BAB III PEMBAHASAN
A. Sumber Data
Sumber data diperoleh dari Koperasi X yang terdiri dari 3 file excel peminjam dengan jaminan sertifikat tanah, tunjuk, dan Buku Pemilik Kendaraan Bermotor (BPKB) serta 25 file excel laporan nominatif pinjaman perbulan dimana setiap file mewakili satu bulan. Data peminjam adalah data mengenai status peminjam, pendapatan keluarga, pengeluaran keluarga, usaha, tempat tinggal, agunan, dan info-info lain yang mencakup 5C yang digunakan sebagai pertimbangan pemberian kredit. Data laporan nominatif pinjaman perbulan adalah data mengenai besar pinjaman, sisa pinjaman, bunga, angsuran, kolektibilitas, dan info-info lain yang berkaitan dengan angsuran perbulan. Rentang waktu dari data peminjam adalah Januari 2011 - Maret 2016 dan rentang waktu pada data laporan nominatif pinjaman perbulan adalah Januari 2014 - Maret 2016. Daftar atribut pada kedua data dapat dilihat pada lampiran 1.
Data yang digunakan adalah data peminjam yang telah melunasi pinjaman dan peminjam yang bermasalah. Pengumpulan data dilakukan secara manual yaitu pada data laporan nominatif pinjaman perbulan dipilih data yang mempunyai nilai bakidebet 0 artinya peminjam telah melunasi pinjaman dan data yang mempunyai nilai kolektibilitas 2-4 artinya peminjam bermasalah dalam mengangsur pinjaman.
Hasil pemilihan pada data laporan nominatif pinjaman perbulan tersebut kemudian dihubungkan dengan file peminjam dengan primary key yaitu No.Anggota diperoleh sebanyak 1.076 dataset.
Pada data peminjam dan data laporan nominatif pinjaman perbulan tidak semua atribut digunakan. Atribut yang digunakan pada data peminjam adalah sebagai berikut:
a. No.Anggota digunakan sebagai primary key,
b. pekerjaan adalah pekerjaan peminjam ketika melakukan permohonan pinjaman,
c. No KTP adalah Nomer Kartu Tanda Kependudukan peminjam,
d. pekerjaan istri/suami adalah pekerjaan suami atau istri peminjam ketika melakukan permohonan pinjaman,
e. pendapatan keluarga adalah jumlah pendapatan peminjam ditambah dengan jumlah pendapatan suami atau istri peminjam,
f. pengeluaran keluarga adalah jumlah pengeluaran keluarga perbulan untuk memenuhi kebutuhan hidup,
g. pinjaman adalah besar pinjaman yang dilakukan,
h. kemampuan angsuran adalah kemampuan peminjam untuk mengangsur, i. jangka waktu adalah jumlah waktu untuk mengembalikan pinjaman, j. agunan adalah jaminan yang diberikan oleh peminjam,
k. status agunan adalah status kepemilikan jaminan,
l. nilai jaminan adalah besar nominal uang yang setara dengan jaminan, m. tujuan adalah tujuan digunakannya dana pinjaman,
n. tanggal peminjaman adalah tanggal dimana peminjam melakukan pinjaman.
Atribut yang digunakan pada data laporan nominatif pinjaman perbulan adalah sebagai berikut:
a. No.Anggota digunakan sebagai primary key,
b. kolektibilitas adalah status kelancaran peminjam dalam mengangsur pinjaman.
Atribut-atribut lain yang tidak digunakan adalah atribut yang telah terwakili oleh atribut yang digunakan, atribut yang tidak ada kaitannya dengan pengklasifikasian, atribut yang nilainya terlalu beragam, dan atribut yang sering tidak mempunyai isian, sehingga atribut tersebut tidak diperlukan pada penelitian ini. Contoh data yang telah dikumpulkan dapat dilihat pada lampiran 2. Setelah data lengkap maka tahap selanjutnya mempersiapkan data tersebut untuk proses data mining yaitu preprocessing yang terdiri dari Data Cleaning, Data Integration, Data Selection, Data Transformation.
B. Pembersihan Data (Data Cleaning) dan Integrasi Data (Data Integration) Preprocessing data yang dilakukan setelah data lengkap adalah pembersihan data. Masih adanya data yang tidak memiliki kelengkapan atribut dapat mengakibatkan hasil dari proses mining tidak baik atau memungkinkan adanya noise. Oleh karena itu perlunya preprocessing pembersihan data.
Pembersihan data dilakukan terhadap data yang tidak memiliki kelengkapan atribut dengan cara menghapus data tersebut.
Dari 1.076 dataset dilakukan penghapusan pada 97 dataset dengan rincian sebagai berikut:
1. Data yang tidak mempunyai kelengkapan atribut pekerjaan sebanyak 1.
2. Data yang tidak mempunyai kelengkapan atribut No KTP sebanyak 7.
3. Data yang tidak mempunyai kelengkapan atribut pekerjaan suami/istri sebanyak 54.
4. Data yang tidak mempunyai kelengkapan atribut pengeluaran keluarga sebanayak 1.
5. Data yang tidak mempunyai kelengkapan atribut kemampuan angsuran sebanyak 10.
6. Data yang tidak mempunyai kelengkapan atribut status agunan sebanyak 2.
7. Data yang tidak mempunyai kelengkapan atribut Nilai jaminan sebanyak 19.
8. Data yang tidak mempunyai kelengkapan atribut tujuan sebanyak 2.
9. Data yang tidak mempunyai kelengkapan atribut kolektibilitas sebanyak 1.
Setelah proses pembersihan data, jumlah data menjadi 979 dataset yang kemudian dilanjutkan dengan proses integrasi data.
Integrasi data pada penelitian ini dilakukan pada awal ketika pemilihan data- data yang diperlukan dan penghubungan data laporan nominatif pinjaman perbulan dengan data peminjam menggunakan primary key yaitu No.Anggota yang kemudian disimpan dalam satu file. Selain itu, integrasi data juga dilakukan dengan penggantian atribut No.KTP dan tanggal peminjaman menjadi atribut umur. Atribut umur tersebut dapat diidentifikasi melalui tahun peminjaman dikurangi dengan tahun lahir peminjam. Tahun lahir peminjam dapat diidentifikasi melalui karakter ke 6 dan 7 dari belakang pada No. KTP.
C. Seleksi Data (Data Selection) dan Transformasi Data (Data Transformation)
Seleksi data yang dilakukan adalah penghapusan atribut No.Anggota dan penghapusan atribut-atribut yang tidak digunakan dalam analisis seperti nama, alamat, nomer telepon, uraian usaha, dan lain-lain. Sehingga atribut-atribut yang digunakan untuk analisis klasifikasi adalah pekerjaan, umur, pekerjaan istri/suami, pendapatan keluarga, pengeluaran keluarga, pinjaman, kemampuan angsuran, jangka waktu, agunan, status agunan, nilai jaminan, tujuan, dan kolektibilitas.
Setelah dilakukan tahap pembersihan data, integrasi data, dan seleksi data, selanjutnya dilakukan tahap transformasi data. Transformasi data yang dilakukan pada penelitian ini adalah pengubahan tipe data ke dalam format yang sesuai sehingga siap untuk diproses menggunakan metode decision tree C4.5 dan naïve bayes.
Transformasi data dilakukan pada data yang bertipe numerik menjadi interval, diantaranya dilakukan pada beberapa atribut. Hasil transformasi dapat dilihat pada Tabel 3.1-3.7.
