First of all, our heartfelt thanks and gratitude to Almighty Allah for His divine blessings that enable us to complete this project successfully. We would like to thank our respected teacher and project supervisor Md Zahid Hasan, Assistant Professor, Department of CSE, Daffodil International University for his endless patience, scholarly guidance, constant encouragement, constant and energetic supervision, constructive criticism, valuable advice, reading of many inferior drafts and correcting them at all stages has enabled the completion of this project. Syed Akhter Hossain, Head, Department of CSE, for his kind help in completing our project and we are also thankful to all the other faculty and staff of our department for their cooperation and help.
Finally, we would like to thank our entire coursemate at Daffodil International University who participated in this discussion while completing the course. In this regard, we propose a framework that relegates scores that are positive or negative to English reviews, in addition to a viewpoint analysis on Bangla surveys. Numerous works have been done on opinion research and report clustering for aspect basis in English.
Since no dataset of e-commerce audits exists, we use a web crawler to elicit the necessary reviews to form a dataset that can be used for this extension. To the best of our knowledge, many studies have been done on the aspect-based estimation study (ABSA) of Bangla content. This will be portrayed as a result of the need for available datasets for ABSA.
In this article, we provide a freely accessible dataset to perform the ABSA assignment in Bangla.
INTRODUCTION
- Introduction
- Motivation
- Rational of the study
- Expected Outcome
- Layout of the Report
In this article, we tested the primary subtask, i.e. perspective category extraction. We will collect customer decision data from the e-commerce site in Bangladesh. So we decided to try to do some research in Artificial Intelligence (AI) and Machine Learning (ML) and then started looking for some ideas.
As we are a lover of online shopping, one day we thought that we can do something on e-commerce business. To develop more efficient classifier application in the field of e-commerce business, we give our best effort to develop our own model. In our paper introduction, we described introduction, objective, motivation, rationale of the study, expected outcome and layout of the report.
In the second chapter we will describe the background and it contains an introduction, related work, summary of the research and challenges. Daffodil International University 4 Chapter five deals with the study, future work and conclusion.
Background Study
Introduction
Related Works
Research Summary
The 6 categories of the International Daffodil University were a combination of substance type and quality variety. For information in English, we first pre-process the information and extract potential highlights from the cleaned data set and transform them into a numerical organization.
Challenges
Data Formatting
To make the process of data tagging easier, we wrote a code that automated the entire data tagging process. Then we took all the text files month by month and comma separated comment, aspect and tag. We then stored all the data in one csv file and this csv file served as our main dataset.
Classifier Selection
- The Multinomial Naive Bayes’ Classifier
Daffodil International University 13 Step 7- Apply classification and create models: To train and validate our data for better accuracy, we choose model. The predictors used by the classifier are the repetition of the words that appear in the document. The basic idea of the Naive Bayes procedure is to discover the probabilities of classes assigned to texts by using the joint probabilities of words and classes.
The algorithm measurable shows we will use is the multinomial Naive Bayes classifier, part of the Gullible Bayes family of classifiers.NB classifiers are probabilistic classifiers, meaning they use the probabilities of observed outcomes to return a sensible measure of an unclear result. Despite this suspicion of near-autonomy being unreasonable, NB classifiers at least perform well. An observation that is well outside the expected range of values in a consideration or experiment and is regularly discarded from the data set.
