Latar belakang masalah
Rumusan masalah
Batasan masalah
Tujuan
Manfaat
Big data
Rapidminer
Clustering
Classification
Association
Flow penulisan
Langkah-langkah penulisan
Gambar 4.7 menunjukkan operator fitur selektif, kita memilih fitur data yang diperlukan untuk digunakan dalam analisis menggunakan metode klasifikasi. Pada Gambar 4.24 diketahui terdapat atribut data yang hilang, sehingga perlu dilakukan filter terhadap operator yang hilang tersebut yang akan dilakukan pada tahap selanjutnya. Pada Gambar 4.28 kita melakukan normalisasi data set karena kita sudah memilih fitur data yang diinginkan, maka pada operator normalisasi kita menggunakan fitur filter type all.
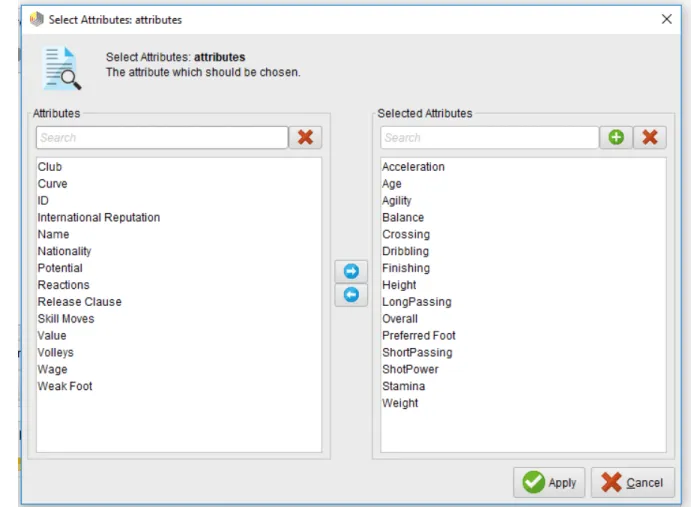
Berikut data fitur yang akan kita gunakan untuk menganalisa Agility, Crossing, Dribbling, Finishing, Height, Power Tendangan, Stamina dan Weight. Pada Gambar 4.37 diketahui terdapat atribut data yang hilang, sehingga perlu dilakukan filter terhadap operator yang hilang tersebut yang akan dilakukan pada tahap selanjutnya. Gambar 4.44 menunjukkan data atribut yang kita pilih yaitu: kelincahan, passing, dribbling, finishing, tinggi badan, daya tembak, stamina dan berat badan.
Tujuan dari metode clustering adalah untuk menentukan atribut data yang mempengaruhi statistik pemain FIFA.
Case study classification
- Case Understanding
- Data Understanding
- Data Preparation
- Modelling
- Evaluation
- Deployment
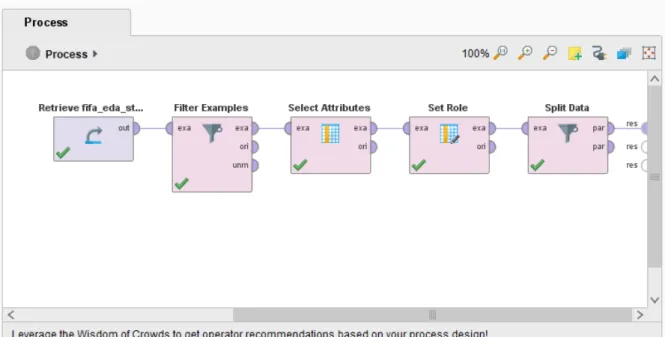
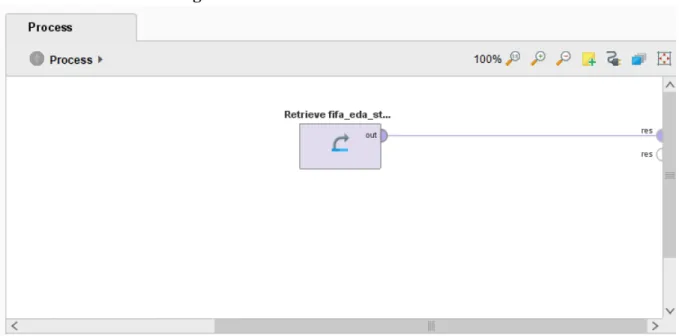
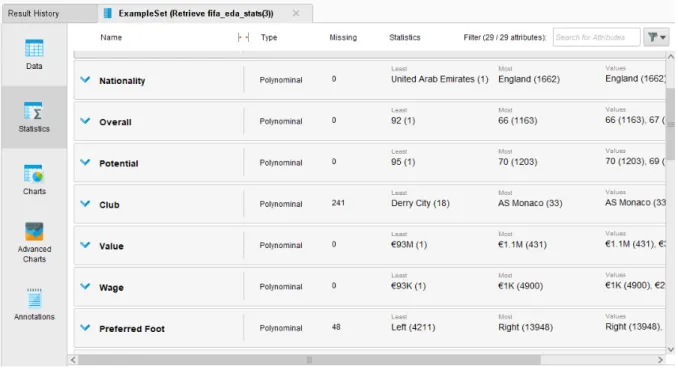