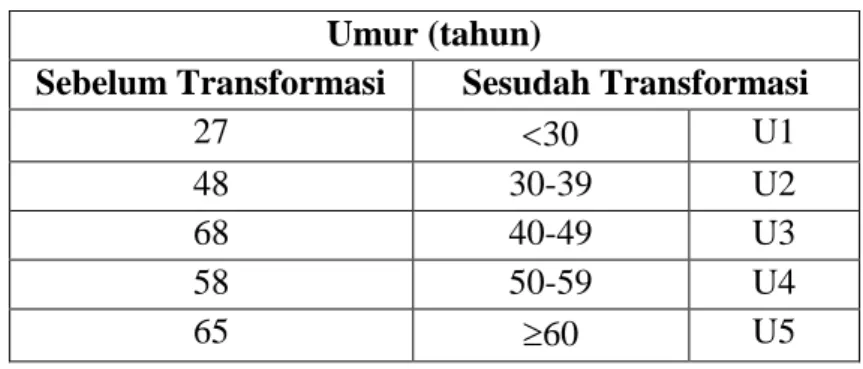
Tabel 3.1 Transformasi Atribut Umur Umur (tahun)
Sebelum Transformasi Sesudah Transformasi
27 30 U1
48 30-39 U2
68 40-49 U3
58 50-59 U4
65 60 U5
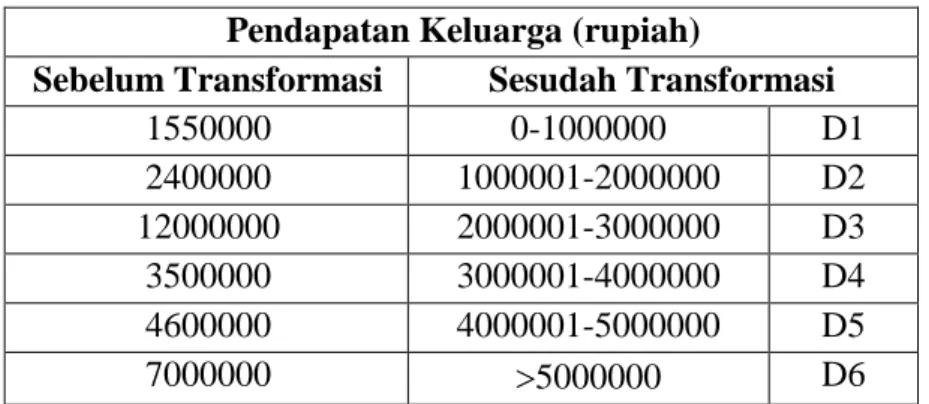
Tabel 3.2 Transformasi Atribut Pendapatan Keluarga Pendapatan Keluarga (rupiah)
Sebelum Transformasi Sesudah Transformasi
1550000 0-1000000 D1
2400000 1000001-2000000 D2
12000000 2000001-3000000 D3
3500000 3000001-4000000 D4
4600000 4000001-5000000 D5
7000000 5000000 D6
Tabel 3.3 Transformasi Atribut Pengeluaran Keluarga Pengeluaran Keluarga (rupiah)
Sebelum Transformasi Sesudah Transformasi
755000 0-1000000 K1
1260000 1000001-2000000 K2
2600000 2000001-3000000 K3
4000000 3000000 K4
Tabel 3.4 Transformasi Atribut Pinjaman Pinjaman (rupiah)
Sebelum Transformasi Sesudah Transformasi
1500000 0-2000000 PJ1
6000000 2000001-4000000 PJ2
8500000 4000001-6000000 PJ3
7000000 6000001-8000000 PJ4
8500000 >8000000 PJ5
Tabel 3.5 Transformasi Atribut Kemampuan Angsuran % Kemampuan angsur %
Sebelum Transformasi Sesudah Transformasi
40 0 – 40 KA1
50 41-60 KA2
80 60 KA3
Tabel 3.6 Transformasi Atribut Jangka Waktu Jangka Waktu (bulan)
Sebelum Transformasi Sesudah Transformasi
12 1-12 J1
24 13-24 J2
36 24 J3
Tabel 3.7 Transformasi Atribut Nilai Jaminan Nilai Jaminan (rupiah)
Sebelum Transformasi Sesudah Transformasi
4000000 0-5000000 N1
7000000 5000001-10000000 N2
12000000 10000001-15000000 N3
18000000 15000001-20000000 N4
30000000 20000000 N5
Transformasi juga dilakukan pada beberapa atribut yang mempunyai nilai atau isian dengan karakter terlalu panjang, maka untuk mempersingkat data ditransformasi menjadi beberapa inisial. Hasil transformasi dapat dilihat pada Tabel 3.8-3.13.
Tabel 3.8 Transformasi Atribut Pekerjaan Pekerjaan
Sebelum Transformasi Sesudah Transformasi
Wiraswasta PK1
Karyawan Swasta PK2
Petani/pedagang/tukang PK3
Buru PK4
PNS PK5
Tidak Bekerja PK6
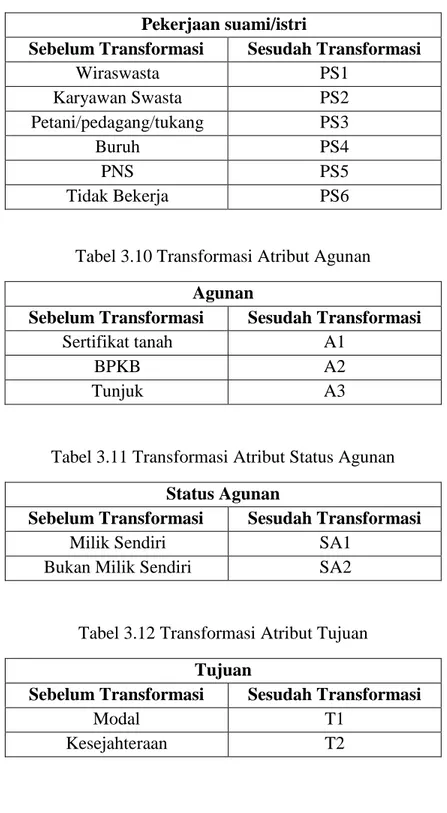
Tabel 3.9 Transformasi Atribut Pekerjaan Suami/Istri Pekerjaan suami/istri
Sebelum Transformasi Sesudah Transformasi
Wiraswasta PS1
Karyawan Swasta PS2
Petani/pedagang/tukang PS3
Buruh PS4
PNS PS5
Tidak Bekerja PS6
Tabel 3.10 Transformasi Atribut Agunan Agunan
Sebelum Transformasi Sesudah Transformasi
Sertifikat tanah A1
BPKB A2
Tunjuk A3
Tabel 3.11 Transformasi Atribut Status Agunan Status Agunan
Sebelum Transformasi Sesudah Transformasi
Milik Sendiri SA1
Bukan Milik Sendiri SA2
Tabel 3.12 Transformasi Atribut Tujuan Tujuan
Sebelum Transformasi Sesudah Transformasi
Modal T1
Kesejahteraan T2
Tabel 3.13 Transformasi Atribut Kolektibilitas Kolektibilitas
Sebelum Transformasi Sesudah Transformasi
1 Lancar KL1
2 Kurang Lancar KL2
3 Diragukan KL3
4 Macet KL4
Setelah data ditransformasikan dan dikelompokkan sesuai kriteria masing- masing maka dihasilkan data yang siap untuk diolah seperti yang disajikan pada Tabel 3.14.
