapat korelasi antar variabel independen (non multikolonieritas), tidak terdapat auto-korelasi, memenuhi asumsi normalitas sehingga sasaan dari regresi menyebar normal, namun pada persamaan regresi tersebut terjadi heteroskedastisitas.
VI. KESIMPULAN
Berdasarkan metode-metode yang telah diujikan untuk menentukan model regresi terbaik dari data Hald (Apendiks B), maka dapat disimpulkan bahwa model terbaik untuk data Hald adalah persamaan ̂ = . + . + . , persamaan ini diperoleh dengan menggunakan metode Backward Elimination dan metode Stepwise Procedure. Sedangkan jika pemilihan model regresi terbaik untuk data Hald menggunakan metode All Possible Regression, Best Subset Regression dan Forward Regression maka diperoleh persamaan ̂ = . + . +
. − . . Persamaan tersebut menjadi kemungkinan model kedua. Namun model ini tidak sebaik model yang pertama, karena pada model kedua terdapat koefisien regresi yang bernilai negatif (X4) memiliki hubungan yang berlawanan arah. Prosedur terbaik yang digunakan untuk data Hald adalah pemilihan model terbaik menggunakan metode Backward Elimination dan metode Stepwise Procedure, karena metode ini lebih efektif dan akurat dibandingkan
DAFTAR PUSTAKA
Draper, N. dan Smith, H.1985. Applied Regression Analysis, ed. 2. John Wiley & Sons, New York.
Sembiring, RK. 1995. Analisis Regresi Edisi Kedua. Bandung : ITB.
LOGBOOK KELOMPOK 4
orang, anggota yang lain berhalangan hadir. 2 Via Medsos(semua hadir)
Kegiatan :
- Mengkonfirmasi data yang akan digunakan dalam makalah.
- Pembagian kerja untuk mencari buku, jurnal atau sumber yang akan dijadikan referensi. 3 Via Medsos
(semua hadir)
Kegiatan :