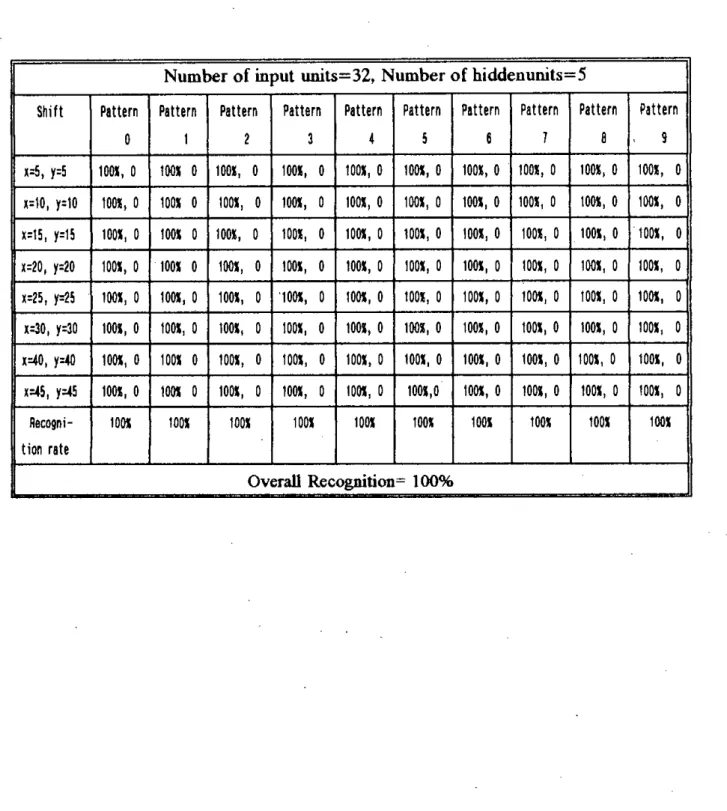
The results presented in this table are the average of ten trials with ten different 32-9-10 networks. The results shown in this table are averaged over ten trials with ten different 16-9-10 networks.

CHAPTER-ONE
INTRODUCTION
- literature Review
- EarlyWorks on Pattern Recognition
- Recent Works
- Neural Networkbased r~ognition system
- Applications of Pattern Recognition Technology
- Objective of this work
- Introduction to the thesis
This section presents brief descriptions of some of the important research works, including automatic system design in pattern recognition. As described in (5), this method does not involve variations in the size and proportion of the input characters.
CHAPTER-TWO
MODELS OF PATTERN RECOGNITION
- Introduction
- Fundamental Problems in Pattern Recognition System Design
- Design Concepts and Methodologies
- Methodology of Design
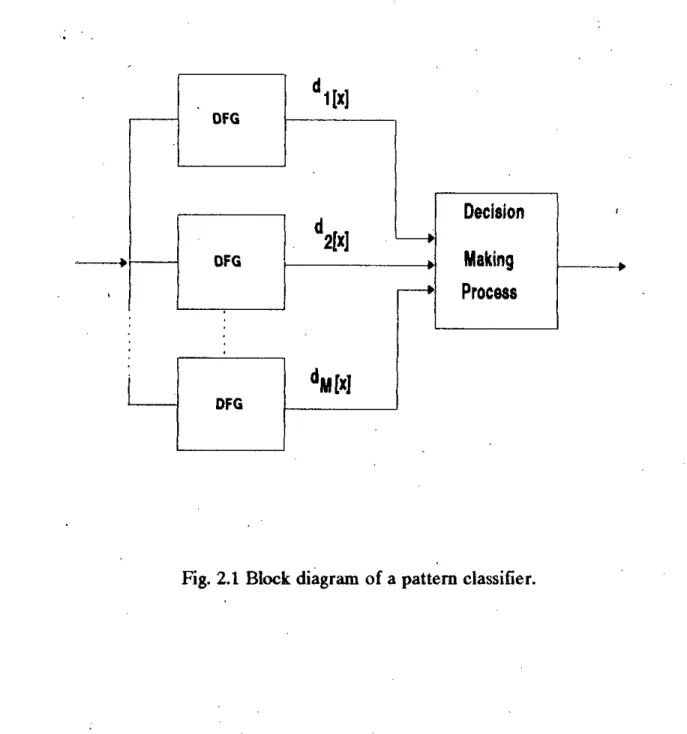
The group of patients belonging to this pattern class is stored in the pattern recognition system. The pattern recognition system classifies the input pattern class if it matches any of the stored patterns belonging to that pattern class.