Tabel 3.14 Contoh Data yang Telah Mengalami Preprocessing Pekerjaan Umur Pekerjaan
Suami/Istri
Pendapatan Keluarga
Pengeluaran
Keluarga Pinjaman Kemampuan Angsuran
Jangka
Waktu Agunan Status Agunan
Nilai
Jaminan Tujuan Kelas
PK1 U1 PS1 D2 K2 PJ2 KA1 J2 A1 SA2 N5 T1 KL3
PK1 U3 PS5 D6 K3 PJ5 KA2 J2 A1 SA1 N5 T1 KL1
PK1 U2 PS1 D4 K3 PJ3 KA2 J2 A2 SA1 N3 T1 KL1
PK2 U4 PS6 D4 K2 PJ2 KA1 J1 A2 SA1 N1 T1 KL3
PK3 U2 PS6 D2 K1 PJ5 KA2 J3 A3 SA1 N4 T2 KL1
PK4 U3 PS4 D2 K1 PJ1 KA3 J2 A3 SA2 N3 T1 KL1
PK6 U2 PS1 D4 K2 PJ4 KA2 J2 A1 SA1 N5 T1 KL1
PK4 U4 PS3 D2 K1 PJ2 KA1 J2 A1 SA1 N2 T2 KL1
PK4 U1 PS4 D2 K1 PJ2 KA2 J1 A3 SA1 N2 T1 KL1
PK4 U2 PS4 D2 K2 PJ3 KA3 J3 A1 SA2 N3 T2 KL4
PK4 U2 PS6 D2 K1 PJ2 KA2 J2 A1 SA2 N2 T1 KL1
PK2 U2 PS1 D3 K2 PJ2 KA2 J2 A3 SA1 N3 T1 KL1
PK3 U3 PS4 D2 K1 PJ1 KA3 J1 A3 SA1 N1 T2 KL3
PK3 U3 PS3 D3 K3 PJ1 KA2 J1 A3 SA1 N1 T1 KL3
PK2 U3 PS1 D4 K2 PJ5 KA3 J3 A1 SA1 N5 T2 KL1
PK4 U3 PS3 D2 K1 PJ3 KA3 J1 A1 SA1 N3 T2 KL4
PK2 U1 PS1 D4 K3 PJ3 KA3 J2 A2 SA1 N2 T1 KL1
PK5 U3 PS3 D2 K2 PJ1 KA2 J2 A3 SA1 N3 T1 KL1
PK5 U3 PS6 D6 K3 PJ5 KA3 J2 A2 SA1 N4 T1 KL3
D. Proses Klasifikasi Menggunakan Decision Tree C4.5
Setelah data ditransformasi, maka data siap diproses menggunakan metode decision tree (pohon keputusan). Langkah-langkah pembentukan pohon keputusan menggunakan algoritma C4.5 sebagai berikut:
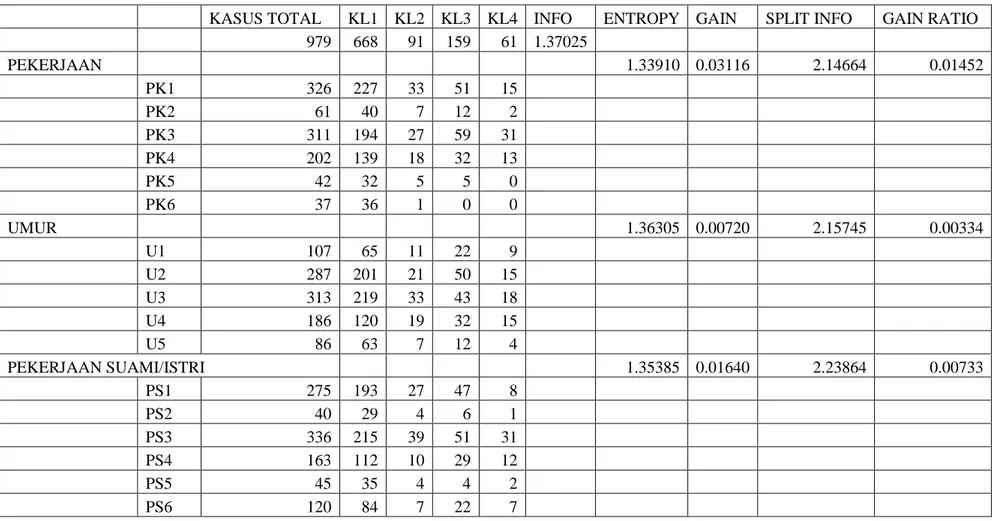
1. Tahap pertama adalah menentukan simpul akar yang dilakukan dengan menghitung total kasus untuk kelas KL1, KL2, KL3, dan KL4 serta gain ratio pada setiap atribut. Proses ini dilakukan sama pada setiap nilai atribut pekerjaan, umur, pekerjaan suami/istri, pendapaan keluarga, pengeluaran keluarga, pinjaman, kemampuan angsuran, jangka waktu, status agunan, tujuan, nilai jaminan. Hasil dari perhitungan dapat dilihat pada Tabel 3.15.
Berdasarkan Persamaan (2.1) nilai untuk kolom info pada Tabel 3.15 diperoleh dari:
𝑖𝑛𝑓𝑜(𝑡𝑜𝑡𝑎𝑙) = −668
979𝑙𝑜𝑔2(668 979) − 91
979𝑙𝑜𝑔2(91
979) −159
979𝑙𝑜𝑔2(159 979)
− 61
979𝑙𝑜𝑔2(61
979) = 1,37025
Tabel 3.15 Proses Pembentukan Simpul Akar
KASUS TOTAL KL1 KL2 KL3 KL4 INFO ENTROPY GAIN SPLIT INFO GAIN RATIO
979 668 91 159 61 1.37025
PEKERJAAN 1.33910 0.03116 2.14664 0.01452
PK1 326 227 33 51 15
PK2 61 40 7 12 2
PK3 311 194 27 59 31
PK4 202 139 18 32 13
PK5 42 32 5 5 0
PK6 37 36 1 0 0
UMUR 1.36305 0.00720 2.15745 0.00334
U1 107 65 11 22 9
U2 287 201 21 50 15
U3 313 219 33 43 18
U4 186 120 19 32 15
U5 86 63 7 12 4
PEKERJAAN SUAMI/ISTRI 1.35385 0.01640 2.23864 0.00733
PS1 275 193 27 47 8
PS2 40 29 4 6 1
PS3 336 215 39 51 31
PS4 163 112 10 29 12
PS5 45 35 4 4 2
PS6 120 84 7 22 7
KASUS TOTAL KL1 KL2 KL3 KL4 INFO ENTROPY GAIN SPLIT INFO GAIN RATIO
PENDAPATAN KELUARGA 1.34080 0.02946 2.06842 0.01424
D1 9 4 1 3 1
D2 412 255 39 85 33
D3 264 179 25 39 21
D4 107 86 7 11 3
D5 54 39 4 10 1
D6 133 105 15 11 2
PENGELUARAN KELUARGA 1.35420 0.01605 1.69681 0.00946
K1 388 246 40 68 34
K2 407 284 32 69 22
K3 91 64 8 15 4
K4 93 74 11 7 1
PINJAMAN 1.31406 0.05620 2.18116 0.02576
PJ1 229 124 19 61 25
PJ2 265 174 26 47 18
PJ3 158 107 14 23 14
PJ4 59 46 3 8 2
PJ5 268 217 29 20 2
KEMAMPUAN ANGSURAN 1.31982 0.05044 1.55174 0.03250
KA1 253 165 33 49 6
KA2 422 331 29 50 12
KA3 304 172 29 60 43
KASUS TOTAL KL1 KL2 KL3 KL4 INFO ENTROPY GAIN SPLIT INFO GAIN RATIO
JANGKA WAKTU 1.33619 0.03406 1.34608 0.02530
J1 310 183 28 63 36
J2 557 395 48 90 24
J3 112 90 15 6 1
AGUNAN 1.30049 0.06977 1.57666 0.04425
A1 339 250 35 40 14
A2 279 220 33 22 4
A3 361 198 23 97 43
STATUS AGUNAN 1.36182 0.00844 0.49469 0.01706
SA1 873 601 71 144 57
SA2 106 67 20 15 4
NILAI JAMINAN 1.35466 0.01560 2.19976 0.00709
N1 186 121 23 32 10
N2 266 172 26 49 19
N3 158 102 9 31 16
N4 77 59 4 9 5
N5 292 214 29 38 11
TUJUAN 1.36875 0.00151 0.98323 0.00153
T1 564 378 57 96 33
T2 415 290 34 63 28
Sementara itu, berdasarkan persamaan (2.2), nilai entropy untuk atribut pekerjaan pada Tabel 3.15 diperoleh dari:
𝐸(𝑝𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛) =326 979× (
−227
326𝑙𝑜𝑔2(227 326) − 33
326𝑙𝑜𝑔2(33 326)
− 51
326𝑙𝑜𝑔2(51
326) − 15
326𝑙𝑜𝑔2(15 326)
)
+ 61 979× (
−40
61𝑙𝑜𝑔2(40 61) − 7
61𝑙𝑜𝑔2(7 61)
−12
61𝑙𝑜𝑔2(12 61) − 2
61𝑙𝑜𝑔2(2 61)
)