Fase ini penting untuk meletakkan landasan awal dalam analisis data dan untuk mendapatkan pemahaman yang lebih baik tentang data yang digunakan. Pada tahap pertama ini, kita menggunakan operator pengambilan yang berfungsi untuk menerima kumpulan data, seperti terlihat pada Gambar 4.1. Dari hasil pengambilan data kita dapat mengetahui jenis data apa yang ada dan data apa saja yang hilang. Terlihat bahwa dataset yang kita pilih mempunyai atribut data yang hilang, oleh karena itu kita perlu memfilter atribut data yang hilang.
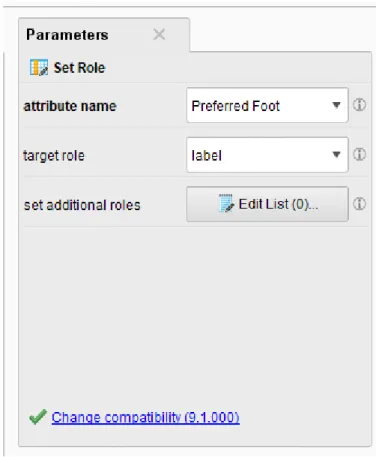
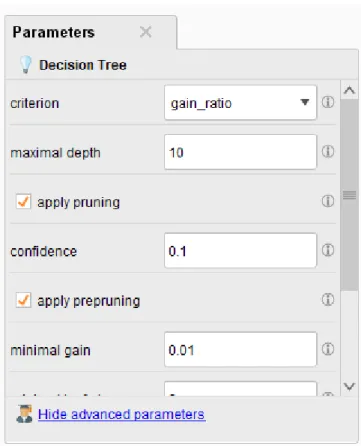
Proses pemahaman data ini melibatkan analisis data secara detail sehingga kita dapat memperoleh informasi yang diperlukan untuk memperoleh hasil yang akurat dalam proses data mining. Gambar 4.4 menunjukkan penggunaan filter untuk memfilter atribut data yang hilang, sehingga data yang hilang tersebut terfilter sehingga data yang tersisa menjadi data yang lengkap sehingga dapat dilakukan analisis. Gambar 4.5 menunjukkan parameter operator filter untuk atribut data yang hilang seperti klab, kaki pilihan, dan klausa pelepasan. Kita menggunakan atribut pilihan foot sebagai atribut labelnya. Untuk proses pemodelan data mining, kita menentukan atribut mana yang akan dijadikan label dengan menggunakan operator set role yang dapat dilihat pada Gambar 4.8.
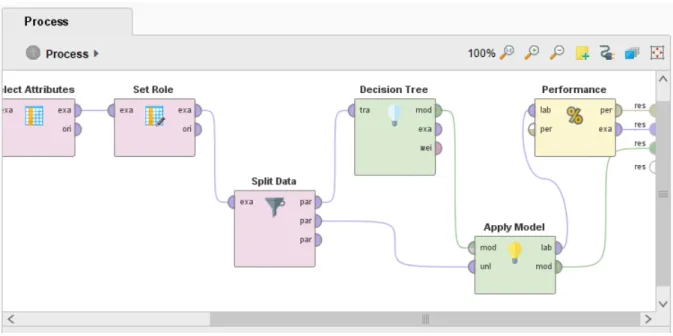
Pada Gambar 4.9 hasil penggunaan operator set role terlihat bahwa atribut kaki yang disukai kini menjadi label pada dataset statistik pemain FIFA. Setelah persiapan data yang matang, kita lanjutkan ke tahap pemodelan yang ditunjukkan pada Gambar 4.11 dan Gambar 4.12. Untuk data pelatihan, kami menggunakan operator data terpisah, yang dikaitkan dengan operator pohon keputusan dan kemudian operator model aplikasi.
