TRANSKRIPSI SUARA KE TEKS BAHASA INDONESIA BERBASIS
SUKU KATA MENGGUNAKAN CODEBOOK DAN 2-LEVEL
DYNAMIC PROGRAMMING
SINTYA ROSDWIANTY
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Transkripsi Suara ke Teks Bahasa Indonesia Berbasis Suku Kata Menggunakan Codebook dan 2-level Dynamic Programming adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
SINTYA ROSDWIANTY. Transkripsi Suara ke Teks Bahasa Indonesia Berbasis Suku Kata Menggunakan Codebook dan 2-level Dynamic Programming. Dibimbing oleh AGUS BUONO dan MUHAMMAD ASYHAR AGMALARO.
Transkripsi suara ke teks sangat berguna karena memudahkan manusia berinteraksi dengan sistem secara lebih cepat. Akan tetapi, sistem sulit mengenali suara berupa rangkaian kata. Penelitian ini mengembangkan sistem yang dapat mengenali rangkaian kata dengan menggunakan metode MFCC sebagai teknik ekstraksi ciri, codebook sebagai metode pengenalan pola, dan 2-level dynamic programming sebagai metode pengenalan rangkaian kata. Teknik cluster yang digunakan pada penelitian ini adalah K-means. Parameter yang digunakan pada teknik MFCC adalah overlap, time frame, dan jumlah koefisien cepstral. Adapun parameter pada teknik K-means adalah jumlah cluster. Penelitian ini menggunakan 900 data suara suku kata yang terdiri atas 18 kelas dan 120 data suara berisi rangkaian kata yang terdiri atas 60 data uji hasil gabungan data latih dan 60 data uji sebenarnya. Hasil penelitian menunjukkan bahwa nilai K optimum adalah 15, dan nilai word error rate terendah yang diperoleh adalah 0.1, diperoleh pada rangkaian
kata kelas ‘Ide Anda’ hasil gabungan suku kata data latih, saat overlap 0.25, time frame 25 ms, koefisien cepstral 13, dan jumlah cluster 20.
Kata kunci: codebook, connected word, dynamic programming, K-means, MFCC
ABSTRACT
SINTYA ROSDWIANTY. Voice to Text Transcription based on Indonesian Syllable using Codebook and 2-level Dynamic Programming. Supervised by AGUS BUONO and MUHAMMAD ASYHAR AGMALARO.
Voice to text transcription is very useful because it allows people to interact with a system more quickly. However, it is hard for a system to recognize a speech which contains of connected words. This research aims to develop a system that recognize a connected word speech. The proposed approach uses MFCC as a feature extraction, codebook as pattern recognition method, and 2-level dynamic programming as connected words recognition method. The parameters used in feature extraction using MFCC are overlap, time frame, and number of cepstral coefficients. Moreover the parameter used in K-means clustering is the number of clusters. This research uses 900 syllable’s speech data from 18 classes, and 120
connected word’s speech data which consist of 60 testing data joined from training data and 60 real testing data. The results showed that the optimum value of K was 15, with the minimum word error rate of 0.1 for the ‘Ide Anda’ words resulted from joining words of training data with the overlap value of 0.25, the time frame value of 25 ms, the number of cepstral coefficients of 13, and the number of clusters of 20.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
TRANSKRIPSI SUARA KE TEKS BAHASA INDONESIA BERBASIS
SUKU KATA MENGGUNAKAN CODEBOOK DAN 2-LEVEL
DYNAMIC PROGRAMMING
SINTYA ROSDWIANTY
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Transkripsi Suara ke Teks Bahasa Indonesia Berbasis Suku Kata Menggunakan Codebook dan 2-level Dynamic Programming Nama : Sintya Rosdwianty
NIM : G64100085
Disetujui oleh
Dr Ir Agus Buono, MSi MKom Pembimbing I
Muhammad Asyhar Agmalaro, SSi MKom Pembimbing II
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Januari 2014 ini ialah pemrosesan bahasa alami, dengan judul Transkripsi Suara ke Teks Bahasa Indonesia Berbasis Suku Kata Menggunakan Codebook dan 2-level Dynamic Programming.
Penulis menyadari bahwa penelitian ini masih memiliki kekurangan. Adapun penulis mengucapkan terima kasih kepada:
1 Kedua orangtua dan kakak yang telah memberikan perhatian, doa, dan dukungan sehingga penulis dapat menyelesaikan penelitian ini.
2 Bapak Dr Ir Agus Buono, MSi MKom dan Bapak Muhammad Ashyar Agmalaro, SSi MKom, selaku pembimbing yang telah memberikan arahan dan saran kepada penulis.