CHAPTER-THREE
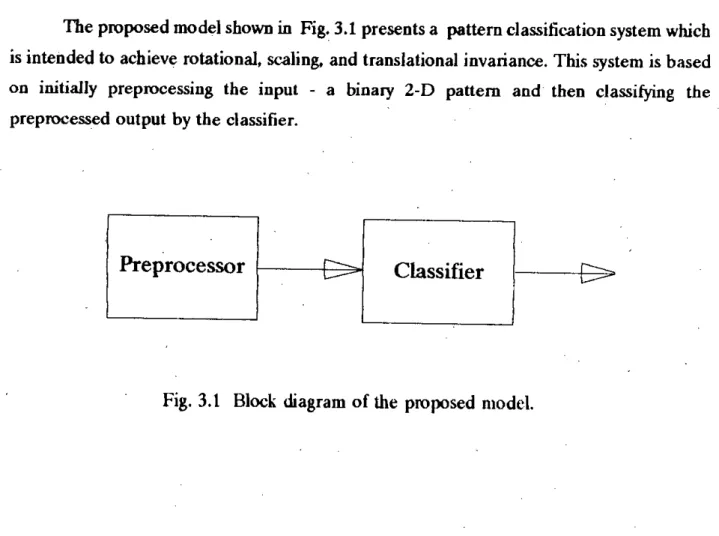
PROPOSED MODEL OF PATTERN RECOGNITION
Introduction
Depending on the nature of the patterns and applications, the recognition process can be straightforward or an extremely difficult task. This representation of the patterns is defined as the pixel-map form of the pattern.
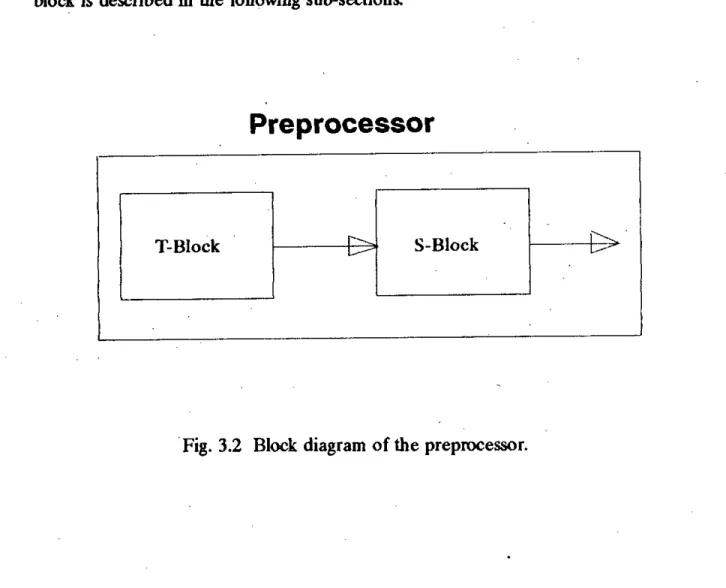
The Preprocessor
Preprocessor
T-block
The T-block calculates the centroid of the pattern by averaging the x and y coordinates of the on-pixels. The next step is to calculate the radial distance of each pixel from the calculated centroid (xav' Yay) of that pattern. The T-block actually calculates the polar coordinate (row' 8ij) of each 'ON' pixel relative to the centroid of the pattern.
This will keep the output from the T block exactly the same even if the pattern is translated. Similarly, normalizing the radial distance of each pixel by the maximum value will keep the output of the T-block unchanged if the pattern is scaled by a certain factor . This is maintained in an ideal case, i.e. it is assumed that scaling does not introduce any error in the scaled version of the pattern. By the same argument, if a pattern is rotated by an angle Sthen, in an ideal case each (rij' 8ij) of the original pattern will be shifted by S.
S- block
In the second step of the transformation, the two groups of variables in column (1) are again divided into two subgroups each.