Sedangkan untuk data pengujian, kami menggunakan data terpisah yang dihubungkan langsung dengan model yang diterapkan. Gini_index kami gunakan sebagai patokan atau target penghitungan algoritma pohon keputusan karena memberikan hasil terbaik dibandingkan yang lain. Karena kita telah menentukan atribut data kaki pilihan sebagai label, pohon keputusan menunjukkan kaki pilihan dengan status berbeda.
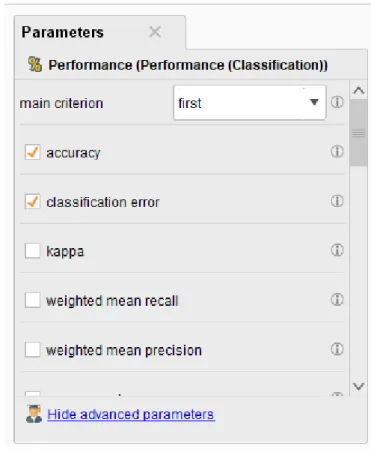
Gambar 4.17 dan Gambar 4.18 menunjukkan hasil pemodelan pohon keputusan. Dari pemodelan tersebut kita dapat mengekstrak statistik dan tabel data yang telah kita analisis. Pada tahap evaluasi, Anda dapat melihat pada Gambar 4.20 bahwa kinerja operator digunakan untuk mengevaluasi kinerja statistik metode klasifikasi. Akurasi Dengan menerapkan parameter Akurasi, kita dapat mengetahui persentase prediksi menggunakan pohon keputusan.
Pada tahap ini kita memperoleh pemahaman tentang hasil proses data mining menggunakan metode klasifikasi dengan model pohon keputusan yang kita buat.
Case study Clustering
- Case Understanding
- Data Understanding
- Data Preparation
- Modelling
- Evaluation
- Deploment
Meskipun hasilnya mungkin tidak sepenuhnya akurat, kami dapat mengklasifikasikan preferensi kaki yang digunakan berdasarkan statistik pemain FIFA. Pada Gambar 4.23, terdapat operator pengambilan untuk menerima kumpulan data. Dataset yang kita punya berformat xlsx, jadi kita bisa menggunakan operator pengambilan biasa. Gambar 4.25 menunjukkan penggunaan filter untuk memfilter atribut data yang hilang, sehingga data yang hilang tersebut terfilter sehingga data yang tersisa menjadi data yang lengkap sehingga dapat dilakukan analisis. Gambar 4.26 menunjukkan parameter operator filter untuk atribut data yang hilang seperti klab, kaki pilihan, dan klausa pelepasan.
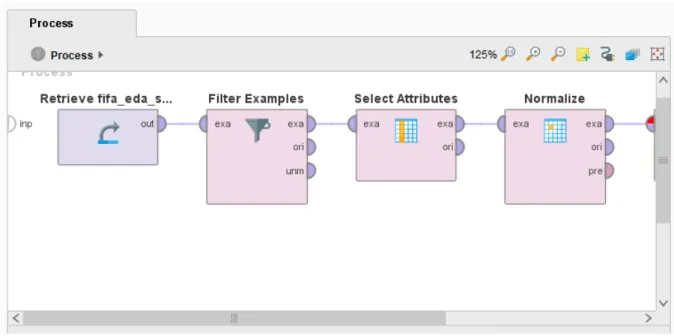
Gambar 4.27 menunjukkan operator atribut yang dipilih, yang menggunakan tipe subgrup, kita memilih atribut data seperti akselerasi, usia, kelincahan, keseimbangan, passing, dribbling, finishing, passing jauh, keseluruhan, potensi, reaksi, passing pendek, kekuatan tembakan dan stamina . Gambar 4.29 menunjukkan pemodelan metode clustering, dimulai dari operator get, operator contoh filter, select atribut, normalize, dan terakhir clustering (k-means). Operator ini berfungsi membentuk kelompok atau cluster yang berbeda berdasarkan data yang serupa.