3 Bapak Auzi Asfarian, SKom MKom, selaku penguji yang telah banyak memberi saran dan masukan kepada penulis.
4 Teman-teman Ilmu Komputer 47 atas segala dukungan, ilmu, perhatian dan kasih sayangnya.
5 Teman-teman UKM MAX!! IPB dan kelas TPB A01 2010 atas segala pengalaman yang diberikan selama kuliah.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Pengambilan Suara 3
Praproses 4
Ekstraksi Ciri MFCC 4
Perangkaian Kata 5
Codebook 5
Time Alignment 6
2-level Dynamic Programming 6
Lingkungan Pengembangan 7
Pengujian 7
HASIL DAN PEMBAHASAN 8
Pengambilan Suara 8
Praproses 8
Ekstraksi Ciri MFCC 8
Perangkaian Kata 8
Codebook 8
Time Alignment 9
2-level Dynamic Programming 9
Pengujian 9
Implementasi Sistem 12
Simpulan 13
Saran 13
DAFTAR PUSTAKA 14
LAMPIRAN 15
DAFTAR TABEL
1 Daftar suku kata sebagai data latih 3
2 Daftar rangkaian kata sebagai data uji 4
3 Word error rate untuk kelas data uji sebenarnya 9
4 Word error rate untuk kelas data uji hasil gabungan data latih 10
DAFTAR GAMBAR
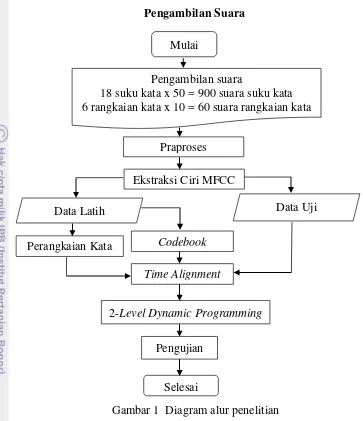
1 Diagram alur penelitian 3
2 Blok diagram MFCC 4
3 Perbedaan data suara asli, setelah pemotongan silent, setelah dinormalisasi 8 4 Rata-rata WER setiap kelas data uji untuk semua nilai K 10 5 Pengaruh nilai K terhadap rata-rata WER untuk semua kelas data uji 11 6 Tingkat akurasi suku kata pada kelas data uji gabungan data latih 12 7 Tingkat akurasi suku kata pada kelas data uji sebenarnya 12 8 Antarmuka program transkripsi suara ke teks berbasis suku kata 13
DAFTAR LAMPIRAN
PENDAHULUAN
Latar Belakang
Perkembangan penelitian tentang pemrosesan suara dan bahasa alami saat ini telah meningkat pesat. Hal tersebut disebabkan karena penelitian di bidang ini dapat diimplementasikan untuk kemudahan berbagai aktivitas manusia. Salah satu contohnya ialah penelitian tentang transkripsi suara ke teks (speech to text recognition), yang memungkinkan suatu sistem komputer berinteraksi dengan manusia selayaknya interaksi antarmanusia.
Proses penting dalam transkripsi suara ke teks adalah proses pengenalan suara yang mengambil suatu gelombang sebagai data input dan menghasilkan sebuah deretan string kata sebagai data output (Jurafsky dan Martin 2007). Sistem transkripsi suara ke teks sangat berguna karena memudahkan manusia untuk berinteraksi dengan sistem secara lebih cepat. Contoh aplikasi terapan yang banyak ditemui sehari-hari adalah fungsi voice dial pada telepon genggam.
Penelitian tentang transkripsi suara ke teks pun sudah banyak dilakukan, misalnya penelitian yang dilakukan oleh Luthfi (2013). Penelitian tersebut mendeteksi kata dengan MFCC sebagai ekstraksi ciri dan codebook sebagai pengenalan pola. Pada penelitian tersebut, Luthfi berhasil membangun codebook yang terdiri atas hasil klustering K-means untuk data latih berupa kata, dengan nilai codeword pada codebook 16 dan 32, dan parameter MFCC yang digunakan ialah time frame 23.7 ms, overlap 0.5, dan koefisien cepstral 13. Penelitian tersebut mendapatkan akurasi rata-rata 98%, dan berhasil mengenali input rangkaian kata yang diproses secara isolated words, atau pemrosesan tiap unit kata.
Atas dasar tersebut, penelitian ini membangun sistem transkripsi suara menggunakan model codebook, yang dapat mengenali rangkaian kata berbasis suku kata, dan diproses secara connected words. Suku kata dipilih sebagai unit transkripsi karena suatu suku kata dapat divariasikan menjadi banyak kata sehingga sistem dapat mentranskripsi lebih banyak kemungkinan kata dibandingkan dengan transkripsi dengan unit berupa kata. Penelitian ini akan dikombinasikan dengan metode 2-level dynamic programming (DP), yaitu salah satu metode yang dapat mengatasi transkripsi suara untuk rangkaian kata/connected words (Juang dan Rabiner 1993).
Perumusan Masalah
Transkripsi sinyal suara ke teks membutuhkan proses yang tidak mudah, karena membutuhkan suatu metode tertentu agar dapat mengenali struktur suara dengan tepat. Atas dasar tersebut, muncul pertanyaan penelitian sebagai berikut: 1 Bagaimana proses membangun metode codebook untuk sistem transkripsi
rangkaian kata berbasis suku kata?
2 Bagaimana proses transkripsi suku kata untuk data input yang terdiri atas rangkaian beberapa kata dengan metode 2-level DP?
2
3 Mengetahui tingkat akurasi transkripsi suara ke teks dengan metode codebook dan 2-level DP.
Manfaat Penelitian
Penelitian ini diharapkan mampu memberikan informasi tentang pengolahan suara untuk rangkaian kata/connected words dan tingkat akurasi transkripsi suara ke teks bahasa Indonesia berbasis suku kata. Selain itu, hasil penelitian ini diharapkan dapat dikembangkan untuk pengenalan semua suku kata dalam bahasa Indonesia dan dikembangkan menjadi sistem yang bersifat speaker independent sehingga sistem yang dikembangkan dapat dimanfaatkan oleh masyarakat umum.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah:
1 Jumlah suku kata yang mampu dikenali dalam sistem berjumlah 18 suku kata. Daftar suku kata tersebut mengacu pada 18 suku kata yang memiliki frekuensi kemunculan terbanyak pada teks penelitian Buono dan Kusumoputro (2007) berjudul Pengembangan Model HMM Berbasis Maksimum Lokal Menggunakan Jarak Euclid Untuk Sistem Identifikasi Pembicara pada halaman 1 sampai 3.
2 Sistem yang dikembangkan bersifat speaker dependent karena sistem hanya dapat mengenali suara yang menjadi data latih (Jurafsky dan Martin 2007) yaitu suara penulis berjenis kelamin wanita.
