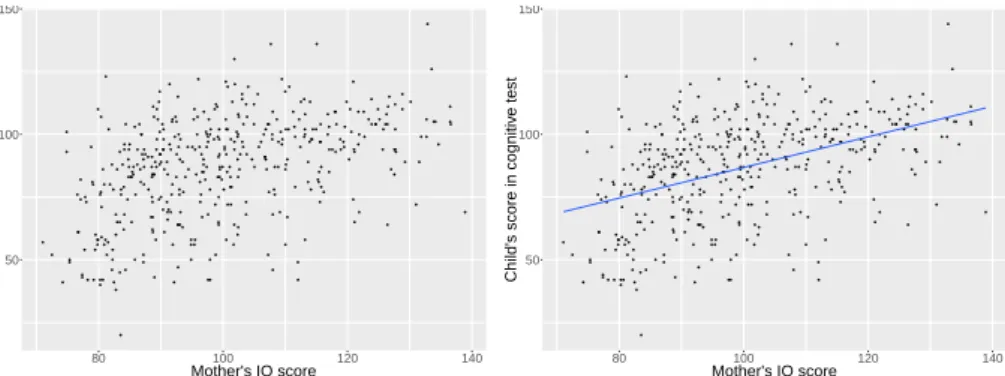
The techniques we will study in this part of the course include stochastic and probabilistic modeling, simulation, dynamic programming, estimation and inference. It is not an exact replica of the system and is not simply a description of the observations.
Why we need to be clever about our computing
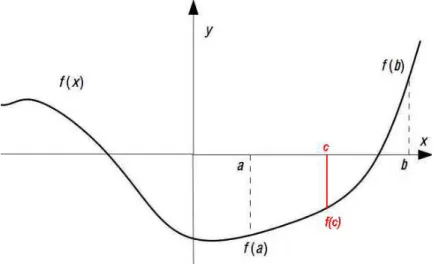
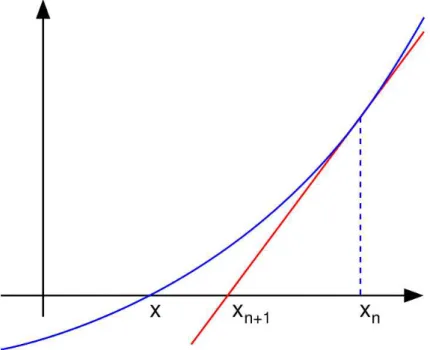
An algorithm is accurate if the competing solution is close to the true solution to the problem. The quality of the approximation also depends on the distance ofx from a— the closer xis to a, the better the approximation.
Newton’s method
An eigenvector of the square matrix A is a non-zero vector e such that Ae = λe for a scalar λ. The range is also called the column space of A because it is the space of all linear combinations of the columns of A.
Review of eigenvectors and eigenvalues
Before leaving this example, it is worth looking at some properties of the eigenvalues of A:.
Review of systems of linear equations
In principle, all we need to do to solve the system of equations Ax=bis is to find the inverse of A,A−1. We will initially concentrate on easily soluble systems and look at how we can force other systems into a form where they (or a close approximation) are also easily soluble.
Easily solvable systems 2: Triangular matrix
The method of Gaussian elimination, or row reduction, which we assume you've seen before, transforms the matrix A into a triangular one to solve the system.
Easily solvable systems 3: Orthonormal or orthogonal matrix
Gaussian elimination to solve systems linear equations (review)
It is easy to show that multiplying both sides of Ax=b from the left by any non-singular matrix M does not affect the solution. Repeated application of these three operations (that is, repeated multiplication by elementary matrices) on both sides of the equation transforms it to Cx =d, where C= M1.
Gaussian elimination as LU decomposition
Rearranging the rows before the row reduction process begins so that the largest leading non-zero elements are selected first can avoid this cause of instability. Note that when m > n (i.e. the problem is overdetermined), there are at most non-zero singular values.
Structure of SVD
Note that the SVD of matrixA is unique only up to permutations of the columns/rows. For this reason, we insist that the singular values and corresponding singular vectors are arranged such that the singular values are in descending order σ1 ≥ σ2.
Condition number of a matrix
When computing SVD with different software, be aware that you may need to enforce this canonical representation. It also means that if we measure a number in the system slightly differently, the results we get can change a lot.
Principal Components Analysis (PCA)
We usually consider this space independent of how it relates to the original dimensional space, but we can consider it nested within the original space. Find the magnitude of the first principal component of the first measure vector of A (that is, the first column) and compute the projection matrix to project A onto the first two principal components.
What is connection between PCA and SVD?