Pada Gambar 4.30 terlihat parameter yang digunakan untuk K-Means yaitu jumlah cluster (k) yang akan terbentuk adalah 5 dan jumlah maksimum percobaan yang akan dilakukan (max run) adalah 10 kali. Sehingga didapat 5 cluster yaitu cluster 0, cluster 1, cluster 2, cluster 3 dan cluster 4 dan pada setiap cluster terdapat beberapa elemen, cluster 0 berjumlah 3498 pcs, cluster 1 berjumlah 2691 pcs, cluster 2 berjumlah 2095 pcs. , cluster 3 memiliki elemen sebanyak 3638 dan cluster 4 memiliki elemen sebanyak 5996 elemen. Gambar 4.32 menunjukkan Tabel Centroid K-Means terlihat bahwa untuk atribut umur nilai mean tertinggi terdapat pada cluster 1, untuk atribut keseluruhan nilai mean tertinggi terdapat pada cluster 3, untuk atribut potensial nilai mean tertinggi terdapat pada cluster 3. cluster 3 merupakan nilai rata-rata tertinggi dari atribut crossover pada cluster 3 yaitu atribut terminating.
Kami memilih kriteria utama rata-rata dalam jarak centroid di operator kinerja karena ini dapat menunjukkan jarak rata-rata antara setiap cluster dan cluster lainnya, yang akan ditampilkan nanti di bagian rekomendasi hasil. Selain itu, kami juga memeriksa bidang normalisasi dan maksimalisasi untuk menghasilkan data yang lebih akurat dan positif. Dari cluster yang dibuat dapat disimpulkan ciri-ciri yang dapat mempengaruhi statistik pemain FIFA.
Case Study Association
- Case Understanding
- Data Understanding
- Data Preparation
- Modelling
- Evaluation
Pada gambar 4.38 merupakan penggunaan filter untuk memfilter karakteristik data yang hilang sehingga data yang hilang akan terfilter sehingga data yang tersisa menjadi data yang lengkap sehingga dapat dilakukan analisis, gambar 4.39 merupakan parameter operator filter untuk karakteristik data yang hilang seperti misal: klub, pijakan pilihan dan klausul pelepasan. Filter range sampel dataset kita, karena dataset kita mempunyai jumlah data yang sangat banyak, maka kita akan membatasi jumlah data yang akan diproses agar tidak terjadi kelebihan beban pada memori komputer kita yang digunakan untuk menganalisis dataset ini. Gunakan operator numerik ke binomial untuk mengubah tipe atribut data dari numerik ke binomial.
Dari gambar 4.40 dan 4.41 setiap operator yang digunakan harus mempunyai filternya masing-masing seperti pada gambar 4.39 dan selebihnya akan kami jelaskan pada bagian selanjutnya. Gambar 4.42 menunjukkan contoh parameter operator filter seri. Kami membatasi data sebanyak 100 buah karena jumlah data pada dataset kami mencapai puluhan ribu, sehingga untuk menghindari kelebihan memori pada komputer yang kami gunakan maka kami perlu membatasi jumlah data yang akan diproses. Gambit 4.43 menunjukkan parameter operator fitur selektif, kita memilih subset tipe filter fitur sehingga kita dapat memilih banyak fitur data yang nantinya akan dianalisis dengan metode asosiasi.
Gambar 4.45 menunjukkan parameter operator diskritisasi, kita menggunakan operator diskritisasi (diskritisasi berdasarkan frekuensi), dan parameter yang kita gunakan mengikuti default dari rapidminer, yang kemudian akan dilanjutkan dengan operator numerik ke binomial. Gambar 4.46 menunjukkan parameter dari operator numerik hingga binomial, dan parameter yang kami gunakan mengikuti nilai default dari rapidminer. Gambar 4.49 dan 4.50 menunjukkan parameter dari operator FP-Growth, nilai minimum support yang kita gunakan adalah 0.95, dan selebihnya kita mengikuti nilai default dari rapidminer.