3 Parameter MFCC yang digunakan pada penelitian ini adalah time frame 25 ms, overlap 0.25, dan koefisien cepstral sebesar 13.
4 Rangkaian kata yang mampu dikenali hanya rangkaian kata yang terdiri atas deretan 4 suku kata.
METODE
3 Pengambilan Suara
Data suara yang digunakan dalam penelitian ini berasal dari satu pembicara yaitu suara penulis, dengan rincian 18 kelas suku kata dan 6 kelas rangkaian kata. Masing-masing data suku kata direkam selama 1 detik dengan pengulangan tiap kelas sebanyak 50 kali sehingga total data suku kata berjumlah 900 data. Suku kata tersebut digunakan sebagai data latih untuk pembangunan codebook seperti disajikan pada Tabel 1, yang diurutkan berdasarkan jumlah kemunculan suku kata terbanyak pada teks yang diacu.
Tabel 1 Daftar suku kata sebagai data latih Suku Kata
Si A Da Di An Se I Kan Ra De Ma Ni Ti Ter Pe Lah Ka Ta Data suara berupa rangkaian kata disusun berdasarkan kombinasi suku kata dari data latih yang tersedia, dan direkam selama 3 detik dengan pengulangan tiap kelas 10 kali. Total data yang direkam sebanyak 60 data dan akan digunakan untuk data uji sebenarnya. Data tersebut berjumlah 6 kelas karena keenam kelas kata
Codebook
Time Alignment Mulai
Pengambilan suara
18 suku kata x 50 = 900 suara suku kata 6 rangkaian kata x 10 = 60 suara rangkaian kata
Praproses Ekstraksi Ciri MFCC Data Latih
Perangkaian Kata
Pengujian
Selesai
2-Level Dynamic Programming
Data Uji
4
tersebut sudah mewakili setiap suku kata yang terdapat pada data latih, seperti disajikan pada Tabel 2.
Tabel 2 Daftar rangkaian kata sebagai data uji
Rangkaian Kata Suku Kata akan diproses. Selain itu, suara memiliki range amplitudo yang berbeda-beda. Oleh karena itu proses normalisasi amplitudo dilakukan agar setiap suara memiliki range amplitudo yang sama.
Ekstraksi Ciri MFCC
Ekstraksi ciri merupakan proses untuk mencari suatu nilai atau vektor yang menjadi ciri khusus dari suatu variabel atau objek. Salah satu teknik ekstraksi ciri yang banyak digunakan dan sesuai dengan persepsi sistem pendengaran manusia adalah Mel Frequency Cepstrum Coefficient (MFCC). Tahapan MFCC disajikan pada Gambar 2.
Gambar 2 Blok diagram MFCC
Tahap pertama MFCC adalah frame blocking yaitu teknik pembagian sinyal menjadi blok-blok (frame) dengan ukuran/lebar tertentu, dan di antara kedua blok yang berdekatan terdapat overlap. Overlap adalah keadaan suatu sinyal yang saling tumpang tindih untuk mencegah adanya informasi yang hilang. Tahap selanjutnya adalah windowing, yaitu proses mengalikan sinyal digital dengan suatu fungsi window tertentu. Tujuan windowing adalah untuk mengurangi distorsi antar frame yang berdekatan. Formula windowing yang digunakan pada penelitian ini adalah Hamming window karena formula ini memiliki kinerja yang baik dan perhitungan sederhana (Buono et al. 2009), seperti disajikan pada Persamaan 1.
Continuous Speech Frame Blocking Frame Windowing
FFT Spectrum
Mel-frequency Wrapping Mel Spectrum
5 � n =0.54-0.46 cos N -2πn1 , 0 ≤n≤N-1 (1) Tahap selanjutnya adalah Fast Fourier Transform (FFT), yaitu salah satu algoritme untuk mengimplementasikan Discrete Fourier Transform (DFT) untuk mentransformasi frame dari domain waktu ke domain frekuensi. Hasil dari tahap ini dinamakan spektrum. Fungsi FFT disajikan pada Persamaan 2.
xk = ∑ n =N -10 xne -j2πkn
N (2)
dengan k = 0, 1, 2, ..., N-1
Xk = nilai-nilai sampel yang akan diproses ke dalam domain frekuensi Xn = magnitudo frekuensi
N = jumlah data pada domain frekuensi j = bilangan imajiner
Secara umum, Xk adalah bilangan kompleks dan hanya dilihat bilangan absolutnya.
Setelah itu, dilakukan mel-frequency wrapping, yaitu proses pemfilteran spektrum setiap frame menggunakan sejumlah M filter segitiga dengan tinggi satu. Filter ini dibuat berdasarkan persepsi manusia terhadap suatu suara. Hubungan skala mel dengan frekuensi (Hz) dinyatakan pada Persamaan 3.
Fmel=2595 log10 1+F700Hz (3)
Cepstrum adalah tahap terakhir yang berfungsi mengubah log mel hasil proses sebelumnya kembali menjadi domain waktu. Hasil dari tahap ini disebut MFCC dengan jumlah koefisien MFCC tertentu yang diinginkan. Pada penelitian ini proses MFCC menggunakan auditary toolbox Matlab yang dikembangkan oleh Slaney (1998).
Perangkaian Kata
Perangkaian kata dilakukan dengan cara merangkaikan data latih berupa suku kata menjadi rangkaian kata seperti data uji. Hal ini dilakukan untuk membandingkan kinerja sistem terhadap data yang terdiri atas gabungan data latih dan data uji sebenarnya.
