Deep knowledge and great interest of our supervisor in the field of "Machine Learning" to realize this project. The experimental research showed more accurate predictions of breast cancer and compared the results of previous recent studies, with the highest performance of 99.122%. As disease is the best part of our daily life, some tissues are getting damaged or growing uncontrollably, known as cancer.
When uncontrolled tissue or damaged tissue causes cancer in a woman's breast, it is known as breast cancer. Machine learning can be the best part of predicting the presence of breast cancer from collected health datasets by examining patients' diagnosis data. In our work we examined the patient's diagnosis reports and found some important parameters to determine the disease.
To improve the prediction of breast cancer in a woman's body, we propose our technique to improve the accuracy rate. They also said evidence of breast cancer was alcohol, higher birth weight and older adults.
The rationale of the study
Research Questions
Expected Output
Project Management and Finance
Report Layout
BACKGROUND
- Preliminaries
- Related works
- Scope of the Problem
- Challenges
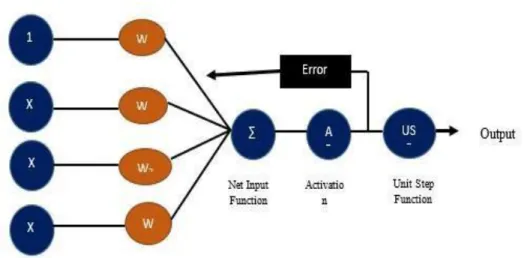
We had to use different types of Machine Learning models to find the best accuracy in predicting the dataset. The problem was to facilitate and familiarize women with the breast cancer diagnosis system. Since we found large related works on machine learning, we tried to achieve the best accuracy with our proposed model.
We had limited space to improve the mechanism, but we could implement the idea with common means to minimize the diagnosis of breast cancer. After completing the data collection, we need to check it manually so that there is any missing data in the data set.
RESEARCH METHODOLOGY
- Research Subject and Instrument
- Data Collection Procedure
- Categorical Data Encoding
- Missing Value Imputation
- Feature Scaling
- Statistical Analysis
- Experimental Setup
- Classifier Algorithms
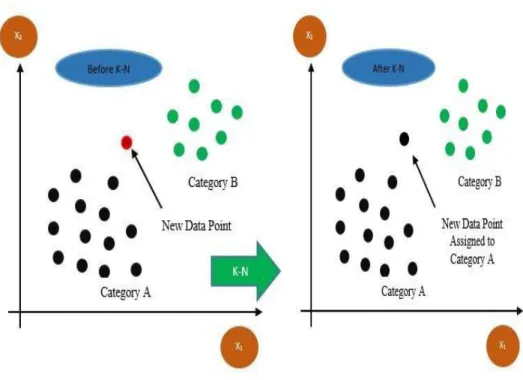
- Nearest
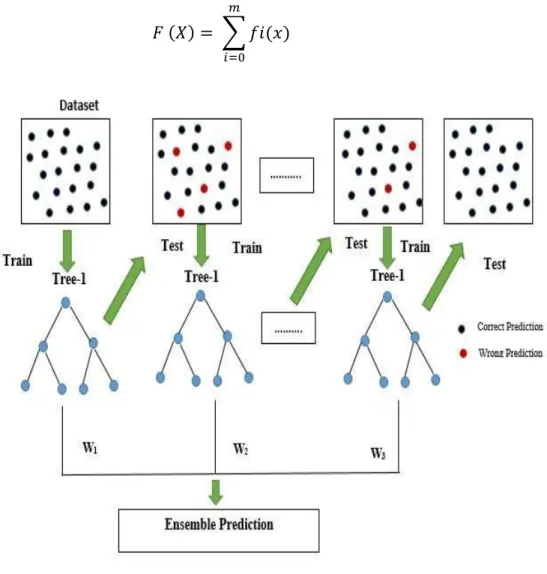
- Ensemble Methods of Machine Learning
- Experimental Result & Analysis
Concave Points_se SE of Concave Points 0 to 0.05 Float Symmetry_se SE of Symmetry 0.01 to 0.08 Float Fractal_dimension_se SE of Fractal Dimension 0 to 0.03 Float. Smoothness_worst Worst Smoothness 0.07 to 0.22 Float Compactness_worst Worst Compactness 0.03 to 1.06 Float Concavity_worst Worst Concavity 0 to 1.25 Float Concave Points_worst Worst Concave W00wortymtrymet. 0.16 to 0.66 Float Fractal_dimension_worst Worst Fractal Dimension 0.06 to 0.21 Float. Since we've chosen the Comma Separated Value (CSV) file to implement, we need to follow a few steps to clean up the dataset and make it usable.
Then Bagging, Boosting and Voting algorithms were used and we got the best result in RF was 99.122%. Daffodil International University 11 for a deeper understanding of the data and helps in our ability to identify the decisive factors [10]. Then we need to cluster, strengthen and poll the models to get the best accuracy.
Then we can decide the best model to implement considering the best accuracy, precision, recall and F-1 score. Random Forest (RF) is a machine learning (ML) based classifier ensemble method consisting of different decision tree algorithms [13]. RF creates several multiple decision trees during the time of algorithm training to result in an optimal decision model that can lead to the best accuracy than the single decision tree model.