+311 979× (
−194
311𝑙𝑜𝑔2(194 311) − 27
311𝑙𝑜𝑔2(27 311)
− 59
311𝑙𝑜𝑔2(59
311) − 31
311𝑙𝑜𝑔2(31 311)
)
+202 979× (
−139
202𝑙𝑜𝑔2(139 202) − 18
202𝑙𝑜𝑔2(18 202)
− 32
202𝑙𝑜𝑔2(32
202) − 13
202𝑙𝑜𝑔2(13 202)
) + 42 979
× (−32
42𝑙𝑜𝑔2(32 42) − 5
53𝑙𝑜𝑔2(5 42) − 5
42𝑙𝑜𝑔2(5 42)) + 37
979× (−36
37𝑙𝑜𝑔2(36 37) − 1
37𝑙𝑜𝑔2(1 37))
= 1,33910
Berdasarkan Persamaan (2.3), nilai information gain untuk atribut pekerjaan pada Tabel 3.15 diperoleh dari:
𝐺𝑎𝑖𝑛(𝑝𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛) = 𝐼𝑛𝑓𝑜(𝑡𝑜𝑡𝑎𝑙) − 𝐸(𝑝𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛)
= 1,37025 − 1,33910
= 0,03116
Berdasarkan persamaan (2.4), nilai split information untuk atribut pekerjaan pada Tabel 3.15 diperoleh dari:
𝑆𝑝𝑙𝑖𝑡 𝑖𝑛𝑓𝑜(𝑝𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛) = −326
979log2(326 979) − 61
979log2(61 979)
−311
979log2(311
979) −202
979log2(202 979)
− 42
979log2(42
979) − 37
979log2(37 979)
= 2,14664
Berdasarkan persamaan (2.5), nilai gain ratio untuk atribut pekerjaan pada Tabel 3.15 diperoleh dari:
𝐺𝑎𝑖𝑛 𝑟𝑎𝑡𝑖𝑜(𝑝𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛) = 𝐺𝑎𝑖𝑛(𝑝𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛) 𝑆𝑝𝑙𝑖𝑡 𝑖𝑛𝑓𝑜 (𝑝𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛)
=0,03116 2,14664
= 0,01452
Berdasarkan Tabel 3.15 dapat diketahui bahwa atribut dengan gain ratio tertinggi adalah atribut agunan yaitu sebesar 0,04425, dengan demikian atribut agunan menjadi simpul akar pada pohon keputusan. Ada tiga nilai atribut dari agunan yaitu A1, A2, dan A3. Dari ketiga nilai atribut tersebut belum mengklasifikasikan kasus menjadi satu atau belum menunjukkan sebuah keputusan akhir, sehingga perlu dilakukan perhitungan nilai gain ratio kembali dari setiap atribut dengan penghapusan simpul agunan. Sebagai contoh, akan dicari simpul internal dari percabngan nilai A3 yaitu simpul internal (1,1). Hasil pohon keputusan sementara ditunjukkan pada Gambar 3.1.
Gambar 3.1 Pohon Keputusan Sementara Perhitungan Simpul Akar
2. Menentukan simpul internal (1.1) dengan menghitung total kasus untuk kategori kelas KL1, KL2, KL3, KL4 pada simpul internal (1.1) dan menghitung gain ratio pada setiap atribut. Proses perhitungan tersebut sama untuk semua atribut. Atribut yang sudah menjadi akar dihapus dari daftar atribut. Hasil perhitungan secara lengkap dapat dilihat pada lampiran 3.
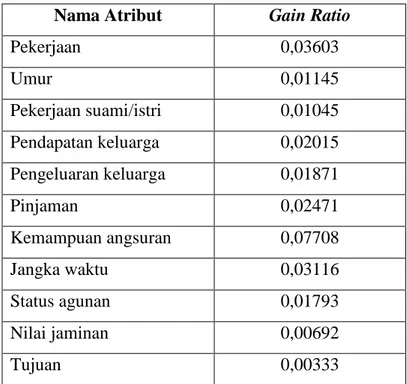
Berdasarkan perhitungan pada lampiran 3 besar gain ratio pada setiap atribut dapat dilihat pada Tabel 3.16.
Tabel 3.16 Nilai Gain Ratio pada Pembentukan Simpul Internal (1.1) Nama Atribut Gain Ratio
Pekerjaan 0,03603
Umur 0,01145
Pekerjaan suami/istri 0,01045 Pendapatan keluarga 0,02015 Pengeluaran keluarga 0,01871
Pinjaman 0,02471
Kemampuan angsuran 0,07708
Jangka waktu 0,03116
Status agunan 0,01793
Nilai jaminan 0,00692
Tujuan 0,00333
Agunan
1.2?
A2 A1
1.1? 1.3?
A3
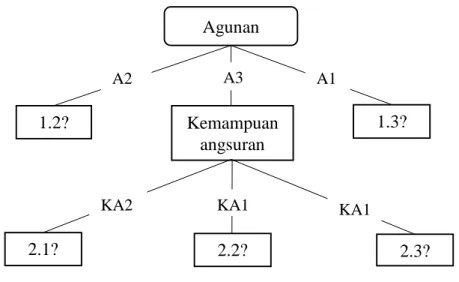
Berdasarkan Tabel 3.16 atribut yang mempunyai nilai gain ratio tertinggi adalah kemampuan angsuran yaitu sebesar 0,07708, oleh karena itu atribut kemampuan angsuran dijadikan sebagai simpul internal (1.1). Ada tiga nilai atribut dari kemampuan angsuran, yaitu KA1, KA2, KA3. Dari ketiga nilai tersebut belum menunjukkan keputusan akhir, sehingga dilakukan perhitungan nilai gain ratio kembali dari setiap atribut dengan penghapusan atribut kemampuan angsuran. Sebagai contoh, akan dicari simpul internal dari percabangan nilai KA1 yaitu simpul internal (2.2). Hasil pohon keputusan sementara ditunjukkan pada Gambar 3.2.
Gambar 3.2 Pohon Keputusan Sementara Perhitungan Simpul Internal (1.1) 3. Menentukan simpul internal (2.2) dengan menghitung total kasus untuk
kategori kelas KL1, KL2, KL3, KL4 dan gain ratio pada simpul internal (2.2).
Proses perhitungan dilakukan sama pada setiap nilai atribut. Atribut kemampuan angsuran yang sudah menjadi simpul internal dihapus. Hasil perhitungan dapat dilihat pada lampiran 4.
2.3?
Agunan
1.2?
A2 A1
Kemampuan angsuran
1.3?
2.1? 2.2?
KA2 KA1 KA1
A3
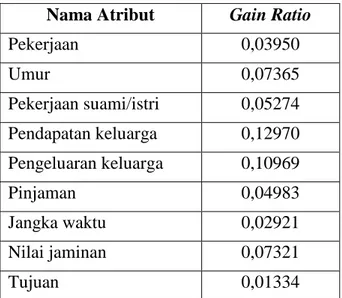
Berdasarkan perhitungan pada lampiran 4 besar gain ratio pada setiap atribut dapat dilihat pada Tabel 3.17.