Codebook
Codebook adalah barisan simbol yang merepresentasikan suatu objek tertentu (Jurafsky dan Martin 2007). Codebook merupakan salah satu metode pengenalan pola yang menghasilkan sebuah cetakan suara. Setiap titik pada codebook dinamakan codeword. Nilai pada codeword diambil dari hasil pengelompokkan/clustering semua data latih berupa vektor ciri masing-masing suara. Algoritme clustering yang digunakan pada penelitian ini adalah K-means, karena algoritme ini memiliki kinerja cepat dan perhitungan sederhana.
6
Time Alignment
Time alignment merupakan metode untuk mengatasi pencarian jarak antara sinyal suara input dan sinyal suara pada model referensi dengan panjang vektor berbeda. Time alignment bekerja dengan cara mencari pasangan frame untuk sebuah sinyal suara input, dan mencari jarak totalnya dengan frame-frame pada sebuah kelas referensi. Karena kemampuannya dalam mengatasi perbedaan panjang vektor frame, time alignment cocok untuk diterapkan pada pengenalan rangkaian kata/connected words, dengan cara diterapkan untuk pencarian jarak di setiap kemungkinan lebar frame. Pencarian jarak pada time alignment dilakukan dengan fungsi squaredeuclidian distance, seperti disajikan pada Persamaan 4.
dist(p,q)= √∑n (Qi-Pi)2
i=1 (4)
2-level Dynamic Programming
Sebuah sistem transkripsi suara yang menggunakan metode dynamic programming (DP), harus bisa mendeteksi jumlah kata pada sebuah kalimat, ending point sebuah kata, dan klasifikasi setiap kata (Morgan dan Silverman 1990). Salah satu metode DP adalah 2-level DP. Metode ini dipilih karena 2-level DP merupakan metode pengenalan rangkaian kata yang sederhana, dan dapat dikembangkan lebih lanjut dengan menambahkan metode lainnya. Ide dasar dari 2-level DP adalah mencari jarak dan jalur/path terbaik dari sebuah matriks data.
Level pertama adalah pencarian jarak minimum dari sebuah barisan vektor input dengan semua vektor pada model referensi (Juang dan Rabiner 1993). Pencarian tersebut direpresentasikan dengan matriks jarak berukuran NxN, N menunjukkan jumlah frame hasil ekstraksi ciri. Nilai jarak ini dicari untuk setiap kemungkinan barisan frame tertentu dengan tiap kelas suku kata pada codebook, dengan asumsi tidak ada suku kata yang direpresentasikan dalam panjang 1 frame. Oleh karena itu, jarak sepanjang 1 frame tidak disertakan dalam penelitian ini. Setelah itu, perbandingan nilai antara satu kelas suku kata dan kelas lainnya dilakukan dan hasil yang memiliki nilai paling kecil diambil.
Level kedua adalah mencari jarak total dan melakukan backtrack terhadap jarak total tersebut. Jarak total dicari dengan perhitungan rekursif sebanyak jumlah suku kata yang akan dikenali. Langkah-langkah pencarian jarak total dan backtrack jalur terbaik disajikan pada persamaan berikut.
1 Inisialisasi
7 b = awal frame pada data uji
e = akhir frame pada data uji
c = jumlah suku kata yang ada pada suatu rangkaian kata M = jumlah frame pada data uji.
Algoritme backtrack pada penelitian ini diterapkan dengan langkah awal menyimpan semua indeks kelas pada matriks jarak yang memiliki nilai paling kecil. Setelah itu, pencarian path diselesaikan dengan menyusuri hasil indeks dari indeks suku kata terakhir, dan berlanjut mundur untuk mencari jarak terkecil berikutnya untuk pencarian suku kata lainnya. Kompleksitas algoritme 2-level DP menurut Juang dan Rabiner (1993) disajikan pada Persamaan 11.
Kompleksitas total = VMN(2R+1), (11) dengan V = jumlah data referensi
M = jumlah startingframe data referensi N = range frame data uji
R = rata-rata banyaknya jumlah frame data uji.
Lingkungan Pengembangan
Pada penelitian ini lingkungan pengembangan yang digunakan ialah perangkat keras CPU Intel-Core i5, 4 GB RAM, dan microphone frekuensi 20-20000 Hz, dengan sensitivitas 103 dB, sedangkan untuk perangkat lunak menggunakan Windows 7 Professional, Microsoft Excel 2013, dan Matlab R2010a 64 bit.
Pengujian
Pengujian dilakukan dengan cara mencocokan hasil output sistem dengan hasil transkripsi seharusnya. Setelah itu, tingkat akurasi dihitung dengan menggunakan word error rate (WER). WER adalah salah satu metode untuk menghitung jarak antara barisan kata pada model referensi dengan keluaran/output sistem transkripsi (Bourlard et al. 2005). Semakin kecil nilai WER, semakin baik kinerja sistem transkripsi. WER didefinisikan pada Persamaan 12.
Word Error Rate = S+D+IN (12) dengan S = banyaknya terjadi output substitution
8
HASIL DAN PEMBAHASAN
Pengambilan Suara
Semua data direkam langsung pada perangkat lunak Matlab dengan sampling rate 11000 Hz dan disimpan dalam format *.wav. Perekaman data dilakukan di tempat yang hening untuk meminimumkan noise dari lingkungan sekitar.