Daffodil International University 17 Here, 𝑔𝑚 = the path of loss function's rapidly decreasing 𝐹(𝑋) = 𝐹𝑛 − 1(𝑋) the decision tree's goal is to solve the mistakes by previous learners [17][18]. The ensemble method refers to the multiple classifiers that lead to the best accuracy and efficiency for the weak classifiers to create them as a strong classifier. Voting classifiers are a group of classifiers used to predict the class with the best majority of votes.
First, we considered the performance of algorithmic classifiers, the best accuracy had achieved at 98.245% using two different algorithms called Random Forest (RF) and Logistic Regression (LR).
Algorithms
Classifier
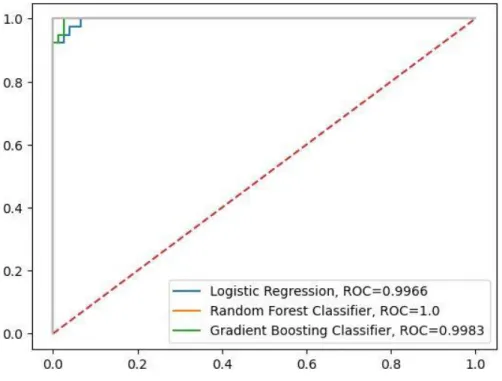
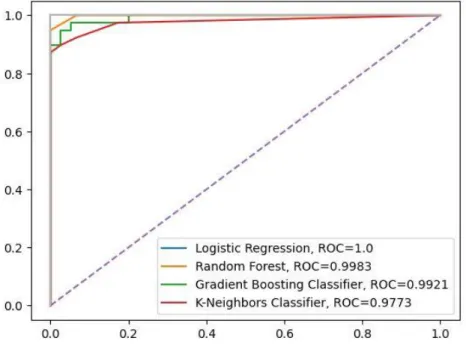
The AUC-ROC curve shown in Fig 4.9 also showed that Logistic Regression (LR) had obtained the best result of 99.99%. Therefore according to the above analysis as well as the detailed results with graphical representation, the Random Forest Classifier can be labeled as the best algorithmic classifier. The best accuracy of 95.614% was obtained from gradient boosting (GB), but the second highest accuracy of 94.736% was obtained from logistic regression (LR) and Random Forest (RF).
Bagging
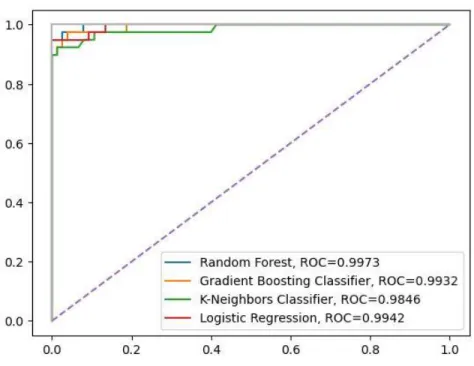
The AUC-ROC curve shown in Figure 4.11 also showed that Random Forest (RF) achieved the best result of 99.83%. Therefore, according to the above analysis and detailed results with graphical representation, Random Forest Classifier is the best algorithmic classifier. After applying the boosting algorithms, the best accuracy was achieved with Random Forest (RF) at about 99.122%.
Random Forest (RF) achieved the best algorithm in our study, as shown in Figure 4.12.
Boosting
Discussion
- Accuracy
- F-1 Score
IMPACT ON SOCIETY, ENVIRONMENT, AND SUSTAINABILITY
Impact on Society
We have some ethical precautions like leaking personal information or diagnosis report or a joke that needs to clarify the research of personal information before the system is launched. Our proposed model can be used for further research and implementation of breast cancer diagnosis and treatment in real life. We have identified the topic as a problem not only for a limited area or region, but also on a global scale.
Any victim or aware woman can use the proposed model to predict the degree of breast cancer involvement.
Sustainability Plan
SUMMARY, CONCLUSION, RECOMMENDATION, AND IMPLICATION FOR FUTURE RESEARCH
- Summary of the Study
- Conclusion
- Implication for Further Study
- Limitations
Dhenakaran, “Classification of ultrasound breast cancer tumor images using neural learning and predicting tumor growth rate,” Multimedia Tools and Applications, vol. Luo, “Radiomics with attribute bagging for breast tumor classification using multimodal ultrasound imaging,” Journal of Ultrasound in Medicine , vol. Hernández-López, "Assessment of invariance and discriminatory power of morphological features under geometric transformations for breast tumor classification".
Aggarwal et al., “Cloud computing-based framework for breast cancer diagnosis using extreme learning machine,” Diagnostics, vol. 9] “Breast Cancer Dataset”, Accessed: 29 December 2021, Available: https://www.kaggle.com/datasets/yasserh/breast-cancer-dataset. Different Bayes Classification Methods for Machine Learning” ARPN Journal of Engineering and Applied Sciences, ISSN Vol -10, No-14, August 2015.
34;Prediction of Liver Disease Using Different Decision Tree Techniques." International Journal of DataMining & Knowledge Management Process 8, No. 34;Comparing Prediction Performance with Support Vector Machine and Random Forest Classification Techniques." International Journal of Computer Applications 69, No. 34; Analyzing the robustness of nearest neighbors to conflicting examples." In International Conference on Machine Learning, p.
34; A Novel Spam Detection Method Using KNN Classification with Spearman Correlation as Distance Measure." International Journal of Computer Applications 136, No. 34; A Study on Deep Learning Algorithms in Effective Performance-Based Heart Disease Prediction." In 2021 2nd International Informatics and Software Engineering Conference (IISEC), pp.