Tabel 3.17 Nilai Gain Ratio pada Pembentukan Simpul Internal (2.2) Nama Atribut Gain Ratio
Pekerjaan 0,03950
Umur 0,07365
Pekerjaan suami/istri 0,05274 Pendapatan keluarga 0,12970 Pengeluaran keluarga 0,10969
Pinjaman 0,04983
Jangka waktu 0,02921
Nilai jaminan 0,07321
Tujuan 0,01334
Berdasarkan Tabel 3.17 atribut yang mempunyai nilai gain ratio tertinggi adalah pendapatan keluarga yaitu sebesar 0,12970, oleh karena itu atribut pendapatan keluarga dijadikan sebagai simpul internal (2.2). Ada enam nilai atribut pada pendapatan keluarga, yaitu D1, D2, D3, D4, D5, D6.
Dari keenam nilai tersebut tidak terdapat nilai yang memiliki keputusan akhir, sehingga dilakukan perhitungan nilai gain ratio kembali dari setiap atribut dengan penghapusan atribut pendapatan keluarga. Sebagai contoh, akan dicari simpul internal dari percabngan nilai D3 yaitu simpul internal (3.3).
Hasil pohon keputusan sementara yang terbentuk ditunjukkan pada Gambar 3.3.
Gambar 3.3 Pohon Keputusan Sementara Perhitungan Simpul Internal (2.2) 4. Menghitung total kasus untuk kategori kelas akhir KL1, KL2, KL3, KL4 pada
simpul internal (3.3) dan menghitung nilai gain ratio pada setiap atribut.
Proses tersebut dilakukan sama pada setiap nilai atribut. Sementara itu atribut pendapatan keluarga dihapus dari daftar atribut. Hasil perhitungan dapat dilihat pada lampiran 5.
Berdasarkan perhitungan pada lampiran 5 besar gain ratio pada setiap atribut dapat dilihat pada Tabel 3.18.
3.1? 3.2? 3.3? 3.4? 3.5? 3.6?
2.3?
Agunan
1.2?
A2 A1
Kemampuan angsuran
1.3?
2.1? Pendapatan
keluarga
KA2 KA1 KA3
A3
D1 D2 D3 D4 D5 D6
Tabel 3.18 Nilai Gain Ratio pada Pembentukan Simpul Internal (3.3) Nama Atribut Gain Ratio
Pekerjaan 0,09200
Umur 0,13840
Pekerjaan suami/istri 0,12065 Pengeluaran keluarga 0,16041
Pinjaman 0,27341
Jangka waktu 0,12215
Nilai jaminan 0,17596
Tujuan 0,05895
Berdasarkan Tabel 3.18 atribut yang mempunyai nilai gain ratio tertinggi adalah pinjaman yaitu sebesar 0,27341, sehingga atribut pinjaman dijadikan sebagai simpul internal (3.3). Pada atribut pinjaman, terdapat satu nilai atribut yang telah memiliki keputusan akhir yaitu nilai PJ3 dengan kategori kelas KL3. Masih terdapat tiga nilai lainnya yang belum memiliki keputusan akhir sehingga perlu dilakukan perhitungan nilai gain ratio kembali dari setiap atribut dengan penghapusan atribut pinjaman. Hasil pohon keputusan sementara yang terbentuk ditunjukkan oleh Gambar 3.4
Gambar 3.4 Pohon Keputusan Sementara Perhitungan Simpul Internal (3.3) Proses pembentukan pohon pada Gambar 3.4 bukan akhir dari pembentukan pohon keputusan pada kasus ini. Perhitungan yang terdapat pada keempat langkah di atas merupakan contoh perhitungan pada salah satu simpul internal.
Pembentukan pohon keputusan akan dilanjutkan dengan menggunakan bantuan software WEKA karena jumlah dataset yang banyak sehingga apabila dihitung manual akan panjang dan membutuhkan waktu yang lama. Setelah menggunakan
3.1? 3.2? Pinjaman 3.4? 3.5? 3.6?
2.3?
Agunan
1.2?
A2 A1
Kemampuan angsuran
1.3?
2.1? Pendapatan
keluarga
KA2 KA1 KA3
A3
D1 D2 D3 D4 D5 D6
4.1? 4.2?
PJ1 PJ2 PJ3 PJ5
KL2 11
4.3?
bantuan software WEKA akan didapatkan pohon keputusan yang lengkap sebagai hasil akhir.
Pembentukan pohon keputusan menggunakan WEKA dimulai dengan menyiapkan data yang telah mengalami preprocessing dengan format file comma separated value (csv). Selanjutnya dilakukan classifier dengan trees J48. Algoritma C4.5 di dalam WEKA direpresentasikan oleh trees J48, sehingga dipilih algoritma tersebut. Ilustrasi klasifikasi menggunakan WEKA ditunjukkan oleh Gambar 3.5.
Gambar 3.5 Decision tree C4.5 menggunakan WEKA
Visualisasi output WEKA menggunakan teknik klasifikasi decision tree C4.5 yang diimplementasikan oleh trees J48 dengan jumlah data 979 ditunjukkan pada Gambar 3.6. Berdasarkan Gambar 3.6 dapat diketahui bahwa model terbentuk dalam waktu 0,27 detik dengan ukuran pohon 53 dan memiliki 41 aturan keputusan.
=== Classifier model (full training set) ===
J48 pruned tree ---
Agunan = A1: KL1 (339.0/89.0) Agunan = A2: KL1 (279.0/59.0) Agunan = A3
| Kemampuan Angsuran = KA1
| | Pendapatan Keluarga = D2
| | | Nilai Jaminan = N5: KL3 (6.0/1.0)
| | | Nilai Jaminan = N3
| | | | Pengeluaran Keluarga = K2: KL1 (2.0)
| | | | Pengeluaran Keluarga = K3: KL3 (0.0)
| | | | Pengeluaran Keluarga = K1: KL3 (3.0)
| | | | Pengeluaran Keluarga = K4: KL3 (0.0)
| | | Nilai Jaminan = N1
| | | | Pengeluaran Keluarga = K2: KL3 (5.0/1.0)
| | | | Pengeluaran Keluarga = K3: KL3 (0.0)
| | | | Pengeluaran Keluarga = K1
| | | | | Pekerjaan = PK1: KL2 (4.0/2.0)
| | | | | Pekerjaan = PK2: KL1 (0.0)
| | | | | Pekerjaan = PK3: KL1 (8.0/3.0)
| | | | | Pekerjaan = PK4: KL2 (5.0/2.0)
| | | | | Pekerjaan = PK6: KL1 (0.0)
| | | | | Pekerjaan = PK5: KL1 (0.0)
| | | | Pengeluaran Keluarga = K4: KL3 (0.0)
| | | Nilai Jaminan = N4: KL1 (3.0)
| | | Nilai Jaminan = N2: KL1 (11.0/4.0)
…………
Number of Leaves : 41 Size of the tree : 53
Time taken to build model: 0.27 seconds
Gambar 3.6 Hasil Output WEKA Berupa Model dan Aturan 979 dataset Gambar 3.7 adalah visualisasi pohon keputusan dari kelas akhir KL1, KL2, KL3, dan KL4 yang dihasilkan menggunakan software WEKA.