Praproses
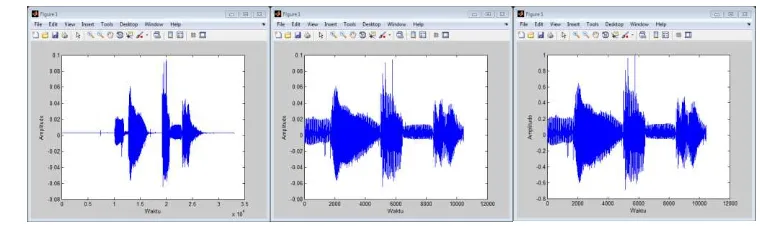
Penghapusan silent dilakukan secara manual untuk 900 data latih dengan cara menghapus langsung data yang terdiri atas data suara silent, dan untuk data uji dilakukan dengan cara menetapkan nilai ambang batas/threshold untuk setiap kelas. Selanjutnya, dilakukan normalisasi amplitudo, yaitu pembagian setiap nilai amplitudo dengan nilai maksimumnya sehingga diperoleh data suara yang lebih seragam. Contoh plot data uji ‘Ide Anda’ sebelum dan sesudah dinormalisasi disajikan pada Gambar 3.
Ekstraksi Ciri MFCC
Parameter-parameter MFCC yang digunakan dalam penelitian ini di antaranya: time frame 25 ms, sampling rate 11000 Hz, overlap 0.25, dan jumlah koefisien yang digunakan pada setiap frame ialah 13. Nilai-nilai ini dipilih agar jumlah frame data yang dihasilkan tidak terlalu besar.
Perangkaian Kata
Perangkaian kata dilakukan dengan cara menyatukan vektor suku kata yang diinginkan sebanyak 10 kali untuk masing-masing kelas data uji sehingga total rangkaian kata yang diperoleh ialah 60 data untuk semua kelas data uji.
Codebook
Pembangunan codebook dilakukan dengan menggabungkan setiap vektor data latih dari tahapan sebelumnya untuk setiap kelas, lalu dilakukan clustering
9 dengan algoritme K-means. K yang digunakan sebagai intitial centroid pada penelitian ini adalah 5, 10, 15, 20, 25, dan 30. Nilai-nilai ini dipilih karena nilai K yang biasa digunakan pada penelitian pengenalan suara berkisar antara 5 sampai 32. Hasil klustering inilah yang dijadikan sebagai nilai-nilai codeword pada codebook.
Time Alignment
Time alignment dilakukan dengan perhitungan euclid untuk setiap kemungkinan lebar frame antara data uji dengan data referensi pada codebook. Hasil time alignment direpresentasikan dalam bentuk matriks jarak.
2-level Dynamic Programming
Level pertama DPadalahmatriks jarak minimum untuk setiap kemungkinan panjang frame data uji dengan semua suku kata pada codebook. Level kedua yaitu pencarian rekursif jarak total menghasilkan matriks berukuran 4xN yang berarti pencarian jarak terbaik untuk 4 suku kata dari N jumlah frame data uji. Tahap terakhir yaitu backtrack jalur terbaik untuk setiap data uji akan menghasilkan path dengan total jarak paling minimum.
Pengujian
Pada hasil pengujian dilakukan percobaan dengan nilai K 5, 10, 15, 20, 25, dan 30 untuk setiap kelas data uji. Parameter MFCC yang digunakan pada pengujian ini sama dengan parameter pada data latih. Data uji sendiri terbagi menjadi data uji sebenarnya berjumlah 60 data, dan data uji hasil gabungan data latih berjumlah 60 data, sehingga total data uji untuk semua kelas adalah 120 data. Word error rate berdasarkan nilai K untuk setiap kelas data uji pada data uji sebenarnya dan data uji hasil gabungan data latih, disajikan pada Tabel 3 dan 4.
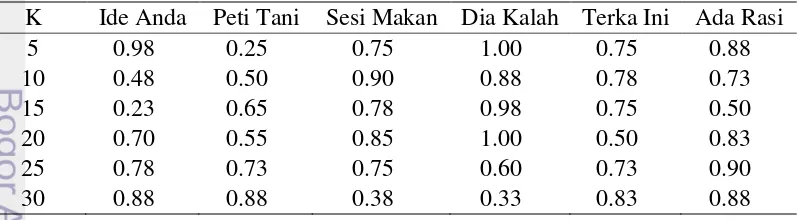
Tabel 3 Word error rate untuk kelas data uji sebenarnya
K Ide Anda Peti Tani Sesi Makan Dia Kalah Terka Ini Ada Rasi
terendah yaitu 0.23 saat nilai K 15, sedangkan WER tertinggi didapatkan kelas data
uji ‘Dia Kalah’ pada saat K 5 dan 20 yaitu 1. Di sisi lain, pada kelas data uji hasil
10
pengucapan suatu suku kata memiliki variasi lebih tinggi dibandingkan dengan kelas data uji hasil gabungan data latih. Oleh karena itu, sistem lebih sulit mengenali suku kata pada kelas data uji sebenarnya.
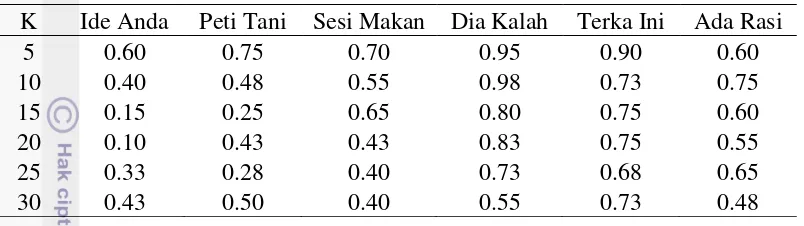
Tabel 4 Word error rate untuk kelas data uji hasil gabungan data latih K Ide Anda Peti Tani Sesi Makan Dia Kalah Terka Ini Ada Rasi tersebut dapat disimpulkan bahwa pada penelitian ini, kelas data uji ‘Ide Anda’ merupakan kelas yang paling mudah dikenali, dengan nilai rata-rata WER sebesar 0.51 untuk semua kelas data dan nilai K. Sementara itu, kelas data uji ‘Dia Kalah’ merupakan kelas yang paling sulit dikenali, dengan nilai rata-rata WER sebesar 0.805 untuk semua kelas data dan nilai K. Hal ini dapat disebabkan karena ada beberapa pengucapan suku kata yang tidak mirip dengan data latih, seperti suku
kata ‘a’ pada kelas data uji ‘Dia Kalah’ cenderung terdengar seperti ‘ya’, sehingga tidak mirip dengan suku kata ‘a’ pada data latih.