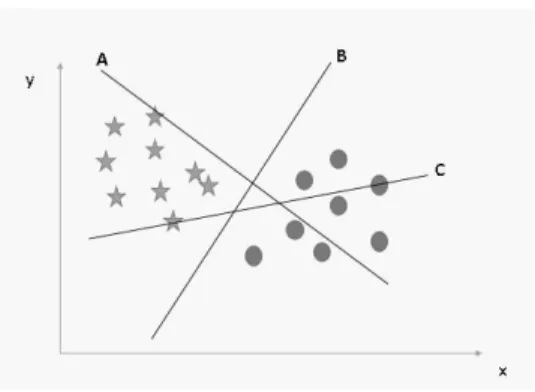
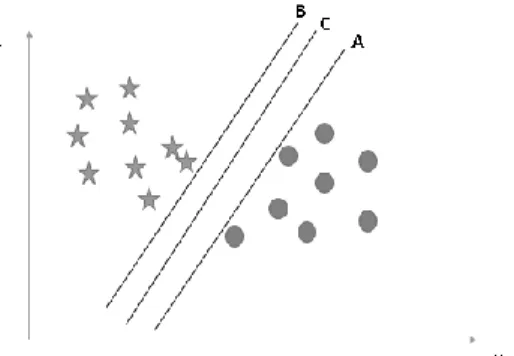
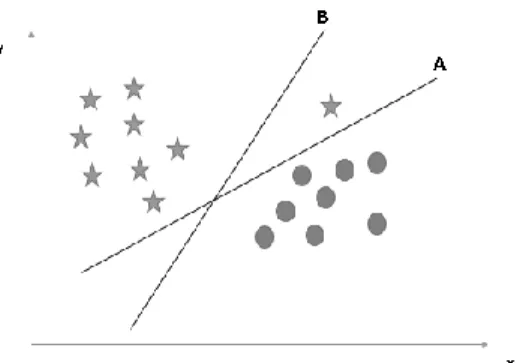
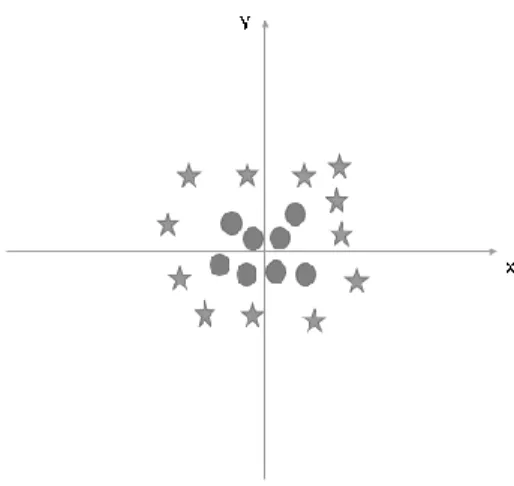
Hyperplane: In geometry, a hyperplane can be a subspace of one measurement smaller than its surrounding space. This idea can be used in any shared space where the concept of measuring a subspace is characterized. We must keep in mind a thumb drive the show to recognize the correct hyper plan.
Here, maximizing the separations between the nearest information point (or course) and hyperplane will help us choose the right hyperplane. Over, you will be able to see that the edge for hyperplane C is higher than A and B. Below we cannot separate two classes with a straight line, since one of the stars is in the region of the other.
SVM has a feature to ignore outliers and find the hyperplane that has the maximum difference.
Introduction
- For Bangla ABSA dataset
- For English Reviews Dataset
After that, we deleted the figures from our data set, as we found that the figures were not essential for the perspective category. Therefore, a dictionary of Bangla words was orchestrated after preprocessing.[15] We made an embedding framework for which each mirror was spoken by a vector of that dictionary. The internal planning organization, the removed consolidated sets were orchestrated by the well-known machine learning facilitation computations.
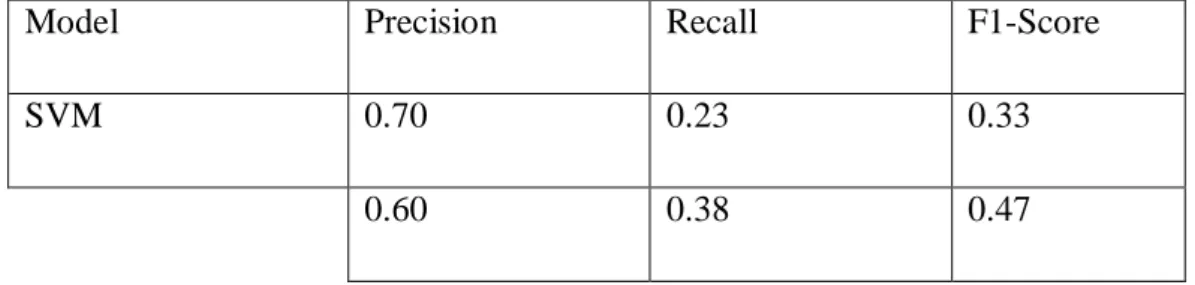
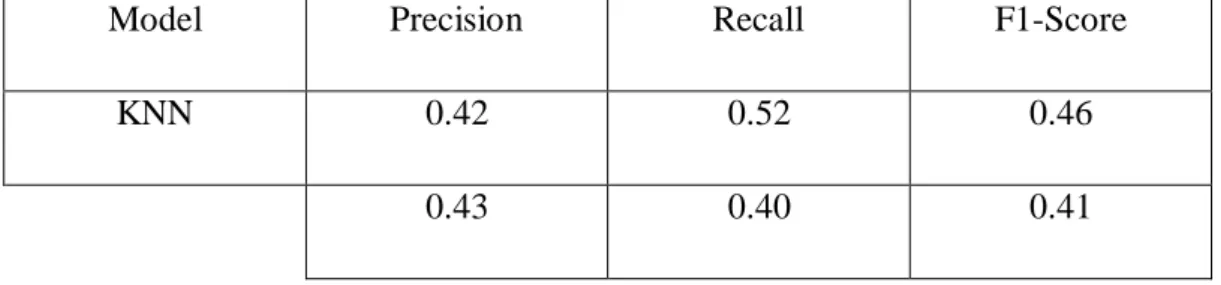
Once the editing was done, our proposed Bangla test dataset was run on the edited illustration. We will see that using SVM we obtained the first increased level of accuracy for both datasets. The common nature of the data sets is the reason for the lower performance of the models for both data sets.