Gambar 3.7 Visualisasi Pohon Keputusan
Pohon keputusan tersebut diperoleh dari proses klasifikasi menggunakan algoritma C4.5. Berdasarkan pohon keputusan yang dihasilkan maka diperoleh aturan ekstraksi dari pohon keputusan. Ekstraksi pohon keputusan dilihat pada lampiran 12, dan beberapa diantaranya dapat dituliskan sebagai berikut:
1. IF AGUNAN=A1 THEN KELAS=KL1;
2. IF AGUNAN=A2 THEN KELAS=KL1;
3. IF AGUNAN=A3 AND KEMAMPUAN ANGSURAN=KA1 AND PENDAPATAN KELUARGA=D2 AND NILAI JAMINAN=N5 THEN KELAS=KL3;
4. IF AGUNAN=A3 AND KEMAMPUAN ANGSURAN=KA1 AND PENDAPATAN KELUARGA=D2 AND NILAI JAMINAN=N3 AND PENGELUARAN KELUARGA=K2 THEN KELAS=KL1;
5. IF AGUNAN=A3 AND KEMAMPUAN ANGSURAN=KA1 AND PENDAPATAN KELUARGA=D2 AND NILAI JAMINAN=N3 AND PENGELUARAN KELUARGA=K3 THEN KELAS=KL3;
Berdasarkan aturan yang terdapat pada ekstraksi pohon keputusan tersebut, maka aturan-aturan tersebut dapat diartikan sebagai berikut:
1. Jika peminjam memberikan agunan A1 maka status peminjam tersebut termasuk dalam kelas KL1.
2. Jika peminjam memberikan agunan A2 maka status peminjam tersebut termasuk dalam kelas KL1.
3. Jika peminjam memberikan agunan A3, dengan besar kemampuan agsuraan pada kelas KA1, pendapatan keluarga D2 , nilai jaminan N5, maka status peminjam tersebut termasuk dalam kelas KL3.
4. Jika peminjam memberikan agunan A3, dengan besar kemampuan agsuraan pada kelas KA1, pendapatan keluarga D2 , nilai jaminan N3, pengeluaran keluarga K2, maka status peminjam tersebut termasuk dalam kelas KL1.
5. Jika peminjam memberikan agunan A3, dengan besar kemampuan agsuraan pada kelas KA1, pendapatan keluarga D2 , nilai jaminan N3, pengeluaran keluarga K3, maka status peminjam tersebut termasuk dalam kelas KL3.
E. Proses Klasifikasi Menggunakan Naïve Bayes
Setelah penerapan klasifikasi dengan metode decision tree C4.5 terhadap data kredit pada Koperasi X maka hasil tersebut akan dibandingkan dengan hasil klasifikasi menggunakan naïve bayes. Pada penerapan algoritma naïve bayes, data yang digunakan adalah data yang telah melewati tahap preprocessing yaitu sebanyak 979 dataset.
Berikut adalah contoh salah satu perhitungan klasifikasi naïve bayes untuk mencari kelas target pada salah satu peminjam kredit koperasi.
Tabel 3.19 Data Prediksi
Pekerjaan Umur Pekerjaan Suami/Istri
Pendapatan Keluarga
Pengeluaran
Keluarga Pinjaman
PK3 U3 PS3 D3 K2 PJ2
Kemampuan angsuran
Jangka
Waktu Agunan Status Agunan
Nilai
Jaminan Tujuan Kelas
KA3 J1 A3 SA1 N3 T2
Data pada Tabel 3.19 menyatakan bahwa pekerjaan pemohon kredit tergolong dalam PK3, umur tergolong dalam U3, pekerjaan suami/istri tergolong dalam PS3, pendapatan keluarga tergolong dalam D3, besar pengeluaran keluarga tergolong dalam K2, pinjaman tergolong dalam PJ2, kemampuan angsuran tergolong dalam KA3, jangka waktu tergolong dalam J1, agunan tergolong dalam A3, status agunan tergolong dalam SA1, nilai jaminan tergolong dalam N3, dan tujuan tergolong dalam T2. Perhitungan klasifikasi naïve bayes dilakukan untuk mengetahui kelas target pada data prediksi tersebut dengan 𝑃(𝐶𝑖) merupakan kelas target. Kemudian akan ditentukan atribut yang digunakan dengan ketentuan:
𝐶1 = (kelas target=”KL1”) 𝐶2 = (kelas target=”KL2”) 𝐶3 = (kelas target=”KL3”) 𝐶4 = (kelas target=”KL4”) 𝑥1 = (pekerjaan=”PK3”) 𝑥2 = (umur=”U3”)
𝑥3 = (pekerjaan suami/istri=”PS3”) 𝑥4 = (pendapatan keluarga=”D3”) 𝑥5 = (pegeluaran keluarga=”K2”) 𝑥6 = (pinjaman=”PJ2”)
𝑥7 = (kemampuan angsuran=”KA3”) 𝑥8 = (jangka waktu=”J1”)
𝑥9 = (agunan=”A3”)
𝑥10 = (status agunan=”SA1”) 𝑥11 = (nilai jaminan=”N3”)
𝑥12 = (tujuan=”T2”)
Langkah-langkah perhitungan klasifikasi naïve bayes berdasarkan data kredit yang telah mengalami preprocessing sebagai berikut:
1. Langkah pertama adalah menghitung probabilitas kelas target yaitu 𝑃(𝐶𝑖) untuk 𝑖 = 1, 2, 3, 4. Pada kelas target atau atribut Kelas yang bernilai “KL1”
sebanyak 668 data, “KL2” sebanyak 91 data, “KL3” sebanyak 159 data,
“KL4” sebanyak 61 data. Maka akan dihitung nilai 𝑃(𝐶𝑖) berdasarkan persamaan (2.11), yaitu:
𝑃(𝐶1) = 𝑃(𝐾𝑒𝑙𝑎𝑠 = "KL1") =668
979= 0,68233 𝑃(𝐶2) = 𝑃(𝐾𝑒𝑙𝑎𝑠 = "KL2") = 91
979= 0,09295 𝑃(𝐶3) = 𝑃(𝐾𝑒𝑙𝑎𝑠 = "KL3") =159
979= 0,16241 𝑃(𝐶4) = 𝑃(𝐾𝑒𝑙𝑎𝑠 = "KL4") = 61
979= 0,06230
2. Menghitung nilai 𝑃(𝑥𝑘|𝐶𝑖)untuk 𝑘 = 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 dan 𝑖 = 1, 2, 3, 4 yaitu:
𝑃(𝑥1|𝐶1) = 𝑃(𝑃𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛 = "PK3"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =194 668 𝑃(𝑥1|𝐶2) = 𝑃(𝑃𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛 = "PK3"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =27