Pada tahap evaluasi ini, seperti terlihat pada Gambar 4.51 dan 4.52, kami menggunakan operator aturan asosiasi sebagai bagian dari operator aturan asosiasi. Gambar 4.53 menunjukkan parameter operator create asosiasi aturan, nilai minimum keyakinan yang kita gunakan adalah 0,8 atau 80%. Gambar 4.54 dan 4.55 menunjukkan hasil pembuatan aturan asosiasi. Ini merupakan hasil pengelompokan variabel dengan menggunakan nilai support dan keyakinan terbaik yang telah ditentukan sebelumnya.
Rekomendasi Hasil
- Classification Decision Tree
- Clustering K-Means
- Association Rules FP GROWTH
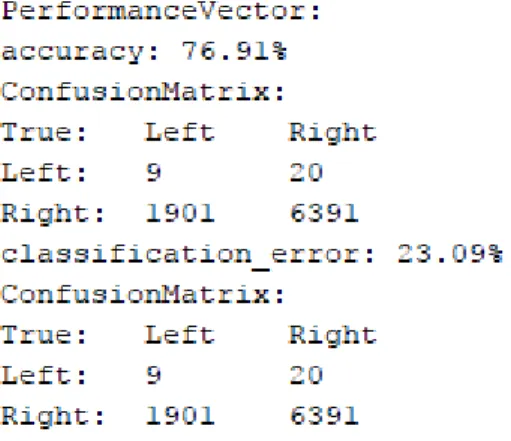
Gambar 4.58 menunjukkan hasil klasifikasi kinerja, terlihat akurasi yang dicapai sebesar 76,91% dan sisanya kesalahan klasifikasi sebesar 23,09%, artinya dataset yang digunakan cukup baik karena mencapai akurasi sebesar 76,91%. . Pada gambar 4.63 dan 4.65 terlihat bahwa pada kolom support angka yang sering muncul adalah 0,200, pada kolom keyakinan adalah angka yang sering muncul. 0,833, kolom Laplace, angka yang paling sering adalah 0,968, kolom gain, angka yang paling sering muncul adalah -0,280, kolom p-s, angka yang paling sering adalah 0,087, kolom lift, angka yang paling sering muncul adalah 1,743, kolom untuk keyakinan jumlah yang sering muncul adalah 3.188.
Saat melakukan analisis data mining untuk dataset pemain FIFA, penting untuk memahami dan menganalisis setiap bagian data dalam dataset yang ingin Anda analisis. Meningkatkan akurasi penambangan data: Ada beberapa metode lain dalam penambangan data yang dapat digunakan untuk meningkatkan akurasi analisis, seperti regresi, jaringan saraf, dan deret waktu. Tim penulis dapat mencoba menggunakan metode ini untuk meningkatkan akurasi analisis data pada kumpulan data ini.
Tingkatkan kualitas data: Beberapa data dalam kumpulan data ini hilang atau memiliki nilai yang tidak valid, hal ini dapat mempengaruhi keakuratan analisis. Perluasan aplikasi data mining: Data mining dapat digunakan di berbagai bidang seperti bisnis, kesehatan dan keamanan. Tim penulis mungkin mencoba memperluas aplikasi data mining di area ini untuk memberikan manfaat yang lebih besar kepada masyarakat.
Dengan menerapkan saran tersebut, kami berharap analisis data mining dataset pemain FIFA menggunakan RapidMiner dapat lebih baik dan bermanfaat bagi pengguna data. Dari penambangan data besar hingga laporan olahraga teknis: kasus metrik inersia”, BMJ Open Sport Exerc. Goes dkk., “Membuka potensi data besar untuk mendukung analisis kinerja taktis dalam sepak bola profesional: tinjauan sistematis,” Eur.
Badheka, "International Journal of Computer Science and Mobile Computing Comparison of Basic Clustering Algorithms," Int. Patan, “Performance analysis of machine learning algorithms for big data classification: Ml and ai-based algorithms for big data analysis,” Int.
Kesimpulan
Analisis ini dilakukan dengan tujuan agar analis dapat mengetahui dan memahami kelas-kelas data dalam kumpulan yang ingin dianalisis.
Saran
Oleh karena itu, tim penulis dapat melakukan perbaikan kualitas data untuk meningkatkan akurasi analisis. 3] Kausik Bandyopadhyay dan Naha Souvik, “Menentukan Momen dalam Sejarah Sepak Bola”, Soccer Soc., vol.