Problems with SVD and PCA
This problem arises when we have an overdetermined linear system: recall that Au=b is overdetermined when A is an ism×n matrix with m > n:. In some cases, the inverse can be found directly (in particular, when A has independent columns, then ATA is positive definite and ATA is invertible, in which case u∗ = (ATA)−1ATb).
Computing u ∗ via Gaussian elimination
In other cases, this approach can be very unstable, so stable numerical techniques must be used.
Computing u ∗ via orthogonalisation (QR decomposition)
Constructing the orthogonal matrix Q by Gram-Schmidt
Computing u ∗ via SVD: the Pseudoinverse
Properties of the pseudo inverse A +
Simulation is one of the tools we use to understand how our models behave and is often used where precise statistical inference is extremely difficult. There are 24 = 16 possible events that we can consider here, since this is the size of the power set (the set of all possible subsets) of Ω.
Conditional probability and independence
Bayes’ Theorem
Random variables
Given a joint probability density function, we obtain the probability density for a subset of the variables by integrating over those not in the subset.
Commonly used distributions
- Bernoulli distribution
- Geometric distribution
- Binomial distribution
- Poisson distribution
- Uniform distribution (discrete or continuous)
- Normal distribution
- Exponential distribution
- Gamma distribution
Note that the model of the process may include our (imperfect or incomplete) method of measuring the outcome. The likelihood tells us the likelihood of the data under the model for any value of θ.
Maximum likelihood
An example of the latter case occurs in Bayesian statistics, where the goal is to find the posterior distributionf(θ|x). For example, we can estimate the shape of distributions by drawing a histogram of the sampled points.
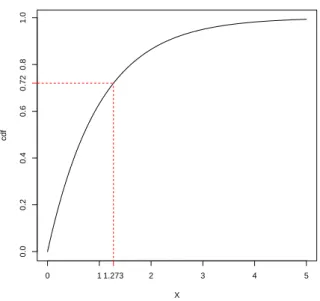
Simulating from univariate distributions via Inversion sampling
The performance of rngs can be tested through the diehard test suite (or more recently, the diehard suite). It is possible to extend the definition of the inverse to derive the following method for simulating discrete random variables.
Stochastic processes
Random walk
Poisson process
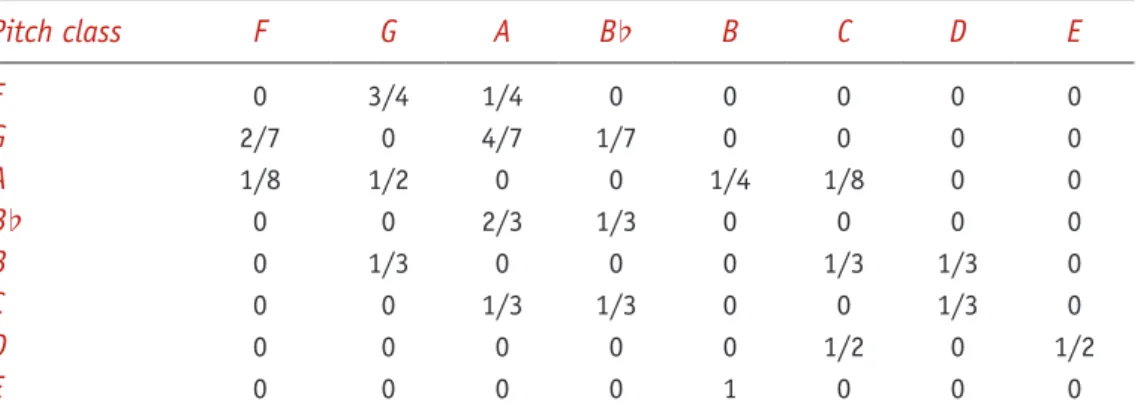
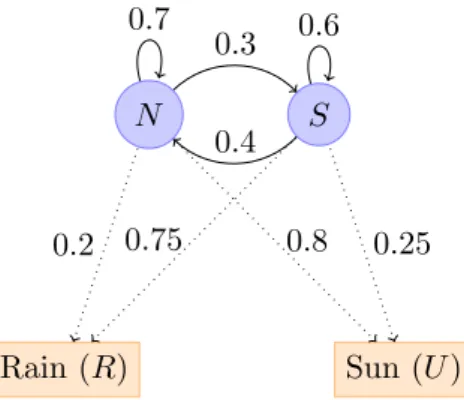
Thus, the distribution of the next state depends on more than just the current state and. The transition matrix between pitches (middle) is constructed from empirical counts of the observed transitions.