Gambar 4 Rata-rata WER setiap kelas data uji untuk semua nilai K
Selain itu, kelas data uji hasil gabungan data latih mendapatkan rata-rata WER sebesar 0.58, sedangkan kelas data uji sebenarnya mendapatkan rata-rata WER sebesar 0.72 untuk semua kelas data dan nilai K. Hal ini menunjukkan bahwa kelas data uji hasil gabungan data latih lebih mudah dikenali oleh sistem dibandingkan dengan kelas data uji sebenarnya.
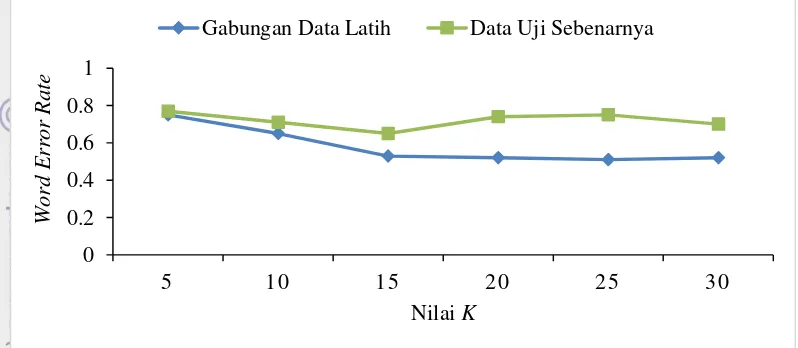
Gambar 5 menggambarkan pengaruh nilai K terhadap nilai rata-rata WER untuk semua kelas data. Dari grafik tersebut, kurva nilai WER cenderung menurun pada nilai K 5 sampai 15, sedangkan pada nilai K 15 sampai 30 nilai WER
Ide Anda Peti Tani Sesi Makan Dia Kalah Terka Ini Ada Rasi
11 penelitian ini dapat disimpulkan bahwa semakin besar nilai K nilai rata-rata WER akan semakin kecil dan mengartikan bahwa kinerja sistem semakin baik. Nilai K terbaik pada penelitian ini adalah 15, dengan rata-rata nilai WER sebesar 0.59, sedangkan nilai K dengan rata-rata WER tertinggi adalah 5 ialah sebesar 0.76.
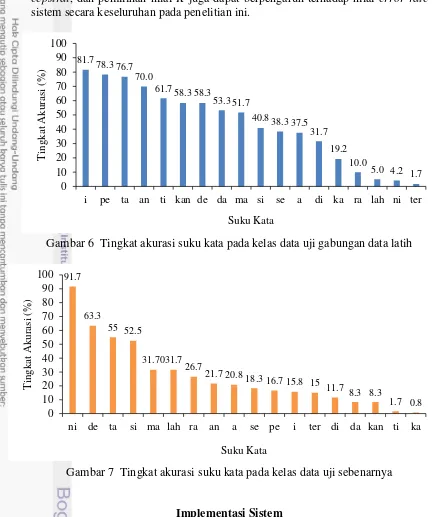
Gambar 5 Pengaruh nilai K terhadap rata-rata WER untuk semua kelas data uji Gambar 6 dan 7 menunjukkan tingkat akurasi suku kata yang berhasil dikenali sistem pada kelas data uji hasil gabungan data latih dan kelas data uji sebenarnya. Tingkat akurasi dihitung berdasarkan jumlah kemunculan suku kata hasil transkripsi dan dibagi dengan kemunculan suku kata tersebut seharusnya. Pada kelas data uji hasil gabungan data latih, rata-rata akurasi untuk semua kelas suku kata adalah 43.24%, lebih baik dibandingkan dengan rata-rata akurasi pada kelas data uji sebenarnya yaitu 27.31%. Akan tetapi, terdapat perbedaan signifikan antara nilai akurasi tiap suku kata pada kedua kelas data uji tersebut. Hal ini menunjukkan bahwa tingkat akurasi sangat bergantung kepada data suara itu sendiri. Suku kata yang berhasil dikenali paling baik dari semua kelas data uji adalah ‘ta’ dengan rata -rata akurasi sebesar 65.83% dan paling sulit dikenali adalah suku kata ‘ter’ dengan rata-rata akurasi sebesar 8.33%.
Nilai WER dan tingkat akurasi suku kata sangat bergantung kepada hasil backtracking path pada algoritme DP. Berdasarkan hasil penelitian ini, sistem masih memiliki kekurangan dalam menentukan path terbaik untuk suatu rangkaian kata/connected words. Hal ini menyebabkan output sistem belum sepenuhnya tepat dalam transkripsi suara tersebut dan menghasilkan error yang cukup tinggi, misalnya terjadi substitusi suatu suku kata dengan suku kata lainnya.
Kesalahan backtracking tersebut dapat disebabkan oleh beberapa faktor, seperti penetapan threshold untuk pemotongan silent yang dilakukan terhadap kelas data uji sebenarnya. Apabila silent dapat dihilangkan dengan baik, output sistem yang dihasilkan juga akan lebih baik karena mendekati data pada model codebook yang tidak memiliki model silent. Faktor lainnya ialah pengucapan kata itu sendiri, seperti intonasi yang digunakan dan lamanya pengucapan kata tersebut. Pengucapan yang semakin mirip dengan data pada model codebook akan menghasilkan nilai WER yang semakin rendah dan akurasi suku kata semakin tinggi. Penggunaan parameter-parameter lain seperti time frame, overlap, koefisien
12
cepstral,dan pemilihan nilai K juga dapat berpengaruh terhadap nilai error rate sistem secara keseluruhan pada penelitian ini.