0 XIII N-1
The Classifier
The classifier in the proposed model is an artificial neural net classifier that has the desired ability to classify patterns even with some noise present. The outputs of the preprocessor in response to a sample pattern are fed to the network as input and a locally represented binary vector is applied to the output layer as a target signal.
CHAPTER-FOUR
THE ARITIFITIAL NEURAL NETWORK CLASSIFIER
Introduction
The use of artificial neural networks (ANN) for pattern classification purposes has become very popular in recent years. The network has input and output layers, as well as one or more intermediate layers called hidden layers. Given the size of the input and output layers, one needs to decide on the number of hidden layers and also the size of each hidden layer.
The decision depends on the type of problem to be dealt with, as well as the size and variety of input outputs. The size of the hidden layer should be large enough so that the network can distinguish the pattern belonging to different classes, while being as compact as possible to avoid memorizing the examples. The number of nodes in the input layer is fixed and equal to the number of outputs of the preprocessor.
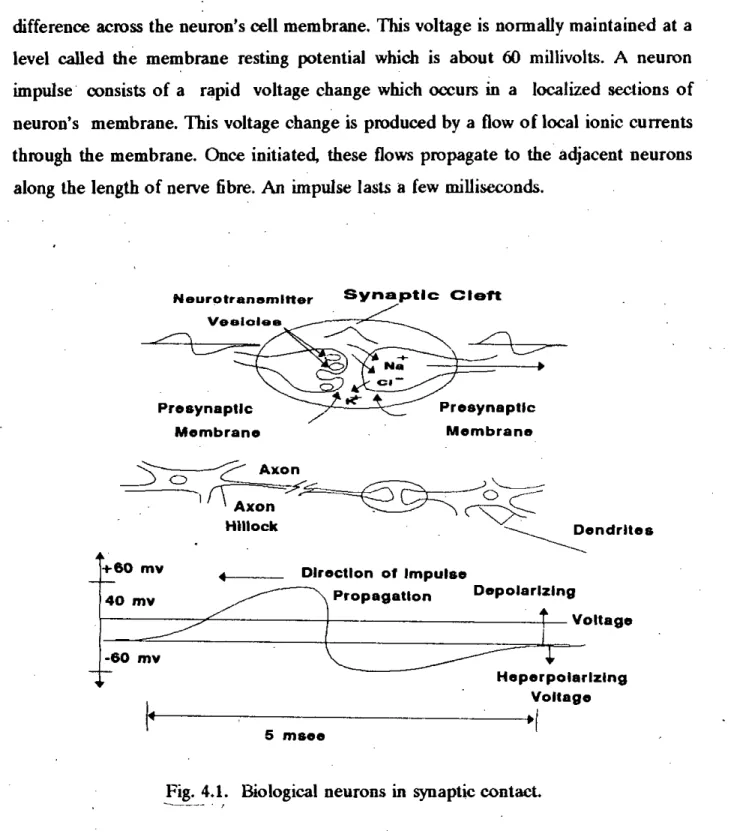
Biological Neurons
This suggests that in our search for solutions to intelligent problems, we need machines built on a large number of parallel processing elements. The soma or nerve cell, the large round central body of the neuron from 5 to 1000. The output fiber, called an axon, attached to the soma is electrically active and produces the pulse emitted by the neuron.
When this chemical reaches the end of the dendrite within a few milliseconds, it causes a change in the voltage across the dendrite's postsynaptic membrane. If the axon hillock membrane of the receiving cell is sufficiently depolarized by incoming impulses, the receiving cell can fire an output impulse down its axon. The processing that occurs at each neural element is relatively simple, but there are a huge number of such operations going on at any given moment.
28- 4.2 Artificial Neural Networks
Back-Propagation I~arning Algorithm
- Update of Output-Layer Weights
- Update of Hidden-Layer Weights
The back-propagation learning algorithm is intuitively appealing because it is based on a relatively simple concept: if the network gives the wrong answer, the weight is corrected so that the error is reduced and, as a result, future results of the network will change. be correct. This is simply the difference between the actual and desired output values times the derivative of the squash function. To determine the direction in which the weights should be changed, the negative of the gradient of Ep, aEp , with respect to weights, Wkj is calculated. The values of the weights can then be adjusted in such a way that the total error is reduced. This is often common to think of Ep as a surface in a weight room.