Homology
Pairwise alignment
Scoring alignments
Model of non-homologous sequences
Model of homologous sequences
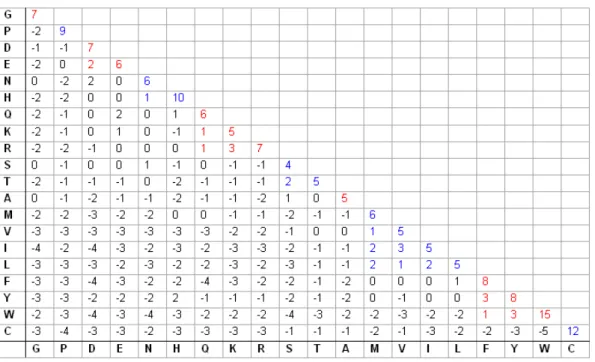
There are various methods for determining reasonable values for matrix entries, discussed below. Note that even when ad hoc values are chosen for the matrix, the underlying probabilities pab and qa can be derived by reversing the above argument.
Choosing the substitution matrix
Scoring gaps
A gap in x corresponds to an insertion in y relative to tox or a deletion in x relative to y.
Global alignment: Needleman-Wunsch algorithm
To calculate the (i, j) entry, we only need to know the 3 entries to the left and above it. After completing the matrix, we return from F(n, m) along the path that got us here.
Elements of an alignment algorithm
Local Alignment: Smith Waterman algorithm
Overlap matches
As an example of how easy it is to establish different types of alignment algorithms, we consider a special type of alignment known as an overlap alignment.
Pairwise alignment with non-linear gap penalties
This means that to calculate the value of each cell in the matrix F(i, j) we need to consider i+j+ 1 other cells - the previous cells in the row, j the previous cells in the column and the adjacent diagonal cell - instead of 3 as we had with the linear gap penalty (see Figure below). To calculate an unknown cell of F, points for gaps of all possible lengths must be calculated, which means that a calculation must be made for each previous cell in the row and column:
Alignment with affine gap scores
This results in a quadratic time and space algorithm again, but the coefficient of the quadratic term is larger for this algorithm than the linear slot. Some clever work by Lipman, Altschul and Kececioglu (the first two co-wrote BLAST) managed to reduce the size of the space to be considered.
Progressive alignment
For example, for 2 rows of length L, the Needleman-Wunsch algorithm requires a 2-dimensional array with L2 cells in total to be stored in memory. The MSA analog on n rows requires storing an n-dimensional array containing Ln cells in total.
Building trees with distances and UPGMA
Example: Given 4 sequences, A, B, C, and D, which have pairwise distances given by the distance matrix d below, construct the UPGMA tree. Now select the pair of clusters that are closest to each other according to the distance matrix d.
Feng-Doolittle progressive alignment
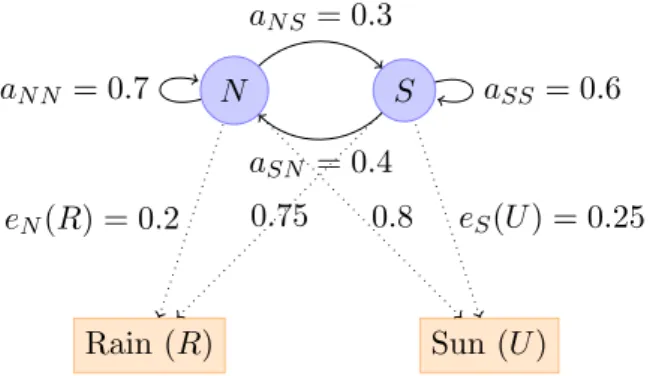
In Markov models, we directly observe the state of the process (for example, in a random walk, the state is completely described by the position of the random walker). The i-state of the state sequence is πi and transitions (of the states) are given by akl = P(πi = l|πi−1 = k).
The forward algorithm and calculating P(x)
Here is a diagram showing how to retrieve the (i+ 1) column from the ith column in the forward algorithm. Solution: The matrix produced by the forward algorithm is given below in log units (base 2).
The backward algorithm and calculating P(x)
What can we do with the posterior estimates?
Estimating the parameters of an HMM
The probability of the jth sequence, P(xj|θ), is exactly what we've called P(xj) so far because we've always assumed that the parameter values, θ, were known. Writing it as P(xj|θ) simply emphasizes the fact that we now consider it a function of the unknown θ.
Baum-Welch algorithm for estimating parameters of HMM
Comments on the Baum-Welch algorithm
Each local maximum is not necessarily a global maximum, so the algorithm must be run from several different initial states to verify that a global maximum has been found. Also remember that convergence is guaranteed only in the limit of an infinite number of iterations, so the exact local maximum is never reached.
Sampling state paths
The Baum-Welch algorithm is guaranteed to converge to the local maximum - exactly which local maximum it converges to depends on the initial condition. The algorithm is a type of expectation-maximization (EM) algorithm widely used for maximum likelihood estimation.