91 𝑃(𝑥1|𝐶3) = 𝑃(𝑃𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛 = "PK3"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 59
159 𝑃(𝑥1|𝐶4) = 𝑃(𝑃𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛 = "PK3"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =31
61 𝑃(𝑥2|𝐶1) = 𝑃(𝑈𝑚𝑢𝑟 = "U3"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =219
668 𝑃(𝑥2|𝐶2) = 𝑃(𝑈𝑚𝑢𝑟 = "U3"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =33
91
𝑃(𝑥2|𝐶3) = 𝑃(𝑈𝑚𝑢𝑟 = "U3"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 43 159 𝑃(𝑥2|𝐶4) = 𝑃(𝑈𝑚𝑢𝑟 = "U3"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =18
61
𝑃(𝑥3|𝐶1) = 𝑃(𝑃𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛 𝑆𝑢𝑎𝑚𝑖/𝐼𝑠𝑡𝑟𝑖 = "PS3"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =215 668 𝑃(𝑥3|𝐶2) = 𝑃(𝑃𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛 𝑆𝑢𝑎𝑚𝑖/𝐼𝑠𝑡𝑟𝑖 = "PS3"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =39
91 𝑃(𝑥3|𝐶3) = 𝑃(𝑃𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛 𝑆𝑢𝑎𝑚𝑖/𝐼𝑠𝑡𝑟𝑖 = "PS3"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 51
159 𝑃(𝑥3|𝐶4) = 𝑃(𝑃𝑒𝑘𝑒𝑟𝑗𝑎𝑎𝑛 𝑆𝑢𝑎𝑚𝑖/𝐼𝑠𝑡𝑟𝑖 = "PS3"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =31
61 𝑃(𝑥4|𝐶1) = 𝑃(𝑃𝑒𝑛𝑑𝑎𝑝𝑎𝑡𝑎𝑛 𝐾𝑒𝑙𝑢𝑎𝑟𝑔𝑎 = "D3"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =179 668 𝑃(𝑥4|𝐶2) = 𝑃(𝑃𝑒𝑛𝑑𝑎𝑝𝑎𝑡𝑎𝑛 𝐾𝑒𝑙𝑢𝑎𝑟𝑔𝑎 = "D3"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =25
91 𝑃(𝑥4|𝐶3) = 𝑃(𝑃𝑒𝑛𝑑𝑎𝑝𝑎𝑡𝑎𝑛 𝐾𝑒𝑙𝑢𝑎𝑟𝑔𝑎 = "D3"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 39
159 𝑃(𝑥4|𝐶4) = 𝑃(𝑃𝑒𝑛𝑑𝑎𝑝𝑎𝑡𝑎𝑛 𝐾𝑒𝑙𝑢𝑎𝑟𝑔𝑎 = "D3"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =21
61 𝑃(𝑥5|𝐶1) = 𝑃(𝑃𝑒𝑛𝑔𝑒𝑙𝑢𝑎𝑟𝑎𝑛 𝑘𝑒𝑙𝑢𝑎𝑟𝑔𝑎 = "K2"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =284
668 𝑃(𝑥5|𝐶2) = 𝑃(𝑃𝑒𝑛𝑔𝑒𝑙𝑢𝑎𝑟𝑎𝑛 𝑘𝑒𝑙𝑢𝑎𝑟𝑔𝑎 = "K2"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =32
91 𝑃(𝑥5|𝐶3) = 𝑃(𝑃𝑒𝑛𝑔𝑒𝑙𝑢𝑎𝑟𝑎𝑛 𝑘𝑒𝑙𝑢𝑎𝑟𝑔𝑎 = "K2"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 69
159 𝑃(𝑥5|𝐶4) = 𝑃(𝑃𝑒𝑛𝑔𝑒𝑙𝑢𝑎𝑟𝑎𝑛 𝑘𝑒𝑙𝑢𝑎𝑟𝑔𝑎 = "K2"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =22
61 𝑃(𝑥6|𝐶1) = 𝑃(𝑃𝑖𝑛𝑗𝑎𝑚𝑎𝑛 = "PJ2"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =174
668 𝑃(𝑥6|𝐶2) = 𝑃(𝑃𝑖𝑛𝑗𝑎𝑚𝑎𝑛 = "PJ2"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =26
91 𝑃(𝑥6|𝐶3) = 𝑃(𝑃𝑖𝑛𝑗𝑎𝑚𝑎𝑛 = "PJ2"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 47
159 𝑃(𝑥6|𝐶4) = 𝑃(𝑃𝑖𝑛𝑗𝑎𝑚𝑎𝑛 = "PJ2"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =18
61
𝑃(𝑥7|𝐶1) = 𝑃(𝐾𝑒𝑚𝑎𝑚𝑝𝑢𝑎𝑛 𝑎𝑛𝑔𝑠𝑢𝑟𝑎𝑛 = "KA3"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =172 668 𝑃(𝑥7|𝐶2) = 𝑃(𝐾𝑒𝑚𝑎𝑚𝑝𝑢𝑎𝑛 𝑎𝑛𝑔𝑠𝑢𝑟𝑎𝑛 = "KA3"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =29
91 𝑃(𝑥7|𝐶3) = 𝑃(𝐾𝑒𝑚𝑎𝑚𝑝𝑢𝑎𝑛 𝑎𝑛𝑔𝑠𝑢𝑟𝑎𝑛 = "KA3"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 60
159 𝑃(𝑥7|𝐶4) = 𝑃(𝐾𝑒𝑚𝑎𝑚𝑝𝑢𝑎𝑛 𝑎𝑛𝑔𝑠𝑢𝑟𝑎𝑛 = "KA3"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =43
61 𝑃(𝑥8|𝐶1) = 𝑃(𝐽𝑎𝑛𝑔𝑘𝑎 𝑤𝑎𝑘𝑡𝑢 = "J1"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =183
668 𝑃(𝑥8|𝐶2) = 𝑃(𝐽𝑎𝑛𝑔𝑘𝑎 𝑤𝑎𝑘𝑡𝑢 = "J1"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =28
91 𝑃(𝑥8|𝐶3) = 𝑃(𝐽𝑎𝑛𝑔𝑘𝑎 𝑤𝑎𝑘𝑡𝑢 = "J1"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 63
159 𝑃(𝑥8|𝐶4) = 𝑃(𝐽𝑎𝑛𝑔𝑘𝑎 𝑤𝑎𝑘𝑡𝑢 = "J1"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =36
61 𝑃(𝑥9|𝐶1) = 𝑃(𝐴𝑔𝑢𝑛𝑎𝑛 = "A3"|𝐾𝑒𝑙𝑎𝑠 = "KL1") = 198
668 𝑃(𝑥9|𝐶2) = 𝑃(𝐴𝑔𝑢𝑛𝑎𝑛 = "A3"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =23
91 𝑃(𝑥9|𝐶3) = 𝑃(𝐴𝑔𝑢𝑛𝑎𝑛 = "A3"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 97
159 𝑃(𝑥9|𝐶4) = 𝑃(𝐴𝑔𝑢𝑛𝑎𝑛 = "A3"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =43
61
𝑃(𝑥10|𝐶1) = 𝑃(𝑆𝑡𝑎𝑡𝑢𝑠 𝑎𝑔𝑢𝑛𝑎𝑛 = "𝑆A1"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =601 668 𝑃(𝑥10|𝐶2) = 𝑃(𝑆𝑡𝑎𝑡𝑢𝑠 𝑎𝑔𝑢𝑛𝑎𝑛 = "𝑆A1"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =71
91 𝑃(𝑥10|𝐶3) = 𝑃(𝑆𝑡𝑎𝑡𝑢𝑠 𝑎𝑔𝑢𝑛𝑎𝑛 = "𝑆A1"|𝐾𝑒𝑙𝑎𝑠 = "KL3") =144
159 𝑃(𝑥10|𝐶4) = 𝑃(𝑆𝑡𝑎𝑡𝑢𝑠 𝑎𝑔𝑢𝑛𝑎𝑛 = "𝑆A1"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =57
61 𝑃(𝑥11|𝐶1) = 𝑃(𝑁𝑖𝑙𝑎𝑖 𝑗𝑎𝑚𝑖𝑛𝑎𝑛 = "𝑁3"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =102
668 𝑃(𝑥11|𝐶2) = 𝑃(𝑁𝑖𝑙𝑎𝑖 𝑗𝑎𝑚𝑖𝑛𝑎𝑛 = "𝑁3"|𝐾𝑒𝑙𝑎𝑠 = "KL2") = 9
91
𝑃(𝑥11|𝐶3) = 𝑃(𝑁𝑖𝑙𝑎𝑖 𝑗𝑎𝑚𝑖𝑛𝑎𝑛 = "𝑁3"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 31 159 𝑃(𝑥11|𝐶4) = 𝑃(𝑁𝑖𝑙𝑎𝑖 𝑗𝑎𝑚𝑖𝑛𝑎𝑛 = "𝑁3"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =16
61 𝑃(𝑥12|𝐶1) = 𝑃(𝑇𝑢𝑗𝑢𝑎𝑛 = "𝑇2"|𝐾𝑒𝑙𝑎𝑠 = "KL1") =290
668 𝑃(𝑥12|𝐶2) = 𝑃(𝑇𝑢𝑗𝑢𝑎𝑛 = "𝑇2"|𝐾𝑒𝑙𝑎𝑠 = "KL2") =34
91 𝑃(𝑥12|𝐶3) = 𝑃(𝑇𝑢𝑗𝑢𝑎𝑛 = "𝑇2"|𝐾𝑒𝑙𝑎𝑠 = "KL3") = 63
159 𝑃(𝑥12|𝐶4) = 𝑃(𝑇𝑢𝑗𝑢𝑎𝑛 = "𝑇2"|𝐾𝑒𝑙𝑎𝑠 = "KL4") =28
91
3. Langkah selanjutnya adalah menghitung 𝑃(𝑋|𝐶𝑖) untuk 𝑖 = 1, 2 dan dengan menggunakan persamaan (2.12) diperoleh:
𝑃(𝑋|𝐶1) = ∏ 𝑃(𝑥𝑘|𝐶1) =
12
𝑘=1
194 668×219
668×215 668×179
668×284 668×174
668×172 668
×183 668×198
668×601 668×102
668×290 668
= 1,13398 × 10−6
𝑃(𝑋|𝐶2) = ∏ 𝑃(𝑥𝑘|𝐶2) =
12
𝑘=1
27 91×33
91×39 91×25
91×32 91×26
91×29 91×28
91×23 91
×71 91× 9
91×34