Gambar 6 Tingkat akurasi suku kata pada kelas data uji gabungan data latih
Gambar 7 Tingkat akurasi suku kata pada kelas data uji sebenarnya
Implementasi Sistem
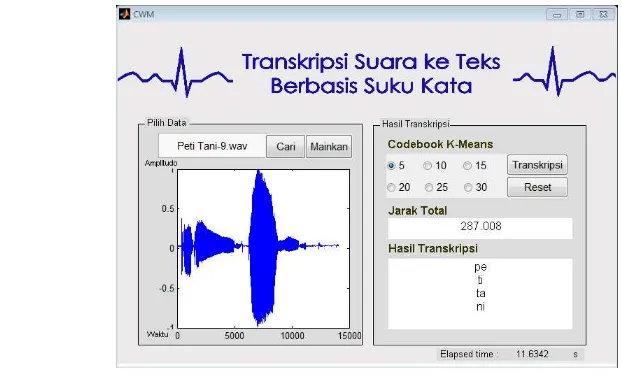
Gambar 8 menunjukkan tampilan antarmuka program pada penelitian ini. Terdapat tombol cari untuk memilih data uji yang akan ditranskripsi, tombol mainkan untuk mendengarkan data uji yang dipilih, dan tombol transkripsi yang disertai dengan radio button 5, 10, 15, 20, 25, dan 30 untuk memilih nilai K pada initial centroid K-means. Tombol reset digunakan untuk menghapus hasil transkripsi sebelumnya. Grafik di kiri bawah berfungsi untuk menunjukkan plot suara data uji, jarak total menunjukkan jumlah jarak untuk satu data uji dengan semua kemungkinan lebar frame yang tidak lain merupakan hasil rekursif level 2
13 DP, sedangkan hasil transkripsi akan menunjukkan hasil backtrack jalur terbaik yang merupakan hasil akhir dari DP.
Gambar 8 Antarmuka program transkripsi suara ke teks berbasis suku kata
SIMPULAN DAN SARAN
Simpulan
Penelitian ini sudah berhasil diselesaikan dengan menerapkan codebook sebagai pengenalan pola dan 2-level DP sebagai metode pengenalan rangkaian kata. Penelitian ini menunjukkan bahwa data uji hasil gabungan data latih lebih mudah dikenali dibandingkan dengan data uji sebenarnya karena memiliki tingkat kemiripan pengucapan kata yang lebih tinggi. Penggunaan nilai K pada clustering K-means juga memiliki pengaruh tinggi terhadap nilai WER. Selain itu, pemilihan nilai parameter lainnya seperti time frame, overlap, koefisien cepstral, dan threshold untuk pemotongan silent juga penting untuk diperhatikan. Nilai K paling optimum pada penelitian ini didapatkan saat K 15. Nilai WER terendah berhasil didapatkan kelas data uji hasil gabungan data latih pada kelas ‘Ide Anda’ dengan nilai K 20 ialah sebesar 0.1.
Saran
Penelitian ini memungkinkan untuk dikembangkan lebih baik lagi. Saran untuk pengembangan selanjutnya adalah:
1 Menggunakan parameter time frame, overlap, koefisien cepstral, threshold untuk pemotongan silent, dan K initial centroid yang berbeda untuk membandingkan nilai WER yang dihasilkan.
2 Menambahkan suku kata lain agar kamus kata menjadi lebih lengkap.
14
4 Menambahkan metode pemrosesan bahasa alami dalam bidang linguistik agar hasil transkripsi sesuai dengan kaidah tata bahasa Indonesia.
5 Menggunakan metode pengenalan connected words lainnya seperti level building atau one stage DP untuk mengetahui kinerja metode tersebut.
DAFTAR PUSTAKA
Buono A, Jatmiko W, Kusumo P. 2009. Perluasan Metode MFCC 1D ke 2D sebagai ekstraksi ciri pada sistem identifikasi pembicara menggunakan hidden markov model (HMM). Jurnal Makara Sains 13(1):87-93.
Buono A, Kusumoputro B. 2007. Pengembangan Model HMM Berbasis Maksimum Lokal Menggunakan Jarak Euclid Untuk Sistem Identifikasi Pembicara. Di dalam: Proceeding of National Conference on Computer Science & Information Technology; 2007 Januari 29-30; Depok, Indonesia.
Bourlard H, Dines J, Flynn M, McCowan I, Moore D, Perez D, Wellner P. 2005. On the Use of Information Retrieval Measures for Speech Recognition Evaluation. Switzerland: IDIAP Research Institute.
Juang BH, Rabiner L. 1993. Fundamentals of Speech Recognition. New Jersey (US): Prentice Hall.
Jurafsky D, Martin JH. 2007. Speech and Language Processing An Introduction to Natural Language Processing, Computational Linguistic, and Speech Recognition. Ed ke-2. New Jersey (US): Prentice Hall.
Luthfi MS. 2013. Pendeteksian Kata dengan MFCC sebagai Ekstraksi Ciri dan Codebook sebagai Pengenalan Pola [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Morgan DP, Silverman HF. 1990. The Application of Dynamic Programming to Connected Speech Recognition. Di dalam: IEEE ASSP Magazine; 1990 Juli. Slaney Malcolm. 1998. Auditory Toolbox [Internet]. [Diakses pada 2014 Maret 1].