This can happen if we randomize and prepare the datasets in a more advanced way. In this work, we have taken the entire lexicon as accents for evaluation after removing accentuation, final words, and digits. Some state-of-the-art data collection methods can be associated with a dataset.
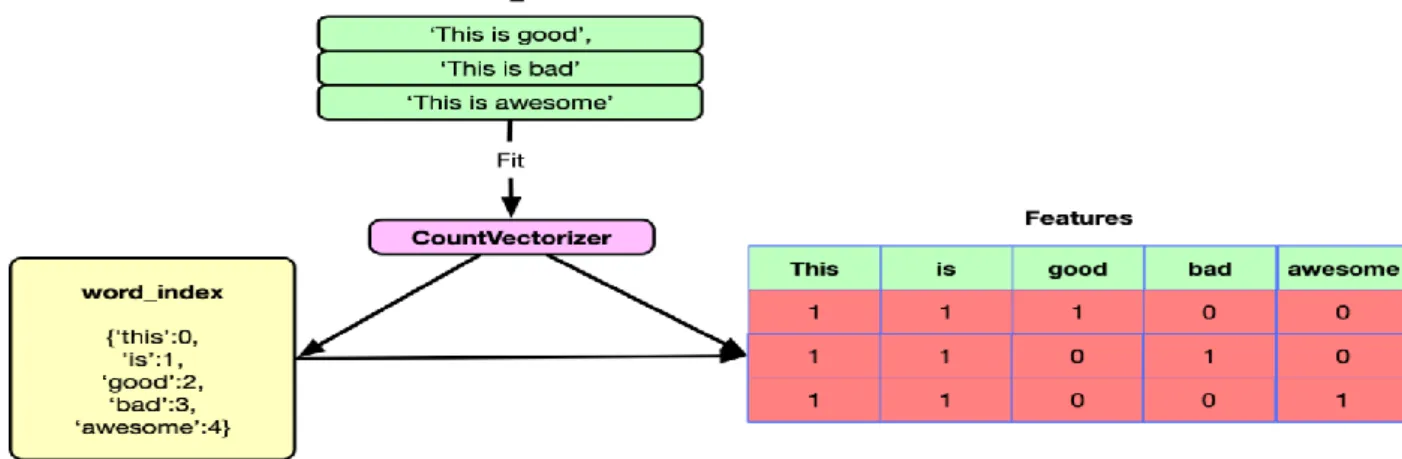
Daffodil International University 24 times recently classification and after pretreatment steps to achieve superior comes around. Constructing a demonstration to predict in the event that the audit is positive or negative, take after steps are done.Importing data sets. Bag-of-words show (Bow ) is perfect way">the most perfect way to remove highlights from the fabric.
Confusion matrix can be a performance estimate for machine learning classification. It is very useful for calculating recall, precision, accuracy.

Conclusion And Future work 5.1 Conclusion
Future Works
In Proceedings of the 2015 2nd International Conference on Electronics and Communications Systems (ICECS), Coimbatore, India, February 26-27, 2015. In Proceedings of the 2015 3rd International Conference on Future Internet of Things and Cloud (FiCloud), Rome , Italy, 24–. Atikur Rahman, Emon Kumar Dey, Data sets for aspect-based sentiment analysis in Bangla and its baseline evaluation.