HMM model structure
Duration modeling
The distance includes a correction for the fact that unrelated sequences will agree simply due to chance. Since the background level of inequality (given by fxy) for unrelated sequences is 34, (1−4f3xy) tends to zero as sequences become more unrelated so xy tends to infinity for unrelated sequences.
Ultrametric distances
This method works well for related sequences where they are expected to be small, but do not grow as much as we would like, as the sequences become less and less related as even unrelated sequences share many bases in common due to randomness. In most cases, the ultrametric assumption is not good, since different regions of the sequences change at different rates and different tree lines may have different mutation rates.
Additive distances
Neighbour joining
Unrooted vs rooted trees
An unrooted tree is an unrooted tree, and a tree with a known root position is called a rooted tree. In some cases, we can determine the position of the root by including a known outgroup in the analysis.
Complexity of neighbour jointing and UPGMA
Parsimony
Parsimony informative sites
It is easy to show that parsimony-informative sites have at least two characters that each occur in two or more taxa. If we instead consider the site corresponding to the column AACC, it would be parsimony informative.
Finding the maximum parsimony tree
Exhaustive search
For example, consider sites that have the same residue for all taxa (an invariant site). In the detailed example above, the site studied (which would be written as the AGCC column in a multi-sequence alignment for the 4 taxa) is not sparingly informative, as there is only one site that occurs more than once.
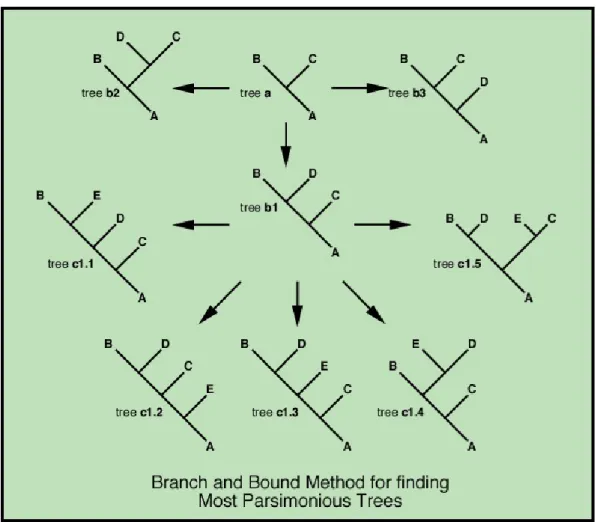
Branch and bound
Heuristic search
Another edge is selected on the rest of the tree and the removed subtree is reattached to this point. To improve the chances of finding the best tree, the method for building the initial tree can be randomized so that the starting point is different in each case.
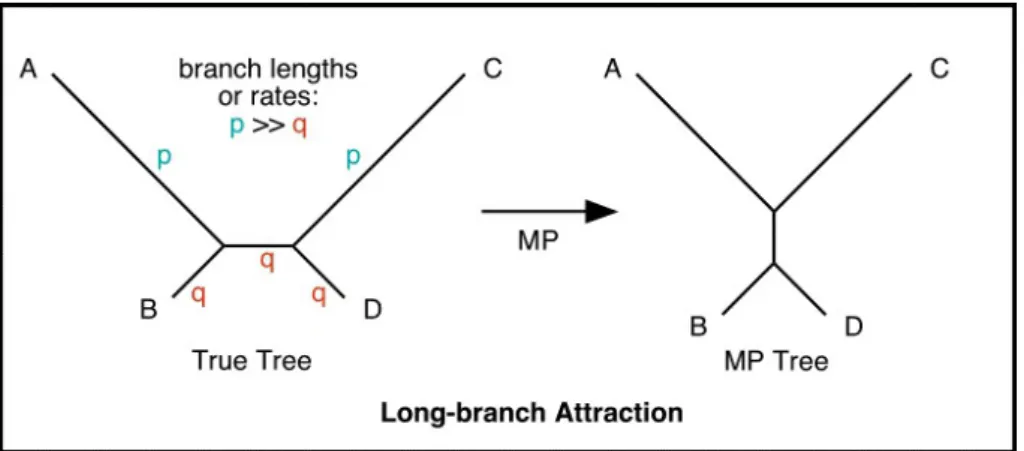
Disadvantages of parsimony
This is the principle of marginalization introduced in Section 11.4: we want to know the probability of the tree and the data, but also have some other random variables floating around (the ancestor. The probability of the tree is the sum of the probability of tree and the values of the ancestors, where the sum is over the values of all ancestors.
Markov processes
Models of sequence mutation
Jukes-Cantor model
Estimating the maximum likelihood tree