91= 9,09437 × 10−7
𝑃(𝑋|𝐶3) = ∏ 𝑃(𝑥𝑘|𝐶3) =
12
𝑘=1
59 159× 43
159× 51 159× 39
159× 69 159× 47
159× 60 159
× 63 159× 97
159×144 159× 31
159× 63 159
= 1,74185 × 10−5
𝑃(𝑋|𝐶4) = ∏ 𝑃(𝑥𝑘|𝐶4) =
12
𝑘=1
31 91×18
91×31 91×21
91×22 91×18
91×43 91×36
91×43 91
×57 91×16
91×28
91= 1,81265 × 10−4
4. Menghitung nilai 𝑃(𝑋|𝐶𝑖)𝑃(𝐶𝑖) yaitu
𝑃(𝑋|𝐶1)𝑃(𝐶1) = 1,13398 × 10−6× 0,68233 = 7,73746 × 10−7 𝑃(𝑋|𝐶2)𝑃(𝐶2) = 9,09437 × 10−7× 10−6× 0,09295 = 8,4534 × 10−8 𝑃(𝑋|𝐶3)𝑃(𝐶3) = 1,74185 × 10−5× 10−6× 0,16241 = 2,82895 × 10−6 𝑃(𝑋|𝐶4)𝑃(𝐶4) = 1,81265 × 10−6× 0,0623 × 10−7= 1,12943 × 10−5 5. Dari perhitungan 𝑃(𝑋|𝐶𝑖)𝑃(𝐶𝑖) di atas, diperoleh bahwa nilai tertinggi
diberikan oleh 𝑃(𝑋|𝐶4)𝑃(𝐶4) sehingga hasil pengklasifikasian pada data di atas dapat dilihat pada Tabel 3.17 berikut.
Tabel 3.20 Hasil Klasifikasi Data
Pekerjaan Umur Pekerjaan Suami/Istri
Pendapatan Keluarga
Pengeluaran
Keluarga Pinjaman
PK3 U3 PS3 D3 K2 PJ2
Kemampuan angsuran
Jangka
Waktu Agunan Status Agunan
Nilai
Jaminan Tujuan Kelas
KA3 J1 A3 SA1 N3 T2 KL4
Berdasarkan Tabel 3.20, diperoleh informasi bahwa peminjam dengan pekerjaan PK3, umur U3, pekerjaan suami/istri PS3, pendapatan keluarga D3, pengeluaran keluarga K2, pinjaman PJ2, kemampuan angsuran KA3, jangka waktu J1, agunan A3, status agunan SA1, nilai jaminan N3, tujuan T2 maka peminjam tersebut termasuk dalam kelas KL4.
Pada proses data mining diperlukan bantuan software WEKA karena jumlah dataset yang cukup banyak sehingga akan sulit jika diolah secara manual dan memerlukan waktu lama. Pengklasifikasian menggunakan WEKA dimulai dengan menyiapkan data yang telah mengalami preprocessing dengan format csv.
Selanjutnya dilakukan classifier dengan naïve bayes. Ilustrasi klasifikasi naïve bayes menggunakan WEKA ditunjukkan oleh Gambar 3.8.
Gambar 3.8 Naïve Bayes menggunakan WEKA
Visualisasi output WEKA menggunakan teknik klasifikasi algoritma naïve bayes dengan jumlah data 979 ditunjukkan pada Gambar 3.9.
=== Classifier model (full training set) ===
Naive Bayes Classifier
Class
Attribute KL3 KL1 KL4 KL2 (0.16) (0.68) (0.06) (0.09)
====================================================
Pekerjaan
PK1 52.0 228.0 16.0 34.0 PK2 13.0 41.0 3.0 8.0 PK3 60.0 195.0 32.0 28.0 PK4 33.0 140.0 14.0 19.0 PK6 1.0 37.0 1.0 2.0 PK5 6.0 33.0 1.0 6.0 [total] 165.0 674.0 67.0 97.0 Umur
U1 23.0 66.0 10.0 12.0 U3 44.0 220.0 19.0 34.0 U2 51.0 202.0 16.0 22.0 U4 33.0 121.0 16.0 20.0 U5 13.0 64.0 5.0 8.0 [total] 164.0 673.0 66.0 96.0
………
Time taken to build model: 0 seconds
Gambar 3.9 Hasil Output WEKA Klasifikasi Menggunakan Naïve Bayes
Output program WEKA Gambar 3.9 merupakan model klasifikasi naïve bayes. Berdasarkan output dapat diketahui bahwa pada atribut pekerjaan mempunyai total class KL1 sebanyak 674, class KL2 sebanyak 97, class KL3 sebanyak 165, class KL4 sebanyak 67 sehingga total class seluruhnya ada 1.003, sedangkan jumlah data sebenarnya adalah 979. Hal ini terjadi karena klasifikasi naïve bayes pada program WEKA menghindari frekuensi nol di setiap class sehingga terjadi penambahan 1 angka di setiap class. Pada output di atas juga dapat diketahui bahwa model naïve bayes terbentuk dalam waktu mendekati 0 detik.
F. Pengujian Model
Pengujian model dilakukan dengan beberapa model tes klasifikasi yaitu menggunakan option use training set, cross validation, dan percentage split.
Menurut Witten, et al (2011: 153) jumlah fold standar untuk memprediksi tingkat error dari data adalah dengan menggunakan 10-fold cross validation. Sehingga pada penelitian ini digunakan 10-fold cross validation. Menurut Hota, Shrivas &
Singhai (2013: 165) terdapat beberapa komposisi data training dan data testing yang sering digunakan, yaitu
1. 60% untuk data training dan 40% untuk data testing, 2. 75% untuk data training dan 25% untuk data testing, 3. 80% untuk data training dan 20% untuk data testing.
Pembagian data pada penelitian ini sebesar 80% untuk data training dan 20% untuk data testing.
Berdasarkan pengujian menggunakan beberapa model tes tersebut akan diketahui nilai akurasi dari masing-masing model. Hasil yang diperoleh dari tes dengan use training set, 10-fold cross validation, dan percentage split dapat dilihat pada Tabel 3.21.
Tabel 3.21 Hasil Evaluasi Decision Tree C4.5 dan Naïve Bayes Decision Tree C4.5
Use Training Set
10-Fold Cross Validation
Percentage Split Correctly Classified 71,91% 68,03% 66,84%
Incorrect Classified 28,09% 31,97% 33,16%
Waktu komputasi (satuan:detik)
0,25 0,14 0,02
Naïve Bayes Use Training
Set
10-Fold Cross Validation
Percentage Split Correctly Classified 67,01% 64,66% 65,82%
Incorrect Classified 32,99% 35,34% 34,18%
Waktu komputasi (satuan:detik)
0,01 0 0