15 Lampiran 1 Matriks konfusi tingkat akurasi suku kata pada data uji gabungan data latih
Suku Kata Si A Da Di An Se I Kan Ra De Ma Ni Ti Ter Pe Lah Ka Ta
Si 40.8 0 0 10.8 0 0 15.0 0 0 0 0 0.8 30.8 0 0 1.7 0 0
A 0 37.5 0 9.2 9.2 0 28.3 1.7 0 0 13.3 0 0 0 0 0 0 0.8
Da 0.8 8.3 53.3 0 5.8 0 0 0 4.2 0 25.8 0 0 0 0 0.8 0 0.8
Di 0 0 0 31.7 0 13.3 50.0 0 0 0 0 5.0 0 0 0 0 0 0
An 0 0 5.0 0 70.0 0 0 0 5.0 16.7 3.3 0 0 0 0 0 0 0
Se 18.3 0 0 5.0 3.3 38.3 0 1.7 3.3 5.0 0 0 16.7 0 5.0 1.7 0 1.7
I 0 0 0 18.3 0 0 81.7 0 0 0 0 0 0 0 0 0 0 0
Kan 0 3.3 0 0 16.7 0 0 58.3 1.7 0 18.3 0 0 0 0 0 1.7 0
Ra 0 0 1.7 0 33.3 0 0 25.0 10.0 0 1.7 0 18.3 1.7 0 5.0 1.7 1.7
De 0 0 0 1.7 1.7 0 38.3 0 0 58.3 0 0 0 0 0 0 0 0
Ma 10.0 5.0 0 0 3.3 3.3 0 3.3 15.0 0 51.7 0 1.7 0 0 6.7 0 0
Ni 10.8 0 0 15.0 0 2.5 66.7 0 0 0 0 4.2 0.8 0 0 0 0 0
Ti 0 0 0 1.7 0 0 6.7 1.7 0 0 0 0 61.7 0 1.7 0 0 26.7
Ter 0 0 1.7 0 0 0 0 8.3 5.0 0 3.3 0 0 1.7 1.7 0 33.3 45.0
Pe 0 0 0 0 0 0 0 0 1.7 0 3.3 0 5.0 0 78.3 0 0 11.7
Lah 0 6.7 0 0 5.0 0 0 16.7 10.0 0 1.7 0 0 0 0 5.0 36.7 18.3
Ka 0 16.7 0 4.2 7.5 0 27.5 3.3 0.8 0 4.2 0 0.8 0.8 0 0 19.2 15.0
16 16 Lampiran 2 Matriks konfusi tingkat akurasi suku kata pada data uji sebenarnya
Suku Kata Si A Da Di An Se I Kan Ra De Ma Ni Ti Ter Pe Lah Ka Ta
Si 52.5 0.8 0 1.7 0.8 2.5 0 8.3 5.0 0 0 10.0 14.2 1.7 0.8 0 0.8 0.8 A 0.8 20.8 5.0 1.7 5.8 0.8 1.7 20.8 8.3 0 12.5 0 0 0.8 1.7 0 3.3 15.8 Da 0 0.8 8.3 0 0 1.7 0 12.5 30.8 5.0 5.0 0 0 0.8 10.8 0 0.8 23.3 Di 11.7 0 3.3 11.7 0 26.7 16.7 0 11.7 5.0 0 11.7 1.7 0 0 0 0 0
An 0 30.0 0 0 21.7 10.0 1.7 3.3 0 15.0 15.0 0 0 0 0 0 0 3.3
Se 1.7 0 6.7 1.7 0 18.3 6.7 0 15.0 0 0 20.0 11.7 0 6.7 0 3.3 8.3 I 20.0 0 0 1.7 0 10.8 15.8 13.3 1.7 29.2 0 1.7 0 0 0 1.7 0 4.2
Kan 0 18.3 5.0 0 20.0 0 0 8.3 0 0 3.3 36.7 0 3.3 0 0 0 5.0
Ra 0 11.7 0 0 5.0 0 0 11.7 26.7 0 13.3 0 0 0 10.0 1.7 0 20.0
De 0 11.7 0 0 1.7 3.3 0 5.0 5.0 63.3 8.3 0 0 0 0 0 0 1.7
Ma 20.0 23.3 3.3 0 6.7 0 0 0 8.3 0 31.7 0 0 0 0 3.3 1.7 1.7
Ni 8.3 0 0 0 0 0 0 0 0 0 0 91.7 0 0 0 0 0 0
Ti 31.7 1.7 0 0 0 0 0 1.7 0 0 0 41.7 1.7 0 6.7 0 8.3 6.7
Ter 0 0 31.7 0 0 0 0 1.7 25.0 0 6.7 3.3 0 15.0 16.7 0 0 0
Pe 5.0 0 10.0 8.3 0 5.0 8.3 1.7 6.7 0 0 16.7 10.0 5.0 16.7 3.3 0 3.3
Lah 8.3 10.0 0 0 15.0 0 0 0 0 0 0 35.0 0 0 0 31.7 0 0
Ka 0 31.7 0 0 21.7 0 0 10.0 14.2 0 5.8 0 0 1.7 0.8 1.7 0.8 11.7
17
RIWAYAT HIDUP
Penulis dilahirkan di Bandung pada tanggal 1 Januari 1992 dari pasangan Asep Roswanda dan Asih Setiawaty. Penulis adalah putri kedua dari dua bersaudara. Tahun 2010 penulis lulus dari SMA Negeri 1 Bogor dan pada tahun yang sama penulis lulus seleksi masuk Institut Pertanian Bogor (IPB) melalui Undangan Seleksi Masuk IPB dan diterima di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.