As for the size of the weight change, it is taken in proportion to the negative gradient. The size of the weight adjustment is proportional to ~ the error value of that unit. Its value - usually between 0.25 and 0.75 - is chosen by the user of the neural network and usually reflects the learning rate of the network<:[351.
CHAPTER-FIVE
SIMULATION RESULTS
Introduction
This chapter describes the invariance achieved by the preprocessor and the recognition capability of the proposed model as a whole when applied to this particular class 10 problem. As for the neural network classifier, there are 9 different network architectures with different numbers of hidden (5, 7 ,9) and input units were examined to investigate the effect of network size on overall recognition performance.
Patterns used in simulation
In this section, the invariance achieved by the preprocessor and the recognition performance of the proposed model as a whole when applied to this specific lO class problem are reported.

Invariance achieved by the preprocessor
- Classification Perfonnance
- Summary
A rotated pattern may contain some degree of distortion compared to that of the sample pattern. The number of input units of the classifier actually depends on the number of inputs and outputs of Rapid Transform. For example, if the number of inputs and outputs of Rapid Transform is 64, the input size of ANN classifier is 64.
5.10 (a), (d) and (g) show that varying the number of input units varies the performance of the recognizer, given the number of hidden units that remain unchanged. In the case of the 32 and 16 input unit networks, varying the number of hidden units made little change in overall performance. Again, it has been observed that the number of input units affects the recognition performance of the system (see Fig.

CHAPTER-SIX
CONCLUSIONS
Conclusions
The case where a pattern is both rotated and scaled is not simulated. The number of input/output of Rapid Transform (which is also the number of input to the ANN classifier) and hidden units of the classifier play an important role in determining the recognition ability of the system. A given classification size can provide the best recognition speed for rotation, while another for scaling. However, the actual capabilities of the proposed system need to be tested with real-world applications such as handwritten character recognition, which is much more extensive.
In both cases, the sample may appear twisted and reduced, which was not simulated in this study. For real-world use, a relatively large dataset of handwritten characters must be selected, passed through a preprocessor, and trained on its outputs by an ANN classifier. A complex architecture for the ANN classifier can be designed instead of the simple three-layer back-propagation network discussed in this work to achieve a better generalization ability of the classifier and thus a higher overall recognition rate.
Future Works
Instead of using one classifier, multiple classifiers can be used. Multiple classifiers can be trained independently, either with different learning algorithms or with the same algorithm but different set of learning parameters. Each classifier will classify the unknown input into a particular category, and a voting scheme between the classifiers will decide the particular category. Because of the similarity between Bangia characters, similar ones can be grouped together. Thus all characters can be divided into a number of groups.
The ANN will be trained to assign an input pattern to a particular group by giving a single high output at the output layer. Each output of this network will be connected to another subnet at the upper level. This will in turn activate a subnet that will classify the input into the correct category within the assigned group.
14] S. S. Yau and C. C. Yang, "Pattern Recognition Using Associative Memory," IEEE TranstJdion On Electronic Computns, vol. Prokop, S. E. Andrews, and F. Kuhl, "Three-Dimensional Shape Analysis Using Moments and Fourier Descriptors," IEEE Trans.. on Pullern Analysis and Machine IlJIelligmce, vol. Suell, "Reconstruction of Two-Dimensional Patterns with Fourier Descriptors," PToceedings of the 9th International Conference On Pattern.
Brody, “A transformation with invariance under cyclic permutation for application to pattern recognition,” InfoTltllltWn and Control. Thomsen, “A fM:celerated lelD'lling algorithm for multi-layer perceptrrJns: per-layer optimization,” IEEE Trans.
APPENDIX-A
SIMULATION RESULT TABLES
The results shown in this table are the average of ten trials, with ten different 32-5-10 networks. The first entry of each box in the table shows the mean recognition rate and the second entry gives the standard deviation. Number of input units=64, Number of hidden units=5.
Number of input units=64, Number of hidden units=? .. scale Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern. Number of input units=64, Number of hidden units-9, Shi It Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern. Number of input units=64, Number of hidden units=9 .. scale Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern.
Number of input units=16, Number of hidden units=5 .. scale Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern. Number of input units=16, Number of ordered units=7 .. scale Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern Pattern.